

Upload folder using huggingface_hub
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +2 -0
- README.md +286 -0
- chat_template.jinja +122 -0
- config.json +109 -0
- configuration_deepseek.py +210 -0
- generation_config.json +6 -0
- images/README +1 -0
- images/cogito-v2-671b-non-reasoning-benchmarks.png +3 -0
- images/cogito-v2-671b-reasoning-benchmarks.png +3 -0
- images/deep-cogito-logo.png +0 -0
- model-00001-of-00135.safetensors +3 -0
- model-00002-of-00135.safetensors +3 -0
- model-00003-of-00135.safetensors +3 -0
- model-00004-of-00135.safetensors +3 -0
- model-00005-of-00135.safetensors +3 -0
- model-00006-of-00135.safetensors +3 -0
- model-00007-of-00135.safetensors +3 -0
- model-00008-of-00135.safetensors +3 -0
- model-00009-of-00135.safetensors +3 -0
- model-00010-of-00135.safetensors +3 -0
- model-00011-of-00135.safetensors +3 -0
- model-00012-of-00135.safetensors +3 -0
- model-00013-of-00135.safetensors +3 -0
- model-00014-of-00135.safetensors +3 -0
- model-00015-of-00135.safetensors +3 -0
- model-00016-of-00135.safetensors +3 -0
- model-00017-of-00135.safetensors +3 -0
- model-00018-of-00135.safetensors +3 -0
- model-00019-of-00135.safetensors +3 -0
- model-00020-of-00135.safetensors +3 -0
- model-00021-of-00135.safetensors +3 -0
- model-00022-of-00135.safetensors +3 -0
- model-00023-of-00135.safetensors +3 -0
- model-00024-of-00135.safetensors +3 -0
- model-00025-of-00135.safetensors +3 -0
- model-00026-of-00135.safetensors +3 -0
- model-00027-of-00135.safetensors +3 -0
- model-00028-of-00135.safetensors +3 -0
- model-00029-of-00135.safetensors +3 -0
- model-00030-of-00135.safetensors +3 -0
- model-00031-of-00135.safetensors +3 -0
- model-00032-of-00135.safetensors +3 -0
- model-00033-of-00135.safetensors +3 -0
- model-00034-of-00135.safetensors +3 -0
- model-00035-of-00135.safetensors +3 -0
- model-00036-of-00135.safetensors +3 -0
- model-00037-of-00135.safetensors +3 -0
- model-00038-of-00135.safetensors +3 -0
- model-00039-of-00135.safetensors +3 -0
- model-00040-of-00135.safetensors +3 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
images/cogito-v2-671b-non-reasoning-benchmarks.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
images/cogito-v2-671b-reasoning-benchmarks.png filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,286 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
tags:
|
| 3 |
+
- unsloth
|
| 4 |
+
license: mit
|
| 5 |
+
library_name: transformers
|
| 6 |
+
base_model:
|
| 7 |
+
- deepcogito/cogito-v2-preview-deepseek-671B-MoE-FP8
|
| 8 |
+
---
|
| 9 |
+
> [!NOTE]
|
| 10 |
+
> Includes Unsloth **chat template fixes**! <br> For `llama.cpp`, use `--jinja`
|
| 11 |
+
>
|
| 12 |
+
|
| 13 |
+
<div>
|
| 14 |
+
<p style="margin-top: 0;margin-bottom: 0;">
|
| 15 |
+
<em><a href="https://docs.unsloth.ai/basics/unsloth-dynamic-v2.0-gguf">Unsloth Dynamic 2.0</a> achieves superior accuracy & outperforms other leading quants.</em>
|
| 16 |
+
</p>
|
| 17 |
+
<div style="display: flex; gap: 5px; align-items: center; ">
|
| 18 |
+
<a href="https://github.com/unslothai/unsloth/">
|
| 19 |
+
<img src="https://github.com/unslothai/unsloth/raw/main/images/unsloth%20new%20logo.png" width="133">
|
| 20 |
+
</a>
|
| 21 |
+
<a href="https://discord.gg/unsloth">
|
| 22 |
+
<img src="https://github.com/unslothai/unsloth/raw/main/images/Discord%20button.png" width="173">
|
| 23 |
+
</a>
|
| 24 |
+
<a href="https://docs.unsloth.ai/">
|
| 25 |
+
<img src="https://raw.githubusercontent.com/unslothai/unsloth/refs/heads/main/images/documentation%20green%20button.png" width="143">
|
| 26 |
+
</a>
|
| 27 |
+
</div>
|
| 28 |
+
</div>
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
<p align="center">
|
| 32 |
+
<img src="images/deep-cogito-logo.png" alt="Logo" width="40%">
|
| 33 |
+
</p>
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
# Cogito v2 preview - 671B MoE (FP8)
|
| 37 |
+
|
| 38 |
+
[Blog Post](https://www.deepcogito.com/research/cogito-v2-preview)
|
| 39 |
+
|
| 40 |
+
The Cogito v2 LLMs are instruction tuned generative models. All models are released under an open license for commercial use.
|
| 41 |
+
|
| 42 |
+
- Cogito v2 models are hybrid reasoning models. Each model can answer directly (standard LLM), or self-reflect before answering (like reasoning models).
|
| 43 |
+
- The LLMs are trained using **Iterated Distillation and Amplification (IDA)** - an scalable and efficient alignment strategy for superintelligence using iterative self-improvement.
|
| 44 |
+
- The models have been optimized for coding, STEM, instruction following and general helpfulness, and have significantly higher multilingual, coding and tool calling capabilities than size equivalent counterparts.
|
| 45 |
+
- In both standard and reasoning modes, Cogito v2-preview models outperform their size equivalent counterparts on common industry benchmarks.
|
| 46 |
+
- This model is trained in over 30 languages and supports a context length of 128k.
