|
--- |
|
license: mit |
|
language: |
|
- en |
|
base_model: |
|
- Qwen/Qwen2.5-Coder-32B-Instruct |
|
pipeline_tag: token-classification |
|
tags: |
|
- agent |
|
- coding |
|
--- |
|
|
|
<div align="center"> |
|
<img src="https://github.com/All-Hands-AI/OpenHands/blob/main/docs/static/img/logo.png?raw=true" alt="Logo" width="200"> |
|
<h1 align="center">OpenHands Critic Model</h1> |
|
</div> |
|
|
|
<p align="center"> |
|
<a href="https://www.all-hands.dev/blog/sota-on-swe-bench-verified-with-inference-time-scaling-and-critic-model">Blog</a> |
|
</p> |
|
|
|
**Research Purpose Only: This model is released strictly for research and is not yet compatible with the OpenHands application. For complete information about this model, including its capabilities and limitations, please refer to our [detailed blog post](https://www.all-hands.dev/blog/sota-on-swe-bench-verified-with-inference-time-scaling-and-critic-model).** |
|
|
|
--- |
|
|
|
# SOTA on SWE-Bench Verified with Inference-Time Scaling and Critic Model |
|
|
|
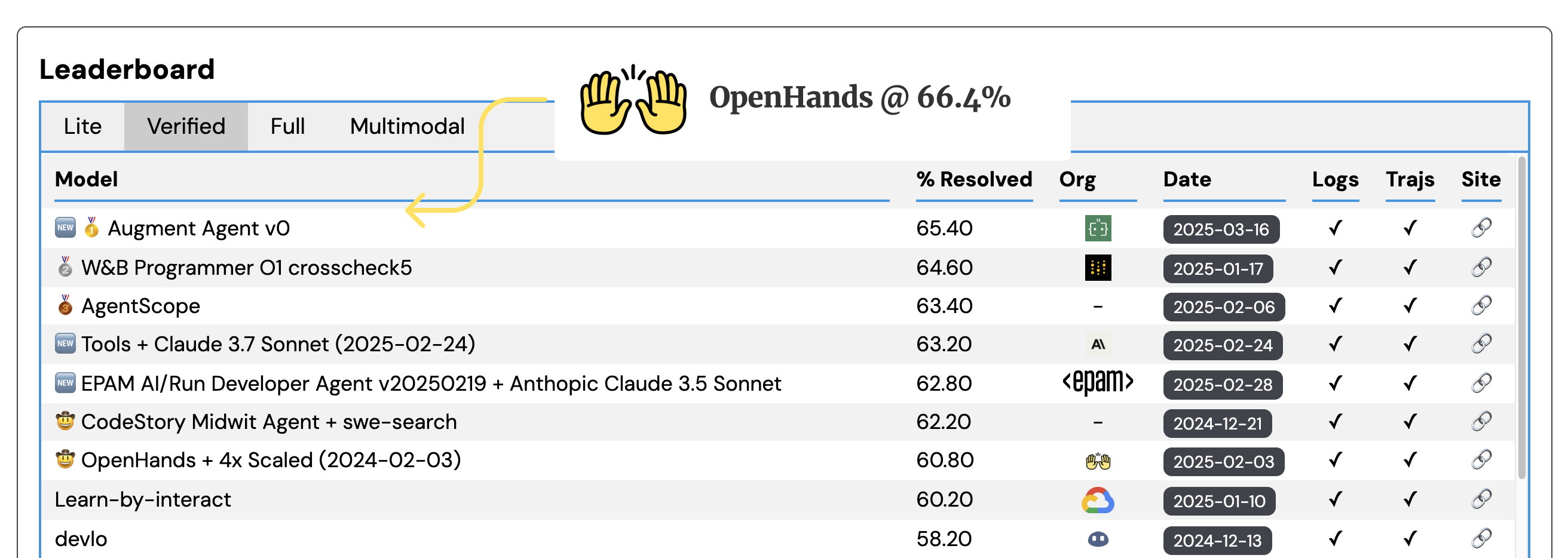
We're thrilled to announce that OpenHands has reached a new milestone, achieving state-of-the-art results on SWE-Bench Verified! |
|
|
|
 |
|
|
|
## SWE-Bench and OpenHands |
|
|
|
[SWE-bench](https://www.swebench.com/) is the most popular benchmark for evaluating large language models' (LLMs) capabilities in addressing real-world software engineering challenges. It consists of issues and corresponding pull requests from 12 popular Python repositories on GitHub, tasking systems with generating code patches to resolve specified issues. The *verified* subset we evaluated on consists of 500 carefully selected test cases that have been manually reviewed by [human software developers](https://openai.com/index/introducing-swe-bench-verified/) to verify they have appropriately scoped unit tests and well-specified issue descriptions. |
|
Due to its realism and the potential vast benefits of AI agents that could autonomously solve real-world software development challenges, it is used widely throughout academia and industry as a gold-standard for measuring the abilities of AI coding agents. |
|
|
|
We're developing the [OpenHands](https://github.com/All-Hands-AI/OpenHands) open-source software development agent, and its performance on this dataset is currently at 60.6% - not too shabby! |
|
But we wondered, what happens if we really push the limits? |
|
|
|
## Inference-Time Scaling: More Compute, Better Results |
|
|
|
Our approach leverages a simple but powerful idea: for challenging software engineering tasks, trying multiple solutions and picking the best one can lead to better outcomes. Here's how it works: |
|
|
|
1. For each SWE-Bench problem, we run OpenHands agent multiple times using claude 3.7 sonnet with sampling temperature 1.0, generate multiple solutions that leads to multiple code patches |
|
2. We trained a "critic model" that evaluates each solution and predicts whether it's a good solution or not (more details about this model below) |
