
Upload config and log files
Browse files- all_results.json +9 -0
- train_results.json +9 -0
- trainer_log.jsonl +0 -0
- trainer_state.json +0 -0
- training_args.yaml +34 -0
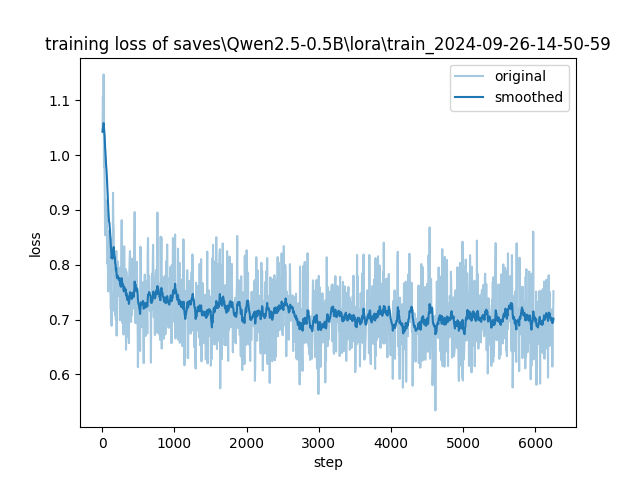
- training_loss.png +0 -0
all_results.json
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 1.0,
|
| 3 |
+
"num_input_tokens_seen": 33437856,
|
| 4 |
+
"total_flos": 7.1914395644928e+16,
|
| 5 |
+
"train_loss": 0.7151971128082275,
|
| 6 |
+
"train_runtime": 36754.4929,
|
| 7 |
+
"train_samples_per_second": 2.721,
|
| 8 |
+
"train_steps_per_second": 0.17
|
| 9 |
+
}
|
train_results.json
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 1.0,
|
| 3 |
+
"num_input_tokens_seen": 33437856,
|
| 4 |
+
"total_flos": 7.1914395644928e+16,
|
| 5 |
+
"train_loss": 0.7151971128082275,
|
| 6 |
+
"train_runtime": 36754.4929,
|
| 7 |
+
"train_samples_per_second": 2.721,
|
| 8 |
+
"train_steps_per_second": 0.17
|
| 9 |
+
}
|
trainer_log.jsonl
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
trainer_state.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
training_args.yaml
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
bf16: true
|
| 2 |
+
cutoff_len: 1024
|
| 3 |
+
dataset: mathinstruct
|
| 4 |
+
dataset_dir: data
|
| 5 |
+
ddp_timeout: 180000000
|
| 6 |
+
do_train: true
|
| 7 |
+
finetuning_type: lora
|
| 8 |
+
flash_attn: auto
|
| 9 |
+
gradient_accumulation_steps: 8
|
| 10 |
+
include_num_input_tokens_seen: true
|
| 11 |
+
learning_rate: 5.0e-05
|
| 12 |
+
logging_steps: 5
|
| 13 |
+
lora_alpha: 2
|
| 14 |
+
lora_dropout: 0
|
| 15 |
+
lora_rank: 1
|
| 16 |
+
lora_target: all
|
| 17 |
+
lr_scheduler_type: cosine
|
| 18 |
+
max_grad_norm: 1.0
|
| 19 |
+
max_samples: 100000
|
| 20 |
+
model_name_or_path: D:/models/Qwen2.5-0.5B
|
| 21 |
+
num_train_epochs: 1.0
|
| 22 |
+
optim: adamw_torch
|
| 23 |
+
output_dir: saves\Qwen2.5-0.5B\lora\train_2024-09-26-14-50-59
|
| 24 |
+
packing: false
|
| 25 |
+
per_device_train_batch_size: 2
|
| 26 |
+
plot_loss: true
|
| 27 |
+
preprocessing_num_workers: 16
|
| 28 |
+
quantization_bit: 4
|
| 29 |
+
quantization_method: bitsandbytes
|
| 30 |
+
report_to: all
|
| 31 |
+
save_steps: 100
|
| 32 |
+
stage: sft
|
| 33 |
+
template: qwen
|
| 34 |
+
warmup_steps: 0
|
training_loss.png
ADDED
|