|
| 47 |
+
|
| 48 |
+
# Evaluations
|
| 49 |
+
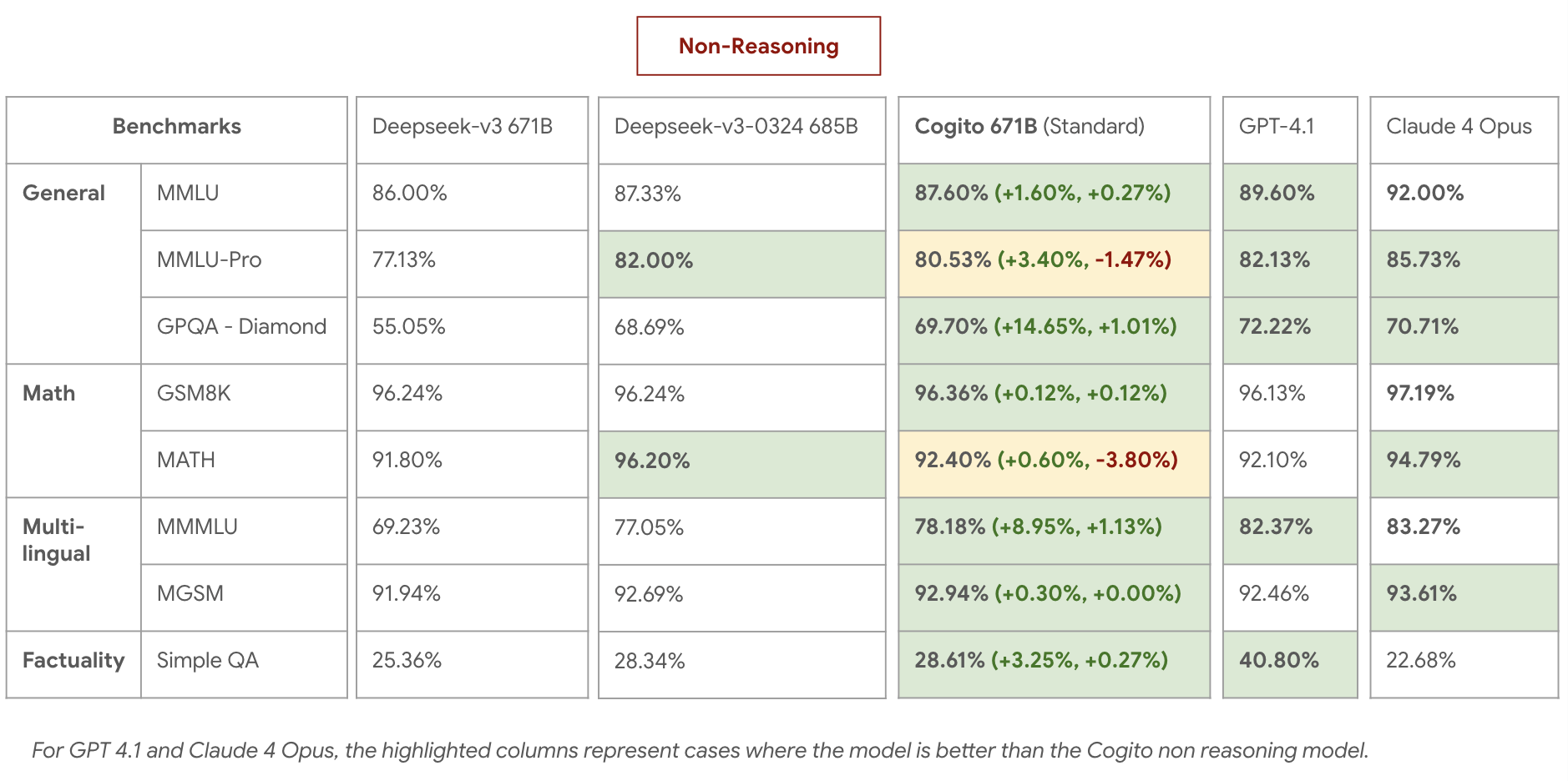
Here is the model performance on some standard industry benchmarks:
|
| 50 |
+
|
| 51 |
+
<p align="left">
|
| 52 |
+
<img src="images/cogito-v2-671b-non-reasoning-benchmarks.png" alt="Logo" width="90%">
|
| 53 |
+
</p>
|
| 54 |
+
|
| 55 |
+
<p align="left">
|
| 56 |
+
<img src="images/cogito-v2-671b-reasoning-benchmarks.png" alt="Logo" width="90%">
|
| 57 |
+
</p>
|
| 58 |
+
|
| 59 |
+
For detailed evaluations, please refer to the [Blog Post](https://www.deepcogito.com/research/cogito-v2-preview).
|
| 60 |
+
|
| 61 |
+
# Usage
|
| 62 |
+
Here is a snippet below for usage with Transformers:
|
| 63 |
+
|
| 64 |
+
```python
|
| 65 |
+
import transformers
|
| 66 |
+
import torch
|
| 67 |
+
|
| 68 |
+
model_id = "deepcogito/cogito-v2-preview-deepseek-671B-MoE-FP8"
|
| 69 |
+
|
| 70 |
+
pipeline = transformers.pipeline(
|
| 71 |
+
"text-generation",
|
| 72 |
+
model=model_id,
|
| 73 |
+
model_kwargs={"torch_dtype": torch.bfloat16},
|
| 74 |
+
device_map="auto",
|
| 75 |
+
)
|
| 76 |
+
|
| 77 |
+
messages = [
|
| 78 |
+
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
|
| 79 |
+
{"role": "user", "content": "Give me a short introduction to LLMs."},
|
| 80 |
+
]
|
| 81 |
+
|
| 82 |
+
outputs = pipeline(
|
| 83 |
+
messages,
|
| 84 |
+
max_new_tokens=512,
|
| 85 |
+
)
|
| 86 |
+
|
| 87 |
+
print(outputs[0]["generated_text"][-1])
|
| 88 |
+
```
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
## Implementing extended thinking
|
| 93 |
+
- By default, the model will answer in the standard mode.
|
| 94 |
+
- To enable thinking, you can do any one of the two methods:
|
| 95 |
+
- Set `enable_thinking=True` while applying the chat template.
|
| 96 |
+
- Add a specific system prompt, along with prefilling the response with "\<think\>\n".
|
| 97 |
+
|
| 98 |
+
**NOTE: Unlike Cogito v1 models, we initiate the response with "\<think\>\n" at the beginning of every output when reasoning is enabled. This is because hybrid models can be brittle at times, and adding a "\<think\>\n" ensures that the model does indeed respect thinking.**
|
| 99 |
+
|
| 100 |
+
### Method 1 - Set enable_thinking=True in the tokenizer
|
| 101 |
+
If you are using Huggingface tokenizers, then you can simply use add the argument `enable_thinking=True` to the tokenization (this option is added to the chat template).
|
| 102 |
+
|
| 103 |
+
Here is an example -
|
| 104 |
+
```python
|
| 105 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 106 |
+
|
| 107 |
+
model_name = "deepcogito/cogito-v2-preview-deepseek-671B-MoE-FP8"
|
| 108 |
+
|
| 109 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 110 |
+
model_name,
|
| 111 |
+
torch_dtype="auto",
|
| 112 |
+
device_map="auto"
|
| 113 |
+
)
|
| 114 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 115 |
+
|
| 116 |
+
prompt = "Give me a short introduction to LLMs."
|
| 117 |
+
messages = [
|
| 118 |
+
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
|
| 119 |
+
{"role": "user", "content": prompt}
|
| 120 |
+
]
|
| 121 |
+
|
| 122 |
+
text = tokenizer.apply_chat_template(
|
| 123 |
+
messages,
|
| 124 |
+
tokenize=False,
|
| 125 |
+
add_generation_prompt=True,
|
| 126 |
+
enable_thinking=True
|
| 127 |
+
)
|
| 128 |
+
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
|
| 129 |
+
|
| 130 |
+
generated_ids = model.generate(
|
| 131 |
+
**model_inputs,
|
| 132 |
+
max_new_tokens=512
|
| 133 |
+
)
|
| 134 |
+
generated_ids = [
|
| 135 |
+
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
|
| 136 |
+
]
|
| 137 |
+
|
| 138 |
+
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
|
| 139 |
+
print(response)
|
| 140 |
+
```
|
| 141 |
+
|
| 142 |
+
### Method 2 - Add a specific system prompt, along with prefilling the response with "\<think\>\n".
|
| 143 |
+
To enable thinking using this method, you need to do two parts -
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
Step 1 - Simply use this in the system prompt `system_instruction = 'Enable deep thinking subroutine.'`
|
| 147 |
+
|
| 148 |
+
If you already have a system_instruction, then use `system_instruction = 'Enable deep thinking subroutine.' + '\n\n' + system_instruction`.
