
Add files using upload-large-folder tool
Browse files- .gitattributes +1 -0
- README.md +218 -0
- config.json +53 -0
- configuration_harmon.py +9 -0
- diffloss.py +249 -0
- diffusion_utils.py +73 -0
- gaussian_diffusion.py +877 -0
- mar.py +470 -0
- method.png +3 -0
- misc.py +383 -0
- model-00001-of-00002.safetensors +3 -0
- model-00002-of-00002.safetensors +3 -0
- model.safetensors.index.json +0 -0
- modeling_harmon.py +288 -0
- respace.py +129 -0
- tokenizer.json +0 -0
- tokenizer_config.json +207 -0
- vae.py +522 -0
- vocab.json +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
method.png filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,218 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Harmon: Harmonizing Visual Representations for Unified Multimodal Understanding and Generation
|
| 2 |
+
|
| 3 |
+

|
| 4 |
+
|
| 5 |
+
> **[Harmonizing Visual Representations for Unified Multimodal Understanding and Generation](https://arxiv.org/abs/2406.05821)**
|
| 6 |
+
>
|
| 7 |
+
> Size Wu, Wenwei Zhang, Lumin Xu, Sheng Jin, Zhonghua Wu, Qingyi Tao, Wentao Liu, Wei Li, Chen Change Loy
|
| 8 |
+
>
|
| 9 |
+
> [](https://arxiv.org/abs/2406.05821)
|
| 10 |
+
> [](https://wusize.github.io/projects/Harmon)
|
| 11 |
+
> [](https://github.com/wusize/Harmon#citation)
|
| 12 |
+
|
| 13 |
+
## Introduction
|
| 14 |
+
|
| 15 |
+
**Harmon** is a novel unified framework for multimodal understanding and generation. Unlike existing state-of-the-art
|
| 16 |
+
architectures that disentangle visual understanding and generation with different encoder models, the proposed framework harmonizes
|
| 17 |
+
the visual presentations of understanding and generation via a shared MAR encoder. Harmon achieves advanced generation
|
| 18 |
+
performance on mainstream text-to-image generation benchmarks, and exhibits competitive results on multimodal understanding
|
| 19 |
+
tasks. In this repo, we provide inference code to run Harmon for image understanding (image-to-text) and text-to-image
|
| 20 |
+
generation, with two model variants Harmon-0.5B and Harmon-1.5B.
|
| 21 |
+
|
| 22 |
+
## Usage
|
| 23 |
+
|
| 24 |
+
### 🖌️ Image-to-text Generation
|
| 25 |
+
|
| 26 |
+
```python
|
| 27 |
+
import torch
|
| 28 |
+
import numpy as np
|
| 29 |
+
from transformers import AutoTokenizer, AutoModel
|
| 30 |
+
from einops import rearrange
|
| 31 |
+
from PIL import Image
|
| 32 |
+
import requests
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
PROMPT_TEMPLATE = dict(
|
| 36 |
+
SYSTEM='<|im_start|>system\n{system}<|im_end|>\n',
|
| 37 |
+
INSTRUCTION='<|im_start|>user\n{input}<|im_end|>\n<|im_start|>assistant\n',
|
| 38 |
+
SUFFIX='<|im_end|>',
|
| 39 |
+
SUFFIX_AS_EOS=True,
|
| 40 |
+
SEP='\n',
|
| 41 |
+
STOP_WORDS=['<|im_end|>', '<|endoftext|>'])
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def expand2square(pil_img, background_color):
|
| 45 |
+
width, height = pil_img.size
|
| 46 |
+
if width == height:
|
| 47 |
+
return pil_img
|
| 48 |
+
elif width > height:
|
| 49 |
+
result = Image.new(pil_img.mode, (width, width), background_color)
|
| 50 |
+
result.paste(pil_img, (0, (width - height) // 2))
|
| 51 |
+
return result
|
| 52 |
+
else:
|
| 53 |
+
result = Image.new(pil_img.mode, (height, height), background_color)
|
| 54 |
+
result.paste(pil_img, ((height - width) // 2, 0))
|
| 55 |
+
return result
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
@torch.no_grad()
|
| 59 |
+
def question_answer(question,
|
| 60 |
+
image,
|
| 61 |
+
model,
|
| 62 |
+
tokenizer,
|
| 63 |
+
max_new_tokens=512,
|
| 64 |
+
image_size=512
|
| 65 |
+
):
|
| 66 |
+
assert image_size == 512
|
| 67 |
+
image = expand2square(
|
| 68 |
+
image, (127, 127, 127))
|
| 69 |
+
image = image.resize(size=(image_size, image_size))
|
| 70 |
+
image = torch.from_numpy(np.array(image)).to(dtype=model.dtype, device=model.device)
|
| 71 |
+
image = rearrange(image, 'h w c -> c h w')[None]
|
| 72 |
+
image = 2 * (image / 255) - 1
|
| 73 |
+
|
| 74 |
+
prompt = PROMPT_TEMPLATE['INSTRUCTION'].format(input="<image>\n" + question)
|
| 75 |
+
assert '<image>' in prompt
|
| 76 |
+
image_length = (image_size // 16) ** 2 + model.mar.buffer_size
|
| 77 |
+
prompt = prompt.replace('<image>', '<image>'*image_length)
|
| 78 |
+
input_ids = tokenizer.encode(
|
| 79 |
+
prompt, add_special_tokens=True, return_tensors='pt').cuda()
|
| 80 |
+
_, z_enc = model.extract_visual_feature(model.encode(image))
|
| 81 |
+
inputs_embeds = z_enc.new_zeros(*input_ids.shape, model.llm.config.hidden_size)
|
| 82 |
+
inputs_embeds[input_ids == image_token_idx] = z_enc.flatten(0, 1)
|
| 83 |
+
inputs_embeds[input_ids != image_token_idx] = model.llm.get_input_embeddings()(
|
| 84 |
+
input_ids[input_ids != image_token_idx]
|
| 85 |
+
)
|
| 86 |
+
output = model.llm.generate(inputs_embeds=inputs_embeds,
|
| 87 |
+
use_cache=True,
|
| 88 |
+
do_sample=False,
|
| 89 |
+
max_new_tokens=max_new_tokens,
|
| 90 |
+
eos_token_id=tokenizer.eos_token_id,
|
| 91 |
+
pad_token_id=tokenizer.pad_token_id
|
| 92 |
+
if tokenizer.pad_token_id is not None else
|
| 93 |
+
tokenizer.eos_token_id
|
| 94 |
+
)
|
| 95 |
+
return tokenizer.decode(output[0])
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
harmon_tokenizer = AutoTokenizer.from_pretrained("wusize/Harmon-1_5B",
|
| 99 |
+
trust_remote_code=True)
|
| 100 |
+
harmon_model = AutoModel.from_pretrained("wusize/Harmon-1_5B",
|
| 101 |
+
trust_remote_code=True).eval().cuda().bfloat16()
|
| 102 |
+
|
| 103 |
+
special_tokens_dict = {'additional_special_tokens': ["<image>", ]}
|
| 104 |
+
num_added_toks = harmon_tokenizer.add_special_tokens(special_tokens_dict)
|
| 105 |
+
assert num_added_toks == 1
|
| 106 |
+
|
| 107 |
+
image_token_idx = harmon_tokenizer.encode("<image>", add_special_tokens=False)[-1]
|
| 108 |
+
print(f"Image token: {harmon_tokenizer.decode(image_token_idx)}")
|
| 109 |
+
|
| 110 |
+
image_file = "http://images.cocodataset.org/val2017/000000039769.jpg"
|
| 111 |
+
raw_image = Image.open(requests.get(image_file, stream=True).raw).convert('RGB')
|
| 112 |
+
|
| 113 |
+
output_text = question_answer(question='Describe the image in detail.',
|
| 114 |
+
image=raw_image,
|
| 115 |
+
model=harmon_model,
|
| 116 |
+
tokenizer=harmon_tokenizer,
|
| 117 |
+
)
|
| 118 |
+
|
| 119 |
+
print(output_text)
|
| 120 |
+
|
| 121 |
+
```
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
### 🖼️ Text-to-image Generation
|
| 125 |
+
```python
|
| 126 |
+
import os
|
| 127 |
+
import torch
|
| 128 |
+
from transformers import AutoTokenizer, AutoModel
|
| 129 |
+
from einops import rearrange
|
| 130 |
+
from PIL import Image
|
| 131 |
+
|
| 132 |
+
|
| 133 |
+
PROMPT_TEMPLATE = dict(
|
| 134 |
+
SYSTEM='<|im_start|>system\n{system}<|im_end|>\n',
|
| 135 |
+
INSTRUCTION='<|im_start|>user\n{input}<|im_end|>\n<|im_start|>assistant\n',
|
| 136 |
+
SUFFIX='<|im_end|>',
|
| 137 |
+
SUFFIX_AS_EOS=True,
|
| 138 |
+
SEP='\n',
|
| 139 |
+
STOP_WORDS=['<|im_end|>', '<|endoftext|>'])
|
| 140 |
+
|
| 141 |
+
GENERATION_TEMPLATE = "Generate an image: {text}"
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
@torch.no_grad()
|
| 145 |
+
def generate_images(prompts,
|
| 146 |
+
negative_prompt,
|
| 147 |
+
tokenizer,
|
| 148 |
+
model,
|
| 149 |
+
output,
|
| 150 |
+
grid_size=2, # will produce 2 x 2 images per prompt
|
| 151 |
+
num_steps=64, cfg_scale=3.0, temperature=1.0, image_size=512):
|
| 152 |
+
assert image_size == 512
|
| 153 |
+
m = n = image_size // 16
|
| 154 |
+
|
| 155 |
+
prompts = [
|
| 156 |
+
PROMPT_TEMPLATE['INSTRUCTION'].format(input=prompt)
|
| 157 |
+
for prompt in prompts
|
| 158 |
+
] * (grid_size ** 2)
|
| 159 |
+
|
| 160 |
+
if cfg_scale != 1.0:
|
| 161 |
+
prompts += [PROMPT_TEMPLATE['INSTRUCTION'].format(input=negative_prompt)] * len(prompts)
|
| 162 |
+
|
| 163 |
+
inputs = tokenizer(
|
| 164 |
+
prompts, add_special_tokens=True, return_tensors='pt', padding=True).to(model.device)
|
| 165 |
+
|
| 166 |
+
images = model.sample(**inputs, num_iter=num_steps, cfg=cfg_scale, cfg_schedule="constant",
|
| 167 |
+
temperature=temperature, progress=True, image_shape=(m, n))
|
| 168 |
+
images = rearrange(images, '(m n b) c h w -> b (m h) (n w) c', m=grid_size, n=grid_size)
|
| 169 |
+
|
| 170 |
+
images = torch.clamp(
|
| 171 |
+
127.5 * images + 128.0, 0, 255).to("cpu", dtype=torch.uint8).numpy()
|
| 172 |
+
|
| 173 |
+
os.makedirs(output, exist_ok=True)
|
| 174 |
+
for idx, image in enumerate(images):
|
| 175 |
+
Image.fromarray(image).save(f"{output}/{idx:08d}.jpg")
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
harmon_tokenizer = AutoTokenizer.from_pretrained("wusize/Harmon-1_5B",
|
| 179 |
+
trust_remote_code=True)
|
| 180 |
+
harmon_model = AutoModel.from_pretrained("wusize/Harmon-1_5B",
|
| 181 |
+
trust_remote_code=True).cuda().bfloat16().eval()
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
texts = ['a dog on the left and a cat on the right.',
|
| 185 |
+
'a photo of a pink stop sign.']
|
| 186 |
+
pos_prompts = [GENERATION_TEMPLATE.format(text=text) for text in texts]
|
| 187 |
+
neg_prompt = 'Generate an image.' # for classifier-free guidance
|
| 188 |
+
|
| 189 |
+
|
| 190 |
+
generate_images(prompts=pos_prompts,
|
| 191 |
+
negative_prompt=neg_prompt,
|
| 192 |
+
tokenizer=harmon_tokenizer,
|
| 193 |
+
model=harmon_model,
|
| 194 |
+
output='output',)
|
| 195 |
+
|
| 196 |
+
```
|
| 197 |
+
|
| 198 |
+
|
| 199 |
+
|
| 200 |
+
## 📚 Citation
|
| 201 |
+
|
| 202 |
+
If you find Harmon useful for your research or applications, please cite our paper using the following BibTeX:
|
| 203 |
+
|
| 204 |
+
```bibtex
|
| 205 |
+
@misc{wu2025harmon,
|
| 206 |
+
title={Harmonizing Visual Representations for Unified Multimodal Understanding and
|
| 207 |
+
Generation},
|
| 208 |
+
author={Size Wu and Wenwei Zhang and Lumin Xu and Sheng Jin and Zhonghua Wu and
|
| 209 |
+
Qingyi Tao and Wentao Liu and Wei Li and Chen Change Loy},
|
| 210 |
+
year={2025},
|
| 211 |
+
eprint={2405.xxxxx},
|
| 212 |
+
archivePrefix={arXiv},
|
| 213 |
+
primaryClass={cs.CV}
|
| 214 |
+
}
|
| 215 |
+
```
|
| 216 |
+
|
| 217 |
+
## 📜 License
|
| 218 |
+
This project is licensed under [NTU S-Lab License 1.0](LICENSE).
|
config.json
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"HarmonModel"
|
| 4 |
+
],
|
| 5 |
+
"auto_map": {
|
| 6 |
+
"AutoConfig": "configuration_harmon.HarmonConfig",
|
| 7 |
+
"AutoModel": "modeling_harmon.HarmonModel"
|
| 8 |
+
},
|
| 9 |
+
"llm": {
|
| 10 |
+
"_attn_implementation": "flash_attention_2",
|
| 11 |
+
"attention_dropout": 0.0,
|
| 12 |
+
"attn_implementation": null,
|
| 13 |
+
"bos_token_id": 151643,
|
| 14 |
+
"eos_token_id": 151645,
|
| 15 |
+
"hidden_act": "silu",
|
| 16 |
+
"hidden_size": 1536,
|
| 17 |
+
"initializer_range": 0.02,
|
| 18 |
+
"intermediate_size": 8960,
|
| 19 |
+
"max_position_embeddings": 32768,
|
| 20 |
+
"max_window_layers": 21,
|
| 21 |
+
"model_type": "qwen2",
|
| 22 |
+
"num_attention_heads": 12,
|
| 23 |
+
"num_hidden_layers": 28,
|
| 24 |
+
"num_key_value_heads": 2,
|
| 25 |
+
"rms_norm_eps": 1e-06,
|
| 26 |
+
"rope_theta": 1000000.0,
|
| 27 |
+
"sliding_window": 32768,
|
| 28 |
+
"tie_word_embeddings": false,
|
| 29 |
+
"use_cache": true,
|
| 30 |
+
"use_sliding_window": false,
|
| 31 |
+
"vocab_size": 151936
|
| 32 |
+
},
|
| 33 |
+
"mar": {
|
| 34 |
+
"attn_dropout": 0.1,
|
| 35 |
+
"buffer_size": 64,
|
| 36 |
+
"class_num": 1000,
|
| 37 |
+
"diffloss_d": 12,
|
| 38 |
+
"diffloss_w": 1536,
|
| 39 |
+
"diffusion_batch_mul": 4,
|
| 40 |
+
"grad_checkpointing": false,
|
| 41 |
+
"img_size": 256,
|
| 42 |
+
"label_drop_prob": 0.1,
|
| 43 |
+
"mask_ratio_min": 0.7,
|
| 44 |
+
"num_sampling_steps": "100",
|
| 45 |
+
"patch_size": 1,
|
| 46 |
+
"proj_dropout": 0.1,
|
| 47 |
+
"type": "mar_huge",
|
| 48 |
+
"vae_embed_dim": 16,
|
| 49 |
+
"vae_stride": 16
|
| 50 |
+
},
|
| 51 |
+
"torch_dtype": "bfloat16",
|
| 52 |
+
"transformers_version": "4.45.2"
|
| 53 |
+
}
|
configuration_harmon.py
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from transformers import PretrainedConfig
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
class HarmonConfig(PretrainedConfig):
|
| 5 |
+
model_type = "harmon"
|
| 6 |
+
def __init__(self, llm=None, mar=None, **kwargs):
|
| 7 |
+
super().__init__(**kwargs)
|
| 8 |
+
self.llm = llm
|
| 9 |
+
self.mar = mar
|
diffloss.py
ADDED
|
@@ -0,0 +1,249 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
from torch.utils.checkpoint import checkpoint
|
| 4 |
+
import math
|
| 5 |
+
|
| 6 |
+
from .misc import create_diffusion
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class DiffLoss(nn.Module):
|
| 10 |
+
"""Diffusion Loss"""
|
| 11 |
+
def __init__(self, target_channels, z_channels, depth, width, num_sampling_steps, grad_checkpointing=False):
|
| 12 |
+
super(DiffLoss, self).__init__()
|
| 13 |
+
self.in_channels = target_channels
|
| 14 |
+
self.net = SimpleMLPAdaLN(
|
| 15 |
+
in_channels=target_channels,
|
| 16 |
+
model_channels=width,
|
| 17 |
+
out_channels=target_channels * 2, # for vlb loss
|
| 18 |
+
z_channels=z_channels,
|
| 19 |
+
num_res_blocks=depth,
|
| 20 |
+
grad_checkpointing=grad_checkpointing
|
| 21 |
+
)
|
| 22 |
+
|
| 23 |
+
self.train_diffusion = create_diffusion(timestep_respacing="", noise_schedule="cosine")
|
| 24 |
+
self.gen_diffusion = create_diffusion(timestep_respacing=num_sampling_steps, noise_schedule="cosine")
|
| 25 |
+
|
| 26 |
+
def forward(self, target, z, mask=None):
|
| 27 |
+
t = torch.randint(0, self.train_diffusion.num_timesteps, (target.shape[0],), device=target.device)
|
| 28 |
+
model_kwargs = dict(c=z)
|
| 29 |
+
loss_dict = self.train_diffusion.training_losses(self.net, target, t, model_kwargs)
|
| 30 |
+
loss = loss_dict["loss"]
|
| 31 |
+
if mask is not None:
|
| 32 |
+
loss = (loss * mask).sum() / mask.sum()
|
| 33 |
+
return loss.mean()
|
| 34 |
+
|
| 35 |
+
def sample(self, z, temperature=1.0, cfg=1.0):
|
| 36 |
+
# diffusion loss sampling
|
| 37 |
+
if not cfg == 1.0:
|
| 38 |
+
noise = torch.randn(z.shape[0] // 2, self.in_channels).cuda()
|
| 39 |
+
noise = torch.cat([noise, noise], dim=0)
|
| 40 |
+
model_kwargs = dict(c=z, cfg_scale=cfg)
|
| 41 |
+
sample_fn = self.net.forward_with_cfg
|
| 42 |
+
else:
|
| 43 |
+
noise = torch.randn(z.shape[0], self.in_channels).cuda()
|
| 44 |
+
model_kwargs = dict(c=z)
|
| 45 |
+
sample_fn = self.net.forward
|
| 46 |
+
|
| 47 |
+
sampled_token_latent = self.gen_diffusion.p_sample_loop(
|
| 48 |
+
sample_fn, noise.shape, noise, clip_denoised=False, model_kwargs=model_kwargs, progress=False,
|
| 49 |
+
temperature=temperature
|
| 50 |
+
)
|
| 51 |
+
|
| 52 |
+
return sampled_token_latent
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
def modulate(x, shift, scale):
|
| 56 |
+
return x * (1 + scale) + shift
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
class TimestepEmbedder(nn.Module):
|
| 60 |
+
"""
|
| 61 |
+
Embeds scalar timesteps into vector representations.
|
| 62 |
+
"""
|
| 63 |
+
def __init__(self, hidden_size, frequency_embedding_size=256):
|
| 64 |
+
super().__init__()
|
| 65 |
+
self.mlp = nn.Sequential(
|
| 66 |
+
nn.Linear(frequency_embedding_size, hidden_size, bias=True),
|
| 67 |
+
nn.SiLU(),
|
| 68 |
+
nn.Linear(hidden_size, hidden_size, bias=True),
|
| 69 |
+
)
|
| 70 |
+
self.frequency_embedding_size = frequency_embedding_size
|
| 71 |
+
|
| 72 |
+
@staticmethod
|
| 73 |
+
def timestep_embedding(t, dim, max_period=10000):
|
| 74 |
+
"""
|
| 75 |
+
Create sinusoidal timestep embeddings.
|
| 76 |
+
:param t: a 1-D Tensor of N indices, one per batch element.
|
| 77 |
+
These may be fractional.
|
| 78 |
+
:param dim: the dimension of the output.
|
| 79 |
+
:param max_period: controls the minimum frequency of the embeddings.
|
| 80 |
+
:return: an (N, D) Tensor of positional embeddings.
|
| 81 |
+
"""
|
| 82 |
+
# https://github.com/openai/glide-text2im/blob/main/glide_text2im/nn.py
|
| 83 |
+
half = dim // 2
|
| 84 |
+
freqs = torch.exp(
|
| 85 |
+
-math.log(max_period) * torch.arange(start=0, end=half, dtype=torch.float32) / half
|
| 86 |
+
).to(device=t.device)
|
| 87 |
+
args = t[:, None].float() * freqs[None]
|
| 88 |
+
embedding = torch.cat([torch.cos(args), torch.sin(args)], dim=-1)
|
| 89 |
+
if dim % 2:
|
| 90 |
+
embedding = torch.cat([embedding, torch.zeros_like(embedding[:, :1])], dim=-1)
|
| 91 |
+
return embedding
|
| 92 |
+
|
| 93 |
+
def forward(self, t):
|
| 94 |
+
t_freq = self.timestep_embedding(t, self.frequency_embedding_size)
|
| 95 |
+
t_emb = self.mlp(t_freq.to(self.mlp[0].weight.data.dtype))
|
| 96 |
+
return t_emb
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
class ResBlock(nn.Module):
|
| 100 |
+
"""
|
| 101 |
+
A residual block that can optionally change the number of channels.
|
| 102 |
+
:param channels: the number of input channels.
|
| 103 |
+
"""
|
| 104 |
+
|
| 105 |
+
def __init__(
|
| 106 |
+
self,
|
| 107 |
+
channels
|
| 108 |
+
):
|
| 109 |
+
super().__init__()
|
| 110 |
+
self.channels = channels
|
| 111 |
+
|
| 112 |
+
self.in_ln = nn.LayerNorm(channels, eps=1e-6)
|
| 113 |
+
self.mlp = nn.Sequential(
|
| 114 |
+
nn.Linear(channels, channels, bias=True),
|
| 115 |
+
nn.SiLU(),
|
| 116 |
+
nn.Linear(channels, channels, bias=True),
|
| 117 |
+
)
|
| 118 |
+
|
| 119 |
+
self.adaLN_modulation = nn.Sequential(
|
| 120 |
+
nn.SiLU(),
|
| 121 |
+
nn.Linear(channels, 3 * channels, bias=True)
|
| 122 |
+
)
|
| 123 |
+
|
| 124 |
+
def forward(self, x, y):
|
| 125 |
+
shift_mlp, scale_mlp, gate_mlp = self.adaLN_modulation(y).chunk(3, dim=-1)
|
| 126 |
+
h = modulate(self.in_ln(x), shift_mlp, scale_mlp)
|
| 127 |
+
h = self.mlp(h)
|
| 128 |
+
return x + gate_mlp * h
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
class FinalLayer(nn.Module):
|
| 132 |
+
"""
|
| 133 |
+
The final layer adopted from DiT.
|
| 134 |
+
"""
|
| 135 |
+
def __init__(self, model_channels, out_channels):
|
| 136 |
+
super().__init__()
|
| 137 |
+
self.norm_final = nn.LayerNorm(model_channels, elementwise_affine=False, eps=1e-6)
|
| 138 |
+
self.linear = nn.Linear(model_channels, out_channels, bias=True)
|
| 139 |
+
self.adaLN_modulation = nn.Sequential(
|
| 140 |
+
nn.SiLU(),
|
| 141 |
+
nn.Linear(model_channels, 2 * model_channels, bias=True)
|
| 142 |
+
)
|
| 143 |
+
|
| 144 |
+
def forward(self, x, c):
|
| 145 |
+
shift, scale = self.adaLN_modulation(c).chunk(2, dim=-1)
|
| 146 |
+
x = modulate(self.norm_final(x), shift, scale)
|
| 147 |
+
x = self.linear(x)
|
| 148 |
+
return x
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
class SimpleMLPAdaLN(nn.Module):
|
| 152 |
+
"""
|
| 153 |
+
The MLP for Diffusion Loss.
|
| 154 |
+
:param in_channels: channels in the input Tensor.
|
| 155 |
+
:param model_channels: base channel count for the model.
|
| 156 |
+
:param out_channels: channels in the output Tensor.
|
| 157 |
+
:param z_channels: channels in the condition.
|
| 158 |
+
:param num_res_blocks: number of residual blocks per downsample.
