
UIGEN-T2-7B GGUF Models
Model Generation Details
This model was generated using llama.cpp at commit 8c83449.
Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)
Our latest quantization method introduces precision-adaptive quantization for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on Llama-3-8B. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
Benchmark Context
All tests conducted on Llama-3-8B-Instruct using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
Method
- Dynamic Precision Allocation:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- Critical Component Protection:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
Quantization Performance Comparison (Llama-3-8B)
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|---|---|---|---|---|---|---|---|---|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
Key:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
Key Improvements:
- 🔥 IQ1_M shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 IQ2_S cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ IQ1_S maintains 39.7% better accuracy despite 1-bit quantization
Tradeoffs:
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
When to Use These Models
📌 Fitting models into GPU VRAM
✔ Memory-constrained deployments
✔ Cpu and Edge Devices where 1-2bit errors can be tolerated
✔ Research into ultra-low-bit quantization
Choosing the Right Model Format
Selecting the correct model format depends on your hardware capabilities and memory constraints.
BF16 (Brain Float 16) – Use if BF16 acceleration is available
- A 16-bit floating-point format designed for faster computation while retaining good precision.
- Provides similar dynamic range as FP32 but with lower memory usage.
- Recommended if your hardware supports BF16 acceleration (check your device's specs).
- Ideal for high-performance inference with reduced memory footprint compared to FP32.
📌 Use BF16 if:
✔ Your hardware has native BF16 support (e.g., newer GPUs, TPUs).
✔ You want higher precision while saving memory.
✔ You plan to requantize the model into another format.
📌 Avoid BF16 if:
❌ Your hardware does not support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
F16 (Float 16) – More widely supported than BF16
- A 16-bit floating-point high precision but with less of range of values than BF16.
- Works on most devices with FP16 acceleration support (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 Use F16 if:
✔ Your hardware supports FP16 but not BF16.
✔ You need a balance between speed, memory usage, and accuracy.
✔ You are running on a GPU or another device optimized for FP16 computations.
📌 Avoid F16 if:
❌ Your device lacks native FP16 support (it may run slower than expected).
❌ You have memory limitations.
Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- Lower-bit models (Q4_K) → Best for minimal memory usage, may have lower precision.
- Higher-bit models (Q6_K, Q8_0) → Better accuracy, requires more memory.
📌 Use Quantized Models if:
✔ You are running inference on a CPU and need an optimized model.
✔ Your device has low VRAM and cannot load full-precision models.
✔ You want to reduce memory footprint while keeping reasonable accuracy.
📌 Avoid Quantized Models if:
❌ You need maximum accuracy (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)
These models are optimized for extreme memory efficiency, making them ideal for low-power devices or large-scale deployments where memory is a critical constraint.
IQ3_XS: Ultra-low-bit quantization (3-bit) with extreme memory efficiency.
- Use case: Best for ultra-low-memory devices where even Q4_K is too large.
- Trade-off: Lower accuracy compared to higher-bit quantizations.
IQ3_S: Small block size for maximum memory efficiency.
- Use case: Best for low-memory devices where IQ3_XS is too aggressive.
IQ3_M: Medium block size for better accuracy than IQ3_S.
- Use case: Suitable for low-memory devices where IQ3_S is too limiting.
Q4_K: 4-bit quantization with block-wise optimization for better accuracy.
- Use case: Best for low-memory devices where Q6_K is too large.
Q4_0: Pure 4-bit quantization, optimized for ARM devices.
- Use case: Best for ARM-based devices or low-memory environments.
Summary Table: Model Format Selection
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|---|---|---|---|---|
| BF16 | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| F16 | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| Q4_K | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| Q6_K | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| Q8_0 | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| IQ3_XS | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| Q4_0 | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
Included Files & Details
UIGEN-T2-7B-bf16.gguf
- Model weights preserved in BF16.
- Use this if you want to requantize the model into a different format.
- Best if your device supports BF16 acceleration.
UIGEN-T2-7B-f16.gguf
- Model weights stored in F16.
- Use if your device supports FP16, especially if BF16 is not available.
UIGEN-T2-7B-bf16-q8_0.gguf
- Output & embeddings remain in BF16.
- All other layers quantized to Q8_0.
- Use if your device supports BF16 and you want a quantized version.
UIGEN-T2-7B-f16-q8_0.gguf
- Output & embeddings remain in F16.
- All other layers quantized to Q8_0.
UIGEN-T2-7B-q4_k.gguf
- Output & embeddings quantized to Q8_0.
- All other layers quantized to Q4_K.
- Good for CPU inference with limited memory.
UIGEN-T2-7B-q4_k_s.gguf
- Smallest Q4_K variant, using less memory at the cost of accuracy.
- Best for very low-memory setups.
UIGEN-T2-7B-q6_k.gguf
- Output & embeddings quantized to Q8_0.
- All other layers quantized to Q6_K .
UIGEN-T2-7B-q8_0.gguf
- Fully Q8 quantized model for better accuracy.
- Requires more memory but offers higher precision.
