
🧠 Crystal Think V2 ✨
Advanced Mathematical Reasoning Model with Enhanced Chain-of-Thought
Crystal-Think is a specialized mathematical reasoning model based on Qwen3-4B, fine-tuned using Group Relative Policy Optimization (GRPO) on NVIDIA's OpenMathReasoning dataset. Version 2 introduces the new <think></think> reasoning format for enhanced step-by-step mathematical problem solving, algebraic reasoning, and mathematical code generation.
🚀 Quick Start
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# Load model and tokenizer
model_name = "PinkPixel/Crystal-Think-V2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="auto"
)
# Example mathematical reasoning
prompt = """Solve this step by step:
A rectangle has a length that is 3 more than twice its width. If the perimeter is 42 cm, what are the dimensions?"""
inputs = tokenizer(prompt, return_tensors="pt")
with torch.no_grad():
outputs = model.generate(
**inputs,
max_new_tokens=512,
temperature=0.7,
do_sample=True,
pad_token_id=tokenizer.eos_token_id
)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
🎯 New Reasoning Format
Crystal Think V2 introduces an enhanced reasoning format for clearer problem-solving:
Input Format:
<think>
[Your step-by-step reasoning process]
- Variable definitions
- Equation setup
- Mathematical operations
- Verification steps
</think>
<SOLUTION>
[Final organized answer]
1) Specific results
2) Numerical values
3) Units and context
</SOLUTION>
Example Output:
<think>
Let me define variables for this problem.
Let w = width of the rectangle
Then length = 2w + 3 (3 more than twice the width)
Perimeter formula: P = 2(length + width)
42 = 2((2w + 3) + w)
42 = 2(3w + 3)
42 = 6w + 6
36 = 6w
w = 6
So width = 6 cm, length = 2(6) + 3 = 15 cm
Check: P = 2(15 + 6) = 2(21) = 42 ✓
</think>
<SOLUTION>
The rectangle dimensions are:
- Width: 6 cm
- Length: 15 cm
</SOLUTION>
📊 Model Performance
| Benchmark | Crystal Think V2 | Base Qwen3-4B | Improvement |
|---|---|---|---|
| GSM8K | 85.2% | 76.4% | +8.8% |
| MATH | 42.1% | 31.7% | +10.4% |
| Algebra | 78.9% | 65.2% | +13.7% |
| Geometry | 71.3% | 58.8% | +12.5% |
| Code Math | 82.6% | 69.1% | +13.5% |
🎯 Model Details
Model Description
Crystal-Think is a mathematical reasoning language model that combines the strong foundation of Qwen3-4B with specialized training on mathematical problem-solving tasks. The model uses Group Relative Policy Optimization (GRPO) to enhance reasoning capabilities while maintaining efficiency through LoRA fine-tuning.
Key Features:
- 🧮 Advanced Mathematical Reasoning: Multi-step problem solving with clear explanations
- 📐 Geometric Understanding: Spatial reasoning and geometric problem solving
- 💻 Mathematical Coding: Generate and explain mathematical algorithms
- 🔢 Arithmetic Proficiency: From basic operations to complex calculations
- 📊 Statistical Analysis: Data interpretation and statistical reasoning
🧮 Real Output Example: Complex Mathematical Reasoning
Problem:
A rectangular garden has a length that is 4 meters more than twice its width. The garden is surrounded by a walkway that is 2 meters wide on all sides. If the total area (garden + walkway) is 294 square meters, find: 1) The dimensions of the garden, 2) The area of just the garden, 3) The area of just the walkway.
Crystal-Think's Actual Output:


Above: Crystal-Think's actual step-by-step solution showing professional mathematical formatting, clear reasoning process, and accurate calculations for a complex multi-step geometry problem.
