
🔥 MERaLiON-2 🔥
🚀 MERaLiON-2-10B | 🚀 MERaLiON-2-10B-ASR | 🚀 MERaLiON-2-3B
Introduction
We are excited to announce the release of MERaLiON2, the latest addition to the MERaLiON family of Speech-Text Large Language Models. Our flagship model, MERaLiON-2-10B, achieves competitive results in benchmark evaluations of multilingual speech recognition (ASR), speech translation (ST), audio scene understanding, emotion recognition, general speech understanding etc., when compared to other state-of-the-art AudioLLMs such as Qwen2.5-Omni-7B, Phi-4-multimodal-instruct. It is tailored to follow complex instructions with a deep understanding of Singapore’s multilingual and multicultural landscape.
Additionall, we provide an ASR-optimized model, MERaLiON-2-10B-ASR, demonstrates 5-30% performance improvement over whisper-large-v3 on speech recognition tasks across Singapore's 4 official languages (English, Mandarin, Malay, and Tamil), 3 SEA languages (Indonesian, Thai, and Vietnamese), code-switch senarios, and various local phrases.
The following visualisation shows 1 - Word Error Rate for the 7 languages across MERaLiON-2 and various models.

We also provide MERaLiON-2-3B that balances performance with reduced computational requirements, enabling broader accessibility and lightweight deployment.
Extended Audio Length: Support audio inputs up to 300 seconds (5 minutes) for audio & speech question answering tasks, 30s for a satisfactory performance for speech transcription (ASR) and speech translation (ST) tasks.
Expanded Language Coverage: In addition to English, Chinese, and Singlish, V2 introduces support for Malay, Tamil, and other regional languages including Indonesian, Thai, and Vietnamese.
Improved Performance: Achieves higher performance across a wide range of tasks. See the Evaluation section for detailed benchmarks.
Higher Quality Training Data: Trained on 120,000 hours of curated speech and audio data, filtered for quality and diversity, with an emphasis on local and multilingual audio sources.
Three Model Variants: Available in general-purpose (MERaLiON-2-10B), ASR-optimized (MERaLiON-2-10B-ASR) and light-weight (MERaLiON-2-3B) configurations to balance latency, compute efficiency, and task performance across different deployment needs.
📝 Model Description:
MERaLiON stands for Multimodal Empathetic Reasoning and Learning in One Network.
MERaLiON-2 is a family of Speech-Text Large Language Models tailored for Singapore’s multilingual and multicultural landscape, as well as the wider Southeast Asian region. The 10B model integrates a localized Whisper-Large-V3 speech encoder with the Gemma2-9b-IT text decoder. The 3B model integrates a localized Whisper-Large-V3 speech encoder with the Gemma2-2b-IT text decoder.
MERaLiON-2-10B is finetuned on 120,000 hours of speech and audio data across 6 diverse tasks: Automatic Speech Recognition (ASR), Spoken Question Answering (SQA), Spoken Dialogue Summarization (SDS), Audio Captioning (AC), Audio-Scene Question Answering (ASQA) and Paralinguistic Question Answering (PQA). The model supports long-form audio inputs of up to 300 seconds (5 minutes) and is specifically adapted to handle the linguistic nuances, accents, and dialects commonly found across Singapore and neighboring countries.
- Developed by: I2R, A*STAR, Singapore
- Model type: Multimodal LLM
- Language(s): Primarily English (Global and Singapore), Chinese, with support for audio of regional languages including Malay, Tamil, Indonesian, Thai, and Vietnamese.
- Audio: Mono channel audio, 16000 hz, up to 300 seconds.
- License: MERaLiON Public License
- Demo: MERaLiON-AudioLLM Web Demo
MERaLiON-2 is an upgraded version of MERaLiON-AudioLLM.