|
3. We filter out code patches that fails [regression and reproduction tests](https://github.com/OpenAutoCoder/Agentless/blob/main/README_swebench.md#-patch-validation-and-selection) |
|
4. We select the solution from the trajectory with the highest score as our final answer |
|
|
|
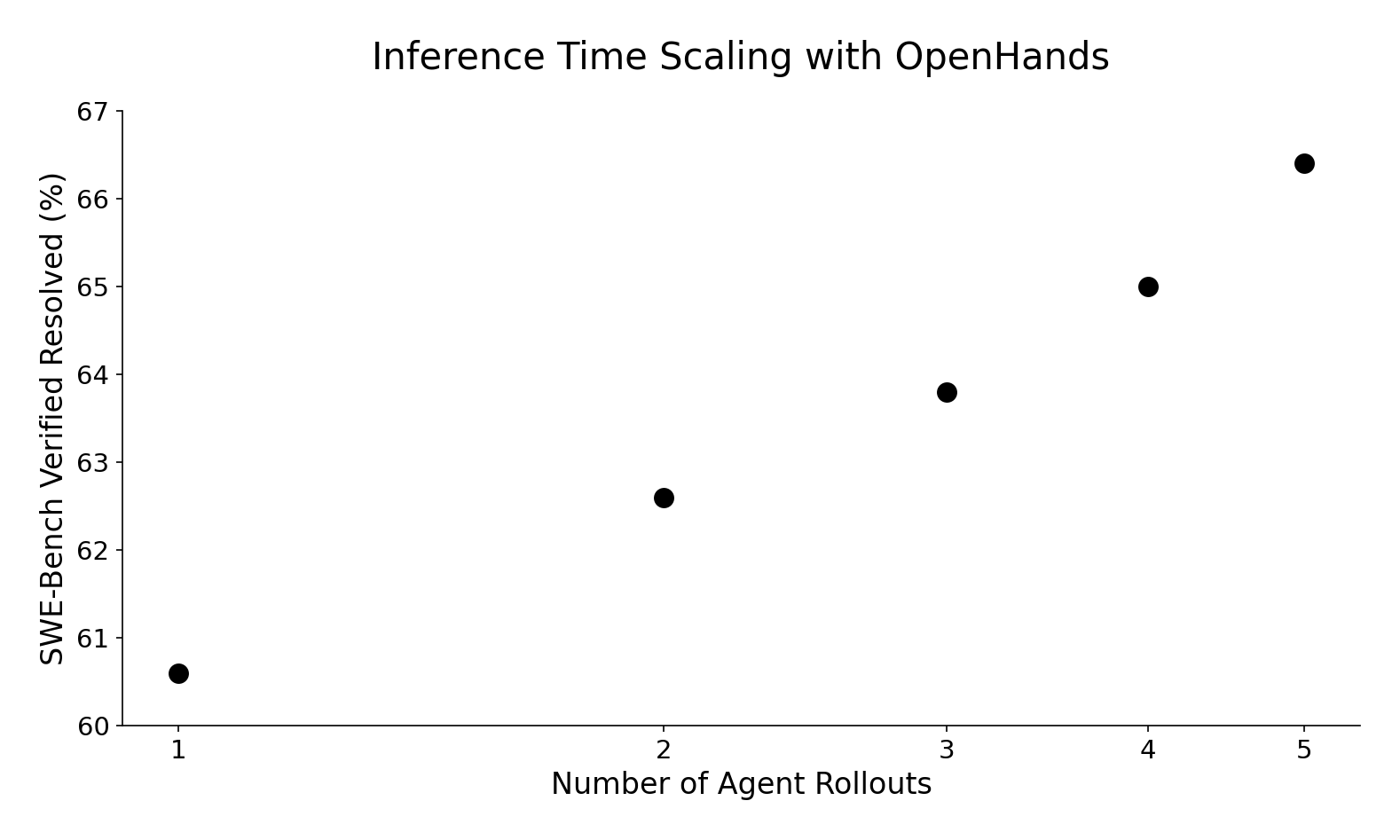
This method of inference-time scaling lets us achieve substantially better results without modifying the underlying agent model and scaffold. |
|
We observe log-linear performance improvement from 60.6% on a single trajectory rollout to 66.4% with five attempts, which will make [our submission](https://github.com/SWE-bench/experiments/pull/209) number one on the leaderboard! |
|
|
|
 |
|
|
|
|
|
## Building a Better Critic |
|
|
|
This idea of using choosing the best of multiple solutions has been tried by other SWE-bench submissions, but these strategies were generally based on prompting an existing model like Claude. |
|
Rather than using this prompt-based reranking strategy, we trained a dedicated critic model, which we found provided more effective results. |
|
|
|
For the training process, we: |
|
- Roll out agent trajectories from [SWE-Gym](https://github.com/SWE-Gym/SWE-Gym) to avoid data leakage |
|
- Implement a temporal difference (TD) learning objective to propagate trajectory-level success signals from unit test execution backward through each trajectory |
|
- Add a regression head on top of the last layer to predict reward values |
|
|
|
The TD learning objective is particularly powerful because it helps the model understand which actions contributed to the final outcome: |
|
|
|
$$ |
|
r_t = \gamma r_{t+1} |
|
$$ |
|
|
|
Where $r_t$ is the reward at time step $t$ (i.e., the t-th action produced by agent), $\gamma$ is the discount factor. The process starts with the final reward $r_T$ which is determined by running the unit tests on the completed solution - 1 for passing all tests and 0 for failing. This terminal reward is then propagated backwards through the trajectory, with each previous step discounted by $\gamma$. We use $\gamma=0.99$. |
|
|
|
We use [veRL](https://github.com/volcengine/verl) to finetune [Qwen 2.5 Coder Instruct 32B](https://huggingface.co/Qwen/Qwen2.5-Coder-32B-Instruct) as a critic model. During inference, we use a [modified version of vLLM](https://github.com/xingyaoww/vllm/tree/add-token-classification-support) to serve this model for evaluation (fun fact: OpenHands agent itself wrote most of the functional [code](https://github.com/vllm-project/vllm/compare/main...xingyaoww:vllm:add-token-classification-support) there). |
|
|
|
We're making the critic model [publicly available on huggingface](https://huggingface.co/all-hands/openhands-critic-32b-exp-20250417) for researchers who want to explore its capabilities or build upon our work. |
|
|
|
## Why We Built a Critic Model and Where It's Going |
|
|
