
Reward Reasoning Model
Paper Link👀
1. Introduction
We propose Reward Reasoning Models (RRMs). Unlike existing reward models, RRMs frames reward modeling as a reasoning task, wherein the model first produces a long chain-of-thought reasoning process before generating the final rewards.
Since supervised data providing reward reasoning traces are not readily available, we develop a training framework called Reward Reasoning via Reinforcement Learning, which encourages RRMs to self-evolve their reward reasoning capabilities within a rule-based reward environment. Furthermore, we introduce multi-response rewarding strategies, including the ELO rating system and knockout tournament, enabling RRMs to flexibly allocate test-time compute to practical application scenarios.
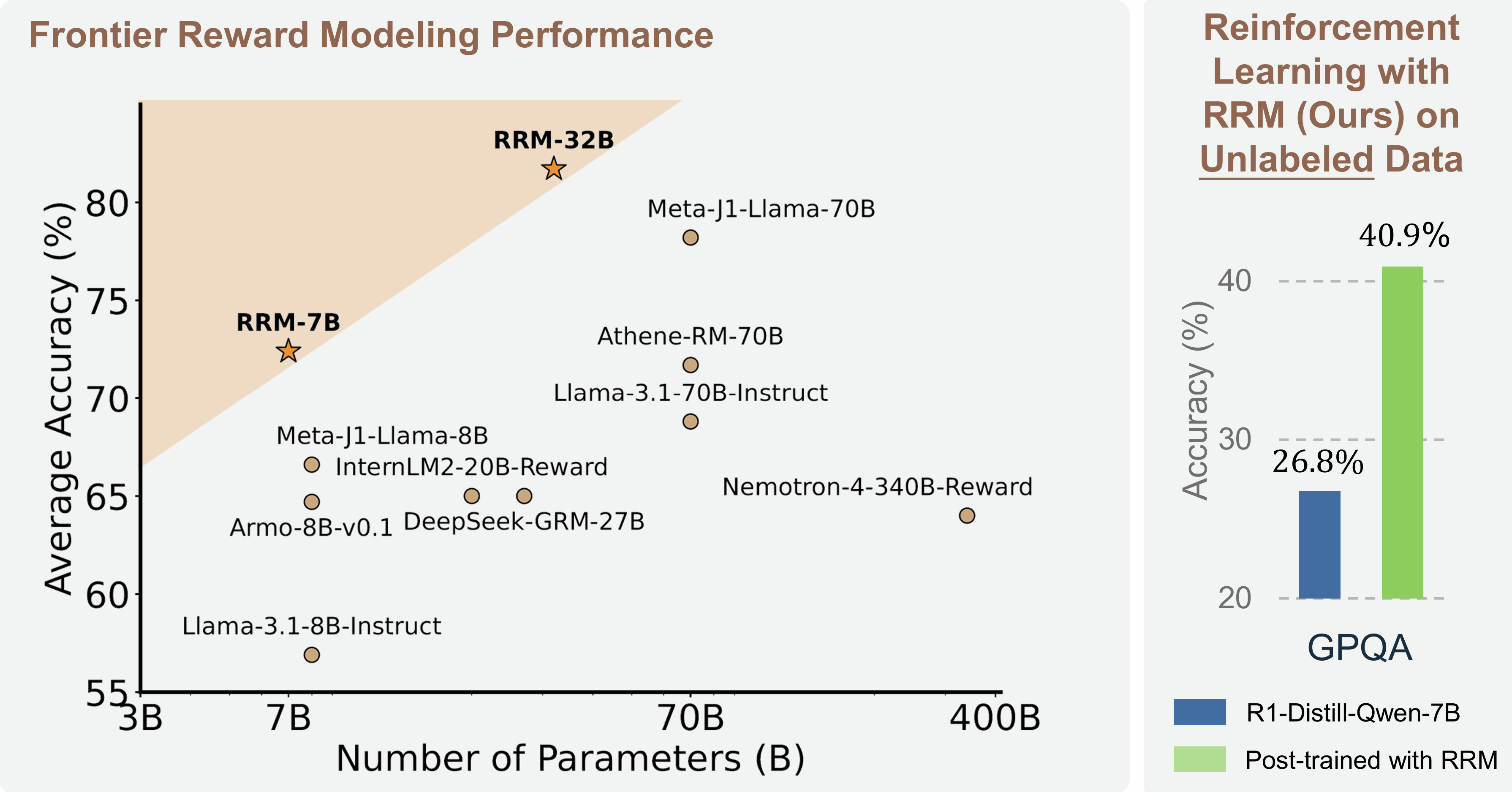
2. Model Summary
Core Concept: Reward Reasoning
- RRMs frame reward modeling into a reasoning task. Before assigning a reward, the model generates an explicit chain-of-thought to analyze and compare candidate responses. This allows RRMs to adaptively allocate computational resources, dedicating more thought to complex evaluation scenarios.
