Spaces:
Running
on
Zero

Running
on
Zero
upload files
Browse files- .gitattributes +4 -0
- app.py +430 -0
- images/1.jpg +0 -0
- images/2.jpg +0 -0
- images/3.jpg +0 -0
- images/4.jpg +0 -0
- images/5.png +0 -0
- images/6.JPG +3 -0
- pdfs/1.pdf +3 -0
- pdfs/2.pdf +0 -0
- requirements.txt +21 -0
- videos/1.mp4 +3 -0
- videos/2.mp4 +3 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,7 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
images/6.JPG filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
pdfs/1.pdf filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
videos/1.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
videos/2.mp4 filter=lfs diff=lfs merge=lfs -text
|
app.py
ADDED
|
@@ -0,0 +1,430 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import random
|
| 3 |
+
import uuid
|
| 4 |
+
import json
|
| 5 |
+
import time
|
| 6 |
+
import asyncio
|
| 7 |
+
from threading import Thread
|
| 8 |
+
|
| 9 |
+
import gradio as gr
|
| 10 |
+
import spaces
|
| 11 |
+
import torch
|
| 12 |
+
import numpy as np
|
| 13 |
+
from PIL import Image
|
| 14 |
+
import cv2
|
| 15 |
+
|
| 16 |
+
from transformers import (
|
| 17 |
+
Qwen2_5_VLForConditionalGeneration,
|
| 18 |
+
AutoProcessor,
|
| 19 |
+
TextIteratorStreamer,
|
| 20 |
+
)
|
| 21 |
+
from transformers.image_utils import load_image
|
| 22 |
+
from pdf2image import convert_from_path
|
| 23 |
+
|
| 24 |
+
# Constants for text generation
|
| 25 |
+
MAX_MAX_NEW_TOKENS = 2048
|
| 26 |
+
DEFAULT_MAX_NEW_TOKENS = 1024
|
| 27 |
+
MAX_INPUT_TOKEN_LENGTH = int(os.getenv("MAX_INPUT_TOKEN_LENGTH", "4096"))
|
| 28 |
+
|
| 29 |
+
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
|
| 30 |
+
|
| 31 |
+
# Load Vision-Matters-7B
|
| 32 |
+
MODEL_ID_M = "Yuting6/Vision-Matters-7B"
|
| 33 |
+
processor_m = AutoProcessor.from_pretrained(MODEL_ID_M, trust_remote_code=True)
|
| 34 |
+
model_m = Qwen2_5_VLForConditionalGeneration.from_pretrained(
|
| 35 |
+
MODEL_ID_M, trust_remote_code=True,
|
| 36 |
+
torch_dtype=torch.float16).to(device).eval()
|
| 37 |
+
|
| 38 |
+
# Load ViGaL-7B
|
| 39 |
+
MODEL_ID_X = "yunfeixie/ViGaL-7B"
|
| 40 |
+
processor_x = AutoProcessor.from_pretrained(MODEL_ID_X, trust_remote_code=True)
|
| 41 |
+
model_x = Qwen2_5_VLForConditionalGeneration.from_pretrained(
|
| 42 |
+
MODEL_ID_X, trust_remote_code=True,
|
| 43 |
+
torch_dtype=torch.float16).to(device).eval()
|
| 44 |
+
|
| 45 |
+
# Load R1-Onevision-7B
|
| 46 |
+
MODEL_ID_T = "FriendliAI/R1-Onevision-7B"
|
| 47 |
+
processor_t = AutoProcessor.from_pretrained(MODEL_ID_T, trust_remote_code=True)
|
| 48 |
+
model_t = Qwen2_5_VLForConditionalGeneration.from_pretrained(
|
| 49 |
+
MODEL_ID_T, trust_remote_code=True,
|
| 50 |
+
torch_dtype=torch.float16).to(device).eval()
|
| 51 |
+
|
| 52 |
+
# Load Visionary-R1
|
| 53 |
+
MODEL_ID_O = "maifoundations/Visionary-R1"
|
| 54 |
+
processor_o = AutoProcessor.from_pretrained(MODEL_ID_O, trust_remote_code=True)
|
| 55 |
+
model_o = Qwen2_5_VLForConditionalGeneration.from_pretrained(
|
| 56 |
+
MODEL_ID_O, trust_remote_code=True,
|
| 57 |
+
torch_dtype=torch.float16).to(device).eval()
|
| 58 |
+
|
| 59 |
+
# Load VLM-R1-Qwen2.5VL-3B-Math-0305
|
| 60 |
+
MODEL_ID_W = "omlab/VLM-R1-Qwen2.5VL-3B-Math-0305"
|
| 61 |
+
processor_w = AutoProcessor.from_pretrained(MODEL_ID_W, trust_remote_code=True)
|
| 62 |
+
model_w = Qwen2_5_VLForConditionalGeneration.from_pretrained(
|
| 63 |
+
MODEL_ID_W, trust_remote_code=True,
|
| 64 |
+
torch_dtype=torch.float16).to(device).eval()
|
| 65 |
+
|
| 66 |
+
# Function to downsample video frames
|
| 67 |
+
def downsample_video(video_path):
|
| 68 |
+
"""
|
| 69 |
+
Downsamples the video to evenly spaced frames.