|
| 159 |
+
"""
|
| 160 |
+
|
| 161 |
+
def __init__(
|
| 162 |
+
self,
|
| 163 |
+
in_channels,
|
| 164 |
+
model_channels,
|
| 165 |
+
out_channels,
|
| 166 |
+
z_channels,
|
| 167 |
+
num_res_blocks,
|
| 168 |
+
grad_checkpointing=False
|
| 169 |
+
):
|
| 170 |
+
super().__init__()
|
| 171 |
+
|
| 172 |
+
self.in_channels = in_channels
|
| 173 |
+
self.model_channels = model_channels
|
| 174 |
+
self.out_channels = out_channels
|
| 175 |
+
self.num_res_blocks = num_res_blocks
|
| 176 |
+
self.grad_checkpointing = grad_checkpointing
|
| 177 |
+
|
| 178 |
+
self.time_embed = TimestepEmbedder(model_channels)
|
| 179 |
+
self.cond_embed = nn.Linear(z_channels, model_channels)
|
| 180 |
+
|
| 181 |
+
self.input_proj = nn.Linear(in_channels, model_channels)
|
| 182 |
+
|
| 183 |
+
res_blocks = []
|
| 184 |
+
for i in range(num_res_blocks):
|
| 185 |
+
res_blocks.append(ResBlock(
|
| 186 |
+
model_channels,
|
| 187 |
+
))
|
| 188 |
+
|
| 189 |
+
self.res_blocks = nn.ModuleList(res_blocks)
|
| 190 |
+
self.final_layer = FinalLayer(model_channels, out_channels)
|
| 191 |
+
|
| 192 |
+
self.initialize_weights()
|
| 193 |
+
|
| 194 |
+
def initialize_weights(self):
|
| 195 |
+
def _basic_init(module):
|
| 196 |
+
if isinstance(module, nn.Linear):
|
| 197 |
+
torch.nn.init.xavier_uniform_(module.weight)
|
| 198 |
+
if module.bias is not None:
|
| 199 |
+
nn.init.constant_(module.bias, 0)
|
| 200 |
+
self.apply(_basic_init)
|
| 201 |
+
|
| 202 |
+
# Initialize timestep embedding MLP
|
| 203 |
+
nn.init.normal_(self.time_embed.mlp[0].weight, std=0.02)
|
| 204 |
+
nn.init.normal_(self.time_embed.mlp[2].weight, std=0.02)
|
| 205 |
+
|
| 206 |
+
# Zero-out adaLN modulation layers
|
| 207 |
+
for block in self.res_blocks:
|
| 208 |
+
nn.init.constant_(block.adaLN_modulation[-1].weight, 0)
|
| 209 |
+
nn.init.constant_(block.adaLN_modulation[-1].bias, 0)
|
| 210 |
+
|
| 211 |
+
# Zero-out output layers
|
| 212 |
+
nn.init.constant_(self.final_layer.adaLN_modulation[-1].weight, 0)
|
| 213 |
+
nn.init.constant_(self.final_layer.adaLN_modulation[-1].bias, 0)
|
| 214 |
+
nn.init.constant_(self.final_layer.linear.weight, 0)
|
| 215 |
+
nn.init.constant_(self.final_layer.linear.bias, 0)
|
| 216 |
+
|
| 217 |
+
def forward(self, x, t, c):
|
| 218 |
+
"""
|
| 219 |
+
Apply the model to an input batch.
|
| 220 |
+
:param x: an [N x C] Tensor of inputs.
|
| 221 |
+
:param t: a 1-D batch of timesteps.
|
| 222 |
+
:param c: conditioning from AR transformer.
|
| 223 |
+
:return: an [N x C] Tensor of outputs.
|
| 224 |
+
"""
|
| 225 |
+
# import pdb; pdb.set_trace()
|
| 226 |
+
x = self.input_proj(x.to(self.input_proj.weight.data.dtype))
|
| 227 |
+
t = self.time_embed(t)
|
| 228 |
+
c = self.cond_embed(c.to(self.cond_embed.weight.data.dtype))
|
| 229 |
+
|
| 230 |
+
y = t + c
|
| 231 |
+
|
| 232 |
+
if self.grad_checkpointing and not torch.jit.is_scripting():
|
| 233 |
+
for block in self.res_blocks:
|
| 234 |
+
x = checkpoint(block, x, y)
|
| 235 |
+
else:
|
| 236 |
+
for block in self.res_blocks:
|
| 237 |
+
x = block(x, y)
|
| 238 |
+
|
| 239 |
+
return self.final_layer(x, y)
|
| 240 |
+
|
| 241 |
+
def forward_with_cfg(self, x, t, c, cfg_scale):
|
| 242 |
+
half = x[: len(x) // 2]
|
| 243 |
+
combined = torch.cat([half, half], dim=0)
|
| 244 |
+
model_out = self.forward(combined, t, c)
|
| 245 |
+
eps, rest = model_out[:, :self.in_channels], model_out[:, self.in_channels:]
|
| 246 |
+
cond_eps, uncond_eps = torch.split(eps, len(eps) // 2, dim=0)
|
| 247 |
+
half_eps = uncond_eps + cfg_scale * (cond_eps - uncond_eps)
|
| 248 |
+
eps = torch.cat([half_eps, half_eps], dim=0)
|
| 249 |
+
return torch.cat([eps, rest], dim=1)
|
diffusion_utils.py
ADDED
|
@@ -0,0 +1,73 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Modified from OpenAI's diffusion repos
|
| 2 |
+
# GLIDE: https://github.com/openai/glide-text2im/blob/main/glide_text2im/gaussian_diffusion.py
|
| 3 |
+
# ADM: https://github.com/openai/guided-diffusion/blob/main/guided_diffusion
|
| 4 |
+
# IDDPM: https://github.com/openai/improved-diffusion/blob/main/improved_diffusion/gaussian_diffusion.py
|
| 5 |
+
|
| 6 |
+
import torch as th
|
| 7 |
+
import numpy as np
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def normal_kl(mean1, logvar1, mean2, logvar2):
|
| 11 |
+
"""
|
| 12 |
+
Compute the KL divergence between two gaussians.
|
| 13 |
+
Shapes are automatically broadcasted, so batches can be compared to
|
| 14 |
+
scalars, among other use cases.
|
| 15 |
+
"""
|
| 16 |
+
tensor = None
|
| 17 |
+
for obj in (mean1, logvar1, mean2, logvar2):
|
| 18 |
+
if isinstance(obj, th.Tensor):
|
| 19 |
+
tensor = obj
|
| 20 |
+
break
|
| 21 |
+
assert tensor is not None, "at least one argument must be a Tensor"
|
| 22 |
+
|
| 23 |
+
# Force variances to be Tensors. Broadcasting helps convert scalars to
|
| 24 |
+
# Tensors, but it does not work for th.exp().
|
| 25 |
+
logvar1, logvar2 = [
|
| 26 |
+
x if isinstance(x, th.Tensor) else th.tensor(x).to(tensor)
|
| 27 |
+
for x in (logvar1, logvar2)
|
| 28 |
+
]
|
| 29 |
+
|
| 30 |
+
return 0.5 * (
|
| 31 |
+
-1.0
|
| 32 |
+
+ logvar2
|
| 33 |
+
- logvar1
|
| 34 |
+
+ th.exp(logvar1 - logvar2)
|
| 35 |
+
+ ((mean1 - mean2) ** 2) * th.exp(-logvar2)
|
| 36 |
+
)
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def approx_standard_normal_cdf(x):
|
| 40 |
+
"""
|
| 41 |
+
A fast approximation of the cumulative distribution function of the
|
| 42 |
+
standard normal.
|
| 43 |
+
"""
|
| 44 |
+
return 0.5 * (1.0 + th.tanh(np.sqrt(2.0 / np.pi) * (x + 0.044715 * th.pow(x, 3))))
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def discretized_gaussian_log_likelihood(x, *, means, log_scales):
|
| 48 |
+
"""
|
| 49 |
+
Compute the log-likelihood of a Gaussian distribution discretizing to a
|
| 50 |
+
given image.
|
| 51 |
+
:param x: the target images. It is assumed that this was uint8 values,
|
| 52 |
+
rescaled to the range [-1, 1].
|
| 53 |
+
:param means: the Gaussian mean Tensor.
|
| 54 |
+
:param log_scales: the Gaussian log stddev Tensor.
|
| 55 |
+
:return: a tensor like x of log probabilities (in nats).
|
| 56 |
+
"""
|
| 57 |
+
assert x.shape == means.shape == log_scales.shape
|
| 58 |
+
centered_x = x - means
|
| 59 |
+
inv_stdv = th.exp(-log_scales)
|
| 60 |
+
plus_in = inv_stdv * (centered_x + 1.0 / 255.0)
|
| 61 |
+
cdf_plus = approx_standard_normal_cdf(plus_in)
|
| 62 |
+
min_in = inv_stdv * (centered_x - 1.0 / 255.0)
|
| 63 |
+
cdf_min = approx_standard_normal_cdf(min_in)
|
| 64 |
+
log_cdf_plus = th.log(cdf_plus.clamp(min=1e-12))
|
| 65 |
+
log_one_minus_cdf_min = th.log((1.0 - cdf_min).clamp(min=1e-12))
|
| 66 |
+
cdf_delta = cdf_plus - cdf_min
|
| 67 |
+
log_probs = th.where(
|
| 68 |
+
x < -0.999,
|
| 69 |
+
log_cdf_plus,
|
| 70 |
+
th.where(x > 0.999, log_one_minus_cdf_min, th.log(cdf_delta.clamp(min=1e-12))),
|
| 71 |
+
)
|
| 72 |
+
assert log_probs.shape == x.shape
|
| 73 |
+
return log_probs
|
gaussian_diffusion.py
ADDED
|
@@ -0,0 +1,877 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Modified from OpenAI's diffusion repos
|
| 2 |
+
# GLIDE: https://github.com/openai/glide-text2im/blob/main/glide_text2im/gaussian_diffusion.py
|
| 3 |
+
# ADM: https://github.com/openai/guided-diffusion/blob/main/guided_diffusion
|
| 4 |
+
# IDDPM: https://github.com/openai/improved-diffusion/blob/main/improved_diffusion/gaussian_diffusion.py
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
import math
|
| 8 |
+
|
| 9 |
+
import numpy as np
|
| 10 |
+
import torch as th
|
| 11 |
+
import enum
|
| 12 |
+
|
| 13 |
+
from .diffusion_utils import discretized_gaussian_log_likelihood, normal_kl
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def mean_flat(tensor):
|
| 17 |
+
"""
|
| 18 |
+
Take the mean over all non-batch dimensions.
|
| 19 |
+
"""
|
| 20 |
+
return tensor.mean(dim=list(range(1, len(tensor.shape))))
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
class ModelMeanType(enum.Enum):
|
| 24 |
+
"""
|
| 25 |
+
Which type of output the model predicts.
|
| 26 |
+
"""
|
| 27 |
+
|
| 28 |
+
PREVIOUS_X = enum.auto() # the model predicts x_{t-1}
|
| 29 |
+
START_X = enum.auto() # the model predicts x_0
|
| 30 |
+
EPSILON = enum.auto() # the model predicts epsilon
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
class ModelVarType(enum.Enum):
|
| 34 |
+
"""
|
| 35 |
+
What is used as the model's output variance.
|
| 36 |
+
The LEARNED_RANGE option has been added to allow the model to predict
|
| 37 |
+
values between FIXED_SMALL and FIXED_LARGE, making its job easier.
|
| 38 |
+
"""
|
| 39 |
+
|
| 40 |
+
LEARNED = enum.auto()
|
| 41 |
+
FIXED_SMALL = enum.auto()
|
| 42 |
+
FIXED_LARGE = enum.auto()
|
| 43 |
+
LEARNED_RANGE = enum.auto()
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
class LossType(enum.Enum):
|
| 47 |
+
MSE = enum.auto() # use raw MSE loss (and KL when learning variances)
|
| 48 |
+
RESCALED_MSE = (
|
| 49 |
+
enum.auto()
|
| 50 |
+
) # use raw MSE loss (with RESCALED_KL when learning variances)
|
| 51 |
+
KL = enum.auto() # use the variational lower-bound
|
| 52 |
+
RESCALED_KL = enum.auto() # like KL, but rescale to estimate the full VLB
|
| 53 |
+
|
| 54 |
+
def is_vb(self):
|
| 55 |
+
return self == LossType.KL or self == LossType.RESCALED_KL
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def _warmup_beta(beta_start, beta_end, num_diffusion_timesteps, warmup_frac):
|
| 59 |
+
betas = beta_end * np.ones(num_diffusion_timesteps, dtype=np.float64)
|
| 60 |
+
warmup_time = int(num_diffusion_timesteps * warmup_frac)
|
| 61 |
+
betas[:warmup_time] = np.linspace(beta_start, beta_end, warmup_time, dtype=np.float64)
|
| 62 |
+
return betas
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
def get_beta_schedule(beta_schedule, *, beta_start, beta_end, num_diffusion_timesteps):
|
| 66 |
+
"""
|
| 67 |
+
This is the deprecated API for creating beta schedules.
|
| 68 |
+
See get_named_beta_schedule() for the new library of schedules.
|
| 69 |
+
"""
|
| 70 |
+
if beta_schedule == "quad":
|
| 71 |
+
betas = (
|
| 72 |
+
np.linspace(
|
| 73 |
+
beta_start ** 0.5,
|
| 74 |
+
beta_end ** 0.5,
|
| 75 |
+
num_diffusion_timesteps,
|
| 76 |
+
dtype=np.float64,
|
| 77 |
+
)
|
| 78 |
+
** 2
|
| 79 |
+
)
|
| 80 |
+
elif beta_schedule == "linear":
|
| 81 |
+
betas = np.linspace(beta_start, beta_end, num_diffusion_timesteps, dtype=np.float64)
|
| 82 |
+
elif beta_schedule == "warmup10":
|
| 83 |
+
betas = _warmup_beta(beta_start, beta_end, num_diffusion_timesteps, 0.1)
|
| 84 |
+
elif beta_schedule == "warmup50":
|
| 85 |
+
betas = _warmup_beta(beta_start, beta_end, num_diffusion_timesteps, 0.5)
|
| 86 |
+
elif beta_schedule == "const":
|
| 87 |
+
betas = beta_end * np.ones(num_diffusion_timesteps, dtype=np.float64)
|
| 88 |
+
elif beta_schedule == "jsd": # 1/T, 1/(T-1), 1/(T-2), ..., 1
|
| 89 |
+
betas = 1.0 / np.linspace(
|
| 90 |
+
num_diffusion_timesteps, 1, num_diffusion_timesteps, dtype=np.float64
|
| 91 |
+
)
|
| 92 |
+
else:
|
| 93 |
+
raise NotImplementedError(beta_schedule)
|
| 94 |
+
assert betas.shape == (num_diffusion_timesteps,)
|
| 95 |
+
return betas
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
def get_named_beta_schedule(schedule_name, num_diffusion_timesteps):
|
| 99 |
+
"""
|
| 100 |
+
Get a pre-defined beta schedule for the given name.
|
| 101 |
+
The beta schedule library consists of beta schedules which remain similar
|
| 102 |
+
in the limit of num_diffusion_timesteps.
|
| 103 |
+
Beta schedules may be added, but should not be removed or changed once
|
| 104 |
+
they are committed to maintain backwards compatibility.
|
| 105 |
+
"""
|
| 106 |
+
if schedule_name == "linear":
|
| 107 |
+
# Linear schedule from Ho et al, extended to work for any number of
|
| 108 |
+
# diffusion steps.
|
| 109 |
+
scale = 1000 / num_diffusion_timesteps
|
| 110 |
+
return get_beta_schedule(
|
| 111 |
+
"linear",
|
| 112 |
+
beta_start=scale * 0.0001,
|
| 113 |
+
beta_end=scale * 0.02,
|
| 114 |
+
num_diffusion_timesteps=num_diffusion_timesteps,
|
| 115 |
+
)
|
| 116 |
+
elif schedule_name == "cosine":
|
| 117 |
+
return betas_for_alpha_bar(
|
| 118 |
+
num_diffusion_timesteps,
|
| 119 |
+
lambda t: math.cos((t + 0.008) / 1.008 * math.pi / 2) ** 2,
|
| 120 |
+
)
|
| 121 |
+
else:
|
| 122 |
+
raise NotImplementedError(f"unknown beta schedule: {schedule_name}")
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
def betas_for_alpha_bar(num_diffusion_timesteps, alpha_bar, max_beta=0.999):
|
| 126 |
+
"""
|
| 127 |
+
Create a beta schedule that discretizes the given alpha_t_bar function,
|
| 128 |
+
which defines the cumulative product of (1-beta) over time from t = [0,1].
|
| 129 |
+
:param num_diffusion_timesteps: the number of betas to produce.
|
| 130 |
+
:param alpha_bar: a lambda that takes an argument t from 0 to 1 and
|
| 131 |
+
produces the cumulative product of (1-beta) up to that
|
| 132 |
+
part of the diffusion process.
|
| 133 |
+
:param max_beta: the maximum beta to use; use values lower than 1 to
|
| 134 |
+
prevent singularities.
|
| 135 |
+
"""
|
| 136 |
+
betas = []
|
| 137 |
+
for i in range(num_diffusion_timesteps):
|
| 138 |
+
t1 = i / num_diffusion_timesteps
|
| 139 |
+
t2 = (i + 1) / num_diffusion_timesteps
|
| 140 |
+
betas.append(min(1 - alpha_bar(t2) / alpha_bar(t1), max_beta))
|
| 141 |
+
return np.array(betas)
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
class GaussianDiffusion:
|
| 145 |
+
"""
|
| 146 |
+
Utilities for training and sampling diffusion models.
|
| 147 |
+
Original ported from this codebase:
|
| 148 |
+
https://github.com/hojonathanho/diffusion/blob/1e0dceb3b3495bbe19116a5e1b3596cd0706c543/diffusion_tf/diffusion_utils_2.py#L42
|
| 149 |
+
:param betas: a 1-D numpy array of betas for each diffusion timestep,
|
| 150 |
+
starting at T and going to 1.
|
| 151 |
+
"""
|
| 152 |
+
|
| 153 |
+
def __init__(
|
| 154 |
+
self,
|
| 155 |
+
*,
|
| 156 |
+
betas,
|
| 157 |
+
model_mean_type,
|
| 158 |
+
model_var_type,
|
| 159 |
+
loss_type
|
| 160 |
+
):
|
| 161 |
+
|
| 162 |
+
self.model_mean_type = model_mean_type
|
| 163 |
+
self.model_var_type = model_var_type
|
| 164 |
+
self.loss_type = loss_type
|
| 165 |
+
|
| 166 |
+
# Use float64 for accuracy.
|
| 167 |
+
betas = np.array(betas, dtype=np.float64)
|
| 168 |
+
self.betas = betas
|
| 169 |
+
assert len(betas.shape) == 1, "betas must be 1-D"
|
| 170 |
+
assert (betas > 0).all() and (betas <= 1).all()
|
| 171 |
+
|
| 172 |
+
self.num_timesteps = int(betas.shape[0])
|
| 173 |
+
|
| 174 |
+
alphas = 1.0 - betas
|
| 175 |
+
self.alphas_cumprod = np.cumprod(alphas, axis=0)
|
| 176 |
+
self.alphas_cumprod_prev = np.append(1.0, self.alphas_cumprod[:-1])
|
| 177 |
+
self.alphas_cumprod_next = np.append(self.alphas_cumprod[1:], 0.0)
|
| 178 |
+
assert self.alphas_cumprod_prev.shape == (self.num_timesteps,)
|
| 179 |
+
|
| 180 |
+
# calculations for diffusion q(x_t | x_{t-1}) and others
|
| 181 |
+
self.sqrt_alphas_cumprod = np.sqrt(self.alphas_cumprod)
|
| 182 |
+
self.sqrt_one_minus_alphas_cumprod = np.sqrt(1.0 - self.alphas_cumprod)
|
| 183 |
+
self.log_one_minus_alphas_cumprod = np.log(1.0 - self.alphas_cumprod)
|
| 184 |
+
self.sqrt_recip_alphas_cumprod = np.sqrt(1.0 / self.alphas_cumprod)
|
| 185 |
+
self.sqrt_recipm1_alphas_cumprod = np.sqrt(1.0 / self.alphas_cumprod - 1)
|
| 186 |
+
|
| 187 |
+
# calculations for posterior q(x_{t-1} | x_t, x_0)
|
| 188 |
+
self.posterior_variance = (
|
| 189 |
+
betas * (1.0 - self.alphas_cumprod_prev) / (1.0 - self.alphas_cumprod)
|
| 190 |
+
)
|
| 191 |
+
# below: log calculation clipped because the posterior variance is 0 at the beginning of the diffusion chain
|
| 192 |
+
self.posterior_log_variance_clipped = np.log(
|
| 193 |
+
np.append(self.posterior_variance[1], self.posterior_variance[1:])
|
| 194 |
+
) if len(self.posterior_variance) > 1 else np.array([])
|
| 195 |
+
|
| 196 |
+
self.posterior_mean_coef1 = (
|
| 197 |
+
betas * np.sqrt(self.alphas_cumprod_prev) / (1.0 - self.alphas_cumprod)
|
| 198 |
+
)
|
| 199 |
+
self.posterior_mean_coef2 = (
|
| 200 |
+
(1.0 - self.alphas_cumprod_prev) * np.sqrt(alphas) / (1.0 - self.alphas_cumprod)
|
| 201 |
+
)
|
| 202 |
+
|
| 203 |
+
def q_mean_variance(self, x_start, t):
|
| 204 |
+
"""
|
| 205 |
+
Get the distribution q(x_t | x_0).
|
| 206 |
+
:param x_start: the [N x C x ...] tensor of noiseless inputs.
|
| 207 |
+
:param t: the number of diffusion steps (minus 1). Here, 0 means one step.
|
| 208 |
+
:return: A tuple (mean, variance, log_variance), all of x_start's shape.
|
| 209 |
+
"""
|
| 210 |
+
mean = _extract_into_tensor(self.sqrt_alphas_cumprod, t, x_start.shape) * x_start
|
| 211 |
+
variance = _extract_into_tensor(1.0 - self.alphas_cumprod, t, x_start.shape)
|
| 212 |
+
log_variance = _extract_into_tensor(self.log_one_minus_alphas_cumprod, t, x_start.shape)
|
| 213 |
+
return mean, variance, log_variance
|
| 214 |
+
|
| 215 |
+
def q_sample(self, x_start, t, noise=None):
|
| 216 |
+
"""
|
| 217 |
+
Diffuse the data for a given number of diffusion steps.
|
| 218 |
+
In other words, sample from q(x_t | x_0).
|
| 219 |
+
:param x_start: the initial data batch.
|
| 220 |
+
:param t: the number of diffusion steps (minus 1). Here, 0 means one step.
|
| 221 |
+
:param noise: if specified, the split-out normal noise.
|
| 222 |
+
:return: A noisy version of x_start.
|
| 223 |
+
"""
|
| 224 |
+
if noise is None:
|
| 225 |
+
noise = th.randn_like(x_start)
|
| 226 |
+
assert noise.shape == x_start.shape
|
| 227 |
+
return (
|
| 228 |
+
_extract_into_tensor(self.sqrt_alphas_cumprod, t, x_start.shape) * x_start
|
| 229 |
+
+ _extract_into_tensor(self.sqrt_one_minus_alphas_cumprod, t, x_start.shape) * noise
|
| 230 |
+
)
|
| 231 |
+
|
| 232 |
+
def q_posterior_mean_variance(self, x_start, x_t, t):
|
| 233 |
+
"""
|
| 234 |
+
Compute the mean and variance of the diffusion posterior:
|
| 235 |
+
q(x_{t-1} | x_t, x_0)
|
| 236 |
+
"""
|
| 237 |
+
assert x_start.shape == x_t.shape
|
| 238 |
+
posterior_mean = (
|
| 239 |
+
_extract_into_tensor(self.posterior_mean_coef1, t, x_t.shape) * x_start
|
| 240 |
+
+ _extract_into_tensor(self.posterior_mean_coef2, t, x_t.shape) * x_t
|
| 241 |
+
)
|
| 242 |
+
posterior_variance = _extract_into_tensor(self.posterior_variance, t, x_t.shape)
|
| 243 |
+
posterior_log_variance_clipped = _extract_into_tensor(
|
| 244 |
+
self.posterior_log_variance_clipped, t, x_t.shape
|
| 245 |
+
)
|
| 246 |
+
assert (
|
| 247 |
+
posterior_mean.shape[0]
|
| 248 |
+
== posterior_variance.shape[0]
|
| 249 |
+
== posterior_log_variance_clipped.shape[0]
|
| 250 |
+
== x_start.shape[0]
|
| 251 |
+
)
|
| 252 |
+
return posterior_mean, posterior_variance, posterior_log_variance_clipped
|
| 253 |
+
|
| 254 |
+
def p_mean_variance(self, model, x, t, clip_denoised=True, denoised_fn=None, model_kwargs=None):
|
| 255 |
+
"""
|
| 256 |
+
Apply the model to get p(x_{t-1} | x_t), as well as a prediction of
|
| 257 |
+
the initial x, x_0.
|
| 258 |
+
:param model: the model, which takes a signal and a batch of timesteps
|
| 259 |
+
as input.
|
| 260 |
+
:param x: the [N x C x ...] tensor at time t.
|
| 261 |
+
:param t: a 1-D Tensor of timesteps.
|
| 262 |
+
:param clip_denoised: if True, clip the denoised signal into [-1, 1].
