
SeedVR
Collection
A diffusion transformer model for high-resolution image and video restoration. • 9 items • Updated • 15
Jianyi Wang, Zhijie Lin, Meng Wei, Ceyuan Yang, Fei Xiao, Chen Change Loy, Lu Jiang
CVPR 2025 (Highlight)
![]()
Why SeedVR: Conventional restoration models achieve inferior performance on both real-world and AIGC video restoration due to limited generation ability. Recent diffusion-based models improve the performance by introducing diffusion prior via ControlNet-like or adaptor-like architectures. Though gaining improvement, these methods generally suffer from constraints brought by the diffusion prior: these models suffer from the same bias as the prior, e.g., limited generation ability on small texts and faces, etc, and only work on fixed resolutions such as 512 or 1024. As a result, most of the existing diffusion-based restoration models rely on patch-based sampling, i.e., dividing the input video into overlapping spatial-temporal patches and fusing these patches using a Gaussian kernel at each diffusion step. The large overlap (e.g., 50% of the patch size), required for ensuring a coherent output without visible patch boundaries, often leads to considerably slow inference speed. This inefficiency becomes even more pronounced when processing long videos at high resolutions. SeedVR follows SOTA video generation training pipelines to tackle the key challenge in diffusion-based restoration, i.e., by enabling arbitrary-resolution restoration w/o relying on any pretrained diffusion prior and introducing advanced video generation technologies suitable for video restoration. Serving as the largest-ever diffusion transformer model towards generic video restoration, we hope SeedVR could push the frontiers of advanced VR and inspire future research in developing large vision models for real-world video restoration.
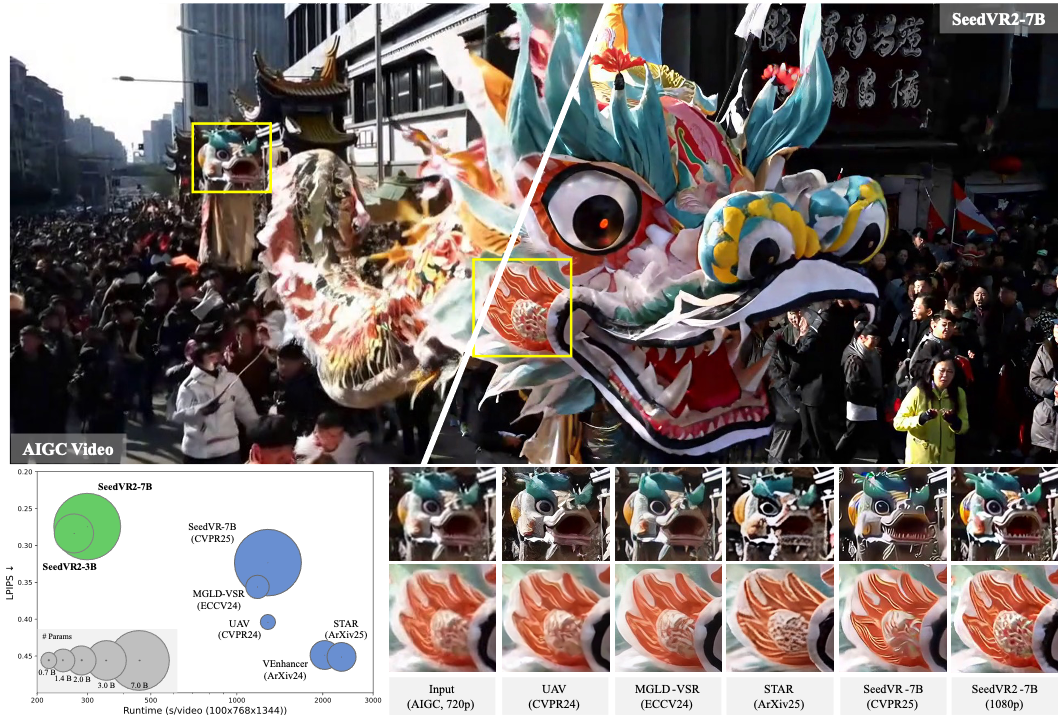
Limitations: These are the prototype models and the performance may not perfectly align with the paper. Our methods are sometimes not robust to heavy degradations and very large motions, and shares some failure cases with existing methods, e.g., fail to fully remove the degradation or simply generate unpleasing details. Moreover, due to the strong generation ability, Our methods tend to overly generate details on inputs with very light degradations, e.g., 720p AIGC videos, leading to oversharpened results occasionally.
@article{wang2025seedvr2,
title={SeedVR2: One-Step Video Restoration via Diffusion Adversarial Post-Training},
author={Wang, Jianyi and Lin, Shanchuan and Lin, Zhijie and Ren, Yuxi and Wei, Meng and Yue, Zongsheng and Zhou, Shangchen and Chen, Hao and Zhao, Yang and Yang, Ceyuan and Xiao, Xuefeng and Loy, Chen Change and Jiang, Lu},
booktitle={arXiv preprint arXiv:2506.05301},
year={2025}
}
@inproceedings{wang2025seedvr,
title={SeedVR: Seeding Infinity in Diffusion Transformer Towards Generic Video Restoration},
author={Wang, Jianyi and Lin, Zhijie and Wei, Meng and Zhao, Yang and Yang, Ceyuan and Loy, Chen Change and Jiang, Lu},
booktitle={CVPR},
year={2025}
}
SeedVR and SeedVR2 are licensed under the Apache 2.0.