|
| 70 |
+
Each frame is returned as a PIL image along with its timestamp.
|
| 71 |
+
"""
|
| 72 |
+
vidcap = cv2.VideoCapture(video_path)
|
| 73 |
+
total_frames = int(vidcap.get(cv2.CAP_PROP_FRAME_COUNT))
|
| 74 |
+
fps = vidcap.get(cv2.CAP_PROP_FPS)
|
| 75 |
+
frames = []
|
| 76 |
+
frame_indices = np.linspace(0, total_frames - 1, 10, dtype=int)
|
| 77 |
+
for i in frame_indices:
|
| 78 |
+
vidcap.set(cv2.CAP_PROP_POS_FRAMES, i)
|
| 79 |
+
success, image = vidcap.read()
|
| 80 |
+
if success:
|
| 81 |
+
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
|
| 82 |
+
pil_image = Image.fromarray(image)
|
| 83 |
+
timestamp = round(i / fps, 2)
|
| 84 |
+
frames.append((pil_image, timestamp))
|
| 85 |
+
vidcap.release()
|
| 86 |
+
return frames
|
| 87 |
+
|
| 88 |
+
# Function to convert PDF to image
|
| 89 |
+
def pdf_to_image(pdf_path):
|
| 90 |
+
"""
|
| 91 |
+
Converts a single-page PDF to a PIL image.
|
| 92 |
+
"""
|
| 93 |
+
images = convert_from_path(pdf_path)
|
| 94 |
+
if not images:
|
| 95 |
+
raise ValueError("Failed to convert PDF to image.")
|
| 96 |
+
return images[0] # Return the first page
|
| 97 |
+
|
| 98 |
+
# Function to generate text responses based on image input
|
| 99 |
+
@spaces.GPU
|
| 100 |
+
def generate_image(model_name: str,
|
| 101 |
+
text: str,
|
| 102 |
+
image: Image.Image,
|
| 103 |
+
max_new_tokens: int = 1024,
|
| 104 |
+
temperature: float = 0.6,
|
| 105 |
+
top_p: float = 0.9,
|
| 106 |
+
top_k: int = 50,
|
| 107 |
+
repetition_penalty: float = 1.2):
|
| 108 |
+
"""
|
| 109 |
+
Generates responses using the selected model for image input.
|
| 110 |
+
"""
|
| 111 |
+
if model_name == "Vision-Matters-7B-Math":
|
| 112 |
+
processor = processor_m
|
| 113 |
+
model = model_m
|
| 114 |
+
elif model_name == "ViGaL-7B":
|
| 115 |
+
processor = processor_x
|
| 116 |
+
model = model_x
|
| 117 |
+
elif model_name == "Visionary-R1":
|
| 118 |
+
processor = processor_o
|
| 119 |
+
model = model_o
|
| 120 |
+
elif model_name == "R1-Onevision-7B":
|
| 121 |
+
processor = processor_t
|
| 122 |
+
model = model_t
|
| 123 |
+
elif model_name == "VLM-R1-Qwen2.5VL-3B-Math-0305":
|
| 124 |
+
processor = processor_w
|
| 125 |
+
model = model_w
|
| 126 |
+
else:
|
| 127 |
+
yield "Invalid model selected.", "Invalid model selected."
|
| 128 |
+
return
|
| 129 |
+
|
| 130 |
+
if image is None:
|
| 131 |
+
yield "Please upload an image.", "Please upload an image."
|
| 132 |
+
return
|
| 133 |
+
|
| 134 |
+
messages = [{
|
| 135 |
+
"role": "user",
|
| 136 |
+
"content": [
|
| 137 |
+
{"type": "image", "image": image},
|
| 138 |
+
{"type": "text", "text": text},
|
| 139 |
+
]
|
| 140 |
+
}]
|
| 141 |
+
prompt_full = processor.apply_chat_template(messages,
|
| 142 |
+
tokenize=False,
|
| 143 |
+
add_generation_prompt=True)
|
| 144 |
+
inputs = processor(text=[prompt_full],
|
| 145 |
+
images=[image],
|
| 146 |
+
return_tensors="pt",
|
| 147 |
+
padding=True,
|
| 148 |
+
truncation=False,
|
| 149 |
+
max_length=MAX_INPUT_TOKEN_LENGTH).to(device)
|
| 150 |
+
streamer = TextIteratorStreamer(processor,
|
| 151 |
+
skip_prompt=True,
|
| 152 |
+
skip_special_tokens=True)
|
| 153 |
+
generation_kwargs = {
|
| 154 |
+
**inputs, "streamer": streamer,
|
| 155 |
+
"max_new_tokens": max_new_tokens
|
| 156 |
+
}
|
| 157 |
+
thread = Thread(target=model.generate, kwargs=generation_kwargs)
|
| 158 |
+
thread.start()
|
| 159 |
+
buffer = ""
|
| 160 |
+
for new_text in streamer:
|
| 161 |
+
buffer += new_text
|
| 162 |
+
time.sleep(0.01)
|
| 163 |
+
yield buffer, buffer
|
| 164 |
+
|
| 165 |
+
# Function to generate text responses based on video input
|
| 166 |
+
@spaces.GPU
|
| 167 |
+
def generate_video(model_name: str,
|
| 168 |
+
text: str,
|
| 169 |
+
video_path: str,
|
| 170 |
+
max_new_tokens: int = 1024,
|
| 171 |
+
temperature: float = 0.6,
|
| 172 |
+
top_p: float = 0.9,
|
| 173 |
+
top_k: int = 50,
|
| 174 |
+
repetition_penalty: float = 1.2):
|
| 175 |
+
"""
|
| 176 |
+
Generates responses using the selected model for video input.
