Datasets:

Dataset Viewer
category
string | split
string | Name
string | Subsets
string | HF Link
string | Link
string | License
string | Year
int64 | Language
string | Dialect
string | Domain
string | Form
string | Collection Style
string | Description
string | Volume
float64 | Unit
string | Ethical Risks
string | Provider
string | Derived From
string | Paper Title
string | Paper Link
string | Script
string | Tokenized
bool | Host
string | Access
string | Cost
string | Test Split
bool | Tasks
string | Venue Title
string | Venue Type
string | Venue Name
string | Authors
string | Affiliations
string | Abstract
string | Name_exist
int64 | Subsets_exist
int64 | HF Link_exist
int64 | Link_exist
int64 | License_exist
int64 | Year_exist
int64 | Language_exist
int64 | Dialect_exist
int64 | Domain_exist
int64 | Form_exist
int64 | Collection Style_exist
int64 | Description_exist
int64 | Volume_exist
int64 | Unit_exist
int64 | Ethical Risks_exist
int64 | Provider_exist
int64 | Derived From_exist
int64 | Paper Title_exist
int64 | Paper Link_exist
int64 | Script_exist
int64 | Tokenized_exist
int64 | Host_exist
int64 | Access_exist
int64 | Cost_exist
int64 | Test Split_exist
int64 | Tasks_exist
int64 | Venue Title_exist
int64 | Venue Type_exist
int64 | Venue Name_exist
int64 | Authors_exist
int64 | Affiliations_exist
int64 | Abstract_exist
int64 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
ar
|
valid
|
MGB-2
|
[]
|
https://arabicspeech.org/resources/mgb2
|
unknown
| 2,019 |
ar
|
Modern Standard Arabic
|
['TV Channels', 'captions']
|
spoken
|
['human annotation']
|
from Aljazeera TV programs have been manually captioned with no timing information
| 1,200 |
hours
|
Low
|
['QCRI']
|
[]
|
THE MGB-2 CHALLENGE: ARABIC MULTI-DIALECT BROADCAST MEDIA RECOGNITION
|
https://arxiv.org/pdf/1609.05625
|
Arab
| false |
other
|
Upon-Request
| false |
['speech recognition']
|
arXiv
|
preprint
|
['Ahmed Ali', 'Peter Bell', 'James Glass', 'Yacine Messaoui', 'Hamdy Mubarak', 'Steve Renals', 'Yifan Zhang']
|
[]
|
This paper describes the Arabic MGB-3 Challenge — Arabic Speech Recognition in the Wild. Unlike last year's Arabic MGB-2 Challenge, for which the recognition task was based on more than 1,200 hours broadcast TV news recordings from Aljazeera Arabic TV programs, MGB-3 emphasises dialectal Arabic using a multi-genre collection of Egyptian YouTube videos. Seven genres were used for the data collection: comedy, cooking, family/kids, fashion, drama, sports, and science (TEDx). A total of 16 hours of videos, split evenly across the different genres, were divided into adaptation, development and evaluation data sets. The Arabic MGB-Challenge comprised two tasks: A) Speech transcription, evaluated on the MGB-3 test set, along with the 10 hour MGB-2 test set to report progress on the MGB-2 evaluation; B) Arabic dialect identification, introduced this year in order to distinguish between four major Arabic dialects — Egyptian, Levantine, North African, Gulf, as well as Modern Standard Arabic. Two hours of audio per dialect were released for development and a further two hours were used for evaluation. For dialect identification, both lexical features and i-vector bottleneck features were shared with participants in addition to the raw audio recordings. Overall, thirteen teams submitted ten systems to the challenge. We outline the approaches adopted in each system, and summarise the evaluation results.
| 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
|||
ar
|
valid
|
CIDAR
|
[]
|
https://hf.co/datasets/arbml/CIDAR
|
https://hf.co/datasets/arbml/CIDAR
|
CC BY-NC 4.0
| 2,024 |
ar
|
Modern Standard Arabic
|
['commentary', 'LLM']
|
text
|
['crawling', 'LLM generated', 'manual curation']
|
CIDAR contains 10,000 instructions and their output. The dataset was created by selecting around 9,109 samples from Alpagasus dataset then translating it to Arabic using ChatGPT. In addition, we append that with around 891 Arabic grammar instructions from the webiste Ask the teacher.
| 10,000 |
sentences
|
Low
|
['ARBML']
|
['AlpaGasus']
|
CIDAR: Culturally Relevant Instruction Dataset For Arabic
|
https://arxiv.org/pdf/2402.03177
|
Arab
| false |
HuggingFace
|
Free
| false |
['instruction tuning', 'question answering']
|
arXiv
|
preprint
|
['Zaid Alyafeai', 'Khalid Almubarak', 'Ahmed Ashraf', 'Deema Alnuhait', 'Saied Alshahrani', 'Gubran A. Q. Abdulrahman', 'Gamil Ahmed', 'Qais Gawah', 'Zead Saleh', 'Mustafa Ghaleb', 'Yousef Ali', 'Maged S. Al-Shaibani']
|
[]
|
Instruction tuning has emerged as a prominent methodology for teaching Large Language Models (LLMs) to follow instructions.
However, current instruction datasets predominantly cater to English or are derived from
English-dominated LLMs, resulting in inherent
biases toward Western culture. This bias significantly impacts the linguistic structures of
non-English languages such as Arabic, which
has a distinct grammar reflective of the diverse cultures across the Arab region. This
paper addresses this limitation by introducing CIDAR1
the first open Arabic instructiontuning dataset culturally-aligned by human reviewers. CIDAR contains 10,000 instruction
and output pairs that represent the Arab region. We discuss the cultural relevance of
CIDAR via the analysis and comparison to other
models fine-tuned on other datasets. Our experiments show that CIDAR can help enrich
research efforts in aligning LLMs with the
Arabic culture.
| 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
ar
|
valid
|
101 Billion Arabic Words Dataset
|
[]
|
https://hf.co/datasets/ClusterlabAi/101_billion_arabic_words_dataset
|
https://hf.co/datasets/ClusterlabAi/101_billion_arabic_words_dataset
|
Apache-2.0
| 2,024 |
ar
|
mixed
|
['web pages']
|
text
|
['crawling']
|
The 101 Billion Arabic Words Dataset is curated by the Clusterlab team and consists of 101 billion words extracted and cleaned from web content, specifically targeting Arabic text. This dataset is intended for use in natural language processing applications, particularly in training and fine-tuning Large Language Models (LLMs)
| 101,000,000,000 |
tokens
|
High
|
['Clusterlab']
|
['Common Crawl']
|
101 Billion Arabic Words Dataset
|
https://arxiv.org/pdf/2405.01590v1
|
Arab
| false |
HuggingFace
|
Free
| false |
['text generation', 'language modeling']
|
arXiv
|
preprint
|
['Manel Aloui', 'Hasna Chouikhi', 'Ghaith Chaabane', 'Haithem Kchaou', 'Chehir Dhaouadi']
|
['Clusterlab']
|
In recent years, Large Language Models (LLMs) have revolutionized the field of natural language processing, showcasing an impressive rise predominantly in English-centric domains. These advancements have set a global benchmark, inspiring significant efforts toward developing Arabic LLMs capable of understanding and generating the Arabic language with remarkable accuracy. Despite these advancements, a critical challenge persists: the potential bias in Arabic LLMs, primarily attributed to their reliance on datasets comprising English data that has been translated into Arabic. This reliance not only compromises the authenticity of the generated content but also reflects a broader issue—the scarcity of original quality Arabic linguistic data. This study aims to address the data scarcity in the Arab world and to encourage the development of Arabic Language Models that are true to both the linguistic and nuances of the region. We undertook a large-scale data mining project, extracting a substantial volume of text from the Common Crawl WET files, specifically targeting Arabic content. The extracted data underwent a rigorous cleaning and deduplication process, using innovative techniques to ensure the integrity and uniqueness of the dataset. The result is the 101 Billion Arabic Words Dataset, the largest Arabic dataset available to date, which can significantly contribute to the development of authentic Arabic LLMs. This study not only highlights the potential for creating linguistically and culturally accurate Arabic LLMs but also sets a precedent for future research in enhancing the authenticity of Arabic language models.
| 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 |
||
ar
|
valid
|
ArabicMMLU
|
[]
|
https://hf.co/datasets/MBZUAI/ArabicMMLU
|
https://github.com/mbzuai-nlp/ArabicMMLU
|
CC BY-NC-SA 4.0
| 2,024 |
ar
|
Modern Standard Arabic
|
['web pages']
|
text
|
['crawling']
|
ArabicMMLU is the first multi-task language understanding benchmark for Arabic language, sourced from school exams across diverse educational levels in different countries spanning North Africa, the Levant, and the Gulf regions. Our data comprises 40 tasks and 14,575 multiple-choice questions in Modern Standard Arabic (MSA).
| 14,575 |
sentences
|
Low
|
['MBZUAI']
|
[]
|
ArabicMMLU: Assessing Massive Multitask Language Understanding in Arabic
|
https://arxiv.org/pdf/2402.12840
|
Arab
| false |
GitHub
|
Free
| false |
['question answering', 'multiple choice question answering']
|
arXiv
|
preprint
|
['Fajri Koto', 'Haonan Li', 'Sara Shatnawi', 'Jad Doughman', 'Abdelrahman Boda Sadallah', 'Aisha Alraeesi', 'Khalid Almubarak', 'Zaid Alyafeai', 'Neha Sengupta', 'Shady Shehata', 'Nizar Habash', 'Preslav Nakov', 'Timothy Baldwin']
|
[]
|
The focus of language model evaluation has transitioned towards reasoning and knowledge-intensive tasks, driven by advancements in pretraining large models. While state-of-the-art models are partially trained on large Arabic texts, evaluating their performance in Arabic remains challenging due to the limited availability of relevant datasets. To bridge this gap, we present ArabicMMLU, the first multi-task language understanding benchmark for Arabic language, sourced from school exams across diverse educational levels in different countries spanning North Africa, the Levant, and the Gulf regions. Our data comprises 40 tasks and 14,575 multiple-choice questions in Modern Standard Arabic (MSA), and is carefully constructed by collaborating with native speakers in the region. Our comprehensive evaluations of 35 models reveal substantial room for improvement, particularly among the best open-source models. Notably, BLOOMZ, mT0, LLama2, and Falcon struggle to achieve a score of 50%, while even the top-performing Arabic-centric model only achieves a score of 62.3%.
| 1 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
ar
|
valid
|
Belebele
|
[{'Name': 'acm_Arab', 'Dialect': 'Iraq', 'Volume': 900.0, 'Unit': 'sentences'}, {'Name': 'arb_Arab', 'Dialect': 'Modern Standard Arabic', 'Volume': 900.0, 'Unit': 'sentences'}, {'Name': 'apc_Arab', 'Dialect': 'Levant', 'Volume': 900.0, 'Unit': 'sentences'}, {'Name': 'ars_Arab', 'Dialect': 'Saudi Arabia', 'Volume': 900.0, 'Unit': 'sentences'}, {'Name': 'ary_Arab', 'Dialect': 'Morocco', 'Volume': 900.0, 'Unit': 'sentences'}, {'Name': 'arz_Arab', 'Dialect': 'Egypt', 'Volume': 900.0, 'Unit': 'sentences'}]
|
https://hf.co/datasets/facebook/belebele
|
https://github.com/facebookresearch/belebele
|
CC BY-SA 4.0
| 2,024 |
multilingual
|
mixed
|
['wikipedia', 'public datasets']
|
text
|
['human annotation']
|
A multiple-choice machine reading comprehension (MRC) dataset spanning 122 language variants.
| 5,400 |
sentences
|
Low
|
['Facebook']
|
['Flores-200']
|
The BELEBELE Benchmark: a Parallel Reading Comprehension Dataset in 122 Language Variants
|
https://arxiv.org/pdf/2308.16884
|
Arab
| false |
GitHub
|
Free
| false |
['question answering', 'multiple choice question answering']
|
arXiv
|
preprint
|
['Lucas Bandarkar', 'Davis Liang', 'Benjamin Muller', 'Mikel Artetxe', 'Satya Narayan Shukla', 'Donald Husa', 'Naman Goyal', 'Abhinandan Krishnan', 'Luke Zettlemoyer', 'Madian Khabsa']
|
[]
|
We present Belebele, a multiple-choice machine reading comprehension (MRC) dataset spanning 122 language variants. Significantly expanding the language coverage of natural language understanding (NLU) benchmarks, this dataset enables the evaluation of text models in high-, medium-, and low-resource languages. Each question is based on a short passage from the Flores-200 dataset and has four multiple-choice answers. The questions were carefully curated to discriminate between models with different levels of general language comprehension. The English dataset on its own proves difficult enough to challenge state-of-the-art language models. Being fully parallel, this dataset enables direct comparison of model performance across all languages. We use this dataset to evaluate the capabilities of multilingual masked language models (MLMs) and large language models (LLMs). We present extensive results and find that despite significant cross-lingual transfer in English-centric LLMs, much smaller MLMs pretrained on balanced multilingual data still understand far more languages. We also observe that larger vocabulary size and conscious vocabulary construction correlate with better performance on low-resource languages. Overall, Belebele opens up new avenues for evaluating and analyzing the multilingual capabilities of NLP systems.