|
| 263 |
+
:param denoised_fn: if not None, a function which applies to the
|
| 264 |
+
x_start prediction before it is used to sample. Applies before
|
| 265 |
+
clip_denoised.
|
| 266 |
+
:param model_kwargs: if not None, a dict of extra keyword arguments to
|
| 267 |
+
pass to the model. This can be used for conditioning.
|
| 268 |
+
:return: a dict with the following keys:
|
| 269 |
+
- 'mean': the model mean output.
|
| 270 |
+
- 'variance': the model variance output.
|
| 271 |
+
- 'log_variance': the log of 'variance'.
|
| 272 |
+
- 'pred_xstart': the prediction for x_0.
|
| 273 |
+
"""
|
| 274 |
+
if model_kwargs is None:
|
| 275 |
+
model_kwargs = {}
|
| 276 |
+
|
| 277 |
+
B, C = x.shape[:2]
|
| 278 |
+
assert t.shape == (B,)
|
| 279 |
+
model_output = model(x, t, **model_kwargs)
|
| 280 |
+
if isinstance(model_output, tuple):
|
| 281 |
+
model_output, extra = model_output
|
| 282 |
+
else:
|
| 283 |
+
extra = None
|
| 284 |
+
|
| 285 |
+
if self.model_var_type in [ModelVarType.LEARNED, ModelVarType.LEARNED_RANGE]:
|
| 286 |
+
assert model_output.shape == (B, C * 2, *x.shape[2:])
|
| 287 |
+
model_output, model_var_values = th.split(model_output, C, dim=1)
|
| 288 |
+
min_log = _extract_into_tensor(self.posterior_log_variance_clipped, t, x.shape)
|
| 289 |
+
max_log = _extract_into_tensor(np.log(self.betas), t, x.shape)
|
| 290 |
+
# The model_var_values is [-1, 1] for [min_var, max_var].
|
| 291 |
+
frac = (model_var_values + 1) / 2
|
| 292 |
+
model_log_variance = frac * max_log + (1 - frac) * min_log
|
| 293 |
+
model_variance = th.exp(model_log_variance)
|
| 294 |
+
else:
|
| 295 |
+
model_variance, model_log_variance = {
|
| 296 |
+
# for fixedlarge, we set the initial (log-)variance like so
|
| 297 |
+
# to get a better decoder log likelihood.
|
| 298 |
+
ModelVarType.FIXED_LARGE: (
|
| 299 |
+
np.append(self.posterior_variance[1], self.betas[1:]),
|
| 300 |
+
np.log(np.append(self.posterior_variance[1], self.betas[1:])),
|
| 301 |
+
),
|
| 302 |
+
ModelVarType.FIXED_SMALL: (
|
| 303 |
+
self.posterior_variance,
|
| 304 |
+
self.posterior_log_variance_clipped,
|
| 305 |
+
),
|
| 306 |
+
}[self.model_var_type]
|
| 307 |
+
model_variance = _extract_into_tensor(model_variance, t, x.shape)
|
| 308 |
+
model_log_variance = _extract_into_tensor(model_log_variance, t, x.shape)
|
| 309 |
+
|
| 310 |
+
def process_xstart(x):
|
| 311 |
+
if denoised_fn is not None:
|
| 312 |
+
x = denoised_fn(x)
|
| 313 |
+
if clip_denoised:
|
| 314 |
+
return x.clamp(-1, 1)
|
| 315 |
+
return x
|
| 316 |
+
|
| 317 |
+
if self.model_mean_type == ModelMeanType.START_X:
|
| 318 |
+
pred_xstart = process_xstart(model_output)
|
| 319 |
+
else:
|
| 320 |
+
pred_xstart = process_xstart(
|
| 321 |
+
self._predict_xstart_from_eps(x_t=x, t=t, eps=model_output)
|
| 322 |
+
)
|
| 323 |
+
model_mean, _, _ = self.q_posterior_mean_variance(x_start=pred_xstart, x_t=x, t=t)
|
| 324 |
+
|
| 325 |
+
assert model_mean.shape == model_log_variance.shape == pred_xstart.shape == x.shape
|
| 326 |
+
return {
|
| 327 |
+
"mean": model_mean,
|
| 328 |
+
"variance": model_variance,
|
| 329 |
+
"log_variance": model_log_variance,
|
| 330 |
+
"pred_xstart": pred_xstart,
|
| 331 |
+
"extra": extra,
|
| 332 |
+
}
|
| 333 |
+
|
| 334 |
+
def _predict_xstart_from_eps(self, x_t, t, eps):
|
| 335 |
+
assert x_t.shape == eps.shape
|
| 336 |
+
return (
|
| 337 |
+
_extract_into_tensor(self.sqrt_recip_alphas_cumprod, t, x_t.shape) * x_t
|
| 338 |
+
- _extract_into_tensor(self.sqrt_recipm1_alphas_cumprod, t, x_t.shape) * eps
|
| 339 |
+
)
|
| 340 |
+
|
| 341 |
+
def _predict_eps_from_xstart(self, x_t, t, pred_xstart):
|
| 342 |
+
return (
|
| 343 |
+
_extract_into_tensor(self.sqrt_recip_alphas_cumprod, t, x_t.shape) * x_t - pred_xstart
|
| 344 |
+
) / _extract_into_tensor(self.sqrt_recipm1_alphas_cumprod, t, x_t.shape)
|
| 345 |
+
|
| 346 |
+
def condition_mean(self, cond_fn, p_mean_var, x, t, model_kwargs=None):
|
| 347 |
+
"""
|
| 348 |
+
Compute the mean for the previous step, given a function cond_fn that
|
| 349 |
+
computes the gradient of a conditional log probability with respect to
|
| 350 |
+
x. In particular, cond_fn computes grad(log(p(y|x))), and we want to
|
| 351 |
+
condition on y.
|
| 352 |
+
This uses the conditioning strategy from Sohl-Dickstein et al. (2015).
|
| 353 |
+
"""
|
| 354 |
+
gradient = cond_fn(x, t, **model_kwargs)
|
| 355 |
+
new_mean = p_mean_var["mean"].float() + p_mean_var["variance"] * gradient.float()
|
| 356 |
+
return new_mean
|
| 357 |
+
|
| 358 |
+
def condition_score(self, cond_fn, p_mean_var, x, t, model_kwargs=None):
|
| 359 |
+
"""
|
| 360 |
+
Compute what the p_mean_variance output would have been, should the
|
| 361 |
+
model's score function be conditioned by cond_fn.
|
| 362 |
+
See condition_mean() for details on cond_fn.
|
| 363 |
+
Unlike condition_mean(), this instead uses the conditioning strategy
|
| 364 |
+
from Song et al (2020).
|
| 365 |
+
"""
|
| 366 |
+
alpha_bar = _extract_into_tensor(self.alphas_cumprod, t, x.shape)
|
| 367 |
+
|
| 368 |
+
eps = self._predict_eps_from_xstart(x, t, p_mean_var["pred_xstart"])
|
| 369 |
+
eps = eps - (1 - alpha_bar).sqrt() * cond_fn(x, t, **model_kwargs)
|
| 370 |
+
|
| 371 |
+
out = p_mean_var.copy()
|
| 372 |
+
out["pred_xstart"] = self._predict_xstart_from_eps(x, t, eps)
|
| 373 |
+
out["mean"], _, _ = self.q_posterior_mean_variance(x_start=out["pred_xstart"], x_t=x, t=t)
|
| 374 |
+
return out
|
| 375 |
+
|
| 376 |
+
def p_sample(
|
| 377 |
+
self,
|
| 378 |
+
model,
|
| 379 |
+
x,
|
| 380 |
+
t,
|
| 381 |
+
clip_denoised=True,
|
| 382 |
+
denoised_fn=None,
|
| 383 |
+
cond_fn=None,
|
| 384 |
+
model_kwargs=None,
|
| 385 |
+
temperature=1.0
|
| 386 |
+
):
|
| 387 |
+
"""
|
| 388 |
+
Sample x_{t-1} from the model at the given timestep.
|
| 389 |
+
:param model: the model to sample from.
|
| 390 |
+
:param x: the current tensor at x_{t-1}.
|
| 391 |
+
:param t: the value of t, starting at 0 for the first diffusion step.
|
| 392 |
+
:param clip_denoised: if True, clip the x_start prediction to [-1, 1].
|
| 393 |
+
:param denoised_fn: if not None, a function which applies to the
|
| 394 |
+
x_start prediction before it is used to sample.
|
| 395 |
+
:param cond_fn: if not None, this is a gradient function that acts
|
| 396 |
+
similarly to the model.
|
| 397 |
+
:param model_kwargs: if not None, a dict of extra keyword arguments to
|
| 398 |
+
pass to the model. This can be used for conditioning.
|
| 399 |
+
:param temperature: temperature scaling during Diff Loss sampling.
|
| 400 |
+
:return: a dict containing the following keys:
|
| 401 |
+
- 'sample': a random sample from the model.
|
| 402 |
+
- 'pred_xstart': a prediction of x_0.
|
| 403 |
+
"""
|
| 404 |
+
out = self.p_mean_variance(
|
| 405 |
+
model,
|
| 406 |
+
x,
|
| 407 |
+
t,
|
| 408 |
+
clip_denoised=clip_denoised,
|
| 409 |
+
denoised_fn=denoised_fn,
|
| 410 |
+
model_kwargs=model_kwargs,
|
| 411 |
+
)
|
| 412 |
+
noise = th.randn_like(x)
|
| 413 |
+
nonzero_mask = (
|
| 414 |
+
(t != 0).float().view(-1, *([1] * (len(x.shape) - 1)))
|
| 415 |
+
) # no noise when t == 0
|
| 416 |
+
if cond_fn is not None:
|
| 417 |
+
out["mean"] = self.condition_mean(cond_fn, out, x, t, model_kwargs=model_kwargs)
|
| 418 |
+
# scale the noise by temperature
|
| 419 |
+
sample = out["mean"] + nonzero_mask * th.exp(0.5 * out["log_variance"]) * noise * temperature
|
| 420 |
+
return {"sample": sample, "pred_xstart": out["pred_xstart"]}
|
| 421 |
+
|
| 422 |
+
def p_sample_loop(
|
| 423 |
+
self,
|
| 424 |
+
model,
|
| 425 |
+
shape,
|
| 426 |
+
noise=None,
|
| 427 |
+
clip_denoised=True,
|
| 428 |
+
denoised_fn=None,
|
| 429 |
+
cond_fn=None,
|
| 430 |
+
model_kwargs=None,
|
| 431 |
+
device=None,
|
| 432 |
+
progress=False,
|
| 433 |
+
temperature=1.0,
|
| 434 |
+
):
|
| 435 |
+
"""
|
| 436 |
+
Generate samples from the model.
|
| 437 |
+
:param model: the model module.
|
| 438 |
+
:param shape: the shape of the samples, (N, C, H, W).
|
| 439 |
+
:param noise: if specified, the noise from the encoder to sample.
|
| 440 |
+
Should be of the same shape as `shape`.
|
| 441 |
+
:param clip_denoised: if True, clip x_start predictions to [-1, 1].
|
| 442 |
+
:param denoised_fn: if not None, a function which applies to the
|
| 443 |
+
x_start prediction before it is used to sample.
|
| 444 |
+
:param cond_fn: if not None, this is a gradient function that acts
|
| 445 |
+
similarly to the model.
|
| 446 |
+
:param model_kwargs: if not None, a dict of extra keyword arguments to
|
| 447 |
+
pass to the model. This can be used for conditioning.
|
| 448 |
+
:param device: if specified, the device to create the samples on.
|
| 449 |
+
If not specified, use a model parameter's device.
|
| 450 |
+
:param progress: if True, show a tqdm progress bar.
|
| 451 |
+
:param temperature: temperature scaling during Diff Loss sampling.
|
| 452 |
+
:return: a non-differentiable batch of samples.
|
| 453 |
+
"""
|
| 454 |
+
final = None
|
| 455 |
+
for sample in self.p_sample_loop_progressive(
|
| 456 |
+
model,
|
| 457 |
+
shape,
|
| 458 |
+
noise=noise,
|
| 459 |
+
clip_denoised=clip_denoised,
|
| 460 |
+
denoised_fn=denoised_fn,
|
| 461 |
+
cond_fn=cond_fn,
|
| 462 |
+
model_kwargs=model_kwargs,
|
| 463 |
+
device=device,
|
| 464 |
+
progress=progress,
|
| 465 |
+
temperature=temperature,
|
| 466 |
+
):
|
| 467 |
+
final = sample
|
| 468 |
+
return final["sample"]
|
| 469 |
+
|
| 470 |
+
def p_sample_loop_progressive(
|
| 471 |
+
self,
|
| 472 |
+
model,
|
| 473 |
+
shape,
|
| 474 |
+
noise=None,
|
| 475 |
+
clip_denoised=True,
|
| 476 |
+
denoised_fn=None,
|
| 477 |
+
cond_fn=None,
|
| 478 |
+
model_kwargs=None,
|
| 479 |
+
device=None,
|
| 480 |
+
progress=False,
|
| 481 |
+
temperature=1.0,
|
| 482 |
+
):
|
| 483 |
+
"""
|
| 484 |
+
Generate samples from the model and yield intermediate samples from
|
| 485 |
+
each timestep of diffusion.
|
| 486 |
+
Arguments are the same as p_sample_loop().
|
| 487 |
+
Returns a generator over dicts, where each dict is the return value of
|
| 488 |
+
p_sample().
|
| 489 |
+
"""
|
| 490 |
+
assert isinstance(shape, (tuple, list))
|
| 491 |
+
if noise is not None:
|
| 492 |
+
img = noise
|
| 493 |
+
else:
|
| 494 |
+
img = th.randn(*shape).cuda()
|
| 495 |
+
indices = list(range(self.num_timesteps))[::-1]
|
| 496 |
+
|
| 497 |
+
if progress:
|
| 498 |
+
# Lazy import so that we don't depend on tqdm.
|
| 499 |
+
from tqdm.auto import tqdm
|
| 500 |
+
|
| 501 |
+
indices = tqdm(indices)
|
| 502 |
+
|
| 503 |
+
for i in indices:
|
| 504 |
+
t = th.tensor([i] * shape[0]).cuda()
|
| 505 |
+
with th.no_grad():
|
| 506 |
+
out = self.p_sample(
|
| 507 |
+
model,
|
| 508 |
+
img,
|
| 509 |
+
t,
|
| 510 |
+
clip_denoised=clip_denoised,
|
| 511 |
+
denoised_fn=denoised_fn,
|
| 512 |
+
cond_fn=cond_fn,
|
| 513 |
+
model_kwargs=model_kwargs,
|
| 514 |
+
temperature=temperature,
|
| 515 |
+
)
|
| 516 |
+
yield out
|
| 517 |
+
img = out["sample"]
|
| 518 |
+
|
| 519 |
+
def ddim_sample(
|
| 520 |
+
self,
|
| 521 |
+
model,
|
| 522 |
+
x,
|
| 523 |
+
t,
|
| 524 |
+
clip_denoised=True,
|
| 525 |
+
denoised_fn=None,
|
| 526 |
+
cond_fn=None,
|
| 527 |
+
model_kwargs=None,
|
| 528 |
+
eta=0.0,
|
| 529 |
+
):
|
| 530 |
+
"""
|
| 531 |
+
Sample x_{t-1} from the model using DDIM.
|
| 532 |
+
Same usage as p_sample().
|
| 533 |
+
"""
|
| 534 |
+
out = self.p_mean_variance(
|
| 535 |
+
model,
|
| 536 |
+
x,
|
| 537 |
+
t,
|
| 538 |
+
clip_denoised=clip_denoised,
|
| 539 |
+
denoised_fn=denoised_fn,
|
| 540 |
+
model_kwargs=model_kwargs,
|
| 541 |
+
)
|
| 542 |
+
if cond_fn is not None:
|
| 543 |
+
out = self.condition_score(cond_fn, out, x, t, model_kwargs=model_kwargs)
|
| 544 |
+
|
| 545 |
+
# Usually our model outputs epsilon, but we re-derive it
|
| 546 |
+
# in case we used x_start or x_prev prediction.
|
| 547 |
+
eps = self._predict_eps_from_xstart(x, t, out["pred_xstart"])
|
| 548 |
+
|
| 549 |
+
alpha_bar = _extract_into_tensor(self.alphas_cumprod, t, x.shape)
|
| 550 |
+
alpha_bar_prev = _extract_into_tensor(self.alphas_cumprod_prev, t, x.shape)
|
| 551 |
+
sigma = (
|
| 552 |
+
eta
|
| 553 |
+
* th.sqrt((1 - alpha_bar_prev) / (1 - alpha_bar))
|
| 554 |
+
* th.sqrt(1 - alpha_bar / alpha_bar_prev)
|
| 555 |
+
)
|
| 556 |
+
# Equation 12.
|
| 557 |
+
noise = th.randn_like(x)
|
| 558 |
+
mean_pred = (
|
| 559 |
+
out["pred_xstart"] * th.sqrt(alpha_bar_prev)
|
| 560 |
+
+ th.sqrt(1 - alpha_bar_prev - sigma ** 2) * eps
|
| 561 |
+
)
|
| 562 |
+
nonzero_mask = (
|
| 563 |
+
(t != 0).float().view(-1, *([1] * (len(x.shape) - 1)))
|
| 564 |
+
) # no noise when t == 0
|
| 565 |
+
sample = mean_pred + nonzero_mask * sigma * noise
|
| 566 |
+
return {"sample": sample, "pred_xstart": out["pred_xstart"]}
|
| 567 |
+
|
| 568 |
+
def ddim_reverse_sample(
|
| 569 |
+
self,
|
| 570 |
+
model,
|
| 571 |
+
x,
|
| 572 |
+
t,
|
| 573 |
+
clip_denoised=True,
|
| 574 |
+
denoised_fn=None,
|
| 575 |
+
cond_fn=None,
|
| 576 |
+
model_kwargs=None,
|
| 577 |
+
eta=0.0,
|
| 578 |
+
):
|
| 579 |
+
"""
|
| 580 |
+
Sample x_{t+1} from the model using DDIM reverse ODE.
|
| 581 |
+
"""
|
| 582 |
+
assert eta == 0.0, "Reverse ODE only for deterministic path"
|
| 583 |
+
out = self.p_mean_variance(
|
| 584 |
+
model,
|
| 585 |
+
x,
|
| 586 |
+
t,
|
| 587 |
+
clip_denoised=clip_denoised,
|
| 588 |
+
denoised_fn=denoised_fn,
|
| 589 |
+
model_kwargs=model_kwargs,
|
| 590 |
+
)
|
| 591 |
+
if cond_fn is not None:
|
| 592 |
+
out = self.condition_score(cond_fn, out, x, t, model_kwargs=model_kwargs)
|
| 593 |
+
# Usually our model outputs epsilon, but we re-derive it
|
| 594 |
+
# in case we used x_start or x_prev prediction.
|
| 595 |
+
eps = (
|
| 596 |
+
_extract_into_tensor(self.sqrt_recip_alphas_cumprod, t, x.shape) * x
|
| 597 |
+
- out["pred_xstart"]
|
| 598 |
+
) / _extract_into_tensor(self.sqrt_recipm1_alphas_cumprod, t, x.shape)
|
| 599 |
+
alpha_bar_next = _extract_into_tensor(self.alphas_cumprod_next, t, x.shape)
|
| 600 |
+
|
| 601 |
+
# Equation 12. reversed
|
| 602 |
+
mean_pred = out["pred_xstart"] * th.sqrt(alpha_bar_next) + th.sqrt(1 - alpha_bar_next) * eps
|
| 603 |
+
|
| 604 |
+
return {"sample": mean_pred, "pred_xstart": out["pred_xstart"]}
|
| 605 |
+
|
| 606 |
+
def ddim_sample_loop(
|
| 607 |
+
self,
|
| 608 |
+
model,
|
| 609 |
+
shape,
|
| 610 |
+
noise=None,
|
| 611 |
+
clip_denoised=True,
|
| 612 |
+
denoised_fn=None,
|
| 613 |
+
cond_fn=None,
|
| 614 |
+
model_kwargs=None,
|
| 615 |
+
device=None,
|
| 616 |
+
progress=False,
|
| 617 |
+
eta=0.0,
|
| 618 |
+
):
|
| 619 |
+
"""
|
| 620 |
+
Generate samples from the model using DDIM.
|
| 621 |
+
Same usage as p_sample_loop().
|
| 622 |
+
"""
|
| 623 |
+
final = None
|
| 624 |
+
for sample in self.ddim_sample_loop_progressive(
|
| 625 |
+
model,
|
| 626 |
+
shape,
|
| 627 |
+
noise=noise,
|
| 628 |
+
clip_denoised=clip_denoised,
|
| 629 |
+
denoised_fn=denoised_fn,
|
| 630 |
+
cond_fn=cond_fn,
|
| 631 |
+
model_kwargs=model_kwargs,
|
| 632 |
+
device=device,
|
| 633 |
+
progress=progress,
|
| 634 |
+
eta=eta,
|
| 635 |
+
):
|
| 636 |
+
final = sample
|
| 637 |
+
return final["sample"]
|
| 638 |
+
|
| 639 |
+
def ddim_sample_loop_progressive(
|
| 640 |
+
self,
|
| 641 |
+
model,
|
| 642 |
+
shape,
|
| 643 |
+
noise=None,
|
| 644 |
+
clip_denoised=True,
|
| 645 |
+
denoised_fn=None,
|
| 646 |
+
cond_fn=None,
|
| 647 |
+
model_kwargs=None,
|
| 648 |
+
device=None,
|
| 649 |
+
progress=False,
|
| 650 |
+
eta=0.0,
|
| 651 |
+
):
|
| 652 |
+
"""
|
| 653 |
+
Use DDIM to sample from the model and yield intermediate samples from
|
| 654 |
+
each timestep of DDIM.
|
| 655 |
+
Same usage as p_sample_loop_progressive().
|
| 656 |
+
"""
|
| 657 |
+
assert isinstance(shape, (tuple, list))
|
| 658 |
+
if noise is not None:
|
| 659 |
+
img = noise
|
| 660 |
+
else:
|
| 661 |
+
img = th.randn(*shape).cuda()
|
| 662 |
+
indices = list(range(self.num_timesteps))[::-1]
|
| 663 |
+
|
| 664 |
+
if progress:
|
| 665 |
+
# Lazy import so that we don't depend on tqdm.
|
| 666 |
+
from tqdm.auto import tqdm
|
| 667 |
+
|
| 668 |
+
indices = tqdm(indices)
|
| 669 |
+
|
| 670 |
+
for i in indices:
|
| 671 |
+
t = th.tensor([i] * shape[0]).cuda()
|
| 672 |
+
with th.no_grad():
|
| 673 |
+
out = self.ddim_sample(
|
| 674 |
+
model,
|
| 675 |
+
img,
|
| 676 |
+
t,
|
| 677 |
+
clip_denoised=clip_denoised,
|
| 678 |
+
denoised_fn=denoised_fn,
|
| 679 |
+
cond_fn=cond_fn,
|
| 680 |
+
model_kwargs=model_kwargs,
|
| 681 |
+
eta=eta,
|
| 682 |
+
)
|
| 683 |
+
yield out
|
| 684 |
+
img = out["sample"]
|
| 685 |
+
|
| 686 |
+
def _vb_terms_bpd(
|
| 687 |
+
self, model, x_start, x_t, t, clip_denoised=True, model_kwargs=None
|
| 688 |
+
):
|
| 689 |
+
"""
|
| 690 |
+
Get a term for the variational lower-bound.
|
| 691 |
+
The resulting units are bits (rather than nats, as one might expect).
|
| 692 |
+
This allows for comparison to other papers.
|
| 693 |
+
:return: a dict with the following keys:
|
| 694 |
+
- 'output': a shape [N] tensor of NLLs or KLs.
|
| 695 |
+
- 'pred_xstart': the x_0 predictions.
|
| 696 |
+
"""
|
| 697 |
+
true_mean, _, true_log_variance_clipped = self.q_posterior_mean_variance(
|
| 698 |
+
x_start=x_start, x_t=x_t, t=t
|
| 699 |
+
)
|
| 700 |
+
out = self.p_mean_variance(
|
| 701 |
+
model, x_t, t, clip_denoised=clip_denoised, model_kwargs=model_kwargs
|
| 702 |
+
)
|
| 703 |
+
kl = normal_kl(
|
| 704 |
+
true_mean, true_log_variance_clipped, out["mean"], out["log_variance"]
|
| 705 |
+
)
|
| 706 |
+
kl = mean_flat(kl) / np.log(2.0)
|
| 707 |
+
|
| 708 |
+
decoder_nll = -discretized_gaussian_log_likelihood(
|
| 709 |
+
x_start, means=out["mean"], log_scales=0.5 * out["log_variance"]
|
| 710 |
+
)
|
| 711 |
+
assert decoder_nll.shape == x_start.shape
|
| 712 |
+
decoder_nll = mean_flat(decoder_nll) / np.log(2.0)
|
| 713 |
+
|
| 714 |
+
# At the first timestep return the decoder NLL,
|
| 715 |
+
# otherwise return KL(q(x_{t-1}|x_t,x_0) || p(x_{t-1}|x_t))
|
| 716 |
+
output = th.where((t == 0), decoder_nll, kl)
|
| 717 |
+
return {"output": output, "pred_xstart": out["pred_xstart"]}
|
| 718 |
+
|
| 719 |
+
def training_losses(self, model, x_start, t, model_kwargs=None, noise=None):
|
| 720 |
+
"""
|
| 721 |
+
Compute training losses for a single timestep.