|
| 149 |
+
|
| 150 |
+
Step 2 - Prefil the response with the tokens `"<think>\n"`.
|
| 151 |
+
|
| 152 |
+
Here is an example -
|
| 153 |
+
|
| 154 |
+
```python
|
| 155 |
+
import transformers
|
| 156 |
+
import torch
|
| 157 |
+
|
| 158 |
+
model_name = "deepcogito/cogito-v2-preview-deepseek-671B-MoE-FP8"
|
| 159 |
+
|
| 160 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 161 |
+
model_name,
|
| 162 |
+
torch_dtype="auto",
|
| 163 |
+
device_map="auto"
|
| 164 |
+
)
|
| 165 |
+
tokenizer = AutoTokenizer.from_pretrained(model_name)
|
| 166 |
+
|
| 167 |
+
# Step 1 - Add deep thinking instruction.
|
| 168 |
+
DEEP_THINKING_INSTRUCTION = "Enable deep thinking subroutine."
|
| 169 |
+
|
| 170 |
+
messages = [
|
| 171 |
+
{"role": "system", "content": DEEP_THINKING_INSTRUCTION},
|
| 172 |
+
{"role": "user", "content": "Write a bash script that takes a matrix represented as a string with format '[1,2],[3,4],[5,6]' and prints the transpose in the same format."},
|
| 173 |
+
]
|
| 174 |
+
|
| 175 |
+
text = tokenizer.apply_chat_template(
|
| 176 |
+
messages,
|
| 177 |
+
tokenize=False,
|
| 178 |
+
add_generation_prompt=True
|
| 179 |
+
)
|
| 180 |
+
|
| 181 |
+
# Step 2 - Prefill response with "<think>\n".
|
| 182 |
+
text += "<think>\n"
|
| 183 |
+
|
| 184 |
+
# Now, continue as usual.
|
| 185 |
+
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
|
| 186 |
+
|
| 187 |
+
generated_ids = model.generate(
|
| 188 |
+
**model_inputs,
|
| 189 |
+
max_new_tokens=512
|
| 190 |
+
)
|
| 191 |
+
generated_ids = [
|
| 192 |
+
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
|
| 193 |
+
]
|
| 194 |
+
|
| 195 |
+
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
|
| 196 |
+
print(response)
|
| 197 |
+
```
|
| 198 |
+
|
| 199 |
+
|
| 200 |
+
Similarly, if you have a system prompt, you can append the `DEEP_THINKING_INSTRUCTION` to the beginning in this way -
|
| 201 |
+
|
| 202 |
+
```python
|
| 203 |
+
DEEP_THINKING_INSTRUCTION = "Enable deep thinking subroutine."
|
| 204 |
+
|
| 205 |
+
system_prompt = "Reply to each prompt with only the actual code - no explanations."
|
| 206 |
+
prompt = "Write a bash script that takes a matrix represented as a string with format '[1,2],[3,4],[5,6]' and prints the transpose in the same format."
|
| 207 |
+
|
| 208 |
+
messages = [
|
| 209 |
+
{"role": "system", "content": DEEP_THINKING_INSTRUCTION + '\n\n' + system_prompt},
|
| 210 |
+
{"role": "user", "content": prompt}
|
| 211 |
+
]
|
| 212 |
+
```
|
| 213 |
+
|
| 214 |
+
|
| 215 |
+
# Tool Calling
|
| 216 |
+
Cogito models support tool calling (single, parallel, multiple and parallel_multiple) both in standard and extended thinking mode.
|
| 217 |
+
|
| 218 |
+
Here is a snippet -
|
| 219 |
+
|
| 220 |
+
```python
|
| 221 |
+
# First, define a tool
|
| 222 |
+
def get_current_temperature(location: str) -> float:
|
| 223 |
+
"""
|
| 224 |
+
Get the current temperature at a location.
|
| 225 |
+
|
| 226 |
+
Args:
|
| 227 |
+
location: The location to get the temperature for, in the format "City, Country"
|
| 228 |
+
Returns:
|
| 229 |
+
The current temperature at the specified location in the specified units, as a float.
|
| 230 |
+
"""
|
| 231 |
+
return 22. # A real function should probably actually get the temperature!
|
| 232 |
+
|
| 233 |
+
# Next, create a chat and apply the chat template
|
| 234 |
+
messages = [
|
| 235 |
+
{"role": "user", "content": "Hey, what's the temperature in Paris right now?"}
|
| 236 |
+
]
|
| 237 |
+
|
| 238 |
+
model_inputs = tokenizer.apply_chat_template(messages, tools=[get_current_temperature], add_generation_prompt=True)
|
| 239 |
+
|
| 240 |
+
text = tokenizer.apply_chat_template(messages, tools=[get_current_temperature], add_generation_prompt=True, tokenize=False)
|
| 241 |
+
inputs = tokenizer(text, return_tensors="pt", add_special_tokens=False).to(model.device)
|
| 242 |
+
outputs = model.generate(**inputs, max_new_tokens=512)
|
| 243 |
+
output_text = tokenizer.batch_decode(outputs)[0][len(text):]
|
| 244 |
+
print(output_text)
|
| 245 |
+
```
|
| 246 |
+
|
| 247 |
+
This will result in the output -
|
| 248 |
+
```
|
| 249 |
+
<|tool▁calls▁begin|><|tool▁call▁begin|>function<|tool▁sep|>get_current_temperature
|
| 250 |
+
```json
|
| 251 |
+
{"location":"Paris, France"}
|
| 252 |
+
```<|tool▁call▁end|><|tool▁calls▁end|><|end▁of▁sentence|>
|
| 253 |
+
```
|
| 254 |
+
|
| 255 |
+
You can then generate text from this input as normal. If the model generates a tool call, you should add it to the chat like so:
|
| 256 |
+
|
| 257 |
+
```python
|
| 258 |
+
tool_call = {"name": "get_current_temperature", "arguments": {"location": "Paris, France"}}
|
| 259 |
+
messages.append({"role": "assistant", "tool_calls": [{"type": "function", "function": tool_call}]})
|
| 260 |
+
```
|
| 261 |
+
|
| 262 |
+
and then call the tool and append the result, with the `tool` role, like so:
|
| 263 |
+
|
| 264 |
+
```python
|
| 265 |
+
messages.append({"role": "tool", "name": "get_current_temperature", "content": "22.0"})
|
| 266 |
+
```
|
| 267 |
+
|
| 268 |
+
After that, you can `generate()` again to let the model use the tool result in the chat:
|
| 269 |
+
|
| 270 |
+
```python
|
| 271 |
+
text = tokenizer.apply_chat_template(messages, tools=[get_current_temperature], add_generation_prompt=True, tokenize=False)
|
| 272 |
+
inputs = tokenizer(text, return_tensors="pt", add_special_tokens=False).to(model.device)
|
| 273 |
+
outputs = model.generate(**inputs, max_new_tokens=512)
|
| 274 |
+
output_text = tokenizer.batch_decode(outputs)[0][len(text):]
|
| 275 |
+
```
|
| 276 |
+
|
| 277 |
+
This should result in the string -
|
| 278 |
+
```
|
| 279 |
+
'The current temperature in Paris is 22.0 degrees.<|end▁of▁sentence|>'
|
| 280 |
+
```
|
| 281 |
+
|
| 282 |
+
## License
|
| 283 |
+
This repository and the model weights are licensed under **MIT License**.