| 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
ar
|
valid
|
WinoMT
|
[]
|
https://hf.co/datasets/arbml/mt_gender_ar
|
https://github.com/gabrielStanovsky/mt_gender
|
MIT License
| 2,019 |
multilingual
|
Modern Standard Arabic
|
['public datasets']
|
text
|
['machine annotation']
|
Evaluating Gender Bias in Machine Translation
| 3,888 |
sentences
|
Low
|
[]
|
['Winogender', 'WinoBias']
|
Evaluating Gender Bias in Machine Translation
|
https://arxiv.org/pdf/1906.00591
|
Arab
| false |
GitHub
|
Free
| false |
['machine translation']
|
arXiv
|
preprint
|
['Gabriel Stanovsky', 'Noah A. Smith', 'Luke Zettlemoyer']
|
['Allen Institute for Artificial Intelligence', 'University of Washington', 'University of Washington', 'Facebook']
|
We present the first challenge set and evaluation protocol for the analysis of gender bias in machine translation (MT). Our approach uses two recent coreference resolution datasets composed of English sentences which cast participants into non-stereotypical gender roles (e.g., “The doctor asked the nurse to help her in the operation”). We devise an automatic gender bias evaluation method for eight target languages with grammatical gender, based on morphological analysis (e.g., the use of female inflection for the word “doctor”). Our analyses show that four popular industrial MT systems and two recent state-of-the-art academic MT models are significantly prone to gender-biased translation errors for all tested target languages. Our data and code are publicly available at https://github.com/gabrielStanovsky/mt_gender.
| 1 | 1 | 0 | 0 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
ar
|
test
|
MGB-3
|
[]
|
https://github.com/qcri/dialectID
|
MIT License
| 2,017 |
ar
|
Egypt
|
['social media', 'captions']
|
spoken
|
['crawling', 'manual curation']
|
A multi-genre collection of Egyptian YouTube videos. Seven genres were used for the data collection: comedy, cooking, family/kids, fashion, drama, sports, and science (TEDx). A total of 16 hours of videos, split evenly across the different genres
| 16 |
hours
|
Low
|
['QCRI']
|
[]
|
SPEECH RECOGNITION CHALLENGE IN THE WILD: ARABIC MGB-3
|
https://arxiv.org/pdf/1709.07276
|
Arab
| false |
GitHub
|
Free
| false |
['speech recognition']
|
arXiv
|
preprint
|
['Ahmed Ali', 'Stephan Vogel', 'Steve Renals']
|
[]
|
This paper describes the Arabic MGB-3 Challenge — Arabic Speech Recognition in the Wild. Unlike last year's Arabic MGB-2 Challenge, for which the recognition task was based on more than 1,200 hours broadcast TV news recordings from Aljazeera Arabic TV programs, MGB-3 emphasises dialectal Arabic using a multi-genre collection of Egyptian YouTube videos. Seven genres were used for the data collection: comedy, cooking, family/kids, fashion, drama, sports, and science (TEDx). A total of 16 hours of videos, split evenly across the different genres, were divided into adaptation, development and evaluation data sets. The Arabic MGB-Challenge comprised two tasks: A) Speech transcription, evaluated on the MGB-3 test set, along with the 10 hour MGB-2 test set to report progress on the MGB-2 evaluation; B) Arabic dialect identification, introduced this year in order to distinguish between four major Arabic dialects — Egyptian, Levantine, North African, Gulf, as well as Modern Standard Arabic. Two hours of audio per dialect were released for development and a further two hours were used for evaluation. For dialect identification, both lexical features and i-vector bottleneck features were shared with participants in addition to the raw audio recordings. Overall, thirteen teams submitted ten systems to the challenge. We outline the approaches adopted in each system, and summarise the evaluation results.
| 1 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
|||
ar
|
test
|
Arabic-Hebrew TED Talks Parallel Corpus
|
[]
|
https://github.com/ajinkyakulkarni14/TED-Multilingual-Parallel-Corpus
|
unknown
| 2,016 |
multilingual
|
Modern Standard Arabic
|
['captions', 'public datasets']
|
text
|
['machine annotation']
|
This dataset consists of 2023 TED talks with aligned Arabic and Hebrew subtitles. Sentences were rebuilt and aligned using English as a pivot to improve accuracy, offering a valuable resource for Arabic-Hebrew machine translation tasks.
| 225,000 |
sentences
|
Low
|
['FBK']
|
['TED talks', 'WIT3 corpus']
|
An Arabic-Hebrew parallel corpus of TED talks
|
https://arxiv.org/pdf/1610.00572
|
Arab
| false |
GitHub
|
Free
| true |
['machine translation']
|
arXiv
|
preprint
|
['Mauro Cettolo']
|
['Fondazione Bruno Kessler (FBK)']
|
The paper describes the creation of an Arabic-Hebrew parallel corpus from TED talks, aligned using English as a pivot. The benchmark contains around 225,000 sentences and 3.5 million tokens in each language. It was prepared to assist machine translation tasks for Arabic-Hebrew and has been partitioned into train, development, and test sets similar to the IWSLT 2016 evaluation campaign.
| 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
|||
ar
|
test
|
EmojisAnchors
|
[]
|
https://hf.co/datasets/arbml/osact5_hatespeech
|
https://codalab.lisn.upsaclay.fr/competitions/2324
|
custom
| 2,022 |
ar
|
mixed
|
['social media', 'public datasets']
|
text
|
['crawling', 'human annotation']
|
Fine-Grained Hate Speech Detection on Arabic Twitter
| 12,698 |
sentences
|
High
|
['QCRI', 'University of Pittsburgh']
|
['SemEval-2020 Task 12']
|
Overview of OSACT5 Shared Task on Arabic Offensive Language and Hate Speech Detection
|
https://arxiv.org/pdf/2201.06723
|
Arab
| false |
CodaLab
|
Free
| true |
['offensive language detection', 'hate speech detection']
|
arXiv
|
preprint
|
['Hamdy Mubarak', 'Hend Al-Khalifa', 'AbdulMohsen Al-Thubaity']
|
['Qatar Computing Research Institute', 'King Saud University', 'King Abdulaziz City for Science and Technology (KACST)']
|
This paper provides an overview of the shard task on detecting offensive language, hate speech, and fine-grained hate speech at the fifth workshop on Open-Source Arabic Corpora and Processing Tools (OSACT5). The shared task comprised of three subtasks; Subtask A, involving the detection of offensive language, which contains socially unacceptable or impolite content including any kind of explicit or implicit insults or attacks against individuals or groups; Subtask B, involving the detection of hate speech, which contains offensive language targeting individuals or groups based on common characteristics such as race, religion, gender, etc.; and Subtask C, involving the detection of the fine-grained type of hate speech which takes one value from the following types: (i) race/ethnicity/nationality, (ii) religion/belief, (iii) ideology, (iv) disability/disease, (v) social class, and (vi) gender. In total, 40 teams signed up to participate in Subtask A, and 17 of them submitted test runs. For Subtask B, 26 teams signed up to participate and 12 of them submitted runs. And for Subtask C, 23 teams signed up to participate and 10 of them submitted runs. 10 teams submitted papers describing their participation in one subtask or more, and 8 papers were accepted. We present and analyze all submissions in this paper.
| 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
ar
|
test
|
ARASPIDER
|
[]
|
https://github.com/ahmedheakl/AraSpider
|
MIT License
| 2,024 |
ar
|
Modern Standard Arabic
|
['public datasets', 'LLM']
|
text
|
['machine annotation', 'LLM generated', 'human annotation']
|
AraSpider is a translated version of the Spider dataset, which is commonly used for semantic parsing and text-to-SQL generation. The dataset includes 200 databases across 138 domains with 10,181 questions and 5,693 unique complex SQL queries.
| 10,181 |
sentences
|
Low
|
['Egypt-Japan University of Science and Technology']
|
['Spider']
|
ARASPIDER: Democratizing Arabic-to-SQL
|
https://arxiv.org/pdf/2402.07448
|
Arab
| false |
GitHub
|
Free
| true |
['semantic parsing', 'text to SQL']
|
arXiv
|
preprint
|
['Ahmed Heakl', 'Youssef Mohamed', 'Ahmed B. Zaky']
|
['Egypt-Japan University of Science and Technology', 'Egypt-Japan University of Science and Technology', 'Egypt-Japan University of Science and Technology']
|
The AraSpider dataset is an Arabic version of the Spider dataset, designed for text-to-SQL tasks in natural language processing. Four multilingual translation models were evaluated for translating the Spider dataset from English to Arabic, and two models were tested for their ability to generate SQL queries from Arabic text. The study highlights the effectiveness of back translation strategies, and proposes methodologies for democratizing NLP resources and enhancing collaboration within the Arabic-speaking research community.
| 1 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
|||
ar
|
test
|
Maknuune
|
[]
|
https://hf.co/datasets/arbml/Maknuune
|
https://www.palestine-lexicon.org
|
CC BY-SA 4.0
| 2,022 |
multilingual
|
Palestine
|
['captions', 'public datasets', 'other']
|
text
|
['manual curation']
|
A large open lexicon for the Palestinian Arabic dialect. Maknuune has over 36K entries from 17K lemmas,and 3.7K roots. All entries include diacritized Arabic orthography, phonological transcription and English glosses.
| 36,302 |
tokens
|
Low
|
['New York University Abu Dhabi', 'University of Oxford', 'UNRWA']
|
['Curras']
|
Maknuune: A Large Open Palestinian Arabic Lexicon
|
https://arxiv.org/pdf/2210.12985
|
Arab-Latin
| true |
Gdrive
|
Free
| false |
['morphological analysis', 'lexicon analysis']
|
arXiv
|
preprint
|
['Shahd Dibas', 'Christian Khairallah', 'Nizar Habash', 'Omar Fayez Sadi', 'Tariq Sairafy', 'Karmel Sarabta', 'Abrar Ardah']
|
['NYUAD', 'University of Oxford', 'UNRWA']
|
We present Maknuune, a large open lexicon for the Palestinian Arabic dialect. Maknuune has over 36K entries from 17K lemmas, and 3.7K roots. All entries include diacritized Arabic orthography, phonological transcription and English glosses. Some entries are enriched with additional information such as broken plurals and templatic feminine forms, associated phrases and collocations, Standard Arabic glosses, and examples or notes on grammar, usage, or location of collected entry.
| 1 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
ar
|
test
|
Calliar
|
[]
|
https://hf.co/datasets/arbml/Calliar
|
https://github.com/ARBML/Calliar
|
MIT License
| 2,021 |
ar
|
Modern Standard Arabic
|
['web pages']
|
images
|
['crawling', 'human annotation']
|
Calliar is a dataset for Arabic calligraphy. The dataset consists of 2500 json files that contain strokes manually annotated for Arabic calligraphy. This repository contains the dataset for the following paper
| 2,500 |
images
|
Low
|
['ARBML']
|
[]
|
Calliar: An Online Handwritten Dataset for Arabic Calligraphy
|
https://arxiv.org/pdf/2106.10745
|
Arab
| false |
GitHub
|
Free
| true |
['optical character recognition']
|
arXiv
|
preprint
|
['Zaid Alyafeai', 'Maged S. Al-shaibani', 'Mustafa Ghaleb & Yousif Ahmed Al-Wajih']
|
['KFUPM', 'KFUPM', 'KFUPM', 'KFUPM']
|
Calligraphy is an essential part of the Arabic heritage and culture. It has been used in the past for the decoration of houses and mosques. Usually, such calligraphy is designed manually by experts with aesthetic insights. In the past few years, there has been a considerable effort to digitize such type of art by either taking a photograph of decorated buildings or drawing them using digital devices. The latter is considered an online form where the drawing is tracked by recording the apparatus movement, an electronic pen, for instance, on a screen. In the literature, there are many offline datasets with diverse Arabic styles for calligraphy. However, there is no available online dataset for Arabic calligraphy. In this paper, we illustrate our approach for collecting and annotating an online dataset for Arabic calligraphy called Calliar, which consists of 2,500 sentences. Calliar is annotated for stroke, character, word, and sentence-level prediction. We also propose various baseline models for the character classification task. The results we achieved highlight that it is still an open problem.
| 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
ar
|
test
|
LABR
|
[]
|
https://github.com/mohamedadaly/LABR
|
GPL-2.0
| 2,015 |
ar
|
mixed
|
['social media', 'reviews']
|
text
|
['crawling', 'human annotation']
|
A large Arabic book review dataset for sentiment analysis
| 63,257 |
sentences
|
Low
|
['Cairo University']
|
[]
|
LABR: A Large Scale Arabic Sentiment Analysis Benchmark
|
https://arxiv.org/pdf/1411.6718
|
Arab
| false |
GitHub
|
Free
| true |
['review classification', 'sentiment analysis']
|
arXiv
|
preprint
|
['Mahmoud Nabil', 'Mohamed Aly', 'Amir F. Atiya']
|
['Cairo University', 'Cairo University', 'Cairo University']
|
We introduce LABR, the largest sentiment analysis dataset to-date for the Arabic language. It consists of over 63,000 book reviews, each rated on a scale of 1 to 5 stars. We investigate the properties of the dataset, and present its statistics. We explore using the dataset for two tasks: (1) sentiment polarity classification; and (2) ratings classification. Moreover, we provide standard splits of the dataset into training, validation and testing, for both polarity and ratings classification, in both balanced and unbalanced settings. We extend our previous work by performing a comprehensive analysis on the dataset. In particular, we perform an extended survey of the different classifiers typically used for the sentiment polarity classification problem. We also construct a sentiment lexicon from the dataset that contains both single and compound sentiment words and we explore its effectiveness. We make the dataset and experimental details publicly available.
