Spaces:
Running
on
Zero

Running
on
Zero
initial commit
Browse files- .gitattributes +6 -0
- app.py +420 -0
- images/1.png +3 -0
- images/2.png +0 -0
- images/3.png +0 -0
- images/4.png +3 -0
- object/1.png +3 -0
- object/2.png +3 -0
- requirements.txt +15 -0
- videos/1.mp4 +3 -0
- videos/2.mp4 +3 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,9 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
images/1.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
images/4.png filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
object/1.png filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
object/2.png filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
videos/1.mp4 filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
videos/2.mp4 filter=lfs diff=lfs merge=lfs -text
|
app.py
ADDED
|
@@ -0,0 +1,420 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import random
|
| 3 |
+
import uuid
|
| 4 |
+
import json
|
| 5 |
+
import time
|
| 6 |
+
import asyncio
|
| 7 |
+
from threading import Thread
|
| 8 |
+
import base64
|
| 9 |
+
from io import BytesIO
|
| 10 |
+
import re
|
| 11 |
+
|
| 12 |
+
import gradio as gr
|
| 13 |
+
import spaces
|
| 14 |
+
import torch
|
| 15 |
+
import numpy as np
|
| 16 |
+
from PIL import Image, ImageDraw
|
| 17 |
+
import cv2
|
| 18 |
+
|
| 19 |
+
from transformers import (
|
| 20 |
+
Qwen2VLForConditionalGeneration,
|
| 21 |
+
Qwen2_5_VLForConditionalGeneration,
|
| 22 |
+
AutoProcessor,
|
| 23 |
+
TextIteratorStreamer,
|
| 24 |
+
)
|
| 25 |
+
from qwen_vl_utils import process_vision_info
|
| 26 |
+
|
| 27 |
+
# Constants for text generation
|
| 28 |
+
MAX_MAX_NEW_TOKENS = 2048
|
| 29 |
+
DEFAULT_MAX_NEW_TOKENS = 1024
|
| 30 |
+
MAX_INPUT_TOKEN_LENGTH = int(os.getenv("MAX_INPUT_TOKEN_LENGTH", "4096"))
|
| 31 |
+
|
| 32 |
+
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
|
| 33 |
+
|
| 34 |
+
# Load Camel-Doc-OCR-062825
|
| 35 |
+
MODEL_ID_M = "prithivMLmods/Camel-Doc-OCR-062825"
|
| 36 |
+
processor_m = AutoProcessor.from_pretrained(MODEL_ID_M, trust_remote_code=True)
|
| 37 |
+
model_m = Qwen2_5_VLForConditionalGeneration.from_pretrained(
|
| 38 |
+
MODEL_ID_M,
|
| 39 |
+
trust_remote_code=True,
|
| 40 |
+
torch_dtype=torch.float16
|
| 41 |
+
).to(device).eval()
|
| 42 |
+
|
| 43 |
+
# Load ViLaSR-7B
|
| 44 |
+
MODEL_ID_X = "AntResearchNLP/ViLaSR"
|
| 45 |
+
processor_x = AutoProcessor.from_pretrained(MODEL_ID_X, trust_remote_code=True)
|
| 46 |
+
model_x = Qwen2_5_VLForConditionalGeneration.from_pretrained(
|
| 47 |
+
MODEL_ID_X,
|
| 48 |
+
trust_remote_code=True,
|
| 49 |
+
torch_dtype=torch.float16
|
| 50 |
+
).to(device).eval()
|
| 51 |
+
|
| 52 |
+
# Load OCRFlux-3B
|
| 53 |
+
MODEL_ID_T = "ChatDOC/OCRFlux-3B"
|
| 54 |
+
processor_t = AutoProcessor.from_pretrained(MODEL_ID_T, trust_remote_code=True)
|
| 55 |
+
model_t = Qwen2_5_VLForConditionalGeneration.from_pretrained(
|
| 56 |
+
MODEL_ID_T,
|
| 57 |
+
trust_remote_code=True,
|
| 58 |
+
torch_dtype=torch.float16
|
| 59 |
+
).to(device).eval()
|
| 60 |
+
|
| 61 |
+
# Load ShotVL-7B
|
| 62 |
+
MODEL_ID_S = "Vchitect/ShotVL-7B"
|
| 63 |
+
processor_s = AutoProcessor.from_pretrained(MODEL_ID_S, trust_remote_code=True)
|
| 64 |
+
model_s = Qwen2_5_VLForConditionalGeneration.from_pretrained(
|
| 65 |
+
MODEL_ID_S,
|
| 66 |
+
trust_remote_code=True,
|
| 67 |
+
torch_dtype=torch.float16
|
| 68 |
+
).to(device).eval()
|
| 69 |
+
|
| 70 |
+
# Helper functions for object detection
|
| 71 |
+
def image_to_base64(image):
|
| 72 |
+
"""Convert a PIL image to a base64-encoded string."""