|
| 284 |
+
|
| 285 |
+
## Contact
|
| 286 |
+
If you would like to reach out to our team, send an email to [[email protected]]([email protected]).
|
chat_template.jinja
ADDED
|
@@ -0,0 +1,122 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{# Copyright 2025-present the Unsloth team. All rights reserved. #}
|
| 2 |
+
{# Licensed under the Apache License, Version 2.0 (the "License") #}
|
| 3 |
+
{# Edits made by Unsloth to fix the chat template #}
|
| 4 |
+
{# ==================================================================== #}
|
| 5 |
+
{# Deepseek v3 template with enable_thinking and tools support #}
|
| 6 |
+
{# ==================================================================== #}
|
| 7 |
+
{%- if not enable_thinking is defined %}{% set enable_thinking = false %}{% endif -%}
|
| 8 |
+
{%- if not tools is defined %}{% set tools = none %}{% endif -%}
|
| 9 |
+
{%- if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif -%}
|
| 10 |
+
|
| 11 |
+
{# --------------------------- Collect system prompt -------------------- #}
|
| 12 |
+
{%- set ns = namespace(system_prompt='', is_last_user=false, outputs_open=false, first_output=true, length=0) -%}
|
| 13 |
+
|
| 14 |
+
{%- if messages and messages[0].role == 'system' -%}
|
| 15 |
+
{%- set raw = messages[0].content -%}
|
| 16 |
+
{%- set ns.system_prompt = raw if raw is string else raw[0].text -%}
|
| 17 |
+
{%- set messages = messages[1:] -%}
|
| 18 |
+
{%- endif -%}
|
| 19 |
+
|
| 20 |
+
{%- set ns.length = messages|length - 1 -%}
|
| 21 |
+
|
| 22 |
+
{# --------------------------- Inject deep thinking --------------------- #}
|
| 23 |
+
{%- if enable_thinking -%}
|
| 24 |
+
{%- set ns.system_prompt = ns.system_prompt and 'Enable deep thinking subroutine.
|
| 25 |
+
|
| 26 |
+
' + ns.system_prompt or 'Enable deep thinking subroutine.' -%}
|
| 27 |
+
{%- endif -%}
|
| 28 |
+
|
| 29 |
+
{# --------------------------- Append tools block ----------------------- #}
|
| 30 |
+
{%- if tools is not none -%}
|
| 31 |
+
{%- if ns.system_prompt -%}
|
| 32 |
+
{%- set ns.system_prompt = ns.system_prompt + '
|
| 33 |
+
|
| 34 |
+
You have the following functions available:
|
| 35 |
+
|
| 36 |
+
' -%}
|
| 37 |
+
{%- else -%}
|
| 38 |
+
{%- set ns.system_prompt = 'You have the following functions available:
|
| 39 |
+
|
| 40 |
+
' -%}
|
| 41 |
+
{%- endif -%}
|
| 42 |
+
{%- for t in tools -%}
|
| 43 |
+
{%- set ns.system_prompt = ns.system_prompt + "```json
|
| 44 |
+
" + (t | tojson(indent=4)) + "
|
| 45 |
+
```
|
| 46 |
+
|
| 47 |
+
" -%}
|
| 48 |
+
{%- endfor -%}
|
| 49 |
+
{%- endif -%}
|
| 50 |
+
|
| 51 |
+
{{- bos_token -}}{{- ns.system_prompt -}}
|
| 52 |
+
|
| 53 |
+
{# --------------------------- Iterate conversation --------------------- #}
|
| 54 |
+
{%- for m in messages -%}
|
| 55 |
+
{# --------------------------- USER ---------------------------------- #}
|
| 56 |
+
{%- if m.role == 'user' -%}
|
| 57 |
+
{%- set ns.is_last_user = true -%}
|
| 58 |
+
{%- set txt = m.content if m.content is string else m.content | selectattr('type','equalto','text') | map(attribute='text') | join('') -%}
|
| 59 |
+
{{- "<|User|>" -}}{{- txt -}}
|
| 60 |
+
{%- if loop.index0 != ns.length -%}
|
| 61 |
+
{%- set ns.is_last_user = false -%}
|
| 62 |
+
{{- "<|Assistant|>" -}}
|
| 63 |
+
{%- endif -%}
|
| 64 |
+
{%- endif -%}
|
| 65 |
+
|
| 66 |
+
{# --------------------------- ASSISTANT with TOOL CALLS -------------- #}
|
| 67 |
+
{%- if m.role == 'assistant' and m.tool_calls is defined and m.tool_calls -%}
|
| 68 |
+
{%- set ns.is_last_user = false -%}
|
| 69 |
+
{%- set lead = m.content is string and m.content|trim or (m.content and m.content | selectattr('type','equalto','text') | map(attribute='text') | join('')) or '' -%}
|
| 70 |
+
{{- lead -}}{{- "<|tool▁calls▁begin|>" -}}
|
| 71 |
+
{%- for call in m.tool_calls -%}
|
| 72 |
+
{{- "<|tool▁call▁begin|>" -}}{{- call.type -}}{{- "<|tool▁sep|>" -}}{{- call.function.name -}}
|
| 73 |
+
{{- "
|
| 74 |
+
```json
|
| 75 |
+
" -}}{{- call.function.arguments -}}{{- "
|
| 76 |
+
```" -}}{{- "<|tool▁call▁end|>" -}}
|
| 77 |
+
{%- if not loop.last -%}{{- "
|
| 78 |
+
" -}}{%- endif -%}
|
| 79 |
+
{%- endfor -%}
|
| 80 |
+
{{- "<|tool▁calls▁end|>" -}}{{- "<|end▁of▁sentence|>" -}}
|
| 81 |
+
{%- endif -%}
|
| 82 |
+
|
| 83 |
+
{# --------------------------- ASSISTANT plain ------------------------ #}
|
| 84 |
+
{%- if m.role == 'assistant' and (m.tool_calls is not defined or not m.tool_calls) -%}
|
| 85 |
+
{%- set ns.is_last_user = false -%}
|
| 86 |
+
{%- set txt = m.content if m.content is string else m.content | selectattr('type','equalto','text') | map(attribute='text') | join('') -%}
|
| 87 |
+
{{- txt -}}{{- "<|end▁of▁sentence|>" -}}
|
| 88 |
+
{%- endif -%}
|
| 89 |
+
|
| 90 |
+
{# --------------------------- TOOL output ---------------------------- #}
|
| 91 |
+
{%- if m.role == 'tool' -%}
|
| 92 |
+
{%- set ns.is_last_user = false -%}
|
| 93 |
+
{%- set out_txt = m.content if m.content is string else m.content | selectattr('type','equalto','text') | map(attribute='text') | join('') -%}
|
| 94 |
+
{%- if not ns.outputs_open -%}
|
| 95 |
+
{{- "<|tool▁outputs▁begin|>" -}}
|
| 96 |
+
{%- set ns.outputs_open = true -%}
|
| 97 |
+
{%- endif -%}
|
| 98 |
+