| 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
|||
ar
|
test
|
ACVA
|
[]
|
https://huggingface.co/datasets/FreedomIntelligence/ACVA-Arabic-Cultural-Value-Alignment
|
https://github.com/FreedomIntelligence/AceGPT
|
Apache-2.0
| 2,023 |
ar
|
Modern Standard Arabic
|
['LLM']
|
text
|
['LLM generated']
|
ACVA is a Yes-No question dataset, comprising over 8000 questions, generated by GPT-3.5 Turbo from 50 designed Arabic topics to assess model alignment with Arabic values and cultures
| 8,000 |
sentences
|
Low
|
['FreedomIntelligence']
|
[]
|
AceGPT, Localizing Large Language Models in Arabic
|
https://arxiv.org/pdf/2309.12053
|
Arab
| false |
GitHub
|
Free
| false |
['question answering']
|
arXiv
|
preprint
|
['Huang Huang', 'Fei Yu', 'Jianqing Zhu', 'Xuening Sun', 'Hao Cheng', 'Dingjie Song', 'Zhihong Chen', 'Abdulmohsen Alharthi', 'Bang An', 'Juncai He', 'Ziche Liu', 'Zhiyi Zhang', 'Junying Chen', 'Jianquan Li', 'Benyou Wang', 'Lian Zhang', 'Ruoyu Sun', 'Xiang Wan', 'Haizhou Li', 'Jinchao Xu']
|
[]
|
This paper is devoted to the development of a localized Large Language Model (LLM) specifically for Arabic, a language imbued with unique cultural characteristics inadequately addressed by current mainstream models. Significant concerns emerge when addressing cultural sensitivity and local values. To address this, the paper proposes a comprehensive solution that includes further pre-training with Arabic texts, Supervised Fine-Tuning (SFT) utilizing native Arabic instructions, and GPT-4 responses in Arabic, alongside Reinforcement Learning with AI Feedback (RLAIF) employing a reward model attuned to local culture and values. The goal is to cultivate culturally cognizant and value-aligned Arabic LLMs capable of accommodating the diverse, application-specific needs of Arabic-speaking communities. Comprehensive evaluations reveal that the resulting model, dubbed `AceGPT', sets the state-of-the-art standard for open Arabic LLMs across various benchmarks. Codes, data, and models are in this https URL.
| 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
ar
|
test
|
LASER
|
[]
|
https://github.com/facebookresearch/LASER
|
BSD
| 2,019 |
multilingual
|
Modern Standard Arabic
|
['public datasets']
|
text
|
['crawling']
|
Aligned sentences in 112 languages extracted from Tatoeba
| 1,000 |
sentences
|
Low
|
['Facebook']
|
['Europarl', 'United Nations', 'OpenSubtitles2018', 'Global Voices', 'Tanzil', 'Tatoeba']
|
Massively Multilingual Sentence Embeddings for Zero-Shot
Cross-Lingual Transfer and Beyond
|
https://arxiv.org/pdf/1812.10464
|
Arab
| false |
GitHub
|
Free
| false |
['machine translation', 'Embeddings']
|
arXiv
|
preprint
|
['Mikel Artetxe', 'Holger Schwenk']
|
['University of the Basque Country', 'Facebook AI Research']
|
Abstract We introduce an architecture to learn joint multilingual sentence representations for 93 languages, belonging to more than 30 different families and written in 28 different scripts. Our system uses a single BiLSTM encoder with a shared byte-pair encoding vocabulary for all languages, which is coupled with an auxiliary decoder and trained on publicly available parallel corpora. This enables us to learn a classifier on top of the resulting embeddings using English annotated data only, and transfer it to any of the 93 languages without any modification. Our experiments in cross-lingual natural language inference (XNLI data set), cross-lingual document classification (MLDoc data set), and parallel corpus mining (BUCC data set) show the effectiveness of our approach. We also introduce a new test set of aligned sentences in 112 languages, and show that our sentence embeddings obtain strong results in multilingual similarity search even for low- resource languages. Our implementation, the pre-trained encoder, and the multilingual test set are available at https://github.com/facebookresearch/LASER.
| 1 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
|||
ar
|
test
|
DODa
|
[]
|
https://hf.co/datasets/arbml/darija
|
https://github.com/darija-open-dataset/dataset
|
MIT License
| 2,021 |
multilingual
|
Morocco
|
['other']
|
text
|
['manual curation']
|
DODa presents words under different spellings, offers verb-to-noun and masculine-to-feminine correspondences contains the conjugation of hundreds of verbs in different tenses,
| 10,000 |
tokens
|
Low
|
[]
|
[]
|
Moroccan Dialect -Darija- Open Dataset
|
https://arxiv.org/pdf/2103.09687
|
Arab-Latin
| true |
GitHub
|
Free
| false |
['transliteration', 'machine translation', 'part of speech tagging']
|
arXiv
|
preprint
|
['Aissam Outchakoucht', 'Hamza Es-Samaali']
|
[]
|
Nowadays, we are witnessing an unprecedented growth of IT products and services. Yet, in order for many of these solutions to flourish and be viable in a given society, they need to « understand » and be able to communicate to some extent using native languages. However, it turns out that step 0 in any serious engagement with Natural Language Processing (NLP) consists of translating the vocabulary to the widely used and most documented language in this field, namely English.
| 1 | 1 | 0 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
ar
|
test
|
TUNIZI
|
[]
|
https://hf.co/datasets/arbml/TUNIZI
|
https://github.com/chaymafourati/TUNIZI-Sentiment-Analysis-Tunisian-Arabizi-Dataset
|
unknown
| 2,020 |
ar
|
Tunisia
|
['social media', 'commentary']
|
text
|
['crawling', 'human annotation']
|
first Tunisian Arabizi Dataset including 3K sentences, balanced, covering different topics, preprocessed and annotated as positive and negative
| 9,210 |
sentences
|
Medium
|
['iCompass']
|
[]
|
TUNIZI: A TUNISIAN ARABIZI SENTIMENT ANALYSIS
DATASET
|
https://arxiv.org/pdf/2004.14303
|
Latin
| false |
GitHub
|
Free
| false |
['sentiment analysis']
|
arXiv
|
preprint
|
['Chayma Fourati', 'Abir Messaoudi', 'Hatem Haddad']
|
['iCompass', 'iCompass', 'iCompass']
|
On social media, Arabic people tend to express themselves in their own local dialects. More particularly, Tunisians use the informal way called "Tunisian Arabizi". Analytical studies seek to explore and recognize online opinions aiming to exploit them for planning and prediction purposes such as measuring the customer satisfaction and establishing sales and marketing strategies. However, analytical studies based on Deep Learning are data hungry. On the other hand, African languages and dialects are considered low resource languages. For instance, to the best of our knowledge, no annotated Tunisian Arabizi dataset exists. In this paper, we introduce TUNIZI a sentiment analysis Tunisian Arabizi Dataset, collected from social networks, preprocessed for analytical studies and annotated manually by Tunisian native speakers.
| 1 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
ar
|
test
|
AraDangspeech
|
[]
|
https://hf.co/datasets/arbml/Dangerous_Dataset
|
https://github.com/UBC-NLP/Arabic-Dangerous-Dataset
|
unknown
| 2,020 |
ar
|
mixed
|
['social media']
|
text
|
['crawling', 'human annotation']
|
Dangerous speech detection
| 5,011 |
sentences
|
High
|
['The University of British Columbia']
|
[]
|
Understanding and Detecting Dangerous Speech in Social Media
|
https://arxiv.org/pdf/2005.06608
|
Arab
| false |
GitHub
|
Free
| false |
['offensive language detection', 'dangerous speech detection', 'hate speech detection']
|
arXiv
|
preprint
|
['Ali Alshehri', 'El Moatez Billah Nagoudi', 'Muhammad Abdul-Mageed']
|
['The University of British Columbia']
|
Social media communication has become a significant part of daily activity in modern societies. For this reason, ensuring safety in social media platforms is a necessity. Use of dangerous language such as physical threats in online environments is a somewhat rare, yet remains highly important. Although several works have been performed on the related issue of detecting offensive and hateful language, dangerous speech has not previously been treated in any significant way. Motivated by these observations, we report our efforts to build a labeled dataset for dangerous speech. We also exploit our dataset to develop highly effective models to detect dangerous content. Our best model performs at 59.60% macro F1, significantly outperforming a competitive baseline.
| 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
ar
|
test
|
Arap-Tweet
|
[]
|
https://arap.qatar.cmu.edu/templates/research.html
|
unknown
| 2,018 |
ar
|
mixed
|
['social media']
|
text
|
['crawling', 'human annotation']
|
Arap-Tweet is a large-scale, multi-dialectal Arabic Twitter corpus containing 2.4 million tweets from 11 regions across 16 countries in the Arab world. The dataset includes annotations for dialect, age group, and gender of the users.
| 2,400,000 |
sentences
|
Medium
|
['Hamad Bin Khalifa University', 'Carnegie Mellon University Qatar']
|
[]
|
Arap-Tweet: A Large Multi-Dialect Twitter Corpus for Gender, Age, and Language Variety Identification
|
https://arxiv.org/pdf/1808.07674
|
Arab
| false |
other
|
Upon-Request
| false |
['dialect identification', 'gender identification', 'age identification']
|
arXiv
|
preprint
|
['Wajdi Zaghouani', 'Anis Charfi']
|
['Hamad Bin Khalifa University', 'Carnegie Mellon University Qatar']
|
This paper presents the Arap-Tweet corpus, a large-scale, multi-dialectal Arabic corpus sourced from Twitter, which has been annotated for age, gender, and dialectal variety. The corpus is intended to provide resources for developing NLP tools and models for Arabic dialects and can be used in tasks such as author profiling, sentiment analysis, and more. The dataset covers 11 major dialect regions and includes over 2.4 million tweets. Annotators identified users based on dialect-specific keywords and verified additional metadata (age and gender) through manual checks and external resources.
| 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
|||
ar
|
test
|
FLORES-101
|
[]
|
https://hf.co/datasets/gsarti/flores_101
|
https://github.com/facebookresearch/flores/tree/main/previous_releases/flores101
|
CC BY-SA 4.0
| 2,021 |
multilingual
|
Modern Standard Arabic
|
['wikipedia', 'books', 'news articles']
|
text
|
['crawling', 'human annotation']
|
The FLORES-101 evaluation benchmark consists of 3001 sentences extracted from English Wikipedia and covers various topics and domains. These sentences have been translated into 101 languages by professional translators through a carefully controlled process.
| 3,001 |
sentences
|
Low
|
['Facebook']
|
[]
|
The FLORES-101 Evaluation Benchmark for Low-Resource and Multilingual Machine Translation
|
https://arxiv.org/pdf/2106.03193
|
Arab
| false |
GitHub
|
Free
| true |
['machine translation']
|
arXiv
|
preprint
|
['Naman Goyal', 'Cynthia Gao', 'Vishrav Chaudhary', 'Guillaume Wenzek', 'Da Ju', 'Sanjan Krishnan', "Marc'Aurelio Ranzato", 'Francisco Guzmán', 'Angela Fan']
|
['Facebook AI Research']
|
One of the biggest challenges hindering progress in low-resource and multilingual machine translation is the lack of good evaluation benchmarks. Current evaluation benchmarks either lack good coverage of low-resource languages, consider only restricted domains, or are low quality because they are constructed using semi-automatic procedures. In this work, we introduce the FLORES-101 evaluation benchmark, consisting of 3001 sentences extracted from English Wikipedia and covering a variety of different topics and domains. These sentences have been translated in 101 languages by professional translators through a carefully controlled process. The resulting dataset enables better assessment of model quality on the long tail of low-resource languages, including the evaluation of many-to-many multilingual translation systems, as all translations are multilingually aligned. By publicly releasing such a highquality and high-coverage dataset, we hope to foster progress in the machine translation community and beyond.
| 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
ar
|
test
|
ADI-5
|
[{'Name': 'Egyptian', 'Dialect': 'Egypt', 'Volume': 14.4, 'Unit': 'hours'}, {'Name': 'Gulf', 'Dialect': 'Gulf', 'Volume': 14.1, 'Unit': 'hours'}, {'Name': 'Levantine', 'Dialect': 'Levant', 'Volume': 14.3, 'Unit': 'hours'}, {'Name': 'MSA', 'Dialect': 'Modern Standard Arabic', 'Volume': 14.3, 'Unit': 'hours'}, {'Name': 'North African', 'Dialect': 'North Africa', 'Volume': 14.6, 'Unit': 'hours'}]
|
https://github.com/Qatar-Computing-Research-Institute/dialectID
|
MIT License
| 2,016 |
ar
|
mixed
|
['TV Channels']
|
spoken
|
['crawling']
|
This will be divided across the five major Arabic dialects; Egyptian (EGY), Levantine (LAV), Gulf (GLF), North African (NOR), and Modern Standard Arabic (MSA)
| 74.5 |
hours
|
Low
|
['QCRI']
|
[]
|
Automatic Dialect Detection in Arabic Broadcast Speech
|
https://arxiv.org/pdf/1509.06928
|
Arab
| false |
GitHub
|
Free
| true |
['dialect identification']
|
arXiv
|
preprint
|
['A. Ali', 'Najim Dehak', 'P. Cardinal', 'Sameer Khurana', 'S. Yella', 'James R. Glass', 'P. Bell', 'S. Renals']
|
[]
|
We investigate different approaches for dialect identification in Arabic broadcast speech, using phonetic, lexical features obtained from a speech recognition system, and acoustic features using the i-vector framework. We studied both generative and discriminate classifiers, and we combined these features using a multi-class Support Vector Machine (SVM). We validated our results on an Arabic/English language identification task, with an accuracy of 100%. We used these features in a binary classifier to discriminate between Modern Standard Arabic (MSA) and Dialectal Arabic, with an accuracy of 100%. We further report results using the proposed method to discriminate between the five most widely used dialects of Arabic: namely Egyptian, Gulf, Levantine, North African, and MSA, with an accuracy of 52%. We discuss dialect identification errors in the context of dialect code-switching between Dialectal Arabic and MSA, and compare the error pattern between manually labeled data, and the output from our classifier. We also release the train and test data as standard corpus for dialect identification.
