

metadata
license: llama3.2
datasets:
- OctoThinker/MegaMath-Web-Pro-Max
- LLM360/MegaMath
language:
- en
base_model:
- meta-llama/Llama-3.2-1B
pipeline_tag: text-generation
OctoThinker: Mid-training Incentivizes Reinforcement Learning Scaling
OctoThinker-1B-Long-Base
The OctoThinker family is built on carefully studied mid-training insights, starting from the Llama-3 family, to create a reinforcement learning–friendly base language model.
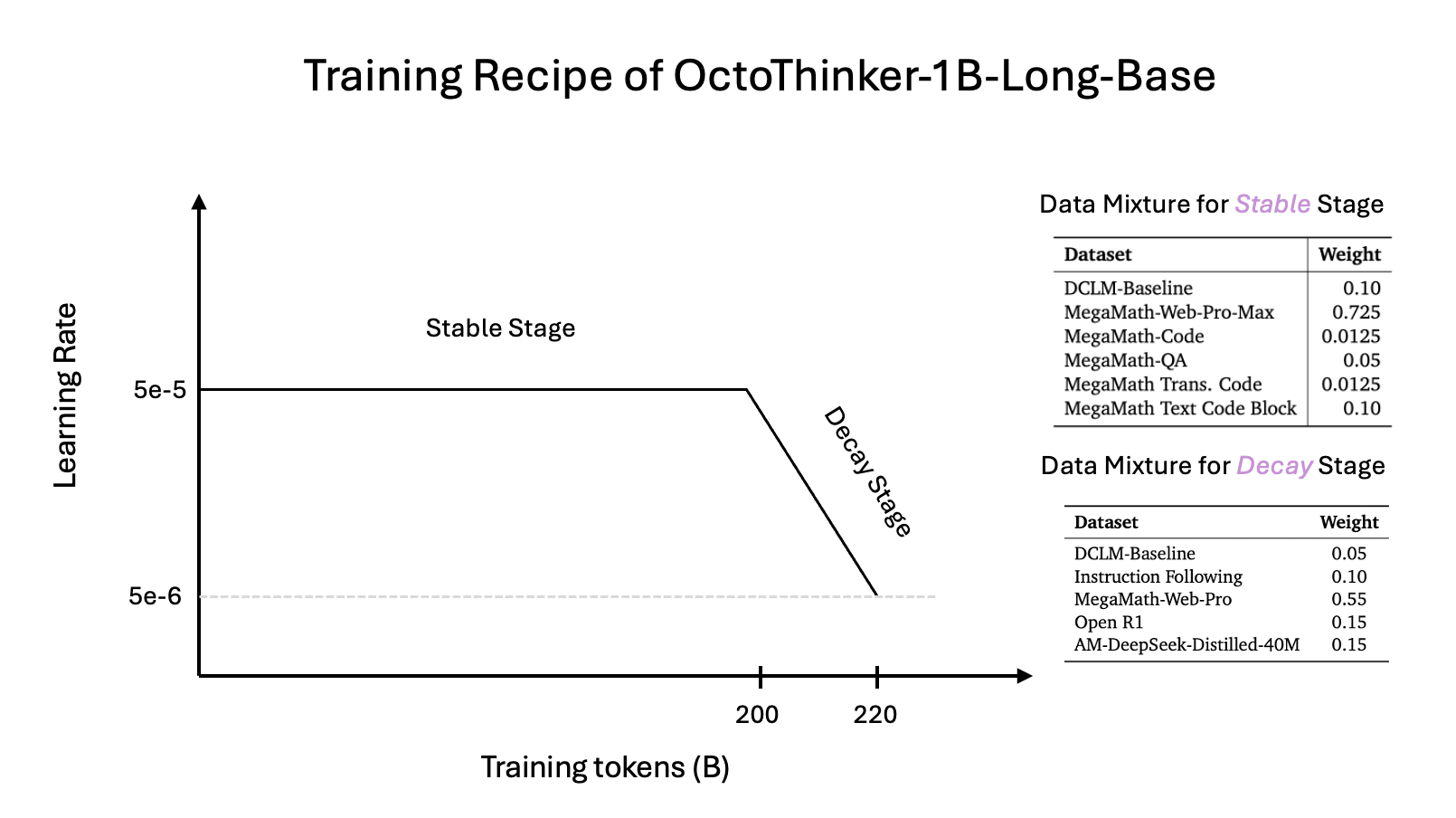
Training Recipe
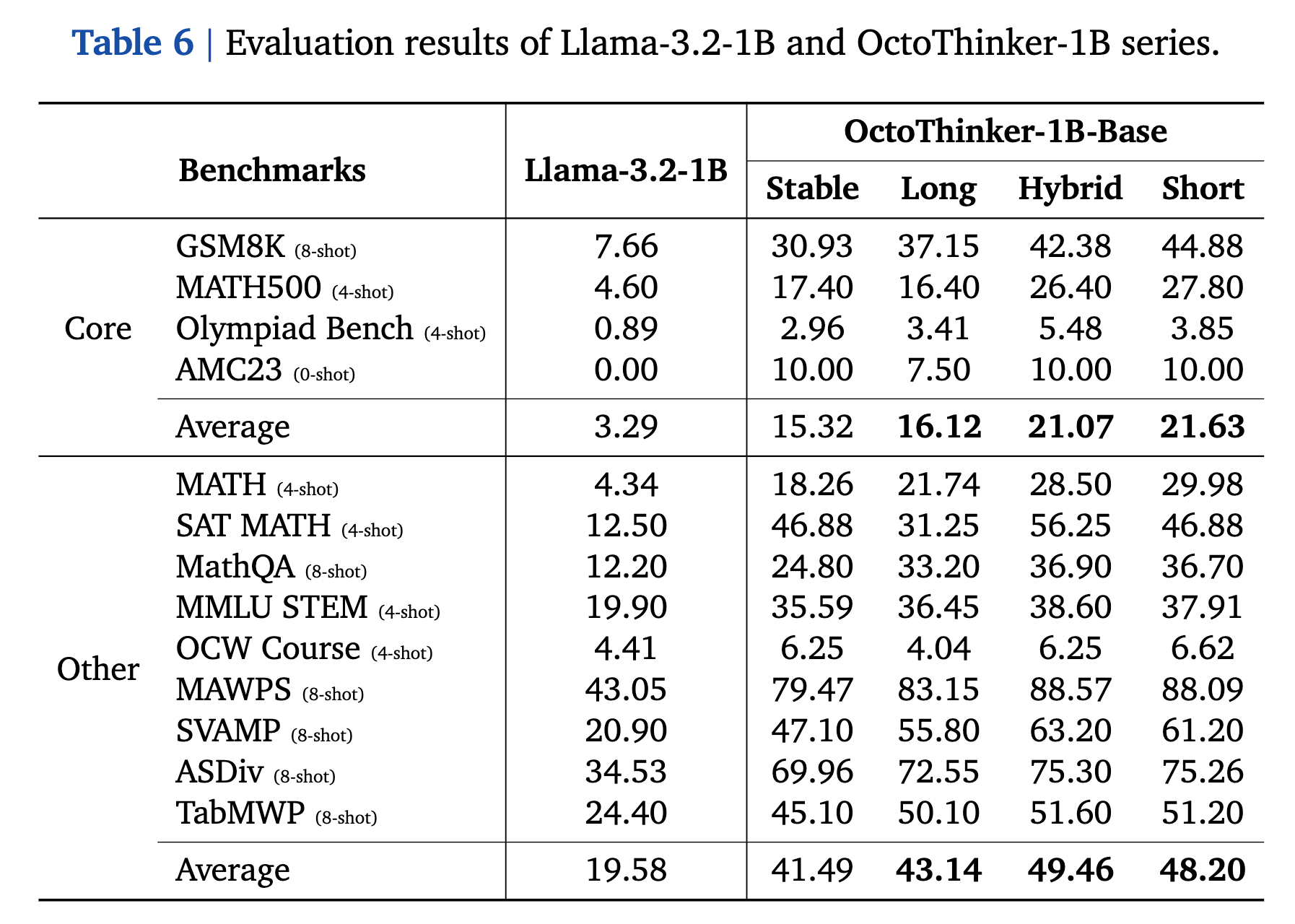
Evaluation Results
Note that we adopt the few-shot prompting evaluation for these base language models.
