
C4AI Aya 23
Collection
Aya 23 is an open weights research release of an instruction fine-tuned model with highly advanced multilingual capabilities.
•
4 items
•
Updated
•
54
This repository is publicly accessible, but you have to accept the conditions to access its files and content.
By submitting this form, you agree to the License Agreement and acknowledge that the information you provide will be collected, used, and shared in accordance with Cohere’s Privacy Policy. You’ll receive email updates about C4AI and Cohere research, events, products and services. You can unsubscribe at any time.
Log in or Sign Up to review the conditions and access this model content.
Try Aya 23
You can try out Aya 23 (35B) before downloading the weights in our hosted Hugging Face Space here.
Aya 23 is an open weights research release of an instruction fine-tuned model with highly advanced multilingual capabilities. Aya 23 focuses on pairing a highly performant pre-trained Command family of models with the recently released Aya Collection. The result is a powerful multilingual large language model serving 23 languages.
This model card corresponds to the 8-billion version of the Aya 23 model. We also released a 35-billion version which you can find here.
We cover 23 languages: Arabic, Chinese (simplified & traditional), Czech, Dutch, English, French, German, Greek, Hebrew, Hindi, Indonesian, Italian, Japanese, Korean, Persian, Polish, Portuguese, Romanian, Russian, Spanish, Turkish, Ukrainian, and Vietnamese
Developed by: Cohere For AI and Cohere
Please install transformers from the source repository that includes the necessary changes for this model
# pip install transformers==4.41.1
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "CohereForAI/aya-23-8B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id)
# Format message with the command-r-plus chat template
messages = [{"role": "user", "content": "Anneme onu ne kadar sevdiğimi anlatan bir mektup yaz"}]
input_ids = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
## <BOS_TOKEN><|START_OF_TURN_TOKEN|><|USER_TOKEN|>Anneme onu ne kadar sevdiğimi anlatan bir mektup yaz<|END_OF_TURN_TOKEN|><|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>
gen_tokens = model.generate(