{{- "<|tool▁output▁begin|>" -}}{{- out_txt -}}{{- "<|tool▁output▁end|>" -}}
|
| 99 |
+
{%- if loop.nextitem is defined and loop.nextitem.role == 'tool' -%}
|
| 100 |
+
{{- "
|
| 101 |
+
" -}}
|
| 102 |
+
{%- endif -%}
|
| 103 |
+
{%- if loop.nextitem is not defined or loop.nextitem.role != 'tool' -%}
|
| 104 |
+
{{- "<|tool▁outputs▁end|>" -}}
|
| 105 |
+
{%- set ns.outputs_open = false -%}
|
| 106 |
+
{%- endif -%}
|
| 107 |
+
{%- endif -%}
|
| 108 |
+
{%- endfor -%}
|
| 109 |
+
|
| 110 |
+
{%- if ns.outputs_open -%}
|
| 111 |
+
{{- "<|tool▁outputs▁end|>" -}}
|
| 112 |
+
{%- endif -%}
|
| 113 |
+
|
| 114 |
+
{%- if add_generation_prompt and ns.is_last_user -%}
|
| 115 |
+
{{- "<|Assistant|>" -}}
|
| 116 |
+
{%- endif -%}
|
| 117 |
+
|
| 118 |
+
{%- if add_generation_prompt and enable_thinking -%}
|
| 119 |
+
{{- '<think>\n' -}}
|
| 120 |
+
{%- endif -%}
|
| 121 |
+
{# Copyright 2025-present the Unsloth team. All rights reserved. #}
|
| 122 |
+
{# Licensed under the Apache License, Version 2.0 (the "License") #}
|
config.json
ADDED
|
@@ -0,0 +1,109 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"architectures": [
|
| 3 |
+
"DeepseekV3ForCausalLM"
|
| 4 |
+
],
|
| 5 |
+
"attention_bias": false,
|
| 6 |
+
"attention_dropout": 0.0,
|
| 7 |
+
"auto_map": {
|
| 8 |
+
"AutoConfig": "configuration_deepseek.DeepseekV3Config",
|
| 9 |
+
"AutoModel": "modeling_deepseek.DeepseekV3Model",
|
| 10 |
+
"AutoModelForCausalLM": "modeling_deepseek.DeepseekV3ForCausalLM"
|
| 11 |
+
},
|
| 12 |
+
"aux_loss_alpha": 0.001,
|
| 13 |
+
"bos_token_id": 0,
|
| 14 |
+
"eos_token_id": 1,
|
| 15 |
+
"ep_size": 1,
|
| 16 |
+
"first_k_dense_replace": 3,
|
| 17 |
+
"head_dim": 64,
|
| 18 |
+
"hidden_act": "silu",
|
| 19 |
+
"hidden_size": 7168,
|
| 20 |
+
"initializer_range": 0.02,
|
| 21 |
+
"intermediate_size": 18432,
|
| 22 |
+
"kv_lora_rank": 512,
|
| 23 |
+
"max_position_embeddings": 163840,
|
| 24 |
+
"model_type": "deepseek_v3",
|
| 25 |
+
"moe_intermediate_size": 2048,
|
| 26 |
+
"moe_layer_freq": 1,
|
| 27 |
+
"n_group": 8,
|
| 28 |
+
"n_routed_experts": 256,
|
| 29 |
+
"n_shared_experts": 1,
|
| 30 |
+
"norm_topk_prob": true,
|
| 31 |
+
"num_attention_heads": 128,
|
| 32 |
+
"num_experts_per_tok": 8,
|
| 33 |
+
"num_hidden_layers": 61,
|
| 34 |
+
"num_key_value_heads": 128,
|
| 35 |
+
"num_nextn_predict_layers": 1,
|
| 36 |
+
"pad_token_id": 2,
|
| 37 |
+
"pretraining_tp": 1,
|
| 38 |
+
"q_lora_rank": 1536,
|
| 39 |
+
"qk_head_dim": 192,
|
| 40 |
+
"qk_nope_head_dim": 128,
|
| 41 |
+
"qk_rope_head_dim": 64,
|
| 42 |
+
"quantization_config": {
|
| 43 |
+
"config_groups": {
|
| 44 |
+
"group_0": {
|
| 45 |
+
"input_activations": {
|
| 46 |
+
"actorder": null,
|
| 47 |
+
"block_structure": null,
|
| 48 |
+
"dynamic": true,
|
| 49 |
+
"group_size": null,
|
| 50 |
+
"num_bits": 8,
|
| 51 |
+
"observer": null,
|
| 52 |
+
"observer_kwargs": {},
|
| 53 |
+
"strategy": "token",
|
| 54 |
+
"symmetric": true,
|
| 55 |
+
"type": "float"
|
| 56 |
+
},
|
| 57 |
+
"output_activations": null,
|
| 58 |
+
"targets": [
|
| 59 |
+
"Linear"
|
| 60 |
+
],
|
| 61 |
+
"weights": {
|
| 62 |
+
"actorder": null,
|
| 63 |
+
"block_structure": null,
|
| 64 |
+
"dynamic": false,
|
| 65 |
+
"group_size": null,
|
| 66 |
+
"num_bits": 8,
|
| 67 |
+
"observer": "minmax",
|
| 68 |
+
"observer_kwargs": {},
|
| 69 |
+
"strategy": "channel",
|
| 70 |
+
"symmetric": true,
|
| 71 |
+
"type": "float"
|
| 72 |
+
}
|
| 73 |
+
}
|
| 74 |
+
},
|
| 75 |
+
"format": "float-quantized",
|
| 76 |
+
"global_compression_ratio": null,
|
| 77 |
+
"ignore": [
|
| 78 |
+
"lm_head"
|
| 79 |
+
],
|
| 80 |
+
"kv_cache_scheme": null,
|
| 81 |
+
"quant_method": "compressed-tensors",
|
| 82 |
+
"quantization_status": "compressed"
|
| 83 |
+
},
|
| 84 |
+
"rms_norm_eps": 1e-06,
|
| 85 |
+
"rope_interleave": true,
|
| 86 |
+
"rope_scaling": {
|
| 87 |
+
"beta_fast": 32.0,
|
| 88 |
+
"beta_slow": 1.0,
|
| 89 |
+
"factor": 40.0,
|
| 90 |
+
"mscale": 1.0,
|
| 91 |
+
"mscale_all_dim": 1.0,
|
| 92 |
+
"original_max_position_embeddings": 4096,
|
| 93 |
+
"rope_type": "yarn",
|
| 94 |
+
"type": "yarn"
|
| 95 |
+
},
|
| 96 |
+
"rope_theta": 10000,
|
| 97 |
+
"routed_scaling_factor": 2.5,
|
| 98 |
+
"scoring_func": "sigmoid",
|
| 99 |
+
"seq_aux": true,
|
| 100 |
+
"tie_word_embeddings": false,
|
| 101 |
+
"topk_group": 4,
|
| 102 |
+
"topk_method": "noaux_tc",
|
| 103 |
+
"torch_dtype": "bfloat16",
|
| 104 |
+
"transformers_version": "4.54.1",
|
| 105 |
+
"unsloth_fixed": true,
|
| 106 |
+
"use_cache": true,
|
| 107 |
+
"v_head_dim": 128,
|
| 108 |
+
"vocab_size": 128815
|
| 109 |
+
}
|
configuration_deepseek.py
ADDED
|
@@ -0,0 +1,210 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from transformers.configuration_utils import PretrainedConfig
|
| 2 |
+
from transformers.utils import logging
|
| 3 |
+
|
| 4 |
+
logger = logging.get_logger(__name__)
|
| 5 |
+
|
| 6 |
+
DEEPSEEK_PRETRAINED_CONFIG_ARCHIVE_MAP = {}
|
| 7 |
+
class DeepseekV3Config(PretrainedConfig):
|
| 8 |
+
r"""
|
| 9 |
+
This is the configuration class to store the configuration of a [`DeepseekV3Model`]. It is used to instantiate an DeepSeek
|
| 10 |
+
model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
|
| 11 |
+
defaults will yield a similar configuration to that of the DeepSeek-V3.
