
BGE
Collection
30 items
•
Updated
•
127
For more details please refer to our Github: FlagEmbedding.
BGE-Multilingual-Gemma2 is a LLM-based multilingual embedding model. It is trained on a diverse range of languages and tasks based on google/gemma-2-9b. BGE-Multilingual-Gemma2 primarily demonstrates the following advancements:
We will release the training data of BGE-Multilingual-Gemma2 in the future.
git clone https://github.com/FlagOpen/FlagEmbedding.git
cd FlagEmbedding
pip install -e .
from FlagEmbedding import FlagLLMModel
queries = ["how much protein should a female eat", "summit define"]
documents = [
"As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"Definition of summit for English Language Learners. : 1 the highest point of a mountain : the top of a mountain. : 2 the highest level. : 3 a meeting or series of meetings between the leaders of two or more governments."
]
model = FlagLLMModel('BAAI/bge-multilingual-gemma2',
query_instruction_for_retrieval="Given a web search query, retrieve relevant passages that answer the query.",
use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
embeddings_1 = model.encode_queries(queries)
embeddings_2 = model.encode_corpus(documents)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
# [[ 0.559 0.01654 ]
# [-0.002575 0.4998 ]]
By default, FlagLLMModel will use all available GPUs when encoding. Please set os.environ["CUDA_VISIBLE_DEVICES"] to select specific GPUs.
You also can set os.environ["CUDA_VISIBLE_DEVICES"]="" to make all GPUs unavailable.
from sentence_transformers import SentenceTransformer
import torch
# Load the model, optionally in float16 precision for faster inference
model = SentenceTransformer("BAAI/bge-multilingual-gemma2", model_kwargs={"torch_dtype": torch.float16})
# Prepare a prompt given an instruction
instruction = 'Given a web search query, retrieve relevant passages that answer the query.'
prompt = f'<instruct>{instruction}\n<query>'
# Prepare queries and documents
queries = [
'how much protein should a female eat',
'summit define',
]
documents = [
"As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"Definition of summit for English Language Learners. : 1 the highest point of a mountain : the top of a mountain. : 2 the highest level. : 3 a meeting or series of meetings between the leaders of two or more governments."
]
# Compute the query and document embeddings
query_embeddings = model.encode(queries, prompt=prompt)
document_embeddings = model.encode(documents)
# Compute the cosine similarity between the query and document embeddings
similarities = model.similarity(query_embeddings, document_embeddings)
print(similarities)
# tensor([[ 0.5591, 0.0164],
# [-0.0026, 0.4993]], dtype=torch.float16)
import torch
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
def last_token_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
left_padding = (attention_mask[:, -1].sum() == attention_mask.shape[0])
if left_padding:
return last_hidden_states[:, -1]
else:
sequence_lengths = attention_mask.sum(dim=1) - 1
batch_size = last_hidden_states.shape[0]
return last_hidden_states[torch.arange(batch_size, device=last_hidden_states.device), sequence_lengths]
def get_detailed_instruct(task_description: str, query: str) -> str:
return f'<instruct>{task_description}\n<query>{query}'
task = 'Given a web search query, retrieve relevant passages that answer the query.'
queries = [
get_detailed_instruct(task, 'how much protein should a female eat'),
get_detailed_instruct(task, 'summit define')
]
# No need to add instructions for documents
documents = [
"As a general guideline, the CDC's average requirement of protein for women ages 19 to 70 is 46 grams per day. But, as you can see from this chart, you'll need to increase that if you're expecting or training for a marathon. Check out the chart below to see how much protein you should be eating each day.",
"Definition of summit for English Language Learners. : 1 the highest point of a mountain : the top of a mountain. : 2 the highest level. : 3 a meeting or series of meetings between the leaders of two or more governments."
