
Kwai Keye-VL 1.5 Technical Report
Paper
• 2509.01563 • Published
• 38
While Multimodal Large Language Models (MLLMs) demonstrate remarkable capabilities on static images, they often fall short in comprehending dynamic, information-dense short-form videos, a dominant medium in today's digital landscape. To bridge this gap, we introduce Kwai Keye-VL, an 8-billion-parameter multimodal foundation model engineered for leading-edge performance in short-video understanding while maintaining robust general-purpose vision-language abilities. The development of Keye-VL rests on two core pillars: a massive, high-quality dataset exceeding 600 billion tokens with a strong emphasis on video, and an innovative training recipe. This recipe features a four-stage pre-training process for solid vision-language alignment, followed by a meticulous two-phase post-training process. The first post-training stage enhances foundational capabilities like instruction following, while the second phase focuses on stimulating advanced reasoning. In this second phase, a key innovation is our five-mode cold-start'' data mixture, which includes thinking'', non-thinking'', auto-think'', ``think with image'', and high-quality video data. This mixture teaches the model to decide when and how to reason. Subsequent reinforcement learning (RL) and alignment steps further enhance these reasoning capabilities and correct abnormal model behaviors, such as repetitive outputs. To validate our approach, we conduct extensive evaluations, showing that Keye-VL achieves state-of-the-art results on public video benchmarks and remains highly competitive on general image-based tasks (Figure 1). Furthermore, we develop and release the KC-MMBench, a new benchmark tailored for real-world short-video scenarios, where Keye-VL shows a significant advantage.
2025.06.26 🌟 We are very proud to launch Kwai Keye-VL, a cutting-edge multimodal large language model meticulously crafted by the Kwai Keye Team at Kuaishou. As a cornerstone AI product within Kuaishou's advanced technology ecosystem, Keye excels in video understanding, visual perception, and reasoning tasks, setting new benchmarks in performance. Our team is working tirelessly to push the boundaries of what's possible, so stay tuned for more exciting updates!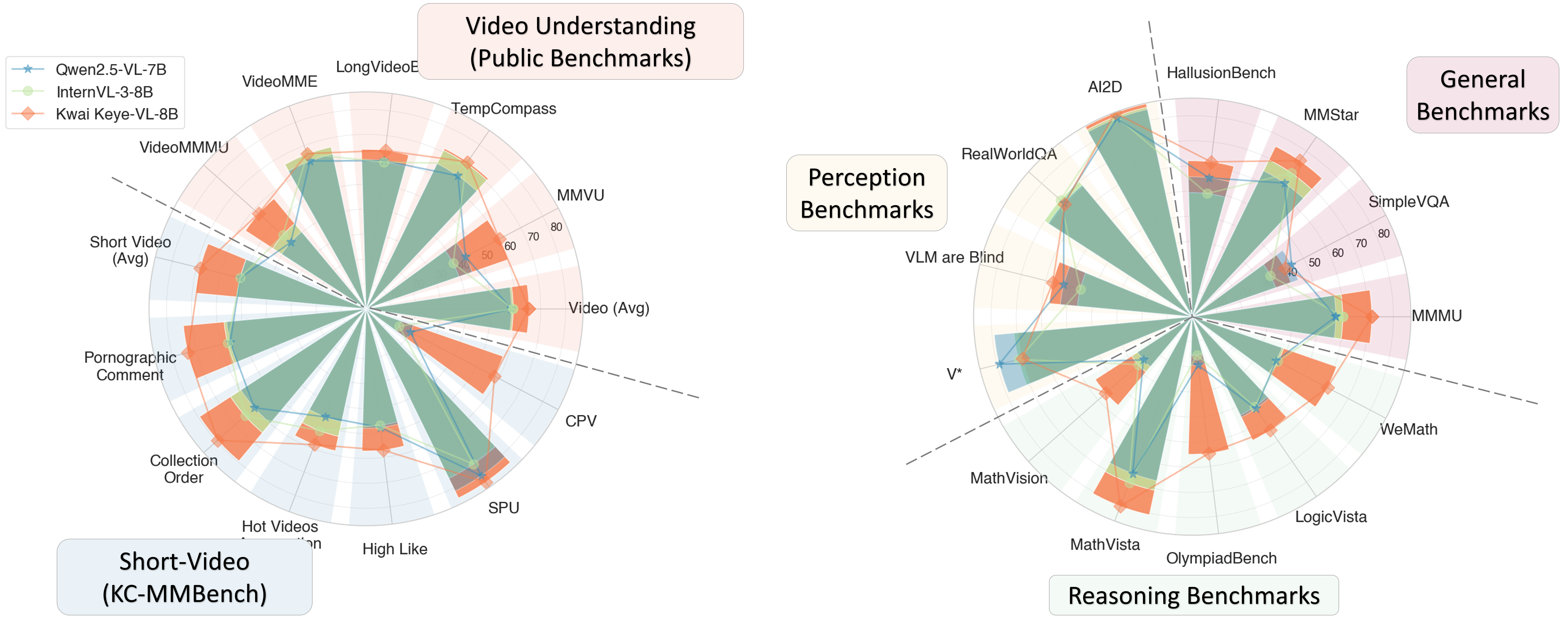
Below, we provide simple examples to show how to use Kwai Keye-VL with 🤗 Transformers.
