
SkyReels-V2
Collection
Infinite-length Film Generative Model
•
9 items
•
Updated
•
36
![]()
📑 Technical Report · 👋 Playground · 💬 Discord · 🤗 Hugging Face · 🤖 ModelScope · 🌐 GitHub
Welcome to the SkyReels V2 repository! Here, you'll find the model weights for our infinite-length film generative models. To the best of our knowledge, it represents the first open-source video generative model employing AutoRegressive Diffusion-Forcing architecture that achieves the SOTA performance among publicly available models.
# clone the repository.
git clone https://github.com/SkyworkAI/SkyReels-V2
cd SkyReels-V2
# Install dependencies. Test environment uses Python 3.10.12.
pip install -r requirements.txt
You can download our models from Hugging Face:
| Type | Model Variant | Recommended Height/Width/Frame | Link |
|---|---|---|---|
| Diffusion Forcing | 1.3B-540P | 544 * 960 * 97f | 🤗 Huggingface 🤖 ModelScope |
| 5B-540P | 544 * 960 * 97f | Coming Soon | |
| 5B-720P | 720 * 1280 * 121f | Coming Soon | |
| 14B-540P | 544 * 960 * 97f | 🤗 Huggingface 🤖 ModelScope | |
| 14B-720P | 720 * 1280 * 121f | 🤗 Huggingface 🤖 ModelScope | |
| Text-to-Video | 1.3B-540P | 544 * 960 * 97f | Coming Soon |
| 5B-540P | 544 * 960 * 97f | Coming Soon | |
| 5B-720P | 720 * 1280 * 121f | Coming Soon | |
| 14B-540P | 544 * 960 * 97f | 🤗 Huggingface 🤖 ModelScope | |
| 14B-720P | 720 * 1280 * 121f | 🤗 Huggingface 🤖 ModelScope | |
| Image-to-Video | 1.3B-540P | 544 * 960 * 97f | 🤗 Huggingface 🤖 ModelScope |
| 5B-540P | 544 * 960 * 97f | Coming Soon | |
| 5B-720P | 720 * 1280 * 121f | Coming Soon | |
| 14B-540P | 544 * 960 * 97f | 🤗 Huggingface 🤖 ModelScope | |
| 14B-720P | 720 * 1280 * 121f | 🤗 Huggingface 🤖 ModelScope | |
| Camera Director | 5B-540P | 544 * 960 * 97f | Coming Soon |
| 5B-720P | 720 * 1280 * 121f | Coming Soon | |
| 14B-720P | 720 * 1280 * 121f | Coming Soon |
After downloading, set the model path in your generation commands:
The Diffusion Forcing version model allows us to generate Infinite-Length videos. This model supports both text-to-video (T2V) and image-to-video (I2V) tasks, and it can perform inference in both synchronous and asynchronous modes. Here we demonstrate 2 running scripts as examples for long video generation. If you want to adjust the inference parameters, e.g., the duration of video, inference mode, read the Note below first.