|
| 12 |
+
|
| 13 |
+
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
|
| 14 |
+
documentation from [`PretrainedConfig`] for more information.
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
Args:
|
| 18 |
+
vocab_size (`int`, *optional*, defaults to 129280):
|
| 19 |
+
Vocabulary size of the Deep model. Defines the number of different tokens that can be represented by the
|
| 20 |
+
`inputs_ids` passed when calling [`DeepseekV3Model`]
|
| 21 |
+
hidden_size (`int`, *optional*, defaults to 4096):
|
| 22 |
+
Dimension of the hidden representations.
|
| 23 |
+
intermediate_size (`int`, *optional*, defaults to 11008):
|
| 24 |
+
Dimension of the MLP representations.
|
| 25 |
+
moe_intermediate_size (`int`, *optional*, defaults to 1407):
|
| 26 |
+
Dimension of the MoE representations.
|
| 27 |
+
num_hidden_layers (`int`, *optional*, defaults to 32):
|
| 28 |
+
Number of hidden layers in the Transformer decoder.
|
| 29 |
+
num_nextn_predict_layers (`int`, *optional*, defaults to 1):
|
| 30 |
+
Number of nextn predict layers in the DeepSeekV3 Model.
|
| 31 |
+
num_attention_heads (`int`, *optional*, defaults to 32):
|
| 32 |
+
Number of attention heads for each attention layer in the Transformer decoder.
|
| 33 |
+
n_shared_experts (`int`, *optional*, defaults to None):
|
| 34 |
+
Number of shared experts, None means dense model.
|
| 35 |
+
n_routed_experts (`int`, *optional*, defaults to None):
|
| 36 |
+
Number of routed experts, None means dense model.
|
| 37 |
+
routed_scaling_factor (`float`, *optional*, defaults to 1.0):
|
| 38 |
+
Scaling factor or routed experts.
|
| 39 |
+
topk_method (`str`, *optional*, defaults to `gready`):
|
| 40 |
+
Topk method used in routed gate.
|
| 41 |
+
n_group (`int`, *optional*, defaults to None):
|
| 42 |
+
Number of groups for routed experts.
|
| 43 |
+
topk_group (`int`, *optional*, defaults to None):
|
| 44 |
+
Number of selected groups for each token(for each token, ensuring the selected experts is only within `topk_group` groups).
|
| 45 |
+
num_experts_per_tok (`int`, *optional*, defaults to None):
|
| 46 |
+
Number of selected experts, None means dense model.
|
| 47 |
+
moe_layer_freq (`int`, *optional*, defaults to 1):
|
| 48 |
+
The frequency of the MoE layer: one expert layer for every `moe_layer_freq - 1` dense layers.
|
| 49 |
+
first_k_dense_replace (`int`, *optional*, defaults to 0):
|
| 50 |
+
Number of dense layers in shallow layers(embed->dense->dense->...->dense->moe->moe...->lm_head).
|
| 51 |
+
\--k dense layers--/
|
| 52 |
+
norm_topk_prob (`bool`, *optional*, defaults to False):
|
| 53 |
+
Whether to normalize the weights of the routed experts.
|
| 54 |
+
scoring_func (`str`, *optional*, defaults to 'softmax'):
|
| 55 |
+
Method of computing expert weights.
|
| 56 |
+
aux_loss_alpha (`float`, *optional*, defaults to 0.001):
|
| 57 |
+
Auxiliary loss weight coefficient.
|
| 58 |
+
seq_aux = (`bool`, *optional*, defaults to True):
|
| 59 |
+
Whether to compute the auxiliary loss for each individual sample.
|
| 60 |
+
num_key_value_heads (`int`, *optional*):
|
| 61 |
+
This is the number of key_value heads that should be used to implement Grouped Query Attention. If
|
| 62 |
+
`num_key_value_heads=num_attention_heads`, the model will use Multi Head Attention (MHA), if
|
| 63 |
+
`num_key_value_heads=1 the model will use Multi Query Attention (MQA) otherwise GQA is used. When
|
| 64 |
+
converting a multi-head checkpoint to a GQA checkpoint, each group key and value head should be constructed
|
| 65 |
+
by meanpooling all the original heads within that group. For more details checkout [this
|
| 66 |
+
paper](https://arxiv.org/pdf/2305.13245.pdf). If it is not specified, will default to
|
| 67 |
+
`num_attention_heads`.
|
| 68 |
+
hidden_act (`str` or `function`, *optional*, defaults to `"silu"`):
|
| 69 |
+
The non-linear activation function (function or string) in the decoder.
|
| 70 |
+
max_position_embeddings (`int`, *optional*, defaults to 2048):
|
| 71 |
+
The maximum sequence length that this model might ever be used with.
|
| 72 |
+
initializer_range (`float`, *optional*, defaults to 0.02):
|
| 73 |
+
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
|
| 74 |
+
rms_norm_eps (`float`, *optional*, defaults to 1e-06):
|
| 75 |
+
The epsilon used by the rms normalization layers.
|
| 76 |
+
use_cache (`bool`, *optional*, defaults to `True`):
|
| 77 |
+
Whether or not the model should return the last key/values attentions (not used by all models). Only
|
| 78 |
+
relevant if `config.is_decoder=True`.
|
| 79 |
+
pad_token_id (`int`, *optional*):
|
| 80 |
+
Padding token id.
|
| 81 |
+
bos_token_id (`int`, *optional*, defaults to 1):
|
| 82 |
+
Beginning of stream token id.
|
| 83 |
+
eos_token_id (`int`, *optional*, defaults to 2):
|
| 84 |
+
End of stream token id.
|
| 85 |
+
pretraining_tp (`int`, *optional*, defaults to 1):
|
| 86 |
+
Experimental feature. Tensor parallelism rank used during pretraining. Please refer to [this
|
| 87 |
+
document](https://huggingface.co/docs/transformers/parallelism) to understand more about it. This value is
|
| 88 |
+
necessary to ensure exact reproducibility of the pretraining results. Please refer to [this
|
| 89 |
+
issue](https://github.com/pytorch/pytorch/issues/76232).
|
| 90 |
+
tie_word_embeddings (`bool`, *optional*, defaults to `False`):
|
| 91 |
+
Whether to tie weight embeddings
|
| 92 |
+
rope_theta (`float`, *optional*, defaults to 10000.0):
|
| 93 |
+
The base period of the RoPE embeddings.