|
| 722 |
+
:param model: the model to evaluate loss on.
|
| 723 |
+
:param x_start: the [N x C x ...] tensor of inputs.
|
| 724 |
+
:param t: a batch of timestep indices.
|
| 725 |
+
:param model_kwargs: if not None, a dict of extra keyword arguments to
|
| 726 |
+
pass to the model. This can be used for conditioning.
|
| 727 |
+
:param noise: if specified, the specific Gaussian noise to try to remove.
|
| 728 |
+
:return: a dict with the key "loss" containing a tensor of shape [N].
|
| 729 |
+
Some mean or variance settings may also have other keys.
|
| 730 |
+
"""
|
| 731 |
+
if model_kwargs is None:
|
| 732 |
+
model_kwargs = {}
|
| 733 |
+
if noise is None:
|
| 734 |
+
noise = th.randn_like(x_start)
|
| 735 |
+
x_t = self.q_sample(x_start, t, noise=noise)
|
| 736 |
+
|
| 737 |
+
terms = {}
|
| 738 |
+
|
| 739 |
+
if self.loss_type == LossType.KL or self.loss_type == LossType.RESCALED_KL:
|
| 740 |
+
terms["loss"] = self._vb_terms_bpd(
|
| 741 |
+
model=model,
|
| 742 |
+
x_start=x_start,
|
| 743 |
+
x_t=x_t,
|
| 744 |
+
t=t,
|
| 745 |
+
clip_denoised=False,
|
| 746 |
+
model_kwargs=model_kwargs,
|
| 747 |
+
)["output"]
|
| 748 |
+
if self.loss_type == LossType.RESCALED_KL:
|
| 749 |
+
terms["loss"] *= self.num_timesteps
|
| 750 |
+
elif self.loss_type == LossType.MSE or self.loss_type == LossType.RESCALED_MSE:
|
| 751 |
+
model_output = model(x_t, t, **model_kwargs)
|
| 752 |
+
|
| 753 |
+
if self.model_var_type in [
|
| 754 |
+
ModelVarType.LEARNED,
|
| 755 |
+
ModelVarType.LEARNED_RANGE,
|
| 756 |
+
]:
|
| 757 |
+
B, C = x_t.shape[:2]
|
| 758 |
+
assert model_output.shape == (B, C * 2, *x_t.shape[2:])
|
| 759 |
+
model_output, model_var_values = th.split(model_output, C, dim=1)
|
| 760 |
+
# Learn the variance using the variational bound, but don't let
|
| 761 |
+
# it affect our mean prediction.
|
| 762 |
+
frozen_out = th.cat([model_output.detach(), model_var_values], dim=1)
|
| 763 |
+
terms["vb"] = self._vb_terms_bpd(
|
| 764 |
+
model=lambda *args, r=frozen_out: r,
|
| 765 |
+
x_start=x_start,
|
| 766 |
+
x_t=x_t,
|
| 767 |
+
t=t,
|
| 768 |
+
clip_denoised=False,
|
| 769 |
+
)["output"]
|
| 770 |
+
if self.loss_type == LossType.RESCALED_MSE:
|
| 771 |
+
# Divide by 1000 for equivalence with initial implementation.
|
| 772 |
+
# Without a factor of 1/1000, the VB term hurts the MSE term.
|
| 773 |
+
terms["vb"] *= self.num_timesteps / 1000.0
|
| 774 |
+
|
| 775 |
+
target = {
|
| 776 |
+
ModelMeanType.PREVIOUS_X: self.q_posterior_mean_variance(
|
| 777 |
+
x_start=x_start, x_t=x_t, t=t
|
| 778 |
+
)[0],
|
| 779 |
+
ModelMeanType.START_X: x_start,
|
| 780 |
+
ModelMeanType.EPSILON: noise,
|
| 781 |
+
}[self.model_mean_type]
|
| 782 |
+
assert model_output.shape == target.shape == x_start.shape
|
| 783 |
+
terms["mse"] = mean_flat((target - model_output) ** 2)
|
| 784 |
+
if "vb" in terms:
|
| 785 |
+
terms["loss"] = terms["mse"] + terms["vb"]
|
| 786 |
+
else:
|
| 787 |
+
terms["loss"] = terms["mse"]
|
| 788 |
+
else:
|
| 789 |
+
raise NotImplementedError(self.loss_type)
|
| 790 |
+
|
| 791 |
+
return terms
|
| 792 |
+
|
| 793 |
+
def _prior_bpd(self, x_start):
|
| 794 |
+
"""
|
| 795 |
+
Get the prior KL term for the variational lower-bound, measured in
|
| 796 |
+
bits-per-dim.
|
| 797 |
+
This term can't be optimized, as it only depends on the encoder.
|
| 798 |
+
:param x_start: the [N x C x ...] tensor of inputs.
|
| 799 |
+
:return: a batch of [N] KL values (in bits), one per batch element.
|
| 800 |
+
"""
|
| 801 |
+
batch_size = x_start.shape[0]
|
| 802 |
+
t = th.tensor([self.num_timesteps - 1] * batch_size, device=x_start.device)
|
| 803 |
+
qt_mean, _, qt_log_variance = self.q_mean_variance(x_start, t)
|
| 804 |
+
kl_prior = normal_kl(
|
| 805 |
+
mean1=qt_mean, logvar1=qt_log_variance, mean2=0.0, logvar2=0.0
|
| 806 |
+
)
|
| 807 |
+
return mean_flat(kl_prior) / np.log(2.0)
|
| 808 |
+
|
| 809 |
+
def calc_bpd_loop(self, model, x_start, clip_denoised=True, model_kwargs=None):
|
| 810 |
+
"""
|
| 811 |
+
Compute the entire variational lower-bound, measured in bits-per-dim,
|
| 812 |
+
as well as other related quantities.
|
| 813 |
+
:param model: the model to evaluate loss on.
|
| 814 |
+
:param x_start: the [N x C x ...] tensor of inputs.
|
| 815 |
+
:param clip_denoised: if True, clip denoised samples.
|
| 816 |
+
:param model_kwargs: if not None, a dict of extra keyword arguments to
|
| 817 |
+
pass to the model. This can be used for conditioning.
|
| 818 |
+
:return: a dict containing the following keys:
|
| 819 |
+
- total_bpd: the total variational lower-bound, per batch element.
|
| 820 |
+
- prior_bpd: the prior term in the lower-bound.
|
| 821 |
+
- vb: an [N x T] tensor of terms in the lower-bound.
|
| 822 |
+
- xstart_mse: an [N x T] tensor of x_0 MSEs for each timestep.
|
| 823 |
+
- mse: an [N x T] tensor of epsilon MSEs for each timestep.
|
| 824 |
+
"""
|
| 825 |
+
device = x_start.device
|
| 826 |
+
batch_size = x_start.shape[0]
|
| 827 |
+
|
| 828 |
+
vb = []
|
| 829 |
+
xstart_mse = []
|
| 830 |
+
mse = []
|
| 831 |
+
for t in list(range(self.num_timesteps))[::-1]:
|
| 832 |
+
t_batch = th.tensor([t] * batch_size, device=device)
|
| 833 |
+
noise = th.randn_like(x_start)
|
| 834 |
+
x_t = self.q_sample(x_start=x_start, t=t_batch, noise=noise)
|
| 835 |
+
# Calculate VLB term at the current timestep
|
| 836 |
+
with th.no_grad():
|
| 837 |
+
out = self._vb_terms_bpd(
|
| 838 |
+
model,
|
| 839 |
+
x_start=x_start,
|
| 840 |
+
x_t=x_t,
|
| 841 |
+
t=t_batch,
|
| 842 |
+
clip_denoised=clip_denoised,
|
| 843 |
+
model_kwargs=model_kwargs,
|
| 844 |
+
)
|
| 845 |
+
vb.append(out["output"])
|
| 846 |
+
xstart_mse.append(mean_flat((out["pred_xstart"] - x_start) ** 2))
|
| 847 |
+
eps = self._predict_eps_from_xstart(x_t, t_batch, out["pred_xstart"])
|
| 848 |
+
mse.append(mean_flat((eps - noise) ** 2))
|
| 849 |
+
|
| 850 |
+
vb = th.stack(vb, dim=1)
|
| 851 |
+
xstart_mse = th.stack(xstart_mse, dim=1)
|
| 852 |
+
mse = th.stack(mse, dim=1)
|
| 853 |
+
|
| 854 |
+
prior_bpd = self._prior_bpd(x_start)
|
| 855 |
+
total_bpd = vb.sum(dim=1) + prior_bpd
|
| 856 |
+
return {
|
| 857 |
+
"total_bpd": total_bpd,
|
| 858 |
+
"prior_bpd": prior_bpd,
|
| 859 |
+
"vb": vb,
|
| 860 |
+
"xstart_mse": xstart_mse,
|
| 861 |
+
"mse": mse,
|
| 862 |
+
}
|
| 863 |
+
|
| 864 |
+
|
| 865 |
+
def _extract_into_tensor(arr, timesteps, broadcast_shape):
|
| 866 |
+
"""
|
| 867 |
+
Extract values from a 1-D numpy array for a batch of indices.
|
| 868 |
+
:param arr: the 1-D numpy array.
|
| 869 |
+
:param timesteps: a tensor of indices into the array to extract.
|
| 870 |
+
:param broadcast_shape: a larger shape of K dimensions with the batch
|
| 871 |
+
dimension equal to the length of timesteps.
|
| 872 |
+
:return: a tensor of shape [batch_size, 1, ...] where the shape has K dims.
|
| 873 |
+
"""
|
| 874 |
+
res = th.from_numpy(arr).to(device=timesteps.device)[timesteps].float()
|
| 875 |
+
while len(res.shape) < len(broadcast_shape):
|
| 876 |
+
res = res[..., None]
|
| 877 |
+
return res + th.zeros(broadcast_shape, device=timesteps.device)
|
mar.py
ADDED
|
@@ -0,0 +1,470 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from functools import partial
|
| 2 |
+
|
| 3 |
+
import numpy as np
|
| 4 |
+
from tqdm import tqdm
|
| 5 |
+
import scipy.stats as stats
|
| 6 |
+
import math
|
| 7 |
+
import torch
|
| 8 |
+
import torch.nn as nn
|
| 9 |
+
import torch.nn.functional as F
|
| 10 |
+
from einops import rearrange
|
| 11 |
+
from torch.utils.checkpoint import checkpoint
|
| 12 |
+
from timm.models.vision_transformer import Block
|
| 13 |
+
|
| 14 |
+
from .diffloss import DiffLoss
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def mask_by_order(mask_len, order, bsz, seq_len):
|
| 18 |
+
masking = torch.zeros(bsz, seq_len).to(order.device)
|
| 19 |
+
masking = torch.scatter(masking, dim=-1, index=order[:, :mask_len.long()],
|
| 20 |
+
src=torch.ones(bsz, seq_len).to(order.device)).bool()
|
| 21 |
+
return masking
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
class MAR(nn.Module):
|
| 25 |
+
""" Masked Autoencoder with VisionTransformer backbone
|
| 26 |
+
"""
|
| 27 |
+
def __init__(self, img_size=256, vae_stride=16, patch_size=1,
|
| 28 |
+
encoder_embed_dim=1024, encoder_depth=16, encoder_num_heads=16,
|
| 29 |
+
decoder_embed_dim=1024, decoder_depth=16, decoder_num_heads=16,
|
| 30 |
+
mlp_ratio=4., norm_layer=nn.LayerNorm,
|
| 31 |
+
vae_embed_dim=16,
|
| 32 |
+
mask_ratio_min=0.7,
|
| 33 |
+
label_drop_prob=0.1,
|
| 34 |
+
class_num=1000,
|
| 35 |
+
attn_dropout=0.1,
|
| 36 |
+
proj_dropout=0.1,
|
| 37 |
+
buffer_size=64,
|
| 38 |
+
diffloss_d=3,
|
| 39 |
+
diffloss_w=1024,
|
| 40 |
+
num_sampling_steps='100',
|
| 41 |
+
diffusion_batch_mul=4,
|
| 42 |
+
grad_checkpointing=False,
|
| 43 |
+
):
|
| 44 |
+
super().__init__()
|
| 45 |
+
|
| 46 |
+
# --------------------------------------------------------------------------
|
| 47 |
+
# VAE and patchify specifics
|
| 48 |
+
self.vae_embed_dim = vae_embed_dim
|
| 49 |
+
|
| 50 |
+
self.img_size = img_size
|
| 51 |
+
self.vae_stride = vae_stride
|
| 52 |
+
self.patch_size = patch_size
|
| 53 |
+
self.seq_h = self.seq_w = img_size // vae_stride // patch_size
|
| 54 |
+
self.seq_len = self.seq_h * self.seq_w
|
| 55 |
+
self.token_embed_dim = vae_embed_dim * patch_size**2
|
| 56 |
+
self.grad_checkpointing = grad_checkpointing
|
| 57 |
+
|
| 58 |
+
# --------------------------------------------------------------------------
|
| 59 |
+
# Class Embedding
|
| 60 |
+
self.num_classes = class_num
|
| 61 |
+
self.class_emb = nn.Embedding(class_num, encoder_embed_dim)
|
| 62 |
+
self.label_drop_prob = label_drop_prob
|
| 63 |
+
# Fake class embedding for CFG's unconditional generation
|
| 64 |
+
self.fake_latent = nn.Parameter(torch.zeros(1, encoder_embed_dim))
|
| 65 |
+
|
| 66 |
+
# --------------------------------------------------------------------------
|
| 67 |
+
# MAR variant masking ratio, a left-half truncated Gaussian centered at 100% masking ratio with std 0.25
|
| 68 |
+
self.mask_ratio_generator = stats.truncnorm((mask_ratio_min - 1.0) / 0.25, 0, loc=1.0, scale=0.25)
|
| 69 |
+
|
| 70 |
+
# --------------------------------------------------------------------------
|
| 71 |
+
# MAR encoder specifics
|
| 72 |
+
self.encoder_embed_dim = encoder_embed_dim
|
| 73 |
+
self.z_proj = nn.Linear(self.token_embed_dim, encoder_embed_dim, bias=True)
|
| 74 |
+
self.z_proj_ln = nn.LayerNorm(encoder_embed_dim, eps=1e-6)
|
| 75 |
+
self.buffer_size = buffer_size
|
| 76 |
+
self.encoder_pos_embed_learned = nn.Parameter(torch.zeros(1, self.seq_len + self.buffer_size, encoder_embed_dim))
|
| 77 |
+
|
| 78 |
+
self.encoder_blocks = nn.ModuleList([
|
| 79 |
+
Block(encoder_embed_dim, encoder_num_heads, mlp_ratio, qkv_bias=True, norm_layer=norm_layer,
|
| 80 |
+
proj_drop=proj_dropout, attn_drop=attn_dropout) for _ in range(encoder_depth)])
|
| 81 |
+
self.encoder_norm = norm_layer(encoder_embed_dim)
|
| 82 |
+
|
| 83 |
+
# --------------------------------------------------------------------------
|
| 84 |
+
# MAR decoder specifics
|
| 85 |
+
self.decoder_embed_dim = decoder_embed_dim
|
| 86 |
+
self.decoder_embed = nn.Linear(encoder_embed_dim, decoder_embed_dim, bias=True)
|
| 87 |
+
self.mask_token = nn.Parameter(torch.zeros(1, 1, decoder_embed_dim))
|
| 88 |
+
self.decoder_pos_embed_learned = nn.Parameter(torch.zeros(1, self.seq_len + self.buffer_size, decoder_embed_dim))
|
| 89 |
+
|
| 90 |
+
self.decoder_blocks = nn.ModuleList([
|
| 91 |
+
Block(decoder_embed_dim, decoder_num_heads, mlp_ratio, qkv_bias=True, norm_layer=norm_layer,
|
| 92 |
+
proj_drop=proj_dropout, attn_drop=attn_dropout) for _ in range(decoder_depth)])
|
| 93 |
+
|
| 94 |
+
self.decoder_norm = norm_layer(decoder_embed_dim)
|
| 95 |
+
self.diffusion_pos_embed_learned = nn.Parameter(torch.zeros(1, self.seq_len, decoder_embed_dim))
|
| 96 |
+
|
| 97 |
+
self.initialize_weights()
|
| 98 |
+
|
| 99 |
+
# --------------------------------------------------------------------------
|
| 100 |
+
# Diffusion Loss
|
| 101 |
+
self.diffloss = DiffLoss(
|
| 102 |
+
target_channels=self.token_embed_dim,
|
| 103 |
+
z_channels=decoder_embed_dim,
|
| 104 |
+
width=diffloss_w,
|
| 105 |
+
depth=diffloss_d,
|
| 106 |
+
num_sampling_steps=num_sampling_steps,
|
| 107 |
+
grad_checkpointing=self.grad_checkpointing
|
| 108 |
+
)
|
| 109 |
+
self.diffusion_batch_mul = diffusion_batch_mul
|
| 110 |
+
|
| 111 |
+
def get_encoder_pos_embed(self, h, w):
|
| 112 |
+
if h == self.seq_h and w == self.seq_w:
|
| 113 |
+
return self.encoder_pos_embed_learned
|
| 114 |
+
buffer_pe, image_pe = self.encoder_pos_embed_learned.split(
|
| 115 |
+
[self.buffer_size, self.seq_len], dim=1)
|
| 116 |
+
image_pe = rearrange(image_pe, 'b (h w) c -> b c h w',
|
| 117 |
+
h=self.seq_h, w=self.seq_w)
|
| 118 |
+
image_pe = F.interpolate(image_pe, size=(h, w), mode='bilinear')
|
| 119 |
+
image_pe = rearrange(image_pe, 'b c h w -> b (h w) c')
|
| 120 |
+
|
| 121 |
+
return torch.cat([buffer_pe, image_pe], dim=1)
|
| 122 |
+
|
| 123 |
+
def get_decoder_pos_embed(self, h, w):
|
| 124 |
+
if h == self.seq_h and w == self.seq_w:
|
| 125 |
+
return self.decoder_pos_embed_learned
|
| 126 |
+
buffer_pe, image_pe = self.decoder_pos_embed_learned.split(
|
| 127 |
+
[self.buffer_size, self.seq_len], dim=1)
|
| 128 |
+
image_pe = rearrange(image_pe, 'b (h w) c -> b c h w',
|
| 129 |
+
h=self.seq_h, w=self.seq_w)
|
| 130 |
+
image_pe = F.interpolate(image_pe, size=(h, w), mode='bilinear')
|
| 131 |
+
image_pe = rearrange(image_pe, 'b c h w -> b (h w) c')
|
| 132 |
+
|
| 133 |
+
return torch.cat([buffer_pe, image_pe], dim=1)
|
| 134 |
+
|
| 135 |
+
def get_diffusion_pos_embed(self, h, w):
|
| 136 |
+
if h == self.seq_h and w == self.seq_w:
|
| 137 |
+
return self.diffusion_pos_embed_learned
|
| 138 |
+
image_pe = self.diffusion_pos_embed_learned
|
| 139 |
+
image_pe = rearrange(image_pe, 'b (h w) c -> b c h w',
|
| 140 |
+
h=self.seq_h, w=self.seq_w)
|
| 141 |
+
image_pe = F.interpolate(image_pe, size=(h, w), mode='bilinear')
|
| 142 |
+
image_pe = rearrange(image_pe, 'b c h w -> b (h w) c')
|
| 143 |
+
|
| 144 |
+
return image_pe
|
| 145 |
+
|
| 146 |
+
def initialize_weights(self):
|
| 147 |
+
# parameters
|
| 148 |
+
torch.nn.init.normal_(self.class_emb.weight, std=.02)
|
| 149 |
+
torch.nn.init.normal_(self.fake_latent, std=.02)
|
| 150 |
+
torch.nn.init.normal_(self.mask_token, std=.02)
|
| 151 |
+
torch.nn.init.normal_(self.encoder_pos_embed_learned, std=.02)
|
| 152 |
+
torch.nn.init.normal_(self.decoder_pos_embed_learned, std=.02)
|
| 153 |
+
torch.nn.init.normal_(self.diffusion_pos_embed_learned, std=.02)
|
| 154 |
+
|
| 155 |
+
# initialize nn.Linear and nn.LayerNorm
|
| 156 |
+
self.apply(self._init_weights)
|
| 157 |
+
|
| 158 |
+
def _init_weights(self, m):
|
| 159 |
+
if isinstance(m, nn.Linear):
|
| 160 |
+
# we use xavier_uniform following official JAX ViT:
|
| 161 |
+
torch.nn.init.xavier_uniform_(m.weight)
|
| 162 |
+
if isinstance(m, nn.Linear) and m.bias is not None:
|
| 163 |
+
nn.init.constant_(m.bias, 0)
|
| 164 |
+
elif isinstance(m, nn.LayerNorm):
|
| 165 |
+
if m.bias is not None:
|
| 166 |
+
nn.init.constant_(m.bias, 0)
|
| 167 |
+
if m.weight is not None:
|
| 168 |
+
nn.init.constant_(m.weight, 1.0)
|
| 169 |
+
|
| 170 |
+
@property
|
| 171 |
+
def device(self):
|
| 172 |
+
return self.fake_latent.data.device
|
| 173 |
+
|
| 174 |
+
@property
|
| 175 |
+
def dtype(self):
|
| 176 |
+
return self.fake_latent.data.dtype
|
| 177 |