|
| 177 |
+
"""
|
| 178 |
+
if model_name == "Vision-Matters-7B-Math":
|
| 179 |
+
processor = processor_m
|
| 180 |
+
model = model_m
|
| 181 |
+
elif model_name == "ViGaL-7B":
|
| 182 |
+
processor = processor_x
|
| 183 |
+
model = model_x
|
| 184 |
+
elif model_name == "Visionary-R1":
|
| 185 |
+
processor = processor_o
|
| 186 |
+
model = model_o
|
| 187 |
+
elif model_name == "R1-Onevision-7B":
|
| 188 |
+
processor = processor_t
|
| 189 |
+
model = model_t
|
| 190 |
+
elif model_name == "VLM-R1-Qwen2.5VL-3B-Math-0305":
|
| 191 |
+
processor = processor_w
|
| 192 |
+
model = model_w
|
| 193 |
+
else:
|
| 194 |
+
yield "Invalid model selected.", "Invalid model selected."
|
| 195 |
+
return
|
| 196 |
+
|
| 197 |
+
if video_path is None:
|
| 198 |
+
yield "Please upload a video.", "Please upload a video."
|
| 199 |
+
return
|
| 200 |
+
|
| 201 |
+
frames = downsample_video(video_path)
|
| 202 |
+
messages = [{
|
| 203 |
+
"role": "system",
|
| 204 |
+
"content": [{"type": "text", "text": "You are a helpful assistant."}]
|
| 205 |
+
}, {
|
| 206 |
+
"role": "user",
|
| 207 |
+
"content": [{"type": "text", "text": text}]
|
| 208 |
+
}]
|
| 209 |
+
for frame in frames:
|
| 210 |
+
image, timestamp = frame
|
| 211 |
+
messages[1]["content"].append({"type": "text", "text": f"Frame {timestamp}:"})
|
| 212 |
+
messages[1]["content"].append({"type": "image", "image": image})
|
| 213 |
+
inputs = processor.apply_chat_template(
|
| 214 |
+
messages,
|
| 215 |
+
tokenize=True,
|
| 216 |
+
add_generation_prompt=True,
|
| 217 |
+
return_dict=True,
|
| 218 |
+
return_tensors="pt",
|
| 219 |
+
truncation=False,
|
| 220 |
+
max_length=MAX_INPUT_TOKEN_LENGTH).to(device)
|
| 221 |
+
streamer = TextIteratorStreamer(processor,
|
| 222 |
+
skip_prompt=True,
|
| 223 |
+
skip_special_tokens=True)
|
| 224 |
+
generation_kwargs = {
|
| 225 |
+
**inputs,
|
| 226 |
+
"streamer": streamer,
|
| 227 |
+
"max_new_tokens": max_new_tokens,
|
| 228 |
+
"do_sample": True,
|
| 229 |
+
"temperature": temperature,
|
| 230 |
+
"top_p": top_p,
|
| 231 |
+
"top_k": top_k,
|
| 232 |
+
"repetition_penalty": repetition_penalty,
|
| 233 |
+
}
|
| 234 |
+
thread = Thread(target=model.generate, kwargs=generation_kwargs)
|
| 235 |
+
thread.start()
|
| 236 |
+
buffer = ""
|
| 237 |
+
for new_text in streamer:
|
| 238 |
+
buffer += new_text
|
| 239 |
+
buffer = buffer.replace("<|im_end|>", "")
|
| 240 |
+
time.sleep(0.01)
|
| 241 |
+
yield buffer, buffer
|
| 242 |
+
|
| 243 |
+
# Function to generate text responses based on PDF input
|
| 244 |
+
@spaces.GPU
|
| 245 |
+
def generate_pdf(model_name: str,
|
| 246 |
+
text: str,
|
| 247 |
+
pdf_path: str,
|
| 248 |
+
max_new_tokens: int = 1024,
|
| 249 |
+
temperature: float = 0.6,
|
| 250 |
+
top_p: float = 0.9,
|
| 251 |
+
top_k: int = 50,
|
| 252 |
+
repetition_penalty: float = 1.2):
|
| 253 |
+
"""
|
| 254 |
+
Generates responses using the selected model for single-page PDF input by converting it to an image.
