OctoThinker: Mid-training Incentivizes Reinforcement Learning Scaling
Llama_32_3B_megamath_web_pro_bs4M_seq8k_20B
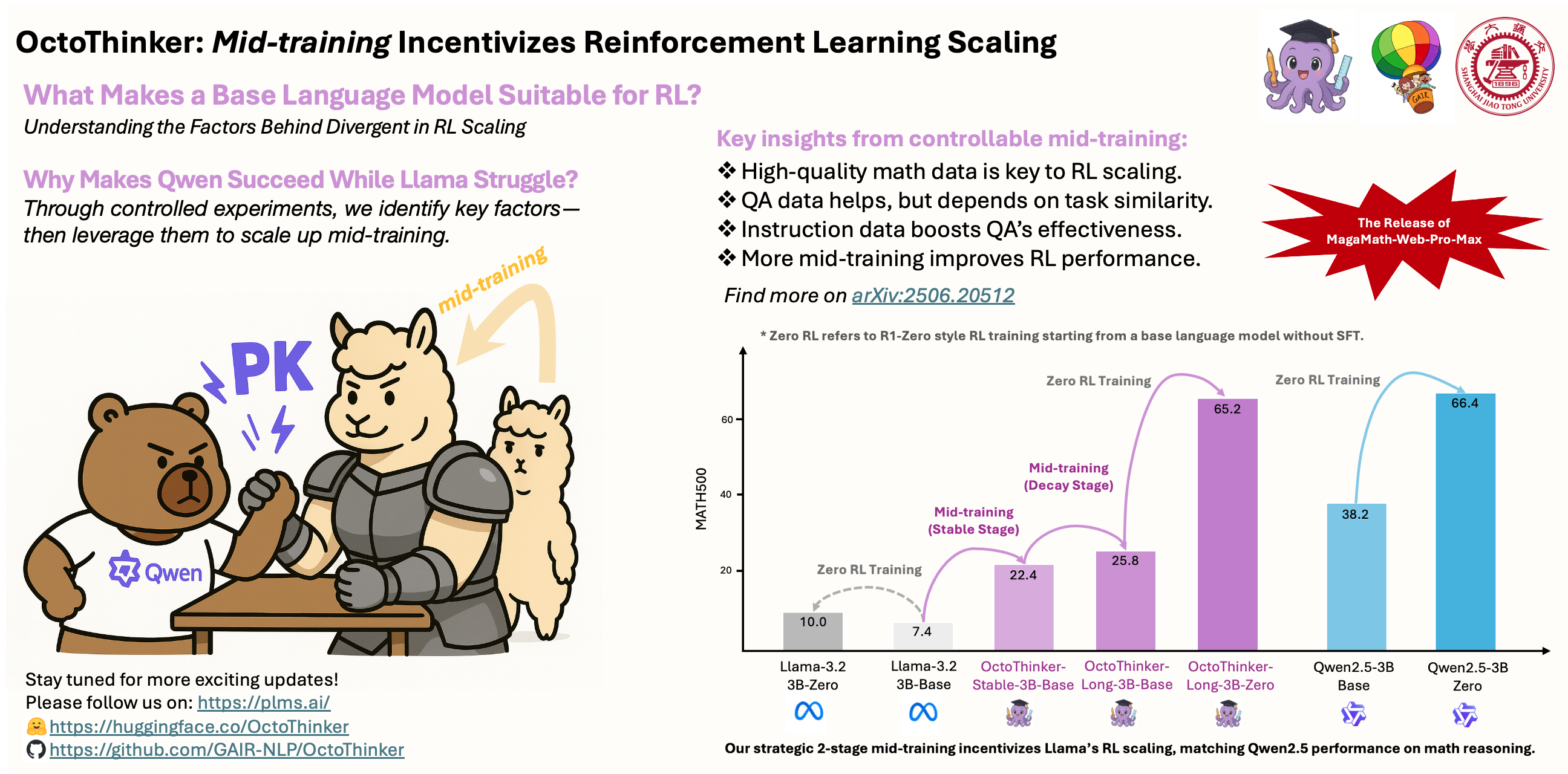
What makes a base language model suitable for RL? Understanding these factors behind divergent RL Scaling remains vital.
We aim to investigate the impact of several factors on RL performance during mid-training through head-to-head experiments, as shown in the Figure below. Specifically, we examine the effects of data quality
of math web corpora, the inclusion or exclusion of QA-format data, the nature of the QA data itself, the presence of general instruction-following data in mid-training, as well as the pre-training token budget. These systematic analyses help us gain a deeper understanding of the connection betweenpre-training and RL dynamics and figure out suitable recipes for scaled-up mid-training.
Mid-training Configuration
RL Training Dynamics
Takeaway: High-quality math pre-training corpora play a dominant role in RL scaling. We finally adopt MegaMath-Web-Pro and our curated MegaMath-Web-Pro-Max in this work.
More about OctoThinker
Citation
Check out our paper for more details. If you use our models, datasets or find our work useful, please cite
@article{wang2025octothinker,
title={OctoThinker: Mid-training Incentivizes Reinforcement Learning Scaling},
author={Wang, Zengzhi and Zhou, Fan and Li, Xuefeng and Liu, Pengfei},
year={2025},
journal={arXiv preprint arXiv:2506.20512},
note={Preprint}
}