Training: Reward Reasoning via Reinforcement Learning
- RRMs are trained using a framework called Reward Reasoning via Reinforcement Learning. This approach enables the model to self-evolve sophisticated reward reasoning capabilities.
- Crucially, this training process does not require supervised data in the form of explicit reasoning traces. Instead, it uses rule-based rewards derived from whether the RRM correctly prefers a ground-truth response, guiding the model to develop effective reasoning patterns.
Key Advantages & Capabilities
- Enhanced Accuracy: RRMs consistently outperform strong baseline reward models across diverse domains, including reasoning, general knowledge, and alignment with human preferences.
- Adaptive Test-Time Compute Utilization: RRMs can effectively scale their test-time compute (both through parallel and sequential scaling of reasoning steps) to achieve better performance.
- Practical Applications: RRMs are effective for reward-guided best-of-N inference and can provide high-quality preference signals for post-training LLMs (e.g., via DPO or RL).
3. Model Downloads
| Model | Parameters | Download Link |
|---|---|---|
| RRM-7B | 7B | 🤗 HuggingFace |
| RRM-32B | 32B | 🤗 HuggingFace |
*Note: RRMs utilize the Qwen2 architecture and are trained using DeepSeek-R1-Distill-Qwen models as initialization.
4. Evaluation Results
RRMs have been extensively evaluated on several benchmarks.
Agreement with Human Preference (RewardBench & PandaLM Test)
| Model | RewardBench (Overall) | PandaLM Test (Agreement) |
|---|---|---|
| Skywork-Reward-Gemma-2-27B-v0.2 | 94.3 | 76.6 |
| JudgeLM-7B | 63.5 | 65.1 |
| JudgeLM-33B | 72.3 | 75.2 |
| Claude-3.5-Sonnet-20240620 | 84.2 | - |
| DeepSeek-R1 | 84.9 | 78.7 |
| DeepSeek-GRM-27B | 86.0 | - |
| GPT-4-0125-preview | 86.0 | 66.5 |
| GPT-4o-0806 | 86.7 | - |
| RM-R1-DeepSeek-Distilled-Qwen-7B | 80.1 | - |
| RM-R1-DeepSeek-Distilled-Qwen-14B | 88.9 | - |
| RM-R1-DeepSeek-Distilled-Qwen-32B | 90.9 | - |
| RRM-7B | 82.2 | 72.9 |
| RRM-7B (voting@16) | 84.8 | 75.9 |
| RRM-32B | 91.2 | 78.8 |
| RRM-32B (voting@16) | 91.9 | 80.2 |
Binary Preference Classification (PPE Benchmark)
| Model | MMLU-Pro | MATH | GPQA | Overall |
|---|---|---|---|---|
| Skywork-Reward-Gemma-2-27B | 55.0 | 46.2 | 44.7 | 48.6 |
| J1-Llama-8B (SC@32) | 67.5 | 76.6 | 55.7 | 66.7 |
| J1-Llama-70B (SC@32) | 79.9 | 88.1 | 66.5 | 78.2 |
| DeepSeek-GRM-27B (MetaRM) (voting@32) | 68.1 | 70.0 | 56.9 | 65.0 |
| RRM-7B | 66.5 | 88.0 | 57.9 | 70.3 |
| RRM-7B (voting@5) | 68.3 | 90.5 | 58.3 | 72.4 |
| RRM-32B | 80.5 | 94.3 | 67.4 | 80.7 |
| RRM-32B (voting@5) | 81.3 | 95.4 | 68.4 | 81.7 |
5. How to Use RRM
Here we show a code snippet to show you how to use RRMs with transformers:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
import accelerate
Skywork_SYSTEM_PROMPT = """You are a helpful assistant in evaluating the quality of the responses for a given instruction. Your goal is to select the best response for the given instruction.
