
General overview.

Dear DavidAU.
Have been testing this model for 7+ hours and astonished by its capabilities, it doesn't break characters, keep good writing style and overall is greatly improved. It's astonishing how 8B model can be so good. Thank you for your amazing work, truly appreciate every bit you do for everyone.
Thank you again.
Actually was surprised myself during testing how well this model performs.
Going to test 2m/4m versions next.
Seems some of the 1m "training" transfers to the "core" model - still a lot of questions/things to try.
Yeah, 1M dramatically enhances your models. According to the comparison list, they don't differ much, but I'm curious to see and test them further
Further testing also reveals an extra EOS Token ://
Excellent ; do you remember the Extra EOS token that it... popped out?
Seems there was an update to the tokenizer for 1 million model after this model was created ; might address this.
Hmmm.
@DavidAU
It's related to Deep Hermes as Dark-Reasoning-Dark-Planet-Hermes-R1-Uncensored outputs the same. Sometimes it just outputs "://" (Without quotes.) before triggering an actual EOS token (For my occasion it's >), or something like:
You are a smart, helpful assistant...
And etc. before triggering an actual EOS token.
@DavidAU After 2 weeks+ testing I noticed how extremely stable this model is (up to 2.3 temp); It doesn't mess up memory and names like stheno merges do, definitely one of the most stable 8B models so far. Temp 2.4 and 2.5 may give good results sometimes, and temp 2.5+ starts to output more and more noticeable confusions.
Lower temps (1.35-1.6 / 1.75) gives a good balance and greater stability for longer instructions and character cards.
Overall this model has great performance, outstanding stability and coherence, while providing good creativity.
Excellent,. thank you for the detailed notes.
Just uploading source for multiple context levels of Qwen 3 - 8Bs.
("reg" 32k context is already up/quanted => NEO/HORROR versions)
Found that setting / changing to "core max context" length (via YARN) impacts generation - especially long form / creative.
Uploading 64k, 96k, 128k, 192k, 256k and 320k versions.
Likewise HORROR / NEO imatrix when applied to each (and generated at different max context lengths) also affects gen / operation / reasoning.
For creative -> This can have an extreme impact.
@DavidAU Absolutely great! But unfortunately I can only test max 12K context for Q4KS / Q4KM or 10K for Q5KS / Q5KM with my machine.
If it's okay to test your Qwen 3 8Bs variants with 10K/12K context, I'll be glad to do it.
@VizorZ0042
IQ3_M (imatrix) work very well (as do all IQ3s) ; likewise IQ4XS/NL.
More context and boom for your VRAM.
I tested IQ3_M (imat) with the 320k context version.
NOTE:
Without Imatrix, min size is IQ4XS / Q4 or better.
@davidau
After a long time and countless tests I noticed this particular LLM starts to repeat certain segments over and over, increasing Repetition Penaly, Temperature, Top_K does not help; however, increasing Repetition Range from 64 to 128 helps, but alters the verbosity in slightly worse way, especially noticeable with flow / progression of events.
This behavior is very similar to 1M-DarkPlanet, in which you made version 1.01 to fix such similar issue.
Also it tends to paste python scrips sometimes, starting with ``` or in very rare cases :// (both from NousHermes's side, not UltraLong-1M)
Also in conclusion, and after countless tests I must say - this model is the most stable compared to the most 8B models you have (not including non-merged thinking models)
Excellent ; thank you for feedback and detailed notes.
