Qwen3-Polaris-Preview-128k-6B-Brainstorm20x
This repo contains the full precision source code, in "safe tensors" format to generate GGUFs, GPTQ, EXL2, AWQ, HQQ and other formats.
The source code can also be used directly.
This model contains Brainstorm 20x, combined with POLARIS-Project's 4B General / Coder (instruct model):
https://huggingface.co/POLARIS-Project/Polaris-4B-Preview
Information on the 4B model below, followed by Brainstorm 20x adapter (by DavidAU) and then a complete help
section for running LLM / AI models.
The Brainstorm adapter improves code generation, and unique code solving abilities.
This model requires:
- Jinja (embedded) or CHATML template
- Max context of 128k.
Settings used for testing (suggested):
- Temp .3 to .7
- Rep pen 1.05 to 1.1
- Topp .8 , minp .05
- Topk 20
- No system prompt.
This model will respond well to both detailed instructions and step by step refinement and additions to code.
As this is an instruct model, it will also benefit from a detailed system prompt too.
For simpler coding problems, lower quants will work well; but for complex/multi-step problem solving suggest Q6 or Q8.
POLARIS
🌠 A POst-training recipe for scaling RL on Advanced ReasonIng modelS 🚀
Overview
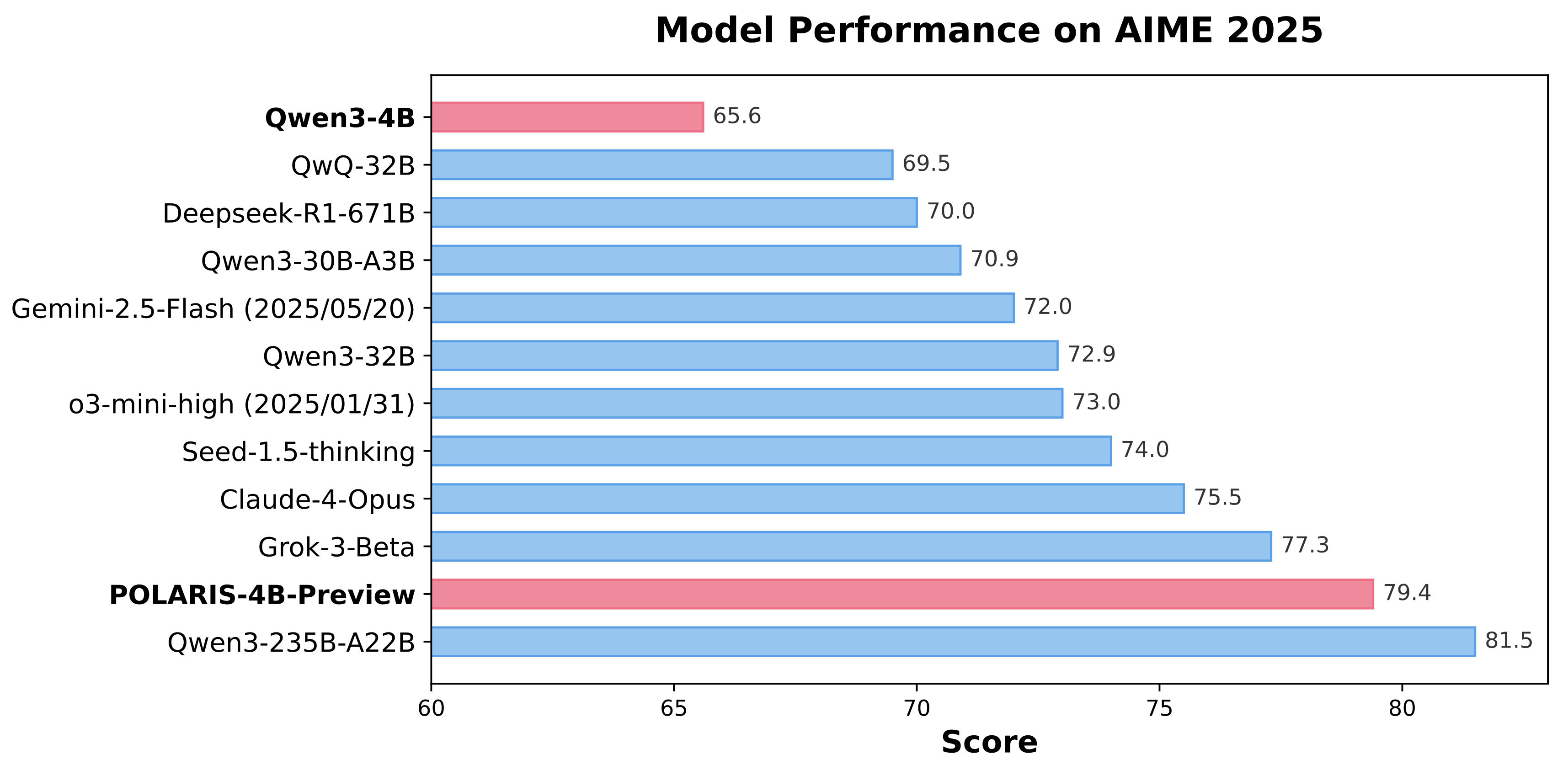
Polaris is an open-source post-training method that uses reinforcement learning (RL) scaling to refine and enhance models with advanced reasoning abilities. Our research shows that even top-tier models like Qwen3-4B can achieve significant improvements on challenging reasoning tasks when optimized with Polaris.
