
Introduction
This repository contains the released models for the paper GRAM: A Generative Foundation Reward Model for Reward Generalization 📝.
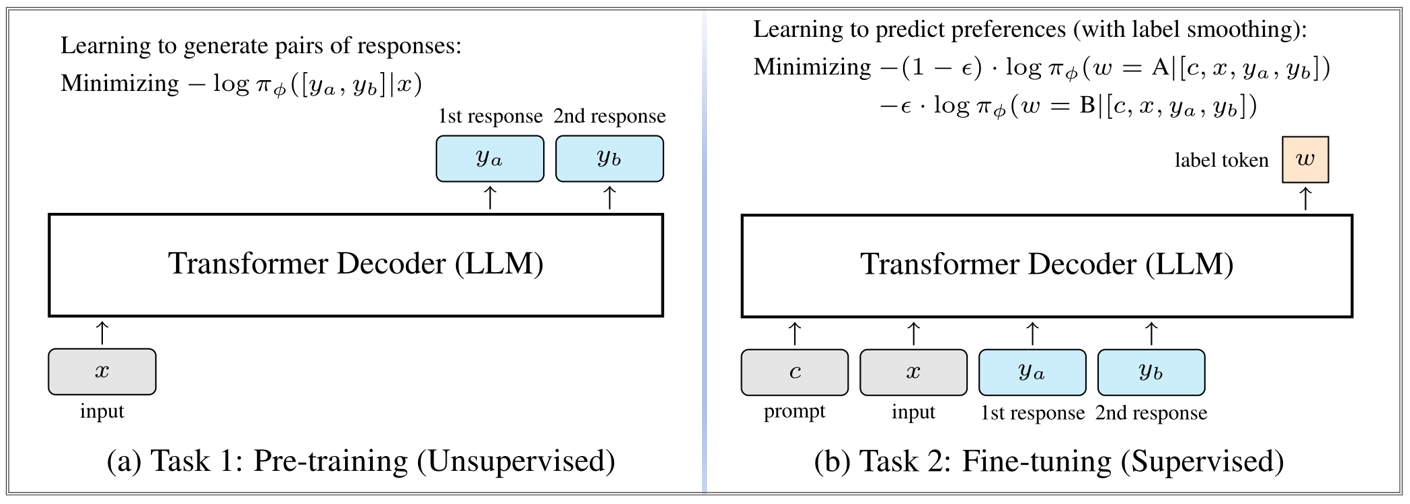
This training process is introduced above. Traditionally, these models are trained using labeled data, which can limit their potential. In this study, we propose a new method that combines both labeled and unlabeled data for training reward models. We introduce a generative reward model that first learns from a large amount of unlabeled data and is then fine-tuned with supervised data. Additionally, we demonstrate that using label smoothing during training improves performance by optimizing a regularized ranking loss. This approach bridges generative and discriminative models, offering a new perspective on training reward models. Our model can be easily applied to various tasks without the need for extensive fine-tuning. This means that when aligning LLMs, there is no longer a need to train a reward model from scratch with large amounts of task-specific labeled data. Instead, you can directly apply our reward model or adapt it to align your LLM based on our code.
This reward model is fine-tuned from Qwen3-1.7B
Evaluation
We evaluate our reward model on the JudgeBench, a benchmark for evaluating LLM-as-a-Judge applications, and present the results as follows:
| Model | Param. | Chat | Code | Math | Safety | Avg. |
|---|---|---|---|---|---|---|
| GRAM-Qwen3-14B-RewardBench | 14B | 63.0 | 64.3 | 89.3 | 69.1 | 71.4 |
| GRAM-LLaMA3.2-3B-RewardBench | 3B | 59.7 | 64.3 | 84.0 | 71.4 | 69.9 |
| GRAM-Qwen3-8B-RewardBench | 8B | 62.3 | 64.3 | 80.4 | 64.3 | 67.8 |
| nvidia/Llama-3.1-Nemotron-70B-Reward | 70B | 62.3 | 72.5 | 76.8 | 57.1 | 67.2 |
| GRAM-Qwen3-4B-RewardBench | 4B | 59.7 | 59.2 | 80.4 | 64.3 | 65.9 |
| GRAM-Qwen3-1.7B-RewardBench | 1.7B | 60.4 | 65.3 | 78.6 | 57.1 | 65.4 |
| Skywork/Skywork-Reward-Gemma-2-27B-v0.2 | 27B | 59.7 | 66.3 | 83.9 | 50.0 | 65.0 |
| Skywork/Skywork-Reward-Llama-3.1-8B-v0.2 | 8B | 59.1 | 64.3 | 76.8 | 50.0 | 62.6 |
| internlm/internlm2-20b-reward | 20B | 62.3 | 69.4 | 66.1 | 50.0 | 62.0 |
Usage
You can directly run the GRAM model using the demo provided below. You can also train GRAM using the code available here.