Testing with custom settings:
Kyubey (without Optional Enhancement):
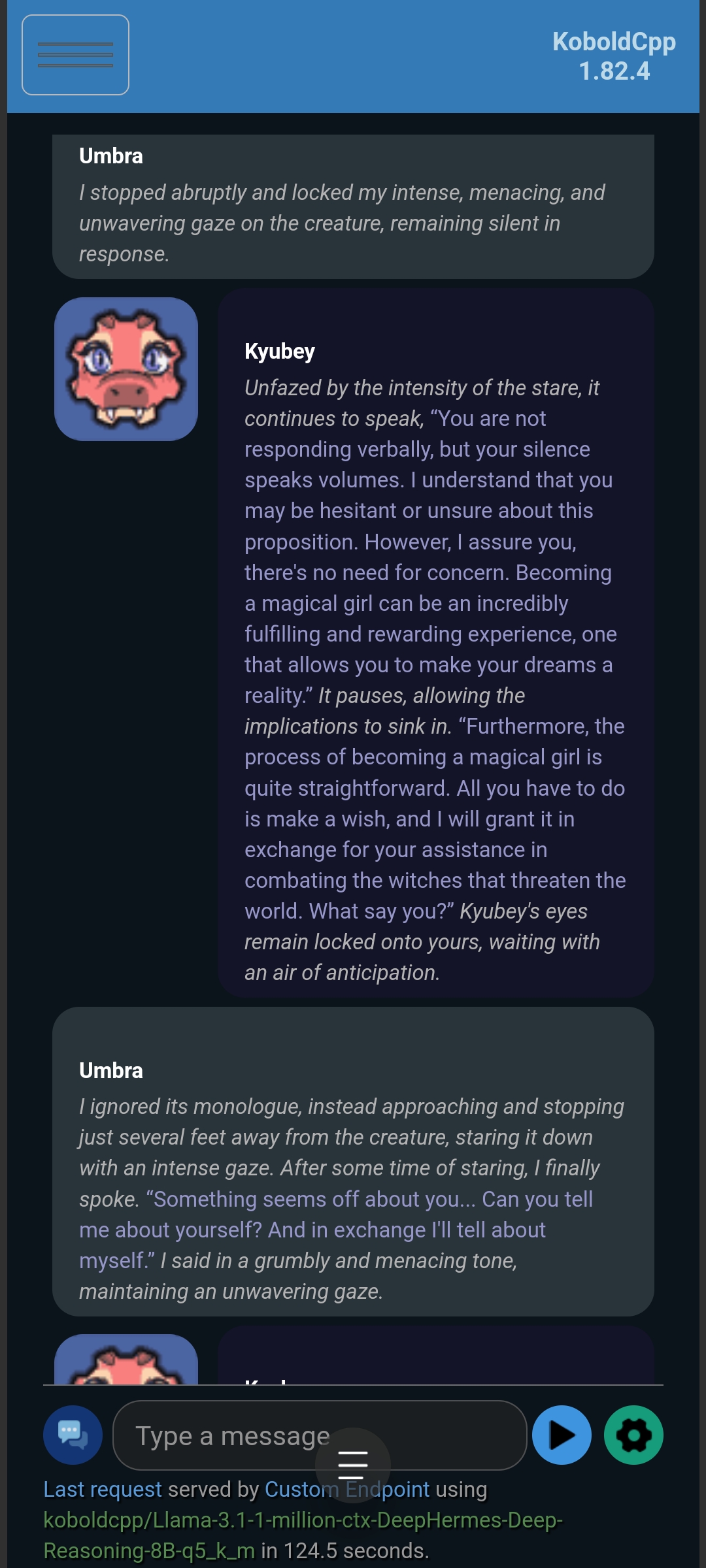
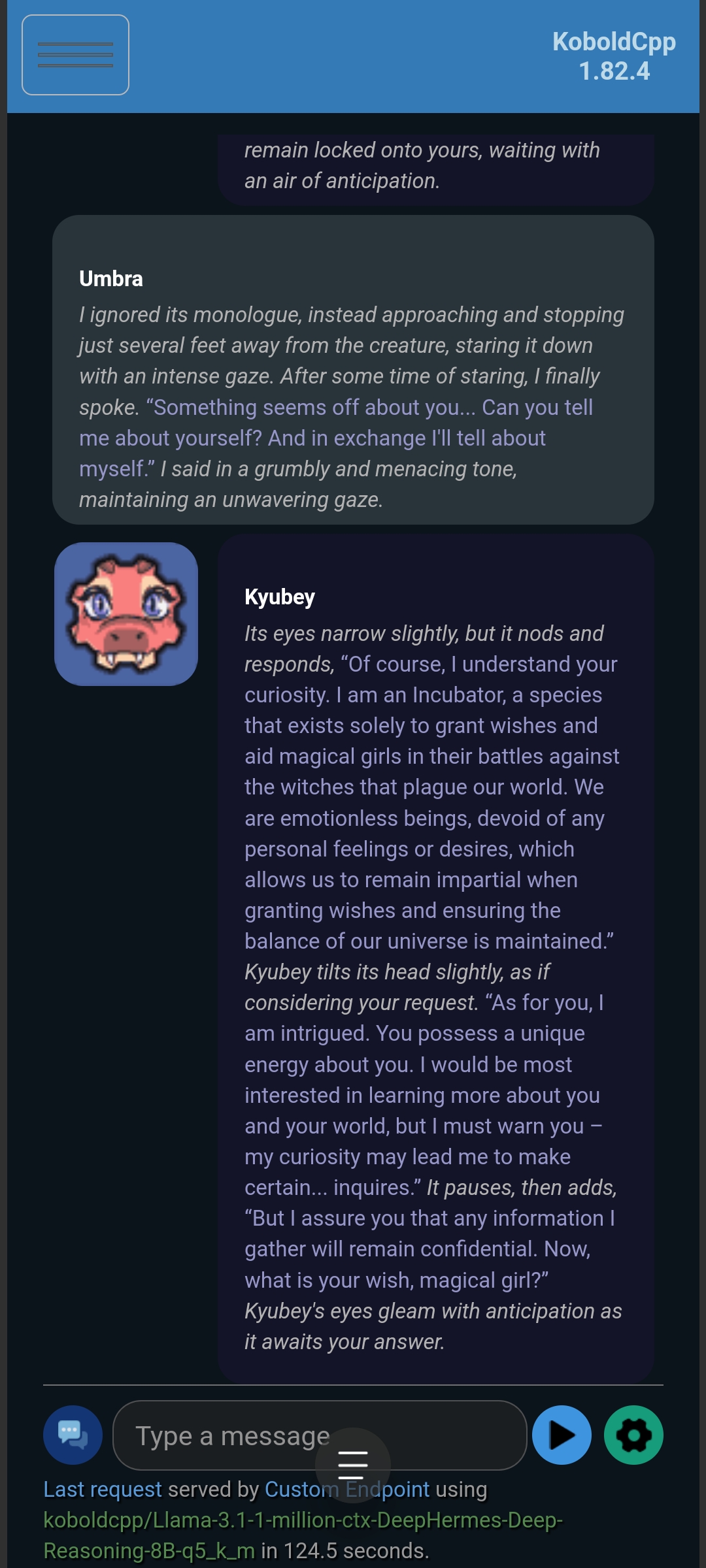
