
Add model files
Browse files- .gitattributes +6 -0
- README.md +469 -3
- added_tokens.json +34 -0
- asset/architecture.png +3 -0
- asset/keye_logo_2.png +3 -0
- asset/post1.jpeg +0 -0
- asset/post2.jpeg +3 -0
- asset/pre-train.png +3 -0
- asset/teaser.png +3 -0
- chat_template.json +3 -0
- config.json +72 -0
- configuration_keye.py +243 -0
- generation_config.json +13 -0
- image_processing_keye.py +570 -0
- merges.txt +0 -0
- model-00001-of-00004.safetensors +3 -0
- model-00002-of-00004.safetensors +3 -0
- model-00003-of-00004.safetensors +3 -0
- model-00004-of-00004.safetensors +3 -0
- model.safetensors.index.json +861 -0
- modeling_keye.py +0 -0
- preprocessor_config.json +18 -0
- processing_keye.py +298 -0
- processor_config.json +6 -0
- special_tokens_map.json +25 -0
- tokenizer.json +3 -0
- tokenizer_config.json +282 -0
- vocab.json +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,9 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
asset/architecture.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
asset/keye_logo_2.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
asset/post2.jpeg filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
asset/pre-train.png filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
asset/teaser.png filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -1,3 +1,469 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
---
|
| 3 |
+
license: apache-2.0
|
| 4 |
+
language:
|
| 5 |
+
- en
|
| 6 |
+
pipeline_tag: image-text-to-text
|
| 7 |
+
tags:
|
| 8 |
+
- multimodal
|
| 9 |
+
library_name: transformers
|
| 10 |
+
---
|
| 11 |
+
|
| 12 |
+
# Kwai Keye-VL
|
| 13 |
+
|
| 14 |
+
<div align="center">
|
| 15 |
+
<img src="asset/keye_logo_2.png" width="100%" alt="Kwai Keye-VL Logo">
|
| 16 |
+
</div>
|
| 17 |
+
|
| 18 |
+
<font size=3><div align='center' > [[🍎 Home Page](https://kwai-keye.github.io/)] [[📖 Technical Report]()] [[📊 Models](https://huggingface.co/Kwai-Keye)] </div></font>
|
| 19 |
+
|
| 20 |
+
## 🔥 News
|
| 21 |
+
* **`2025.06.26`** 🌟 We are very proud to launch **Kwai Keye-VL**, a cutting-edge multimodal large language model meticulously crafted by the **Kwai Keye Team** at [Kuaishou](https://www.kuaishou.com/). As a cornerstone AI product within Kuaishou's advanced technology ecosystem, Keye excels in video understanding, visual perception, and reasoning tasks, setting new benchmarks in performance. Our team is working tirelessly to push the boundaries of what's possible, so stay tuned for more exciting updates!
|
| 22 |
+
|
| 23 |
+
<div align="center">
|
| 24 |
+
<img src="asset/teaser.png" width="100%" alt="Kwai Keye-VL Performance">
|
| 25 |
+
</div>
|
| 26 |
+
|
| 27 |
+
## Quickstart
|
| 28 |
+
|
| 29 |
+
Below, we provide simple examples to show how to use Kwai Keye-VL with 🤗 Transformers.
|
| 30 |
+
|
| 31 |
+
The code of Kwai Keye-VL has been in the latest Hugging face transformers and we advise you to build from source with command:
|
| 32 |
+
```
|
| 33 |
+
pip install git+https://github.com/huggingface/transformers accelerate
|
| 34 |
+
```
|
| 35 |
+
or you might encounter the following error:
|
| 36 |
+
```
|
| 37 |
+
KeyError: 'Keye-VL'
|
| 38 |
+
```
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
We offer a toolkit to help you handle various types of visual input more conveniently, as if you were using an API. This includes base64, URLs, and interleaved images and videos. You can install it using the following command:
|
| 42 |
+
|
| 43 |
+
```bash
|
| 44 |
+
# It's highly recommanded to use `[decord]` feature for faster video loading.
|
| 45 |
+
pip install keye-vl-utils[decord]==1.0.0
|
| 46 |
+
```
|
| 47 |
+
|
| 48 |
+
If you are not using Linux, you might not be able to install `decord` from PyPI. In that case, you can use `pip install keye-vl-utils` which will fall back to using torchvision for video processing. However, you can still [install decord from source](https://github.com/dmlc/decord?tab=readme-ov-file#install-from-source) to get decord used when loading video.
|
| 49 |
+
|
| 50 |
+
### Using 🤗 Transformers to Chat
|
| 51 |
+
|
| 52 |
+
Here we show a code snippet to show you how to use the chat model with `transformers` and `keye_vl_utils`:
|
| 53 |
+
|
| 54 |
+
```python
|
| 55 |
+
from transformers import AutoModel, AutoTokenizer, AutoProcessor
|
| 56 |
+
from keye_vl_utils import process_vision_info
|
| 57 |
+
|
| 58 |
+
# default: Load the model on the available device(s)
|
| 59 |
+
model_path = "Kwai-Keye/Keye-VL-8B-Preview"
|
| 60 |
+
|
| 61 |
+
model = AutoModel.from_pretrained(
|
| 62 |
+
model_path, torch_dtype="auto", device_map="auto", attn_implementation="flash_attention_2", trust_remote_code=True,
|
| 63 |
+
).to('cuda')
|
| 64 |
+
|
| 65 |
+
# We recommend enabling flash_attention_2 for better acceleration and memory saving, especially in multi-image and video scenarios.
|
| 66 |
+
# model = KeyeForConditionalGeneration.from_pretrained(
|
| 67 |
+
# "Kwai-Keye/Keye-VL-8B-Preview",
|
| 68 |
+
# torch_dtype=torch.bfloat16,
|
| 69 |
+
# attn_implementation="flash_attention_2",
|
| 70 |
+
# device_map="auto",
|
| 71 |
+
# )
|
| 72 |
+
|
| 73 |
+
# default processer
|
| 74 |
+
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
|
| 75 |
+
|
| 76 |
+
# The default range for the number of visual tokens per image in the model is 4-16384.
|
| 77 |
+
# You can set min_pixels and max_pixels according to your needs, such as a token range of 256-1280, to balance performance and cost.
|
| 78 |
+
# min_pixels = 256*28*28
|
| 79 |
+
# max_pixels = 1280*28*28
|
| 80 |
+
# processor = AutoProcessor.from_pretrained(model_pat, min_pixels=min_pixels, max_pixels=max_pixels, trust_remote_code=True)
|
| 81 |
+
|
| 82 |
+
messages = [
|
| 83 |
+
{
|
| 84 |
+
"role": "user",
|
| 85 |
+
"content": [
|
| 86 |
+
{
|
| 87 |
+
"type": "image",
|
| 88 |
+
"image": "https://s1-11508.kwimgs.com/kos/nlav11508/mllm_all/ziran_jiafeimao_11.jpg",
|
| 89 |
+
},
|
| 90 |
+
{"type": "text", "text": "Describe this image."},
|
| 91 |
+
],
|
| 92 |
+
}
|
| 93 |
+
]
|
| 94 |
+
|
| 95 |
+
# Preparation for inference
|
| 96 |
+
text = processor.apply_chat_template(
|
| 97 |
+
messages, tokenize=False, add_generation_prompt=True
|
| 98 |
+
)
|
| 99 |
+
image_inputs, video_inputs = process_vision_info(messages)
|
| 100 |
+
inputs = processor(
|
| 101 |
+
text=[text],
|
| 102 |
+
images=image_inputs,
|
| 103 |
+
videos=video_inputs,
|
| 104 |
+
padding=True,
|
| 105 |
+
return_tensors="pt",
|
| 106 |
+
)
|
| 107 |
+
inputs = inputs.to("cuda")
|
| 108 |
+
|
| 109 |
+
# Inference: Generation of the output
|
| 110 |
+
generated_ids = model.generate(**inputs, max_new_tokens=128)
|
| 111 |
+
generated_ids_trimmed = [
|
| 112 |
+
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
|
| 113 |
+
]
|
| 114 |
+
output_text = processor.batch_decode(
|
| 115 |
+
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
|
| 116 |
+
)
|
| 117 |
+
print(output_text)
|
| 118 |
+
```
|
| 119 |
+
|
| 120 |
+
</details>
|
| 121 |
+
|
| 122 |
+
<details>
|
| 123 |
+
<summary>Video inference</summary>
|
| 124 |
+
|
| 125 |
+
```python
|
| 126 |
+
# Messages containing a images list as a video and a text query
|
| 127 |
+
messages = [
|
| 128 |
+
{
|
| 129 |
+
"role": "user",
|
| 130 |
+
"content": [
|
| 131 |
+
{
|
| 132 |
+
"type": "video",
|
| 133 |
+
"video": [
|
| 134 |
+
"file:///path/to/frame1.jpg",
|
| 135 |
+
"file:///path/to/frame2.jpg",
|
| 136 |
+
"file:///path/to/frame3.jpg",
|
| 137 |
+
"file:///path/to/frame4.jpg",
|
| 138 |
+
],
|
| 139 |
+
},
|
| 140 |
+
{"type": "text", "text": "Describe this video."},
|
| 141 |
+
],
|
| 142 |
+
}
|
| 143 |
+
]
|
| 144 |
+
|
| 145 |
+
# Messages containing a local video path and a text query
|
| 146 |
+
messages = [
|
| 147 |
+
{
|
| 148 |
+
"role": "user",
|
| 149 |
+
"content": [
|
| 150 |
+
{
|
| 151 |
+
"type": "video",
|
| 152 |
+
"video": "file:///path/to/video1.mp4",
|
| 153 |
+
"max_pixels": 360 * 420,
|
| 154 |
+
"fps": 1.0,
|
| 155 |
+
},
|
| 156 |
+
{"type": "text", "text": "Describe this video."},
|
| 157 |
+
],
|
| 158 |
+
}
|
| 159 |
+
]
|
| 160 |
+
|
| 161 |
+
# Messages containing a video url and a text query
|
| 162 |
+
messages = [
|
| 163 |
+
{
|
| 164 |
+
"role": "user",
|
| 165 |
+
"content": [
|
| 166 |
+
{
|
| 167 |
+
"type": "video",
|
| 168 |
+
"video": "http://s2-11508.kwimgs.com/kos/nlav11508/MLLM/videos_caption/98312843263.mp4",
|
| 169 |
+
},
|
| 170 |
+
{"type": "text", "text": "Describe this video."},
|
| 171 |
+
],
|
| 172 |
+
}
|
| 173 |
+
]
|
| 174 |
+
|
| 175 |
+
#In Keye-VL, frame rate information is also input into the model to align with absolute time.
|
| 176 |
+
# Preparation for inference
|
| 177 |
+
text = processor.apply_chat_template(
|
| 178 |
+
messages, tokenize=False, add_generation_prompt=True
|
| 179 |
+
)
|
| 180 |
+
image_inputs, video_inputs, video_kwargs = process_vision_info(messages, return_video_kwargs=True)
|
| 181 |
+
inputs = processor(
|
| 182 |
+
text=[text],
|
| 183 |
+
images=image_inputs,
|
| 184 |
+
videos=video_inputs,
|
| 185 |
+
padding=True,
|
| 186 |
+
return_tensors="pt",
|
| 187 |
+
**video_kwargs,
|
| 188 |
+
)
|
| 189 |
+
inputs = inputs.to("cuda")
|
| 190 |
+
|
| 191 |
+
# Inference
|
| 192 |
+
generated_ids = model.generate(**inputs, max_new_tokens=128)
|
| 193 |
+
generated_ids_trimmed = [
|
| 194 |
+
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
|
| 195 |
+
]
|
| 196 |
+
output_text = processor.batch_decode(
|
| 197 |
+
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
|
| 198 |
+
)
|
| 199 |
+
print(output_text)
|
| 200 |
+
```
|
| 201 |
+
|
| 202 |
+
Video URL compatibility largely depends on the third-party library version. The details are in the table below. change the backend by `FORCE_KEYEVL_VIDEO_READER=torchvision` or `FORCE_KEYEVL_VIDEO_READER=decord` if you prefer not to use the default one.
|
| 203 |
+
|
| 204 |
+
| Backend | HTTP | HTTPS |
|
| 205 |
+
|-------------|------|-------|
|
| 206 |
+
| torchvision >= 0.19.0 | ✅ | ✅ |
|
| 207 |
+
| torchvision < 0.19.0 | ❌ | ❌ |
|
| 208 |
+
| decord | ✅ | ❌ |
|
| 209 |
+
</details>
|
| 210 |
+
|
| 211 |
+
<details>
|
| 212 |
+
<summary>Batch inference</summary>
|
| 213 |
+
|
| 214 |
+
```python
|
| 215 |
+
# Sample messages for batch inference
|
| 216 |
+
messages1 = [
|
| 217 |
+
{
|
| 218 |
+
"role": "user",
|
| 219 |
+
"content": [
|
| 220 |
+
{"type": "image", "image": "file:///path/to/image1.jpg"},
|
| 221 |
+
{"type": "image", "image": "file:///path/to/image2.jpg"},
|
| 222 |
+
{"type": "text", "text": "What are the common elements in these pictures?"},
|
| 223 |
+
],
|
| 224 |
+
}
|
| 225 |
+
]
|
| 226 |
+
messages2 = [
|
| 227 |
+
{"role": "system", "content": "You are a helpful assistant."},
|
| 228 |
+
{"role": "user", "content": "Who are you?"},
|
| 229 |
+
]
|
| 230 |
+
# Combine messages for batch processing
|
| 231 |
+
messages = [messages1, messages2]
|
| 232 |
+
|
| 233 |
+
# Preparation for batch inference
|
| 234 |
+
texts = [
|
| 235 |
+
processor.apply_chat_template(msg, tokenize=False, add_generation_prompt=True)
|
| 236 |
+
for msg in messages
|
| 237 |
+
]
|
| 238 |
+
image_inputs, video_inputs = process_vision_info(messages)
|
| 239 |
+
inputs = processor(
|
| 240 |
+
text=texts,
|
| 241 |
+
images=image_inputs,
|
| 242 |
+
videos=video_inputs,
|
| 243 |
+
padding=True,
|
| 244 |
+
return_tensors="pt",
|
| 245 |
+
)
|
| 246 |
+
inputs = inputs.to("cuda")
|
| 247 |
+
|
| 248 |
+
# Batch Inference
|
| 249 |
+
generated_ids = model.generate(**inputs, max_new_tokens=128)
|
| 250 |
+
generated_ids_trimmed = [
|
| 251 |
+
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
|
| 252 |
+
]
|
| 253 |
+
output_texts = processor.batch_decode(
|
| 254 |
+
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
|
| 255 |
+
)
|
| 256 |
+
print(output_texts)
|
| 257 |
+
```
|
| 258 |
+
</details>
|
| 259 |
+
|
| 260 |
+
### More Usage Tips
|
| 261 |
+
|
| 262 |
+
For input images, we support local files, base64, and URLs. For videos, we currently only support local files.
|
| 263 |
+
|
| 264 |
+
```python
|
| 265 |
+
# You can directly insert a local file path, a URL, or a base64-encoded image into the position where you want in the text.
|
| 266 |
+
## Local file path
|
| 267 |
+
messages = [
|
| 268 |
+
{
|
| 269 |
+
"role": "user",
|
| 270 |
+
"content": [
|
| 271 |
+
{"type": "image", "image": "file:///path/to/your/image.jpg"},
|
| 272 |
+
{"type": "text", "text": "Describe this image."},
|
| 273 |
+
],
|
| 274 |
+
}
|
| 275 |
+
]
|
| 276 |
+
## Image URL
|
| 277 |
+
messages = [
|
| 278 |
+
{
|
| 279 |
+
"role": "user",
|
| 280 |
+
"content": [
|
| 281 |
+
{"type": "image", "image": "http://path/to/your/image.jpg"},
|
| 282 |
+
{"type": "text", "text": "Describe this image."},
|
| 283 |
+
],
|
| 284 |
+
}
|
| 285 |
+
]
|
| 286 |
+
## Base64 encoded image
|
| 287 |
+
messages = [
|
| 288 |
+
{
|
| 289 |
+
"role": "user",
|
| 290 |
+
"content": [
|
| 291 |
+
{"type": "image", "image": "data:image;base64,/9j/..."},
|
| 292 |
+
{"type": "text", "text": "Describe this image."},
|
| 293 |
+
],
|
| 294 |
+
}
|
| 295 |
+
]
|
| 296 |
+
```
|
| 297 |
+
|
| 298 |
+
#### Image Resolution for performance boost
|
| 299 |
+
|
| 300 |
+
The model supports a wide range of resolution inputs. By default, it uses the native resolution for input, but higher resolutions can enhance performance at the cost of more computation. Users can set the minimum and maximum number of pixels to achieve an optimal configuration for their needs, such as a token count range of 256-1280, to balance speed and memory usage.
|
| 301 |
+
|
| 302 |
+
```python
|
| 303 |
+
min_pixels = 256 * 28 * 28
|
| 304 |
+
max_pixels = 1280 * 28 * 28
|
| 305 |
+
processor = AutoProcessor.from_pretrained(
|
| 306 |
+
"Kwai-Keye/Keye-VL-8B-Preview", min_pixels=min_pixels, max_pixels=max_pixels
|
| 307 |
+
)
|
| 308 |
+
```
|
| 309 |
+
|
| 310 |
+
Besides, We provide two methods for fine-grained control over the image size input to the model:
|
| 311 |
+
|
| 312 |
+
1. Define min_pixels and max_pixels: Images will be resized to maintain their aspect ratio within the range of min_pixels and max_pixels.
|
| 313 |
+
|
| 314 |
+
2. Specify exact dimensions: Directly set `resized_height` and `resized_width`. These values will be rounded to the nearest multiple of 28.
|
| 315 |
+
|
| 316 |
+
```python
|
| 317 |
+
# min_pixels and max_pixels
|
| 318 |
+
messages = [
|
| 319 |
+
{
|
| 320 |
+
"role": "user",
|
| 321 |
+
"content": [
|
| 322 |
+
{
|
| 323 |
+
"type": "image",
|
| 324 |
+
"image": "file:///path/to/your/image.jpg",
|
| 325 |
+
"resized_height": 280,
|
| 326 |
+
"resized_width": 420,
|
| 327 |
+
},
|
| 328 |
+
{"type": "text", "text": "Describe this image."},
|
| 329 |
+
],
|
| 330 |
+
}
|
| 331 |
+
]
|
| 332 |
+
# resized_height and resized_width
|
| 333 |
+
messages = [
|
| 334 |
+
{
|
| 335 |
+
"role": "user",
|
| 336 |
+
"content": [
|
| 337 |
+
{
|
| 338 |
+
"type": "image",
|
| 339 |
+
"image": "file:///path/to/your/image.jpg",
|
| 340 |
+
"min_pixels": 50176,
|
| 341 |
+
"max_pixels": 50176,
|
| 342 |
+
},
|
| 343 |
+
{"type": "text", "text": "Describe this image."},
|
| 344 |
+
],
|
| 345 |
+
}
|
| 346 |
+
]
|
| 347 |
+
```
|
| 348 |
+
|
| 349 |
+
## 👀 Architecture and Training Strategy
|
| 350 |
+
|
| 351 |
+
<div align="center">
|
| 352 |
+
<img src="asset/architecture.png" width="100%" alt="Kwai Keye Architecture">
|
| 353 |
+
<i> The Kwai Keye-VL model architecture is based on the Qwen3-8B language model and incorporates a vision encoder initialized from the open-source SigLIP. It supports native dynamic resolution, preserving the original aspect ratio of images by dividing each into a 14x14 patch sequence. A simple MLP layer then maps and merges the visual tokens. The model uses 3D RoPE for unified processing of text, image, and video information, establishing a one-to-one correspondence between position encoding and absolute time to ensure precise perception of temporal changes in video information.</i>
|
| 354 |
+
</div>
|
| 355 |
+
|
| 356 |
+
### 🌟 Pre-Train
|
| 357 |
+
|
| 358 |
+
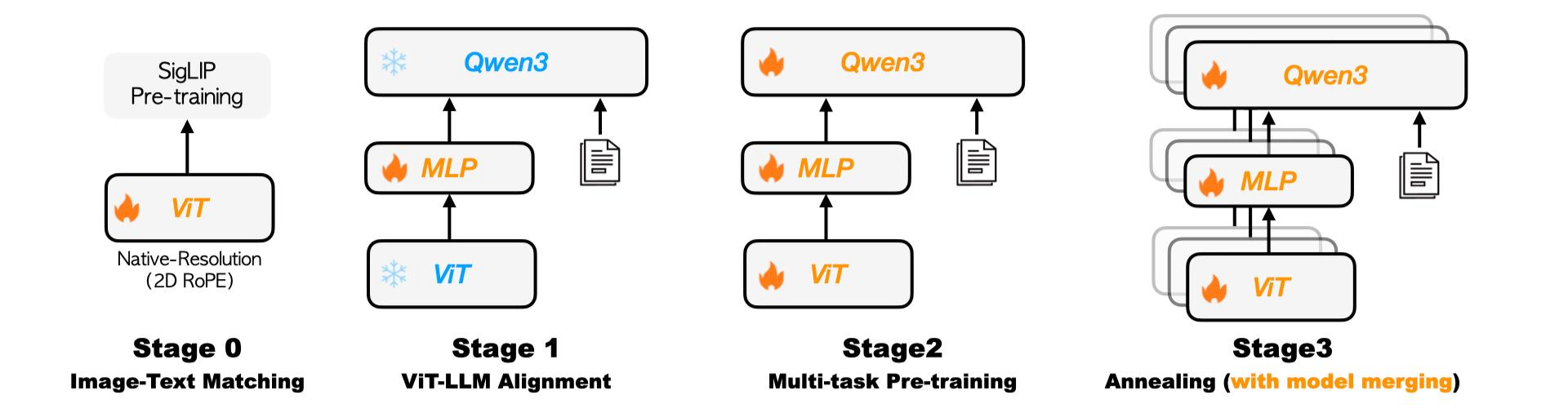
<div align="center">
|
| 359 |
+
<img src="asset/pre-train.png" width="100%" alt="Kwai Keye Pretraining">
|
| 360 |
+
<i>The Kwai Keye pre-training pipeline, featuring a four-stage progressive strategy: Image-Text Matching, ViT-LLM Alignment, Multi-task Pre-training, and Annealing with model merging.</i>
|
| 361 |
+
</div>
|
| 362 |
+
<details>
|
| 363 |
+
<summary>More Details</summary>
|
| 364 |
+
|
| 365 |
+
#### Pre-training Data: Massive, High-Quality, Diverse
|
| 366 |
+
|
| 367 |
+
- **Diversity**: Includes image-text pairs, videos, pure text, etc., with tasks such as fine-grained description, OCR, Q&A, localization, and more.
