
RobotArm-eff-single-action
Collection
Collection of VLMs model fine-tuned to predict a single action end-effector location/position to reach a target based on the prompts and camera feeds
•
4 items
•
Updated
This project focuses on fine-tuning visual language models to predict the position and orientation of a robotic arm for reaching a target object based on a human command and an image from a camera view. The system interprets natural language instructions and visual context to generate actionable pose outputs.
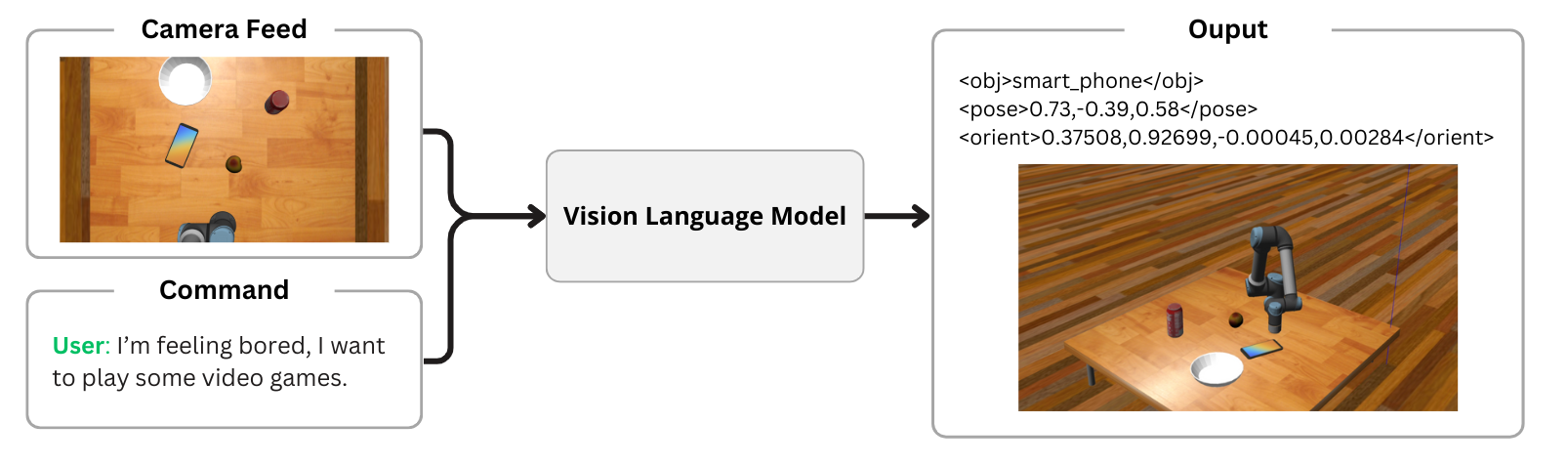
Inference with unsloth
from unsloth import FastVisionModel
from PIL import Image
from transformers import TextStreamer
model, processor = FastVisionModel.from_pretrained(
'SakalYin\Qwen2-VL-2B-RobotArm',
load_in_4bit=True,
local_files_only=True,
attn_implementation="flash_attention_2",
)
def resize_image(image_input, size=None):
"""Load image from path or matrices and resize them"""
size = size if size else (854,480)
if isinstance(image_input, str):
image = Image.open(image_input)
else:
image = image_input
size = size if size else (854,480)
image = image.resize(size).convert('RGB')
return image
image_path = "https://i.imgur.com/vAleq1e.png"
size = (854, 480) # Recommeded Size
system_message = "You are a Visual Language Model Trained to output robot arm end-effectors parameters. Base on the user requests, locate the appropriate object in the image and you must return the position and orientation to reach it in xml format."
prompt = "Give me a cup."
image = resize_image(image_path, size=size)
messages = [
{
"role": "system",
"content": [{"type": "text", "text": system_message if system_message else "You are a helpful assistant."}],
},
{"role": "user", "content": [
{"type": "image"},
{"type": "text", "text": prompt}]
}
]
input_text = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(
image,
input_text,
add_special_tokens=False,
return_tensors="pt",
).to("cuda")
# Generate text without using the streamer
text_streamer = TextStreamer(processor, skip_prompt=True)
generated_tokens = model.generate(
**inputs,
streamer=text_streamer,
max_new_tokens=128,
use_cache=True,
temperature=1.5,
min_p=0.1
)
# Decode output properly
output_text = processor.decode(generated_tokens[0], skip_special_tokens=True).strip()
Output: <obj>plastic_cup</obj> <pose>0.625,-0.785,0.548</pose> <orient>0.35478,0.71881,0.30505,0.5141</orient><|im_end|>
Result compared to other model in the Collection
| Model | Euclidean | X MSE | Y MSE | Z MSE | Roll Error | Pitch Error | Yaw Error |
|---|---|---|---|---|---|---|---|
| Qwen2VL-2B (Trained with Camera Location) | 0.1089 | 0.0505 | 0.0575 | 0.0363 | 6.8334 | 5.4204 | 6.7619 |
| Qwen2VL-2B | 0.3865 | 0.1239 | 0.3411 | 0.0000 | 2.1462 | 0.9029 | 1.1926 |
| Qwen2VL-7B | 0.0509 | 0.0305 | 0.0320 | 0.0008 | 0.4148 | 0.1066 | 0.1734 |
| LlaVA-NeXT 7B | 0.0480 | 0.0306 | 0.0296 | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| Llama Vision 11B | - | - | - | - | - | - | - |
Base model
Qwen/Qwen2-VL-2B