|
| 255 |
+
"""
|
| 256 |
+
try:
|
| 257 |
+
image = pdf_to_image(pdf_path)
|
| 258 |
+
except Exception as e:
|
| 259 |
+
yield f"Error converting PDF to image: {str(e)}", f"Error converting PDF to image: {str(e)}"
|
| 260 |
+
return
|
| 261 |
+
yield from generate_image(model_name, text, image, max_new_tokens, temperature, top_p, top_k, repetition_penalty)
|
| 262 |
+
|
| 263 |
+
# Function to save the output text to a Markdown file
|
| 264 |
+
def save_to_md(output_text):
|
| 265 |
+
"""
|
| 266 |
+
Saves the output text to a Markdown file and returns the file path for download.
|
| 267 |
+
"""
|
| 268 |
+
file_path = f"result_{uuid.uuid4()}.md"
|
| 269 |
+
with open(file_path, "w") as f:
|
| 270 |
+
f.write(output_text)
|
| 271 |
+
return file_path
|
| 272 |
+
|
| 273 |
+
# Define examples for image, video, and PDF inference
|
| 274 |
+
image_examples = [
|
| 275 |
+
["Solve the problem to find the value.", "images/1.jpg"],
|
| 276 |
+
["Explain the scene.", "images/6.jpg"],
|
| 277 |
+
["Solve the problem step by step.", "images/2.jpg"],
|
| 278 |
+
["Find the value of 'X'.", "images/3.jpg"],
|
| 279 |
+
["Simplify the expression.", "images/4.jpg"],
|
| 280 |
+
["Solve for the value.", "images/5.png"]
|
| 281 |
+
]
|
| 282 |
+
|
| 283 |
+
video_examples = [
|
| 284 |
+
["Explain the video in detail.", "videos/1.mp4"],
|
| 285 |
+
["Explain the video in detail.", "videos/2.mp4"]
|
| 286 |
+
|
| 287 |
+
]
|
| 288 |
+
|
| 289 |
+
pdf_examples = [
|
| 290 |
+
["Explain the content briefly.", "pdfs/1.pdf"],
|
| 291 |
+
["What is the content about?", "pdfs/2.pdf"]
|
| 292 |
+
]
|
| 293 |
+
|
| 294 |
+
# Added CSS to style the output area as a "Canvas"
|
| 295 |
+
css = """
|
| 296 |
+
.submit-btn {
|
| 297 |
+
background-color: #2980b9 !important;
|
| 298 |
+
color: white !important;
|
| 299 |
+
}
|
| 300 |
+
.submit-btn:hover {
|
| 301 |
+
background-color: #3498db !important;
|
| 302 |
+
}
|
| 303 |
+
.canvas-output {
|
| 304 |
+
border: 2px solid #4682B4;
|
| 305 |
+
border-radius: 10px;
|
| 306 |
+
padding: 20px;
|
| 307 |
+
}
|
| 308 |
+
"""
|
| 309 |
+
|
| 310 |
+
# Create the Gradio Interface
|
| 311 |
+
with gr.Blocks(css=css, theme="bethecloud/storj_theme") as demo:
|
| 312 |
+
gr.Markdown(
|
| 313 |
+
"# **[Multimodal VLMs 5x](https://huggingface.co/collections/prithivMLmods/multimodal-implementations-67c9982ea04b39f0608badb0)**"
|
| 314 |
+
)
|
| 315 |
+
with gr.Row():
|
| 316 |
+
with gr.Column():
|
| 317 |
+
with gr.Tabs():
|
| 318 |
+
with gr.TabItem("Image Inference"):
|
| 319 |
+
image_query = gr.Textbox(
|
| 320 |
+
label="Query Input",
|
| 321 |
+
placeholder="Enter your query here...")
|
| 322 |
+
image_upload = gr.Image(type="pil", label="Image")
|
| 323 |
+
image_submit = gr.Button("Submit",
|
| 324 |
+
elem_classes="submit-btn")
|
| 325 |
+
gr.Examples(examples=image_examples,
|
| 326 |
+
inputs=[image_query, image_upload])
|
| 327 |
+
with gr.TabItem("Video Inference"):
|
| 328 |
+
video_query = gr.Textbox(
|
| 329 |
+
label="Query Input",
|
| 330 |
+
placeholder="Enter your query here...")
|
| 331 |
+
video_upload = gr.Video(label="Video")
|
| 332 |
+
video_submit = gr.Button("Submit",
|
| 333 |
+
elem_classes="submit-btn")
|
| 334 |
+
gr.Examples(examples=video_examples,
|
| 335 |
+
inputs=[video_query, video_upload])
|
| 336 |
+
with gr.TabItem("Single Page PDF Inference"):
|
| 337 |
+
pdf_query = gr.Textbox(
|
| 338 |
+
label="Query Input",
|
| 339 |
+
placeholder="Enter your query here...")