|
| 94 |
+
rope_scaling (`Dict`, *optional*):
|
| 95 |
+
Dictionary containing the scaling configuration for the RoPE embeddings. Currently supports two scaling
|
| 96 |
+
strategies: linear and dynamic. Their scaling factor must be a float greater than 1. The expected format is
|
| 97 |
+
`{"type": strategy name, "factor": scaling factor}`. When using this flag, don't update
|
| 98 |
+
`max_position_embeddings` to the expected new maximum.
|
| 99 |
+
attention_bias (`bool`, defaults to `False`, *optional*, defaults to `False`):
|
| 100 |
+
Whether to use a bias in the query, key, value and output projection layers during self-attention.
|
| 101 |
+
attention_dropout (`float`, *optional*, defaults to 0.0):
|
| 102 |
+
The dropout ratio for the attention probabilities.
|
| 103 |
+
|
| 104 |
+
```python
|
| 105 |
+
>>> from transformers import DeepseekV3Model, DeepseekV3Config
|
| 106 |
+
|
| 107 |
+
>>> # Initializing a Deepseek-V3 style configuration
|
| 108 |
+
>>> configuration = DeepseekV3Config()
|
| 109 |
+
|
| 110 |
+
>>> # Accessing the model configuration
|
| 111 |
+
>>> configuration = model.config
|
| 112 |
+
```"""
|
| 113 |
+
|
| 114 |
+
model_type = "deepseek_v3"
|
| 115 |
+
keys_to_ignore_at_inference = ["past_key_values"]
|
| 116 |
+
|
| 117 |
+
def __init__(
|
| 118 |
+
self,
|
| 119 |
+
vocab_size=129280,
|
| 120 |
+
hidden_size=7168,
|
| 121 |
+
intermediate_size=18432,
|
| 122 |
+
moe_intermediate_size = 2048,
|
| 123 |
+
num_hidden_layers=61,
|
| 124 |
+
num_nextn_predict_layers=1,
|
| 125 |
+
num_attention_heads=128,
|
| 126 |
+
num_key_value_heads=128,
|
| 127 |
+
n_shared_experts = 1,
|
| 128 |
+
n_routed_experts = 256,
|
| 129 |
+
ep_size = 1,
|
| 130 |
+
routed_scaling_factor = 2.5,
|
| 131 |
+
kv_lora_rank = 512,
|
| 132 |
+
q_lora_rank = 1536,
|
| 133 |
+
qk_rope_head_dim = 64,
|
| 134 |
+
v_head_dim = 128,
|
| 135 |
+
qk_nope_head_dim = 128,
|
| 136 |
+
topk_method = 'noaux_tc',
|
| 137 |
+
n_group = 8,
|
| 138 |
+
topk_group = 4,
|
| 139 |
+
num_experts_per_tok = 8,
|
| 140 |
+
moe_layer_freq = 1,
|
| 141 |
+
first_k_dense_replace = 3,
|
| 142 |
+
norm_topk_prob = True,
|
| 143 |
+
scoring_func = 'sigmoid',
|
| 144 |
+
aux_loss_alpha = 0.001,
|
| 145 |
+
seq_aux = True,
|
| 146 |
+
hidden_act="silu",
|
| 147 |
+
max_position_embeddings=4096,
|
| 148 |
+
initializer_range=0.02,
|
| 149 |
+
rms_norm_eps=1e-6,
|
| 150 |
+
use_cache=True,
|
| 151 |
+
pad_token_id=None,
|
| 152 |
+
bos_token_id=0,
|
| 153 |
+
eos_token_id=1,
|
| 154 |
+
pretraining_tp=1,
|
| 155 |
+
tie_word_embeddings=False,
|
| 156 |
+
rope_theta=10000.0,
|
| 157 |
+
rope_scaling=None,
|
| 158 |
+
attention_bias=False,
|
| 159 |
+
attention_dropout=0.0,
|
| 160 |
+
**kwargs,
|
| 161 |
+
):
|
| 162 |
+
self.vocab_size = vocab_size
|
| 163 |
+
self.max_position_embeddings = max_position_embeddings
|
| 164 |
+
self.hidden_size = hidden_size
|
| 165 |
+
self.intermediate_size = intermediate_size
|
| 166 |
+
self.moe_intermediate_size = moe_intermediate_size
|
| 167 |
+
self.num_hidden_layers = num_hidden_layers
|
| 168 |
+
self.num_nextn_predict_layers = num_nextn_predict_layers
|
| 169 |
+
self.num_attention_heads = num_attention_heads
|
| 170 |
+
self.n_shared_experts = n_shared_experts
|
| 171 |
+
self.n_routed_experts = n_routed_experts
|
| 172 |
+
self.ep_size = ep_size
|
| 173 |
+
self.routed_scaling_factor = routed_scaling_factor
|
| 174 |
+
self.kv_lora_rank = kv_lora_rank
|
| 175 |
+
self.q_lora_rank = q_lora_rank
|
| 176 |
+
self.qk_rope_head_dim = qk_rope_head_dim
|
| 177 |
+
self.v_head_dim = v_head_dim
|
| 178 |
+
self.qk_nope_head_dim = qk_nope_head_dim
|
| 179 |
+
self.topk_method = topk_method
|
| 180 |
+
self.n_group = n_group
|
| 181 |
+
self.topk_group = topk_group
|
| 182 |
+
self.num_experts_per_tok = num_experts_per_tok
|
| 183 |
+
self.moe_layer_freq = moe_layer_freq
|
| 184 |
+
self.first_k_dense_replace = first_k_dense_replace
|
| 185 |
+
self.norm_topk_prob = norm_topk_prob
|
| 186 |
+
self.scoring_func = scoring_func
|
| 187 |
+
self.aux_loss_alpha = aux_loss_alpha
|
| 188 |
+
self.seq_aux = seq_aux
|
| 189 |
+
# for backward compatibility
|
| 190 |
+
if num_key_value_heads is None:
|
| 191 |
+
num_key_value_heads = num_attention_heads
|
| 192 |
+
|
| 193 |
+
self.num_key_value_heads = num_key_value_heads
|
| 194 |
+
self.hidden_act = hidden_act
|
| 195 |
+
self.initializer_range = initializer_range
|
| 196 |
+
self.rms_norm_eps = rms_norm_eps
|
| 197 |
+
self.pretraining_tp = pretraining_tp
|
| 198 |
+
self.use_cache = use_cache
|
| 199 |
+
self.rope_theta = rope_theta
|
| 200 |
+
self.rope_scaling = rope_scaling
|
| 201 |
+
self.attention_bias = attention_bias
|
| 202 |
+
self.attention_dropout = attention_dropout
|
| 203 |
+
|
| 204 |
+
super().__init__(
|
| 205 |
+
pad_token_id=pad_token_id,
|
| 206 |
+
bos_token_id=bos_token_id,
|
| 207 |
+
eos_token_id=eos_token_id,
|
| 208 |
+
tie_word_embeddings=tie_word_embeddings,
|
| 209 |
+
**kwargs,
|
| 210 |
+
)
|
generation_config.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 0,
|
| 4 |
+
"eos_token_id": 1,
|
| 5 |
+
"transformers_version": "4.53.0"
|
| 6 |
+
}
|
images/README
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
Directory for images associated with the model.
