
model stringclasses 5
values | query_prefix stringclasses 1
value | passage_prefix stringclasses 1
value | embedding_size int64 1.02k 1.54k | revision stringclasses 5
values | model_type stringclasses 2
values | torch_dtype stringclasses 1
value | max_length int64 512 32k |
|---|---|---|---|---|---|---|---|
intfloat/multilingual-e5-large | query: | passage: | 1,024 | ab10c1a | xlm-roberta | float32 | 512 |
Snowflake/snowflake-arctic-embed-l | null | null | 1,024 | ecaabe9 | xlm-roberta | float32 | 512 |
Alibaba-NLP/gte-Qwen2-1.5B-instruct | null | null | 1,536 | 5652710 | qwen2 | float32 | 32,000 |
BAAI/bge-m3 | null | null | 1,024 | 5617a9f | xlm-roberta | float32 | 8,192 |
FacebookAI/xlm-roberta-large | null | null | 1,024 | c23d21b | xlm-roberta | float32 | 512 |
Reference models for integration into HF for Legal 🤗
This dataset comprises a collection of models aimed at streamlining and partially automating the embedding process. Each model entry within this dataset includes essential information such as model identifiers, embedding configurations, and specific parameters, ensuring that users can seamlessly integrate these models into their workflows with minimal setup and maximum efficiency.
Dataset Structure
| Field | Type | Description |
|---|---|---|
model |
str | The identifier of the model, typically formatted as organization/model-name. |
query_prefix |
str | A prefix string added to query inputs to delineate them. |
passage_prefix |
str | A prefix string added to passage inputs to delineate them. |
embedding_size |
int | The dimensional size of the embedding vectors produced by the model. |
revision |
str | The specific revision identifier of the model to ensure consistency. |
model_type |
str | The architectural type of the model, such as xlm-roberta or qwen2. |
torch_dtype |
str | The data type utilized in PyTorch operations, such as float32. |
max_length |
int | The maximum input length the model can process, specified in tokens. |
Organization architecture
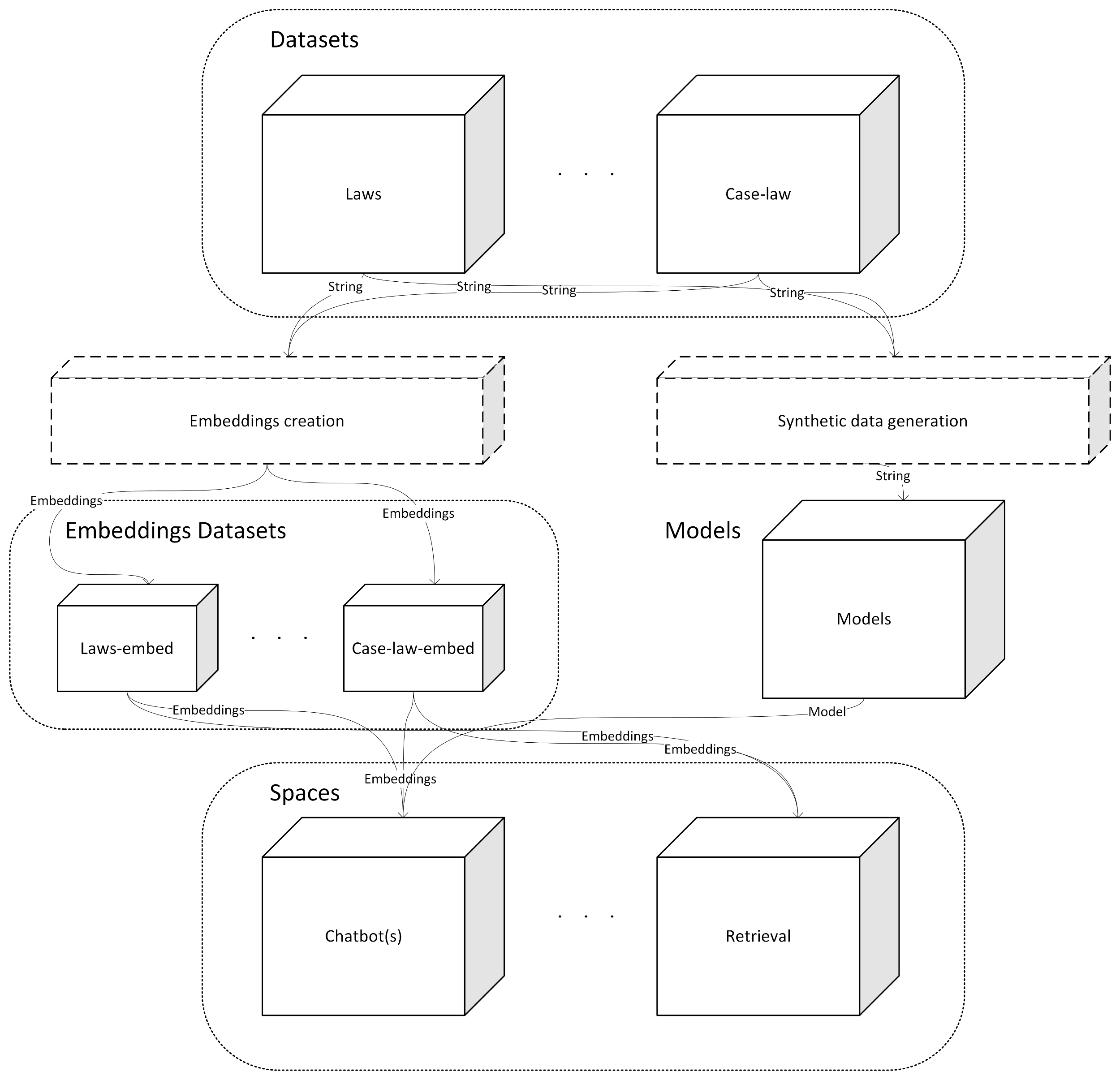
In order to simplify the deployment of the organization's various tools, we propose a simple architecture in which datasets containing the various legal and contractual texts are doubled by datasets containing embeddings for different models, to enable simplified index creation for Spaces initialization and the provision of vector data for the GPU-poor. A simplified representation might look like this:
Citing & Authors
If you use this dataset in your research, please use the following BibTeX entry.
@misc{HFforLegal2024,
author = {Louis Brulé Naudet},
title = {Reference models for integration into HF for Legal},
year = {2024}
howpublished = {\url{https://huggingface.co/datasets/HFforLegal/embedding-models}},
}
Feedback
If you have any feedback, please reach out at louisbrulenaudet@icloud.com.
- Downloads last month
- 61