Spaces:
Running
on
L4

Running
on
L4
Upload 44 files
Browse files- R3GAN/FusedOperators.py +33 -0
- R3GAN/Networks.py +173 -0
- R3GAN/Resamplers.py +104 -0
- R3GAN/Trainer.py +44 -0
- README.md +87 -14
- calc_metrics.py +184 -0
- dataset_tool.py +456 -0
- dnnlib/__init__.py +9 -0
- dnnlib/util.py +491 -0
- doc/teaser.png +0 -0
- gen_images.py +85 -0
- legacy.py +327 -0
- metrics/__init__.py +9 -0
- metrics/frechet_inception_distance.py +41 -0
- metrics/inception_score.py +38 -0
- metrics/kernel_inception_distance.py +46 -0
- metrics/metric_main.py +128 -0
- metrics/metric_utils.py +279 -0
- metrics/precision_recall.py +62 -0
- torch_utils/__init__.py +9 -0
- torch_utils/custom_ops.py +157 -0
- torch_utils/misc.py +249 -0
- torch_utils/ops/__init__.py +9 -0
- torch_utils/ops/bias_act.cpp +99 -0
- torch_utils/ops/bias_act.cu +176 -0
- torch_utils/ops/bias_act.h +38 -0
- torch_utils/ops/bias_act.py +209 -0
- torch_utils/ops/conv2d_gradfix.py +203 -0
- torch_utils/ops/conv2d_resample.py +143 -0
- torch_utils/ops/fma.py +60 -0
- torch_utils/ops/grid_sample_gradfix.py +83 -0
- torch_utils/ops/upfirdn2d.cpp +107 -0
- torch_utils/ops/upfirdn2d.cu +387 -0
- torch_utils/ops/upfirdn2d.h +59 -0
- torch_utils/ops/upfirdn2d.py +389 -0
- torch_utils/persistence.py +251 -0
- torch_utils/training_stats.py +268 -0
- train.py +322 -0
- training/__init__.py +9 -0
- training/augment.py +437 -0
- training/dataset.py +238 -0
- training/loss.py +43 -0
- training/networks.py +47 -0
- training/training_loop.py +474 -0
R3GAN/FusedOperators.py
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import math
|
| 4 |
+
from torch_utils.ops import bias_act
|
| 5 |
+
|
| 6 |
+
class BiasedActivationReference(nn.Module):
|
| 7 |
+
Gain = math.sqrt(2 / (1 + 0.2 ** 2))
|
| 8 |
+
Function = nn.LeakyReLU(0.2)
|
| 9 |
+
|
| 10 |
+
def __init__(self, InputUnits):
|
| 11 |
+
super(BiasedActivationReference, self).__init__()
|
| 12 |
+
|
| 13 |
+
self.Bias = nn.Parameter(torch.empty(InputUnits))
|
| 14 |
+
self.Bias.data.zero_()
|
| 15 |
+
|
| 16 |
+
def forward(self, x):
|
| 17 |
+
y = x + self.Bias.to(x.dtype).view(1, -1, 1, 1) if len(x.shape) > 2 else x + self.Bias.to(x.dtype).view(1, -1)
|
| 18 |
+
return BiasedActivationReference.Function(y)
|
| 19 |
+
|
| 20 |
+
class BiasedActivationCUDA(nn.Module):
|
| 21 |
+
Gain = math.sqrt(2 / (1 + 0.2 ** 2))
|
| 22 |
+
Function = 'lrelu'
|
| 23 |
+
|
| 24 |
+
def __init__(self, InputUnits):
|
| 25 |
+
super(BiasedActivationCUDA, self).__init__()
|
| 26 |
+
|
| 27 |
+
self.Bias = nn.Parameter(torch.empty(InputUnits))
|
| 28 |
+
self.Bias.data.zero_()
|
| 29 |
+
|
| 30 |
+
def forward(self, x):
|
| 31 |
+
return bias_act.bias_act(x, self.Bias.to(x.dtype), act=BiasedActivationCUDA.Function, gain=1)
|
| 32 |
+
|
| 33 |
+
BiasedActivation = BiasedActivationCUDA
|
R3GAN/Networks.py
ADDED
|
@@ -0,0 +1,173 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
from .Resamplers import InterpolativeUpsampler, InterpolativeDownsampler
|
| 5 |
+
from .FusedOperators import BiasedActivation
|
| 6 |
+
|
| 7 |
+
def MSRInitializer(Layer, ActivationGain=1):
|
| 8 |
+
FanIn = Layer.weight.data.size(1) * Layer.weight.data[0][0].numel()
|
| 9 |
+
Layer.weight.data.normal_(0, ActivationGain / math.sqrt(FanIn))
|
| 10 |
+
|
| 11 |
+
if Layer.bias is not None:
|
| 12 |
+
Layer.bias.data.zero_()
|
| 13 |
+
|
| 14 |
+
return Layer
|
| 15 |
+
|
| 16 |
+
class Convolution(nn.Module):
|
| 17 |
+
def __init__(self, InputChannels, OutputChannels, KernelSize, Groups=1, ActivationGain=1):
|
| 18 |
+
super(Convolution, self).__init__()
|
| 19 |
+
|
| 20 |
+
self.Layer = MSRInitializer(nn.Conv2d(InputChannels, OutputChannels, kernel_size=KernelSize, stride=1, padding=(KernelSize - 1) // 2, groups=Groups, bias=False), ActivationGain=ActivationGain)
|
| 21 |
+
|
| 22 |
+
def forward(self, x):
|
| 23 |
+
return nn.functional.conv2d(x, self.Layer.weight.to(x.dtype), padding=self.Layer.padding, groups=self.Layer.groups)
|
| 24 |
+
|
| 25 |
+
class ResidualBlock(nn.Module):
|
| 26 |
+
def __init__(self, InputChannels, Cardinality, ExpansionFactor, KernelSize, VarianceScalingParameter):
|
| 27 |
+
super(ResidualBlock, self).__init__()
|
| 28 |
+
|
| 29 |
+
NumberOfLinearLayers = 3
|
| 30 |
+
ExpandedChannels = InputChannels * ExpansionFactor
|
| 31 |
+
ActivationGain = BiasedActivation.Gain * VarianceScalingParameter ** (-1 / (2 * NumberOfLinearLayers - 2))
|
| 32 |
+
|
| 33 |
+
self.LinearLayer1 = Convolution(InputChannels, ExpandedChannels, KernelSize=1, ActivationGain=ActivationGain)
|
| 34 |
+
self.LinearLayer2 = Convolution(ExpandedChannels, ExpandedChannels, KernelSize=KernelSize, Groups=Cardinality, ActivationGain=ActivationGain)
|
| 35 |
+
self.LinearLayer3 = Convolution(ExpandedChannels, InputChannels, KernelSize=1, ActivationGain=0)
|
| 36 |
+
|
| 37 |
+
self.NonLinearity1 = BiasedActivation(ExpandedChannels)
|
| 38 |
+
self.NonLinearity2 = BiasedActivation(ExpandedChannels)
|
| 39 |
+
|
| 40 |
+
def forward(self, x):
|
| 41 |
+
y = self.LinearLayer1(x)
|
| 42 |
+
y = self.LinearLayer2(self.NonLinearity1(y))
|
| 43 |
+
y = self.LinearLayer3(self.NonLinearity2(y))
|
| 44 |
+
|
| 45 |
+
return x + y
|
| 46 |
+
|
| 47 |
+
class UpsampleLayer(nn.Module):
|
| 48 |
+
def __init__(self, InputChannels, OutputChannels, ResamplingFilter):
|
| 49 |
+
super(UpsampleLayer, self).__init__()
|
| 50 |
+
|
| 51 |
+
self.Resampler = InterpolativeUpsampler(ResamplingFilter)
|
| 52 |
+
|
| 53 |
+
if InputChannels != OutputChannels:
|
| 54 |
+
self.LinearLayer = Convolution(InputChannels, OutputChannels, KernelSize=1)
|
| 55 |
+
|
| 56 |
+
def forward(self, x):
|
| 57 |
+
x = self.LinearLayer(x) if hasattr(self, 'LinearLayer') else x
|
| 58 |
+
x = self.Resampler(x)
|
| 59 |
+
|
| 60 |
+
return x
|
| 61 |
+
|
| 62 |
+
class DownsampleLayer(nn.Module):
|
| 63 |
+
def __init__(self, InputChannels, OutputChannels, ResamplingFilter):
|
| 64 |
+
super(DownsampleLayer, self).__init__()
|
| 65 |
+
|
| 66 |
+
self.Resampler = InterpolativeDownsampler(ResamplingFilter)
|
| 67 |
+
|
| 68 |
+
if InputChannels != OutputChannels:
|
| 69 |
+
self.LinearLayer = Convolution(InputChannels, OutputChannels, KernelSize=1)
|
| 70 |
+
|
| 71 |
+
def forward(self, x):
|
| 72 |
+
x = self.Resampler(x)
|
| 73 |
+
x = self.LinearLayer(x) if hasattr(self, 'LinearLayer') else x
|
| 74 |
+
|
| 75 |
+
return x
|
| 76 |
+
|
| 77 |
+
class GenerativeBasis(nn.Module):
|
| 78 |
+
def __init__(self, InputDimension, OutputChannels):
|
| 79 |
+
super(GenerativeBasis, self).__init__()
|
| 80 |
+
|
| 81 |
+
self.Basis = nn.Parameter(torch.empty(OutputChannels, 4, 4).normal_(0, 1))
|
| 82 |
+
self.LinearLayer = MSRInitializer(nn.Linear(InputDimension, OutputChannels, bias=False))
|
| 83 |
+
|
| 84 |
+
def forward(self, x):
|
| 85 |
+
return self.Basis.view(1, -1, 4, 4) * self.LinearLayer(x).view(x.shape[0], -1, 1, 1)
|
| 86 |
+
|
| 87 |
+
class DiscriminativeBasis(nn.Module):
|
| 88 |
+
def __init__(self, InputChannels, OutputDimension):
|
| 89 |
+
super(DiscriminativeBasis, self).__init__()
|
| 90 |
+
|
| 91 |
+
self.Basis = MSRInitializer(nn.Conv2d(InputChannels, InputChannels, kernel_size=4, stride=1, padding=0, groups=InputChannels, bias=False))
|
| 92 |
+
self.LinearLayer = MSRInitializer(nn.Linear(InputChannels, OutputDimension, bias=False))
|
| 93 |
+
|
| 94 |
+
def forward(self, x):
|
| 95 |
+
return self.LinearLayer(self.Basis(x).view(x.shape[0], -1))
|
| 96 |
+
|
| 97 |
+
class GeneratorStage(nn.Module):
|
| 98 |
+
def __init__(self, InputChannels, OutputChannels, Cardinality, NumberOfBlocks, ExpansionFactor, KernelSize, VarianceScalingParameter, ResamplingFilter=None, DataType=torch.float32):
|
| 99 |
+
super(GeneratorStage, self).__init__()
|
| 100 |
+
|
| 101 |
+
TransitionLayer = GenerativeBasis(InputChannels, OutputChannels) if ResamplingFilter is None else UpsampleLayer(InputChannels, OutputChannels, ResamplingFilter)
|
| 102 |
+
self.Layers = nn.ModuleList([TransitionLayer] + [ResidualBlock(OutputChannels, Cardinality, ExpansionFactor, KernelSize, VarianceScalingParameter) for _ in range(NumberOfBlocks)])
|
| 103 |
+
self.DataType = DataType
|
| 104 |
+
|
| 105 |
+
def forward(self, x):
|
| 106 |
+
x = x.to(self.DataType)
|
| 107 |
+
|
| 108 |
+
for Layer in self.Layers:
|
| 109 |
+
x = Layer(x)
|
| 110 |
+
|
| 111 |
+
return x
|
| 112 |
+
|
| 113 |
+
class DiscriminatorStage(nn.Module):
|
| 114 |
+
def __init__(self, InputChannels, OutputChannels, Cardinality, NumberOfBlocks, ExpansionFactor, KernelSize, VarianceScalingParameter, ResamplingFilter=None, DataType=torch.float32):
|
| 115 |
+
super(DiscriminatorStage, self).__init__()
|
| 116 |
+
|
| 117 |
+
TransitionLayer = DiscriminativeBasis(InputChannels, OutputChannels) if ResamplingFilter is None else DownsampleLayer(InputChannels, OutputChannels, ResamplingFilter)
|
| 118 |
+
self.Layers = nn.ModuleList([ResidualBlock(InputChannels, Cardinality, ExpansionFactor, KernelSize, VarianceScalingParameter) for _ in range(NumberOfBlocks)] + [TransitionLayer])
|
| 119 |
+
self.DataType = DataType
|
| 120 |
+
|
| 121 |
+
def forward(self, x):
|
| 122 |
+
x = x.to(self.DataType)
|
| 123 |
+
|
| 124 |
+
for Layer in self.Layers:
|
| 125 |
+
x = Layer(x)
|
| 126 |
+
|
| 127 |
+
return x
|
| 128 |
+
|
| 129 |
+
class Generator(nn.Module):
|
| 130 |
+
def __init__(self, NoiseDimension, WidthPerStage, CardinalityPerStage, BlocksPerStage, ExpansionFactor, ConditionDimension=None, ConditionEmbeddingDimension=0, KernelSize=3, ResamplingFilter=[1, 2, 1]):
|
| 131 |
+
super(Generator, self).__init__()
|
| 132 |
+
|
| 133 |
+
VarianceScalingParameter = sum(BlocksPerStage)
|
| 134 |
+
MainLayers = [GeneratorStage(NoiseDimension + ConditionEmbeddingDimension, WidthPerStage[0], CardinalityPerStage[0], BlocksPerStage[0], ExpansionFactor, KernelSize, VarianceScalingParameter)]
|
| 135 |
+
MainLayers += [GeneratorStage(WidthPerStage[x], WidthPerStage[x + 1], CardinalityPerStage[x + 1], BlocksPerStage[x + 1], ExpansionFactor, KernelSize, VarianceScalingParameter, ResamplingFilter) for x in range(len(WidthPerStage) - 1)]
|
| 136 |
+
|
| 137 |
+
self.MainLayers = nn.ModuleList(MainLayers)
|
| 138 |
+
self.AggregationLayer = Convolution(WidthPerStage[-1], 3, KernelSize=1)
|
| 139 |
+
|
| 140 |
+
if ConditionDimension is not None:
|
| 141 |
+
self.EmbeddingLayer = MSRInitializer(nn.Linear(ConditionDimension, ConditionEmbeddingDimension, bias=False))
|
| 142 |
+
|
| 143 |
+
def forward(self, x, y=None):
|
| 144 |
+
x = torch.cat([x, self.EmbeddingLayer(y)], dim=1) if hasattr(self, 'EmbeddingLayer') else x
|
| 145 |
+
|
| 146 |
+
for Layer in self.MainLayers:
|
| 147 |
+
x = Layer(x)
|
| 148 |
+
|
| 149 |
+
return self.AggregationLayer(x)
|
| 150 |
+
|
| 151 |
+
class Discriminator(nn.Module):
|
| 152 |
+
def __init__(self, WidthPerStage, CardinalityPerStage, BlocksPerStage, ExpansionFactor, ConditionDimension=None, ConditionEmbeddingDimension=0, KernelSize=3, ResamplingFilter=[1, 2, 1]):
|
| 153 |
+
super(Discriminator, self).__init__()
|
| 154 |
+
|
| 155 |
+
VarianceScalingParameter = sum(BlocksPerStage)
|
| 156 |
+
MainLayers = [DiscriminatorStage(WidthPerStage[x], WidthPerStage[x + 1], CardinalityPerStage[x], BlocksPerStage[x], ExpansionFactor, KernelSize, VarianceScalingParameter, ResamplingFilter) for x in range(len(WidthPerStage) - 1)]
|
| 157 |
+
MainLayers += [DiscriminatorStage(WidthPerStage[-1], 1 if ConditionDimension is None else ConditionEmbeddingDimension, CardinalityPerStage[-1], BlocksPerStage[-1], ExpansionFactor, KernelSize, VarianceScalingParameter)]
|
| 158 |
+
|
| 159 |
+
self.ExtractionLayer = Convolution(3, WidthPerStage[0], KernelSize=1)
|
| 160 |
+
self.MainLayers = nn.ModuleList(MainLayers)
|
| 161 |
+
|
| 162 |
+
if ConditionDimension is not None:
|
| 163 |
+
self.EmbeddingLayer = MSRInitializer(nn.Linear(ConditionDimension, ConditionEmbeddingDimension, bias=False), ActivationGain=1 / math.sqrt(ConditionEmbeddingDimension))
|
| 164 |
+
|
| 165 |
+
def forward(self, x, y=None):
|
| 166 |
+
x = self.ExtractionLayer(x.to(self.MainLayers[0].DataType))
|
| 167 |
+
|
| 168 |
+
for Layer in self.MainLayers:
|
| 169 |
+
x = Layer(x)
|
| 170 |
+
|
| 171 |
+
x = (x * self.EmbeddingLayer(y)).sum(dim=1, keepdim=True) if hasattr(self, 'EmbeddingLayer') else x
|
| 172 |
+
|
| 173 |
+
return x.view(x.shape[0])
|
R3GAN/Resamplers.py
ADDED
|
@@ -0,0 +1,104 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import numpy
|
| 4 |
+
from torch_utils.ops import upfirdn2d
|
| 5 |
+
|
| 6 |
+
def CreateLowpassKernel(Weights, Inplace):
|
| 7 |
+
Kernel = numpy.array([Weights]) if Inplace else numpy.convolve(Weights, [1, 1]).reshape(1, -1)
|
| 8 |
+
Kernel = torch.Tensor(Kernel.T @ Kernel)
|
| 9 |
+
return Kernel / torch.sum(Kernel)
|
| 10 |
+
|
| 11 |
+
class InterpolativeUpsamplerReference(nn.Module):
|
| 12 |
+
def __init__(self, Filter):
|
| 13 |
+
super(InterpolativeUpsamplerReference, self).__init__()
|
| 14 |
+
|
| 15 |
+
self.register_buffer('Kernel', CreateLowpassKernel(Filter, Inplace=False))
|
| 16 |
+
self.FilterRadius = len(Filter) // 2
|
| 17 |
+
|
| 18 |
+
def forward(self, x):
|
| 19 |
+
Kernel = 4 * self.Kernel.view(1, 1, self.Kernel.shape[0], self.Kernel.shape[1]).to(x.dtype)
|
| 20 |
+
y = nn.functional.conv_transpose2d(x.view(x.shape[0] * x.shape[1], 1, x.shape[2], x.shape[3]), Kernel, stride=2, padding=self.FilterRadius)
|
| 21 |
+
|
| 22 |
+
return y.view(x.shape[0], x.shape[1], y.shape[2], y.shape[3])
|
| 23 |
+
|
| 24 |
+
class InterpolativeDownsamplerReference(nn.Module):
|
| 25 |
+
def __init__(self, Filter):
|
| 26 |
+
super(InterpolativeDownsamplerReference, self).__init__()
|
| 27 |
+
|
| 28 |
+
self.register_buffer('Kernel', CreateLowpassKernel(Filter, Inplace=False))
|
| 29 |
+
self.FilterRadius = len(Filter) // 2
|
| 30 |
+
|
| 31 |
+
def forward(self, x):
|
| 32 |
+
Kernel = self.Kernel.view(1, 1, self.Kernel.shape[0], self.Kernel.shape[1]).to(x.dtype)
|
| 33 |
+
y = nn.functional.conv2d(x.view(x.shape[0] * x.shape[1], 1, x.shape[2], x.shape[3]), Kernel, stride=2, padding=self.FilterRadius)
|
| 34 |
+
|
| 35 |
+
return y.view(x.shape[0], x.shape[1], y.shape[2], y.shape[3])
|
| 36 |
+
|
| 37 |
+
class InplaceUpsamplerReference(nn.Module):
|
| 38 |
+
def __init__(self, Filter):
|
| 39 |
+
super(InplaceUpsamplerReference, self).__init__()
|
| 40 |
+
|
| 41 |
+
self.register_buffer('Kernel', CreateLowpassKernel(Filter, Inplace=True))
|
| 42 |
+
self.FilterRadius = len(Filter) // 2
|
| 43 |
+
|
| 44 |
+
def forward(self, x):
|
| 45 |
+
Kernel = self.Kernel.view(1, 1, self.Kernel.shape[0], self.Kernel.shape[1]).to(x.dtype)
|
| 46 |
+
x = nn.functional.pixel_shuffle(x, 2)
|
| 47 |
+
|
| 48 |
+
return nn.functional.conv2d(x.view(x.shape[0] * x.shape[1], 1, x.shape[2], x.shape[3]), Kernel, stride=1, padding=self.FilterRadius).view(*x.shape)
|
| 49 |
+
|
| 50 |
+
class InplaceDownsamplerReference(nn.Module):
|
| 51 |
+
def __init__(self, Filter):
|
| 52 |
+
super(InplaceDownsamplerReference, self).__init__()
|
| 53 |
+
|
| 54 |
+
self.register_buffer('Kernel', CreateLowpassKernel(Filter, Inplace=True))
|
| 55 |
+
self.FilterRadius = len(Filter) // 2
|
| 56 |
+
|
| 57 |
+
def forward(self, x):
|
| 58 |
+
Kernel = self.Kernel.view(1, 1, self.Kernel.shape[0], self.Kernel.shape[1]).to(x.dtype)
|
| 59 |
+
y = nn.functional.conv2d(x.view(x.shape[0] * x.shape[1], 1, x.shape[2], x.shape[3]), Kernel, stride=1, padding=self.FilterRadius).view(*x.shape)
|
| 60 |
+
|
| 61 |
+
return nn.functional.pixel_unshuffle(y, 2)
|
| 62 |
+
|
| 63 |
+
class InterpolativeUpsamplerCUDA(nn.Module):
|
| 64 |
+
def __init__(self, Filter):
|
| 65 |
+
super(InterpolativeUpsamplerCUDA, self).__init__()
|
| 66 |
+
|
| 67 |
+
self.register_buffer('Kernel', CreateLowpassKernel(Filter, Inplace=False))
|
| 68 |
+
|
| 69 |
+
def forward(self, x):
|
| 70 |
+
return upfirdn2d.upsample2d(x, self.Kernel)
|
| 71 |
+
|
| 72 |
+
class InterpolativeDownsamplerCUDA(nn.Module):
|
| 73 |
+
def __init__(self, Filter):
|
| 74 |
+
super(InterpolativeDownsamplerCUDA, self).__init__()
|
| 75 |
+
|
| 76 |
+
self.register_buffer('Kernel', CreateLowpassKernel(Filter, Inplace=False))
|
| 77 |
+
|
| 78 |
+
def forward(self, x):
|
| 79 |
+
return upfirdn2d.downsample2d(x, self.Kernel)
|
| 80 |
+
|
| 81 |
+
class InplaceUpsamplerCUDA(nn.Module):
|
| 82 |
+
def __init__(self, Filter):
|
| 83 |
+
super(InplaceUpsamplerCUDA, self).__init__()
|
| 84 |
+
|
| 85 |
+
self.register_buffer('Kernel', CreateLowpassKernel(Filter, Inplace=True))
|
| 86 |
+
self.FilterRadius = len(Filter) // 2
|
| 87 |
+
|
| 88 |
+
def forward(self, x):
|
| 89 |
+
return upfirdn2d.upfirdn2d(nn.functional.pixel_shuffle(x, 2), self.Kernel, padding=self.FilterRadius)
|
| 90 |
+
|
| 91 |
+
class InplaceDownsamplerCUDA(nn.Module):
|
| 92 |
+
def __init__(self, Filter):
|
| 93 |
+
super(InplaceDownsamplerCUDA, self).__init__()
|
| 94 |
+
|
| 95 |
+
self.register_buffer('Kernel', CreateLowpassKernel(Filter, Inplace=True))
|
| 96 |
+
self.FilterRadius = len(Filter) // 2
|
| 97 |
+
|
| 98 |
+
def forward(self, x):
|
| 99 |
+
return nn.functional.pixel_unshuffle(upfirdn2d.upfirdn2d(x, self.Kernel, padding=self.FilterRadius), 2)
|
| 100 |
+
|
| 101 |
+
InterpolativeUpsampler = InterpolativeUpsamplerCUDA
|
| 102 |
+
InterpolativeDownsampler = InterpolativeDownsamplerCUDA
|
| 103 |
+
InplaceUpsampler = InplaceUpsamplerCUDA
|
| 104 |
+
InplaceDownsampler = InplaceDownsamplerCUDA
|
R3GAN/Trainer.py
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
|
| 4 |
+
class AdversarialTraining:
|
| 5 |
+
def __init__(self, Generator, Discriminator):
|
| 6 |
+
self.Generator = Generator
|
| 7 |
+
self.Discriminator = Discriminator
|
| 8 |
+
|
| 9 |
+
@staticmethod
|
| 10 |
+
def ZeroCenteredGradientPenalty(Samples, Critics):
|
| 11 |
+
Gradient, = torch.autograd.grad(outputs=Critics.sum(), inputs=Samples, create_graph=True)
|
| 12 |
+
return Gradient.square().sum([1, 2, 3])
|
| 13 |
+
|
| 14 |
+
def AccumulateGeneratorGradients(self, Noise, RealSamples, Conditions, Scale=1, Preprocessor=lambda x: x):
|
| 15 |
+
FakeSamples = self.Generator(Noise, Conditions)
|
| 16 |
+
RealSamples = RealSamples.detach()
|
| 17 |
+
|
| 18 |
+
FakeLogits = self.Discriminator(Preprocessor(FakeSamples), Conditions)
|
| 19 |
+
RealLogits = self.Discriminator(Preprocessor(RealSamples), Conditions)
|
| 20 |
+
|
| 21 |
+
RelativisticLogits = FakeLogits - RealLogits
|
| 22 |
+
AdversarialLoss = nn.functional.softplus(-RelativisticLogits)
|
| 23 |
+
|
| 24 |
+
(Scale * AdversarialLoss.mean()).backward()
|
| 25 |
+
|
| 26 |
+
return [x.detach() for x in [AdversarialLoss, RelativisticLogits]]
|
| 27 |
+
|
| 28 |
+
def AccumulateDiscriminatorGradients(self, Noise, RealSamples, Conditions, Gamma, Scale=1, Preprocessor=lambda x: x):
|
| 29 |
+
RealSamples = RealSamples.detach().requires_grad_(True)
|
| 30 |
+
FakeSamples = self.Generator(Noise, Conditions).detach().requires_grad_(True)
|
| 31 |
+
|
| 32 |
+
RealLogits = self.Discriminator(Preprocessor(RealSamples), Conditions)
|
| 33 |
+
FakeLogits = self.Discriminator(Preprocessor(FakeSamples), Conditions)
|
| 34 |
+
|
| 35 |
+
R1Penalty = AdversarialTraining.ZeroCenteredGradientPenalty(RealSamples, RealLogits)
|
| 36 |
+
R2Penalty = AdversarialTraining.ZeroCenteredGradientPenalty(FakeSamples, FakeLogits)
|
| 37 |
+
|
| 38 |
+
RelativisticLogits = RealLogits - FakeLogits
|
| 39 |
+
AdversarialLoss = nn.functional.softplus(-RelativisticLogits)
|
| 40 |
+
|
| 41 |
+
DiscriminatorLoss = AdversarialLoss + (Gamma / 2) * (R1Penalty + R2Penalty)
|
| 42 |
+
(Scale * DiscriminatorLoss.mean()).backward()
|
| 43 |
+
|
| 44 |
+
return [x.detach() for x in [AdversarialLoss, RelativisticLogits, R1Penalty, R2Penalty]]
|
README.md
CHANGED
|
@@ -1,14 +1,87 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
| 14 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## The GAN is dead; long live the GAN! A Modern Baseline GAN (R3GAN)<br><sub>Official PyTorch implementation of the NeurIPS 2024 paper</sub>
|
| 2 |
+
|
| 3 |
+

|
| 4 |
+
|
| 5 |
+
**The GAN is dead; long live the GAN! A Modern Baseline GAN**<br>
|
| 6 |
+
Nick Huang, [Aaron Gokaslan](https://skylion007.github.io/), [Volodymyr Kuleshov](https://www.cs.cornell.edu/~kuleshov/), [James Tompkin](https://www.jamestompkin.com)
|
| 7 |
+
<br>https://openreview.net/forum?id=OrtN9hPP7V
|
| 8 |
+
<br>https://arxiv.org/abs/2501.05441
|
| 9 |
+
<br>
|
| 10 |
+
|
| 11 |
+
Abstract: *There is a widely-spread claim that GANs are difficult to train, and GAN architectures in the literature are littered with empirical tricks. We provide evidence against this claim and build a modern GAN baseline in a more principled manner. First, we derive a well-behaved regularized relativistic GAN loss that addresses issues of mode dropping and non-convergence that were previously tackled via a bag of ad-hoc tricks. We analyze our loss mathematically and prove that it admits local convergence guarantees, unlike most existing relativistic losses. Second, this loss allows us to discard all ad-hoc tricks and replace outdated backbones used in common GANs with modern architectures. Using StyleGAN2 as an example, we present a roadmap of simplification and modernization that results in a new minimalist baseline. Despite being simple, our approach surpasses StyleGAN2 on FFHQ, ImageNet, CIFAR, and Stacked MNIST datasets, and compares favorably against state-of-the-art GANs and diffusion models.*
|
| 12 |
+
|
| 13 |
+
## Requirements
|
| 14 |
+
|
| 15 |
+
Our code requires the same packages as the official StyleGAN3 repo. However, we have updated the code so it is compatible with the latest version of the required packages (including PyTorch, etc).
