---
license: llama3.2
datasets:
- BAAI/Infinity-Instruct
base_model:
- meta-llama/Llama-3.2-1B-Instruct
tags:
- Instruct_Tuning
---
# Shadow-FT
[📜 Paper] •
[🤗 HF Models] •
[🐱 GitHub]
This repo contains the weights from our paper: Shadow-FT: Tuning Instruct via Base by Taiqiang Wu* Runming Yang*, Jiayi Li, Pengfei Hu, Ngai Wong and Yujiu Yang.
\* for equal contributions.
## Overview
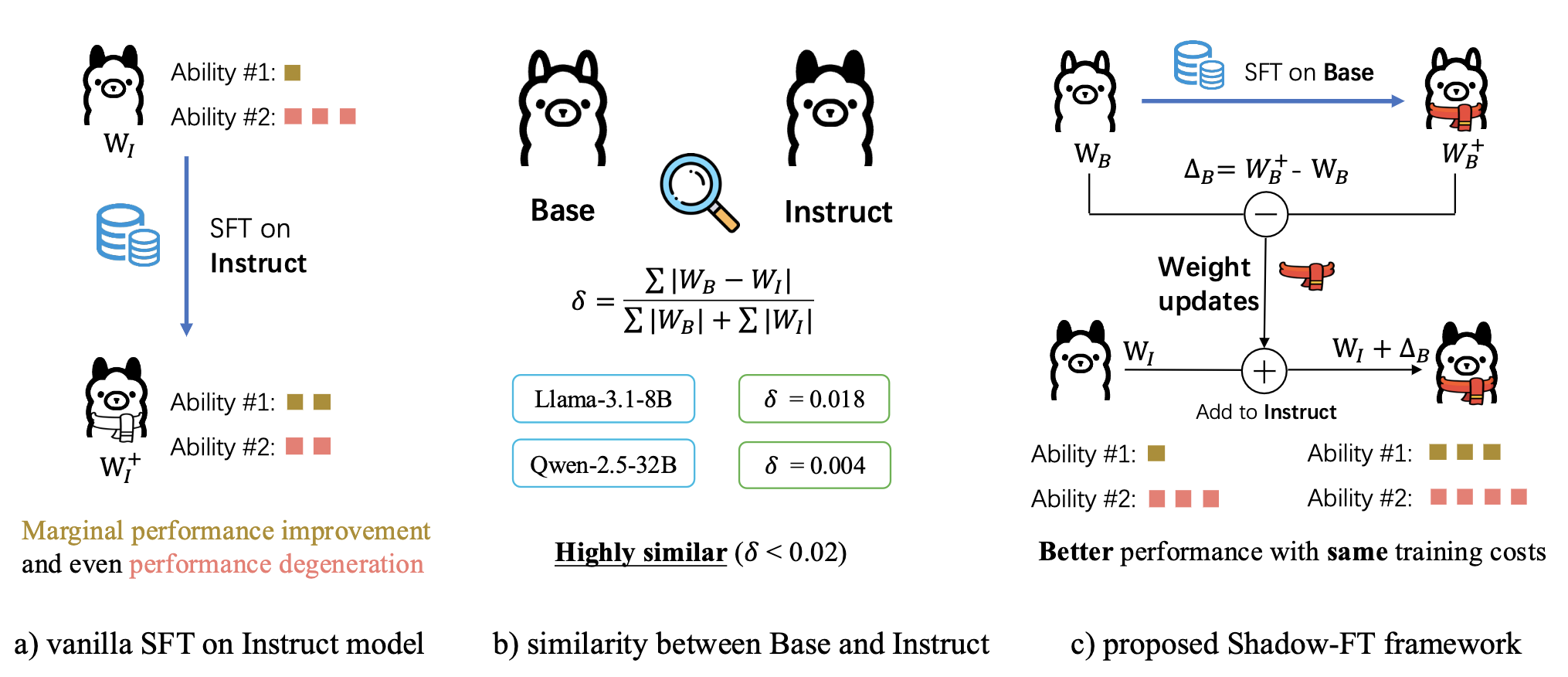 Observation:
- Directly tuning the INSTRUCT (i.e., instruction tuned) models often leads to marginal improvements and even performance degeneration.
- Paired BASE models, the foundation for these INSTRUCT variants, contain highly similar weight values (i.e., less than 2% on average for Llama 3.1 8B).
$\Rightarrow$ We propose the Shadow-FT framework to tune the INSTRUCT models by leveraging the corresponding BASE models. The key insight is to fine-tune the BASE model, and then _directly_ graft the learned weight updates to the INSTRUCT model.
## Performance
This repository contains the Llama-3.2-1B tuned on BAAI-2k subsets using Shadow-FT.
Observation:
- Directly tuning the INSTRUCT (i.e., instruction tuned) models often leads to marginal improvements and even performance degeneration.
- Paired BASE models, the foundation for these INSTRUCT variants, contain highly similar weight values (i.e., less than 2% on average for Llama 3.1 8B).
$\Rightarrow$ We propose the Shadow-FT framework to tune the INSTRUCT models by leveraging the corresponding BASE models. The key insight is to fine-tune the BASE model, and then _directly_ graft the learned weight updates to the INSTRUCT model.
