
MotionCLR: Motion Generation and Training-free Editing via Understanding Attention Mechanisms
Ling-Hao Chen, Wenxun Dai, Xuan Ju, Shunlin Lu, Lei Zhang
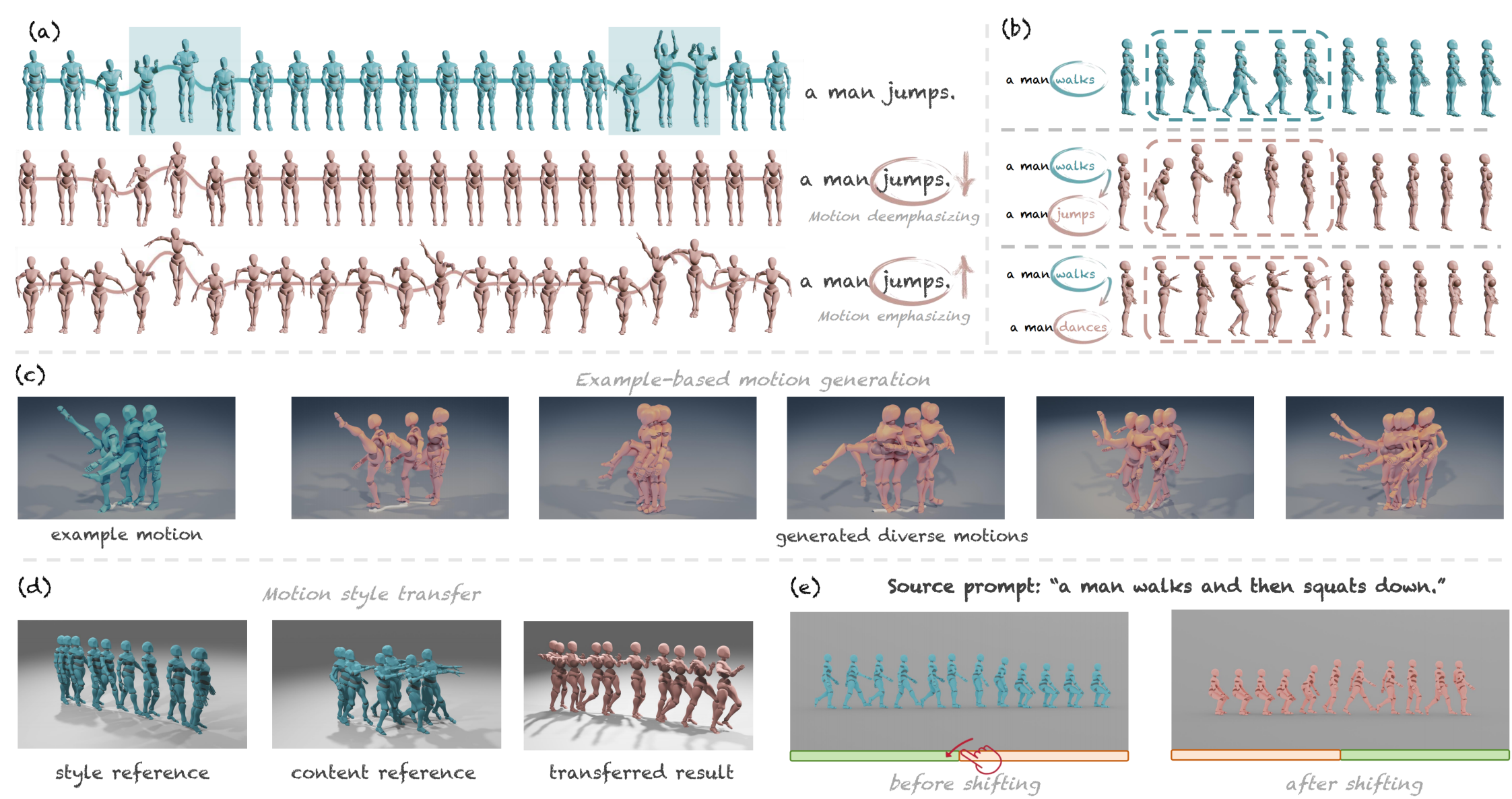
🤩 Abstract
This research delves into analyzing the attention mechanism of diffusion models in human motion generation. Previous motion diffusion models lack explicit modeling of the word-level text-motion correspondence and explainability. Regarding these issues, we propose an attention-based motion diffusion model, namely MotionCLR, with CLeaR modeling of attention mechanisms. Based on the proposed model, we thoroughly analyze the formulation of the attention mechanism theoretically and empirically. Importantly, we highlight that the self-attention mechanism works to find the fine-grained word-sequence correspondence and activate the corresponding timesteps in the motion sequence. Besides, the cross-attention mechanism aims to measure the sequential similarity between frames and order the sequentiality of motion features. Motivated by these key insights, we propose versatile simple yet effective motion editing methods via manipulating attention maps, such as motion (de)-emphasizing, in-place motion replacement, and example-based motion generation etc.. For further verification of the explainability of the attention mechanism, we additionally explore the potential of action-counting and grounded motion generation ability via attention maps.