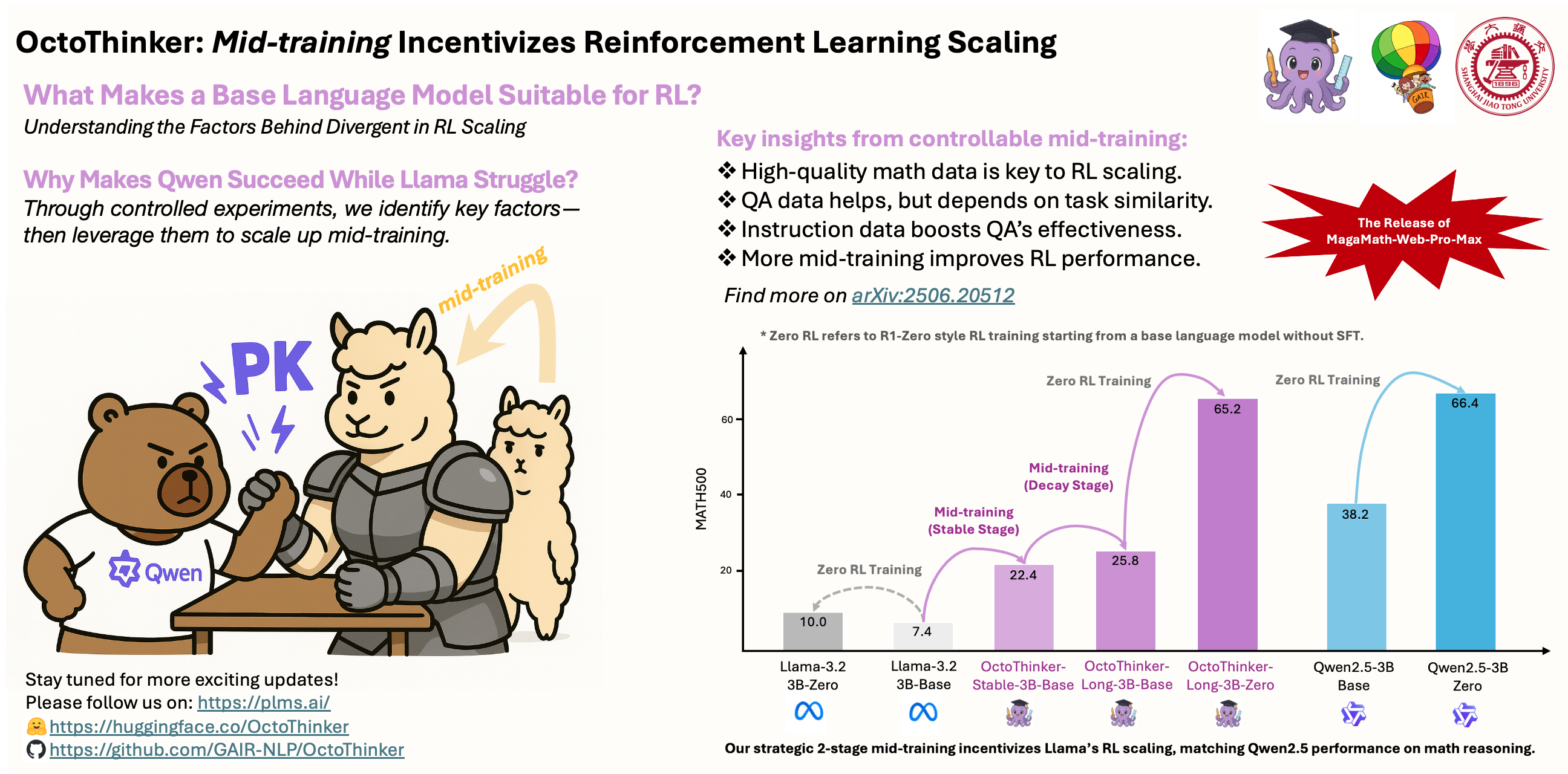
More about OctoThinker
Citation
Check out our paper for more details. If you use our models, datasets or find our work useful, please cite
@article{wang2025octothinker,
title={OctoThinker: Mid-training Incentivizes Reinforcement Learning Scaling},
author={Wang, Zengzhi and Zhou, Fan and Li, Xuefeng and Liu, Pengfei},
year={2025},
journal={arXiv preprint arXiv:2506.20512},
note={Preprint}
}