|
| 16 |
+
|
| 17 |
+
## Getting started
|
| 18 |
+
To generate images using a given model, run:
|
| 19 |
+
|
| 20 |
+
```
|
| 21 |
+
# Generate 8 images using pre-trained FFHQ 256x256 model
|
| 22 |
+
gen_images.py --seeds=0-7 --outdir=out --network=ffhq-256x256.pkl
|
| 23 |
+
|
| 24 |
+
# Generate 64 airplane images using pre-trained CIFAR10 model
|
| 25 |
+
gen_images.py --seeds=0-63 --outdir=out --class=0 --network=cifar10.pkl
|
| 26 |
+
```
|
| 27 |
+
|
| 28 |
+
To reproduce the main results from our paper, run the following commands:
|
| 29 |
+
|
| 30 |
+
```
|
| 31 |
+
# CIFAR10
|
| 32 |
+
python train.py --outdir=./training-runs --data=./datasets/cifar10.zip --gpus=8 --batch=512 --mirror=1 --aug=1 --cond=1 --preset=CIFAR10 --tick=1 --snap=200
|
| 33 |
+
|
| 34 |
+
# FFHQ 64x64
|
| 35 |
+
python train.py --outdir=./training-runs --data=./datasets/ffhq-64x64.zip --gpus=8 --batch=256 --mirror=1 --aug=1 --preset=FFHQ-64 --tick=1 --snap=200
|
| 36 |
+
|
| 37 |
+
# FFHQ 256x256
|
| 38 |
+
python train.py --outdir=./training-runs --data=./datasets/ffhq-256x256.zip --gpus=8 --batch=256 --mirror=1 --aug=1 --preset=FFHQ-256 --tick=1 --snap=200
|
| 39 |
+
|
| 40 |
+
# ImageNet 32x32
|
| 41 |
+
python train.py --outdir=./training-runs --data=./datasets/imagenet-32x32.zip --gpus=32 --batch=4096 --mirror=1 --aug=1 --cond=1 --preset=ImageNet-32 --tick=1 --snap=200
|
| 42 |
+
|
| 43 |
+
# Imagenet 64x64
|
| 44 |
+
python train.py --outdir=./training-runs --data=./datasets/imagenet-64x64.zip --gpus=64 --batch=4096 --mirror=1 --aug=1 --cond=1 --preset=ImageNet-64 --tick=1 --snap=200
|
| 45 |
+
```
|
| 46 |
+
|
| 47 |
+
The easiest way to explore different training settings is to modify [`train.py`](./train.py) directly.
|
| 48 |
+
|
| 49 |
+
## Pre-trained models
|
| 50 |
+
|
| 51 |
+
We provide pre-trained models for our proposed training configuration (config E) on each dataset:
|
| 52 |
+
|
| 53 |
+
- [https://huggingface.co/brownvc/BaselineGAN-CIFAR10/tree/main](https://huggingface.co/brownvc/BaselineGAN-CIFAR10/tree/main)
|
| 54 |
+
- [https://huggingface.co/brownvc/BaselineGAN-FFHQ-64x64/tree/main](https://huggingface.co/brownvc/BaselineGAN-FFHQ-64x64/tree/main)
|
| 55 |
+
- [https://huggingface.co/brownvc/BaselineGAN-FFHQ-256x256/tree/main](https://huggingface.co/brownvc/BaselineGAN-FFHQ-256x256/tree/main)
|
| 56 |
+
- [https://huggingface.co/brownvc/BaselineGAN-ImgNet-64x64-v0/tree/main](https://huggingface.co/brownvc/BaselineGAN-ImgNet-64x64-v0/tree/main)
|
| 57 |
+
- [https://huggingface.co/brownvc/BaselineGAN-ImgNet-32x32/tree/main](https://huggingface.co/brownvc/BaselineGAN-ImgNet-32x32/tree/main)
|
| 58 |
+
|
| 59 |
+
## Preparing datasets
|
| 60 |
+
We use the same dataset format and dataset preprocessing tool as StyleGAN3 and EDM, refer to their repos for more details.
|
| 61 |
+
|
| 62 |
+
## Quality metrics
|
| 63 |
+
We support the following metrics:
|
| 64 |
+
|
| 65 |
+
* `fid50k_full`: Fréchet inception distance against the full dataset.
|
| 66 |
+
* `kid50k_full`: Kernel inception distance against the full dataset.
|
| 67 |
+
* `pr50k3_full`: Precision and recall againt the full dataset.
|
| 68 |
+
* `is50k`: Inception score for CIFAR-10.
|
| 69 |
+
|
| 70 |
+
Refer to the StyleGAN3 code base for more details.
|
| 71 |
+
|
| 72 |
+
## Citation
|
| 73 |
+
|
| 74 |
+
```
|
| 75 |
+
@inproceedings{
|
| 76 |
+
huang2024the,
|
| 77 |
+
title={The {GAN} is dead; long live the {GAN}! A Modern {GAN} Baseline},
|
| 78 |
+
author={Nick Huang and Aaron Gokaslan and Volodymyr Kuleshov and James Tompkin},
|
| 79 |
+
booktitle={The Thirty-eighth Annual Conference on Neural Information Processing Systems},
|
| 80 |
+
year={2024},
|
| 81 |
+
url={https://openreview.net/forum?id=OrtN9hPP7V}
|
| 82 |
+
}
|
| 83 |
+
```
|
| 84 |
+
|
| 85 |
+
## Acknowledgements
|
| 86 |
+
|
| 87 |
+
The authors thank Xinjie Jayden Yi for contributing to the proof and Yu Cheng for helpful discussion. For compute, the authors thank Databricks Mosaic Research. Nick Huang was supported by a Brown University Division of Research Seed Award, and James Tompkin was supported by NSF CAREER 2144956. Volodymyr Kuleshov was supported by NSF CAREER 2145577 and NIH MIRA 1R35GM15124301.
|
calc_metrics.py
ADDED
|
@@ -0,0 +1,184 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
"""Calculate quality metrics for previous training run or pretrained network pickle."""
|
| 10 |
+
|
| 11 |
+
import os
|
| 12 |
+
import click
|
| 13 |
+
import json
|
| 14 |
+
import tempfile
|
| 15 |
+
import copy
|
| 16 |
+
import torch
|
| 17 |
+
|
| 18 |
+
import dnnlib
|
| 19 |
+
import legacy
|
| 20 |
+
from metrics import metric_main
|
| 21 |
+
from metrics import metric_utils
|
| 22 |
+
from torch_utils import training_stats
|
| 23 |
+
from torch_utils import custom_ops
|
| 24 |
+
from torch_utils import misc
|
| 25 |
+
from torch_utils.ops import conv2d_gradfix
|
| 26 |
+
|
| 27 |
+
#----------------------------------------------------------------------------
|
| 28 |
+
|
| 29 |
+
def subprocess_fn(rank, args, temp_dir):
|
| 30 |
+
dnnlib.util.Logger(should_flush=True)
|
| 31 |
+
|
| 32 |
+
# Init torch.distributed.
|
| 33 |
+
if args.num_gpus > 1:
|
| 34 |
+
init_file = os.path.abspath(os.path.join(temp_dir, '.torch_distributed_init'))
|
| 35 |
+
if os.name == 'nt':
|
| 36 |
+
init_method = 'file:///' + init_file.replace('\\', '/')
|
| 37 |
+
torch.distributed.init_process_group(backend='gloo', init_method=init_method, rank=rank, world_size=args.num_gpus)
|
| 38 |
+
else:
|
| 39 |
+
init_method = f'file://{init_file}'
|
| 40 |
+
torch.distributed.init_process_group(backend='nccl', init_method=init_method, rank=rank, world_size=args.num_gpus)
|
| 41 |
+
|
| 42 |
+
# Init torch_utils.
|
| 43 |
+
sync_device = torch.device('cuda', rank) if args.num_gpus > 1 else None
|
| 44 |
+
training_stats.init_multiprocessing(rank=rank, sync_device=sync_device)
|
| 45 |
+
if rank != 0 or not args.verbose:
|
| 46 |
+
custom_ops.verbosity = 'none'
|
| 47 |
+
|
| 48 |
+
# Configure torch.
|
| 49 |
+
device = torch.device('cuda', rank)
|
| 50 |
+
torch.backends.cuda.matmul.allow_tf32 = False
|
| 51 |
+
torch.backends.cudnn.allow_tf32 = False
|
| 52 |
+
conv2d_gradfix.enabled = True
|
| 53 |
+
|
| 54 |
+
# Print network summary.
|
| 55 |
+
G = copy.deepcopy(args.G).eval().requires_grad_(False).to(device)
|
| 56 |
+
if rank == 0 and args.verbose:
|
| 57 |
+
z = torch.empty([1, G.z_dim], device=device)
|
| 58 |
+
c = torch.empty([1, G.c_dim], device=device)
|
| 59 |
+
misc.print_module_summary(G, [z, c])
|
| 60 |
+
|
| 61 |
+
# Calculate each metric.
|
| 62 |
+
for metric in args.metrics:
|
| 63 |
+
if rank == 0 and args.verbose:
|
| 64 |
+
print(f'Calculating {metric}...')
|
| 65 |
+
progress = metric_utils.ProgressMonitor(verbose=args.verbose)
|
| 66 |
+
result_dict = metric_main.calc_metric(metric=metric, G=G, dataset_kwargs=args.dataset_kwargs,
|
| 67 |
+
num_gpus=args.num_gpus, rank=rank, device=device, progress=progress)
|
| 68 |
+
if rank == 0:
|
| 69 |
+
metric_main.report_metric(result_dict, run_dir=args.run_dir, snapshot_pkl=args.network_pkl)
|
| 70 |
+
if rank == 0 and args.verbose:
|
| 71 |
+
print()
|
| 72 |
+
|
| 73 |
+
# Done.
|
| 74 |
+
if rank == 0 and args.verbose:
|
| 75 |
+
print('Exiting...')
|
| 76 |
+
|
| 77 |
+
#----------------------------------------------------------------------------
|
| 78 |
+
|
| 79 |
+
def parse_comma_separated_list(s):
|
| 80 |
+
if isinstance(s, list):
|
| 81 |
+
return s
|
| 82 |
+
if s is None or s.lower() == 'none' or s == '':
|
| 83 |
+
return []
|
| 84 |
+
return s.split(',')
|
| 85 |
+
|
| 86 |
+
#----------------------------------------------------------------------------
|
| 87 |
+
|
| 88 |
+
@click.command()
|
| 89 |
+
@click.pass_context
|
| 90 |
+
@click.option('network_pkl', '--network', help='Network pickle filename or URL', metavar='PATH', required=True)
|
| 91 |
+
@click.option('--metrics', help='Quality metrics', metavar='[NAME|A,B,C|none]', type=parse_comma_separated_list, default='fid50k_full', show_default=True)
|
| 92 |
+
@click.option('--data', help='Dataset to evaluate against [default: look up]', metavar='[ZIP|DIR]')
|
| 93 |
+
@click.option('--mirror', help='Enable dataset x-flips [default: look up]', type=bool, metavar='BOOL')
|
| 94 |
+
@click.option('--gpus', help='Number of GPUs to use', type=int, default=1, metavar='INT', show_default=True)
|
| 95 |
+
@click.option('--verbose', help='Print optional information', type=bool, default=True, metavar='BOOL', show_default=True)
|
| 96 |
+
|
| 97 |
+
def calc_metrics(ctx, network_pkl, metrics, data, mirror, gpus, verbose):
|
| 98 |
+
"""Calculate quality metrics for previous training run or pretrained network pickle.
|
| 99 |
+
|
| 100 |
+
Examples:
|
| 101 |
+
|
| 102 |
+
\b
|
| 103 |
+
# Previous training run: look up options automatically, save result to JSONL file.
|
| 104 |
+
python calc_metrics.py --metrics=eqt50k_int,eqr50k \\
|
| 105 |
+
--network=~/training-runs/00000-stylegan3-r-mydataset/network-snapshot-000000.pkl
|
| 106 |
+
|
| 107 |
+
\b
|
| 108 |
+
# Pre-trained network pickle: specify dataset explicitly, print result to stdout.
|
| 109 |
+
python calc_metrics.py --metrics=fid50k_full --data=~/datasets/ffhq-1024x1024.zip --mirror=1 \\
|
| 110 |
+
--network=https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/stylegan3-t-ffhq-1024x1024.pkl
|
| 111 |
+
|
| 112 |
+
\b
|
| 113 |
+
Recommended metrics:
|
| 114 |
+
fid50k_full Frechet inception distance against the full dataset.
|
| 115 |
+
kid50k_full Kernel inception distance against the full dataset.
|
| 116 |
+
pr50k3_full Precision and recall againt the full dataset.
|
| 117 |
+
|
| 118 |
+
\b
|
| 119 |
+
Legacy metrics:
|
| 120 |
+
fid50k Frechet inception distance against 50k real images.
|
| 121 |
+
kid50k Kernel inception distance against 50k real images.
|
| 122 |
+
pr50k3 Precision and recall against 50k real images.
|
| 123 |
+
is50k Inception score for CIFAR-10.
|
| 124 |
+
"""
|
| 125 |
+
dnnlib.util.Logger(should_flush=True)
|
| 126 |
+
|
| 127 |
+
# Validate arguments.
|
| 128 |
+
args = dnnlib.EasyDict(metrics=metrics, num_gpus=gpus, network_pkl=network_pkl, verbose=verbose)
|
| 129 |
+
if not all(metric_main.is_valid_metric(metric) for metric in args.metrics):
|
| 130 |
+
ctx.fail('\n'.join(['--metrics can only contain the following values:'] + metric_main.list_valid_metrics()))
|
| 131 |
+
if not args.num_gpus >= 1:
|
| 132 |
+
ctx.fail('--gpus must be at least 1')
|
| 133 |
+
|
| 134 |
+
# Load network.
|
| 135 |
+
if not dnnlib.util.is_url(network_pkl, allow_file_urls=True) and not os.path.isfile(network_pkl):
|
| 136 |
+
ctx.fail('--network must point to a file or URL')
|
| 137 |
+
if args.verbose:
|
| 138 |
+
print(f'Loading network from "{network_pkl}"...')
|
| 139 |
+
with dnnlib.util.open_url(network_pkl, verbose=args.verbose) as f:
|
| 140 |
+
network_dict = legacy.load_network_pkl(f)
|
| 141 |
+
args.G = network_dict['G_ema'] # subclass of torch.nn.Module
|
| 142 |
+
|
| 143 |
+
# Initialize dataset options.
|
| 144 |
+
if data is not None:
|
| 145 |
+
args.dataset_kwargs = dnnlib.EasyDict(class_name='training.dataset.ImageFolderDataset', path=data)
|
| 146 |
+
elif network_dict['training_set_kwargs'] is not None:
|
| 147 |
+
args.dataset_kwargs = dnnlib.EasyDict(network_dict['training_set_kwargs'])
|
| 148 |
+
else:
|
| 149 |
+
ctx.fail('Could not look up dataset options; please specify --data')
|
| 150 |
+
|
| 151 |
+
# Finalize dataset options.
|
| 152 |
+
args.dataset_kwargs.resolution = args.G.img_resolution
|
| 153 |
+
args.dataset_kwargs.use_labels = (args.G.c_dim != 0)
|
| 154 |
+
if mirror is not None:
|
| 155 |
+
args.dataset_kwargs.xflip = mirror
|
| 156 |
+
|
| 157 |
+
# Print dataset options.
|
| 158 |
+
if args.verbose:
|
| 159 |
+
print('Dataset options:')
|
| 160 |
+
print(json.dumps(args.dataset_kwargs, indent=2))
|
| 161 |
+
|
| 162 |
+
# Locate run dir.
|
| 163 |
+
args.run_dir = None
|
| 164 |
+
if os.path.isfile(network_pkl):
|
| 165 |
+
pkl_dir = os.path.dirname(network_pkl)
|
| 166 |
+
if os.path.isfile(os.path.join(pkl_dir, 'training_options.json')):
|
| 167 |
+
args.run_dir = pkl_dir
|
| 168 |
+
|
| 169 |
+
# Launch processes.
|
| 170 |
+
if args.verbose:
|
| 171 |
+
print('Launching processes...')
|
| 172 |
+
torch.multiprocessing.set_start_method('spawn')
|
| 173 |
+
with tempfile.TemporaryDirectory() as temp_dir:
|
| 174 |
+
if args.num_gpus == 1:
|
| 175 |
+
subprocess_fn(rank=0, args=args, temp_dir=temp_dir)
|
| 176 |
+
else:
|
| 177 |
+
torch.multiprocessing.spawn(fn=subprocess_fn, args=(args, temp_dir), nprocs=args.num_gpus)
|
| 178 |
+
|
| 179 |
+
#----------------------------------------------------------------------------
|
| 180 |
+
|
| 181 |
+
if __name__ == "__main__":
|
| 182 |
+
calc_metrics() # pylint: disable=no-value-for-parameter
|
| 183 |
+
|
| 184 |
+
#----------------------------------------------------------------------------
|
dataset_tool.py
ADDED
|
@@ -0,0 +1,456 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
"""Tool for creating ZIP/PNG based datasets."""