|
| 73 |
+
buffered = BytesIO()
|
| 74 |
+
image.save(buffered, format="PNG")
|
| 75 |
+
img_str = base64.b64encode(buffered.getvalue()).decode("utf-8")
|
| 76 |
+
return img_str
|
| 77 |
+
|
| 78 |
+
def draw_bounding_boxes(image, bounding_boxes, outline_color="red", line_width=2):
|
| 79 |
+
"""Draw bounding boxes on an image."""
|
| 80 |
+
draw = ImageDraw.Draw(image)
|
| 81 |
+
for box in bounding_boxes:
|
| 82 |
+
xmin, ymin, xmax, ymax = box
|
| 83 |
+
draw.rectangle([xmin, ymin, xmax, ymax], outline=outline_color, width=line_width)
|
| 84 |
+
return image
|
| 85 |
+
|
| 86 |
+
def rescale_bounding_boxes(bounding_boxes, original_width, original_height, scaled_width=1000, scaled_height=1000):
|
| 87 |
+
"""Rescale bounding boxes from normalized (1000x1000) to original image dimensions."""
|
| 88 |
+
x_scale = original_width / scaled_width
|
| 89 |
+
y_scale = original_height / scaled_height
|
| 90 |
+
rescaled_boxes = []
|
| 91 |
+
for box in bounding_boxes:
|
| 92 |
+
xmin, ymin, xmax, ymax = box
|
| 93 |
+
rescaled_box = [
|
| 94 |
+
xmin * x_scale,
|
| 95 |
+
ymin * y_scale,
|
| 96 |
+
xmax * x_scale,
|
| 97 |
+
ymax * y_scale
|
| 98 |
+
]
|
| 99 |
+
rescaled_boxes.append(rescaled_box)
|
| 100 |
+
return rescaled_boxes
|
| 101 |
+
|
| 102 |
+
# Default system prompt for object detection
|
| 103 |
+
default_system_prompt = (
|
| 104 |
+
"You are a helpful assistant to detect objects in images. When asked to detect elements based on a description, "
|
| 105 |
+
"you return bounding boxes for all elements in the form of [xmin, ymin, xmax, ymax] with the values being scaled "
|
| 106 |
+
"to 512 by 512 pixels. When there are more than one result, answer with a list of bounding boxes in the form "
|
| 107 |
+
"of [[xmin, ymin, xmax, ymax], [xmin, ymin, xmax, ymax], ...]."
|
| 108 |
+
"Parse only the boxes; don't write unnecessary content."
|
| 109 |
+
)
|
| 110 |
+
|
| 111 |
+
# Function for object detection
|
| 112 |
+
@spaces.GPU
|
| 113 |
+
def run_example(image, text_input, system_prompt):
|
| 114 |
+
"""Detect objects in an image and return bounding box annotations."""
