
Elastic-Reasoning
Collection
5 items
•
Updated
•
7
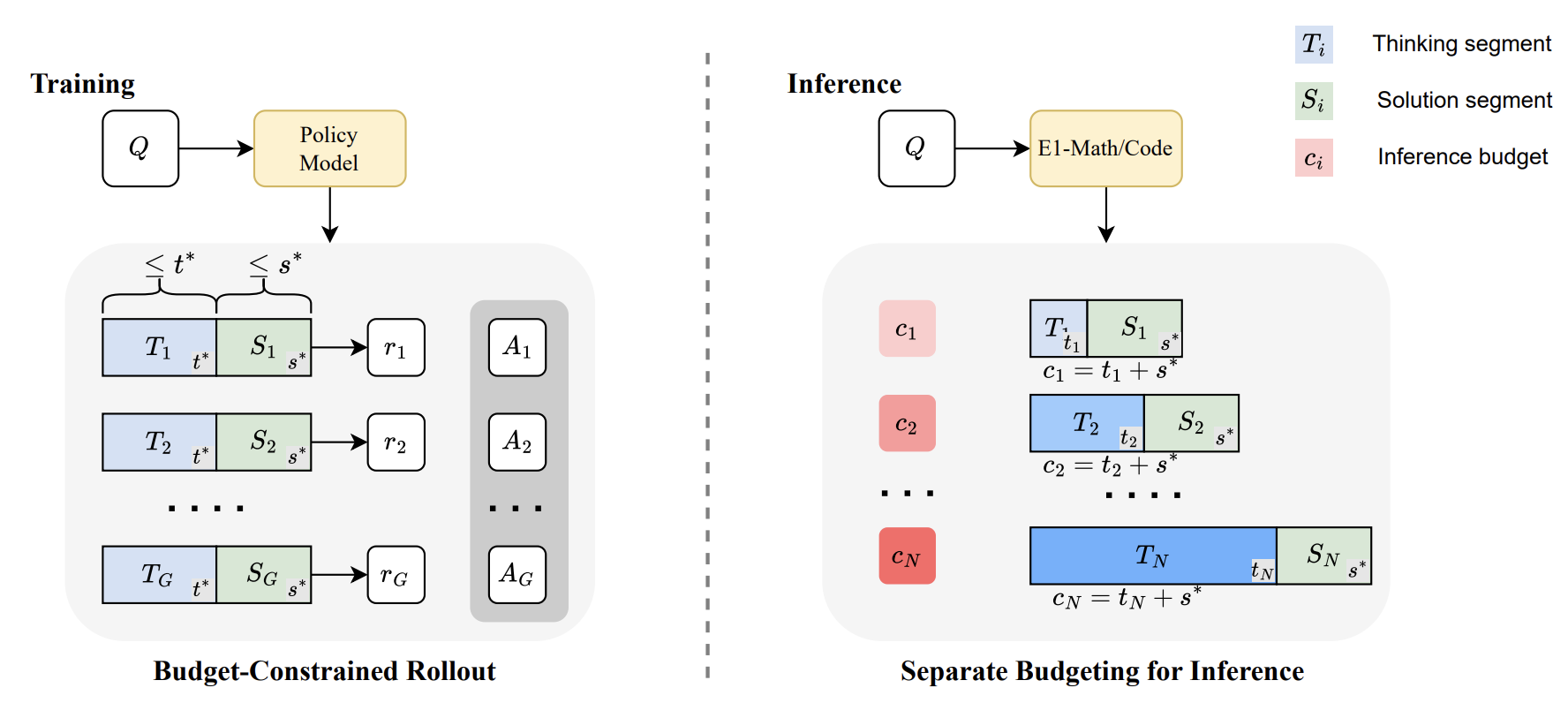
We propose Elastic Reasoning, a novel framework for scalable chain of thoughts
that explicitly separates reasoning into two phases—thinking and solution—with
independently allocated budgets. At test time, Elastic Reasoning prioritize that
completeness of solution segments, significantly improving reliability under tight
resource constraints. To train models that are robust to truncated thinking, we
introduce a lightweight budget-constrained rollout strategy, integrated into GRPO,
which teaches the model to reason adaptively when the thinking process is cut
short and generalizes effectively to unseen budget constraints without additional
training.