|
| 340 |
+
pdf_upload = gr.File(label="PDF", type="filepath")
|
| 341 |
+
pdf_submit = gr.Button("Submit",
|
| 342 |
+
elem_classes="submit-btn")
|
| 343 |
+
gr.Examples(examples=pdf_examples,
|
| 344 |
+
inputs=[pdf_query, pdf_upload])
|
| 345 |
+
|
| 346 |
+
with gr.Accordion("Advanced options", open=False):
|
| 347 |
+
max_new_tokens = gr.Slider(label="Max new tokens",
|
| 348 |
+
minimum=1,
|
| 349 |
+
maximum=MAX_MAX_NEW_TOKENS,
|
| 350 |
+
step=1,
|
| 351 |
+
value=DEFAULT_MAX_NEW_TOKENS)
|
| 352 |
+
temperature = gr.Slider(label="Temperature",
|
| 353 |
+
minimum=0.1,
|
| 354 |
+
maximum=4.0,
|
| 355 |
+
step=0.1,
|
| 356 |
+
value=0.6)
|
| 357 |
+
top_p = gr.Slider(label="Top-p (nucleus sampling)",
|
| 358 |
+
minimum=0.05,
|
| 359 |
+
maximum=1.0,
|
| 360 |
+
step=0.05,
|
| 361 |
+
value=0.9)
|
| 362 |
+
top_k = gr.Slider(label="Top-k",
|
| 363 |
+
minimum=1,
|
| 364 |
+
maximum=1000,
|
| 365 |
+
step=1,
|
| 366 |
+
value=50)
|
| 367 |
+
repetition_penalty = gr.Slider(label="Repetition penalty",
|
| 368 |
+
minimum=1.0,
|
| 369 |
+
maximum=2.0,
|
| 370 |
+
step=0.05,
|
| 371 |
+
value=1.2)
|
| 372 |
+
|
| 373 |
+
with gr.Column():
|
| 374 |
+
with gr.Column(elem_classes="canvas-output"):
|
| 375 |
+
gr.Markdown("## Result.Md")
|
| 376 |
+
output = gr.Textbox(label="Raw Output Stream",
|
| 377 |
+
interactive=False,
|
| 378 |
+
lines=2)
|
| 379 |
+
with gr.Accordion("Formatted Result (Result.md)", open=False):
|
| 380 |
+
markdown_output = gr.Markdown(
|
| 381 |
+
label="Formatted Result (Result.Md)")
|
| 382 |
+
#download_btn = gr.Button("Download Result.md")
|
| 383 |
+
|
| 384 |
+
model_choice = gr.Radio(choices=[
|
| 385 |
+
"Vision-Matters-7B-Math", "ViGaL-7B", "Visionary-R1",
|
| 386 |
+
"R1-Onevision-7B", "VLM-R1-Qwen2.5VL-3B-Math-0305"
|
| 387 |
+
],
|
| 388 |
+
label="Select Model",
|
| 389 |
+
value="Vision-Matters-7B-Math")
|
| 390 |
+
|
| 391 |
+
gr.Markdown("**Model Info 💻** | [Report Bug](https://huggingface.co/spaces/prithivMLmods/Multimodal-VLMs-5x/discussions)")
|
| 392 |
+
gr.Markdown("> [Vision Matters 7B Math](https://huggingface.co/Yuting6/Vision-Matters-7B): vision-matters is a simple visual perturbation framework that can be easily integrated into existing post-training pipelines including sft, dpo, and grpo. our findings highlight the critical role of visual perturbation: better reasoning begins with better seeing.")
|
| 393 |
+
gr.Markdown("> [ViGaL 7B](https://huggingface.co/yunfeixie/ViGaL-7B): vigal-7b shows that training a 7b mllm on simple games like snake using reinforcement learning boosts performance on benchmarks like mathvista and mmmu without needing worked solutions or diagrams indicating transferable reasoning skills.")
|
| 394 |
+
gr.Markdown("> [Visionary-R1](https://huggingface.co/maifoundations/Visionary-R1): visionary-r1 is a novel framework for training visual language models (vlms) to perform robust visual reasoning using reinforcement learning (rl). unlike traditional approaches that rely heavily on (sft) or (cot) annotations, visionary-r1 leverages only visual question-answer pairs and rl, making the process more scalable and accessible.")
|
| 395 |
+
gr.Markdown("> [R1-Onevision-7B](https://huggingface.co/Fancy-MLLM/R1-Onevision-7B): r1-onevision model enhances vision-language understanding and reasoning capabilities, making it suitable for various tasks such as visual reasoning and image understanding. with its robust ability to perform multimodal reasoning, r1-onevision emerges as a powerful ai assistant capable of addressing different domains.")
|
| 396 |
+
gr.Markdown("> [VLM-R1-Qwen2.5VL-3B-Math-0305](https://huggingface.co/omlab/VLM-R1-Qwen2.5VL-3B-Math-0305): vlm-r1 is a framework designed to enhance the reasoning and generalization capabilities of vision-language models (vlms) using a reinforcement learning (rl) approach inspired by the r1 methodology originally developed for large language models.")
|
| 397 |
+
gr.Markdown(">⚠️note: all the models in space are not guaranteed to perform well in video inference use cases.")
