
End of training
Browse files- README.md +64 -34
- adapter_config.json +2 -2
- adapter_model.safetensors +1 -1
- loss_plot.png +0 -0
- training_args.bin +2 -2
README.md
CHANGED
|
@@ -16,7 +16,7 @@ should probably proofread and complete it, then remove this comment. -->
|
|
| 16 |
|
| 17 |
This model is a fine-tuned version of [deepseek-ai/deepseek-coder-1.3b-base](https://huggingface.co/deepseek-ai/deepseek-coder-1.3b-base) on an unknown dataset.
|
| 18 |
It achieves the following results on the evaluation set:
|
| 19 |
-
- Loss: 0.
|
| 20 |
|
| 21 |
## Model description
|
| 22 |
|
|
@@ -45,43 +45,73 @@ The following hyperparameters were used during training:
|
|
| 45 |
- total_eval_batch_size: 16
|
| 46 |
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
|
| 47 |
- lr_scheduler_type: linear
|
| 48 |
-
- num_epochs:
|
| 49 |
- mixed_precision_training: Native AMP
|
| 50 |
|
| 51 |
### Training results
|
| 52 |
|
| 53 |
-
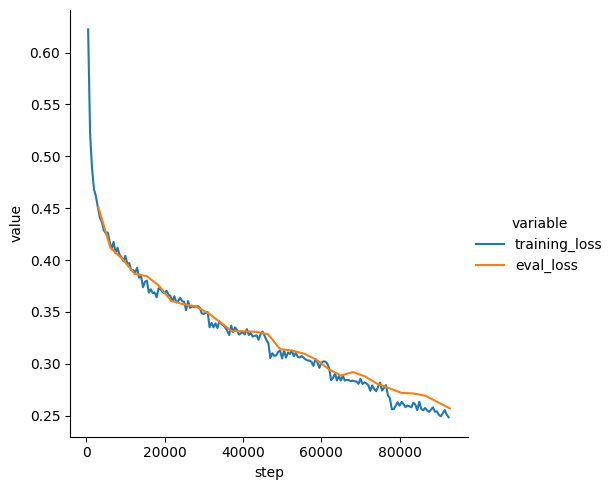
| Training Loss | Epoch | Step
|
| 54 |
-
|
| 55 |
-
| 0.
|
| 56 |
-
| 0.
|
| 57 |
-
| 0.
|
| 58 |
-
| 0.
|
| 59 |
-
| 0.
|
| 60 |
-
| 0.
|
| 61 |
-
| 0.
|
| 62 |
-
| 0.
|
| 63 |
-
| 0.
|
| 64 |
-
| 0.
|
| 65 |
-
| 0.
|
| 66 |
-
| 0.
|
| 67 |
-
| 0.
|
| 68 |
-
| 0.
|
| 69 |
-
| 0.
|
| 70 |
-
| 0.
|
| 71 |
-
| 0.
|
| 72 |
-
| 0.
|
| 73 |
-
| 0.
|
| 74 |
-
| 0.
|
| 75 |
-
| 0.
|
| 76 |
-
| 0.
|
| 77 |
-
| 0.
|
| 78 |
-
| 0.
|
| 79 |
-
| 0.
|
| 80 |
-
| 0.
|
| 81 |
-
| 0.
|
| 82 |
-
| 0.
|
| 83 |
-
| 0.
|
| 84 |
-
| 0.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 85 |
|
| 86 |
|
| 87 |
### Framework versions
|
|
|
|
| 16 |
|
| 17 |
This model is a fine-tuned version of [deepseek-ai/deepseek-coder-1.3b-base](https://huggingface.co/deepseek-ai/deepseek-coder-1.3b-base) on an unknown dataset.
