
GLM-Z1-32B-0414 GGUF Models
Model Generation Details
This model was generated using llama.cpp at commit e291450.
Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)
Our latest quantization method introduces precision-adaptive quantization for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on Llama-3-8B. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
Benchmark Context
All tests conducted on Llama-3-8B-Instruct using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
Method
- Dynamic Precision Allocation:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- Critical Component Protection:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
Quantization Performance Comparison (Llama-3-8B)
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|---|---|---|---|---|---|---|---|---|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
Key:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
Key Improvements:
- 🔥 IQ1_M shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 IQ2_S cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ IQ1_S maintains 39.7% better accuracy despite 1-bit quantization
Tradeoffs:
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
When to Use These Models
📌 Fitting models into GPU VRAM
✔ Memory-constrained deployments
✔ Cpu and Edge Devices where 1-2bit errors can be tolerated
✔ Research into ultra-low-bit quantization
Choosing the Right Model Format
Selecting the correct model format depends on your hardware capabilities and memory constraints.
BF16 (Brain Float 16) – Use if BF16 acceleration is available
- A 16-bit floating-point format designed for faster computation while retaining good precision.
- Provides similar dynamic range as FP32 but with lower memory usage.
- Recommended if your hardware supports BF16 acceleration (check your device's specs).
- Ideal for high-performance inference with reduced memory footprint compared to FP32.
📌 Use BF16 if:
✔ Your hardware has native BF16 support (e.g., newer GPUs, TPUs).
✔ You want higher precision while saving memory.
✔ You plan to requantize the model into another format.
📌 Avoid BF16 if:
❌ Your hardware does not support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
F16 (Float 16) – More widely supported than BF16
- A 16-bit floating-point high precision but with less of range of values than BF16.
- Works on most devices with FP16 acceleration support (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 Use F16 if:
✔ Your hardware supports FP16 but not BF16.
✔ You need a balance between speed, memory usage, and accuracy.
✔ You are running on a GPU or another device optimized for FP16 computations.
📌 Avoid F16 if:
❌ Your device lacks native FP16 support (it may run slower than expected).
❌ You have memory limitations.
Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- Lower-bit models (Q4_K) → Best for minimal memory usage, may have lower precision.
- Higher-bit models (Q6_K, Q8_0) → Better accuracy, requires more memory.
📌 Use Quantized Models if:
✔ You are running inference on a CPU and need an optimized model.
✔ Your device has low VRAM and cannot load full-precision models.
✔ You want to reduce memory footprint while keeping reasonable accuracy.
📌 Avoid Quantized Models if:
❌ You need maximum accuracy (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)
These models are optimized for extreme memory efficiency, making them ideal for low-power devices or large-scale deployments where memory is a critical constraint.
IQ3_XS: Ultra-low-bit quantization (3-bit) with extreme memory efficiency.
- Use case: Best for ultra-low-memory devices where even Q4_K is too large.
- Trade-off: Lower accuracy compared to higher-bit quantizations.
IQ3_S: Small block size for maximum memory efficiency.
- Use case: Best for low-memory devices where IQ3_XS is too aggressive.
IQ3_M: Medium block size for better accuracy than IQ3_S.
- Use case: Suitable for low-memory devices where IQ3_S is too limiting.
Q4_K: 4-bit quantization with block-wise optimization for better accuracy.
- Use case: Best for low-memory devices where Q6_K is too large.
Q4_0: Pure 4-bit quantization, optimized for ARM devices.
- Use case: Best for ARM-based devices or low-memory environments.
Summary Table: Model Format Selection
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|---|---|---|---|---|
| BF16 | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| F16 | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| Q4_K | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| Q6_K | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| Q8_0 | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| IQ3_XS | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| Q4_0 | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
Included Files & Details
GLM-Z1-32B-0414-bf16.gguf
- Model weights preserved in BF16.
- Use this if you want to requantize the model into a different format.
- Best if your device supports BF16 acceleration.
GLM-Z1-32B-0414-f16.gguf
- Model weights stored in F16.
- Use if your device supports FP16, especially if BF16 is not available.
GLM-Z1-32B-0414-bf16-q8_0.gguf
- Output & embeddings remain in BF16.
- All other layers quantized to Q8_0.
- Use if your device supports BF16 and you want a quantized version.
GLM-Z1-32B-0414-f16-q8_0.gguf
- Output & embeddings remain in F16.
- All other layers quantized to Q8_0.
GLM-Z1-32B-0414-q4_k.gguf
- Output & embeddings quantized to Q8_0.
- All other layers quantized to Q4_K.
- Good for CPU inference with limited memory.
GLM-Z1-32B-0414-q4_k_s.gguf
- Smallest Q4_K variant, using less memory at the cost of accuracy.