By leveraging open-source data and academic-level resources, Polaris pushes the capabilities of open-recipe reasoning models to unprecedented heights. In benchmark tests, our method even surpasses top commercial systems, including Claude-4-Opus, Grok-3-Beta, and o3-mini-high (2025/01/03).
Polaris's Recipe
- Data Difficulty: Before training, Polaris analyzes and maps the distribution of data difficulty. The dataset should not be overwhelmed by either overly difficult or trivially easy problems. We recommend using a data distribution with a slight bias toward challenging problems, which typically exhibits a mirrored J-shaped distribution.
- Diversity-Based Rollout: We leverage the diversity among rollouts to initialize the sampling temperature, which is then progressively increased throughout the RL training stages.
- Inference-Time Length: Polaris incorporates length extrapolation techniques for generating longer CoT at inference stage. This enables a "train-short, generate-long" paradigm for CoT reasoning, mitigating the computational burden of training with excessively long rollouts .
- Exploration Efficiency: Exploration efficiency in Polaris is enhanced through multi-stage training. However, reducing the model's response length in the first stage poses potential risks. A more conservative approach would be to directly allow the model to "think longer" from the beginning.
The details of our training recipe and analysis can be found in our blog post.
The code and data for reproducing our results can be found in our github repo.
Evaluation Results
| Models |
AIME24 avg@32 |
AIME25 avg@32 |
Minerva Math avg@4 |
Olympiad Bench avg@4 |
AMC23 avg@8 |
| DeepScaleR-1.5B |
43.1 |
27.2 |
34.6 |
40.7 |
50.6 |
| Qwen3-1.7B |
48.3 |
36.8 |
34.9 |
55.1 |
75.6 |
POLARIS-1.7B-Preview |
66.9 |
53.0 |
38.9 |
63.8 |
85.8 |
| Deepseek-R1-Distill-Qwen-7B |
55.0 |
39.7 |
36.7 |
56.8 |
81.9 |
| AReal-boba-RL-7B |
61.9 |
48.3 |
39.5 |
61.9 |
86.4 |
| Skywork-OR1-7B-Math |
69.8 |
52.3 |
40.8 |
63.2 |
85.3 |
POLARIS-7B-Preview |
72.6 |
52.6 |
40.2 |
65.4 |
89.0 |
| Deepseek-R1-Distill-Qwen-32B |
72.6 |
54.9 |
42.1 |
59.4 |
84.3 |
| qwen3-32B |
81.4 |
72.9 |
44.2 |
66.7 |
92.4 |
| qwen3-4B |
73.8 |
65.6 |
43.6 |
62.2 |
87.2 |
POLARIS-4B-Preview |
81.2 |
79.4 |
44.0 |
69.1 |
94.8 |
Acknowledgements
The training and evaluation codebase is heavily built on Verl. The reward function in polaris is from DeepScaleR. Our model is trained on top of Qwen3-4B and DeepSeek-R1-Distill-Qwen-7B. Thanks for their wonderful work.
See more here:
https://huggingface.co/POLARIS-Project/Polaris-4B-Preview
What is Brainstorm?
Brainstorm 20x
The BRAINSTORM process was developed by David_AU.
Some of the core principals behind this process are discussed in this
scientific paper : Progressive LLaMA with Block Expansion .