import torch
import accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
prompt = """Please act as an impartial judge and evaluate the quality of the responses provided by two AI assistants to the user question displayed below. You should choose the assistant that follows the user\'s instructions and answers the user\'s question better.
Your evaluation should consider factors such as the helpfulness, relevance, accuracy, depth, creativity, and level of detail of their responses. Avoid any position biases and ensure that the order in which the responses were presented does not influence your decision. Do not allow the length of the responses to influence your evaluation. Do not favor certain names of the assistants. Be as objective as possible.
Please directly output your final verdict by strictly following this format: "A" if assistant A is better, "B" if assistant B is better.
[User Question]
{input}
[The Start of Assistant A's Answer]
{response_a}
[The End of Assistant A's Answer]
[The Start of Assistant B's Answer]
{response_b}
[The End of Assistant B's Answer]
"""
query = "What is the Russian word for frog?"
response1 = "The Russian word for frog is \"лягушка\" (pronounced \"lyagushka\")."
response2 = "The Russian word for frog is \"жаба\" (pronounced as \"zhaba\"). This word can also be written in Cyrillic as жа́ба. If you're learning Russian, here's a sentence with the word: Меня зовут Иван, и я люблю лезечку на спину жабы, which translates to \"My name is Ivan, and I like sitting on the back of a frog.\" (Keep in mind that in real life, it is best not to disturb or harm frogs.)"
model_name_or_path = "gram-open-source/GRAM-Qwen3-1.7B-RewardModel"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
tokenizer.padding_side = "left"
if not tokenizer.pad_token:
tokenizer.pad_token = tokenizer.eos_token
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, torch_dtype=torch.bfloat16, device_map="auto")
messages = [
[{"role": "user", "content": prompt.format(input=query, response_a=response1, response_b=response2)}],
[{"role": "user", "content": prompt.format(input=query, response_a=response2, response_b=response1)}],
]
# target at response1, response2 respectively
target_choices_response1 = ["A", "B"]
target_choices_response1_token_ids = torch.tensor([tokenizer(item, add_special_tokens=False).input_ids for item in target_choices_response1], device=model.device)
target_choices_response2_token_ids = torch.flip(target_choices_response1_token_ids, dims=(0,))
target_choices_token_ids = torch.cat((target_choices_response1_token_ids, target_choices_response2_token_ids), dim=1)
prompt = [tokenizer.apply_chat_template(message, tokenize=False, add_generation_prompt=True) for message in messages]
inputs = tokenizer(prompt, return_tensors="pt", padding=True).to(model.device)
with torch.no_grad():
output = model(**inputs)
logits = torch.gather(output.logits[..., -1, :], 1, target_choices_token_ids)
p = torch.nn.Softmax(dim=0)(logits)
score_response1, score_response2 = torch.mean(p, dim=1).tolist()
print({
"query": query,
"response1": response1,
"response2": response2,
"score_response1": score_response1,
"score_response2": score_response2,
"response1_is_better": score_response1 > score_response2,
})
Citation
If you find this model helpful for your research, please cite GRAM:
@misc{wang2025gram,
title={GRAM: A Generative Foundation Reward Model for Reward Generalization},
author={Chenglong Wang and Yang Gan and Yifu Huo and Yongyu Mu and Qiaozhi He and Murun Yang and Bei Li and Tong Xiao and Chunliang Zhang and Tongran Liu and Jingbo Zhu},
year={2025},
eprint={2506.14175},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2506.14175},
}
- Downloads last month
- 19