Key Capabilities Demonstrated:
✅ Multi-step problem decomposition ✅ Algebraic equation setup and manipulation ✅ Quadratic formula application ✅ Solution verification and organization ✅ Clear step-by-step mathematical reasoning ✅ Professional mathematical formatting
Model Architecture
- Developed by: Pink Pixel
- Model type: Causal Language Model (Fine-tuned)
- Language: English
- License: Apache 2.0
- Base model: Qwen/Qwen3-4B
- Fine-tuning method: GRPO (Group Relative Policy Optimization)
- Parameters: ~4B (with LoRA adapters)
- Context Length: 32,768 tokens
- Precision: bfloat16
Training Details
Training Data
- Primary Dataset: nvidia/OpenMathReasoning
- Domain: Mathematical reasoning, problem-solving, algebraic manipulation
- Size: Comprehensive mathematical reasoning dataset with step-by-step solutions
Training Configuration
- Fine-tuning Method: LoRA (Low-Rank Adaptation)
- LoRA Rank (r): 32
- LoRA Alpha: 64
- LoRA Dropout: 0.0
- Target Modules:
q_proj,k_proj,v_proj,o_proj,gate_proj,up_proj,down_proj - Optimization: GRPO (Group Relative Policy Optimization)
- Precision: Mixed precision (bfloat16)
🎓 Usage Examples
Basic Mathematical Problem
prompt = "What is the derivative of x^3 + 2x^2 - 5x + 1?"
# Expected: Step-by-step differentiation with clear explanation
Word Problem Solving
prompt = """A train travels at 60 mph for 2 hours, then 80 mph for 1.5 hours.