- Best for very low-memory setups.
GLM-Z1-32B-0414-q6_k.gguf
- Output & embeddings quantized to Q8_0.
- All other layers quantized to Q6_K .
GLM-Z1-32B-0414-q8_0.gguf
- Fully Q8 quantized model for better accuracy.
- Requires more memory but offers higher precision.
GLM-Z1-32B-0414-iq3_xs.gguf
- IQ3_XS quantization, optimized for extreme memory efficiency.
- Best for ultra-low-memory devices.
GLM-Z1-32B-0414-iq3_m.gguf
- IQ3_M quantization, offering a medium block size for better accuracy.
- Suitable for low-memory devices.
GLM-Z1-32B-0414-q4_0.gguf
- Pure Q4_0 quantization, optimized for ARM devices.
- Best for low-memory environments.
- Prefer IQ4_NL for better accuracy.
🚀 If you find these models useful
❤ Please click "Like" if you find this useful!
Help me test my AI-Powered Network Monitor Assistant with quantum-ready security checks:
👉 Quantum Network Monitor
💬 How to test:
- Click the chat icon (bottom right on any page)
- Choose an AI assistant type:
TurboLLM(GPT-4-mini)FreeLLM(Open-source)TestLLM(Experimental CPU-only)
What I’m Testing
I’m pushing the limits of small open-source models for AI network monitoring, specifically:
- Function calling against live network services
- How small can a model go while still handling:
- Automated Nmap scans
- Quantum-readiness checks
- Metasploit integration
🟡 TestLLM – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ Zero-configuration setup
- ⏳ 30s load time (slow inference but no API costs)
- 🔧 Help wanted! If you’re into edge-device AI, let’s collaborate!
Other Assistants
🟢 TurboLLM – Uses gpt-4-mini for:
- Real-time network diagnostics
- Automated penetration testing (Nmap/Metasploit)
- 🔑 Get more tokens by downloading our Quantum Network Monitor Agent
🔵 HugLLM – Open-source models (≈8B params):
- 2x more tokens than TurboLLM
- AI-powered log analysis
- 🌐 Runs on Hugging Face Inference API
💡 Example AI Commands to Test:
"Give me info on my websites SSL certificate""Check if my server is using quantum safe encyption for communication""Run a quick Nmap vulnerability test"- '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is open source. Feel free to use what you find useful. Please support my work and consider buying me a coffee . This will help me pay for the services and increase the token limits for everyone.
Thank you :)
GLM-4-Z1-32B-0414
Introduction
The GLM family welcomes a new generation of open-source models, the GLM-4-32B-0414 series, featuring 32 billion parameters. Its performance is comparable to OpenAI's GPT series and DeepSeek's V3/R1 series, and it supports very user-friendly local deployment features. GLM-4-32B-Base-0414 was pre-trained on 15T of high-quality data, including a large amount of reasoning-type synthetic data, laying the foundation for subsequent reinforcement learning extensions. In the post-training stage, in addition to human preference alignment for dialogue scenarios, we also enhanced the model's performance in instruction following, engineering code, and function calling using techniques such as rejection sampling and reinforcement learning, strengthening the atomic capabilities required for agent tasks. GLM-4-32B-0414 achieves good results in areas such as engineering code, Artifact generation, function calling, search-based Q&A, and report generation. Some benchmarks even rival larger models like GPT-4o and DeepSeek-V3-0324 (671B).
GLM-Z1-32B-0414 is a reasoning model with deep thinking capabilities. This was developed based on GLM-4-32B-0414 through cold start and extended reinforcement learning, as well as further training of the model on tasks involving mathematics, code, and logic. Compared to the base model, GLM-Z1-32B-0414 significantly improves mathematical abilities and the capability to solve complex tasks. During the training process, we also introduced general reinforcement learning based on pairwise ranking feedback, further enhancing the model's general capabilities.
GLM-Z1-Rumination-32B-0414 is a deep reasoning model with rumination capabilities (benchmarked against OpenAI's Deep Research). Unlike typical deep thinking models, the rumination model employs longer periods of deep thought to solve more open-ended and complex problems (e.g., writing a comparative analysis of AI development in two cities and their future development plans). The rumination model integrates search tools during its deep thinking process to handle complex tasks and is trained by utilizing multiple rule-based rewards to guide and extend end-to-end reinforcement learning. Z1-Rumination shows significant improvements in research-style writing and complex retrieval tasks.