|
| 18 |
It achieves the following results on the evaluation set:
|
| 19 |
+
- Loss: 0.2261
|
| 20 |
|
| 21 |
## Model description
|
| 22 |
|
|
|
|
| 45 |
- total_eval_batch_size: 16
|
| 46 |
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
|
| 47 |
- lr_scheduler_type: linear
|
| 48 |
+
- num_epochs: 12
|
| 49 |
- mixed_precision_training: Native AMP
|
| 50 |
|
| 51 |
### Training results
|
| 52 |
|
| 53 |
+
| Training Loss | Epoch | Step | Validation Loss |
|
| 54 |
+
|:-------------:|:-----:|:------:|:---------------:|
|
| 55 |
+
| 0.4519 | 0.2 | 3094 | 0.4528 |
|
| 56 |
+
| 0.4192 | 0.4 | 6188 | 0.4162 |
|
| 57 |
+
| 0.4051 | 0.6 | 9282 | 0.4043 |
|
| 58 |
+
| 0.3928 | 0.8 | 12376 | 0.3904 |
|
| 59 |
+
| 0.3846 | 1.0 | 15470 | 0.3827 |
|
| 60 |
+
| 0.3797 | 1.2 | 18564 | 0.3772 |
|
| 61 |
+
| 0.3744 | 1.4 | 21658 | 0.3697 |
|
| 62 |
+
| 0.3697 | 1.6 | 24752 | 0.3640 |
|
| 63 |
+
| 0.3643 | 1.8 | 27846 | 0.3624 |
|
| 64 |
+
| 0.3614 | 2.0 | 30940 | 0.3526 |
|
| 65 |
+
| 0.3546 | 2.2 | 34034 | 0.3512 |
|
| 66 |
+
| 0.3503 | 2.4 | 37128 | 0.3487 |
|
| 67 |
+
| 0.345 | 2.6 | 40222 | 0.3421 |
|
| 68 |
+
| 0.3449 | 2.8 | 43316 | 0.3431 |
|
| 69 |
+
| 0.3421 | 3.0 | 46410 | 0.3432 |
|
| 70 |
+
| 0.335 | 3.2 | 49504 | 0.3359 |
|
| 71 |
+
| 0.3351 | 3.4 | 52598 | 0.3336 |
|
| 72 |
+
| 0.33 | 3.6 | 55692 | 0.3340 |
|
| 73 |
+
| 0.3283 | 3.8 | 58786 | 0.3282 |
|
| 74 |
+
| 0.3266 | 4.0 | 61880 | 0.3166 |
|
| 75 |
+
| 0.317 | 4.2 | 64974 | 0.3149 |
|
| 76 |
+
| 0.3122 | 4.4 | 68068 | 0.3149 |
|
| 77 |
+
| 0.313 | 4.6 | 71162 | 0.3147 |
|
| 78 |
+
| 0.3043 | 4.8 | 74256 | 0.3130 |
|
| 79 |
+
| 0.3019 | 5.0 | 77350 | 0.3036 |
|
| 80 |
+
| 0.2952 | 5.2 | 80444 | 0.3000 |
|
| 81 |
+
| 0.2996 | 5.4 | 83538 | 0.3003 |
|
| 82 |
+
| 0.2957 | 5.6 | 86632 | 0.2993 |
|
| 83 |
+
| 0.2935 | 5.8 | 89726 | 0.3047 |
|
| 84 |
+
| 0.2885 | 6.0 | 92820 | 0.2928 |
|
| 85 |
+
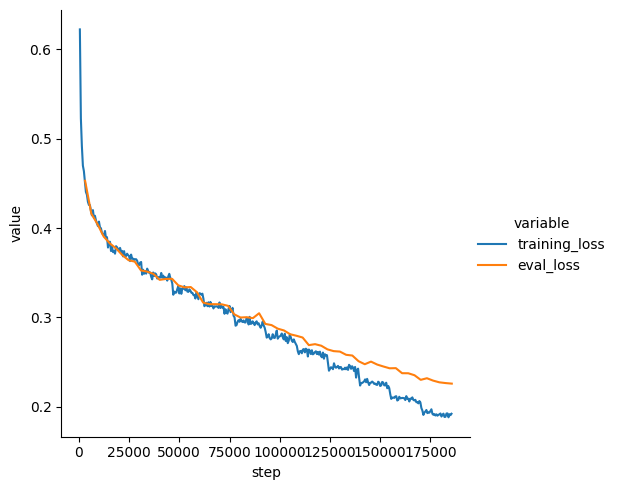
| 0.2755 | 6.2 | 95914 | 0.2915 |
|
| 86 |
+
| 0.2763 | 6.4 | 99008 | 0.2875 |
|
| 87 |
+
| 0.2755 | 6.6 | 102102 | 0.2855 |
|
| 88 |
+
| 0.2811 | 6.8 | 105196 | 0.2812 |
|
| 89 |
+
| 0.2704 | 7.0 | 108290 | 0.2796 |
|
| 90 |
+
| 0.26 | 7.2 | 111384 | 0.2776 |