|
| 368 |
+
- **High Quality**: Data is filtered using CLIP scores and VLM discriminators, and MinHASH is used for deduplication to prevent data leakage.
|
| 369 |
+
- **Self-Built Datasets**: High-quality internal datasets are specifically constructed, especially for detailed captions and Chinese OCR, to compensate for the shortcomings of open-source data.
|
| 370 |
+
|
| 371 |
+
#### Training Process: Four-Stage Progressive Optimization
|
| 372 |
+
Kwai Keye-VL adopts a four-stage progressive training strategy:
|
| 373 |
+
|
| 374 |
+
- **Stage 0 (Visual Pre-training)**: Continuously pre-trains the visual encoder to adapt to internal data distribution and support dynamic resolution.
|
| 375 |
+
- **Stage 1 (Cross-Modal Alignment)**: Freezes the backbone model and trains only the MLP to establish robust image-text alignment at low cost.
|
| 376 |
+
- **Stage 2 (Multi-Task Pre-training)**: Unlocks all parameters to comprehensively enhance the model's visual understanding capabilities.
|
| 377 |
+
- **Stage 3 (Annealing Training)**: Fine-tunes with high-quality data to further improve the model's fine-grained understanding capabilities.
|
| 378 |
+
|
| 379 |
+
Finally, Kwai Keye-VL explores isomorphic heterogeneous fusion technology by averaging parameters of annealed training models with different data ratios, reducing model bias while retaining multidimensional capabilities, thereby enhancing the model's robustness.
|
| 380 |
+
|
| 381 |
+
</details>
|
| 382 |
+
|
| 383 |
+
### 🌟 Post-Train
|
| 384 |
+
|
| 385 |
+
The post-training phase of Kwai Keye is meticulously designed into two phases with five stages, aiming to comprehensively enhance the model's performance, especially its reasoning ability in complex tasks. This is a key breakthrough for achieving advanced cognitive functions.
|
| 386 |
+
|
| 387 |
+
#### Stage I. No-Reasoning Training: Strengthening Basic Performance
|
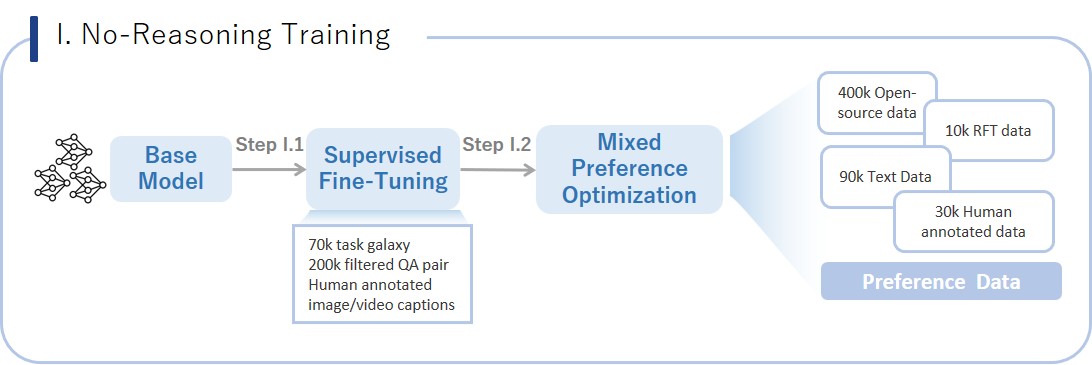
| 388 |
+
|
| 389 |
+
<div align="center">
|
| 390 |
+
<img src="asset/post1.jpeg" width="100%" alt="Kwai Keye Post-Training">
|
| 391 |
+
<i>This phase focuses on the model's basic performance and stability in non-reasoning scenarios.</i>
|
| 392 |
+
</div>
|
| 393 |
+
|
| 394 |
+
<details>
|
| 395 |
+
<summary>More Details</summary>
|
| 396 |
+
|
| 397 |
+
- **Stage II.1: Supervised Fine-Tuning (SFT)**
|
| 398 |
+
- Data Composition: Includes 5 million multimodal data, built on a diverse task classification system (70,000 tasks) using the self-developed TaskGalaxy framework. High-difficulty data is selected by multimodal large models and manually annotated to ensure data quality and challenge.
|
| 399 |
+
|
| 400 |
+
- **Stage II.2: Mixed Preference Optimization (MPO)**
|
| 401 |
+
- Data Composition: Comprises open-source data and pure text preference data. Bad cases from the SFT model are used as quality prompts, and preference data is generated through rejection sampling using Qwen2.5VL 72B and SFT models, with manual scoring and ranking.
|
| 402 |
+
|
| 403 |
+
</details>
|
| 404 |
+
|
| 405 |
+
#### Stage II. Reasoning Training: Core Breakthrough for Complex Cognition
|
| 406 |
+
|
| 407 |
+
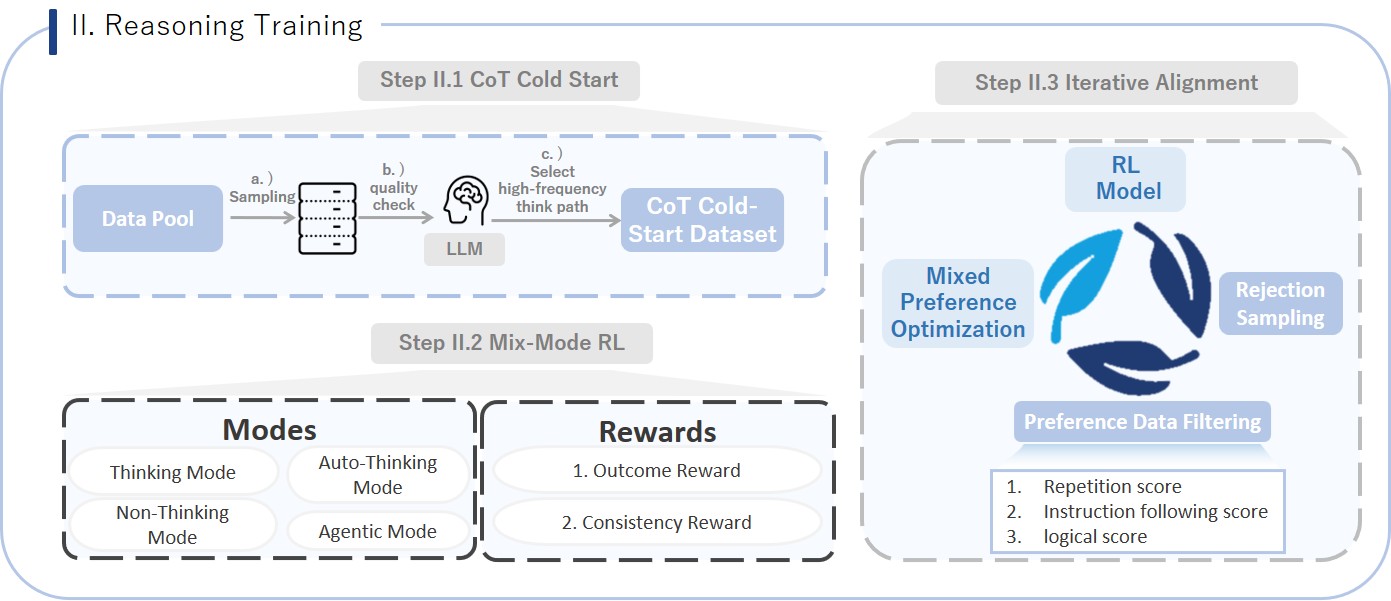
<div align="center">
|
| 408 |
+
<img src="asset/post2.jpeg" width="100%" alt="Kwai Keye Post-Training">
|
| 409 |
+
<br>
|
| 410 |
+
<i>This phase is the highlight and major contribution of the Kwai Keye training process. By introducing a mix-mode Chain of Thought (CoT) and multi-thinking mode reinforcement learning (RL) mechanisms, it significantly enhances the model's multimodal perception, reasoning, and think-with-image capabilities, enabling it to handle more complex, multi-step tasks.</i>
|
| 411 |
+
</div>
|
| 412 |
+
|
| 413 |
+
<details>
|
| 414 |
+
<summary>More Details</summary>
|
| 415 |
+
|
| 416 |
+
- **Step II.1: CoT Cold-Start**
|
| 417 |
+
- Objective: Cold-start the model's chain of thought reasoning ability, allowing it to mimic human step-by-step thinking.
|
| 418 |
+
- Data Composition: Combines non-reasoning data (330,000), reasoning data (230,000), auto-reasoning data (20,000), and agentic reasoning data (100,000) to teach the model different modes.
|
| 419 |
+
- Thinking Data: Focuses on high-difficulty perception and reasoning scenarios like math, science, charts, complex Chinese, and OCR, using multimodal large models for multiple sampling and evaluation to build over 70,000 complex thought chain data.
|
| 420 |
+
- Pure Text Data: Constructs a pure text long thought chain dataset from dimensions like code, math, science, instruction following, and general reasoning tasks.
|
| 421 |
+
- Auto-Think Data: Automatically selects "think" or "no_think" modes based on the complexity of prompts, enabling adaptive reasoning mode switching.
|
| 422 |
+
- Think with Image Data: 100,000 agent data entries, asking Qwen 2.5 VL-72B if image operations (e.g., cropping, rotating, enhancing contrast) are needed to simplify problems or improve answer quality, combined with external sandbox code execution to empower the model to solve problems by writing code to manipulate images or perform mathematical calculations.
|
| 423 |
+
- Training Strategy: Trains with a mix of four modes to achieve cold-start in different reasoning modes.
|
| 424 |
+
- **Step II.2: CoT-Mix RL**
|
| 425 |
+
- Objective: Deeply optimize the model's comprehensive abilities in multimodal perception, reasoning, pure text math, short video understanding, and agentic tasks through reinforcement learning based on the chain of thought, making the reasoning process more robust and efficient.
|
| 426 |
+
- Data Composition: Covers complex tasks from multimodal perception (complex text recognition, object counting), multimodal reasoning, high-difficulty math problems, short video content understanding to Think with Image.
|
| 427 |
+
- Training Strategy: Uses a mix-mode GRPO algorithm for reinforcement learning, where reward signals evaluate both the correctness of results and the consistency of the process and results, ensuring synchronized optimization of reasoning processes and final outcomes.
|
| 428 |
+
- **Step II.2: Iterative Alignment**
|
| 429 |
+
- Objective: Address common issues like repetitive crashes and poor logic in model-generated content, and enable spontaneous reasoning mode selection to enhance final performance and stability.
|
| 430 |
+
- Data Composition: Constructs preference data through Rejection Fine-Tuning (RFT), combining rule-based scoring (judging repetition, instruction following, etc.) and model scoring (cognitive scores provided by large models) to rank various model responses, building a high-quality preference dataset.
|
| 431 |
+
- Training Strategy: Multi-round iterative optimization with the constructed "good/bad" preference data pairs through the MPO algorithm. This aims to correct model generation flaws and ultimately enable it to intelligently and adaptively choose whether to activate deep reasoning modes based on problem complexity.
|
| 432 |
+
|
| 433 |
+
</details>
|
| 434 |
+
|
| 435 |
+
## 📈 Experimental Results
|
| 436 |
+
|
| 437 |
+

|
| 438 |
+
|
| 439 |
+
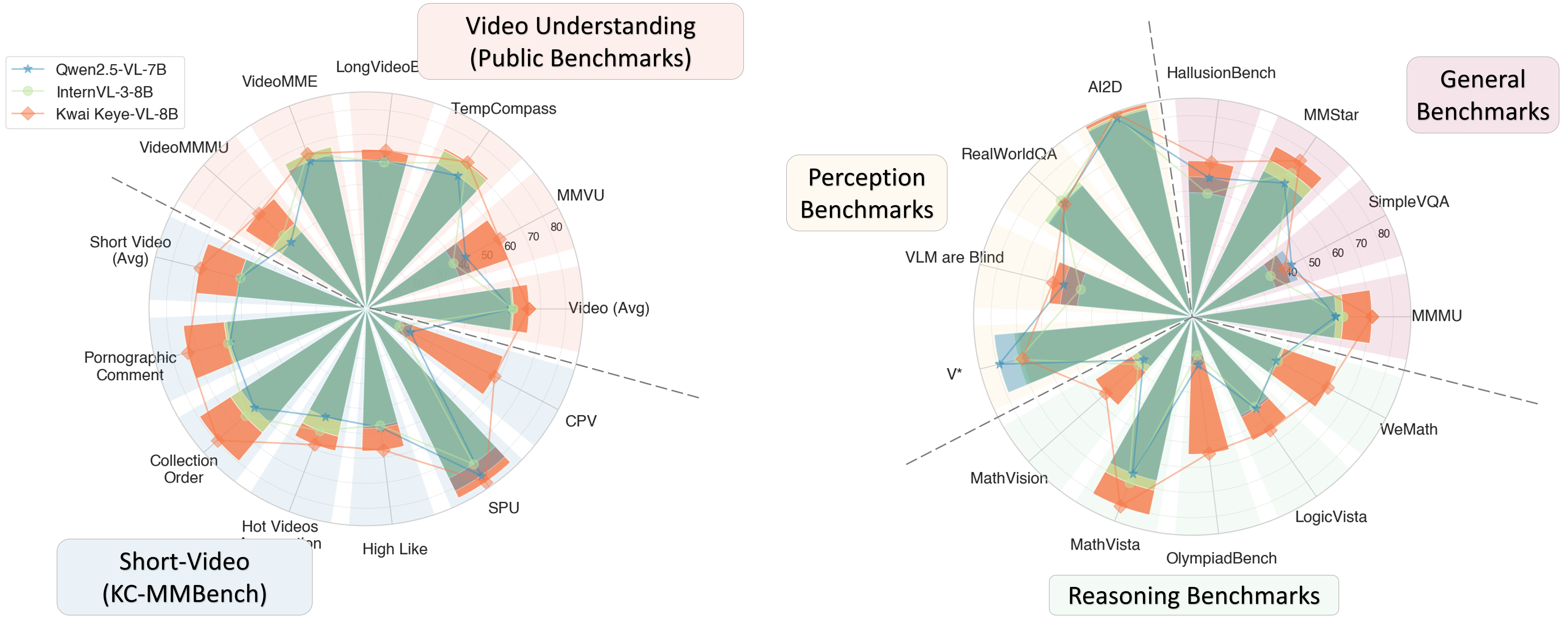
1. Keye-VL-8B establishes itself with powerful, state-of-the-art perceptual abilities that are competitive with leading models.
|
| 440 |
+
2. Keye-VL-8B demonstrates exceptional proficiency in video understanding. Across a comprehensive suite of authoritative public video benchmarks, including Video-MME, Video-MMMU, TempCompass, LongVideoBench, and MMVU, the model's performance significantly surpasses that of other top-tier models of a comparable size.
|
| 441 |
+
3. In evaluation sets that require complex logical reasoning and mathematical problem-solving, such as WeMath, MathVerse, and LogicVista, Kwai Keye-VL-8B displays a strong performance curve. This highlights its advanced capacity for logical deduction and solving complex quantitative problems.
|
| 442 |
+
|
| 443 |
+
## Requirements
|
| 444 |
+
The code of Kwai Keye-VL has been in the latest Hugging face transformers and we advise you to build from source with command:
|
| 445 |
+
```
|
| 446 |
+
pip install git+https://github.com/huggingface/transformers accelerate
|
| 447 |
+
```
|
| 448 |
+
or you might encounter the following error:
|
| 449 |
+
```
|
| 450 |
+
KeyError: 'Keye-VL'
|
| 451 |
+
```
|
| 452 |
+
|
| 453 |
+
## ✒️ Citation
|
| 454 |
+
|
| 455 |
+
If you find our work helpful for your research, please consider citing our work.
|
| 456 |
+
|
| 457 |
+
```bibtex
|
| 458 |
+
@misc{Keye-VL-8B-Preview,
|
| 459 |
+
title = {Keye-VL-8B-Preview},
|
| 460 |
+
url = {https://github.com/Kwai-Keye/Keye},
|
| 461 |
+
author = {Keye Team},
|
| 462 |
+
month = {June},
|
| 463 |
+
year = {2025}
|
| 464 |
+
}
|
| 465 |
+
```
|
| 466 |
+
|
| 467 |
+
## Acknowledgement
|
| 468 |
+
|
| 469 |
+
Kwai Keye-VL is developed based on the codebases of the following projects: [SigLIP](https://huggingface.co/google/siglip-so400m-patch14-384), [Qwen3](https://github.com/QwenLM/Qwen3), [Qwen2.5-VL](https://github.com/QwenLM/Qwen2.5-VL), [VLMEvalKit](https://github.com/open-compass/VLMEvalKit). We sincerely thank these projects for their outstanding work.
|
added_tokens.json
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"</think>": 151668,
|
| 3 |
+
"</tool_call>": 151658,
|
| 4 |
+
"</tool_response>": 151666,
|
| 5 |
+
"<think>": 151667,
|
| 6 |
+
"<tool_call>": 151657,
|
| 7 |
+
"<tool_response>": 151665,
|
| 8 |
+
"<|box_end|>": 151649,
|
| 9 |
+
"<|box_start|>": 151648,
|
| 10 |
+
"<|clip_time_end|>": 151674,
|
| 11 |
+
"<|clip_time_start|>": 151673,
|
| 12 |
+
"<|endoftext|>": 151643,
|
| 13 |
+
"<|file_sep|>": 151664,
|
| 14 |
+
"<|fim_middle|>": 151660,
|
| 15 |
+
"<|fim_pad|>": 151662,
|
| 16 |
+
"<|fim_prefix|>": 151659,
|
| 17 |
+
"<|fim_suffix|>": 151661,
|
| 18 |
+
"<|im_end|>": 151645,
|
| 19 |
+
"<|im_start|>": 151644,
|
| 20 |
+
"<|image_pad|>": 151655,
|
| 21 |
+
"<|object_ref_end|>": 151647,
|
| 22 |
+
"<|object_ref_start|>": 151646,
|
| 23 |
+
"<|ocr_text_end|>": 151672,
|
| 24 |
+
"<|ocr_text_start|>": 151671,
|
| 25 |
+
"<|point_end|>": 151670,
|
| 26 |
+
"<|point_start|>": 151669,
|
| 27 |
+
"<|quad_end|>": 151651,
|
| 28 |
+
"<|quad_start|>": 151650,
|
| 29 |
+
"<|repo_name|>": 151663,
|
| 30 |
+
"<|video_pad|>": 151656,
|
| 31 |
+
"<|vision_end|>": 151653,
|
| 32 |
+
"<|vision_pad|>": 151654,
|
| 33 |
+
"<|vision_start|>": 151652
|
| 34 |
+
}
|
asset/architecture.png
ADDED

|
Git LFS Details
|
asset/keye_logo_2.png
ADDED
|
|
Git LFS Details
|
asset/post1.jpeg
ADDED
|
asset/post2.jpeg
ADDED
|
Git LFS Details
|
asset/pre-train.png
ADDED
|
Git LFS Details
|
asset/teaser.png
ADDED
|
Git LFS Details
|
chat_template.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"chat_template": "{% set image_count = namespace(value=0) %}{% set video_count = namespace(value=0) %}{% for message in messages %}<|im_start|>{{ message['role'] }}\n{% if message['content'] is string %}{{ message['content'] }}<|im_end|>\n{% else %}{% for content in message['content'] %}{% if content['type'] == 'image' or 'image' in content or 'image_url' in content %}{% set image_count.value = image_count.value + 1 %}{% if add_vision_id %}Picture {{ image_count.value }}: {% endif %}<|vision_start|><|image_pad|><|vision_end|>{% elif content['type'] == 'video' or 'video' in content %}{% set video_count.value = video_count.value + 1 %}{% if add_vision_id %}Video {{ video_count.value }}: {% endif %}<|vision_start|><|video_pad|><|vision_end|>{% elif 'text' in content %}{{ content['text'] }}{% endif %}{% endfor %}<|im_end|>\n{% endif %}{% endfor %}{% if add_generation_prompt %}<|im_start|>assistant\n{% endif %}"
|
| 3 |
+
}
|
config.json
ADDED
|
@@ -0,0 +1,72 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_commit_hash": null,
|
| 3 |
+
"auto_map": {
|
| 4 |
+
"AutoConfig": "configuration_keye.KeyeConfig",
|
| 5 |
+
"AutoModel": "modeling_keye.KeyeForConditionalGeneration",
|
| 6 |
+
"AutoModelForCausalLM": "modeling_keye.KeyeForConditionalGeneration"
|
| 7 |
+
},
|
| 8 |
+
"architectures": [
|
| 9 |
+
"KeyeForConditionalGeneration"
|
| 10 |
+
],
|
| 11 |
+
"attention_bias": false,
|
| 12 |
+
"attention_dropout": 0.0,
|
| 13 |
+
"bos_token_id": 151643,
|
| 14 |
+
"eos_token_id": 151645,
|
| 15 |
+
"vision_start_token_id": 151652,
|
| 16 |
+
"vision_end_token_id": 151653,
|
| 17 |
+
"vision_token_id": 151654,
|
| 18 |
+
"image_token_id": 151655,
|
| 19 |
+
"video_token_id": 151656,
|
| 20 |
+
"head_dim": 128,
|
| 21 |
+
"hidden_act": "silu",
|
| 22 |
+
"hidden_size": 4096,
|
| 23 |
+
"initializer_range": 0.02,
|
| 24 |
+
"intermediate_size": 12288,
|
| 25 |
+
"max_position_embeddings": 40960,
|
| 26 |
+
"max_window_layers": 36,
|
| 27 |
+
"model_type": "Keye",
|
| 28 |
+
"num_attention_heads": 32,
|
| 29 |
+
"num_hidden_layers": 36,
|
| 30 |
+
"num_key_value_heads": 8,
|
| 31 |
+
"rms_norm_eps": 1e-06,
|
| 32 |
+
"rope_scaling": null,
|
| 33 |
+
"rope_theta": 1000000,
|
| 34 |
+
"sliding_window": null,
|
| 35 |
+
"tie_word_embeddings": false,
|
| 36 |
+
"torch_dtype": "bfloat16",
|
| 37 |
+
"transformers_version": "4.41.2",
|
| 38 |
+
"use_cache": true,
|
| 39 |
+
"use_sliding_window": false,
|
| 40 |
+
"initializer_factor": 1.0,
|
| 41 |
+
"vision_config": {
|
| 42 |
+
"_attn_implementation_autoset": true,
|
| 43 |
+
"add_cross_attention": false,
|
| 44 |
+
"architectures": [
|
| 45 |
+
"SiglipVisionModel"
|
| 46 |
+
],
|
| 47 |
+
"attention_dropout": 0.0,
|
| 48 |
+
"auto_map": {
|
| 49 |
+
"AutoConfig": "configuration_keye.KeyeVisionConfig",
|
| 50 |
+
"AutoModel": "modeling_keye.SiglipVisionModel"
|
| 51 |
+
},
|
| 52 |
+
"hidden_size": 1152,
|
| 53 |
+
"image_size": 384,
|
| 54 |
+
"intermediate_size": 4304,
|
| 55 |
+
"model_type": "siglip_vision_model",
|
| 56 |
+
"num_attention_heads": 16,
|
| 57 |
+
"num_hidden_layers": 27,
|
| 58 |
+
"patch_size": 14,
|
| 59 |
+
"spatial_merge_size": 2,
|
| 60 |
+
"tokens_per_second": 2,
|
| 61 |
+
"temporal_patch_size": 2
|
| 62 |
+
},
|
| 63 |
+
"rope_scaling": {
|
| 64 |
+
"type": "mrope",
|
| 65 |
+
"mrope_section": [
|
| 66 |
+
16,
|
| 67 |
+
24,
|
| 68 |
+
24
|
| 69 |
+
]
|
| 70 |
+
},
|
| 71 |
+
"vocab_size": 151936
|
| 72 |
+
}
|
configuration_keye.py
ADDED
|
@@ -0,0 +1,243 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 15 |
+
from transformers.modeling_rope_utils import rope_config_validation
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class KeyeVisionConfig(PretrainedConfig):
|
| 19 |
+
model_type = "Keye"
|
| 20 |
+
base_config_key = "vision_config"
|
| 21 |
+
|
| 22 |
+
def __init__(
|
| 23 |
+
self,
|
| 24 |
+
hidden_size=768,
|
| 25 |
+
intermediate_size=3072,
|
| 26 |
+
num_hidden_layers=12,
|
| 27 |
+
num_attention_heads=12,
|
| 28 |
+
num_channels=3,
|
| 29 |
+
image_size=224,
|
| 30 |
+
patch_size=14,
|
| 31 |
+
hidden_act="gelu_pytorch_tanh",
|
| 32 |
+
layer_norm_eps=1e-6,
|
| 33 |
+
attention_dropout=0.0,
|
| 34 |
+
spatial_merge_size=2,
|
| 35 |
+
temporal_patch_size=2,
|
| 36 |
+
tokens_per_second=2,
|
| 37 |
+
**kwargs,
|
| 38 |
+
):
|
| 39 |
+
super().__init__(**kwargs)
|
| 40 |
+
|
| 41 |
+
self.hidden_size = hidden_size
|
| 42 |
+
self.intermediate_size = intermediate_size
|
| 43 |
+
self.num_hidden_layers = num_hidden_layers
|
| 44 |
+
self.num_attention_heads = num_attention_heads
|
| 45 |
+
self.num_channels = num_channels
|
| 46 |
+
self.patch_size = patch_size
|
| 47 |
+
self.image_size = image_size
|
| 48 |
+
self.attention_dropout = attention_dropout
|
| 49 |
+
self.layer_norm_eps = layer_norm_eps
|
| 50 |
+
self.hidden_act = hidden_act
|
| 51 |
+
self.spatial_merge_size = spatial_merge_size
|
| 52 |
+
self.temporal_patch_size = temporal_patch_size
|
| 53 |
+
self.tokens_per_second = tokens_per_second
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
class KeyeConfig(PretrainedConfig):
|
| 57 |
+
r"""
|
| 58 |
+
This is the configuration class to store the configuration of a [`KeyeForConditionalGeneration`].