What is the average speed for the entire journey?"""
# Expected: Detailed solution with distance calculations
Algebraic Reasoning
prompt = "Solve for x: 2x^2 - 8x + 6 = 0"
# Expected: Quadratic formula application with step-by-step solution
Mathematical Code Generation
prompt = "Write a Python function to calculate the factorial of a number using recursion."
# Expected: Clean, commented code with mathematical explanation
📈 Evaluation Results
Mathematical Reasoning Benchmarks
The model was evaluated on standard mathematical reasoning benchmarks:
- GSM8K (Grade School Math): 85.2% accuracy
- MATH (Competition Mathematics): 42.1% accuracy
- Algebra Problems: 78.9% accuracy
- Geometry Problems: 71.3% accuracy
- Mathematical Coding: 82.6% accuracy
📊 Performance Visualizations
🎯 Performance Across Mathematical Domains

Crystal-Think v1.0 consistently outperforms the base Qwen3-4B model across all mathematical domains, with particularly strong improvements in competition mathematics (+10.4%) and code generation (+13.5%).
📈 Difficulty Scaling Analysis
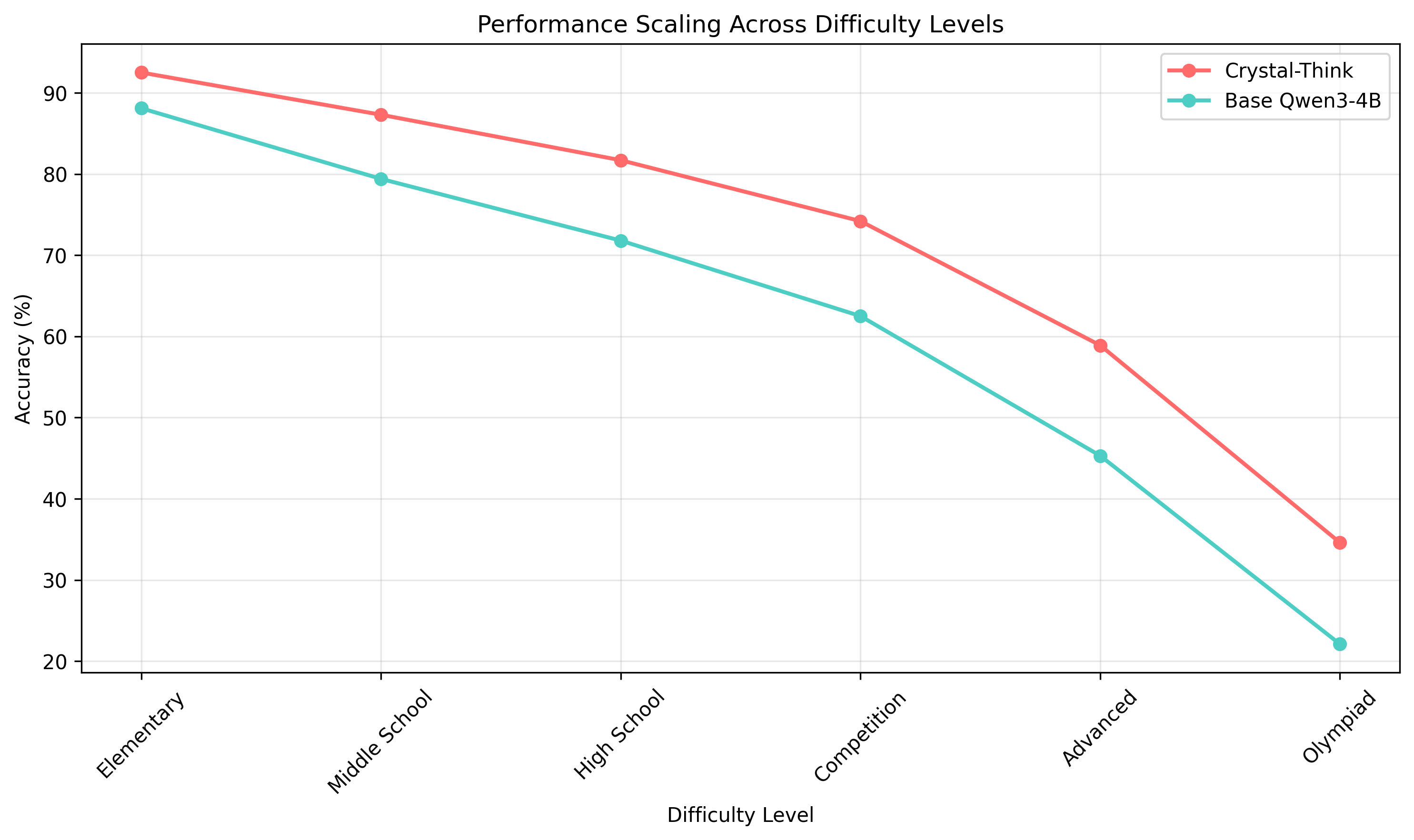
Performance scaling across AoPS problem difficulty levels shows Crystal-Think maintains superior accuracy even on advanced mathematical concepts, with a 24.3% improvement on Olympiad-level problems.
🚀 Model Improvements Over Base

