
Slow GPTQ inference

It seems like some weights(model.layers.*.mlp.gate) are not quantized. This slows down the inference a lot, about 2x slower the 32B dense variant model.
Mmm, i'm not sure the problem comes from this (moe gates are never quantized because they use vanilla matmul and not linear layers, hence most quant engine do not support them).
Gonna take a look into them.
What engine did you use to run it? Vllm and SGlang do not seem to support the moe variant yet, and exllama does not support the architecture at all yet (loads but output giberish)
Dense version are good tho, near fp16 performance.
I did a speed bench on my 2x3090, got:
- 4B : 205 t/s generation
- 8B : 160 t/s
- 14B : 110 t/s
- 32B : just finished quantizing it so haven't tested yet
Update:
32B model runs at 55 t/s
I created an issue on the GPTQModel repo and thats what they told me: https://github.com/ModelCloud/GPTQModel/issues/1575
I guess this pull request is related: https://github.com/ModelCloud/GPTQModel/pull/1569/files
For inference i just used the GPTQModel as is, im in a phase of exploration to find the next model to fine tune :)
Yeah i tried another 32B GPTQ dense quant and it was as fast as i expected, its just the moe that has issues rn.
Also, it seems like the gate weights are for a linear layer: https://github.com/huggingface/transformers/blob/main/src/transformers/models/qwen3_moe/modeling_qwen3_moe.py#L254
Did you done the 30B moe quants with the 2x3090 setup? How much time it took? Guess i can try to do it myself but i think i limited by ram.(only have 64gb)
cool, I'll retry when model cloud release a patch.
I did it on a single 3090 (the other one was quantizing the 14b at the same time). It took about 3 hours, with batch size 8, sequence length 1024 and about 2048 samples.
64gb should be more than enough (you only need to load layers one by one in memory.
Below is my code if you want to try it :)
%env CUDA_VISIBLE_DEVICES=0
from gptqmodel import GPTQModel, QuantizeConfig
from transformers import AutoTokenizer, AutoModelForCausalLM
from datasets import load_dataset
from tqdm.auto import tqdm
import unidecode
import shutil
import shutil
import os
os.environ['HF_TOKEN']='your token'
model_id = "Qwen3-32B"
quant_path = model_id+"-GPTQ"
n_sample=2048
max_char=1024*4
tokenizer=AutoTokenizer.from_pretrained(model_id)
dataset=load_dataset("AlphaGaO/fused_distillation_dataset")
dataset = [unidecode.unidecode(tokenizer.apply_chat_template(eval(elt), tokenize=False, add_generation_prompt=False))[:max_char] for elt in tqdm(dataset['train']['messages'][:n_sample])]
quant_config = QuantizeConfig(
bits=4,
group_size=128,
is_marlin_format=True,
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = GPTQModel.load(model_id, quant_config)
model.quantize(
dataset,
batch_size=4
)
model.save(quant_path)
shutil.copy(model_id+"/README.md", quant_path+"/README.md")
GPTQModel.push_to_hub(
"AlphaGaO/"+model_id+"-GPTQ",
quant_path
)
Ohh, 3h on a single 3090 is not that bad. Thx for the code snippet, i will try it later and report back.
Well 64gb ram+swap was not enough, got OOM killed at the save part. Tried turning off the parallel_packing but still got OOM. Maybe the dev version has some memory leaks. I think i will wait for the new release/working quants.
maybe try to reduce the batch size / total number of sample / sequence length (intermediate states are kept in memory so this can quickly become quite big)
plus if you are doing this on CPU / RAM, chances are that the weights are converted to float 32, might explain why the OOM.
I rented a vm and did the quant, speed was the same as before so i did some digging. It seems like the hf implementation is crap, running the experts in a for loop and its mostly cpu limited based on the profiler. Did some vibe optimizing just for fun and got a 2x speedup that is comparable to the 32B dense model. I guess we just have to wait for a better implementation.
Thats weird, i just took a look at the implementation and it seems good (same one as Mixtral)
If you want to optimize it, you might want to take a look at deepseek v2 lite, they have a separate implementation depending on if you are doing training / inference, and the inference one should be much more optimal :)
I might give that a try early next week if i'm feeling motivated.
For torch, the for loop shouldn't be an issue (at least not if you are compiling) but indeed the current implementation iterates over all experts, instead of just the ones activated for the token being generated, so the slow down might be due to the torch.where operation being used even on unused experts (so 128 times instead of just 8) and experts being dequantized even though they inference on empty set.
Link to the deepseek implementation : https://huggingface.co/deepseek-ai/DeepSeek-Coder-V2-Lite-Instruct/blob/main/modeling_deepseek.py
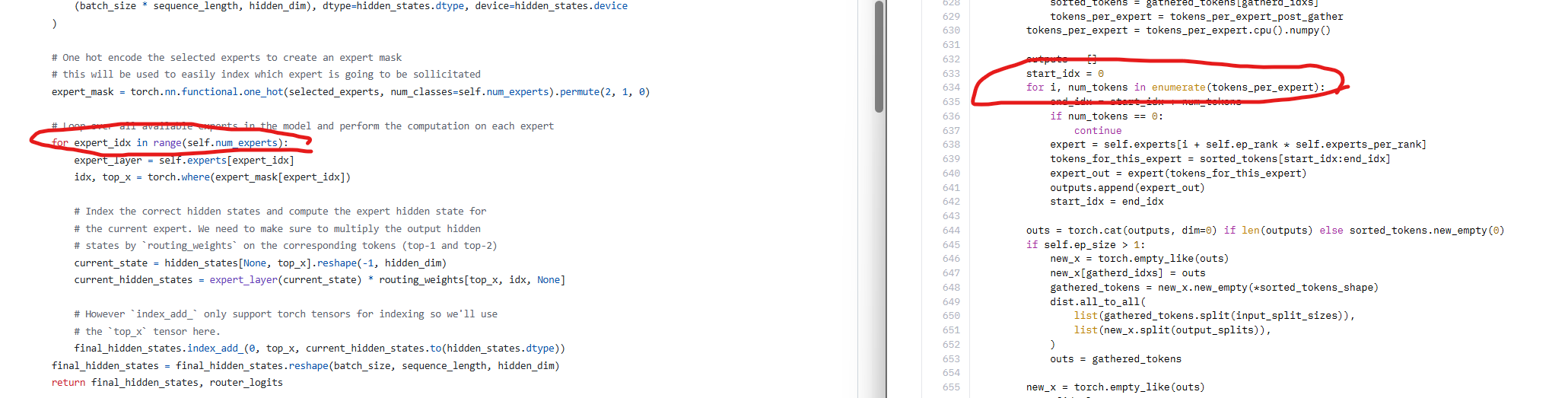
Its much more complicated then i thought. All the solutions i tried produces different output above ~512 token context size compared to the hf implementation. Its hard to verify the correctness.
I spent too much time on this already so i will just wait for the hf team to make it faster.
Did some more testing, i can get 3x speedup(thats for 3700 prefill + 10 decode) by only running the loop on the experts that required for the computation. Much more if i generate a lot of tokens, but even prefill gets a bit faster. And finally i managed to do it so it produces the same results :)