Finally, GLM-Z1-9B-0414 is a surprise. We employed the aforementioned series of techniques to train a 9B small-sized model that maintains the open-source tradition. Despite its smaller scale, GLM-Z1-9B-0414 still exhibits excellent capabilities in mathematical reasoning and general tasks. Its overall performance is already at a leading level among open-source models of the same size. Especially in resource-constrained scenarios, this model achieves an excellent balance between efficiency and effectiveness, providing a powerful option for users seeking lightweight deployment.
Performance
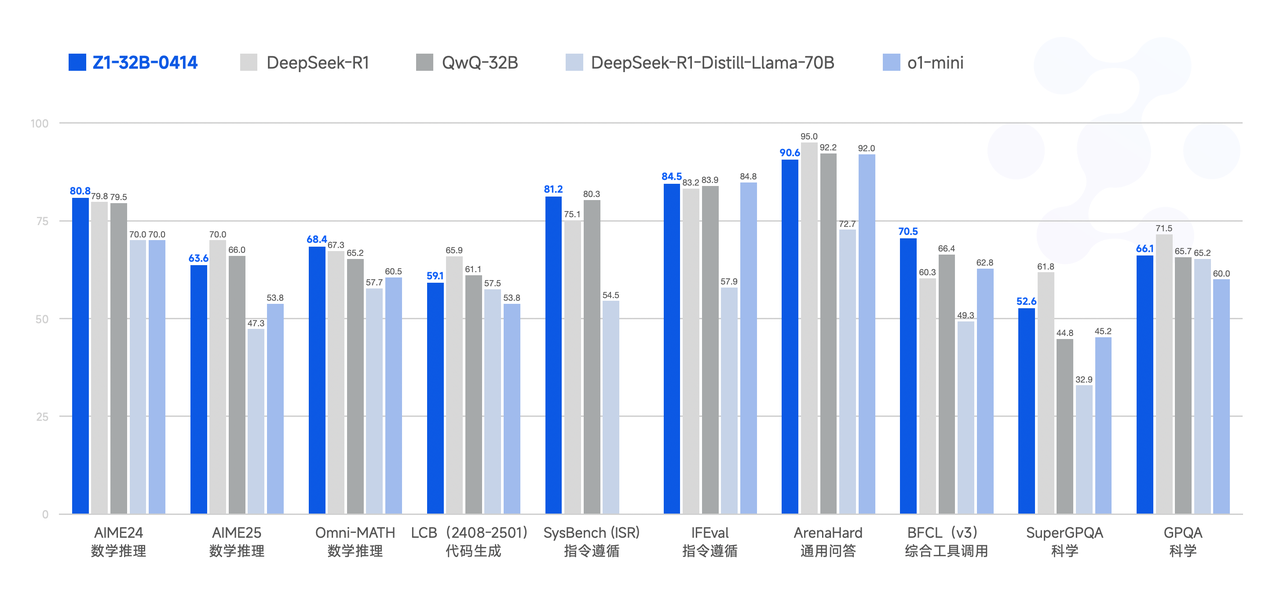
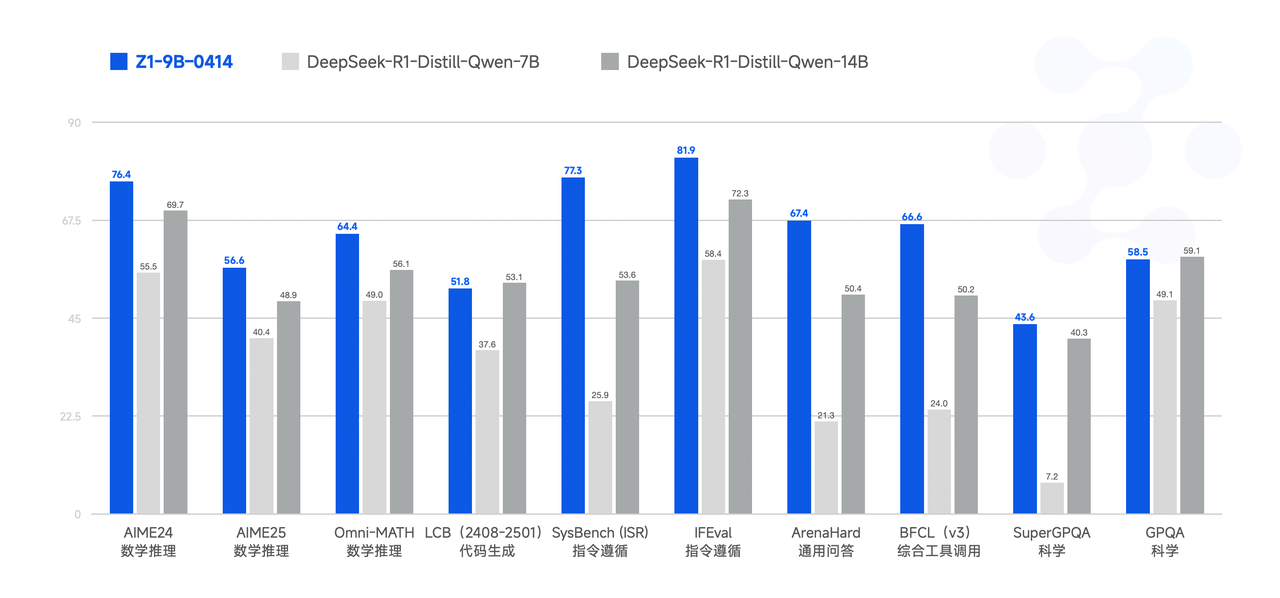
Model Usage Guidelines
I. Sampling Parameters
| Parameter | Recommended Value | Description |
|---|---|---|
| temperature | 0.6 | Balances creativity and stability |
| top_p | 0.95 | Cumulative probability threshold for sampling |
| top_k | 40 | Filters out rare tokens while maintaining diversity |
| max_new_tokens | 30000 | Leaves enough tokens for thinking |
II. Enforced Thinking
- Add <think>\n to the first line: Ensures the model thinks before responding
- When using
chat_template.jinja, the prompt is automatically injected to enforce this behavior
III. Dialogue History Trimming
- Retain only the final user-visible reply.