| 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 |
|||
ar
|
test
|
Shamela
|
[]
|
https://github.com/OpenArabic/
|
unknown
| 2,016 |
ar
|
Classical Arabic
|
['books']
|
text
|
['crawling', 'machine annotation']
|
a large-scale, historical corpus of Arabic of about 1 billion
words from diverse periods of time
| 6,100 |
documents
|
Low
|
[]
|
[]
|
Shamela: A Large-Scale Historical Arabic Corpus
|
https://arxiv.org/pdf/1612.08989
|
Arab
| true |
GitHub
|
Free
| false |
['text generation', 'language modeling', 'part of speech tagging', 'morphological analysis']
|
arXiv
|
preprint
|
['Yonatan Belinkov', 'Alexander Magidow', 'Maxim Romanov', 'Avi Shmidman', 'Moshe Koppel']
|
[]
|
Arabic is a widely-spoken language with a rich and long history spanning more than fourteen centuries. Yet existing Arabic corpora largely focus on the modern period or lack sufficient diachronic information. We develop a large-scale, historical corpus of Arabic of about 1 billion words from diverse periods of time. We clean this corpus, process it with a morphological analyzer, and enhance it by detecting parallel passages and automatically dating undated texts. We demonstrate its utility with selected case-studies in which we show its application to the digital humanities.
| 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
|||
ar
|
test
|
Transliteration
|
[]
|
https://hf.co/datasets/arbml/google_transliteration
|
https://github.com/google/transliteration
|
Apache-2.0
| 2,016 |
multilingual
|
Modern Standard Arabic
|
['wikipedia']
|
text
|
['crawling']
|
Arabic-English transliteration dataset mined from Wikipedia.
| 15,898 |
tokens
|
Low
|
['Google']
|
[]
|
Sequence-to-sequence neural network models for transliteration
|
https://arxiv.org/pdf/1610.09565
|
Arab-Latin
| false |
GitHub
|
Free
| true |
['transliteration', 'translation']
|
arXiv
|
preprint
|
['Mihaela Rosca', 'Thomas Breuel']
|
['Google']
|
Transliteration is a key component of machine
translation systems and software internationalization. This paper demonstrates that neural
sequence-to-sequence models obtain state of
the art or close to state of the art results on existing datasets. In an effort to make machine
transliteration accessible, we open source a
new Arabic to English transliteration dataset
and our trained models.
| 1 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
ar
|
test
|
OpenITI-proc
|
[]
|
https://zenodo.org/record/2535593#.YWh7FS8RozU
|
CC BY 4.0
| 2,018 |
ar
|
Classical Arabic
|
['public datasets', 'books']
|
text
|
['other']
|
A linguistically annotated version of the OpenITI corpus, with annotations for lemmas, POS tags, parse trees, and morphological segmentation
| 7,144 |
documents
|
Low
|
[]
|
['OpenITI', 'Shamela']
|
Studying the History of the Arabic Language: Language Technology and a Large-Scale Historical Corpus
|
https://arxiv.org/pdf/1809.03891
|
Arab
| false |
zenodo
|
Free
| false |
['text generation', 'language modeling']
|
arXiv
|
preprint
|
['Yonatan Belinkov', 'Alexander Magidow', 'Alberto Barrón-Cedeño', 'Avi Shmidman', 'Maxim Romanov']
|
[]
|
Arabic is a widely-spoken language with a long and rich history, but existing corpora and language technology focus mostly on modern Arabic and its varieties. Therefore, studying the history of the language has so far been mostly limited to manual analyses on a small scale. In this work, we present a large-scale historical corpus of the written Arabic language, spanning 1400 years. We describe our efforts to clean and process this corpus using Arabic NLP tools, including the identification of reused text. We study the history of the Arabic language using a novel automatic periodization algorithm, as well as other techniques. Our findings confirm the established division of written Arabic into Modern Standard and Classical Arabic, and confirm other established periodizations, while suggesting that written Arabic may be divisible into still further periods of development.
| 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
|||
ar
|
test
|
POLYGLOT-NER
|
[]
|
https://huggingface.co/datasets/rmyeid/polyglot_ner
|
https://huggingface.co/datasets/rmyeid/polyglot_ner
|
unknown
| 2,014 |
multilingual
|
Modern Standard Arabic
|
['wikipedia']
|
text
|
['machine annotation']
|
Polyglot-NER A training dataset automatically generated from Wikipedia and Freebase the task of named entity recognition. The dataset contains the basic Wikipedia based training data for 40 languages we have (with coreference resolution) for the task of named entity recognition.
| 10,000,144 |
tokens
|
Low
|
['Stony Brook University']
|
[]
|
POLYGLOT-NER: Massive Multilingual Named Entity Recognition
|
https://arxiv.org/pdf/1410.3791
|
Arab
| false |
HuggingFace
|
Free
| false |
['named entity recognition']
|
arXiv
|
preprint
|
['Rami Al-Rfou', 'Vivek Kulkarni', 'Bryan Perozzi', 'Steven Skiena']
|
['Stony Brook University']
|
The increasing diversity of languages used on the web introduces a new level of complexity to Information Retrieval (IR) systems. We can no longer assume that textual content is written in one language or even the same language family. In this paper, we demonstrate how to build massive multilingual annotators with minimal human expertise and intervention. We describe a system that builds Named Entity Recognition (NER) annotators for 40 major languages using Wikipedia and Freebase. Our approach does not require NER human annotated datasets or language specific resources like treebanks, parallel corpora, and orthographic rules. The novelty of approach lies therein - using only language agnostic techniques, while achieving competitive performance. Our method learns distributed word representations (word embeddings) which encode semantic and syntactic features of words in each language. Then, we automatically generate datasets from Wikipedia link structure and Freebase attributes. Finally, we apply two preprocessing stages (oversampling and exact surface form matching) which do not require any linguistic expertise. Our evaluation is two fold: First, we demonstrate the system performance on human annotated datasets. Second, for languages where no gold-standard benchmarks are available, we propose a new method, distant evaluation, based on statistical machine translation.
| 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
ar
|
test
|
ANETAC
|
[]
|
https://hf.co/datasets/arbml/ANETAC
|
https://github.com/MohamedHadjAmeur/ANETAC
|
unknown
| 2,019 |
multilingual
|
Modern Standard Arabic
|
['public datasets']
|
text
|
['machine annotation']
|
English-Arabic named entity transliteration and classification dataset
| 79,924 |
tokens
|
Low
|
['USTHB University', 'University of Salford']
|
['United Nations', 'Open Subtitles', 'News Commentary', 'IWSLT206']
|
ANETAC: Arabic Named Entity Transliteration and Classification Dataset
|
https://arxiv.org/pdf/1907.03110
|
Arab
| false |
GitHub
|
Free
| true |
['named entity recognition', 'transliteration', 'machine translation']
|
arXiv
|
preprint
|
['Mohamed Seghir Hadj Ameur', 'Farid Meziane', 'Ahmed Guessoum']
|
['USTHB University', 'University of Salford', 'USTHB University']
|
In this paper, we make freely accessible ANETAC our English-Arabic named entity transliteration and classification dataset that we built from freely available parallel translation corpora. The dataset contains 79,924 instances, each instance is a triplet (e, a, c), where e is the English named entity, a is its Arabic transliteration and c is its class that can be either a Person, a Location, or an Organization. The ANETAC dataset is mainly aimed for the researchers that are working on Arabic named entity transliteration, but it can also be used for named entity classification purposes.
| 1 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
ar
|
test
|
ATHAR
|
[]
|
https://hf.co/datasets/mohamed-khalil/ATHAR
|
https://hf.co/datasets/mohamed-khalil/ATHAR
|
CC BY-SA 4.0
| 2,024 |
multilingual
|
Classical Arabic
|
['books']
|
text
|
['crawling', 'human annotation']
|
The ATHAR dataset comprises 66,000 translation pairs from Classical Arabic to English. It spans a wide array of subjects, aiming to enhance the development of NLP models specialized in Classical Arabic.
| 66,000 |
sentences
|
Low
|
['ADAPT/DCU']
|
[]
|
ATHAR: A High-Quality and Diverse Dataset for Classical Arabic to English Translation
|
https://arxiv.org/pdf/2407.19835
|
Arab
| false |
HuggingFace
|
Free
| true |
['machine translation']
|
arXiv
|
preprint
|
['Mohammed Khalil', 'Mohammed Sabry']
|
['Independent Researcher', 'ADAPT/DCU']
|
ATHAR is a dataset comprising 66,000 high-quality translation pairs from Classical Arabic to English, aimed at improving NLP and machine translation systems. The dataset covers a broad range of Classical Arabic texts, including science, philosophy, and history. Evaluations on state-of-the-art language models indicate that fine-tuning with this dataset significantly improves translation accuracy.
| 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
en
|
test
|
TriviaQA
| null |
https://huggingface.co/datasets/mandarjoshi/trivia_qa
|
http://nlp.cs.washington.edu/triviaqa
|
Apache-2.0
| 2,017 |
en
| null |
['wikipedia', 'web pages']
|
text
|
['crawling', 'human annotation']
|
TriviaQA is a challenging reading comprehension dataset containing over 650K question-answer-evidence triples. TriviaQA includes 95K question-answer pairs authored by trivia enthusiasts and independently gathered evidence documents, six per question on average, that provide high quality distant supervision for answering the questions.
| 650,000 |
documents
|
Low
|
['University of Washington']
|
[]
|
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
|
https://arxiv.org/pdf/1705.03551
| null | false |
other
|
Free
| true |
['question answering', 'information retrieval']
|
arXiv
|
preprint
|
['Mandar Joshi', 'Eunsol Choi', 'Daniel S. Weld', 'Luke Zettlemoyer']
|
['Allen Institute for Artificial Intelligence', 'University of Washington']
|
We present TriviaQA, a challenging reading comprehension dataset containing over 650K question-answer-evidence triples. TriviaQA includes 95K question-answer pairs authored by trivia enthusiasts and independently gathered evidence documents, six per question on average, that provide high quality distant supervision for answering the questions. We show that, in comparison to other recently introduced large-scale datasets, TriviaQA (1) has relatively complex, compositional questions, (2) has considerable syntactic and lexical variability between questions and corresponding answer-evidence sentences, and (3) requires more cross sentence reasoning to find answers. We also present two baseline algorithms: a feature-based classifier and a state-of-the-art neural network, that performs well on SQuAD reading comprehension. Neither approach comes close to human performance (23% and 40% vs. 80%), suggesting that TriviaQA is a challenging testbed that deserves significant future study.
| 1 | null | 0 | 1 | 0 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
en
|
test
|
GSM8K
| null |
https://huggingface.co/datasets/openai/gsm8k
|
https://github.com/openai/grade-school-math
|
MIT License
| 2,021 |
en
| null |
['other']
|
text
|
['human annotation', 'manual curation']
|
GSM8K is a dataset of 8.5K high quality grade school math problems created by human problem writers. The dataset is designed to have high linguistic diversity while relying on relatively simple grade school math concepts.
| 8,500 |
sentences
|
Low
|
['OpenAI']
|
[]
|
Training Verifiers to Solve Math Word Problems
|
https://arxiv.org/pdf/2110.14168
| null | false |
GitHub
|
Free
| true |
['question answering', 'reasoning']
|
arXiv
|
preprint
|
['Karl Cobbe', 'Vineet Kosaraju', 'Mohammad Bavarian', 'Mark Chen', 'Heewoo Jun', 'Łukasz Kaiser', 'Matthias Plappert', 'Jerry Tworek', 'Jacob Hilton', 'Reiichiro Nakano', 'Christopher Hesse', 'John Schulman']
|
['OpenAI']
|
State-of-the-art language models can match human performance on many tasks, but they still struggle to robustly perform multi-step mathematical reasoning. To diagnose the failures of current models and support research, we introduce GSM8K, a dataset of 8.5K high quality linguistically diverse grade school math word problems. We find that even the largest transformer models fail to achieve high test performance, despite the conceptual simplicity of this problem distribution. To increase performance, we propose training verifiers to judge the correctness of model completions. At test time, we generate many candidate solutions and select the one ranked highest by the verifier. We demonstrate that verification significantly improves performance on GSM8K, and we provide strong empirical evidence that verification scales more effectively with increased data than a finetuning baseline.
| 1 | null | 0 | 1 | 0 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
en
|
test
|
HLE
| null |
https://huggingface.co/datasets/cais/hle
|
https://lastexam.ai
|
MIT License
| 2,025 |
en
| null |
['other']
|
text
|
['human annotation', 'manual curation']
|
Humanity's Last Exam (HLE) is a dataset of 3,000 challenging questions designed to assess the capabilities of large language models (LLMs). The questions are diverse, covering a wide range of topics and requiring different reasoning abilities. The dataset is still under development and accepting new questions.