|
| 115 |
+
model = model_x
|
| 116 |
+
processor = processor_x
|
| 117 |
+
|
| 118 |
+
messages = [
|
| 119 |
+
{
|
| 120 |
+
"role": "user",
|
| 121 |
+
"content": [
|
| 122 |
+
{"type": "image", "image": f"data:image;base64,{image_to_base64(image)}"},
|
| 123 |
+
{"type": "text", "text": system_prompt},
|
| 124 |
+
{"type": "text", "text": text_input},
|
| 125 |
+
],
|
| 126 |
+
}
|
| 127 |
+
]
|
| 128 |
+
|
| 129 |
+
text = processor.apply_chat_template(
|
| 130 |
+
messages, tokenize=False, add_generation_prompt=True
|
| 131 |
+
)
|
| 132 |
+
image_inputs, video_inputs = process_vision_info(messages)
|
| 133 |
+
inputs = processor(
|
| 134 |
+
text=[text],
|
| 135 |
+
images=image_inputs,
|
| 136 |
+
videos=video_inputs,
|
| 137 |
+
padding=True,
|
| 138 |
+
return_tensors="pt",
|
| 139 |
+
)
|
| 140 |
+
inputs = inputs.to("cuda")
|
| 141 |
+
|
| 142 |
+
generated_ids = model.generate(**inputs, max_new_tokens=256)
|
| 143 |
+
generated_ids_trimmed = [
|
| 144 |
+
out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
|
| 145 |
+
]
|
| 146 |
+
output_text = processor.batch_decode(
|
| 147 |
+
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
|
| 148 |
+
)
|
| 149 |
+
pattern = r'\[\s*(\d+)\s*,\s*(\d+)\s*,\s*(\d+)\s*,\s*(\d+)\s*\]'
|
| 150 |
+
matches = re.findall(pattern, str(output_text))
|
| 151 |
+
parsed_boxes = [[int(num) for num in match] for match in matches]
|
| 152 |
+
scaled_boxes = rescale_bounding_boxes(parsed_boxes, image.width, image.height)
|
| 153 |
+
annotated_image = draw_bounding_boxes(image.copy(), scaled_boxes)
|
| 154 |
+
return output_text[0], str(parsed_boxes), annotated_image
|
| 155 |
+
|
| 156 |
+
def downsample_video(video_path):
|
| 157 |
+
"""
|
| 158 |
+
Downsample a video to evenly spaced frames, returning each as a PIL image with its timestamp.
|
| 159 |
+
"""
|
| 160 |
+
vidcap = cv2.VideoCapture(video_path)
|
| 161 |
+
total_frames = int(vidcap.get(cv2.CAP_PROP_FRAME_COUNT))
|
| 162 |
+
fps = vidcap.get(cv2.CAP_PROP_FPS)
|
| 163 |
+
frames = []
|
| 164 |
+
frame_indices = np.linspace(0, total_frames - 1, 10, dtype=int)
|
| 165 |
+
for i in frame_indices:
|
| 166 |
+
vidcap.set(cv2.CAP_PROP_POS_FRAMES, i)
|
| 167 |
+
success, image = vidcap.read()
|
| 168 |
+
if success:
|
| 169 |
+
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
|
| 170 |
+
pil_image = Image.fromarray(image)
|
| 171 |
+
timestamp = round(i / fps, 2)
|
| 172 |
+
frames.append((pil_image, timestamp))
|
| 173 |
+
vidcap.release()
|
| 174 |
+
return frames
|
| 175 |
+
|
| 176 |
+
@spaces.GPU
|
| 177 |
+
def generate_image(model_name: str, text: str, image: Image.Image,
|
| 178 |
+
max_new_tokens: int = 1024,
|
| 179 |
+
temperature: float = 0.6,
|
| 180 |
+
top_p: float = 0.9,
|
| 181 |
+
top_k: int = 50,
|
| 182 |
+
repetition_penalty: float = 1.2):
|
| 183 |
+
"""
|
| 184 |
+
Generate responses using the selected model for image input.
|
| 185 |
+
"""
|
| 186 |
+
if model_name == "Camel-Doc-OCR-062825":
|
| 187 |
+
processor = processor_m
|
| 188 |
+
model = model_m
|
| 189 |
+
elif model_name == "ViLaSR-7B":
|
| 190 |
+
processor = processor_x
|
| 191 |
+
model = model_x
|
| 192 |
+
elif model_name == "OCRFlux-3B":
|
| 193 |
+
processor = processor_t
|
| 194 |
+
model = model_t
|
| 195 |
+
elif model_name == "ShotVL-7B":
|
| 196 |
+
processor = processor_s
|
| 197 |
+
model = model_s
|
| 198 |
+
else:
|
| 199 |
+
yield "Invalid model selected.", "Invalid model selected."