- 📌 Due to some issues with latest gradio 5, MotionCLR v1-preview huggingface demo for motion editing will be supported next week.
📢 News
- [2024-11-014] MotionCLR v1-preview demo is released at HuggingFace.
- [2024-10-25] Project, code, and paper are released.
☕️ Preparation
Environment preparation
conda create python=3.10 --name motionclr
conda activate motionclr
pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 --extra-index-url https://download.pytorch.org/whl/cu113
pip install -r requirements.txt
Dependencies
If you have the sudo permission, install ffmpeg for visualizing stick figure (if not already installed):
sudo apt update
sudo apt install ffmpeg
ffmpeg -version # check!
If you do not have the sudo permission to install it, please install it via conda:
conda install conda-forge::ffmpeg
ffmpeg -version # check!
Run the following command to install git-lfs:
conda install conda-forge::git-lfs
Run the script to download dependencies materials:
bash prepare/download_glove.sh
bash prepare/download_t2m_evaluators.sh
Dataset preparation
Please refer to HumanML3D for text-to-motion dataset setup. Copy the result dataset to our repository:
cp -r ../HumanML3D/HumanML3D ./datasets/humanml3d
The unofficial method of data preparation can be found in this issue.
Pretrained Model
from huggingface_hub import hf_hub_download
ckptdir = './checkpoints/t2m/release'
mean_path = hf_hub_download(
repo_id="EvanTHU/MotionCLR",
filename="meta/mean.npy",
local_dir=ckptdir,
local_dir_use_symlinks=False
)
std_path = hf_hub_download(
repo_id="EvanTHU/MotionCLR",
filename="meta/std.npy",
local_dir=ckptdir,
local_dir_use_symlinks=False
)
model_path = hf_hub_download(
repo_id="EvanTHU/MotionCLR",
filename="model/latest.tar",
local_dir=ckptdir,
local_dir_use_symlinks=False
)
opt_path = hf_hub_download(
repo_id="EvanTHU/MotionCLR",
filename="opt.txt",
local_dir=ckptdir,
local_dir_use_symlinks=False
)
The downloaded files will be saved in the checkpoints/t2m/release/ directory as follows:
checkpoints/
└── t2m
├── release
│ ├── meta
│ │ ├── mean.npy
│ │ └── std.npy
│ ├── model
│ │ └── latest.tar
│ └── opt.txt
Folder Structure
After the whole setup pipeline, the folder structure will look like:
MotionCLR
└── data
├── glove
│ ├── our_vab_data.npy
│ ├── our_vab_idx.pkl
│ └── out_vab_words.pkl
├── pretrained_models
│ ├── t2m
│ │ ├── text_mot_match
│ │ │ └── model
│ │ │ └── finest.tar
│ │ └── length_est_bigru
│ │ └── model
│ │ └── finest.tar
├── HumanML3D
│ ├── new_joint_vecs
│ │ └── ...