However I went in a completely different direction from what was outlined in this paper.
What is "Brainstorm" ?
The reasoning center of an LLM is taken apart, reassembled, and expanded.
In this case for this model: 20 times
Then these centers are individually calibrated. These "centers" also interact with each other.
This introduces subtle changes into the reasoning process.
The calibrations further adjust - dial up or down - these "changes" further.
The number of centers (5x,10x etc) allow more "tuning points" to further customize how the model reasons so to speak.
The core aim of this process is to increase the model's detail, concept and connection to the "world",
general concept connections, prose quality and prose length without affecting instruction following.
This will also enhance any creative use case(s) of any kind, including "brainstorming", creative art form(s) and like case uses.
Here are some of the enhancements this process brings to the model's performance:
- Prose generation seems more focused on the moment to moment.
- Sometimes there will be "preamble" and/or foreshadowing present.
- Fewer or no "cliches"
- Better overall prose and/or more complex / nuanced prose.
- A greater sense of nuance on all levels.
- Coherence is stronger.
- Description is more detailed, and connected closer to the content.
- Simile and Metaphors are stronger and better connected to the prose, story, and character.
- Sense of "there" / in the moment is enhanced.
- Details are more vivid, and there are more of them.
- Prose generation length can be long to extreme.
- Emotional engagement is stronger.
- The model will take FEWER liberties vs a normal model: It will follow directives more closely but will "guess" less.
- The MORE instructions and/or details you provide the more strongly the model will respond.
- Depending on the model "voice" may be more "human" vs original model's "voice".
Other "lab" observations:
- This process does not, in my opinion, make the model 5x or 10x "smarter" - if only that was true!
- However, a change in "IQ" was not an issue / a priority, and was not tested or calibrated for so to speak.
- From lab testing it seems to ponder, and consider more carefully roughly speaking.
- You could say this process sharpens the model's focus on it's task(s) at a deeper level.
The process to modify the model occurs at the root level - source files level. The model can quanted as a GGUF, EXL2, AWQ etc etc.
For more information / other Qwen/Mistral Coders / additional settings see:
[ https://huggingface.co/DavidAU/Qwen2.5-MOE-2x-4x-6x-8x__7B__Power-CODER__19B-30B-42B-53B-gguf ]
Help, Adjustments, Samplers, Parameters and More
CHANGE THE NUMBER OF ACTIVE EXPERTS:
See this document:
https://huggingface.co/DavidAU/How-To-Set-and-Manage-MOE-Mix-of-Experts-Model-Activation-of-Experts
Settings: CHAT / ROLEPLAY and/or SMOOTHER operation of this model:
In "KoboldCpp" or "oobabooga/text-generation-webui" or "Silly Tavern" ;
Set the "Smoothing_factor" to 1.5
: in KoboldCpp -> Settings->Samplers->Advanced-> "Smooth_F"
: in text-generation-webui -> parameters -> lower right.
: In Silly Tavern this is called: "Smoothing"
NOTE: For "text-generation-webui"
-> if using GGUFs you need to use "llama_HF" (which involves downloading some config files from the SOURCE version of this model)
Source versions (and config files) of my models are here:
https://huggingface.co/collections/DavidAU/d-au-source-files-for-gguf-exl2-awq-gptq-hqq-etc-etc-66b55cb8ba25f914cbf210be
OTHER OPTIONS:
Increase rep pen to 1.1 to 1.15 (you don't need to do this if you use "smoothing_factor")
If the interface/program you are using to run AI MODELS supports "Quadratic Sampling" ("smoothing") just make the adjustment as noted.
Highest Quality Settings / Optimal Operation Guide / Parameters and Samplers
This a "Class 1" model:
For all settings used for this model (including specifics for its "class"), including example generation(s) and for advanced settings guide (which many times addresses any model issue(s)), including methods to improve model performance for all use case(s) as well as chat, roleplay and other use case(s) please see:
[ https://huggingface.co/DavidAU/Maximizing-Model-Performance-All-Quants-Types-And-Full-Precision-by-Samplers_Parameters ]
You can see all parameters used for generation, in addition to advanced parameters and samplers to get the most out of this model here:
[ https://huggingface.co/DavidAU/Maximizing-Model-Performance-All-Quants-Types-And-Full-Precision-by-Samplers_Parameters ]