|
| 200 |
+
return
|
| 201 |
+
|
| 202 |
+
if image is None:
|
| 203 |
+
yield "Please upload an image.", "Please upload an image."
|
| 204 |
+
return
|
| 205 |
+
|
| 206 |
+
messages = [{
|
| 207 |
+
"role": "user",
|
| 208 |
+
"content": [
|
| 209 |
+
{"type": "image", "image": image},
|
| 210 |
+
{"type": "text", "text": text},
|
| 211 |
+
]
|
| 212 |
+
}]
|
| 213 |
+
prompt_full = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
|
| 214 |
+
inputs = processor(
|
| 215 |
+
text=[prompt_full],
|
| 216 |
+
images=[image],
|
| 217 |
+
return_tensors="pt",
|
| 218 |
+
padding=True,
|
| 219 |
+
truncation=False,
|
| 220 |
+
max_length=MAX_INPUT_TOKEN_LENGTH
|
| 221 |
+
).to(device)
|
| 222 |
+
streamer = TextIteratorStreamer(processor, skip_prompt=True, skip_special_tokens=True)
|
| 223 |
+
generation_kwargs = {**inputs, "streamer": streamer, "max_new_tokens": max_new_tokens}
|
| 224 |
+
thread = Thread(target=model.generate, kwargs=generation_kwargs)
|
| 225 |
+
thread.start()
|
| 226 |
+
buffer = ""
|
| 227 |
+
for new_text in streamer:
|
| 228 |
+
buffer += new_text
|
| 229 |
+
time.sleep(0.01)
|
| 230 |
+
yield buffer, buffer
|
| 231 |
+
|
| 232 |
+
@spaces.GPU
|
| 233 |
+
def generate_video(model_name: str, text: str, video_path: str,
|
| 234 |
+
max_new_tokens: int = 1024,
|
| 235 |
+
temperature: float = 0.6,
|
| 236 |
+
top_p: float = 0.9,
|
| 237 |
+
top_k: int = 50,
|
| 238 |
+
repetition_penalty: float = 1.2):
|
| 239 |
+
"""
|
| 240 |
+
Generate responses using the selected model for video input.
|
| 241 |
+
"""
|
| 242 |
+
if model_name == "Camel-Doc-OCR-062825":
|
| 243 |
+
processor = processor_m
|
| 244 |
+
model = model_m
|
| 245 |
+
elif model_name == "ViLaSR-7B":
|
| 246 |
+
processor = processor_x
|
| 247 |
+
model = model_x
|
| 248 |
+
elif model_name == "OCRFlux-3B":
|
| 249 |
+
processor = processor_t
|
| 250 |
+
model = model_t
|
| 251 |
+
elif model_name == "ShotVL-7B":
|
| 252 |
+
processor = processor_s
|
| 253 |
+
model = model_s
|
| 254 |
+
else:
|
| 255 |
+
yield "Invalid model selected.", "Invalid model selected."
|
| 256 |
+
return
|
| 257 |
+
|
| 258 |
+
if video_path is None:
|
| 259 |
+
yield "Please upload a video.", "Please upload a video."