synchronous generation for 10s video
model_id=Skywork/SkyReels-V2-DF-14B-540P
# synchronous inference
python3 generate_video_df.py \
--model_id ${model_id} \
--resolution 540P \
--ar_step 0 \
--base_num_frames 97 \
--num_frames 257 \
--overlap_history 17 \
--prompt "A graceful white swan with a curved neck and delicate feathers swimming in a serene lake at dawn, its reflection perfectly mirrored in the still water as mist rises from the surface, with the swan occasionally dipping its head into the water to feed." \
--addnoise_condition 20 \
--offload \
--teacache \
--use_ret_steps \
--teacache_thresh 0.3
asynchronous generation for 30s video
model_id=Skywork/SkyReels-V2-DF-14B-540P
# asynchronous inference
python3 generate_video_df.py \
--model_id ${model_id} \
--resolution 540P \
--ar_step 5 \
--causal_block_size 5 \
--base_num_frames 97 \
--num_frames 737 \
--overlap_history 17 \
--prompt "A graceful white swan with a curved neck and delicate feathers swimming in a serene lake at dawn, its reflection perfectly mirrored in the still water as mist rises from the surface, with the swan occasionally dipping its head into the water to feed." \
--addnoise_condition 20 \
--offload
Note:
- If you want to run the image-to-video (I2V) task, add
--image ${image_path}to your command and it is also better to use text-to-video (T2V)-like prompt which includes some descriptions of the first-frame image.- For long video generation, you can just switch the
--num_frames, e.g.,--num_frames 257for 10s video,--num_frames 377for 15s video,--num_frames 737for 30s video,--num_frames 1457for 60s video. The number is not strictly aligned with the logical frame number for specified time duration, but it is aligned with some training parameters, which means it may perform better. When you use asynchronous inference with causal_block_size > 1, the--num_framesshould be carefully set.- You can use
--ar_step 5to enable asynchronous inference. When asynchronous inference,--causal_block_size 5is recommended while it is not supposed to be set for synchronous generation. REMEMBER that the frame latent number inputted into the model in every iteration, e.g., base frame latent number (e.g., (97-1)//4+1=25 for base_num_frames=97) and (e.g., (237-97-(97-17)x1+17-1)//4+1=20 for base_num_frames=97, num_frames=237, overlap_history=17) for the last iteration, MUST be divided by causal_block_size. If you find it too hard to calculate and set proper values, just use our recommended setting above :). Asynchronous inference will take more steps to diffuse the whole sequence which means it will be SLOWER than synchronous mode. In our experiments, asynchronous inference may improve the instruction following and visual consistent performance.- To reduce peak VRAM, just lower the
--base_num_frames, e.g., to 77 or 57, while keeping the same generative length--num_framesyou want to generate. This may slightly reduce video quality, and it should not be set too small.--addnoise_conditionis used to help smooth the long video generation by adding some noise to the clean condition. Too large noise can cause the inconsistency as well. 20 is a recommended value, and you may try larger ones, but it is recommended to not exceed 50.- Generating a 540P video using the 1.3B model requires approximately 14.7GB peak VRAM, while the same resolution video using the 14B model demands around 51.2GB peak VRAM.
# run Text-to-Video Generation
model_id=Skywork/SkyReels-V2-T2V-14B-540P
python3 generate_video.py \
--model_id ${model_id} \
--resolution 540P \
--num_frames 97 \
--guidance_scale 6.0 \
--shift 8.0 \
--fps 24 \
--prompt "A serene lake surrounded by towering mountains, with a few swans gracefully gliding across the water and sunlight dancing on the surface." \
--offload \
--teacache \
--use_ret_steps \
--teacache_thresh 0.3
Note:
- When using an image-to-video (I2V) model, you must provide an input image using the
--image ${image_path}parameter. The--guidance_scale 5.0and--shift 3.0is recommended for I2V model.- Generating a 540P video using the 1.3B model requires approximately 14.7GB peak VRAM, while the same resolution video using the 14B model demands around 43.4GB peak VRAM.
The prompt enhancer is implemented based on Qwen2.5-32B-Instruct and is utilized via the --prompt_enhancer parameter. It works ideally for short prompts, while for long prompts, it might generate an excessively lengthy prompt that could lead to over-saturation in the generative video. Note the peak memory of GPU is 64G+ if you use --prompt_enhancer. If you want to obtain the enhanced prompt separately, you can also run the prompt_enhancer script separately for testing. The steps are as follows:
cd skyreels_v2_infer/pipelines
python3 prompt_enhancer.py --prompt "A serene lake surrounded by towering mountains, with a few swans gracefully gliding across the water and sunlight dancing on the surface."
Note:
--prompt_enhanceris not allowed if using--use_usp. We recommend running the skyreels_v2_infer/pipelines/prompt_enhancer.py script first to generate enhanced prompt before enabling the--use_uspparameter.
