
Skywork-R1V2
Collection
Multimodal Hybrid Reinforcement Learning for Reasoning
•
7 items
•
Updated
•
10


Skywork-R1V2-38B is a state-of-the-art open-source multimodal reasoning model, achieving top-tier performance across multiple benchmarks:
| Model Name | Vision Encoder | Language Model | Hugging Face Link |
|---|---|---|---|
| Skywork-R1V2-38B | InternViT-6B-448px-V2_5 | Qwen/QwQ-32B | 🤗 Link |

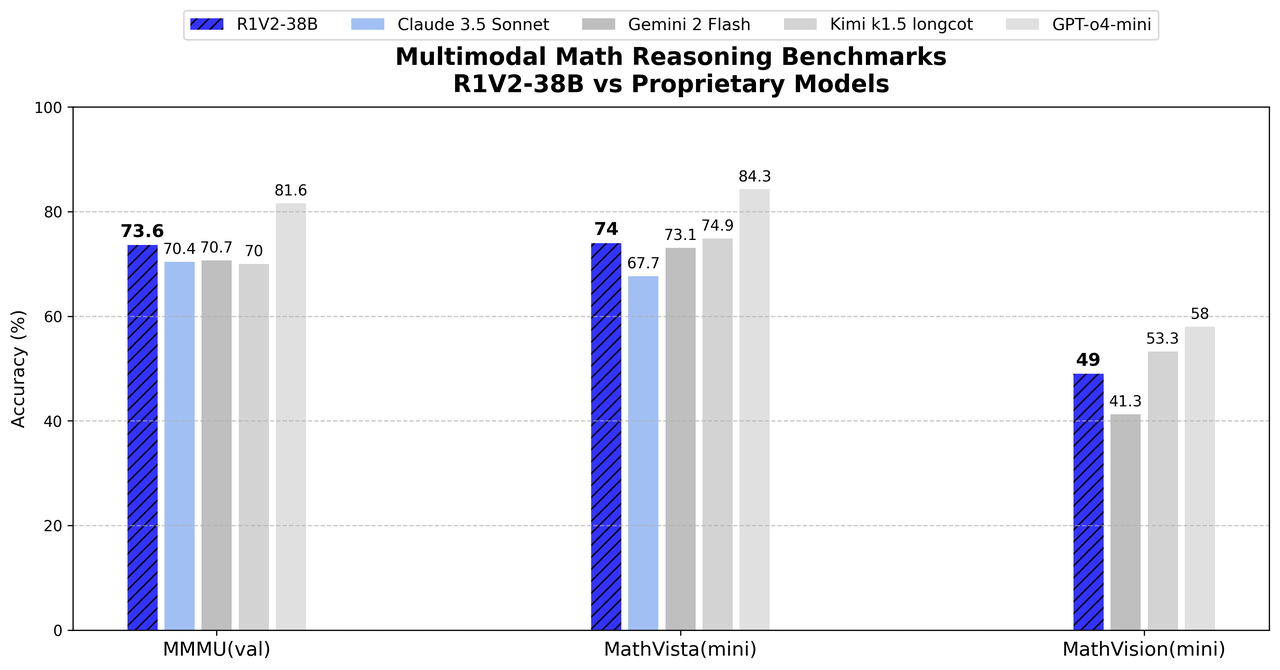
| Model | Supports Vision | Text Reasoning (%) | Multimodal Reasoning (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AIME24 | LiveCodebench | liveBench | IFEVAL | BFCL | GPQA | MMMU(val) | MathVista(mini) | MathVision(mini) | OlympiadBench | mmmu‑pro | ||
| R1V2‑38B | ✅ | 78.9 | 63.6 | 73.2 | 82.9 | 66.3 | 61.6 | 73.6 | 74.0 | 49.0 | 62.6 | 52.0 |
| R1V1‑38B | ✅ | 72.0 | 57.2 | 54.6 | 72.5 | 53.5 | – | 68.0 | 67.0 | – | 40.4 | – |
| Deepseek‑R1‑671B | ❌ | 74.3 | 65.9 | 71.6 | 83.3 | 60.3 | 71.5 | – | – | – | – | – |
| GPT‑o1 | ❌ | 79.8 | 63.4 | 72.2 | – | – | – | – | – | – | – | – |
| GPT‑o4‑mini | ✅ | 93.4 | 74.6 | 78.1 | – | – | 49.9 | 81.6 | 84.3 | 58.0 | – | – |
| Claude 3.5 Sonnet | ✅ | – | – | – | – | – | 65.0 | 66.4 | 65.3 | – | – | – |
| Kimi k1.5 long-cot | ✅ | – | – | – | – | – | – | 70.0 | 74.9 | – | – | – |
| Qwen2.5‑VL‑72B‑Instruct | ✅ | – | – | – | – | – | – | 70.2 | 74.8 | – | – | – |
| InternVL2.5‑78B | ✅ | – | – | – | – | – | – | 70.1 | 72.3 | – | 33.2 | – |
git clone https://github.com/SkyworkAI/Skywork-R1V.git
cd skywork-r1v/inference
# For Transformers
conda create -n r1-v python=3.10 && conda activate r1-v
bash setup.sh
# For vLLM
conda create -n r1v-vllm python=3.10 && conda activate r1v-vllm
pip install -U vllm
transformers inference
CUDA_VISIBLE_DEVICES="0,1" python inference_with_transformers.py \
--model_path path \
--image_paths image1_path \
--question "your question"
vllm inference
python inference_with_vllm.py \
--model_path path \
--image_paths image1_path image2_path \
--question "your question" \
--tensor_parallel_size 4
If you use Skywork-R1V in your research, please cite:
@misc{chris2025skyworkr1v2multimodalhybrid,
title={Skywork R1V2: Multimodal Hybrid Reinforcement Learning for Reasoning},
author={Peiyu Wang and Yichen Wei and Yi Peng and Xiaokun Wang and Weijie Qiu and Wei Shen and Tianyidan Xie and Jiangbo Pei and Jianhao Zhang and Yunzhuo Hao and Xuchen Song and Yang Liu and Yahui Zhou},
year={2025},
eprint={2504.16656},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2504.16656},
}
@misc{peng2025skyworkr1vpioneeringmultimodal,
title={Skywork R1V: Pioneering Multimodal Reasoning with Chain-of-Thought},
author={Yi Peng and Peiyu Wang and Xiaokun Wang and Yichen Wei and Jiangbo Pei and Weijie Qiu and Ai Jian and Yunzhuo Hao and Jiachun Pan and Tianyidan Xie and Li Ge and Rongxian Zhuang and Xuchen Song and Yang Liu and Yahui Zhou},
year={2025},
eprint={2504.05599},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2504.05599},
}
This project is released under an open-source license.