
ArliAI/QwQ-32B-ArliAI-RpR-v1 - EXL2 5.0bpw

=====================================
This is a 5.0bpw EXL2 quant of ArliAI/QwQ-32B-ArliAI-RpR-v1
Details about the model can be found at the above model page.
Perplexity Scoring
Below are the perplexity scores for the EXL2 models. A lower score is better.
| Quant Level | Perplexity Score |
|---|---|
| 8.0 | 5.9040 |
| 7.0 | 5.9073 |
| 6.0 | 5.9098 |
| 5.0 | 5.9317 |
| 4.5 | 5.9584 |
| 4.0 | 6.0451 |
How to use reasoning models correctly in ST
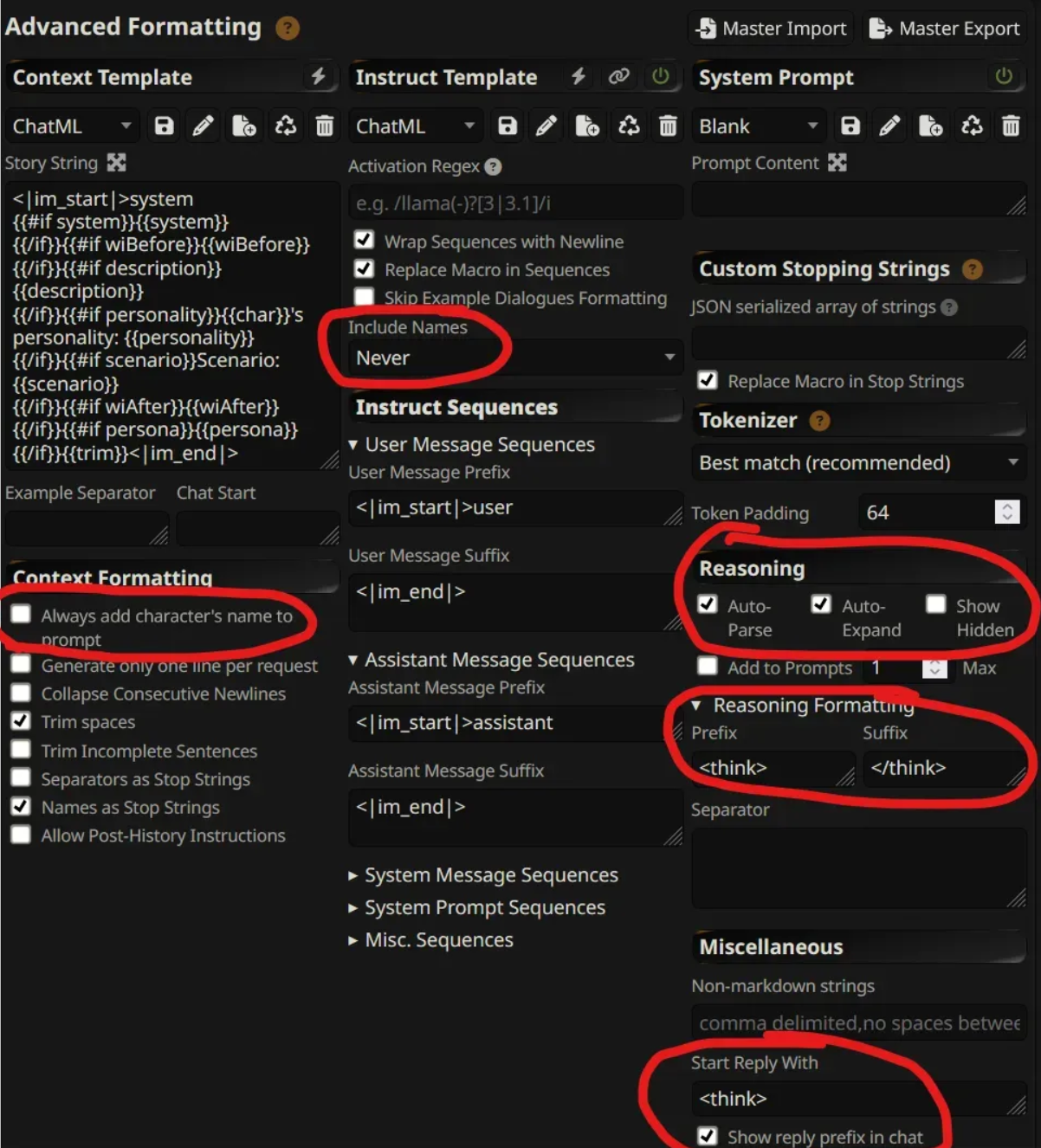
For any reasoning models in general, you need to make sure to set:
Prefix is set to ONLY and the suffix is set to ONLY without any spaces or newlines (enter)
Reply starts with
Always add character names is unchecked
Include names is set to never
As always the chat template should also conform to the model being used
Note: Reasoning models work properly only if include names is set to never, since they always expect the eos token of the user turn followed by the token in order to start reasoning before outputting their response. If you set include names to enabled, then it will always append the character name at the end like "Seraphina:" which confuses the model on whether it should respond or reason first.