The code of Kwai Keye-VL has been in the latest Hugging face transformers and we advise you to build from source with command:
pip install git+https://github.com/huggingface/transformers accelerate
We offer a toolkit to help you handle various types of visual input more conveniently, as if you were using an API. This includes base64, URLs, and interleaved images and videos. You can install it using the following command:
# It's highly recommanded to use `[decord]` feature for faster video loading.
pip install "keye-vl-utils[decord]==1.0.0"
If you are not using Linux, you might not be able to install decord from PyPI. In that case, you can use pip install keye-vl-utils which will fall back to using torchvision for video processing. However, you can still install decord from source to get decord used when loading video.
Here we show a code snippet to show you how to use the chat model with transformers and keye_vl_utils:
Following Qwen3, we also offer a soft switch mechanism that lets users dynamically control the model's behavior. You can add /think, /no_think, or nothing to user prompts to switch the model's thinking modes.
from transformers import AutoModel, AutoTokenizer, AutoProcessor
from keye_vl_utils import process_vision_info
# default: Load the model on the available device(s)
model_path = "Kwai-Keye/Keye-VL-8B-Preview"
model = AutoModel.from_pretrained(
model_path,
torch_dtype="auto",
device_map="auto",
trust_remote_code=True,
)
# We recommend enabling flash_attention_2 for better acceleration and memory saving, especially in multi-image and video scenarios.
# model = KeyeForConditionalGeneration.from_pretrained(
# "Kwai-Keye/Keye-VL-8B-Preview",
# torch_dtype=torch.bfloat16,
# attn_implementation="flash_attention_2",
# device_map="auto",
# )
# default processer
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
# The default range for the number of visual tokens per image in the model is 4-16384.
# You can set min_pixels and max_pixels according to your needs, such as a token range of 256-1280, to balance performance and cost.
# min_pixels = 256*28*28
# max_pixels = 1280*28*28
# processor = AutoProcessor.from_pretrained(model_pat, min_pixels=min_pixels, max_pixels=max_pixels, trust_remote_code=True)
# Non-Thinking Mode
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://s1-11508.kwimgs.com/kos/nlav11508/mllm_all/ziran_jiafeimao_11.jpg",
},
{"type": "text", "text": "Describe this image./no_think"},
],
}
]
# Auto-Thinking Mode
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://s1-11508.kwimgs.com/kos/nlav11508/mllm_all/ziran_jiafeimao_11.jpg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Thinking mode
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://s1-11508.kwimgs.com/kos/nlav11508/mllm_all/ziran_jiafeimao_11.jpg",
},
{"type": "text", "text": "Describe this image./think"},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=1024)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
# Messages containing a images list as a video and a text query
messages = [
{
"role": "user",
"content": [
{
"type": "video",
"video": [
"file:///path/to/frame1.jpg",
"file:///path/to/frame2.jpg",
"file:///path/to/frame3.jpg",
"file:///path/to/frame4.jpg",
],
},
{"type": "text", "text": "Describe this video."},
],
}
]
# Messages containing a local video path and a text query
messages = [
{
"role": "user",
"content": [
{
"type": "video",
"video": "file:///path/to/video1.mp4",
"max_pixels": 360 * 420,
"fps": 1.0,
},
{"type": "text", "text": "Describe this video."},
],
}
]
# Messages containing a video url and a text query
messages = [
{
"role": "user",
"content": [
{
"type": "video",
"video": "http://s2-11508.kwimgs.com/kos/nlav11508/MLLM/videos_caption/98312843263.mp4",
},
{"type": "text", "text": "Describe this video."},
],
}
]
#In Keye-VL, frame rate information is also input into the model to align with absolute time.