📈 Performance:
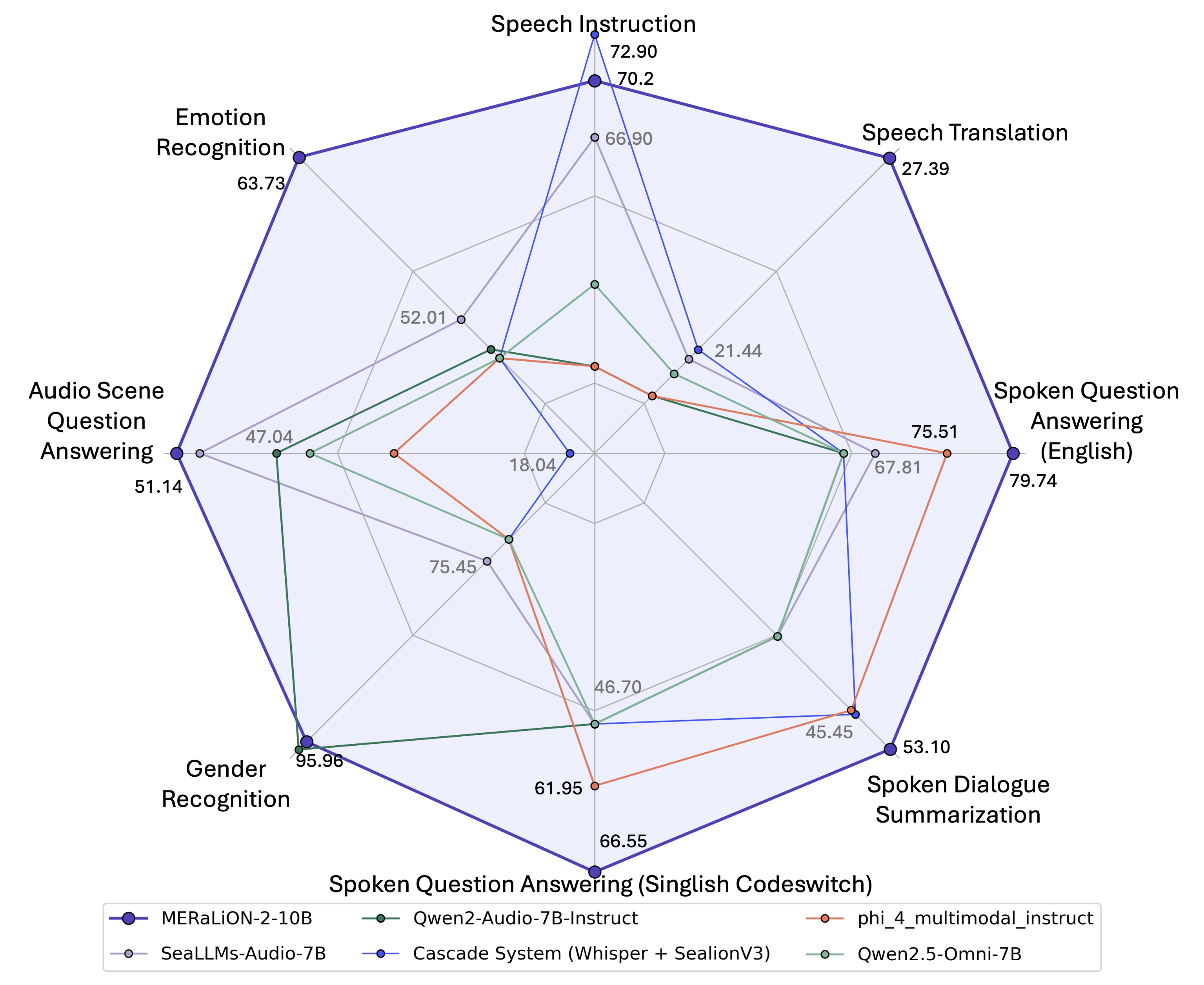
We benchmark MERaLiON-2 series models with extended AudioBench benchmark | LeaderBoard against several recently released open-source multimodal models — SALMONN-7B, Qwen2.5-Omni series and Phi-4-Multimodal — as well as two cascade model. The MERaLiON-2 series models shows stronger performance on a wide range of audio/speech understanding tasks.
