
CCI4.0
Collection
A Bilingual Pretraining Dataset for Enhancing Reasoning in Large Language Models • 5 items • Updated • 16
This repository is publicly accessible, but you have to accept the conditions to access its files and content.
You agree to not use the dataset to conduct experiments that cause harm to human subjects.
Log in or Sign Up to review the conditions and access this dataset content.
CCI4.0-M2 v1 is a comprehensive dataset collection consisting of two specialized subsets designed for language model training.
| CCI4.0-M2-Base v1 | CCI4.0-M2-CoT v1 | |
|---|---|---|
| Download Link | BAAI_datahub / modelscope / hf | BAAI_datahub / modelscope / hf |
| Notes | 5.2TB Chinese webpage, 22TB English webpage, some data released in CCI4.0-M2-Extra(BAAI_datahub / modelscope / hf) due to the license concern. | 430 million CoT sample covers math, code, arxiv, wiki and webpage |
The disk storage for different subdomain datasets is shown in the table below:
| DataSets | Lines | Volume (G) |
|---|---|---|
| Web-EN | 7,175,101,435 | 22,498.641 |
| Web-ZH | 1,643,503,909 | 5,161.0895 |
| Code | 215,521,589.3 | 896.57865 |
| Math | 49,685,043.87 | 269.06715 |
| Books | 255,369,254.6 | 858.55473 |
| Wiki | 44,086,649.31 | 96.667659 |
| Arxiv | 1,536,117.66 | 87.12 |
| ForumQA | 28,664,137.6 | 78.00555 |
| pes2o | 4,354,668.22 | 117.14234 |
| CoT_synthesis | 392,470,068.8 | 4,121.978 |
The Chain-of-Thought (CoT) in the CCI4.0-M2-CoT v1 subset is synthesized to enhance the reasoning capabilities of language models. This synthesis process involves generating step-by-step reasoning trajectories based on various data sources
The following image illustrates the CoT synthesis pipeline:
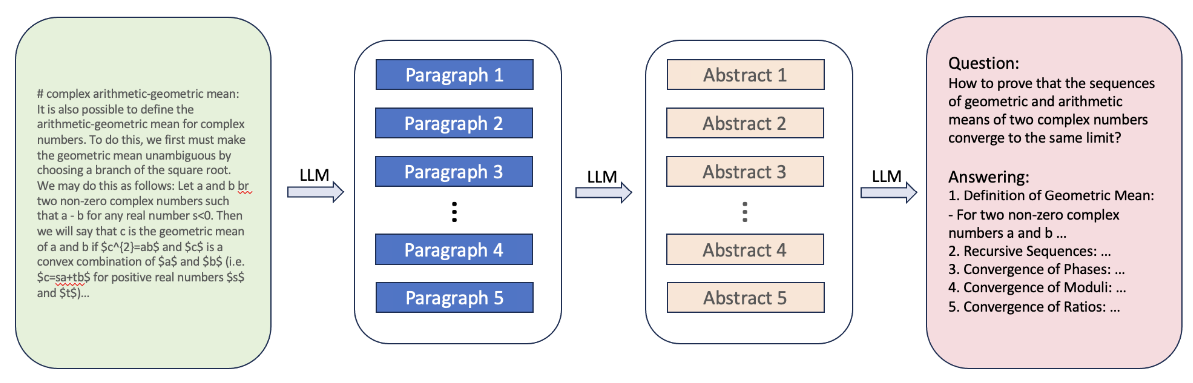
This pipeline showcases how the raw data from different sources is processed and transformed into structured CoT data, which can be used for training language models to perform complex reasoning tasks.
**Disclaimer: If any violations of the dataset usage agreement or licensing terms are identified, we kindly request that you notify us as soon as possible. **
We have organized the agreements for the open-source datasets and confirmed them individually. Below is a list of the main datasets and their corresponding licenses.
| Data Source | Open Source License |
|---|---|
| ChineseWebText2.0 | apache-2.0 |
| HPLT2.0_cleaned/zho_Hans | cc0-1.0 |
| TeleChat-PTD | apache-2.0 |
| data from cooperation projects | apache-2.0 |
| Nemotron-CC | Common Crawl License |
| CCI | apache-2.0 |
| --- | --- |
| MAP-CC | CC-BY-NC-ND-4.0 |
| fineweb-2 | ODC-BY |
| wanjuan/data/raw/nlp/CN | CC-BY-4.0 |
| starcoder | Multiple Licenses, see https://huggingface.co/datasets/bigcode/the-stack-dedup/blob/main/licenses.json |
| opc-annealing-corpus | Multiple agreements. Some corpora are from the-stack-v2. See agreements at: https://huggingface.co/datasets/bigcode/the-stack-v2/blob/main/license_stats.csv |
| smollm-corpu | Multiple agreements. Some corpora are from the-stack-v2. See agreements at: https://huggingface.co/datasets/bigcode/the-stack-v2/blob/main/license_stats.csv |
| dolma_pes2o_v2 | ODC-BY |
| pes2o | ODC-BY |
| dolma | ODC-BY |
| opc-fineweb-math-corpus | ODC-BY |
| proof-pile-2 | MIT, BSD, or Apache, ODC-By 1.0 license, etc. |
| --- | --- |
| KodCode/KodCode-V1 | cc-by-nc-4.0 |
| facebook/natural_reasoning | cc-by-nc-4.0 |
| allenai/dolma | odc-by |
| allenai/dolmino-mix-1124 | odc-by |
| HuggingFaceTB/finemath | odc-by |
| open-web-math/open-web-math | ODC-By 1.0 |
| allenai/dolmino-mix-1124 | odc-by |
We gratefully acknowledge the valuable contributions of Institutions Alibaba Cloud (阿里云), Shanghai AI Laboratory (上海人工智能实验室), Huawei (华为), Mobvoi (出门问问), Kingsoft Office Software (金山办公), Kunlun (昆仑万维), ModelBest (面壁智能), Qihoo (奇虎科技), Meituan (美团), MiniMax (稀宇科技), Moonshot AI (月之暗面), Zidong Taichu (紫东太初), Wenge (中科闻歌) and iFLYTEK (科大讯飞) in providing the Chinese data.
Users need to comply with the usage agreement of the CCI dataset. You can view the agreement by clicking on the following link: (View Usage Agreement).
Please cite using:
@misc{liu2025cci40bilingualpretrainingdataset,
title={CCI4.0: A Bilingual Pretraining Dataset for Enhancing Reasoning in Large Language Models},
author={Guang Liu and Liangdong Wang and Jijie Li and Yang Yu and Yao Xu and Jiabei Chen and Yu Bai and Feng Liao and Yonghua Lin},
year={2025},
eprint={2506.07463},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2506.07463},
}