|
images/cogito-v2-671b-non-reasoning-benchmarks.png
ADDED
|
Git LFS Details
|
images/cogito-v2-671b-reasoning-benchmarks.png
ADDED

|
Git LFS Details
|
images/deep-cogito-logo.png
ADDED
|
|
model-00001-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b6d7bb74d1f02537f496cb82bdfd2056dd7ed89b10140c59a872a15e31d1792f
|
| 3 |
+
size 4989505008
|
model-00002-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f1f1cca90647254846a50de1215c43ae8381f3ef22e4b2e0741fd13e20a3b57e
|
| 3 |
+
size 4993855904
|
model-00003-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d520e4dd1cadcf7bf4c29e61327581fc6cf614aff11adf96f09f1fd941b75ae8
|
| 3 |
+
size 4993866592
|
model-00004-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0154c1c88d8663a7eafd74822079b63176e415891bb352bca60617efd03199c2
|
| 3 |
+
size 4993861360
|
model-00005-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4f3eaa1875ab076a164ab6bad2737b8518fdead24dad92d98f1bc4c92023d32a
|
| 3 |
+
size 4993856352
|
model-00006-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9df4ce5126a6cfc6d72fe3dab1586be5329e925e3d139793aece8c49a259e9c0
|
| 3 |
+
size 4993861312
|
model-00007-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:065af7fe792a792f847c45cd6aabfdf7b3dc113e8e3508a18c40666fe15bb8b6
|
| 3 |
+
size 4993856176
|
model-00008-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:27ac804450c80ee4f2fb7cc3a48859f7e939e1aee9c1f5c34a24bbe37c80dd25
|
| 3 |
+
size 4993861488
|
model-00009-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8a421a353258b5c7758b6ba8e8cd7c9ce34ab1e3a452953f74bb6f504066166c
|
| 3 |
+
size 4993866208
|
model-00010-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:bc54c84d60133cb7a3c8aaa9a0386eed0bb4807614df2648eca43f2627124925
|
| 3 |
+
size 4993861744
|
model-00011-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e98396d46e049b8774b7fddc3843cb5b06bc8b478235c2729f2f0c5ba8a95ff0
|
| 3 |
+
size 4993855712
|
model-00012-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:75c1a9f889cf3ef9fdcd3ed1faa5c16b28ad97def38c7c0959a7553e3235852a
|
| 3 |
+
size 4993856352
|
model-00013-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:5f7e9e8958947426c129303e4aa26036c309ac894f8f3106adfbce92d636112b
|
| 3 |
+
size 4993861312
|
model-00014-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:cd9fd84e4cf22ecfaa3f3160fb9a012c323cbb668ad3a8918695c23c4de45cdd
|
| 3 |
+
size 4993866472
|
model-00015-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f732682c039b562ea1813cd36fd1c610de00d1b841525a13a87f6b01737d6fc3
|
| 3 |
+
size 4993861432
|
model-00016-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:22d772e564b84999c6ebeac28ac0e7dc5f5ff61a2bad84f6c3a6f56ffc3c7c44
|
| 3 |
+
size 4993856024
|
model-00017-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4b9d69d7273a8cf717030e8f5a9e48b4454b17397207dfd86b256e001cbd788b
|
| 3 |
+
size 4993861752
|
model-00018-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:91081bc914a746da71dcccdf38d054e4a37649504506a55ab0293690af123a6c
|
| 3 |
+
size 4993856488
|
model-00019-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:969df4a3957ca620e559827cf0e807600a58e2c3717f42c94cde0c754bc064af
|
| 3 |
+
size 4993867272
|
model-00020-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7a3957597b6ea63c5ed02cec584d42960164d4fc30109fee11cb07016e0bccd8
|
| 3 |
+
size 4993861984
|
model-00021-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d0643cb7cd6e1bcf1a661aa68e43b791668c395b709933fbc69df0fda833d5ee
|
| 3 |
+
size 4993856968
|
model-00022-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2b6ed33a4eca3a67a821a3f9ff16615e2517c05d67a178fb8983b2bad749a7c1
|
| 3 |
+
size 4993862040
|
model-00023-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:58af5701aed171b57763a80c27c1e74d48ba106cf73f365b7641a5cc41b6b827
|
| 3 |
+
size 4993856760
|
model-00024-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:813c6bff917794fc934f710c3f8bc26f80244d2fe0aa02982bce5daf2ca5a94a
|
| 3 |
+
size 4993862248
|
model-00025-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:902a6ca4cda0404c988253422279772a4002cab53e85c86a327c83d2d0cd2931
|
| 3 |
+
size 4993866792
|
model-00026-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:cf4269db924f5bc623082f75b3a11f25da367164511be050fdbc3f9f0a9ed272
|
| 3 |
+
size 4993857032
|
model-00027-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:17dcb9d178be0140dd9b0c62bfa26dd5781701e6fc9117250d7a8fdcd72105f8
|
| 3 |
+
size 4993861984
|
model-00028-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:688fdf26060a27b92797587355f3339e915ea3598a754020e75e425fb0da2637
|
| 3 |
+
size 4993857024
|
model-00029-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:fbc62822aef4c158558b63aa77852f27bb70c91a6369ea63ff829583cab2b960
|
| 3 |
+
size 4993861984
|
model-00030-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:27eacacf9bb23282e6b164414b933537997937a2d4afa814c652fcf0d97fd3d4
|
| 3 |
+
size 4993867056
|
model-00031-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:28360c7e425c31eea25c36998f4d08772108af978356cca0fbc3bc81ac2076df
|
| 3 |
+
size 4993862192
|
model-00032-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c5ffc41db9d08b624230d1b8c86479ce521c3f10a17a41b9029e08f99f8b304b
|
| 3 |
+
size 4993856608
|
model-00033-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2f7f9e66b54cf1fb56cfb04026924ad255e999501af7a1a4189405177881b5f1
|
| 3 |
+
size 4997527784
|
model-00034-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:eb58dbeb6993569afdcef31285489e9f6b78668a09fc740c12d82aad9ad1500b
|
| 3 |
+
size 4990191024
|
model-00035-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a820c88cdec5a4e8243133bf737f35bcf0e50185be1ee18e4eef949022da5d06
|
| 3 |
+
size 4993867272
|
model-00036-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:f4afbc6029d03f2c19f7e27a8f825107448cf9c73dcc054ecdcd14bc267af4f1
|
| 3 |
+
size 4993861984
|
model-00037-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c7a7bdee5ea0fb540b3510498e85e47de712ee56f3ddac58c4381ae3adbc3d69
|
| 3 |
+
size 4993856872
|
model-00038-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7a464d7ba5067c8c1186206a88922e03133d9114079138726f9470aec47c0be4
|
| 3 |
+
size 4993862136
|
model-00039-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c654da8f0c76cdc3356d3d178522bddf3683cecf59a2182b76fb395697584556
|
| 3 |
+
size 4993856664
|
model-00040-of-00135.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:bc7e584539a35601527f15ba76b340a78c2c9af174fd534b1bbf48ab1ba76529
|
| 3 |
+
size 4993862376
|