|
| 10 |
+
|
| 11 |
+
import functools
|
| 12 |
+
import gzip
|
| 13 |
+
import io
|
| 14 |
+
import json
|
| 15 |
+
import os
|
| 16 |
+
import pickle
|
| 17 |
+
import re
|
| 18 |
+
import sys
|
| 19 |
+
import tarfile
|
| 20 |
+
import zipfile
|
| 21 |
+
from pathlib import Path
|
| 22 |
+
from typing import Callable, Optional, Tuple, Union
|
| 23 |
+
|
| 24 |
+
import click
|
| 25 |
+
import numpy as np
|
| 26 |
+
import PIL.Image
|
| 27 |
+
from tqdm import tqdm
|
| 28 |
+
|
| 29 |
+
#----------------------------------------------------------------------------
|
| 30 |
+
|
| 31 |
+
def error(msg):
|
| 32 |
+
print('Error: ' + msg)
|
| 33 |
+
sys.exit(1)
|
| 34 |
+
|
| 35 |
+
#----------------------------------------------------------------------------
|
| 36 |
+
|
| 37 |
+
def parse_tuple(s: str) -> Tuple[int, int]:
|
| 38 |
+
'''Parse a 'M,N' or 'MxN' integer tuple.
|
| 39 |
+
|
| 40 |
+
Example:
|
| 41 |
+
'4x2' returns (4,2)
|
| 42 |
+
'0,1' returns (0,1)
|
| 43 |
+
'''
|
| 44 |
+
m = re.match(r'^(\d+)[x,](\d+)$', s)
|
| 45 |
+
if m:
|
| 46 |
+
return (int(m.group(1)), int(m.group(2)))
|
| 47 |
+
raise ValueError(f'cannot parse tuple {s}')
|
| 48 |
+
|
| 49 |
+
#----------------------------------------------------------------------------
|
| 50 |
+
|
| 51 |
+
def maybe_min(a: int, b: Optional[int]) -> int:
|
| 52 |
+
if b is not None:
|
| 53 |
+
return min(a, b)
|
| 54 |
+
return a
|
| 55 |
+
|
| 56 |
+
#----------------------------------------------------------------------------
|
| 57 |
+
|
| 58 |
+
def file_ext(name: Union[str, Path]) -> str:
|
| 59 |
+
return str(name).split('.')[-1]
|
| 60 |
+
|
| 61 |
+
#----------------------------------------------------------------------------
|
| 62 |
+
|
| 63 |
+
def is_image_ext(fname: Union[str, Path]) -> bool:
|
| 64 |
+
ext = file_ext(fname).lower()
|
| 65 |
+
return f'.{ext}' in PIL.Image.EXTENSION # type: ignore
|
| 66 |
+
|
| 67 |
+
#----------------------------------------------------------------------------
|
| 68 |
+
|
| 69 |
+
def open_image_folder(source_dir, *, max_images: Optional[int]):
|
| 70 |
+
input_images = [str(f) for f in sorted(Path(source_dir).rglob('*')) if is_image_ext(f) and os.path.isfile(f)]
|
| 71 |
+
|
| 72 |
+
# Load labels.
|
| 73 |
+
labels = {}
|
| 74 |
+
meta_fname = os.path.join(source_dir, 'dataset.json')
|
| 75 |
+
if os.path.isfile(meta_fname):
|
| 76 |
+
with open(meta_fname, 'r') as file:
|
| 77 |
+
labels = json.load(file)['labels']
|
| 78 |
+
if labels is not None:
|
| 79 |
+
labels = { x[0]: x[1] for x in labels }
|
| 80 |
+
else:
|
| 81 |
+
labels = {}
|
| 82 |
+
|
| 83 |
+
max_idx = maybe_min(len(input_images), max_images)
|
| 84 |
+
|
| 85 |
+
def iterate_images():
|
| 86 |
+
for idx, fname in enumerate(input_images):
|
| 87 |
+
arch_fname = os.path.relpath(fname, source_dir)
|
| 88 |
+
arch_fname = arch_fname.replace('\\', '/')
|
| 89 |
+
img = np.array(PIL.Image.open(fname))
|
| 90 |
+
yield dict(img=img, label=labels.get(arch_fname))
|
| 91 |
+
if idx >= max_idx-1:
|
| 92 |
+
break
|
| 93 |
+
return max_idx, iterate_images()
|
| 94 |
+
|
| 95 |
+
#----------------------------------------------------------------------------
|
| 96 |
+
|
| 97 |
+
def open_image_zip(source, *, max_images: Optional[int]):
|
| 98 |
+
with zipfile.ZipFile(source, mode='r') as z:
|
| 99 |
+
input_images = [str(f) for f in sorted(z.namelist()) if is_image_ext(f)]
|
| 100 |
+
|
| 101 |
+
# Load labels.
|
| 102 |
+
labels = {}
|
| 103 |
+
if 'dataset.json' in z.namelist():
|
| 104 |
+
with z.open('dataset.json', 'r') as file:
|
| 105 |
+
labels = json.load(file)['labels']
|
| 106 |
+
if labels is not None:
|
| 107 |
+
labels = { x[0]: x[1] for x in labels }
|
| 108 |
+
else:
|
| 109 |
+
labels = {}
|
| 110 |
+
|
| 111 |
+
max_idx = maybe_min(len(input_images), max_images)
|
| 112 |
+
|
| 113 |
+
def iterate_images():
|
| 114 |
+
with zipfile.ZipFile(source, mode='r') as z:
|
| 115 |
+
for idx, fname in enumerate(input_images):
|
| 116 |
+
with z.open(fname, 'r') as file:
|
| 117 |
+
img = PIL.Image.open(file) # type: ignore
|
| 118 |
+
img = np.array(img)
|
| 119 |
+
yield dict(img=img, label=labels.get(fname))
|
| 120 |
+
if idx >= max_idx-1:
|
| 121 |
+
break
|
| 122 |
+
return max_idx, iterate_images()
|
| 123 |
+
|
| 124 |
+
#----------------------------------------------------------------------------
|
| 125 |
+
|
| 126 |
+
def open_lmdb(lmdb_dir: str, *, max_images: Optional[int]):
|
| 127 |
+
import cv2 # pip install opencv-python # pylint: disable=import-error
|
| 128 |
+
import lmdb # pip install lmdb # pylint: disable=import-error
|
| 129 |
+
|
| 130 |
+
with lmdb.open(lmdb_dir, readonly=True, lock=False).begin(write=False) as txn:
|
| 131 |
+
max_idx = maybe_min(txn.stat()['entries'], max_images)
|
| 132 |
+
|
| 133 |
+
def iterate_images():
|
| 134 |
+
with lmdb.open(lmdb_dir, readonly=True, lock=False).begin(write=False) as txn:
|
| 135 |
+
for idx, (_key, value) in enumerate(txn.cursor()):
|
| 136 |
+
try:
|
| 137 |
+
try:
|
| 138 |
+
img = cv2.imdecode(np.frombuffer(value, dtype=np.uint8), 1)
|
| 139 |
+
if img is None:
|
| 140 |
+
raise IOError('cv2.imdecode failed')
|
| 141 |
+
img = img[:, :, ::-1] # BGR => RGB
|
| 142 |
+
except IOError:
|
| 143 |
+
img = np.array(PIL.Image.open(io.BytesIO(value)))
|
| 144 |
+
yield dict(img=img, label=None)
|
| 145 |
+
if idx >= max_idx-1:
|
| 146 |
+
break
|
| 147 |
+
except:
|
| 148 |
+
print(sys.exc_info()[1])
|
| 149 |
+
|
| 150 |
+
return max_idx, iterate_images()
|
| 151 |
+
|
| 152 |
+
#----------------------------------------------------------------------------
|
| 153 |
+
|
| 154 |
+
def open_cifar10(tarball: str, *, max_images: Optional[int]):
|
| 155 |
+
images = []
|
| 156 |
+
labels = []
|
| 157 |
+
|
| 158 |
+
with tarfile.open(tarball, 'r:gz') as tar:
|
| 159 |
+
for batch in range(1, 6):
|
| 160 |
+
member = tar.getmember(f'cifar-10-batches-py/data_batch_{batch}')
|
| 161 |
+
with tar.extractfile(member) as file:
|
| 162 |
+
data = pickle.load(file, encoding='latin1')
|
| 163 |
+
images.append(data['data'].reshape(-1, 3, 32, 32))
|
| 164 |
+
labels.append(data['labels'])
|
| 165 |
+
|
| 166 |
+
images = np.concatenate(images)
|
| 167 |
+
labels = np.concatenate(labels)
|
| 168 |
+
images = images.transpose([0, 2, 3, 1]) # NCHW -> NHWC
|
| 169 |
+
assert images.shape == (50000, 32, 32, 3) and images.dtype == np.uint8
|
| 170 |
+
assert labels.shape == (50000,) and labels.dtype in [np.int32, np.int64]
|
| 171 |
+
assert np.min(images) == 0 and np.max(images) == 255
|
| 172 |
+
assert np.min(labels) == 0 and np.max(labels) == 9
|
| 173 |
+
|
| 174 |
+
max_idx = maybe_min(len(images), max_images)
|
| 175 |
+
|
| 176 |
+
def iterate_images():
|
| 177 |
+
for idx, img in enumerate(images):
|
| 178 |
+
yield dict(img=img, label=int(labels[idx]))
|
| 179 |
+
if idx >= max_idx-1:
|
| 180 |
+
break
|
| 181 |
+
|
| 182 |
+
return max_idx, iterate_images()
|
| 183 |
+
|
| 184 |
+
#----------------------------------------------------------------------------
|
| 185 |
+
|
| 186 |
+
def open_mnist(images_gz: str, *, max_images: Optional[int]):
|
| 187 |
+
labels_gz = images_gz.replace('-images-idx3-ubyte.gz', '-labels-idx1-ubyte.gz')
|
| 188 |
+
assert labels_gz != images_gz
|
| 189 |
+
images = []
|
| 190 |
+
labels = []
|
| 191 |
+
|
| 192 |
+
with gzip.open(images_gz, 'rb') as f:
|
| 193 |
+
images = np.frombuffer(f.read(), np.uint8, offset=16)
|
| 194 |
+
with gzip.open(labels_gz, 'rb') as f:
|
| 195 |
+
labels = np.frombuffer(f.read(), np.uint8, offset=8)
|
| 196 |
+
|
| 197 |
+
images = images.reshape(-1, 28, 28)
|
| 198 |
+
images = np.pad(images, [(0,0), (2,2), (2,2)], 'constant', constant_values=0)
|
| 199 |
+
assert images.shape == (60000, 32, 32) and images.dtype == np.uint8
|
| 200 |
+
assert labels.shape == (60000,) and labels.dtype == np.uint8
|
| 201 |
+
assert np.min(images) == 0 and np.max(images) == 255
|
| 202 |
+
assert np.min(labels) == 0 and np.max(labels) == 9
|
| 203 |
+
|
| 204 |
+
max_idx = maybe_min(len(images), max_images)
|
| 205 |
+
|
| 206 |
+
def iterate_images():
|
| 207 |
+
for idx, img in enumerate(images):
|
| 208 |
+
yield dict(img=img, label=int(labels[idx]))
|
| 209 |
+
if idx >= max_idx-1:
|
| 210 |
+
break
|
| 211 |
+
|
| 212 |
+
return max_idx, iterate_images()
|
| 213 |
+
|
| 214 |
+
#----------------------------------------------------------------------------
|
| 215 |
+
|
| 216 |
+
def make_transform(
|
| 217 |
+
transform: Optional[str],
|
| 218 |
+
output_width: Optional[int],
|
| 219 |
+
output_height: Optional[int]
|
| 220 |
+
) -> Callable[[np.ndarray], Optional[np.ndarray]]:
|
| 221 |
+
def scale(width, height, img):
|
| 222 |
+
w = img.shape[1]
|
| 223 |
+
h = img.shape[0]
|
| 224 |
+
if width == w and height == h:
|
| 225 |
+
return img
|
| 226 |
+
img = PIL.Image.fromarray(img)
|
| 227 |
+
ww = width if width is not None else w
|
| 228 |
+
hh = height if height is not None else h
|
| 229 |
+
img = img.resize((ww, hh), PIL.Image.LANCZOS)
|
| 230 |
+
return np.array(img)
|
| 231 |
+
|
| 232 |
+
def center_crop(width, height, img):
|
| 233 |
+
crop = np.min(img.shape[:2])
|
| 234 |
+
img = img[(img.shape[0] - crop) // 2 : (img.shape[0] + crop) // 2, (img.shape[1] - crop) // 2 : (img.shape[1] + crop) // 2]
|
| 235 |
+
img = PIL.Image.fromarray(img, 'RGB')
|
| 236 |
+
img = img.resize((width, height), PIL.Image.LANCZOS)
|
| 237 |
+
return np.array(img)
|
| 238 |
+
|
| 239 |
+
def center_crop_wide(width, height, img):
|
| 240 |
+
ch = int(np.round(width * img.shape[0] / img.shape[1]))
|
| 241 |
+
if img.shape[1] < width or ch < height:
|
| 242 |
+
return None
|
| 243 |
+
|
| 244 |
+
img = img[(img.shape[0] - ch) // 2 : (img.shape[0] + ch) // 2]
|
| 245 |
+
img = PIL.Image.fromarray(img, 'RGB')
|
| 246 |
+
img = img.resize((width, height), PIL.Image.LANCZOS)
|
| 247 |
+
img = np.array(img)
|
| 248 |
+
|
| 249 |
+
canvas = np.zeros([width, width, 3], dtype=np.uint8)
|
| 250 |
+
canvas[(width - height) // 2 : (width + height) // 2, :] = img
|
| 251 |
+
return canvas
|
| 252 |
+
|
| 253 |
+
if transform is None:
|
| 254 |
+
return functools.partial(scale, output_width, output_height)
|
| 255 |
+
if transform == 'center-crop':
|
| 256 |
+
if (output_width is None) or (output_height is None):
|
| 257 |
+
error ('must specify --resolution=WxH when using ' + transform + 'transform')
|
| 258 |
+
return functools.partial(center_crop, output_width, output_height)
|
| 259 |
+
if transform == 'center-crop-wide':
|
| 260 |
+
if (output_width is None) or (output_height is None):
|
| 261 |
+
error ('must specify --resolution=WxH when using ' + transform + ' transform')
|
| 262 |
+
return functools.partial(center_crop_wide, output_width, output_height)
|
| 263 |
+
assert False, 'unknown transform'
|
| 264 |
+
|
| 265 |
+
#----------------------------------------------------------------------------
|
| 266 |
+
|
| 267 |
+
def open_dataset(source, *, max_images: Optional[int]):
|
| 268 |
+
if os.path.isdir(source):
|
| 269 |
+
if source.rstrip('/').endswith('_lmdb'):
|
| 270 |
+
return open_lmdb(source, max_images=max_images)
|
| 271 |
+
else:
|
| 272 |
+
return open_image_folder(source, max_images=max_images)
|
| 273 |
+
elif os.path.isfile(source):
|
| 274 |
+
if os.path.basename(source) == 'cifar-10-python.tar.gz':
|
| 275 |
+
return open_cifar10(source, max_images=max_images)
|
| 276 |
+
elif os.path.basename(source) == 'train-images-idx3-ubyte.gz':
|
| 277 |
+
return open_mnist(source, max_images=max_images)
|
| 278 |
+
elif file_ext(source) == 'zip':
|
| 279 |
+
return open_image_zip(source, max_images=max_images)
|
| 280 |
+
else:
|
| 281 |
+
assert False, 'unknown archive type'
|
| 282 |
+
else:
|
| 283 |
+
error(f'Missing input file or directory: {source}')
|
| 284 |
+
|
| 285 |
+
#----------------------------------------------------------------------------
|
| 286 |
+
|
| 287 |
+
def open_dest(dest: str) -> Tuple[str, Callable[[str, Union[bytes, str]], None], Callable[[], None]]:
|
| 288 |
+
dest_ext = file_ext(dest)
|
| 289 |
+
|
| 290 |
+
if dest_ext == 'zip':
|
| 291 |
+
if os.path.dirname(dest) != '':
|
| 292 |
+
os.makedirs(os.path.dirname(dest), exist_ok=True)
|
| 293 |
+
zf = zipfile.ZipFile(file=dest, mode='w', compression=zipfile.ZIP_STORED)
|
| 294 |
+
def zip_write_bytes(fname: str, data: Union[bytes, str]):
|
| 295 |
+
zf.writestr(fname, data)
|
| 296 |
+
return '', zip_write_bytes, zf.close
|
| 297 |
+
else:
|
| 298 |
+
# If the output folder already exists, check that is is
|
| 299 |
+
# empty.
|
| 300 |
+
#
|
| 301 |
+
# Note: creating the output directory is not strictly
|
| 302 |
+
# necessary as folder_write_bytes() also mkdirs, but it's better
|
| 303 |
+
# to give an error message earlier in case the dest folder
|
| 304 |
+
# somehow cannot be created.
|
| 305 |
+
if os.path.isdir(dest) and len(os.listdir(dest)) != 0:
|
| 306 |
+
error('--dest folder must be empty')
|
| 307 |
+
os.makedirs(dest, exist_ok=True)
|
| 308 |
+
|
| 309 |
+
def folder_write_bytes(fname: str, data: Union[bytes, str]):
|
| 310 |
+
os.makedirs(os.path.dirname(fname), exist_ok=True)
|
| 311 |
+
with open(fname, 'wb') as fout:
|
| 312 |
+
if isinstance(data, str):
|
| 313 |
+
data = data.encode('utf8')
|
| 314 |
+
fout.write(data)
|
| 315 |
+
return dest, folder_write_bytes, lambda: None
|
| 316 |
+
|
| 317 |
+
#----------------------------------------------------------------------------
|
| 318 |
+
|
| 319 |
+
@click.command()
|
| 320 |
+
@click.pass_context
|
| 321 |
+
@click.option('--source', help='Directory or archive name for input dataset', required=True, metavar='PATH')
|
| 322 |
+
@click.option('--dest', help='Output directory or archive name for output dataset', required=True, metavar='PATH')
|
| 323 |
+
@click.option('--max-images', help='Output only up to `max-images` images', type=int, default=None)
|
| 324 |
+
@click.option('--transform', help='Input crop/resize mode', type=click.Choice(['center-crop', 'center-crop-wide']))
|
| 325 |
+
@click.option('--resolution', help='Output resolution (e.g., \'512x512\')', metavar='WxH', type=parse_tuple)
|
| 326 |
+
def convert_dataset(
|
| 327 |
+
ctx: click.Context,
|
| 328 |
+
source: str,
|
| 329 |
+
dest: str,
|
| 330 |
+
max_images: Optional[int],
|
| 331 |
+
transform: Optional[str],
|
| 332 |
+
resolution: Optional[Tuple[int, int]]
|
| 333 |
+
):
|
| 334 |
+
"""Convert an image dataset into a dataset archive usable with StyleGAN2 ADA PyTorch.
|
| 335 |
+
|
| 336 |
+
The input dataset format is guessed from the --source argument:
|
| 337 |
+
|
| 338 |
+
\b
|
| 339 |
+
--source *_lmdb/ Load LSUN dataset
|
| 340 |
+
--source cifar-10-python.tar.gz Load CIFAR-10 dataset
|
| 341 |
+
--source train-images-idx3-ubyte.gz Load MNIST dataset
|
| 342 |
+
--source path/ Recursively load all images from path/
|
| 343 |
+
--source dataset.zip Recursively load all images from dataset.zip
|
| 344 |
+
|
| 345 |
+
Specifying the output format and path:
|
| 346 |
+
|
| 347 |
+
\b
|
| 348 |
+
--dest /path/to/dir Save output files under /path/to/dir
|
| 349 |
+
--dest /path/to/dataset.zip Save output files into /path/to/dataset.zip
|
| 350 |
+
|
| 351 |
+
The output dataset format can be either an image folder or an uncompressed zip archive.
|
| 352 |
+
Zip archives makes it easier to move datasets around file servers and clusters, and may
|
| 353 |
+
offer better training performance on network file systems.
|
| 354 |
+
|
| 355 |
+
Images within the dataset archive will be stored as uncompressed PNG.
|
| 356 |
+
Uncompresed PNGs can be efficiently decoded in the training loop.
|
| 357 |
+
|
| 358 |
+
Class labels are stored in a file called 'dataset.json' that is stored at the
|
| 359 |
+
dataset root folder. This file has the following structure:
|
| 360 |
+
|
| 361 |
+
\b
|
| 362 |
+
{
|
| 363 |
+
"labels": [
|
| 364 |
+
["00000/img00000000.png",6],
|
| 365 |
+
["00000/img00000001.png",9],
|
| 366 |
+
... repeated for every image in the datase
|
| 367 |
+
["00049/img00049999.png",1]
|
| 368 |
+
]
|
| 369 |
+
}
|
| 370 |
+
|
| 371 |
+
If the 'dataset.json' file cannot be found, the dataset is interpreted as
|
| 372 |
+
not containing class labels.
|
| 373 |
+
|
| 374 |
+
Image scale/crop and resolution requirements:
|
| 375 |
+
|
| 376 |
+
Output images must be square-shaped and they must all have the same power-of-two
|
| 377 |
+
dimensions.
|
| 378 |
+
|
| 379 |
+
To scale arbitrary input image size to a specific width and height, use the
|
| 380 |
+
--resolution option. Output resolution will be either the original
|
| 381 |
+
input resolution (if resolution was not specified) or the one specified with
|
| 382 |
+
--resolution option.
|
| 383 |
+
|
| 384 |
+
Use the --transform=center-crop or --transform=center-crop-wide options to apply a
|
| 385 |
+
center crop transform on the input image. These options should be used with the
|
| 386 |
+
--resolution option. For example:
|
| 387 |
+
|
| 388 |
+
\b
|
| 389 |
+
python dataset_tool.py --source LSUN/raw/cat_lmdb --dest /tmp/lsun_cat \\
|
| 390 |
+
--transform=center-crop-wide --resolution=512x384
|
| 391 |
+
"""
|
| 392 |
+
|
| 393 |
+
PIL.Image.init() # type: ignore
|
| 394 |
+
|
| 395 |
+
if dest == '':
|
| 396 |
+
ctx.fail('--dest output filename or directory must not be an empty string')
|
| 397 |
+
|
| 398 |
+
num_files, input_iter = open_dataset(source, max_images=max_images)
|
| 399 |
+
archive_root_dir, save_bytes, close_dest = open_dest(dest)
|
| 400 |
+
|
| 401 |
+
if resolution is None: resolution = (None, None)
|
| 402 |
+
transform_image = make_transform(transform, *resolution)
|
| 403 |
+
|
| 404 |
+
dataset_attrs = None
|
| 405 |
+
|
| 406 |
+
labels = []
|
| 407 |
+
for idx, image in tqdm(enumerate(input_iter), total=num_files):
|
| 408 |
+
idx_str = f'{idx:08d}'
|
| 409 |
+
archive_fname = f'{idx_str[:5]}/img{idx_str}.png'
|
| 410 |
+
|
| 411 |
+
# Apply crop and resize.
|
| 412 |
+
img = transform_image(image['img'])
|
| 413 |
+
|
| 414 |
+
# Transform may drop images.
|
| 415 |
+
if img is None:
|
| 416 |
+
continue
|
| 417 |
+
|
| 418 |
+
# Error check to require uniform image attributes across
|
| 419 |
+
# the whole dataset.
|
| 420 |
+
channels = img.shape[2] if img.ndim == 3 else 1
|
| 421 |
+
cur_image_attrs = {
|
| 422 |
+
'width': img.shape[1],
|
| 423 |
+
'height': img.shape[0],
|
| 424 |
+
'channels': channels
|
| 425 |
+
}
|
| 426 |
+
if dataset_attrs is None:
|
| 427 |
+
dataset_attrs = cur_image_attrs
|
| 428 |
+
width = dataset_attrs['width']
|
| 429 |
+
height = dataset_attrs['height']
|
| 430 |
+
if width != height:
|
| 431 |
+
error(f'Image dimensions after scale and crop are required to be square. Got {width}x{height}')
|
| 432 |
+
if dataset_attrs['channels'] not in [1, 3]:
|
| 433 |
+
error('Input images must be stored as RGB or grayscale')
|
| 434 |
+
# if width != 2 ** int(np.floor(np.log2(width))):
|
| 435 |
+
# error('Image width/height after scale and crop are required to be power-of-two')
|
| 436 |
+
elif dataset_attrs != cur_image_attrs:
|
| 437 |
+
err = [f' dataset {k}/cur image {k}: {dataset_attrs[k]}/{cur_image_attrs[k]}' for k in dataset_attrs.keys()] # pylint: disable=unsubscriptable-object
|
| 438 |
+
error(f'Image {archive_fname} attributes must be equal across all images of the dataset. Got:\n' + '\n'.join(err))
|
| 439 |
+
|
| 440 |
+
# Save the image as an uncompressed PNG.
|
| 441 |
+
img = PIL.Image.fromarray(img, { 1: 'L', 3: 'RGB' }[channels])
|
| 442 |
+
image_bits = io.BytesIO()
|
| 443 |
+
img.save(image_bits, format='png', compress_level=0, optimize=False)
|
| 444 |
+
save_bytes(os.path.join(archive_root_dir, archive_fname), image_bits.getbuffer())
|
| 445 |
+
labels.append([archive_fname, image['label']] if image['label'] is not None else None)
|
| 446 |
+
|
| 447 |
+
metadata = {
|
| 448 |
+
'labels': labels if all(x is not None for x in labels) else None
|
| 449 |
+
}
|
| 450 |
+
save_bytes(os.path.join(archive_root_dir, 'dataset.json'), json.dumps(metadata))
|
| 451 |
+
close_dest()
|
| 452 |
+
|
| 453 |
+
#----------------------------------------------------------------------------
|
| 454 |
+
|
| 455 |
+
if __name__ == "__main__":
|
| 456 |
+
convert_dataset() # pylint: disable=no-value-for-parameter
|
dnnlib/__init__.py
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
from .util import EasyDict, make_cache_dir_path
|
dnnlib/util.py
ADDED
|
@@ -0,0 +1,491 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
"""Miscellaneous utility classes and functions."""
