
GenXD Model Card
![]()





Model Details
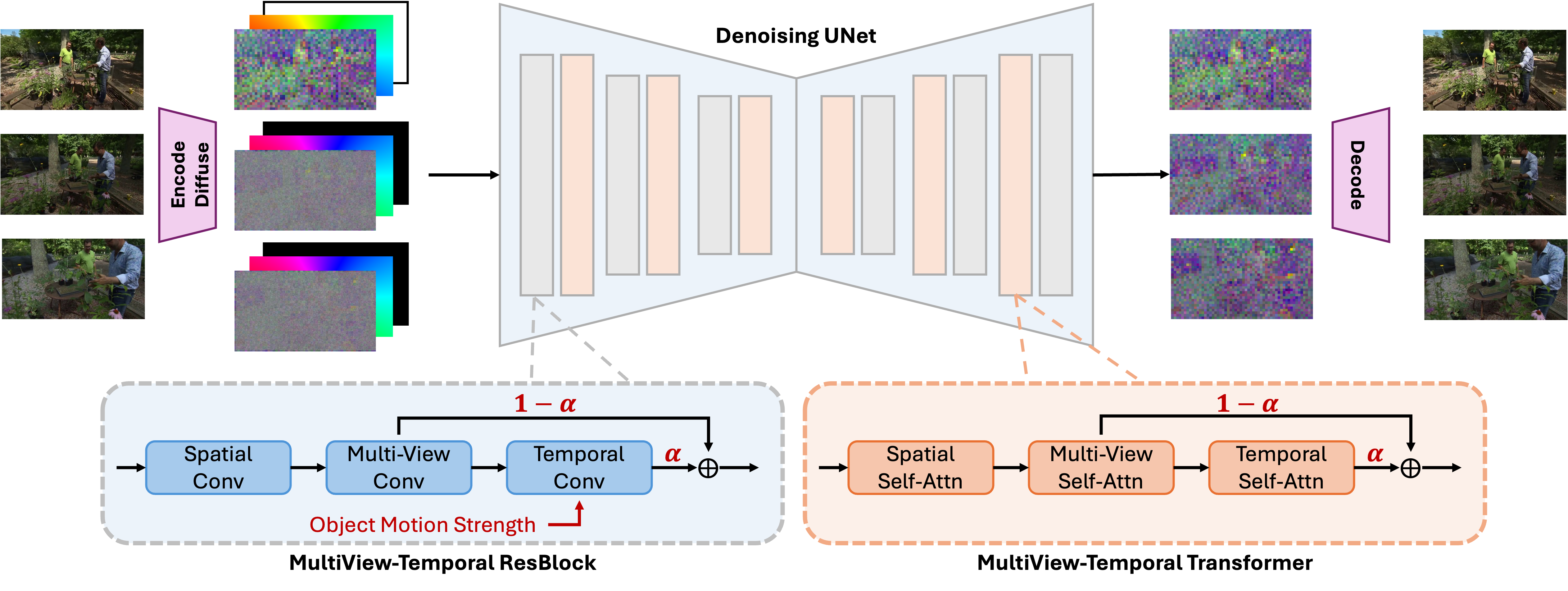
Model Description
GenXD leverages mask latent conditioned diffusion model to generate 3D and 4D samples with both camera and image conditions. In addition, multiview-temporal modules together with alpha-fusing are proposed to effectively disentangle and fuse multiview and temporal information.
- Developed by: NUS, Microsoft
- Model type: image-to-3D diffusion model, image-to-video diffusion model, image-to-4D diffusion model
- License: Apache-2.0
Model Sources
- Project Page: https://gen-x-d.github.io
- Repository: https://github.com/HeliosZhao/GenXD
- Paper: https://arxiv.org/abs/2411.02319
- Data: https://huggingface.co/datasets/Yuyang-z/CamVid-30K
Uses
Direct Use
The model is intended for research purposes only. Possible research areas and tasks include
Generation of artworks and use in design and other artistic processes.
Applications in educational or creative tools.
Research on generative models.
Safe deployment of models which have the potential to generate harmful content.
Probing and understanding the limitations and biases of generative models.
Excluded uses are described below.
Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
Limitations and Bias
Limitations
- The model does not achieve perfect photorealism.
- The model does not achieve perfect 3D consistency.
Bias
While the capabilities of generation model is impressive, it can also reinforce or exacerbate social biases.
- Downloads last month
- 0