Advanced Configuration Options
Below are the key parameters you can customize for video generation:
| Parameter | Recommended Value | Description |
|---|---|---|
| --prompt | Text description for generating your video | |
| --image | Path to input image for image-to-video generation | |
| --resolution | 540P or 720P | Output video resolution (select based on model type) |
| --num_frames | 97 or 121 | Total frames to generate (97 for 540P models, 121 for 720P models) |
| --inference_steps | 50 | Number of denoising steps |
| --fps | 24 | Frames per second in the output video |
| --shift | 8.0 or 5.0 | Flow matching scheduler parameter (8.0 for T2V, 5.0 for I2V) |
| --guidance_scale | 6.0 or 5.0 | Controls text adherence strength (6.0 for T2V, 5.0 for I2V) |
| --seed | Fixed seed for reproducible results (omit for random generation) | |
| --offload | True | Offloads model components to CPU to reduce VRAM usage (recommended) |
| --use_usp | True | Enables multi-GPU acceleration with xDiT USP |
| --outdir | ./video_out | Directory where generated videos will be saved |
| --prompt_enhancer | True | Expand the prompt into a more detailed description |
| --teacache | False | Enables teacache for faster inference |
| --teacache_thresh | 0.2 | Higher speedup will cause to worse quality |
| --use_ret_steps | False | Retention Steps for teacache |
Diffusion Forcing Additional Parameters
| Parameter | Recommended Value | Description |
|---|---|---|
| --ar_step | 0 | Controls asynchronous inference (0 for synchronous mode) |
| --base_num_frames | 97 or 121 | Base frame count (97 for 540P, 121 for 720P) |
| --overlap_history | 17 | Number of frames to overlap for smooth transitions in long videos |
| --addnoise_condition | 20 | Improves consistency in long video generation |
| --causal_block_size | 5 | Recommended when using asynchronous inference (--ar_step > 0) |
We use xDiT USP to accelerate inference. For example, to generate a video with 2 GPUs, you can use the following command:
model_id=Skywork/SkyReels-V2-DF-14B-540P
# diffusion forcing synchronous inference
torchrun --nproc_per_node=2 generate_video_df.py \
--model_id ${model_id} \
--resolution 540P \
--ar_step 0 \
--base_num_frames 97 \
--num_frames 257 \
--overlap_history 17 \
--prompt "A graceful white swan with a curved neck and delicate feathers swimming in a serene lake at dawn, its reflection perfectly mirrored in the still water as mist rises from the surface, with the swan occasionally dipping its head into the water to feed." \
--addnoise_condition 20 \
--use_usp \
--offload \
--seed 42
# run Text-to-Video Generation
model_id=Skywork/SkyReels-V2-T2V-14B-540P
torchrun --nproc_per_node=2 generate_video.py \
--model_id ${model_id} \
--resolution 540P \
--num_frames 97 \
--guidance_scale 6.0 \
--shift 8.0 \
--fps 24 \
--offload \
--prompt "A serene lake surrounded by towering mountains, with a few swans gracefully gliding across the water and sunlight dancing on the surface." \
--use_usp \
--seed 42
Note:
- When using an image-to-video (I2V) model, you must provide an input image using the
--image ${image_path}parameter. The--guidance_scale 5.0and--shift 3.0is recommended for I2V model.
Recent advances in video generation have been driven by diffusion models and autoregressive frameworks, yet critical challenges persist in harmonizing prompt adherence, visual quality, motion dynamics, and duration: compromises in motion dynamics to enhance temporal visual quality, constrained video duration (5-10 seconds) to prioritize resolution, and inadequate shot-aware generation stemming from general-purpose MLLMs' inability to interpret cinematic grammar, such as shot composition, actor expressions, and camera motions. These intertwined limitations hinder realistic long-form synthesis and professional film-style generation.
To address these limitations, we introduce SkyReels-V2, the world's first infinite-length film generative model using a Diffusion Forcing framework. Our approach synergizes Multi-modal Large Language Models (MLLM), Multi-stage Pretraining, Reinforcement Learning, and Diffusion Forcing techniques to achieve comprehensive optimization. Beyond its technical innovations, SkyReels-V2 enables multiple practical applications, including Story Generation, Image-to-Video Synthesis, Camera Director functionality, and multi-subject consistent video generation through our Skyreels-A2 system.
