Spaces:
Runtime error

Runtime error
Upload 111 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +1 -0
- examples/0000004.png +0 -0
- examples/0000005.png +0 -0
- examples/0000006.png +0 -0
- examples/0000007.png +0 -0
- examples/0000011.png +0 -0
- unimernet/__init__.py +31 -0
- unimernet/__pycache__/__init__.cpython-310.pyc +0 -0
- unimernet/common/__init__.py +0 -0
- unimernet/common/__pycache__/__init__.cpython-310.pyc +0 -0
- unimernet/common/__pycache__/config.cpython-310.pyc +0 -0
- unimernet/common/__pycache__/dist_utils.cpython-310.pyc +0 -0
- unimernet/common/__pycache__/logger.cpython-310.pyc +0 -0
- unimernet/common/__pycache__/registry.cpython-310.pyc +0 -0
- unimernet/common/__pycache__/utils.cpython-310.pyc +0 -0
- unimernet/common/config.py +468 -0
- unimernet/common/dist_utils.py +137 -0
- unimernet/common/gradcam.py +24 -0
- unimernet/common/logger.py +195 -0
- unimernet/common/optims.py +120 -0
- unimernet/common/registry.py +329 -0
- unimernet/common/utils.py +424 -0
- unimernet/configs/datasets/formula/formula_eval.yaml +6 -0
- unimernet/configs/datasets/formula/formula_train.yaml +6 -0
- unimernet/configs/datasets/formula/multi_scale_formula_train.yaml +21 -0
- unimernet/configs/default.yaml +10 -0
- unimernet/configs/models/unimernet_base.yaml +31 -0
- unimernet/datasets/__init__.py +0 -0
- unimernet/datasets/__pycache__/__init__.cpython-310.pyc +0 -0
- unimernet/datasets/__pycache__/data_utils.cpython-310.pyc +0 -0
- unimernet/datasets/builders/__init__.py +69 -0
- unimernet/datasets/builders/__pycache__/__init__.cpython-310.pyc +0 -0
- unimernet/datasets/builders/__pycache__/base_dataset_builder.cpython-310.pyc +0 -0
- unimernet/datasets/builders/__pycache__/formula.cpython-310.pyc +0 -0
- unimernet/datasets/builders/base_dataset_builder.py +233 -0
- unimernet/datasets/builders/formula.py +105 -0
- unimernet/datasets/data_utils.py +284 -0
- unimernet/datasets/datasets/__pycache__/base_dataset.cpython-310.pyc +0 -0
- unimernet/datasets/datasets/__pycache__/formula.cpython-310.pyc +0 -0
- unimernet/datasets/datasets/__pycache__/formula_multi_scale.cpython-310.pyc +0 -0
- unimernet/datasets/datasets/base_dataset.py +103 -0
- unimernet/datasets/datasets/dataloader_utils.py +200 -0
- unimernet/datasets/datasets/formula.py +71 -0
- unimernet/datasets/datasets/formula_multi_scale.py +32 -0
- unimernet/models/__init__.py +198 -0
- unimernet/models/__pycache__/__init__.cpython-310.pyc +0 -0
- unimernet/models/__pycache__/base_model.cpython-310.pyc +0 -0
- unimernet/models/__pycache__/clip_vit.cpython-310.pyc +0 -0
- unimernet/models/__pycache__/eva_vit.cpython-310.pyc +0 -0
- unimernet/models/base_model.py +251 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
unimernet/processors/formula_processor_helper/frost/frost1.png filter=lfs diff=lfs merge=lfs -text
|
examples/0000004.png
ADDED
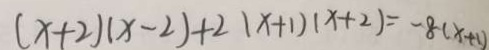
|
examples/0000005.png
ADDED
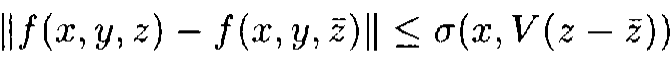
|
examples/0000006.png
ADDED
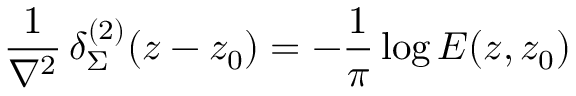
|
examples/0000007.png
ADDED
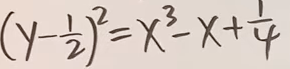
|
examples/0000011.png
ADDED
|
unimernet/__init__.py
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import os
|
| 9 |
+
import sys
|
| 10 |
+
|
| 11 |
+
from omegaconf import OmegaConf
|
| 12 |
+
|
| 13 |
+
from unimernet.common.registry import registry
|
| 14 |
+
|
| 15 |
+
from unimernet.datasets.builders import *
|
| 16 |
+
from unimernet.models import *
|
| 17 |
+
from unimernet.processors import *
|
| 18 |
+
from unimernet.tasks import *
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
root_dir = os.path.dirname(os.path.abspath(__file__))
|
| 22 |
+
default_cfg = OmegaConf.load(os.path.join(root_dir, "configs/default.yaml"))
|
| 23 |
+
|
| 24 |
+
registry.register_path("library_root", root_dir)
|
| 25 |
+
repo_root = os.path.join(root_dir, "..")
|
| 26 |
+
registry.register_path("repo_root", repo_root)
|
| 27 |
+
cache_root = os.path.join(repo_root, default_cfg.env.cache_root)
|
| 28 |
+
registry.register_path("cache_root", cache_root)
|
| 29 |
+
|
| 30 |
+
registry.register("MAX_INT", sys.maxsize)
|
| 31 |
+
registry.register("SPLIT_NAMES", ["train", "val", "test"])
|
unimernet/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (1.02 kB). View file
|
|
|
unimernet/common/__init__.py
ADDED
|
File without changes
|
unimernet/common/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (160 Bytes). View file
|
|
|
unimernet/common/__pycache__/config.cpython-310.pyc
ADDED
|
Binary file (12.1 kB). View file
|
|
|
unimernet/common/__pycache__/dist_utils.cpython-310.pyc
ADDED
|
Binary file (3.77 kB). View file
|
|
|
unimernet/common/__pycache__/logger.cpython-310.pyc
ADDED
|
Binary file (6.42 kB). View file
|
|
|
unimernet/common/__pycache__/registry.cpython-310.pyc
ADDED
|
Binary file (8.39 kB). View file
|
|
|
unimernet/common/__pycache__/utils.cpython-310.pyc
ADDED
|
Binary file (12.8 kB). View file
|
|
|
unimernet/common/config.py
ADDED
|
@@ -0,0 +1,468 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import logging
|
| 9 |
+
import json
|
| 10 |
+
from typing import Dict
|
| 11 |
+
|
| 12 |
+
from omegaconf import OmegaConf
|
| 13 |
+
from unimernet.common.registry import registry
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class Config:
|
| 17 |
+
def __init__(self, args):
|
| 18 |
+
self.config = {}
|
| 19 |
+
|
| 20 |
+
self.args = args
|
| 21 |
+
|
| 22 |
+
# Register the config and configuration for setup
|
| 23 |
+
registry.register("configuration", self)
|
| 24 |
+
|
| 25 |
+
user_config = self._build_opt_list(self.args.options)
|
| 26 |
+
|
| 27 |
+
config = OmegaConf.load(self.args.cfg_path)
|
| 28 |
+
|
| 29 |
+
runner_config = self.build_runner_config(config)
|
| 30 |
+
model_config = self.build_model_config(config, **user_config)
|
| 31 |
+
dataset_config = self.build_dataset_config(config)
|
| 32 |
+
|
| 33 |
+
# Validate the user-provided runner configuration
|
| 34 |
+
# model and dataset configuration are supposed to be validated by the respective classes
|
| 35 |
+
# [TODO] validate the model/dataset configuration
|
| 36 |
+
# self._validate_runner_config(runner_config)
|
| 37 |
+
|
| 38 |
+
# Override the default configuration with user options.
|
| 39 |
+
self.config = OmegaConf.merge(
|
| 40 |
+
runner_config, model_config, dataset_config, user_config
|
| 41 |
+
)
|
| 42 |
+
|
| 43 |
+
def _validate_runner_config(self, runner_config):
|
| 44 |
+
"""
|
| 45 |
+
This method validates the configuration, such that
|
| 46 |
+
1) all the user specified options are valid;
|
| 47 |
+
2) no type mismatches between the user specified options and the config.
|
| 48 |
+
"""
|
| 49 |
+
runner_config_validator = create_runner_config_validator()
|
| 50 |
+
runner_config_validator.validate(runner_config)
|
| 51 |
+
|
| 52 |
+
def _build_opt_list(self, opts):
|
| 53 |
+
opts_dot_list = self._convert_to_dot_list(opts)
|
| 54 |
+
return OmegaConf.from_dotlist(opts_dot_list)
|
| 55 |
+
|
| 56 |
+
@staticmethod
|
| 57 |
+
def build_model_config(config, **kwargs):
|
| 58 |
+
model = config.get("model", None)
|
| 59 |
+
assert model is not None, "Missing model configuration file."
|
| 60 |
+
|
| 61 |
+
model_cls = registry.get_model_class(model.arch)
|
| 62 |
+
assert model_cls is not None, f"Model '{model.arch}' has not been registered."
|
| 63 |
+
|
| 64 |
+
model_type = kwargs.get("model.model_type", None)
|
| 65 |
+
if not model_type:
|
| 66 |
+
model_type = model.get("model_type", None)
|
| 67 |
+
# else use the model type selected by user.
|
| 68 |
+
|
| 69 |
+
assert model_type is not None, "Missing model_type."
|
| 70 |
+
|
| 71 |
+
model_config_path = model_cls.default_config_path(model_type=model_type)
|
| 72 |
+
|
| 73 |
+
model_config = OmegaConf.create()
|
| 74 |
+
# hiararchy override, customized config > default config
|
| 75 |
+
model_config = OmegaConf.merge(
|
| 76 |
+
model_config,
|
| 77 |
+
OmegaConf.load(model_config_path),
|
| 78 |
+
{"model": config["model"]},
|
| 79 |
+
)
|
| 80 |
+
|
| 81 |
+
return model_config
|
| 82 |
+
|
| 83 |
+
@staticmethod
|
| 84 |
+
def build_runner_config(config):
|
| 85 |
+
return {"run": config.run}
|
| 86 |
+
|
| 87 |
+
@staticmethod
|
| 88 |
+
def build_dataset_config(config):
|
| 89 |
+
datasets = config.get("datasets", None)
|
| 90 |
+
if datasets is None:
|
| 91 |
+
raise KeyError(
|
| 92 |
+
"Expecting 'datasets' as the root key for dataset configuration."
|
| 93 |
+
)
|
| 94 |
+
|
| 95 |
+
dataset_config = OmegaConf.create()
|
| 96 |
+
|
| 97 |
+
for dataset_name in datasets:
|
| 98 |
+
builder_cls = registry.get_builder_class(dataset_name)
|
| 99 |
+
|
| 100 |
+
dataset_config_type = datasets[dataset_name].get("type", "default")
|
| 101 |
+
dataset_config_path = builder_cls.default_config_path(
|
| 102 |
+
type=dataset_config_type
|
| 103 |
+
)
|
| 104 |
+
|
| 105 |
+
# hiararchy override, customized config > default config
|
| 106 |
+
dataset_config = OmegaConf.merge(
|
| 107 |
+
dataset_config,
|
| 108 |
+
OmegaConf.load(dataset_config_path),
|
| 109 |
+
{"datasets": {dataset_name: config["datasets"][dataset_name]}},
|
| 110 |
+
)
|
| 111 |
+
|
| 112 |
+
return dataset_config
|
| 113 |
+
|
| 114 |
+
def _convert_to_dot_list(self, opts):
|
| 115 |
+
if opts is None:
|
| 116 |
+
opts = []
|
| 117 |
+
|
| 118 |
+
if len(opts) == 0:
|
| 119 |
+
return opts
|
| 120 |
+
|
| 121 |
+
has_equal = opts[0].find("=") != -1
|
| 122 |
+
|
| 123 |
+
if has_equal:
|
| 124 |
+
return opts
|
| 125 |
+
|
| 126 |
+
return [(opt + "=" + value) for opt, value in zip(opts[0::2], opts[1::2])]
|
| 127 |
+
|
| 128 |
+
def get_config(self):
|
| 129 |
+
return self.config
|
| 130 |
+
|
| 131 |
+
@property
|
| 132 |
+
def run_cfg(self):
|
| 133 |
+
return self.config.run
|
| 134 |
+
|
| 135 |
+
@property
|
| 136 |
+
def datasets_cfg(self):
|
| 137 |
+
return self.config.datasets
|
| 138 |
+
|
| 139 |
+
@property
|
| 140 |
+
def model_cfg(self):
|
| 141 |
+
return self.config.model
|
| 142 |
+
|
| 143 |
+
def pretty_print(self):
|
| 144 |
+
logging.info("\n===== Running Parameters =====")
|
| 145 |
+
logging.info(self._convert_node_to_json(self.config.run))
|
| 146 |
+
|
| 147 |
+
logging.info("\n====== Dataset Attributes ======")
|
| 148 |
+
datasets = self.config.datasets
|
| 149 |
+
|
| 150 |
+
for dataset in datasets:
|
| 151 |
+
if dataset in self.config.datasets:
|
| 152 |
+
logging.info(f"\n======== {dataset} =======")
|
| 153 |
+
dataset_config = self.config.datasets[dataset]
|
| 154 |
+
logging.info(self._convert_node_to_json(dataset_config))
|
| 155 |
+
else:
|
| 156 |
+
logging.warning(f"No dataset named '{dataset}' in config. Skipping")
|
| 157 |
+
|
| 158 |
+
logging.info(f"\n====== Model Attributes ======")
|
| 159 |
+
logging.info(self._convert_node_to_json(self.config.model))
|
| 160 |
+
|
| 161 |
+
def _convert_node_to_json(self, node):
|
| 162 |
+
container = OmegaConf.to_container(node, resolve=True)
|
| 163 |
+
return json.dumps(container, indent=4, sort_keys=True)
|
| 164 |
+
|
| 165 |
+
def to_dict(self):
|
| 166 |
+
return OmegaConf.to_container(self.config)
|
| 167 |
+
|
| 168 |
+
|
| 169 |
+
def node_to_dict(node):
|
| 170 |
+
return OmegaConf.to_container(node)
|
| 171 |
+
|
| 172 |
+
|
| 173 |
+
class ConfigValidator:
|
| 174 |
+
"""
|
| 175 |
+
This is a preliminary implementation to centralize and validate the configuration.
|
| 176 |
+
May be altered in the future.
|
| 177 |
+
|
| 178 |
+
A helper class to validate configurations from yaml file.
|
| 179 |
+
|
| 180 |
+
This serves the following purposes:
|
| 181 |
+
1. Ensure all the options in the yaml are defined, raise error if not.
|
| 182 |
+
2. when type mismatches are found, the validator will raise an error.
|
| 183 |
+
3. a central place to store and display helpful messages for supported configurations.
|
| 184 |
+
|
| 185 |
+
"""
|
| 186 |
+
|
| 187 |
+
class _Argument:
|
| 188 |
+
def __init__(self, name, choices=None, type=None, help=None):
|
| 189 |
+
self.name = name
|
| 190 |
+
self.val = None
|
| 191 |
+
self.choices = choices
|
| 192 |
+
self.type = type
|
| 193 |
+
self.help = help
|
| 194 |
+
|
| 195 |
+
def __str__(self):
|
| 196 |
+
s = f"{self.name}={self.val}"
|
| 197 |
+
if self.type is not None:
|
| 198 |
+
s += f", ({self.type})"
|
| 199 |
+
if self.choices is not None:
|
| 200 |
+
s += f", choices: {self.choices}"
|
| 201 |
+
if self.help is not None:
|
| 202 |
+
s += f", ({self.help})"
|
| 203 |
+
return s
|
| 204 |
+
|
| 205 |
+
def __init__(self, description):
|
| 206 |
+
self.description = description
|
| 207 |
+
|
| 208 |
+
self.arguments = dict()
|
| 209 |
+
|
| 210 |
+
self.parsed_args = None
|
| 211 |
+
|
| 212 |
+
def __getitem__(self, key):
|
| 213 |
+
assert self.parsed_args is not None, "No arguments parsed yet."
|
| 214 |
+
|
| 215 |
+
return self.parsed_args[key]
|
| 216 |
+
|
| 217 |
+
def __str__(self) -> str:
|
| 218 |
+
return self.format_help()
|
| 219 |
+
|
| 220 |
+
def add_argument(self, *args, **kwargs):
|
| 221 |
+
"""
|
| 222 |
+
Assume the first argument is the name of the argument.
|
| 223 |
+
"""
|
| 224 |
+
self.arguments[args[0]] = self._Argument(*args, **kwargs)
|
| 225 |
+
|
| 226 |
+
def validate(self, config=None):
|
| 227 |
+
"""
|
| 228 |
+
Convert yaml config (dict-like) to list, required by argparse.
|
| 229 |
+
"""
|
| 230 |
+
for k, v in config.items():
|
| 231 |
+
assert (
|
| 232 |
+
k in self.arguments
|
| 233 |
+
), f"""{k} is not a valid argument. Support arguments are {self.format_arguments()}."""
|
| 234 |
+
|
| 235 |
+
if self.arguments[k].type is not None:
|
| 236 |
+
try:
|
| 237 |
+
self.arguments[k].val = self.arguments[k].type(v)
|
| 238 |
+
except ValueError:
|
| 239 |
+
raise ValueError(f"{k} is not a valid {self.arguments[k].type}.")
|
| 240 |
+
|
| 241 |
+
if self.arguments[k].choices is not None:
|
| 242 |
+
assert (
|
| 243 |
+
v in self.arguments[k].choices
|
| 244 |
+
), f"""{k} must be one of {self.arguments[k].choices}."""
|
| 245 |
+
|
| 246 |
+
return config
|
| 247 |
+
|
| 248 |
+
def format_arguments(self):
|
| 249 |
+
return str([f"{k}" for k in sorted(self.arguments.keys())])
|
| 250 |
+
|
| 251 |
+
def format_help(self):
|
| 252 |
+
# description + key-value pair string for each argument
|
| 253 |
+
help_msg = str(self.description)
|
| 254 |
+
return help_msg + ", available arguments: " + self.format_arguments()
|
| 255 |
+
|
| 256 |
+
def print_help(self):
|
| 257 |
+
# display help message
|
| 258 |
+
print(self.format_help())
|
| 259 |
+
|
| 260 |
+
|
| 261 |
+
def create_runner_config_validator():
|
| 262 |
+
validator = ConfigValidator(description="Runner configurations")
|
| 263 |
+
|
| 264 |
+
validator.add_argument(
|
| 265 |
+
"runner",
|
| 266 |
+
type=str,
|
| 267 |
+
choices=["runner_base", "runner_iter"],
|
| 268 |
+
help="""Runner to use. The "runner_base" uses epoch-based training while iter-based
|
| 269 |
+
runner runs based on iters. Default: runner_base""",
|
| 270 |
+
)
|
| 271 |
+
# add argumetns for training dataset ratios
|
| 272 |
+
validator.add_argument(
|
| 273 |
+
"train_dataset_ratios",
|
| 274 |
+
type=Dict[str, float],
|
| 275 |
+
help="""Ratios of training dataset. This is used in iteration-based runner.
|
| 276 |
+
Do not support for epoch-based runner because how to define an epoch becomes tricky.