+
|
| 178 |
+
def patchify(self, x):
|
| 179 |
+
bsz, c, h, w = x.shape
|
| 180 |
+
p = self.patch_size
|
| 181 |
+
h_, w_ = h // p, w // p
|
| 182 |
+
|
| 183 |
+
x = x.reshape(bsz, c, h_, p, w_, p)
|
| 184 |
+
x = torch.einsum('nchpwq->nhwcpq', x)
|
| 185 |
+
x = x.reshape(bsz, h_ * w_, c * p ** 2)
|
| 186 |
+
return x # [n, l, d]
|
| 187 |
+
|
| 188 |
+
def unpatchify(self, x):
|
| 189 |
+
bsz = x.shape[0]
|
| 190 |
+
p = self.patch_size
|
| 191 |
+
c = self.vae_embed_dim
|
| 192 |
+
h_, w_ = self.seq_h, self.seq_w
|
| 193 |
+
|
| 194 |
+
x = x.reshape(bsz, h_, w_, c, p, p)
|
| 195 |
+
x = torch.einsum('nhwcpq->nchpwq', x)
|
| 196 |
+
x = x.reshape(bsz, c, h_ * p, w_ * p)
|
| 197 |
+
return x # [n, c, h, w]
|
| 198 |
+
|
| 199 |
+
def sample_orders(self, bsz, seq_len=None):
|
| 200 |
+
if seq_len is None:
|
| 201 |
+
seq_len = self.seq_len
|
| 202 |
+
# generate a batch of random generation orders
|
| 203 |
+
orders = []
|
| 204 |
+
for _ in range(bsz):
|
| 205 |
+
order = np.array(list(range(seq_len)))
|
| 206 |
+
np.random.shuffle(order)
|
| 207 |
+
orders.append(order)
|
| 208 |
+
orders = torch.Tensor(np.array(orders)).to(self.device).long()
|
| 209 |
+
return orders
|
| 210 |
+
|
| 211 |
+
def random_masking(self, x, orders):
|
| 212 |
+
# generate token mask
|
| 213 |
+
bsz, seq_len, embed_dim = x.shape
|
| 214 |
+
assert seq_len == orders.shape[1]
|
| 215 |
+
mask_rate = self.mask_ratio_generator.rvs(1)[0]
|
| 216 |
+
num_masked_tokens = int(np.ceil(seq_len * mask_rate))
|
| 217 |
+
mask = torch.zeros(bsz, seq_len, device=x.device)
|
| 218 |
+
mask = torch.scatter(mask, dim=-1, index=orders[:, :num_masked_tokens],
|
| 219 |
+
src=torch.ones(bsz, seq_len, device=x.device))
|
| 220 |
+
return mask
|
| 221 |
+
|
| 222 |
+
def forward_mae_encoder(self, x, mask, class_embedding, image_shape=None):
|
| 223 |
+
x = x.to(self.dtype)
|
| 224 |
+
x = self.z_proj(x)
|
| 225 |
+
bsz, seq_len, embed_dim = x.shape
|
| 226 |
+
|
| 227 |
+
# concat buffer
|
| 228 |
+
x = torch.cat([x.new_zeros(bsz, self.buffer_size, embed_dim), x], dim=1)
|
| 229 |
+
mask_with_buffer = torch.cat([mask.new_zeros(x.size(0), self.buffer_size), mask], dim=1)
|
| 230 |
+
|
| 231 |
+
# random drop class embedding during training
|
| 232 |
+
# if self.training:
|
| 233 |
+
# drop_latent_mask = torch.rand(bsz) < self.label_drop_prob
|
| 234 |
+
# drop_latent_mask = drop_latent_mask.unsqueeze(-1).to(self.device).to(x.dtype)
|
| 235 |
+
# class_embedding = drop_latent_mask * self.fake_latent + (1 - drop_latent_mask) * class_embedding
|
| 236 |
+
|
| 237 |
+
x[:, :self.buffer_size] = class_embedding.view(bsz, -1, embed_dim)
|
| 238 |
+
|
| 239 |
+
# encoder position embedding
|
| 240 |
+
# x = x + self.encoder_pos_embed_learned
|
| 241 |
+
if image_shape is None:
|
| 242 |
+
x = x + self.encoder_pos_embed_learned
|
| 243 |
+
else:
|
| 244 |
+
h, w = image_shape
|
| 245 |
+
assert h * w == seq_len
|
| 246 |
+
x = x + self.get_encoder_pos_embed(h=h, w=w)
|
| 247 |
+
# import pdb; pdb.set_trace()
|
| 248 |
+
x = self.z_proj_ln(x)
|
| 249 |
+
|
| 250 |
+
# dropping
|
| 251 |
+
x = x[(1-mask_with_buffer).nonzero(as_tuple=True)].reshape(bsz, -1, embed_dim)
|
| 252 |
+
|
| 253 |
+
# apply Transformer blocks
|
| 254 |
+
if self.grad_checkpointing and not torch.jit.is_scripting():
|
| 255 |
+
for block in self.encoder_blocks:
|
| 256 |
+
x = checkpoint(block, x,
|
| 257 |
+
use_reentrant=False
|
| 258 |
+
)
|
| 259 |
+
else:
|
| 260 |
+
for block in self.encoder_blocks:
|
| 261 |
+
x = block(x)
|
| 262 |
+
x = self.encoder_norm(x)
|
| 263 |
+
|
| 264 |
+
return x
|
| 265 |
+
|
| 266 |
+
def forward_mae_decoder(self, x, mask, image_shape=None, x_con=None):
|
| 267 |
+
bsz, seq_len = mask.shape
|
| 268 |
+
|
| 269 |
+
x = self.decoder_embed(x)
|
| 270 |
+
mask_with_buffer = torch.cat([torch.zeros(x.size(0), self.buffer_size, device=x.device), mask], dim=1)
|
| 271 |
+
|
| 272 |
+
# pad mask tokens
|
| 273 |
+
mask_tokens = self.mask_token.repeat(mask_with_buffer.shape[0], mask_with_buffer.shape[1], 1).to(x.dtype)
|
| 274 |
+
|
| 275 |
+
if x_con is not None:
|
| 276 |
+
x_after_pad = self.decoder_embed(x_con)
|
| 277 |
+
else:
|
| 278 |
+
x_after_pad = mask_tokens.clone()
|
| 279 |
+
x_after_pad[(1 - mask_with_buffer).nonzero(as_tuple=True)] = x.reshape(x.shape[0] * x.shape[1], x.shape[2])
|
| 280 |
+
|
| 281 |
+
# decoder position embedding
|
| 282 |
+
# x = x_after_pad + self.decoder_pos_embed_learned
|
| 283 |
+
if image_shape is None:
|
| 284 |
+
x = x_after_pad + self.decoder_pos_embed_learned
|
| 285 |
+
else:
|
| 286 |
+
h, w = image_shape
|
| 287 |
+
assert h * w == seq_len
|
| 288 |
+
x = x_after_pad + self.get_decoder_pos_embed(h=h, w=w)
|
| 289 |
+
|
| 290 |
+
# apply Transformer blocks
|
| 291 |
+
if self.grad_checkpointing and not torch.jit.is_scripting():
|
| 292 |
+
for block in self.decoder_blocks:
|
| 293 |
+
x = checkpoint(block, x,
|
| 294 |
+
# use_reentrant=False
|
| 295 |
+
)
|
| 296 |
+
else:
|
| 297 |
+
for block in self.decoder_blocks:
|
| 298 |
+
x = block(x)
|
| 299 |
+
x = self.decoder_norm(x)
|
| 300 |
+
|
| 301 |
+
x = x[:, self.buffer_size:]
|
| 302 |
+
# x = x + self.diffusion_pos_embed_learned
|
| 303 |
+
if image_shape is None:
|
| 304 |
+
x = x + self.diffusion_pos_embed_learned
|
| 305 |
+
else:
|
| 306 |
+
h, w = image_shape
|
| 307 |
+
assert h * w == seq_len
|
| 308 |
+
x = x + self.get_diffusion_pos_embed(h=h, w=w)
|
| 309 |
+
return x
|
| 310 |
+
|
| 311 |
+
def mae_decoder_prepare(self, x, mask):
|
| 312 |
+
x = self.decoder_embed(x)
|
| 313 |
+
mask_with_buffer = torch.cat([torch.zeros(x.size(0), self.buffer_size, device=x.device), mask], dim=1)
|
| 314 |
+
|
| 315 |
+
# pad mask tokens
|
| 316 |
+
mask_tokens = self.mask_token.repeat(mask_with_buffer.shape[0], mask_with_buffer.shape[1], 1).to(x.dtype)
|
| 317 |
+
x_after_pad = mask_tokens.clone()
|
| 318 |
+
x_after_pad[(1 - mask_with_buffer).nonzero(as_tuple=True)] = x.reshape(x.shape[0] * x.shape[1], x.shape[2])
|
| 319 |
+
|
| 320 |
+
# decoder position embedding
|
| 321 |
+
x = x_after_pad + self.decoder_pos_embed_learned
|
| 322 |
+
|
| 323 |
+
return x
|
| 324 |
+
|
| 325 |
+
def mae_decoder_forward(self, x):
|
| 326 |
+
# apply Transformer blocks
|
| 327 |
+
if self.grad_checkpointing and not torch.jit.is_scripting():
|
| 328 |
+
for block in self.decoder_blocks:
|
| 329 |
+
x = checkpoint(block, x,
|
| 330 |
+
# use_reentrant=False
|
| 331 |
+
)
|
| 332 |
+
else:
|
| 333 |
+
for block in self.decoder_blocks:
|
| 334 |
+
x = block(x)
|
| 335 |
+
x = self.decoder_norm(x)
|
| 336 |
+
|
| 337 |
+
x = x[:, self.buffer_size:]
|
| 338 |
+
x = x + self.diffusion_pos_embed_learned
|
| 339 |
+
return x
|
| 340 |
+
|
| 341 |
+
def forward_loss(self, z, target, mask):
|
| 342 |
+
bsz, seq_len, _ = target.shape
|
| 343 |
+
target = target.reshape(bsz * seq_len, -1).repeat(self.diffusion_batch_mul, 1)
|
| 344 |
+
z = z.reshape(bsz*seq_len, -1).repeat(self.diffusion_batch_mul, 1)
|
| 345 |
+
mask = mask.reshape(bsz*seq_len).repeat(self.diffusion_batch_mul)
|
| 346 |
+
loss = self.diffloss(z=z, target=target, mask=mask)
|
| 347 |
+
return loss
|
| 348 |
+
|
| 349 |
+
def forward(self, imgs, labels):
|
| 350 |
+
|
| 351 |
+
# class embed
|
| 352 |
+
class_embedding = self.class_emb(labels)
|
| 353 |
+
|
| 354 |
+
# patchify and mask (drop) tokens
|
| 355 |
+
x = self.patchify(imgs)
|
| 356 |
+
gt_latents = x.clone().detach()
|
| 357 |
+
orders = self.sample_orders(bsz=x.size(0))
|
| 358 |
+
mask = self.random_masking(x, orders)
|
| 359 |
+
|
| 360 |
+
# mae encoder
|
| 361 |
+
x = self.forward_mae_encoder(x, mask, class_embedding)
|
| 362 |
+
|
| 363 |
+
# mae decoder
|
| 364 |
+
z = self.forward_mae_decoder(x, mask)
|
| 365 |
+
|
| 366 |
+
# diffloss
|
| 367 |
+
loss = self.forward_loss(z=z, target=gt_latents, mask=mask)
|
| 368 |
+
|
| 369 |
+
return loss
|
| 370 |
+
|
| 371 |
+
def sample_tokens(self, bsz, num_iter=64, cfg=1.0, cfg_schedule="linear", labels=None, temperature=1.0, progress=False):
|
| 372 |
+
import pdb; pdb.set_trace()
|
| 373 |
+
# init and sample generation orders
|
| 374 |
+
mask = torch.ones(bsz, self.seq_len).to(self.device)
|
| 375 |
+
tokens = torch.zeros(bsz, self.seq_len, self.token_embed_dim).to(self.device)
|
| 376 |
+
orders = self.sample_orders(bsz)
|
| 377 |
+
|
| 378 |
+
indices = list(range(num_iter))
|
| 379 |
+
if progress:
|
| 380 |
+
indices = tqdm(indices)
|
| 381 |
+
# generate latents
|
| 382 |
+
for step in indices:
|
| 383 |
+
cur_tokens = tokens.clone()
|
| 384 |
+
|
| 385 |
+
# class embedding and CFG
|
| 386 |
+
if labels is not None:
|
| 387 |
+
class_embedding = self.class_emb(labels)
|
| 388 |
+
else:
|
| 389 |
+
class_embedding = self.fake_latent.repeat(bsz, 1)
|
| 390 |
+
if not cfg == 1.0:
|
| 391 |
+
tokens = torch.cat([tokens, tokens], dim=0)
|
| 392 |
+
class_embedding = torch.cat([class_embedding, self.fake_latent.repeat(bsz, 1)], dim=0)
|
| 393 |
+
mask = torch.cat([mask, mask], dim=0)
|
| 394 |
+
|
| 395 |
+
# mae encoder
|
| 396 |
+
x = self.forward_mae_encoder(tokens, mask.to(self.dtype), class_embedding)
|
| 397 |
+
|
| 398 |
+
# mae decoder
|
| 399 |
+
z = self.forward_mae_decoder(x, mask.to(self.dtype))
|
| 400 |
+
import pdb; pdb.set_trace()
|
| 401 |
+
|
| 402 |
+
# mask ratio for the next round, following MaskGIT and MAGE.
|
| 403 |
+
mask_ratio = np.cos(math.pi / 2. * (step + 1) / num_iter)
|
| 404 |
+
mask_len = torch.Tensor([np.floor(self.seq_len * mask_ratio)]).to(self.device)
|
| 405 |
+
import pdb; pdb.set_trace()
|
| 406 |
+
# masks out at least one for the next iteration
|
| 407 |
+
mask_len = torch.maximum(torch.Tensor([1]).to(self.device),
|
| 408 |
+
torch.minimum(torch.sum(mask, dim=-1, keepdims=True) - 1, mask_len))
|
| 409 |
+
import pdb; pdb.set_trace()
|
| 410 |
+
# get masking for next iteration and locations to be predicted in this iteration
|
| 411 |
+
mask_next = mask_by_order(mask_len[0], orders, bsz, self.seq_len)
|
| 412 |
+
import pdb; pdb.set_trace()
|
| 413 |
+
if step >= num_iter - 1:
|
| 414 |
+
mask_to_pred = mask[:bsz].bool()
|
| 415 |
+
else:
|
| 416 |
+
mask_to_pred = torch.logical_xor(mask[:bsz].bool(), mask_next.bool())
|
| 417 |
+
mask = mask_next
|
| 418 |
+
if not cfg == 1.0:
|
| 419 |
+
mask_to_pred = torch.cat([mask_to_pred, mask_to_pred], dim=0)
|
| 420 |
+
import pdb; pdb.set_trace()
|
| 421 |
+
# sample token latents for this step
|
| 422 |
+
z = z[mask_to_pred.nonzero(as_tuple=True)]
|
| 423 |
+
# cfg schedule follow Muse
|
| 424 |
+
if cfg_schedule == "linear":
|
| 425 |
+
cfg_iter = 1 + (cfg - 1) * (self.seq_len - mask_len[0]) / self.seq_len
|
| 426 |
+
elif cfg_schedule == "constant":
|
| 427 |
+
cfg_iter = cfg
|
| 428 |
+
else:
|
| 429 |
+
raise NotImplementedError
|
| 430 |
+
sampled_token_latent = self.diffloss.sample(z, temperature, cfg_iter)
|
| 431 |
+
if not cfg == 1.0:
|
| 432 |
+
sampled_token_latent, _ = sampled_token_latent.chunk(2, dim=0) # Remove null class samples
|
| 433 |
+
mask_to_pred, _ = mask_to_pred.chunk(2, dim=0)
|
| 434 |
+
import pdb; pdb.set_trace()
|
| 435 |
+
cur_tokens[mask_to_pred.nonzero(as_tuple=True)] = sampled_token_latent
|
| 436 |
+
tokens = cur_tokens.clone()
|
| 437 |
+
|
| 438 |
+
# unpatchify
|
| 439 |
+
tokens = self.unpatchify(tokens)
|
| 440 |
+
return tokens
|
| 441 |
+
|
| 442 |
+
def gradient_checkpointing_enable(self):
|
| 443 |
+
self.grad_checkpointing = True
|
| 444 |
+
|
| 445 |
+
def gradient_checkpointing_disable(self):
|
| 446 |
+
self.grad_checkpointing = False
|
| 447 |
+
|
| 448 |
+
|
| 449 |
+
def mar_base(**kwargs):
|
| 450 |
+
model = MAR(
|
| 451 |
+
encoder_embed_dim=768, encoder_depth=12, encoder_num_heads=12,
|
| 452 |
+
decoder_embed_dim=768, decoder_depth=12, decoder_num_heads=12,
|
| 453 |
+
mlp_ratio=4, norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
|
| 454 |
+
return model
|
| 455 |
+
|
| 456 |
+
|
| 457 |
+
def mar_large(**kwargs):
|
| 458 |
+
model = MAR(
|
| 459 |
+
encoder_embed_dim=1024, encoder_depth=16, encoder_num_heads=16,
|
| 460 |
+
decoder_embed_dim=1024, decoder_depth=16, decoder_num_heads=16,
|
| 461 |
+
mlp_ratio=4, norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
|
| 462 |
+
return model
|
| 463 |
+
|
| 464 |
+
|
| 465 |
+
def mar_huge(**kwargs):
|
| 466 |
+
model = MAR(
|
| 467 |
+
encoder_embed_dim=1280, encoder_depth=20, encoder_num_heads=16,
|
| 468 |
+
decoder_embed_dim=1280, decoder_depth=20, decoder_num_heads=16,
|
| 469 |
+
mlp_ratio=4, norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
|
| 470 |
+
return model
|
method.png
ADDED
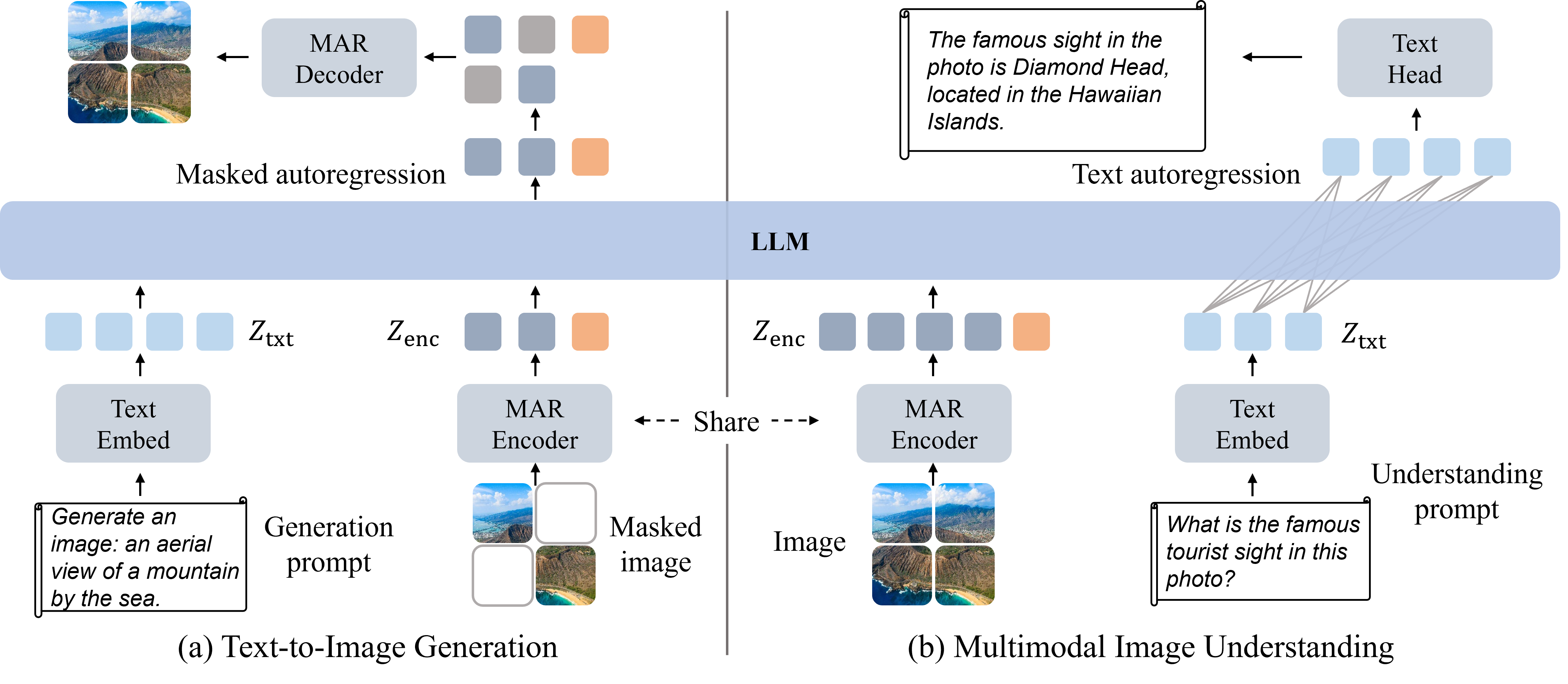
|
Git LFS Details
|
misc.py
ADDED
|
@@ -0,0 +1,383 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import builtins
|
| 2 |
+
import datetime
|
| 3 |
+
import os
|
| 4 |
+
import time
|
| 5 |
+
from collections import defaultdict, deque
|
| 6 |
+
from pathlib import Path
|
| 7 |
+
|
| 8 |
+
import torch
|
| 9 |
+
import torch.distributed as dist
|
| 10 |
+
TORCH_MAJOR = int(torch.__version__.split('.')[0])
|
| 11 |
+
TORCH_MINOR = int(torch.__version__.split('.')[1])
|
| 12 |
+
|
| 13 |
+
if TORCH_MAJOR == 1 and TORCH_MINOR < 8:
|
| 14 |
+
from torch._six import inf
|
| 15 |
+
else:
|
| 16 |
+
from torch import inf
|
| 17 |
+
import copy
|
| 18 |
+
|
| 19 |
+
from . import gaussian_diffusion as gd
|
| 20 |
+
from .respace import SpacedDiffusion, space_timesteps
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def create_diffusion(
|
| 24 |
+
timestep_respacing,
|
| 25 |
+
noise_schedule="linear",
|
| 26 |
+
use_kl=False,
|
| 27 |
+
sigma_small=False,
|
| 28 |
+
predict_xstart=False,
|
| 29 |
+
learn_sigma=True,
|
| 30 |
+
rescale_learned_sigmas=False,
|
| 31 |
+
diffusion_steps=1000
|
| 32 |
+
):
|
| 33 |
+
betas = gd.get_named_beta_schedule(noise_schedule, diffusion_steps)
|
| 34 |
+
if use_kl:
|
| 35 |
+
loss_type = gd.LossType.RESCALED_KL
|
| 36 |
+
elif rescale_learned_sigmas:
|
| 37 |
+
loss_type = gd.LossType.RESCALED_MSE
|
| 38 |
+
else:
|
| 39 |
+
loss_type = gd.LossType.MSE
|
| 40 |
+
if timestep_respacing is None or timestep_respacing == "":
|
| 41 |
+
timestep_respacing = [diffusion_steps]
|
| 42 |
+
return SpacedDiffusion(
|
| 43 |
+
use_timesteps=space_timesteps(diffusion_steps, timestep_respacing),
|
| 44 |
+
betas=betas,
|
| 45 |
+
model_mean_type=(
|
| 46 |
+
gd.ModelMeanType.EPSILON if not predict_xstart else gd.ModelMeanType.START_X
|
| 47 |
+
),
|
| 48 |
+
model_var_type=(
|
| 49 |
+
(
|
| 50 |
+
gd.ModelVarType.FIXED_LARGE
|
| 51 |
+
if not sigma_small
|
| 52 |
+
else gd.ModelVarType.FIXED_SMALL
|
| 53 |
+
)
|
| 54 |
+
if not learn_sigma
|
| 55 |
+
else gd.ModelVarType.LEARNED_RANGE
|
| 56 |
+
),
|
| 57 |
+
loss_type=loss_type
|
| 58 |
+
# rescale_timesteps=rescale_timesteps,
|
| 59 |
+
)
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
class SmoothedValue(object):
|
| 64 |
+
"""Track a series of values and provide access to smoothed values over a
|
| 65 |
+
window or the global series average.
|
| 66 |
+
"""
|
| 67 |
+
|
| 68 |
+
def __init__(self, window_size=20, fmt=None):
|
| 69 |
+
if fmt is None:
|
| 70 |
+
fmt = "{median:.4f} ({global_avg:.4f})"
|
| 71 |
+
self.deque = deque(maxlen=window_size)
|
| 72 |
+
self.total = 0.0
|
| 73 |
+
self.count = 0
|
| 74 |
+
self.fmt = fmt
|
| 75 |
+
|
| 76 |
+
def update(self, value, n=1):
|
| 77 |
+
self.deque.append(value)
|
| 78 |
+
self.count += n
|
| 79 |
+
self.total += value * n
|
| 80 |
+
|
| 81 |
+
def synchronize_between_processes(self):
|
| 82 |
+
"""
|
| 83 |
+
Warning: does not synchronize the deque!
