
{kind=link}
Qwen
Collection
Qwen
•
16 items
•
Updated
•
17
![]()
🤗 Hugging Face | 🤖 ModelScope | 📑 Paper | 🖥️ Demo
WeChat (微信) | Discord | API
通义千问-1.8B(Qwen-1.8B)是阿里云研发的通义千问大模型系列的18亿参数规模的模型。Qwen-1.8B是基于Transformer的大语言模型, 在超大规模的预训练数据上进行训练得到。预训练数据类型多样,覆盖广泛,包括大量网络文本、专业书籍、代码等。同时,在Qwen-1.8B的基础上,我们使用对齐机制打造了基于大语言模型的AI助手Qwen-1.8B-Chat。本仓库为Qwen-1.8B的仓库。
通义千问-1.8B(Qwen-1.8B)主要有以下特点:
如果您想了解更多关于通义千问1.8B开源模型的细节,我们建议您参阅GitHub代码库。
Qwen-1.8B is the 1.8B-parameter version of the large language model series, Qwen (abbr. Tongyi Qianwen), proposed by Aibaba Cloud. Qwen-1.8B is a Transformer-based large language model, which is pretrained on a large volume of data, including web texts, books, codes, etc. Additionally, based on the pretrained Qwen-1.8B, we release Qwen-1.8B-Chat, a large-model-based AI assistant, which is trained with alignment techniques. This repository is the one for Qwen-1.8B.
The features of Qwen-1.8B include:
For more details about the open-source model of Qwen-1.8B, please refer to the GitHub code repository.
运行Qwen-1.8B,请确保满足上述要求,再执行以下pip命令安装依赖库
To run Qwen-1.8B, please make sure you meet the above requirements, and then execute the following pip commands to install the dependent libraries.
pip install transformers==4.32.0 accelerate tiktoken einops
另外,推荐安装flash-attention库(当前已支持flash attention 2),以实现更高的效率和更低的显存占用。
In addition, it is recommended to install the flash-attention library (we support flash attention 2 now.) for higher efficiency and lower memory usage.
git clone https://github.com/Dao-AILab/flash-attention
cd flash-attention && pip install .
# 下方安装可选,安装可能比较缓慢。
# pip install csrc/layer_norm
# pip install csrc/rotary
您可以通过以下代码轻松调用:
You can easily call the model with the following code:
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
# Note: The default behavior now has injection attack prevention off.
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-1_8B", trust_remote_code=True)
# use bf16
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-1_8B", device_map="auto", trust_remote_code=True, bf16=True).eval()
# use fp16
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-1_8B", device_map="auto", trust_remote_code=True, fp16=True).eval()
# use cpu only
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-1_8B", device_map="cpu", trust_remote_code=True).eval()
# use auto mode, automatically select precision based on the device.
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-1_8B", device_map="auto", trust_remote_code=True).eval()
# Specify hyperparameters for generation. But if you use transformers>=4.32.0, there is no need to do this.
# model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-1_8B", trust_remote_code=True)
inputs = tokenizer('蒙古国的首都是乌兰巴托(Ulaanbaatar)\n冰岛的首都是雷克雅未克(Reykjavik)\n埃塞俄比亚的首都是', return_tensors='pt')
inputs = inputs.to(model.device)
pred = model.generate(**inputs)
print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
# 蒙古国的首都是乌兰巴托(Ulaanbaatar)\n冰岛的首都是雷克雅未克(Reykjavik)\n埃塞俄比亚的首都是亚的斯亚贝巴(Addis Ababa)...
关于更多的使用说明,请参考我们的GitHub repo获取更多信息。
For more information, please refer to our GitHub repo for more information.
注:作为术语的“tokenization”在中文中尚无共识的概念对应,本文档采用英文表达以利说明。
基于tiktoken的分词器有别于其他分词器,比如sentencepiece分词器。尤其在微调阶段,需要特别注意特殊token的使用。关于tokenizer的更多信息,以及微调时涉及的相关使用,请参阅文档。
Our tokenizer based on tiktoken is different from other tokenizers, e.g., sentencepiece tokenizer. You need to pay attention to special tokens, especially in finetuning. For more detailed information on the tokenizer and related use in fine-tuning, please refer to the documentation.