|
| 398 |
+
|
| 399 |
+
# Define the submit button actions
|
| 400 |
+
image_submit.click(fn=generate_image,
|
| 401 |
+
inputs=[
|
| 402 |
+
model_choice, image_query, image_upload,
|
| 403 |
+
max_new_tokens, temperature, top_p, top_k,
|
| 404 |
+
repetition_penalty
|
| 405 |
+
],
|
| 406 |
+
outputs=[output, markdown_output])
|
| 407 |
+
video_submit.click(fn=generate_video,
|
| 408 |
+
inputs=[
|
| 409 |
+
model_choice, video_query, video_upload,
|
| 410 |
+
max_new_tokens, temperature, top_p, top_k,
|
| 411 |
+
repetition_penalty
|
| 412 |
+
],
|
| 413 |
+
outputs=[output, markdown_output])
|
| 414 |
+
pdf_submit.click(fn=generate_pdf,
|
| 415 |
+
inputs=[
|
| 416 |
+
model_choice, pdf_query, pdf_upload,
|
| 417 |
+
max_new_tokens, temperature, top_p, top_k,
|
| 418 |
+
repetition_penalty
|
| 419 |
+
],
|
| 420 |
+
outputs=[output, markdown_output])
|
| 421 |
+
|
| 422 |
+
# Uncomment the following lines to enable download functionality(ps:no needed for now)
|
| 423 |
+
#download_btn.click(
|
| 424 |
+
# fn=save_to_md,
|
| 425 |
+
# inputs=output,
|
| 426 |
+
# outputs=None
|
| 427 |
+
#)
|
| 428 |
+
|
| 429 |
+
if __name__ == "__main__":
|
| 430 |
+
demo.queue(max_size=30).launch(share=True, mcp_server=True, ssr_mode=False, show_error=True)
|
images/1.jpg
ADDED
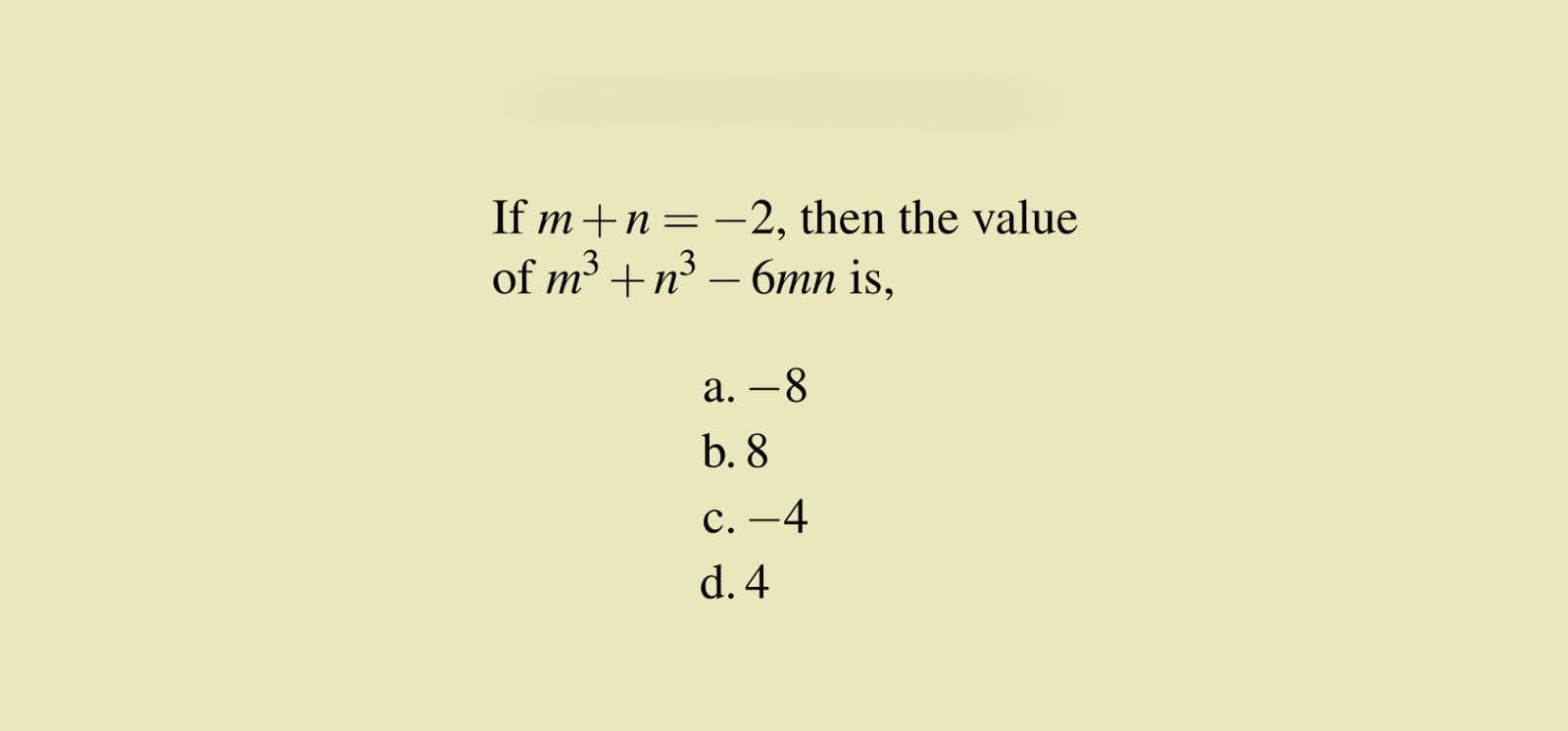
|
images/2.jpg
ADDED
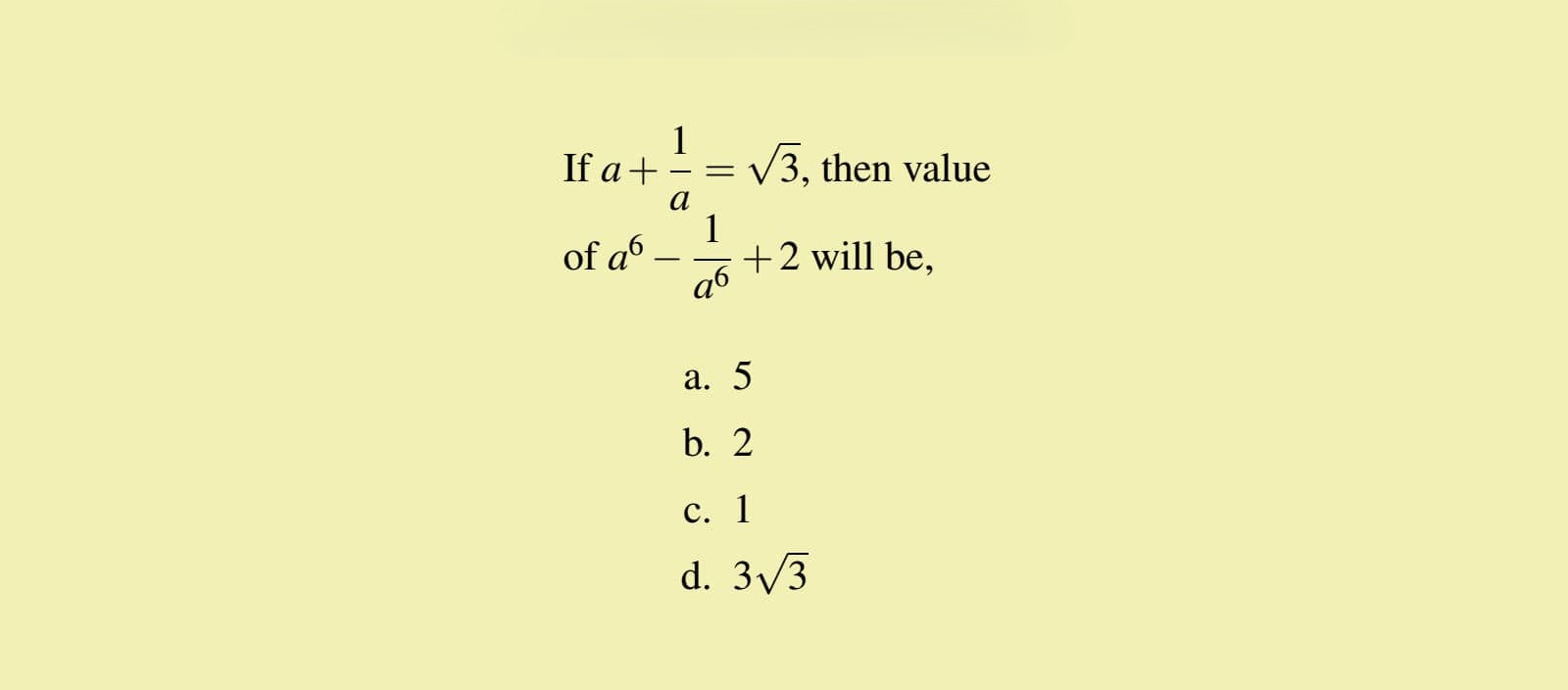
|
images/3.jpg
ADDED
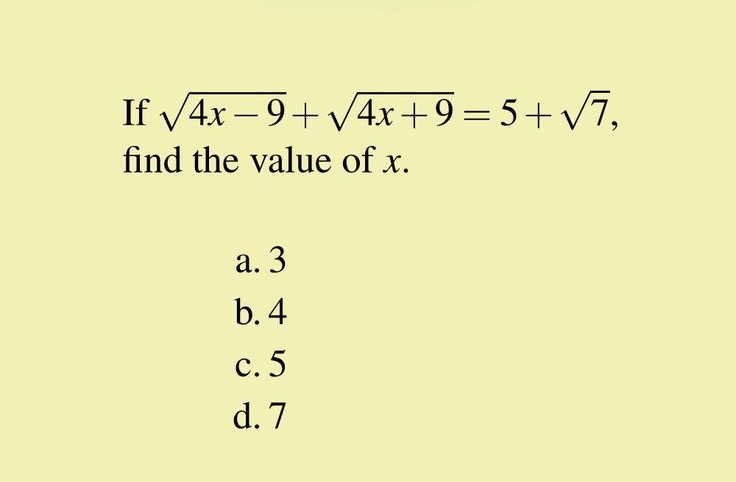
|
images/4.jpg
ADDED
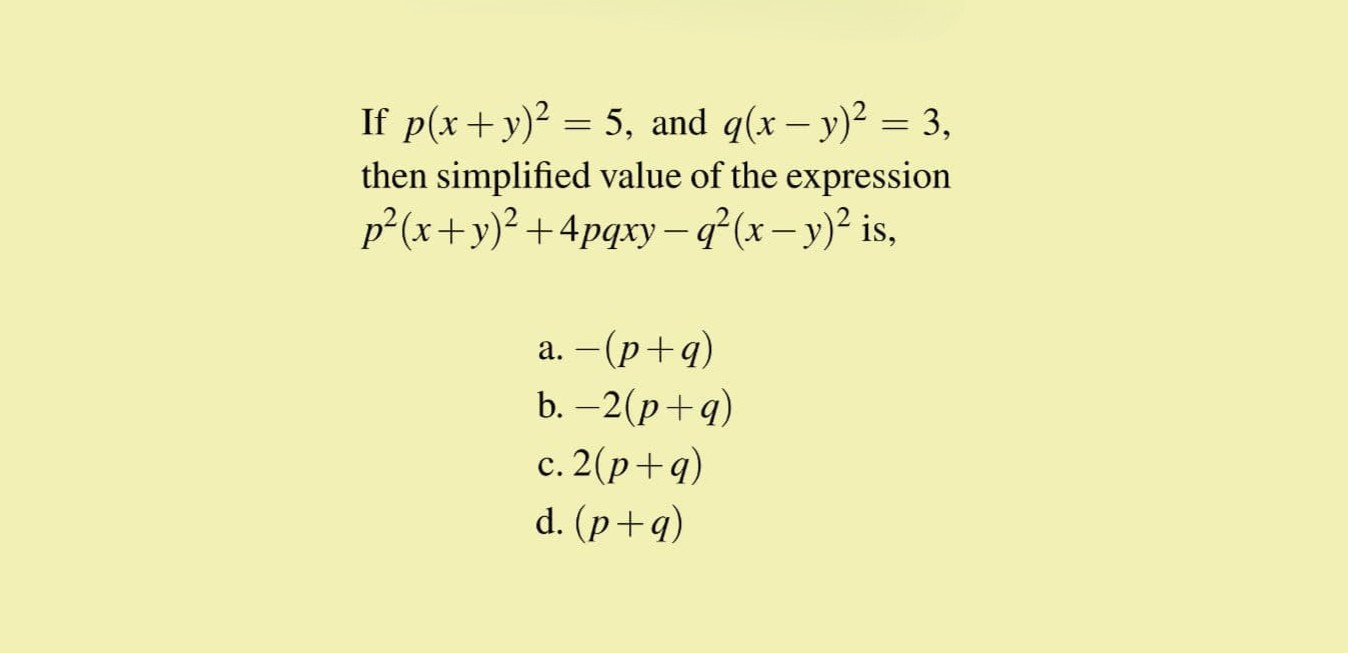
|
images/5.png
ADDED
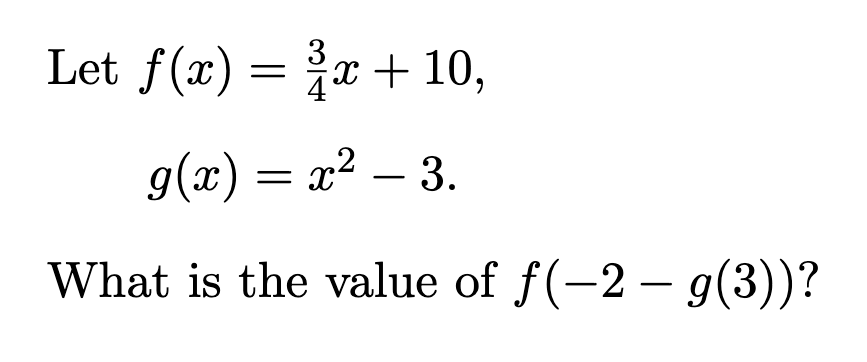
|
images/6.JPG
ADDED

|
Git LFS Details
|
pdfs/1.pdf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a9995f820cce258dda8ad7691bdb43c1c7f78d8244698b6276c7981e72c10854
|
| 3 |
+
size 128524
|
pdfs/2.pdf
ADDED
|
Binary file (25.8 kB). View file
|
|
|
requirements.txt
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
gradio
|
| 2 |
+
pdf2image
|
| 3 |
+
numpy
|
| 4 |
+
hf_xet
|
| 5 |
+
transformers
|
| 6 |
+
transformers-stream-generator
|
| 7 |
+
qwen-vl-utils
|
| 8 |
+
torchvision
|
| 9 |
+
torch
|
| 10 |
+
requests
|
| 11 |
+
huggingface_hub
|
| 12 |
+
spaces
|
| 13 |
+
accelerate
|
| 14 |
+
pillow
|
| 15 |
+
opencv-python
|
| 16 |
+
av
|
| 17 |
+
timm
|
| 18 |
+
einops
|
| 19 |
+
pyvips
|
| 20 |
+
pyvips-binary
|
| 21 |
+
pydantic
|
videos/1.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:7133ef10b52f9d9965cff4c747e23e1aa9a049e5fefe097e7a0dbf54ed99ab46
|
| 3 |
+
size 1366775
|
videos/2.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:440a1f196e8e173d04a839fe6192619db7139682565fe648c5195859d7a70cc9
|
| 3 |
+
size 1670517
|