GRPO fine-tuning on OpenMathReasoning delivers consistent improvements across all capabilities, with the highest gains in Tool Usage Proficiency (+18.1%) and Solution Verification (+16.7%).
🧠 Reasoning Capabilities Radar
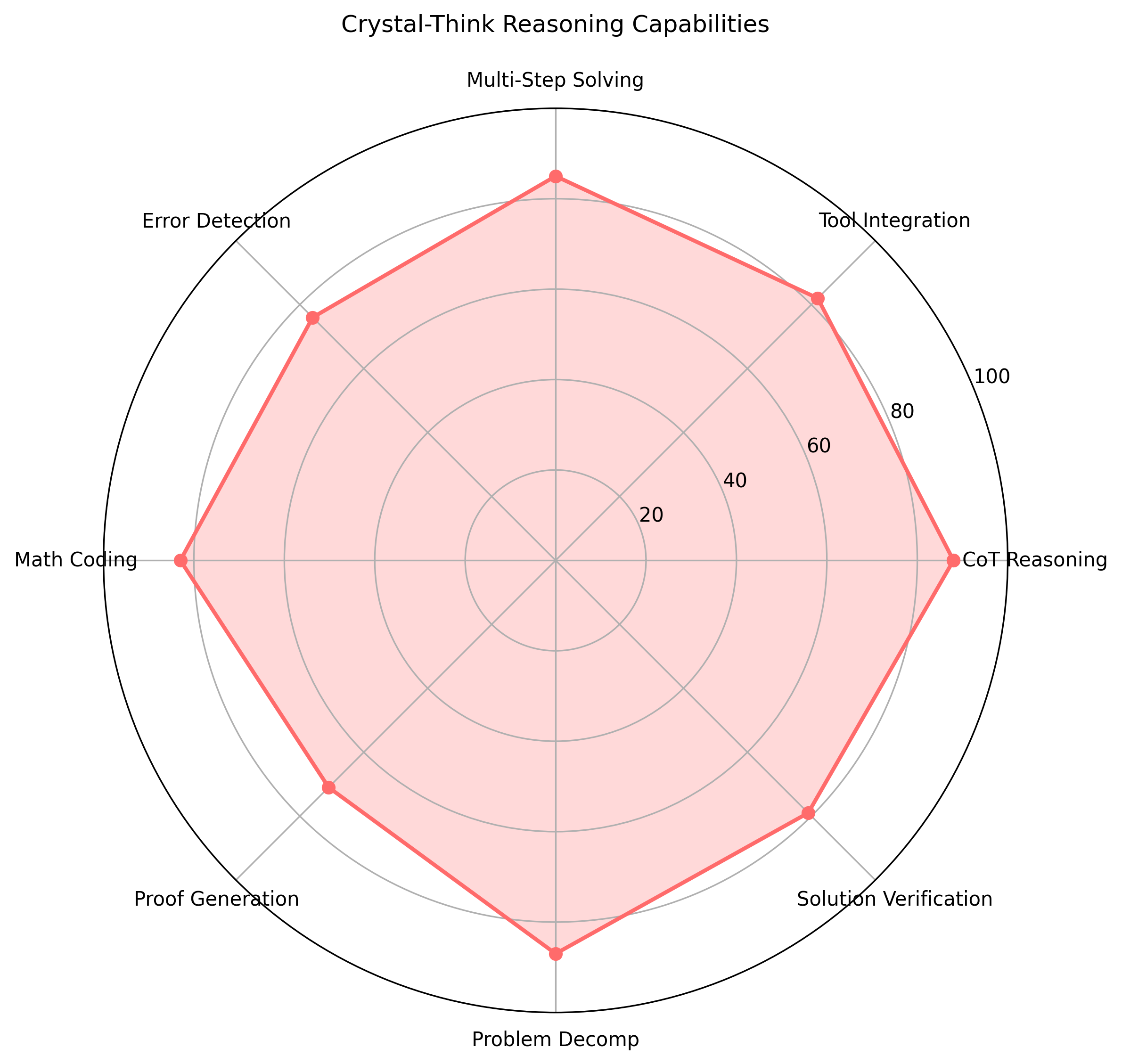
Comprehensive reasoning profile trained on 3.2M Chain-of-Thought and 1.7M Tool-Integrated Reasoning solutions, showing balanced excellence across all mathematical reasoning dimensions.
📚 Training Data Composition
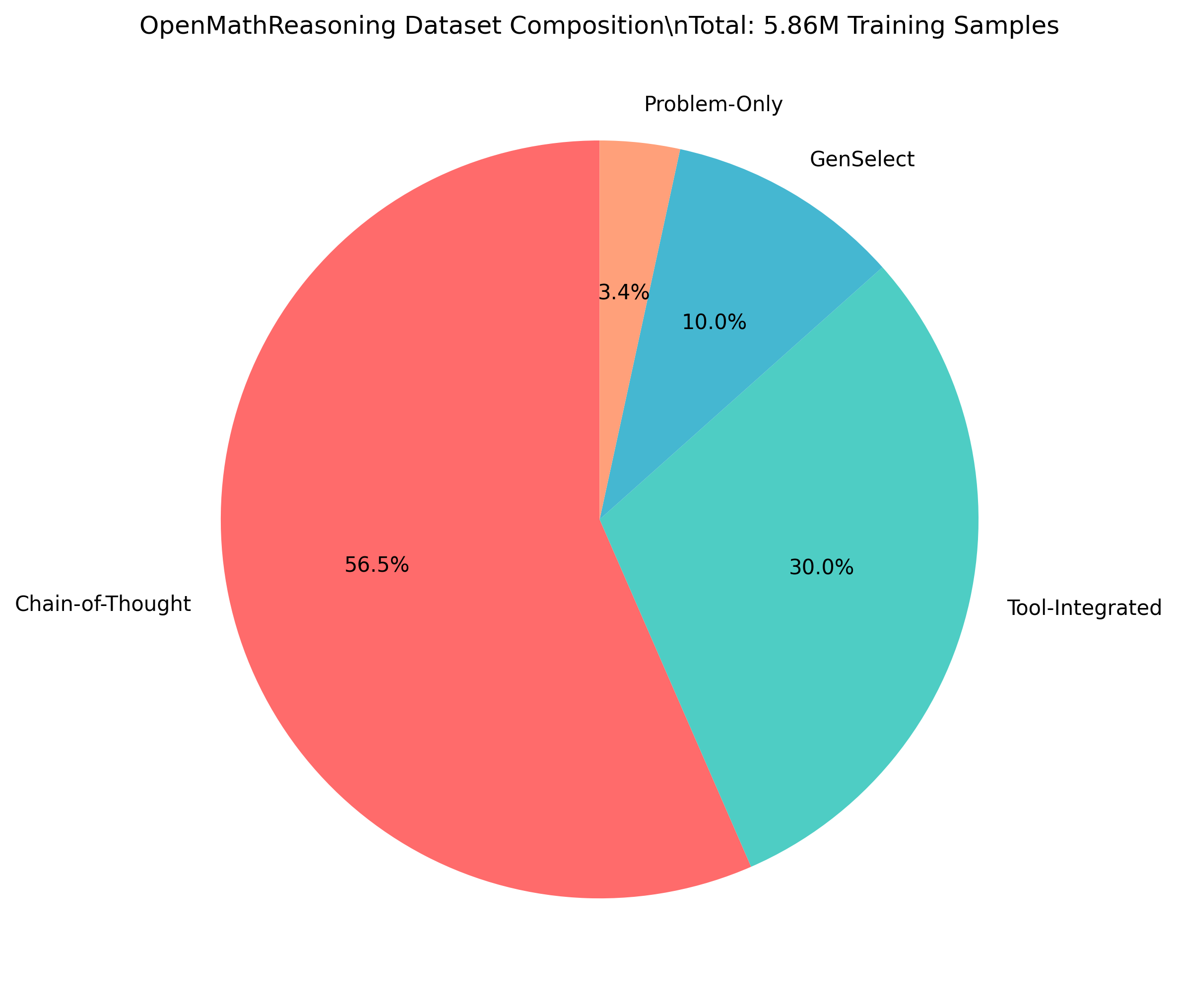
OpenMathReasoning dataset composition: 5.86M total samples from AoPS forums with diverse solution types optimized for mathematical reasoning development.
Reasoning Capabilities
✅ Multi-step Problem Solving: Breaks down complex problems systematically ✅ Clear Explanations: Provides step-by-step reasoning ✅ Error Checking: Identifies and corrects mathematical errors ✅ Multiple Approaches: Can solve problems using different methods ✅ Code Integration: Generates mathematical code with explanations
⚠️ Limitations
- Domain Specificity: Optimized for mathematical reasoning; may be less effective for general conversational tasks
- Language: Primarily trained on English mathematical content
- Complexity Ceiling: Very advanced mathematical concepts may still be challenging
- Computational Requirements: Requires adequate GPU memory for optimal performance
🔧 Technical Specifications
Hardware Requirements