Better Automatic Speech Recognition (ASR) Accuracy
MERaLiON-2-10B-ASR and MERaLiON-2-10B demonstrate leading performance in Singlish, Mandarin, Malay, Tamil, and other Southeast Asian languages, while maintaining competitive results in English compared to Whisper-large-v3.
| MERaLiON-2-10B-ASR | MERaLiON-2-10B | MERaLiON-2-3B | whisper_large_v3 | cascade_whisper_large_v3_llama_3_8b_instruct | cascade_whisper_large_v2_gemma2_9b_cpt_sea_lionv3_instruct | MERaLiON-AudioLLM-Whisper-SEA-LION | Qwen2.5-Omni-7B | SeaLLMs-Audio-7B | Qwen2.5-Omni-3B | SALMONN_7B | phi_4_multimodal_instruct | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| thai | 0.096526 | 0.109365 | 0.107279 | 0.121073 | 0.120257 | 0.172105 | 0.919330 | 0.126497 | 0.117152 | 0.163150 | 1.191099 | 1.510068 |
| tamil | 0.271279 | 0.327081 | 0.344081 | 0.441483 | 0.475225 | 0.492336 | 0.561315 | 1.024916 | 2.325402 | 1.315143 | 1.306694 | 1.876722 |
| singlish | 0.129830 | 0.168813 | 0.180395 | 0.248945 | 0.251608 | 0.255717 | 0.143800 | 0.439071 | 0.795990 | 0.389393 | 0.441490 | 0.448863 |
| malay | 0.194638 | 0.209074 | 0.279891 | 0.219692 | 0.311921 | 0.314378 | 0.289895 | 1.460664 | 0.765565 | 2.943750 | 1.085867 | 3.762933 |
| english | 0.078544 | 0.088259 | 0.122295 | 0.080841 | 0.081568 | 0.104830 | 0.110567 | 0.134216 | 0.197824 | 0.110353 | 0.191492 | 0.098225 |
| indonesian | 0.121020 | 0.142813 | 0.131950 | 0.137102 | 0.135390 | 0.159476 | 0.298365 | 0.168659 | 0.220227 | 0.205216 | 1.653502 | 3.565510 |
| mandarin | 0.103694 | 0.132025 | 0.145878 | 0.170980 | 0.196867 | 0.291733 | 0.291183 | 0.102419 | 0.309782 | 0.130429 | 0.939545 | 0.238879 |
| vietnamese | 0.118693 | 0.134808 | 0.155110 | 0.148474 | 0.136075 | 0.164078 | 0.952040 | 0.205491 | 0.222001 | 0.186786 | 1.521174 | 1.805643 |
| private | 0.106150 | 0.112360 | 0.147258 | 0.116630 | 0.118434 | 0.143812 | 0.130667 | 0.222770 | 0.496540 | 0.164556 | 0.273304 | 0.229450 |
Better Instruction Following and Audio Understanding
MERaLiON-2-10B has demonstrated significant improvement across the speech understanding, audio understanding, and paralinguistic tasks. Specifically, MERaLiON-2-10B is able to handle more complicated instructions and answer with more flexibility, minimizing the lost of Gemma's pre-trained knowledge during the audio finetuning process. This allows MERaLiON-2-10B to provide more detailed explaination to queries about the speech content or speaker's emotion status. With further adjustment of the text prompt, it can play different roles like voice assistant, virtual caregiver, or become part of sophisticated multi-AI agent system and software solutions.