The SkyReels-V2 methodology consists of several interconnected components. It starts with a comprehensive data processing pipeline that prepares various quality training data. At its core is the Video Captioner architecture, which provides detailed annotations for video content. The system employs a multi-task pretraining strategy to build fundamental video generation capabilities. Post-training optimization includes Reinforcement Learning to enhance motion quality, Diffusion Forcing Training for generating extended videos, and High-quality Supervised Fine-Tuning (SFT) stages for visual refinement. The model runs on optimized computational infrastructure for efficient training and inference. SkyReels-V2 supports multiple applications, including Story Generation, Image-to-Video Synthesis, Camera Director functionality, and Elements-to-Video Generation.
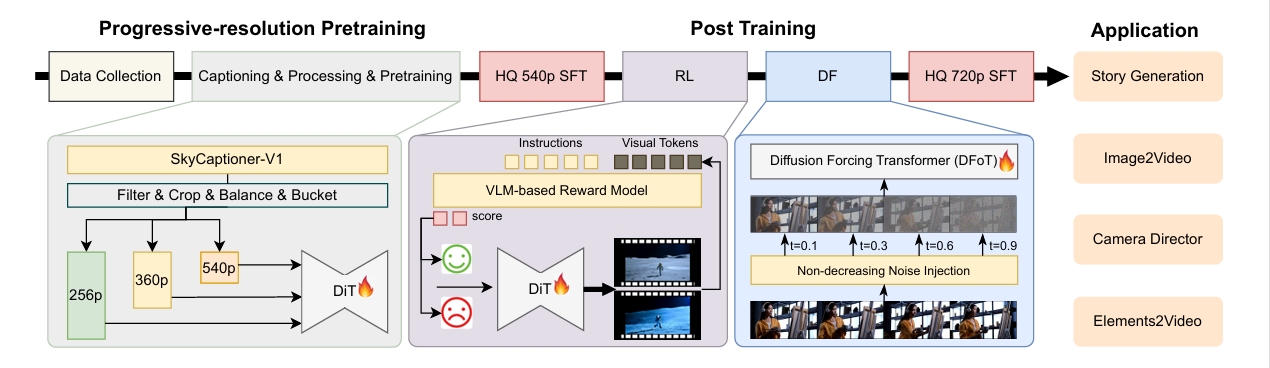
SkyCaptioner-V1 serves as our video captioning model for data annotation. This model is trained on the captioning result from the base model Qwen2.5-VL-72B-Instruct and the sub-expert captioners on a balanced video data. The balanced video data is a carefully curated dataset of approximately 2 million videos to ensure conceptual balance and annotation quality. Built upon the Qwen2.5-VL-7B-Instruct foundation model, SkyCaptioner-V1 is fine-tuned to enhance performance in domain-specific video captioning tasks. To compare the performance with the SOTA models, we conducted a manual assessment of accuracy across different captioning fields using a test set of 1,000 samples. The proposed SkyCaptioner-V1 achieves the highest average accuracy among the baseline models, and show a dramatic result in the shot related fields
| model | Qwen2.5-VL-7B-Ins. | Qwen2.5-VL-72B-Ins. | Tarsier2-Recap-7b | SkyCaptioner-V1 |
|---|---|---|---|---|
| Avg accuracy | 51.4% | 58.7% | 49.4% | 76.3% |
| shot type | 76.8% | 82.5% | 60.2% | 93.7% |
| shot angle | 60.0% | 73.7% | 52.4% | 89.8% |
| shot position | 28.4% | 32.7% | 23.6% | 83.1% |
| camera motion | 62.0% | 61.2% | 45.3% | 85.3% |
| expression | 43.6% | 51.5% | 54.3% | 68.8% |
| TYPES_type | 43.5% | 49.7% | 47.6% | 82.5% |
| TYPES_sub_type | 38.9% | 44.9% | 45.9% | 75.4% |
| appearance | 40.9% | 52.0% | 45.6% | 59.3% |
| action | 32.4% | 52.0% | 69.8% | 68.8% |
| position | 35.4% | 48.6% | 45.5% | 57.5% |
| is_main_subject | 58.5% | 68.7% | 69.7% | 80.9% |
| environment | 70.4% | 72.7% | 61.4% | 70.5% |
| lighting | 77.1% | 80.0% | 21.2% | 76.5% |
Inspired by the previous success in LLM, we propose to enhance the performance of the generative model by Reinforcement Learning. Specifically, we focus on the motion quality because we find that the main drawback of our generative model is:
To avoid the degradation in other metrics, such as text alignment and video quality, we ensure the preference data pairs have comparable text alignment and video quality, while only the motion quality varies. This requirement poses greater challenges in obtaining preference annotations due to the inherently higher costs of human annotation. To address this challenge, we propose a semi-automatic pipeline that strategically combines automatically generated motion pairs and human annotation results. This hybrid approach not only enhances the data scale but also improves alignment with human preferences through curated quality control. Leveraging this enhanced dataset, we first train a specialized reward model to capture the generic motion quality differences between paired samples. This learned reward function subsequently guides the sample selection process for Direct Preference Optimization (DPO), enhancing the motion quality of the generative model.