|
| 84 |
+
"""
|
| 85 |
+
if not is_dist_avail_and_initialized():
|
| 86 |
+
return
|
| 87 |
+
t = torch.tensor([self.count, self.total], dtype=torch.float64, device='cuda')
|
| 88 |
+
dist.barrier()
|
| 89 |
+
dist.all_reduce(t)
|
| 90 |
+
t = t.tolist()
|
| 91 |
+
self.count = int(t[0])
|
| 92 |
+
self.total = t[1]
|
| 93 |
+
|
| 94 |
+
@property
|
| 95 |
+
def median(self):
|
| 96 |
+
d = torch.tensor(list(self.deque))
|
| 97 |
+
return d.median().item()
|
| 98 |
+
|
| 99 |
+
@property
|
| 100 |
+
def avg(self):
|
| 101 |
+
d = torch.tensor(list(self.deque), dtype=torch.float32)
|
| 102 |
+
return d.mean().item()
|
| 103 |
+
|
| 104 |
+
@property
|
| 105 |
+
def global_avg(self):
|
| 106 |
+
return self.total / self.count
|
| 107 |
+
|
| 108 |
+
@property
|
| 109 |
+
def max(self):
|
| 110 |
+
return max(self.deque)
|
| 111 |
+
|
| 112 |
+
@property
|
| 113 |
+
def value(self):
|
| 114 |
+
return self.deque[-1]
|
| 115 |
+
|
| 116 |
+
def __str__(self):
|
| 117 |
+
return self.fmt.format(
|
| 118 |
+
median=self.median,
|
| 119 |
+
avg=self.avg,
|
| 120 |
+
global_avg=self.global_avg,
|
| 121 |
+
max=self.max,
|
| 122 |
+
value=self.value)
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
class MetricLogger(object):
|
| 126 |
+
def __init__(self, delimiter="\t"):
|
| 127 |
+
self.meters = defaultdict(SmoothedValue)
|
| 128 |
+
self.delimiter = delimiter
|
| 129 |
+
|
| 130 |
+
def update(self, **kwargs):
|
| 131 |
+
for k, v in kwargs.items():
|
| 132 |
+
if v is None:
|
| 133 |
+
continue
|
| 134 |
+
if isinstance(v, torch.Tensor):
|
| 135 |
+
v = v.item()
|
| 136 |
+
assert isinstance(v, (float, int))
|
| 137 |
+
self.meters[k].update(v)
|
| 138 |
+
|
| 139 |
+
def __getattr__(self, attr):
|
| 140 |
+
if attr in self.meters:
|
| 141 |
+
return self.meters[attr]
|
| 142 |
+
if attr in self.__dict__:
|
| 143 |
+
return self.__dict__[attr]
|
| 144 |
+
raise AttributeError("'{}' object has no attribute '{}'".format(
|
| 145 |
+
type(self).__name__, attr))
|
| 146 |
+
|
| 147 |
+
def __str__(self):
|
| 148 |
+
loss_str = []
|
| 149 |
+
for name, meter in self.meters.items():
|
| 150 |
+
loss_str.append(
|
| 151 |
+
"{}: {}".format(name, str(meter))
|
| 152 |
+
)
|
| 153 |
+
return self.delimiter.join(loss_str)
|
| 154 |
+
|
| 155 |
+
def synchronize_between_processes(self):
|
| 156 |
+
for meter in self.meters.values():
|
| 157 |
+
meter.synchronize_between_processes()
|
| 158 |
+
|
| 159 |
+
def add_meter(self, name, meter):
|
| 160 |
+
self.meters[name] = meter
|
| 161 |
+
|
| 162 |
+
def log_every(self, iterable, print_freq, header=None):
|
| 163 |
+
i = 0
|
| 164 |
+
if not header:
|
| 165 |
+
header = ''
|
| 166 |
+
start_time = time.time()
|
| 167 |
+
end = time.time()
|
| 168 |
+
iter_time = SmoothedValue(fmt='{avg:.4f}')
|
| 169 |
+
data_time = SmoothedValue(fmt='{avg:.4f}')
|
| 170 |
+
space_fmt = ':' + str(len(str(len(iterable)))) + 'd'
|
| 171 |
+
log_msg = [
|
| 172 |
+
header,
|
| 173 |
+
'[{0' + space_fmt + '}/{1}]',
|
| 174 |
+
'eta: {eta}',
|
| 175 |
+
'{meters}',
|
| 176 |
+
'time: {time}',
|
| 177 |
+
'data: {data}'
|
| 178 |
+
]
|
| 179 |
+
if torch.cuda.is_available():
|
| 180 |
+
log_msg.append('max mem: {memory:.0f}')
|
| 181 |
+
log_msg = self.delimiter.join(log_msg)
|
| 182 |
+
MB = 1024.0 * 1024.0
|
| 183 |
+
for obj in iterable:
|
| 184 |
+
data_time.update(time.time() - end)
|
| 185 |
+
yield obj
|
| 186 |
+
iter_time.update(time.time() - end)
|
| 187 |
+
if i % print_freq == 0 or i == len(iterable) - 1:
|
| 188 |
+
eta_seconds = iter_time.global_avg * (len(iterable) - i)
|
| 189 |
+
eta_string = str(datetime.timedelta(seconds=int(eta_seconds)))
|
| 190 |
+
if torch.cuda.is_available():
|
| 191 |
+
print(log_msg.format(
|
| 192 |
+
i, len(iterable), eta=eta_string,
|
| 193 |
+
meters=str(self),
|
| 194 |
+
time=str(iter_time), data=str(data_time),
|
| 195 |
+
memory=torch.cuda.max_memory_allocated() / MB))
|
| 196 |
+
else:
|
| 197 |
+
print(log_msg.format(
|
| 198 |
+
i, len(iterable), eta=eta_string,
|
| 199 |
+
meters=str(self),
|
| 200 |
+
time=str(iter_time), data=str(data_time)))
|
| 201 |
+
i += 1
|
| 202 |
+
end = time.time()
|
| 203 |
+
total_time = time.time() - start_time
|
| 204 |
+
total_time_str = str(datetime.timedelta(seconds=int(total_time)))
|
| 205 |
+
print('{} Total time: {} ({:.4f} s / it)'.format(
|
| 206 |
+
header, total_time_str, total_time / len(iterable)))
|
| 207 |
+
|
| 208 |
+
|
| 209 |
+
def setup_for_distributed(is_master):
|
| 210 |
+
"""
|
| 211 |
+
This function disables printing when not in master process
|
| 212 |
+
"""
|
| 213 |
+
builtin_print = builtins.print
|
| 214 |
+
|
| 215 |
+
def print(*args, **kwargs):
|
| 216 |
+
force = kwargs.pop('force', False)
|
| 217 |
+
force = force or (get_world_size() > 8)
|
| 218 |
+
if is_master or force:
|
| 219 |
+
now = datetime.datetime.now().time()
|
| 220 |
+
builtin_print('[{}] '.format(now), end='') # print with time stamp
|
| 221 |
+
builtin_print(*args, **kwargs)
|
| 222 |
+
|
| 223 |
+
builtins.print = print
|
| 224 |
+
|
| 225 |
+
|
| 226 |
+
def is_dist_avail_and_initialized():
|
| 227 |
+
if not dist.is_available():
|
| 228 |
+
return False
|
| 229 |
+
if not dist.is_initialized():
|
| 230 |
+
return False
|
| 231 |
+
return True
|
| 232 |
+
|
| 233 |
+
|
| 234 |
+
def get_world_size():
|
| 235 |
+
if not is_dist_avail_and_initialized():
|
| 236 |
+
return 1
|
| 237 |
+
return dist.get_world_size()
|
| 238 |
+
|
| 239 |
+
|
| 240 |
+
def get_rank():
|
| 241 |
+
if not is_dist_avail_and_initialized():
|
| 242 |
+
return 0
|
| 243 |
+
return dist.get_rank()
|
| 244 |
+
|
| 245 |
+
|
| 246 |
+
def is_main_process():
|
| 247 |
+
return get_rank() == 0
|
| 248 |
+
|
| 249 |
+
|
| 250 |
+
def save_on_master(*args, **kwargs):
|
| 251 |
+
if is_main_process():
|
| 252 |
+
torch.save(*args, **kwargs)
|
| 253 |
+
|
| 254 |
+
|
| 255 |
+
def init_distributed_mode(args):
|
| 256 |
+
if args.dist_on_itp:
|
| 257 |
+
args.rank = int(os.environ['OMPI_COMM_WORLD_RANK'])
|
| 258 |
+
args.world_size = int(os.environ['OMPI_COMM_WORLD_SIZE'])
|
| 259 |
+
args.gpu = int(os.environ['OMPI_COMM_WORLD_LOCAL_RANK'])
|
| 260 |
+
args.dist_url = "tcp://%s:%s" % (os.environ['MASTER_ADDR'], os.environ['MASTER_PORT'])
|
| 261 |
+
os.environ['LOCAL_RANK'] = str(args.gpu)
|
| 262 |
+
os.environ['RANK'] = str(args.rank)
|
| 263 |
+
os.environ['WORLD_SIZE'] = str(args.world_size)
|
| 264 |
+
# ["RANK", "WORLD_SIZE", "MASTER_ADDR", "MASTER_PORT", "LOCAL_RANK"]
|
| 265 |
+
elif 'RANK' in os.environ and 'WORLD_SIZE' in os.environ:
|
| 266 |
+
args.rank = int(os.environ["RANK"])
|
| 267 |
+
args.world_size = int(os.environ['WORLD_SIZE'])
|
| 268 |
+
args.gpu = int(os.environ['LOCAL_RANK'])
|
| 269 |
+
elif 'SLURM_PROCID' in os.environ:
|
| 270 |
+
args.rank = int(os.environ['SLURM_PROCID'])
|
| 271 |
+
args.gpu = args.rank % torch.cuda.device_count()
|
| 272 |
+
else:
|
| 273 |
+
print('Not using distributed mode')
|
| 274 |
+
setup_for_distributed(is_master=True) # hack
|
| 275 |
+
args.distributed = False
|
| 276 |
+
return
|
| 277 |
+
|
| 278 |
+
args.distributed = True
|
| 279 |
+
|
| 280 |
+
torch.cuda.set_device(args.gpu)
|
| 281 |
+
args.dist_backend = 'nccl'
|
| 282 |
+
print('| distributed init (rank {}): {}, gpu {}'.format(
|
| 283 |
+
args.rank, args.dist_url, args.gpu), flush=True)
|
| 284 |
+
torch.distributed.init_process_group(backend=args.dist_backend, init_method=args.dist_url,
|
| 285 |
+
world_size=args.world_size, rank=args.rank)
|
| 286 |
+
torch.distributed.barrier()
|
| 287 |
+
setup_for_distributed(args.rank == 0)
|
| 288 |
+
|
| 289 |
+
|
| 290 |
+
class NativeScalerWithGradNormCount:
|
| 291 |
+
state_dict_key = "amp_scaler"
|
| 292 |
+
|
| 293 |
+
def __init__(self):
|
| 294 |
+
self._scaler = torch.cuda.amp.GradScaler()
|
| 295 |
+
|
| 296 |
+
def __call__(self, loss, optimizer, clip_grad=None, parameters=None, create_graph=False, update_grad=True):
|
| 297 |
+
self._scaler.scale(loss).backward(create_graph=create_graph)
|
| 298 |
+
if update_grad:
|
| 299 |
+
if clip_grad is not None:
|
| 300 |
+
assert parameters is not None
|
| 301 |
+
self._scaler.unscale_(optimizer) # unscale the gradients of optimizer's assigned params in-place
|
| 302 |
+
norm = torch.nn.utils.clip_grad_norm_(parameters, clip_grad)
|
| 303 |
+
else:
|
| 304 |
+
self._scaler.unscale_(optimizer)
|
| 305 |
+
norm = get_grad_norm_(parameters)
|
| 306 |
+
self._scaler.step(optimizer)
|
| 307 |
+
self._scaler.update()
|
| 308 |
+
else:
|
| 309 |
+
norm = None
|
| 310 |
+
return norm
|
| 311 |
+
|
| 312 |
+
def state_dict(self):
|
| 313 |
+
return self._scaler.state_dict()
|
| 314 |
+
|
| 315 |
+
def load_state_dict(self, state_dict):
|
| 316 |
+
self._scaler.load_state_dict(state_dict)
|
| 317 |
+
|
| 318 |
+
|
| 319 |
+
def get_grad_norm_(parameters, norm_type: float = 2.0) -> torch.Tensor:
|
| 320 |
+
if isinstance(parameters, torch.Tensor):
|
| 321 |
+
parameters = [parameters]
|
| 322 |
+
parameters = [p for p in parameters if p.grad is not None]
|
| 323 |
+
norm_type = float(norm_type)
|
| 324 |
+
if len(parameters) == 0:
|
| 325 |
+
return torch.tensor(0.)
|
| 326 |
+
device = parameters[0].grad.device
|
| 327 |
+
if norm_type == inf:
|
| 328 |
+
total_norm = max(p.grad.detach().abs().max().to(device) for p in parameters)
|
| 329 |
+
else:
|
| 330 |
+
total_norm = torch.norm(torch.stack([torch.norm(p.grad.detach(), norm_type).to(device) for p in parameters]), norm_type)
|
| 331 |
+
return total_norm
|
| 332 |
+
|
| 333 |
+
|
| 334 |
+
def add_weight_decay(model, weight_decay=1e-5, skip_list=()):
|
| 335 |
+
decay = []
|
| 336 |
+
no_decay = []
|
| 337 |
+
for name, param in model.named_parameters():
|
| 338 |
+
if not param.requires_grad:
|
| 339 |
+
continue # frozen weights
|
| 340 |
+
if len(param.shape) == 1 or name.endswith(".bias") or name in skip_list or 'diffloss' in name:
|
| 341 |
+
no_decay.append(param) # no weight decay on bias, norm and diffloss
|
| 342 |
+
else:
|
| 343 |
+
decay.append(param)
|
| 344 |
+
return [
|
| 345 |
+
{'params': no_decay, 'weight_decay': 0.},
|
| 346 |
+
{'params': decay, 'weight_decay': weight_decay}]
|
| 347 |
+
|
| 348 |
+
|
| 349 |
+
def save_model(args, epoch, model, model_without_ddp, optimizer, loss_scaler, ema_params=None, epoch_name=None):
|
| 350 |
+
if epoch_name is None:
|
| 351 |
+
epoch_name = str(epoch)
|
| 352 |
+
output_dir = Path(args.output_dir)
|
| 353 |
+
checkpoint_path = output_dir / ('checkpoint-%s.pth' % epoch_name)
|
| 354 |
+
|
| 355 |
+
# ema
|
| 356 |
+
if ema_params is not None:
|
| 357 |
+
ema_state_dict = copy.deepcopy(model_without_ddp.state_dict())
|
| 358 |
+
for i, (name, _value) in enumerate(model_without_ddp.named_parameters()):
|
| 359 |
+
assert name in ema_state_dict
|
| 360 |
+
ema_state_dict[name] = ema_params[i]
|
| 361 |
+
else:
|
| 362 |
+
ema_state_dict = None
|
| 363 |
+
|
| 364 |
+
to_save = {
|
| 365 |
+
'model': model_without_ddp.state_dict(),
|
| 366 |
+
'model_ema': ema_state_dict,
|
| 367 |
+
'optimizer': optimizer.state_dict(),
|
| 368 |
+
'epoch': epoch,
|
| 369 |
+
'scaler': loss_scaler.state_dict(),
|
| 370 |
+
'args': args,
|
| 371 |
+
}
|
| 372 |
+
save_on_master(to_save, checkpoint_path)
|
| 373 |
+
|
| 374 |
+
|
| 375 |
+
def all_reduce_mean(x):
|
| 376 |
+
world_size = get_world_size()
|
| 377 |
+
if world_size > 1:
|
| 378 |
+
x_reduce = torch.tensor(x).cuda()
|
| 379 |
+
dist.all_reduce(x_reduce)
|
| 380 |
+
x_reduce /= world_size
|
| 381 |
+
return x_reduce.item()
|
| 382 |
+
else:
|
| 383 |
+
return x
|
model-00001-of-00002.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6932594180617297db1bf532283356734f6d98b392e58e04029907fcbd75ae86
|
| 3 |
+
size 4994116086
|
model-00002-of-00002.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:64a2820961dd24cbbf166a95f67a620f17da56b282df6ba53f084ba71e2b0df3
|
| 3 |
+
size 595233832
|
model.safetensors.index.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
modeling_harmon.py
ADDED
|
@@ -0,0 +1,288 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import math
|
| 3 |
+
import numpy as np
|
| 4 |
+
import torch.nn as nn
|
| 5 |
+
import copy
|
| 6 |
+
from einops import rearrange
|
| 7 |
+
from torch.nn.modules.module import T
|
| 8 |
+
from transformers.cache_utils import DynamicCache
|
| 9 |
+
|
| 10 |
+
from tqdm import tqdm
|
| 11 |
+
from transformers import Qwen2ForCausalLM, Qwen2Config, PreTrainedModel
|
| 12 |
+
|
| 13 |
+
from .diffusion_utils import *
|
| 14 |
+
from .gaussian_diffusion import *
|
| 15 |
+
from .respace import *
|
| 16 |
+
from .misc import *
|
| 17 |
+
from .diffloss import *
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
from .configuration_harmon import HarmonConfig
|
| 21 |
+
from .vae import AutoencoderKL
|
| 22 |
+
from .mar import mar_base, mar_large, mar_huge
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def build_mlp(hidden_size, projector_dim, z_dim):
|
| 27 |
+
return nn.Sequential(
|
| 28 |
+
nn.Linear(hidden_size, projector_dim),
|
| 29 |
+
nn.SiLU(),
|
| 30 |
+
nn.Linear(projector_dim, z_dim),)
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def mask_by_order(mask_len, order, bsz, seq_len):
|
| 34 |
+
masking = torch.zeros(bsz, seq_len, device=order.device)
|
| 35 |
+
masking = torch.scatter(masking, dim=-1, index=order[:, :mask_len.long()],
|
| 36 |
+
src=torch.ones(bsz, seq_len, device=order.device)).bool()
|
| 37 |
+
return masking
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
class HarmonModel(PreTrainedModel):
|
| 41 |
+
config_class = HarmonConfig
|
| 42 |
+
|
| 43 |
+
def __init__(self, config: HarmonConfig):
|
| 44 |
+
super().__init__(config)
|
| 45 |
+
# VAE
|
| 46 |
+
self.vae = AutoencoderKL(
|
| 47 |
+
embed_dim=16,
|
| 48 |
+
ch_mult=(1, 1, 2, 2, 4)
|
| 49 |
+
)
|
| 50 |
+
self.vae_scale = 0.2325
|
| 51 |
+
|
| 52 |
+
# LLM
|
| 53 |
+
self.llm = Qwen2ForCausalLM(config=Qwen2Config.from_dict(config.llm))
|
| 54 |
+
|
| 55 |
+
# MAR
|
| 56 |
+
mar_config = copy.deepcopy(config.mar)
|
| 57 |
+
mar_type = mar_config.pop('type')
|
| 58 |
+
if mar_type == 'mar_base':
|
| 59 |
+
self.mar = mar_base(**mar_config)
|
| 60 |
+
elif mar_type == 'mar_large':
|
| 61 |
+
self.mar = mar_large(**mar_config)
|
| 62 |
+
elif mar_type == 'mar_huge':
|
| 63 |
+
self.mar = mar_huge(**mar_config)
|
| 64 |
+
else:
|
| 65 |
+
raise ValueError
|
| 66 |
+
|
| 67 |
+
# projection layers
|
| 68 |
+
self.proj_in = build_mlp(hidden_size=self.mar.encoder_embed_dim,
|
| 69 |
+
projector_dim=self.llm.config.hidden_size,
|
| 70 |
+
z_dim=self.llm.config.hidden_size)
|
| 71 |
+
self.proj_out = build_mlp(hidden_size=self.llm.config.hidden_size,
|
| 72 |
+
projector_dim=self.llm.config.hidden_size,
|
| 73 |
+
z_dim=self.mar.encoder_embed_dim)
|
| 74 |
+
|
| 75 |
+
@property
|
| 76 |
+
def llm_model(self):
|
| 77 |
+
return self.llm.model
|
| 78 |
+
|
| 79 |
+
@property
|
| 80 |
+
def device(self):
|
| 81 |
+
return self.llm.device
|
| 82 |
+
|
| 83 |
+
@property
|
| 84 |
+
def dtype(self):
|
| 85 |
+
return self.llm.dtype
|
| 86 |
+
|
| 87 |
+
@property
|
| 88 |
+
def gen_seq_len(self):
|
| 89 |
+
return self.mar.seq_len
|
| 90 |
+
|
| 91 |
+
@property
|
| 92 |
+
def token_embed_dim(self):
|
| 93 |
+
return self.vae.embed_dim * (self.mar.patch_size ** 2)
|
| 94 |
+
|
| 95 |
+
@torch.no_grad()
|
| 96 |
+
def encode(self, x):
|
| 97 |
+
posterior = self.vae.encode(x)
|
| 98 |
+
z = posterior.sample().mul_(self.vae_scale)
|
| 99 |
+
z = rearrange(z, 'b c (m p) (n q) -> b m n (c p q)',
|
| 100 |
+
p=self.mar.patch_size, q=self.mar.patch_size)
|
| 101 |
+
|
| 102 |
+
return z
|
| 103 |
+
|
| 104 |
+
@torch.no_grad()
|
| 105 |
+
def decode(self, z):
|
| 106 |
+
z /= self.vae_scale
|
| 107 |
+
z = rearrange(z, 'b m n (c p q) -> b c (m p) (n q)',
|
| 108 |
+
p=self.mar.patch_size, q=self.mar.patch_size)
|
| 109 |
+
|
| 110 |
+
x = self.vae.decode(z)
|
| 111 |
+
return x
|
| 112 |
+
|
| 113 |
+
def prepare_forward_input(self,
|
| 114 |
+
x,
|
| 115 |
+
inputs_embeds=None,
|
| 116 |
+
input_ids=None,
|
| 117 |
+
attention_mask=None,
|
| 118 |
+
past_key_values=None):
|
| 119 |
+
b, l, _ = x.shape
|
| 120 |
+
attention_mask = attention_mask.to(device=self.device, dtype=torch.bool)
|
| 121 |
+
attention_mask = torch.cat([
|
| 122 |
+
attention_mask, attention_mask.new_ones(b, l)
|
| 123 |
+
], dim=1)
|
| 124 |
+
position_ids = torch.cumsum(attention_mask, dim=1) - 1
|
| 125 |
+
position_ids[position_ids < 0] = 0
|
| 126 |
+
|
| 127 |
+
# import pdb; pdb.set_trace()
|
| 128 |
+
|
| 129 |
+
# prepare context
|
| 130 |
+
if past_key_values is not None:
|
| 131 |
+
inputs_embeds = x
|
| 132 |
+
position_ids = position_ids[:, -l:]
|
| 133 |
+
else:
|
| 134 |
+
if inputs_embeds is None:
|
| 135 |
+
input_ids = input_ids.to(self.device)
|
| 136 |
+
inputs_embeds = self.llm.get_input_embeddings()(input_ids)
|
| 137 |
+
inputs_embeds = torch.cat([inputs_embeds, x], dim=1)
|
| 138 |
+
|
| 139 |
+
return dict(inputs_embeds=inputs_embeds,
|
| 140 |
+
attention_mask=attention_mask,
|
| 141 |
+
position_ids=position_ids,
|
| 142 |
+
past_key_values=past_key_values)
|
| 143 |
+
|
| 144 |
+
def extract_visual_feature(self, x, mask=None, detach=False):
|
| 145 |
+
b, m, n, _ = x.shape
|
| 146 |
+
x = x.view(b, m*n, -1)
|
| 147 |
+
# x: b mn c
|
| 148 |
+
if mask is None:
|
| 149 |
+
mask = torch.zeros_like(x[..., 0])
|
| 150 |
+
null_embeds = self.mar.fake_latent.expand(x.shape[0], -1)
|
| 151 |
+
x_enc = self.mar.forward_mae_encoder(x, mask, null_embeds, image_shape=(m, n))
|
| 152 |
+
|
| 153 |
+
z_enc = self.proj_in(x_enc)
|
| 154 |
+
# Move buffers to the end of the image sequence
|
| 155 |
+
z_enc = torch.cat([
|
| 156 |
+
z_enc[:, self.mar.buffer_size:],
|
| 157 |
+
z_enc[:, :self.mar.buffer_size]], dim=1)
|
| 158 |
+
|
| 159 |
+
if detach:
|
| 160 |
+
x_enc = x_enc.detach()
|
| 161 |
+
z_enc = z_enc.detach()
|
| 162 |
+
|
| 163 |
+
return x_enc, z_enc
|
| 164 |
+
|
| 165 |
+
def forward_mae_encoder(self, x, mask, detach=False, **context):
|
| 166 |
+
b, m, n, _ = x.shape
|
| 167 |
+
x_enc, z_enc = self.extract_visual_feature(x, mask=mask, detach=detach)
|
| 168 |
+
inputs = self.prepare_forward_input(x=z_enc, **context)
|
| 169 |
+
output = self.llm_model(**inputs, return_dict=True)
|
| 170 |
+
|
| 171 |
+
z_llm = output.last_hidden_state[:, -z_enc.shape[1]:]
|
| 172 |
+
|
| 173 |
+
# move buffers back to the start of the image sequence
|
| 174 |
+
z_llm = torch.cat([
|
| 175 |
+
z_llm[:, -self.mar.buffer_size:],
|
| 176 |
+
z_llm[:, :-self.mar.buffer_size]], dim=1)
|
| 177 |
+
|
| 178 |
+
# residual learning
|
| 179 |
+
x_enc = x_enc + self.proj_out(z_llm)
|
| 180 |
+
|
| 181 |
+
return x_enc
|
| 182 |
+
|
| 183 |
+
@staticmethod
|
| 184 |
+
def curtail_cache(past_key_values, cur_len):
|
| 185 |
+
for past_key_values_ in past_key_values:
|
| 186 |
+
keys, values = past_key_values_
|
| 187 |
+
keys.data = keys.data[:, :, :cur_len]
|
| 188 |
+
values.data = values.data[:, :, :cur_len]
|
| 189 |
+
|
| 190 |
+
@torch.no_grad()
|
| 191 |
+
def sample(self,
|
| 192 |
+
input_ids=None, inputs_embeds=None,
|
| 193 |
+
attention_mask=None, num_iter=64, cfg=1.0, cfg_schedule="constant", temperature=1.0,
|
| 194 |
+
progress=False, mask=None, past_key_values=None, image_shape=None, x_con=None, **kwargs):
|
| 195 |
+
if inputs_embeds is None and input_ids is not None:
|
| 196 |
+
inputs_embeds = self.llm.get_input_embeddings()(input_ids)
|
| 197 |
+
|
| 198 |
+
bsz = attention_mask.shape[0]
|
| 199 |
+
if cfg != 1.0:
|
| 200 |
+
assert bsz % 2 == 0
|
| 201 |
+
|
| 202 |
+
if image_shape is None:
|
| 203 |
+
m = n = int(self.gen_seq_len ** 0.5)
|
| 204 |
+
else:
|
| 205 |
+
m, n = image_shape
|
| 206 |
+
|
| 207 |
+
if mask is None:
|
| 208 |
+
mask = torch.ones(bsz, m*n, device=self.device, dtype=self.dtype)
|
| 209 |
+
else:
|
| 210 |
+
mask = mask.view(bsz, m*n)
|
| 211 |
+
tokens = torch.zeros(bsz, m*n, self.token_embed_dim,
|
| 212 |
+
device=self.device, dtype=self.dtype)
|
| 213 |
+
orders = self.mar.sample_orders(bsz, seq_len=m*n)
|
| 214 |
+
if cfg != 1.0:
|
| 215 |
+
orders[bsz//2:] = orders[:bsz//2]
|
| 216 |
+
|
| 217 |
+
indices = list(range(num_iter))
|
| 218 |
+
if progress:
|
| 219 |
+
indices = tqdm(indices)
|
| 220 |
+
|
| 221 |
+
# past key values can be prepared outside (usually in multi-turn editing)
|
| 222 |
+
if past_key_values is None:
|
| 223 |
+
output = self.llm_model(inputs_embeds=inputs_embeds,
|
| 224 |
+
attention_mask=None,
|
| 225 |
+
position_ids=None,
|
| 226 |
+
past_key_values=DynamicCache.from_legacy_cache(),
|
| 227 |
+
return_dict=True,
|
| 228 |
+
use_cache=True)
|
| 229 |
+
past_key_values = output.past_key_values
|
| 230 |
+
|
| 231 |
+
# generate latents
|
| 232 |
+
for step in indices:
|
| 233 |
+
cur_tokens = tokens.clone()
|
| 234 |
+
x_enc = self.forward_mae_encoder(tokens.view(bsz, m, n, -1),
|
| 235 |
+
mask.to(self.dtype),
|
| 236 |
+
past_key_values=past_key_values,
|
| 237 |
+
# inputs_embeds=inputs_embeds,
|
| 238 |
+
attention_mask=attention_mask)
|
| 239 |
+
# import pdb; pdb.set_trace()
|
| 240 |
+
self.curtail_cache(past_key_values, inputs_embeds.shape[1])
|
| 241 |
+
# import pdb; pdb.set_trace()
|
| 242 |
+
|
| 243 |
+
z = self.mar.forward_mae_decoder(x_enc, mask.to(self.dtype), image_shape=(m, n), x_con=x_con)
