
SAILViT
Collection
Visual Foundation Models Powering Vision-Language Models
•
3 items
•
Updated
•
1
[SAILViT Paper] [BibTeX]
We are pleased to announce the release of SAILViT, a series of versatile vision foundation models of our sota SAIL-VL-1d6-8B and SAIL-VL-1d5-2B. The core philosophy is to mitigate parameter initialization conflicts and modality semantic discrepancies among components by progressive learning before MLLMs perform target training. The main contributions are summarized as follows:
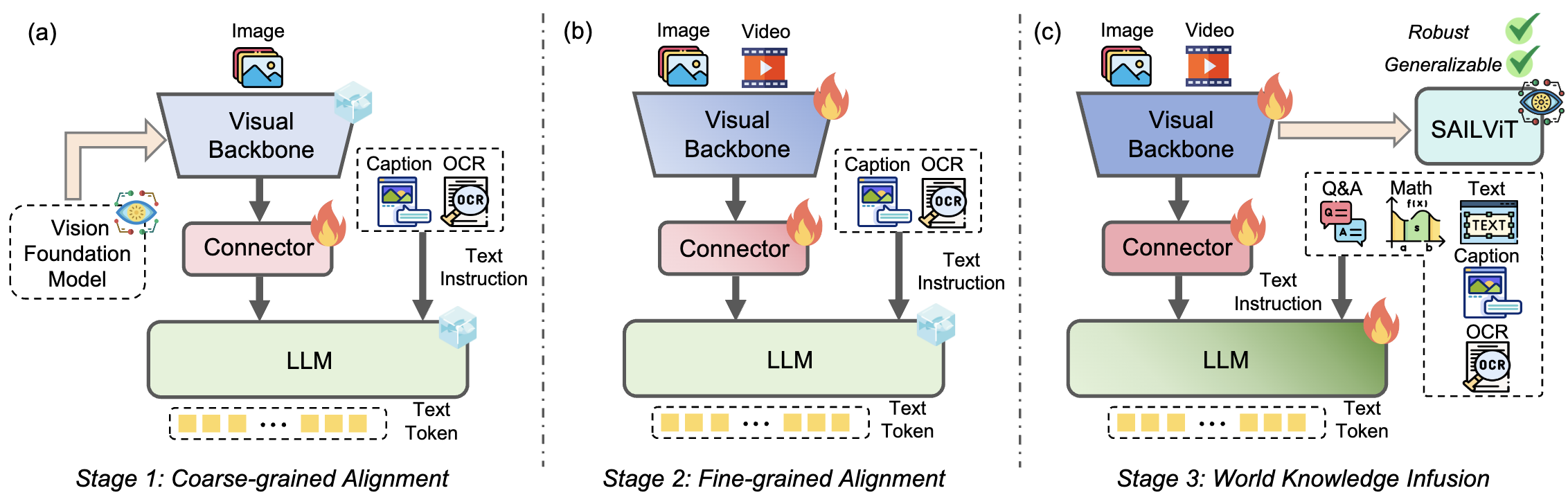
We progressively inculcate hierarchical multimodal knowledge for the vision foundation model through three training stages in order to enhance visual representations and accomplish a seamless modality-semantic transition with LLMs.
| Architecture | Parameter | Patch Size | Resolution |
|---|---|---|---|
| 🤗SAILViT-Large-300M-448px | 300M | 14 | 448x448 |
| 🤗SAILViT-Huge-600M-448px | 600M | 14 | 448x448 |
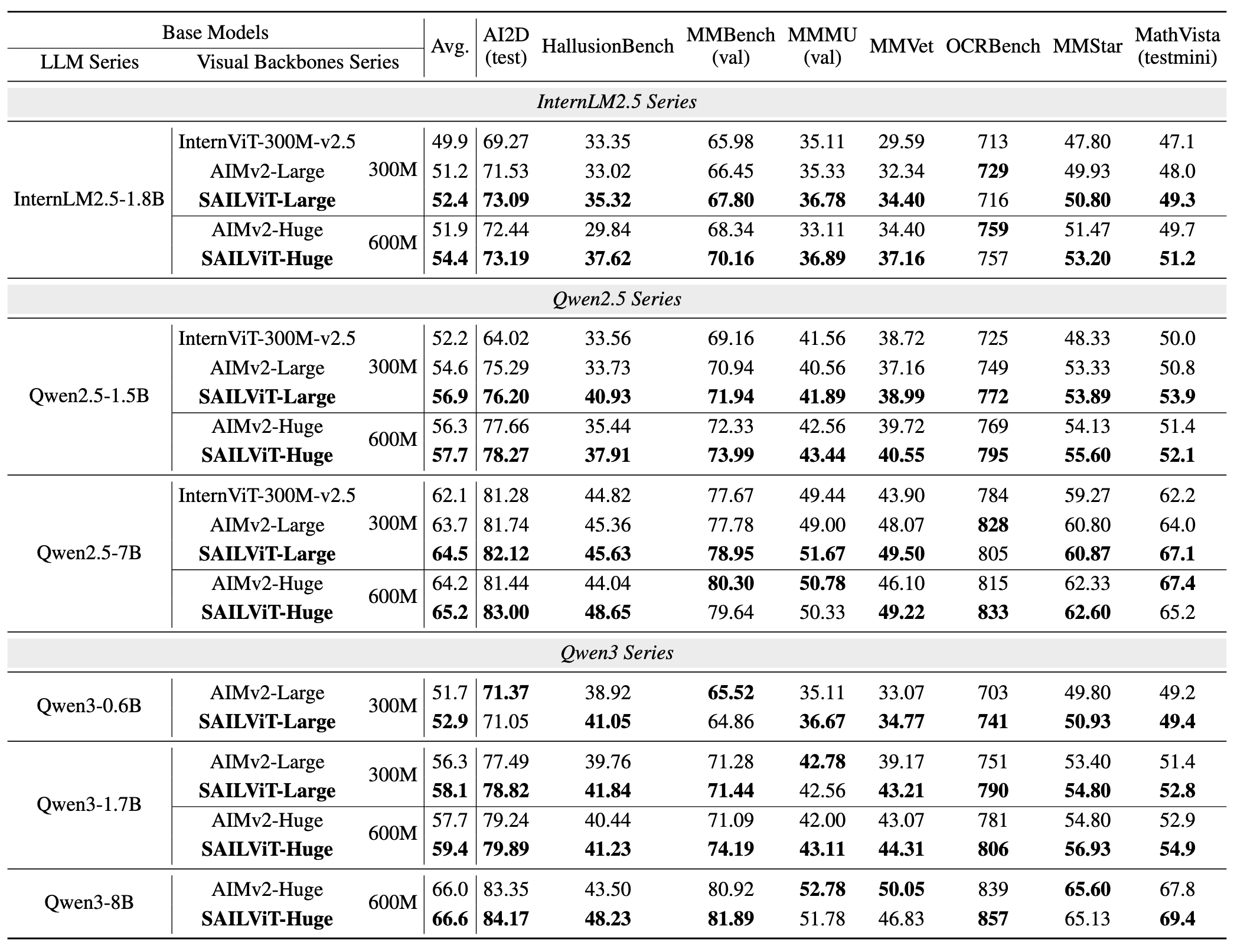
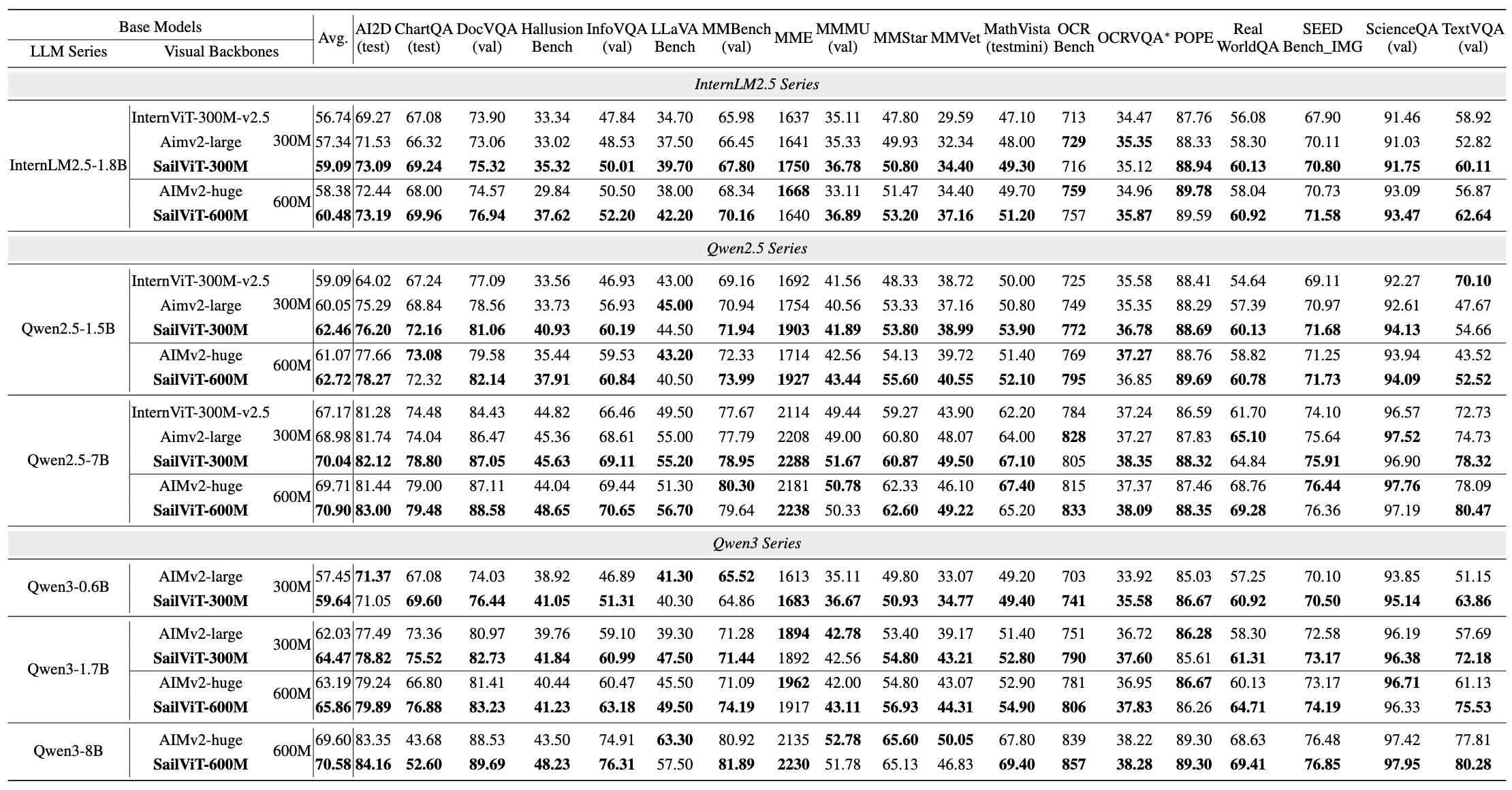
We compared SAILViT with other visual backbones connected with various LLMs on OpenCompass and OpenSource. The SAILViT series has significant performance gains on different families of LLMs.