|
| 10 |
+
|
| 11 |
+
import ctypes
|
| 12 |
+
import fnmatch
|
| 13 |
+
import importlib
|
| 14 |
+
import inspect
|
| 15 |
+
import numpy as np
|
| 16 |
+
import os
|
| 17 |
+
import shutil
|
| 18 |
+
import sys
|
| 19 |
+
import types
|
| 20 |
+
import io
|
| 21 |
+
import pickle
|
| 22 |
+
import re
|
| 23 |
+
import requests
|
| 24 |
+
import html
|
| 25 |
+
import hashlib
|
| 26 |
+
import glob
|
| 27 |
+
import tempfile
|
| 28 |
+
import urllib
|
| 29 |
+
import urllib.request
|
| 30 |
+
import uuid
|
| 31 |
+
|
| 32 |
+
from distutils.util import strtobool
|
| 33 |
+
from typing import Any, List, Tuple, Union
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
# Util classes
|
| 37 |
+
# ------------------------------------------------------------------------------------------
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
class EasyDict(dict):
|
| 41 |
+
"""Convenience class that behaves like a dict but allows access with the attribute syntax."""
|
| 42 |
+
|
| 43 |
+
def __getattr__(self, name: str) -> Any:
|
| 44 |
+
try:
|
| 45 |
+
return self[name]
|
| 46 |
+
except KeyError:
|
| 47 |
+
raise AttributeError(name)
|
| 48 |
+
|
| 49 |
+
def __setattr__(self, name: str, value: Any) -> None:
|
| 50 |
+
self[name] = value
|
| 51 |
+
|
| 52 |
+
def __delattr__(self, name: str) -> None:
|
| 53 |
+
del self[name]
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
class Logger(object):
|
| 57 |
+
"""Redirect stderr to stdout, optionally print stdout to a file, and optionally force flushing on both stdout and the file."""
|
| 58 |
+
|
| 59 |
+
def __init__(self, file_name: str = None, file_mode: str = "w", should_flush: bool = True):
|
| 60 |
+
self.file = None
|
| 61 |
+
|
| 62 |
+
if file_name is not None:
|
| 63 |
+
self.file = open(file_name, file_mode)
|
| 64 |
+
|
| 65 |
+
self.should_flush = should_flush
|
| 66 |
+
self.stdout = sys.stdout
|
| 67 |
+
self.stderr = sys.stderr
|
| 68 |
+
|
| 69 |
+
sys.stdout = self
|
| 70 |
+
sys.stderr = self
|
| 71 |
+
|
| 72 |
+
def __enter__(self) -> "Logger":
|
| 73 |
+
return self
|
| 74 |
+
|
| 75 |
+
def __exit__(self, exc_type: Any, exc_value: Any, traceback: Any) -> None:
|
| 76 |
+
self.close()
|
| 77 |
+
|
| 78 |
+
def write(self, text: Union[str, bytes]) -> None:
|
| 79 |
+
"""Write text to stdout (and a file) and optionally flush."""
|
| 80 |
+
if isinstance(text, bytes):
|
| 81 |
+
text = text.decode()
|
| 82 |
+
if len(text) == 0: # workaround for a bug in VSCode debugger: sys.stdout.write(''); sys.stdout.flush() => crash
|
| 83 |
+
return
|
| 84 |
+
|
| 85 |
+
if self.file is not None:
|
| 86 |
+
self.file.write(text)
|
| 87 |
+
|
| 88 |
+
self.stdout.write(text)
|
| 89 |
+
|
| 90 |
+
if self.should_flush:
|
| 91 |
+
self.flush()
|
| 92 |
+
|
| 93 |
+
def flush(self) -> None:
|
| 94 |
+
"""Flush written text to both stdout and a file, if open."""
|
| 95 |
+
if self.file is not None:
|
| 96 |
+
self.file.flush()
|
| 97 |
+
|
| 98 |
+
self.stdout.flush()
|
| 99 |
+
|
| 100 |
+
def close(self) -> None:
|
| 101 |
+
"""Flush, close possible files, and remove stdout/stderr mirroring."""
|
| 102 |
+
self.flush()
|
| 103 |
+
|
| 104 |
+
# if using multiple loggers, prevent closing in wrong order
|
| 105 |
+
if sys.stdout is self:
|
| 106 |
+
sys.stdout = self.stdout
|
| 107 |
+
if sys.stderr is self:
|
| 108 |
+
sys.stderr = self.stderr
|
| 109 |
+
|
| 110 |
+
if self.file is not None:
|
| 111 |
+
self.file.close()
|
| 112 |
+
self.file = None
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
# Cache directories
|
| 116 |
+
# ------------------------------------------------------------------------------------------
|
| 117 |
+
|
| 118 |
+
_dnnlib_cache_dir = None
|
| 119 |
+
|
| 120 |
+
def set_cache_dir(path: str) -> None:
|
| 121 |
+
global _dnnlib_cache_dir
|
| 122 |
+
_dnnlib_cache_dir = path
|
| 123 |
+
|
| 124 |
+
def make_cache_dir_path(*paths: str) -> str:
|
| 125 |
+
if _dnnlib_cache_dir is not None:
|
| 126 |
+
return os.path.join(_dnnlib_cache_dir, *paths)
|
| 127 |
+
if 'DNNLIB_CACHE_DIR' in os.environ:
|
| 128 |
+
return os.path.join(os.environ['DNNLIB_CACHE_DIR'], *paths)
|
| 129 |
+
if 'HOME' in os.environ:
|
| 130 |
+
return os.path.join(os.environ['HOME'], '.cache', 'dnnlib', *paths)
|
| 131 |
+
if 'USERPROFILE' in os.environ:
|
| 132 |
+
return os.path.join(os.environ['USERPROFILE'], '.cache', 'dnnlib', *paths)
|
| 133 |
+
return os.path.join(tempfile.gettempdir(), '.cache', 'dnnlib', *paths)
|
| 134 |
+
|
| 135 |
+
# Small util functions
|
| 136 |
+
# ------------------------------------------------------------------------------------------
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
def format_time(seconds: Union[int, float]) -> str:
|
| 140 |
+
"""Convert the seconds to human readable string with days, hours, minutes and seconds."""
|
| 141 |
+
s = int(np.rint(seconds))
|
| 142 |
+
|
| 143 |
+
if s < 60:
|
| 144 |
+
return "{0}s".format(s)
|
| 145 |
+
elif s < 60 * 60:
|
| 146 |
+
return "{0}m {1:02}s".format(s // 60, s % 60)
|
| 147 |
+
elif s < 24 * 60 * 60:
|
| 148 |
+
return "{0}h {1:02}m {2:02}s".format(s // (60 * 60), (s // 60) % 60, s % 60)
|
| 149 |
+
else:
|
| 150 |
+
return "{0}d {1:02}h {2:02}m".format(s // (24 * 60 * 60), (s // (60 * 60)) % 24, (s // 60) % 60)
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
def format_time_brief(seconds: Union[int, float]) -> str:
|
| 154 |
+
"""Convert the seconds to human readable string with days, hours, minutes and seconds."""
|
| 155 |
+
s = int(np.rint(seconds))
|
| 156 |
+
|
| 157 |
+
if s < 60:
|
| 158 |
+
return "{0}s".format(s)
|
| 159 |
+
elif s < 60 * 60:
|
| 160 |
+
return "{0}m {1:02}s".format(s // 60, s % 60)
|
| 161 |
+
elif s < 24 * 60 * 60:
|
| 162 |
+
return "{0}h {1:02}m".format(s // (60 * 60), (s // 60) % 60)
|
| 163 |
+
else:
|
| 164 |
+
return "{0}d {1:02}h".format(s // (24 * 60 * 60), (s // (60 * 60)) % 24)
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
def ask_yes_no(question: str) -> bool:
|
| 168 |
+
"""Ask the user the question until the user inputs a valid answer."""
|
| 169 |
+
while True:
|
| 170 |
+
try:
|
| 171 |
+
print("{0} [y/n]".format(question))
|
| 172 |
+
return strtobool(input().lower())
|
| 173 |
+
except ValueError:
|
| 174 |
+
pass
|
| 175 |
+
|
| 176 |
+
|
| 177 |
+
def tuple_product(t: Tuple) -> Any:
|
| 178 |
+
"""Calculate the product of the tuple elements."""
|
| 179 |
+
result = 1
|
| 180 |
+
|
| 181 |
+
for v in t:
|
| 182 |
+
result *= v
|
| 183 |
+
|
| 184 |
+
return result
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
_str_to_ctype = {
|
| 188 |
+
"uint8": ctypes.c_ubyte,
|
| 189 |
+
"uint16": ctypes.c_uint16,
|
| 190 |
+
"uint32": ctypes.c_uint32,
|
| 191 |
+
"uint64": ctypes.c_uint64,
|
| 192 |
+
"int8": ctypes.c_byte,
|
| 193 |
+
"int16": ctypes.c_int16,
|
| 194 |
+
"int32": ctypes.c_int32,
|
| 195 |
+
"int64": ctypes.c_int64,
|
| 196 |
+
"float32": ctypes.c_float,
|
| 197 |
+
"float64": ctypes.c_double
|
| 198 |
+
}
|
| 199 |
+
|
| 200 |
+
|
| 201 |
+
def get_dtype_and_ctype(type_obj: Any) -> Tuple[np.dtype, Any]:
|
| 202 |
+
"""Given a type name string (or an object having a __name__ attribute), return matching Numpy and ctypes types that have the same size in bytes."""
|
| 203 |
+
type_str = None
|
| 204 |
+
|
| 205 |
+
if isinstance(type_obj, str):
|
| 206 |
+
type_str = type_obj
|
| 207 |
+
elif hasattr(type_obj, "__name__"):
|
| 208 |
+
type_str = type_obj.__name__
|
| 209 |
+
elif hasattr(type_obj, "name"):
|
| 210 |
+
type_str = type_obj.name
|
| 211 |
+
else:
|
| 212 |
+
raise RuntimeError("Cannot infer type name from input")
|
| 213 |
+
|
| 214 |
+
assert type_str in _str_to_ctype.keys()
|
| 215 |
+
|
| 216 |
+
my_dtype = np.dtype(type_str)
|
| 217 |
+
my_ctype = _str_to_ctype[type_str]
|
| 218 |
+
|
| 219 |
+
assert my_dtype.itemsize == ctypes.sizeof(my_ctype)
|
| 220 |
+
|
| 221 |
+
return my_dtype, my_ctype
|
| 222 |
+
|
| 223 |
+
|
| 224 |
+
def is_pickleable(obj: Any) -> bool:
|
| 225 |
+
try:
|
| 226 |
+
with io.BytesIO() as stream:
|
| 227 |
+
pickle.dump(obj, stream)
|
| 228 |
+
return True
|
| 229 |
+
except:
|
| 230 |
+
return False
|
| 231 |
+
|
| 232 |
+
|
| 233 |
+
# Functionality to import modules/objects by name, and call functions by name
|
| 234 |
+
# ------------------------------------------------------------------------------------------
|
| 235 |
+
|
| 236 |
+
def get_module_from_obj_name(obj_name: str) -> Tuple[types.ModuleType, str]:
|
| 237 |
+
"""Searches for the underlying module behind the name to some python object.
|
| 238 |
+
Returns the module and the object name (original name with module part removed)."""
|
| 239 |
+
|
| 240 |
+
# allow convenience shorthands, substitute them by full names
|
| 241 |
+
obj_name = re.sub("^np.", "numpy.", obj_name)
|
| 242 |
+
obj_name = re.sub("^tf.", "tensorflow.", obj_name)
|
| 243 |
+
|
| 244 |
+
# list alternatives for (module_name, local_obj_name)
|
| 245 |
+
parts = obj_name.split(".")
|
| 246 |
+
name_pairs = [(".".join(parts[:i]), ".".join(parts[i:])) for i in range(len(parts), 0, -1)]
|
| 247 |
+
|
| 248 |
+
# try each alternative in turn
|
| 249 |
+
for module_name, local_obj_name in name_pairs:
|
| 250 |
+
try:
|
| 251 |
+
module = importlib.import_module(module_name) # may raise ImportError
|
| 252 |
+
get_obj_from_module(module, local_obj_name) # may raise AttributeError
|
| 253 |
+
return module, local_obj_name
|
| 254 |
+
except:
|
| 255 |
+
pass
|
| 256 |
+
|
| 257 |
+
# maybe some of the modules themselves contain errors?
|
| 258 |
+
for module_name, _local_obj_name in name_pairs:
|
| 259 |
+
try:
|
| 260 |
+
importlib.import_module(module_name) # may raise ImportError
|
| 261 |
+
except ImportError:
|
| 262 |
+
if not str(sys.exc_info()[1]).startswith("No module named '" + module_name + "'"):
|
| 263 |
+
raise
|
| 264 |
+
|
| 265 |
+
# maybe the requested attribute is missing?
|
| 266 |
+
for module_name, local_obj_name in name_pairs:
|
| 267 |
+
try:
|
| 268 |
+
module = importlib.import_module(module_name) # may raise ImportError
|
| 269 |
+
get_obj_from_module(module, local_obj_name) # may raise AttributeError
|
| 270 |
+
except ImportError:
|
| 271 |
+
pass
|
| 272 |
+
|
| 273 |
+
# we are out of luck, but we have no idea why
|
| 274 |
+
raise ImportError(obj_name)
|
| 275 |
+
|
| 276 |
+
|
| 277 |
+
def get_obj_from_module(module: types.ModuleType, obj_name: str) -> Any:
|
| 278 |
+
"""Traverses the object name and returns the last (rightmost) python object."""
|
| 279 |
+
if obj_name == '':
|
| 280 |
+
return module
|
| 281 |
+
obj = module
|
| 282 |
+
for part in obj_name.split("."):
|
| 283 |
+
obj = getattr(obj, part)
|
| 284 |
+
return obj
|
| 285 |
+
|
| 286 |
+
|
| 287 |
+
def get_obj_by_name(name: str) -> Any:
|
| 288 |
+
"""Finds the python object with the given name."""
|
| 289 |
+
module, obj_name = get_module_from_obj_name(name)
|
| 290 |
+
return get_obj_from_module(module, obj_name)
|
| 291 |
+
|
| 292 |
+
|
| 293 |
+
def call_func_by_name(*args, func_name: str = None, **kwargs) -> Any:
|
| 294 |
+
"""Finds the python object with the given name and calls it as a function."""
|
| 295 |
+
assert func_name is not None
|
| 296 |
+
func_obj = get_obj_by_name(func_name)
|
| 297 |
+
assert callable(func_obj)
|
| 298 |
+
return func_obj(*args, **kwargs)
|
| 299 |
+
|
| 300 |
+
|
| 301 |
+
def construct_class_by_name(*args, class_name: str = None, **kwargs) -> Any:
|
| 302 |
+
"""Finds the python class with the given name and constructs it with the given arguments."""
|
| 303 |
+
return call_func_by_name(*args, func_name=class_name, **kwargs)
|
| 304 |
+
|
| 305 |
+
|
| 306 |
+
def get_module_dir_by_obj_name(obj_name: str) -> str:
|
| 307 |
+
"""Get the directory path of the module containing the given object name."""
|
| 308 |
+
module, _ = get_module_from_obj_name(obj_name)
|
| 309 |
+
return os.path.dirname(inspect.getfile(module))
|
| 310 |
+
|
| 311 |
+
|
| 312 |
+
def is_top_level_function(obj: Any) -> bool:
|
| 313 |
+
"""Determine whether the given object is a top-level function, i.e., defined at module scope using 'def'."""
|
| 314 |
+
return callable(obj) and obj.__name__ in sys.modules[obj.__module__].__dict__
|
| 315 |
+
|
| 316 |
+
|
| 317 |
+
def get_top_level_function_name(obj: Any) -> str:
|
| 318 |
+
"""Return the fully-qualified name of a top-level function."""
|
| 319 |
+
assert is_top_level_function(obj)
|
| 320 |
+
module = obj.__module__
|
| 321 |
+
if module == '__main__':
|
| 322 |
+
module = os.path.splitext(os.path.basename(sys.modules[module].__file__))[0]
|
| 323 |
+
return module + "." + obj.__name__
|
| 324 |
+
|
| 325 |
+
|
| 326 |
+
# File system helpers
|
| 327 |
+
# ------------------------------------------------------------------------------------------
|
| 328 |
+
|
| 329 |
+
def list_dir_recursively_with_ignore(dir_path: str, ignores: List[str] = None, add_base_to_relative: bool = False) -> List[Tuple[str, str]]:
|
| 330 |
+
"""List all files recursively in a given directory while ignoring given file and directory names.
|
| 331 |
+
Returns list of tuples containing both absolute and relative paths."""
|
| 332 |
+
assert os.path.isdir(dir_path)
|
| 333 |
+
base_name = os.path.basename(os.path.normpath(dir_path))
|
| 334 |
+
|
| 335 |
+
if ignores is None:
|
| 336 |
+
ignores = []
|
| 337 |
+
|
| 338 |
+
result = []
|
| 339 |
+
|
| 340 |
+
for root, dirs, files in os.walk(dir_path, topdown=True):
|
| 341 |
+
for ignore_ in ignores:
|
| 342 |
+
dirs_to_remove = [d for d in dirs if fnmatch.fnmatch(d, ignore_)]
|
| 343 |
+
|
| 344 |
+
# dirs need to be edited in-place
|
| 345 |
+
for d in dirs_to_remove:
|
| 346 |
+
dirs.remove(d)
|
| 347 |
+
|
| 348 |
+
files = [f for f in files if not fnmatch.fnmatch(f, ignore_)]
|
| 349 |
+
|
| 350 |
+
absolute_paths = [os.path.join(root, f) for f in files]
|
| 351 |
+
relative_paths = [os.path.relpath(p, dir_path) for p in absolute_paths]
|
| 352 |
+
|
| 353 |
+
if add_base_to_relative:
|
| 354 |
+
relative_paths = [os.path.join(base_name, p) for p in relative_paths]
|
| 355 |
+
|
| 356 |
+
assert len(absolute_paths) == len(relative_paths)
|
| 357 |
+
result += zip(absolute_paths, relative_paths)
|
| 358 |
+
|
| 359 |
+
return result
|
| 360 |
+
|
| 361 |
+
|
| 362 |
+
def copy_files_and_create_dirs(files: List[Tuple[str, str]]) -> None:
|
| 363 |
+
"""Takes in a list of tuples of (src, dst) paths and copies files.
|
| 364 |
+
Will create all necessary directories."""
|
| 365 |
+
for file in files:
|
| 366 |
+
target_dir_name = os.path.dirname(file[1])
|
| 367 |
+
|
| 368 |
+
# will create all intermediate-level directories
|
| 369 |
+
if not os.path.exists(target_dir_name):
|
| 370 |
+
os.makedirs(target_dir_name)
|
| 371 |
+
|
| 372 |
+
shutil.copyfile(file[0], file[1])
|
| 373 |
+
|
| 374 |
+
|
| 375 |
+
# URL helpers
|
| 376 |
+
# ------------------------------------------------------------------------------------------
|
| 377 |
+
|
| 378 |
+
def is_url(obj: Any, allow_file_urls: bool = False) -> bool:
|
| 379 |
+
"""Determine whether the given object is a valid URL string."""
|
| 380 |
+
if not isinstance(obj, str) or not "://" in obj:
|
| 381 |
+
return False
|
| 382 |
+
if allow_file_urls and obj.startswith('file://'):
|
| 383 |
+
return True
|
| 384 |
+
try:
|
| 385 |
+
res = requests.compat.urlparse(obj)
|
| 386 |
+
if not res.scheme or not res.netloc or not "." in res.netloc:
|
| 387 |
+
return False
|
| 388 |
+
res = requests.compat.urlparse(requests.compat.urljoin(obj, "/"))
|
| 389 |
+
if not res.scheme or not res.netloc or not "." in res.netloc:
|
| 390 |
+
return False
|
| 391 |
+
except:
|
| 392 |
+
return False
|
| 393 |
+
return True
|
| 394 |
+
|
| 395 |
+
|
| 396 |
+
def open_url(url: str, cache_dir: str = None, num_attempts: int = 10, verbose: bool = True, return_filename: bool = False, cache: bool = True) -> Any:
|
| 397 |
+
"""Download the given URL and return a binary-mode file object to access the data."""