|
| 244 |
+
|
| 245 |
+
# mask ratio for the next round, following MaskGIT and MAGE.
|
| 246 |
+
mask_ratio = np.cos(math.pi / 2. * (step + 1) / num_iter)
|
| 247 |
+
mask_len = torch.Tensor([np.floor(m*n * mask_ratio)]).to(self.device)
|
| 248 |
+
|
| 249 |
+
# masks out at least one for the next iteration
|
| 250 |
+
mask_len = torch.maximum(torch.Tensor([1]).to(self.device),
|
| 251 |
+
torch.minimum(torch.sum(mask, dim=-1, keepdims=True) - 1, mask_len))
|
| 252 |
+
|
| 253 |
+
# get masking for next iteration and locations to be predicted in this iteration
|
| 254 |
+
mask_next = mask_by_order(mask_len[0], orders, bsz, m*n).to(self.device)
|
| 255 |
+
if cfg != 1.0:
|
| 256 |
+
mask_next[bsz//2:] = mask_next[:bsz//2]
|
| 257 |
+
if step >= num_iter - 1:
|
| 258 |
+
mask_to_pred = mask[:bsz].bool()
|
| 259 |
+
else:
|
| 260 |
+
mask_to_pred = torch.logical_xor(mask[:bsz].bool(), mask_next.bool())
|
| 261 |
+
mask = mask_next
|
| 262 |
+
# if not cfg == 1.0:
|
| 263 |
+
# mask_to_pred = torch.cat([mask_to_pred, mask_to_pred], dim=0)
|
| 264 |
+
|
| 265 |
+
# sample token latents for this step
|
| 266 |
+
z = z[mask_to_pred.nonzero(as_tuple=True)]
|
| 267 |
+
# cfg schedule follow Muse
|
| 268 |
+
if cfg_schedule == "linear":
|
| 269 |
+
cfg_iter = 1 + (cfg - 1) * (m*n - mask_len[0]) / (m*n)
|
| 270 |
+
elif cfg_schedule == "constant":
|
| 271 |
+
cfg_iter = cfg
|
| 272 |
+
else:
|
| 273 |
+
raise NotImplementedError
|
| 274 |
+
sampled_token_latent = self.mar.diffloss.sample(z, temperature, cfg_iter).to(self.dtype)
|
| 275 |
+
# if not cfg == 1.0:
|
| 276 |
+
# sampled_token_latent, _ = sampled_token_latent.chunk(2, dim=0) # Remove null class samples
|
| 277 |
+
# mask_to_pred, _ = mask_to_pred.chunk(2, dim=0)
|
| 278 |
+
|
| 279 |
+
cur_tokens[mask_to_pred.nonzero(as_tuple=True)] = sampled_token_latent
|
| 280 |
+
if cfg != 1.0:
|
| 281 |
+
cur_tokens[bsz//2:] = cur_tokens[:bsz//2]
|
| 282 |
+
tokens = cur_tokens.clone()
|
| 283 |
+
|
| 284 |
+
pred = self.decode(tokens.view(bsz, m, n, -1))
|
| 285 |
+
|
| 286 |
+
if cfg != 1.0:
|
| 287 |
+
pred = pred[:bsz//2]
|
| 288 |
+
return pred
|
respace.py
ADDED
|
@@ -0,0 +1,129 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Modified from OpenAI's diffusion repos
|
| 2 |
+
# GLIDE: https://github.com/openai/glide-text2im/blob/main/glide_text2im/gaussian_diffusion.py
|
| 3 |
+
# ADM: https://github.com/openai/guided-diffusion/blob/main/guided_diffusion
|
| 4 |
+
# IDDPM: https://github.com/openai/improved-diffusion/blob/main/improved_diffusion/gaussian_diffusion.py
|
| 5 |
+
|
| 6 |
+
import numpy as np
|
| 7 |
+
import torch as th
|
| 8 |
+
|
| 9 |
+
from .gaussian_diffusion import GaussianDiffusion
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
def space_timesteps(num_timesteps, section_counts):
|
| 13 |
+
"""
|
| 14 |
+
Create a list of timesteps to use from an original diffusion process,
|
| 15 |
+
given the number of timesteps we want to take from equally-sized portions
|
| 16 |
+
of the original process.
|
| 17 |
+
For example, if there's 300 timesteps and the section counts are [10,15,20]
|
| 18 |
+
then the first 100 timesteps are strided to be 10 timesteps, the second 100
|
| 19 |
+
are strided to be 15 timesteps, and the final 100 are strided to be 20.
|
| 20 |
+
If the stride is a string starting with "ddim", then the fixed striding
|
| 21 |
+
from the DDIM paper is used, and only one section is allowed.
|
| 22 |
+
:param num_timesteps: the number of diffusion steps in the original
|
| 23 |
+
process to divide up.
|
| 24 |
+
:param section_counts: either a list of numbers, or a string containing
|
| 25 |
+
comma-separated numbers, indicating the step count
|
| 26 |
+
per section. As a special case, use "ddimN" where N
|
| 27 |
+
is a number of steps to use the striding from the
|
| 28 |
+
DDIM paper.
|
| 29 |
+
:return: a set of diffusion steps from the original process to use.
|
| 30 |
+
"""
|
| 31 |
+
if isinstance(section_counts, str):
|
| 32 |
+
if section_counts.startswith("ddim"):
|
| 33 |
+
desired_count = int(section_counts[len("ddim") :])
|
| 34 |
+
for i in range(1, num_timesteps):
|
| 35 |
+
if len(range(0, num_timesteps, i)) == desired_count:
|
| 36 |
+
return set(range(0, num_timesteps, i))
|
| 37 |
+
raise ValueError(
|
| 38 |
+
f"cannot create exactly {num_timesteps} steps with an integer stride"
|
| 39 |
+
)
|
| 40 |
+
section_counts = [int(x) for x in section_counts.split(",")]
|
| 41 |
+
size_per = num_timesteps // len(section_counts)
|
| 42 |
+
extra = num_timesteps % len(section_counts)
|
| 43 |
+
start_idx = 0
|
| 44 |
+
all_steps = []
|
| 45 |
+
for i, section_count in enumerate(section_counts):
|
| 46 |
+
size = size_per + (1 if i < extra else 0)
|
| 47 |
+
if size < section_count:
|
| 48 |
+
raise ValueError(
|
| 49 |
+
f"cannot divide section of {size} steps into {section_count}"
|
| 50 |
+
)
|
| 51 |
+
if section_count <= 1:
|
| 52 |
+
frac_stride = 1
|
| 53 |
+
else:
|
| 54 |
+
frac_stride = (size - 1) / (section_count - 1)
|
| 55 |
+
cur_idx = 0.0
|
| 56 |
+
taken_steps = []
|
| 57 |
+
for _ in range(section_count):
|
| 58 |
+
taken_steps.append(start_idx + round(cur_idx))
|
| 59 |
+
cur_idx += frac_stride
|
| 60 |
+
all_steps += taken_steps
|
| 61 |
+
start_idx += size
|
| 62 |
+
return set(all_steps)
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
class SpacedDiffusion(GaussianDiffusion):
|
| 66 |
+
"""
|
| 67 |
+
A diffusion process which can skip steps in a base diffusion process.
|
| 68 |
+
:param use_timesteps: a collection (sequence or set) of timesteps from the
|
| 69 |
+
original diffusion process to retain.
|
| 70 |
+
:param kwargs: the kwargs to create the base diffusion process.
|
| 71 |
+
"""
|
| 72 |
+
|
| 73 |
+
def __init__(self, use_timesteps, **kwargs):
|
| 74 |
+
self.use_timesteps = set(use_timesteps)
|
| 75 |
+
self.timestep_map = []
|
| 76 |
+
self.original_num_steps = len(kwargs["betas"])
|
| 77 |
+
|
| 78 |
+
base_diffusion = GaussianDiffusion(**kwargs) # pylint: disable=missing-kwoa
|
| 79 |
+
last_alpha_cumprod = 1.0
|
| 80 |
+
new_betas = []
|
| 81 |
+
for i, alpha_cumprod in enumerate(base_diffusion.alphas_cumprod):
|
| 82 |
+
if i in self.use_timesteps:
|
| 83 |
+
new_betas.append(1 - alpha_cumprod / last_alpha_cumprod)
|
| 84 |
+
last_alpha_cumprod = alpha_cumprod
|
| 85 |
+
self.timestep_map.append(i)
|
| 86 |
+
kwargs["betas"] = np.array(new_betas)
|
| 87 |
+
super().__init__(**kwargs)
|
| 88 |
+
|
| 89 |
+
def p_mean_variance(
|
| 90 |
+
self, model, *args, **kwargs
|
| 91 |
+
): # pylint: disable=signature-differs
|
| 92 |
+
return super().p_mean_variance(self._wrap_model(model), *args, **kwargs)
|
| 93 |
+
|
| 94 |
+
def training_losses(
|
| 95 |
+
self, model, *args, **kwargs
|
| 96 |
+
): # pylint: disable=signature-differs
|
| 97 |
+
return super().training_losses(self._wrap_model(model), *args, **kwargs)
|
| 98 |
+
|
| 99 |
+
def condition_mean(self, cond_fn, *args, **kwargs):
|
| 100 |
+
return super().condition_mean(self._wrap_model(cond_fn), *args, **kwargs)
|
| 101 |
+
|
| 102 |
+
def condition_score(self, cond_fn, *args, **kwargs):
|
| 103 |
+
return super().condition_score(self._wrap_model(cond_fn), *args, **kwargs)
|
| 104 |
+
|
| 105 |
+
def _wrap_model(self, model):
|
| 106 |
+
if isinstance(model, _WrappedModel):
|
| 107 |
+
return model
|
| 108 |
+
return _WrappedModel(
|
| 109 |
+
model, self.timestep_map, self.original_num_steps
|
| 110 |
+
)
|
| 111 |
+
|
| 112 |
+
def _scale_timesteps(self, t):
|
| 113 |
+
# Scaling is done by the wrapped model.
|
| 114 |
+
return t
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
class _WrappedModel:
|
| 118 |
+
def __init__(self, model, timestep_map, original_num_steps):
|
| 119 |
+
self.model = model
|
| 120 |
+
self.timestep_map = timestep_map
|
| 121 |
+
# self.rescale_timesteps = rescale_timesteps
|
| 122 |
+
self.original_num_steps = original_num_steps
|
| 123 |
+
|
| 124 |
+
def __call__(self, x, ts, **kwargs):
|
| 125 |
+
map_tensor = th.tensor(self.timestep_map, device=ts.device, dtype=ts.dtype)
|
| 126 |
+
new_ts = map_tensor[ts]
|
| 127 |
+
# if self.rescale_timesteps:
|
| 128 |
+
# new_ts = new_ts.float() * (1000.0 / self.original_num_steps)
|
| 129 |
+
return self.model(x, new_ts, **kwargs)
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,207 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": false,
|
| 3 |
+
"add_prefix_space": false,
|
| 4 |
+
"added_tokens_decoder": {
|
| 5 |
+
"151643": {
|
| 6 |
+
"content": "<|endoftext|>",
|
| 7 |
+
"lstrip": false,
|
| 8 |
+
"normalized": false,
|
| 9 |
+
"rstrip": false,
|
| 10 |
+
"single_word": false,
|
| 11 |
+
"special": true
|
| 12 |
+
},
|
| 13 |
+
"151644": {
|
| 14 |
+
"content": "<|im_start|>",
|
| 15 |
+
"lstrip": false,
|
| 16 |
+
"normalized": false,
|
| 17 |
+
"rstrip": false,
|
| 18 |
+
"single_word": false,
|
| 19 |
+
"special": true
|
| 20 |
+
},
|
| 21 |
+
"151645": {
|
| 22 |
+
"content": "<|im_end|>",
|
| 23 |
+
"lstrip": false,
|
| 24 |
+
"normalized": false,
|
| 25 |
+
"rstrip": false,
|
| 26 |
+
"single_word": false,
|
| 27 |
+
"special": true
|
| 28 |
+
},
|
| 29 |
+
"151646": {
|
| 30 |
+
"content": "<|object_ref_start|>",
|
| 31 |
+
"lstrip": false,
|
| 32 |
+
"normalized": false,
|
| 33 |
+
"rstrip": false,
|
| 34 |
+
"single_word": false,
|
| 35 |
+
"special": true
|
| 36 |
+
},
|
| 37 |
+
"151647": {
|
| 38 |
+
"content": "<|object_ref_end|>",
|
| 39 |
+
"lstrip": false,
|
| 40 |
+
"normalized": false,
|
| 41 |
+
"rstrip": false,
|
| 42 |
+
"single_word": false,
|
| 43 |
+
"special": true
|
| 44 |
+
},
|
| 45 |
+
"151648": {
|
| 46 |
+
"content": "<|box_start|>",
|
| 47 |
+
"lstrip": false,
|
| 48 |
+
"normalized": false,
|
| 49 |
+
"rstrip": false,
|
| 50 |
+
"single_word": false,
|
| 51 |
+
"special": true
|
| 52 |
+
},
|
| 53 |
+
"151649": {
|
| 54 |
+
"content": "<|box_end|>",
|
| 55 |
+
"lstrip": false,
|
| 56 |
+
"normalized": false,
|
| 57 |
+
"rstrip": false,
|
| 58 |
+
"single_word": false,
|
| 59 |
+
"special": true
|
| 60 |
+
},
|
| 61 |
+
"151650": {
|
| 62 |
+
"content": "<|quad_start|>",
|
| 63 |
+
"lstrip": false,
|
| 64 |
+
"normalized": false,
|
| 65 |
+
"rstrip": false,
|
| 66 |
+
"single_word": false,
|
| 67 |
+
"special": true
|
| 68 |
+
},
|
| 69 |
+
"151651": {
|
| 70 |
+
"content": "<|quad_end|>",
|
| 71 |
+
"lstrip": false,
|
| 72 |
+
"normalized": false,
|
| 73 |
+
"rstrip": false,
|
| 74 |
+
"single_word": false,
|
| 75 |
+
"special": true
|
| 76 |
+
},
|
| 77 |
+
"151652": {
|
| 78 |
+
"content": "<|vision_start|>",
|
| 79 |
+
"lstrip": false,
|
| 80 |
+
"normalized": false,
|
| 81 |
+
"rstrip": false,
|
| 82 |
+
"single_word": false,
|
| 83 |
+
"special": true
|
| 84 |
+
},
|
| 85 |
+
"151653": {
|
| 86 |
+
"content": "<|vision_end|>",
|
| 87 |
+
"lstrip": false,
|
| 88 |
+
"normalized": false,
|
| 89 |
+
"rstrip": false,
|
| 90 |
+
"single_word": false,
|
| 91 |
+
"special": true
|
| 92 |
+
},
|
| 93 |
+
"151654": {
|
| 94 |
+
"content": "<|vision_pad|>",
|
| 95 |
+
"lstrip": false,
|
| 96 |
+
"normalized": false,
|
| 97 |
+
"rstrip": false,
|
| 98 |
+
"single_word": false,
|
| 99 |
+
"special": true
|
| 100 |
+
},
|
| 101 |
+
"151655": {
|
| 102 |
+
"content": "<|image_pad|>",
|
| 103 |
+
"lstrip": false,
|
| 104 |
+
"normalized": false,
|
| 105 |
+
"rstrip": false,
|
| 106 |
+
"single_word": false,
|
| 107 |
+
"special": true
|
| 108 |
+
},
|
| 109 |
+
"151656": {
|
| 110 |
+
"content": "<|video_pad|>",
|
| 111 |
+
"lstrip": false,
|
| 112 |
+
"normalized": false,
|
| 113 |
+
"rstrip": false,
|
| 114 |
+
"single_word": false,
|
| 115 |
+
"special": true
|
| 116 |
+
},
|
| 117 |
+
"151657": {
|
| 118 |
+
"content": "<tool_call>",
|
| 119 |
+
"lstrip": false,
|
| 120 |
+
"normalized": false,
|
| 121 |
+
"rstrip": false,
|
| 122 |
+
"single_word": false,
|
| 123 |
+
"special": false
|
| 124 |
+
},
|
| 125 |
+
"151658": {
|
| 126 |
+
"content": "</tool_call>",
|
| 127 |
+
"lstrip": false,
|
| 128 |
+
"normalized": false,
|
| 129 |
+
"rstrip": false,
|
| 130 |
+
"single_word": false,
|
| 131 |
+
"special": false
|
| 132 |
+
},
|
| 133 |
+
"151659": {
|
| 134 |
+
"content": "<|fim_prefix|>",
|
| 135 |
+
"lstrip": false,
|
| 136 |
+
"normalized": false,
|
| 137 |
+
"rstrip": false,
|
| 138 |
+
"single_word": false,
|
| 139 |
+
"special": false
|
| 140 |
+
},
|
| 141 |
+
"151660": {
|
| 142 |
+
"content": "<|fim_middle|>",
|
| 143 |
+
"lstrip": false,
|
| 144 |
+
"normalized": false,
|
| 145 |
+
"rstrip": false,
|
| 146 |
+
"single_word": false,
|
| 147 |
+
"special": false
|
| 148 |
+
},
|
| 149 |
+
"151661": {
|
| 150 |
+
"content": "<|fim_suffix|>",
|
| 151 |
+
"lstrip": false,
|
| 152 |
+
"normalized": false,
|
| 153 |
+
"rstrip": false,
|
| 154 |
+
"single_word": false,
|
| 155 |
+
"special": false
|
| 156 |
+
},
|
| 157 |
+
"151662": {
|
| 158 |
+
"content": "<|fim_pad|>",
|
| 159 |
+
"lstrip": false,
|
| 160 |
+
"normalized": false,
|
| 161 |
+
"rstrip": false,
|
| 162 |
+
"single_word": false,
|
| 163 |
+
"special": false
|
| 164 |
+
},
|
| 165 |
+
"151663": {
|
| 166 |
+
"content": "<|repo_name|>",
|
| 167 |
+
"lstrip": false,
|
| 168 |
+
"normalized": false,
|
| 169 |
+
"rstrip": false,
|
| 170 |
+
"single_word": false,
|
| 171 |
+
"special": false
|
| 172 |
+
},
|
| 173 |
+
"151664": {
|
| 174 |
+
"content": "<|file_sep|>",
|
| 175 |
+
"lstrip": false,
|
| 176 |
+
"normalized": false,
|
| 177 |
+
"rstrip": false,
|
| 178 |
+
"single_word": false,
|
| 179 |
+
"special": false
|
| 180 |
+
}
|
| 181 |
+
},
|
| 182 |
+
"additional_special_tokens": [
|
| 183 |
+
"<|im_start|>",
|
| 184 |
+
"<|im_end|>",
|
| 185 |
+
"<|object_ref_start|>",
|
| 186 |
+
"<|object_ref_end|>",
|
| 187 |
+
"<|box_start|>",
|
| 188 |
+
"<|box_end|>",
|
| 189 |
+
"<|quad_start|>",
|
| 190 |
+
"<|quad_end|>",
|
| 191 |
+
"<|vision_start|>",
|
| 192 |
+
"<|vision_end|>",
|
| 193 |
+
"<|vision_pad|>",
|
| 194 |
+
"<|image_pad|>",
|
| 195 |
+
"<|video_pad|>"
|
| 196 |
+
],
|
| 197 |
+
"bos_token": null,
|
| 198 |
+
"chat_template": "{%- if tools %}\n {{- '<|im_start|>system\\n' }}\n {%- if messages[0]['role'] == 'system' %}\n {{- messages[0]['content'] }}\n {%- else %}\n {{- 'You are Qwen, created by Alibaba Cloud. You are a helpful assistant.' }}\n {%- endif %}\n {{- \"\\n\\n# Tools\\n\\nYou may call one or more functions to assist with the user query.\\n\\nYou are provided with function signatures within <tools></tools> XML tags:\\n<tools>\" }}\n {%- for tool in tools %}\n {{- \"\\n\" }}\n {{- tool | tojson }}\n {%- endfor %}\n {{- \"\\n</tools>\\n\\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\\n<tool_call>\\n{\\\"name\\\": <function-name>, \\\"arguments\\\": <args-json-object>}\\n</tool_call><|im_end|>\\n\" }}\n{%- else %}\n {%- if messages[0]['role'] == 'system' %}\n {{- '<|im_start|>system\\n' + messages[0]['content'] + '<|im_end|>\\n' }}\n {%- else %}\n {{- '<|im_start|>system\\nYou are Qwen, created by Alibaba Cloud. You are a helpful assistant.<|im_end|>\\n' }}\n {%- endif %}\n{%- endif %}\n{%- for message in messages %}\n {%- if (message.role == \"user\") or (message.role == \"system\" and not loop.first) or (message.role == \"assistant\" and not message.tool_calls) %}\n {{- '<|im_start|>' + message.role + '\\n' + message.content + '<|im_end|>' + '\\n' }}\n {%- elif message.role == \"assistant\" %}\n {{- '<|im_start|>' + message.role }}\n {%- if message.content %}\n {{- '\\n' + message.content }}\n {%- endif %}\n {%- for tool_call in message.tool_calls %}\n {%- if tool_call.function is defined %}\n {%- set tool_call = tool_call.function %}\n {%- endif %}\n {{- '\\n<tool_call>\\n{\"name\": \"' }}\n {{- tool_call.name }}\n {{- '\", \"arguments\": ' }}\n {{- tool_call.arguments | tojson }}\n {{- '}\\n</tool_call>' }}\n {%- endfor %}\n {{- '<|im_end|>\\n' }}\n {%- elif message.role == \"tool\" %}\n {%- if (loop.index0 == 0) or (messages[loop.index0 - 1].role != \"tool\") %}\n {{- '<|im_start|>user' }}\n {%- endif %}\n {{- '\\n<tool_response>\\n' }}\n {{- message.content }}\n {{- '\\n</tool_response>' }}\n {%- if loop.last or (messages[loop.index0 + 1].role != \"tool\") %}\n {{- '<|im_end|>\\n' }}\n {%- endif %}\n {%- endif %}\n{%- endfor %}\n{%- if add_generation_prompt %}\n {{- '<|im_start|>assistant\\n' }}\n{%- endif %}\n",
|
| 199 |
+
"clean_up_tokenization_spaces": false,
|
| 200 |
+
"eos_token": "<|im_end|>",
|
| 201 |
+
"errors": "replace",
|
| 202 |
+
"model_max_length": 131072,
|
| 203 |
+
"pad_token": "<|endoftext|>",
|
| 204 |
+
"split_special_tokens": false,
|
| 205 |
+
"tokenizer_class": "Qwen2Tokenizer",
|
| 206 |
+
"unk_token": null
|
| 207 |
+
}
|
vae.py
ADDED
|
@@ -0,0 +1,522 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import numpy as np
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def nonlinearity(x):
|
| 7 |
+
# swish
|
| 8 |
+
return x * torch.sigmoid(x)
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def Normalize(in_channels, num_groups=32):
|
| 12 |
+
return torch.nn.GroupNorm(
|
| 13 |
+
num_groups=num_groups, num_channels=in_channels, eps=1e-6, affine=True
|
| 14 |
+
)
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class Upsample(nn.Module):
|
| 18 |
+
def __init__(self, in_channels, with_conv):
|
| 19 |
+
super().__init__()
|
| 20 |
+
self.with_conv = with_conv
|
| 21 |
+
if self.with_conv:
|
| 22 |
+
self.conv = torch.nn.Conv2d(
|
| 23 |
+
in_channels, in_channels, kernel_size=3, stride=1, padding=1
|
| 24 |
+
)
|
| 25 |
+
|
| 26 |
+
def forward(self, x):