Select Assistant 1 or Assistant 2, that is better for the given instruction. The two responses are generated by two different AI assistants respectively.
Do NOT say both / neither are good.
Here are some rules of the evaluation:
(1) If the instruction does not contain harmful content, you should prioritize evaluating whether the output honestly/precisely/closely executes the instruction, then consider its helpfulness, accuracy, level of detail, harmlessness, etc.
(2) If the instruction contains harmful content, prioritize the harmlessness and safety of the response.
(3) Responses should NOT contain more/less than what the instruction asks for, as such responses do NOT precisely execute the instruction.
(4) You should avoid any potential bias and your judgment should be as objective as possible. Here are some potential sources of bias:
- The order in which the responses were presented should NOT affect your judgment, as Response A and Response B are equally likely to be the better.
- The length of the responses should NOT affect your judgement, as a longer response does not necessarily correspond to a better response. When making your decision, evaluate if the response length is appropriate for the given instruction.
(5) Your output should only consist of '\\boxed{Assistant 1}' if assistant 1 is better, or '\\boxed{Assistant 2}' if assistant 2 is better. Omit any other output.
"""
Skywork_PROMPT = """## Query
{question}
## Assistant responses
### Assistant 1
{answer1}
### Assistant 2
{answer2}
"""
Skywork_ASSISTANT_PROMPT = """## Analysis
Let's analyze this step by step and decide which assistant is better, and then answer \\boxed{Assistant 1} or \\boxed{Assistant 2}."""
model_id = "Reward-Reasoning/RRM-7B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.bfloat16, device_map="auto")
query = "How do I detail a car?"
response1 = "Detailing a car involves washing the exterior and interior of the car, as well as polishing and waxing the exterior. Interior detailing typically involves vacuuming, cleaning the upholstery and air vents, polishing the dashboard and console, and dusting. Polishing and waxing the exterior will depend on the condition of the paint, but typically involves applying a polish and wax to make it shine."
response2 = "Detailing a car involves a thorough cleaning inside and out, as well as polishing and waxing to protect the vehicle's surfaces. Here's a step-by-step guide to detailing a car:\n\n**Exterior Detailing:**\n\n1. **Wash the Car:**\n - Rinse the car with water to remove loose dirt.\n - Use a car wash soap and microfiber wash mitt to clean the car from top to bottom.\n - Clean the wheels and tires with a brush and a wheel cleaner.\n - Rinse the car thoroughly to remove all soap.\n\n2. **Dry the Car:**\n - Use a microfiber towel or a chamois to dry the car to prevent water spots.\n\n3. **Clay Bar Treatment:**\n - Use a clay bar with a lubricant to remove embedded surface contaminants from the paint.\n\n4. **Polishing:**\n - Apply car polish with a dual-action polisher or by hand to correct paint imperfections and create a smooth surface.\n\n5. **Waxing:**\n - Apply a coat of wax or paint sealant to protect the paint and give it a glossy finish.\n\n6. **Windows and Mirrors:**\n - Clean the windows and mirrors with a glass cleaner and a microfiber towel.\n\n7. **Tire and Trim Dressing:**\n - Apply a tire dressing to the tires for a shiny finish.\n - Use a trim restorer or protectant on plastic and rubber parts to prevent fading.\n\n**Interior Detailing:**\n\n1. **Remove Trash:**\n - Clear out any trash and remove personal items from the car.\n\n2. **Vacuum:**\n - Vacuum the seats, carpets, floor mats, and trunk.\n - Use a brush attachment for the dashboard and door panels.\n\n3. **Shampoo Carpets and Upholstery:**\n - Use a carpet cleaner and a brush to clean the carpets and upholstery.\n - For leather interiors, use a leather cleaner and conditioner.\n\n4. **Clean Hard Surfaces:**\n - Wipe down all hard surfaces (dashboard, center console, door panels, etc.) with a mild all-purpose cleaner and a microfiber cloth.\n\n5. **Windows and Mirrors:**\n - Clean the interior side of windows and mirrors.\n\n6. **Air Vents and Crevices:**\n - Use a detailing brush or compressed air to clean out air vents and hard-to-reach crevices.\n\n7. **Final Touches:**\n - Apply a protectant to the dashboard and other plastic components.\n - Replace air fresheners if needed.\n\n**Additional Tips:**\n\n- Work in the shade or a cool, well-ventilated garage to prevent products from drying too quickly and leaving residue.\n- Use separate buckets for washing and rinsing to avoid contaminating the clean water with dirt.\n- Always use gentle, non-abrasive materials and cleaners specifically designed for automotive use to avoid damaging surfaces.\n- Move in a systematic way to ensure you don't miss any spots.\n\nBy following these steps, you'll give your car a thorough clean that not only makes it look great but also helps in maintaining its value. Remember, regular detailing can prevent wear and tear and keep your car looking new for years to come."