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs, video_kwargs = process_vision_info(messages, return_video_kwargs=True)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
**video_kwargs,
)
inputs = inputs.to("cuda")
# Inference
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
Video URL compatibility largely depends on the third-party library version. The details are in the table below. change the backend by FORCE_KEYEVL_VIDEO_READER=torchvision or FORCE_KEYEVL_VIDEO_READER=decord if you prefer not to use the default one.
| Backend | HTTP | HTTPS |
|---|---|---|
| torchvision >= 0.19.0 | ✅ | ✅ |
| torchvision < 0.19.0 | ❌ | ❌ |
| decord | ✅ | ❌ |
# Sample messages for batch inference
messages1 = [
{
"role": "user",
"content": [
{"type": "image", "image": "file:///path/to/image1.jpg"},
{"type": "image", "image": "file:///path/to/image2.jpg"},
{"type": "text", "text": "What are the common elements in these pictures?"},
],
}
]
messages2 = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who are you?"},
]
# Combine messages for batch processing
messages = [messages1, messages2]
# Preparation for batch inference
texts = [
processor.apply_chat_template(msg, tokenize=False, add_generation_prompt=True)
for msg in messages
]
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=texts,
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Batch Inference
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_texts = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_texts)
For input images, we support local files, base64, and URLs. For videos, we currently only support local files.
# You can directly insert a local file path, a URL, or a base64-encoded image into the position where you want in the text.
## Local file path
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "file:///path/to/your/image.jpg"},
{"type": "text", "text": "Describe this image."},
],
}
]
## Image URL
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "http://path/to/your/image.jpg"},
{"type": "text", "text": "Describe this image."},
],
}
]
## Base64 encoded image
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "data:image;base64,/9j/..."},
{"type": "text", "text": "Describe this image."},
],
}
]
The model supports a wide range of resolution inputs. By default, it uses the native resolution for input, but higher resolutions can enhance performance at the cost of more computation. Users can set the minimum and maximum number of pixels to achieve an optimal configuration for their needs, such as a token count range of 256-1280, to balance speed and memory usage.
min_pixels = 256 * 28 * 28
max_pixels = 1280 * 28 * 28
processor = AutoProcessor.from_pretrained(
"Kwai-Keye/Keye-VL-8B-Preview", min_pixels=min_pixels, max_pixels=max_pixels
)
Besides, We provide two methods for fine-grained control over the image size input to the model:
Define min_pixels and max_pixels: Images will be resized to maintain their aspect ratio within the range of min_pixels and max_pixels.
Specify exact dimensions: Directly set resized_height and resized_width. These values will be rounded to the nearest multiple of 28.
# min_pixels and max_pixels
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "file:///path/to/your/image.jpg",
"resized_height": 280,
"resized_width": 420,
},
{"type": "text", "text": "Describe this image."},
],
}
]
# resized_height and resized_width
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "file:///path/to/your/image.jpg",
"min_pixels": 50176,
"max_pixels": 50176,
},
{"type": "text", "text": "Describe this image."},
],
}
]
 The Kwai Keye-VL model architecture is based on the Qwen3-8B language model and incorporates a vision encoder initialized from the open-source SigLIP. It supports native dynamic resolution, preserving the original aspect ratio of images by dividing each into a 14x14 patch sequence. A simple MLP layer then maps and merges the visual tokens. The model uses 3D RoPE for unified processing of text, image, and video information, establishing a one-to-one correspondence between position encoding and absolute time to ensure precise perception of temporal changes in video information.