|
| 277 |
+
Default: None""",
|
| 278 |
+
)
|
| 279 |
+
validator.add_argument(
|
| 280 |
+
"max_iters",
|
| 281 |
+
type=float,
|
| 282 |
+
help="Maximum number of iterations to run.",
|
| 283 |
+
)
|
| 284 |
+
validator.add_argument(
|
| 285 |
+
"max_epoch",
|
| 286 |
+
type=int,
|
| 287 |
+
help="Maximum number of epochs to run.",
|
| 288 |
+
)
|
| 289 |
+
# add arguments for iters_per_inner_epoch
|
| 290 |
+
validator.add_argument(
|
| 291 |
+
"iters_per_inner_epoch",
|
| 292 |
+
type=float,
|
| 293 |
+
help="Number of iterations per inner epoch. This is required when runner is runner_iter.",
|
| 294 |
+
)
|
| 295 |
+
lr_scheds_choices = registry.list_lr_schedulers()
|
| 296 |
+
validator.add_argument(
|
| 297 |
+
"lr_sched",
|
| 298 |
+
type=str,
|
| 299 |
+
choices=lr_scheds_choices,
|
| 300 |
+
help="Learning rate scheduler to use, from {}".format(lr_scheds_choices),
|
| 301 |
+
)
|
| 302 |
+
task_choices = registry.list_tasks()
|
| 303 |
+
validator.add_argument(
|
| 304 |
+
"task",
|
| 305 |
+
type=str,
|
| 306 |
+
choices=task_choices,
|
| 307 |
+
help="Task to use, from {}".format(task_choices),
|
| 308 |
+
)
|
| 309 |
+
# add arguments for init_lr
|
| 310 |
+
validator.add_argument(
|
| 311 |
+
"init_lr",
|
| 312 |
+
type=float,
|
| 313 |
+
help="Initial learning rate. This will be the learning rate after warmup and before decay.",
|
| 314 |
+
)
|
| 315 |
+
# add arguments for min_lr
|
| 316 |
+
validator.add_argument(
|
| 317 |
+
"min_lr",
|
| 318 |
+
type=float,
|
| 319 |
+
help="Minimum learning rate (after decay).",
|
| 320 |
+
)
|
| 321 |
+
# add arguments for warmup_lr
|
| 322 |
+
validator.add_argument(
|
| 323 |
+
"warmup_lr",
|
| 324 |
+
type=float,
|
| 325 |
+
help="Starting learning rate for warmup.",
|
| 326 |
+
)
|
| 327 |
+
# add arguments for learning rate decay rate
|
| 328 |
+
validator.add_argument(
|
| 329 |
+
"lr_decay_rate",
|
| 330 |
+
type=float,
|
| 331 |
+
help="Learning rate decay rate. Required if using a decaying learning rate scheduler.",
|
| 332 |
+
)
|
| 333 |
+
# add arguments for weight decay
|
| 334 |
+
validator.add_argument(
|
| 335 |
+
"weight_decay",
|
| 336 |
+
type=float,
|
| 337 |
+
help="Weight decay rate.",
|
| 338 |
+
)
|
| 339 |
+
# add arguments for training batch size
|
| 340 |
+
validator.add_argument(
|
| 341 |
+
"batch_size_train",
|
| 342 |
+
type=int,
|
| 343 |
+
help="Training batch size.",
|
| 344 |
+
)
|
| 345 |
+
# add arguments for evaluation batch size
|
| 346 |
+
validator.add_argument(
|
| 347 |
+
"batch_size_eval",
|
| 348 |
+
type=int,
|
| 349 |
+
help="Evaluation batch size, including validation and testing.",
|
| 350 |
+
)
|
| 351 |
+
# add arguments for number of workers for data loading
|
| 352 |
+
validator.add_argument(
|
| 353 |
+
"num_workers",
|
| 354 |
+
help="Number of workers for data loading.",
|
| 355 |
+
)
|
| 356 |
+
# add arguments for warm up steps
|
| 357 |
+
validator.add_argument(
|
| 358 |
+
"warmup_steps",
|
| 359 |
+
type=int,
|
| 360 |
+
help="Number of warmup steps. Required if a warmup schedule is used.",
|
| 361 |
+
)
|
| 362 |
+
# add arguments for random seed
|
| 363 |
+
validator.add_argument(
|
| 364 |
+
"seed",
|
| 365 |
+
type=int,
|
| 366 |
+
help="Random seed.",
|
| 367 |
+
)
|
| 368 |
+
# add arguments for output directory
|
| 369 |
+
validator.add_argument(
|
| 370 |
+
"output_dir",
|
| 371 |
+
type=str,
|
| 372 |
+
help="Output directory to save checkpoints and logs.",
|
| 373 |
+
)
|
| 374 |
+
# add arguments for whether only use evaluation
|
| 375 |
+
validator.add_argument(
|
| 376 |
+
"evaluate",
|
| 377 |
+
help="Whether to only evaluate the model. If true, training will not be performed.",
|
| 378 |
+
)
|
| 379 |
+
# add arguments for splits used for training, e.g. ["train", "val"]
|
| 380 |
+
validator.add_argument(
|
| 381 |
+
"train_splits",
|
| 382 |
+
type=list,
|
| 383 |
+
help="Splits to use for training.",
|
| 384 |
+
)
|
| 385 |
+
# add arguments for splits used for validation, e.g. ["val"]
|
| 386 |
+
validator.add_argument(
|
| 387 |
+
"valid_splits",
|
| 388 |
+
type=list,
|
| 389 |
+
help="Splits to use for validation. If not provided, will skip the validation.",
|
| 390 |
+
)
|
| 391 |
+
# add arguments for splits used for testing, e.g. ["test"]
|
| 392 |
+
validator.add_argument(
|
| 393 |
+
"test_splits",
|
| 394 |
+
type=list,
|
| 395 |
+
help="Splits to use for testing. If not provided, will skip the testing.",
|
| 396 |
+
)
|
| 397 |
+
# add arguments for accumulating gradient for iterations
|
| 398 |
+
validator.add_argument(
|
| 399 |
+
"accum_grad_iters",
|
| 400 |
+
type=int,
|
| 401 |
+
help="Number of iterations to accumulate gradient for.",
|
| 402 |
+
)
|
| 403 |
+
|
| 404 |
+
# ====== distributed training ======
|
| 405 |
+
validator.add_argument(
|
| 406 |
+
"device",
|
| 407 |
+
type=str,
|
| 408 |
+
choices=["cpu", "cuda"],
|
| 409 |
+
help="Device to use. Support 'cuda' or 'cpu' as for now.",
|
| 410 |
+
)
|
| 411 |
+
validator.add_argument(
|
| 412 |
+
"world_size",
|
| 413 |
+
type=int,
|
| 414 |
+
help="Number of processes participating in the job.",
|
| 415 |
+
)
|
| 416 |
+
validator.add_argument("dist_url", type=str)
|
| 417 |
+
validator.add_argument("distributed", type=bool)
|
| 418 |
+
# add arguments to opt using distributed sampler during evaluation or not
|
| 419 |
+
validator.add_argument(
|
| 420 |
+
"use_dist_eval_sampler",
|
| 421 |
+
type=bool,
|
| 422 |
+
help="Whether to use distributed sampler during evaluation or not.",
|
| 423 |
+
)
|
| 424 |
+
|
| 425 |
+
# ====== task specific ======
|
| 426 |
+
# generation task specific arguments
|
| 427 |
+
# add arguments for maximal length of text output
|
| 428 |
+
validator.add_argument(
|
| 429 |
+
"max_len",
|
| 430 |
+
type=int,
|
| 431 |
+
help="Maximal length of text output.",
|
| 432 |
+
)
|
| 433 |
+
# add arguments for minimal length of text output
|
| 434 |
+
validator.add_argument(
|
| 435 |
+
"min_len",
|
| 436 |
+
type=int,
|
| 437 |
+
help="Minimal length of text output.",
|
| 438 |
+
)
|
| 439 |
+
# add arguments number of beams
|
| 440 |
+
validator.add_argument(
|
| 441 |
+
"num_beams",
|
| 442 |
+
type=int,
|
| 443 |
+
help="Number of beams used for beam search.",
|
| 444 |
+
)
|
| 445 |
+
|
| 446 |
+
# vqa task specific arguments
|
| 447 |
+
# add arguments for number of answer candidates
|
| 448 |
+
validator.add_argument(
|
| 449 |
+
"num_ans_candidates",
|
| 450 |
+
type=int,
|
| 451 |
+
help="""For ALBEF and BLIP, these models first rank answers according to likelihood to select answer candidates.""",
|
| 452 |
+
)
|
| 453 |
+
# add arguments for inference method
|
| 454 |
+
validator.add_argument(
|
| 455 |
+
"inference_method",
|
| 456 |
+
type=str,
|
| 457 |
+
choices=["genearte", "rank"],
|
| 458 |
+
help="""Inference method to use for question answering. If rank, requires a answer list.""",
|
| 459 |
+
)
|
| 460 |
+
|
| 461 |
+
# ====== model specific ======
|
| 462 |
+
validator.add_argument(
|
| 463 |
+
"k_test",
|
| 464 |
+
type=int,
|
| 465 |
+
help="Number of top k most similar samples from ITC/VTC selection to be tested.",
|
| 466 |
+
)
|
| 467 |
+
|
| 468 |
+
return validator
|
unimernet/common/dist_utils.py
ADDED
|
@@ -0,0 +1,137 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import datetime
|
| 9 |
+
import functools
|
| 10 |
+
import os
|
| 11 |
+
|
| 12 |
+
import torch
|
| 13 |
+
import torch.distributed as dist
|
| 14 |
+
import timm.models.hub as timm_hub
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def setup_for_distributed(is_master):
|
| 18 |
+
"""
|
| 19 |
+
This function disables printing when not in master process
|
| 20 |
+
"""
|
| 21 |
+
import builtins as __builtin__
|
| 22 |
+
|
| 23 |
+
builtin_print = __builtin__.print
|
| 24 |
+
|
| 25 |
+
def print(*args, **kwargs):
|
| 26 |
+
force = kwargs.pop("force", False)
|
| 27 |
+
if is_master or force:
|
| 28 |
+
builtin_print(*args, **kwargs)
|
| 29 |
+
|
| 30 |
+
__builtin__.print = print
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def is_dist_avail_and_initialized():
|
| 34 |
+
if not dist.is_available():
|
| 35 |
+
return False
|
| 36 |
+
if not dist.is_initialized():
|
| 37 |
+
return False
|
| 38 |
+
return True
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def get_world_size():
|
| 42 |
+
if not is_dist_avail_and_initialized():
|
| 43 |
+
return 1
|
| 44 |
+
return dist.get_world_size()
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def get_rank():
|
| 48 |
+
if not is_dist_avail_and_initialized():
|
| 49 |
+
return 0
|
| 50 |
+
return dist.get_rank()
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def is_main_process():
|
| 54 |
+
return get_rank() == 0
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def init_distributed_mode(args):
|
| 58 |
+
if "RANK" in os.environ and "WORLD_SIZE" in os.environ:
|
| 59 |
+
args.rank = int(os.environ["RANK"])
|
| 60 |
+
args.world_size = int(os.environ["WORLD_SIZE"])
|
| 61 |
+
args.gpu = int(os.environ["LOCAL_RANK"])
|
| 62 |
+
elif "SLURM_PROCID" in os.environ:
|
| 63 |
+
args.rank = int(os.environ["SLURM_PROCID"])
|
| 64 |
+
args.gpu = args.rank % torch.cuda.device_count()
|
| 65 |
+
else:
|
| 66 |
+
print("Not using distributed mode")
|
| 67 |
+
args.distributed = False
|
| 68 |
+
return
|
| 69 |
+
|
| 70 |
+
args.distributed = True
|
| 71 |
+
|
| 72 |
+
torch.cuda.set_device(args.gpu)
|
| 73 |
+
args.dist_backend = "nccl"
|
| 74 |
+
print(
|
| 75 |
+
"| distributed init (rank {}, world {}): {}".format(
|
| 76 |
+
args.rank, args.world_size, args.dist_url
|
| 77 |
+
),
|
| 78 |
+
flush=True,
|
| 79 |
+
)
|
| 80 |
+
torch.distributed.init_process_group(
|
| 81 |
+
backend=args.dist_backend,
|
| 82 |
+
init_method=args.dist_url,
|
| 83 |
+
world_size=args.world_size,
|
| 84 |
+
rank=args.rank,
|
| 85 |
+
timeout=datetime.timedelta(
|
| 86 |
+
days=365
|
| 87 |
+
), # allow auto-downloading and de-compressing
|
| 88 |
+
)
|
| 89 |
+
torch.distributed.barrier()
|
| 90 |
+
setup_for_distributed(args.rank == 0)
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
def get_dist_info():
|
| 94 |
+
if torch.__version__ < "1.0":
|
| 95 |
+
initialized = dist._initialized
|
| 96 |
+
else:
|
| 97 |
+
initialized = dist.is_initialized()
|
| 98 |
+
if initialized:
|
| 99 |
+
rank = dist.get_rank()
|
| 100 |
+
world_size = dist.get_world_size()
|
| 101 |
+
else: # non-distributed training
|
| 102 |
+
rank = 0
|
| 103 |
+
world_size = 1
|
| 104 |
+
return rank, world_size
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
def main_process(func):
|
| 108 |
+
@functools.wraps(func)
|
| 109 |
+
def wrapper(*args, **kwargs):
|
| 110 |
+
rank, _ = get_dist_info()
|
| 111 |
+
if rank == 0:
|
| 112 |
+
return func(*args, **kwargs)
|
| 113 |
+
|
| 114 |
+
return wrapper
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
def download_cached_file(url, check_hash=True, progress=False):
|
| 118 |
+
"""
|
| 119 |
+
Download a file from a URL and cache it locally. If the file already exists, it is not downloaded again.
|
| 120 |
+
If distributed, only the main process downloads the file, and the other processes wait for the file to be downloaded.
|
| 121 |
+
"""
|
| 122 |
+
|
| 123 |
+
def get_cached_file_path():
|
| 124 |
+
# a hack to sync the file path across processes
|
| 125 |
+
parts = torch.hub.urlparse(url)
|
| 126 |
+
filename = os.path.basename(parts.path)
|
| 127 |
+
cached_file = os.path.join(timm_hub.get_cache_dir(), filename)
|
| 128 |
+
|
| 129 |
+
return cached_file
|
| 130 |
+
|
| 131 |
+
if is_main_process():
|
| 132 |
+
timm_hub.download_cached_file(url, check_hash, progress)
|
| 133 |
+
|
| 134 |
+
if is_dist_avail_and_initialized():
|
| 135 |
+
dist.barrier()
|
| 136 |
+
|
| 137 |
+
return get_cached_file_path()
|
unimernet/common/gradcam.py
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
from matplotlib import pyplot as plt
|
| 3 |
+
from scipy.ndimage import filters
|
| 4 |
+
from skimage import transform as skimage_transform
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def getAttMap(img, attMap, blur=True, overlap=True):
|
| 8 |
+
attMap -= attMap.min()
|
| 9 |
+
if attMap.max() > 0:
|
| 10 |
+
attMap /= attMap.max()
|
| 11 |
+
attMap = skimage_transform.resize(attMap, (img.shape[:2]), order=3, mode="constant")
|
| 12 |
+
if blur:
|
| 13 |
+
attMap = filters.gaussian_filter(attMap, 0.02 * max(img.shape[:2]))
|
| 14 |
+
attMap -= attMap.min()
|
| 15 |
+
attMap /= attMap.max()
|
| 16 |
+
cmap = plt.get_cmap("jet")
|
| 17 |
+
attMapV = cmap(attMap)
|
| 18 |
+
attMapV = np.delete(attMapV, 3, 2)
|
| 19 |
+
if overlap:
|
| 20 |
+
attMap = (
|
| 21 |
+
1 * (1 - attMap**0.7).reshape(attMap.shape + (1,)) * img
|
| 22 |
+
+ (attMap**0.7).reshape(attMap.shape + (1,)) * attMapV
|
| 23 |
+
)
|
| 24 |
+
return attMap
|
unimernet/common/logger.py
ADDED
|
@@ -0,0 +1,195 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import datetime
|
| 9 |
+
import logging
|
| 10 |
+
import time
|
| 11 |
+
from collections import defaultdict, deque
|
| 12 |
+
|
| 13 |
+
import torch
|
| 14 |
+
import torch.distributed as dist
|
| 15 |
+
|
| 16 |
+
from unimernet.common import dist_utils
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
class SmoothedValue(object):
|
| 20 |
+
"""Track a series of values and provide access to smoothed values over a
|
| 21 |
+
window or the global series average.
|
| 22 |
+
"""
|
| 23 |
+
|
| 24 |
+
def __init__(self, window_size=20, fmt=None):
|
| 25 |
+
if fmt is None:
|
| 26 |
+
fmt = "{median:.4f} ({global_avg:.4f})"
|
| 27 |
+
self.deque = deque(maxlen=window_size)
|
| 28 |
+
self.total = 0.0
|
| 29 |
+
self.count = 0
|
| 30 |
+
self.fmt = fmt
|
| 31 |
+
|
| 32 |
+
def update(self, value, n=1):
|
| 33 |
+
self.deque.append(value)
|
| 34 |
+
self.count += n
|
| 35 |
+
self.total += value * n
|
| 36 |
+
|
| 37 |
+
def synchronize_between_processes(self):
|
| 38 |
+
"""
|
| 39 |
+
Warning: does not synchronize the deque!
