## Introduction
We introduce Trillion-7B-preview, a preview of our latest large language model designed to push the boundaries of multilingual scalability and performance.
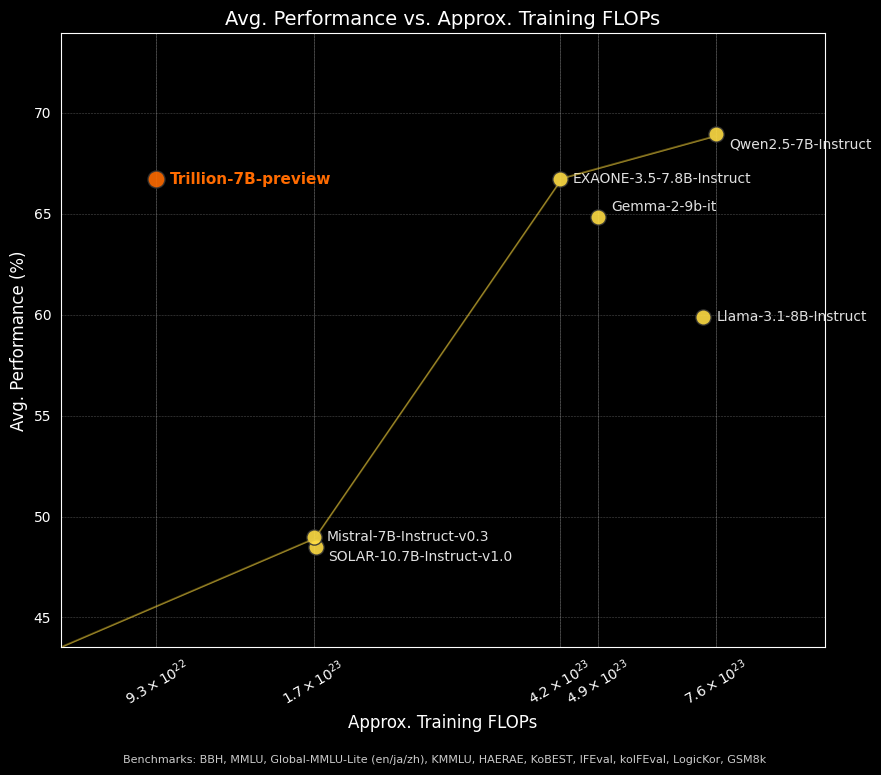
When comparing performance to training FLOPs for Trillion-7B-preview with competitive models, our model pushes the Pareto frontier, achieving around 66.5% average performance while using significantly fewer compute (~9.3×10²² FLOPs). It outperforms models like Mistral-7B-Instruct-v0.3 and SOLAR-10.7B-Instruct-v1.0 while remaining competitive with models requiring 3-8× more compute such as Qwen2.5-7B-Instruct and EXAONE-3.5-7.8B-Instruct. For full benchmark results, see tables below.
- Type: Causal Language Model
- Training Stage: Pre-training & Post-training
- Architecture: Transformer Decoder with RoPE, SwiGLU, RMSNorm
- Number of Parameters: 7.76B
- Number of Layers: 32
- Number of Attention Heads: 32
- Context Length: 4,096
- Number of Tokens seen: 2T
- Vocab Size: 128,128
## Quickstart
Here is a code snippet with `apply_chat_template` that demonstrates how to load the tokenizer and model and generate text.
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "trillionlabs/Trillion-7B-preview"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "Tell me a hilarious knock knock joke."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
model_inputs["input_ids"],
attention_mask=model_inputs["attention_mask"],
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
"""
Sure! Here's a classic knock-knock joke that's guaranteed to make you chuckle:
Knock, knock.
Who's there?
Lettuce.
Lettuce who?
Lettuce in, it's too cold out here!
"""
```
## Evaluation
We select a wide variety of benchmarks that evaluate general reasoning, knowledge recall, coding abilities, mathematical reasoning, and instruction following capabilities. We evaluated Trillion-7B-preview along with several leading large language models of similar size. Our model especially demonstrates strong performance on Korean benchmarks.
