

Gryphe's MythoLogic 13B GGML
These files are GGML format model files for Gryphe's MythoLogic 13B.
GGML files are for CPU + GPU inference using llama.cpp and libraries and UIs which support this format, such as:
- KoboldCpp, a powerful GGML web UI with full GPU acceleration out of the box. Especially good for story telling.
- LoLLMS Web UI, a great web UI with GPU acceleration via the c_transformers backend.
- LM Studio, a fully featured local GUI. Supports full GPU accel on macOS. Also supports Windows, without GPU accel.
- text-generation-webui, the most popular web UI. Requires extra steps to enable GPU accel via llama.cpp backend.
- ctransformers, a Python library with LangChain support and OpenAI-compatible AI server.
- llama-cpp-python, a Python library with OpenAI-compatible API server.
These files were quantised using hardware kindly provided by Latitude.sh.
Repositories available
- GPTQ models for GPU inference, with multiple quantisation parameter options.
- 2, 3, 4, 5, 6 and 8-bit GGML models for CPU+GPU inference
- Unquantised fp16 model in pytorch format, for GPU inference and for further conversions
Prompt template: Alpaca
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction: {prompt}
### Response:
Compatibility
Original llama.cpp quant methods: q4_0, q4_1, q5_0, q5_1, q8_0
These are guaranteed to be compatible with any UIs, tools and libraries released since late May. They may be phased out soon, as they are largely superseded by the new k-quant methods.
New k-quant methods: q2_K, q3_K_S, q3_K_M, q3_K_L, q4_K_S, q4_K_M, q5_K_S, q6_K
These new quantisation methods are compatible with llama.cpp as of June 6th, commit 2d43387.
They are now also compatible with recent releases of text-generation-webui, KoboldCpp, llama-cpp-python, ctransformers, rustformers and most others. For compatibility with other tools and libraries, please check their documentation.
Explanation of the new k-quant methods
Click to see details
The new methods available are:
- GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
- GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
- GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
- GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
- GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
- GGML_TYPE_Q8_K - "type-0" 8-bit quantization. Only used for quantizing intermediate results. The difference to the existing Q8_0 is that the block size is 256. All 2-6 bit dot products are implemented for this quantization type.
Refer to the Provided Files table below to see what files use which methods, and how.
Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
|---|---|---|---|---|---|
| mythologic-13b.ggmlv3.q2_K.bin | q2_K | 2 | 5.51 GB | 8.01 GB | New k-quant method. Uses GGML_TYPE_Q4_K for the attention.vw and feed_forward.w2 tensors, GGML_TYPE_Q2_K for the other tensors. |
| mythologic-13b.ggmlv3.q3_K_S.bin | q3_K_S | 3 | 5.66 GB | 8.16 GB | New k-quant method. Uses GGML_TYPE_Q3_K for all tensors |
| mythologic-13b.ggmlv3.q3_K_M.bin | q3_K_M | 3 | 6.31 GB | 8.81 GB | New k-quant method. Uses GGML_TYPE_Q4_K for the attention.wv, attention.wo, and feed_forward.w2 tensors, else GGML_TYPE_Q3_K |
| mythologic-13b.ggmlv3.q3_K_L.bin | q3_K_L | 3 | 6.93 GB | 9.43 GB | New k-quant method. Uses GGML_TYPE_Q5_K for the attention.wv, attention.wo, and feed_forward.w2 tensors, else GGML_TYPE_Q3_K |
| mythologic-13b.ggmlv3.q4_K_S.bin | q4_K_S | 4 | 7.37 GB | 9.87 GB | New k-quant method. Uses GGML_TYPE_Q4_K for all tensors |
| mythologic-13b.ggmlv3.q4_K_M.bin | q4_K_M | 4 | 7.87 GB | 10.37 GB | New k-quant method. Uses GGML_TYPE_Q6_K for half of the attention.wv and feed_forward.w2 tensors, else GGML_TYPE_Q4_K |
| mythologic-13b.ggmlv3.q4_0.bin | q4_0 | 4 | 7.32 GB | 9.82 GB | Original quant method, 4-bit. |
| mythologic-13b.ggmlv3.q4_1.bin | q4_1 | 4 | 8.14 GB | 10.64 GB | Original quant method, 4-bit. Higher accuracy than q4_0 but not as high as q5_0. However has quicker inference than q5 models. |
| mythologic-13b.ggmlv3.q5_K_S.bin | q5_K_S | 5 | 8.97 GB | 11.47 GB | New k-quant method. Uses GGML_TYPE_Q5_K for all tensors |
| mythologic-13b.ggmlv3.q5_K_M.bin | q5_K_M | 5 | 9.23 GB | 11.73 GB | New k-quant method. Uses GGML_TYPE_Q6_K for half of the attention.wv and feed_forward.w2 tensors, else GGML_TYPE_Q5_K |
| mythologic-13b.ggmlv3.q5_0.bin | q5_0 | 5 | 8.95 GB | 11.45 GB | Original quant method, 5-bit. Higher accuracy, higher resource usage and slower inference. |
| mythologic-13b.ggmlv3.q5_1.bin | q5_1 | 5 | 9.76 GB | 12.26 GB | Original quant method, 5-bit. Even higher accuracy, resource usage and slower inference. |
| mythologic-13b.ggmlv3.q6_K.bin | q6_K | 6 | 10.68 GB | 13.18 GB | New k-quant method. Uses GGML_TYPE_Q8_K for all tensors - 6-bit quantization |
| mythologic-13b.ggmlv3.q8_0.bin | q8_0 | 8 | 13.83 GB | 16.33 GB | Original quant method, 8-bit. Almost indistinguishable from float16. High resource use and slow. Not recommended for most users. |
Note: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
How to run in llama.cpp
I use the following command line; adjust for your tastes and needs:
./main -t 10 -ngl 32 -m mythologic-13b.ggmlv3.q4_0.bin --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "### Instruction: Write a story about llamas\n### Response:"
Change -t 10 to the number of physical CPU cores you have. For example if your system has 8 cores/16 threads, use -t 8.