Qwen-1.8B模型规模基本情况如下所示:
The details of the model architecture of Qwen-1.8B are listed as follows:
| Hyperparameter | Value |
|---|---|
| n_layers | 24 |
| n_heads | 16 |
| d_model | 2048 |
| vocab size | 151851 |
| sequence length | 8192 |
在位置编码、FFN激活函数和normalization的实现方式上,我们也采用了目前最流行的做法, 即RoPE相对位置编码、SwiGLU激活函数、RMSNorm(可选安装flash-attention加速)。
在分词器方面,相比目前主流开源模型以中英词表为主,Qwen-1.8B使用了超过15万token大小的词表。 该词表在GPT-4使用的BPE词表cl100k_base基础上,对中文、多语言进行了优化,在对中、英、代码数据的高效编解码的基础上,对部分多语言更加友好,方便用户在不扩展词表的情况下对部分语种进行能力增强。
词表对数字按单个数字位切分。调用较为高效的tiktoken分词库进行分词。
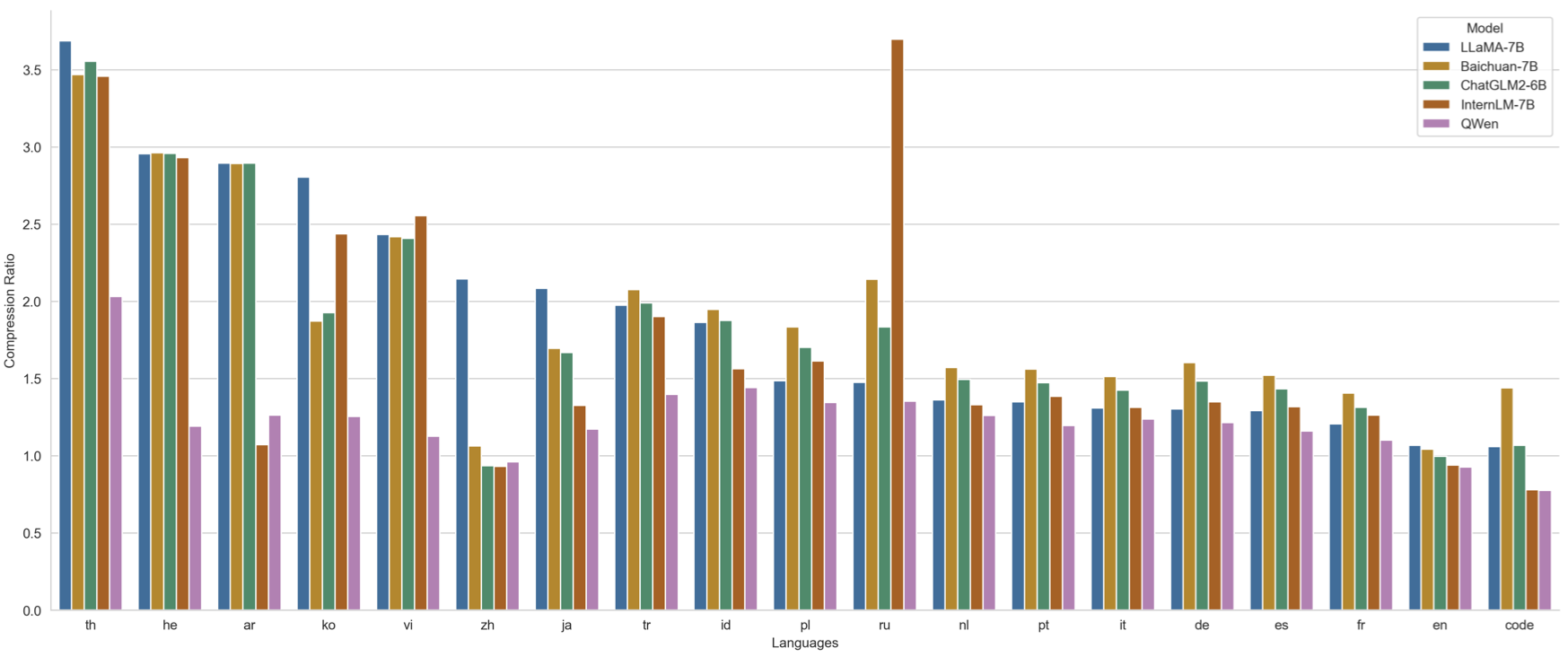
我们从部分语种各随机抽取100万个文档语料,以对比不同模型的编码压缩率(以支持100语种的XLM-R为基准值1,越低越好),具体性能见图。
可以看到Qwen-1.8B在保持中英代码高效解码的前提下,对部分使用人群较多的语种(泰语th、希伯来语he、阿拉伯语ar、韩语ko、越南语vi、日语ja、土耳其语tr、印尼语id、波兰语pl、俄语ru、荷兰语nl、葡萄牙语pt、意大利语it、德语de、西班牙语es、法语fr等)上也实现了较高的压缩率,使得模型在这些语种上也具备较强的可扩展性和较高的训练和推理效率。
在预训练数据方面,Qwen-1.8B模型一方面利用了部分开源通用语料, 另一方面也积累了海量全网语料以及高质量文本内容,去重及过滤后的语料超过2.2T tokens。 囊括全网文本、百科、书籍、代码、数学及各个领域垂类。
For position encoding, FFN activation function, and normalization methods, we adopt the prevalent practices, i.e., RoPE relative position encoding, SwiGLU for activation function, and RMSNorm for normalization (optional installation of flash-attention for acceleration).
For tokenization, compared to the current mainstream open-source models based on Chinese and English vocabularies, Qwen-1.8B uses a vocabulary of over 150K tokens. It first considers efficient encoding of Chinese, English, and code data, and is also more friendly to multilingual languages, enabling users to directly enhance the capability of some languages without expanding the vocabulary. It segments numbers by single digit, and calls the tiktoken tokenizer library for efficient tokenization.