Full evaluation settings
| Benchmark | Language | Evaluation Setting | Metric |
|:----------|:---------|:------------------|:-------|
| **General Reasoning and Reading Comprehension** | | | |
| • HellaSwag | English | 0-shot | accuracy |
| • TruthfulQA_mc1 | English | 6-shot | accuracy |
| • TruthfulQA_mc2 | English | 6-shot | accuracy |
| • ARC:C | English | 0-shot | accuracy |
| • HAERAE | Korean | 3-shot | accuracy |
| • KoBEST | Korean | 5-shot | accuracy |
| • BBH | English | 0-shot, CoT | accuracy |
| • xwinograd_en | English | 0-shot | accuracy |
| • xwinograd_jp | Japanese | 0-shot | accuracy |
| • xwinograd_zh | Chinese | 0-shot | accuracy |
| **Knowledge Recall** | | | |
| • KMMLU | Korean | 5-shot | accuracy |
| • MMLU | English | 5-shot | accuracy |
| • Global-MMLU-Lite-en | English | 5-shot | accuracy |
| • Global-MMLU-Lite-ko | Korean | 5-shot | accuracy |
| • Global-MMLU-Lite-ja | Japanese | 5-shot | accuracy |
| • Global-MMLU-Lite-zh | Chinese | 5-shot | accuracy |
| **Coding** | | | |
| • HumanEval | English | 0-shot, CoT | pass@1 |
| • MBPP | English | 0-shot, CoT| pass@1 |
| **Mathematical Reasoning** | | | |
| • GSM8k | English | 0-shot, CoT | exact-match |
| • MATH | English | 0-shot, CoT | exact-match |
| • GPQA | English | 4-shot | accuracy |
| • HRM8k | Korean | 0-shot, CoT | exact-match |
| **Instruction Following and Chat** | | | |
| • IFEval | English | 0-shot | strict-average |
| • koIFEval* | Korean | 0-shot | strict-average |
| • MT-Bench** | English | LLM-as-a-judge (gpt-4o-2024-08-06) | LLM score |
| • KO-MT-Bench** | Korean | LLM-as-a-judge (gpt-4o-2024-08-06) | LLM score |
| • LogicKor** | Korean | LLM-as-a-judge (gpt-4o-2024-08-06) | LLM score |
- *Note that koIFEval is our in-house evaluation benchmark for assessing instruction-following capabilities in Korean.
- **Note that MT-Bench, KO-MT-Bench, and LogicKor use a 10-point scale.
### Benchmark Results
- Trillion-7B-preview
- [LGAI-EXAONE/EXAONE-3.5-7.8B-Instruct](https://huggingface.co/LGAI-EXAONE/EXAONE-3.5-7.8B-Instruct)
- [google/gemma-2-9b-it](https://huggingface.co/google/gemma-2-9b-it)
- [meta-llama/Llama-3.1-8B-Instruct](meta-llama/Llama-3.1-8B-Instruct)
- [Qwen/Qwen2.5-7B-Instruct](Qwen/Qwen2.5-7B-Instruct)
- [upstage/SOLAR-10.7B-Instruct-v1.0](upstage/SOLAR-10.7B-Instruct-v1.0)
- [mistralai/Mistral-7B-Instruct-v0.3](mistralai/Mistral-7B-Instruct-v0.3)
### General Reasoning and Factuality
| Benchmark | Trillion-7B-preview | EXAONE-3.5-7.8B-Instruct | gemma-2-9b-it | Llama-3.1-8B-Instruct | Qwen2.5-7B-Instruct | SOLAR-10.7B-Instruct-v1.0 | Mistral-7B-Instruct-v0.3 |
| --- | --- | --- | --- | --- | --- | --- | --- |
| HellaSwag | 58.94 | 60.04 | 59.72 | 59.81 | 61.97 | 68.72 | 65.79 |
| TruthfulQA_mc1 | 36.10 | 40.64 | 42.96 | 38.07 | 47.74 | 56.18 | 42.47 |
| TruthfulQA_mc2 | 54.10 | 59.74 | 60.09 | 54.54 | 64.72 | 70.64 | 59.41 |
| ARC:C | 54.44 | 56.40 | 62.97 | 53.58 | 52.99 | 60.07 | 58.11 |
| HAERAE | 80.02 | 76.08 | 68.01 | 63.15 | 65.17 | 60.86 | 47.75 |