|
| 398 |
+
assert num_attempts >= 1
|
| 399 |
+
assert not (return_filename and (not cache))
|
| 400 |
+
|
| 401 |
+
# Doesn't look like an URL scheme so interpret it as a local filename.
|
| 402 |
+
if not re.match('^[a-z]+://', url):
|
| 403 |
+
return url if return_filename else open(url, "rb")
|
| 404 |
+
|
| 405 |
+
# Handle file URLs. This code handles unusual file:// patterns that
|
| 406 |
+
# arise on Windows:
|
| 407 |
+
#
|
| 408 |
+
# file:///c:/foo.txt
|
| 409 |
+
#
|
| 410 |
+
# which would translate to a local '/c:/foo.txt' filename that's
|
| 411 |
+
# invalid. Drop the forward slash for such pathnames.
|
| 412 |
+
#
|
| 413 |
+
# If you touch this code path, you should test it on both Linux and
|
| 414 |
+
# Windows.
|
| 415 |
+
#
|
| 416 |
+
# Some internet resources suggest using urllib.request.url2pathname() but
|
| 417 |
+
# but that converts forward slashes to backslashes and this causes
|
| 418 |
+
# its own set of problems.
|
| 419 |
+
if url.startswith('file://'):
|
| 420 |
+
filename = urllib.parse.urlparse(url).path
|
| 421 |
+
if re.match(r'^/[a-zA-Z]:', filename):
|
| 422 |
+
filename = filename[1:]
|
| 423 |
+
return filename if return_filename else open(filename, "rb")
|
| 424 |
+
|
| 425 |
+
assert is_url(url)
|
| 426 |
+
|
| 427 |
+
# Lookup from cache.
|
| 428 |
+
if cache_dir is None:
|
| 429 |
+
cache_dir = make_cache_dir_path('downloads')
|
| 430 |
+
|
| 431 |
+
url_md5 = hashlib.md5(url.encode("utf-8")).hexdigest()
|
| 432 |
+
if cache:
|
| 433 |
+
cache_files = glob.glob(os.path.join(cache_dir, url_md5 + "_*"))
|
| 434 |
+
if len(cache_files) == 1:
|
| 435 |
+
filename = cache_files[0]
|
| 436 |
+
return filename if return_filename else open(filename, "rb")
|
| 437 |
+
|
| 438 |
+
# Download.
|
| 439 |
+
url_name = None
|
| 440 |
+
url_data = None
|
| 441 |
+
with requests.Session() as session:
|
| 442 |
+
if verbose:
|
| 443 |
+
print("Downloading %s ..." % url, end="", flush=True)
|
| 444 |
+
for attempts_left in reversed(range(num_attempts)):
|
| 445 |
+
try:
|
| 446 |
+
with session.get(url) as res:
|
| 447 |
+
res.raise_for_status()
|
| 448 |
+
if len(res.content) == 0:
|
| 449 |
+
raise IOError("No data received")
|
| 450 |
+
|
| 451 |
+
if len(res.content) < 8192:
|
| 452 |
+
content_str = res.content.decode("utf-8")
|
| 453 |
+
if "download_warning" in res.headers.get("Set-Cookie", ""):
|
| 454 |
+
links = [html.unescape(link) for link in content_str.split('"') if "export=download" in link]
|
| 455 |
+
if len(links) == 1:
|
| 456 |
+
url = requests.compat.urljoin(url, links[0])
|
| 457 |
+
raise IOError("Google Drive virus checker nag")
|
| 458 |
+
if "Google Drive - Quota exceeded" in content_str:
|
| 459 |
+
raise IOError("Google Drive download quota exceeded -- please try again later")
|
| 460 |
+
|
| 461 |
+
match = re.search(r'filename="([^"]*)"', res.headers.get("Content-Disposition", ""))
|
| 462 |
+
url_name = match[1] if match else url
|
| 463 |
+
url_data = res.content
|
| 464 |
+
if verbose:
|
| 465 |
+
print(" done")
|
| 466 |
+
break
|
| 467 |
+
except KeyboardInterrupt:
|
| 468 |
+
raise
|
| 469 |
+
except:
|
| 470 |
+
if not attempts_left:
|
| 471 |
+
if verbose:
|
| 472 |
+
print(" failed")
|
| 473 |
+
raise
|
| 474 |
+
if verbose:
|
| 475 |
+
print(".", end="", flush=True)
|
| 476 |
+
|
| 477 |
+
# Save to cache.
|
| 478 |
+
if cache:
|
| 479 |
+
safe_name = re.sub(r"[^0-9a-zA-Z-._]", "_", url_name)
|
| 480 |
+
cache_file = os.path.join(cache_dir, url_md5 + "_" + safe_name)
|
| 481 |
+
temp_file = os.path.join(cache_dir, "tmp_" + uuid.uuid4().hex + "_" + url_md5 + "_" + safe_name)
|
| 482 |
+
os.makedirs(cache_dir, exist_ok=True)
|
| 483 |
+
with open(temp_file, "wb") as f:
|
| 484 |
+
f.write(url_data)
|
| 485 |
+
os.replace(temp_file, cache_file) # atomic
|
| 486 |
+
if return_filename:
|
| 487 |
+
return cache_file
|
| 488 |
+
|
| 489 |
+
# Return data as file object.
|
| 490 |
+
assert not return_filename
|
| 491 |
+
return io.BytesIO(url_data)
|
doc/teaser.png
ADDED
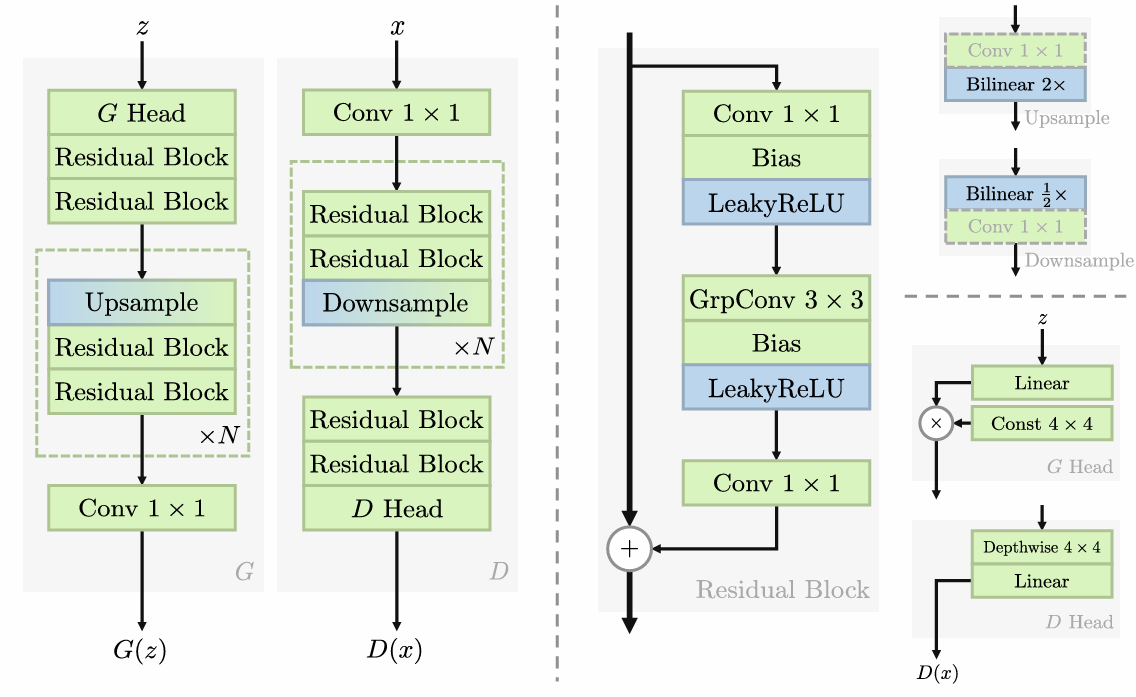
|
gen_images.py
ADDED
|
@@ -0,0 +1,85 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
"""Generate images using pretrained network pickle."""
|
| 10 |
+
|
| 11 |
+
import os
|
| 12 |
+
import re
|
| 13 |
+
from typing import List, Optional, Union
|
| 14 |
+
|
| 15 |
+
import click
|
| 16 |
+
import dnnlib
|
| 17 |
+
import numpy as np
|
| 18 |
+
import PIL.Image
|
| 19 |
+
import torch
|
| 20 |
+
|
| 21 |
+
import legacy
|
| 22 |
+
|
| 23 |
+
#----------------------------------------------------------------------------
|
| 24 |
+
|
| 25 |
+
def parse_range(s: Union[str, List]) -> List[int]:
|
| 26 |
+
'''Parse a comma separated list of numbers or ranges and return a list of ints.
|
| 27 |
+
|
| 28 |
+
Example: '1,2,5-10' returns [1, 2, 5, 6, 7]
|
| 29 |
+
'''
|
| 30 |
+
if isinstance(s, list): return s
|
| 31 |
+
ranges = []
|
| 32 |
+
range_re = re.compile(r'^(\d+)-(\d+)$')
|
| 33 |
+
for p in s.split(','):
|
| 34 |
+
m = range_re.match(p)
|
| 35 |
+
if m:
|
| 36 |
+
ranges.extend(range(int(m.group(1)), int(m.group(2))+1))
|
| 37 |
+
else:
|
| 38 |
+
ranges.append(int(p))
|
| 39 |
+
return ranges
|
| 40 |
+
|
| 41 |
+
#----------------------------------------------------------------------------
|
| 42 |
+
|
| 43 |
+
@click.command()
|
| 44 |
+
@click.option('--network', 'network_pkl', help='Network pickle filename', required=True)
|
| 45 |
+
@click.option('--seeds', type=parse_range, help='List of random seeds (e.g., \'0,1,4-6\')', required=True)
|
| 46 |
+
@click.option('--class', 'class_idx', type=int, help='Class label (unconditional if not specified)')
|
| 47 |
+
@click.option('--outdir', help='Where to save the output images', type=str, required=True, metavar='DIR')
|
| 48 |
+
def generate_images(
|
| 49 |
+
network_pkl: str,
|
| 50 |
+
seeds: List[int],
|
| 51 |
+
outdir: str,
|
| 52 |
+
class_idx: Optional[int]
|
| 53 |
+
):
|
| 54 |
+
print('Loading networks from "%s"...' % network_pkl)
|
| 55 |
+
device = torch.device('cuda')
|
| 56 |
+
with dnnlib.util.open_url(network_pkl) as f:
|
| 57 |
+
G = legacy.load_network_pkl(f)['G_ema'].to(device) # type: ignore
|
| 58 |
+
|
| 59 |
+
os.makedirs(outdir, exist_ok=True)
|
| 60 |
+
|
| 61 |
+
# Labels.
|
| 62 |
+
label = torch.zeros([1, G.c_dim], device=device)
|
| 63 |
+
if G.c_dim != 0:
|
| 64 |
+
if class_idx is None:
|
| 65 |
+
raise click.ClickException('Must specify class label with --class when using a conditional network')
|
| 66 |
+
label[:, class_idx] = 1
|
| 67 |
+
else:
|
| 68 |
+
if class_idx is not None:
|
| 69 |
+
print ('warn: --class=lbl ignored when running on an unconditional network')
|
| 70 |
+
|
| 71 |
+
# Generate images.
|
| 72 |
+
for seed_idx, seed in enumerate(seeds):
|
| 73 |
+
print('Generating image for seed %d (%d/%d) ...' % (seed, seed_idx, len(seeds)))
|
| 74 |
+
z = torch.from_numpy(np.random.RandomState(seed).randn(1, G.z_dim)).to(device)
|
| 75 |
+
img = G(z, label)
|
| 76 |
+
img = (img.permute(0, 2, 3, 1) * 127.5 + 128).clamp(0, 255).to(torch.uint8)
|
| 77 |
+
PIL.Image.fromarray(img[0].cpu().numpy(), 'RGB').save(f'{outdir}/seed{seed:04d}.png')
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
#----------------------------------------------------------------------------
|
| 81 |
+
|
| 82 |
+
if __name__ == "__main__":
|
| 83 |
+
generate_images() # pylint: disable=no-value-for-parameter
|
| 84 |
+
|
| 85 |
+
#----------------------------------------------------------------------------
|
legacy.py
ADDED
|
@@ -0,0 +1,327 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
"""Converting legacy network pickle into the new format."""
|
| 10 |
+
|
| 11 |
+
import click
|
| 12 |
+
import pickle
|
| 13 |
+
import re
|
| 14 |
+
import copy
|
| 15 |
+
import numpy as np
|
| 16 |
+
import torch
|
| 17 |
+
import dnnlib
|
| 18 |
+
from torch_utils import misc
|
| 19 |
+
|
| 20 |
+
#----------------------------------------------------------------------------
|
| 21 |
+
|
| 22 |
+
def load_network_pkl(f, force_fp16=False):
|
| 23 |
+
data = _LegacyUnpickler(f).load()
|
| 24 |
+
|
| 25 |
+
# Legacy TensorFlow pickle => convert.
|
| 26 |
+
if isinstance(data, tuple) and len(data) == 3 and all(isinstance(net, _TFNetworkStub) for net in data):
|
| 27 |
+
tf_G, tf_D, tf_Gs = data
|
| 28 |
+
G = convert_tf_generator(tf_G)
|
| 29 |
+
D = convert_tf_discriminator(tf_D)
|
| 30 |
+
G_ema = convert_tf_generator(tf_Gs)
|
| 31 |
+
data = dict(G=G, D=D, G_ema=G_ema)
|
| 32 |
+
|
| 33 |
+
# Add missing fields.
|
| 34 |
+
if 'training_set_kwargs' not in data:
|
| 35 |
+
data['training_set_kwargs'] = None
|
| 36 |
+
if 'augment_pipe' not in data:
|
| 37 |
+
data['augment_pipe'] = None
|
| 38 |
+
|
| 39 |
+
# Validate contents.
|
| 40 |
+
assert isinstance(data['G'], torch.nn.Module)
|
| 41 |
+
assert isinstance(data['D'], torch.nn.Module)
|
| 42 |
+
assert isinstance(data['G_ema'], torch.nn.Module)
|
| 43 |
+
assert isinstance(data['training_set_kwargs'], (dict, type(None)))
|
| 44 |
+
assert isinstance(data['augment_pipe'], (torch.nn.Module, type(None)))
|
| 45 |
+
|
| 46 |
+
# Force FP16.
|
| 47 |
+
if force_fp16:
|
| 48 |
+
for key in ['G', 'D', 'G_ema']:
|
| 49 |
+
old = data[key]
|
| 50 |
+
kwargs = copy.deepcopy(old.init_kwargs)
|
| 51 |
+
fp16_kwargs = kwargs.get('synthesis_kwargs', kwargs)
|
| 52 |
+
fp16_kwargs.num_fp16_res = 4
|
| 53 |
+
fp16_kwargs.conv_clamp = 256
|
| 54 |
+
if kwargs != old.init_kwargs:
|
| 55 |
+
new = type(old)(**kwargs).eval().requires_grad_(False)
|
| 56 |
+
misc.copy_params_and_buffers(old, new, require_all=True)
|
| 57 |
+
data[key] = new
|
| 58 |
+
return data
|
| 59 |
+
|
| 60 |
+
#----------------------------------------------------------------------------
|
| 61 |
+
|
| 62 |
+
class _TFNetworkStub(dnnlib.EasyDict):
|
| 63 |
+
pass
|
| 64 |
+
|
| 65 |
+
class _LegacyUnpickler(pickle.Unpickler):
|
| 66 |
+
def find_class(self, module, name):
|
| 67 |
+
if module == 'dnnlib.tflib.network' and name == 'Network':
|
| 68 |
+
return _TFNetworkStub
|
| 69 |
+
if module == 'training.networks_baseline':
|
| 70 |
+
module = 'training.networks'
|
| 71 |
+
if module[:12] == 'BaselineGAN.':
|
| 72 |
+
module = 'R3GAN.' + module[12:]
|
| 73 |
+
return super().find_class(module, name)
|
| 74 |
+
|
| 75 |
+
#----------------------------------------------------------------------------
|
| 76 |
+
|
| 77 |
+
def _collect_tf_params(tf_net):
|
| 78 |
+
# pylint: disable=protected-access
|
| 79 |
+
tf_params = dict()
|
| 80 |
+
def recurse(prefix, tf_net):
|
| 81 |
+
for name, value in tf_net.variables:
|
| 82 |
+
tf_params[prefix + name] = value
|
| 83 |
+
for name, comp in tf_net.components.items():
|
| 84 |
+
recurse(prefix + name + '/', comp)
|
| 85 |
+
recurse('', tf_net)
|
| 86 |
+
return tf_params
|
| 87 |
+
|
| 88 |
+
#----------------------------------------------------------------------------
|
| 89 |
+
|
| 90 |
+
def _populate_module_params(module, *patterns):
|
| 91 |
+
for name, tensor in misc.named_params_and_buffers(module):
|
| 92 |
+
found = False
|
| 93 |
+
value = None
|
| 94 |
+
for pattern, value_fn in zip(patterns[0::2], patterns[1::2]):
|
| 95 |
+
match = re.fullmatch(pattern, name)
|
| 96 |
+
if match:
|
| 97 |
+
found = True
|
| 98 |
+
if value_fn is not None:
|
| 99 |
+
value = value_fn(*match.groups())
|
| 100 |
+
break
|
| 101 |
+
try:
|
| 102 |
+
assert found
|
| 103 |
+
if value is not None:
|
| 104 |
+
tensor.copy_(torch.from_numpy(np.array(value)))
|
| 105 |
+
except:
|
| 106 |
+
print(name, list(tensor.shape))
|
| 107 |
+
raise
|
| 108 |
+
|
| 109 |
+
#----------------------------------------------------------------------------
|
| 110 |
+
|
| 111 |
+
def convert_tf_generator(tf_G):
|
| 112 |
+
if tf_G.version < 4:
|
| 113 |
+
raise ValueError('TensorFlow pickle version too low')
|
| 114 |
+
|
| 115 |
+
# Collect kwargs.
|
| 116 |
+
tf_kwargs = tf_G.static_kwargs
|
| 117 |
+
known_kwargs = set()
|
| 118 |
+
def kwarg(tf_name, default=None, none=None):
|
| 119 |
+
known_kwargs.add(tf_name)
|
| 120 |
+
val = tf_kwargs.get(tf_name, default)
|
| 121 |
+
return val if val is not None else none
|
| 122 |
+
|
| 123 |
+
# Convert kwargs.
|
| 124 |
+
from training import networks_stylegan2
|
| 125 |
+
network_class = networks_stylegan2.Generator
|
| 126 |
+
kwargs = dnnlib.EasyDict(
|
| 127 |
+
z_dim = kwarg('latent_size', 512),
|
| 128 |
+
c_dim = kwarg('label_size', 0),
|
| 129 |
+
w_dim = kwarg('dlatent_size', 512),
|
| 130 |
+
img_resolution = kwarg('resolution', 1024),
|
| 131 |
+
img_channels = kwarg('num_channels', 3),
|
| 132 |
+
channel_base = kwarg('fmap_base', 16384) * 2,
|
| 133 |
+
channel_max = kwarg('fmap_max', 512),
|
| 134 |
+
num_fp16_res = kwarg('num_fp16_res', 0),
|
| 135 |
+
conv_clamp = kwarg('conv_clamp', None),
|
| 136 |
+
architecture = kwarg('architecture', 'skip'),
|
| 137 |
+
resample_filter = kwarg('resample_kernel', [1,3,3,1]),
|
| 138 |
+
use_noise = kwarg('use_noise', True),
|
| 139 |
+
activation = kwarg('nonlinearity', 'lrelu'),
|
| 140 |
+
mapping_kwargs = dnnlib.EasyDict(
|
| 141 |
+
num_layers = kwarg('mapping_layers', 8),
|
| 142 |
+
embed_features = kwarg('label_fmaps', None),
|
| 143 |
+
layer_features = kwarg('mapping_fmaps', None),
|
| 144 |
+
activation = kwarg('mapping_nonlinearity', 'lrelu'),
|
| 145 |
+
lr_multiplier = kwarg('mapping_lrmul', 0.01),
|
| 146 |
+
w_avg_beta = kwarg('w_avg_beta', 0.995, none=1),
|
| 147 |
+
),
|
| 148 |
+
)
|
| 149 |
+
|
| 150 |
+
# Check for unknown kwargs.
|
| 151 |
+
kwarg('truncation_psi')
|
| 152 |
+
kwarg('truncation_cutoff')
|
| 153 |
+
kwarg('style_mixing_prob')
|
| 154 |
+
kwarg('structure')
|
| 155 |
+
kwarg('conditioning')
|
| 156 |
+
kwarg('fused_modconv')
|
| 157 |
+
unknown_kwargs = list(set(tf_kwargs.keys()) - known_kwargs)
|
| 158 |
+
if len(unknown_kwargs) > 0:
|
| 159 |
+
raise ValueError('Unknown TensorFlow kwarg', unknown_kwargs[0])
|
| 160 |
+
|
| 161 |
+
# Collect params.
|
| 162 |
+
tf_params = _collect_tf_params(tf_G)
|
| 163 |
+
for name, value in list(tf_params.items()):
|
| 164 |
+
match = re.fullmatch(r'ToRGB_lod(\d+)/(.*)', name)
|
| 165 |
+
if match:
|
| 166 |
+
r = kwargs.img_resolution // (2 ** int(match.group(1)))
|
| 167 |
+
tf_params[f'{r}x{r}/ToRGB/{match.group(2)}'] = value
|
| 168 |
+
kwargs.synthesis.kwargs.architecture = 'orig'
|
| 169 |
+
#for name, value in tf_params.items(): print(f'{name:<50s}{list(value.shape)}')