The Kwai Keye-VL model architecture is based on the Qwen3-8B language model and incorporates a vision encoder initialized from the open-source SigLIP. It supports native dynamic resolution, preserving the original aspect ratio of images by dividing each into a 14x14 patch sequence. A simple MLP layer then maps and merges the visual tokens. The model uses 3D RoPE for unified processing of text, image, and video information, establishing a one-to-one correspondence between position encoding and absolute time to ensure precise perception of temporal changes in video information.
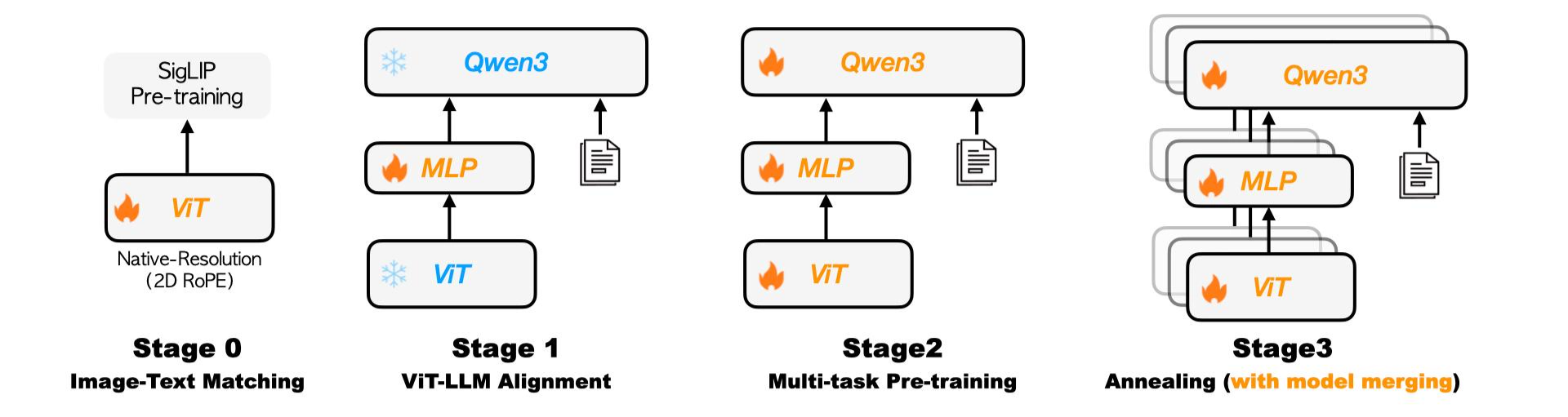 The Kwai Keye pre-training pipeline, featuring a four-stage progressive strategy: Image-Text Matching, ViT-LLM Alignment, Multi-task Pre-training, and Annealing with model merging.
The Kwai Keye pre-training pipeline, featuring a four-stage progressive strategy: Image-Text Matching, ViT-LLM Alignment, Multi-task Pre-training, and Annealing with model merging.
Kwai Keye-VL adopts a four-stage progressive training strategy:
Finally, Kwai Keye-VL explores isomorphic heterogeneous fusion technology by averaging parameters of annealed training models with different data ratios, reducing model bias while retaining multidimensional capabilities, thereby enhancing the model's robustness.