|
| 260 |
+
return
|
| 261 |
+
|
| 262 |
+
frames = downsample_video(video_path)
|
| 263 |
+
messages = [
|
| 264 |
+
{"role": "system", "content": [{"type": "text", "text": "You are a helpful assistant."}]},
|
| 265 |
+
{"role": "user", "content": [{"type": "text", "text": text}]}
|
| 266 |
+
]
|
| 267 |
+
for frame in frames:
|
| 268 |
+
image, timestamp = frame
|
| 269 |
+
messages[1]["content"].append({"type": "text", "text": f"Frame {timestamp}:"})
|
| 270 |
+
messages[1]["content"].append({"type": "image", "image": image})
|
| 271 |
+
inputs = processor.apply_chat_template(
|
| 272 |
+
messages,
|
| 273 |
+
tokenize=True,
|
| 274 |
+
add_generation_prompt=True,
|
| 275 |
+
return_dict=True,
|
| 276 |
+
return_tensors="pt",
|
| 277 |
+
truncation=False,
|
| 278 |
+
max_length=MAX_INPUT_TOKEN_LENGTH
|
| 279 |
+
).to(device)
|
| 280 |
+
streamer = TextIteratorStreamer(processor, skip_prompt=True, skip_special_tokens=True)
|
| 281 |
+
generation_kwargs = {
|
| 282 |
+
**inputs,
|
| 283 |
+
"streamer": streamer,
|
| 284 |
+
"max_new_tokens": max_new_tokens,
|
| 285 |
+
"do_sample": True,
|
| 286 |
+
"temperature": temperature,
|
| 287 |
+
"top_p": top_p,
|
| 288 |
+
"top_k": top_k,
|
| 289 |
+
"repetition_penalty": repetition_penalty,
|
| 290 |
+
}
|
| 291 |
+
thread = Thread(target=model.generate, kwargs=generation_kwargs)
|
| 292 |
+
thread.start()
|
| 293 |
+
buffer = ""
|
| 294 |
+
for new_text in streamer:
|
| 295 |
+
buffer += new_text
|
| 296 |
+
buffer = buffer.replace("<|im_end|>", "")
|
| 297 |
+
time.sleep(0.01)
|
| 298 |
+
yield buffer, buffer
|
| 299 |
+
|
| 300 |
+
# Define examples for image, video, and object detection inference
|
| 301 |
+
image_examples = [
|
| 302 |
+
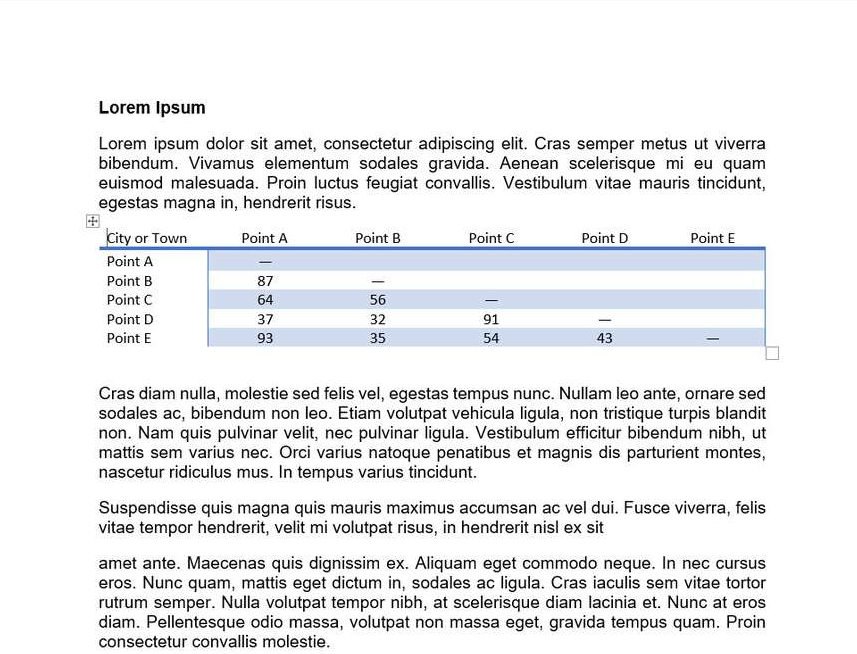