|
| 170 |
+
|
| 171 |
+
# Convert params.
|
| 172 |
+
G = network_class(**kwargs).eval().requires_grad_(False)
|
| 173 |
+
# pylint: disable=unnecessary-lambda
|
| 174 |
+
# pylint: disable=f-string-without-interpolation
|
| 175 |
+
_populate_module_params(G,
|
| 176 |
+
r'mapping\.w_avg', lambda: tf_params[f'dlatent_avg'],
|
| 177 |
+
r'mapping\.embed\.weight', lambda: tf_params[f'mapping/LabelEmbed/weight'].transpose(),
|
| 178 |
+
r'mapping\.embed\.bias', lambda: tf_params[f'mapping/LabelEmbed/bias'],
|
| 179 |
+
r'mapping\.fc(\d+)\.weight', lambda i: tf_params[f'mapping/Dense{i}/weight'].transpose(),
|
| 180 |
+
r'mapping\.fc(\d+)\.bias', lambda i: tf_params[f'mapping/Dense{i}/bias'],
|
| 181 |
+
r'synthesis\.b4\.const', lambda: tf_params[f'synthesis/4x4/Const/const'][0],
|
| 182 |
+
r'synthesis\.b4\.conv1\.weight', lambda: tf_params[f'synthesis/4x4/Conv/weight'].transpose(3, 2, 0, 1),
|
| 183 |
+
r'synthesis\.b4\.conv1\.bias', lambda: tf_params[f'synthesis/4x4/Conv/bias'],
|
| 184 |
+
r'synthesis\.b4\.conv1\.noise_const', lambda: tf_params[f'synthesis/noise0'][0, 0],
|
| 185 |
+
r'synthesis\.b4\.conv1\.noise_strength', lambda: tf_params[f'synthesis/4x4/Conv/noise_strength'],
|
| 186 |
+
r'synthesis\.b4\.conv1\.affine\.weight', lambda: tf_params[f'synthesis/4x4/Conv/mod_weight'].transpose(),
|
| 187 |
+
r'synthesis\.b4\.conv1\.affine\.bias', lambda: tf_params[f'synthesis/4x4/Conv/mod_bias'] + 1,
|
| 188 |
+
r'synthesis\.b(\d+)\.conv0\.weight', lambda r: tf_params[f'synthesis/{r}x{r}/Conv0_up/weight'][::-1, ::-1].transpose(3, 2, 0, 1),
|
| 189 |
+
r'synthesis\.b(\d+)\.conv0\.bias', lambda r: tf_params[f'synthesis/{r}x{r}/Conv0_up/bias'],
|
| 190 |
+
r'synthesis\.b(\d+)\.conv0\.noise_const', lambda r: tf_params[f'synthesis/noise{int(np.log2(int(r)))*2-5}'][0, 0],
|
| 191 |
+
r'synthesis\.b(\d+)\.conv0\.noise_strength', lambda r: tf_params[f'synthesis/{r}x{r}/Conv0_up/noise_strength'],
|
| 192 |
+
r'synthesis\.b(\d+)\.conv0\.affine\.weight', lambda r: tf_params[f'synthesis/{r}x{r}/Conv0_up/mod_weight'].transpose(),
|
| 193 |
+
r'synthesis\.b(\d+)\.conv0\.affine\.bias', lambda r: tf_params[f'synthesis/{r}x{r}/Conv0_up/mod_bias'] + 1,
|
| 194 |
+
r'synthesis\.b(\d+)\.conv1\.weight', lambda r: tf_params[f'synthesis/{r}x{r}/Conv1/weight'].transpose(3, 2, 0, 1),
|
| 195 |
+
r'synthesis\.b(\d+)\.conv1\.bias', lambda r: tf_params[f'synthesis/{r}x{r}/Conv1/bias'],
|
| 196 |
+
r'synthesis\.b(\d+)\.conv1\.noise_const', lambda r: tf_params[f'synthesis/noise{int(np.log2(int(r)))*2-4}'][0, 0],
|
| 197 |
+
r'synthesis\.b(\d+)\.conv1\.noise_strength', lambda r: tf_params[f'synthesis/{r}x{r}/Conv1/noise_strength'],
|
| 198 |
+
r'synthesis\.b(\d+)\.conv1\.affine\.weight', lambda r: tf_params[f'synthesis/{r}x{r}/Conv1/mod_weight'].transpose(),
|
| 199 |
+
r'synthesis\.b(\d+)\.conv1\.affine\.bias', lambda r: tf_params[f'synthesis/{r}x{r}/Conv1/mod_bias'] + 1,
|
| 200 |
+
r'synthesis\.b(\d+)\.torgb\.weight', lambda r: tf_params[f'synthesis/{r}x{r}/ToRGB/weight'].transpose(3, 2, 0, 1),
|
| 201 |
+
r'synthesis\.b(\d+)\.torgb\.bias', lambda r: tf_params[f'synthesis/{r}x{r}/ToRGB/bias'],
|
| 202 |
+
r'synthesis\.b(\d+)\.torgb\.affine\.weight', lambda r: tf_params[f'synthesis/{r}x{r}/ToRGB/mod_weight'].transpose(),
|
| 203 |
+
r'synthesis\.b(\d+)\.torgb\.affine\.bias', lambda r: tf_params[f'synthesis/{r}x{r}/ToRGB/mod_bias'] + 1,
|
| 204 |
+
r'synthesis\.b(\d+)\.skip\.weight', lambda r: tf_params[f'synthesis/{r}x{r}/Skip/weight'][::-1, ::-1].transpose(3, 2, 0, 1),
|
| 205 |
+
r'.*\.resample_filter', None,
|
| 206 |
+
r'.*\.act_filter', None,
|
| 207 |
+
)
|
| 208 |
+
return G
|
| 209 |
+
|
| 210 |
+
#----------------------------------------------------------------------------
|
| 211 |
+
|
| 212 |
+
def convert_tf_discriminator(tf_D):
|
| 213 |
+
if tf_D.version < 4:
|
| 214 |
+
raise ValueError('TensorFlow pickle version too low')
|
| 215 |
+
|
| 216 |
+
# Collect kwargs.
|
| 217 |
+
tf_kwargs = tf_D.static_kwargs
|
| 218 |
+
known_kwargs = set()
|
| 219 |
+
def kwarg(tf_name, default=None):
|
| 220 |
+
known_kwargs.add(tf_name)
|
| 221 |
+
return tf_kwargs.get(tf_name, default)
|
| 222 |
+
|
| 223 |
+
# Convert kwargs.
|
| 224 |
+
kwargs = dnnlib.EasyDict(
|
| 225 |
+
c_dim = kwarg('label_size', 0),
|
| 226 |
+
img_resolution = kwarg('resolution', 1024),
|
| 227 |
+
img_channels = kwarg('num_channels', 3),
|
| 228 |
+
architecture = kwarg('architecture', 'resnet'),
|
| 229 |
+
channel_base = kwarg('fmap_base', 16384) * 2,
|
| 230 |
+
channel_max = kwarg('fmap_max', 512),
|
| 231 |
+
num_fp16_res = kwarg('num_fp16_res', 0),
|
| 232 |
+
conv_clamp = kwarg('conv_clamp', None),
|
| 233 |
+
cmap_dim = kwarg('mapping_fmaps', None),
|
| 234 |
+
block_kwargs = dnnlib.EasyDict(
|
| 235 |
+
activation = kwarg('nonlinearity', 'lrelu'),
|
| 236 |
+
resample_filter = kwarg('resample_kernel', [1,3,3,1]),
|
| 237 |
+
freeze_layers = kwarg('freeze_layers', 0),
|
| 238 |
+
),
|
| 239 |
+
mapping_kwargs = dnnlib.EasyDict(
|
| 240 |
+
num_layers = kwarg('mapping_layers', 0),
|
| 241 |
+
embed_features = kwarg('mapping_fmaps', None),
|
| 242 |
+
layer_features = kwarg('mapping_fmaps', None),
|
| 243 |
+
activation = kwarg('nonlinearity', 'lrelu'),
|
| 244 |
+
lr_multiplier = kwarg('mapping_lrmul', 0.1),
|
| 245 |
+
),
|
| 246 |
+
epilogue_kwargs = dnnlib.EasyDict(
|
| 247 |
+
mbstd_group_size = kwarg('mbstd_group_size', None),
|
| 248 |
+
mbstd_num_channels = kwarg('mbstd_num_features', 1),
|
| 249 |
+
activation = kwarg('nonlinearity', 'lrelu'),
|
| 250 |
+
),
|
| 251 |
+
)
|
| 252 |
+
|
| 253 |
+
# Check for unknown kwargs.
|
| 254 |
+
kwarg('structure')
|
| 255 |
+
kwarg('conditioning')
|
| 256 |
+
unknown_kwargs = list(set(tf_kwargs.keys()) - known_kwargs)
|
| 257 |
+
if len(unknown_kwargs) > 0:
|
| 258 |
+
raise ValueError('Unknown TensorFlow kwarg', unknown_kwargs[0])
|
| 259 |
+
|
| 260 |
+
# Collect params.
|
| 261 |
+
tf_params = _collect_tf_params(tf_D)
|
| 262 |
+
for name, value in list(tf_params.items()):
|
| 263 |
+
match = re.fullmatch(r'FromRGB_lod(\d+)/(.*)', name)
|
| 264 |
+
if match:
|
| 265 |
+
r = kwargs.img_resolution // (2 ** int(match.group(1)))
|
| 266 |
+
tf_params[f'{r}x{r}/FromRGB/{match.group(2)}'] = value
|
| 267 |
+
kwargs.architecture = 'orig'
|
| 268 |
+
#for name, value in tf_params.items(): print(f'{name:<50s}{list(value.shape)}')
|
| 269 |
+
|
| 270 |
+
# Convert params.
|
| 271 |
+
from training import networks_stylegan2
|
| 272 |
+
D = networks_stylegan2.Discriminator(**kwargs).eval().requires_grad_(False)
|
| 273 |
+
# pylint: disable=unnecessary-lambda
|
| 274 |
+
# pylint: disable=f-string-without-interpolation
|
| 275 |
+
_populate_module_params(D,
|
| 276 |
+
r'b(\d+)\.fromrgb\.weight', lambda r: tf_params[f'{r}x{r}/FromRGB/weight'].transpose(3, 2, 0, 1),
|
| 277 |
+
r'b(\d+)\.fromrgb\.bias', lambda r: tf_params[f'{r}x{r}/FromRGB/bias'],
|
| 278 |
+
r'b(\d+)\.conv(\d+)\.weight', lambda r, i: tf_params[f'{r}x{r}/Conv{i}{["","_down"][int(i)]}/weight'].transpose(3, 2, 0, 1),
|
| 279 |
+
r'b(\d+)\.conv(\d+)\.bias', lambda r, i: tf_params[f'{r}x{r}/Conv{i}{["","_down"][int(i)]}/bias'],
|
| 280 |
+
r'b(\d+)\.skip\.weight', lambda r: tf_params[f'{r}x{r}/Skip/weight'].transpose(3, 2, 0, 1),
|
| 281 |
+
r'mapping\.embed\.weight', lambda: tf_params[f'LabelEmbed/weight'].transpose(),
|
| 282 |
+
r'mapping\.embed\.bias', lambda: tf_params[f'LabelEmbed/bias'],
|
| 283 |
+
r'mapping\.fc(\d+)\.weight', lambda i: tf_params[f'Mapping{i}/weight'].transpose(),
|
| 284 |
+
r'mapping\.fc(\d+)\.bias', lambda i: tf_params[f'Mapping{i}/bias'],
|
| 285 |
+
r'b4\.conv\.weight', lambda: tf_params[f'4x4/Conv/weight'].transpose(3, 2, 0, 1),
|
| 286 |
+
r'b4\.conv\.bias', lambda: tf_params[f'4x4/Conv/bias'],
|
| 287 |
+
r'b4\.fc\.weight', lambda: tf_params[f'4x4/Dense0/weight'].transpose(),
|
| 288 |
+
r'b4\.fc\.bias', lambda: tf_params[f'4x4/Dense0/bias'],
|
| 289 |
+
r'b4\.out\.weight', lambda: tf_params[f'Output/weight'].transpose(),
|
| 290 |
+
r'b4\.out\.bias', lambda: tf_params[f'Output/bias'],
|
| 291 |
+
r'.*\.resample_filter', None,
|
| 292 |
+
)
|
| 293 |
+
return D
|
| 294 |
+
|
| 295 |
+
#----------------------------------------------------------------------------
|
| 296 |
+
|
| 297 |
+
@click.command()
|
| 298 |
+
@click.option('--source', help='Input pickle', required=True, metavar='PATH')
|
| 299 |
+
@click.option('--dest', help='Output pickle', required=True, metavar='PATH')
|
| 300 |
+
@click.option('--force-fp16', help='Force the networks to use FP16', type=bool, default=False, metavar='BOOL', show_default=True)
|
| 301 |
+
def convert_network_pickle(source, dest, force_fp16):
|
| 302 |
+
"""Convert legacy network pickle into the native PyTorch format.
|
| 303 |
+
|
| 304 |
+
The tool is able to load the main network configurations exported using the TensorFlow version of StyleGAN2 or StyleGAN2-ADA.
|
| 305 |
+
It does not support e.g. StyleGAN2-ADA comparison methods, StyleGAN2 configs A-D, or StyleGAN1 networks.
|
| 306 |
+
|
| 307 |
+
Example:
|
| 308 |
+
|
| 309 |
+
\b
|
| 310 |
+
python legacy.py \\
|
| 311 |
+
--source=https://nvlabs-fi-cdn.nvidia.com/stylegan2/networks/stylegan2-cat-config-f.pkl \\
|
| 312 |
+
--dest=stylegan2-cat-config-f.pkl
|
| 313 |
+
"""
|
| 314 |
+
print(f'Loading "{source}"...')
|
| 315 |
+
with dnnlib.util.open_url(source) as f:
|
| 316 |
+
data = load_network_pkl(f, force_fp16=force_fp16)
|
| 317 |
+
print(f'Saving "{dest}"...')
|
| 318 |
+
with open(dest, 'wb') as f:
|
| 319 |
+
pickle.dump(data, f)
|
| 320 |
+
print('Done.')
|
| 321 |
+
|
| 322 |
+
#----------------------------------------------------------------------------
|
| 323 |
+
|
| 324 |
+
if __name__ == "__main__":
|
| 325 |
+
convert_network_pickle() # pylint: disable=no-value-for-parameter
|
| 326 |
+
|
| 327 |
+
#----------------------------------------------------------------------------
|
metrics/__init__.py
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
# empty
|
metrics/frechet_inception_distance.py
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
"""Frechet Inception Distance (FID) from the paper
|
| 10 |
+
"GANs trained by a two time-scale update rule converge to a local Nash
|
| 11 |
+
equilibrium". Matches the original implementation by Heusel et al. at
|
| 12 |
+
https://github.com/bioinf-jku/TTUR/blob/master/fid.py"""
|
| 13 |
+
|
| 14 |
+
import numpy as np
|
| 15 |
+
import scipy.linalg
|
| 16 |
+
from . import metric_utils
|
| 17 |
+
|
| 18 |
+
#----------------------------------------------------------------------------
|
| 19 |
+
|
| 20 |
+
def compute_fid(opts, max_real, num_gen):
|
| 21 |
+
# Direct TorchScript translation of http://download.tensorflow.org/models/image/imagenet/inception-2015-12-05.tgz
|
| 22 |
+
detector_url = 'https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/metrics/inception-2015-12-05.pkl'
|
| 23 |
+
detector_kwargs = dict(return_features=True) # Return raw features before the softmax layer.
|
| 24 |
+
|
| 25 |
+
mu_real, sigma_real = metric_utils.compute_feature_stats_for_dataset(
|
| 26 |
+
opts=opts, detector_url=detector_url, detector_kwargs=detector_kwargs,
|
| 27 |
+
rel_lo=0, rel_hi=0, capture_mean_cov=True, max_items=max_real).get_mean_cov()
|
| 28 |
+
|
| 29 |
+
mu_gen, sigma_gen = metric_utils.compute_feature_stats_for_generator(
|
| 30 |
+
opts=opts, detector_url=detector_url, detector_kwargs=detector_kwargs,
|
| 31 |
+
rel_lo=0, rel_hi=1, capture_mean_cov=True, max_items=num_gen).get_mean_cov()
|
| 32 |
+
|
| 33 |
+
if opts.rank != 0:
|
| 34 |
+
return float('nan')
|
| 35 |
+
|
| 36 |
+
m = np.square(mu_gen - mu_real).sum()
|
| 37 |
+
s, _ = scipy.linalg.sqrtm(np.dot(sigma_gen, sigma_real), disp=False) # pylint: disable=no-member
|
| 38 |
+
fid = np.real(m + np.trace(sigma_gen + sigma_real - s * 2))
|
| 39 |
+
return float(fid)
|
| 40 |
+
|
| 41 |
+
#----------------------------------------------------------------------------
|
metrics/inception_score.py
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
"""Inception Score (IS) from the paper "Improved techniques for training
|
| 10 |
+
GANs". Matches the original implementation by Salimans et al. at
|
| 11 |
+
https://github.com/openai/improved-gan/blob/master/inception_score/model.py"""
|
| 12 |
+
|
| 13 |
+
import numpy as np
|
| 14 |
+
from . import metric_utils
|
| 15 |
+
|
| 16 |
+
#----------------------------------------------------------------------------
|
| 17 |
+
|
| 18 |
+
def compute_is(opts, num_gen, num_splits):
|
| 19 |
+
# Direct TorchScript translation of http://download.tensorflow.org/models/image/imagenet/inception-2015-12-05.tgz
|
| 20 |
+
detector_url = 'https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/metrics/inception-2015-12-05.pkl'
|
| 21 |
+
detector_kwargs = dict(no_output_bias=True) # Match the original implementation by not applying bias in the softmax layer.
|
| 22 |
+
|
| 23 |
+
gen_probs = metric_utils.compute_feature_stats_for_generator(
|
| 24 |
+
opts=opts, detector_url=detector_url, detector_kwargs=detector_kwargs,
|
| 25 |
+
capture_all=True, max_items=num_gen).get_all()
|
| 26 |
+
|
| 27 |
+
if opts.rank != 0:
|
| 28 |
+
return float('nan'), float('nan')
|
| 29 |
+
|
| 30 |
+
scores = []
|
| 31 |
+
for i in range(num_splits):
|
| 32 |
+
part = gen_probs[i * num_gen // num_splits : (i + 1) * num_gen // num_splits]
|
| 33 |
+
kl = part * (np.log(part) - np.log(np.mean(part, axis=0, keepdims=True)))
|
| 34 |
+
kl = np.mean(np.sum(kl, axis=1))
|
| 35 |
+
scores.append(np.exp(kl))
|
| 36 |
+
return float(np.mean(scores)), float(np.std(scores))
|
| 37 |
+
|
| 38 |
+
#----------------------------------------------------------------------------
|
metrics/kernel_inception_distance.py
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
"""Kernel Inception Distance (KID) from the paper "Demystifying MMD
|
| 10 |
+
GANs". Matches the original implementation by Binkowski et al. at
|
| 11 |
+
https://github.com/mbinkowski/MMD-GAN/blob/master/gan/compute_scores.py"""
|
| 12 |
+
|
| 13 |
+
import numpy as np
|
| 14 |
+
from . import metric_utils
|
| 15 |
+
|
| 16 |
+
#----------------------------------------------------------------------------
|
| 17 |
+
|
| 18 |
+
def compute_kid(opts, max_real, num_gen, num_subsets, max_subset_size):
|
| 19 |
+
# Direct TorchScript translation of http://download.tensorflow.org/models/image/imagenet/inception-2015-12-05.tgz
|
| 20 |
+
detector_url = 'https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/metrics/inception-2015-12-05.pkl'
|
| 21 |
+
detector_kwargs = dict(return_features=True) # Return raw features before the softmax layer.
|
| 22 |
+
|
| 23 |
+
real_features = metric_utils.compute_feature_stats_for_dataset(
|
| 24 |
+
opts=opts, detector_url=detector_url, detector_kwargs=detector_kwargs,
|
| 25 |
+
rel_lo=0, rel_hi=0, capture_all=True, max_items=max_real).get_all()
|
| 26 |
+
|
| 27 |
+
gen_features = metric_utils.compute_feature_stats_for_generator(
|
| 28 |
+
opts=opts, detector_url=detector_url, detector_kwargs=detector_kwargs,
|
| 29 |
+
rel_lo=0, rel_hi=1, capture_all=True, max_items=num_gen).get_all()
|
| 30 |
+
|
| 31 |
+
if opts.rank != 0:
|
| 32 |
+
return float('nan')
|
| 33 |
+
|
| 34 |
+
n = real_features.shape[1]
|
| 35 |
+
m = min(min(real_features.shape[0], gen_features.shape[0]), max_subset_size)
|
| 36 |
+
t = 0
|
| 37 |
+
for _subset_idx in range(num_subsets):
|
| 38 |
+
x = gen_features[np.random.choice(gen_features.shape[0], m, replace=False)]
|
| 39 |
+
y = real_features[np.random.choice(real_features.shape[0], m, replace=False)]
|
| 40 |
+
a = (x @ x.T / n + 1) ** 3 + (y @ y.T / n + 1) ** 3
|
| 41 |
+
b = (x @ y.T / n + 1) ** 3
|
| 42 |
+
t += (a.sum() - np.diag(a).sum()) / (m - 1) - b.sum() * 2 / m
|
| 43 |
+
kid = t / num_subsets / m
|
| 44 |
+
return float(kid)
|
| 45 |
+
|
| 46 |
+
#----------------------------------------------------------------------------
|
metrics/metric_main.py
ADDED
|
@@ -0,0 +1,128 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
"""Main API for computing and reporting quality metrics."""
|
| 10 |
+
|
| 11 |
+
import os
|
| 12 |
+
import time
|
| 13 |
+
import json
|
| 14 |
+
import torch
|
| 15 |
+
import dnnlib
|
| 16 |
+
|
| 17 |
+
from . import metric_utils
|
| 18 |
+
from . import frechet_inception_distance
|
| 19 |
+
from . import kernel_inception_distance
|
| 20 |
+
from . import precision_recall
|
| 21 |
+
from . import inception_score
|
| 22 |
+
|
| 23 |
+
#----------------------------------------------------------------------------
|
| 24 |
+
|
| 25 |
+
_metric_dict = dict() # name => fn
|
| 26 |
+
|
| 27 |
+
def register_metric(fn):
|
| 28 |
+
assert callable(fn)
|
| 29 |
+
_metric_dict[fn.__name__] = fn
|
| 30 |
+
return fn
|
| 31 |
+
|
| 32 |
+
def is_valid_metric(metric):
|
| 33 |
+
return metric in _metric_dict
|
| 34 |
+
|
| 35 |
+
def list_valid_metrics():
|
| 36 |
+
return list(_metric_dict.keys())
|
| 37 |
+
|
| 38 |
+
#----------------------------------------------------------------------------
|
| 39 |
+
|
| 40 |
+
def calc_metric(metric, **kwargs): # See metric_utils.MetricOptions for the full list of arguments.
|
| 41 |
+
assert is_valid_metric(metric)
|
| 42 |
+
opts = metric_utils.MetricOptions(**kwargs)
|
| 43 |
+
|
| 44 |
+
# Calculate.
|
| 45 |
+
start_time = time.time()
|
| 46 |
+
results = _metric_dict[metric](opts)
|
| 47 |
+
total_time = time.time() - start_time
|
| 48 |
+
|
| 49 |
+
# Broadcast results.
|
| 50 |
+
for key, value in list(results.items()):
|
| 51 |
+
if opts.num_gpus > 1:
|
| 52 |
+
value = torch.as_tensor(value, dtype=torch.float64, device=opts.device)
|
| 53 |
+
torch.distributed.broadcast(tensor=value, src=0)
|
| 54 |
+
value = float(value.cpu())
|
| 55 |
+
results[key] = value
|
| 56 |
+
|
| 57 |
+
# Decorate with metadata.
|
| 58 |
+
return dnnlib.EasyDict(
|
| 59 |
+
results = dnnlib.EasyDict(results),
|
| 60 |
+
metric = metric,
|
| 61 |
+
total_time = total_time,
|
| 62 |
+
total_time_str = dnnlib.util.format_time(total_time),
|
| 63 |
+
num_gpus = opts.num_gpus,
|
| 64 |
+
)
|
| 65 |
+
|
| 66 |
+
#----------------------------------------------------------------------------
|
| 67 |
+
|
| 68 |
+
def report_metric(result_dict, run_dir=None, snapshot_pkl=None):
|
| 69 |
+
metric = result_dict['metric']
|
| 70 |
+
assert is_valid_metric(metric)
|
| 71 |
+
if run_dir is not None and snapshot_pkl is not None:
|
| 72 |
+
snapshot_pkl = os.path.relpath(snapshot_pkl, run_dir)
|
| 73 |
+
|
| 74 |
+
jsonl_line = json.dumps(dict(result_dict, snapshot_pkl=snapshot_pkl, timestamp=time.time()))
|
| 75 |
+
print(jsonl_line)
|
| 76 |
+
if run_dir is not None and os.path.isdir(run_dir):
|
| 77 |
+
with open(os.path.join(run_dir, f'metric-{metric}.jsonl'), 'at') as f:
|
| 78 |
+
f.write(jsonl_line + '\n')
|
| 79 |
+
|
| 80 |
+
#----------------------------------------------------------------------------
|
| 81 |
+
# Recommended metrics.
|
| 82 |
+
|
| 83 |
+
@register_metric
|
| 84 |
+
def fid50k_full(opts):
|
| 85 |
+
opts.dataset_kwargs.update(max_size=None, xflip=False)
|
| 86 |
+
fid = frechet_inception_distance.compute_fid(opts, max_real=None, num_gen=50000)
|
| 87 |
+
return dict(fid50k_full=fid)
|
| 88 |
+
|
| 89 |
+
@register_metric
|
| 90 |
+
def kid50k_full(opts):
|
| 91 |
+
opts.dataset_kwargs.update(max_size=None, xflip=False)
|
| 92 |
+
kid = kernel_inception_distance.compute_kid(opts, max_real=1000000, num_gen=50000, num_subsets=100, max_subset_size=1000)
|
| 93 |
+
return dict(kid50k_full=kid)
|
| 94 |
+
|
| 95 |
+
@register_metric
|
| 96 |
+
def pr50k3_full(opts):
|
| 97 |
+
opts.dataset_kwargs.update(max_size=None, xflip=False)
|
| 98 |
+
precision, recall = precision_recall.compute_pr(opts, max_real=200000, num_gen=50000, nhood_size=3, row_batch_size=10000, col_batch_size=10000)
|
| 99 |
+
return dict(pr50k3_full_precision=precision, pr50k3_full_recall=recall)
|
| 100 |
+
|
| 101 |
+
#----------------------------------------------------------------------------
|
| 102 |
+
# Legacy metrics.
|
| 103 |
+
|
| 104 |
+
@register_metric
|
| 105 |
+
def fid50k(opts):
|
| 106 |
+
opts.dataset_kwargs.update(max_size=None)
|
| 107 |
+
fid = frechet_inception_distance.compute_fid(opts, max_real=50000, num_gen=50000)
|
| 108 |
+
return dict(fid50k=fid)
|
| 109 |
+
|
| 110 |
+
@register_metric
|
| 111 |
+
def kid50k(opts):
|
| 112 |
+
opts.dataset_kwargs.update(max_size=None)
|
| 113 |
+
kid = kernel_inception_distance.compute_kid(opts, max_real=50000, num_gen=50000, num_subsets=100, max_subset_size=1000)
|
| 114 |
+
return dict(kid50k=kid)
|
| 115 |
+
|
| 116 |
+
@register_metric
|
| 117 |
+
def pr50k3(opts):
|
| 118 |
+
opts.dataset_kwargs.update(max_size=None)
|
| 119 |
+
precision, recall = precision_recall.compute_pr(opts, max_real=50000, num_gen=50000, nhood_size=3, row_batch_size=10000, col_batch_size=10000)
|
| 120 |
+
return dict(pr50k3_precision=precision, pr50k3_recall=recall)
|
| 121 |
+
|
| 122 |
+
@register_metric
|
| 123 |
+
def is50k(opts):
|
| 124 |
+
opts.dataset_kwargs.update(max_size=None, xflip=False)
|
| 125 |
+
mean, std = inception_score.compute_is(opts, num_gen=50000, num_splits=10)
|
| 126 |
+
return dict(is50k_mean=mean, is50k_std=std)
|
| 127 |
+
|
| 128 |
+
#----------------------------------------------------------------------------
|
metrics/metric_utils.py
ADDED
|
@@ -0,0 +1,279 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
"""Miscellaneous utilities used internally by the quality metrics."""