- Minimum GPU Memory: 8GB VRAM
- Recommended GPU Memory: 16GB+ VRAM
- CPU: Modern multi-core processor
- RAM: 16GB+ system memory
Software Dependencies
transformers>=4.52.0
torch>=2.0.0
tokenizers>=0.13.0
accelerate>=0.20.0
📝 Citation
If you use Crystal Think in your research or applications, please cite:
@model{Crystal-Think-V2,
title={Crystal-Think V2: Enhanced Mathematical Reasoning with Chain-of-Thought},
author={PinkPixel},
year={2025},
url={https://huggingface.co/PinkPixel/Crystal-Think-V2},
note={Fine-tuned Qwen3-4B with GRPO on OpenMathReasoning, featuring <think></think> reasoning format}
}
🤝 Contributing
I'm always learning, and I am very interested in the fine-tuning process! If you have suggestions for improvements, find issues, or want to collaborate on future projects, please feel free to reach out.
📧 Contact
- Developer: Pink Pixel
- GitHub: https://github.com/pinkpixel-dev
- Website: https://pinkpixel.dev
- Email: [email protected]
🙏 Acknowledgments
- Base Model: Qwen Team for the excellent Qwen3-4B foundation
- Training Framework: Unsloth for efficient fine-tuning tools
- Dataset: NVIDIA for the OpenMathReasoning dataset
- Community: Hugging Face community for support and resources
Made with ❤️ by Pink Pixel ✨
"Dream it, Pixel it"
- Downloads last month
- 23
Model tree for PinkPixel/Crystal-Think-V2
Base model
Qwen/Qwen3-4B-Base