
CoMemo-2B
[📂 GitHub] [📜 Paper] [🚀 Quick Start] [🌐 Project Page]
Introduction
LVLMs inherited LLMs architectural designs, which introduce suboptimal characteristics for multimodal processing. First, LVLMs exhibit a bimodal distribution in attention allocation, leading to the progressive neglect of central visual content as context expands. Second, conventional positional encoding schemes fail to preserve vital 2D structural relationships when processing dynamic high-resolution images.
To address these issues, we propose CoMemo, a novel model architecture. CoMemo employs a dual-path approach for visual processing: one path maps image tokens to the text token representation space for causal self-attention, while the other introduces cross-attention, enabling context-agnostic computation between the input sequence and image information. Additionally, we developed RoPE-DHR, a new positional encoding method tailored for LVLMs with dynamic high-resolution inputs. RoPE-DHR mitigates the remote decay problem caused by dynamic high-resolution inputs while preserving the 2D structural information of images.
Evaluated on seven diverse tasks, including long-context understanding, multi-image reasoning, and visual question answering, CoMemo achieves relative improvements of 17.2%, 7.0%, and 5.6% on Caption, Long-Generation, and Long-Context tasks, respectively, with consistent performance gains across various benchmarks. For more details, please refer to our paper and GitHub.
| Model Name | Vision Part | Language Part | HF Link |
|---|---|---|---|
| CoMemo-2B | InternViT-300M-448px | internlm2-chat-1_8b | 🤗 link |
| CoMemo-9B | InternViT-300M-448px | internlm2-chat-7b | 🤗 link |
Method Overview
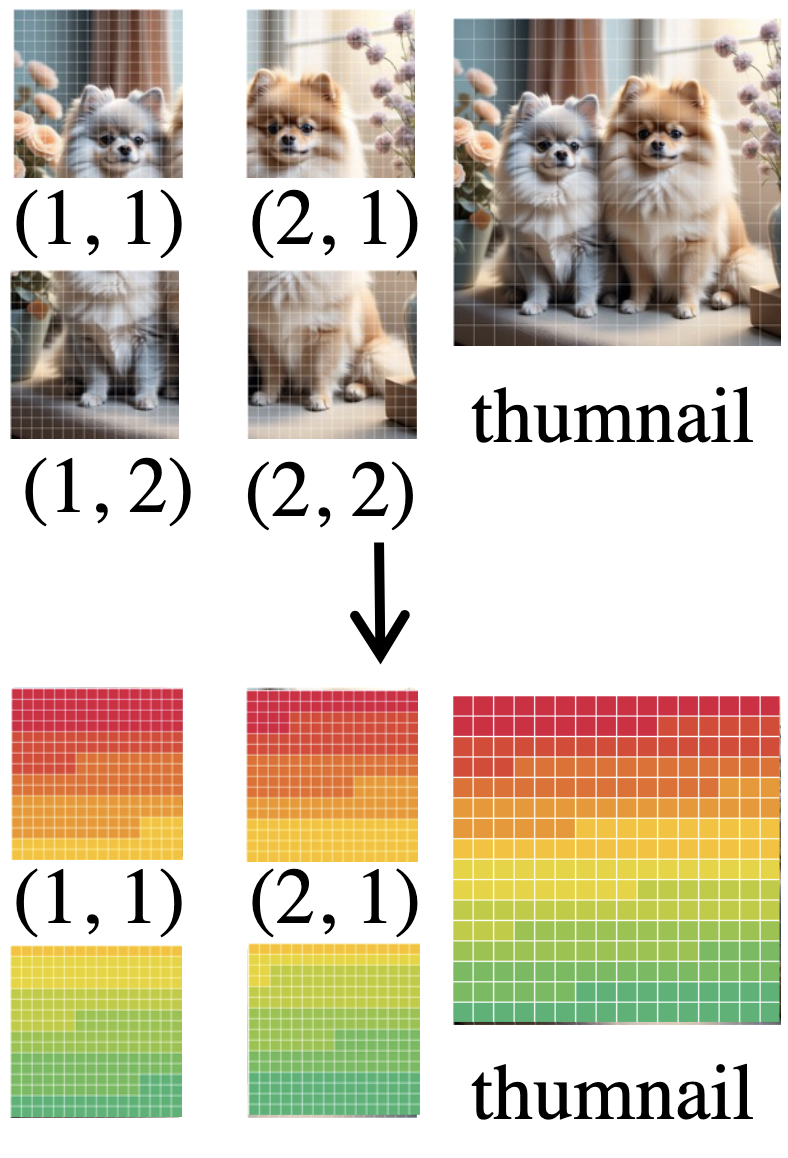
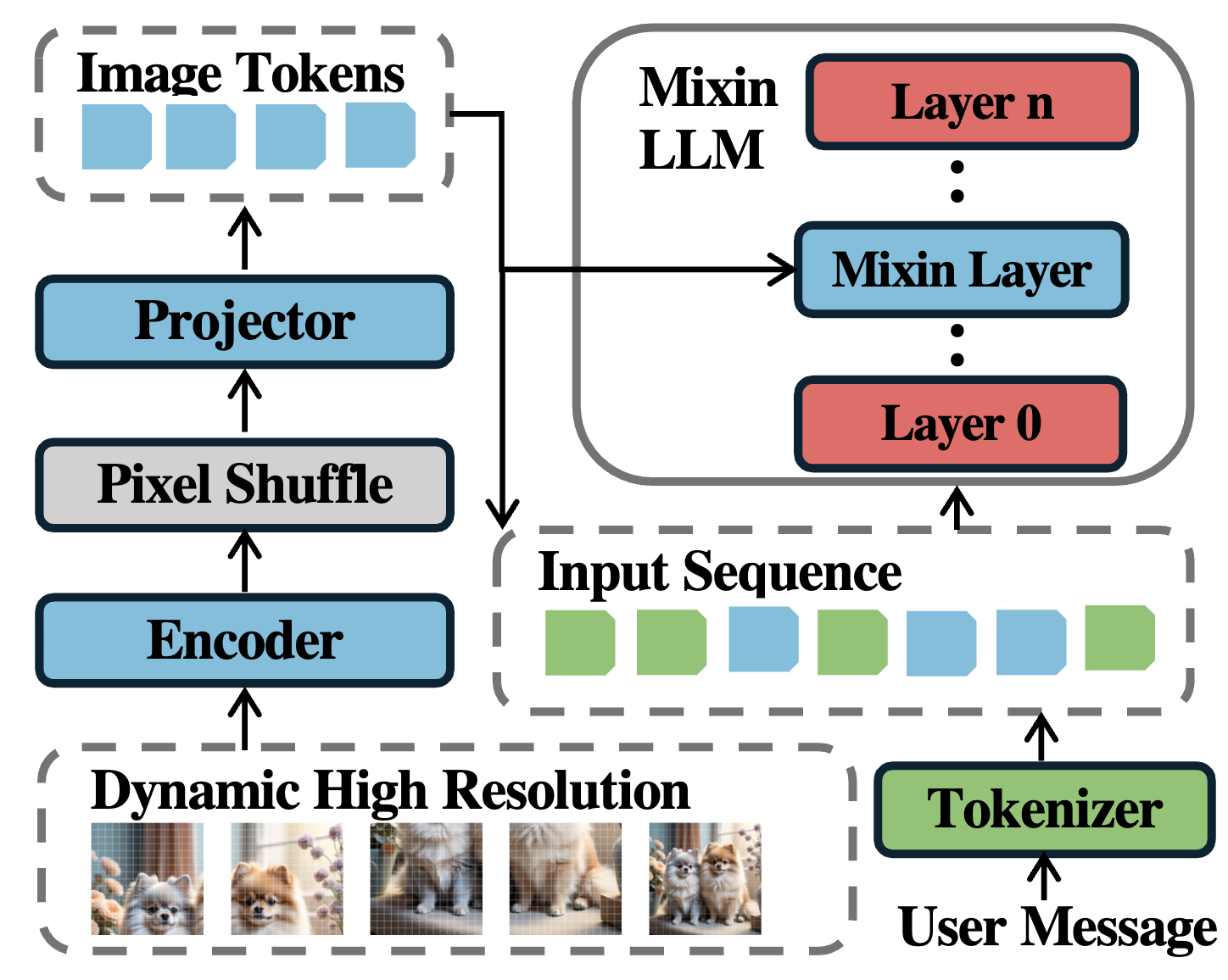
Left: The computation process of Rope-DHR. The colors are assigned based on a mapping of position IDs in RoPE. Right: Framework of CoMemo. Both paths share the same encoder and projector
Quick Start
We provide an example code to run CoMemo-2B using transformers.