UIGEN-T2-7B-iq3_xs.gguf
- IQ3_XS quantization, optimized for extreme memory efficiency.
- Best for ultra-low-memory devices.
UIGEN-T2-7B-iq3_m.gguf
- IQ3_M quantization, offering a medium block size for better accuracy.
- Suitable for low-memory devices.
UIGEN-T2-7B-q4_0.gguf
- Pure Q4_0 quantization, optimized for ARM devices.
- Best for low-memory environments.
- Prefer IQ4_NL for better accuracy.
🚀 If you find these models useful
❤ Please click "Like" if you find this useful!
Help me test my AI-Powered Network Monitor Assistant with quantum-ready security checks:
👉 Quantum Network Monitor
💬 How to test:
Choose an AI assistant type:
TurboLLM(GPT-4o-mini)HugLLM(Hugginface Open-source)TestLLM(Experimental CPU-only)
What I’m Testing
I’m pushing the limits of small open-source models for AI network monitoring, specifically:
- Function calling against live network services
- How small can a model go while still handling:
- Automated Nmap scans
- Quantum-readiness checks
- Network Monitoring tasks
🟡 TestLLM – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ Zero-configuration setup
- ⏳ 30s load time (slow inference but no API costs)
- 🔧 Help wanted! If you’re into edge-device AI, let’s collaborate!
Other Assistants
🟢 TurboLLM – Uses gpt-4o-mini for:
- Create custom cmd processors to run .net code on Quantum Network Monitor Agents
- Real-time network diagnostics and monitoring
- Security Audits
- Penetration testing (Nmap/Metasploit)
🔵 HugLLM – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
💡 Example commands to you could test:
"Give me info on my websites SSL certificate""Check if my server is using quantum safe encyption for communication""Run a comprehensive security audit on my server"- '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is open source. Feel free to use whatever you find helpful.
If you appreciate the work, please consider buying me a coffee ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
Model Card for UIGEN-T2-7B

Model Overview
We're excited to introduce UIGEN-T2, the next evolution in our UI generation model series. Fine-tuned from the highly capable Qwen2.5-Coder-7B-Instruct base model using PEFT/LoRA, UIGEN-T2 is specifically designed to generate HTML and Tailwind CSS code for web interfaces. What sets UIGEN-T2 apart is its training on a massive 50,000 sample dataset (up from 400) and its unique UI-based reasoning capability, allowing it to generate not just code, but code informed by thoughtful design principles.
Model Highlights
- High-Quality UI Code Generation: Produces functional and semantic HTML combined with utility-first Tailwind CSS.
- Massive Training Dataset: Trained on 50,000 diverse UI examples, enabling broader component understanding and stylistic range.
- Innovative UI-Based Reasoning: Incorporates detailed reasoning traces generated by a specialized "teacher" model, ensuring outputs consider usability, layout, and aesthetics. (See example reasoning in description below)
- PEFT/LoRA Trained (Rank 128): Efficiently fine-tuned for UI generation. We've published LoRA checkpoints at each training step for transparency and community use!
- Improved Chat Interaction: Streamlined prompt flow – no more need for the awkward double
thinkprompt! Interaction feels more natural.
Example Reasoning (Internal Guide for Generation)
Here's a glimpse into the kind of reasoning that guides UIGEN-T2 internally, generated by our specialized teacher model:
<|begin_of_thought|>
When approaching the challenge of crafting an elegant stopwatch UI, my first instinct is to dissect what truly makes such an interface delightful yet functional—hence, I consider both aesthetic appeal and usability grounded in established heuristics like Nielsen’s “aesthetic and minimalist design” alongside Gestalt principles... placing the large digital clock prominently aligns with Fitts’ Law... The glassmorphism effect here enhances visual separation... typography choices—the use of a monospace font family ("Fira Code" via Google Fonts) supports readability... iconography paired with labels inside buttons provides dual coding... Tailwind CSS v4 enables utility-driven consistency... critical reflection concerns responsiveness: flexbox layouts combined with relative sizing guarantee graceful adaptation...