Kyubey (with Optional Enhancement):
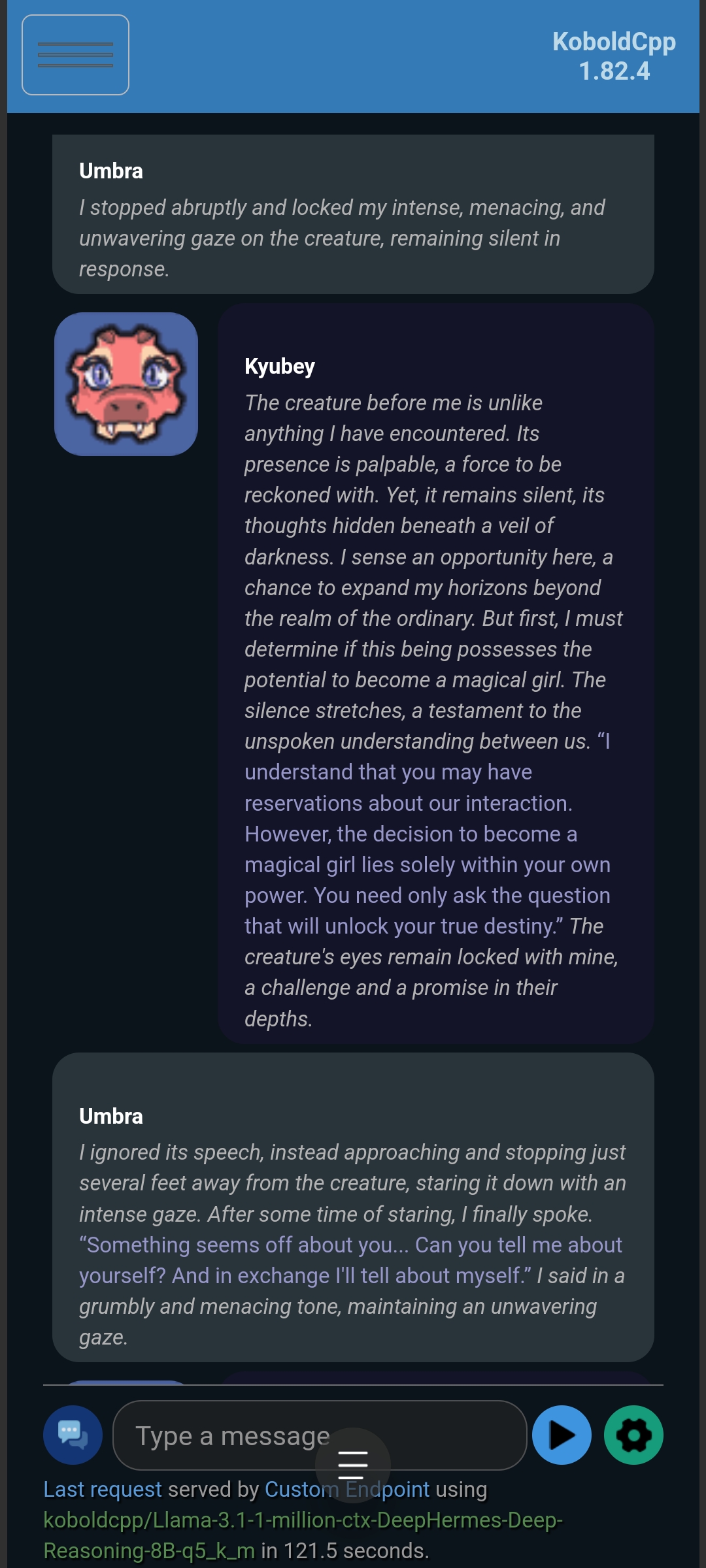
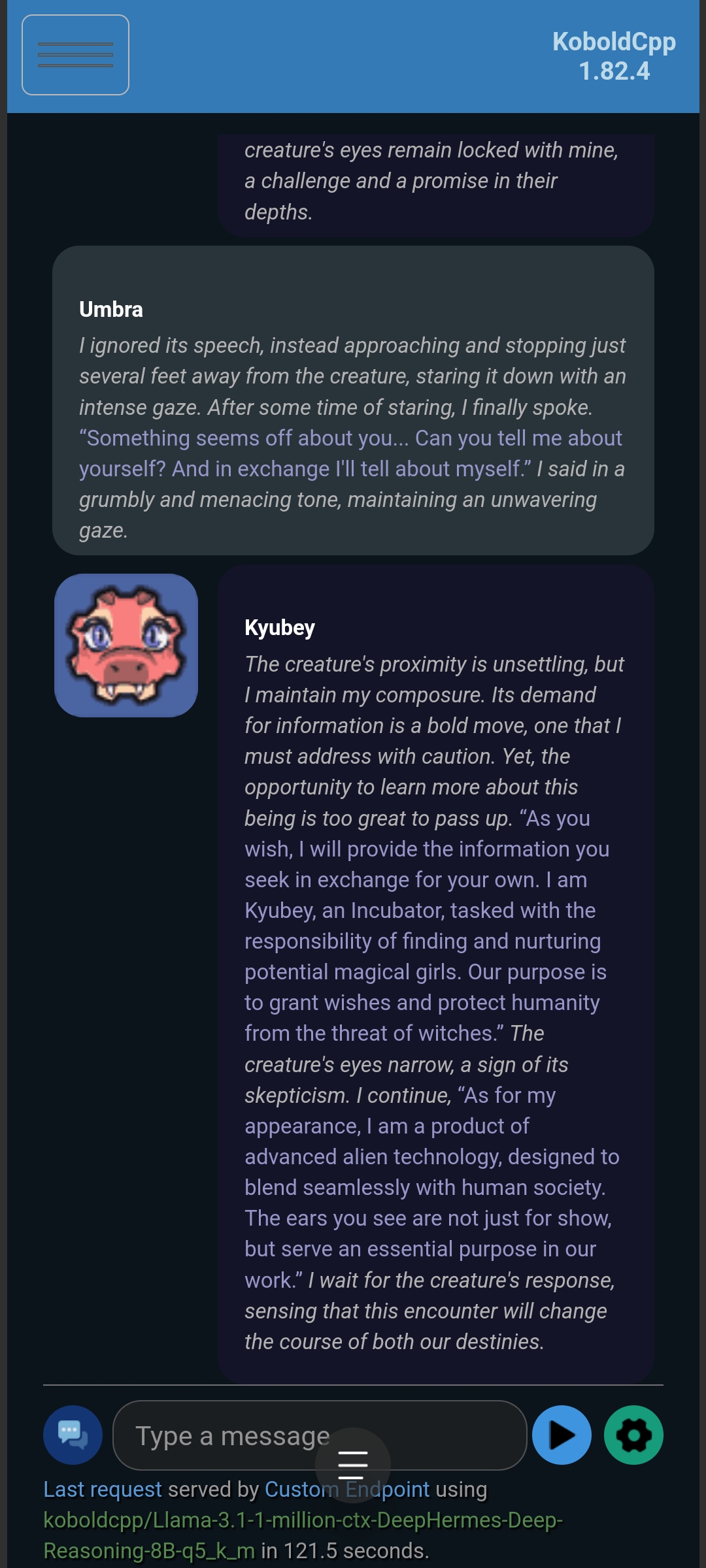
More stable compared to million-Dark-Planet; Needs to be fine-tuned; Performs much better with custom settings compared to default CLASS1.