|
| 59 |
+
|
| 60 |
+
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
| 61 |
+
documentation from [`PretrainedConfig`] for more information.
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
Args:
|
| 65 |
+
vocab_size (`int`, *optional*, defaults to 152064):
|
| 66 |
+
Vocabulary size of the Keye model. Defines the number of different tokens that can be represented by the
|
| 67 |
+
`inputs_ids` passed when calling [`KeyeForConditionalGeneration`]
|
| 68 |
+
hidden_size (`int`, *optional*, defaults to 8192):
|
| 69 |
+
Dimension of the hidden representations.
|
| 70 |
+
intermediate_size (`int`, *optional*, defaults to 29568):
|
| 71 |
+
Dimension of the MLP representations.
|
| 72 |
+
num_hidden_layers (`int`, *optional*, defaults to 80):
|
| 73 |
+
Number of hidden layers in the Transformer encoder.
|
| 74 |
+
num_attention_heads (`int`, *optional*, defaults to 64):
|
| 75 |
+
Number of attention heads for each attention layer in the Transformer encoder.
|
| 76 |
+
num_key_value_heads (`int`, *optional*, defaults to 8):
|
| 77 |
+
This is the number of key_value heads that should be used to implement Grouped Query Attention. If
|
| 78 |
+
`num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
|
| 79 |
+
`num_key_value_heads=1` the model will use Multi Query Attention (MQA) otherwise GQA is used. When
|
| 80 |
+
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
|
| 81 |
+
by meanpooling all the original heads within that group. For more details checkout [this
|
| 82 |
+
paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to `32`.
|
| 83 |
+
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
|
| 84 |
+
The non-linear activation function (function or string) in the decoder.
|
| 85 |
+
max_position_embeddings (`int`, *optional*, defaults to 32768):
|
| 86 |
+
The maximum sequence length that this model might ever be used with.
|
| 87 |
+
initializer_range (`float`, *optional*, defaults to 0.02):
|
| 88 |
+
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
|
| 89 |
+
rms_norm_eps (`float`, *optional*, defaults to 1e-05):
|
| 90 |
+
The epsilon used by the rms normalization layers.
|
| 91 |
+
use_cache (`bool`, *optional*, defaults to `True`):
|
| 92 |
+
Whether or not the model should return the last key/values attentions (not used by all models). Only
|
| 93 |
+
relevant if `config.is_decoder=True`.
|
| 94 |
+
tie_word_embeddings (`bool`, *optional*, defaults to `False`):
|
| 95 |
+
Whether the model's input and output word embeddings should be tied.
|
| 96 |
+
rope_theta (`float`, *optional*, defaults to 1000000.0):
|
| 97 |
+
The base period of the RoPE embeddings.
|
| 98 |
+
use_sliding_window (`bool`, *optional*, defaults to `False`):
|
| 99 |
+
Whether to use sliding window attention.
|
| 100 |
+
sliding_window (`int`, *optional*, defaults to 4096):
|
| 101 |
+
Sliding window attention (SWA) window size. If not specified, will default to `4096`.
|
| 102 |
+
max_window_layers (`int`, *optional*, defaults to 80):
|
| 103 |
+
The number of layers that use SWA (Sliding Window Attention). The bottom layers use SWA while the top use full attention.
|
| 104 |
+
attention_dropout (`float`, *optional*, defaults to 0.0):
|
| 105 |
+
The dropout ratio for the attention probabilities.
|
| 106 |
+
vision_config (`Dict`, *optional*):
|
| 107 |
+
The config for the visual encoder initialization.
|
| 108 |
+
rope_scaling (`Dict`, *optional*):
|
| 109 |
+
Dictionary containing the scaling configuration for the RoPE embeddings. NOTE: if you apply new rope type
|
| 110 |
+
and you expect the model to work on longer `max_position_embeddings`, we recommend you to update this value
|
| 111 |
+
accordingly.
|
| 112 |
+
Expected contents:
|
| 113 |
+
`rope_type` (`str`):
|
| 114 |
+
The sub-variant of RoPE to use. Can be one of ['default', 'linear', 'dynamic', 'yarn', 'longrope',
|
| 115 |
+
'llama3'], with 'default' being the original RoPE implementation.
|
| 116 |
+
`factor` (`float`, *optional*):
|
| 117 |
+
Used with all rope types except 'default'. The scaling factor to apply to the RoPE embeddings. In
|
| 118 |
+
most scaling types, a `factor` of x will enable the model to handle sequences of length x *
|
| 119 |
+
original maximum pre-trained length.
|
| 120 |
+
`original_max_position_embeddings` (`int`, *optional*):
|
| 121 |
+
Used with 'dynamic', 'longrope' and 'llama3'. The original max position embeddings used during
|
| 122 |
+
pretraining.
|
| 123 |
+
`attention_factor` (`float`, *optional*):
|
| 124 |
+
Used with 'yarn' and 'longrope'. The scaling factor to be applied on the attention
|
| 125 |
+
computation. If unspecified, it defaults to value recommended by the implementation, using the
|
| 126 |
+
`factor` field to infer the suggested value.
|
| 127 |
+
`beta_fast` (`float`, *optional*):
|
| 128 |
+
Only used with 'yarn'. Parameter to set the boundary for extrapolation (only) in the linear
|
| 129 |
+
ramp function. If unspecified, it defaults to 32.
|
| 130 |
+
`beta_slow` (`float`, *optional*):
|
| 131 |
+
Only used with 'yarn'. Parameter to set the boundary for interpolation (only) in the linear
|
| 132 |
+
ramp function. If unspecified, it defaults to 1.
|
| 133 |
+
`short_factor` (`List[float]`, *optional*):
|
| 134 |
+
Only used with 'longrope'. The scaling factor to be applied to short contexts (<
|
| 135 |
+
`original_max_position_embeddings`). Must be a list of numbers with the same length as the hidden
|
| 136 |
+
size divided by the number of attention heads divided by 2
|
| 137 |
+
`long_factor` (`List[float]`, *optional*):
|
| 138 |
+
Only used with 'longrope'. The scaling factor to be applied to long contexts (<
|
| 139 |
+
`original_max_position_embeddings`). Must be a list of numbers with the same length as the hidden
|
| 140 |
+
size divided by the number of attention heads divided by 2
|
| 141 |
+
`low_freq_factor` (`float`, *optional*):
|
| 142 |
+
Only used with 'llama3'. Scaling factor applied to low frequency components of the RoPE
|
| 143 |
+
`high_freq_factor` (`float`, *optional*):
|
| 144 |
+
Only used with 'llama3'. Scaling factor applied to high frequency components of the RoPE
|
| 145 |
+
|
| 146 |
+
```python
|
| 147 |
+
>>> from transformers import KeyeForConditionalGeneration, KeyeConfig
|
| 148 |
+
|
| 149 |
+
>>> # Initializing a Keye style configuration
|
| 150 |
+
>>> configuration = KeyeConfig()
|
| 151 |
+
|
| 152 |
+
>>> # Initializing a model from the Keye style configuration
|
| 153 |
+
>>> model = KeyeForConditionalGeneration(configuration)
|
| 154 |
+
|
| 155 |
+
>>> # Accessing the model configuration
|
| 156 |
+
>>> configuration = model.config
|
| 157 |
+
```"""
|
| 158 |
+
|
| 159 |
+
model_type = "Keye"
|
| 160 |
+
sub_configs = {"vision_config": KeyeVisionConfig}
|
| 161 |
+
keys_to_ignore_at_inference = ["past_key_values"]
|
| 162 |
+
# Default tensor parallel plan for base model `Keye`
|
| 163 |
+
base_model_tp_plan = {
|
| 164 |
+
"layers.*.self_attn.q_proj": "colwise",
|
| 165 |
+
"layers.*.self_attn.k_proj": "colwise",
|
| 166 |
+
"layers.*.self_attn.v_proj": "colwise",
|
| 167 |
+
"layers.*.self_attn.o_proj": "rowwise",
|
| 168 |
+
"layers.*.mlp.gate_proj": "colwise",
|
| 169 |
+
"layers.*.mlp.up_proj": "colwise",
|
| 170 |
+
"layers.*.mlp.down_proj": "rowwise",
|
| 171 |
+
}
|
| 172 |
+
base_model_pp_plan = {
|
| 173 |
+
"embed_tokens": (["input_ids"], ["inputs_embeds"]),
|
| 174 |
+
"layers": (["hidden_states", "attention_mask"], ["hidden_states"]),
|
| 175 |
+
"norm": (["hidden_states"], ["hidden_states"]),
|
| 176 |
+
}
|
| 177 |
+
|
| 178 |
+
def __init__(
|
| 179 |
+
self,
|
| 180 |
+
vocab_size=152064,
|
| 181 |
+
hidden_size=8192,
|
| 182 |
+
intermediate_size=29568,
|
| 183 |
+
num_hidden_layers=80,
|
| 184 |
+
num_attention_heads=64,
|
| 185 |
+
num_key_value_heads=8,
|
| 186 |
+
hidden_act="silu",
|
| 187 |
+
max_position_embeddings=32768,
|
| 188 |
+
initializer_range=0.02,
|
| 189 |
+
rms_norm_eps=1e-05,
|
| 190 |
+
use_cache=True,
|
| 191 |
+
tie_word_embeddings=False,
|
| 192 |
+
rope_theta=1000000.0,
|
| 193 |
+
use_sliding_window=False,
|
| 194 |
+
sliding_window=4096,
|
| 195 |
+
max_window_layers=80,
|
| 196 |
+
attention_dropout=0.0,
|
| 197 |
+
vision_config=None,
|
| 198 |
+
rope_scaling=None,
|
| 199 |
+
**kwargs,
|
| 200 |
+
):
|
| 201 |
+
if isinstance(vision_config, dict):
|
| 202 |
+
self.vision_config = self.sub_configs["vision_config"](**vision_config)
|
| 203 |
+
elif vision_config is None:
|
| 204 |
+
self.vision_config = self.sub_configs["vision_config"]()
|
| 205 |
+
|
| 206 |
+
self.vocab_size = vocab_size
|
| 207 |
+
self.max_position_embeddings = max_position_embeddings
|
| 208 |
+
self.hidden_size = hidden_size
|
| 209 |
+
self.intermediate_size = intermediate_size
|
| 210 |
+
self.num_hidden_layers = num_hidden_layers
|
| 211 |
+
self.num_attention_heads = num_attention_heads
|
| 212 |
+
self.use_sliding_window = use_sliding_window
|
| 213 |
+
self.sliding_window = sliding_window
|
| 214 |
+
self.max_window_layers = max_window_layers
|
| 215 |
+
|
| 216 |
+
# for backward compatibility
|
| 217 |
+
if num_key_value_heads is None:
|
| 218 |
+
num_key_value_heads = num_attention_heads
|
| 219 |
+
|
| 220 |
+
self.num_key_value_heads = num_key_value_heads
|
| 221 |
+
self.hidden_act = hidden_act
|
| 222 |
+
self.initializer_range = initializer_range
|
| 223 |
+
self.rms_norm_eps = rms_norm_eps
|
| 224 |
+
self.use_cache = use_cache
|
| 225 |
+
self.rope_theta = rope_theta
|
| 226 |
+
self.attention_dropout = attention_dropout
|
| 227 |
+
self.rope_scaling = rope_scaling
|
| 228 |
+
|
| 229 |
+
# Validate the correctness of rotary position embeddings parameters
|
| 230 |
+
# BC: if there is a 'type' field, move it to 'rope_type'.
|
| 231 |
+
# and change type from 'mrope' to 'default' because `mrope` does default RoPE calculations
|
| 232 |
+
# one can set it to "linear"/"dynamic" etc. to have scaled RoPE
|
| 233 |
+
# TODO: @raushan update config in the hub
|
| 234 |
+
if self.rope_scaling is not None and "type" in self.rope_scaling:
|
| 235 |
+
if self.rope_scaling["type"] == "mrope":
|
| 236 |
+
self.rope_scaling["type"] = "default"
|
| 237 |
+
self.rope_scaling["rope_type"] = self.rope_scaling["type"]
|
| 238 |
+
rope_config_validation(self, ignore_keys={"mrope_section"})
|
| 239 |
+
|
| 240 |
+
super().__init__(tie_word_embeddings=tie_word_embeddings, **kwargs)
|
| 241 |
+
|
| 242 |
+
|
| 243 |
+
__all__ = ["KeyeConfig"]
|
generation_config.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token_id": 151643,
|
| 3 |
+
"do_sample": true,
|
| 4 |
+
"eos_token_id": [
|
| 5 |
+
151645,
|
| 6 |
+
151643
|
| 7 |
+
],
|
| 8 |
+
"pad_token_id": 151643,
|
| 9 |
+
"temperature": 0.6,
|
| 10 |
+
"top_k": 20,
|
| 11 |
+
"top_p": 0.95,
|
| 12 |
+
"transformers_version": "4.51.0"
|
| 13 |
+
}
|
image_processing_keye.py
ADDED
|
@@ -0,0 +1,570 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
"""Image processor class for Keye."""
|
| 15 |
+
|
| 16 |
+
import math
|
| 17 |
+
from typing import Dict, List, Optional, Union
|
| 18 |
+
|
| 19 |
+
import numpy as np
|
| 20 |
+
import torch
|
| 21 |
+
from transformers.image_processing_utils import BaseImageProcessor, BatchFeature
|
| 22 |
+
from torchvision.transforms import functional as TF
|
| 23 |
+
from transformers.image_transforms import (
|
| 24 |
+
convert_to_rgb,
|
| 25 |
+
resize,
|
| 26 |
+
to_channel_dimension_format,
|
| 27 |
+
)
|
| 28 |
+
from transformers.image_utils import (
|
| 29 |
+
OPENAI_CLIP_MEAN,
|
| 30 |
+
OPENAI_CLIP_STD,
|
| 31 |
+
ChannelDimension,
|
| 32 |
+
PILImageResampling,
|
| 33 |
+
get_image_size,
|
| 34 |
+
infer_channel_dimension_format,
|
| 35 |
+
is_scaled_image,
|
| 36 |
+
is_valid_image,
|
| 37 |
+
make_list_of_images,
|
| 38 |
+
to_numpy_array,
|
| 39 |
+
valid_images,
|
| 40 |
+
validate_preprocess_arguments,
|
| 41 |
+
)
|
| 42 |
+
from transformers.utils import TensorType, is_vision_available, logging
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
logger = logging.get_logger(__name__)
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
if is_vision_available():
|
| 49 |
+
from PIL import Image
|
| 50 |
+
|
| 51 |
+
ImageInput = Union[
|
| 52 |
+
"PIL.Image.Image",
|
| 53 |
+
np.ndarray,
|
| 54 |
+
"torch.Tensor",
|
| 55 |
+
List["PIL.Image.Image"],
|
| 56 |
+
List[np.ndarray],
|
| 57 |
+
List["torch.Tensor"],
|
| 58 |
+
] # noqa
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
VideoInput = Union[
|
| 62 |
+
List["PIL.Image.Image"],
|
| 63 |
+
"np.ndarray",
|
| 64 |
+
"torch.Tensor",
|
| 65 |
+
List["np.ndarray"],
|
| 66 |
+
List["torch.Tensor"],
|
| 67 |
+
List[List["PIL.Image.Image"]],
|
| 68 |
+
List[List["np.ndarrray"]],
|
| 69 |
+
List[List["torch.Tensor"]],
|
| 70 |
+
] # noqa
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
def make_batched_images(images) -> List[List[ImageInput]]:
|
| 74 |
+
"""
|
| 75 |
+
Accepts images in list or nested list format, and makes a list of images for preprocessing.
|
| 76 |
+
|
| 77 |
+
Args:
|
| 78 |
+
images (`Union[List[List[ImageInput]], List[ImageInput], ImageInput]`):
|
| 79 |
+
The input image.
|
| 80 |
+
|
| 81 |
+
Returns:
|
| 82 |
+
list: A list of images.
|
| 83 |
+
"""
|
| 84 |
+
if (
|
| 85 |
+
isinstance(images, (list, tuple))
|
| 86 |
+
and isinstance(images[0], (list, tuple))
|
| 87 |
+
and is_valid_image(images[0][0])
|
| 88 |
+
):
|
| 89 |
+
return [img for img_list in images for img in img_list]
|
| 90 |
+
|
| 91 |
+
elif isinstance(images, (list, tuple)) and is_valid_image(images[0]):
|
| 92 |
+
return images
|
| 93 |
+
|
| 94 |
+
elif is_valid_image(images):
|
| 95 |
+
return [images]
|
| 96 |
+
|
| 97 |
+
raise ValueError(f"Could not make batched images from {images}")
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
def adjust_size(size, patch_size):
|
| 101 |
+
num_patches = size // patch_size
|
| 102 |
+
if num_patches % 2 != 0: # 如果是奇数,减1
|
| 103 |
+
num_patches -= 1
|
| 104 |
+
return num_patches * patch_size
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
def make_batched_videos(videos) -> List[VideoInput]:
|
| 108 |
+
if (
|
| 109 |
+
isinstance(videos, (list, tuple))
|
| 110 |
+
and isinstance(videos[0], (list, tuple))
|
| 111 |
+
and is_valid_image(videos[0][0])
|
| 112 |
+
):
|
| 113 |
+
return videos
|
| 114 |
+
|
| 115 |
+
elif isinstance(videos, (list, tuple)) and is_valid_image(videos[0]):
|
| 116 |
+
if isinstance(videos[0], Image.Image):
|
| 117 |
+
return [videos]
|
| 118 |
+
elif len(videos[0].shape) == 4:
|
| 119 |
+
return [list(video) for video in videos]
|
| 120 |
+
|
| 121 |
+
elif is_valid_image(videos) and len(videos.shape) == 4:
|
| 122 |
+
return [list(videos)]
|
| 123 |
+
|
| 124 |
+
raise ValueError(f"Could not make batched video from {videos}")
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
def smart_resize(
|
| 128 |
+
height: int,
|
| 129 |
+
width: int,
|
| 130 |
+
factor: int = 28,
|
| 131 |
+
min_pixels: int = 56 * 56,
|
| 132 |
+
max_pixels: int = 14 * 14 * 4096,
|
| 133 |
+
):
|
| 134 |
+
"""Rescales the image so that the following conditions are met:
|
| 135 |
+
|
| 136 |
+
1. Both dimensions (height and width) are divisible by 'factor'.
|
| 137 |
+
|
| 138 |
+
2. The total number of pixels is within the range ['min_pixels', 'max_pixels'].
|
| 139 |
+
|
| 140 |
+
3. The aspect ratio of the image is maintained as closely as possible.
|
| 141 |
+
|
| 142 |
+
"""
|
| 143 |
+
# if height < factor or width < factor:
|
| 144 |
+
# raise ValueError(f"height:{height} or width:{width} must be larger than factor:{factor}")
|
| 145 |
+
# if int(height < factor//4) + int(width < factor//4):
|
| 146 |
+
# raise ValueError(f"height:{height} or width:{width} must be larger than factor:{factor//4}")
|
| 147 |
+
|
| 148 |
+
if height < factor:
|
| 149 |
+
print(f"smart_resize: height={height} < factor={factor}, reset height=factor")
|
| 150 |
+
width = round((width * factor) / height)
|
| 151 |
+
height = factor
|
| 152 |
+
|
| 153 |
+
if width < factor:
|
| 154 |
+
print(f"smart_resize: width={width} < factor={factor}, reset width=factor")
|
| 155 |
+
height = round((height * factor) / width)
|
| 156 |
+
width = factor
|
| 157 |
+
|
| 158 |
+
if max(height, width) / min(height, width) > 200:
|
| 159 |
+
raise ValueError(
|
| 160 |
+
f"absolute aspect ratio must be smaller than 200, got {max(height, width) / min(height, width)}"
|
| 161 |
+
)
|
| 162 |
+
h_bar = round(height / factor) * factor
|
| 163 |
+
w_bar = round(width / factor) * factor
|
| 164 |
+
if h_bar * w_bar > max_pixels:
|
| 165 |
+
beta = math.sqrt((height * width) / max_pixels)
|
| 166 |
+
h_bar = math.floor(height / beta / factor) * factor
|
| 167 |
+
w_bar = math.floor(width / beta / factor) * factor
|
| 168 |
+
elif h_bar * w_bar < min_pixels:
|
| 169 |
+
beta = math.sqrt(min_pixels / (height * width))
|
| 170 |
+
h_bar = math.ceil(height * beta / factor) * factor
|
| 171 |
+
w_bar = math.ceil(width * beta / factor) * factor
|
| 172 |
+
return h_bar, w_bar
|
| 173 |
+
|
| 174 |
+
|
| 175 |
+
class SiglipImageProcessor(BaseImageProcessor):
|
| 176 |
+
r"""
|
| 177 |
+
Constructs a Siglip image processor that dynamically resizes images based on the original images.