|
| 40 |
+
"""
|
| 41 |
+
if not dist_utils.is_dist_avail_and_initialized():
|
| 42 |
+
return
|
| 43 |
+
t = torch.tensor([self.count, self.total], dtype=torch.float64, device="cuda")
|
| 44 |
+
dist.barrier()
|
| 45 |
+
dist.all_reduce(t)
|
| 46 |
+
t = t.tolist()
|
| 47 |
+
self.count = int(t[0])
|
| 48 |
+
self.total = t[1]
|
| 49 |
+
|
| 50 |
+
@property
|
| 51 |
+
def median(self):
|
| 52 |
+
d = torch.tensor(list(self.deque))
|
| 53 |
+
return d.median().item()
|
| 54 |
+
|
| 55 |
+
@property
|
| 56 |
+
def avg(self):
|
| 57 |
+
d = torch.tensor(list(self.deque), dtype=torch.float32)
|
| 58 |
+
return d.mean().item()
|
| 59 |
+
|
| 60 |
+
@property
|
| 61 |
+
def global_avg(self):
|
| 62 |
+
return self.total / self.count
|
| 63 |
+
|
| 64 |
+
@property
|
| 65 |
+
def max(self):
|
| 66 |
+
return max(self.deque)
|
| 67 |
+
|
| 68 |
+
@property
|
| 69 |
+
def value(self):
|
| 70 |
+
return self.deque[-1]
|
| 71 |
+
|
| 72 |
+
def __str__(self):
|
| 73 |
+
return self.fmt.format(
|
| 74 |
+
median=self.median,
|
| 75 |
+
avg=self.avg,
|
| 76 |
+
global_avg=self.global_avg,
|
| 77 |
+
max=self.max,
|
| 78 |
+
value=self.value,
|
| 79 |
+
)
|
| 80 |
+
|
| 81 |
+
|
| 82 |
+
class MetricLogger(object):
|
| 83 |
+
def __init__(self, delimiter="\t"):
|
| 84 |
+
self.meters = defaultdict(SmoothedValue)
|
| 85 |
+
self.delimiter = delimiter
|
| 86 |
+
|
| 87 |
+
def update(self, **kwargs):
|
| 88 |
+
for k, v in kwargs.items():
|
| 89 |
+
if isinstance(v, torch.Tensor):
|
| 90 |
+
v = v.item()
|
| 91 |
+
assert isinstance(v, (float, int))
|
| 92 |
+
self.meters[k].update(v)
|
| 93 |
+
|
| 94 |
+
def __getattr__(self, attr):
|
| 95 |
+
if attr in self.meters:
|
| 96 |
+
return self.meters[attr]
|
| 97 |
+
if attr in self.__dict__:
|
| 98 |
+
return self.__dict__[attr]
|
| 99 |
+
raise AttributeError(
|
| 100 |
+
"'{}' object has no attribute '{}'".format(type(self).__name__, attr)
|
| 101 |
+
)
|
| 102 |
+
|
| 103 |
+
def __str__(self):
|
| 104 |
+
loss_str = []
|
| 105 |
+
for name, meter in self.meters.items():
|
| 106 |
+
loss_str.append("{}: {}".format(name, str(meter)))
|
| 107 |
+
return self.delimiter.join(loss_str)
|
| 108 |
+
|
| 109 |
+
def global_avg(self):
|
| 110 |
+
loss_str = []
|
| 111 |
+
for name, meter in self.meters.items():
|
| 112 |
+
loss_str.append("{}: {:.4f}".format(name, meter.global_avg))
|
| 113 |
+
return self.delimiter.join(loss_str)
|
| 114 |
+
|
| 115 |
+
def synchronize_between_processes(self):
|
| 116 |
+
for meter in self.meters.values():
|
| 117 |
+
meter.synchronize_between_processes()
|
| 118 |
+
|
| 119 |
+
def add_meter(self, name, meter):
|
| 120 |
+
self.meters[name] = meter
|
| 121 |
+
|
| 122 |
+
def log_every(self, iterable, print_freq, header=None):
|
| 123 |
+
i = 0
|
| 124 |
+
if not header:
|
| 125 |
+
header = ""
|
| 126 |
+
start_time = time.time()
|
| 127 |
+
end = time.time()
|
| 128 |
+
iter_time = SmoothedValue(fmt="{avg:.4f}")
|
| 129 |
+
data_time = SmoothedValue(fmt="{avg:.4f}")
|
| 130 |
+
space_fmt = ":" + str(len(str(len(iterable)))) + "d"
|
| 131 |
+
log_msg = [
|
| 132 |
+
header,
|
| 133 |
+
"[{0" + space_fmt + "}/{1}]",
|
| 134 |
+
"eta: {eta}",
|
| 135 |
+
"{meters}",
|
| 136 |
+
"time: {time}",
|
| 137 |
+
"data: {data}",
|
| 138 |
+
]
|
| 139 |
+
if torch.cuda.is_available():
|
| 140 |
+
log_msg.append("max mem: {memory:.0f}")
|
| 141 |
+
log_msg = self.delimiter.join(log_msg)
|
| 142 |
+
MB = 1024.0 * 1024.0
|
| 143 |
+
for obj in iterable:
|
| 144 |
+
data_time.update(time.time() - end)
|
| 145 |
+
yield obj
|
| 146 |
+
iter_time.update(time.time() - end)
|
| 147 |
+
if i % print_freq == 0 or i == len(iterable) - 1:
|
| 148 |
+
eta_seconds = iter_time.global_avg * (len(iterable) - i)
|
| 149 |
+
eta_string = str(datetime.timedelta(seconds=int(eta_seconds)))
|
| 150 |
+
if torch.cuda.is_available():
|
| 151 |
+
print(
|
| 152 |
+
log_msg.format(
|
| 153 |
+
i,
|
| 154 |
+
len(iterable),
|
| 155 |
+
eta=eta_string,
|
| 156 |
+
meters=str(self),
|
| 157 |
+
time=str(iter_time),
|
| 158 |
+
data=str(data_time),
|
| 159 |
+
memory=torch.cuda.max_memory_allocated() / MB,
|
| 160 |
+
)
|
| 161 |
+
)
|
| 162 |
+
else:
|
| 163 |
+
print(
|
| 164 |
+
log_msg.format(
|
| 165 |
+
i,
|
| 166 |
+
len(iterable),
|
| 167 |
+
eta=eta_string,
|
| 168 |
+
meters=str(self),
|
| 169 |
+
time=str(iter_time),
|
| 170 |
+
data=str(data_time),
|
| 171 |
+
)
|
| 172 |
+
)
|
| 173 |
+
i += 1
|
| 174 |
+
end = time.time()
|
| 175 |
+
total_time = time.time() - start_time
|
| 176 |
+
total_time_str = str(datetime.timedelta(seconds=int(total_time)))
|
| 177 |
+
print(
|
| 178 |
+
"{} Total time: {} ({:.4f} s / it)".format(
|
| 179 |
+
header, total_time_str, total_time / len(iterable)
|
| 180 |
+
)
|
| 181 |
+
)
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
class AttrDict(dict):
|
| 185 |
+
def __init__(self, *args, **kwargs):
|
| 186 |
+
super(AttrDict, self).__init__(*args, **kwargs)
|
| 187 |
+
self.__dict__ = self
|
| 188 |
+
|
| 189 |
+
|
| 190 |
+
def setup_logger():
|
| 191 |
+
logging.basicConfig(
|
| 192 |
+
level=logging.INFO if dist_utils.is_main_process() else logging.WARN,
|
| 193 |
+
format="%(asctime)s [%(levelname)s] %(message)s",
|
| 194 |
+
handlers=[logging.StreamHandler()],
|
| 195 |
+
)
|
unimernet/common/optims.py
ADDED
|
@@ -0,0 +1,120 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import math
|
| 9 |
+
|
| 10 |
+
from unimernet.common.registry import registry
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
@registry.register_lr_scheduler("linear_warmup_step_lr")
|
| 14 |
+
class LinearWarmupStepLRScheduler:
|
| 15 |
+
def __init__(
|
| 16 |
+
self,
|
| 17 |
+
optimizer,
|
| 18 |
+
max_epoch,
|
| 19 |
+
min_lr,
|
| 20 |
+
init_lr,
|
| 21 |
+
decay_rate=1,
|
| 22 |
+
warmup_start_lr=-1,
|
| 23 |
+
warmup_steps=0,
|
| 24 |
+
**kwargs
|
| 25 |
+
):
|
| 26 |
+
self.optimizer = optimizer
|
| 27 |
+
|
| 28 |
+
self.max_epoch = max_epoch
|
| 29 |
+
self.min_lr = min_lr
|
| 30 |
+
|
| 31 |
+
self.decay_rate = decay_rate
|
| 32 |
+
|
| 33 |
+
self.init_lr = init_lr
|
| 34 |
+
self.warmup_steps = warmup_steps
|
| 35 |
+
self.warmup_start_lr = warmup_start_lr if warmup_start_lr >= 0 else init_lr
|
| 36 |
+
|
| 37 |
+
def step(self, cur_epoch, cur_step):
|
| 38 |
+
if cur_epoch == 0:
|
| 39 |
+
warmup_lr_schedule(
|
| 40 |
+
step=cur_step,
|
| 41 |
+
optimizer=self.optimizer,
|
| 42 |
+
max_step=self.warmup_steps,
|
| 43 |
+
init_lr=self.warmup_start_lr,
|
| 44 |
+
max_lr=self.init_lr,
|
| 45 |
+
)
|
| 46 |
+
else:
|
| 47 |
+
step_lr_schedule(
|
| 48 |
+
epoch=cur_epoch,
|
| 49 |
+
optimizer=self.optimizer,
|
| 50 |
+
init_lr=self.init_lr,
|
| 51 |
+
min_lr=self.min_lr,
|
| 52 |
+
decay_rate=self.decay_rate,
|
| 53 |
+
)
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
@registry.register_lr_scheduler("linear_warmup_cosine_lr")
|
| 57 |
+
class LinearWarmupCosineLRScheduler:
|
| 58 |
+
def __init__(
|
| 59 |
+
self,
|
| 60 |
+
optimizer,
|
| 61 |
+
max_epoch,
|
| 62 |
+
min_lr,
|
| 63 |
+
init_lr,
|
| 64 |
+
iters_per_epoch,
|
| 65 |
+
warmup_steps=0,
|
| 66 |
+
warmup_start_lr=-1,
|
| 67 |
+
**kwargs
|
| 68 |
+
):
|
| 69 |
+
self.optimizer = optimizer
|
| 70 |
+
|
| 71 |
+
self.max_epoch = max_epoch
|
| 72 |
+
self.min_lr = min_lr
|
| 73 |
+
|
| 74 |
+
self.init_lr = init_lr
|
| 75 |
+
self.warmup_steps = warmup_steps
|
| 76 |
+
self.iters_per_epoch = iters_per_epoch
|
| 77 |
+
self.warmup_start_lr = warmup_start_lr if warmup_start_lr >= 0 else init_lr
|
| 78 |
+
|
| 79 |
+
def step(self, cur_epoch, cur_step):
|
| 80 |
+
# assuming the warmup iters less than one epoch
|
| 81 |
+
total_steps = cur_epoch * self.iters_per_epoch + cur_step
|
| 82 |
+
if total_steps < self.warmup_steps:
|
| 83 |
+
warmup_lr_schedule(
|
| 84 |
+
step=cur_step,
|
| 85 |
+
optimizer=self.optimizer,
|
| 86 |
+
max_step=self.warmup_steps,
|
| 87 |
+
init_lr=self.warmup_start_lr,
|
| 88 |
+
max_lr=self.init_lr,
|
| 89 |
+
)
|
| 90 |
+
else:
|
| 91 |
+
cosine_lr_schedule(
|
| 92 |
+
epoch=total_steps,
|
| 93 |
+
optimizer=self.optimizer,
|
| 94 |
+
max_epoch=self.max_epoch * self.iters_per_epoch,
|
| 95 |
+
init_lr=self.init_lr,
|
| 96 |
+
min_lr=self.min_lr,
|
| 97 |
+
)
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
def cosine_lr_schedule(optimizer, epoch, max_epoch, init_lr, min_lr):
|
| 101 |
+
"""Decay the learning rate"""
|
| 102 |
+
lr = (init_lr - min_lr) * 0.5 * (
|
| 103 |
+
1.0 + math.cos(math.pi * epoch / max_epoch)
|
| 104 |
+
) + min_lr
|
| 105 |
+
for param_group in optimizer.param_groups:
|
| 106 |
+
param_group["lr"] = lr
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
def warmup_lr_schedule(optimizer, step, max_step, init_lr, max_lr):
|
| 110 |
+
"""Warmup the learning rate"""
|
| 111 |
+
lr = min(max_lr, init_lr + (max_lr - init_lr) * step / max(max_step, 1))
|
| 112 |
+
for param_group in optimizer.param_groups:
|
| 113 |
+
param_group["lr"] = lr
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
def step_lr_schedule(optimizer, epoch, init_lr, min_lr, decay_rate):
|
| 117 |
+
"""Decay the learning rate"""
|
| 118 |
+
lr = max(min_lr, init_lr * (decay_rate**epoch))
|
| 119 |
+
for param_group in optimizer.param_groups:
|
| 120 |
+
param_group["lr"] = lr
|
unimernet/common/registry.py
ADDED
|
@@ -0,0 +1,329 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class Registry:
|
| 10 |
+
mapping = {
|
| 11 |
+
"builder_name_mapping": {},
|
| 12 |
+
"task_name_mapping": {},
|
| 13 |
+
"processor_name_mapping": {},
|
| 14 |
+
"model_name_mapping": {},
|
| 15 |
+
"lr_scheduler_name_mapping": {},
|
| 16 |
+
"runner_name_mapping": {},
|
| 17 |
+
"state": {},
|
| 18 |
+
"paths": {},
|
| 19 |
+
}
|
| 20 |
+
|
| 21 |
+
@classmethod
|
| 22 |
+
def register_builder(cls, name):
|
| 23 |
+
r"""Register a dataset builder to registry with key 'name'
|
| 24 |
+
|
| 25 |
+
Args:
|
| 26 |
+
name: Key with which the builder will be registered.
|
| 27 |
+
|
| 28 |
+
Usage:
|
| 29 |
+
|
| 30 |
+
from unimernet.common.registry import registry
|
| 31 |
+
from unimernet.datasets.base_dataset_builder import BaseDatasetBuilder
|
| 32 |
+
"""
|
| 33 |
+
|
| 34 |
+
def wrap(builder_cls):
|
| 35 |
+
from unimernet.datasets.builders.base_dataset_builder import BaseDatasetBuilder
|
| 36 |
+
|
| 37 |
+
assert issubclass(
|
| 38 |
+
builder_cls, BaseDatasetBuilder
|
| 39 |
+
), "All builders must inherit BaseDatasetBuilder class, found {}".format(
|
| 40 |
+
builder_cls
|
| 41 |
+
)
|
| 42 |
+
if name in cls.mapping["builder_name_mapping"]:
|
| 43 |
+
raise KeyError(
|
| 44 |
+
"Name '{}' already registered for {}.".format(
|
| 45 |
+
name, cls.mapping["builder_name_mapping"][name]
|
| 46 |
+
)
|
| 47 |
+
)
|
| 48 |
+
cls.mapping["builder_name_mapping"][name] = builder_cls
|
| 49 |
+
return builder_cls
|
| 50 |
+
|
| 51 |
+
return wrap
|
| 52 |
+
|
| 53 |
+
@classmethod
|
| 54 |
+
def register_task(cls, name):
|
| 55 |
+
r"""Register a task to registry with key 'name'
|
| 56 |
+
|
| 57 |
+
Args:
|
| 58 |
+
name: Key with which the task will be registered.
|
| 59 |
+
|
| 60 |
+
Usage:
|
| 61 |
+
|
| 62 |
+
from unimernet.common.registry import registry
|
| 63 |
+
"""
|
| 64 |
+
|
| 65 |
+
def wrap(task_cls):
|
| 66 |
+
from unimernet.tasks.base_task import BaseTask
|
| 67 |
+
|
| 68 |
+
assert issubclass(
|
| 69 |
+
task_cls, BaseTask
|
| 70 |
+
), "All tasks must inherit BaseTask class"
|
| 71 |
+
if name in cls.mapping["task_name_mapping"]:
|
| 72 |
+
raise KeyError(
|
| 73 |
+
"Name '{}' already registered for {}.".format(
|
| 74 |
+
name, cls.mapping["task_name_mapping"][name]
|
| 75 |
+
)
|
| 76 |
+
)
|
| 77 |
+
cls.mapping["task_name_mapping"][name] = task_cls
|
| 78 |
+
return task_cls
|
| 79 |
+
|
| 80 |
+
return wrap
|
| 81 |
+
|
| 82 |
+
@classmethod
|
| 83 |
+
def register_model(cls, name):
|
| 84 |
+
r"""Register a task to registry with key 'name'
|
| 85 |
+
|
| 86 |
+
Args:
|
| 87 |
+
name: Key with which the task will be registered.
|
| 88 |
+
|
| 89 |
+
Usage:
|
| 90 |
+
|
| 91 |
+
from unimernet.common.registry import registry
|
| 92 |
+
"""
|
| 93 |
+
|
| 94 |
+
def wrap(model_cls):
|
| 95 |
+
from unimernet.models import BaseModel
|
| 96 |
+
|
| 97 |
+
assert issubclass(
|
| 98 |
+
model_cls, BaseModel
|
| 99 |
+
), "All models must inherit BaseModel class"
|
| 100 |
+
if name in cls.mapping["model_name_mapping"]:
|
| 101 |
+
raise KeyError(
|
| 102 |
+
"Name '{}' already registered for {}.".format(
|
| 103 |
+
name, cls.mapping["model_name_mapping"][name]
|
| 104 |
+
)
|
| 105 |
+
)
|
| 106 |
+
cls.mapping["model_name_mapping"][name] = model_cls
|
| 107 |
+
return model_cls
|
| 108 |
+
|
| 109 |
+
return wrap
|
| 110 |
+
|
| 111 |
+
@classmethod
|
| 112 |
+
def register_processor(cls, name):
|
| 113 |
+
r"""Register a processor to registry with key 'name'
|
| 114 |
+
|
| 115 |
+
Args:
|
| 116 |
+
name: Key with which the task will be registered.
|
| 117 |
+
|
| 118 |
+
Usage:
|
| 119 |
+
|
| 120 |
+
from unimernet.common.registry import registry
|
| 121 |
+
"""
|
| 122 |
+
|
| 123 |
+
def wrap(processor_cls):
|
| 124 |
+
from unimernet.processors import BaseProcessor
|
| 125 |
+
|
| 126 |
+
assert issubclass(
|
| 127 |
+
processor_cls, BaseProcessor
|
| 128 |
+
), "All processors must inherit BaseProcessor class"
|
| 129 |
+
if name in cls.mapping["processor_name_mapping"]:
|
| 130 |
+
raise KeyError(
|
| 131 |
+
"Name '{}' already registered for {}.".format(
|
| 132 |
+
name, cls.mapping["processor_name_mapping"][name]
|
| 133 |
+
)
|
| 134 |
+
)
|
| 135 |
+
cls.mapping["processor_name_mapping"][name] = processor_cls
|
| 136 |
+
return processor_cls
|
| 137 |
+
|
| 138 |
+
return wrap
|
| 139 |
+
|
| 140 |
+
@classmethod
|
| 141 |
+
def register_lr_scheduler(cls, name):
|
| 142 |
+
r"""Register a model to registry with key 'name'
|
| 143 |
+
|
| 144 |
+
Args:
|
| 145 |
+
name: Key with which the task will be registered.
|
| 146 |
+
|
| 147 |
+
Usage:
|
| 148 |
+
|
| 149 |
+
from unimernet.common.registry import registry
|
| 150 |
+
"""
|
| 151 |
+
|
| 152 |
+
def wrap(lr_sched_cls):
|
| 153 |
+
if name in cls.mapping["lr_scheduler_name_mapping"]:
|
| 154 |
+
raise KeyError(
|
| 155 |
+
"Name '{}' already registered for {}.".format(
|
| 156 |
+
name, cls.mapping["lr_scheduler_name_mapping"][name]
|
| 157 |
+
)
|
| 158 |
+
)
|
| 159 |
+
cls.mapping["lr_scheduler_name_mapping"][name] = lr_sched_cls
|
| 160 |
+
return lr_sched_cls
|
| 161 |
+
|
| 162 |
+
return wrap
|
| 163 |
+
|
| 164 |
+
@classmethod
|
| 165 |
+
def register_runner(cls, name):
|
| 166 |
+
r"""Register a model to registry with key 'name'
|
| 167 |
+
|
| 168 |
+
Args:
|
| 169 |
+
name: Key with which the task will be registered.
|
| 170 |
+
|
| 171 |
+
Usage:
|
| 172 |
+
|
| 173 |
+
from unimernet.common.registry import registry
|
| 174 |
+
"""
|
| 175 |
+
|
| 176 |
+
def wrap(runner_cls):
|
| 177 |
+
if name in cls.mapping["runner_name_mapping"]:
|
| 178 |
+
raise KeyError(
|
| 179 |
+
"Name '{}' already registered for {}.".format(
|
| 180 |
+
name, cls.mapping["runner_name_mapping"][name]
|
| 181 |
+
)
|
| 182 |
+
)
|
| 183 |
+
cls.mapping["runner_name_mapping"][name] = runner_cls
|
| 184 |
+
return runner_cls
|
| 185 |
+
|
| 186 |
+
return wrap
|
| 187 |
+
|
| 188 |
+
@classmethod
|
| 189 |
+
def register_path(cls, name, path):
|
| 190 |
+
r"""Register a path to registry with key 'name'
|
| 191 |
+
|
| 192 |
+
Args:
|
| 193 |
+
name: Key with which the path will be registered.
|
| 194 |
+
|
| 195 |
+
Usage:
|
| 196 |
+
|
| 197 |
+
from unimernet.common.registry import registry
|
| 198 |
+
"""
|
| 199 |
+
assert isinstance(path, str), "All path must be str."
|
| 200 |
+
if name in cls.mapping["paths"]:
|
| 201 |
+
raise KeyError("Name '{}' already registered.".format(name))
|
| 202 |
+
cls.mapping["paths"][name] = path
|
| 203 |
+
|
| 204 |
+
@classmethod
|
| 205 |
+
def register(cls, name, obj):
|
| 206 |
+
r"""Register an item to registry with key 'name'
|
| 207 |
+
|
| 208 |
+
Args:
|
| 209 |
+
name: Key with which the item will be registered.
|
| 210 |
+
|
| 211 |
+
Usage::
|
| 212 |
+
|
| 213 |
+
from unimernet.common.registry import registry
|
| 214 |
+
|
| 215 |
+
registry.register("config", {})
|
| 216 |
+
"""
|
| 217 |
+
path = name.split(".")
|
| 218 |
+
current = cls.mapping["state"]
|
| 219 |
+
|
| 220 |
+
for part in path[:-1]:
|
| 221 |
+
if part not in current:
|
| 222 |
+
current[part] = {}
|
| 223 |
+
current = current[part]
|
| 224 |
+
|
| 225 |
+
current[path[-1]] = obj
|
| 226 |
+
|
| 227 |
+
# @classmethod
|
| 228 |
+
# def get_trainer_class(cls, name):
|
| 229 |
+
# return cls.mapping["trainer_name_mapping"].get(name, None)
|
| 230 |
+
|
| 231 |
+
@classmethod
|
| 232 |
+
def get_builder_class(cls, name):
|
| 233 |
+
return cls.mapping["builder_name_mapping"].get(name, None)
|
| 234 |
+
|
| 235 |
+
@classmethod
|
| 236 |
+
def get_model_class(cls, name):
|
| 237 |
+
return cls.mapping["model_name_mapping"].get(name, None)
|
| 238 |
+
|
| 239 |
+
@classmethod
|
| 240 |
+
def get_task_class(cls, name):
|
| 241 |
+
return cls.mapping["task_name_mapping"].get(name, None)
|
| 242 |
+
|
| 243 |
+
@classmethod
|
| 244 |
+
def get_processor_class(cls, name):
|
| 245 |
+
return cls.mapping["processor_name_mapping"].get(name, None)
|
| 246 |
+
|
| 247 |
+
@classmethod
|
| 248 |
+
def get_lr_scheduler_class(cls, name):
|
| 249 |
+
return cls.mapping["lr_scheduler_name_mapping"].get(name, None)
|
| 250 |
+
|
| 251 |
+
@classmethod
|
| 252 |
+
def get_runner_class(cls, name):
|
| 253 |
+
return cls.mapping["runner_name_mapping"].get(name, None)
|
| 254 |
+
|
| 255 |
+
@classmethod
|
| 256 |
+
def list_runners(cls):
|
| 257 |
+
return sorted(cls.mapping["runner_name_mapping"].keys())
|
| 258 |
+
|
| 259 |
+
@classmethod
|
| 260 |
+
def list_models(cls):
|
| 261 |
+
return sorted(cls.mapping["model_name_mapping"].keys())
|
| 262 |
+
|
| 263 |
+
@classmethod
|
| 264 |
+
def list_tasks(cls):
|
| 265 |
+
return sorted(cls.mapping["task_name_mapping"].keys())
|
| 266 |
+
|
| 267 |
+
@classmethod
|
| 268 |
+
def list_processors(cls):
|
| 269 |
+
return sorted(cls.mapping["processor_name_mapping"].keys())
|
| 270 |
+
|
| 271 |
+
@classmethod
|
| 272 |
+
def list_lr_schedulers(cls):
|
| 273 |
+
return sorted(cls.mapping["lr_scheduler_name_mapping"].keys())
|
| 274 |
+
|
| 275 |
+
@classmethod
|
| 276 |
+
def list_datasets(cls):
|
| 277 |
+
return sorted(cls.mapping["builder_name_mapping"].keys())
|
| 278 |
+
|
| 279 |
+
@classmethod
|
| 280 |
+
def get_path(cls, name):
|
| 281 |
+
return cls.mapping["paths"].get(name, None)
|
| 282 |
+
|
| 283 |
+
@classmethod
|
| 284 |
+
def get(cls, name, default=None, no_warning=False):
|
| 285 |
+
r"""Get an item from registry with key 'name'
|
| 286 |
+
|
| 287 |
+
Args:
|
| 288 |
+
name (string): Key whose value needs to be retrieved.