We randomly selected 1 million document corpus of each language to test and compare the encoding compression rates of different models (with XLM-R, which supports 100 languages, as the base value 1). The specific performance is shown in the figure above.
As can be seen, while ensuring the efficient decoding of Chinese, English, and code, Qwen-1.8B also achieves a high compression rate for many other languages (such as th, he, ar, ko, vi, ja, tr, id, pl, ru, nl, pt, it, de, es, fr etc.), equipping the model with strong scalability as well as high training and inference efficiency in these languages.
For pre-training data, on the one hand, Qwen-1.8B uses part of the open-source generic corpus. On the other hand, it uses a massive amount of accumulated web corpus and high-quality text content. The scale of corpus reaches over 2.2T tokens after deduplication and filtration, encompassing web text, encyclopedias, books, code, mathematics, and various domain.
C-Eval是评测预训练模型中文常识能力的常用测评框架,覆盖人文、社科、理工、其他专业四个大方向共52个学科。 我们按照标准做法,以开发集样本作为few-shot来源,评价Qwen-1.8B预训练模型的5-shot验证集与测试集准确率。
C-Eval is a common evaluation benchmark for testing the common sense capability of pre-trained models in Chinese. It covers 52 subjects in four major directions: humanities, social sciences, STEM, and other specialties. According to the standard practice, we use the development set samples as the source of few-shot, to evaluate the 5-shot validation set and test set accuracy of the Qwen-1.8B pre-trained model.