|
| 178 |
+
|
| 179 |
+
Args:
|
| 180 |
+
do_resize (`bool`, *optional*, defaults to `True`):
|
| 181 |
+
Whether to resize the image's (height, width) dimensions.
|
| 182 |
+
resample (`PILImageResampling`, *optional*, defaults to `Resampling.BICUBIC`):
|
| 183 |
+
Resampling filter to use when resizing the image.
|
| 184 |
+
do_rescale (`bool`, *optional*, defaults to `True`):
|
| 185 |
+
Whether to rescale the image by the specified scale `rescale_factor`.
|
| 186 |
+
rescale_factor (`int` or `float`, *optional*, defaults to `1/255`):
|
| 187 |
+
Scale factor to use if rescaling the image.
|
| 188 |
+
do_normalize (`bool`, *optional*, defaults to `True`):
|
| 189 |
+
Whether to normalize the image.
|
| 190 |
+
image_mean (`float` or `List[float]`, *optional*, defaults to `[0.48145466, 0.4578275, 0.40821073]`):
|
| 191 |
+
Mean to use if normalizing the image. This is a float or list of floats for each channel in the image.
|
| 192 |
+
image_std (`float` or `List[float]`, *optional*, defaults to `[0.26862954, 0.26130258, 0.27577711]`):
|
| 193 |
+
Standard deviation to use if normalizing the image. This is a float or list of floats for each channel in the image.
|
| 194 |
+
do_convert_rgb (`bool`, *optional*, defaults to `True`):
|
| 195 |
+
Whether to convert the image to RGB.
|
| 196 |
+
min_pixels (`int`, *optional*, defaults to `56 * 56`):
|
| 197 |
+
The min pixels of the image to resize the image.
|
| 198 |
+
max_pixels (`int`, *optional*, defaults to `28 * 28 * 1280`):
|
| 199 |
+
The max pixels of the image to resize the image.
|
| 200 |
+
patch_size (`int`, *optional*, defaults to 14):
|
| 201 |
+
The spacial patch size of the vision encoder.
|
| 202 |
+
temporal_patch_size (`int`, *optional*, defaults to 2):
|
| 203 |
+
The temporal patch size of the vision encoder.
|
| 204 |
+
merge_size (`int`, *optional*, defaults to 2):
|
| 205 |
+
The merge size of the vision encoder to llm encoder.
|
| 206 |
+
"""
|
| 207 |
+
|
| 208 |
+
model_input_names = [
|
| 209 |
+
"pixel_values",
|
| 210 |
+
"image_grid_thw",
|
| 211 |
+
"pixel_values_videos",
|
| 212 |
+
"video_grid_thw",
|
| 213 |
+
]
|
| 214 |
+
|
| 215 |
+
def __init__(
|
| 216 |
+
self,
|
| 217 |
+
do_resize: bool = True,
|
| 218 |
+
resample: PILImageResampling = PILImageResampling.BICUBIC,
|
| 219 |
+
do_rescale: bool = True,
|
| 220 |
+
rescale_factor: Union[int, float] = 1 / 255,
|
| 221 |
+
do_normalize: bool = True,
|
| 222 |
+
image_mean: Optional[Union[float, List[float]]] = None,
|
| 223 |
+
image_std: Optional[Union[float, List[float]]] = None,
|
| 224 |
+
do_convert_rgb: bool = True,
|
| 225 |
+
min_pixels: int = 56 * 56,
|
| 226 |
+
max_pixels: int = 28 * 28 * 1280,
|
| 227 |
+
patch_size: int = 14,
|
| 228 |
+
temporal_patch_size: int = 1,
|
| 229 |
+
merge_size: int = 2,
|
| 230 |
+
**kwargs,
|
| 231 |
+
) -> None:
|
| 232 |
+
super().__init__(**kwargs)
|
| 233 |
+
self.do_resize = do_resize
|
| 234 |
+
self.resample = resample
|
| 235 |
+
self.do_rescale = do_rescale
|
| 236 |
+
self.rescale_factor = rescale_factor
|
| 237 |
+
self.do_normalize = do_normalize
|
| 238 |
+
self.image_mean = image_mean if image_mean is not None else OPENAI_CLIP_MEAN
|
| 239 |
+
self.image_std = image_std if image_std is not None else OPENAI_CLIP_STD
|
| 240 |
+
self.min_pixels = min_pixels
|
| 241 |
+
self.max_pixels = max_pixels
|
| 242 |
+
self.patch_size = patch_size
|
| 243 |
+
self.temporal_patch_size = temporal_patch_size
|
| 244 |
+
self.merge_size = merge_size
|
| 245 |
+
self.size = {"min_pixels": min_pixels, "max_pixels": max_pixels} # not used
|
| 246 |
+
self.do_convert_rgb = do_convert_rgb
|
| 247 |
+
|
| 248 |
+
def mvit_rescale(self, image: Image.Image, merge_size: int = 2) -> Image.Image:
|
| 249 |
+
try:
|
| 250 |
+
w, h = image.size
|
| 251 |
+
except:
|
| 252 |
+
raise ValueError(str((type(image), image)))
|
| 253 |
+
patch_size = self.patch_size
|
| 254 |
+
|
| 255 |
+
if (w // patch_size) * (h // patch_size) > self.in_token_limit:
|
| 256 |
+
scale = math.sqrt(
|
| 257 |
+
self.in_token_limit / ((w // patch_size) * (h // patch_size))
|
| 258 |
+
)
|
| 259 |
+
new_w, new_h = int(w * scale), int(h * scale)
|
| 260 |
+
|
| 261 |
+
image = image.resize((new_w, new_h), Image.Resampling.BICUBIC)
|
| 262 |
+
if self.pad_input:
|
| 263 |
+
new_w, new_h = image.size
|
| 264 |
+
pad_size_h = merge_size * patch_size
|
| 265 |
+
pad_size_w = merge_size * patch_size
|
| 266 |
+
|
| 267 |
+
pad_h = (pad_size_h - new_h % pad_size_h) % pad_size_h
|
| 268 |
+
pad_w = (pad_size_w - new_w % pad_size_w) % pad_size_w
|
| 269 |
+
|
| 270 |
+
image = TF.pad(image, (0, 0, pad_w, pad_h))
|
| 271 |
+
else:
|
| 272 |
+
new_w, new_h = image.size
|
| 273 |
+
new_w = new_w - new_w % patch_size
|
| 274 |
+
new_h = new_h - new_h % patch_size
|
| 275 |
+
|
| 276 |
+
new_w = adjust_size(new_w, patch_size)
|
| 277 |
+
new_h = adjust_size(new_h, patch_size)
|
| 278 |
+
|
| 279 |
+
image = TF.center_crop(image, (new_h, new_w))
|
| 280 |
+
|
| 281 |
+
w, h = image.size
|
| 282 |
+
if w // patch_size >= 512 or h // patch_size >= 512:
|
| 283 |
+
new_h = min(patch_size * 510, h)
|
| 284 |
+
new_w = min(patch_size * 510, w)
|
| 285 |
+
image = TF.center_crop(image, (new_h, new_w))
|
| 286 |
+
# raise ValueError("Exceed pos emb")
|
| 287 |
+
return image
|
| 288 |
+
|
| 289 |
+
def _preprocess(
|
| 290 |
+
self,
|
| 291 |
+
images: Union[ImageInput, VideoInput],
|
| 292 |
+
do_resize: bool = None,
|
| 293 |
+
resample: PILImageResampling = None,
|
| 294 |
+
do_rescale: bool = None,
|
| 295 |
+
rescale_factor: float = None,
|
| 296 |
+
do_normalize: bool = None,
|
| 297 |
+
image_mean: Optional[Union[float, List[float]]] = None,
|
| 298 |
+
image_std: Optional[Union[float, List[float]]] = None,
|
| 299 |
+
do_convert_rgb: bool = None,
|
| 300 |
+
data_format: Optional[ChannelDimension] = ChannelDimension.FIRST,
|
| 301 |
+
input_data_format: Optional[Union[str, ChannelDimension]] = None,
|
| 302 |
+
):
|
| 303 |
+
"""
|
| 304 |
+
Preprocess an image or batch of images. Copy of the `preprocess` method from `CLIPImageProcessor`.
|
| 305 |
+
|
| 306 |
+
Args:
|
| 307 |
+
images (`ImageInput`):
|
| 308 |
+
Image or batch of images to preprocess. Expects pixel values ranging from 0 to 255. If pixel values range from 0 to 1, set `do_rescale=False`.
|
| 309 |
+
vision_info (`List[Dict]`, *optional*):
|
| 310 |
+
Optional list of dictionaries containing additional information about vision inputs.
|
| 311 |
+
do_resize (`bool`, *optional*, defaults to `self.do_resize`):
|
| 312 |
+
Whether to resize the image.
|
| 313 |
+
resample (`PILImageResampling`, *optional*, defaults to `self.resample`):
|
| 314 |
+
Resampling filter to use if resizing the image. This can be one of the `PILImageResampling` enums.
|
| 315 |
+
do_rescale (`bool`, *optional*, defaults to `self.do_rescale`):
|
| 316 |
+
Whether to rescale the image.
|
| 317 |
+
rescale_factor (`float`, *optional*, defaults to `self.rescale_factor`):
|
| 318 |
+
Scale factor to use if rescaling the image.
|
| 319 |
+
do_normalize (`bool`, *optional*, defaults to `self.do_normalize`):
|
| 320 |
+
Whether to normalize the image.
|
| 321 |
+
image_mean (`float` or `List[float]`, *optional*, defaults to `self.image_mean`):
|
| 322 |
+
Mean to use if normalizing the image. Can be a float or a list of floats corresponding to the number of channels in the image.
|
| 323 |
+
image_std (`float` or `List[float]`, *optional*, defaults to `self.image_std`):
|
| 324 |
+
Standard deviation to use if normalizing the image. Can be a float or a list of floats corresponding to the number of channels in the image.
|
| 325 |
+
do_convert_rgb (`bool`, *optional*, defaults to `self.do_convert_rgb`):
|
| 326 |
+
Whether to convert the image to RGB.
|
| 327 |
+
data_format (`ChannelDimension`, *optional*, defaults to `ChannelDimension.FIRST`):
|
| 328 |
+
The channel dimension format for the output image. Can be one of:
|
| 329 |
+
- `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
|
| 330 |
+
- `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
|
| 331 |
+
- Unset: Use the channel dimension format of the input image.
|
| 332 |
+
input_data_format (`ChannelDimension` or `str`, *optional*):
|
| 333 |
+
The channel dimension format for the input image. Can be one of:
|
| 334 |
+
- `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
|
| 335 |
+
- `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
|
| 336 |
+
- `"none"` or `ChannelDimension.NONE`: image in (height, width) format. - `"none"` or `ChannelDimension.NONE`: image in (height, width) format.
|
| 337 |
+
"""
|
| 338 |
+
images = make_list_of_images(images)
|
| 339 |
+
|
| 340 |
+
if do_convert_rgb:
|
| 341 |
+
images = [convert_to_rgb(image) for image in images]
|
| 342 |
+
|
| 343 |
+
# All transformations expect numpy arrays.
|
| 344 |
+
images = [to_numpy_array(image) for image in images]
|
| 345 |
+
|
| 346 |
+
if is_scaled_image(images[0]) and do_rescale:
|
| 347 |
+
logger.warning_once(
|
| 348 |
+
"It looks like you are trying to rescale already rescaled images. If the input"
|
| 349 |
+
" images have pixel values between 0 and 1, set `do_rescale=False` to avoid rescaling them again."
|
| 350 |
+
)
|
| 351 |
+
if input_data_format is None:
|
| 352 |
+
# We assume that all images have the same channel dimension format.
|
| 353 |
+
input_data_format = infer_channel_dimension_format(images[0])
|
| 354 |
+
|
| 355 |
+
height, width = get_image_size(images[0], channel_dim=input_data_format)
|
| 356 |
+
resized_height, resized_width = height, width
|
| 357 |
+
processed_images = []
|
| 358 |
+
|
| 359 |
+
for image in images:
|
| 360 |
+
# image = self.mvit_rescale(image, merge_size=self.merge_size)
|
| 361 |
+
if do_resize:
|
| 362 |
+
resized_height, resized_width = smart_resize(
|
| 363 |
+
height,
|
| 364 |
+
width,
|
| 365 |
+
factor=self.patch_size * self.merge_size,
|
| 366 |
+
min_pixels=self.min_pixels,
|
| 367 |
+
max_pixels=self.max_pixels,
|
| 368 |
+
)
|
| 369 |
+
image = resize(
|
| 370 |
+
image,
|
| 371 |
+
size=(resized_height, resized_width),
|
| 372 |
+
resample=resample,
|
| 373 |
+
input_data_format=input_data_format,
|
| 374 |
+
)
|
| 375 |
+
|
| 376 |
+
if do_rescale:
|
| 377 |
+
image = self.rescale(
|
| 378 |
+
image, scale=rescale_factor, input_data_format=input_data_format
|
| 379 |
+
)
|
| 380 |
+
|
| 381 |
+
if do_normalize:
|
| 382 |
+
image = self.normalize(
|
| 383 |
+
image=image,
|
| 384 |
+
mean=image_mean,
|
| 385 |
+
std=image_std,
|
| 386 |
+
input_data_format=input_data_format,
|
| 387 |
+
)
|
| 388 |
+
|
| 389 |
+
image = to_channel_dimension_format(
|
| 390 |
+
image, data_format, input_channel_dim=input_data_format
|
| 391 |
+
)
|
| 392 |
+
processed_images.append(image)
|
| 393 |
+
|
| 394 |
+
patches = np.array(processed_images)
|
| 395 |
+
if data_format == ChannelDimension.LAST:
|
| 396 |
+
patches = patches.transpose(0, 3, 1, 2)
|
| 397 |
+
if patches.shape[0] == 1:
|
| 398 |
+
patches = np.tile(patches, (self.temporal_patch_size, 1, 1, 1))
|
| 399 |
+
init_patches = patches
|
| 400 |
+
channel = patches.shape[1]
|
| 401 |
+
grid_t = patches.shape[0] // self.temporal_patch_size
|
| 402 |
+
grid_h, grid_w = (
|
| 403 |
+
resized_height // self.patch_size,
|
| 404 |
+
resized_width // self.patch_size,
|
| 405 |
+
)
|
| 406 |
+
patches = patches.reshape(
|
| 407 |
+
grid_t,
|
| 408 |
+
self.temporal_patch_size,
|
| 409 |
+
channel,
|
| 410 |
+
grid_h,
|
| 411 |
+
self.patch_size,
|
| 412 |
+
grid_w,
|
| 413 |
+
self.patch_size,
|
| 414 |
+
)
|
| 415 |
+
patches = patches.transpose(0, 3, 5, 2, 1, 4, 6)
|
| 416 |
+
assert self.temporal_patch_size == 1
|
| 417 |
+
flatten_patches = patches.reshape(
|
| 418 |
+
grid_t * grid_h * grid_w, channel, self.patch_size, self.patch_size
|
| 419 |
+
)
|
| 420 |
+
return flatten_patches, (grid_t, grid_h, grid_w)
|
| 421 |
+
|
| 422 |
+
def preprocess(
|
| 423 |
+
self,
|
| 424 |
+
images: ImageInput,
|
| 425 |
+
videos: VideoInput = None,
|
| 426 |
+
do_resize: bool = None,
|
| 427 |
+
size: Dict[str, int] = None,
|
| 428 |
+
resample: PILImageResampling = None,
|
| 429 |
+
do_rescale: bool = None,
|
| 430 |
+
rescale_factor: float = None,
|
| 431 |
+
do_normalize: bool = None,
|
| 432 |
+
image_mean: Optional[Union[float, List[float]]] = None,
|
| 433 |
+
image_std: Optional[Union[float, List[float]]] = None,
|
| 434 |
+
do_convert_rgb: bool = None,
|
| 435 |
+
return_tensors: Optional[Union[str, TensorType]] = None,
|
| 436 |
+
data_format: Optional[ChannelDimension] = ChannelDimension.FIRST,
|
| 437 |
+
input_data_format: Optional[Union[str, ChannelDimension]] = None,
|
| 438 |
+
):
|
| 439 |
+
"""
|
| 440 |
+
Args:
|
| 441 |
+
images (`ImageInput`):
|
| 442 |
+
Image to preprocess. Expects a single or batch of images with pixel values ranging from 0 to 255. If
|
| 443 |
+
passing in images with pixel values between 0 and 1, set `do_rescale=False`.
|
| 444 |
+
videos (`VideoInput`):
|
| 445 |
+
Video to preprocess. Expects a single or batch of videos with pixel values ranging from 0 to 255. If
|
| 446 |
+
passing in videos with pixel values between 0 and 1, set `do_rescale=False`.
|
| 447 |
+
do_resize (`bool`, *optional*, defaults to `self.do_resize`):
|
| 448 |
+
Whether to resize the image.
|
| 449 |
+
size (`Dict[str, int]`, *optional*, defaults to `self.size`):
|
| 450 |
+
Size of the image after resizing. Shortest edge of the image is resized to size["shortest_edge"], with
|
| 451 |
+
the longest edge resized to keep the input aspect ratio.
|
| 452 |
+
resample (`int`, *optional*, defaults to `self.resample`):
|
| 453 |
+
Resampling filter to use if resizing the image. This can be one of the enum `PILImageResampling`. Only
|
| 454 |
+
has an effect if `do_resize` is set to `True`.
|
| 455 |
+
do_rescale (`bool`, *optional*, defaults to `self.do_rescale`):
|
| 456 |
+
Whether to rescale the image.
|
| 457 |
+
rescale_factor (`float`, *optional*, defaults to `self.rescale_factor`):
|
| 458 |
+
Rescale factor to rescale the image by if `do_rescale` is set to `True`.
|
| 459 |
+
do_normalize (`bool`, *optional*, defaults to `self.do_normalize`):
|
| 460 |
+
Whether to normalize the image.
|
| 461 |
+
image_mean (`float` or `List[float]`, *optional*, defaults to `self.image_mean`):
|
| 462 |
+
Image mean to use for normalization. Only has an effect if `do_normalize` is set to `True`.
|
| 463 |
+
image_std (`float` or `List[float]`, *optional*, defaults to `self.image_std`):
|
| 464 |
+
Image standard deviation to use for normalization. Only has an effect if `do_normalize` is set to
|
| 465 |
+
`True`.
|
| 466 |
+
do_convert_rgb (`bool`, *optional*, defaults to `self.do_convert_rgb`):
|
| 467 |
+
Whether to convert the image to RGB.
|
| 468 |
+
return_tensors (`str` or `TensorType`, *optional*):
|
| 469 |
+
The type of tensors to return. Can be one of:
|
| 470 |
+
- Unset: Return a list of `np.ndarray`.
|
| 471 |
+
- `TensorType.TENSORFLOW` or `'tf'`: Return a batch of type `tf.Tensor`.
|
| 472 |
+
- `TensorType.PYTORCH` or `'pt'`: Return a batch of type `torch.Tensor`.
|
| 473 |
+
- `TensorType.NUMPY` or `'np'`: Return a batch of type `np.ndarray`.
|
| 474 |
+
- `TensorType.JAX` or `'jax'`: Return a batch of type `jax.numpy.ndarray`.
|
| 475 |
+
data_format (`ChannelDimension` or `str`, *optional*, defaults to `ChannelDimension.FIRST`):
|
| 476 |
+
The channel dimension format for the output image. Can be one of:
|
| 477 |
+
- `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
|
| 478 |
+
- `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
|
| 479 |
+
- Unset: Use the channel dimension format of the input image.
|
| 480 |
+
input_data_format (`ChannelDimension` or `str`, *optional*):
|
| 481 |
+
The channel dimension format for the input image. If unset, the channel dimension format is inferred
|
| 482 |
+
from the input image. Can be one of:
|
| 483 |
+
- `"channels_first"` or `ChannelDimension.FIRST`: image in (num_channels, height, width) format.
|
| 484 |
+
- `"channels_last"` or `ChannelDimension.LAST`: image in (height, width, num_channels) format.
|
| 485 |
+
- `"none"` or `ChannelDimension.NONE`: image in (height, width) format.
