
End of training
Browse files- README.md +123 -0
- adapter_config.json +32 -0
- adapter_model.safetensors +3 -0
- loss_plot.png +0 -0
- training_args.bin +3 -0
README.md
ADDED
|
@@ -0,0 +1,123 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
library_name: peft
|
| 3 |
+
license: other
|
| 4 |
+
base_model: deepseek-ai/deepseek-coder-1.3b-base
|
| 5 |
+
tags:
|
| 6 |
+
- generated_from_trainer
|
| 7 |
+
model-index:
|
| 8 |
+
- name: lemexp-task1-v2-lemma_object_full_notypes-deepseek-coder-1.3b-base-ddp-8lr-v2
|
| 9 |
+
results: []
|
| 10 |
+
---
|
| 11 |
+
|
| 12 |
+
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 13 |
+
should probably proofread and complete it, then remove this comment. -->
|
| 14 |
+
|
| 15 |
+
# lemexp-task1-v2-lemma_object_full_notypes-deepseek-coder-1.3b-base-ddp-8lr-v2
|
| 16 |
+
|
| 17 |
+
This model is a fine-tuned version of [deepseek-ai/deepseek-coder-1.3b-base](https://huggingface.co/deepseek-ai/deepseek-coder-1.3b-base) on an unknown dataset.
|
| 18 |
+
It achieves the following results on the evaluation set:
|
| 19 |
+
- Loss: 0.2454
|
| 20 |
+
|
| 21 |
+
## Model description
|
| 22 |
+
|
| 23 |
+
More information needed
|
| 24 |
+
|
| 25 |
+
## Intended uses & limitations
|
| 26 |
+
|
| 27 |
+
More information needed
|
| 28 |
+
|
| 29 |
+
## Training and evaluation data
|
| 30 |
+
|
| 31 |
+
More information needed
|
| 32 |
+
|
| 33 |
+
## Training procedure
|
| 34 |
+
|
| 35 |
+
### Training hyperparameters
|
| 36 |
+
|
| 37 |
+
The following hyperparameters were used during training:
|
| 38 |
+
- learning_rate: 0.0008
|
| 39 |
+
- train_batch_size: 2
|
| 40 |
+
- eval_batch_size: 2
|
| 41 |
+
- seed: 42
|
| 42 |
+
- distributed_type: multi-GPU
|
| 43 |
+
- num_devices: 8
|
| 44 |
+
- total_train_batch_size: 16
|
| 45 |
+
- total_eval_batch_size: 16
|
| 46 |
+
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
|
| 47 |
+
- lr_scheduler_type: linear
|
| 48 |
+
- num_epochs: 12
|
| 49 |
+
- mixed_precision_training: Native AMP
|
| 50 |
+
|
| 51 |
+
### Training results
|
| 52 |
+
|
| 53 |
+
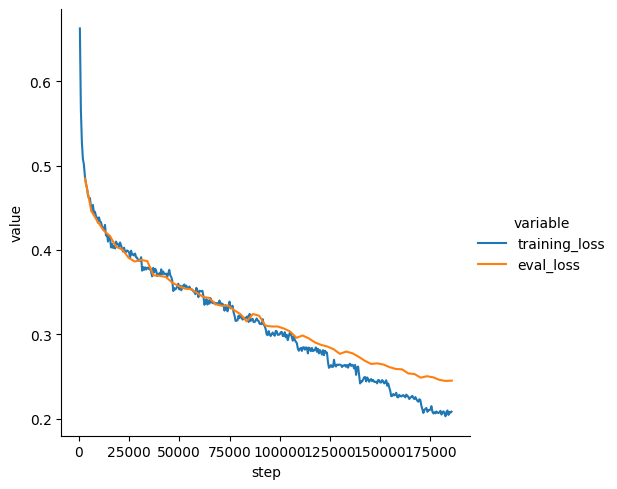
| Training Loss | Epoch | Step | Validation Loss |
|
| 54 |
+
|:-------------:|:-----:|:------:|:---------------:|