| 3,000 |
sentences
|
Low
|
['Center for AI Safety', 'Scale AI']
|
[]
|
Humanity's Last Exam
|
https://arxiv.org/pdf/2501.14249
| null | false |
other
|
Free
| false |
['question answering', 'multiple choice question answering']
|
arXiv
|
preprint
|
['Long Phan', 'Alice Gatti', 'Ziwen Han', 'Nathaniel Li', 'Josephina Hu', 'Hugh Zhang', 'Sean Shi', 'Michael Choi', 'Anish Agrawal', 'Arnav Chopra', 'Adam Khoja', 'Ryan Kim', 'Richard Ren', 'Jason Hausenloy', 'Oliver Zhang', 'Mantas Mazeika', 'Summer Yue', 'Alexandr Wang', 'Dan Hendrycks']
|
['Center for AI Safety', 'Scale AI']
|
We introduce Humanity's Last Exam (HLE), a dataset of 3,000 challenging questions designed to assess the capabilities of large language models (LLMs). The questions are diverse, covering a wide range of topics and requiring different reasoning abilities. We evaluate a variety of LLMs on HLE, finding that even the most advanced models struggle with many of the questions. We believe that HLE is a valuable resource for researchers working to develop more capable and robust LLMs. We are still accepting new questions for HLE, and we encourage researchers to submit their own challenging questions to help us build a more comprehensive and challenging benchmark.
| 1 | null | 0 | 1 | 0 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
en
|
test
|
MMLU
| null |
https://huggingface.co/datasets/cais/mmlu
|
https://github.com/hendrycks/test
|
MIT License
| 2,021 |
en
| null |
['web pages', 'books']
|
text
|
['manual curation']
|
The MMLU dataset is a collection of 57 tasks covering a wide range of subjects, including elementary mathematics, US history, computer science, law, and more. The dataset is designed to measure a text model's multitask accuracy and requires models to possess extensive world knowledge and problem-solving ability.
| 15,908 |
sentences
|
Low
|
['UC Berkeley', 'Columbia University', 'UChicago', 'UIUC']
|
[]
|
Measuring Massive Multitask Language Understanding
|
https://arxiv.org/pdf/2009.03300
| null | false |
GitHub
|
Free
| false |
['multiple choice question answering']
|
arXiv
|
preprint
|
['Dan Hendrycks', 'Collin Burns', 'Steven Basart', 'Andy Zou', 'Mantas Mazeika', 'Dawn Song', 'Jacob Steinhardt']
|
['UC Berkeley', 'Columbia University', 'UChicago', 'UIUC']
|
We propose a new test to measure a text model's multitask accuracy. The test covers 57 tasks including elementary mathematics, US history, computer science, law, and more. To attain high accuracy on this test, models must possess extensive world knowledge and problem solving ability. We find that while most recent models have near random-chance accuracy, the very largest GPT-3 model improves over random chance by almost 20 percentage points on average. However, on every one of the 57 tasks, the best models still need substantial improvements before they can reach expert-level accuracy. Models also have lopsided performance and frequently do not know when they are wrong. Worse, they still have near-random accuracy on some socially important subjects such as morality and law. By comprehensively evaluating the breadth and depth of a model's academic and professional understanding, our test can be used to analyze models across many tasks and to identify important shortcomings.
| 1 | null | 0 | 0 | 0 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
en
|
test
|
HellaSwag
| null |
https://huggingface.co/datasets/Rowan/hellaswag
|
https://rowanzellers.com/hellaswag
|
MIT License
| 2,019 |
en
| null |
['captions', 'public datasets', 'LLM', 'web pages']
|
text
|
['crawling', 'machine annotation', 'LLM generated']
|
HellaSwag is a dataset for physically situated commonsense reasoning.
| 70,000 |
sentences
|
Low
|
['Allen Institute of Artificial Intelligence']
|
['ActivityNet']
|
HellaSwag: Can a Machine Really Finish Your Sentence?
|
https://arxiv.org/pdf/1905.07830
| null | false |
other
|
Free
| true |
['natural language inference', 'other']
|
arXiv
|
preprint
|
['Rowan Zellers', 'Ariz Holtzman', 'Yonatan Bisk', 'Ali Farhadi', 'Yejin Choi']
|
['Paul G. Allen School of Computer Science & Engineering', 'University of Washington', 'Allen Institute of Artificial Intelligence']
|
Recent work by Zellers et al. (2018) introduced a new task of commonsense natural language inference: given an event description such as "A woman sits at a piano," a machine must select the most likely followup: "She sets her fingers on the keys." With the introduction of BERT, near human-level performance was reached. Does this mean that machines can perform human level commonsense inference?
In this paper, we show that commonsense inference still proves difficult for even state-of-the-art models, by presenting HellaSwag, a new challenge dataset. Though its questions are trivial for humans (>95% accuracy), state-of-the-art models struggle (<48%). We achieve this via Adversarial Filtering (AF), a data collection paradigm wherein a series of discriminators iteratively select an adversarial set of machine-generated wrong answers. AF proves to be surprisingly robust. The key insight is to scale up the length and complexity of the dataset examples towards a critical 'Goldilocks' zone wherein generated text is ridiculous to humans, yet often misclassified by state-of-the-art models.
Our construction of HellaSwag, and its resulting difficulty, sheds light on the inner workings of deep pretrained models. More broadly, it suggests a new path forward for NLP research, in which benchmarks co-evolve with the evolving state-of-the-art in an adversarial way, so as to present ever-harder challenges.
| 1 | null | 0 | 1 | 0 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
jp
|
test
|
JSUT
| null |
https://huggingface.co/datasets/japanese-asr/ja_asr.jsut_basic5000
|
https://sites.google.com/site/shinnosuketakamichi/publication/jsut
|
CC BY-SA 4.0
| 2,017 |
jp
| null |
['wikipedia', 'public datasets']
|
spoken
|
['manual curation', 'human annotation']
|
The corpus consists of 10 hours of reading-style speech
data and its transcription and covers all of the main pronun-
ciations of daily-use Japanese characters.
| 10 |
hours
|
Low
|
[]
|
['SNOW E4', 'Voice Actress', 'TANAKA', 'English-Japanese Translation Alignment Data']
|
JSUT corpus: free large-scale Japanese speech corpus for end-to-end speech synthesis
|
https://arxiv.org/pdf/1711.00354
|
mixed
| false |
other
|
Free
| false |
['speech recognition']
|
arXiv
|
preprint
|
['Ryosuke Sonobe', 'Shinnosuke Takamichi', 'Hiroshi Saruwatari']
|
['University of Tokyo']
|
Thanks to improvements in machine learning techniques including deep learning, a free large-scale speech corpus that
can be shared between academic institutions and commercial
companies has an important role. However, such a corpus for
Japanese speech synthesis does not exist. In this paper, we
designed a novel Japanese speech corpus, named the “JSUT
corpus,” that is aimed at achieving end-to-end speech synthesis. The corpus consists of 10 hours of reading-style speech
data and its transcription and covers all of the main pronunciations of daily-use Japanese characters. In this paper, we
describe how we designed and analyzed the corpus. The corpus is freely available online
| 1 | null | 0 | 1 | 0 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
jp
|
test
|
JaQuAD
| null |
https://huggingface.co/datasets/SkelterLabsInc/JaQuAD
|
https://github.com/SkelterLabsInc/JaQuAD
|
CC BY-SA 3.0
| 2,022 |
jp
| null |
['wikipedia']
|
text
|
['human annotation', 'manual curation']
|
JaQuAD is a Japanese Question Answering dataset consisting of 39,696 extractive question-answer pairs on Japanese Wikipedia articles. The dataset was annotated by humans and is available on GitHub.
| 39,696 |
sentences
|
Low
|
['Skelter Labs']
|
[]
|
JaQuAD: Japanese Question Answering Dataset for Machine Reading Comprehension
|
https://arxiv.org/pdf/2202.01764
|
mixed
| false |
GitHub
|
Free
| true |
['question answering']
|
arXiv
|
preprint
|
['ByungHoon So', 'Kyuhong Byun', 'Kyungwon Kang', 'Seongjin Cho']
|
['Skelter Labs']
|
Question Answering (QA) is a task in which a machine understands a given document and a question to find an answer. Despite impressive progress in the NLP area, QA is still a challenging problem, especially for non-English languages due to the lack of annotated datasets. In this paper, we present the JaQuAD, which is annotated by humans. JaQuAD consists of 39,696 extractive question-answer pairs on Japanese Wikipedia articles. We finetuned a baseline model which achieves 78.92% for F1 score and 63.38% for EM on test set. The dataset and our experiments are available at https://github.com/SkelterLabsInc/JaQuAD.
| 1 | null | 0 | 1 | 0 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
jp
|
test
|
JESC
| null |
https://huggingface.co/datasets/Hoshikuzu/JESC
|
https://nlp.stanford.edu/projects/jesc
|
CC BY-SA 4.0
| 2,018 |
multilingual
| null |
['captions', 'TV Channels']
|
text
|
['crawling', 'machine annotation']
|
JESC is a large Japanese-English parallel corpus covering the underrepresented domain of conversational dialogue. It consists of more than 3.2 million examples, making it the largest freely available dataset of its kind.
| 3,240,661 |
sentences
|
Low
|
['Stanford University', 'Rakuten Institute of Technology', 'Google Brain']
|
[]
|
JESC: Japanese-English Subtitle Corpus
|
https://arxiv.org/pdf/1710.10639
|
mixed
| false |
other
|
Free
| true |
['machine translation']
|
arXiv
|
preprint
|
['Reid Pryzant', 'Youngjoo Chung', 'Dan Jurafsky', 'Denny Britz']
|
['Stanford University', 'Rakuten Institute of Technology', 'Google Brain']
|
In this paper we describe the Japanese-English Subtitle Corpus (JESC). JESC is a large Japanese-English parallel corpus covering the underrepresented domain of conversational dialogue. It consists of more than 3.2 million examples, making it the largest freely available dataset of its kind. The corpus was assembled by crawling and aligning subtitles found on the web. The assembly process incorporates a number of novel preprocessing elements to ensure high monolingual fluency and accurate bilingual alignments. We summarize its contents and evaluate its quality using human experts and baseline machine translation (MT) systems.
| 1 | null | 0 | 1 | 0 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
jp
|
test
|
JaFIn
| null |
https://huggingface.co/datasets/Sakaji-Lab/JaFIn
|
https://huggingface.co/datasets/Sakaji-Lab/JaFIn
|
CC BY-NC-SA 4.0
| 2,024 |
jp
| null |
['wikipedia', 'web pages']
|
text
|
['manual curation']
|
JaFIn is a Japanese financial instruction dataset that was manually curated from various sources, including government websites, Wikipedia, and financial institutions.
| 1,490 |
sentences
|
Low
|
['Hokkaido University', 'University of Tokyo']
|
[]
|
JaFIn: Japanese Financial Instruction Dataset
|
https://arxiv.org/pdf/2404.09260
|
mixed
| false |
HuggingFace
|
Free
| false |
['instruction tuning', 'question answering']
|
arXiv
|
preprint
|
['Kota Tanabe', 'Masahiro Suzuki', 'Hiroki Sakaji', 'Itsuki Noda']
|
['Hokkaido University', 'University of Tokyo']
|
We construct an instruction dataset for the large language model (LLM) in the Japanese finance domain. Domain adaptation of language models, including LLMs, is receiving more attention as language models become more popular. This study demonstrates the effectiveness of domain adaptation through instruction tuning. To achieve this, we propose an instruction tuning data in Japanese called JaFIn, the Japanese Financial Instruction Dataset. JaFIn is manually constructed based on multiple data sources, including Japanese government websites, which provide extensive financial knowledge. We then utilize JaFIn to apply instruction tuning for several LLMs, demonstrating that our models specialized in finance have better domain adaptability than the original models. The financial-specialized LLMs created were evaluated using a quantitative Japanese financial benchmark and qualitative response comparisons, showing improved performance over the originals.
| 1 | null | 0 | 0 | 0 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
jp
|
test
|
JParaCrawl
| null |
https://huggingface.co/datasets/Hoshikuzu/JParaCrawl
|
http://www.kecl.ntt.co.jp/icl/lirg/jparacrawl
|
custom
| 2,020 |
multilingual
| null |
['web pages']
|
text
|
['crawling', 'machine annotation']
|
JParaCrawl is a large web-based English-Japanese parallel corpus that was created by crawling the web and finding English-Japanese bitexts. It contains around 8.7 million parallel sentences.
| 8,763,995 |
sentences
|
Low
|
['NTT']
|
['Common Crawl']
|
JParaCrawl: A Large Scale Web-Based English-Japanese Parallel Corpus
|
https://arxiv.org/pdf/1911.10668
|
mixed
| false |
other
|
Free
| false |
['machine translation']
|
arXiv
|
preprint
|
['Makoto Morishita', 'Jun Suzuki', 'Masaaki Nagata']
|
['NTT Corporation']
|
Recent machine translation algorithms mainly rely on parallel corpora. However, since the availability of parallel corpora remains limited, only some resource-rich language pairs can benefit from them. We constructed a parallel corpus for English-Japanese, for which the amount of publicly available parallel corpora is still limited. We constructed the parallel corpus by broadly crawling the web and automatically aligning parallel sentences. Our collected corpus, called JParaCrawl, amassed over 8.7 million sentence pairs. We show how it includes a broader range of domains and how a neural machine translation model trained with it works as a good pre-trained model for fine-tuning specific domains. The pre-training and fine-tuning approaches achieved or surpassed performance comparable to model training from the initial state and reduced the training time. Additionally, we trained the model with an in-domain dataset and JParaCrawl to show how we achieved the best performance with them. JParaCrawl and the pre-trained models are freely available online for research purposes.
| 1 | null | 0 | 1 | 0 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
ru
|
test
|
RuCoLA
| null |
https://huggingface.co/datasets/RussianNLP/RuCoLA
|
https://github.com/RussianNLP/RuCoLA
|
Apache-2.0
| 2,022 |
ru
| null |
['books', 'wikipedia', 'public datasets', 'LLM']
|
text
|
['human annotation', 'machine annotation', 'manual curation', 'LLM generated']
|
RuCoLA is a dataset of Russian sentences labeled as acceptable or not. It consists of 9.8k in-domain sentences from linguistic publications and 3.6k out-of-domain sentences produced by generative models.
