metadata
license: apache-2.0
base_model:
- Qwen/Qwen-Image-Edit
pipeline_tag: image-to-image
tags:
- gguf-connector
- gguf-node
widget:
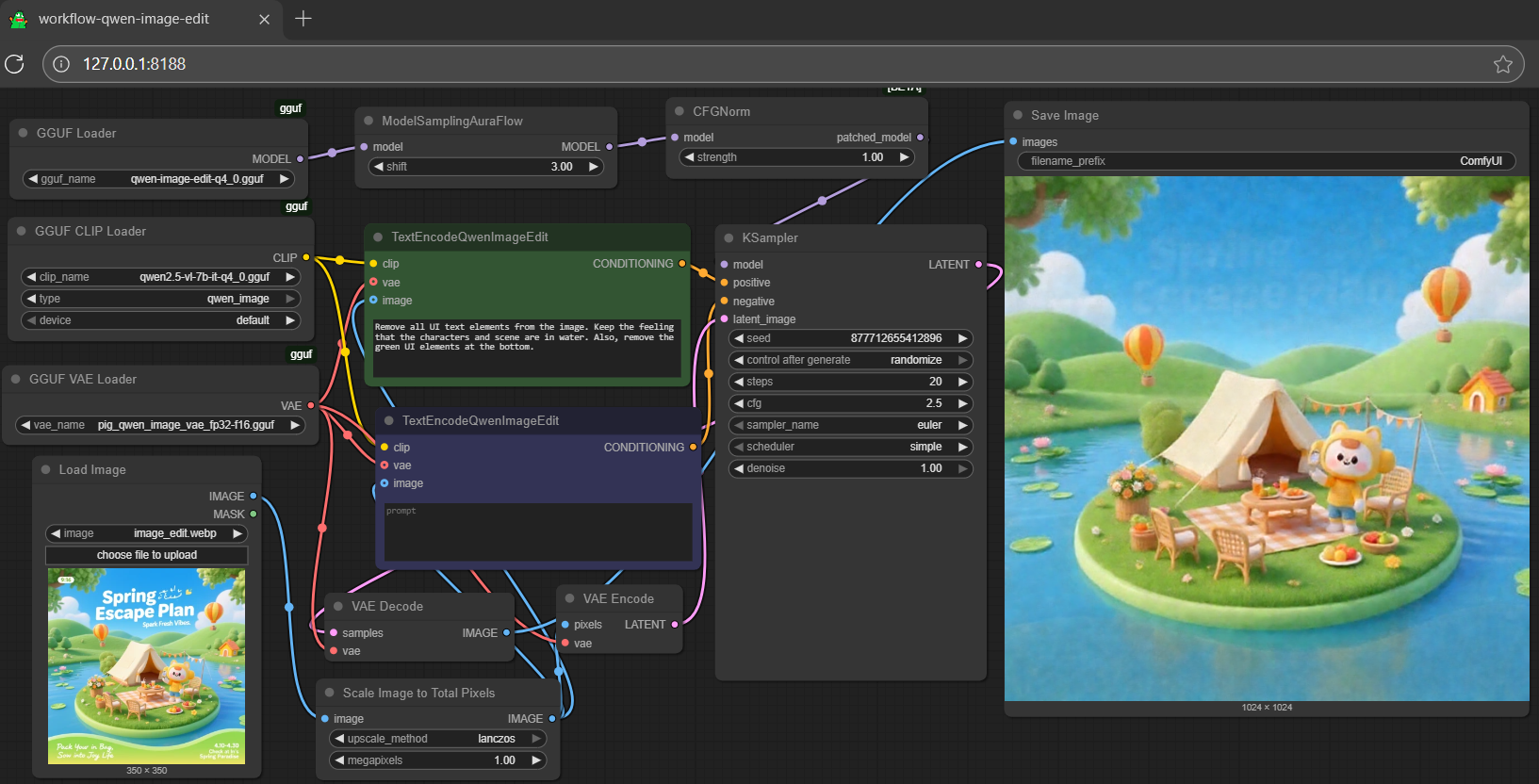
- text: >-
remove all UI text elements from the image. Keep the feeling that the
characters and scene are in water. Also, remove the green UI elements at
the bottom
output:
url: workflow-demo1.png
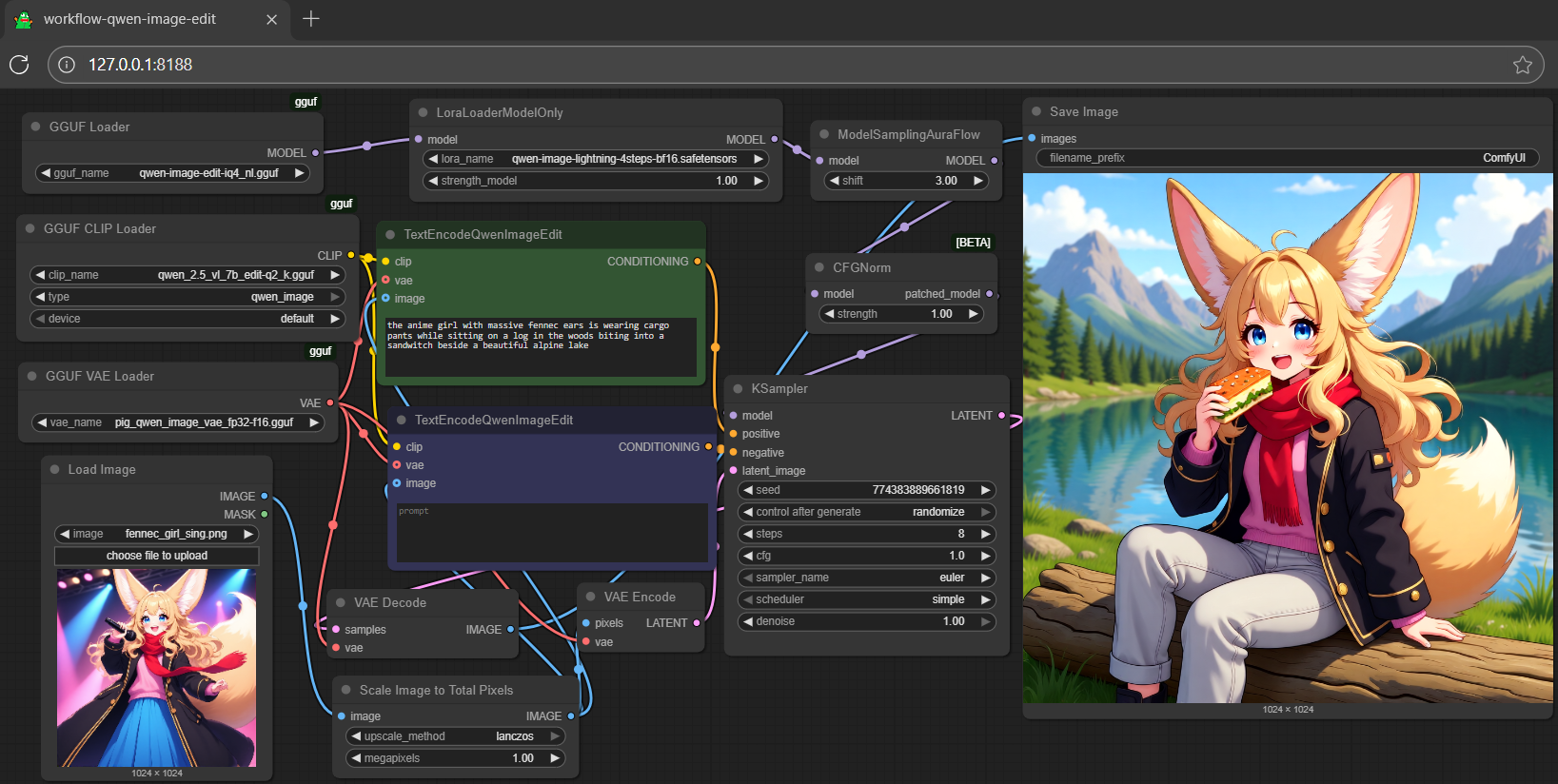
- text: >-
the anime girl with massive fennec ears is wearing cargo pants while
sitting on a log in the woods biting into a sandwitch beside a beautiful
alpine lake
output:
url: workflow-demo2.png
- text: >-
the anime girl with massive fennec ears is wearing a maid outfit with a
long black gold leaf pattern dress and a white apron mouth open holding a
fancy black forest cake with candles on top in the kitchen of an old dark
Victorian mansion lit by candlelight with a bright window to the foggy
forest and very expensive stuff everywhere
output:
url: workflow-demo3.png
qwen-image-edit-gguf
- drag qwen-image-edit to >
./ComfyUI/models/diffusion_models - either 1 or 2 below, drag it to >
./ComfyUI/models/text_encoders - drag pig [254MB] to >
./ComfyUI/models/vae
*note: option 1 (pig quant) is recommended since less chance for oom; option 2 (llama.cpp quant) is also fine if you have good gpu and make sure preparing both text-model and mmproj (vision clip)

- Prompt
- remove all UI text elements from the image. Keep the feeling that the characters and scene are in water. Also, remove the green UI elements at the bottom

- Prompt
- the anime girl with massive fennec ears is wearing cargo pants while sitting on a log in the woods biting into a sandwitch beside a beautiful alpine lake

- Prompt
- the anime girl with massive fennec ears is wearing a maid outfit with a long black gold leaf pattern dress and a white apron mouth open holding a fancy black forest cake with candles on top in the kitchen of an old dark Victorian mansion lit by candlelight with a bright window to the foggy forest and very expensive stuff everywhere