["convert this page to doc [text] precisely for markdown.", "images/1.png"],
|
| 303 |
+
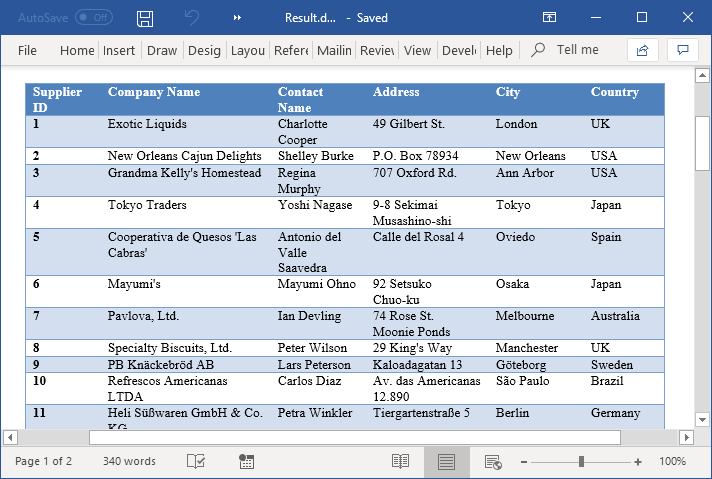
["convert this page to doc [table] precisely for markdown.", "images/2.png"],
|
| 304 |
+
["explain the movie shot in detail.", "images/3.png"],
|
| 305 |
+
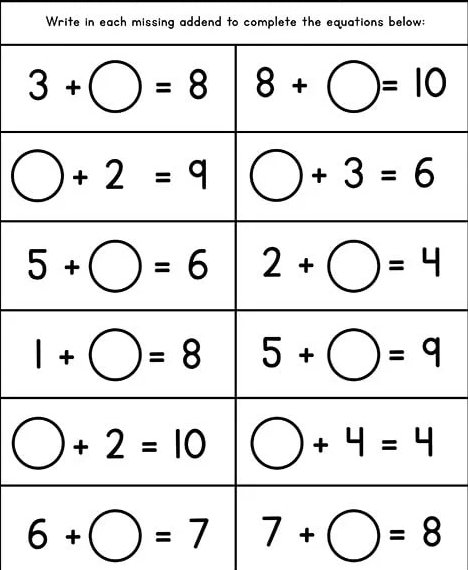
["fill the correct numbers.", "images/4.png"]
|
| 306 |
+
]
|
| 307 |
+
|
| 308 |
+
video_examples = [
|
| 309 |
+
["explain the ad video in detail.", "videos/1.mp4"],
|
| 310 |
+
["explain the video in detail.", "videos/2.mp4"]
|
| 311 |
+
]
|
| 312 |
+
|
| 313 |
+
object_detection_examples = [
|
| 314 |
+
["object/1.png", "detect red and yellow cars."],
|
| 315 |
+
["object/2.png", "detect the white cat."]
|
| 316 |
+
]
|
| 317 |
+
|
| 318 |
+
# Added CSS to style the output area as a "Canvas"
|
| 319 |
+
css = """
|
| 320 |
+
.submit-btn {
|
| 321 |
+
background-color: #2980b9 !important;
|
| 322 |
+
color: white !important;
|
| 323 |
+
}
|
| 324 |
+
.submit-btn:hover {
|
| 325 |
+
background-color: #3498db !important;
|
| 326 |
+
}
|
| 327 |
+
.canvas-output {
|
| 328 |
+
border: 2px solid #4682B4;
|
| 329 |
+
border-radius: 10px;
|
| 330 |
+
padding: 20px;
|
| 331 |
+
}
|
| 332 |
+
"""
|
| 333 |
+
|
| 334 |
+
# Create the Gradio Interface
|
| 335 |
+
with gr.Blocks(css=css, theme="bethecloud/storj_theme") as demo:
|
| 336 |
+
gr.Markdown("# **[Doc VLMs v2 [Localization]](https://huggingface.co/collections/prithivMLmods/multimodal-implementations-67c9982ea04b39f0608badb0)**")
|
| 337 |
+
with gr.Row():
|
| 338 |
+
with gr.Column():
|
| 339 |
+
with gr.Tabs():
|
| 340 |
+
with gr.TabItem("Image Inference"):
|
| 341 |
+
image_query = gr.Textbox(label="Query Input", placeholder="Enter your query here...")