|
| 289 |
+
default: If passed and key is not in registry, default value will
|
| 290 |
+
be returned with a warning. Default: None
|
| 291 |
+
no_warning (bool): If passed as True, warning when key doesn't exist
|
| 292 |
+
will not be generated. Useful for MMF's
|
| 293 |
+
internal operations. Default: False
|
| 294 |
+
"""
|
| 295 |
+
original_name = name
|
| 296 |
+
name = name.split(".")
|
| 297 |
+
value = cls.mapping["state"]
|
| 298 |
+
for subname in name:
|
| 299 |
+
value = value.get(subname, default)
|
| 300 |
+
if value is default:
|
| 301 |
+
break
|
| 302 |
+
|
| 303 |
+
if (
|
| 304 |
+
"writer" in cls.mapping["state"]
|
| 305 |
+
and value == default
|
| 306 |
+
and no_warning is False
|
| 307 |
+
):
|
| 308 |
+
cls.mapping["state"]["writer"].warning(
|
| 309 |
+
"Key {} is not present in registry, returning default value "
|
| 310 |
+
"of {}".format(original_name, default)
|
| 311 |
+
)
|
| 312 |
+
return value
|
| 313 |
+
|
| 314 |
+
@classmethod
|
| 315 |
+
def unregister(cls, name):
|
| 316 |
+
r"""Remove an item from registry with key 'name'
|
| 317 |
+
|
| 318 |
+
Args:
|
| 319 |
+
name: Key which needs to be removed.
|
| 320 |
+
Usage::
|
| 321 |
+
|
| 322 |
+
from mmf.common.registry import registry
|
| 323 |
+
|
| 324 |
+
config = registry.unregister("config")
|
| 325 |
+
"""
|
| 326 |
+
return cls.mapping["state"].pop(name, None)
|
| 327 |
+
|
| 328 |
+
|
| 329 |
+
registry = Registry()
|
unimernet/common/utils.py
ADDED
|
@@ -0,0 +1,424 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import io
|
| 9 |
+
import json
|
| 10 |
+
import logging
|
| 11 |
+
import os
|
| 12 |
+
import pickle
|
| 13 |
+
import re
|
| 14 |
+
import shutil
|
| 15 |
+
import urllib
|
| 16 |
+
import urllib.error
|
| 17 |
+
import urllib.request
|
| 18 |
+
from typing import Optional
|
| 19 |
+
from urllib.parse import urlparse
|
| 20 |
+
|
| 21 |
+
import numpy as np
|
| 22 |
+
import pandas as pd
|
| 23 |
+
import yaml
|
| 24 |
+
from iopath.common.download import download
|
| 25 |
+
from iopath.common.file_io import file_lock, g_pathmgr
|
| 26 |
+
from unimernet.common.registry import registry
|
| 27 |
+
from torch.utils.model_zoo import tqdm
|
| 28 |
+
from torchvision.datasets.utils import (
|
| 29 |
+
check_integrity,
|
| 30 |
+
download_file_from_google_drive,
|
| 31 |
+
extract_archive,
|
| 32 |
+
)
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
def now():
|
| 36 |
+
from datetime import datetime
|
| 37 |
+
|
| 38 |
+
return datetime.now().strftime("%Y%m%d%H%M")[:-1]
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def is_url(url_or_filename):
|
| 42 |
+
parsed = urlparse(url_or_filename)
|
| 43 |
+
return parsed.scheme in ("http", "https")
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def get_cache_path(rel_path):
|
| 47 |
+
return os.path.expanduser(os.path.join(registry.get_path("cache_root"), rel_path))
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def get_abs_path(rel_path):
|
| 51 |
+
return os.path.join(registry.get_path("library_root"), rel_path)
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def load_json(filename):
|
| 55 |
+
with open(filename, "r") as f:
|
| 56 |
+
return json.load(f)
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
# The following are adapted from torchvision and vissl
|
| 60 |
+
# torchvision: https://github.com/pytorch/vision
|
| 61 |
+
# vissl: https://github.com/facebookresearch/vissl/blob/main/vissl/utils/download.py
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
def makedir(dir_path):
|
| 65 |
+
"""
|
| 66 |
+
Create the directory if it does not exist.
|
| 67 |
+
"""
|
| 68 |
+
is_success = False
|
| 69 |
+
try:
|
| 70 |
+
if not g_pathmgr.exists(dir_path):
|
| 71 |
+
g_pathmgr.mkdirs(dir_path)
|
| 72 |
+
is_success = True
|
| 73 |
+
except BaseException:
|
| 74 |
+
print(f"Error creating directory: {dir_path}")
|
| 75 |
+
return is_success
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def get_redirected_url(url: str):
|
| 79 |
+
"""
|
| 80 |
+
Given a URL, returns the URL it redirects to or the
|
| 81 |
+
original URL in case of no indirection
|
| 82 |
+
"""
|
| 83 |
+
import requests
|
| 84 |
+
|
| 85 |
+
with requests.Session() as session:
|
| 86 |
+
with session.get(url, stream=True, allow_redirects=True) as response:
|
| 87 |
+
if response.history:
|
| 88 |
+
return response.url
|
| 89 |
+
else:
|
| 90 |
+
return url
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
def to_google_drive_download_url(view_url: str) -> str:
|
| 94 |
+
"""
|
| 95 |
+
Utility function to transform a view URL of google drive
|
| 96 |
+
to a download URL for google drive
|
| 97 |
+
Example input:
|
| 98 |
+
https://drive.google.com/file/d/137RyRjvTBkBiIfeYBNZBtViDHQ6_Ewsp/view
|
| 99 |
+
Example output:
|
| 100 |
+
https://drive.google.com/uc?export=download&id=137RyRjvTBkBiIfeYBNZBtViDHQ6_Ewsp
|
| 101 |
+
"""
|
| 102 |
+
splits = view_url.split("/")
|
| 103 |
+
assert splits[-1] == "view"
|
| 104 |
+
file_id = splits[-2]
|
| 105 |
+
return f"https://drive.google.com/uc?export=download&id={file_id}"
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
def download_google_drive_url(url: str, output_path: str, output_file_name: str):
|
| 109 |
+
"""
|
| 110 |
+
Download a file from google drive
|
| 111 |
+
Downloading an URL from google drive requires confirmation when
|
| 112 |
+
the file of the size is too big (google drive notifies that
|
| 113 |
+
anti-viral checks cannot be performed on such files)
|
| 114 |
+
"""
|
| 115 |
+
import requests
|
| 116 |
+
|
| 117 |
+
with requests.Session() as session:
|
| 118 |
+
|
| 119 |
+
# First get the confirmation token and append it to the URL
|
| 120 |
+
with session.get(url, stream=True, allow_redirects=True) as response:
|
| 121 |
+
for k, v in response.cookies.items():
|
| 122 |
+
if k.startswith("download_warning"):
|
| 123 |
+
url = url + "&confirm=" + v
|
| 124 |
+
|
| 125 |
+
# Then download the content of the file
|
| 126 |
+
with session.get(url, stream=True, verify=True) as response:
|
| 127 |
+
makedir(output_path)
|
| 128 |
+
path = os.path.join(output_path, output_file_name)
|
| 129 |
+
total_size = int(response.headers.get("Content-length", 0))
|
| 130 |
+
with open(path, "wb") as file:
|
| 131 |
+
from tqdm import tqdm
|
| 132 |
+
|
| 133 |
+
with tqdm(total=total_size) as progress_bar:
|
| 134 |
+
for block in response.iter_content(
|
| 135 |
+
chunk_size=io.DEFAULT_BUFFER_SIZE
|
| 136 |
+
):
|
| 137 |
+
file.write(block)
|
| 138 |
+
progress_bar.update(len(block))
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
def _get_google_drive_file_id(url: str) -> Optional[str]:
|
| 142 |
+
parts = urlparse(url)
|
| 143 |
+
|
| 144 |
+
if re.match(r"(drive|docs)[.]google[.]com", parts.netloc) is None:
|
| 145 |
+
return None
|
| 146 |
+
|
| 147 |
+
match = re.match(r"/file/d/(?P<id>[^/]*)", parts.path)
|
| 148 |
+
if match is None:
|
| 149 |
+
return None
|
| 150 |
+
|
| 151 |
+
return match.group("id")
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
def _urlretrieve(url: str, filename: str, chunk_size: int = 1024) -> None:
|
| 155 |
+
with open(filename, "wb") as fh:
|
| 156 |
+
with urllib.request.urlopen(
|
| 157 |
+
urllib.request.Request(url, headers={"User-Agent": "vissl"})
|
| 158 |
+
) as response:
|
| 159 |
+
with tqdm(total=response.length) as pbar:
|
| 160 |
+
for chunk in iter(lambda: response.read(chunk_size), ""):
|
| 161 |
+
if not chunk:
|
| 162 |
+
break
|
| 163 |
+
pbar.update(chunk_size)
|
| 164 |
+
fh.write(chunk)
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
def download_url(
|
| 168 |
+
url: str,
|
| 169 |
+
root: str,
|
| 170 |
+
filename: Optional[str] = None,
|
| 171 |
+
md5: Optional[str] = None,
|
| 172 |
+
) -> None:
|
| 173 |
+
"""Download a file from a url and place it in root.
|
| 174 |
+
Args:
|
| 175 |
+
url (str): URL to download file from
|
| 176 |
+
root (str): Directory to place downloaded file in
|
| 177 |
+
filename (str, optional): Name to save the file under.
|
| 178 |
+
If None, use the basename of the URL.
|
| 179 |
+
md5 (str, optional): MD5 checksum of the download. If None, do not check
|
| 180 |
+
"""
|
| 181 |
+
root = os.path.expanduser(root)
|
| 182 |
+
if not filename:
|
| 183 |
+
filename = os.path.basename(url)
|
| 184 |
+
fpath = os.path.join(root, filename)
|
| 185 |
+
|
| 186 |
+
makedir(root)
|
| 187 |
+
|
| 188 |
+
# check if file is already present locally
|
| 189 |
+
if check_integrity(fpath, md5):
|
| 190 |
+
print("Using downloaded and verified file: " + fpath)
|
| 191 |
+
return
|
| 192 |
+
|
| 193 |
+
# expand redirect chain if needed
|
| 194 |
+
url = get_redirected_url(url)
|
| 195 |
+
|
| 196 |
+
# check if file is located on Google Drive
|
| 197 |
+
file_id = _get_google_drive_file_id(url)
|
| 198 |
+
if file_id is not None:
|
| 199 |
+
return download_file_from_google_drive(file_id, root, filename, md5)
|
| 200 |
+
|
| 201 |
+
# download the file
|
| 202 |
+
try:
|
| 203 |
+
print("Downloading " + url + " to " + fpath)
|
| 204 |
+
_urlretrieve(url, fpath)
|
| 205 |
+
except (urllib.error.URLError, IOError) as e: # type: ignore[attr-defined]
|
| 206 |
+
if url[:5] == "https":
|
| 207 |
+
url = url.replace("https:", "http:")
|
| 208 |
+
print(
|
| 209 |
+
"Failed download. Trying https -> http instead."
|
| 210 |
+
" Downloading " + url + " to " + fpath
|
| 211 |
+
)
|
| 212 |
+
_urlretrieve(url, fpath)
|
| 213 |
+
else:
|
| 214 |
+
raise e
|
| 215 |
+
|
| 216 |
+
# check integrity of downloaded file
|
| 217 |
+
if not check_integrity(fpath, md5):
|
| 218 |
+
raise RuntimeError("File not found or corrupted.")
|
| 219 |
+
|
| 220 |
+
|
| 221 |
+
def download_and_extract_archive(
|
| 222 |
+
url: str,
|
| 223 |
+
download_root: str,
|
| 224 |
+
extract_root: Optional[str] = None,
|
| 225 |
+
filename: Optional[str] = None,
|
| 226 |
+
md5: Optional[str] = None,
|
| 227 |
+
remove_finished: bool = False,
|
| 228 |
+
) -> None:
|
| 229 |
+
download_root = os.path.expanduser(download_root)
|
| 230 |
+
if extract_root is None:
|
| 231 |
+
extract_root = download_root
|
| 232 |
+
if not filename:
|
| 233 |
+
filename = os.path.basename(url)
|
| 234 |
+
|
| 235 |
+
download_url(url, download_root, filename, md5)
|
| 236 |
+
|
| 237 |
+
archive = os.path.join(download_root, filename)
|
| 238 |
+
print("Extracting {} to {}".format(archive, extract_root))
|
| 239 |
+
extract_archive(archive, extract_root, remove_finished)
|
| 240 |
+
|
| 241 |
+
|
| 242 |
+
def cache_url(url: str, cache_dir: str) -> str:
|
| 243 |
+
"""
|
| 244 |
+
This implementation downloads the remote resource and caches it locally.
|
| 245 |
+
The resource will only be downloaded if not previously requested.
|
| 246 |
+
"""
|
| 247 |
+
parsed_url = urlparse(url)
|
| 248 |
+
dirname = os.path.join(cache_dir, os.path.dirname(parsed_url.path.lstrip("/")))
|
| 249 |
+
makedir(dirname)
|
| 250 |
+
filename = url.split("/")[-1]
|
| 251 |
+
cached = os.path.join(dirname, filename)
|
| 252 |
+
with file_lock(cached):
|
| 253 |
+
if not os.path.isfile(cached):
|
| 254 |
+
logging.info(f"Downloading {url} to {cached} ...")
|
| 255 |
+
cached = download(url, dirname, filename=filename)
|
| 256 |
+
logging.info(f"URL {url} cached in {cached}")
|
| 257 |
+
return cached
|
| 258 |
+
|
| 259 |
+
|
| 260 |
+
# TODO (prigoyal): convert this into RAII-style API
|
| 261 |
+
def create_file_symlink(file1, file2):
|
| 262 |
+
"""
|
| 263 |
+
Simply create the symlinks for a given file1 to file2.
|
| 264 |
+
Useful during model checkpointing to symlinks to the
|
| 265 |
+
latest successful checkpoint.
|
| 266 |
+
"""
|
| 267 |
+
try:
|
| 268 |
+
if g_pathmgr.exists(file2):
|
| 269 |
+
g_pathmgr.rm(file2)
|
| 270 |
+
g_pathmgr.symlink(file1, file2)
|
| 271 |
+
except Exception as e:
|
| 272 |
+
logging.info(f"Could NOT create symlink. Error: {e}")
|
| 273 |
+
|
| 274 |
+
|
| 275 |
+
def save_file(data, filename, append_to_json=True, verbose=True):
|
| 276 |
+
"""
|
| 277 |
+
Common i/o utility to handle saving data to various file formats.
|
| 278 |
+
Supported:
|
| 279 |
+
.pkl, .pickle, .npy, .json
|
| 280 |
+
Specifically for .json, users have the option to either append (default)
|
| 281 |
+
or rewrite by passing in Boolean value to append_to_json.
|
| 282 |
+
"""
|
| 283 |
+
if verbose:
|
| 284 |
+
logging.info(f"Saving data to file: {filename}")
|
| 285 |
+
file_ext = os.path.splitext(filename)[1]
|
| 286 |
+
if file_ext in [".pkl", ".pickle"]:
|
| 287 |
+
with g_pathmgr.open(filename, "wb") as fopen:
|
| 288 |
+
pickle.dump(data, fopen, pickle.HIGHEST_PROTOCOL)
|
| 289 |
+
elif file_ext == ".npy":
|
| 290 |
+
with g_pathmgr.open(filename, "wb") as fopen:
|
| 291 |
+
np.save(fopen, data)
|
| 292 |
+
elif file_ext == ".json":
|
| 293 |
+
if append_to_json:
|
| 294 |
+
with g_pathmgr.open(filename, "a") as fopen:
|
| 295 |
+
fopen.write(json.dumps(data, sort_keys=True) + "\n")
|
| 296 |
+
fopen.flush()
|
| 297 |
+
else:
|
| 298 |
+
with g_pathmgr.open(filename, "w") as fopen:
|
| 299 |
+
fopen.write(json.dumps(data, sort_keys=True) + "\n")
|
| 300 |
+
fopen.flush()
|
| 301 |
+
elif file_ext == ".yaml":
|
| 302 |
+
with g_pathmgr.open(filename, "w") as fopen:
|
| 303 |
+
dump = yaml.dump(data)
|
| 304 |
+
fopen.write(dump)
|
| 305 |
+
fopen.flush()
|
| 306 |
+
else:
|
| 307 |
+
raise Exception(f"Saving {file_ext} is not supported yet")
|
| 308 |
+
|
| 309 |
+
if verbose:
|
| 310 |
+
logging.info(f"Saved data to file: {filename}")
|
| 311 |
+
|
| 312 |
+
|
| 313 |
+
def load_file(filename, mmap_mode=None, verbose=True, allow_pickle=False):
|
| 314 |
+
"""
|
| 315 |
+
Common i/o utility to handle loading data from various file formats.
|
| 316 |
+
Supported:
|
| 317 |
+
.pkl, .pickle, .npy, .json
|
| 318 |
+
For the npy files, we support reading the files in mmap_mode.
|
| 319 |
+
If the mmap_mode of reading is not successful, we load data without the
|
| 320 |
+
mmap_mode.
|
| 321 |
+
"""
|
| 322 |
+
if verbose:
|
| 323 |
+
logging.info(f"Loading data from file: {filename}")
|
| 324 |
+
|
| 325 |
+
file_ext = os.path.splitext(filename)[1]
|
| 326 |
+
if file_ext == ".txt":
|
| 327 |
+
with g_pathmgr.open(filename, "r") as fopen:
|
| 328 |
+
data = fopen.readlines()
|
| 329 |
+
elif file_ext in [".pkl", ".pickle"]:
|
| 330 |
+
with g_pathmgr.open(filename, "rb") as fopen:
|
| 331 |
+
data = pickle.load(fopen, encoding="latin1")
|
| 332 |
+
elif file_ext == ".npy":
|
| 333 |
+
if mmap_mode:
|
| 334 |
+
try:
|
| 335 |
+
with g_pathmgr.open(filename, "rb") as fopen:
|
| 336 |
+
data = np.load(
|
| 337 |
+
fopen,
|
| 338 |
+
allow_pickle=allow_pickle,
|
| 339 |
+
encoding="latin1",
|
| 340 |
+
mmap_mode=mmap_mode,
|
| 341 |
+
)
|
| 342 |
+
except ValueError as e:
|
| 343 |
+
logging.info(
|
| 344 |
+
f"Could not mmap {filename}: {e}. Trying without g_pathmgr"
|
| 345 |
+
)
|
| 346 |
+
data = np.load(
|
| 347 |
+
filename,
|
| 348 |
+
allow_pickle=allow_pickle,
|
| 349 |
+
encoding="latin1",
|
| 350 |
+
mmap_mode=mmap_mode,
|
| 351 |
+
)
|
| 352 |
+
logging.info("Successfully loaded without g_pathmgr")
|
| 353 |
+
except Exception:
|
| 354 |
+
logging.info("Could not mmap without g_pathmgr. Trying without mmap")
|
| 355 |
+
with g_pathmgr.open(filename, "rb") as fopen:
|
| 356 |
+
data = np.load(fopen, allow_pickle=allow_pickle, encoding="latin1")
|
| 357 |
+
else:
|
| 358 |
+
with g_pathmgr.open(filename, "rb") as fopen:
|
| 359 |
+
data = np.load(fopen, allow_pickle=allow_pickle, encoding="latin1")
|
| 360 |
+
elif file_ext == ".json":
|
| 361 |
+
with g_pathmgr.open(filename, "r") as fopen:
|
| 362 |
+
data = json.load(fopen)
|
| 363 |
+
elif file_ext == ".yaml":
|
| 364 |
+
with g_pathmgr.open(filename, "r") as fopen:
|
| 365 |
+
data = yaml.load(fopen, Loader=yaml.FullLoader)
|
| 366 |
+
elif file_ext == ".csv":
|
| 367 |
+
with g_pathmgr.open(filename, "r") as fopen:
|
| 368 |
+
data = pd.read_csv(fopen)
|
| 369 |
+
else:
|
| 370 |
+
raise Exception(f"Reading from {file_ext} is not supported yet")
|
| 371 |
+
return data
|
| 372 |
+
|
| 373 |
+
|
| 374 |
+
def abspath(resource_path: str):
|
| 375 |
+
"""
|
| 376 |
+
Make a path absolute, but take into account prefixes like
|
| 377 |
+
"http://" or "manifold://"
|
| 378 |
+
"""
|
| 379 |
+
regex = re.compile(r"^\w+://")
|
| 380 |
+
if regex.match(resource_path) is None:
|
| 381 |
+
return os.path.abspath(resource_path)
|
| 382 |
+
else:
|
| 383 |
+
return resource_path
|
| 384 |
+
|
| 385 |
+
|
| 386 |
+
def makedir(dir_path):
|
| 387 |
+
"""
|
| 388 |
+
Create the directory if it does not exist.