We introduce the Diffusion Forcing Transformer to unlock our model’s ability to generate long videos. Diffusion Forcing is a training and sampling strategy where each token is assigned an independent noise level. This allows tokens to be denoised according to arbitrary, per-token schedules. Conceptually, this approach functions as a form of partial masking: a token with zero noise is fully unmasked, while complete noise fully masks it. Diffusion Forcing trains the model to "unmask" any combination of variably noised tokens, using the cleaner tokens as conditional information to guide the recovery of noisy ones. Building on this, our Diffusion Forcing Transformer can extend video generation indefinitely based on the last frames of the previous segment. Note that the synchronous full sequence diffusion is a special case of Diffusion Forcing, where all tokens share the same noise level. This relationship allows us to fine-tune the Diffusion Forcing Transformer from a full-sequence diffusion model.
We implement two sequential high-quality supervised fine-tuning (SFT) stages at 540p and 720p resolutions respectively, with the initial SFT phase conducted immediately after pretraining but prior to reinforcement learning (RL) stage.This first-stage SFT serves as a conceptual equilibrium trainer, building upon the foundation model’s pretraining outcomes that utilized only fps24 video data, while strategically removing FPS embedding components to streamline thearchitecture. Trained with the high-quality concept-balanced samples, this phase establishes optimized initialization parameters for subsequent training processes. Following this, we execute a secondary high-resolution SFT at 720p after completing the diffusion forcing stage, incorporating identical loss formulations and the higher-quality concept-balanced datasets by the manually filter. This final refinement phase focuses on resolution increase such that the overall video quality will be further enhanced.
To comprehensively evaluate our proposed method, we construct the SkyReels-Bench for human assessment and leveraged the open-source V-Bench for automated evaluation. This allows us to compare our model with the state-of-the-art (SOTA) baselines, including both open-source and proprietary models.
For human evaluation, we design SkyReels-Bench with 1,020 text prompts, systematically assessing three dimensions: Instruction Adherence, Motion Quality, Consistency and Visual Quality. This benchmark is designed to evaluate both text-to-video (T2V) and image-to-video (I2V) generation models, providing comprehensive assessment across different generation paradigms. To ensure fairness, all models were evaluated under default settings with consistent resolutions, and no post-generation filtering was applied.