|
| 91 |
+
| 0.2564 | 7.4 | 114478 | 0.2691 |
|
| 92 |
+
| 0.2613 | 7.6 | 117572 | 0.2702 |
|
| 93 |
+
| 0.2568 | 7.8 | 120666 | 0.2684 |
|
| 94 |
+
| 0.2579 | 8.0 | 123760 | 0.2643 |
|
| 95 |
+
| 0.2422 | 8.2 | 126854 | 0.2624 |
|
| 96 |
+
| 0.243 | 8.4 | 129948 | 0.2619 |
|
| 97 |
+
| 0.2421 | 8.6 | 133042 | 0.2583 |
|
| 98 |
+
| 0.2455 | 8.8 | 136136 | 0.2575 |
|
| 99 |
+
| 0.2428 | 9.0 | 139230 | 0.2511 |
|
| 100 |
+
| 0.2286 | 9.2 | 142324 | 0.2478 |
|
| 101 |
+
| 0.227 | 9.4 | 145418 | 0.2507 |
|
| 102 |
+
| 0.2246 | 9.6 | 148512 | 0.2474 |
|
| 103 |
+
| 0.2273 | 9.8 | 151606 | 0.2452 |
|
| 104 |
+
| 0.2211 | 10.0 | 154700 | 0.2432 |
|
| 105 |
+
| 0.2117 | 10.2 | 157794 | 0.2434 |
|
| 106 |
+
| 0.2098 | 10.4 | 160888 | 0.2377 |
|
| 107 |
+
| 0.2092 | 10.6 | 163982 | 0.2376 |
|
| 108 |
+
| 0.2073 | 10.8 | 167076 | 0.2355 |
|
| 109 |
+
| 0.2051 | 11.0 | 170170 | 0.2303 |
|
| 110 |
+
| 0.1966 | 11.2 | 173264 | 0.2321 |
|
| 111 |
+
| 0.1923 | 11.4 | 176358 | 0.2294 |
|
| 112 |
+
| 0.1913 | 11.6 | 179452 | 0.2275 |
|
| 113 |
+
| 0.189 | 11.8 | 182546 | 0.2267 |
|
| 114 |
+
| 0.1924 | 12.0 | 185640 | 0.2261 |
|
| 115 |
|
| 116 |
|
| 117 |
### Framework versions
|
adapter_config.json
CHANGED
|
@@ -23,8 +23,8 @@
|
|
| 23 |
"rank_pattern": {},
|
| 24 |
"revision": null,
|
| 25 |
"target_modules": [
|
| 26 |
-
"
|
| 27 |
-
"
|
| 28 |
],
|
| 29 |
"task_type": "CAUSAL_LM",
|
| 30 |
"use_dora": false,
|
|
|
|
| 23 |
"rank_pattern": {},
|
| 24 |
"revision": null,
|
| 25 |
"target_modules": [
|
| 26 |
+
"q_proj",
|
| 27 |
+
"v_proj"
|
| 28 |
],
|
| 29 |
"task_type": "CAUSAL_LM",
|
| 30 |
"use_dora": false,
|
adapter_model.safetensors
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
size 268636736
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:22253574595cd04088755a3c511c1b3722206ed2cdaf7dba620e1b61cdffcf5b
|
| 3 |
size 268636736
|
loss_plot.png
CHANGED
|
|
training_args.bin
CHANGED
|
@@ -1,3 +1,3 @@
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
-
oid sha256:
|
| 3 |
-
size
|
|
|
|
| 1 |
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3476aecc2e7edfbf65feed98e3e459c9ff12870258371744a90a8e58d9761d2e
|
| 3 |
+
size 5432
|