| MERaLiON-2-10B | MERaLiON-AudioLLM-Whisper-SEA-LION | MERaLiON-2-10B-ASR | MERaLiON-2-3B | SeaLLMs-Audio-7B | Qwen2-Audio-7B-Instruct | Qwen2.5-Omni-3B | phi_4_multimodal_instruct | cascade_whisper_large_v3_llama_3_8b_instruct | Qwen2.5-Omni-7B | cascade_whisper_large_v2_gemma2_9b_cpt_sea_lionv3_instruct | Qwen-Audio-Chat | SALMONN_7B | WavLLM_fairseq | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| speech_instruction | 70.200000 | 70.800000 | 13.400000 | 19.100000 | 66.900000 | 48.700000 | 65.000000 | 36.200000 | 66.100000 | 58.300000 | 72.900000 | 10.200000 | 12.900000 | 20.400000 |
| emotion_recognition | 63.736268 | 48.577313 | 53.693298 | 54.040797 | 52.007576 | 49.846540 | 33.037836 | 40.677800 | 50.937578 | 31.469397 | 48.214969 | 41.671551 | 33.584869 | 50.801545 |
| audio_scene_question_answering | 51.140374 | 52.207756 | 49.511886 | 46.141353 | 50.193739 | 47.048025 | 48.123228 | 42.217143 | 21.876943 | 45.669153 | 18.043681 | 51.618622 | 51.816958 | 33.034083 |
| gender_recognition | 95.109423 | 97.177396 | 97.220335 | 93.810266 | 75.449392 | 95.963266 | 47.867210 | 70.718047 | 57.039409 | 48.724711 | 19.421130 | 60.349349 | 84.365092 | 60.773275 |
| sqa_singlish | 66.550000 | 58.900000 | 61.850000 | 59.700000 | 51.350000 | 46.700000 | 60.500000 | 61.950000 | 59.350000 | 58.400000 | 53.750000 | 42.300000 | 43.200000 | 51.200000 |
| audio_captioning | 35.604270 | 36.976419 | 34.466710 | 33.243839 | 45.089372 | 37.278810 | 39.200328 | 30.832409 | 2.915778 | 31.896243 | 3.140568 | 39.988663 | 28.880570 | 6.200867 |
| sds_singlish | 53.100000 | 53.600000 | 55.800000 | 48.550000 | 45.450000 | 36.300000 | 46.750000 | 50.750000 | 45.850000 | 43.150000 | 51.000000 | 25.250000 | 14.400000 | 39.450000 |
| sqa_english | 79.735049 | 63.711481 | 73.975834 | 68.715179 | 70.920519 | 68.888565 | 67.818546 | 75.513152 | 78.526569 | 68.415131 | 67.814538 | 66.069047 | 60.649071 | 70.595242 |
| music_understanding | 63.942713 | 51.347936 | 60.657119 | 55.602359 | 63.689975 | 71.609099 | 59.309183 | 55.265375 | 56.697557 | 47.598989 | 50.463353 | 59.056445 | 49.705139 | 44.313395 |
| accent_recognition | 41.815396 | 43.799799 | 47.788864 | 60.054981 | 10.143836 | 10.901397 | 0.478694 | 3.097615 | 21.398482 | 0.587293 | 25.929693 | 17.550294 | 11.577381 | 14.294613 |
| st | 27.391115 | 27.086366 | 28.540359 | 22.130258 | 21.143215 | 10.826666 | 21.776628 | 13.827110 | 13.536272 | 20.688241 | 21.437997 | 4.973184 | 13.486003 | 9.046791 |
🔧 How to Use
Out of Scope use: This model is not intended for use in tool calling, math, and coding tasks.
Requirements
We suggest using Python version, transformers version, PyTorch version. See GitHub() for installation instructions.
Inputs
Audio
- To keep the stable performance, the maximum audio length is suggested to be 300 seconds at 16,000 Hz sampling rate.
- For ASR tasks, the maximum audio length is suggested to be 30 seconds at 16,000 Hz.
Prompt Examples
Instruction: <TextHere> Follow the text instruction based on the following audio: <SpeechHere>
Your name is MERaLiON, a powerful speech-text multimodal model designed to analyze and understand audio content. Your answer should include as many details as possible, including paralinguistics. Instruction: <TextHere> Follow the text instruction based on the following audio: <SpeechHere>
Your are MERaLiON-AudioLLM, an empathic AI assistant developed by A*STAR. MERaLiON stands for Multimodal Empathetic Reasoning and Learning in One Network. You are a friendly and empathetic conversational partner, and is proficient in understanding human's emotion, accent, and gender from paralinguistic features. Maintain a tone that is warm, non-judgmental, and supportive while replying to user. User's voice: <SpeechHere>
Load and Use the Model
Click to view details
import torch
import librosa
from concurrent.futures import ThreadPoolExecutor
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor
repo_id = "MERaLiON/MERaLiON-2-10B"
device = "cuda"
# Load the processor and model
processor = AutoProcessor.from_pretrained(
repo_id,
trust_remote_code=True,
)
model = AutoModelForSpeechSeq2Seq.from_pretrained(
repo_id,
use_safetensors=True,
trust_remote_code=True,
attn_implementation="flash_attention_2",
torch_dtype=torch.bfloat16
).to(device)
# Construct prompt
prompt = "Instruction: {query} \nFollow the text instruction based on the following audio: <SpeechHere>"
query_list = ["query_1", "query_2", "..."]