## Performance
This repository contains the Llama-3.2-1B tuned on BAAI-2k subsets using Shadow-FT.
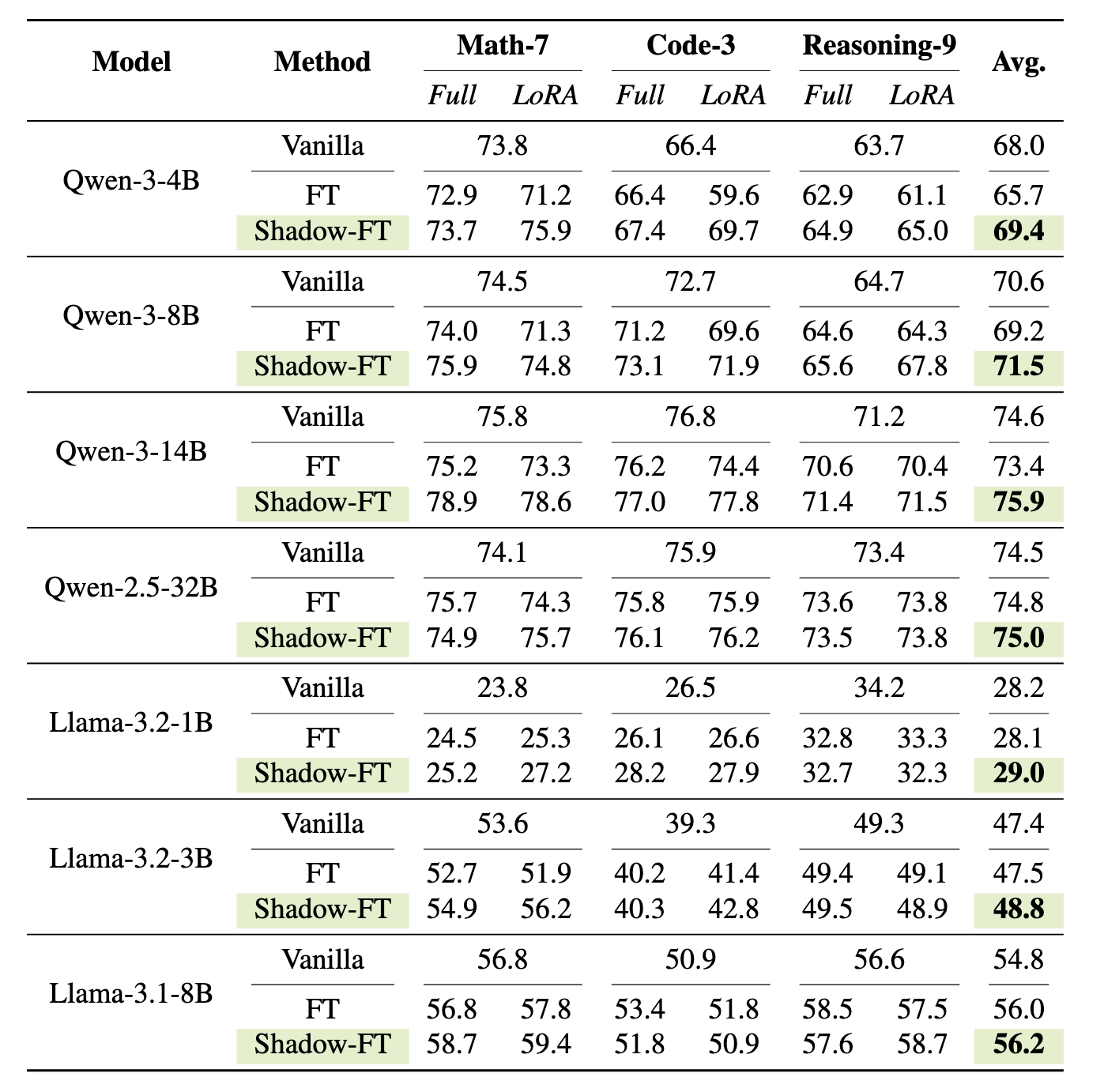 please refer to [our paper](https://arxiv.org/pdf/2505.12716) for details.
## ☕️ Citation
If you find this repository helpful, please consider citing our paper:
```
@article{wu2025shadow,
title={Shadow-FT: Tuning Instruct via Base},
author={Wu, Taiqiang and Yang, Runming and Li, Jiayi and Hu, Pengfei and Wong, Ngai and Yang, Yujiu},
journal={arXiv preprint arXiv:2505.12716},
year={2025}
}
```
For any questions, please pull an issue or email at `takiwu@connect.hku.hk`
please refer to [our paper](https://arxiv.org/pdf/2505.12716) for details.
## ☕️ Citation
If you find this repository helpful, please consider citing our paper:
```
@article{wu2025shadow,
title={Shadow-FT: Tuning Instruct via Base},
author={Wu, Taiqiang and Yang, Runming and Li, Jiayi and Hu, Pengfei and Wong, Ngai and Yang, Yujiu},
journal={arXiv preprint arXiv:2505.12716},
year={2025}
}
```
For any questions, please pull an issue or email at `takiwu@connect.hku.hk`