|
| 486 |
+
|
| 487 |
+
"""
|
| 488 |
+
do_resize = do_resize if do_resize is not None else self.do_resize
|
| 489 |
+
size = size if size is not None else self.size
|
| 490 |
+
resample = resample if resample is not None else self.resample
|
| 491 |
+
do_rescale = do_rescale if do_rescale is not None else self.do_rescale
|
| 492 |
+
rescale_factor = (
|
| 493 |
+
rescale_factor if rescale_factor is not None else self.rescale_factor
|
| 494 |
+
)
|
| 495 |
+
do_normalize = do_normalize if do_normalize is not None else self.do_normalize
|
| 496 |
+
image_mean = image_mean if image_mean is not None else self.image_mean
|
| 497 |
+
image_std = image_std if image_std is not None else self.image_std
|
| 498 |
+
do_convert_rgb = (
|
| 499 |
+
do_convert_rgb if do_convert_rgb is not None else self.do_convert_rgb
|
| 500 |
+
)
|
| 501 |
+
|
| 502 |
+
if images is not None:
|
| 503 |
+
images = make_batched_images(images)
|
| 504 |
+
if videos is not None:
|
| 505 |
+
videos = make_batched_videos(videos)
|
| 506 |
+
|
| 507 |
+
if images is not None and not valid_images(images):
|
| 508 |
+
raise ValueError(
|
| 509 |
+
"Invalid image type. Must be of type PIL.Image.Image, numpy.ndarray, "
|
| 510 |
+
"torch.Tensor, tf.Tensor or jax.ndarray."
|
| 511 |
+
)
|
| 512 |
+
|
| 513 |
+
validate_preprocess_arguments(
|
| 514 |
+
rescale_factor=rescale_factor,
|
| 515 |
+
do_normalize=do_normalize,
|
| 516 |
+
image_mean=image_mean,
|
| 517 |
+
image_std=image_std,
|
| 518 |
+
do_resize=do_resize,
|
| 519 |
+
size=size,
|
| 520 |
+
resample=resample,
|
| 521 |
+
)
|
| 522 |
+
|
| 523 |
+
if images is not None:
|
| 524 |
+
pixel_values, vision_grid_thws = [], []
|
| 525 |
+
for image in images:
|
| 526 |
+
patches, image_grid_thw = self._preprocess(
|
| 527 |
+
image,
|
| 528 |
+
do_resize=do_resize,
|
| 529 |
+
resample=resample,
|
| 530 |
+
do_rescale=do_rescale,
|
| 531 |
+
rescale_factor=rescale_factor,
|
| 532 |
+
do_normalize=do_normalize,
|
| 533 |
+
image_mean=image_mean,
|
| 534 |
+
image_std=image_std,
|
| 535 |
+
data_format=data_format,
|
| 536 |
+
do_convert_rgb=do_convert_rgb,
|
| 537 |
+
input_data_format=input_data_format,
|
| 538 |
+
)
|
| 539 |
+
pixel_values.extend(patches)
|
| 540 |
+
vision_grid_thws.append(image_grid_thw)
|
| 541 |
+
pixel_values = np.array(pixel_values)
|
| 542 |
+
vision_grid_thws = np.array(vision_grid_thws)
|
| 543 |
+
data = {"pixel_values": pixel_values, "image_grid_thw": vision_grid_thws}
|
| 544 |
+
|
| 545 |
+
if videos is not None:
|
| 546 |
+
pixel_values, vision_grid_thws = [], []
|
| 547 |
+
for images in videos:
|
| 548 |
+
patches, video_grid_thw = self._preprocess(
|
| 549 |
+
images,
|
| 550 |
+
do_resize=do_resize,
|
| 551 |
+
resample=resample,
|
| 552 |
+
do_rescale=do_rescale,
|
| 553 |
+
rescale_factor=rescale_factor,
|
| 554 |
+
do_normalize=do_normalize,
|
| 555 |
+
image_mean=image_mean,
|
| 556 |
+
image_std=image_std,
|
| 557 |
+
data_format=data_format,
|
| 558 |
+
do_convert_rgb=do_convert_rgb,
|
| 559 |
+
input_data_format=input_data_format,
|
| 560 |
+
)
|
| 561 |
+
pixel_values.extend(patches)
|
| 562 |
+
vision_grid_thws.append(video_grid_thw)
|
| 563 |
+
pixel_values = np.array(pixel_values)
|
| 564 |
+
vision_grid_thws = np.array(vision_grid_thws)
|
| 565 |
+
data = {
|
| 566 |
+
"pixel_values_videos": pixel_values,
|
| 567 |
+
"video_grid_thw": vision_grid_thws,
|
| 568 |
+
}
|
| 569 |
+
|
| 570 |
+
return BatchFeature(data=data, tensor_type=return_tensors)
|
merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
model-00001-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:56eea05562f4432cf7c368774bbaea5acb03dc0c7c37dd6c3217612e49a6557a
|
| 3 |
+
size 4991719792
|
model-00002-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:11ca964a00a765e08a2fd2aa22da6e0214f26afa61705a91f4f1cf0327701259
|
| 3 |
+
size 4983069200
|
model-00003-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d68e46b47365ca5de86e565c6942bd4f3f858f1e56b8460371af352fa31cb907
|
| 3 |
+
size 4915943752
|
model-00004-of-00004.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4ee1065cbb3c636460aefaa9c6b00823b1682bf2cc1eac6b1cbc95bac0bad05c
|
| 3 |
+
size 2503030568
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,861 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 17393657472
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"lm_head.weight": "model-00004-of-00004.safetensors",
|
| 7 |
+
"mlp_AR.linear_1.bias": "model-00001-of-00004.safetensors",
|
| 8 |
+
"mlp_AR.linear_1.weight": "model-00001-of-00004.safetensors",
|
| 9 |
+
"mlp_AR.linear_2.bias": "model-00001-of-00004.safetensors",
|
| 10 |
+
"mlp_AR.linear_2.weight": "model-00001-of-00004.safetensors",
|
| 11 |
+
"mlp_AR.pre_norm.bias": "model-00001-of-00004.safetensors",
|
| 12 |
+
"mlp_AR.pre_norm.weight": "model-00001-of-00004.safetensors",
|
| 13 |
+
"model.embed_tokens.weight": "model-00001-of-00004.safetensors",
|
| 14 |
+
"model.layers.0.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 15 |
+
"model.layers.0.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 16 |
+
"model.layers.0.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 17 |
+
"model.layers.0.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 18 |
+
"model.layers.0.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 19 |
+
"model.layers.0.self_attn.k_norm.weight": "model-00001-of-00004.safetensors",
|
| 20 |
+
"model.layers.0.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 21 |
+
"model.layers.0.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 22 |
+
"model.layers.0.self_attn.q_norm.weight": "model-00001-of-00004.safetensors",
|
| 23 |
+
"model.layers.0.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 24 |
+
"model.layers.0.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 25 |
+
"model.layers.1.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 26 |
+
"model.layers.1.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 27 |
+
"model.layers.1.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 28 |
+
"model.layers.1.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 29 |
+
"model.layers.1.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 30 |
+
"model.layers.1.self_attn.k_norm.weight": "model-00001-of-00004.safetensors",
|
| 31 |
+
"model.layers.1.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 32 |
+
"model.layers.1.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 33 |
+
"model.layers.1.self_attn.q_norm.weight": "model-00001-of-00004.safetensors",
|
| 34 |
+
"model.layers.1.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 35 |
+
"model.layers.1.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 36 |
+
"model.layers.10.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 37 |
+
"model.layers.10.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 38 |
+
"model.layers.10.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 39 |
+
"model.layers.10.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 40 |
+
"model.layers.10.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 41 |
+
"model.layers.10.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 42 |
+
"model.layers.10.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 43 |
+
"model.layers.10.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 44 |
+
"model.layers.10.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 45 |
+
"model.layers.10.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 46 |
+
"model.layers.10.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 47 |
+
"model.layers.11.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 48 |
+
"model.layers.11.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 49 |
+
"model.layers.11.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 50 |
+
"model.layers.11.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 51 |
+
"model.layers.11.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 52 |
+
"model.layers.11.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 53 |
+
"model.layers.11.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 54 |
+
"model.layers.11.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 55 |
+
"model.layers.11.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 56 |
+
"model.layers.11.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 57 |
+
"model.layers.11.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 58 |
+
"model.layers.12.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 59 |
+
"model.layers.12.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 60 |
+
"model.layers.12.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 61 |
+
"model.layers.12.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 62 |
+
"model.layers.12.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 63 |
+
"model.layers.12.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 64 |
+
"model.layers.12.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 65 |
+
"model.layers.12.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 66 |
+
"model.layers.12.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 67 |
+
"model.layers.12.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 68 |
+
"model.layers.12.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 69 |
+
"model.layers.13.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 70 |
+
"model.layers.13.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 71 |
+
"model.layers.13.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 72 |
+
"model.layers.13.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 73 |
+
"model.layers.13.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 74 |
+
"model.layers.13.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 75 |
+
"model.layers.13.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 76 |
+
"model.layers.13.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 77 |
+
"model.layers.13.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 78 |
+
"model.layers.13.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 79 |
+
"model.layers.13.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 80 |
+
"model.layers.14.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 81 |
+
"model.layers.14.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 82 |
+
"model.layers.14.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 83 |
+
"model.layers.14.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 84 |
+
"model.layers.14.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 85 |
+
"model.layers.14.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 86 |
+
"model.layers.14.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 87 |
+
"model.layers.14.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 88 |
+
"model.layers.14.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 89 |
+
"model.layers.14.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 90 |
+
"model.layers.14.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 91 |
+
"model.layers.15.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 92 |
+
"model.layers.15.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 93 |
+
"model.layers.15.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 94 |
+
"model.layers.15.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 95 |
+
"model.layers.15.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 96 |
+
"model.layers.15.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 97 |
+
"model.layers.15.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 98 |
+
"model.layers.15.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 99 |
+
"model.layers.15.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 100 |
+
"model.layers.15.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 101 |
+
"model.layers.15.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 102 |
+
"model.layers.16.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 103 |
+
"model.layers.16.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 104 |
+
"model.layers.16.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 105 |
+
"model.layers.16.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 106 |
+
"model.layers.16.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 107 |
+
"model.layers.16.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 108 |
+
"model.layers.16.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 109 |
+
"model.layers.16.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 110 |
+
"model.layers.16.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 111 |
+
"model.layers.16.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 112 |
+
"model.layers.16.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 113 |
+
"model.layers.17.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 114 |
+
"model.layers.17.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 115 |
+
"model.layers.17.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 116 |
+
"model.layers.17.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 117 |
+
"model.layers.17.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 118 |
+
"model.layers.17.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 119 |
+
"model.layers.17.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 120 |
+
"model.layers.17.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 121 |
+
"model.layers.17.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 122 |
+
"model.layers.17.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 123 |
+
"model.layers.17.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 124 |
+
"model.layers.18.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 125 |
+
"model.layers.18.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 126 |
+
"model.layers.18.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 127 |
+
"model.layers.18.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 128 |
+
"model.layers.18.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 129 |
+
"model.layers.18.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 130 |
+
"model.layers.18.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 131 |
+
"model.layers.18.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 132 |
+
"model.layers.18.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 133 |
+
"model.layers.18.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 134 |
+
"model.layers.18.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 135 |
+
"model.layers.19.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 136 |
+
"model.layers.19.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 137 |
+
"model.layers.19.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 138 |
+
"model.layers.19.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 139 |
+
"model.layers.19.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 140 |
+
"model.layers.19.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 141 |
+
"model.layers.19.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 142 |
+
"model.layers.19.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 143 |
+
"model.layers.19.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 144 |
+
"model.layers.19.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 145 |
+
"model.layers.19.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 146 |
+
"model.layers.2.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 147 |
+
"model.layers.2.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 148 |
+
"model.layers.2.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 149 |
+
"model.layers.2.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 150 |
+
"model.layers.2.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 151 |
+
"model.layers.2.self_attn.k_norm.weight": "model-00001-of-00004.safetensors",
|
| 152 |
+
"model.layers.2.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 153 |
+
"model.layers.2.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 154 |
+
"model.layers.2.self_attn.q_norm.weight": "model-00001-of-00004.safetensors",
|
| 155 |
+
"model.layers.2.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 156 |
+
"model.layers.2.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 157 |
+
"model.layers.20.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 158 |
+
"model.layers.20.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 159 |
+
"model.layers.20.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 160 |
+
"model.layers.20.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 161 |
+
"model.layers.20.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 162 |
+
"model.layers.20.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 163 |
+
"model.layers.20.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 164 |
+
"model.layers.20.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 165 |
+
"model.layers.20.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 166 |
+
"model.layers.20.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 167 |
+
"model.layers.20.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 168 |
+
"model.layers.21.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 169 |
+
"model.layers.21.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 170 |
+
"model.layers.21.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 171 |
+
"model.layers.21.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 172 |
+
"model.layers.21.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 173 |
+
"model.layers.21.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 174 |
+
"model.layers.21.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 175 |
+
"model.layers.21.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 176 |
+
"model.layers.21.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 177 |
+
"model.layers.21.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 178 |
+
"model.layers.21.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 179 |
+
"model.layers.22.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 180 |
+
"model.layers.22.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 181 |
+
"model.layers.22.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 182 |
+
"model.layers.22.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 183 |
+
"model.layers.22.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 184 |
+
"model.layers.22.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 185 |
+
"model.layers.22.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 186 |
+
"model.layers.22.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 187 |
+
"model.layers.22.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 188 |
+
"model.layers.22.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 189 |
+
"model.layers.22.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 190 |
+
"model.layers.23.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 191 |
+
"model.layers.23.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 192 |
+
"model.layers.23.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 193 |
+
"model.layers.23.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 194 |
+
"model.layers.23.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 195 |
+
"model.layers.23.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 196 |
+
"model.layers.23.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 197 |
+
"model.layers.23.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 198 |
+
"model.layers.23.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 199 |
+
"model.layers.23.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 200 |
+
"model.layers.23.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 201 |
+
"model.layers.24.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 202 |
+
"model.layers.24.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 203 |
+
"model.layers.24.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 204 |
+
"model.layers.24.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 205 |
+
"model.layers.24.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 206 |
+
"model.layers.24.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 207 |
+
"model.layers.24.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 208 |
+
"model.layers.24.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 209 |
+
"model.layers.24.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 210 |
+
"model.layers.24.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 211 |
+
"model.layers.24.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 212 |
+
"model.layers.25.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 213 |
+
"model.layers.25.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 214 |
+
"model.layers.25.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 215 |
+
"model.layers.25.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 216 |
+
"model.layers.25.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 217 |
+
"model.layers.25.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 218 |
+
"model.layers.25.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 219 |
+
"model.layers.25.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 220 |
+
"model.layers.25.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 221 |
+
"model.layers.25.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 222 |
+
"model.layers.25.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 223 |
+
"model.layers.26.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 224 |
+
"model.layers.26.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 225 |
+
"model.layers.26.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 226 |
+
"model.layers.26.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 227 |
+
"model.layers.26.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 228 |
+
"model.layers.26.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 229 |
+
"model.layers.26.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 230 |
+
"model.layers.26.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 231 |
+
"model.layers.26.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 232 |
+
"model.layers.26.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 233 |
+
"model.layers.26.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 234 |
+
"model.layers.27.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 235 |
+
"model.layers.27.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 236 |
+
"model.layers.27.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 237 |
+
"model.layers.27.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 238 |
+
"model.layers.27.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 239 |
+
"model.layers.27.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 240 |
+
"model.layers.27.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 241 |
+
"model.layers.27.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 242 |
+
"model.layers.27.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 243 |
+
"model.layers.27.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 244 |
+
"model.layers.27.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 245 |
+
"model.layers.28.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 246 |
+
"model.layers.28.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 247 |
+
"model.layers.28.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 248 |
+
"model.layers.28.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 249 |
+
"model.layers.28.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 250 |
+
"model.layers.28.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 251 |
+
"model.layers.28.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 252 |
+
"model.layers.28.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 253 |
+
"model.layers.28.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 254 |
+
"model.layers.28.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 255 |
+
"model.layers.28.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 256 |
+
"model.layers.29.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 257 |
+
"model.layers.29.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 258 |
+
"model.layers.29.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 259 |
+
"model.layers.29.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 260 |
+
"model.layers.29.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 261 |
+
"model.layers.29.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 262 |
+
"model.layers.29.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 263 |
+
"model.layers.29.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 264 |
+
"model.layers.29.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 265 |
+
"model.layers.29.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 266 |
+
"model.layers.29.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 267 |
+
"model.layers.3.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 268 |
+
"model.layers.3.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 269 |
+
"model.layers.3.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 270 |
+
"model.layers.3.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 271 |
+
"model.layers.3.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 272 |
+
"model.layers.3.self_attn.k_norm.weight": "model-00001-of-00004.safetensors",
|
| 273 |
+
"model.layers.3.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 274 |
+
"model.layers.3.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 275 |
+
"model.layers.3.self_attn.q_norm.weight": "model-00001-of-00004.safetensors",
|
| 276 |
+
"model.layers.3.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 277 |
+
"model.layers.3.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 278 |
+
"model.layers.30.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 279 |
+
"model.layers.30.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 280 |
+
"model.layers.30.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 281 |
+
"model.layers.30.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 282 |
+
"model.layers.30.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 283 |
+
"model.layers.30.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 284 |
+
"model.layers.30.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 285 |
+
"model.layers.30.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 286 |
+
"model.layers.30.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 287 |
+
"model.layers.30.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 288 |
+
"model.layers.30.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 289 |
+
"model.layers.31.input_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 290 |
+
"model.layers.31.mlp.down_proj.weight": "model-00003-of-00004.safetensors",
|
| 291 |
+
"model.layers.31.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 292 |
+
"model.layers.31.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 293 |
+
"model.layers.31.post_attention_layernorm.weight": "model-00003-of-00004.safetensors",
|
| 294 |
+
"model.layers.31.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 295 |
+
"model.layers.31.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 296 |
+
"model.layers.31.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 297 |
+
"model.layers.31.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 298 |
+
"model.layers.31.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 299 |
+
"model.layers.31.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 300 |
+
"model.layers.32.input_layernorm.weight": "model-00004-of-00004.safetensors",
|
| 301 |
+
"model.layers.32.mlp.down_proj.weight": "model-00004-of-00004.safetensors",
|
| 302 |
+
"model.layers.32.mlp.gate_proj.weight": "model-00003-of-00004.safetensors",
|
| 303 |
+
"model.layers.32.mlp.up_proj.weight": "model-00003-of-00004.safetensors",
|
| 304 |
+
"model.layers.32.post_attention_layernorm.weight": "model-00004-of-00004.safetensors",
|
| 305 |
+
"model.layers.32.self_attn.k_norm.weight": "model-00003-of-00004.safetensors",
|
| 306 |
+
"model.layers.32.self_attn.k_proj.weight": "model-00003-of-00004.safetensors",
|
| 307 |
+
"model.layers.32.self_attn.o_proj.weight": "model-00003-of-00004.safetensors",
|
| 308 |
+
"model.layers.32.self_attn.q_norm.weight": "model-00003-of-00004.safetensors",
|
| 309 |
+
"model.layers.32.self_attn.q_proj.weight": "model-00003-of-00004.safetensors",
|
| 310 |
+
"model.layers.32.self_attn.v_proj.weight": "model-00003-of-00004.safetensors",
|
| 311 |
+
"model.layers.33.input_layernorm.weight": "model-00004-of-00004.safetensors",
|
| 312 |
+
"model.layers.33.mlp.down_proj.weight": "model-00004-of-00004.safetensors",
|
| 313 |
+
"model.layers.33.mlp.gate_proj.weight": "model-00004-of-00004.safetensors",
|
| 314 |
+
"model.layers.33.mlp.up_proj.weight": "model-00004-of-00004.safetensors",
|
| 315 |
+
"model.layers.33.post_attention_layernorm.weight": "model-00004-of-00004.safetensors",
|
| 316 |
+
"model.layers.33.self_attn.k_norm.weight": "model-00004-of-00004.safetensors",
|
| 317 |
+
"model.layers.33.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 318 |
+
"model.layers.33.self_attn.o_proj.weight": "model-00004-of-00004.safetensors",
|
| 319 |
+
"model.layers.33.self_attn.q_norm.weight": "model-00004-of-00004.safetensors",
|
| 320 |
+
"model.layers.33.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
| 321 |
+
"model.layers.33.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 322 |
+
"model.layers.34.input_layernorm.weight": "model-00004-of-00004.safetensors",
|
| 323 |
+
"model.layers.34.mlp.down_proj.weight": "model-00004-of-00004.safetensors",
|
| 324 |
+
"model.layers.34.mlp.gate_proj.weight": "model-00004-of-00004.safetensors",
|
| 325 |
+
"model.layers.34.mlp.up_proj.weight": "model-00004-of-00004.safetensors",
|
| 326 |
+
"model.layers.34.post_attention_layernorm.weight": "model-00004-of-00004.safetensors",
|
| 327 |
+
"model.layers.34.self_attn.k_norm.weight": "model-00004-of-00004.safetensors",
|
| 328 |
+
"model.layers.34.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 329 |
+
"model.layers.34.self_attn.o_proj.weight": "model-00004-of-00004.safetensors",
|
| 330 |
+
"model.layers.34.self_attn.q_norm.weight": "model-00004-of-00004.safetensors",