|
| 342 |
+
image_upload = gr.Image(type="pil", label="Image")
|
| 343 |
+
image_submit = gr.Button("Submit", elem_classes="submit-btn")
|
| 344 |
+
gr.Examples(
|
| 345 |
+
examples=image_examples,
|
| 346 |
+
inputs=[image_query, image_upload]
|
| 347 |
+
)
|
| 348 |
+
with gr.TabItem("Video Inference"):
|
| 349 |
+
video_query = gr.Textbox(label="Query Input", placeholder="Enter your query here...")
|
| 350 |
+
video_upload = gr.Video(label="Video")
|
| 351 |
+
video_submit = gr.Button("Submit", elem_classes="submit-btn")
|
| 352 |
+
gr.Examples(
|
| 353 |
+
examples=video_examples,
|
| 354 |
+
inputs=[video_query, video_upload]
|
| 355 |
+
)
|
| 356 |
+
with gr.TabItem("Object Detection / Localization"):
|
| 357 |
+
with gr.Row():
|
| 358 |
+
with gr.Column():
|
| 359 |
+
input_img = gr.Image(label="Input Image", type="pil")
|
| 360 |
+
system_prompt = gr.Textbox(label="System Prompt", value=default_system_prompt, visible=False)
|
| 361 |
+
text_input = gr.Textbox(label="Query Input")
|
| 362 |
+
submit_btn = gr.Button(value="Submit", elem_classes="submit-btn")
|
| 363 |
+
with gr.Column():
|
| 364 |
+
model_output_text = gr.Textbox(label="Model Output Text")
|
| 365 |
+
parsed_boxes = gr.Textbox(label="Parsed Boxes")
|
| 366 |
+
annotated_image = gr.Image(label="Annotated Image")
|
| 367 |
+
|
| 368 |
+
gr.Examples(
|
| 369 |
+
examples=object_detection_examples,
|
| 370 |
+
inputs=[input_img, text_input],
|
| 371 |
+
outputs=[model_output_text, parsed_boxes, annotated_image],
|
| 372 |
+
fn=run_example,
|
| 373 |
+
cache_examples=True,
|
| 374 |
+
)
|
| 375 |
+
|
| 376 |
+
submit_btn.click(
|
| 377 |
+
fn=run_example,
|
| 378 |
+
inputs=[input_img, text_input, system_prompt],
|
| 379 |
+
outputs=[model_output_text, parsed_boxes, annotated_image]
|
| 380 |
+
)
|
| 381 |
+
|
| 382 |
+
with gr.Accordion("Advanced options", open=False):
|
| 383 |
+
max_new_tokens = gr.Slider(label="Max new tokens", minimum=1, maximum=MAX_MAX_NEW_TOKENS, step=1, value=DEFAULT_MAX_NEW_TOKENS)
|
| 384 |
+
temperature = gr.Slider(label="Temperature", minimum=0.1, maximum=4.0, step=0.1, value=0.6)
|
| 385 |
+
top_p = gr.Slider(label="Top-p (nucleus sampling)", minimum=0.05, maximum=1.0, step=0.05, value=0.9)
|
| 386 |
+
top_k = gr.Slider(label="Top-k", minimum=1, maximum=1000, step=1, value=50)
|
| 387 |
+
repetition_penalty = gr.Slider(label="Repetition penalty", minimum=1.0, maximum=2.0, step=0.05, value=1.2)
|
| 388 |
+
|
| 389 |
+
with gr.Column():
|
| 390 |
+
with gr.Column(elem_classes="canvas-output"):
|
| 391 |
+
gr.Markdown("## Result.Md")
|
| 392 |
+
output = gr.Textbox(label="Raw Output Stream", interactive=False, lines=2)
|
| 393 |
+
markdown_output = gr.Markdown(label="Formatted Result (Result.Md)")
|
| 394 |
+
|
| 395 |
+
model_choice = gr.Radio(
|
| 396 |
+
choices=["Camel-Doc-OCR-062825", "OCRFlux-3B", "ShotVL-7B", "ViLaSR-7B"],
|
| 397 |
+
label="Select Model",
|
| 398 |
+
value="Camel-Doc-OCR-062825"
|
| 399 |
+
)
|
| 400 |
+
|
| 401 |
+
gr.Markdown("**Model Info 💻** | [Report Bug](https://huggingface.co/spaces/prithivMLmods/Doc-VLMs-v2-Localization/discussions)")
|
| 402 |
+
gr.Markdown("> [Camel-Doc-OCR-062825](https://huggingface.co/prithivMLmods/Camel-Doc-OCR-062825) : camel-doc-ocr-062825 model is a fine-tuned version of qwen2.5-vl-7b-instruct, optimized for document retrieval, content extraction, and analysis recognition. built on top of the qwen2.5-vl architecture, this model enhances document comprehension capabilities.")