Hidden thinking content should not be saved to history to reduce interference—this is already implemented inchat_template.jinja
IV. Handling Long Contexts (YaRN)
When input length exceeds 8,192 tokens, consider enabling YaRN (Rope Scaling)
In supported frameworks, add the following snippet to
config.json:"rope_scaling": { "type": "yarn", "factor": 4.0, "original_max_position_embeddings": 32768 }Static YaRN applies uniformly to all text. It may slightly degrade performance on short texts, so enable as needed.
Inference Code
Make Sure Using transforemrs>=4.51.3.
from transformers import AutoModelForCausalLM, AutoTokenizer
MODEL_PATH = "THUDM/GLM-4-Z1-32B-0414"
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
model = AutoModelForCausalLM.from_pretrained(MODEL_PATH, device_map="auto")
message = [{"role": "user", "content": "Let a, b be positive real numbers such that ab = a + b + 3. Determine the range of possible values for a + b."}]
inputs = tokenizer.apply_chat_template(
message,
return_tensors="pt",
add_generation_prompt=True,
return_dict=True,
).to(model.device)
generate_kwargs = {
"input_ids": inputs["input_ids"],
"attention_mask": inputs["attention_mask"],
"max_new_tokens": 4096,
"do_sample": False,
}
out = model.generate(**generate_kwargs)
print(tokenizer.decode(out[0][inputs["input_ids"].shape[1]:], skip_special_tokens=True))
Citations
If you find our work useful, please consider citing the following paper.
@misc{glm2024chatglm,
title={ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools},
author={Team GLM and Aohan Zeng and Bin Xu and Bowen Wang and Chenhui Zhang and Da Yin and Diego Rojas and Guanyu Feng and Hanlin Zhao and Hanyu Lai and Hao Yu and Hongning Wang and Jiadai Sun and Jiajie Zhang and Jiale Cheng and Jiayi Gui and Jie Tang and Jing Zhang and Juanzi Li and Lei Zhao and Lindong Wu and Lucen Zhong and Mingdao Liu and Minlie Huang and Peng Zhang and Qinkai Zheng and Rui Lu and Shuaiqi Duan and Shudan Zhang and Shulin Cao and Shuxun Yang and Weng Lam Tam and Wenyi Zhao and Xiao Liu and Xiao Xia and Xiaohan Zhang and Xiaotao Gu and Xin Lv and Xinghan Liu and Xinyi Liu and Xinyue Yang and Xixuan Song and Xunkai Zhang and Yifan An and Yifan Xu and Yilin Niu and Yuantao Yang and Yueyan Li and Yushi Bai and Yuxiao Dong and Zehan Qi and Zhaoyu Wang and Zhen Yang and Zhengxiao Du and Zhenyu Hou and Zihan Wang},
year={2024},
eprint={2406.12793},
archivePrefix={arXiv},
primaryClass={id='cs.CL' full_name='Computation and Language' is_active=True alt_name='cmp-lg' in_archive='cs' is_general=False description='Covers natural language processing. Roughly includes material in ACM Subject Class I.2.7. Note that work on artificial languages (programming languages, logics, formal systems) that does not explicitly address natural-language issues broadly construed (natural-language processing, computational linguistics, speech, text retrieval, etc.) is not appropriate for this area.'}
}
- Downloads last month
- 978
1-bit
2-bit
3-bit
4-bit
5-bit
6-bit
8-bit
16-bit