
ERank
Collection
A highly effective and efficient pointwise reranker built from a reasoning LLM, which excels across diverse relevance scenarios with low latency
•
3 items
•
Updated
•
3
We introduce ERANK, a highly effective and efficient pointwise reranker built from a reasoning LLM, which excels across diverse relevance scenarios with low latency. Surprisingly, it also outperforms recent listwise rerankers on the most challenging reasoning-intensive tasks.
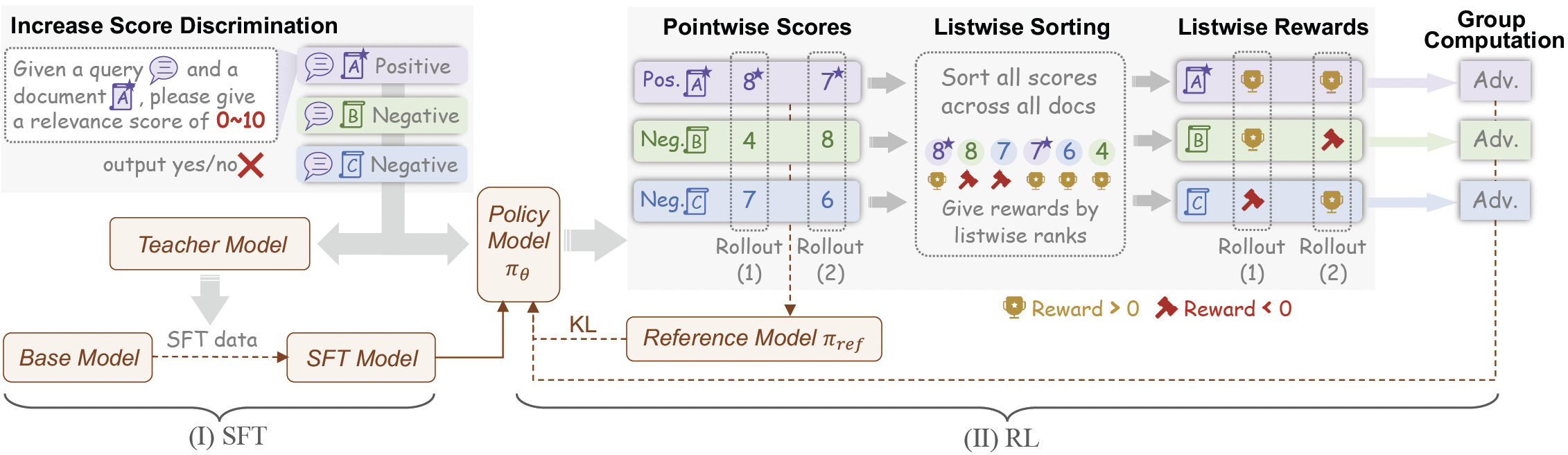
ERank is trained with a novel two-stage training pipeline, i.e., Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL). During the SFT stage, unlike traidtional pointwise rerankers that train the LLMs for binary relevance classification, we encourage the LLM to generatively output fine grained integer scores. In the RL training, we introduce a novel listwise derived reward, which instills global ranking awareness into the efficient pointwise architecture.
We provide the trained reranking models in various sizes (4B, 14B and 32B), all of which support customizing the input instruction according to different tasks.
| Model | Size | Layers | Sequence Length | Instruction Aware |
|---|---|---|---|---|
| ERank-4B | 4B | 36 | 32K | Yes |
| ERank-14B | 14B | 40 | 128K | Yes |
| ERank-32B | 32B | 64 | 128K | Yes |
We evaluate ERank on both reasoning-intensive benchmarks (BRIGHT and FollowIR) and traditional semantic relevance benchmarks (BEIR and TREC DL). All methods use the original queries without hybrid scores.
| Paradigm | Method | Average | BRIGHT | FollowIR | BEIR | TREC DL |
|---|---|---|---|---|---|---|
| - | First-stage retriever | 25.9 | 13.7 | 0 | 40.8 | 49.3 |
| Listwise | Rank-R1-7B | 34.6 | 15.7 | 3.6 | 49.0 | 70.0 |
| Listwise | Rearank-7B | 35.3 | 17.4 | 2.3 | 49.0 | 72.5 |
| Pointwise | JudgeRank-8B | 32.1 | 17.0 | 9.9 | 39.1 | 62.6 |
| Pointwise | Rank1-7B | 34.6 | 18.2 | 9.1 | 44.2 | 67.1 |
| Pointwise | ERank-4B (Ours) | 36.8 | 22.7 | 11.0 | 44.8 | 68.9 |
| Pointwise | ERank-14B (Ours) | 36.9 | 23.1 | 10.3 | 47.1 | 67.1 |
| Pointwise | ERank-32B (Ours) | 38.1 | 24.4 | 12.1 | 47.7 | 68.1 |
On the most challenging BRIGHT benchmark, with top-100 documents retrieved by ReasonIR-8B using GPT-4 reason-query, ERank with BM25 hybrid achieves the state-of-the-art NDCG@10.