<|end_of_thought|>
Example Outputs


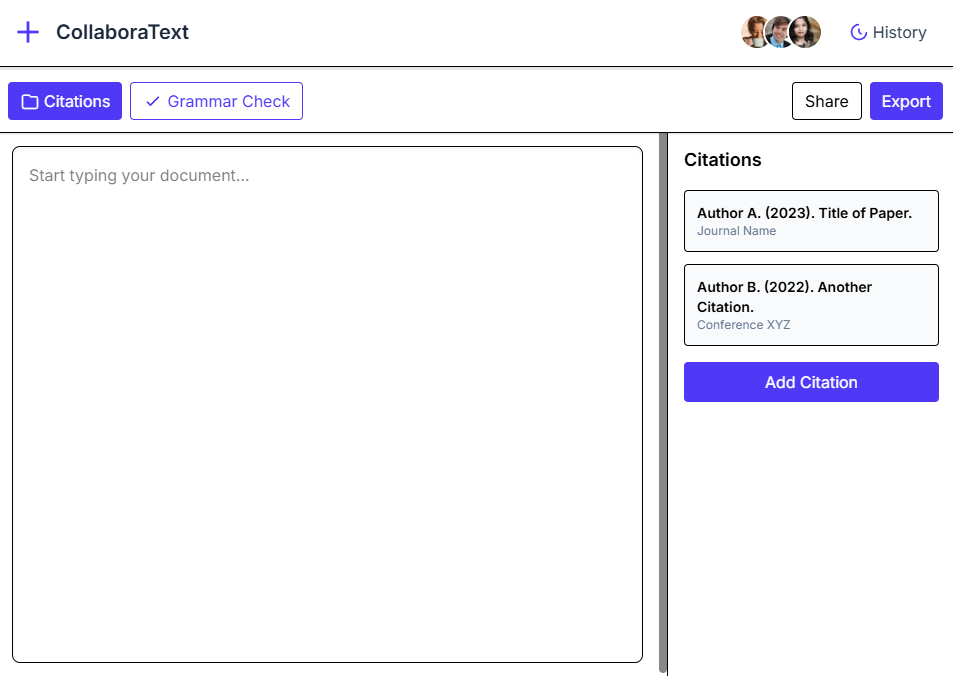


Use Cases
Recommended Uses
- Rapid UI Prototyping: Quickly generate HTML/Tailwind code snippets from descriptions or wireframes.
- Component Generation: Create standard and custom UI components (buttons, cards, forms, layouts).
- Frontend Development Assistance: Accelerate development by generating baseline component structures.
- Design-to-Code Exploration: Bridge the gap between design concepts and initial code implementation.
Limitations
- Current Framework Focus: Primarily generates HTML and Tailwind CSS. (Bootstrap support is planned!).
- Complex JavaScript Logic: Focuses on structure and styling; dynamic behavior and complex state management typically require manual implementation.
- Highly Specific Design Systems: May need further fine-tuning for strict adherence to unique, complex corporate design systems.
How to Use
You have to use this system prompt:
You are Tesslate, a helpful assistant specialized in UI generation.
These are the reccomended parameters: 0.7 Temp, Top P 0.9.
Inference Example
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# Make sure you have PEFT installed: pip install peft
from peft import PeftModel
# Use your specific model name/path once uploaded
model_name_or_path = "tesslate/UIGEN-T2" # Placeholder - replace with actual HF repo name
base_model_name = "Qwen/Qwen2.5-Coder-7B-Instruct"
# Load the base model
base_model = AutoModelForCausalLM.from_pretrained(
base_model_name,
torch_dtype=torch.bfloat16, # or float16 if bf16 not supported
device_map="auto"
)
# Load the PEFT model (LoRA weights)
model = PeftModel.from_pretrained(base_model, model_name_or_path)
tokenizer = AutoTokenizer.from_pretrained(base_model_name) # Use base tokenizer
# Note the simplified prompt structure (no double 'think')
prompt = """<|im_start|>user
Create a simple card component using Tailwind CSS with an image, title, and description.<|im_end|>
<|im_start|>assistant
""" # Model will generate reasoning and code following this
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
# Adjust generation parameters as needed
outputs = model.generate(**inputs, max_new_tokens=1024, do_sample=True, temperature=0.6, top_p=0.9)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Performance and Evaluation
- Strengths:
- Generates semantically correct and well-structured HTML/Tailwind CSS.
- Leverages a large dataset (50k samples) for improved robustness and diversity.
- Incorporates design reasoning for more thoughtful UI outputs.
- Improved usability via streamlined chat template.
- Openly published LoRA checkpoints for community use.
- Weaknesses:
- Currently limited to HTML/Tailwind CSS (Bootstrap planned).
- Complex JavaScript interactivity requires manual implementation.
- Reinforcement Learning refinement (for stricter adherence to principles/rewards) is a future step.
Technical Specifications
- Architecture: Transformer-based LLM adapted with PEFT/LoRA
- Base Model: Qwen/Qwen2.5-Coder-7B-Instruct
- Adapter Rank (LoRA): 128
- Training Data Size: 50,000 samples
- Precision: Trained using bf16/fp16. Base model requires appropriate precision handling.
- Hardware Requirements: Recommend GPU with >= 16GB VRAM for efficient inference (depends on quantization/precision).
- Software Dependencies:
- Hugging Face Transformers (
transformers) - PyTorch (
torch) - Parameter-Efficient Fine-Tuning (
peft)
- Hugging Face Transformers (
Citation
If you use UIGEN-T2 or the LoRA checkpoints in your work, please cite us:
@misc{tesslate_UIGEN-T2,
title={UIGEN-T2: Scaling UI Generation with Reasoning on Qwen2.5-Coder-7B},
author={tesslate},
year={2024}, # Adjust year if needed
publisher={Hugging Face},
url={https://huggingface.co/tesslate/UIGEN-T2} # Placeholder URL
}
Contact & Community
- Downloads last month
- 326
2-bit
3-bit
4-bit
5-bit
6-bit
8-bit
16-bit