input_ids,
max_new_tokens=100,
do_sample=True,
temperature=0.3,
)
gen_text = tokenizer.decode(gen_tokens[0])
print(gen_text)
This notebook showcases a detailed use of Aya 23 (8B) including inference and fine-tuning with QLoRA.
Input: Models input text only.
Output: Models generate text only.
Model Architecture: Aya-23-8B is an auto-regressive language model that uses an optimized transformer architecture. After pretraining, this model is fine-tuned (IFT) to follow human instructions.
Languages covered: The model is particularly optimized for multilinguality and supports the following languages: Arabic, Chinese (simplified & traditional), Czech, Dutch, English, French, German, Greek, Hebrew, Hindi, Indonesian, Italian, Japanese, Korean, Persian, Polish, Portuguese, Romanian, Russian, Spanish, Turkish, Ukrainian, and Vietnamese
Context length: 8192
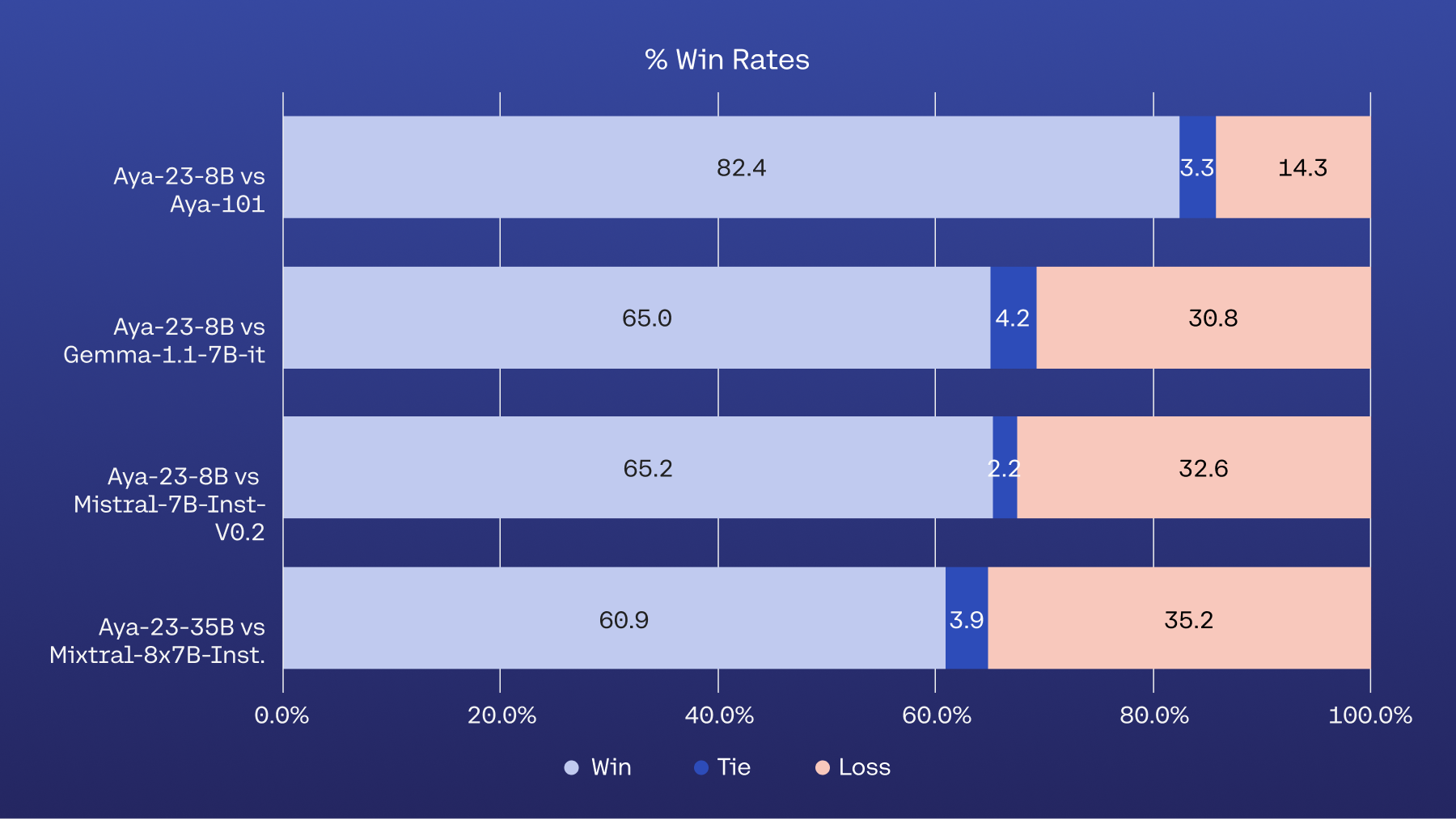
Please refer to the Aya 23 technical report for further details about the base model, data, instruction tuning, and evaluation.
For errors or additional questions about details in this model card, contact [email protected].
We hope that the release of this model will make community-based research efforts more accessible, by releasing the weights of a highly performant multilingual model to researchers all over the world. This model is governed by a CC-BY-NC License with an acceptable use addendum, and also requires adhering to C4AI's Acceptable Use Policy.
You can try Aya 23 in the Cohere playground here. You can also use it in our dedicated Hugging Face Space here.
@misc{aryabumi2024aya,
title={Aya 23: Open Weight Releases to Further Multilingual Progress},
author={Viraat Aryabumi and John Dang and Dwarak Talupuru and Saurabh Dash and David Cairuz and Hangyu Lin and Bharat Venkitesh and Madeline Smith and Kelly Marchisio and Sebastian Ruder and Acyr Locatelli and Julia Kreutzer and Nick Frosst and Phil Blunsom and Marzieh Fadaee and Ahmet Üstün and Sara Hooker},
year={2024},
eprint={2405.15032},
archivePrefix={arXiv},
primaryClass={cs.CL}
}