|
| 55 |
+
| 0.4873 | 0.2 | 3094 | 0.4845 |
|
| 56 |
+
| 0.4521 | 0.4 | 6188 | 0.4463 |
|
| 57 |
+
| 0.4379 | 0.6 | 9282 | 0.4339 |
|
| 58 |
+
| 0.4256 | 0.8 | 12376 | 0.4230 |
|
| 59 |
+
| 0.4164 | 1.0 | 15470 | 0.4166 |
|
| 60 |
+
| 0.4099 | 1.2 | 18564 | 0.4037 |
|
| 61 |
+
| 0.4011 | 1.4 | 21658 | 0.4006 |
|
| 62 |
+
| 0.3985 | 1.6 | 24752 | 0.3908 |
|
| 63 |
+
| 0.3935 | 1.8 | 27846 | 0.3863 |
|
| 64 |
+
| 0.388 | 2.0 | 30940 | 0.3882 |
|
| 65 |
+
| 0.3787 | 2.2 | 34034 | 0.3869 |
|
| 66 |
+
| 0.3788 | 2.4 | 37128 | 0.3700 |
|
| 67 |
+
| 0.3724 | 2.6 | 40222 | 0.3694 |
|
| 68 |
+
| 0.3718 | 2.8 | 43316 | 0.3681 |
|
| 69 |
+
| 0.368 | 3.0 | 46410 | 0.3615 |
|
| 70 |
+
| 0.3601 | 3.2 | 49504 | 0.3575 |
|
| 71 |
+
| 0.3592 | 3.4 | 52598 | 0.3544 |
|
| 72 |
+
| 0.3541 | 3.6 | 55692 | 0.3536 |
|
| 73 |
+
| 0.3552 | 3.8 | 58786 | 0.3493 |
|
| 74 |
+
| 0.3517 | 4.0 | 61880 | 0.3444 |
|
| 75 |
+
| 0.3401 | 4.2 | 64974 | 0.3432 |
|
| 76 |
+
| 0.3357 | 4.4 | 68068 | 0.3358 |
|
| 77 |
+
| 0.3368 | 4.6 | 71162 | 0.3340 |
|
| 78 |
+
| 0.3274 | 4.8 | 74256 | 0.3342 |
|
| 79 |
+
| 0.3264 | 5.0 | 77350 | 0.3287 |
|
| 80 |
+
| 0.3193 | 5.2 | 80444 | 0.3240 |
|
| 81 |
+
| 0.3209 | 5.4 | 83538 | 0.3155 |
|
| 82 |
+
| 0.3186 | 5.6 | 86632 | 0.3242 |
|
| 83 |
+
| 0.316 | 5.8 | 89726 | 0.3222 |
|
| 84 |
+
| 0.3097 | 6.0 | 92820 | 0.3105 |
|
| 85 |
+
| 0.2982 | 6.2 | 95914 | 0.3095 |
|
| 86 |
+
| 0.2996 | 6.4 | 99008 | 0.3094 |
|
| 87 |
+
| 0.2983 | 6.6 | 102102 | 0.3070 |
|
| 88 |
+
| 0.3019 | 6.8 | 105196 | 0.3034 |
|
| 89 |
+
| 0.2914 | 7.0 | 108290 | 0.2960 |
|
| 90 |
+
| 0.2805 | 7.2 | 111384 | 0.2988 |
|
| 91 |
+
| 0.2776 | 7.4 | 114478 | 0.2953 |
|
| 92 |
+
| 0.2821 | 7.6 | 117572 | 0.2906 |
|
| 93 |
+
| 0.2792 | 7.8 | 120666 | 0.2876 |
|
| 94 |
+
| 0.2786 | 8.0 | 123760 | 0.2857 |
|
| 95 |
+
| 0.2617 | 8.2 | 126854 | 0.2825 |
|
| 96 |
+
| 0.2643 | 8.4 | 129948 | 0.2771 |
|
| 97 |
+
| 0.2618 | 8.6 | 133042 | 0.2797 |
|
| 98 |
+
| 0.2641 | 8.8 | 136136 | 0.2778 |
|
| 99 |
+
| 0.262 | 9.0 | 139230 | 0.2736 |
|
| 100 |
+
| 0.2492 | 9.2 | 142324 | 0.2689 |
|
| 101 |
+
| 0.2459 | 9.4 | 145418 | 0.2651 |
|
| 102 |
+
| 0.2421 | 9.6 | 148512 | 0.2658 |
|