|
| 389 |
+
"""
|
| 390 |
+
is_success = False
|
| 391 |
+
try:
|
| 392 |
+
if not g_pathmgr.exists(dir_path):
|
| 393 |
+
g_pathmgr.mkdirs(dir_path)
|
| 394 |
+
is_success = True
|
| 395 |
+
except BaseException:
|
| 396 |
+
logging.info(f"Error creating directory: {dir_path}")
|
| 397 |
+
return is_success
|
| 398 |
+
|
| 399 |
+
|
| 400 |
+
def is_url(input_url):
|
| 401 |
+
"""
|
| 402 |
+
Check if an input string is a url. look for http(s):// and ignoring the case
|
| 403 |
+
"""
|
| 404 |
+
is_url = re.match(r"^(?:http)s?://", input_url, re.IGNORECASE) is not None
|
| 405 |
+
return is_url
|
| 406 |
+
|
| 407 |
+
|
| 408 |
+
def cleanup_dir(dir):
|
| 409 |
+
"""
|
| 410 |
+
Utility for deleting a directory. Useful for cleaning the storage space
|
| 411 |
+
that contains various training artifacts like checkpoints, data etc.
|
| 412 |
+
"""
|
| 413 |
+
if os.path.exists(dir):
|
| 414 |
+
logging.info(f"Deleting directory: {dir}")
|
| 415 |
+
shutil.rmtree(dir)
|
| 416 |
+
logging.info(f"Deleted contents of directory: {dir}")
|
| 417 |
+
|
| 418 |
+
|
| 419 |
+
def get_file_size(filename):
|
| 420 |
+
"""
|
| 421 |
+
Given a file, get the size of file in MB
|
| 422 |
+
"""
|
| 423 |
+
size_in_mb = os.path.getsize(filename) / float(1024**2)
|
| 424 |
+
return size_in_mb
|
unimernet/configs/datasets/formula/formula_eval.yaml
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
datasets:
|
| 2 |
+
formula_rec_eval:
|
| 3 |
+
data_type: images
|
| 4 |
+
build_info:
|
| 5 |
+
images: /mnt/petrelfs/share_data/hanxiao/latex-ocr/pdf/val
|
| 6 |
+
annotation: /mnt/petrelfs/share_data/hanxiao/latex-ocr/pdf/pdfmath.txt
|
unimernet/configs/datasets/formula/formula_train.yaml
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
datasets:
|
| 2 |
+
formula_rec_train:
|
| 3 |
+
data_type: images
|
| 4 |
+
build_info:
|
| 5 |
+
images: /mnt/petrelfs/share_data/hanxiao/latex-ocr/pdf/train
|
| 6 |
+
annotation: /mnt/petrelfs/share_data/hanxiao/latex-ocr/pdf/pdfmath.txt
|
unimernet/configs/datasets/formula/multi_scale_formula_train.yaml
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
datasets:
|
| 2 |
+
multi_scale_formula_rec_train:
|
| 3 |
+
data_type: images
|
| 4 |
+
build_info:
|
| 5 |
+
images: /mnt/petrelfs/share_data/hanxiao/latex-ocr/pdf/train
|
| 6 |
+
annotation: /mnt/petrelfs/share_data/hanxiao/latex-ocr/pdf/pdfmath.txt
|
| 7 |
+
|
| 8 |
+
vis_processor:
|
| 9 |
+
train:
|
| 10 |
+
name: "formula_image_multi_scale_train"
|
| 11 |
+
all_scales:
|
| 12 |
+
- [ 96, 336 ]
|
| 13 |
+
- [ 128, 448 ]
|
| 14 |
+
- [ 192, 672 ]
|
| 15 |
+
- [ 288, 1008 ]
|
| 16 |
+
- [ 384, 1344 ]
|
| 17 |
+
|
| 18 |
+
text_processor:
|
| 19 |
+
train:
|
| 20 |
+
name: "blip_caption"
|
| 21 |
+
max_words: 256
|
unimernet/configs/default.yaml
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2022, salesforce.com, inc.
|
| 2 |
+
# All rights reserved.
|
| 3 |
+
# SPDX-License-Identifier: BSD-3-Clause
|
| 4 |
+
# For full license text, see the LICENSE file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 5 |
+
|
| 6 |
+
env:
|
| 7 |
+
# For default users
|
| 8 |
+
# cache_root: "cache"
|
| 9 |
+
# For internal use with persistent storage
|
| 10 |
+
cache_root: "/export/home/.cache/vigc"
|
unimernet/configs/models/unimernet_base.yaml
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
model:
|
| 2 |
+
arch: unimernet
|
| 3 |
+
load_finetuned: False
|
| 4 |
+
load_pretrained: False
|
| 5 |
+
pretrained: "path/to/pretrained/weight"
|
| 6 |
+
finetuned: ""
|
| 7 |
+
tokenizer_name: nougat
|
| 8 |
+
tokenizer_config:
|
| 9 |
+
path: ./models/unimernet
|
| 10 |
+
model_name: unimernet
|
| 11 |
+
model_config:
|
| 12 |
+
max_seq_len: 384
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
preprocess:
|
| 16 |
+
vis_processor:
|
| 17 |
+
train:
|
| 18 |
+
name: "formula_image_train"
|
| 19 |
+
image_size:
|
| 20 |
+
- 192
|
| 21 |
+
- 672
|
| 22 |
+
eval:
|
| 23 |
+
name: "formula_image_eval"
|
| 24 |
+
image_size:
|
| 25 |
+
- 192
|
| 26 |
+
- 672
|
| 27 |
+
text_processor:
|
| 28 |
+
train:
|
| 29 |
+
name: "blip_caption"
|
| 30 |
+
eval:
|
| 31 |
+
name: "blip_caption"
|
unimernet/datasets/__init__.py
ADDED
|
File without changes
|
unimernet/datasets/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (162 Bytes). View file
|
|
|
unimernet/datasets/__pycache__/data_utils.cpython-310.pyc
ADDED
|
Binary file (8.18 kB). View file
|
|
|
unimernet/datasets/builders/__init__.py
ADDED
|
@@ -0,0 +1,69 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
from unimernet.datasets.builders.base_dataset_builder import load_dataset_config
|
| 9 |
+
from unimernet.common.registry import registry
|
| 10 |
+
from unimernet.datasets.builders.formula import FormulaRecTrainBuilder, FormulaRecEvalBuilder, \
|
| 11 |
+
MultiScaleFormulaRecTrainBuilder
|
| 12 |
+
|
| 13 |
+
__all__ = [
|
| 14 |
+
"FormulaRecTrainBuilder",
|
| 15 |
+
"FormulaRecEvalBuilder",
|
| 16 |
+
"MultiScaleFormulaRecTrainBuilder",
|
| 17 |
+
]
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def load_dataset(name, cfg_path=None, vis_path=None, data_type=None):
|
| 21 |
+
"""
|
| 22 |
+
Example
|
| 23 |
+
|
| 24 |
+
>>> dataset = load_dataset("coco_caption", cfg=None)
|
| 25 |
+
>>> splits = dataset.keys()
|
| 26 |
+
>>> print([len(dataset[split]) for split in splits])
|
| 27 |
+
|
| 28 |
+
"""
|
| 29 |
+
if cfg_path is None:
|
| 30 |
+
cfg = None
|
| 31 |
+
else:
|
| 32 |
+
cfg = load_dataset_config(cfg_path)
|
| 33 |
+
|
| 34 |
+
try:
|
| 35 |
+
builder = registry.get_builder_class(name)(cfg)
|
| 36 |
+
except TypeError:
|
| 37 |
+
print(
|
| 38 |
+
f"Dataset {name} not found. Available datasets:\n"
|
| 39 |
+
+ ", ".join([str(k) for k in dataset_zoo.get_names()])
|
| 40 |
+
)
|
| 41 |
+
exit(1)
|
| 42 |
+
|
| 43 |
+
if vis_path is not None:
|
| 44 |
+
if data_type is None:
|
| 45 |
+
# use default data type in the config
|
| 46 |
+
data_type = builder.config.data_type
|
| 47 |
+
|
| 48 |
+
assert (
|
| 49 |
+
data_type in builder.config.build_info
|
| 50 |
+
), f"Invalid data_type {data_type} for {name}."
|
| 51 |
+
|
| 52 |
+
builder.config.build_info.get(data_type).storage = vis_path
|
| 53 |
+
|
| 54 |
+
dataset = builder.build_datasets()
|
| 55 |
+
return dataset
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
class DatasetZoo:
|
| 59 |
+
def __init__(self) -> None:
|
| 60 |
+
self.dataset_zoo = {
|
| 61 |
+
k: list(v.DATASET_CONFIG_DICT.keys())
|
| 62 |
+
for k, v in sorted(registry.mapping["builder_name_mapping"].items())
|
| 63 |
+
}
|
| 64 |
+
|
| 65 |
+
def get_names(self):
|
| 66 |
+
return list(self.dataset_zoo.keys())
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
dataset_zoo = DatasetZoo()
|
unimernet/datasets/builders/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (2.4 kB). View file
|
|
|
unimernet/datasets/builders/__pycache__/base_dataset_builder.cpython-310.pyc
ADDED
|
Binary file (6.05 kB). View file
|
|
|
unimernet/datasets/builders/__pycache__/formula.cpython-310.pyc
ADDED
|
Binary file (2.44 kB). View file
|
|
|
unimernet/datasets/builders/base_dataset_builder.py
ADDED
|
@@ -0,0 +1,233 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import logging
|
| 9 |
+
import os
|
| 10 |
+
import shutil
|
| 11 |
+
import warnings
|
| 12 |
+
|
| 13 |
+
import unimernet.common.utils as utils
|
| 14 |
+
import torch.distributed as dist
|
| 15 |
+
from unimernet.common.dist_utils import is_dist_avail_and_initialized, is_main_process
|
| 16 |
+
from unimernet.common.registry import registry
|
| 17 |
+
from unimernet.processors.base_processor import BaseProcessor
|
| 18 |
+
from omegaconf import OmegaConf
|
| 19 |
+
from torchvision.datasets.utils import download_url
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
class BaseDatasetBuilder:
|
| 23 |
+
train_dataset_cls, eval_dataset_cls = None, None
|
| 24 |
+
|
| 25 |
+
def __init__(self, cfg=None):
|
| 26 |
+
super().__init__()
|
| 27 |
+
|
| 28 |
+
if cfg is None:
|
| 29 |
+
# help to create datasets from default config.
|
| 30 |
+
self.config = load_dataset_config(self.default_config_path())
|
| 31 |
+
elif isinstance(cfg, str):
|
| 32 |
+
self.config = load_dataset_config(cfg)
|
| 33 |
+
else:
|
| 34 |
+
# when called from task.build_dataset()
|
| 35 |
+
self.config = cfg
|
| 36 |
+
|
| 37 |
+
self.data_type = self.config.data_type
|
| 38 |
+
|
| 39 |
+
self.vis_processors = {"train": BaseProcessor(), "eval": BaseProcessor()}
|
| 40 |
+
self.text_processors = {"train": BaseProcessor(), "eval": BaseProcessor()}
|
| 41 |
+
|
| 42 |
+
def build_datasets(self):
|
| 43 |
+
# download, split, etc...
|
| 44 |
+
# only called on 1 GPU/TPU in distributed
|
| 45 |
+
|
| 46 |
+
if is_main_process():
|
| 47 |
+
self._download_data()
|
| 48 |
+
|
| 49 |
+
if is_dist_avail_and_initialized():
|
| 50 |
+
dist.barrier()
|
| 51 |
+
|
| 52 |
+
# at this point, all the annotations and image/videos should be all downloaded to the specified locations.
|
| 53 |
+
logging.info("Building datasets...")
|
| 54 |
+
datasets = self.build() # dataset['train'/'val'/'test']
|
| 55 |
+
|
| 56 |
+
return datasets
|
| 57 |
+
|
| 58 |
+
def build_processors(self):
|
| 59 |
+
vis_proc_cfg = self.config.get("vis_processor")
|
| 60 |
+
txt_proc_cfg = self.config.get("text_processor")
|
| 61 |
+
|
| 62 |
+
if vis_proc_cfg is not None:
|
| 63 |
+
vis_train_cfg = vis_proc_cfg.get("train")
|
| 64 |
+
vis_eval_cfg = vis_proc_cfg.get("eval")
|
| 65 |
+
|
| 66 |
+
self.vis_processors["train"] = self._build_proc_from_cfg(vis_train_cfg)
|
| 67 |
+
self.vis_processors["eval"] = self._build_proc_from_cfg(vis_eval_cfg)
|
| 68 |
+
|
| 69 |
+
if txt_proc_cfg is not None:
|
| 70 |
+
txt_train_cfg = txt_proc_cfg.get("train")
|
| 71 |
+
txt_eval_cfg = txt_proc_cfg.get("eval")
|
| 72 |
+
|
| 73 |
+
self.text_processors["train"] = self._build_proc_from_cfg(txt_train_cfg)
|
| 74 |
+
self.text_processors["eval"] = self._build_proc_from_cfg(txt_eval_cfg)
|
| 75 |
+
|
| 76 |
+
@staticmethod
|
| 77 |
+
def _build_proc_from_cfg(cfg):
|
| 78 |
+
return (
|
| 79 |
+
registry.get_processor_class(cfg.name).from_config(cfg)
|
| 80 |
+
if cfg is not None
|
| 81 |
+
else None
|
| 82 |
+
)
|
| 83 |
+
|
| 84 |
+
@classmethod
|
| 85 |
+
def default_config_path(cls, type="default"):
|
| 86 |
+
return utils.get_abs_path(cls.DATASET_CONFIG_DICT[type])
|
| 87 |
+
|
| 88 |
+
def _download_data(self):
|
| 89 |
+
self._download_ann()
|
| 90 |
+
self._download_vis()
|
| 91 |
+
|
| 92 |
+
def _download_ann(self):
|
| 93 |
+
"""
|
| 94 |
+
Download annotation files if necessary.
|
| 95 |
+
All the vision-language datasets should have annotations of unified format.
|
| 96 |
+
|
| 97 |
+
storage_path can be:
|
| 98 |
+
(1) relative/absolute: will be prefixed with env.cache_root to make full path if relative.
|
| 99 |
+
(2) basename/dirname: will be suffixed with base name of URL if dirname is provided.
|
| 100 |
+
|
| 101 |
+
Local annotation paths should be relative.
|
| 102 |
+
"""
|
| 103 |
+
anns = self.config.build_info.annotations
|
| 104 |
+
|
| 105 |
+
splits = anns.keys()
|
| 106 |
+
|
| 107 |
+
cache_root = registry.get_path("cache_root")
|
| 108 |
+
|
| 109 |
+
for split in splits:
|
| 110 |
+
info = anns[split]
|
| 111 |
+
|
| 112 |
+
urls, storage_paths = info.get("url", None), info.storage
|
| 113 |
+
|
| 114 |
+
if isinstance(urls, str):
|
| 115 |
+
urls = [urls]
|
| 116 |
+
if isinstance(storage_paths, str):
|
| 117 |
+
storage_paths = [storage_paths]
|
| 118 |
+
|
| 119 |
+
assert len(urls) == len(storage_paths)
|
| 120 |
+
|
| 121 |
+
for url_or_filename, storage_path in zip(urls, storage_paths):
|
| 122 |
+
# if storage_path is relative, make it full by prefixing with cache_root.
|
| 123 |
+
if not os.path.isabs(storage_path):
|
| 124 |
+
storage_path = os.path.join(cache_root, storage_path)
|
| 125 |
+
|
| 126 |
+
dirname = os.path.dirname(storage_path)
|
| 127 |
+
if not os.path.exists(dirname):
|
| 128 |
+
os.makedirs(dirname)
|
| 129 |
+
|
| 130 |
+
if os.path.isfile(url_or_filename):
|
| 131 |
+
src, dst = url_or_filename, storage_path
|
| 132 |
+
if not os.path.exists(dst):
|
| 133 |
+
shutil.copyfile(src=src, dst=dst)
|
| 134 |
+
else:
|
| 135 |
+
logging.info("Using existing file {}.".format(dst))
|
| 136 |
+
else:
|
| 137 |
+
if os.path.isdir(storage_path):
|
| 138 |
+
# if only dirname is provided, suffix with basename of URL.
|
| 139 |
+
raise ValueError(
|
| 140 |
+
"Expecting storage_path to be a file path, got directory {}".format(
|
| 141 |
+
storage_path
|
| 142 |
+
)
|
| 143 |
+
)
|
| 144 |
+
else:
|
| 145 |
+
filename = os.path.basename(storage_path)
|
| 146 |
+
|
| 147 |
+
download_url(url=url_or_filename, root=dirname, filename=filename)
|
| 148 |
+
|
| 149 |
+
def _download_vis(self):
|
| 150 |
+
|
| 151 |
+
storage_path = self.config.build_info.get(self.data_type).storage
|
| 152 |
+
storage_path = utils.get_cache_path(storage_path)
|
| 153 |
+
|
| 154 |
+
if not os.path.exists(storage_path):
|
| 155 |
+
warnings.warn(
|
| 156 |
+
f"""
|
| 157 |
+
The specified path {storage_path} for visual inputs does not exist.
|
| 158 |
+
Please provide a correct path to the visual inputs or
|
| 159 |
+
refer to datasets/download_scripts/README.md for downloading instructions.
|
| 160 |
+
"""
|
| 161 |
+
)
|
| 162 |
+
|
| 163 |
+
def build(self):
|
| 164 |
+
"""
|
| 165 |
+
Create by split datasets inheriting torch.utils.data.Datasets.
|
| 166 |
+
|
| 167 |
+
# build() can be dataset-specific. Overwrite to customize.
|
| 168 |
+
"""
|
| 169 |
+
self.build_processors()
|
| 170 |
+
|
| 171 |
+
build_info = self.config.build_info
|
| 172 |
+
|
| 173 |
+
ann_info = build_info.annotations
|
| 174 |
+
vis_info = build_info.get(self.data_type)
|
| 175 |
+
|
| 176 |
+
datasets = dict()
|
| 177 |
+
for split in ann_info.keys():
|
| 178 |
+
if split not in ["train", "val", "test"]:
|
| 179 |
+
continue
|
| 180 |
+
|
| 181 |
+
is_train = split == "train"
|
| 182 |
+
|
| 183 |
+
# processors
|
| 184 |
+
vis_processor = (
|
| 185 |
+
self.vis_processors["train"]
|
| 186 |
+
if is_train
|
| 187 |
+
else self.vis_processors["eval"]
|
| 188 |
+
)
|
| 189 |
+
text_processor = (
|
| 190 |
+
self.text_processors["train"]
|
| 191 |
+
if is_train
|
| 192 |
+
else self.text_processors["eval"]
|
| 193 |
+
)
|
| 194 |
+
|
| 195 |
+
# annotation path
|
| 196 |
+
ann_paths = ann_info.get(split).storage
|
| 197 |
+
if isinstance(ann_paths, str):
|
| 198 |
+
ann_paths = [ann_paths]
|
| 199 |
+
|
| 200 |
+
abs_ann_paths = []
|
| 201 |
+
for ann_path in ann_paths:
|
| 202 |
+
if not os.path.isabs(ann_path):
|
| 203 |
+
ann_path = utils.get_cache_path(ann_path)
|
| 204 |
+
abs_ann_paths.append(ann_path)
|
| 205 |
+
ann_paths = abs_ann_paths
|
| 206 |
+
|
| 207 |
+
# visual data storage path
|
| 208 |
+
vis_path = vis_info.storage
|
| 209 |
+
|
| 210 |
+
if not os.path.isabs(vis_path):
|
| 211 |
+
# vis_path = os.path.join(utils.get_cache_path(), vis_path)
|
| 212 |
+
vis_path = utils.get_cache_path(vis_path)
|
| 213 |
+
|
| 214 |
+
if not os.path.exists(vis_path):
|
| 215 |
+
warnings.warn("storage path {} does not exist.".format(vis_path))
|
| 216 |
+
|
| 217 |
+
# create datasets
|
| 218 |
+
dataset_cls = self.train_dataset_cls if is_train else self.eval_dataset_cls
|
| 219 |
+
datasets[split] = dataset_cls(
|
| 220 |
+
vis_processor=vis_processor,
|
| 221 |
+
text_processor=text_processor,
|
| 222 |
+
ann_paths=ann_paths,
|
| 223 |
+
vis_root=vis_path,
|
| 224 |
+
)
|
| 225 |
+
|
| 226 |
+
return datasets
|
| 227 |
+
|
| 228 |
+
|
| 229 |
+
def load_dataset_config(cfg_path):
|
| 230 |
+
cfg = OmegaConf.load(cfg_path).datasets
|
| 231 |
+
cfg = cfg[list(cfg.keys())[0]]
|
| 232 |
+
|
| 233 |
+
return cfg
|
unimernet/datasets/builders/formula.py
ADDED
|
@@ -0,0 +1,105 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
from unimernet.common.registry import registry
|
| 3 |
+
from unimernet.datasets.builders.base_dataset_builder import BaseDatasetBuilder
|
| 4 |
+
from unimernet.datasets.datasets.formula import Im2LatexDataset
|
| 5 |
+
from unimernet.datasets.datasets.formula_multi_scale import MultiScaleIm2LatexDataset
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
@registry.register_builder("formula_rec_train")
|
| 9 |
+
class FormulaRecTrainBuilder(BaseDatasetBuilder):
|
| 10 |
+
train_dataset_cls = Im2LatexDataset
|
| 11 |
+
DATASET_CONFIG_DICT = {
|
| 12 |
+
"default": "configs/datasets/formula/formula_train.yaml"
|
| 13 |
+
}
|
| 14 |
+
LOG_INFO = "Formula Recgnition Train"
|
| 15 |
+
|
| 16 |
+
def build_datasets(self):
|
| 17 |
+
logging.info(f"Building {self.LOG_INFO} datasets ...")