|
| 10 |
+
|
| 11 |
+
import os
|
| 12 |
+
import time
|
| 13 |
+
import hashlib
|
| 14 |
+
import pickle
|
| 15 |
+
import copy
|
| 16 |
+
import uuid
|
| 17 |
+
import numpy as np
|
| 18 |
+
import torch
|
| 19 |
+
import dnnlib
|
| 20 |
+
|
| 21 |
+
#----------------------------------------------------------------------------
|
| 22 |
+
|
| 23 |
+
class MetricOptions:
|
| 24 |
+
def __init__(self, G=None, G_kwargs={}, dataset_kwargs={}, num_gpus=1, rank=0, device=None, progress=None, cache=True):
|
| 25 |
+
assert 0 <= rank < num_gpus
|
| 26 |
+
self.G = G
|
| 27 |
+
self.G_kwargs = dnnlib.EasyDict(G_kwargs)
|
| 28 |
+
self.dataset_kwargs = dnnlib.EasyDict(dataset_kwargs)
|
| 29 |
+
self.num_gpus = num_gpus
|
| 30 |
+
self.rank = rank
|
| 31 |
+
self.device = device if device is not None else torch.device('cuda', rank)
|
| 32 |
+
self.progress = progress.sub() if progress is not None and rank == 0 else ProgressMonitor()
|
| 33 |
+
self.cache = cache
|
| 34 |
+
|
| 35 |
+
#----------------------------------------------------------------------------
|
| 36 |
+
|
| 37 |
+
_feature_detector_cache = dict()
|
| 38 |
+
|
| 39 |
+
def get_feature_detector_name(url):
|
| 40 |
+
return os.path.splitext(url.split('/')[-1])[0]
|
| 41 |
+
|
| 42 |
+
def get_feature_detector(url, device=torch.device('cpu'), num_gpus=1, rank=0, verbose=False):
|
| 43 |
+
assert 0 <= rank < num_gpus
|
| 44 |
+
key = (url, device)
|
| 45 |
+
if key not in _feature_detector_cache:
|
| 46 |
+
is_leader = (rank == 0)
|
| 47 |
+
if not is_leader and num_gpus > 1:
|
| 48 |
+
torch.distributed.barrier() # leader goes first
|
| 49 |
+
with dnnlib.util.open_url(url, verbose=(verbose and is_leader)) as f:
|
| 50 |
+
_feature_detector_cache[key] = pickle.load(f).to(device)
|
| 51 |
+
if is_leader and num_gpus > 1:
|
| 52 |
+
torch.distributed.barrier() # others follow
|
| 53 |
+
return _feature_detector_cache[key]
|
| 54 |
+
|
| 55 |
+
#----------------------------------------------------------------------------
|
| 56 |
+
|
| 57 |
+
def iterate_random_labels(opts, batch_size):
|
| 58 |
+
if opts.G.c_dim == 0:
|
| 59 |
+
c = torch.zeros([batch_size, opts.G.c_dim], device=opts.device)
|
| 60 |
+
while True:
|
| 61 |
+
yield c
|
| 62 |
+
else:
|
| 63 |
+
dataset = dnnlib.util.construct_class_by_name(**opts.dataset_kwargs)
|
| 64 |
+
while True:
|
| 65 |
+
c = [dataset.get_label(np.random.randint(len(dataset))) for _i in range(batch_size)]
|
| 66 |
+
c = torch.from_numpy(np.stack(c)).pin_memory().to(opts.device)
|
| 67 |
+
yield c
|
| 68 |
+
|
| 69 |
+
#----------------------------------------------------------------------------
|
| 70 |
+
|
| 71 |
+
class FeatureStats:
|
| 72 |
+
def __init__(self, capture_all=False, capture_mean_cov=False, max_items=None):
|
| 73 |
+
self.capture_all = capture_all
|
| 74 |
+
self.capture_mean_cov = capture_mean_cov
|
| 75 |
+
self.max_items = max_items
|
| 76 |
+
self.num_items = 0
|
| 77 |
+
self.num_features = None
|
| 78 |
+
self.all_features = None
|
| 79 |
+
self.raw_mean = None
|
| 80 |
+
self.raw_cov = None
|
| 81 |
+
|
| 82 |
+
def set_num_features(self, num_features):
|
| 83 |
+
if self.num_features is not None:
|
| 84 |
+
assert num_features == self.num_features
|
| 85 |
+
else:
|
| 86 |
+
self.num_features = num_features
|
| 87 |
+
self.all_features = []
|
| 88 |
+
self.raw_mean = np.zeros([num_features], dtype=np.float64)
|
| 89 |
+
self.raw_cov = np.zeros([num_features, num_features], dtype=np.float64)
|
| 90 |
+
|
| 91 |
+
def is_full(self):
|
| 92 |
+
return (self.max_items is not None) and (self.num_items >= self.max_items)
|
| 93 |
+
|
| 94 |
+
def append(self, x):
|
| 95 |
+
x = np.asarray(x, dtype=np.float32)
|
| 96 |
+
assert x.ndim == 2
|
| 97 |
+
if (self.max_items is not None) and (self.num_items + x.shape[0] > self.max_items):
|
| 98 |
+
if self.num_items >= self.max_items:
|
| 99 |
+
return
|
| 100 |
+
x = x[:self.max_items - self.num_items]
|
| 101 |
+
|
| 102 |
+
self.set_num_features(x.shape[1])
|
| 103 |
+
self.num_items += x.shape[0]
|
| 104 |
+
if self.capture_all:
|
| 105 |
+
self.all_features.append(x)
|
| 106 |
+
if self.capture_mean_cov:
|
| 107 |
+
x64 = x.astype(np.float64)
|
| 108 |
+
self.raw_mean += x64.sum(axis=0)
|
| 109 |
+
self.raw_cov += x64.T @ x64
|
| 110 |
+
|
| 111 |
+
def append_torch(self, x, num_gpus=1, rank=0):
|
| 112 |
+
assert isinstance(x, torch.Tensor) and x.ndim == 2
|
| 113 |
+
assert 0 <= rank < num_gpus
|
| 114 |
+
if num_gpus > 1:
|
| 115 |
+
ys = []
|
| 116 |
+
for src in range(num_gpus):
|
| 117 |
+
y = x.clone()
|
| 118 |
+
torch.distributed.broadcast(y, src=src)
|
| 119 |
+
ys.append(y)
|
| 120 |
+
x = torch.stack(ys, dim=1).flatten(0, 1) # interleave samples
|
| 121 |
+
self.append(x.cpu().numpy())
|
| 122 |
+
|
| 123 |
+
def get_all(self):
|
| 124 |
+
assert self.capture_all
|
| 125 |
+
return np.concatenate(self.all_features, axis=0)
|
| 126 |
+
|
| 127 |
+
def get_all_torch(self):
|
| 128 |
+
return torch.from_numpy(self.get_all())
|
| 129 |
+
|
| 130 |
+
def get_mean_cov(self):
|
| 131 |
+
assert self.capture_mean_cov
|
| 132 |
+
mean = self.raw_mean / self.num_items
|
| 133 |
+
cov = self.raw_cov / self.num_items
|
| 134 |
+
cov = cov - np.outer(mean, mean)
|
| 135 |
+
return mean, cov
|
| 136 |
+
|
| 137 |
+
def save(self, pkl_file):
|
| 138 |
+
with open(pkl_file, 'wb') as f:
|
| 139 |
+
pickle.dump(self.__dict__, f)
|
| 140 |
+
|
| 141 |
+
@staticmethod
|
| 142 |
+
def load(pkl_file):
|
| 143 |
+
with open(pkl_file, 'rb') as f:
|
| 144 |
+
s = dnnlib.EasyDict(pickle.load(f))
|
| 145 |
+
obj = FeatureStats(capture_all=s.capture_all, max_items=s.max_items)
|
| 146 |
+
obj.__dict__.update(s)
|
| 147 |
+
return obj
|
| 148 |
+
|
| 149 |
+
#----------------------------------------------------------------------------
|
| 150 |
+
|
| 151 |
+
class ProgressMonitor:
|
| 152 |
+
def __init__(self, tag=None, num_items=None, flush_interval=1000, verbose=False, progress_fn=None, pfn_lo=0, pfn_hi=1000, pfn_total=1000):
|
| 153 |
+
self.tag = tag
|
| 154 |
+
self.num_items = num_items
|
| 155 |
+
self.verbose = verbose
|
| 156 |
+
self.flush_interval = flush_interval
|
| 157 |
+
self.progress_fn = progress_fn
|
| 158 |
+
self.pfn_lo = pfn_lo
|
| 159 |
+
self.pfn_hi = pfn_hi
|
| 160 |
+
self.pfn_total = pfn_total
|
| 161 |
+
self.start_time = time.time()
|
| 162 |
+
self.batch_time = self.start_time
|
| 163 |
+
self.batch_items = 0
|
| 164 |
+
if self.progress_fn is not None:
|
| 165 |
+
self.progress_fn(self.pfn_lo, self.pfn_total)
|
| 166 |
+
|
| 167 |
+
def update(self, cur_items):
|
| 168 |
+
assert (self.num_items is None) or (cur_items <= self.num_items)
|
| 169 |
+
if (cur_items < self.batch_items + self.flush_interval) and (self.num_items is None or cur_items < self.num_items):
|
| 170 |
+
return
|
| 171 |
+
cur_time = time.time()
|
| 172 |
+
total_time = cur_time - self.start_time
|
| 173 |
+
time_per_item = (cur_time - self.batch_time) / max(cur_items - self.batch_items, 1)
|
| 174 |
+
if (self.verbose) and (self.tag is not None):
|
| 175 |
+
print(f'{self.tag:<19s} items {cur_items:<7d} time {dnnlib.util.format_time(total_time):<12s} ms/item {time_per_item*1e3:.2f}')
|
| 176 |
+
self.batch_time = cur_time
|
| 177 |
+
self.batch_items = cur_items
|
| 178 |
+
|
| 179 |
+
if (self.progress_fn is not None) and (self.num_items is not None):
|
| 180 |
+
self.progress_fn(self.pfn_lo + (self.pfn_hi - self.pfn_lo) * (cur_items / self.num_items), self.pfn_total)
|
| 181 |
+
|
| 182 |
+
def sub(self, tag=None, num_items=None, flush_interval=1000, rel_lo=0, rel_hi=1):
|
| 183 |
+
return ProgressMonitor(
|
| 184 |
+
tag = tag,
|
| 185 |
+
num_items = num_items,
|
| 186 |
+
flush_interval = flush_interval,
|
| 187 |
+
verbose = self.verbose,
|
| 188 |
+
progress_fn = self.progress_fn,
|
| 189 |
+
pfn_lo = self.pfn_lo + (self.pfn_hi - self.pfn_lo) * rel_lo,
|
| 190 |
+
pfn_hi = self.pfn_lo + (self.pfn_hi - self.pfn_lo) * rel_hi,
|
| 191 |
+
pfn_total = self.pfn_total,
|
| 192 |
+
)
|
| 193 |
+
|
| 194 |
+
#----------------------------------------------------------------------------
|
| 195 |
+
|
| 196 |
+
def compute_feature_stats_for_dataset(opts, detector_url, detector_kwargs, rel_lo=0, rel_hi=1, batch_size=64, data_loader_kwargs=None, max_items=None, **stats_kwargs):
|
| 197 |
+
dataset = dnnlib.util.construct_class_by_name(**opts.dataset_kwargs)
|
| 198 |
+
if data_loader_kwargs is None:
|
| 199 |
+
data_loader_kwargs = dict(pin_memory=True, num_workers=3, prefetch_factor=2)
|
| 200 |
+
|
| 201 |
+
# Try to lookup from cache.
|
| 202 |
+
cache_file = None
|
| 203 |
+
if opts.cache:
|
| 204 |
+
# Choose cache file name.
|
| 205 |
+
args = dict(dataset_kwargs=opts.dataset_kwargs, detector_url=detector_url, detector_kwargs=detector_kwargs, stats_kwargs=stats_kwargs)
|
| 206 |
+
md5 = hashlib.md5(repr(sorted(args.items())).encode('utf-8'))
|
| 207 |
+
cache_tag = f'{dataset.name}-{get_feature_detector_name(detector_url)}-{md5.hexdigest()}'
|
| 208 |
+
cache_file = dnnlib.make_cache_dir_path('gan-metrics', cache_tag + '.pkl')
|
| 209 |
+
|
| 210 |
+
# Check if the file exists (all processes must agree).
|
| 211 |
+
flag = os.path.isfile(cache_file) if opts.rank == 0 else False
|
| 212 |
+
if opts.num_gpus > 1:
|
| 213 |
+
flag = torch.as_tensor(flag, dtype=torch.float32, device=opts.device)
|
| 214 |
+
torch.distributed.broadcast(tensor=flag, src=0)
|
| 215 |
+
flag = (float(flag.cpu()) != 0)
|
| 216 |
+
|
| 217 |
+
# Load.
|
| 218 |
+
if flag:
|
| 219 |
+
return FeatureStats.load(cache_file)
|
| 220 |
+
|
| 221 |
+
# Initialize.
|
| 222 |
+
num_items = len(dataset)
|
| 223 |
+
if max_items is not None:
|
| 224 |
+
num_items = min(num_items, max_items)
|
| 225 |
+
stats = FeatureStats(max_items=num_items, **stats_kwargs)
|
| 226 |
+
progress = opts.progress.sub(tag='dataset features', num_items=num_items, rel_lo=rel_lo, rel_hi=rel_hi)
|
| 227 |
+
detector = get_feature_detector(url=detector_url, device=opts.device, num_gpus=opts.num_gpus, rank=opts.rank, verbose=progress.verbose)
|
| 228 |
+
|
| 229 |
+
# Main loop.
|
| 230 |
+
item_subset = [(i * opts.num_gpus + opts.rank) % num_items for i in range((num_items - 1) // opts.num_gpus + 1)]
|
| 231 |
+
for images, _labels in torch.utils.data.DataLoader(dataset=dataset, sampler=item_subset, batch_size=batch_size, **data_loader_kwargs):
|
| 232 |
+
if images.shape[1] == 1:
|
| 233 |
+
images = images.repeat([1, 3, 1, 1])
|
| 234 |
+
features = detector(images.to(opts.device), **detector_kwargs)
|
| 235 |
+
stats.append_torch(features, num_gpus=opts.num_gpus, rank=opts.rank)
|
| 236 |
+
progress.update(stats.num_items)
|
| 237 |
+
|
| 238 |
+
# Save to cache.
|
| 239 |
+
if cache_file is not None and opts.rank == 0:
|
| 240 |
+
os.makedirs(os.path.dirname(cache_file), exist_ok=True)
|
| 241 |
+
temp_file = cache_file + '.' + uuid.uuid4().hex
|
| 242 |
+
stats.save(temp_file)
|
| 243 |
+
os.replace(temp_file, cache_file) # atomic
|
| 244 |
+
return stats
|
| 245 |
+
|
| 246 |
+
#----------------------------------------------------------------------------
|
| 247 |
+
|
| 248 |
+
def compute_feature_stats_for_generator(opts, detector_url, detector_kwargs, rel_lo=0, rel_hi=1, batch_size=64, batch_gen=None, **stats_kwargs):
|
| 249 |
+
if batch_gen is None:
|
| 250 |
+
batch_gen = min(batch_size, 4)
|
| 251 |
+
assert batch_size % batch_gen == 0
|
| 252 |
+
|
| 253 |
+
# Setup generator and labels.
|
| 254 |
+
G = copy.deepcopy(opts.G).eval().requires_grad_(False).to(opts.device)
|
| 255 |
+
c_iter = iterate_random_labels(opts=opts, batch_size=batch_gen)
|
| 256 |
+
|
| 257 |
+
# Initialize.
|
| 258 |
+
stats = FeatureStats(**stats_kwargs)
|
| 259 |
+
assert stats.max_items is not None
|
| 260 |
+
progress = opts.progress.sub(tag='generator features', num_items=stats.max_items, rel_lo=rel_lo, rel_hi=rel_hi)
|
| 261 |
+
detector = get_feature_detector(url=detector_url, device=opts.device, num_gpus=opts.num_gpus, rank=opts.rank, verbose=progress.verbose)
|
| 262 |
+
|
| 263 |
+
# Main loop.
|
| 264 |
+
while not stats.is_full():
|
| 265 |
+
images = []
|
| 266 |
+
for _i in range(batch_size // batch_gen):
|
| 267 |
+
z = torch.randn([batch_gen, G.z_dim], device=opts.device)
|
| 268 |
+
img = G(z, next(c_iter))
|
| 269 |
+
img = (img * 127.5 + 128).clamp(0, 255).to(torch.uint8)
|
| 270 |
+
images.append(img)
|
| 271 |
+
images = torch.cat(images)
|
| 272 |
+
if images.shape[1] == 1:
|
| 273 |
+
images = images.repeat([1, 3, 1, 1])
|
| 274 |
+
features = detector(images, **detector_kwargs)
|
| 275 |
+
stats.append_torch(features, num_gpus=opts.num_gpus, rank=opts.rank)
|
| 276 |
+
progress.update(stats.num_items)
|
| 277 |
+
return stats
|
| 278 |
+
|
| 279 |
+
#----------------------------------------------------------------------------
|
metrics/precision_recall.py
ADDED
|
@@ -0,0 +1,62 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
"""Precision/Recall (PR) from the paper "Improved Precision and Recall
|
| 10 |
+
Metric for Assessing Generative Models". Matches the original implementation
|
| 11 |
+
by Kynkaanniemi et al. at
|
| 12 |
+
https://github.com/kynkaat/improved-precision-and-recall-metric/blob/master/precision_recall.py"""
|
| 13 |
+
|
| 14 |
+
import torch
|
| 15 |
+
from . import metric_utils
|
| 16 |
+
|
| 17 |
+
#----------------------------------------------------------------------------
|
| 18 |
+
|
| 19 |
+
def compute_distances(row_features, col_features, num_gpus, rank, col_batch_size):
|
| 20 |
+
assert 0 <= rank < num_gpus
|
| 21 |
+
num_cols = col_features.shape[0]
|
| 22 |
+
num_batches = ((num_cols - 1) // col_batch_size // num_gpus + 1) * num_gpus
|
| 23 |
+
col_batches = torch.nn.functional.pad(col_features, [0, 0, 0, -num_cols % num_batches]).chunk(num_batches)
|
| 24 |
+
dist_batches = []
|
| 25 |
+
for col_batch in col_batches[rank :: num_gpus]:
|
| 26 |
+
dist_batch = torch.cdist(row_features.unsqueeze(0), col_batch.unsqueeze(0))[0]
|
| 27 |
+
for src in range(num_gpus):
|
| 28 |
+
dist_broadcast = dist_batch.clone()
|
| 29 |
+
if num_gpus > 1:
|
| 30 |
+
torch.distributed.broadcast(dist_broadcast, src=src)
|
| 31 |
+
dist_batches.append(dist_broadcast.cpu() if rank == 0 else None)
|
| 32 |
+
return torch.cat(dist_batches, dim=1)[:, :num_cols] if rank == 0 else None
|
| 33 |
+
|
| 34 |
+
#----------------------------------------------------------------------------
|
| 35 |
+
|
| 36 |
+
def compute_pr(opts, max_real, num_gen, nhood_size, row_batch_size, col_batch_size):
|
| 37 |
+
detector_url = 'https://api.ngc.nvidia.com/v2/models/nvidia/research/stylegan3/versions/1/files/metrics/vgg16.pkl'
|
| 38 |
+
detector_kwargs = dict(return_features=True)
|
| 39 |
+
|
| 40 |
+
real_features = metric_utils.compute_feature_stats_for_dataset(
|
| 41 |
+
opts=opts, detector_url=detector_url, detector_kwargs=detector_kwargs,
|
| 42 |
+
rel_lo=0, rel_hi=0, capture_all=True, max_items=max_real).get_all_torch().to(torch.float16).to(opts.device)
|
| 43 |
+
|
| 44 |
+
gen_features = metric_utils.compute_feature_stats_for_generator(
|
| 45 |
+
opts=opts, detector_url=detector_url, detector_kwargs=detector_kwargs,
|
| 46 |
+
rel_lo=0, rel_hi=1, capture_all=True, max_items=num_gen).get_all_torch().to(torch.float16).to(opts.device)
|
| 47 |
+
|
| 48 |
+
results = dict()
|
| 49 |
+
for name, manifold, probes in [('precision', real_features, gen_features), ('recall', gen_features, real_features)]:
|
| 50 |
+
kth = []
|
| 51 |
+
for manifold_batch in manifold.split(row_batch_size):
|
| 52 |
+
dist = compute_distances(row_features=manifold_batch, col_features=manifold, num_gpus=opts.num_gpus, rank=opts.rank, col_batch_size=col_batch_size)
|
| 53 |
+
kth.append(dist.to(torch.float32).kthvalue(nhood_size + 1).values.to(torch.float16) if opts.rank == 0 else None)
|
| 54 |
+
kth = torch.cat(kth) if opts.rank == 0 else None
|
| 55 |
+
pred = []
|
| 56 |
+
for probes_batch in probes.split(row_batch_size):
|
| 57 |
+
dist = compute_distances(row_features=probes_batch, col_features=manifold, num_gpus=opts.num_gpus, rank=opts.rank, col_batch_size=col_batch_size)
|
| 58 |
+
pred.append((dist <= kth).any(dim=1) if opts.rank == 0 else None)
|
| 59 |
+
results[name] = float(torch.cat(pred).to(torch.float32).mean() if opts.rank == 0 else 'nan')
|
| 60 |
+
return results['precision'], results['recall']