| 103 |
+
| 0.2444 | 9.8 | 151606 | 0.2644 |
|
| 104 |
+
| 0.2373 | 10.0 | 154700 | 0.2613 |
|
| 105 |
+
| 0.2288 | 10.2 | 157794 | 0.2592 |
|
| 106 |
+
| 0.2266 | 10.4 | 160888 | 0.2587 |
|
| 107 |
+
| 0.2275 | 10.6 | 163982 | 0.2539 |
|
| 108 |
+
| 0.2236 | 10.8 | 167076 | 0.2532 |
|
| 109 |
+
| 0.2223 | 11.0 | 170170 | 0.2489 |
|
| 110 |
+
| 0.213 | 11.2 | 173264 | 0.2506 |
|
| 111 |
+
| 0.2086 | 11.4 | 176358 | 0.2493 |
|
| 112 |
+
| 0.2069 | 11.6 | 179452 | 0.2463 |
|
| 113 |
+
| 0.2031 | 11.8 | 182546 | 0.2450 |
|
| 114 |
+
| 0.2086 | 12.0 | 185640 | 0.2454 |
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
### Framework versions
|
| 118 |
+
|
| 119 |
+
- PEFT 0.14.0
|
| 120 |
+
- Transformers 4.47.0
|
| 121 |
+
- Pytorch 2.5.1+cu124
|
| 122 |
+
- Datasets 3.2.0
|
| 123 |
+
- Tokenizers 0.21.0
|
adapter_config.json
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"alpha_pattern": {},
|
| 3 |
+
"auto_mapping": null,
|
| 4 |
+
"base_model_name_or_path": "deepseek-ai/deepseek-coder-1.3b-base",
|
| 5 |
+
"bias": "none",
|
| 6 |
+
"eva_config": null,
|
| 7 |
+
"exclude_modules": null,
|
| 8 |
+
"fan_in_fan_out": false,
|
| 9 |
+
"inference_mode": true,
|
| 10 |
+
"init_lora_weights": true,
|
| 11 |
+
"layer_replication": null,
|
| 12 |
+
"layers_pattern": null,
|
| 13 |
+
"layers_to_transform": null,
|
| 14 |
+
"loftq_config": {},
|
| 15 |
+
"lora_alpha": 32,
|
| 16 |
+
"lora_bias": false,
|
| 17 |
+
"lora_dropout": 0.05,
|
| 18 |
+
"megatron_config": null,
|
| 19 |
+
"megatron_core": "megatron.core",
|
| 20 |
+
"modules_to_save": null,
|
| 21 |
+
"peft_type": "LORA",
|
| 22 |
+
"r": 8,
|
| 23 |
+
"rank_pattern": {},
|
| 24 |
+
"revision": null,
|
| 25 |
+
"target_modules": [
|
| 26 |
+
"q_proj",
|
| 27 |
+
"v_proj"
|
| 28 |
+
],
|
| 29 |
+
"task_type": "CAUSAL_LM",
|
| 30 |
+
"use_dora": false,
|
| 31 |
+
"use_rslora": false
|
| 32 |
+
}
|
adapter_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9176d47319830e3bad3f418bc38c32f739d629afd73dda6c4c0099ce2f733911
|
| 3 |
+
size 268636736
|
loss_plot.png
ADDED
|
training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d1060a812a1d888d0dec222e6285022b96c4282bb63fd696956038c570ff5118
|
| 3 |
+
size 5496
|