|
| 18 |
+
self.build_processors()
|
| 19 |
+
|
| 20 |
+
build_info = self.config.build_info
|
| 21 |
+
anno_path = build_info.annotation,
|
| 22 |
+
vis_root = build_info.images
|
| 23 |
+
anno_path = [anno_path] if isinstance(anno_path, str) else anno_path
|
| 24 |
+
vis_root = [vis_root] if isinstance(vis_root, str) else vis_root
|
| 25 |
+
datasets = dict()
|
| 26 |
+
|
| 27 |
+
# create datasets
|
| 28 |
+
dataset_cls = self.train_dataset_cls
|
| 29 |
+
datasets['train'] = dataset_cls(
|
| 30 |
+
vis_processor=self.vis_processors["train"],
|
| 31 |
+
text_processor=self.text_processors["train"],
|
| 32 |
+
vis_root=vis_root,
|
| 33 |
+
anno_path=anno_path,
|
| 34 |
+
)
|
| 35 |
+
print(datasets['train'][0])
|
| 36 |
+
|
| 37 |
+
return datasets
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
@registry.register_builder("multi_scale_formula_rec_train")
|
| 41 |
+
class MultiScaleFormulaRecTrainBuilder(BaseDatasetBuilder):
|
| 42 |
+
train_dataset_cls = MultiScaleIm2LatexDataset
|
| 43 |
+
DATASET_CONFIG_DICT = {
|
| 44 |
+
"default": "configs/datasets/formula/multi_scale_formula_train.yaml"
|
| 45 |
+
}
|
| 46 |
+
LOG_INFO = "Multi Scale Formula Recgnition Train"
|
| 47 |
+
|
| 48 |
+
def build_datasets(self):
|
| 49 |
+
logging.info(f"Building {self.LOG_INFO} datasets ...")
|
| 50 |
+
self.build_processors()
|
| 51 |
+
|
| 52 |
+
build_info = self.config.build_info
|
| 53 |
+
anno_path = build_info.annotation,
|
| 54 |
+
vis_root = build_info.images
|
| 55 |
+
|
| 56 |
+
anno_path = [anno_path] if isinstance(anno_path, str) else anno_path
|
| 57 |
+
vis_root = [vis_root] if isinstance(vis_root, str) else vis_root
|
| 58 |
+
|
| 59 |
+
datasets = dict()
|
| 60 |
+
|
| 61 |
+
# create datasets
|
| 62 |
+
dataset_cls = self.train_dataset_cls
|
| 63 |
+
datasets['train'] = dataset_cls(
|
| 64 |
+
vis_processor=self.vis_processors["train"],
|
| 65 |
+
text_processor=self.text_processors["train"],
|
| 66 |
+
vis_root=vis_root,
|
| 67 |
+
anno_path=anno_path,
|
| 68 |
+
)
|
| 69 |
+
print(datasets['train'][0])
|
| 70 |
+
|
| 71 |
+
return datasets
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
@registry.register_builder("formula_rec_eval")
|
| 75 |
+
class FormulaRecEvalBuilder(BaseDatasetBuilder):
|
| 76 |
+
eval_dataset_cls = Im2LatexDataset
|
| 77 |
+
DATASET_CONFIG_DICT = {
|
| 78 |
+
"default": "configs/datasets/formula/formula_eval.yaml"
|
| 79 |
+
}
|
| 80 |
+
LOG_INFO = "Formula Recgnition Eval"
|
| 81 |
+
|
| 82 |
+
def build_datasets(self):
|
| 83 |
+
logging.info(f"Building {self.LOG_INFO} datasets ...")
|
| 84 |
+
self.build_processors()
|
| 85 |
+
|
| 86 |
+
build_info = self.config.build_info
|
| 87 |
+
anno_path = build_info.annotation,
|
| 88 |
+
vis_root = build_info.images
|
| 89 |
+
|
| 90 |
+
anno_path = [anno_path] if isinstance(anno_path, str) else anno_path
|
| 91 |
+
vis_root = [vis_root] if isinstance(vis_root, str) else vis_root
|
| 92 |
+
|
| 93 |
+
datasets = dict()
|
| 94 |
+
|
| 95 |
+
# create datasets
|
| 96 |
+
dataset_cls = self.eval_dataset_cls
|
| 97 |
+
datasets['eval'] = dataset_cls(
|
| 98 |
+
vis_processor=self.vis_processors["eval"],
|
| 99 |
+
text_processor=self.text_processors["eval"],
|
| 100 |
+
vis_root=vis_root,
|
| 101 |
+
anno_path=anno_path,
|
| 102 |
+
)
|
| 103 |
+
print(datasets['eval'][0])
|
| 104 |
+
|
| 105 |
+
return datasets
|
unimernet/datasets/data_utils.py
ADDED
|
@@ -0,0 +1,284 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import gzip
|
| 9 |
+
import logging
|
| 10 |
+
import os
|
| 11 |
+
import random as rnd
|
| 12 |
+
import tarfile
|
| 13 |
+
import zipfile
|
| 14 |
+
|
| 15 |
+
import decord
|
| 16 |
+
import webdataset as wds
|
| 17 |
+
import numpy as np
|
| 18 |
+
import torch
|
| 19 |
+
from torch.utils.data.dataset import IterableDataset, ChainDataset
|
| 20 |
+
from decord import VideoReader
|
| 21 |
+
from unimernet.common.registry import registry
|
| 22 |
+
from unimernet.datasets.datasets.base_dataset import ConcatDataset
|
| 23 |
+
from tqdm import tqdm
|
| 24 |
+
|
| 25 |
+
decord.bridge.set_bridge("torch")
|
| 26 |
+
MAX_INT = registry.get("MAX_INT")
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def load_video(video_path, n_frms=MAX_INT, height=-1, width=-1, sampling="uniform"):
|
| 30 |
+
vr = VideoReader(uri=video_path, height=height, width=width)
|
| 31 |
+
|
| 32 |
+
vlen = len(vr)
|
| 33 |
+
start, end = 0, vlen
|
| 34 |
+
|
| 35 |
+
n_frms = min(n_frms, vlen)
|
| 36 |
+
|
| 37 |
+
if sampling == "uniform":
|
| 38 |
+
indices = np.arange(start, end, vlen / n_frms).astype(int)
|
| 39 |
+
elif sampling == "headtail":
|
| 40 |
+
indices_h = sorted(rnd.sample(range(vlen // 2), n_frms // 2))
|
| 41 |
+
indices_t = sorted(rnd.sample(range(vlen // 2, vlen), n_frms // 2))
|
| 42 |
+
indices = indices_h + indices_t
|
| 43 |
+
else:
|
| 44 |
+
raise NotImplementedError
|
| 45 |
+
|
| 46 |
+
# get_batch -> T, H, W, C
|
| 47 |
+
frms = vr.get_batch(indices).permute(3, 0, 1, 2).float() # (C, T, H, W)
|
| 48 |
+
|
| 49 |
+
return frms
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def apply_to_sample(f, sample):
|
| 53 |
+
if len(sample) == 0:
|
| 54 |
+
return {}
|
| 55 |
+
|
| 56 |
+
def _apply(x):
|
| 57 |
+
if torch.is_tensor(x):
|
| 58 |
+
return f(x)
|
| 59 |
+
elif isinstance(x, dict):
|
| 60 |
+
return {key: _apply(value) for key, value in x.items()}
|
| 61 |
+
elif isinstance(x, list):
|
| 62 |
+
return [_apply(x) for x in x]
|
| 63 |
+
else:
|
| 64 |
+
return x
|
| 65 |
+
|
| 66 |
+
return _apply(sample)
|
| 67 |
+
|
| 68 |
+
|
| 69 |
+
def move_to_cuda(sample):
|
| 70 |
+
def _move_to_cuda(tensor):
|
| 71 |
+
return tensor.cuda()
|
| 72 |
+
|
| 73 |
+
return apply_to_sample(_move_to_cuda, sample)
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
def prepare_sample(samples, cuda_enabled=True):
|
| 77 |
+
if cuda_enabled:
|
| 78 |
+
samples = move_to_cuda(samples)
|
| 79 |
+
|
| 80 |
+
# TODO fp16 support
|
| 81 |
+
|
| 82 |
+
return samples
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
def reorg_datasets_by_split(datasets):
|
| 86 |
+
"""
|
| 87 |
+
Organizes datasets by split.
|
| 88 |
+
|
| 89 |
+
Args:
|
| 90 |
+
datasets: dict of torch.utils.data.Dataset objects by name.
|
| 91 |
+
|
| 92 |
+
Returns:
|
| 93 |
+
Dict of datasets by split {split_name: List[Datasets]}.
|
| 94 |
+
"""
|
| 95 |
+
# if len(datasets) == 1:
|
| 96 |
+
# return datasets[list(datasets.keys())[0]]
|
| 97 |
+
# else:
|
| 98 |
+
reorg_datasets = dict()
|
| 99 |
+
|
| 100 |
+
# reorganize by split
|
| 101 |
+
for _, dataset in datasets.items():
|
| 102 |
+
for split_name, dataset_split in dataset.items():
|
| 103 |
+
if split_name not in reorg_datasets:
|
| 104 |
+
reorg_datasets[split_name] = [dataset_split]
|
| 105 |
+
else:
|
| 106 |
+
reorg_datasets[split_name].append(dataset_split)
|
| 107 |
+
|
| 108 |
+
return reorg_datasets
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
def concat_datasets(datasets):
|
| 112 |
+
"""
|
| 113 |
+
Concatenates multiple datasets into a single dataset.
|
| 114 |
+
|
| 115 |
+
It supports may-style datasets and DataPipeline from WebDataset. Currently, does not support
|
| 116 |
+
generic IterableDataset because it requires creating separate samplers.
|
| 117 |
+
|
| 118 |
+
Now only supports conctenating training datasets and assuming validation and testing
|
| 119 |
+
have only a single dataset. This is because metrics should not be computed on the concatenated
|
| 120 |
+
datasets.
|
| 121 |
+
|
| 122 |
+
Args:
|
| 123 |
+
datasets: dict of torch.utils.data.Dataset objects by split.
|
| 124 |
+
|
| 125 |
+
Returns:
|
| 126 |
+
Dict of concatenated datasets by split, "train" is the concatenation of multiple datasets,
|
| 127 |
+
"val" and "test" remain the same.
|
| 128 |
+
|
| 129 |
+
If the input training datasets contain both map-style and DataPipeline datasets, returns
|
| 130 |
+
a tuple, where the first element is a concatenated map-style dataset and the second
|
| 131 |
+
element is a chained DataPipeline dataset.
|
| 132 |
+
|
| 133 |
+
"""
|
| 134 |
+
# concatenate datasets in the same split
|
| 135 |
+
for split_name in datasets:
|
| 136 |
+
if split_name != "train":
|
| 137 |
+
assert (
|
| 138 |
+
len(datasets[split_name]) == 1
|
| 139 |
+
), "Do not support multiple {} datasets.".format(split_name)
|
| 140 |
+
datasets[split_name] = datasets[split_name][0]
|
| 141 |
+
else:
|
| 142 |
+
iterable_datasets, map_datasets = [], []
|
| 143 |
+
for dataset in datasets[split_name]:
|
| 144 |
+
if isinstance(dataset, wds.DataPipeline):
|
| 145 |
+
logging.info(
|
| 146 |
+
"Dataset {} is IterableDataset, can't be concatenated.".format(
|
| 147 |
+
dataset
|
| 148 |
+
)
|
| 149 |
+
)
|
| 150 |
+
iterable_datasets.append(dataset)
|
| 151 |
+
elif isinstance(dataset, IterableDataset):
|
| 152 |
+
raise NotImplementedError(
|
| 153 |
+
"Do not support concatenation of generic IterableDataset."
|
| 154 |
+
)
|
| 155 |
+
else:
|
| 156 |
+
map_datasets.append(dataset)
|
| 157 |
+
|
| 158 |
+
# if len(iterable_datasets) > 0:
|
| 159 |
+
# concatenate map-style datasets and iterable-style datasets separately
|
| 160 |
+
chained_datasets = (
|
| 161 |
+
ChainDataset(iterable_datasets) if len(iterable_datasets) > 0 else None
|
| 162 |
+
)
|
| 163 |
+
concat_datasets = (
|
| 164 |
+
ConcatDataset(map_datasets) if len(map_datasets) > 0 else None
|
| 165 |
+
)
|
| 166 |
+
|
| 167 |
+
train_datasets = concat_datasets, chained_datasets
|
| 168 |
+
train_datasets = tuple([x for x in train_datasets if x is not None])
|
| 169 |
+
train_datasets = (
|
| 170 |
+
train_datasets[0] if len(train_datasets) == 1 else train_datasets
|
| 171 |
+
)
|
| 172 |
+
|
| 173 |
+
datasets[split_name] = train_datasets
|
| 174 |
+
|
| 175 |
+
return datasets
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
def extract_archive(from_path, to_path=None, overwrite=False):
|
| 179 |
+
"""Extract archive.
|
| 180 |
+
|
| 181 |
+
Args:
|
| 182 |
+
from_path: the path of the archive.
|
| 183 |
+
to_path: the root path of the extracted files (directory of from_path)
|
| 184 |
+
overwrite: overwrite existing files (False)
|
| 185 |
+
|
| 186 |
+
Returns:
|
| 187 |
+
List of paths to extracted files even if not overwritten.
|
| 188 |
+
|
| 189 |
+
Examples:
|
| 190 |
+
>>> url = 'http://www.quest.dcs.shef.ac.uk/wmt16_files_mmt/validation.tar.gz'
|
| 191 |
+
>>> from_path = './validation.tar.gz'
|
| 192 |
+
>>> to_path = './'
|
| 193 |
+
>>> torchtext.utils.download_from_url(url, from_path)
|
| 194 |
+
>>> torchtext.utils.extract_archive(from_path, to_path)
|
| 195 |
+
>>> ['.data/val.de', '.data/val.en']
|
| 196 |
+
>>> torchtext.utils.download_from_url(url, from_path)
|
| 197 |
+
>>> torchtext.utils.extract_archive(from_path, to_path)
|
| 198 |
+
>>> ['.data/val.de', '.data/val.en']
|
| 199 |
+
|
| 200 |
+
"""
|
| 201 |
+
|
| 202 |
+
if to_path is None:
|
| 203 |
+
to_path = os.path.dirname(from_path)
|
| 204 |
+
|
| 205 |
+
if from_path.endswith((".tar.gz", ".tgz")):
|
| 206 |
+
logging.info("Opening tar file {} to {}.".format(from_path, to_path))
|
| 207 |
+
with tarfile.open(from_path, "r") as tar:
|
| 208 |
+
files = []
|
| 209 |
+
for file_ in tqdm(tar):
|
| 210 |
+
file_path = os.path.join(to_path, file_.name)
|
| 211 |
+
if file_.isfile():
|
| 212 |
+
files.append(file_path)
|
| 213 |
+
if os.path.exists(file_path):
|
| 214 |
+
logging.info("{} already extracted.".format(file_path))
|
| 215 |
+
if not overwrite:
|
| 216 |
+
continue
|
| 217 |
+
tar.extract(file_, to_path)
|
| 218 |
+
logging.info("Finished extracting tar file {}.".format(from_path))
|
| 219 |
+
return files
|
| 220 |
+
|
| 221 |
+
elif from_path.endswith(".zip"):
|
| 222 |
+
assert zipfile.is_zipfile(from_path), from_path
|
| 223 |
+
logging.info("Opening zip file {} to {}.".format(from_path, to_path))
|
| 224 |
+
with zipfile.ZipFile(from_path, "r") as zfile:
|
| 225 |
+
files = []
|
| 226 |
+
for file_ in tqdm(zfile.namelist()):
|
| 227 |
+
file_path = os.path.join(to_path, file_)
|
| 228 |
+
files.append(file_path)
|
| 229 |
+
if os.path.exists(file_path):
|
| 230 |
+
logging.info("{} already extracted.".format(file_path))
|
| 231 |
+
if not overwrite:
|
| 232 |
+
continue
|
| 233 |
+
zfile.extract(file_, to_path)
|
| 234 |
+
files = [f for f in files if os.path.isfile(f)]
|
| 235 |
+
logging.info("Finished extracting zip file {}.".format(from_path))
|
| 236 |
+
return files
|
| 237 |
+
|
| 238 |
+
elif from_path.endswith(".gz"):
|
| 239 |
+
logging.info("Opening gz file {} to {}.".format(from_path, to_path))
|
| 240 |
+
default_block_size = 65536
|
| 241 |
+
filename = from_path[:-3]
|
| 242 |
+
files = [filename]
|
| 243 |
+
with gzip.open(from_path, "rb") as gzfile, open(filename, "wb") as d_file:
|
| 244 |
+
while True:
|
| 245 |
+
block = gzfile.read(default_block_size)
|
| 246 |
+
if not block:
|
| 247 |
+
break
|
| 248 |
+
else:
|
| 249 |
+
d_file.write(block)
|
| 250 |
+
d_file.write(block)
|
| 251 |
+
logging.info("Finished extracting gz file {}.".format(from_path))
|
| 252 |
+
return files
|
| 253 |
+
|
| 254 |
+
else:
|
| 255 |
+
raise NotImplementedError(
|
| 256 |
+
"We currently only support tar.gz, .tgz, .gz and zip achives."
|
| 257 |
+
)
|
| 258 |
+
|
| 259 |
+
|
| 260 |
+
def save_frames_grid(img_array, out_path):
|
| 261 |
+
import torch
|
| 262 |
+
from PIL import Image
|
| 263 |
+
from torchvision.utils import make_grid
|
| 264 |
+
|
| 265 |
+
if len(img_array.shape) == 3:
|
| 266 |
+
img_array = img_array.unsqueeze(0)
|
| 267 |
+
elif len(img_array.shape) == 5:
|
| 268 |
+
b, t, c, h, w = img_array.shape
|
| 269 |
+
img_array = img_array.view(-1, c, h, w)
|
| 270 |
+
elif len(img_array.shape) == 4:
|
| 271 |
+
pass
|
| 272 |
+
else:
|
| 273 |
+
raise NotImplementedError(
|
| 274 |
+
"Supports only (b,t,c,h,w)-shaped inputs. First two dimensions can be ignored."
|
| 275 |
+
)
|
| 276 |
+
|
| 277 |
+
assert img_array.shape[1] == 3, "Exepcting input shape of (H, W, 3), i.e. RGB-only."