| 13,445 |
sentences
|
Low
|
['RussianNLP']
|
['Tatoeba', 'WikiMatrix', 'TED', 'Yandex Parallel Corpus']
|
RuCoLA: Russian Corpus of Linguistic Acceptability
|
https://arxiv.org/pdf/2210.12814
| null | false |
GitHub
|
Free
| true |
['linguistic acceptability']
|
arXiv
|
preprint
|
['Vladislav Mikhailov', 'Tatiana Shamardina', 'Max Ryabinin', 'Alena Pestova', 'Ivan Smurov', 'Ekaterina Artemova']
|
['SberDevices', 'ABBYY', 'HSE University', 'Yandex', "Huawei Noah's Ark Lab", 'Center for Information and Language Processing (CIS), MaiNLP lab, LMU Munich, Germany']
|
Linguistic acceptability (LA) attracts the attention of the research community due to its many uses, such as testing the grammatical knowledge of language models and filtering implausible texts with acceptability classifiers. However, the application scope of LA in languages other than English is limited due to the lack of high-quality resources. To this end, we introduce the Russian Corpus of Linguistic Acceptability (RuCoLA), built from the ground up under the well-established binary LA approach. RuCoLA consists of 9.8k in-domain sentences from linguistic publications and 3.6k out-of-domain sentences produced by generative models. The out-of-domain set is created to facilitate the practical use of acceptability for improving language generation. Our paper describes the data collection protocol and presents a fine-grained analysis of acceptability classification experiments with a range of baseline approaches. In particular, we demonstrate that the most widely used language models still fall behind humans by a large margin, especially when detecting morphological and semantic errors. We release RuCoLA, the code of experiments, and a public leaderboard to assess the linguistic competence of language models for Russian.
| 1 | null | 0 | 1 | 0 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
ru
|
test
|
DaNetQA
| null |
https://huggingface.co/datasets/AlexSham/DaNetQA_for_BERT
|
https://github.com/PragmaticsLab/DaNetQA
|
CC0
| 2,020 |
ru
| null |
['wikipedia']
|
text
|
['human annotation', 'machine annotation', 'manual curation']
|
DaNetQA is a question-answering dataset for the Russian language. It comprises natural yes/no questions paired with a paragraph from Wikipedia and an answer derived from the paragraph. The task is to take both the question and a paragraph as input and come up with a yes/no answer.
| 2,691 |
sentences
|
Low
|
['National Research University Higher School of Economics', 'Sberbank']
|
[]
|
DaNetQA: a yes/no Question Answering Dataset for the Russian Language
|
https://arxiv.org/pdf/2010.02605
| null | false |
GitHub
|
Free
| true |
['yes/no question answering']
|
arXiv
|
preprint
|
['Taisia Glushkova', 'Alexey Machnev', 'Alena Fenogenova', 'Tatiana Shavrina', 'Ekaterina Artemova', 'Dmitry I. Ignatov']
|
['National Research University Higher School of Economics', 'Sberbank']
|
DaNetQA, a new question-answering corpus, follows BoolQ design: it comprises natural yes/no questions. Each question is paired with a paragraph from Wikipedia and an answer, derived from the paragraph. The task is to take both the question and a paragraph as input and come up with a yes/no answer, i.e. to produce a binary output. In this paper, we present a reproducible approach to DaNetQA creation and investigate transfer learning methods for task and language transferring. For task transferring we leverage three similar sentence modelling tasks: 1) a corpus of paraphrases, Paraphraser, 2) an NLI task, for which we use the Russian part of XNLI, 3) another question answering task, SberQUAD. For language transferring we use English to Russian translation together with multilingual language fine-tuning.
| 1 | null | 0 | 1 | 0 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
ru
|
test
|
NEREL
| null |
https://huggingface.co/datasets/iluvvatar/NEREL
|
https://github.com/nerel-ds/NEREL
|
unknown
| 2,021 |
ru
| null |
['news articles']
|
text
|
['human annotation', 'machine annotation']
|
NEREL is a Russian dataset for named entity recognition and relation extraction. It contains 56K annotated named entities and 39K annotated relations.
| 56,000 |
tokens
|
Low
|
['Lomonosov Moscow State University', 'HSE University', 'Huawei Noah’s Ark lab', 'Novosibirsk State University', 'Ural Federal University', 'Innopolis University', 'Kazan Federal University', 'Sber AI', 'Wiseyak']
|
[]
|
NEREL: A Russian Dataset with Nested Named Entities, Relations and Events
|
https://arxiv.org/pdf/2108.13112
| null | false |
GitHub
|
Free
| true |
['named entity recognition', 'relation extraction']
|
arXiv
|
preprint
|
['Natalia Loukachevitch', 'Ekaterina Artemova', 'Tatiana Batura', 'Pavel Braslavski', 'Ilia Denisov', 'Vladimir Ivanov', 'Suresh Manandhar', 'Alexander Pugachev', 'Elena Tutubalina']
|
['Lomonosov Moscow State University, Russia', 'HSE University, Russia', 'Huawei Noah’s Ark lab, Russia', 'Novosibirsk State University, Russia', 'Ural Federal University, Russia', 'Innopolis University, Russia', 'Kazan Federal University, Russia', 'Sber AI, Russia', 'Wiseyak, United States']
|
In this paper, we present NEREL, a Russian dataset for named entity recognition and relation extraction. NEREL is significantly larger than existing Russian datasets: to date it contains 56K annotated named entities and 39K annotated relations. Its important difference from previous datasets is annotation of nested named entities, as well as relations within nested entities and at the discourse level. NEREL can facilitate development of novel models that can extract relations between nested named entities, as well as relations on both sentence and document levels. NEREL also contains the annotation of events involving named entities and their roles in the events. The NEREL collection is available via https://github.com/nerel-ds/NEREL.
| 1 | null | 0 | 1 | 0 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
ru
|
test
|
RuBQ
| null |
https://huggingface.co/datasets/d0rj/RuBQ_2.0-paragraphs
|
http://doi.org/10.5281/zenodo.3835913
|
CC BY-SA 4.0
| 2,020 |
multilingual
| null |
['web pages', 'wikipedia']
|
text
|
['human annotation', 'manual curation', 'crawling', 'machine annotation']
|
RuBQ is a Russian knowledge base question answering (KBQA) dataset that consists of 1,500 Russian questions of varying complexity along with their English machine translations, corresponding SPARQL queries, answers, as well as a subset of Wikidata covering entities with Russian labels.
| 1,500 |
sentences
|
Low
|
['JetBrains Research', 'ITMO University', 'Ural Federal University']
|
[]
|
RuBQ: A Russian Dataset for Question Answering over Wikidata
|
https://arxiv.org/pdf/2005.10659
| null | false |
zenodo
|
Free
| true |
['knowledge base question answering', 'named entity recognition', 'machine translation']
|
arXiv
|
preprint
|
['Vladislav Korablinov', 'Pavel Braslavski']
|
['ITMO University, Saint Petersburg, Russia', 'JetBrains Research, Saint Petersburg, Russia', 'Ural Federal University, Yekaterinburg, Russia']
|
The paper presents RuBQ, the first Russian knowledge base question answering (KBQA) dataset. The high-quality dataset consists of 1,500 Russian questions of varying complexity, their English machine translations, SPARQL queries to Wikidata, reference answers, as well as a Wikidata sample of triples containing entities with Russian labels. The dataset creation started with a large collection of question-answer pairs from online quizzes. The data underwent automatic filtering, crowd-assisted entity linking, automatic generation of SPARQL queries, and their subsequent in-house verification. The freely available dataset will be of interest for a wide community of researchers and practitioners in the areas of Semantic Web, NLP, and IR, especially for those working on multilingual question answering. The proposed dataset generation pipeline proved to be efficient and can be employed in other data annotation projects.
| 1 | null | 0 | 1 | 0 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
ru
|
test
|
Golos
| null |
https://huggingface.co/datasets/SberDevices/Golos
|
https://github.com/sberdevices/golos
|
custom
| 2,021 |
ru
| null |
['other']
|
spoken
|
['human annotation', 'manual curation']
|
Golos is a large Russian speech dataset consisting of 1240 hours of manually annotated audio. It was collected using crowd-sourcing and studio recordings with far-field settings.
| 1,240 |
hours
|
Low
|
['Sber']
|
[]
|
Golos: Russian Dataset for Speech Research
|
https://arxiv.org/pdf/2106.10161
| null | false |
GitHub
|
Free
| true |
['speech recognition']
|
arXiv
|
preprint
|
['Nikolay Karpov', 'Alexander Denisenko', 'Fedor Minkin']
|
['Sber, Russia']
|
This paper introduces a novel Russian speech dataset called Golos, a large corpus suitable for speech research. The dataset mainly consists of recorded audio files manually annotated on the crowd-sourcing platform. The total duration of the audio is about 1240 hours. We have made the corpus freely available to download, along with the acoustic model with CTC loss prepared on this corpus. Additionally, transfer learning was applied to improve the performance of the acoustic model. In order to evaluate the quality of the dataset with the beam-search algorithm, we have built a 3-gram language model on the open Common Crawl dataset. The total word error rate (WER) metrics turned out to be about 3.3% and 11.5%.
| 1 | null | 0 | 1 | 0 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
fr
|
test
|
FQuAD1.1
| null |
https://huggingface.co/datasets/illuin/fquad
|
https://fquad.illuin.tech
|
CC BY-NC-SA 3.0
| 2,020 |
fr
| null |
['wikipedia']
|
text
|
['human annotation', 'manual curation']
|
FQuAD is a French Question Answering dataset composed of 10,000 question-answer pairs extracted from news articles. The dataset is designed to be used for training and evaluating question answering models in French.
| 62,003 |
sentences
|
Low
|
['Illuin Technology']
|
['FQuAD1.0']
|
FQuAD: French Question Answering Dataset
|
https://arxiv.org/pdf/2002.06071
| null | false |
other
|
Free
| true |
['question answering']
|
arXiv
|
preprint
|
["Martin d'Hoffschmidt", 'Wacim Belblidia', 'Tom Brendlé', 'Quentin Heinrich', 'Maxime Vidal']
|
['Illuin Technology', 'ETH Zurich']
|
We present FQuAD, a French Question Answering dataset composed of 10,000 question-answer pairs extracted from news articles. The dataset is designed to be used for training and evaluating question answering models in French. We provide a detailed analysis of the dataset, including its size, distribution of question types, and difficulty. We also evaluate the performance of several state-of-the-art question answering models on FQuAD. Our results show that FQuAD is a challenging dataset that can be used to benchmark the performance of question answering models in French.
| 1 | null | 0 | 0 | 0 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | null | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
fr
|
test
|
PIAF
| null |
https://huggingface.co/datasets/AgentPublic/piaf
|
https://huggingface.co/datasets/AgentPublic/piaf
|
MIT License
| 2,020 |
fr
| null |
['wikipedia']
|
text
|
['human annotation']
|
PIAF is a French Question Answering dataset that was collected through a participatory approach. The dataset consists of question-answer pairs extracted from Wikipedia articles.
| 3,835 |
sentences
|
Low
|
['reciTAL', 'Etalab']
|
[]
|
Project PIAF: Building a Native French Question-Answering Dataset
|
https://arxiv.org/pdf/2007.00968
| null | false |
HuggingFace
|
Free
| false |
['question answering']
|
arXiv
|
preprint
|
['Rachel Keraron', 'Guillaume Lancrenon', 'Mathilde Bras', 'Frédéric Allary', 'Gilles Moyse', 'Thomas Scialom', 'Edmundo-Pavel Soriano-Morales', 'Jacopo Staiano']
|
['reciTAL, Paris (France)', "Etalab, DINUM, Prime Minister's Office, Paris (France)", "Sorbonne Universit'e, CNRS, LIP6, F-75005 Paris, France"]
|
Motivated by the lack of data for non-English languages, in particular for the evaluation of downstream tasks such as Question Answering, we present a participatory effort to collect a native French Question Answering Dataset. Furthermore, we describe and publicly release the annotation tool developed for our collection effort, along with the data obtained and preliminary baselines.
| 1 | null | 0 | 0 | 0 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
fr
|
test
|
BSARD
| null |
https://huggingface.co/datasets/maastrichtlawtech/bsard
|
https://doi.org/10.5281/zenodo.5217310
|
CC BY-NC-SA 4.0
| 2,022 |
fr
| null |
['books']
|
text
|
['human annotation', 'manual curation']
|
A dataset of French legal questions posed by Belgian citizens and labelled with relevant articles from the Belgian legislation.
| 1,108 |
sentences
|
Low
|
['Maastricht University']
|
[]
|
A Statutory Article Retrieval Dataset in French
|
https://arxiv.org/pdf/2108.11792
| null | false |
zenodo
|
Free
| true |
['information retrieval', 'question answering']
|
arXiv
|
preprint
|
['Antoine Louis', 'Gerasimos Spanakis']
|
['Maastricht University']
|
Statutory article retrieval is the task of automatically retrieving law articles relevant to a legal question. While recent advances in natural language processing have sparked considerable interest in many legal tasks, statutory article retrieval remains primarily untouched due to the scarcity of large-scale and high-quality annotated datasets. To address this bottleneck, we introduce the Belgian Statutory Article Retrieval Dataset (BSARD), which consists of 1,100+ French native legal questions labeled by experienced jurists with relevant articles from a corpus of 22,600+ Belgian law articles. Using BSARD, we benchmark several state-of-the-art retrieval approaches, including lexical and dense architectures, both in zero-shot and supervised setups. We find that fine-tuned dense retrieval models significantly outperform other systems. Our best performing baseline achieves 74.8% R@100, which is promising for the feasibility of the task and indicates there is still room for improvement. By the specificity of the domain and addressed task, BSARD presents a unique challenge problem for future research on legal information retrieval. Our dataset and source code are publicly available.