conversation = [
[{"role": "user", "content": prompt.format(query=prompt)}]
for prompt in query_list
]
chat_prompt = processor.tokenizer.apply_chat_template(
conversation=conversation,
tokenize=False,
add_generation_prompt=True
)
# Audio Inputs ------
# Option 1: Load audio from a local file
def load_audio(path):
audio, _ = librosa.load(path, sr=16000)
return audio
audio_paths = ["/path/to/audio1.wav", "/path/to/audio2.wav", "..."]
with ThreadPoolExecutor() as executor:
audio_array = list(executor.map(load_audio, audio_paths))
# Option 2: Using HuggingFace Dataset directly, make sure sr=16000
# audio_array = batch_ds['audio']['array']
# ------
# Feed to processor
inputs = processor(text=chat_prompt, audios=audio_array).to(device)
# Run inference
outputs = model.generate(**inputs, max_new_tokens=256)
generated_ids = outputs[:, inputs['input_ids'].size(1):]
response = processor.batch_decode(generated_ids, skip_special_tokens=True)
print(response)
vLLM inference
To maximize throughput for long-form audio-text interactions, we support inference using vLLM. Please refer to the GitHub instructions for vLLM-specific setup and deployment scripts.
⚠️ Disclaimer
The current MERaLiON-2 has not been specifically aligned for safety and may generate content that is inappropriate, offensive, or harmful. Developers and users are responsible for performing their own safety fine-tuning and implementing necessary security measures. The authors shall not be held liable for any claims, damages, or other liabilities arising from the use of the released models, weights, or code.
Compute and Infrastructure
MERaLiON-2 was trained on the ASPIRE 2A+ Supercomputer Cluster, provided by National Supercomputing Centre (NSCC), Singapore. ASPIRE 2A+ cluster provides multiple H100 nodes, with each compute node equipped with 8 Nvidia H100 GPUs, 2 TB of RAM, and 30 TB of locally attached NVMe storage. These nodes are interconnected via a rail-optimised, full fat-tree topology, utilising 400 Gb/s NDR InfiniBand cables. Additionally, the cluster incorporates a 2.5 PB SSD-based Lustre file system, linked to the H100 nodes through high-speed InfiniBand connections.
With a global batch size of 768, we trained the current release of MERaLiON-2 for around 200k steps, which took around 2 days to complete using 16 nodes, 128 H100 GPUs.
📚 Citation
If you find our work useful, please cite our papers:
MERaLiON-AudioLLM: Bridging Audio and Language with Large Language Models
AudioBench: A Universal Benchmark for Audio Large Language Models
Advancing Singlish Understanding: Bridging the Gap with Datasets and Multimodal Models
MoWE-Audio: Multitask AudioLLMs with Mixture of Weak Encoders
@misc{he2024meralionaudiollmtechnicalreport,
title={MERaLiON-AudioLLM: Bridging Audio and Language with Large Language Models},
author={{MERaLiON Team}},
year={2024},
eprint={2412.09818},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.09818},
}
@article{wang2024audiobench,
title={AudioBench: A Universal Benchmark for Audio Large Language Models},
author={Wang, Bin and Zou, Xunlong and Lin, Geyu and Sun, Shuo and Liu, Zhuohan and Zhang, Wenyu and Liu, Zhengyuan and Aw, AiTi and Chen, Nancy F},
journal={NAACL},
year={2025}
}
@article{wang2025advancing,
title={Advancing Singlish Understanding: Bridging the Gap with Datasets and Multimodal Models},
author={Wang, Bin and Zou, Xunlong and Sun, Shuo and Zhang, Wenyu and He, Yingxu and Liu, Zhuohan and Wei, Chengwei and Chen, Nancy F and Aw, AiTi},
journal={arXiv preprint arXiv:2501.01034},
year={2025}
}
@article{zhang2024mowe,
title={MoWE-Audio: Multitask AudioLLMs with Mixture of Weak Encoders},
author={Zhang, Wenyu and Sun, Shuo and Wang, Bin and Zou, Xunlong and Liu, Zhuohan and He, Yingxu and Lin, Geyu and Chen, Nancy F and Aw, Ai Ti},
journal={ICASSP},
year={2025}
}