|
| 278 |
+
|
| 279 |
+
grid = make_grid(img_array)
|
| 280 |
+
ndarr = grid.permute(1, 2, 0).to("cpu", torch.uint8).numpy()
|
| 281 |
+
|
| 282 |
+
img = Image.fromarray(ndarr)
|
| 283 |
+
|
| 284 |
+
img.save(out_path)
|
unimernet/datasets/datasets/__pycache__/base_dataset.cpython-310.pyc
ADDED
|
Binary file (3.55 kB). View file
|
|
|
unimernet/datasets/datasets/__pycache__/formula.cpython-310.pyc
ADDED
|
Binary file (2.85 kB). View file
|
|
|
unimernet/datasets/datasets/__pycache__/formula_multi_scale.cpython-310.pyc
ADDED
|
Binary file (1.23 kB). View file
|
|
|
unimernet/datasets/datasets/base_dataset.py
ADDED
|
@@ -0,0 +1,103 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
from PIL import Image, ImageFile
|
| 3 |
+
import os.path as osp
|
| 4 |
+
|
| 5 |
+
ImageFile.LOAD_TRUNCATED_IMAGES = True
|
| 6 |
+
|
| 7 |
+
from io import BytesIO
|
| 8 |
+
from typing import Iterable
|
| 9 |
+
from torch.utils.data import Dataset, ConcatDataset
|
| 10 |
+
import torch
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class BaseDataset(Dataset):
|
| 14 |
+
|
| 15 |
+
def __init__(self, vis_processor, text_processor, vis_root, anno_path):
|
| 16 |
+
|
| 17 |
+
self.vis_root = vis_root
|
| 18 |
+
# if isinstance(anno_path, tuple) or isinstance(anno_path, list):
|
| 19 |
+
# anno_path = anno_path[0]
|
| 20 |
+
self.anno_path = anno_path
|
| 21 |
+
|
| 22 |
+
self.vis_processor = vis_processor
|
| 23 |
+
self.text_processor = text_processor
|
| 24 |
+
|
| 25 |
+
self.samples = self.init_samples()
|
| 26 |
+
self.reader = self.init_reader()
|
| 27 |
+
|
| 28 |
+
print('total {} {} samples'.format(self.__len__(), self.__class__.__name__))
|
| 29 |
+
|
| 30 |
+
for idx in range(10):
|
| 31 |
+
self.__getitem__(idx)
|
| 32 |
+
|
| 33 |
+
def __len__(self):
|
| 34 |
+
return len(self.samples)
|
| 35 |
+
|
| 36 |
+
def __getitem__(self, index):
|
| 37 |
+
raise NotImplementedError
|
| 38 |
+
|
| 39 |
+
def init_samples(self):
|
| 40 |
+
# read annotation from ceph
|
| 41 |
+
if self.anno_path.startswith('cluster'):
|
| 42 |
+
from petrel_client.client import Client
|
| 43 |
+
client = Client("~/petreloss.conf")
|
| 44 |
+
samples = json.loads(client.get(self.anno_path))
|
| 45 |
+
else:
|
| 46 |
+
samples = json.load(open(self.anno_path, 'r'))
|
| 47 |
+
return samples
|
| 48 |
+
|
| 49 |
+
def init_reader(self):
|
| 50 |
+
if self.vis_root.startswith('cluster'):
|
| 51 |
+
from petrel_client.client import Client
|
| 52 |
+
client = Client("~/petreloss.conf")
|
| 53 |
+
reader = {'type': 'PetrelReader', 'body': client.get}
|
| 54 |
+
else:
|
| 55 |
+
reader = {'type': 'LocalReader', 'body': Image.open}
|
| 56 |
+
return reader
|
| 57 |
+
|
| 58 |
+
def _read_image(self, sample, image_key="image"):
|
| 59 |
+
img_file = sample[image_key]
|
| 60 |
+
image_path = osp.join(self.vis_root, img_file)
|
| 61 |
+
image = self.reader['body'](image_path)
|
| 62 |
+
if isinstance(image, bytes):
|
| 63 |
+
bytes_stream = BytesIO(image)
|
| 64 |
+
image = Image.open(bytes_stream)
|
| 65 |
+
image = image.convert("RGB")
|
| 66 |
+
return image
|
| 67 |
+
|
| 68 |
+
def collater(self, samples):
|
| 69 |
+
image_list, question_list, answer_list = [], [], []
|
| 70 |
+
|
| 71 |
+
for sample in samples:
|
| 72 |
+
image_list.append(sample["image"])
|
| 73 |
+
question_list.append(sample["text_input"])
|
| 74 |
+
answer_list.append(sample["text_output"])
|
| 75 |
+
|
| 76 |
+
return {
|
| 77 |
+
"image": torch.stack(image_list, dim=0),
|
| 78 |
+
"text_input": question_list,
|
| 79 |
+
"text_output": answer_list,
|
| 80 |
+
"data_type": "vqa",
|
| 81 |
+
}
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
class ConcatDataset(ConcatDataset):
|
| 85 |
+
def __init__(self, datasets: Iterable[Dataset]) -> None:
|
| 86 |
+
super().__init__(datasets)
|
| 87 |
+
|
| 88 |
+
def collater(self, samples):
|
| 89 |
+
# TODO For now only supports datasets with same underlying collater implementations
|
| 90 |
+
|
| 91 |
+
all_keys = set()
|
| 92 |
+
for s in samples:
|
| 93 |
+
all_keys.update(s)
|
| 94 |
+
|
| 95 |
+
shared_keys = all_keys
|
| 96 |
+
for s in samples:
|
| 97 |
+
shared_keys = shared_keys & set(s.keys())
|
| 98 |
+
|
| 99 |
+
samples_shared_keys = []
|
| 100 |
+
for s in samples:
|
| 101 |
+
samples_shared_keys.append({k: s[k] for k in s.keys() if k in shared_keys})
|
| 102 |
+
|
| 103 |
+
return self.datasets[0].collater(samples_shared_keys)
|
unimernet/datasets/datasets/dataloader_utils.py
ADDED
|
@@ -0,0 +1,200 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import time
|
| 9 |
+
import random
|
| 10 |
+
import torch
|
| 11 |
+
from unimernet.datasets.data_utils import move_to_cuda
|
| 12 |
+
from torch.utils.data import DataLoader
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class MultiIterLoader:
|
| 16 |
+
"""
|
| 17 |
+
A simple wrapper for iterating over multiple iterators.
|
| 18 |
+
|
| 19 |
+
Args:
|
| 20 |
+
loaders (List[Loader]): List of Iterator loaders.
|
| 21 |
+
ratios (List[float]): List of ratios to sample from each loader. If None, all loaders are sampled uniformly.
|
| 22 |
+
"""
|
| 23 |
+
|
| 24 |
+
def __init__(self, loaders, ratios=None):
|
| 25 |
+
# assert all loaders has __next__ method
|
| 26 |
+
for loader in loaders:
|
| 27 |
+
assert hasattr(
|
| 28 |
+
loader, "__next__"
|
| 29 |
+
), "Loader {} has no __next__ method.".format(loader)
|
| 30 |
+
|
| 31 |
+
if ratios is None:
|
| 32 |
+
ratios = [1.0] * len(loaders)
|
| 33 |
+
else:
|
| 34 |
+
assert len(ratios) == len(loaders)
|
| 35 |
+
ratios = [float(ratio) / sum(ratios) for ratio in ratios]
|
| 36 |
+
|
| 37 |
+
self.loaders = loaders
|
| 38 |
+
self.ratios = ratios
|
| 39 |
+
|
| 40 |
+
def __next__(self):
|
| 41 |
+
# random sample from each loader by ratio
|
| 42 |
+
loader_idx = random.choices(range(len(self.loaders)), self.ratios, k=1)[0]
|
| 43 |
+
return next(self.loaders[loader_idx])
|
| 44 |
+
|
| 45 |
+
def __len__(self):
|
| 46 |
+
return sum([len(_) for _ in self.loaders if hasattr(_, "__len__")])
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
class ConcatLoader:
|
| 50 |
+
"""
|
| 51 |
+
A simple wrapper for iterating over multiple iterators.
|
| 52 |
+
|
| 53 |
+
Args:
|
| 54 |
+
loaders (List[Loader]): List of Iterator loaders.
|
| 55 |
+
ratios (List[float]): List of ratios to sample from each loader. If None, all loaders are sampled uniformly.
|
| 56 |
+
"""
|
| 57 |
+
|
| 58 |
+
def __init__(self, loaders):
|
| 59 |
+
# assert all loaders has __next__ method
|
| 60 |
+
for loader in loaders:
|
| 61 |
+
assert hasattr(
|
| 62 |
+
loader, "__len__"
|
| 63 |
+
), "Loader {} has no __len__ method.".format(loader)
|
| 64 |
+
|
| 65 |
+
self._epoch = 0
|
| 66 |
+
self._loader_lens = [len(_) for _ in loaders]
|
| 67 |
+
self._rest_lens = self._loader_lens.copy()
|
| 68 |
+
|
| 69 |
+
self.loaders = loaders
|
| 70 |
+
|
| 71 |
+
def __next__(self):
|
| 72 |
+
# random sample from each loader by ratio
|
| 73 |
+
loader_idx = random.choices(range(len(self.loaders)), self._rest_lens, k=1)[0]
|
| 74 |
+
self._rest_lens[loader_idx] -= 1
|
| 75 |
+
if sum(self._rest_lens) == 0:
|
| 76 |
+
self._epoch += 1
|
| 77 |
+
self._rest_lens = self._loader_lens.copy()
|
| 78 |
+
return next(self.loaders[loader_idx])
|
| 79 |
+
|
| 80 |
+
def __len__(self):
|
| 81 |
+
return sum([len(_) for _ in self.loaders if hasattr(_, "__len__")])
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
class PrefetchLoader(object):
|
| 85 |
+
"""
|
| 86 |
+
Modified from https://github.com/ChenRocks/UNITER.
|
| 87 |
+
|
| 88 |
+
overlap compute and cuda data transfer
|
| 89 |
+
(copied and then modified from nvidia apex)
|
| 90 |
+
"""
|
| 91 |
+
|
| 92 |
+
def __init__(self, loader):
|
| 93 |
+
self.loader = loader
|
| 94 |
+
self.stream = torch.cuda.Stream()
|
| 95 |
+
|
| 96 |
+
def __iter__(self):
|
| 97 |
+
loader_it = iter(self.loader)
|
| 98 |
+
self.preload(loader_it)
|
| 99 |
+
batch = self.next(loader_it)
|
| 100 |
+
while batch is not None:
|
| 101 |
+
is_tuple = isinstance(batch, tuple)
|
| 102 |
+
if is_tuple:
|
| 103 |
+
task, batch = batch
|
| 104 |
+
|
| 105 |
+
if is_tuple:
|
| 106 |
+
yield task, batch
|
| 107 |
+
else:
|
| 108 |
+
yield batch
|
| 109 |
+
batch = self.next(loader_it)
|
| 110 |
+
|
| 111 |
+
def __len__(self):
|
| 112 |
+
return len(self.loader)
|
| 113 |
+
|
| 114 |
+
def preload(self, it):
|
| 115 |
+
try:
|
| 116 |
+
self.batch = next(it)
|
| 117 |
+
except StopIteration:
|
| 118 |
+
self.batch = None
|
| 119 |
+
return
|
| 120 |
+
# if record_stream() doesn't work, another option is to make sure
|
| 121 |
+
# device inputs are created on the main stream.
|
| 122 |
+
# self.next_input_gpu = torch.empty_like(self.next_input,
|
| 123 |
+
# device='cuda')
|
| 124 |
+
# self.next_target_gpu = torch.empty_like(self.next_target,
|
| 125 |
+
# device='cuda')
|
| 126 |
+
# Need to make sure the memory allocated for next_* is not still in use
|
| 127 |
+
# by the main stream at the time we start copying to next_*:
|
| 128 |
+
# self.stream.wait_stream(torch.cuda.current_stream())
|
| 129 |
+
with torch.cuda.stream(self.stream):
|
| 130 |
+
self.batch = move_to_cuda(self.batch)
|
| 131 |
+
# more code for the alternative if record_stream() doesn't work:
|
| 132 |
+
# copy_ will record the use of the pinned source tensor in this
|
| 133 |
+
# side stream.
|
| 134 |
+
# self.next_input_gpu.copy_(self.next_input, non_blocking=True)
|
| 135 |
+
# self.next_target_gpu.copy_(self.next_target, non_blocking=True)
|
| 136 |
+
# self.next_input = self.next_input_gpu
|
| 137 |
+
# self.next_target = self.next_target_gpu
|
| 138 |
+
|
| 139 |
+
def next(self, it):
|
| 140 |
+
torch.cuda.current_stream().wait_stream(self.stream)
|
| 141 |
+
batch = self.batch
|
| 142 |
+
if batch is not None:
|
| 143 |
+
record_cuda_stream(batch)
|
| 144 |
+
self.preload(it)
|
| 145 |
+
return batch
|
| 146 |
+
|
| 147 |
+
def __getattr__(self, name):
|
| 148 |
+
method = self.loader.__getattribute__(name)
|
| 149 |
+
return method
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
def record_cuda_stream(batch):
|
| 153 |
+
if isinstance(batch, torch.Tensor):
|
| 154 |
+
batch.record_stream(torch.cuda.current_stream())
|
| 155 |
+
elif isinstance(batch, list) or isinstance(batch, tuple):
|
| 156 |
+
for t in batch:
|
| 157 |
+
record_cuda_stream(t)
|
| 158 |
+
elif isinstance(batch, dict):
|
| 159 |
+
for t in batch.values():
|
| 160 |
+
record_cuda_stream(t)
|
| 161 |
+
else:
|
| 162 |
+
pass
|
| 163 |
+
|
| 164 |
+
|
| 165 |
+
class IterLoader:
|
| 166 |
+
"""
|
| 167 |
+
A wrapper to convert DataLoader as an infinite iterator.
|
| 168 |
+
|
| 169 |
+
Modified from:
|
| 170 |
+
https://github.com/open-mmlab/mmcv/blob/master/mmcv/runner/iter_based_runner.py
|
| 171 |
+
"""
|
| 172 |
+
|
| 173 |
+
def __init__(self, dataloader: DataLoader, use_distributed: bool = False):
|
| 174 |
+
self._dataloader = dataloader
|
| 175 |
+
self.iter_loader = iter(self._dataloader)
|
| 176 |
+
self._use_distributed = use_distributed
|
| 177 |
+
self._epoch = 0
|
| 178 |
+
|
| 179 |
+
@property
|
| 180 |
+
def epoch(self) -> int:
|
| 181 |
+
return self._epoch
|
| 182 |
+
|
| 183 |
+
def __next__(self):
|
| 184 |
+
try:
|
| 185 |
+
data = next(self.iter_loader)
|
| 186 |
+
except StopIteration:
|
| 187 |
+
self._epoch += 1
|
| 188 |
+
if hasattr(self._dataloader.sampler, "set_epoch") and self._use_distributed:
|
| 189 |
+
self._dataloader.sampler.set_epoch(self._epoch)
|
| 190 |
+
time.sleep(2) # Prevent possible deadlock during epoch transition
|
| 191 |
+
self.iter_loader = iter(self._dataloader)
|
| 192 |
+
data = next(self.iter_loader)
|
| 193 |
+
|
| 194 |
+
return data
|
| 195 |
+
|
| 196 |
+
def __iter__(self):
|
| 197 |
+
return self
|
| 198 |
+
|
| 199 |
+
def __len__(self):
|
| 200 |
+
return len(self._dataloader)
|
unimernet/datasets/datasets/formula.py
ADDED
|
@@ -0,0 +1,71 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from .base_dataset import BaseDataset
|
| 3 |
+
import os.path as osp
|
| 4 |
+
import glob
|
| 5 |
+
from io import BytesIO
|
| 6 |
+
from PIL import Image
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class Im2LatexDataset(BaseDataset):
|
| 10 |
+
|
| 11 |
+
def init_samples(self):
|
| 12 |
+
samples = []
|
| 13 |
+
for vis_root, anno_path in zip(self.vis_root, self.anno_path):
|
| 14 |
+
images = [path.replace('\\', '/') for path in glob.glob(osp.join(vis_root, '*.png'))]
|
| 15 |
+
indices = [int(osp.basename(img).split('.')[0]) for img in images]
|
| 16 |
+
|
| 17 |
+
eqs = open(anno_path, 'r').read().split('\n')
|
| 18 |
+
eqs = [eqs[_] for _ in indices]
|
| 19 |
+
|
| 20 |
+
for i, e in zip(images, eqs):
|
| 21 |
+
samples.append({"image": i, "equation": e, "vis_root": vis_root})
|
| 22 |
+
return samples
|
| 23 |
+
|
| 24 |
+
def __getitem__(self, index):
|
| 25 |
+
ann = self.samples[index]
|
| 26 |
+
try:
|
| 27 |
+
image = self.vis_processor(self._read_image(ann))
|
| 28 |
+
except Exception:
|
| 29 |
+
return self[(index + 1) % len(self)]
|
| 30 |
+
if image is None:
|
| 31 |
+
return self[(index + 1) % len(self)]
|
| 32 |
+
equation = ann["equation"]
|
| 33 |
+
return {"image": image, "text_input": equation, "id": index}
|
| 34 |
+
|
| 35 |
+
def _read_image(self, sample, image_key="image"):
|
| 36 |
+
img_file = sample[image_key]
|
| 37 |
+
vis_root = sample["vis_root"]
|
| 38 |
+
image_path = osp.join(vis_root, img_file)
|
| 39 |
+
image = self.reader['body'](image_path)
|
| 40 |
+
if isinstance(image, bytes):
|
| 41 |
+
bytes_stream = BytesIO(image)
|
| 42 |
+
image = Image.open(bytes_stream)
|
| 43 |
+
image = image.convert("RGB")
|
| 44 |
+
return image
|
| 45 |
+
|
| 46 |
+
def init_reader(self):
|
| 47 |
+
if not isinstance(self.vis_root, str):
|
| 48 |
+
vis_root = self.vis_root[0]
|
| 49 |
+
else:
|
| 50 |
+
vis_root = self.vis_root
|
| 51 |
+
if vis_root.startswith('cluster'):
|
| 52 |
+
from petrel_client.client import Client
|
| 53 |
+
client = Client("~/petreloss.conf")
|
| 54 |
+
reader = {'type': 'PetrelReader', 'body': client.get}
|
| 55 |
+
else:
|
| 56 |
+
reader = {'type': 'LocalReader', 'body': Image.open}
|
| 57 |
+
return reader
|
| 58 |
+
|
| 59 |
+
def collater(self, samples):
|
| 60 |
+
image_list, question_list, id_list = [], [], []
|
| 61 |
+
|
| 62 |
+
for sample in samples:
|
| 63 |
+
image_list.append(sample["image"])
|
| 64 |
+
question_list.append(sample["text_input"])
|
| 65 |
+
id_list.append(sample["id"])
|
| 66 |
+
|
| 67 |
+
return {
|
| 68 |
+
"image": torch.stack(image_list, dim=0),
|
| 69 |
+
"text_input": question_list,
|
| 70 |
+
"id": id_list
|
| 71 |
+
}
|
unimernet/datasets/datasets/formula_multi_scale.py
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from .formula import Im2LatexDataset
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
class MultiScaleIm2LatexDataset(Im2LatexDataset):
|
| 6 |
+
|
| 7 |
+
def __getitem__(self, index):
|
| 8 |
+
ann = self.samples[index]
|
| 9 |
+
try:
|
| 10 |
+
pil_image = self._read_image(ann)
|
| 11 |
+
image = self.vis_processor(pil_image)
|
| 12 |
+
except Exception:
|
| 13 |
+
return self[(index + 1) % len(self)]
|
| 14 |
+
if image is None:
|
| 15 |
+
return self[(index + 1) % len(self)]
|
| 16 |
+
equation = ann["equation"]
|
| 17 |
+
return {"image": image, "text_input": equation, "id": index, "raw_image": pil_image}
|
| 18 |
+
|
| 19 |
+
def collater(self, samples):
|
| 20 |
+
self.vis_processor.reset_scale()
|
| 21 |
+
image_list, question_list, id_list = [], [], []
|
| 22 |
+
|
| 23 |
+
for sample in samples:
|
| 24 |
+
image_list.append(self.vis_processor(sample["raw_image"]))
|
| 25 |
+
question_list.append(sample["text_input"])
|
| 26 |
+
id_list.append(sample["id"])
|
| 27 |
+
|
| 28 |
+
return {
|
| 29 |
+
"image": torch.stack(image_list, dim=0),
|
| 30 |
+
"text_input": question_list,
|
| 31 |
+
"id": id_list
|
| 32 |
+
}
|
unimernet/models/__init__.py
ADDED
|
@@ -0,0 +1,198 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import logging
|
| 9 |
+
import torch
|
| 10 |
+
from omegaconf import OmegaConf
|
| 11 |
+
from unimernet.common.registry import registry
|
| 12 |
+
|
| 13 |
+
from unimernet.models.base_model import BaseModel
|
| 14 |
+
|
| 15 |
+
from unimernet.processors.base_processor import BaseProcessor
|
| 16 |
+
from unimernet.models.unimernet.unimernet import UniMERModel
|
| 17 |
+
|
| 18 |
+
__all__ = [
|
| 19 |
+
"load_model",
|
| 20 |
+
"BaseModel",
|
| 21 |
+
"UniMERModel",
|
| 22 |
+
]
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def load_model(name, model_type, is_eval=False, device="cpu", checkpoint=None):
|
| 26 |
+
"""
|
| 27 |
+
Load supported models.
|
| 28 |
+
|
| 29 |
+
To list all available models and types in registry:
|
| 30 |
+
>>> from unimernet.models import model_zoo
|
| 31 |
+
>>> print(model_zoo)
|
| 32 |
+
|
| 33 |
+
Args:
|
| 34 |
+
name (str): name of the model.
|
| 35 |
+
model_type (str): type of the model.
|
| 36 |
+
is_eval (bool): whether the model is in eval mode. Default: False.
|
| 37 |
+
device (str): device to use. Default: "cpu".
|
| 38 |
+
checkpoint (str): path or to checkpoint. Default: None.
|
| 39 |
+
Note that expecting the checkpoint to have the same keys in state_dict as the model.
