
Bamboo Nano
This is a WIP foundational (aka base) model trained only on public domain (CC0) datasets, primarily in the English language. The primary goal of this model is to see how a limited tokenizer influences model training speed & coherency.
Further training is planned & ongoing, but currently no multi-language datasets are in use or planned; though this may change in the future and the current datasets can contain languages other than English.
License
Though the training data of this model is CC0, the model itself is not. The model is released under the OpenRAIL license, as tagged.
Planned updates
As mentioned, a few updates are planned:
- Experiment with extending the context length using YaRN to 32k tokens.
- Fine-tuning the resulting model for instruct, code and storywriting. These will then be combined using MergeKit to create a MoE model.
Model Performance Tracking
This table tracks the performance of our model on various tasks over time. The metric used is 'acc'.
| Date (YYYY-MM-DD) | arc_easy | hellaswag | sglue_rte | truthfulqa | preplexity (wikitext) | Avg |
|---|
Legend
- Date: The date of the model that the evaluation was run on. Pretraining is ongoing and tests are re-run with that date's model.
- Metric: The evaluation metric used (acc = accuracy)
- Task columns: Results for each task in the format "Percentage ± Standard Error"
Notes
- All accuracy values are presented as percentages
- Empty cells indicate that the task was not evaluated on that date or for that metric
- Standard errors are also converted to percentages for consistency
- Averages do not include preplexity scores.
Tokenizer
Our tokenizer was trained from scratch on 500,000 samples from the Openwebtext dataset. For variation, we also included 250,000 samples from our GitHub-CC0 dataset, in the hopes that code would be tokenized properly despite our small vocab_size. Like Mistral, we use the LlamaTokenizerFast as our tokenizer class; in legacy mode.
Our vocabulary size is 5100 tokens. A far cry from larger model's sizes of typically 32000 or greater.
Tokenization Analysis
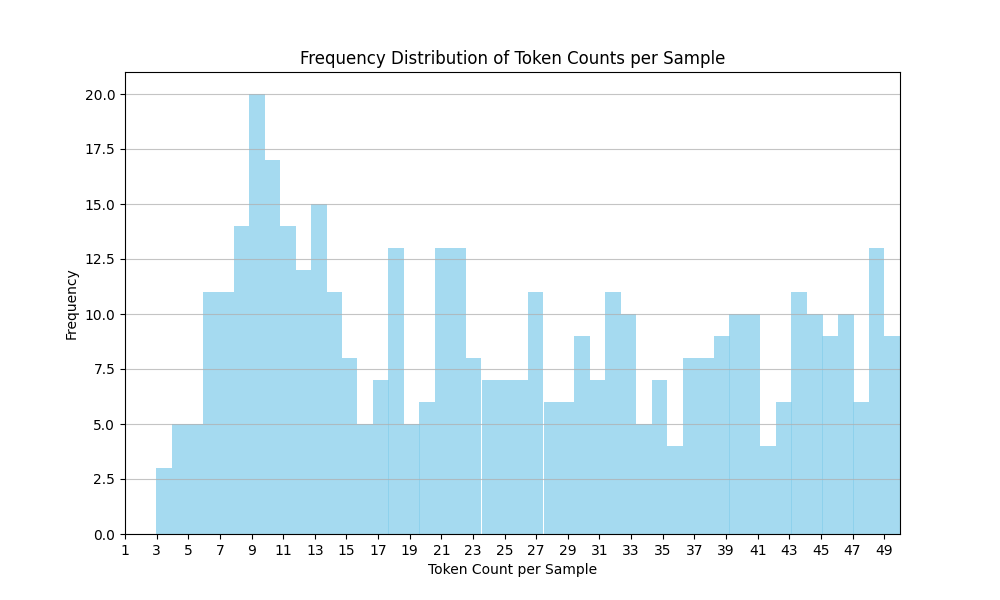
A histogram of the token counts per sample in the dataset reveals some interesting insights:
- Bimodal Distribution: The graph shows a bimodal distribution, with a primary peak around 11-12 tokens per sample and a secondary peak around 15-16 tokens per sample. This suggests there are two distinct groups of samples with different token count characteristics.
- Long Tail: The distribution has a long tail, with a number of samples containing 25-50 tokens. This indicates the presence of some outlier samples with significantly longer text lengths compared to the bulk of the data.
- Vocab Size Limitations: Given the small vocabulary size of 5,100, the tokenizer may struggle to efficiently encode longer or more complex text samples. This could lead to higher token counts for some inputs, as the tokenizer needs to use more tokens to represent the same content.
- Potential Data Heterogeneity: The bimodal nature of the distribution suggests the dataset may be comprised of different types of text content, with some samples being more concise and others being more verbose. This could be an artifact of the data curation process or the nature of the source material.
Comparison to Other Datasets
When comparing the token count statistics to another dataset, OpenWebText (OWT), some key differences emerge:
GitHub Dataset:
- Average token length: 1,510.87
- Average original text length (characters): 3583.65
- Token to Character Ratio: 0.42
OpenWebText (OWT) Dataset:
- Average token length: 76.60
- Average original text length (characters): 213.18
- Token to Character Ratio: 0.36
The significantly higher average token length and token-to-character ratio for the GitHub dataset compared to OWT indicates the GitHub samples contain much longer and more verbose text. This aligns with the bimodal distribution and long tail observed in the histogram, which suggests the dataset contains a mix of both concise and more complex, lengthier text samples.
Conclusions
This analysis highlights the challenges of using a limited vocabulary tokenizer on a diverse dataset with varying text complexity. The bimodal distribution and long tail in the token count histogram suggest the tokenizer may not be optimally suited for the full range of text samples, leading to increased token counts for some inputs. Further investigation into the dataset composition and tokenizer performance may be warranted to understand how the vocabulary size impacts the model's ability to efficiently represent the text.
- Downloads last month
- 23