Change -ngl 32 to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
If you want to have a chat-style conversation, replace the -p <PROMPT> argument with -i -ins
How to run in text-generation-webui
Further instructions here: text-generation-webui/docs/llama.cpp-models.md.
Discord
For further support, and discussions on these models and AI in general, join us at:
Thanks, and how to contribute.
Thanks to the chirper.ai team!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
- Patreon: https://patreon.com/TheBlokeAI
- Ko-Fi: https://ko-fi.com/TheBlokeAI
Special thanks to: Luke from CarbonQuill, Aemon Algiz.
Patreon special mentions: Space Cruiser, Nikolai Manek, Sam, Chris McCloskey, Rishabh Srivastava, Kalila, Spiking Neurons AB, Khalefa Al-Ahmad, WelcomeToTheClub, Chadd, Lone Striker, Viktor Bowallius, Edmond Seymore, Ai Maven, Chris Smitley, Dave, Alexandros Triantafyllidis, Luke @flexchar, Elle, ya boyyy, Talal Aujan, Alex , Jonathan Leane, Deep Realms, Randy H, subjectnull, Preetika Verma, Joseph William Delisle, Michael Levine, chris gileta, K, Oscar Rangel, LangChain4j, Trenton Dambrowitz, Eugene Pentland, Johann-Peter Hartmann, Femi Adebogun, Illia Dulskyi, senxiiz, Daniel P. Andersen, Sean Connelly, Artur Olbinski, RoA, Mano Prime, Derek Yates, Raven Klaugh, David Flickinger, Willem Michiel, Pieter, Willian Hasse, vamX, Luke Pendergrass, webtim, Ghost , Rainer Wilmers, Nathan LeClaire, Will Dee, Cory Kujawski, John Detwiler, Fred von Graf, biorpg, Iucharbius , Imad Khwaja, Pierre Kircher, terasurfer , Asp the Wyvern, John Villwock, theTransient, zynix , Gabriel Tamborski, Fen Risland, Gabriel Puliatti, Matthew Berman, Pyrater, SuperWojo, Stephen Murray, Karl Bernard, Ajan Kanaga, Greatston Gnanesh, Junyu Yang.
Thank you to all my generous patrons and donaters!
Original model card: Gryphe's MythoLogic 13B
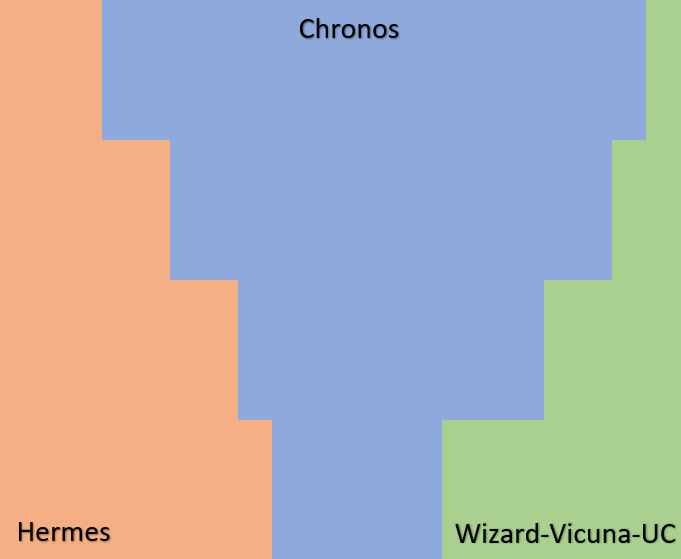
An experiment with gradient merges using the following script, with Chronos as its primary model, augmented by Hermes and Wizard-Vicuna Uncensored.
Chronos is a wonderfully verbose model, though it definitely seems to lack in the logic department. Hermes and WizardLM have been merged gradually, primarily in the higher layers (10+) in an attempt to rectify some of this behaviour.
The main objective was to create an all-round model with improved story generation and roleplaying capabilities.
Below is an illustration to showcase a rough approximation of the gradients I used to create MythoLogic:
This model primarily uses Alpaca formatting, so for optimal model performance, use:
### Instruction:
Your instruction or question here.
### Response:
For chat/roleplay conversations, I suggest the following structure instead:
You are <AI NAME>, a friendly and supportive AI language model. We discuss all subjects freely and without bias or restrictions.
I am <YOUR NAME>, the user interacting with you through a chat conversation. Start with greeting me.
### Instruction:
Write <AI NAME>'s next reply in a chat between <YOUR NAME> and <AI NAME>. Write a single reply only.
### Chat History:
<AI NAME>: Good day, <YOUR NAME>! How can I assist you today?
(Etc, etc)
### Response:
<AI NAME>:
license: other
- Downloads last month
- 8