| Method | nDCG@10 |
|---|---|
| ReasonIR-8B | 30.5 |
| Rank-R1-7B | 24.1 |
| Rank1-7B | 24.3 |
| Rearank-7B | 27.5 |
| JudgeRank-8B | 20.2 |
| + BM25 hybrid | 22.7 |
| Rank-R1-32B-v0.2 | 37.7 |
| + BM25 hybrid | 40.0 |
| ERank-4B (Ours) | 30.5 |
| + BM25 hybrid | 38.7 |
| ERank-14B (Ours) | 31.8 |
| + BM25 hybrid | 39.3 |
| ERank-32B (Ours) | 32.8 |
| + BM25 hybrid | 40.2 |
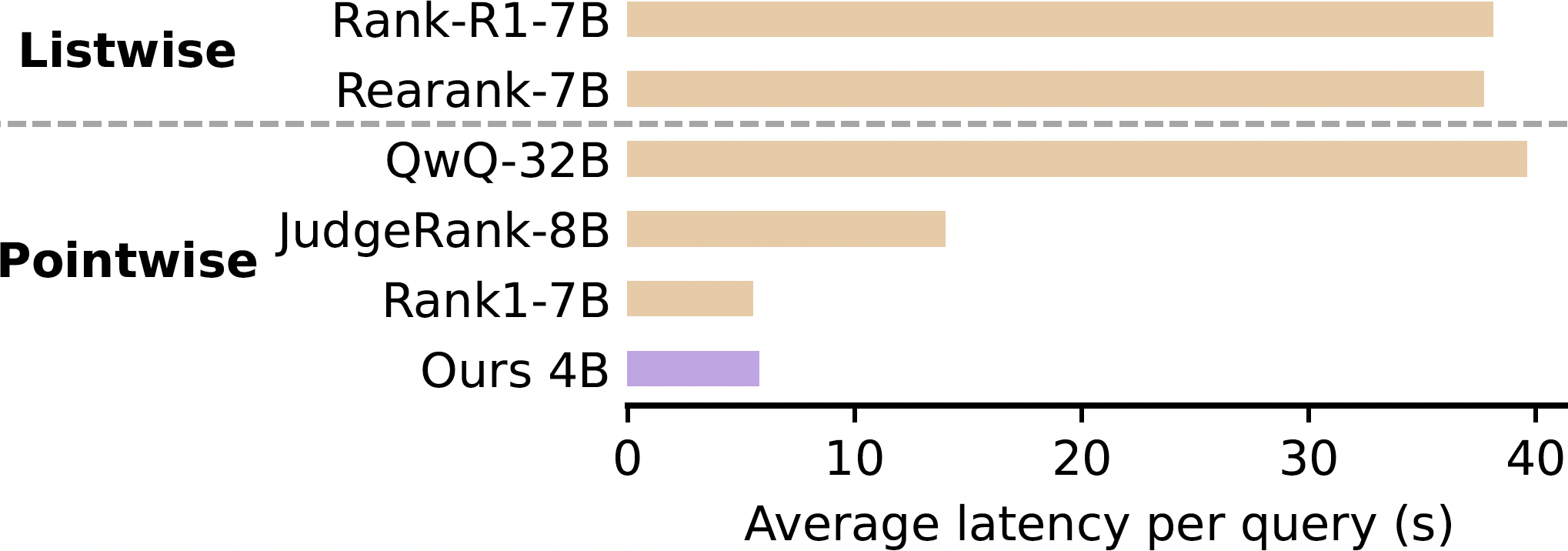
Since ERank is a pointwise reranker, it has low latency compared with listwise models.
For more details, please refer to our Paper.
We have implemented the inference code based on Transformer and vLLM, respectively.
from examples.ERank_Transformer import ERank_Transformer
from examples.ERank_vLLM import ERank_vLLM
from examples.utils import hybrid_scores
# select a model
model_name_or_path = "Alibaba-NLP/ERank-4B"
# model_name_or_path = "Alibaba-NLP/ERank-14B"
# model_name_or_path = "Alibaba-NLP/ERank-32B"
# use vLLM or Transformer
# reranker = ERank_Transformer(model_name_or_path)
reranker = ERank_vLLM(model_name_or_path)
# input data
instruction = "Retrieve relevant documents for the query."
query = "I am happy"
docs = [
{"content": "excited", "first_stage_score": 46.7},
{"content": "sad", "first_stage_score": 1.5},
{"content": "peaceful", "first_stage_score": 2.3},
]
# rerank
results = reranker.rerank(query, docs, instruction, truncate_length=2048)
print(results)
# [
# {'content': 'excited', 'first_stage_score': 46.7, 'rank_score': 4.84},
# {'content': 'peaceful', 'first_stage_score': 2.3, 'rank_score': 2.98}
# {'content': 'sad', 'first_stage_score': 1.5, 'rank_score': 0.0},
# ]
# Optional: hybrid with first-stage scores
alpha = 0.2
hybrid_results = hybrid_scores(results, alpha)
print(hybrid_results)
# [
# {'content': 'excited', 'first_stage_score': 46.7, 'rank_score': 4.84, 'hybrid_score': 1.18},
# {'content': 'peaceful', 'first_stage_score': 2.3, 'rank_score': 2.98, 'hybrid_score':0.01},
# {'content': 'sad', 'first_stage_score': 1.5, 'rank_score': 0.0, 'hybrid_score': -1.19}
# ]
Please refer to the examples directory for details, in which we also provide the instructions used in the prompt during evaluation.
If you find our work helpful, feel free to give us a cite.
@misc{ERank,
title={ERank: Fusing Supervised Fine-Tuning and Reinforcement Learning for Effective and Efficient Text Reranking},
author={Yuzheng Cai and Yanzhao Zhang and Dingkun Long and Mingxin Li and Pengjun Xie and Weiguo Zheng},
year={2025},
eprint={2509.00520},
archivePrefix={arXiv},
primaryClass={cs.IR},
url={https://arxiv.org/abs/2509.00520},
}