
Base Model?

It appears the base model for the 30B MoE was uploaded, but there's none for this one.
Is that an oversight?

It seems like this model is the only one lacking a base variant. That's a shame, I could really use it.

yep the base model would be great for the 32b variant

this is true! need the base model!

is a base model or instruct model???
Bump. Any word on this?

Adding to this, we really could use the base model as well.

Indeed, a 32B base model is really needed.

please release the base model for 32b qwen3
the paper
Writing-Zero: Bridge the Gap Between Non-verifiable Problems and Verifiable Rewards
contains evidence that it exists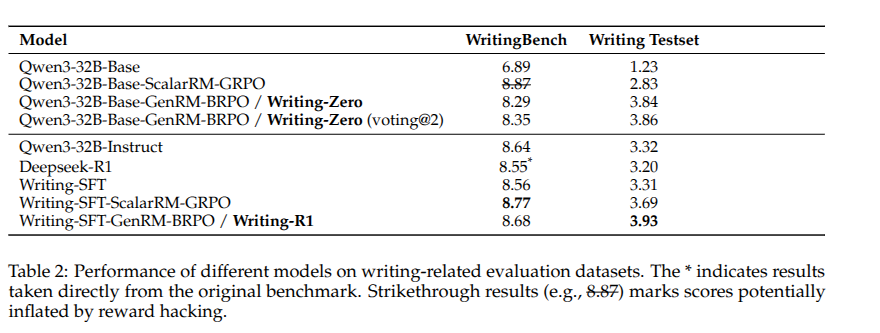

Hello

is it out?
people already do continued pretraining to restore a base model from the fine tuned version:
"Our Approach to DeepSeek-R1-0528-Distill-Qwen3-32B-Preview0-QAT:
Since Qwen3 did not provide a pre-trained base for its 32B model, our initial step was to perform additional pre-training on Qwen3-32B using a self-constructed multilingual pre-training dataset. This was done to restore a "pre-training style" model base as much as possible, ensuring that subsequent work would not be influenced by Qwen3's inherent SFT language style. This model will also be open-sourced in the future."
https://www.reddit.com/r/LocalLLaMA/comments/1l7mijq/i_found_a_deepseekr10528distillqwen332b/

people already do continued pretraining to restore a base model from the fine tuned version:
"Our Approach to DeepSeek-R1-0528-Distill-Qwen3-32B-Preview0-QAT:
Since Qwen3 did not provide a pre-trained base for its 32B model, our initial step was to perform additional pre-training on Qwen3-32B using a self-constructed multilingual pre-training dataset. This was done to restore a "pre-training style" model base as much as possible, ensuring that subsequent work would not be influenced by Qwen3's inherent SFT language style. This model will also be open-sourced in the future."https://www.reddit.com/r/LocalLLaMA/comments/1l7mijq/i_found_a_deepseekr10528distillqwen332b/
What's the difference between doing that and cold-starting the training?