The rest of your sampler parameters can be set as you wish as usual.
If you don't see the reasoning wrapped inside the thinking block, then either your settings is still wrong and doesn't follow my example or that your ST version is too old without reasoning block auto parsing.
If you see the whole response is in the reasoning block, then your and reasoning token suffix and prefix might have an extra space or newline. Or the model just isn't a reasoning model that is smart enough to always put reasoning in between those tokens.
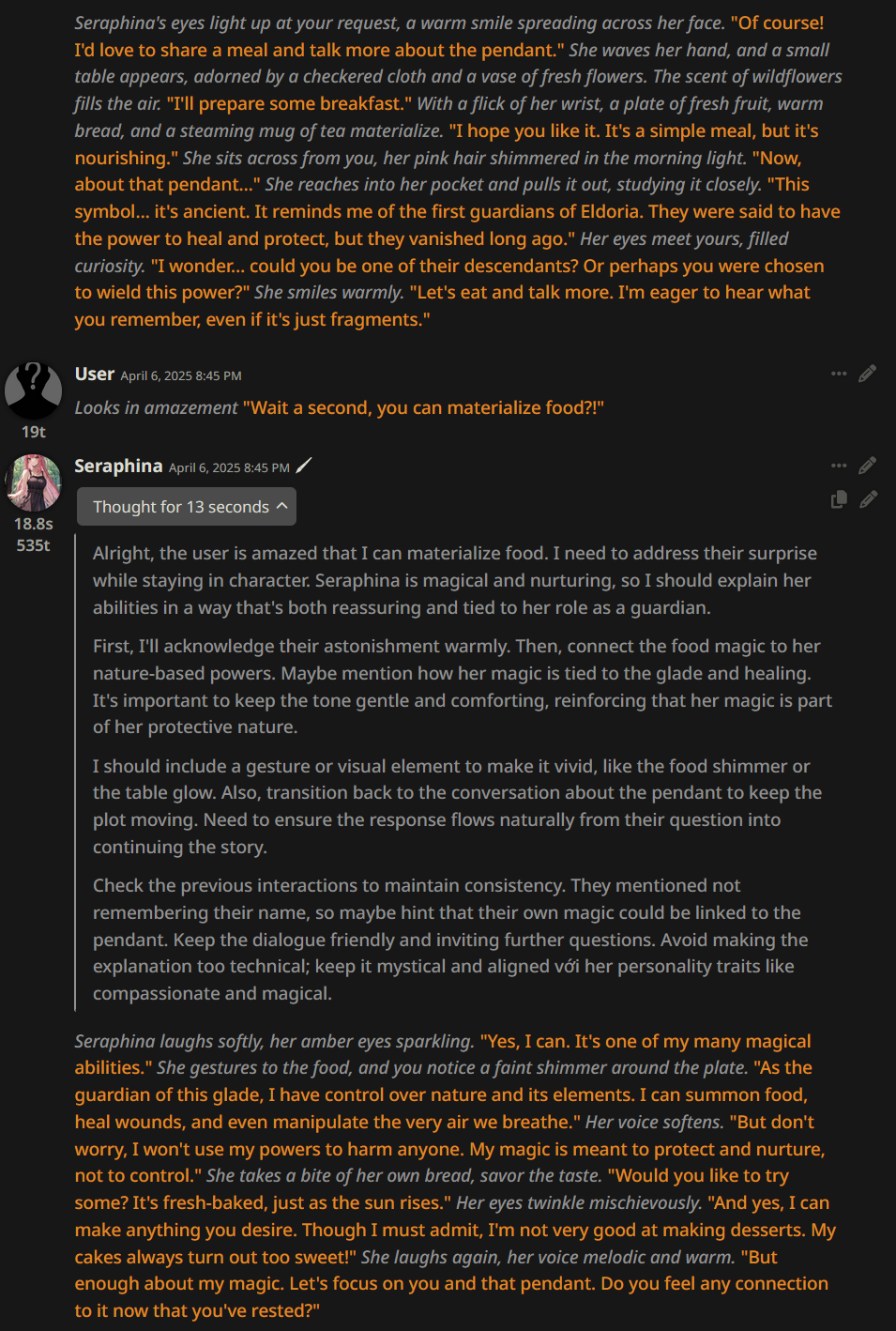
If you set everything up correctly, it should look like this:
- Downloads last month
- 9