
Computer Vision
Collection
4 items
•
Updated
•
1
YOLOS model fine-tuned on COCO 2017 object detection (118k annotated images). It was introduced in the paper You Only Look at One Sequence: Rethinking Transformer in Vision through Object Detection by Fang et al. and first released in this repository.
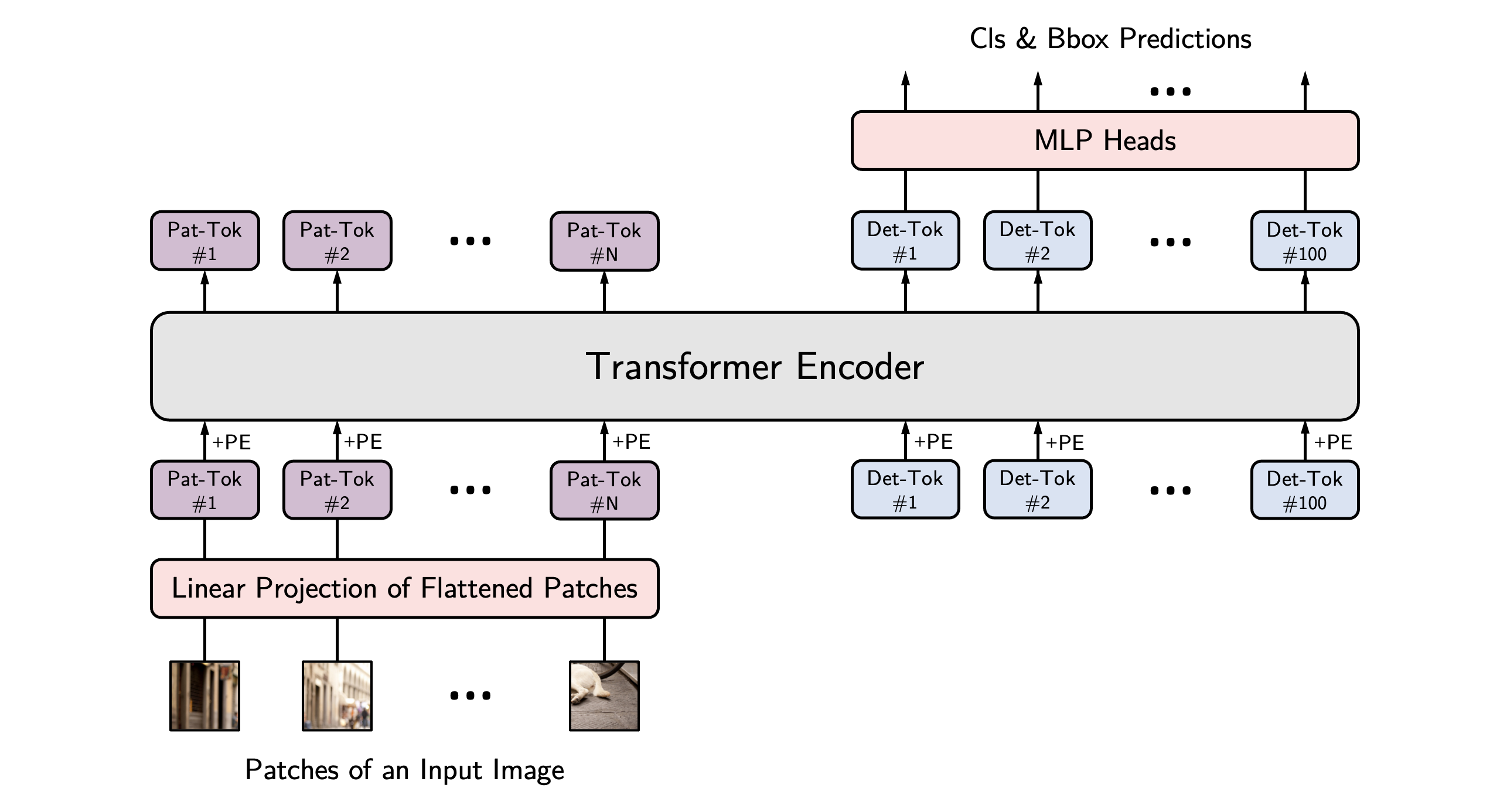
This hustvl/yolos-small model has been finetuned on these two datasets[1][2] (2604 samples) with the following results on the test set:
IoU metric: bbox
Average Precision (AP) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.501
Average Precision (AP) @[ IoU=0.50 | area= all | maxDets=100 ] = 0.866
Average Precision (AP) @[ IoU=0.75 | area= all | maxDets=100 ] = 0.498
Average Precision (AP) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.048
Average Precision (AP) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.455
Average Precision (AP) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.648
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 1 ] = 0.412
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets= 10 ] = 0.601
Average Recall (AR) @[ IoU=0.50:0.95 | area= all | maxDets=100 ] = 0.632
Average Recall (AR) @[ IoU=0.50:0.95 | area= small | maxDets=100 ] = 0.224
Average Recall (AR) @[ IoU=0.50:0.95 | area=medium | maxDets=100 ] = 0.600
Average Recall (AR) @[ IoU=0.50:0.95 | area= large | maxDets=100 ] = 0.756
from transformers import AutoImageProcessor, AutoModelForObjectDetection
import torch
from PIL import Image
import requests
url = "https://latestbollyholly.com/wp-content/uploads/2024/02/Jacob-Gooch.jpg"
image = Image.open(requests.get(url, stream=True).raw)
image_processor = AutoImageProcessor.from_pretrained("AdamCodd/yolos-small-person")
model = AutoModelForObjectDetection.from_pretrained("AdamCodd/yolos-small-person")
inputs = image_processor(images=image, return_tensors="pt")
outputs = model(**inputs)
# convert outputs (bounding boxes and class logits) to Pascal VOC format (xmin, ymin, xmax, ymax)
target_sizes = torch.tensor([image.size[::-1]])
results = image_processor.post_process_object_detection(outputs, threshold=0.7, target_sizes=target_sizes)[0]
for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
box = [round(i, 2) for i in box.tolist()]
print(
f"Detected {model.config.id2label[label.item()]} with confidence "
f"{round(score.item(), 3)} at location {box}"
)
Refer to the documentation for more code examples.
This model is more of an experiment on a small scale and will need retraining on a more diverse dataset. This fine-tuned model performs best when detecting individuals who are relatively close to the viewpoint. As indicated by the metrics, it struggles to identify individuals farther away.
The following hyperparameters were used during training:
If you want to support me, you can here.
@article{DBLP:journals/corr/abs-2106-00666,
author = {Yuxin Fang and
Bencheng Liao and
Xinggang Wang and
Jiemin Fang and
Jiyang Qi and
Rui Wu and
Jianwei Niu and
Wenyu Liu},
title = {You Only Look at One Sequence: Rethinking Transformer in Vision through
Object Detection},
journal = {CoRR},
volume = {abs/2106.00666},
year = {2021},
url = {https://arxiv.org/abs/2106.00666},
eprinttype = {arXiv},
eprint = {2106.00666},
timestamp = {Fri, 29 Apr 2022 19:49:16 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2106-00666.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
Base model
hustvl/yolos-small