| Model Name | Average | Instruction Adherence | Consistency | Visual Quality | Motion Quality |
|---|---|---|---|---|---|
| Runway-Gen3 Alpha | 2.53 | 2.19 | 2.57 | 3.23 | 2.11 |
| HunyuanVideo-13B | 2.82 | 2.64 | 2.81 | 3.20 | 2.61 |
| Kling-1.6 STD Mode | 2.99 | 2.77 | 3.05 | 3.39 | 2.76 |
| Hailuo-01 | 3.0 | 2.8 | 3.08 | 3.29 | 2.74 |
| Wan2.1-14B | 3.12 | 2.91 | 3.31 | 3.54 | 2.71 |
| SkyReels-V2 | 3.14 | 3.15 | 3.35 | 3.34 | 2.74 |
The evaluation demonstrates that our model achieves significant advancements in instruction adherence (3.15) compared to baseline methods, while maintaining competitive performance in motion quality (2.74) without sacrificing the consistency (3.35).
| Model | Average | Instruction Adherence | Consistency | Visual Quality | Motion Quality |
|---|---|---|---|---|---|
| HunyuanVideo-13B | 2.84 | 2.97 | 2.95 | 2.87 | 2.56 |
| Wan2.1-14B | 2.85 | 3.10 | 2.81 | 3.00 | 2.48 |
| Hailuo-01 | 3.05 | 3.31 | 2.58 | 3.55 | 2.74 |
| Kling-1.6 Pro Mode | 3.4 | 3.56 | 3.03 | 3.58 | 3.41 |
| Runway-Gen4 | 3.39 | 3.75 | 3.2 | 3.4 | 3.37 |
| SkyReels-V2-DF | 3.24 | 3.64 | 3.21 | 3.18 | 2.93 |
| SkyReels-V2-I2V | 3.29 | 3.42 | 3.18 | 3.56 | 3.01 |
Our results demonstrate that both SkyReels-V2-I2V (3.29) and SkyReels-V2-DF (3.24) achieve state-of-the-art performance among open-source models, significantly outperforming HunyuanVideo-13B (2.84) and Wan2.1-14B (2.85) across all quality dimensions. With an average score of 3.29, SkyReels-V2-I2V demonstrates comparable performance to proprietary models Kling-1.6 (3.4) and Runway-Gen4 (3.39).
To objectively compare SkyReels-V2 Model against other leading open-source Text-To-Video models, we conduct comprehensive evaluations using the public benchmark V-Bench. Our evaluation specifically leverages the benchmark’s longer version prompt. For fair comparison with baseline models, we strictly follow their recommended setting for inference.
| Model | Total Score | Quality Score | Semantic Score |
|---|---|---|---|
| OpenSora 2.0 | 81.5 % | 82.1 % | 78.2 % |
| CogVideoX1.5-5B | 80.3 % | 80.9 % | 77.9 % |
| HunyuanVideo-13B | 82.7 % | 84.4 % | 76.2 % |
| Wan2.1-14B | 83.7 % | 84.2 % | 81.4 % |
| SkyReels-V2 | 83.9 % | 84.7 % | 80.8 % |
The VBench results demonstrate that SkyReels-V2 outperforms all compared models including HunyuanVideo-13B and Wan2.1-14B, With the highest total score (83.9%) and quality score (84.7%). In this evaluation, the semantic score is slightly lower than Wan2.1-14B, while we outperform Wan2.1-14B in human evaluations, with the primary gap attributed to V-Bench’s insufficient evaluation of shot-scenario semantic adherence.
We would like to thank the contributors of Wan 2.1, XDit and Qwen 2.5 repositories, for their open research and contributions.
@misc{chen2025skyreelsv2infinitelengthfilmgenerative,
title={SkyReels-V2: Infinite-length Film Generative Model},
author={Guibin Chen and Dixuan Lin and Jiangping Yang and Chunze Lin and Junchen Zhu and Mingyuan Fan and Hao Zhang and Sheng Chen and Zheng Chen and Chengcheng Ma and Weiming Xiong and Wei Wang and Nuo Pang and Kang Kang and Zhiheng Xu and Yuzhe Jin and Yupeng Liang and Yubing Song and Peng Zhao and Boyuan Xu and Di Qiu and Debang Li and Zhengcong Fei and Yang Li and Yahui Zhou},
year={2025},
eprint={2504.13074},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2504.13074},
}