|
| 40 |
+
|
| 41 |
+
Returns:
|
| 42 |
+
model (torch.nn.Module): model.
|
| 43 |
+
"""
|
| 44 |
+
|
| 45 |
+
model = registry.get_model_class(name).from_pretrained(model_type=model_type)
|
| 46 |
+
|
| 47 |
+
if checkpoint is not None:
|
| 48 |
+
model.load_checkpoint(checkpoint)
|
| 49 |
+
|
| 50 |
+
if is_eval:
|
| 51 |
+
model.eval()
|
| 52 |
+
|
| 53 |
+
if device == "cpu":
|
| 54 |
+
model = model.float()
|
| 55 |
+
|
| 56 |
+
return model.to(device)
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
def load_preprocess(config):
|
| 60 |
+
"""
|
| 61 |
+
Load preprocessor configs and construct preprocessors.
|
| 62 |
+
|
| 63 |
+
If no preprocessor is specified, return BaseProcessor, which does not do any preprocessing.
|
| 64 |
+
|
| 65 |
+
Args:
|
| 66 |
+
config (dict): preprocessor configs.
|
| 67 |
+
|
| 68 |
+
Returns:
|
| 69 |
+
vis_processors (dict): preprocessors for visual inputs.
|
| 70 |
+
txt_processors (dict): preprocessors for text inputs.
|
| 71 |
+
|
| 72 |
+
Key is "train" or "eval" for processors used in training and evaluation respectively.
|
| 73 |
+
"""
|
| 74 |
+
|
| 75 |
+
def _build_proc_from_cfg(cfg):
|
| 76 |
+
return (
|
| 77 |
+
registry.get_processor_class(cfg.name).from_config(cfg)
|
| 78 |
+
if cfg is not None
|
| 79 |
+
else BaseProcessor()
|
| 80 |
+
)
|
| 81 |
+
|
| 82 |
+
vis_processors = dict()
|
| 83 |
+
txt_processors = dict()
|
| 84 |
+
|
| 85 |
+
vis_proc_cfg = config.get("vis_processor")
|
| 86 |
+
txt_proc_cfg = config.get("text_processor")
|
| 87 |
+
|
| 88 |
+
if vis_proc_cfg is not None:
|
| 89 |
+
vis_train_cfg = vis_proc_cfg.get("train")
|
| 90 |
+
vis_eval_cfg = vis_proc_cfg.get("eval")
|
| 91 |
+
else:
|
| 92 |
+
vis_train_cfg = None
|
| 93 |
+
vis_eval_cfg = None
|
| 94 |
+
|
| 95 |
+
vis_processors["train"] = _build_proc_from_cfg(vis_train_cfg)
|
| 96 |
+
vis_processors["eval"] = _build_proc_from_cfg(vis_eval_cfg)
|
| 97 |
+
|
| 98 |
+
if txt_proc_cfg is not None:
|
| 99 |
+
txt_train_cfg = txt_proc_cfg.get("train")
|
| 100 |
+
txt_eval_cfg = txt_proc_cfg.get("eval")
|
| 101 |
+
else:
|
| 102 |
+
txt_train_cfg = None
|
| 103 |
+
txt_eval_cfg = None
|
| 104 |
+
|
| 105 |
+
txt_processors["train"] = _build_proc_from_cfg(txt_train_cfg)
|
| 106 |
+
txt_processors["eval"] = _build_proc_from_cfg(txt_eval_cfg)
|
| 107 |
+
|
| 108 |
+
return vis_processors, txt_processors
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
def load_model_and_preprocess(name, model_type, is_eval=False, device="cpu"):
|
| 112 |
+
"""
|
| 113 |
+
Load model and its related preprocessors.
|
| 114 |
+
|
| 115 |
+
List all available models and types in registry:
|
| 116 |
+
>>> from unimernet.models import model_zoo
|
| 117 |
+
>>> print(model_zoo)
|
| 118 |
+
|
| 119 |
+
Args:
|
| 120 |
+
name (str): name of the model.
|
| 121 |
+
model_type (str): type of the model.
|
| 122 |
+
is_eval (bool): whether the model is in eval mode. Default: False.
|
| 123 |
+
device (str): device to use. Default: "cpu".
|
| 124 |
+
|
| 125 |
+
Returns:
|
| 126 |
+
model (torch.nn.Module): model.
|
| 127 |
+
vis_processors (dict): preprocessors for visual inputs.
|
| 128 |
+
txt_processors (dict): preprocessors for text inputs.
|
| 129 |
+
"""
|
| 130 |
+
model_cls = registry.get_model_class(name)
|
| 131 |
+
|
| 132 |
+
# load model
|
| 133 |
+
model = model_cls.from_pretrained(model_type=model_type)
|
| 134 |
+
|
| 135 |
+
if is_eval:
|
| 136 |
+
model.eval()
|
| 137 |
+
|
| 138 |
+
# load preprocess
|
| 139 |
+
cfg = OmegaConf.load(model_cls.default_config_path(model_type))
|
| 140 |
+
if cfg is not None:
|
| 141 |
+
preprocess_cfg = cfg.preprocess
|
| 142 |
+
|
| 143 |
+
vis_processors, txt_processors = load_preprocess(preprocess_cfg)
|
| 144 |
+
else:
|
| 145 |
+
vis_processors, txt_processors = None, None
|
| 146 |
+
logging.info(
|
| 147 |
+
f"""No default preprocess for model {name} ({model_type}).
|
| 148 |
+
This can happen if the model is not finetuned on downstream datasets,
|
| 149 |
+
or it is not intended for direct use without finetuning.
|
| 150 |
+
"""
|
| 151 |
+
)
|
| 152 |
+
|
| 153 |
+
if device == "cpu" or device == torch.device("cpu"):
|
| 154 |
+
model = model.float()
|
| 155 |
+
|
| 156 |
+
return model.to(device), vis_processors, txt_processors
|
| 157 |
+
|
| 158 |
+
|
| 159 |
+
class ModelZoo:
|
| 160 |
+
"""
|
| 161 |
+
A utility class to create string representation of available model architectures and types.
|
| 162 |
+
|
| 163 |
+
>>> from unimernet.models import model_zoo
|
| 164 |
+
>>> # list all available models
|
| 165 |
+
>>> print(model_zoo)
|
| 166 |
+
>>> # show total number of models
|
| 167 |
+
>>> print(len(model_zoo))
|
| 168 |
+
"""
|
| 169 |
+
|
| 170 |
+
def __init__(self) -> None:
|
| 171 |
+
self.model_zoo = {
|
| 172 |
+
k: list(v.PRETRAINED_MODEL_CONFIG_DICT.keys())
|
| 173 |
+
for k, v in registry.mapping["model_name_mapping"].items()
|
| 174 |
+
}
|
| 175 |
+
|
| 176 |
+
def __str__(self) -> str:
|
| 177 |
+
return (
|
| 178 |
+
"=" * 50
|
| 179 |
+
+ "\n"
|
| 180 |
+
+ f"{'Architectures':<30} {'Types'}\n"
|
| 181 |
+
+ "=" * 50
|
| 182 |
+
+ "\n"
|
| 183 |
+
+ "\n".join(
|
| 184 |
+
[
|
| 185 |
+
f"{name:<30} {', '.join(types)}"
|
| 186 |
+
for name, types in self.model_zoo.items()
|
| 187 |
+
]
|
| 188 |
+
)
|
| 189 |
+
)
|
| 190 |
+
|
| 191 |
+
def __iter__(self):
|
| 192 |
+
return iter(self.model_zoo.items())
|
| 193 |
+
|
| 194 |
+
def __len__(self):
|
| 195 |
+
return sum([len(v) for v in self.model_zoo.values()])
|
| 196 |
+
|
| 197 |
+
|
| 198 |
+
model_zoo = ModelZoo()
|
unimernet/models/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (6.04 kB). View file
|
|
|
unimernet/models/__pycache__/base_model.cpython-310.pyc
ADDED
|
Binary file (8.8 kB). View file
|
|
|
unimernet/models/__pycache__/clip_vit.cpython-310.pyc
ADDED
|
Binary file (9.22 kB). View file
|
|
|
unimernet/models/__pycache__/eva_vit.cpython-310.pyc
ADDED
|
Binary file (14.1 kB). View file
|
|
|
unimernet/models/base_model.py
ADDED
|
@@ -0,0 +1,251 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (c) 2022, salesforce.com, inc.
|
| 3 |
+
All rights reserved.
|
| 4 |
+
SPDX-License-Identifier: BSD-3-Clause
|
| 5 |
+
For full license text, see the LICENSE file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import logging
|
| 9 |
+
import os
|
| 10 |
+
|
| 11 |
+
import numpy as np
|
| 12 |
+
import torch
|
| 13 |
+
import torch.nn as nn
|
| 14 |
+
from unimernet.common.dist_utils import download_cached_file, is_dist_avail_and_initialized
|
| 15 |
+
from unimernet.common.utils import get_abs_path, is_url
|
| 16 |
+
from omegaconf import OmegaConf
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
class BaseModel(nn.Module):
|
| 20 |
+
"""Base class for models."""
|
| 21 |
+
|
| 22 |
+
def __init__(self):
|
| 23 |
+
super().__init__()
|
| 24 |
+
|
| 25 |
+
@property
|
| 26 |
+
def device(self):
|
| 27 |
+
return list(self.parameters())[0].device
|
| 28 |
+
|
| 29 |
+
def load_checkpoint(self, url_or_filename):
|
| 30 |
+
"""
|
| 31 |
+
Load from a finetuned checkpoint.
|
| 32 |
+
|
| 33 |
+
This should expect no mismatch in the model keys and the checkpoint keys.
|
| 34 |
+
"""
|
| 35 |
+
|
| 36 |
+
if is_url(url_or_filename):
|
| 37 |
+
cached_file = download_cached_file(
|
| 38 |
+
url_or_filename, check_hash=False, progress=True
|
| 39 |
+
)
|
| 40 |
+
checkpoint = torch.load(cached_file, map_location="cpu")
|
| 41 |
+
elif os.path.isfile(url_or_filename):
|
| 42 |
+
checkpoint = torch.load(url_or_filename, map_location="cpu")
|
| 43 |
+
else:
|
| 44 |
+
raise RuntimeError("checkpoint url or path is invalid")
|
| 45 |
+
|
| 46 |
+
if "model" in checkpoint.keys():
|
| 47 |
+
state_dict = checkpoint["model"]
|
| 48 |
+
else:
|
| 49 |
+
state_dict = checkpoint
|
| 50 |
+
|
| 51 |
+
msg = self.load_state_dict(state_dict, strict=False)
|
| 52 |
+
|
| 53 |
+
# logging.info("Missing keys {}".format(msg.missing_keys))
|
| 54 |
+
logging.info(f"Missing keys exist when loading '{url_or_filename}'.")
|
| 55 |
+
logging.info("load checkpoint from %s" % url_or_filename)
|
| 56 |
+
|
| 57 |
+
return msg
|
| 58 |
+
|
| 59 |
+
@classmethod
|
| 60 |
+
def from_pretrained(cls, model_type):
|
| 61 |
+
"""
|
| 62 |
+
Build a pretrained model from default configuration file, specified by model_type.
|
| 63 |
+
|
| 64 |
+
Args:
|
| 65 |
+
- model_type (str): model type, specifying architecture and checkpoints.
|
| 66 |
+
|
| 67 |
+
Returns:
|
| 68 |
+
- model (nn.Module): pretrained or finetuned model, depending on the configuration.
|
| 69 |
+
"""
|
| 70 |
+
model_cfg = OmegaConf.load(cls.default_config_path(model_type)).model
|
| 71 |
+
model = cls.from_config(model_cfg)
|
| 72 |
+
|
| 73 |
+
return model
|
| 74 |
+
|
| 75 |
+
@classmethod
|
| 76 |
+
def default_config_path(cls, model_type):
|
| 77 |
+
assert (
|
| 78 |
+
model_type in cls.PRETRAINED_MODEL_CONFIG_DICT
|
| 79 |
+
), "Unknown model type {}".format(model_type)
|
| 80 |
+
return get_abs_path(cls.PRETRAINED_MODEL_CONFIG_DICT[model_type])
|
| 81 |
+
|
| 82 |
+
def load_checkpoint_from_config(self, cfg, **kwargs):
|
| 83 |
+
"""
|
| 84 |
+
Load checkpoint as specified in the config file.
|
| 85 |
+
|
| 86 |
+
If load_finetuned is True, load the finetuned model; otherwise, load the pretrained model.
|
| 87 |
+
When loading the pretrained model, each task-specific architecture may define their
|
| 88 |
+
own load_from_pretrained() method.
|
| 89 |
+
"""
|
| 90 |
+
load_pretrained = cfg.get("load_pretrained", True)
|
| 91 |
+
load_finetuned = cfg.get("load_finetuned", False)
|
| 92 |
+
|
| 93 |
+
if load_pretrained:
|
| 94 |
+
# load pre-trained weights
|
| 95 |
+
pretrain_path = cfg.get("pretrained", None)
|
| 96 |
+
assert pretrain_path, "Found load_finetuned is False, but pretrain_path is None."
|
| 97 |
+
self.load_from_pretrained(url_or_filename=pretrain_path, **kwargs)
|
| 98 |
+
logging.info(f"Loaded pretrained model '{pretrain_path}'.")
|
| 99 |
+
|
| 100 |
+
if load_finetuned:
|
| 101 |
+
finetune_path = cfg.get("finetuned", None)
|
| 102 |
+
assert finetune_path is not None, "Found load_finetuned is True, but finetune_path is None."
|
| 103 |
+
self.load_checkpoint(url_or_filename=finetune_path)
|
| 104 |
+
logging.info(f"Loaded finetuned model '{finetune_path}'.")
|
| 105 |
+
|
| 106 |
+
def before_evaluation(self, **kwargs):
|
| 107 |
+
pass
|
| 108 |
+
|
| 109 |
+
def show_n_params(self, return_str=True):
|
| 110 |
+
tot = 0
|
| 111 |
+
for p in self.parameters():
|
| 112 |
+
w = 1
|
| 113 |
+
for x in p.shape:
|
| 114 |
+
w *= x
|
| 115 |
+
tot += w
|
| 116 |
+
if return_str:
|
| 117 |
+
if tot >= 1e6:
|
| 118 |
+
return "{:.1f}M".format(tot / 1e6)
|
| 119 |
+
else:
|
| 120 |
+
return "{:.1f}K".format(tot / 1e3)
|
| 121 |
+
else:
|
| 122 |
+
return tot
|
| 123 |
+
|
| 124 |
+
|
| 125 |
+
class BaseEncoder(nn.Module):
|
| 126 |
+
"""
|
| 127 |
+
Base class for primitive encoders, such as ViT, TimeSformer, etc.
|
| 128 |
+
"""
|
| 129 |
+
|
| 130 |
+
def __init__(self):
|
| 131 |
+
super().__init__()
|
| 132 |
+
|
| 133 |
+
def forward_features(self, samples, **kwargs):
|
| 134 |
+
raise NotImplementedError
|
| 135 |
+
|
| 136 |
+
@property
|
| 137 |
+
def device(self):
|
| 138 |
+
return list(self.parameters())[0].device
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
class SharedQueueMixin:
|
| 142 |
+
@torch.no_grad()
|
| 143 |
+
def _dequeue_and_enqueue(self, image_feat, text_feat, idxs=None):
|
| 144 |
+
# gather keys before updating queue
|
| 145 |
+
image_feats = concat_all_gather(image_feat)
|
| 146 |
+
text_feats = concat_all_gather(text_feat)
|
| 147 |
+
|
| 148 |
+
batch_size = image_feats.shape[0]
|
| 149 |
+
|
| 150 |
+
ptr = int(self.queue_ptr)
|
| 151 |
+
assert self.queue_size % batch_size == 0 # for simplicity
|
| 152 |
+
|
| 153 |
+
# replace the keys at ptr (dequeue and enqueue)
|
| 154 |
+
self.image_queue[:, ptr: ptr + batch_size] = image_feats.T
|
| 155 |
+
self.text_queue[:, ptr: ptr + batch_size] = text_feats.T
|
| 156 |
+
|
| 157 |
+
if idxs is not None:
|
| 158 |
+
idxs = concat_all_gather(idxs)
|
| 159 |
+
self.idx_queue[:, ptr: ptr + batch_size] = idxs.T
|
| 160 |
+
|
| 161 |
+
ptr = (ptr + batch_size) % self.queue_size # move pointer
|
| 162 |
+
self.queue_ptr[0] = ptr
|
| 163 |
+
|
| 164 |
+
|
| 165 |
+
class MomentumDistilationMixin:
|
| 166 |
+
@torch.no_grad()
|
| 167 |
+
def copy_params(self):
|
| 168 |
+
for model_pair in self.model_pairs:
|
| 169 |
+
for param, param_m in zip(
|
| 170 |
+
model_pair[0].parameters(), model_pair[1].parameters()
|
| 171 |
+
):
|
| 172 |
+
param_m.data.copy_(param.data) # initialize
|
| 173 |
+
param_m.requires_grad = False # not update by gradient
|
| 174 |
+
|
| 175 |
+
@torch.no_grad()
|
| 176 |
+
def _momentum_update(self):
|
| 177 |
+
for model_pair in self.model_pairs:
|
| 178 |
+
for param, param_m in zip(
|
| 179 |
+
model_pair[0].parameters(), model_pair[1].parameters()
|
| 180 |
+
):
|
| 181 |
+
param_m.data = param_m.data * self.momentum + param.data * (
|
| 182 |
+
1.0 - self.momentum
|
| 183 |
+
)
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
class GatherLayer(torch.autograd.Function):
|
| 187 |
+
"""
|
| 188 |
+
Gather tensors from all workers with support for backward propagation:
|
| 189 |
+
This implementation does not cut the gradients as torch.distributed.all_gather does.
|
| 190 |
+
"""
|
| 191 |
+
|
| 192 |
+
@staticmethod
|
| 193 |
+
def forward(ctx, x):
|
| 194 |
+
output = [
|
| 195 |
+
torch.zeros_like(x) for _ in range(torch.distributed.get_world_size())
|
| 196 |
+
]
|
| 197 |
+
torch.distributed.all_gather(output, x)
|
| 198 |
+
return tuple(output)
|
| 199 |
+
|
| 200 |
+
@staticmethod
|
| 201 |
+
def backward(ctx, *grads):
|
| 202 |
+
all_gradients = torch.stack(grads)
|
| 203 |
+
torch.distributed.all_reduce(all_gradients)
|
| 204 |
+
return all_gradients[torch.distributed.get_rank()]
|
| 205 |
+
|
| 206 |
+
|
| 207 |
+
def all_gather_with_grad(tensors):
|
| 208 |
+
"""
|
| 209 |
+
Performs all_gather operation on the provided tensors.
|
| 210 |
+
Graph remains connected for backward grad computation.
|
| 211 |
+
"""
|
| 212 |
+
# Queue the gathered tensors
|
| 213 |
+
world_size = torch.distributed.get_world_size()
|
| 214 |
+
# There is no need for reduction in the single-proc case
|
| 215 |
+
if world_size == 1:
|
| 216 |
+
return tensors
|
| 217 |
+
|
| 218 |
+
# tensor_all = GatherLayer.apply(tensors)
|
| 219 |
+
tensor_all = GatherLayer.apply(tensors)
|
| 220 |
+
|
| 221 |
+
return torch.cat(tensor_all, dim=0)
|
| 222 |
+
|
| 223 |
+
|
| 224 |
+
@torch.no_grad()
|
| 225 |
+
def concat_all_gather(tensor):
|
| 226 |
+
"""
|
| 227 |
+
Performs all_gather operation on the provided tensors.
|
| 228 |
+
*** Warning ***: torch.distributed.all_gather has no gradient.
|
| 229 |
+
"""
|
| 230 |
+
# if use distributed training
|
| 231 |
+
if not is_dist_avail_and_initialized():
|
| 232 |
+
return tensor
|
| 233 |
+
|
| 234 |
+
tensors_gather = [
|
| 235 |
+
torch.ones_like(tensor) for _ in range(torch.distributed.get_world_size())
|
| 236 |
+
]
|
| 237 |
+
torch.distributed.all_gather(tensors_gather, tensor, async_op=False)
|
| 238 |
+
|
| 239 |
+
output = torch.cat(tensors_gather, dim=0)
|
| 240 |
+
return output
|
| 241 |
+
|
| 242 |
+
|
| 243 |
+
def tile(x, dim, n_tile):
|
| 244 |
+
init_dim = x.size(dim)
|
| 245 |
+
repeat_idx = [1] * x.dim()
|
| 246 |
+
repeat_idx[dim] = n_tile
|
| 247 |
+
x = x.repeat(*(repeat_idx))
|
| 248 |
+
order_index = torch.LongTensor(
|
| 249 |
+
np.concatenate([init_dim * np.arange(n_tile) + i for i in range(init_dim)])
|
| 250 |
+
)
|
| 251 |
+
return torch.index_select(x, dim, order_index.to(x.device))
|