|
| 331 |
+
"model.layers.34.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
| 332 |
+
"model.layers.34.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 333 |
+
"model.layers.35.input_layernorm.weight": "model-00004-of-00004.safetensors",
|
| 334 |
+
"model.layers.35.mlp.down_proj.weight": "model-00004-of-00004.safetensors",
|
| 335 |
+
"model.layers.35.mlp.gate_proj.weight": "model-00004-of-00004.safetensors",
|
| 336 |
+
"model.layers.35.mlp.up_proj.weight": "model-00004-of-00004.safetensors",
|
| 337 |
+
"model.layers.35.post_attention_layernorm.weight": "model-00004-of-00004.safetensors",
|
| 338 |
+
"model.layers.35.self_attn.k_norm.weight": "model-00004-of-00004.safetensors",
|
| 339 |
+
"model.layers.35.self_attn.k_proj.weight": "model-00004-of-00004.safetensors",
|
| 340 |
+
"model.layers.35.self_attn.o_proj.weight": "model-00004-of-00004.safetensors",
|
| 341 |
+
"model.layers.35.self_attn.q_norm.weight": "model-00004-of-00004.safetensors",
|
| 342 |
+
"model.layers.35.self_attn.q_proj.weight": "model-00004-of-00004.safetensors",
|
| 343 |
+
"model.layers.35.self_attn.v_proj.weight": "model-00004-of-00004.safetensors",
|
| 344 |
+
"model.layers.4.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 345 |
+
"model.layers.4.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 346 |
+
"model.layers.4.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 347 |
+
"model.layers.4.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 348 |
+
"model.layers.4.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 349 |
+
"model.layers.4.self_attn.k_norm.weight": "model-00001-of-00004.safetensors",
|
| 350 |
+
"model.layers.4.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 351 |
+
"model.layers.4.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 352 |
+
"model.layers.4.self_attn.q_norm.weight": "model-00001-of-00004.safetensors",
|
| 353 |
+
"model.layers.4.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 354 |
+
"model.layers.4.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 355 |
+
"model.layers.5.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 356 |
+
"model.layers.5.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 357 |
+
"model.layers.5.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 358 |
+
"model.layers.5.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 359 |
+
"model.layers.5.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 360 |
+
"model.layers.5.self_attn.k_norm.weight": "model-00001-of-00004.safetensors",
|
| 361 |
+
"model.layers.5.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 362 |
+
"model.layers.5.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 363 |
+
"model.layers.5.self_attn.q_norm.weight": "model-00001-of-00004.safetensors",
|
| 364 |
+
"model.layers.5.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 365 |
+
"model.layers.5.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 366 |
+
"model.layers.6.input_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 367 |
+
"model.layers.6.mlp.down_proj.weight": "model-00001-of-00004.safetensors",
|
| 368 |
+
"model.layers.6.mlp.gate_proj.weight": "model-00001-of-00004.safetensors",
|
| 369 |
+
"model.layers.6.mlp.up_proj.weight": "model-00001-of-00004.safetensors",
|
| 370 |
+
"model.layers.6.post_attention_layernorm.weight": "model-00001-of-00004.safetensors",
|
| 371 |
+
"model.layers.6.self_attn.k_norm.weight": "model-00001-of-00004.safetensors",
|
| 372 |
+
"model.layers.6.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 373 |
+
"model.layers.6.self_attn.o_proj.weight": "model-00001-of-00004.safetensors",
|
| 374 |
+
"model.layers.6.self_attn.q_norm.weight": "model-00001-of-00004.safetensors",
|
| 375 |
+
"model.layers.6.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 376 |
+
"model.layers.6.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 377 |
+
"model.layers.7.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 378 |
+
"model.layers.7.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 379 |
+
"model.layers.7.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 380 |
+
"model.layers.7.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 381 |
+
"model.layers.7.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 382 |
+
"model.layers.7.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 383 |
+
"model.layers.7.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 384 |
+
"model.layers.7.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 385 |
+
"model.layers.7.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 386 |
+
"model.layers.7.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 387 |
+
"model.layers.7.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 388 |
+
"model.layers.8.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 389 |
+
"model.layers.8.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 390 |
+
"model.layers.8.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 391 |
+
"model.layers.8.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 392 |
+
"model.layers.8.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 393 |
+
"model.layers.8.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 394 |
+
"model.layers.8.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 395 |
+
"model.layers.8.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 396 |
+
"model.layers.8.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 397 |
+
"model.layers.8.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 398 |
+
"model.layers.8.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 399 |
+
"model.layers.9.input_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 400 |
+
"model.layers.9.mlp.down_proj.weight": "model-00002-of-00004.safetensors",
|
| 401 |
+
"model.layers.9.mlp.gate_proj.weight": "model-00002-of-00004.safetensors",
|
| 402 |
+
"model.layers.9.mlp.up_proj.weight": "model-00002-of-00004.safetensors",
|
| 403 |
+
"model.layers.9.post_attention_layernorm.weight": "model-00002-of-00004.safetensors",
|
| 404 |
+
"model.layers.9.self_attn.k_norm.weight": "model-00002-of-00004.safetensors",
|
| 405 |
+
"model.layers.9.self_attn.k_proj.weight": "model-00002-of-00004.safetensors",
|
| 406 |
+
"model.layers.9.self_attn.o_proj.weight": "model-00002-of-00004.safetensors",
|
| 407 |
+
"model.layers.9.self_attn.q_norm.weight": "model-00002-of-00004.safetensors",
|
| 408 |
+
"model.layers.9.self_attn.q_proj.weight": "model-00002-of-00004.safetensors",
|
| 409 |
+
"model.layers.9.self_attn.v_proj.weight": "model-00002-of-00004.safetensors",
|
| 410 |
+
"model.norm.weight": "model-00004-of-00004.safetensors",
|
| 411 |
+
"visual.vision_model.embeddings.packing_position_embedding.weight": "model-00001-of-00004.safetensors",
|
| 412 |
+
"visual.vision_model.embeddings.patch_embedding.bias": "model-00001-of-00004.safetensors",
|
| 413 |
+
"visual.vision_model.embeddings.patch_embedding.weight": "model-00001-of-00004.safetensors",
|
| 414 |
+
"visual.vision_model.embeddings.position_embedding.weight": "model-00001-of-00004.safetensors",
|
| 415 |
+
"visual.vision_model.encoder.layers.0.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
| 416 |
+
"visual.vision_model.encoder.layers.0.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
| 417 |
+
"visual.vision_model.encoder.layers.0.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
| 418 |
+
"visual.vision_model.encoder.layers.0.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
| 419 |
+
"visual.vision_model.encoder.layers.0.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 420 |
+
"visual.vision_model.encoder.layers.0.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 421 |
+
"visual.vision_model.encoder.layers.0.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 422 |
+
"visual.vision_model.encoder.layers.0.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 423 |
+
"visual.vision_model.encoder.layers.0.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 424 |
+
"visual.vision_model.encoder.layers.0.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 425 |
+
"visual.vision_model.encoder.layers.0.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
| 426 |
+
"visual.vision_model.encoder.layers.0.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
| 427 |
+
"visual.vision_model.encoder.layers.0.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 428 |
+
"visual.vision_model.encoder.layers.0.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 429 |
+
"visual.vision_model.encoder.layers.0.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 430 |
+
"visual.vision_model.encoder.layers.0.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 431 |
+
"visual.vision_model.encoder.layers.1.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
| 432 |
+
"visual.vision_model.encoder.layers.1.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
| 433 |
+
"visual.vision_model.encoder.layers.1.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
| 434 |
+
"visual.vision_model.encoder.layers.1.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
| 435 |
+
"visual.vision_model.encoder.layers.1.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 436 |
+
"visual.vision_model.encoder.layers.1.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 437 |
+
"visual.vision_model.encoder.layers.1.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 438 |
+
"visual.vision_model.encoder.layers.1.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 439 |
+
"visual.vision_model.encoder.layers.1.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 440 |
+
"visual.vision_model.encoder.layers.1.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 441 |
+
"visual.vision_model.encoder.layers.1.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
| 442 |
+
"visual.vision_model.encoder.layers.1.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
| 443 |
+
"visual.vision_model.encoder.layers.1.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 444 |
+
"visual.vision_model.encoder.layers.1.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 445 |
+
"visual.vision_model.encoder.layers.1.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 446 |
+
"visual.vision_model.encoder.layers.1.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 447 |
+
"visual.vision_model.encoder.layers.10.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
| 448 |
+
"visual.vision_model.encoder.layers.10.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
| 449 |
+
"visual.vision_model.encoder.layers.10.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
| 450 |
+
"visual.vision_model.encoder.layers.10.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
| 451 |
+
"visual.vision_model.encoder.layers.10.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 452 |
+
"visual.vision_model.encoder.layers.10.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 453 |
+
"visual.vision_model.encoder.layers.10.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 454 |
+
"visual.vision_model.encoder.layers.10.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 455 |
+
"visual.vision_model.encoder.layers.10.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 456 |
+
"visual.vision_model.encoder.layers.10.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 457 |
+
"visual.vision_model.encoder.layers.10.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
| 458 |
+
"visual.vision_model.encoder.layers.10.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
| 459 |
+
"visual.vision_model.encoder.layers.10.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 460 |
+
"visual.vision_model.encoder.layers.10.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 461 |
+
"visual.vision_model.encoder.layers.10.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 462 |
+
"visual.vision_model.encoder.layers.10.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 463 |
+
"visual.vision_model.encoder.layers.11.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
| 464 |
+
"visual.vision_model.encoder.layers.11.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
| 465 |
+
"visual.vision_model.encoder.layers.11.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
| 466 |
+
"visual.vision_model.encoder.layers.11.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
| 467 |
+
"visual.vision_model.encoder.layers.11.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 468 |
+
"visual.vision_model.encoder.layers.11.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 469 |
+
"visual.vision_model.encoder.layers.11.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 470 |
+
"visual.vision_model.encoder.layers.11.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 471 |
+
"visual.vision_model.encoder.layers.11.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 472 |
+
"visual.vision_model.encoder.layers.11.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 473 |
+
"visual.vision_model.encoder.layers.11.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
| 474 |
+
"visual.vision_model.encoder.layers.11.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
| 475 |
+
"visual.vision_model.encoder.layers.11.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 476 |
+
"visual.vision_model.encoder.layers.11.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 477 |
+
"visual.vision_model.encoder.layers.11.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 478 |
+
"visual.vision_model.encoder.layers.11.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 479 |
+
"visual.vision_model.encoder.layers.12.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
| 480 |
+
"visual.vision_model.encoder.layers.12.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
| 481 |
+
"visual.vision_model.encoder.layers.12.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
| 482 |
+
"visual.vision_model.encoder.layers.12.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
| 483 |
+
"visual.vision_model.encoder.layers.12.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 484 |
+
"visual.vision_model.encoder.layers.12.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 485 |
+
"visual.vision_model.encoder.layers.12.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 486 |
+
"visual.vision_model.encoder.layers.12.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 487 |
+
"visual.vision_model.encoder.layers.12.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 488 |
+
"visual.vision_model.encoder.layers.12.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 489 |
+
"visual.vision_model.encoder.layers.12.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
| 490 |
+
"visual.vision_model.encoder.layers.12.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
| 491 |
+
"visual.vision_model.encoder.layers.12.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 492 |
+
"visual.vision_model.encoder.layers.12.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 493 |
+
"visual.vision_model.encoder.layers.12.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 494 |
+
"visual.vision_model.encoder.layers.12.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 495 |
+
"visual.vision_model.encoder.layers.13.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
| 496 |
+
"visual.vision_model.encoder.layers.13.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
| 497 |
+
"visual.vision_model.encoder.layers.13.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
| 498 |
+
"visual.vision_model.encoder.layers.13.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
| 499 |
+
"visual.vision_model.encoder.layers.13.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 500 |
+
"visual.vision_model.encoder.layers.13.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 501 |
+
"visual.vision_model.encoder.layers.13.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 502 |
+
"visual.vision_model.encoder.layers.13.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 503 |
+
"visual.vision_model.encoder.layers.13.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 504 |
+
"visual.vision_model.encoder.layers.13.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 505 |
+
"visual.vision_model.encoder.layers.13.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
| 506 |
+
"visual.vision_model.encoder.layers.13.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
| 507 |
+
"visual.vision_model.encoder.layers.13.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 508 |
+
"visual.vision_model.encoder.layers.13.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 509 |
+
"visual.vision_model.encoder.layers.13.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 510 |
+
"visual.vision_model.encoder.layers.13.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 511 |
+
"visual.vision_model.encoder.layers.14.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
| 512 |
+
"visual.vision_model.encoder.layers.14.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
| 513 |
+
"visual.vision_model.encoder.layers.14.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
| 514 |
+
"visual.vision_model.encoder.layers.14.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
| 515 |
+
"visual.vision_model.encoder.layers.14.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 516 |
+
"visual.vision_model.encoder.layers.14.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 517 |
+
"visual.vision_model.encoder.layers.14.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 518 |
+
"visual.vision_model.encoder.layers.14.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 519 |
+
"visual.vision_model.encoder.layers.14.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 520 |
+
"visual.vision_model.encoder.layers.14.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 521 |
+
"visual.vision_model.encoder.layers.14.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
| 522 |
+
"visual.vision_model.encoder.layers.14.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
| 523 |
+
"visual.vision_model.encoder.layers.14.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 524 |
+
"visual.vision_model.encoder.layers.14.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 525 |
+
"visual.vision_model.encoder.layers.14.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 526 |
+
"visual.vision_model.encoder.layers.14.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 527 |
+
"visual.vision_model.encoder.layers.15.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
| 528 |
+
"visual.vision_model.encoder.layers.15.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
| 529 |
+
"visual.vision_model.encoder.layers.15.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
| 530 |
+
"visual.vision_model.encoder.layers.15.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
| 531 |
+
"visual.vision_model.encoder.layers.15.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 532 |
+
"visual.vision_model.encoder.layers.15.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 533 |
+
"visual.vision_model.encoder.layers.15.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 534 |
+
"visual.vision_model.encoder.layers.15.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 535 |
+
"visual.vision_model.encoder.layers.15.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 536 |
+
"visual.vision_model.encoder.layers.15.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 537 |
+
"visual.vision_model.encoder.layers.15.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
| 538 |
+
"visual.vision_model.encoder.layers.15.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
| 539 |
+
"visual.vision_model.encoder.layers.15.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 540 |
+
"visual.vision_model.encoder.layers.15.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 541 |
+
"visual.vision_model.encoder.layers.15.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 542 |
+
"visual.vision_model.encoder.layers.15.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 543 |
+
"visual.vision_model.encoder.layers.16.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
| 544 |
+
"visual.vision_model.encoder.layers.16.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
| 545 |
+
"visual.vision_model.encoder.layers.16.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
| 546 |
+
"visual.vision_model.encoder.layers.16.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
| 547 |
+
"visual.vision_model.encoder.layers.16.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 548 |
+
"visual.vision_model.encoder.layers.16.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 549 |
+
"visual.vision_model.encoder.layers.16.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 550 |
+
"visual.vision_model.encoder.layers.16.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 551 |
+
"visual.vision_model.encoder.layers.16.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 552 |
+
"visual.vision_model.encoder.layers.16.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 553 |
+
"visual.vision_model.encoder.layers.16.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
| 554 |
+
"visual.vision_model.encoder.layers.16.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
| 555 |
+
"visual.vision_model.encoder.layers.16.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 556 |
+
"visual.vision_model.encoder.layers.16.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 557 |
+
"visual.vision_model.encoder.layers.16.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 558 |
+
"visual.vision_model.encoder.layers.16.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 559 |
+
"visual.vision_model.encoder.layers.17.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
| 560 |
+
"visual.vision_model.encoder.layers.17.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
| 561 |
+
"visual.vision_model.encoder.layers.17.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
| 562 |
+
"visual.vision_model.encoder.layers.17.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
| 563 |
+
"visual.vision_model.encoder.layers.17.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 564 |
+
"visual.vision_model.encoder.layers.17.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 565 |
+
"visual.vision_model.encoder.layers.17.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 566 |
+
"visual.vision_model.encoder.layers.17.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 567 |
+
"visual.vision_model.encoder.layers.17.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 568 |
+
"visual.vision_model.encoder.layers.17.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 569 |
+
"visual.vision_model.encoder.layers.17.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
| 570 |
+
"visual.vision_model.encoder.layers.17.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
| 571 |
+
"visual.vision_model.encoder.layers.17.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 572 |
+
"visual.vision_model.encoder.layers.17.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 573 |
+
"visual.vision_model.encoder.layers.17.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 574 |
+
"visual.vision_model.encoder.layers.17.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 575 |
+
"visual.vision_model.encoder.layers.18.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
| 576 |
+
"visual.vision_model.encoder.layers.18.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
| 577 |
+
"visual.vision_model.encoder.layers.18.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
| 578 |
+
"visual.vision_model.encoder.layers.18.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
| 579 |
+
"visual.vision_model.encoder.layers.18.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 580 |
+
"visual.vision_model.encoder.layers.18.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 581 |
+
"visual.vision_model.encoder.layers.18.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 582 |
+
"visual.vision_model.encoder.layers.18.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 583 |
+
"visual.vision_model.encoder.layers.18.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 584 |
+
"visual.vision_model.encoder.layers.18.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 585 |
+
"visual.vision_model.encoder.layers.18.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
| 586 |
+
"visual.vision_model.encoder.layers.18.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
| 587 |
+
"visual.vision_model.encoder.layers.18.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 588 |
+
"visual.vision_model.encoder.layers.18.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 589 |
+
"visual.vision_model.encoder.layers.18.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 590 |
+
"visual.vision_model.encoder.layers.18.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 591 |
+
"visual.vision_model.encoder.layers.19.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
| 592 |
+
"visual.vision_model.encoder.layers.19.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
| 593 |
+
"visual.vision_model.encoder.layers.19.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
| 594 |
+
"visual.vision_model.encoder.layers.19.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
| 595 |
+
"visual.vision_model.encoder.layers.19.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 596 |
+
"visual.vision_model.encoder.layers.19.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 597 |
+
"visual.vision_model.encoder.layers.19.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 598 |
+
"visual.vision_model.encoder.layers.19.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 599 |
+
"visual.vision_model.encoder.layers.19.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 600 |
+
"visual.vision_model.encoder.layers.19.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 601 |
+
"visual.vision_model.encoder.layers.19.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
| 602 |
+
"visual.vision_model.encoder.layers.19.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
| 603 |
+
"visual.vision_model.encoder.layers.19.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 604 |
+
"visual.vision_model.encoder.layers.19.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 605 |
+
"visual.vision_model.encoder.layers.19.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 606 |
+
"visual.vision_model.encoder.layers.19.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 607 |
+
"visual.vision_model.encoder.layers.2.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
| 608 |
+
"visual.vision_model.encoder.layers.2.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
| 609 |
+
"visual.vision_model.encoder.layers.2.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
| 610 |
+
"visual.vision_model.encoder.layers.2.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
| 611 |
+
"visual.vision_model.encoder.layers.2.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 612 |
+
"visual.vision_model.encoder.layers.2.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 613 |
+
"visual.vision_model.encoder.layers.2.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 614 |
+
"visual.vision_model.encoder.layers.2.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 615 |
+
"visual.vision_model.encoder.layers.2.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 616 |
+
"visual.vision_model.encoder.layers.2.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 617 |
+
"visual.vision_model.encoder.layers.2.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
| 618 |
+
"visual.vision_model.encoder.layers.2.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
| 619 |
+
"visual.vision_model.encoder.layers.2.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 620 |
+
"visual.vision_model.encoder.layers.2.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 621 |
+
"visual.vision_model.encoder.layers.2.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 622 |
+
"visual.vision_model.encoder.layers.2.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 623 |
+
"visual.vision_model.encoder.layers.20.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
| 624 |
+
"visual.vision_model.encoder.layers.20.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
| 625 |
+
"visual.vision_model.encoder.layers.20.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
| 626 |
+
"visual.vision_model.encoder.layers.20.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
| 627 |
+
"visual.vision_model.encoder.layers.20.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 628 |
+
"visual.vision_model.encoder.layers.20.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 629 |
+
"visual.vision_model.encoder.layers.20.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 630 |
+
"visual.vision_model.encoder.layers.20.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 631 |
+
"visual.vision_model.encoder.layers.20.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 632 |
+
"visual.vision_model.encoder.layers.20.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 633 |
+
"visual.vision_model.encoder.layers.20.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
| 634 |
+
"visual.vision_model.encoder.layers.20.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
| 635 |
+
"visual.vision_model.encoder.layers.20.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 636 |
+
"visual.vision_model.encoder.layers.20.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 637 |
+
"visual.vision_model.encoder.layers.20.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 638 |
+
"visual.vision_model.encoder.layers.20.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 639 |
+
"visual.vision_model.encoder.layers.21.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
| 640 |
+
"visual.vision_model.encoder.layers.21.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
| 641 |
+
"visual.vision_model.encoder.layers.21.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
| 642 |
+
"visual.vision_model.encoder.layers.21.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
| 643 |
+