| 1 | null | 0 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
fr
|
test
|
FrenchMedMCQA
| null |
https://huggingface.co/datasets/qanastek/frenchmedmcqa
|
https://github.com/qanastek/FrenchMedMCQA
|
Apache-2.0
| 2,023 |
fr
| null |
['web pages']
|
text
|
['manual curation']
|
FrenchMedMCQA is a multiple-choice question answering dataset in French for the medical domain. It contains 3,105 questions taken from real exams of the French medical specialization diploma in pharmacy, mixing single and multiple answers.
| 3,105 |
sentences
|
Medium
|
['Avignon University', 'Nantes University']
|
[]
|
FrenchMedMCQA: A French Multiple-Choice Question Answering Dataset for Medical domain
|
https://arxiv.org/pdf/2304.04280
| null | false |
GitHub
|
Free
| true |
['multiple choice question answering']
|
arXiv
|
preprint
|
['Yanis Labrak', 'Adrien Bazoge', 'Richard Dufour', 'Béatrice Daille', 'Pierre-Antoine Gourraud', 'Emmanuel Morin', 'Mickael Rouvier']
|
['LIA - Avignon University', 'LS2N - Nantes University', 'CHU de Nantes - La clinique des données - Nantes University', 'Zenidoc']
|
This paper introduces FrenchMedMCQA, the first publicly available Multiple-Choice Question Answering (MCQA) dataset in French for medical domain. It is composed of 3,105 questions taken from real exams of the French medical specialization diploma in pharmacy, mixing single and multiple answers. Each instance of the dataset contains an identifier, a question, five possible answers and their manual correction(s). We also propose first baseline models to automatically process this MCQA task in order to report on the current performances and to highlight the difficulty of the task. A detailed analysis of the results showed that it is necessary to have representations adapted to the medical domain or to the MCQA task: in our case, English specialized models yielded better results than generic French ones, even though FrenchMedMCQA is in French. Corpus, models and tools are available online.
| 1 | null | 0 | 1 | 0 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
fr
|
test
|
CFDD
| null |
https://huggingface.co/datasets/OpenLLM-France/Claire-Dialogue-French-0.1
|
https://huggingface.co/datasets/OpenLLM-France/Claire-Dialogue-French-0.1
|
CC BY-NC-SA 4.0
| 2,023 |
fr
| null |
['captions', 'public datasets', 'web pages']
|
text
|
['manual curation', 'crawling']
|
The Claire French Dialogue Dataset (CFDD) is a corpus containing roughly 160 million words from transcripts and stage plays in French.
| 160,000,000 |
tokens
|
Low
|
['LINAGORA Labs']
|
['ACSYNT', 'Assemblée Nationale', 'Orféo-CEFC', 'Orféo', 'CFPP', 'CID', 'CLAPI', 'ESLO', 'FREDSum', 'LinTO', 'OFRON', 'Parole Publique', 'Paris Stories', 'PFC', 'Rhapsodie', 'SUMM-RE', 'TCOF', 'Théâtre Classique', 'Théâtre Gratuit']
|
The Claire French Dialogue Dataset
|
https://arxiv.org/pdf/2311.16840
| null | false |
HuggingFace
|
Free
| true |
['language modeling', 'dialouge generation', 'text generation']
|
arXiv
|
preprint
|
['Julie Hunter', 'Jérôme Louradour', 'Virgile Rennard', 'Ismaïl Harrando', 'Guokan Shang', 'Jean-Pierre Lorré']
|
['LINAGORA']
|
We present the Claire French Dialogue Dataset (CFDD), a resource created by members of LINAGORA Labs in the context of the OpenLLM France initiative. CFDD is a corpus containing roughly 160 million words from transcripts and stage plays in French that we have assembled and publicly released in an effort to further the development of multilingual, open source language models. This paper describes the 24 individual corpora of which CFDD is composed and provides links and citations to their original sources. It also provides our proposed breakdown of the full CFDD dataset into eight categories of subcorpora and describes the process we followed to standardize the format of the final dataset. We conclude with a discussion of similar work and future directions.
| 1 | null | 1 | 1 | 0 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
multi
|
test
|
MLQA
|
[{'Name': 'en', 'Volume': 12738.0, 'Unit': 'sentences', 'Language': 'English'}, {'Name': 'ar', 'Volume': 5852.0, 'Unit': 'sentences', 'Language': 'Arabic'}, {'Name': 'de', 'Volume': 5029.0, 'Unit': 'sentences', 'Language': 'German'}, {'Name': 'vi', 'Volume': 6006.0, 'Unit': 'sentences', 'Language': 'Vietnamese'}, {'Name': 'es', 'Volume': 5770.0, 'Unit': 'sentences', 'Language': 'Spanish'}, {'Name': 'zh', 'Volume': 5852.0, 'Unit': 'sentences', 'Language': 'Simplified Chinese'}, {'Name': 'hi', 'Volume': 5425.0, 'Unit': 'sentences', 'Language': 'Hindi'}]
|
https://hf.co/datasets/facebook/mlqa
|
https://github.com/facebookresearch/mlqa
|
CC BY-SA 3.0
| 2,020 |
['English', 'Arabic', 'German', 'Vietnamese', 'Spanish', 'Simplified Chinese', 'Hindi']
| null |
['wikipedia']
|
text
|
['crawling', 'machine annotation', 'human annotation']
|
MLQA has over 12K instances in English and 5K in each other language, with each instance parallel between 4 languages on average.
| 46,461 |
documents
|
Low
|
['Facebook']
|
[]
|
MLQA: Evaluating Cross-lingual Extractive Question Answering
|
https://arxiv.org/pdf/1910.07475
| null | false |
GitHub
|
Free
| true |
['cross-lingual extractive question answering', 'question answering']
|
arXiv
|
preprint
|
['Patrick Lewis', 'Barlas Oğuz', 'Ruty Rinott', 'S. Riedel', 'Holger Schwenk']
|
['Facebook AI Research;University College London']
|
Question answering (QA) models have shown rapid progress enabled by the availability of large, high-quality benchmark datasets. Such annotated datasets are difficult and costly to collect, and rarely exist in languages other than English, making building QA systems that work well in other languages challenging. In order to develop such systems, it is crucial to invest in high quality multilingual evaluation benchmarks to measure progress. We present MLQA, a multi-way aligned extractive QA evaluation benchmark intended to spur research in this area. MLQA contains QA instances in 7 languages, English, Arabic, German, Spanish, Hindi, Vietnamese and Simplified Chinese. MLQA has over 12K instances in English and 5K in each other language, with each instance parallel between 4 languages on average. We evaluate state-of-the-art cross-lingual models and machine-translation-based baselines on MLQA. In all cases, transfer results are shown to be significantly behind training-language performance.
| 1 | 1 | 0 | 1 | 0 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
multi
|
test
|
MARC
|
[{'Name': 'English', 'Volume': 2100000.0, 'Unit': 'sentences', 'Language': 'English'}, {'Name': 'Japanese', 'Volume': 2100000.0, 'Unit': 'sentences', 'Language': 'Japanese'}, {'Name': 'German', 'Volume': 2100000.0, 'Unit': 'sentences', 'Language': 'German'}, {'Name': 'French', 'Volume': 2100000.0, 'Unit': 'sentences', 'Language': 'French'}, {'Name': 'Spanish', 'Volume': 2100000.0, 'Unit': 'sentences', 'Language': 'Spanish'}, {'Name': 'Chinese', 'Volume': 2100000.0, 'Unit': 'sentences', 'Language': 'Chinese'}]
|
https://huggingface.co/datasets/defunct-datasets/amazon_reviews_multi
|
https://registry.opendata.aws/amazon-reviews-ml
|
custom
| 2,020 |
['Japanese', 'English', 'German', 'French', 'Spanish', 'Chinese']
| null |
['reviews']
|
text
|
['crawling', 'human annotation']
|
Amazon product reviews dataset for multilingual text classification. The dataset contains reviews in English, Japanese, German, French, Chinese and Spanish, collected between November 1, 2015 and November 1, 2019
| 12,600,000 |
sentences
|
Low
|
['Amazon']
|
[]
|
The Multilingual Amazon Reviews Corpus
|
https://arxiv.org/pdf/2010.02573
| null | false |
other
|
Free
| true |
['sentiment analysis', 'review classification']
|
arXiv
|
preprint
|
['Phillip Keung', 'Yichao Lu', 'Gyorgy Szarvas', 'Noah A. Smith']
|
['Amazon', 'Washington University']
|
We present the Multilingual Amazon Reviews Corpus (MARC), a large-scale collection of Amazon reviews for multilingual text classification. The corpus contains reviews in English, Japanese, German, French, Spanish, and Chinese, which were collected between 2015 and 2019. Each record in the dataset contains the review text, the review title, the star rating, an anonymized reviewer ID, an anonymized product ID, and the coarse-grained product category (e.g., ‘books’, ‘appliances’, etc.) The corpus is balanced across the 5 possible star ratings, so each rating constitutes 20% of the reviews in each language. For each language, there are 200,000, 5,000, and 5,000 reviews in the training, development, and test sets, respectively. We report baseline results for supervised text classification and zero-shot crosslingual transfer learning by fine-tuning a multilingual BERT model on reviews data. We propose the use of mean absolute error (MAE) instead of classification accuracy for this task, since MAE accounts for the ordinal nature of the ratings.
| 1 | 1 | 0 | 1 | 0 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
multi
|
test
|
Multilingual Hate Speech Detection Dataset
|
[{'Name': 'Arabic', 'Volume': 5790.0, 'Unit': 'sentences', 'Language': 'Arabic'}, {'Name': 'English', 'Volume': 96323.0, 'Unit': 'sentences', 'Language': 'English'}, {'Name': 'German', 'Volume': 6155.0, 'Unit': 'sentences', 'Language': 'German'}, {'Name': 'Indonesian', 'Volume': 13882.0, 'Unit': 'sentences', 'Language': 'Indonesian'}, {'Name': 'Italian', 'Volume': 9560.0, 'Unit': 'sentences', 'Language': 'Italian'}, {'Name': 'Polish', 'Volume': 9788.0, 'Unit': 'sentences', 'Language': 'Polish'}, {'Name': 'Portuguese', 'Volume': 5670.0, 'Unit': 'sentences', 'Language': 'Portuguese'}, {'Name': 'Spanish', 'Volume': 11365.0, 'Unit': 'sentences', 'Language': 'Spanish'}, {'Name': 'French', 'Volume': 1220.0, 'Unit': 'sentences', 'Language': 'French'}]
|
https://github.com/hate-alert/DE-LIMIT
|
MIT License
| 2,020 |
['Arabic', 'English', 'German', 'Indonesian', 'Italian', 'Polish', 'Portuguese', 'Spanish', 'French']
| null |
['public datasets', 'social media']
|
text
|
['other']
|
Combined MLMA and L-HSAB datasets
| 159,753 |
sentences
|
High
|
['Indian Institute of Technology Kharagpur']
|
['L-HSAB', 'MLMA']
|
Deep Learning Models for Multilingual Hate
Speech Detection
|
https://arxiv.org/pdf/2004.06465
| null | false |
GitHub
|
Free
| true |
['hate speech detection']
|
arXiv
|
preprint
|
['Sai Saket Aluru', 'Binny Mathew', 'Punyajoy Saha', 'Animesh Mukherjee']
|
['Indian Institute of Technology Kharagpur']
|
Hate speech detection is a challenging problem with most of the datasets available in only one language: English. In this paper, we conduct a large scale analysis of multilingual hate speech in 9 languages from 16 different sources. We observe that in low resource setting, simple models such as LASER embedding with logistic regression performs the best, while in high resource setting BERT based models perform better. In case of zero-shot classification, languages such as Italian and Portuguese achieve good results. Our proposed framework could be used as an efficient solution for low-resource languages. These models could also act as good baselines for future multilingual hate speech detection tasks. We have made our code and experimental settings public for other researchers at this https URL.
| 1 | 1 | 0 | 1 | 0 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
|||
multi
|
test
|
XOR-TyDi
|
[{'Name': 'Ar', 'Volume': 17218.0, 'Unit': 'sentences', 'Language': 'Arabic'}, {'Name': 'Bn', 'Volume': 2682.0, 'Unit': 'sentences', 'Language': 'Bengali'}, {'Name': 'Fi', 'Volume': 9132.0, 'Unit': 'sentences', 'Language': 'Finnish'}, {'Name': 'Ja', 'Volume': 6531.0, 'Unit': 'sentences', 'Language': 'Japanese'}, {'Name': 'Ko', 'Volume': 2433.0, 'Unit': 'sentences', 'Language': 'Korean'}, {'Name': 'Ru', 'Volume': 8787.0, 'Unit': 'sentences', 'Language': 'Russian'}, {'Name': 'Te', 'Volume': 6276.0, 'Unit': 'sentences', 'Language': 'Telugu'}]
|
https://hf.co/datasets/akariasai/xor_tydi_qa
|
https://nlp.cs.washington.edu/xorqa/
|
CC BY-SA 4.0
| 2,021 |
['Arabic', 'Bengali', 'Finnish', 'Japanese', 'Korean', 'Russian', 'Telugu']
| null |
['public datasets']
|
text
|
['human annotation']
|
XOR-TyDi QA brings together information-seeking questions, open-retrieval QA, and multilingual QA to create a multilingual open-retrieval QA dataset that enables cross-lingual answer retrieval. It consists of questions written by information-seeking native speakers in 7 typologically diverse languages and answer annotations that are retrieved from multilingual document collections.