Please use transformers>=4.37.2 to ensure the model works normally.
Inference with Transformers
Note: We determine whether to use RoPE-DHR by checking if the target_aspect_ratio parameter is passed to generate. For OCR-related tasks requiring fine-grained image information, we recommend using the original RoPE. For long-context tasks, we recommend using RoPE-DHR.
import torch
from PIL import Image
import torchvision.transforms as T
from torchvision.transforms.functional import InterpolationMode
from transformers import AutoModel, AutoTokenizer
path = "CLLBJ16/CoMemo-2B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
low_cpu_mem_usage=True).eval().cuda()
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True, use_fast=False)
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
def build_transform(input_size):
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)
])
return transform
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
best_ratio_diff = float('inf')
best_ratio = (1, 1)
area = width * height
for ratio in target_ratios:
target_aspect_ratio = ratio[0] / ratio[1]
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
if ratio_diff < best_ratio_diff:
best_ratio_diff = ratio_diff
best_ratio = ratio
elif ratio_diff == best_ratio_diff:
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
best_ratio = ratio
return best_ratio
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
# calculate the existing image aspect ratio
target_ratios = set(
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
i * j <= max_num and i * j >= min_num)
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
# find the closest aspect ratio to the target
target_aspect_ratio = find_closest_aspect_ratio(
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
# calculate the target width and height
target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
# resize the image
resized_img = image.resize((target_width, target_height))
processed_images = []
for i in range(blocks):
box = (
(i % (target_width // image_size)) * image_size,
(i // (target_width // image_size)) * image_size,
((i % (target_width // image_size)) + 1) * image_size,
((i // (target_width // image_size)) + 1) * image_size
)
# split the image
split_img = resized_img.crop(box)
processed_images.append(split_img)
assert len(processed_images) == blocks
if use_thumbnail and len(processed_images) != 1:
thumbnail_img = image.resize((image_size, image_size))
processed_images.append(thumbnail_img)
return processed_images, target_aspect_ratio
def load_image(image_file, input_size=448, max_num=12):
image = Image.open(image_file).convert('RGB')
transform = build_transform(input_size=input_size)
images, target_aspect_ratio = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(image) for image in images]
pixel_values = torch.stack(pixel_values)
return pixel_values, target_aspect_ratio
pixel_values, target_aspect_ratio = load_image('./assets/image1.jpg', max_num=12)
pixel_values = pixel_values.to(torch.bfloat16).cuda()
generation_config = dict(max_new_tokens=1024, do_sample=True)
# single-image single-round conversation (单图单轮对话)
question = '<image>
Please describe the image shortly.'
target_aspect_ratio = [target_aspect_ratio]
# Use RoPE-DHR
response = model.chat(tokenizer, pixel_values, question, generation_config, target_aspect_ratio=target_aspect_ratio)
# # Use Original Rope
# response = model.chat(tokenizer, pixel_values, question, generation_config, target_aspect_ratio=target_aspect_ratio)
print(f'User: {question}
Assistant: {response}')
# multi-image single-round conversation, separate images (多图多轮对话,独立图像)
pixel_values1, target_aspect_ratio1 = load_image('./assets/image1.jpg', max_num=12)
pixel_values1 = pixel_values1.to(torch.bfloat16).cuda()
pixel_values2, target_aspect_ratio2 = load_image('./assets/image2.jpg', max_num=12)
pixel_values2 = pixel_values2.to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
target_aspect_ratio = [target_aspect_ratio1, target_aspect_ratio2]
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
question = 'Image-1: <image>
Image-2: <image>
What are the similarities and differences between these two images.'
# Use RoPE-DHR
response = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list, target_aspect_ratio=target_aspect_ratio)
# # Use Original RoPE
# response = model.chat(tokenizer, pixel_values, question, generation_config,
# num_patches_list=num_patches_list, target_aspect_ratio=target_aspect_ratio)
print(f'User: {question}
Assistant: {response}')
License
This project is released under the MIT license. Parts of this project contain code and models from other sources, which are subject to their respective licenses.
Citation
If you find this project useful in your research, please consider citing:
@article{liu2025comemo,
title={CoMemo: LVLMs Need Image Context with Image Memory},
author={Liu, Shi and Su, Weijie and Zhu, Xizhou and Wang, Wenhai and Dai, Jifeng},
journal={arXiv preprint arXiv:2506.06279},
year={2025}
}
- Downloads last month
- 24