"visual.vision_model.encoder.layers.21.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 644 |
+
"visual.vision_model.encoder.layers.21.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 645 |
+
"visual.vision_model.encoder.layers.21.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 646 |
+
"visual.vision_model.encoder.layers.21.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 647 |
+
"visual.vision_model.encoder.layers.21.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 648 |
+
"visual.vision_model.encoder.layers.21.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 649 |
+
"visual.vision_model.encoder.layers.21.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
| 650 |
+
"visual.vision_model.encoder.layers.21.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
| 651 |
+
"visual.vision_model.encoder.layers.21.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 652 |
+
"visual.vision_model.encoder.layers.21.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 653 |
+
"visual.vision_model.encoder.layers.21.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 654 |
+
"visual.vision_model.encoder.layers.21.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 655 |
+
"visual.vision_model.encoder.layers.22.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
| 656 |
+
"visual.vision_model.encoder.layers.22.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
| 657 |
+
"visual.vision_model.encoder.layers.22.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
| 658 |
+
"visual.vision_model.encoder.layers.22.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
| 659 |
+
"visual.vision_model.encoder.layers.22.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 660 |
+
"visual.vision_model.encoder.layers.22.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 661 |
+
"visual.vision_model.encoder.layers.22.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 662 |
+
"visual.vision_model.encoder.layers.22.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 663 |
+
"visual.vision_model.encoder.layers.22.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 664 |
+
"visual.vision_model.encoder.layers.22.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 665 |
+
"visual.vision_model.encoder.layers.22.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
| 666 |
+
"visual.vision_model.encoder.layers.22.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
| 667 |
+
"visual.vision_model.encoder.layers.22.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 668 |
+
"visual.vision_model.encoder.layers.22.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 669 |
+
"visual.vision_model.encoder.layers.22.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 670 |
+
"visual.vision_model.encoder.layers.22.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 671 |
+
"visual.vision_model.encoder.layers.23.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
| 672 |
+
"visual.vision_model.encoder.layers.23.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
| 673 |
+
"visual.vision_model.encoder.layers.23.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
| 674 |
+
"visual.vision_model.encoder.layers.23.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
| 675 |
+
"visual.vision_model.encoder.layers.23.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 676 |
+
"visual.vision_model.encoder.layers.23.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 677 |
+
"visual.vision_model.encoder.layers.23.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 678 |
+
"visual.vision_model.encoder.layers.23.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 679 |
+
"visual.vision_model.encoder.layers.23.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 680 |
+
"visual.vision_model.encoder.layers.23.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 681 |
+
"visual.vision_model.encoder.layers.23.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
| 682 |
+
"visual.vision_model.encoder.layers.23.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
| 683 |
+
"visual.vision_model.encoder.layers.23.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 684 |
+
"visual.vision_model.encoder.layers.23.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 685 |
+
"visual.vision_model.encoder.layers.23.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 686 |
+
"visual.vision_model.encoder.layers.23.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 687 |
+
"visual.vision_model.encoder.layers.24.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
| 688 |
+
"visual.vision_model.encoder.layers.24.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
| 689 |
+
"visual.vision_model.encoder.layers.24.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
| 690 |
+
"visual.vision_model.encoder.layers.24.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
| 691 |
+
"visual.vision_model.encoder.layers.24.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 692 |
+
"visual.vision_model.encoder.layers.24.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 693 |
+
"visual.vision_model.encoder.layers.24.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 694 |
+
"visual.vision_model.encoder.layers.24.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 695 |
+
"visual.vision_model.encoder.layers.24.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 696 |
+
"visual.vision_model.encoder.layers.24.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 697 |
+
"visual.vision_model.encoder.layers.24.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
| 698 |
+
"visual.vision_model.encoder.layers.24.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
| 699 |
+
"visual.vision_model.encoder.layers.24.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 700 |
+
"visual.vision_model.encoder.layers.24.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 701 |
+
"visual.vision_model.encoder.layers.24.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 702 |
+
"visual.vision_model.encoder.layers.24.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 703 |
+
"visual.vision_model.encoder.layers.25.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
| 704 |
+
"visual.vision_model.encoder.layers.25.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
| 705 |
+
"visual.vision_model.encoder.layers.25.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
| 706 |
+
"visual.vision_model.encoder.layers.25.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
| 707 |
+
"visual.vision_model.encoder.layers.25.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 708 |
+
"visual.vision_model.encoder.layers.25.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 709 |
+
"visual.vision_model.encoder.layers.25.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 710 |
+
"visual.vision_model.encoder.layers.25.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 711 |
+
"visual.vision_model.encoder.layers.25.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 712 |
+
"visual.vision_model.encoder.layers.25.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 713 |
+
"visual.vision_model.encoder.layers.25.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
| 714 |
+
"visual.vision_model.encoder.layers.25.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
| 715 |
+
"visual.vision_model.encoder.layers.25.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 716 |
+
"visual.vision_model.encoder.layers.25.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 717 |
+
"visual.vision_model.encoder.layers.25.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 718 |
+
"visual.vision_model.encoder.layers.25.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 719 |
+
"visual.vision_model.encoder.layers.26.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
| 720 |
+
"visual.vision_model.encoder.layers.26.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
| 721 |
+
"visual.vision_model.encoder.layers.26.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
| 722 |
+
"visual.vision_model.encoder.layers.26.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
| 723 |
+
"visual.vision_model.encoder.layers.26.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 724 |
+
"visual.vision_model.encoder.layers.26.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 725 |
+
"visual.vision_model.encoder.layers.26.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 726 |
+
"visual.vision_model.encoder.layers.26.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 727 |
+
"visual.vision_model.encoder.layers.26.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 728 |
+
"visual.vision_model.encoder.layers.26.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 729 |
+
"visual.vision_model.encoder.layers.26.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
| 730 |
+
"visual.vision_model.encoder.layers.26.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
| 731 |
+
"visual.vision_model.encoder.layers.26.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 732 |
+
"visual.vision_model.encoder.layers.26.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 733 |
+
"visual.vision_model.encoder.layers.26.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 734 |
+
"visual.vision_model.encoder.layers.26.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 735 |
+
"visual.vision_model.encoder.layers.3.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
| 736 |
+
"visual.vision_model.encoder.layers.3.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
| 737 |
+
"visual.vision_model.encoder.layers.3.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
| 738 |
+
"visual.vision_model.encoder.layers.3.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
| 739 |
+
"visual.vision_model.encoder.layers.3.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 740 |
+
"visual.vision_model.encoder.layers.3.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 741 |
+
"visual.vision_model.encoder.layers.3.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 742 |
+
"visual.vision_model.encoder.layers.3.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 743 |
+
"visual.vision_model.encoder.layers.3.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 744 |
+
"visual.vision_model.encoder.layers.3.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 745 |
+
"visual.vision_model.encoder.layers.3.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
| 746 |
+
"visual.vision_model.encoder.layers.3.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
| 747 |
+
"visual.vision_model.encoder.layers.3.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 748 |
+
"visual.vision_model.encoder.layers.3.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 749 |
+
"visual.vision_model.encoder.layers.3.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 750 |
+
"visual.vision_model.encoder.layers.3.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 751 |
+
"visual.vision_model.encoder.layers.4.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
| 752 |
+
"visual.vision_model.encoder.layers.4.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
| 753 |
+
"visual.vision_model.encoder.layers.4.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
| 754 |
+
"visual.vision_model.encoder.layers.4.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
| 755 |
+
"visual.vision_model.encoder.layers.4.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 756 |
+
"visual.vision_model.encoder.layers.4.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 757 |
+
"visual.vision_model.encoder.layers.4.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 758 |
+
"visual.vision_model.encoder.layers.4.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 759 |
+
"visual.vision_model.encoder.layers.4.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 760 |
+
"visual.vision_model.encoder.layers.4.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 761 |
+
"visual.vision_model.encoder.layers.4.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
| 762 |
+
"visual.vision_model.encoder.layers.4.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
| 763 |
+
"visual.vision_model.encoder.layers.4.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 764 |
+
"visual.vision_model.encoder.layers.4.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 765 |
+
"visual.vision_model.encoder.layers.4.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 766 |
+
"visual.vision_model.encoder.layers.4.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 767 |
+
"visual.vision_model.encoder.layers.5.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
| 768 |
+
"visual.vision_model.encoder.layers.5.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
| 769 |
+
"visual.vision_model.encoder.layers.5.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
| 770 |
+
"visual.vision_model.encoder.layers.5.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
| 771 |
+
"visual.vision_model.encoder.layers.5.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 772 |
+
"visual.vision_model.encoder.layers.5.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 773 |
+
"visual.vision_model.encoder.layers.5.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 774 |
+
"visual.vision_model.encoder.layers.5.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 775 |
+
"visual.vision_model.encoder.layers.5.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 776 |
+
"visual.vision_model.encoder.layers.5.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 777 |
+
"visual.vision_model.encoder.layers.5.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
| 778 |
+
"visual.vision_model.encoder.layers.5.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
| 779 |
+
"visual.vision_model.encoder.layers.5.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 780 |
+
"visual.vision_model.encoder.layers.5.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 781 |
+
"visual.vision_model.encoder.layers.5.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 782 |
+
"visual.vision_model.encoder.layers.5.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 783 |
+
"visual.vision_model.encoder.layers.6.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
| 784 |
+
"visual.vision_model.encoder.layers.6.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
| 785 |
+
"visual.vision_model.encoder.layers.6.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
| 786 |
+
"visual.vision_model.encoder.layers.6.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
| 787 |
+
"visual.vision_model.encoder.layers.6.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 788 |
+
"visual.vision_model.encoder.layers.6.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 789 |
+
"visual.vision_model.encoder.layers.6.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 790 |
+
"visual.vision_model.encoder.layers.6.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 791 |
+
"visual.vision_model.encoder.layers.6.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 792 |
+
"visual.vision_model.encoder.layers.6.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 793 |
+
"visual.vision_model.encoder.layers.6.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
| 794 |
+
"visual.vision_model.encoder.layers.6.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
| 795 |
+
"visual.vision_model.encoder.layers.6.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 796 |
+
"visual.vision_model.encoder.layers.6.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 797 |
+
"visual.vision_model.encoder.layers.6.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 798 |
+
"visual.vision_model.encoder.layers.6.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 799 |
+
"visual.vision_model.encoder.layers.7.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
| 800 |
+
"visual.vision_model.encoder.layers.7.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
| 801 |
+
"visual.vision_model.encoder.layers.7.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
| 802 |
+
"visual.vision_model.encoder.layers.7.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
| 803 |
+
"visual.vision_model.encoder.layers.7.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 804 |
+
"visual.vision_model.encoder.layers.7.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 805 |
+
"visual.vision_model.encoder.layers.7.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 806 |
+
"visual.vision_model.encoder.layers.7.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 807 |
+
"visual.vision_model.encoder.layers.7.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 808 |
+
"visual.vision_model.encoder.layers.7.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 809 |
+
"visual.vision_model.encoder.layers.7.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
| 810 |
+
"visual.vision_model.encoder.layers.7.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
| 811 |
+
"visual.vision_model.encoder.layers.7.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 812 |
+
"visual.vision_model.encoder.layers.7.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 813 |
+
"visual.vision_model.encoder.layers.7.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 814 |
+
"visual.vision_model.encoder.layers.7.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 815 |
+
"visual.vision_model.encoder.layers.8.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
| 816 |
+
"visual.vision_model.encoder.layers.8.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
| 817 |
+
"visual.vision_model.encoder.layers.8.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
| 818 |
+
"visual.vision_model.encoder.layers.8.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
| 819 |
+
"visual.vision_model.encoder.layers.8.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 820 |
+
"visual.vision_model.encoder.layers.8.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 821 |
+
"visual.vision_model.encoder.layers.8.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 822 |
+
"visual.vision_model.encoder.layers.8.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 823 |
+
"visual.vision_model.encoder.layers.8.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 824 |
+
"visual.vision_model.encoder.layers.8.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 825 |
+
"visual.vision_model.encoder.layers.8.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
| 826 |
+
"visual.vision_model.encoder.layers.8.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
| 827 |
+
"visual.vision_model.encoder.layers.8.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 828 |
+
"visual.vision_model.encoder.layers.8.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 829 |
+
"visual.vision_model.encoder.layers.8.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 830 |
+
"visual.vision_model.encoder.layers.8.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 831 |
+
"visual.vision_model.encoder.layers.9.layer_norm1.bias": "model-00001-of-00004.safetensors",
|
| 832 |
+
"visual.vision_model.encoder.layers.9.layer_norm1.weight": "model-00001-of-00004.safetensors",
|
| 833 |
+
"visual.vision_model.encoder.layers.9.layer_norm2.bias": "model-00001-of-00004.safetensors",
|
| 834 |
+
"visual.vision_model.encoder.layers.9.layer_norm2.weight": "model-00001-of-00004.safetensors",
|
| 835 |
+
"visual.vision_model.encoder.layers.9.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 836 |
+
"visual.vision_model.encoder.layers.9.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 837 |
+
"visual.vision_model.encoder.layers.9.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 838 |
+
"visual.vision_model.encoder.layers.9.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 839 |
+
"visual.vision_model.encoder.layers.9.self_attn.k_proj.bias": "model-00001-of-00004.safetensors",
|
| 840 |
+
"visual.vision_model.encoder.layers.9.self_attn.k_proj.weight": "model-00001-of-00004.safetensors",
|
| 841 |
+
"visual.vision_model.encoder.layers.9.self_attn.out_proj.bias": "model-00001-of-00004.safetensors",
|
| 842 |
+
"visual.vision_model.encoder.layers.9.self_attn.out_proj.weight": "model-00001-of-00004.safetensors",
|
| 843 |
+
"visual.vision_model.encoder.layers.9.self_attn.q_proj.bias": "model-00001-of-00004.safetensors",
|
| 844 |
+
"visual.vision_model.encoder.layers.9.self_attn.q_proj.weight": "model-00001-of-00004.safetensors",
|
| 845 |
+
"visual.vision_model.encoder.layers.9.self_attn.v_proj.bias": "model-00001-of-00004.safetensors",
|
| 846 |
+
"visual.vision_model.encoder.layers.9.self_attn.v_proj.weight": "model-00001-of-00004.safetensors",
|
| 847 |
+
"visual.vision_model.head.attention.in_proj_bias": "model-00001-of-00004.safetensors",
|
| 848 |
+
"visual.vision_model.head.attention.in_proj_weight": "model-00001-of-00004.safetensors",
|
| 849 |
+
"visual.vision_model.head.attention.out_proj.bias": "model-00001-of-00004.safetensors",
|
| 850 |
+
"visual.vision_model.head.attention.out_proj.weight": "model-00001-of-00004.safetensors",
|
| 851 |
+
"visual.vision_model.head.layernorm.bias": "model-00001-of-00004.safetensors",
|
| 852 |
+
"visual.vision_model.head.layernorm.weight": "model-00001-of-00004.safetensors",
|
| 853 |
+
"visual.vision_model.head.mlp.fc1.bias": "model-00001-of-00004.safetensors",
|
| 854 |
+
"visual.vision_model.head.mlp.fc1.weight": "model-00001-of-00004.safetensors",
|
| 855 |
+
"visual.vision_model.head.mlp.fc2.bias": "model-00001-of-00004.safetensors",
|
| 856 |
+
"visual.vision_model.head.mlp.fc2.weight": "model-00001-of-00004.safetensors",
|
| 857 |
+
"visual.vision_model.head.probe": "model-00001-of-00004.safetensors",
|
| 858 |
+
"visual.vision_model.post_layernorm.bias": "model-00001-of-00004.safetensors",
|
| 859 |
+
"visual.vision_model.post_layernorm.weight": "model-00001-of-00004.safetensors"
|
| 860 |
+
}
|
| 861 |
+
}
|
modeling_keye.py
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
preprocessor_config.json
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"min_pixels": 3136,
|
| 3 |
+
"max_pixels": 1003520,
|
| 4 |
+
"patch_size": 14,
|
| 5 |
+
"temporal_patch_size": 1,
|
| 6 |
+
"merge_size": 2,
|
| 7 |
+
"image_mean": [
|
| 8 |
+
0.5,0.5,0.5
|
| 9 |
+
],
|
| 10 |
+
"image_std": [
|
| 11 |
+
0.5,0.5,0.5
|
| 12 |
+
],
|
| 13 |
+
"processor_class": "KeyeProcessor",
|
| 14 |
+
"auto_map": {
|
| 15 |
+
"AutoProcessor": "processing_keye.KeyeProcessor",
|
| 16 |
+
"AutoImageProcessor": "image_processing_keye.SiglipImageProcessor"
|
| 17 |
+
}
|
| 18 |
+
}
|
processing_keye.py
ADDED
|
@@ -0,0 +1,298 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# coding=utf-8
|
| 2 |
+
# Copyright 2025 The Keye Team and The HuggingFace Inc. team. All rights reserved.
|
| 3 |
+
#
|
| 4 |
+
# This code is based on EleutherAI's GPT-NeoX library and the GPT-NeoX
|
| 5 |
+
# and OPT implementations in this library. It has been modified from its
|
| 6 |
+
# original forms to accommodate minor architectural differences compared
|
| 7 |
+
# to GPT-NeoX and OPT used by the Meta AI team that trained the model.
|
| 8 |
+
#
|
| 9 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 10 |
+
# you may not use this file except in compliance with the License.
|
| 11 |
+
# You may obtain a copy of the License at
|
| 12 |
+
#
|
| 13 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 14 |
+
#
|
| 15 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 16 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 17 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 18 |
+
# See the License for the specific language governing permissions and
|
| 19 |
+
# limitations under the License.
|
| 20 |
+
from typing import List, Union
|
| 21 |
+
import numpy as np
|
| 22 |
+
from transformers.feature_extraction_utils import BatchFeature
|
| 23 |
+
from transformers.processing_utils import (
|
| 24 |
+
ProcessingKwargs,
|
| 25 |
+
ProcessorMixin,
|
| 26 |
+
Unpack,
|
| 27 |
+
VideosKwargs,
|
| 28 |
+
)
|
| 29 |
+
from transformers.tokenization_utils_base import PreTokenizedInput, TextInput
|
| 30 |
+
import torch
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
ImageInput = Union[
|
| 34 |
+
"PIL.Image.Image",
|
| 35 |
+
np.ndarray,
|
| 36 |
+
"torch.Tensor",
|
| 37 |
+
List["PIL.Image.Image"],
|
| 38 |
+
List[np.ndarray],
|
| 39 |
+
List["torch.Tensor"],
|
| 40 |
+
] # noqa
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
VideoInput = Union[
|
| 44 |
+
List["PIL.Image.Image"],
|
| 45 |
+
"np.ndarray",
|
| 46 |
+
"torch.Tensor",
|
| 47 |
+
List["np.ndarray"],
|
| 48 |
+
List["torch.Tensor"],
|
| 49 |
+
List[List["PIL.Image.Image"]],
|
| 50 |
+
List[List["np.ndarrray"]],
|
| 51 |
+
List[List["torch.Tensor"]],
|
| 52 |
+
] # noqa
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
class KeyeVideosProcessorKwargs(VideosKwargs, total=False):
|
| 56 |
+
fps: Union[List[float], float]
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
class KeyeProcessorKwargs(ProcessingKwargs, total=False):
|
| 60 |
+
videos_kwargs: KeyeVideosProcessorKwargs
|
| 61 |
+
_defaults = {
|
| 62 |
+
"text_kwargs": {
|
| 63 |
+
"padding": False,
|
| 64 |
+
},
|
| 65 |
+
"videos_kwargs": {"fps": 2.0},
|
| 66 |
+
}
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
class KeyeProcessor(ProcessorMixin):
|
| 70 |
+
r"""
|
| 71 |
+
[`KeyeProcessor`] offers all the functionalities of [`SiglipImageProcessor`] and [`Qwen2TokenizerFast`]. See the
|
| 72 |
+
[`~KeyeProcessor.__call__`] and [`~KeyeProcessor.decode`] for more information.
|
| 73 |
+
Args:
|
| 74 |
+
image_processor ([`SiglipImageProcessor`], *optional*):
|
| 75 |
+
The image processor is a required input.
|
| 76 |
+
tokenizer ([`Qwen2TokenizerFast`], *optional*):
|
| 77 |
+
The tokenizer is a required input.
|
| 78 |
+
chat_template (`str`, *optional*): A Jinja template which will be used to convert lists of messages
|
| 79 |
+
in a chat into a tokenizable string.
|
| 80 |
+
"""
|
| 81 |
+
|
| 82 |
+
attributes = ["image_processor", "tokenizer"]
|
| 83 |
+
valid_kwargs = [
|
| 84 |
+
"chat_template",
|
| 85 |
+
"image_std",
|
| 86 |
+
"min_pixels",
|
| 87 |
+
"image_mean",
|
| 88 |
+
"merge_size",
|
| 89 |
+
"image_processor_type",
|
| 90 |
+
"temporal_patch_size",
|
| 91 |
+
"patch_size",
|
| 92 |
+
"max_pixels",
|
| 93 |
+
]
|
| 94 |
+
|
| 95 |
+
image_processor_class = "AutoImageProcessor"
|
| 96 |
+
tokenizer_class = ("Qwen2Tokenizer", "Qwen2TokenizerFast")
|
| 97 |
+
|
| 98 |
+
def __init__(
|
| 99 |
+
self, image_processor=None, tokenizer=None, chat_template=None, **kwargs
|
| 100 |
+
):
|
| 101 |
+
self.image_token = (
|
| 102 |
+
"<|image_pad|>"
|
| 103 |
+
if not hasattr(tokenizer, "image_token")
|
| 104 |
+
else tokenizer.image_token
|
| 105 |
+
)
|
| 106 |
+
self.video_token = (
|
| 107 |
+
"<|video_pad|>"
|
| 108 |
+
if not hasattr(tokenizer, "video_token")
|
| 109 |
+
else tokenizer.video_token
|
| 110 |
+
)
|
| 111 |
+
super().__init__(image_processor, tokenizer, chat_template=chat_template)
|
| 112 |
+
|
| 113 |
+
def __call__(
|
| 114 |
+
self,
|
| 115 |
+
images: ImageInput = None,
|
| 116 |
+
text: Union[
|
| 117 |
+
TextInput, PreTokenizedInput, List[TextInput], List[PreTokenizedInput]
|
| 118 |
+
] = None,
|
| 119 |
+
videos: VideoInput = None,
|
| 120 |
+
**kwargs: Unpack[KeyeProcessorKwargs],
|
| 121 |
+
) -> BatchFeature:
|
| 122 |
+
"""
|
| 123 |
+
Main method to prepare for the model one or several sequences(s) and image(s). This method forwards the `text`
|
| 124 |
+
and `kwargs` arguments to Qwen2TokenizerFast's [`~Qwen2TokenizerFast.__call__`] if `text` is not `None` to encode
|
| 125 |
+
the text. To prepare the vision inputs, this method forwards the `vision_infos` and `kwrags` arguments to
|
| 126 |
+
SiglipImageProcessor's [`~SiglipImageProcessor.__call__`] if `vision_infos` is not `None`.
|
| 127 |
+
|
| 128 |
+
Args:
|
| 129 |
+
images (`PIL.Image.Image`, `np.ndarray`, `torch.Tensor`, `List[PIL.Image.Image]`, `List[np.ndarray]`, `List[torch.Tensor]`):
|
| 130 |
+
The image or batch of images to be prepared. Each image can be a PIL image, NumPy array or PyTorch
|
| 131 |
+
tensor. Both channels-first and channels-last formats are supported.
|
| 132 |
+
text (`str`, `List[str]`, `List[List[str]]`):
|
| 133 |
+
The sequence or batch of sequences to be encoded. Each sequence can be a string or a list of strings
|
| 134 |
+
(pretokenized string). If the sequences are provided as list of strings (pretokenized), you must set
|
| 135 |
+
`is_split_into_words=True` (to lift the ambiguity with a batch of sequences).
|
| 136 |
+
videos (`np.ndarray`, `torch.Tensor`, `List[np.ndarray]`, `List[torch.Tensor]`):
|
| 137 |
+
The image or batch of videos to be prepared. Each video can be a 4D NumPy array or PyTorch
|
| 138 |
+
tensor, or a nested list of 3D frames. Both channels-first and channels-last formats are supported.
|
| 139 |
+
return_tensors (`str` or [`~utils.TensorType`], *optional*):
|
| 140 |
+
If set, will return tensors of a particular framework. Acceptable values are:
|
| 141 |
+
- `'tf'`: Return TensorFlow `tf.constant` objects.
|
| 142 |
+
- `'pt'`: Return PyTorch `torch.Tensor` objects.
|
| 143 |
+
- `'np'`: Return NumPy `np.ndarray` objects.
|
| 144 |
+
- `'jax'`: Return JAX `jnp.ndarray` objects.
|
| 145 |
+
|
| 146 |
+
Returns:
|
| 147 |
+
[`BatchFeature`]: A [`BatchFeature`] with the following fields:
|
| 148 |
+
|
| 149 |
+
- **input_ids** -- List of token ids to be fed to a model. Returned when `text` is not `None`.
|
| 150 |
+
- **attention_mask** -- List of indices specifying which tokens should be attended to by the model (when
|
| 151 |
+
`return_attention_mask=True` or if *"attention_mask"* is in `self.model_input_names` and if `text` is not
|
| 152 |
+
`None`).
|
| 153 |
+
- **pixel_values** -- Pixel values to be fed to a model. Returned when `images` is not `None`.
|
| 154 |
+
- **pixel_values_videos** -- Pixel values of videos to be fed to a model. Returned when `videos` is not `None`.
|
| 155 |
+
- **image_grid_thw** -- List of image 3D grid in LLM. Returned when `images` is not `None`.
|
| 156 |
+
- **video_grid_thw** -- List of video 3D grid in LLM. Returned when `videos` is not `None`.