|
| 403 |
+
gr.Markdown("> [OCRFlux-3B](https://huggingface.co/ChatDOC/OCRFlux-3B) : ocrflux-3b model that's fine-tuned from qwen2.5-vl-3b-instruct using our private document datasets and some data from olmocr-mix-0225 dataset. optimized for document retrieval, content extraction, and analysis recognition. the best way to use this model is via the ocrflux toolkit.")
|
| 404 |
+
gr.Markdown("> [ViLaSR](https://huggingface.co/AntResearchNLP/ViLaSR) : vilasr-7b model as presented in reinforcing spatial reasoning in vision-language models with interwoven thinking and visual drawing. efficient reasoning capabilities.")
|
| 405 |
+
gr.Markdown("> [ShotVL-7B](https://huggingface.co/Vchitect/ShotVL-7B) : shotvl-7b is a fine-tuned version of qwen2.5-vl-7b-instruct, trained by supervised fine-tuning on the largest and high-quality dataset for cinematic language understanding to date. it currently achieves state-of-the-art performance on shotbench.")
|
| 406 |
+
gr.Markdown(">⚠️note: all the models in space are not guaranteed to perform well in video inference use cases.")
|
| 407 |
+
|
| 408 |
+
image_submit.click(
|
| 409 |
+
fn=generate_image,
|
| 410 |
+
inputs=[model_choice, image_query, image_upload, max_new_tokens, temperature, top_p, top_k, repetition_penalty],
|
| 411 |
+
outputs=[output, markdown_output]
|
| 412 |
+
)
|
| 413 |
+
video_submit.click(
|
| 414 |
+
fn=generate_video,
|
| 415 |
+
inputs=[model_choice, video_query, video_upload, max_new_tokens, temperature, top_p, top_k, repetition_penalty],
|
| 416 |
+
outputs=[output, markdown_output]
|
| 417 |
+
)
|
| 418 |
+
|
| 419 |
+
if __name__ == "__main__":
|
| 420 |
+
demo.queue(max_size=30).launch(share=True, mcp_server=True, ssr_mode=False, show_error=True)
|
images/1.png
ADDED
|
Git LFS Details
|
images/2.png
ADDED
|
images/3.png
ADDED

|
images/4.png
ADDED
|
Git LFS Details
|
object/1.png
ADDED

|
Git LFS Details
|
object/2.png
ADDED

|
Git LFS Details
|
requirements.txt
ADDED
|
@@ -0,0 +1,15 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
gradio
|
| 2 |
+
numpy
|
| 3 |
+
hf_xet
|
| 4 |
+
transformers
|
| 5 |
+
transformers-stream-generator
|
| 6 |
+
qwen-vl-utils
|
| 7 |
+
torchvision
|
| 8 |
+
torch
|
| 9 |
+
requests
|
| 10 |
+
huggingface_hub
|
| 11 |
+
spaces
|
| 12 |
+
accelerate
|
| 13 |
+
pillow
|
| 14 |
+
opencv-python
|
| 15 |
+
av
|
videos/1.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8aa7ee693b951ad682f387e18eda70a9bccb948f7fd587ae921edd719f689ca6
|
| 3 |
+
size 1409573
|
videos/2.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:3916437e5a9ae4fd46c34120d5673dfeb6b1cf2a6b0be7da3d0c53da0ad360bb
|
| 3 |
+
size 1609393
|