We conducted a comparison of SAILViT against other visual backbones in visual recognition tasks, specifically focusing on image classification. Under strictly fair experimental conditions, our findings show that SAILViT outperforms peer models of similar scale, such as Aimv2 and InternViT. Impressively, SAILViT-huge even matches the performance of InternViT-6B on challenging benchmarks like ImageNet-R and ImageNet-v2.
| Settings | AIMv2-Large | InternViT-300M-448px-V2.5 | SAILViT-Large | AIMv2-Huge | SAILViT-Huge | InternViT-6B-448px-V2.5 |
|---|---|---|---|---|---|---|
| ImageNet-1k | 79.88% | 73.70% | 80.71% | 81.68% | 82.21% | 84.18% |
| ImageNet-A | 25.41% | 13.45% | 29.31% | 28.96% | 33.04% | 46.27% |
| ImageNet-R | 55.73% | 39.99% | 56.42% | 58.13% | 60.33% | 59.88% |
| ImageNet-V2 | 76.45% | 69.55% | 77.06% | 77.32% | 78.94% | 80.92% |
| Average | 59.37% | 49.17% | 60.87% | 61.52% | 63.63% | 67.81% |
import torch
import torchvision.transforms as T
from PIL import Image
import requests
from torchvision.transforms.functional import InterpolationMode
from transformers import AutoModel, AutoTokenizer
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
def build_transform(input_size):
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)
])
return transform
path = "BytedanceDouyinContent/SAILViT-Large-300M-448px"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
trust_remote_code=True).eval().cuda()
url = "https://img-blog.csdnimg.cn/fcc22710385e4edabccf2451d5f64a99.jpeg"
input_size = 448
image = Image.open(requests.get(url, stream=True).raw).convert('RGB')
transform = build_transform(input_size=input_size)
pixel_values = transform(image).unsqueeze(0).to(torch.bfloat16).cuda()
visual_tokens = model(pixel_values=pixel_values)
Our model is built upon Aimv2 and Ovis2 and we are grateful for their contributions.
If you find our work useful, please consider citing us as :
@article{Wei2025SAILViT,
title={SAILViT: Towards Robust and Generalizable Visual Backbones for MLLMs via Gradual Feature Refinement},
author={Yin, Weijie and Yang, Dingkang and Dong, Hongyuan and Kang, Zijian and Wang, Jiacong and Liang, Xiao and Feng, Chao and Ran, Jiao},
journal={arXiv preprint arXiv:2507.01643},
year={2025}
}
This project is licensed under Apache License 2.0.
If you have any question, please feel free to contact us: [email protected]
Base model
apple/aimv2-large-patch14-448