]
input_texts = queries + documents
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-multilingual-gemma2')
model = AutoModel.from_pretrained('BAAI/bge-multilingual-gemma2')
model.eval()
max_length = 4096
# Tokenize the input texts
batch_dict = tokenizer(input_texts, max_length=max_length, padding=True, truncation=True, return_tensors='pt', pad_to_multiple_of=8)
with torch.no_grad():
outputs = model(**batch_dict)
embeddings = last_token_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:2] @ embeddings[2:].T) * 100
print(scores.tolist())
# [[55.92064666748047, 1.6549524068832397], [-0.2698777914047241, 49.95653533935547]]
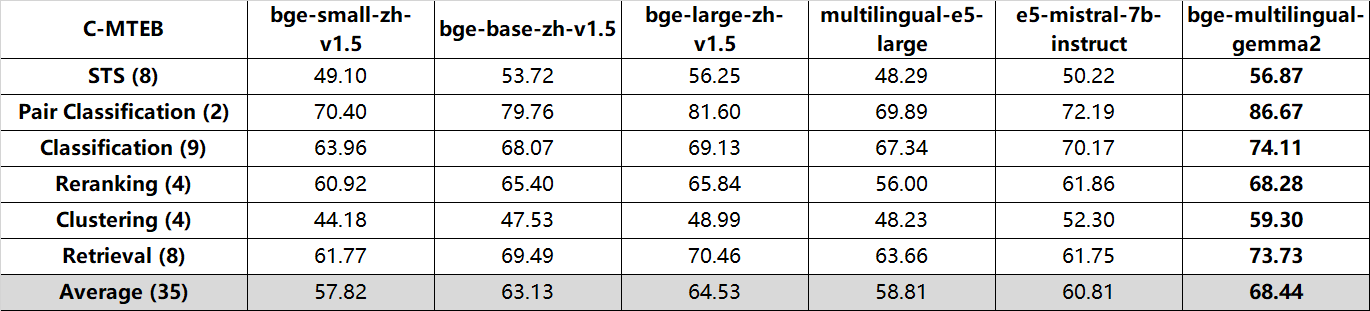
bge-multilingual-gemma2 exhibits state-of-the-art (SOTA) results on benchmarks like MIRACL, MTEB-pl, and MTEB-fr. It also achieves excellent performance on other major evaluations, including MTEB, C-MTEB and AIR-Bench.
nDCG@10:
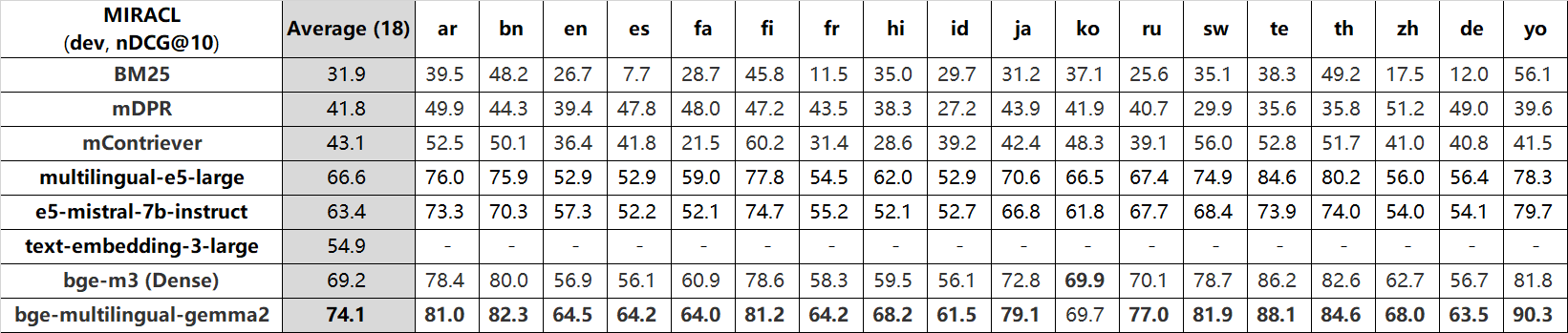
Recall@100:

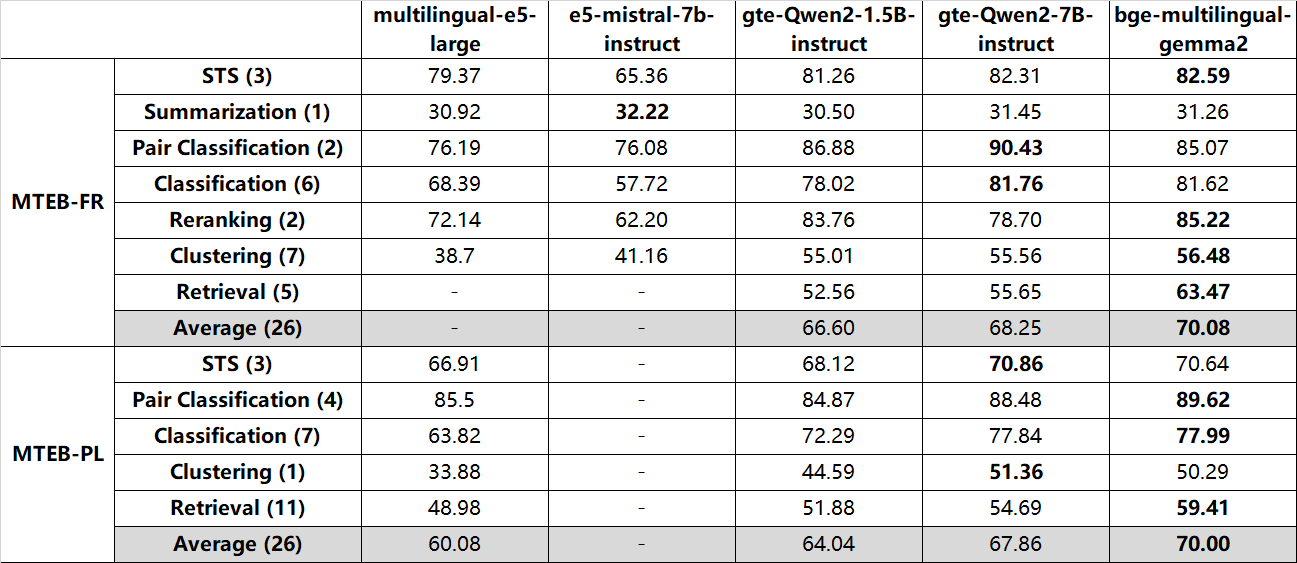

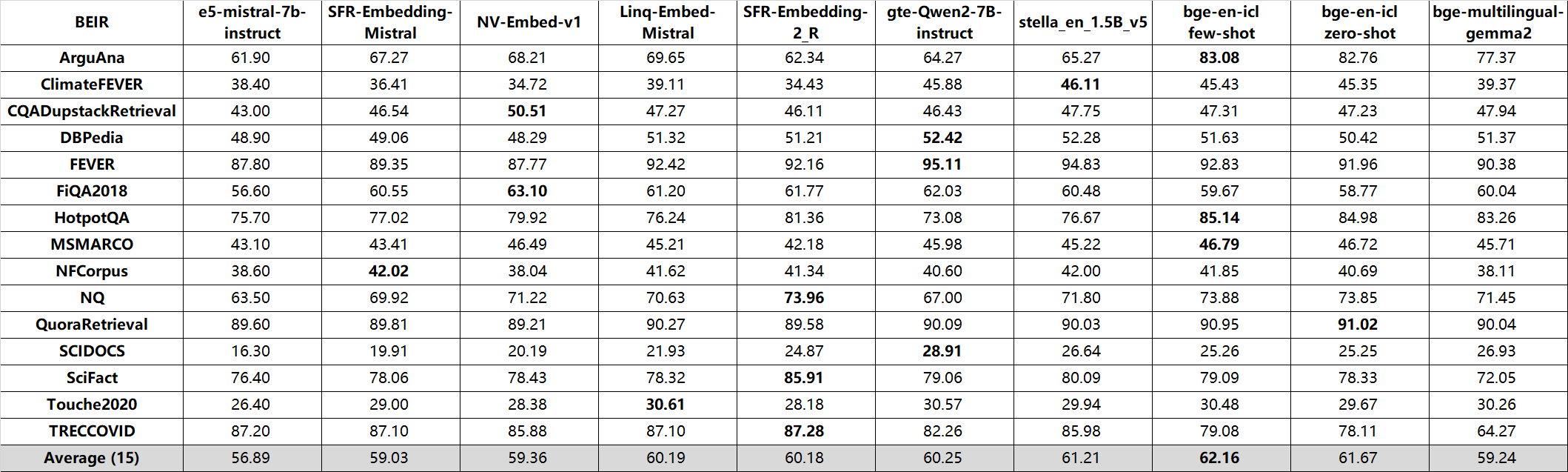
Long-Doc (en, Recall@10):

QA (en&zh, nDCG@10):
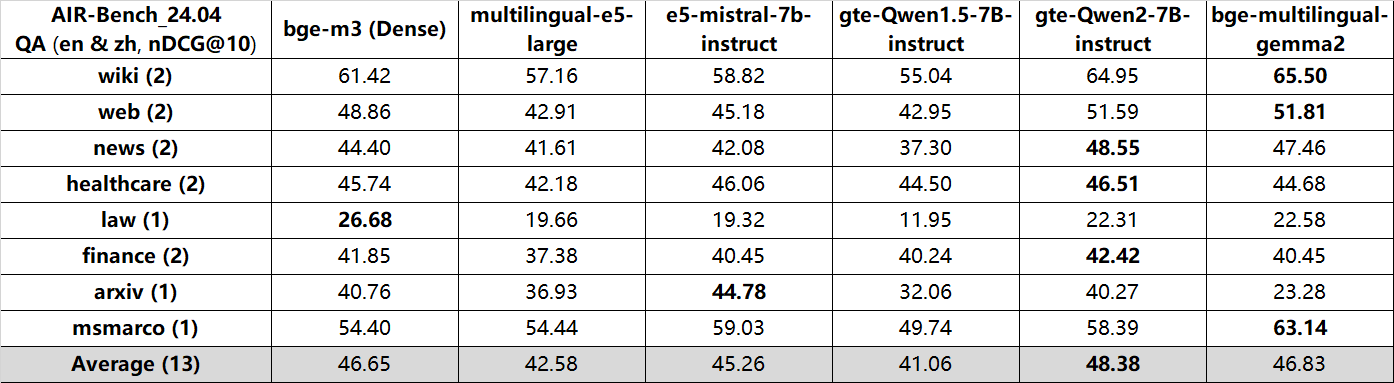
bge is short for BAAI general embedding.
