|
|
--- |
|
|
license: apache-2.0 |
|
|
language: |
|
|
- en |
|
|
base_model: |
|
|
- nari-labs/Dia-1.6B |
|
|
pipeline_tag: text-to-speech |
|
|
tags: |
|
|
- gguf-connector |
|
|
--- |
|
|
## gguf quantized and fp8/16/32 scaled dia-1.6b |
|
|
- base model from [nari-labs](https://huggingface.co/nari-labs) |
|
|
- text-to-speech synthesis |
|
|
|
|
|
### **run it with gguf-connector** |
|
|
``` |
|
|
ggc s2 |
|
|
``` |
|
|
|
|
|
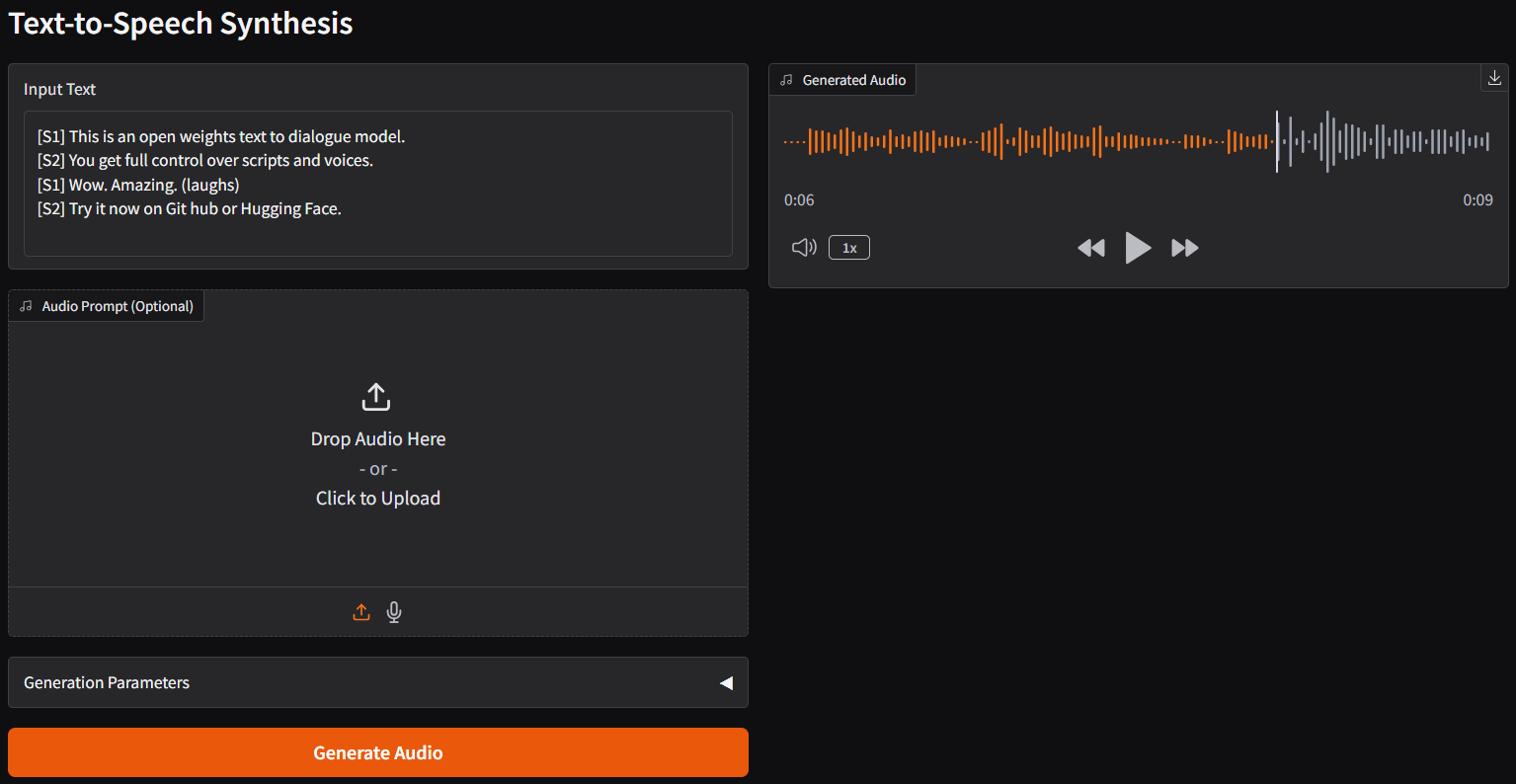 |
|
|
|
|
|
| Prompt | Audio Sample | |
|
|
|--------|---------------| |
|
|
|`[S1] This is an open weights text to dialogue model.`<br/>`[S2] You get full control over scripts and voices.`<br/>`[S1] Wow. Amazing. (laughs)`<br/>`[S2] Try it now on Git hub or Hugging Face.`<br/> | 🎧 **dia-sample-1**<br><audio controls src="https://huggingface.co/calcuis/dia-gguf/resolve/main/samples%5Caudio1.wav"></audio> | |
|
|
|`[S1] Hey Connector, why your appearance looks so stupid?`<br/>`[S2] Oh, really? maybe I ate too much smart beans.`<br/>`[S1] Wow. Amazing. (laughs)`<br/>`[S2] Let's go to get some more smart beans and you will become stupid as well.`<br/> | 🎧 **dia-sample-2**<br><audio controls src="https://huggingface.co/calcuis/dia-gguf/resolve/main/samples%5Caudio2.wav"></audio> | |
|
|
|
|
|
### **review/reference** |
|
|
- simply execute the command (`ggc s2`) above in console/terminal |
|
|
- note: model file(s) will be pulled to local cache automatically during the first launch; then opt to run it entirely offline; i.e., from local URL: http://127.0.0.1:7860 with lazy webui |
|
|
- gguf-connector ([pypi](https://pypi.org/project/gguf-connector)) |
