
wan i2v

The gguf files for T2V are much appreciated; they have been very useful to me. Is it possible that you could generate the gguf version of WAN2.1 i2V 1.3b?
thanks; but no i2v 1.3b safetensors right away
The gguf files for T2V are much appreciated; they have been very useful to me. Is it possible that you could generate the gguf version of WAN2.1 i2V 1.3b?
the newly released vace-1.3b can serve t2v, i2v and even v2v; uploaded; check it out

which one? you have normal, v3, and revisited. have a preference on which works better? did they have different quantization methods?
the structure is a little bit different; the first version contains only one working 5d tensor; v2 has two 5d tensors in f32 status; v3 has two 5d tensors but one in f32 and one in f16 status; all works, just different attempts

The gguf files for T2V are much appreciated; they have been very useful to me. Is it possible that you could generate the gguf version of WAN2.1 i2V 1.3b?
the newly released vace-1.3b can serve t2v, i2v and even v2v; uploaded; check it out
Trying to use the wan2.1-v3-vace-1.3b-q8_0.gguf model using the node wanvacetovideo on comfyui and it's not doing image to video, only text to video. Any advice?
you could drag this video or json to browser for vace i2v workflow
My workflow is pretty much exactly the same as yours, but I tried anyway, still no go. I wanted to use the 1.3b version because it's faster, has decent quality and I don't have to use a highly quantized model.
Image I used:
Prompt: The bunny is talking.
Result video with 10 steps to test the 1.3b model:
Meanwhile with the 14b Q3ks model I get this:
Tested with all the settings from your workflow as well, to see if it wasn't something with the steps or number of frames. I just changed the resolution to the recommended one for the model. And I also used other gguf loaders, which doesn't seem to affect the 14b model, or any other quantized model for that matter.
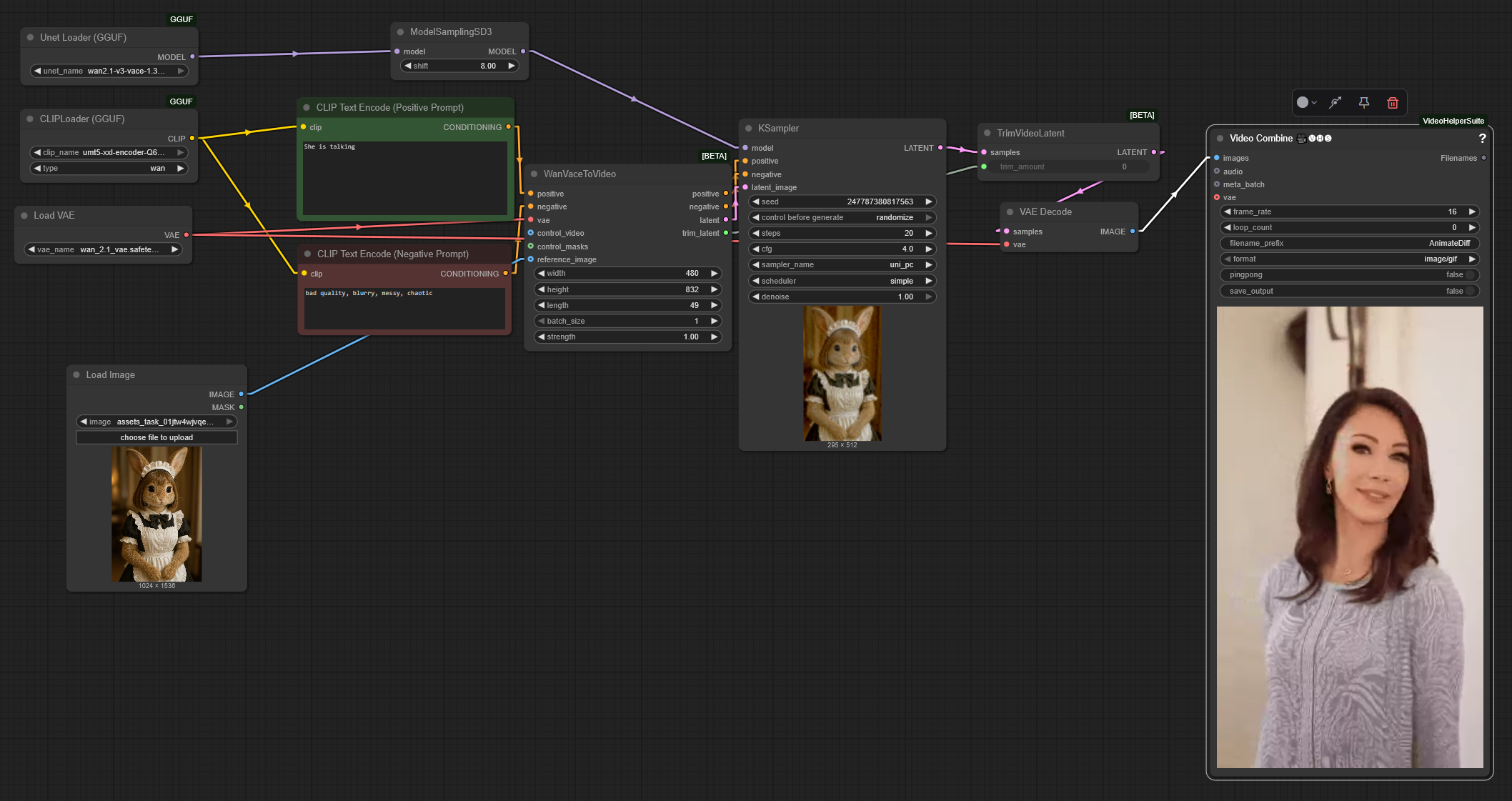
1.3b is a test model; don't expect that much with this size; and the vace i2v seems working similar to the controlnet adapter, without vision clip, the recognition accuracy is very poor, since the input will be converted as merely a sharp or shadow; possibly won't match your image prompt