| Model | Language | Description | query instruction for retrieval [1] | |
|---|---|---|---|---|
| BAAI/bge-multilingual-gemma2 | Multilingual | - | A LLM-based multilingual embedding model, trained on a diverse range of languages and tasks. | |
| BAAI/bge-en-icl | English | - | A LLM-based dense retriever with in-context learning capabilities can fully leverage the model's potential based on a few shot examples(4096 tokens) | Provide instructions and few-shot examples freely based on the given task. |
| BAAI/bge-m3 | Multilingual | Inference Fine-tune | Multi-Functionality(dense retrieval, sparse retrieval, multi-vector(colbert)), Multi-Linguality, and Multi-Granularity(8192 tokens) | |
| BAAI/llm-embedder | English | Inference Fine-tune | a unified embedding model to support diverse retrieval augmentation needs for LLMs | See README |
| BAAI/bge-reranker-large | Chinese and English | Inference Fine-tune | a cross-encoder model which is more accurate but less efficient [2] | |
| BAAI/bge-reranker-base | Chinese and English | Inference Fine-tune | a cross-encoder model which is more accurate but less efficient [2] | |
| BAAI/bge-large-en-v1.5 | English | Inference Fine-tune | version 1.5 with more reasonable similarity distribution | Represent this sentence for searching relevant passages: |
| BAAI/bge-base-en-v1.5 | English | Inference Fine-tune | version 1.5 with more reasonable similarity distribution | Represent this sentence for searching relevant passages: |
| BAAI/bge-small-en-v1.5 | English | Inference Fine-tune | version 1.5 with more reasonable similarity distribution | Represent this sentence for searching relevant passages: |
| BAAI/bge-large-zh-v1.5 | Chinese | Inference Fine-tune | version 1.5 with more reasonable similarity distribution | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-base-zh-v1.5 | Chinese | Inference Fine-tune | version 1.5 with more reasonable similarity distribution | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-small-zh-v1.5 | Chinese | Inference Fine-tune | version 1.5 with more reasonable similarity distribution | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-large-en | English | Inference Fine-tune | :trophy: rank 1st in MTEB leaderboard | Represent this sentence for searching relevant passages: |
| BAAI/bge-base-en | English | Inference Fine-tune | a base-scale model but with similar ability to bge-large-en |
Represent this sentence for searching relevant passages: |
| BAAI/bge-small-en | English | Inference Fine-tune | a small-scale model but with competitive performance | Represent this sentence for searching relevant passages: |
| BAAI/bge-large-zh | Chinese | Inference Fine-tune | :trophy: rank 1st in C-MTEB benchmark | 为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-base-zh | Chinese | Inference Fine-tune | a base-scale model but with similar ability to bge-large-zh |
为这个句子生成表示以用于检索相关文章: |
| BAAI/bge-small-zh | Chinese | Inference Fine-tune | a small-scale model but with competitive performance | 为这个句子生成表示以用于检索相关文章: |
If you find this repository useful, please consider giving a star :star: and citation
@misc{bge-m3,
title={BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation},
author={Jianlv Chen and Shitao Xiao and Peitian Zhang and Kun Luo and Defu Lian and Zheng Liu},
year={2024},
eprint={2402.03216},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@misc{bge_embedding,
title={C-Pack: Packaged Resources To Advance General Chinese Embedding},
author={Shitao Xiao and Zheng Liu and Peitian Zhang and Niklas Muennighoff},
year={2023},
eprint={2309.07597},
archivePrefix={arXiv},
primaryClass={cs.CL}
}