在C-Eval验证集、测试集上,Qwen-1.8B模型和其他模型的准确率对比如下:
The accuracy comparison of Qwen-1.8B and the other models on the C-Eval validation set is shown as follows:
| Model | Avg. (Val) | Avg. (Test) |
|---|---|---|
| Bloom-1B7 | 23.8 | - |
| Bloomz-1B7 | 29.6 | - |
| Bloom-3B | 25.8 | - |
| Bloomz-3B | 32.5 | - |
| MiLM-1.3B | - | 45.8 |
| Qwen-1.8B | 56.1 | 56.2 |
MMLU是目前评测英文综合能力最权威的基准评测之一,同样覆盖了不同学科领域、不同难度层级的57个子任务。
Qwen-1.8B在MMLU 5-shot准确率表现如下表:
MMLU is currently one of the most recognized benchmarks for evaluating English comprehension abilities, covering 57 subtasks across different academic fields and difficulty levels. The MMLU 5-shot accuracy performance of Qwen-1.8B is shown in the following table:
| Model | Avg. |
|---|---|
| GPT-Neo-1.3B | 24.6 |
| OPT-1.3B | 25.1 |
| Pythia-1B | 26.6 |
| Bloom-1.1B | 26.7 |
| Bloom-1.7B | 27.7 |
| Bloomz-1.7B | 30.7 |
| Bloomz-3B | 33.3 |
| Qwen-1.8B | 45.3 |
我们在HumanEval(0-shot)上对比预训练模型的代码能力,结果如下:
We compared the code capabilities of pre-trained models on HumanEval, and the results are as follows:
| Model | Pass@1 |
|---|---|
| GPT-Neo-1.3B | 3.66 |
| GPT-Neo-2.7B | 7.93 |
| Pythia-1B | 3.67 |
| Pythia-2.8B | 5.49 |
| Bloom-1.1B | 2.48 |
| Bloom-1.7B | 4.03 |
| Bloom-3B | 6.48 |
| Bloomz-1.7B | 4.38 |
| Bloomz-3B | 6.71 |
| Qwen-1.8B | 15.2 |
数学能力使用常用的GSM8K数据集(8-shot)评价:
We compared the math capabilities of pre-trained models on GSM8K (8-shot), and the results are as follows:
| Model | Acc. |
|---|---|
| GPT-Neo-1.3B | 1.97 |
| GPT-Neo-2.7B | 1.74 |
| Pythia-1B | 2.20 |
| Pythia-2.8B | 3.11 |
| Openllama-3B | 3.11 |
| Bloom-1.1B | 1.82 |
| Bloom-1.7B | 2.05 |
| Bloom-3B | 1.82 |
| Bloomz-1.7B | 2.05 |
| Bloomz-3B | 3.03 |
| Qwen-1.8B | 32.3 |
我们提供了评测脚本,方便大家复现模型效果,详见链接。提示:由于硬件和框架造成的舍入误差,复现结果如有小幅波动属于正常现象。
We have provided evaluation scripts to reproduce the performance of our model, details as link.
如遇到问题,敬请查阅FAQ以及issue区,如仍无法解决再提交issue。
If you meet problems, please refer to FAQ and the issues first to search a solution before you launch a new issue.
如果你觉得我们的工作对你有帮助,欢迎引用!
If you find our work helpful, feel free to give us a cite.
@article{qwen,
title={Qwen Technical Report},
author={Jinze Bai and Shuai Bai and Yunfei Chu and Zeyu Cui and Kai Dang and Xiaodong Deng and Yang Fan and Wenbin Ge and Yu Han and Fei Huang and Binyuan Hui and Luo Ji and Mei Li and Junyang Lin and Runji Lin and Dayiheng Liu and Gao Liu and Chengqiang Lu and Keming Lu and Jianxin Ma and Rui Men and Xingzhang Ren and Xuancheng Ren and Chuanqi Tan and Sinan Tan and Jianhong Tu and Peng Wang and Shijie Wang and Wei Wang and Shengguang Wu and Benfeng Xu and Jin Xu and An Yang and Hao Yang and Jian Yang and Shusheng Yang and Yang Yao and Bowen Yu and Hongyi Yuan and Zheng Yuan and Jianwei Zhang and Xingxuan Zhang and Yichang Zhang and Zhenru Zhang and Chang Zhou and Jingren Zhou and Xiaohuan Zhou and Tianhang Zhu},
journal={arXiv preprint arXiv:2309.16609},
year={2023}
}
我们的代码和模型权重对学术研究完全开放。请查看LICENSE文件了解具体的开源协议细节。如需商用,请联系我们。
Our code and checkpoints are open to research purpose. Check the LICENSE for more details about the license. For commercial use, please contact us.
如果你想给我们的研发团队和产品团队留言,欢迎加入我们的微信群、钉钉群以及Discord!同时,也欢迎通过邮件([email protected])联系我们。
If you are interested to leave a message to either our research team or product team, join our Discord or WeChat groups! Also, feel free to send an email to [email protected].