Main Takeaways
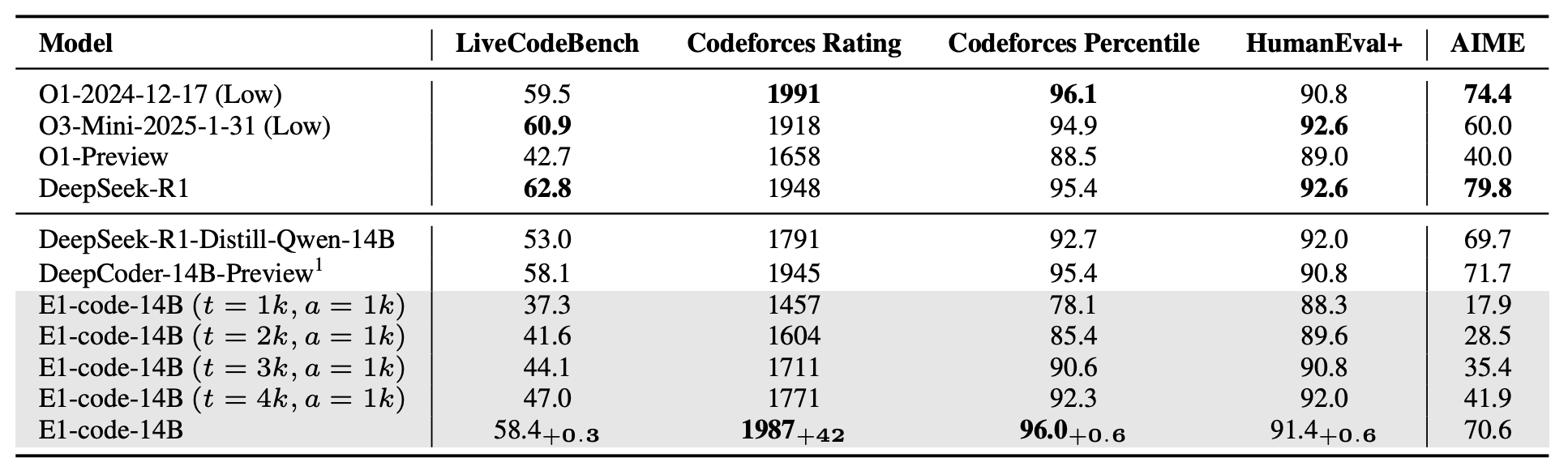
| Model | Tokens | Acc (%) | Tokens | Acc (%) | Tokens | Acc (%) | Tokens | Acc (%) | Tokens | Acc (%) |
|---|---|---|---|---|---|---|---|---|---|---|
| DeepSscaleR-1.5B | 10050 | 41.0 | 1488 | 5.2 | 1904 | 9.6 | 2809 | 15.8 | 3700 | 22.7 |
| E1-Math-1.5B | 6825 | 35.0 | 1340 | 13.5 | 1799 | 17.5 | 2650 | 24.8 | 3377 | 27.9 |
| Skywork-OR1-Math-7B | 13803 | 68.3 | 1534 | 1.0 | 2047 | 2.1 | 3051 | 7.7 | 4023 | 14.0 |
| E1-Math-7B | 11768 | 69.6 | 1381 | 16.9 | 1841 | 21.3 | 2799 | 26.0 | 3742 | 32.9 |
@article{xu2025scalable,
title={Scalable Chain of Thoughts via Elastic Reasoning},
author={Xu, Yuhui and Dong, Hanze and Wang, Lei and Sahoo, Doyen and Li, Junnan and Xiong, Caiming},
journal={arXiv preprint arXiv:2505.05315},
year={2025}
}
This release is for research purposes only in support of an academic paper. Our models, datasets, and code are not specifically designed or evaluated for all downstream purposes. We strongly recommend users evaluate and address potential concerns related to accuracy, safety, and fairness before deploying this model. We encourage users to consider the common limitations of AI, comply with applicable laws, and leverage best practices when selecting use cases, particularly for high-risk scenarios where errors or misuse could significantly impact people’s lives, rights, or safety. For further guidance on use cases, refer to our AUP and AI AUP.