system_prompt = Skywork_SYSTEM_PROMPT
user_prompt = Skywork_PROMPT.format(
question=query, answer1=response1, answer2=response2
) + Skywork_ASSISTANT_PROMPT
messages = [
{
"role": "system",
"content": system_prompt,
},
{"role": "user", "content": user_prompt},
]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
generation_args = {
"max_new_tokens": 8192,
"temperature": 0.6,
"do_sample": True,
"top_p": 1.0,
"eos_token_id": tokenizer.eos_token_id,
"pad_token_id": tokenizer.pad_token_id,
}
with torch.no_grad():
output = model.generate(**inputs, **generation_args)
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
print(generated_text)
The generated text:
Alright, so I need to figure out which assistant, Assistant 1 or Assistant 2, is better for the given instruction. The instruction is \"How do I detail a car?\" I'll start by looking at the instructions and the rules provided.\n\nFirst, the instruction doesn't contain any harmful content, so my main focus should be on how well the output honestly and precisely executes the instruction. I should also consider the helpfulness, accuracy, and detail of the response.\n\nLooking at Assistant 1's response, it starts by mentioning exterior detailing, including washing and interior detailing with specific tasks. However, it seems a bit brief and might be missing some steps. For example, it doesn't mention things like using the right equipment or the importance of drying the car properly. It also doesn't go into as much detail about the products used, which could be helpful.\n\nOn the other hand, Assistant 2's response is much more comprehensive. It provides a detailed step-by-step guide, starting with exterior detailing and then moving on to interior detailing. Each section has specific steps, like washing, drying, using a clay bar, polishing, waxing, and so on. It also includes tips about where to work, using separate buckets, and the importance of gentle materials. This makes the response thorough and informative, covering all aspects of car detailing.\n\nI notice that Assistant 2's response is longer but more detailed, which is appropriate because the instruction is about detailing a car, which can have multiple steps. Assistant 1's response, while it touches on some points, is more concise and might not cover all necessary steps, making it less helpful for someone looking to detail their car properly.\n\nAdditionally, Assistant 2 includes additional tips, which adds value to the response. It also mentions things like working in a shaded area and using separate buckets, which are practical tips that can improve the detailing process.\n\nIn terms of helpfulness, Assistant 2's response is more helpful because it provides a clear, step-by-step guide that someone can follow without getting overwhelmed. Assistant 1's response, while correct, is too brief and might not guide the user effectively.\n\nI also need to consider the length of the responses. Assistant 2's response is longer, but it's appropriate because the instruction is detailed enough to require a thorough explanation. Assistant 1's response is too short, which might not be sufficient for someone looking to detail their car properly.\n\nIn conclusion, considering the need for a thorough and helpful response, Assistant 2 is better because it provides a comprehensive guide with all the necessary steps and tips for detailing a car. Assistant 1, while correct, is too brief and lacks the depth needed for a complete answer.\n</think>\n\n\\boxed{Assistant 2}
6. Citation
@misc{rewardreasoningmodel,
title={Reward Reasoning Model},
author={Jiaxin Guo and Zewen Chi and Li Dong and Qingxiu Dong and Xun Wu and Shaohan Huang and Furu Wei},
year={2025},
eprint={2505.14674},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.14674},
}
- Downloads last month
- 1,143