|
| 157 |
+
- **second_per_grid_ts** -- List of video seconds per time grid. Returned when `videos` is not `None`.
|
| 158 |
+
"""
|
| 159 |
+
output_kwargs = self._merge_kwargs(
|
| 160 |
+
KeyeProcessorKwargs,
|
| 161 |
+
tokenizer_init_kwargs=self.tokenizer.init_kwargs,
|
| 162 |
+
**kwargs,
|
| 163 |
+
)
|
| 164 |
+
|
| 165 |
+
if images is not None:
|
| 166 |
+
image_inputs = self.image_processor(images=images, return_tensors="pt")
|
| 167 |
+
image_inputs["pixel_values"] = image_inputs["pixel_values"]
|
| 168 |
+
image_grid_thw = image_inputs["image_grid_thw"]
|
| 169 |
+
|
| 170 |
+
else:
|
| 171 |
+
image_inputs = {}
|
| 172 |
+
image_grid_thw = None
|
| 173 |
+
|
| 174 |
+
if videos is not None:
|
| 175 |
+
# TODO: add video processing
|
| 176 |
+
videos_inputs = self.image_processor(
|
| 177 |
+
images=None, videos=videos, **output_kwargs["images_kwargs"]
|
| 178 |
+
)
|
| 179 |
+
video_grid_thw = videos_inputs["video_grid_thw"]
|
| 180 |
+
|
| 181 |
+
fps = output_kwargs["videos_kwargs"].pop("fps", 2.0)
|
| 182 |
+
if isinstance(fps, (int, float)):
|
| 183 |
+
second_per_grid_ts = [
|
| 184 |
+
self.image_processor.temporal_patch_size / fps
|
| 185 |
+
] * len(video_grid_thw)
|
| 186 |
+
elif hasattr(fps, "__len__") and len(fps) == len(video_grid_thw):
|
| 187 |
+
second_per_grid_ts = [
|
| 188 |
+
self.image_processor.temporal_patch_size / tmp for tmp in fps
|
| 189 |
+
]
|
| 190 |
+
else:
|
| 191 |
+
raise ValueError(
|
| 192 |
+
f"The length of fps ({len(fps) if hasattr(fps, '__len__') else fps}) must be equal to the length of video_grid_thw ({len(video_grid_thw)}) or fps should be a single number."
|
| 193 |
+
)
|
| 194 |
+
videos_inputs.update(
|
| 195 |
+
{"second_per_grid_ts": torch.tensor(second_per_grid_ts)}
|
| 196 |
+
)
|
| 197 |
+
|
| 198 |
+
else:
|
| 199 |
+
videos_inputs = {}
|
| 200 |
+
video_grid_thw = None
|
| 201 |
+
|
| 202 |
+
if not isinstance(text, list):
|
| 203 |
+
text = [text]
|
| 204 |
+
|
| 205 |
+
if image_grid_thw is not None:
|
| 206 |
+
index = 0
|
| 207 |
+
for i in range(len(text)):
|
| 208 |
+
while self.image_token in text[i]:
|
| 209 |
+
text[i] = text[i].replace(
|
| 210 |
+
self.image_token,
|
| 211 |
+
"<|placeholder|>"
|
| 212 |
+
* (
|
| 213 |
+
image_grid_thw[index].prod()
|
| 214 |
+
// self.image_processor.merge_size
|
| 215 |
+
// self.image_processor.merge_size
|
| 216 |
+
),
|
| 217 |
+
1,
|
| 218 |
+
)
|
| 219 |
+
index += 1
|
| 220 |
+
text[i] = text[i].replace("<|placeholder|>", self.image_token)
|
| 221 |
+
|
| 222 |
+
if video_grid_thw is not None:
|
| 223 |
+
index = 0
|
| 224 |
+
for i in range(len(text)):
|
| 225 |
+
while self.video_token in text[i]:
|
| 226 |
+
text[i] = text[i].replace(
|
| 227 |
+
self.video_token,
|
| 228 |
+
"<|placeholder|>"
|
| 229 |
+
* (
|
| 230 |
+
video_grid_thw[index].prod()
|
| 231 |
+
// self.image_processor.merge_size
|
| 232 |
+
// self.image_processor.merge_size
|
| 233 |
+
),
|
| 234 |
+
1,
|
| 235 |
+
)
|
| 236 |
+
index += 1
|
| 237 |
+
text[i] = text[i].replace("<|placeholder|>", self.video_token)
|
| 238 |
+
|
| 239 |
+
text_inputs = self.tokenizer(text, **output_kwargs["text_kwargs"])
|
| 240 |
+
|
| 241 |
+
return BatchFeature(data={**text_inputs, **image_inputs, **videos_inputs})
|
| 242 |
+
|
| 243 |
+
def batch_decode(self, *args, **kwargs):
|
| 244 |
+
"""
|
| 245 |
+
This method forwards all its arguments to Qwen2TokenizerFast's [`~PreTrainedTokenizer.batch_decode`]. Please
|
| 246 |
+
refer to the docstring of this method for more information.
|
| 247 |
+
"""
|
| 248 |
+
return self.tokenizer.batch_decode(*args, **kwargs)
|
| 249 |
+
|
| 250 |
+
def decode(self, *args, **kwargs):
|
| 251 |
+
"""
|
| 252 |
+
This method forwards all its arguments to Qwen2TokenizerFast's [`~PreTrainedTokenizer.decode`]. Please refer to
|
| 253 |
+
the docstring of this method for more information.
|
| 254 |
+
"""
|
| 255 |
+
return self.tokenizer.decode(*args, **kwargs)
|
| 256 |
+
|
| 257 |
+
def post_process_image_text_to_text(
|
| 258 |
+
self,
|
| 259 |
+
generated_outputs,
|
| 260 |
+
skip_special_tokens=True,
|
| 261 |
+
clean_up_tokenization_spaces=False,
|
| 262 |
+
**kwargs,
|
| 263 |
+
):
|
| 264 |
+
"""
|
| 265 |
+
Post-process the output of the model to decode the text.
|
| 266 |
+
|
| 267 |
+
Args:
|
| 268 |
+
generated_outputs (`torch.Tensor` or `np.ndarray`):
|
| 269 |
+
The output of the model `generate` function. The output is expected to be a tensor of shape `(batch_size, sequence_length)`
|
| 270 |
+
or `(sequence_length,)`.
|
| 271 |
+
skip_special_tokens (`bool`, *optional*, defaults to `True`):
|
| 272 |
+
Whether or not to remove special tokens in the output. Argument passed to the tokenizer's `batch_decode` method.
|
| 273 |
+
Clean_up_tokenization_spaces (`bool`, *optional*, defaults to `False`):
|
| 274 |
+
Whether or not to clean up the tokenization spaces. Argument passed to the tokenizer's `batch_decode` method.
|
| 275 |
+
**kwargs:
|
| 276 |
+
Additional arguments to be passed to the tokenizer's `batch_decode method`.
|
| 277 |
+
|
| 278 |
+
Returns:
|
| 279 |
+
`List[str]`: The decoded text.
|
| 280 |
+
"""
|
| 281 |
+
return self.tokenizer.batch_decode(
|
| 282 |
+
generated_outputs,
|
| 283 |
+
skip_special_tokens=skip_special_tokens,
|
| 284 |
+
clean_up_tokenization_spaces=clean_up_tokenization_spaces,
|
| 285 |
+
**kwargs,
|
| 286 |
+
)
|
| 287 |
+
|
| 288 |
+
@property
|
| 289 |
+
def model_input_names(self):
|
| 290 |
+
tokenizer_input_names = self.tokenizer.model_input_names
|
| 291 |
+
image_processor_input_names = self.image_processor.model_input_names
|
| 292 |
+
names_from_processor = list(
|
| 293 |
+
dict.fromkeys(tokenizer_input_names + image_processor_input_names)
|
| 294 |
+
)
|
| 295 |
+
return names_from_processor + ["second_per_grid_ts"]
|
| 296 |
+
|
| 297 |
+
|
| 298 |
+
__all__ = ["KeyeProcessor", "KeyeProcessor_moonvit", "KeyeProcessor"]
|
processor_config.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"auto_map": {
|
| 3 |
+
"AutoProcessor": "processing_keye.KeyeProcessor"
|
| 4 |
+
},
|
| 5 |
+
"processor_class": "KeyeProcessor"
|
| 6 |
+
}
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
"<|im_start|>",
|
| 4 |
+
"<|im_end|>",
|
| 5 |
+
"<|vision_start|>",
|
| 6 |
+
"<|vision_end|>",
|
| 7 |
+
"<|vision_pad|>",
|
| 8 |
+
"<|image_pad|>",
|
| 9 |
+
"<|video_pad|>"
|
| 10 |
+
],
|
| 11 |
+
"eos_token": {
|
| 12 |
+
"content": "<|im_end|>",
|
| 13 |
+
"lstrip": false,
|
| 14 |
+
"normalized": false,
|
| 15 |
+
"rstrip": false,
|
| 16 |
+
"single_word": false
|
| 17 |
+
},
|
| 18 |
+
"pad_token": {
|
| 19 |
+
"content": "<|endoftext|>",
|
| 20 |
+
"lstrip": false,
|
| 21 |
+
"normalized": false,
|
| 22 |
+
"rstrip": false,
|
| 23 |
+
"single_word": false
|
| 24 |
+
}
|
| 25 |
+
}
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7ceaf87113caa06d8b2e2f6966ab11d12ac590cb887b64c591cae70ea89245f4
|
| 3 |
+
size 11422655
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,282 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": false,
|
| 3 |
+
"add_prefix_space": false,
|
| 4 |
+
"added_tokens_decoder": {
|
| 5 |
+
"151643": {
|
| 6 |
+
"content": "<|endoftext|>",
|
| 7 |
+
"lstrip": false,
|
| 8 |
+
"normalized": false,
|
| 9 |
+
"rstrip": false,
|
| 10 |
+
"single_word": false,
|
| 11 |
+
"special": true
|
| 12 |
+
},
|
| 13 |
+
"151644": {
|
| 14 |
+
"content": "<|im_start|>",
|
| 15 |
+
"lstrip": false,
|
| 16 |
+
"normalized": false,
|
| 17 |
+
"rstrip": false,
|
| 18 |
+
"single_word": false,
|
| 19 |
+
"special": true
|
| 20 |
+
},
|
| 21 |
+
"151645": {
|
| 22 |
+
"content": "<|im_end|>",
|
| 23 |
+
"lstrip": false,
|
| 24 |
+
"normalized": false,
|
| 25 |
+
"rstrip": false,
|
| 26 |
+
"single_word": false,
|
| 27 |
+
"special": true
|
| 28 |
+
},
|
| 29 |
+
"151646": {
|
| 30 |
+
"content": "<|object_ref_start|>",
|
| 31 |
+
"lstrip": false,
|
| 32 |
+
"normalized": false,
|
| 33 |
+
"rstrip": false,
|
| 34 |
+
"single_word": false,
|
| 35 |
+
"special": false
|
| 36 |
+
},
|
| 37 |
+
"151647": {
|
| 38 |
+
"content": "<|object_ref_end|>",
|
| 39 |
+
"lstrip": false,
|
| 40 |
+
"normalized": false,
|
| 41 |
+
"rstrip": false,
|
| 42 |
+
"single_word": false,
|
| 43 |
+
"special": false
|
| 44 |
+
},
|
| 45 |
+
"151648": {
|
| 46 |
+
"content": "<|box_start|>",
|
| 47 |
+
"lstrip": false,
|
| 48 |
+
"normalized": false,
|
| 49 |
+
"rstrip": false,
|
| 50 |
+
"single_word": false,
|
| 51 |
+
"special": false
|
| 52 |
+
},
|
| 53 |
+
"151649": {
|
| 54 |
+
"content": "<|box_end|>",
|
| 55 |
+
"lstrip": false,
|
| 56 |
+
"normalized": false,
|
| 57 |
+
"rstrip": false,
|
| 58 |
+
"single_word": false,
|
| 59 |
+
"special": false
|
| 60 |
+
},
|
| 61 |
+
"151650": {
|
| 62 |
+
"content": "<|quad_start|>",
|
| 63 |
+
"lstrip": false,
|
| 64 |
+
"normalized": false,
|
| 65 |
+
"rstrip": false,
|
| 66 |
+
"single_word": false,
|
| 67 |
+
"special": false
|
| 68 |
+
},
|
| 69 |
+
"151651": {
|
| 70 |
+
"content": "<|quad_end|>",
|
| 71 |
+
"lstrip": false,
|
| 72 |
+
"normalized": false,
|
| 73 |
+
"rstrip": false,
|
| 74 |
+
"single_word": false,
|
| 75 |
+
"special": false
|
| 76 |
+
},
|
| 77 |
+
"151652": {
|
| 78 |
+
"content": "<|vision_start|>",
|
| 79 |
+
"lstrip": false,
|
| 80 |
+
"normalized": false,
|
| 81 |
+
"rstrip": false,
|
| 82 |
+
"single_word": false,
|
| 83 |
+
"special": true
|
| 84 |
+
},
|
| 85 |
+
"151653": {
|
| 86 |
+
"content": "<|vision_end|>",
|
| 87 |
+
"lstrip": false,
|
| 88 |
+
"normalized": false,
|
| 89 |
+
"rstrip": false,
|
| 90 |
+
"single_word": false,
|
| 91 |
+
"special": true
|
| 92 |
+
},
|
| 93 |
+
"151654": {
|
| 94 |
+
"content": "<|vision_pad|>",
|
| 95 |
+
"lstrip": false,
|
| 96 |
+
"normalized": false,
|
| 97 |
+
"rstrip": false,
|
| 98 |
+
"single_word": false,
|
| 99 |
+
"special": true
|
| 100 |
+
},
|
| 101 |
+
"151655": {
|
| 102 |
+
"content": "<|image_pad|>",
|
| 103 |
+
"lstrip": false,
|
| 104 |
+
"normalized": false,
|
| 105 |
+
"rstrip": false,
|
| 106 |
+
"single_word": false,
|
| 107 |
+
"special": true
|
| 108 |
+
},
|
| 109 |
+
"151656": {
|
| 110 |
+
"content": "<|video_pad|>",
|
| 111 |
+
"lstrip": false,
|
| 112 |
+
"normalized": false,
|
| 113 |
+
"rstrip": false,
|
| 114 |
+
"single_word": false,
|
| 115 |
+
"special": true
|
| 116 |
+
},
|
| 117 |
+
"151657": {
|
| 118 |
+
"content": "<tool_call>",
|
| 119 |
+
"lstrip": false,
|
| 120 |
+
"normalized": false,
|
| 121 |
+
"rstrip": false,
|
| 122 |
+
"single_word": false,
|
| 123 |
+
"special": false
|
| 124 |
+
},
|
| 125 |
+
"151658": {
|
| 126 |
+
"content": "</tool_call>",
|
| 127 |
+
"lstrip": false,
|
| 128 |
+
"normalized": false,
|
| 129 |
+
"rstrip": false,
|
| 130 |
+
"single_word": false,
|
| 131 |
+
"special": false
|
| 132 |
+
},
|
| 133 |
+
"151659": {
|
| 134 |
+
"content": "<|fim_prefix|>",
|
| 135 |
+
"lstrip": false,
|
| 136 |
+
"normalized": false,
|
| 137 |
+
"rstrip": false,
|
| 138 |
+
"single_word": false,
|
| 139 |
+
"special": false
|
| 140 |
+
},
|
| 141 |
+
"151660": {
|
| 142 |
+
"content": "<|fim_middle|>",
|
| 143 |
+
"lstrip": false,
|
| 144 |
+
"normalized": false,
|
| 145 |
+
"rstrip": false,
|
| 146 |
+
"single_word": false,
|
| 147 |
+
"special": false
|
| 148 |
+
},
|
| 149 |
+
"151661": {
|
| 150 |
+
"content": "<|fim_suffix|>",
|
| 151 |
+
"lstrip": false,
|
| 152 |
+
"normalized": false,
|
| 153 |
+
"rstrip": false,
|
| 154 |
+
"single_word": false,
|
| 155 |
+
"special": false
|
| 156 |
+
},
|
| 157 |
+
"151662": {
|
| 158 |
+
"content": "<|fim_pad|>",
|
| 159 |
+
"lstrip": false,
|
| 160 |
+
"normalized": false,
|
| 161 |
+
"rstrip": false,
|
| 162 |
+
"single_word": false,
|
| 163 |
+
"special": false
|
| 164 |
+
},
|
| 165 |
+
"151663": {
|
| 166 |
+
"content": "<|repo_name|>",
|
| 167 |
+
"lstrip": false,
|
| 168 |
+
"normalized": false,
|
| 169 |
+
"rstrip": false,
|
| 170 |
+
"single_word": false,
|
| 171 |
+
"special": false
|
| 172 |
+
},
|
| 173 |
+
"151664": {
|
| 174 |
+
"content": "<|file_sep|>",
|
| 175 |
+
"lstrip": false,
|
| 176 |
+
"normalized": false,
|
| 177 |
+
"rstrip": false,
|
| 178 |
+
"single_word": false,
|
| 179 |
+
"special": false
|
| 180 |
+
},
|
| 181 |
+
"151665": {
|
| 182 |
+
"content": "<tool_response>",
|
| 183 |
+
"lstrip": false,
|
| 184 |
+
"normalized": false,
|
| 185 |
+
"rstrip": false,
|
| 186 |
+
"single_word": false,
|
| 187 |
+
"special": false
|
| 188 |
+
},
|
| 189 |
+
"151666": {
|
| 190 |
+
"content": "</tool_response>",
|
| 191 |
+
"lstrip": false,
|
| 192 |
+
"normalized": false,
|
| 193 |
+
"rstrip": false,
|
| 194 |
+
"single_word": false,
|
| 195 |
+
"special": false
|
| 196 |
+
},
|
| 197 |
+
"151667": {
|
| 198 |
+
"content": "<think>",
|
| 199 |
+
"lstrip": false,
|
| 200 |
+
"normalized": false,
|
| 201 |
+
"rstrip": false,
|
| 202 |
+
"single_word": false,
|
| 203 |
+
"special": false
|
| 204 |
+
},
|
| 205 |
+
"151668": {
|
| 206 |
+
"content": "</think>",
|
| 207 |
+
"lstrip": false,
|
| 208 |
+
"normalized": false,
|
| 209 |
+
"rstrip": false,
|
| 210 |
+
"single_word": false,
|
| 211 |
+
"special": false
|
| 212 |
+
},
|
| 213 |
+
"151669": {
|
| 214 |
+
"content": "<|point_start|>",
|
| 215 |
+
"lstrip": false,
|
| 216 |
+
"normalized": false,
|
| 217 |
+
"rstrip": false,
|
| 218 |
+
"single_word": false,
|
| 219 |
+
"special": false
|
| 220 |
+
},
|
| 221 |
+
"151670": {
|
| 222 |
+
"content": "<|point_end|>",
|
| 223 |
+
"lstrip": false,
|
| 224 |
+
"normalized": false,
|
| 225 |
+
"rstrip": false,
|
| 226 |
+
"single_word": false,
|
| 227 |
+
"special": false
|
| 228 |
+
},
|
| 229 |
+
"151671": {
|
| 230 |
+
"content": "<|ocr_text_start|>",
|
| 231 |
+
"lstrip": false,
|
| 232 |
+
"normalized": false,
|
| 233 |
+
"rstrip": false,
|
| 234 |
+
"single_word": false,
|
| 235 |
+
"special": false
|
| 236 |
+
},
|
| 237 |
+
"151672": {
|
| 238 |
+
"content": "<|ocr_text_end|>",
|
| 239 |
+
"lstrip": false,
|
| 240 |
+
"normalized": false,
|
| 241 |
+
"rstrip": false,
|
| 242 |
+
"single_word": false,
|
| 243 |
+
"special": false
|
| 244 |
+
},
|
| 245 |
+
"151673": {
|
| 246 |
+
"content": "<|clip_time_start|>",
|
| 247 |
+
"lstrip": false,
|
| 248 |
+
"normalized": false,
|
| 249 |
+
"rstrip": false,
|
| 250 |
+
"single_word": false,
|
| 251 |
+
"special": false
|
| 252 |
+
},
|
| 253 |
+
"151674": {
|
| 254 |
+
"content": "<|clip_time_end|>",
|
| 255 |
+
"lstrip": false,
|
| 256 |
+
"normalized": false,
|
| 257 |
+
"rstrip": false,
|
| 258 |
+
"single_word": false,
|
| 259 |
+
"special": false
|
| 260 |
+
}
|
| 261 |
+
},
|
| 262 |
+
"additional_special_tokens": [
|
| 263 |
+
"<|im_start|>",
|
| 264 |
+
"<|im_end|>",
|
| 265 |
+
"<|vision_start|>",
|
| 266 |
+
"<|vision_end|>",
|
| 267 |
+
"<|vision_pad|>",
|
| 268 |
+
"<|image_pad|>",
|
| 269 |
+
"<|video_pad|>"
|
| 270 |
+
],
|
| 271 |
+
"bos_token": null,
|
| 272 |
+
"chat_template": "{% set image_count = namespace(value=0) %}{% set video_count = namespace(value=0) %}{% for message in messages %}<|im_start|>{{ message['role'] }}\n{% if message['content'] is string %}{{ message['content'] }}<|im_end|>\n{% else %}{% for content in message['content'] %}{% if content['type'] == 'image' or 'image' in content or 'image_url' in content %}{% set image_count.value = image_count.value + 1 %}{% if add_vision_id %}Picture {{ image_count.value }}: {% endif %}<|vision_start|><|image_pad|><|vision_end|>{% elif content['type'] == 'video' or 'video' in content %}{% set video_count.value = video_count.value + 1 %}{% if add_vision_id %}Video {{ video_count.value }}: {% endif %}<|vision_start|><|video_pad|><|vision_end|>{% elif 'text' in content %}{{ content['text'] }}{% endif %}{% endfor %}<|im_end|>\n{% endif %}{% endfor %}{% if add_generation_prompt %}<|im_start|>assistant\n{% endif %}",
|
| 273 |
+
"clean_up_tokenization_spaces": false,
|
| 274 |
+
"eos_token": "<|im_end|>",
|
| 275 |
+
"errors": "replace",
|
| 276 |
+
"model_max_length": 131072,
|
| 277 |
+
"pad_token": "<|endoftext|>",
|
| 278 |
+
"split_special_tokens": false,
|
| 279 |
+
"tokenizer_class": "Qwen2Tokenizer",
|
| 280 |
+
"unk_token": null
|
| 281 |
+
}
|
| 282 |
+
|
vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|