│ ├── new_joints
│ │ └── ...
│ ├── texts
│ │ └── ...
│ ├── Mean.npy
│ ├── Std.npy
│ ├── test.txt
│ ├── train_val.txt
│ ├── train.txt
│ └── val.txt
|── t2m_mean.npy
|── t2m_std.npy
👨🏫 Quick Start
Training
bash train.sh
Testing for Evaluation
bash test.sh
Generate Results from Text
Please replace $EXP_DIR with the experiment directory name.
Generate motion from a set of text prompts (
./assets/prompts-replace.txt), each line is a prompt. (results will be saved in./checkpoints/t2m/$EXP_DIR/samples_*/)python -m scripts.generate --input_text ./assets/prompts-replace.txt \ --motion_length 8 \ --self_attention \ --no_eff \ --edit_mode \ --opt_path ./checkpoints/t2m/$EXP_DIR/opt.txtExplanation of the arguments
--input_text: the path to the text file containing prompts.--motion_length: the length (s) of the generated motion.--self_attention: use self-attention mechanism.--no_eff: do not use efficient attention.--edit_mode: enable editing mode.--opt_path: the path to the trained models.
Generate motion from a prompt. (results will be saved in
./checkpoints/t2m/$EXP_DIR/samples_*/)python -m scripts.generate --text_prompt "a man jumps." --motion_length 8 --self_attention --no_eff --opt_path ./checkpoints/t2m/$EXP_DIR/opt.txtExplanation of the arguments
--text_prompt: the text prompt.--motion_length: the length (s) of the generated motion.--self_attention: use self-attention mechanism.--no_eff: do not use efficient attention.--opt_path: the path to the trained models.--vis_attn: visualize attention maps. (save in./checkpoints/t2m/$EXP_DIR/vis_attn/)
Other arguments
--vis_attn: visualize attention maps.
🔧 Downstream Editing Applications
Deploy the demo locally
Our project is supported by the latest Gradio 5, which provides a user-friendly interface for motion editing. The demo is available at HuggingFace. If you want to run the demo locally, please refer to the following instructions:
pip install gradio --upgrade
Launch the demo:
python app.py
Interaction with commands
You can also use generate or edit the motion via command line. The command is the same as the generation command:
python -m scripts.generate --input_text ./assets/prompts-replace.txt \
--motion_length 8 \
--self_attention \
--no_eff \
--edit_mode \
--opt_path ./checkpoints/t2m/$EXP_DIR/opt.txt
Besides, you also need to edit the configuration in ./options/edit.yaml to specify the editing mode. The detailed clarification of the configuration can be found in the comment of the configuration file.
🌹 Acknowledgement
The author team would like to acknowledge Dr. Jingbo Wang from Shanghai AI Laboratory and Dr. Xingyu Chen from Peking University for his constructive suggestions and discussions on downstream applications. We also would like to acknowledge Mr. Hongyang Li and Mr. Zhenhua Yang from SCUT for their detailed discussion on some technical details and writing. Mr. Bohong Chen from ZJU also provided us with insightful feedback on the evaluation and the presentations. We convey our thanks to all of them.
We would like to thank the authors of the following repositories for their excellent work: HumanML3D, UniMoCap, joints2smpl, HumanTOMATO, MotionLCM, StableMoFusion.
📜 Citation
If you find this work useful, please consider citing our paper:
@article{motionclr,
title={MotionCLR: Motion Generation and Training-free Editing via Understanding Attention Mechanisms},
author={Chen, Ling-Hao and Dai, Wenxun and Ju, Xuan and Lu, Shunlin and Zhang, Lei},
journal={arxiv:2410.18977},
year={2024}
}
📚 License
This code is distributed under an IDEA LICENSE, which not allowed for commercial usage. Note that our code depends on other libraries and datasets which each have their own respective licenses that must also be followed.
Model tree for EvanTHU/MotionCLR
Unable to build the model tree, the base model loops to the model itself. Learn more.