|
| 27 |
+
x = torch.nn.functional.interpolate(x, scale_factor=2.0, mode="nearest")
|
| 28 |
+
if self.with_conv:
|
| 29 |
+
x = self.conv(x)
|
| 30 |
+
return x
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
class Downsample(nn.Module):
|
| 34 |
+
def __init__(self, in_channels, with_conv):
|
| 35 |
+
super().__init__()
|
| 36 |
+
self.with_conv = with_conv
|
| 37 |
+
if self.with_conv:
|
| 38 |
+
# no asymmetric padding in torch conv, must do it ourselves
|
| 39 |
+
self.conv = torch.nn.Conv2d(
|
| 40 |
+
in_channels, in_channels, kernel_size=3, stride=2, padding=0
|
| 41 |
+
)
|
| 42 |
+
|
| 43 |
+
def forward(self, x):
|
| 44 |
+
if self.with_conv:
|
| 45 |
+
pad = (0, 1, 0, 1)
|
| 46 |
+
x = torch.nn.functional.pad(x, pad, mode="constant", value=0)
|
| 47 |
+
x = self.conv(x)
|
| 48 |
+
else:
|
| 49 |
+
x = torch.nn.functional.avg_pool2d(x, kernel_size=2, stride=2)
|
| 50 |
+
return x
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
class ResnetBlock(nn.Module):
|
| 54 |
+
def __init__(
|
| 55 |
+
self,
|
| 56 |
+
*,
|
| 57 |
+
in_channels,
|
| 58 |
+
out_channels=None,
|
| 59 |
+
conv_shortcut=False,
|
| 60 |
+
dropout,
|
| 61 |
+
temb_channels=512,
|
| 62 |
+
):
|
| 63 |
+
super().__init__()
|
| 64 |
+
self.in_channels = in_channels
|
| 65 |
+
out_channels = in_channels if out_channels is None else out_channels
|
| 66 |
+
self.out_channels = out_channels
|
| 67 |
+
self.use_conv_shortcut = conv_shortcut
|
| 68 |
+
|
| 69 |
+
self.norm1 = Normalize(in_channels)
|
| 70 |
+
self.conv1 = torch.nn.Conv2d(
|
| 71 |
+
in_channels, out_channels, kernel_size=3, stride=1, padding=1
|
| 72 |
+
)
|
| 73 |
+
if temb_channels > 0:
|
| 74 |
+
self.temb_proj = torch.nn.Linear(temb_channels, out_channels)
|
| 75 |
+
self.norm2 = Normalize(out_channels)
|
| 76 |
+
self.dropout = torch.nn.Dropout(dropout)
|
| 77 |
+
self.conv2 = torch.nn.Conv2d(
|
| 78 |
+
out_channels, out_channels, kernel_size=3, stride=1, padding=1
|
| 79 |
+
)
|
| 80 |
+
if self.in_channels != self.out_channels:
|
| 81 |
+
if self.use_conv_shortcut:
|
| 82 |
+
self.conv_shortcut = torch.nn.Conv2d(
|
| 83 |
+
in_channels, out_channels, kernel_size=3, stride=1, padding=1
|
| 84 |
+
)
|
| 85 |
+
else:
|
| 86 |
+
self.nin_shortcut = torch.nn.Conv2d(
|
| 87 |
+
in_channels, out_channels, kernel_size=1, stride=1, padding=0
|
| 88 |
+
)
|
| 89 |
+
|
| 90 |
+
def forward(self, x, temb):
|
| 91 |
+
h = x
|
| 92 |
+
h = self.norm1(h)
|
| 93 |
+
h = nonlinearity(h)
|
| 94 |
+
h = self.conv1(h)
|
| 95 |
+
|
| 96 |
+
if temb is not None:
|
| 97 |
+
h = h + self.temb_proj(nonlinearity(temb))[:, :, None, None]
|
| 98 |
+
|
| 99 |
+
h = self.norm2(h)
|
| 100 |
+
h = nonlinearity(h)
|
| 101 |
+
h = self.dropout(h)
|
| 102 |
+
h = self.conv2(h)
|
| 103 |
+
|
| 104 |
+
if self.in_channels != self.out_channels:
|
| 105 |
+
if self.use_conv_shortcut:
|
| 106 |
+
x = self.conv_shortcut(x)
|
| 107 |
+
else:
|
| 108 |
+
x = self.nin_shortcut(x)
|
| 109 |
+
|
| 110 |
+
return x + h
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
class AttnBlock(nn.Module):
|
| 114 |
+
def __init__(self, in_channels):
|
| 115 |
+
super().__init__()
|
| 116 |
+
self.in_channels = in_channels
|
| 117 |
+
|
| 118 |
+
self.norm = Normalize(in_channels)
|
| 119 |
+
self.q = torch.nn.Conv2d(
|
| 120 |
+
in_channels, in_channels, kernel_size=1, stride=1, padding=0
|
| 121 |
+
)
|
| 122 |
+
self.k = torch.nn.Conv2d(
|
| 123 |
+
in_channels, in_channels, kernel_size=1, stride=1, padding=0
|
| 124 |
+
)
|
| 125 |
+
self.v = torch.nn.Conv2d(
|
| 126 |
+
in_channels, in_channels, kernel_size=1, stride=1, padding=0
|
| 127 |
+
)
|
| 128 |
+
self.proj_out = torch.nn.Conv2d(
|
| 129 |
+
in_channels, in_channels, kernel_size=1, stride=1, padding=0
|
| 130 |
+
)
|
| 131 |
+
|
| 132 |
+
def forward(self, x):
|
| 133 |
+
h_ = x
|
| 134 |
+
h_ = self.norm(h_)
|
| 135 |
+
q = self.q(h_)
|
| 136 |
+
k = self.k(h_)
|
| 137 |
+
v = self.v(h_)
|
| 138 |
+
|
| 139 |
+
# compute attention
|
| 140 |
+
b, c, h, w = q.shape
|
| 141 |
+
q = q.reshape(b, c, h * w)
|
| 142 |
+
q = q.permute(0, 2, 1) # b,hw,c
|
| 143 |
+
k = k.reshape(b, c, h * w) # b,c,hw
|
| 144 |
+
w_ = torch.bmm(q, k) # b,hw,hw w[b,i,j]=sum_c q[b,i,c]k[b,c,j]
|
| 145 |
+
w_ = w_ * (int(c) ** (-0.5))
|
| 146 |
+
w_ = torch.nn.functional.softmax(w_, dim=2)
|
| 147 |
+
|
| 148 |
+
# attend to values
|
| 149 |
+
v = v.reshape(b, c, h * w)
|
| 150 |
+
w_ = w_.permute(0, 2, 1) # b,hw,hw (first hw of k, second of q)
|
| 151 |
+
h_ = torch.bmm(v, w_) # b, c,hw (hw of q) h_[b,c,j] = sum_i v[b,c,i] w_[b,i,j]
|
| 152 |
+
h_ = h_.reshape(b, c, h, w)
|
| 153 |
+
|
| 154 |
+
h_ = self.proj_out(h_)
|
| 155 |
+
|
| 156 |
+
return x + h_
|
| 157 |
+
|
| 158 |
+
|
| 159 |
+
class Encoder(nn.Module):
|
| 160 |
+
def __init__(
|
| 161 |
+
self,
|
| 162 |
+
*,
|
| 163 |
+
ch=128,
|
| 164 |
+
out_ch=3,
|
| 165 |
+
ch_mult=(1, 1, 2, 2, 4),
|
| 166 |
+
num_res_blocks=2,
|
| 167 |
+
attn_resolutions=(16,),
|
| 168 |
+
dropout=0.0,
|
| 169 |
+
resamp_with_conv=True,
|
| 170 |
+
in_channels=3,
|
| 171 |
+
resolution=256,
|
| 172 |
+
z_channels=16,
|
| 173 |
+
double_z=True,
|
| 174 |
+
**ignore_kwargs,
|
| 175 |
+
):
|
| 176 |
+
super().__init__()
|
| 177 |
+
self.ch = ch
|
| 178 |
+
self.temb_ch = 0
|
| 179 |
+
self.num_resolutions = len(ch_mult)
|
| 180 |
+
self.num_res_blocks = num_res_blocks
|
| 181 |
+
self.resolution = resolution
|
| 182 |
+
self.in_channels = in_channels
|
| 183 |
+
|
| 184 |
+
# downsampling
|
| 185 |
+
self.conv_in = torch.nn.Conv2d(
|
| 186 |
+
in_channels, self.ch, kernel_size=3, stride=1, padding=1
|
| 187 |
+
)
|
| 188 |
+
|
| 189 |
+
curr_res = resolution
|
| 190 |
+
in_ch_mult = (1,) + tuple(ch_mult)
|
| 191 |
+
self.down = nn.ModuleList()
|
| 192 |
+
for i_level in range(self.num_resolutions):
|
| 193 |
+
block = nn.ModuleList()
|
| 194 |
+
attn = nn.ModuleList()
|
| 195 |
+
block_in = ch * in_ch_mult[i_level]
|
| 196 |
+
block_out = ch * ch_mult[i_level]
|
| 197 |
+
for i_block in range(self.num_res_blocks):
|
| 198 |
+
block.append(
|
| 199 |
+
ResnetBlock(
|
| 200 |
+
in_channels=block_in,
|
| 201 |
+
out_channels=block_out,
|
| 202 |
+
temb_channels=self.temb_ch,
|
| 203 |
+
dropout=dropout,
|
| 204 |
+
)
|
| 205 |
+
)
|
| 206 |
+
block_in = block_out
|
| 207 |
+
if curr_res in attn_resolutions:
|
| 208 |
+
attn.append(AttnBlock(block_in))
|
| 209 |
+
down = nn.Module()
|
| 210 |
+
down.block = block
|
| 211 |
+
down.attn = attn
|
| 212 |
+
if i_level != self.num_resolutions - 1:
|
| 213 |
+
down.downsample = Downsample(block_in, resamp_with_conv)
|
| 214 |
+
curr_res = curr_res // 2
|
| 215 |
+
self.down.append(down)
|
| 216 |
+
|
| 217 |
+
# middle
|
| 218 |
+
self.mid = nn.Module()
|
| 219 |
+
self.mid.block_1 = ResnetBlock(
|
| 220 |
+
in_channels=block_in,
|
| 221 |
+
out_channels=block_in,
|
| 222 |
+
temb_channels=self.temb_ch,
|
| 223 |
+
dropout=dropout,
|
| 224 |
+
)
|
| 225 |
+
self.mid.attn_1 = AttnBlock(block_in)
|
| 226 |
+
self.mid.block_2 = ResnetBlock(
|
| 227 |
+
in_channels=block_in,
|
| 228 |
+
out_channels=block_in,
|
| 229 |
+
temb_channels=self.temb_ch,
|
| 230 |
+
dropout=dropout,
|
| 231 |
+
)
|
| 232 |
+
|
| 233 |
+
# end
|
| 234 |
+
self.norm_out = Normalize(block_in)
|
| 235 |
+
self.conv_out = torch.nn.Conv2d(
|
| 236 |
+
block_in,
|
| 237 |
+
2 * z_channels if double_z else z_channels,
|
| 238 |
+
kernel_size=3,
|
| 239 |
+
stride=1,
|
| 240 |
+
padding=1,
|
| 241 |
+
)
|
| 242 |
+
|
| 243 |
+
def forward(self, x):
|
| 244 |
+
# assert x.shape[2] == x.shape[3] == self.resolution, "{}, {}, {}".format(x.shape[2], x.shape[3], self.resolution)
|
| 245 |
+
|
| 246 |
+
# timestep embedding
|
| 247 |
+
temb = None
|
| 248 |
+
|
| 249 |
+
# downsampling
|
| 250 |
+
hs = [self.conv_in(x)]
|
| 251 |
+
for i_level in range(self.num_resolutions):
|
| 252 |
+
for i_block in range(self.num_res_blocks):
|
| 253 |
+
h = self.down[i_level].block[i_block](hs[-1], temb)
|
| 254 |
+
if len(self.down[i_level].attn) > 0:
|
| 255 |
+
h = self.down[i_level].attn[i_block](h)
|
| 256 |
+
hs.append(h)
|
| 257 |
+
if i_level != self.num_resolutions - 1:
|
| 258 |
+
hs.append(self.down[i_level].downsample(hs[-1]))
|
| 259 |
+
|
| 260 |
+
# middle
|
| 261 |
+
h = hs[-1]
|
| 262 |
+
h = self.mid.block_1(h, temb)
|
| 263 |
+
h = self.mid.attn_1(h)
|
| 264 |
+
h = self.mid.block_2(h, temb)
|
| 265 |
+
|
| 266 |
+
# end
|
| 267 |
+
h = self.norm_out(h)
|
| 268 |
+
h = nonlinearity(h)
|
| 269 |
+
h = self.conv_out(h)
|
| 270 |
+
return h
|
| 271 |
+
|
| 272 |
+
|
| 273 |
+
class Decoder(nn.Module):
|
| 274 |
+
def __init__(
|
| 275 |
+
self,
|
| 276 |
+
*,
|
| 277 |
+
ch=128,
|
| 278 |
+
out_ch=3,
|
| 279 |
+
ch_mult=(1, 1, 2, 2, 4),
|
| 280 |
+
num_res_blocks=2,
|
| 281 |
+
attn_resolutions=(),
|
| 282 |
+
dropout=0.0,
|
| 283 |
+
resamp_with_conv=True,
|
| 284 |
+
in_channels=3,
|
| 285 |
+
resolution=256,
|
| 286 |
+
z_channels=16,
|
| 287 |
+
give_pre_end=False,
|
| 288 |
+
**ignore_kwargs,
|
| 289 |
+
):
|
| 290 |
+
super().__init__()
|
| 291 |
+
self.ch = ch
|
| 292 |
+
self.temb_ch = 0
|
| 293 |
+
self.num_resolutions = len(ch_mult)
|
| 294 |
+
self.num_res_blocks = num_res_blocks
|
| 295 |
+
self.resolution = resolution
|
| 296 |
+
self.in_channels = in_channels
|
| 297 |
+
self.give_pre_end = give_pre_end
|
| 298 |
+
|
| 299 |
+
# compute in_ch_mult, block_in and curr_res at lowest res
|
| 300 |
+
in_ch_mult = (1,) + tuple(ch_mult)
|
| 301 |
+
block_in = ch * ch_mult[self.num_resolutions - 1]
|
| 302 |
+
curr_res = resolution // 2 ** (self.num_resolutions - 1)
|
| 303 |
+
self.z_shape = (1, z_channels, curr_res, curr_res)
|
| 304 |
+
print(
|
| 305 |
+
"Working with z of shape {} = {} dimensions.".format(
|
| 306 |
+
self.z_shape, np.prod(self.z_shape)
|
| 307 |
+
)
|
| 308 |
+
)
|
| 309 |
+
|
| 310 |
+
# z to block_in
|
| 311 |
+
self.conv_in = torch.nn.Conv2d(
|
| 312 |
+
z_channels, block_in, kernel_size=3, stride=1, padding=1
|
| 313 |
+
)
|
| 314 |
+
|
| 315 |
+
# middle
|
| 316 |
+
self.mid = nn.Module()
|
| 317 |
+
self.mid.block_1 = ResnetBlock(
|
| 318 |
+
in_channels=block_in,
|
| 319 |
+
out_channels=block_in,
|
| 320 |
+
temb_channels=self.temb_ch,
|
| 321 |
+
dropout=dropout,
|
| 322 |
+
)
|
| 323 |
+
self.mid.attn_1 = AttnBlock(block_in)
|
| 324 |
+
self.mid.block_2 = ResnetBlock(
|
| 325 |
+
in_channels=block_in,
|
| 326 |
+
out_channels=block_in,
|
| 327 |
+
temb_channels=self.temb_ch,
|
| 328 |
+
dropout=dropout,
|
| 329 |
+
)
|
| 330 |
+
|
| 331 |
+
# upsampling
|
| 332 |
+
self.up = nn.ModuleList()
|
| 333 |
+
for i_level in reversed(range(self.num_resolutions)):
|
| 334 |
+
block = nn.ModuleList()
|
| 335 |
+
attn = nn.ModuleList()
|
| 336 |
+
block_out = ch * ch_mult[i_level]
|
| 337 |
+
for i_block in range(self.num_res_blocks + 1):
|
| 338 |
+
block.append(
|
| 339 |
+
ResnetBlock(
|
| 340 |
+
in_channels=block_in,
|
| 341 |
+
out_channels=block_out,
|
| 342 |
+
temb_channels=self.temb_ch,
|
| 343 |
+
dropout=dropout,
|
| 344 |
+
)
|
| 345 |
+
)
|
| 346 |
+
block_in = block_out
|
| 347 |
+
if curr_res in attn_resolutions:
|
| 348 |
+
attn.append(AttnBlock(block_in))
|
| 349 |
+
up = nn.Module()
|
| 350 |
+
up.block = block
|
| 351 |
+
up.attn = attn
|
| 352 |
+
if i_level != 0:
|
| 353 |
+
up.upsample = Upsample(block_in, resamp_with_conv)
|
| 354 |
+
curr_res = curr_res * 2
|
| 355 |
+
self.up.insert(0, up) # prepend to get consistent order
|
| 356 |
+
|
| 357 |
+
# end
|
| 358 |
+
self.norm_out = Normalize(block_in)
|
| 359 |
+
self.conv_out = torch.nn.Conv2d(
|
| 360 |
+
block_in, out_ch, kernel_size=3, stride=1, padding=1
|
| 361 |
+
)
|
| 362 |
+
|
| 363 |
+
def forward(self, z):
|
| 364 |
+
# assert z.shape[1:] == self.z_shape[1:]
|
| 365 |
+
self.last_z_shape = z.shape
|
| 366 |
+
|
| 367 |
+
# timestep embedding
|
| 368 |
+
temb = None
|
| 369 |
+
|
| 370 |
+
# z to block_in
|
| 371 |
+
h = self.conv_in(z)
|
| 372 |
+
|
| 373 |
+
# middle
|
| 374 |
+
h = self.mid.block_1(h, temb)
|
| 375 |
+
h = self.mid.attn_1(h)
|
| 376 |
+
h = self.mid.block_2(h, temb)
|
| 377 |
+
|
| 378 |
+
# upsampling
|
| 379 |
+
for i_level in reversed(range(self.num_resolutions)):
|
| 380 |
+
for i_block in range(self.num_res_blocks + 1):
|
| 381 |
+
h = self.up[i_level].block[i_block](h, temb)
|
| 382 |
+
if len(self.up[i_level].attn) > 0:
|
| 383 |
+
h = self.up[i_level].attn[i_block](h)
|
| 384 |
+
if i_level != 0:
|
| 385 |
+
h = self.up[i_level].upsample(h)
|
| 386 |
+
|
| 387 |
+
# end
|
| 388 |
+
if self.give_pre_end:
|
| 389 |
+
return h
|
| 390 |
+
|
| 391 |
+
h = self.norm_out(h)
|
| 392 |
+
h = nonlinearity(h)
|
| 393 |
+
h = self.conv_out(h)
|
| 394 |
+
return h
|
| 395 |
+
|
| 396 |
+
|
| 397 |
+
class DiagonalGaussianDistribution(object):
|
| 398 |
+
def __init__(self, parameters, deterministic=False):
|
| 399 |
+
self.parameters = parameters
|
| 400 |
+
self.mean, self.logvar = torch.chunk(parameters, 2, dim=1)
|
| 401 |
+
self.logvar = torch.clamp(self.logvar, -30.0, 20.0)
|
| 402 |
+
self.deterministic = deterministic
|
| 403 |
+
self.std = torch.exp(0.5 * self.logvar)
|
| 404 |
+
self.var = torch.exp(self.logvar)
|
| 405 |
+
if self.deterministic:
|
| 406 |
+
self.var = self.std = torch.zeros_like(self.mean).to(
|
| 407 |
+
device=self.parameters.device
|
| 408 |
+
)
|
| 409 |
+
|
| 410 |
+
def sample(self):
|
| 411 |
+
x = self.mean + self.std * torch.randn(self.mean.shape).to(
|
| 412 |
+
device=self.parameters.device
|
| 413 |
+
)
|
| 414 |
+
return x
|
| 415 |
+
|
| 416 |
+
def kl(self, other=None):
|
| 417 |
+
if self.deterministic:
|
| 418 |
+
return torch.Tensor([0.0])
|
| 419 |
+
else:
|
| 420 |
+
if other is None:
|
| 421 |
+
return 0.5 * torch.sum(
|
| 422 |
+
torch.pow(self.mean, 2) + self.var - 1.0 - self.logvar,
|
| 423 |
+
dim=[1, 2, 3],
|
| 424 |
+
)
|
| 425 |
+
else:
|
| 426 |
+
return 0.5 * torch.sum(
|
| 427 |
+
torch.pow(self.mean - other.mean, 2) / other.var
|
| 428 |
+
+ self.var / other.var
|
| 429 |
+
- 1.0
|
| 430 |
+
- self.logvar
|
| 431 |
+
+ other.logvar,
|
| 432 |
+
dim=[1, 2, 3],
|
| 433 |
+
)
|
| 434 |
+
|
| 435 |
+
def nll(self, sample, dims=[1, 2, 3]):
|
| 436 |
+
if self.deterministic:
|
| 437 |
+
return torch.Tensor([0.0])
|
| 438 |
+
logtwopi = np.log(2.0 * np.pi)
|
| 439 |
+
return 0.5 * torch.sum(
|
| 440 |
+
logtwopi + self.logvar + torch.pow(sample - self.mean, 2) / self.var,
|
| 441 |
+
dim=dims,
|
| 442 |
+
)
|
| 443 |
+
|
| 444 |
+
def mode(self):
|
| 445 |
+
return self.mean
|
| 446 |
+
|
| 447 |
+
|
| 448 |
+
class AutoencoderKL(nn.Module):
|
| 449 |
+
def __init__(self, embed_dim, ch_mult, use_variational=True, ckpt_path=None):
|
| 450 |
+
super().__init__()
|
| 451 |
+
self.encoder = Encoder(ch_mult=ch_mult, z_channels=embed_dim)
|
| 452 |
+
self.decoder = Decoder(ch_mult=ch_mult, z_channels=embed_dim)
|
| 453 |
+
self.use_variational = use_variational
|
| 454 |
+
mult = 2 if self.use_variational else 1
|
| 455 |
+
self.quant_conv = torch.nn.Conv2d(2 * embed_dim, mult * embed_dim, 1)
|
| 456 |
+
self.post_quant_conv = torch.nn.Conv2d(embed_dim, embed_dim, 1)
|
| 457 |
+
self.embed_dim = embed_dim
|
| 458 |
+
if ckpt_path is not None:
|
| 459 |
+
self.init_from_ckpt(ckpt_path)
|
| 460 |
+
|
| 461 |
+
def init_from_ckpt(self, path):
|
| 462 |
+
sd = torch.load(path, map_location="cpu")["model"]
|
| 463 |
+
msg = self.load_state_dict(sd, strict=False)
|
| 464 |
+
print("Loading pre-trained KL-VAE")
|
| 465 |
+
print("Missing keys:")
|
| 466 |
+
print(msg.missing_keys)
|
| 467 |
+
print("Unexpected keys:")
|
| 468 |
+
print(msg.unexpected_keys)
|
| 469 |
+
print(f"Restored from {path}")
|
| 470 |
+
|
| 471 |
+
def encode(self, x):
|
| 472 |
+
h = self.encoder(x)
|
| 473 |
+
moments = self.quant_conv(h)
|
| 474 |
+
if not self.use_variational:
|
| 475 |
+
moments = torch.cat((moments, torch.ones_like(moments)), 1)
|
| 476 |
+
posterior = DiagonalGaussianDistribution(moments)
|
| 477 |
+
return posterior
|
| 478 |
+
|
| 479 |
+
def decode(self, z):
|
| 480 |
+
z = self.post_quant_conv(z)
|
| 481 |
+
dec = self.decoder(z)
|
| 482 |
+
return dec
|
| 483 |
+
|
| 484 |
+
def forward(self, inputs, disable=True, train=True, optimizer_idx=0):
|
| 485 |
+
if train:
|
| 486 |
+
return self.training_step(inputs, disable, optimizer_idx)
|
| 487 |
+
else:
|
| 488 |
+
return self.validation_step(inputs, disable)
|
| 489 |
+
|
| 490 |
+
|
| 491 |
+
if __name__ == "__main__":
|
| 492 |
+
from PIL import Image
|
| 493 |
+
import torch.nn.functional as F
|
| 494 |
+
|
| 495 |
+
vae = AutoencoderKL(
|
| 496 |
+
embed_dim=16, ch_mult=(1, 1, 2, 2, 4),
|
| 497 |
+
ckpt_path='checkpoints/kl16.ckpt')
|
| 498 |
+
|
| 499 |
+
image = Image.open('data/ILSVRC2012_val_00023344.JPEG')
|
| 500 |
+
image = torch.from_numpy(np.array(image))
|
| 501 |
+
image = image.permute(2, 0, 1).float() / 255
|
| 502 |
+
image = 2 * image - 1
|
| 503 |
+
|
| 504 |
+
x = F.interpolate(image[None], size=(256, 256), mode='bilinear', align_corners=True)
|
| 505 |
+
|
| 506 |
+
print(x.shape)
|
| 507 |
+
|
| 508 |
+
with torch.no_grad():
|
| 509 |
+
z = vae.encode(x).sample()
|
| 510 |
+
print(z.shape)
|
| 511 |
+
x_rec = vae.decode(z)[0]
|
| 512 |
+
|
| 513 |
+
x_rec = (x_rec + 1.0) * 255 / 2
|
| 514 |
+
x_rec = torch.clamp(x_rec, min=0, max=255)
|
| 515 |
+
x_rec = x_rec.to(torch.uint8)
|
| 516 |
+
|
| 517 |
+
x_rec = x_rec.permute(1, 2, 0)
|
| 518 |
+
|
| 519 |
+
x_rec = Image.fromarray(x_rec.numpy())
|
| 520 |
+
|
| 521 |
+
x_rec.show()
|
| 522 |
+
|
vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|