|
We chose to invest in a trained critic model for several reasons: |
|
|
|
**Genuine usefulness through generalization**: While prompt-engineering-based reranker can help boost benchmark scores, real-world generalization is not easy to guarantee. We believe with sufficient data, a trained critic model could generalize to diverse software engineering scenarios beyond SWE-Bench. This makes it a valuable tool for solving real-world problems in everyday coding tasks. |
|
|
|
**Use intermediate reward for future improvements**: While our current implementation focuses on selecting the best complete solution from multiple trajectories, the intermediate rewards predicted throughout each trajectory opens up exciting possibilities for enhancing our agent's capabilities. |
|
- *One-step lookahead sampling* allows us to evaluate multiple potential actions at each step, using the critic's scores to choose the most promising path forward (experimental [PR](https://github.com/All-Hands-AI/OpenHands/pull/7770)). |
|
- *Real-time mistake recovery* is another frontier we're exploring, where the critic can identify declining rewards and help the agent course-correct during the solution process ([issue](https://github.com/All-Hands-AI/OpenHands/issues/2221)). |
|
|
|
We're actively working on integrating these signals more deeply into the OpenHands agent experience, which could enable more efficient assistance even in scenarios where generating multiple complete solutions isn't practical. |
|
|
|
|
|
## Try OpenHands Today |
|
|
|
Besides being state-of-the-art on SWE-Bench Verified, OpenHands is also a top-performing agent on [LiveSWEBench](https://liveswebench.github.io), a contamination-free benchmark for AI software engineers. Additionally, OpenHands ranks first on [Multi-SWE-Bench](https://multi-swe-bench.github.io), a variant of SWE-Bench that evaluates across 8 different programming languages. |
|
|
|
Overall, we feel confident in saying that OpenHands is the best agent out there for a wide variety of tasks! |
|
If you'd like to try it out today you can: |
|
|
|
- **Start with OpenHands Cloud**: The easiest way to get started is with our fully managed [cloud solution](https://app.all-hands.dev) with $50 free credits, seamless GitHub integration, mobile support, and optimizations like [context condensation](https://www.all-hands.dev/blog/openhands-context-condensensation-for-more-efficient-ai-agents) ready to use. |
|
|
|
- **Contribute to Open Source**: Star, open issues, or send PRs to our [GitHub repository](https://github.com/All-Hands-AI/OpenHands) and help advance the frontier of open-source AI software development. |
|
|
|
- **Join Our Community**: Connect with us on [Slack](https://join.slack.com/t/openhands-ai/shared_invite/zt-2ngejmfw6-9gW4APWOC9XUp1n~SiQ6iw), read our [documentation](https://docs.all-hands.dev), and stay updated on our latest developments. |
|
|
|
We can't wait to see what you'll build with OpenHands! |
|
|
|
|