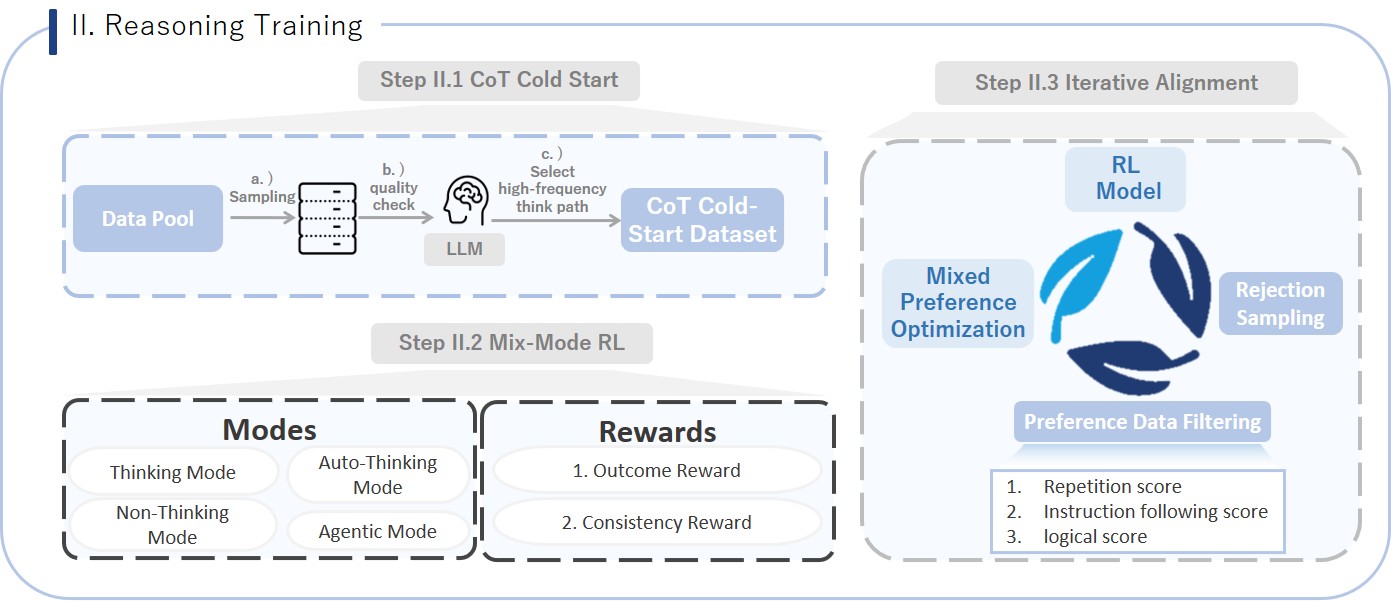
The post-training phase of Kwai Keye is meticulously designed into two phases with five stages, aiming to comprehensively enhance the model's performance, especially its reasoning ability in complex tasks. This is a key breakthrough for achieving advanced cognitive functions.
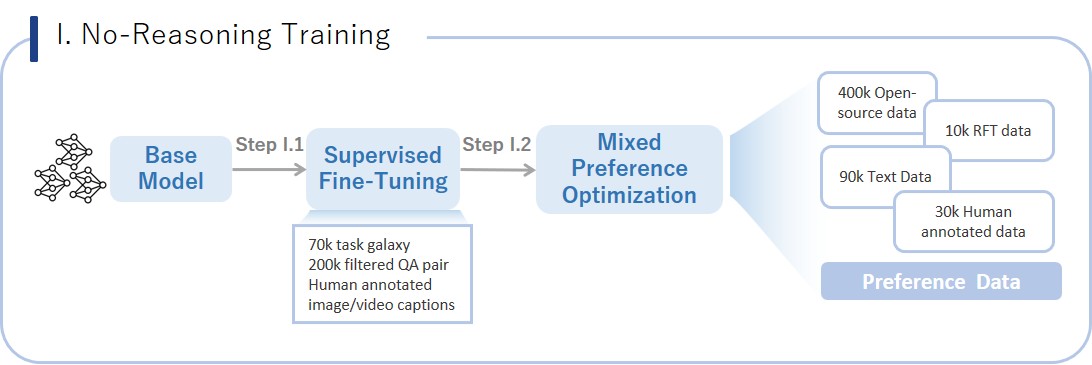 This phase focuses on the model's basic performance and stability in non-reasoning scenarios.
This phase focuses on the model's basic performance and stability in non-reasoning scenarios.
Stage II.1: Supervised Fine-Tuning (SFT)
Stage II.2: Mixed Preference Optimization (MPO)
If you find our work helpful for your research, please consider citing our work.
@misc{kwaikeyeteam2025kwaikeyevltechnicalreport,
title={Kwai Keye-VL Technical Report},
author={Kwai Keye Team},
year={2025},
eprint={2507.01949},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2507.01949},
}
Kwai Keye-VL is developed based on the codebases of the following projects: SigLIP, Qwen3, Qwen2.5-VL, VLMEvalKit. We sincerely thank these projects for their outstanding work.