| KoBEST | 79.61 | 78.57 | 79.98 | 70.09 | 79.24 | 75.20 | 66.50 |
| KMMLU | 48.09 | 45.39 | 46.66 | 41.41 | 50.15 | 41.66 | 33.59 |
| MMLU | 63.52 | 65.65 | 72.24 | 68.32 | 74.23 | 65.20 | 61.84 |
| Global-MMLU-Lite-en | 67.75 | 69.50 | 76.25 | 67.50 | 77.25 | 71.75 | 65.50 |
| Global-MMLU-Lite-ko | 60.75 | 60.00 | 64.25 | 54.00 | 59.25 | 53.75 | 43.00 |
| Global-MMLU-Lite-ja | 60.75 | 45.75 | 66.50 | 54.50 | 65.75 | 50.75 | 50.00 |
| Global-MMLU-Lite-zh | 59.50 | 50.00 | 63.75 | 60.25 | 68.75 | 57.00 | 47.25 |
| BBH | 41.94 | 53.30 | 28.77 | 43.16 | 53.68 | 52.91 | 45.09 |
| xwinograd_en | 87.78 | 87.10 | 89.55 | 88.09 | 85.63 | 87.35 | 88.39 |
| xwinograd_jp | 79.98 | 74.45 | 80.92 | 76.02 | 72.89 | 72.58 | 70.70 |
| xwinograd_zh | 73.81 | 69.44 | 68.06 | 76.19 | 81.55 | 74.60 | 71.83 |
### Coding
| Benchmark | Trillion-7B-preview | EXAONE-3.5-7.8B-Instruct | gemma-2-9b-it | Llama-3.1-8B-Instruct | Qwen2.5-7B-Instruct | SOLAR-10.7B-Instruct-v1.0 | Mistral-7B-Instruct-v0.3 |
| --- | --- | --- | --- | --- | --- | --- | --- |
| HumanEval | 55.48 | 79.26 | 60.98 | 67.68 | 81.71 | 34.76 | 36.59 |
| MBPP | 40.40 | 61.40 | 8.40 | 39.20 | 51.00 | 29.40 | 36.00 |
### Mathematical Reasoning
| Benchmark | Trillion-7B-preview | EXAONE-3.5-7.8B-Instruct | gemma-2-9b-it | Llama-3.1-8B-Instruct | Qwen2.5-7B-Instruct | SOLAR-10.7B-Instruct-v1.0 | Mistral-7B-Instruct-v0.3 |
| --- | --- | --- | --- | --- | --- | --- | --- |
| GSM8k | 72.25 | 87.79 | 73.69 | 74.98 | 88.86 | 62.93 | 35.94 |
| MATH | 32.70 | 70.68 | - | 38.30 | 71.50 | 14.38 | 12.12 |
| GPQA | 32.81 | 38.61 | 36.83 | 30.58 | 34.15 | 28.35 | 32.59 |
| HRM8k | 30.10 | 38.99 | 16.04 | - | 41.51 | 20.68 | 7.89 |
### Instruction Following and Chat
| Benchmark | Trillion-7B-preview | EXAONE-3.5-7.8B-Instruct | gemma-2-9b-it | Llama-3.1-8B-Instruct | Qwen2.5-7B-Instruct | SOLAR-10.7B-Instruct-v1.0 | Mistral-7B-Instruct-v0.3 |
| --- | --- | --- | --- | --- | --- | --- | --- |
| IFEval | 79.13 | 81.42 | 75.48 | 74.93 | 75.85 | 51.61 | 52.64 |
| koIFEval | 66.58 | 54.65 | 43.30 | 36.07 | 48.55 | 26.12 | 34.22 |
| MT-Bench | 7.00 | 8.15 | 7.81 | 6.32 | 7.86 | 6.76 | 6.84 |
| KO-MT-Bench | 6.27 | 8.13 | 7.01 | 4.27 | 6.31 | 2.89 | 4.07 |
| LogicKor | 8.14 | 9.25 | 8.33 | 6.45 | 7.99 | 1.85 | 4.76
## Limitations
- Language Support: The model is optimized for English, Korean, Japanese, and Chinese. Usage with other languages may result in degraded performance.
- Knowledge Cutoff: The model's information is limited to data available up to August 2023.
- Safety Mechanisms: This release does not yet include comprehensive safety features. Future updates will address this area.
- Release Status: This is a preliminary release version with planned enhancements and updates forthcoming.
## License
This model repository is licensed under the Apache-2.0 License.
## Citation
```
@article{trillion7Bpreview,
title={Trillion-7B-preview},
author={trillionlabs},
year={2025},
url={https://huggingface.co/trillionlabs/Trillion-7B-preview}
}
```
## Contact
For inquiries, please contact: info@trillionlabs.co