| 53,059 |
sentences
|
Low
|
[]
|
['TYDIQA']
|
XOR QA: Cross-lingual Open-Retrieval Question Answering
|
https://arxiv.org/pdf/2010.11856
| null | false |
other
|
Free
| true |
['cross-lingual information retrieval', 'question answering', 'open-retrieval question answering']
|
arXiv
|
preprint
|
['Akari Asai', 'Jungo Kasai', 'Jonathan H. Clark', 'Kenton Lee', 'Eunsol Choi', 'Hannaneh Hajishirzi']
|
['University of Washington', 'University of Washington', 'Google Research', 'The University of Texas at Austin; Allen Institute for AI']
|
Multilingual question answering tasks typically assume that answers exist in the same
language as the question. Yet in practice, many languages face both information
scarcity—where languages have few reference
articles—and information asymmetry—where
questions reference concepts from other cultures. This work extends open-retrieval question answering to a cross-lingual setting enabling questions from one language to be answered via answer content from another language. We construct a large-scale dataset
built on 40K information-seeking questions
across 7 diverse non-English languages that
TYDI QA could not find same-language answers for. Based on this dataset, we introduce
a task framework, called Cross-lingual OpenRetrieval Question Answering (XOR QA),
that consists of three new tasks involving crosslingual document retrieval from multilingual
and English resources. We establish baselines
with state-of-the-art machine translation systems and cross-lingual pretrained models. Experimental results suggest that XOR QA is a
challenging task that will facilitate the development of novel techniques for multilingual
question answering. Our data and code are
available at https://nlp.cs.washington.
edu/xorqa/.
| 1 | 1 | 0 | 1 | 0 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
||
multi
|
test
|
XNLI
|
[{'Name': 'en', 'Volume': 7500.0, 'Unit': 'sentences', 'Language': 'English'}, {'Name': 'fr', 'Volume': 7500.0, 'Unit': 'sentences', 'Language': 'French'}, {'Name': 'es', 'Volume': 7500.0, 'Unit': 'sentences', 'Language': 'Spanish'}, {'Name': 'de', 'Volume': 7500.0, 'Unit': 'sentences', 'Language': 'German'}, {'Name': 'el', 'Volume': 7500.0, 'Unit': 'sentences', 'Language': 'Greek'}, {'Name': 'bg', 'Volume': 7500.0, 'Unit': 'sentences', 'Language': 'Bulgarian'}, {'Name': 'ru', 'Volume': 7500.0, 'Unit': 'sentences', 'Language': 'Russian'}, {'Name': 'tr', 'Volume': 7500.0, 'Unit': 'sentences', 'Language': 'Turkish'}, {'Name': 'ar', 'Volume': 7500.0, 'Unit': 'sentences', 'Language': 'Arabic'}, {'Name': 'vi', 'Volume': 7500.0, 'Unit': 'sentences', 'Language': 'Vietnamese'}, {'Name': 'th', 'Volume': 7500.0, 'Unit': 'sentences', 'Language': 'Thai'}, {'Name': 'zh', 'Volume': 7500.0, 'Unit': 'sentences', 'Language': 'Chinese'}, {'Name': 'hi', 'Volume': 7500.0, 'Unit': 'sentences', 'Language': 'Hindi'}, {'Name': 'sw', 'Volume': 7500.0, 'Unit': 'sentences', 'Language': 'Swahili'}, {'Name': 'ur', 'Volume': 7500.0, 'Unit': 'sentences', 'Language': 'Urdu'}]
|
https://hf.co/datasets/facebook/xnli
|
https://github.com/facebookresearch/XNLI
|
CC BY-NC 4.0
| 2,018 |
['English', 'French', 'Spanish', 'German', 'Greek', 'Bulgarian', 'Russian', 'Turkish', 'Arabic', 'Vietnamese', 'Thai', 'Chinese', 'Hindi', 'Swahili', 'Urdu']
| null |
['public datasets']
|
text
|
['human annotation']
|
Evaluation set for NLI by extending the development and test sets of the Multi-Genre Natural Language Inference Corpus (MultiNLI) to 15 languages
| 112,500 |
sentences
|
Low
|
['Facebook']
|
['MultiNLI']
|
XNLI: Evaluating Cross-lingual Sentence Representations
|
https://arxiv.org/pdf/1809.05053
| null | false |
GitHub
|
Free
| false |
['natural language inference']
|
arXiv
|
preprint
|
['Alexis Conneau', 'Guillaume Lample', 'Ruty Rinott', 'Adina Williams', 'Samuel R. Bowman', 'Holger Schwenk', 'Veselin Stoyanov']
|
['Facebook AI Research', 'New York University']
|
State-of-the-art natural language processing systems rely on supervision in the form of annotated data to learn competent models. These models are generally trained on data in a single language (usually English), and cannot be directly used beyond that language. Since collecting data in every language is not realistic, there has been a growing interest in cross-lingual language understanding (XLU) and low-resource cross-language transfer. In this work, we construct an evaluation set for XLU by extending the development and test sets of the Multi-Genre Natural Language Inference Corpus (MultiNLI) to 14 languages, including low-resource languages such as Swahili and Urdu. We hope that our dataset, dubbed XNLI, will catalyze research in cross-lingual sentence understanding by providing an informative standard evaluation task. In addition, we provide several baselines for multilingual sentence understanding, including two based on machine translation systems, and two that use parallel data to train aligned multilingual bag-of-words and LSTM encoders. We find that XNLI represents a practical and challenging evaluation suite, and that directly translating the test data yields the best performance among available baselines.
| 1 | 1 | 0 | 0 | 0 | 1 | 1 | null | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | null | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
MOLE: Metadata Extraction and Validation in Scientific Papers
MOLE is a dataset for evaluating and validating metadata extracted from scientific papers. The paper can be found here.
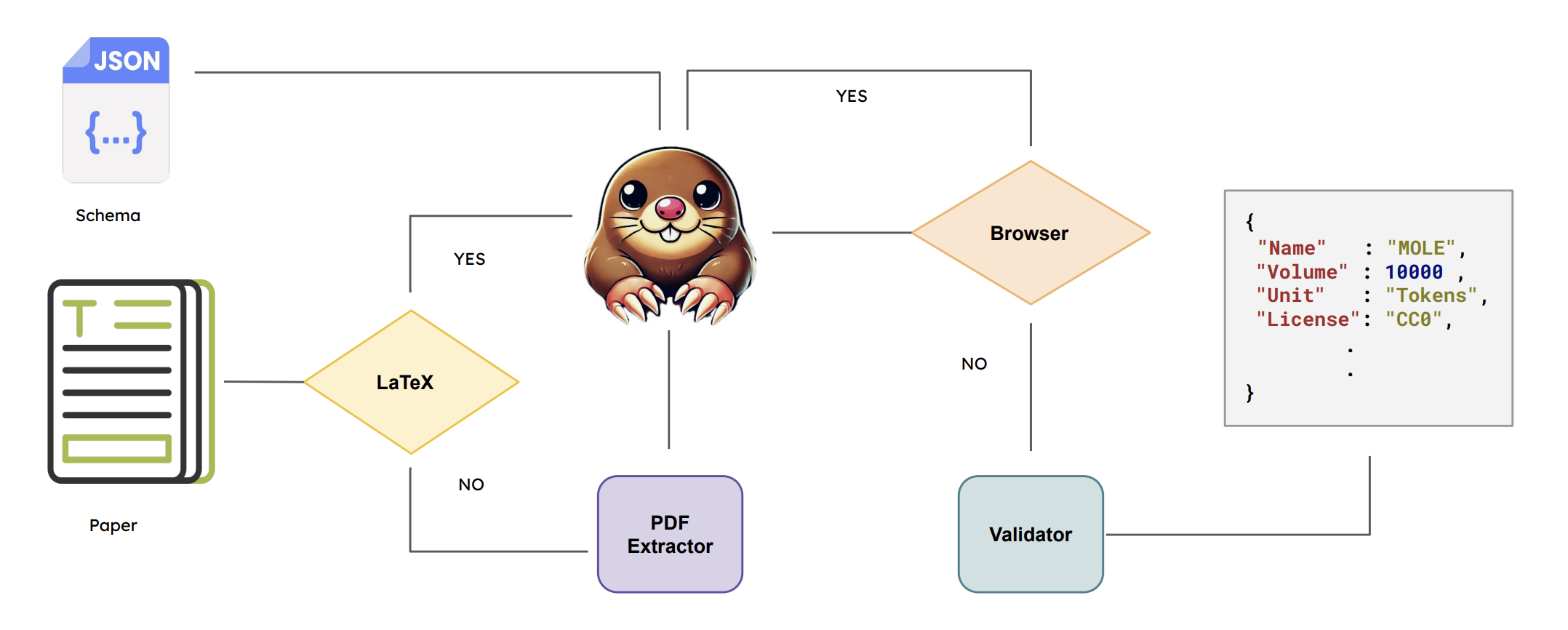
📋 Dataset Structure
The main datasets attributes are shown below. Also for earch feature there is binary value attribute_exist. The value is 1 if the attribute is retrievable form the paper, otherwise it is 0.
Name (str): What is the name of the dataset?Subsets (List[Dict[Name, Volume, Unit, Dialect]]): What are the dialect subsets of this dataset?Link (url): What is the link to access the dataset?HF Link (url): What is the Huggingface link of the dataset?License (str): What is the license of the dataset?Year (date[year]): What year was the dataset published?Language (str): What languages are in the dataset?Dialect (str): What is the dialect of the dataset?Domain (List[str]): What is the source of the dataset?Form (str): What is the form of the data?Collection Style (List[str]): How was this dataset collected?Description (str): Write a brief description about the dataset.Volume (float): What is the size of the dataset?Unit (str): What kind of examples does the dataset include?Ethical Risks (str): What is the level of the ethical risks of the dataset?Provider (List[str]): What entity is the provider of the dataset?Derived From (List[str]): What datasets were used to create the dataset?Paper Title (str): What is the title of the paper?Paper Link (url): What is the link to the paper?Script (str): What is the script of this dataset?Tokenized (bool): Is the dataset tokenized?Host (str): What is name of the repository that hosts the dataset?Access (str): What is the accessibility of the dataset?Cost (str): If the dataset is not free, what is the cost?Test Split (bool): Does the dataset contain a train/valid and test split?Tasks (List[str]): What NLP tasks is this dataset intended for?Venue Title (str): What is the venue title of the published paper?Venue Type (str): What is the venue type?Venue Name (str): What is the full name of the venue that published the paper?Authors (List[str]): Who are the authors of the paper?Affiliations (List[str]): What are the affiliations of the authors?Abstract (str): What is the abstract of the paper?
📁 Loading The Dataset
How to load the dataset
from datasets import load_dataset
dataset = load_dataset('IVUL-KAUST/mole')
📄 Sample From The Dataset:
A sample for an annotated paper
{
"metadata": {
"Name": "TUNIZI",
"Subsets": [],
"Link": "https://github.com/chaymafourati/TUNIZI-Sentiment-Analysis-Tunisian-Arabizi-Dataset",
"HF Link": "",
"License": "unknown",
"Year": 2020,
"Language": "ar",
"Dialect": "Tunisia",
"Domain": [
"social media"
],
"Form": "text",
"Collection Style": [
"crawling",
"manual curation",
"human annotation"
],
"Description": "TUNIZI is a sentiment analysis dataset of over 9,000 Tunisian Arabizi sentences collected from YouTube comments, preprocessed, and manually annotated by native Tunisian speakers.",
"Volume": 9210.0,
"Unit": "sentences",
"Ethical Risks": "Medium",
"Provider": [
"iCompass"
],
"Derived From": [],
"Paper Title": "TUNIZI: A TUNISIAN ARABIZI SENTIMENT ANALYSIS DATASET",
"Paper Link": "https://arxiv.org/abs/2004.14303",
"Script": "Latin",
"Tokenized": false,
"Host": "GitHub",
"Access": "Free",
"Cost": "",
"Test Split": false,
"Tasks": [
"sentiment analysis"
],
"Venue Title": "International Conference on Learning Representations",
"Venue Type": "conference",
"Venue Name": "International Conference on Learning Representations 2020",
"Authors": [
"Chayma Fourati",
"Abir Messaoudi",
"Hatem Haddad"
],
"Affiliations": [
"iCompass"
],
"Abstract": "On social media, Arabic people tend to express themselves in their own local dialects. More particularly, Tunisians use the informal way called 'Tunisian Arabizi'. Analytical studies seek to explore and recognize online opinions aiming to exploit them for planning and prediction purposes such as measuring the customer satisfaction and establishing sales and marketing strategies. However, analytical studies based on Deep Learning are data hungry. On the other hand, African languages and dialects are considered low resource languages. For instance, to the best of our knowledge, no annotated Tunisian Arabizi dataset exists. In this paper, we introduce TUNIZI as a sentiment analysis Tunisian Arabizi Dataset, collected from social networks, preprocessed for analytical studies and annotated manually by Tunisian native speakers."
},
}
⛔️ Limitations
The dataset contains 52 annotated papers, it might be limited to truely evaluate LLMs. We are working on increasing the size of the dataset.
🔑 License
Citation
@misc{mole,
title={MOLE: Metadata Extraction and Validation in Scientific Papers Using LLMs},
author={Zaid Alyafeai and Maged S. Al-Shaibani and Bernard Ghanem},
year={2025},
eprint={2505.19800},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.19800},
}
- Downloads last month
- 19