|
| 61 |
+
|
| 62 |
+
#----------------------------------------------------------------------------
|
torch_utils/__init__.py
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
# empty
|
torch_utils/custom_ops.py
ADDED
|
@@ -0,0 +1,157 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
import glob
|
| 10 |
+
import hashlib
|
| 11 |
+
import importlib
|
| 12 |
+
import os
|
| 13 |
+
import re
|
| 14 |
+
import shutil
|
| 15 |
+
import uuid
|
| 16 |
+
|
| 17 |
+
import torch
|
| 18 |
+
import torch.utils.cpp_extension
|
| 19 |
+
from torch.utils.file_baton import FileBaton
|
| 20 |
+
|
| 21 |
+
#----------------------------------------------------------------------------
|
| 22 |
+
# Global options.
|
| 23 |
+
|
| 24 |
+
verbosity = 'brief' # Verbosity level: 'none', 'brief', 'full'
|
| 25 |
+
|
| 26 |
+
#----------------------------------------------------------------------------
|
| 27 |
+
# Internal helper funcs.
|
| 28 |
+
|
| 29 |
+
def _find_compiler_bindir():
|
| 30 |
+
patterns = [
|
| 31 |
+
'C:/Program Files*/Microsoft Visual Studio/*/Professional/VC/Tools/MSVC/*/bin/Hostx64/x64',
|
| 32 |
+
'C:/Program Files*/Microsoft Visual Studio/*/BuildTools/VC/Tools/MSVC/*/bin/Hostx64/x64',
|
| 33 |
+
'C:/Program Files*/Microsoft Visual Studio/*/Community/VC/Tools/MSVC/*/bin/Hostx64/x64',
|
| 34 |
+
'C:/Program Files*/Microsoft Visual Studio */vc/bin',
|
| 35 |
+
]
|
| 36 |
+
for pattern in patterns:
|
| 37 |
+
matches = sorted(glob.glob(pattern))
|
| 38 |
+
if len(matches):
|
| 39 |
+
return matches[-1]
|
| 40 |
+
return None
|
| 41 |
+
|
| 42 |
+
#----------------------------------------------------------------------------
|
| 43 |
+
|
| 44 |
+
def _get_mangled_gpu_name():
|
| 45 |
+
name = torch.cuda.get_device_name().lower()
|
| 46 |
+
out = []
|
| 47 |
+
for c in name:
|
| 48 |
+
if re.match('[a-z0-9_-]+', c):
|
| 49 |
+
out.append(c)
|
| 50 |
+
else:
|
| 51 |
+
out.append('-')
|
| 52 |
+
return ''.join(out)
|
| 53 |
+
|
| 54 |
+
#----------------------------------------------------------------------------
|
| 55 |
+
# Main entry point for compiling and loading C++/CUDA plugins.
|
| 56 |
+
|
| 57 |
+
_cached_plugins = dict()
|
| 58 |
+
|
| 59 |
+
def get_plugin(module_name, sources, headers=None, source_dir=None, **build_kwargs):
|
| 60 |
+
assert verbosity in ['none', 'brief', 'full']
|
| 61 |
+
if headers is None:
|
| 62 |
+
headers = []
|
| 63 |
+
if source_dir is not None:
|
| 64 |
+
sources = [os.path.join(source_dir, fname) for fname in sources]
|
| 65 |
+
headers = [os.path.join(source_dir, fname) for fname in headers]
|
| 66 |
+
|
| 67 |
+
# Already cached?
|
| 68 |
+
if module_name in _cached_plugins:
|
| 69 |
+
return _cached_plugins[module_name]
|
| 70 |
+
|
| 71 |
+
# Print status.
|
| 72 |
+
if verbosity == 'full':
|
| 73 |
+
print(f'Setting up PyTorch plugin "{module_name}"...')
|
| 74 |
+
elif verbosity == 'brief':
|
| 75 |
+
print(f'Setting up PyTorch plugin "{module_name}"... ', end='', flush=True)
|
| 76 |
+
verbose_build = (verbosity == 'full')
|
| 77 |
+
|
| 78 |
+
# Compile and load.
|
| 79 |
+
try: # pylint: disable=too-many-nested-blocks
|
| 80 |
+
# Make sure we can find the necessary compiler binaries.
|
| 81 |
+
if os.name == 'nt' and os.system("where cl.exe >nul 2>nul") != 0:
|
| 82 |
+
compiler_bindir = _find_compiler_bindir()
|
| 83 |
+
if compiler_bindir is None:
|
| 84 |
+
raise RuntimeError(f'Could not find MSVC/GCC/CLANG installation on this computer. Check _find_compiler_bindir() in "{__file__}".')
|
| 85 |
+
os.environ['PATH'] += ';' + compiler_bindir
|
| 86 |
+
|
| 87 |
+
# Some containers set TORCH_CUDA_ARCH_LIST to a list that can either
|
| 88 |
+
# break the build or unnecessarily restrict what's available to nvcc.
|
| 89 |
+
# Unset it to let nvcc decide based on what's available on the
|
| 90 |
+
# machine.
|
| 91 |
+
os.environ['TORCH_CUDA_ARCH_LIST'] = ''
|
| 92 |
+
|
| 93 |
+
# Incremental build md5sum trickery. Copies all the input source files
|
| 94 |
+
# into a cached build directory under a combined md5 digest of the input
|
| 95 |
+
# source files. Copying is done only if the combined digest has changed.
|
| 96 |
+
# This keeps input file timestamps and filenames the same as in previous
|
| 97 |
+
# extension builds, allowing for fast incremental rebuilds.
|
| 98 |
+
#
|
| 99 |
+
# This optimization is done only in case all the source files reside in
|
| 100 |
+
# a single directory (just for simplicity) and if the TORCH_EXTENSIONS_DIR
|
| 101 |
+
# environment variable is set (we take this as a signal that the user
|
| 102 |
+
# actually cares about this.)
|
| 103 |
+
#
|
| 104 |
+
# EDIT: We now do it regardless of TORCH_EXTENSIOS_DIR, in order to work
|
| 105 |
+
# around the *.cu dependency bug in ninja config.
|
| 106 |
+
#
|
| 107 |
+
all_source_files = sorted(sources + headers)
|
| 108 |
+
all_source_dirs = set(os.path.dirname(fname) for fname in all_source_files)
|
| 109 |
+
if len(all_source_dirs) == 1: # and ('TORCH_EXTENSIONS_DIR' in os.environ):
|
| 110 |
+
|
| 111 |
+
# Compute combined hash digest for all source files.
|
| 112 |
+
hash_md5 = hashlib.md5()
|
| 113 |
+
for src in all_source_files:
|
| 114 |
+
with open(src, 'rb') as f:
|
| 115 |
+
hash_md5.update(f.read())
|
| 116 |
+
|
| 117 |
+
# Select cached build directory name.
|
| 118 |
+
source_digest = hash_md5.hexdigest()
|
| 119 |
+
build_top_dir = torch.utils.cpp_extension._get_build_directory(module_name, verbose=verbose_build) # pylint: disable=protected-access
|
| 120 |
+
cached_build_dir = os.path.join(build_top_dir, f'{source_digest}-{_get_mangled_gpu_name()}')
|
| 121 |
+
|
| 122 |
+
if not os.path.isdir(cached_build_dir):
|
| 123 |
+
tmpdir = f'{build_top_dir}/srctmp-{uuid.uuid4().hex}'
|
| 124 |
+
os.makedirs(tmpdir)
|
| 125 |
+
for src in all_source_files:
|
| 126 |
+
shutil.copyfile(src, os.path.join(tmpdir, os.path.basename(src)))
|
| 127 |
+
try:
|
| 128 |
+
os.replace(tmpdir, cached_build_dir) # atomic
|
| 129 |
+
except OSError:
|
| 130 |
+
# source directory already exists, delete tmpdir and its contents.
|
| 131 |
+
shutil.rmtree(tmpdir)
|
| 132 |
+
if not os.path.isdir(cached_build_dir): raise
|
| 133 |
+
|
| 134 |
+
# Compile.
|
| 135 |
+
cached_sources = [os.path.join(cached_build_dir, os.path.basename(fname)) for fname in sources]
|
| 136 |
+
torch.utils.cpp_extension.load(name=module_name, build_directory=cached_build_dir,
|
| 137 |
+
verbose=verbose_build, sources=cached_sources, **build_kwargs)
|
| 138 |
+
else:
|
| 139 |
+
torch.utils.cpp_extension.load(name=module_name, verbose=verbose_build, sources=sources, **build_kwargs)
|
| 140 |
+
|
| 141 |
+
# Load.
|
| 142 |
+
module = importlib.import_module(module_name)
|
| 143 |
+
|
| 144 |
+
except:
|
| 145 |
+
if verbosity == 'brief':
|
| 146 |
+
print('Failed!')
|
| 147 |
+
raise
|
| 148 |
+
|
| 149 |
+
# Print status and add to cache dict.
|
| 150 |
+
if verbosity == 'full':
|
| 151 |
+
print(f'Done setting up PyTorch plugin "{module_name}".')
|
| 152 |
+
elif verbosity == 'brief':
|
| 153 |
+
print('Done.')
|
| 154 |
+
_cached_plugins[module_name] = module
|
| 155 |
+
return module
|
| 156 |
+
|
| 157 |
+
#----------------------------------------------------------------------------
|
torch_utils/misc.py
ADDED
|
@@ -0,0 +1,249 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
import re
|
| 10 |
+
import contextlib
|
| 11 |
+
import numpy as np
|
| 12 |
+
import torch
|
| 13 |
+
import warnings
|
| 14 |
+
import dnnlib
|
| 15 |
+
|
| 16 |
+
#----------------------------------------------------------------------------
|
| 17 |
+
# Cached construction of constant tensors. Avoids CPU=>GPU copy when the
|
| 18 |
+
# same constant is used multiple times.
|
| 19 |
+
|
| 20 |
+
_constant_cache = dict()
|
| 21 |
+
|
| 22 |
+
def constant(value, shape=None, dtype=None, device=None, memory_format=None):
|
| 23 |
+
value = np.asarray(value)
|
| 24 |
+
if shape is not None:
|
| 25 |
+
shape = tuple(shape)
|
| 26 |
+
if dtype is None:
|
| 27 |
+
dtype = torch.get_default_dtype()
|
| 28 |
+
if device is None:
|
| 29 |
+
device = torch.device('cpu')
|
| 30 |
+
if memory_format is None:
|
| 31 |
+
memory_format = torch.contiguous_format
|
| 32 |
+
|
| 33 |
+
key = (value.shape, value.dtype, value.tobytes(), shape, dtype, device, memory_format)
|
| 34 |
+
tensor = _constant_cache.get(key, None)
|
| 35 |
+
if tensor is None:
|
| 36 |
+
tensor = torch.as_tensor(value.copy(), dtype=dtype, device=device)
|
| 37 |
+
if shape is not None:
|
| 38 |
+
tensor, _ = torch.broadcast_tensors(tensor, torch.empty(shape))
|
| 39 |
+
tensor = tensor.contiguous(memory_format=memory_format)
|
| 40 |
+
_constant_cache[key] = tensor
|
| 41 |
+
return tensor
|
| 42 |
+
|
| 43 |
+
#----------------------------------------------------------------------------
|
| 44 |
+
# Symbolic assert.
|
| 45 |
+
|
| 46 |
+
try:
|
| 47 |
+
symbolic_assert = torch._assert # 1.8.0a0 # pylint: disable=protected-access
|
| 48 |
+
except AttributeError:
|
| 49 |
+
symbolic_assert = torch.Assert # 1.7.0
|
| 50 |
+
|
| 51 |
+
#----------------------------------------------------------------------------
|
| 52 |
+
# Context manager to temporarily suppress known warnings in torch.jit.trace().
|
| 53 |
+
# Note: Cannot use catch_warnings because of https://bugs.python.org/issue29672
|
| 54 |
+
|
| 55 |
+
@contextlib.contextmanager
|
| 56 |
+
def suppress_tracer_warnings():
|
| 57 |
+
flt = ('ignore', None, torch.jit.TracerWarning, None, 0)
|
| 58 |
+
warnings.filters.insert(0, flt)
|
| 59 |
+
yield
|
| 60 |
+
warnings.filters.remove(flt)
|
| 61 |
+
|
| 62 |
+
#----------------------------------------------------------------------------
|
| 63 |
+
# Assert that the shape of a tensor matches the given list of integers.
|
| 64 |
+
# None indicates that the size of a dimension is allowed to vary.
|
| 65 |
+
# Performs symbolic assertion when used in torch.jit.trace().
|
| 66 |
+
|
| 67 |
+
def assert_shape(tensor, ref_shape):
|
| 68 |
+
if tensor.ndim != len(ref_shape):
|
| 69 |
+
raise AssertionError(f'Wrong number of dimensions: got {tensor.ndim}, expected {len(ref_shape)}')
|
| 70 |
+
for idx, (size, ref_size) in enumerate(zip(tensor.shape, ref_shape)):
|
| 71 |
+
if ref_size is None:
|
| 72 |
+
pass
|
| 73 |
+
elif isinstance(ref_size, torch.Tensor):
|
| 74 |
+
with suppress_tracer_warnings(): # as_tensor results are registered as constants
|
| 75 |
+
symbolic_assert(torch.equal(torch.as_tensor(size), ref_size), f'Wrong size for dimension {idx}')
|
| 76 |
+
elif isinstance(size, torch.Tensor):
|
| 77 |
+
with suppress_tracer_warnings(): # as_tensor results are registered as constants
|
| 78 |
+
symbolic_assert(torch.equal(size, torch.as_tensor(ref_size)), f'Wrong size for dimension {idx}: expected {ref_size}')
|
| 79 |
+
elif size != ref_size:
|
| 80 |
+
raise AssertionError(f'Wrong size for dimension {idx}: got {size}, expected {ref_size}')
|
| 81 |
+
|
| 82 |
+
#----------------------------------------------------------------------------
|
| 83 |
+
# Function decorator that calls torch.autograd.profiler.record_function().
|
| 84 |
+
|
| 85 |
+
def profiled_function(fn):
|
| 86 |
+
def decorator(*args, **kwargs):
|
| 87 |
+
with torch.autograd.profiler.record_function(fn.__name__):
|
| 88 |
+
return fn(*args, **kwargs)
|
| 89 |
+
decorator.__name__ = fn.__name__
|
| 90 |
+
return decorator
|
| 91 |
+
|
| 92 |
+
#----------------------------------------------------------------------------
|
| 93 |
+
# Sampler for torch.utils.data.DataLoader that loops over the dataset
|
| 94 |
+
# indefinitely, shuffling items as it goes.
|
| 95 |
+
|
| 96 |
+
class InfiniteSampler(torch.utils.data.Sampler):
|
| 97 |
+
def __init__(self, dataset, rank=0, num_replicas=1, shuffle=True, seed=0, window_size=0.5):
|
| 98 |
+
assert len(dataset) > 0
|
| 99 |
+
assert num_replicas > 0
|
| 100 |
+
assert 0 <= rank < num_replicas
|
| 101 |
+
assert 0 <= window_size <= 1
|
| 102 |
+
super().__init__(None)
|
| 103 |
+
self.dataset = dataset
|
| 104 |
+
self.rank = rank
|
| 105 |
+
self.num_replicas = num_replicas
|
| 106 |
+
self.shuffle = shuffle
|
| 107 |
+
self.seed = seed
|
| 108 |
+
self.window_size = window_size
|
| 109 |
+
|
| 110 |
+
def __iter__(self):
|
| 111 |
+
order = np.arange(len(self.dataset))
|
| 112 |
+
rnd = None
|
| 113 |
+
window = 0
|
| 114 |
+
if self.shuffle:
|
| 115 |
+
rnd = np.random.RandomState(self.seed)
|
| 116 |
+
rnd.shuffle(order)
|
| 117 |
+
window = int(np.rint(order.size * self.window_size))
|
| 118 |
+
|
| 119 |
+
idx = 0
|
| 120 |
+
while True:
|
| 121 |
+
i = idx % order.size
|
| 122 |
+
if idx % self.num_replicas == self.rank:
|
| 123 |
+
yield order[i]
|
| 124 |
+
if window >= 2:
|
| 125 |
+
j = (i - rnd.randint(window)) % order.size
|
| 126 |
+
order[i], order[j] = order[j], order[i]
|
| 127 |
+
idx += 1
|
| 128 |
+
|
| 129 |
+
#----------------------------------------------------------------------------
|
| 130 |
+
# Utilities for operating with torch.nn.Module parameters and buffers.
|
| 131 |
+
|
| 132 |
+
def params_and_buffers(module):
|
| 133 |
+
assert isinstance(module, torch.nn.Module)
|
| 134 |
+
return list(module.parameters()) + list(module.buffers())
|
| 135 |
+
|
| 136 |
+
def named_params_and_buffers(module):
|
| 137 |
+
assert isinstance(module, torch.nn.Module)
|
| 138 |
+
return list(module.named_parameters()) + list(module.named_buffers())
|
| 139 |
+
|
| 140 |
+
def copy_params_and_buffers(src_module, dst_module, require_all=False):
|
| 141 |
+
assert isinstance(src_module, torch.nn.Module)
|
| 142 |
+
assert isinstance(dst_module, torch.nn.Module)
|
| 143 |
+
src_tensors = dict(named_params_and_buffers(src_module))
|
| 144 |
+
for name, tensor in named_params_and_buffers(dst_module):
|
| 145 |
+
assert (name in src_tensors) or (not require_all)
|
| 146 |
+
if name in src_tensors:
|
| 147 |
+
tensor.copy_(src_tensors[name].detach()).requires_grad_(tensor.requires_grad)
|
| 148 |
+
|
| 149 |
+
#----------------------------------------------------------------------------
|
| 150 |
+
# Context manager for easily enabling/disabling DistributedDataParallel
|
| 151 |
+
# synchronization.
|
| 152 |
+
|
| 153 |
+
@contextlib.contextmanager
|
| 154 |
+
def ddp_sync(module, sync):
|
| 155 |
+
assert isinstance(module, torch.nn.Module)
|
| 156 |
+
if sync or not isinstance(module, torch.nn.parallel.DistributedDataParallel):
|
| 157 |
+
yield
|
| 158 |
+
else:
|
| 159 |
+
with module.no_sync():
|
| 160 |
+
yield
|
| 161 |
+
|
| 162 |
+
#----------------------------------------------------------------------------
|
| 163 |
+
# Check DistributedDataParallel consistency across processes.
|
| 164 |
+
|
| 165 |
+
def check_ddp_consistency(module, ignore_regex=None):
|
| 166 |
+
assert isinstance(module, torch.nn.Module)
|
| 167 |
+
for name, tensor in named_params_and_buffers(module):
|
| 168 |
+
fullname = type(module).__name__ + '.' + name
|
| 169 |
+
if ignore_regex is not None and re.fullmatch(ignore_regex, fullname):
|
| 170 |
+
continue
|
| 171 |
+
tensor = tensor.detach()
|
| 172 |
+
other = tensor.clone()
|
| 173 |
+
torch.distributed.broadcast(tensor=other, src=0)
|
| 174 |
+
assert (tensor == other).all(), fullname
|
| 175 |
+
|
| 176 |
+
#----------------------------------------------------------------------------
|
| 177 |
+
# Print summary table of module hierarchy.
|
| 178 |
+
|
| 179 |
+
def print_module_summary(module, inputs, max_nesting=3, skip_redundant=True):
|
| 180 |
+
assert isinstance(module, torch.nn.Module)
|
| 181 |
+
assert not isinstance(module, torch.jit.ScriptModule)
|
| 182 |
+
assert isinstance(inputs, (tuple, list))
|
| 183 |
+
|
| 184 |
+
# Register hooks.
|
| 185 |
+
entries = []
|
| 186 |
+
nesting = [0]
|
| 187 |
+
def pre_hook(_mod, _inputs):
|
| 188 |
+
nesting[0] += 1
|
| 189 |
+
def post_hook(mod, _inputs, outputs):
|
| 190 |
+
nesting[0] -= 1
|
| 191 |
+
if nesting[0] <= max_nesting:
|
| 192 |
+
outputs = list(outputs) if isinstance(outputs, (tuple, list)) else [outputs]
|
| 193 |
+
outputs = [t for t in outputs if isinstance(t, torch.Tensor)]
|
| 194 |
+
entries.append(dnnlib.EasyDict(mod=mod, outputs=outputs))
|
| 195 |
+
hooks = [mod.register_forward_pre_hook(pre_hook) for mod in module.modules()]
|
| 196 |
+
hooks += [mod.register_forward_hook(post_hook) for mod in module.modules()]
|
| 197 |
+
|
| 198 |
+
# Run module.
|
| 199 |
+
outputs = module(*inputs)
|
| 200 |
+
for hook in hooks:
|
| 201 |
+
hook.remove()
|
| 202 |
+
|
| 203 |
+
# Identify unique outputs, parameters, and buffers.
|
| 204 |
+
tensors_seen = set()
|
| 205 |
+
for e in entries:
|
| 206 |
+
e.unique_params = [t for t in e.mod.parameters() if id(t) not in tensors_seen]
|
| 207 |
+
e.unique_buffers = [t for t in e.mod.buffers() if id(t) not in tensors_seen]
|
| 208 |
+
e.unique_outputs = [t for t in e.outputs if id(t) not in tensors_seen]
|
| 209 |
+
tensors_seen |= {id(t) for t in e.unique_params + e.unique_buffers + e.unique_outputs}
|
| 210 |
+
|
| 211 |
+
# Filter out redundant entries.
|
| 212 |
+
if skip_redundant:
|
| 213 |
+
entries = [e for e in entries if len(e.unique_params) or len(e.unique_buffers) or len(e.unique_outputs)]
|
| 214 |
+
|
| 215 |
+
# Construct table.
|
| 216 |
+
rows = [[type(module).__name__, 'Parameters', 'Buffers', 'Output shape', 'Datatype']]
|
| 217 |
+
rows += [['---'] * len(rows[0])]
|
| 218 |
+
param_total = 0
|
| 219 |
+
buffer_total = 0
|
| 220 |
+
submodule_names = {mod: name for name, mod in module.named_modules()}
|
| 221 |
+
for e in entries:
|
| 222 |
+
name = '<top-level>' if e.mod is module else submodule_names[e.mod]
|
| 223 |
+
param_size = sum(t.numel() for t in e.unique_params)
|
| 224 |
+
buffer_size = sum(t.numel() for t in e.unique_buffers)
|
| 225 |
+
output_shapes = [str(list(t.shape)) for t in e.outputs]
|
| 226 |
+
output_dtypes = [str(t.dtype).split('.')[-1] for t in e.outputs]
|
| 227 |
+
rows += [[
|
| 228 |
+
name + (':0' if len(e.outputs) >= 2 else ''),
|
| 229 |
+
str(param_size) if param_size else '-',
|
| 230 |
+
str(buffer_size) if buffer_size else '-',
|
| 231 |
+
(output_shapes + ['-'])[0],
|
| 232 |
+
(output_dtypes + ['-'])[0],
|
| 233 |
+
]]
|
| 234 |
+
for idx in range(1, len(e.outputs)):
|
| 235 |
+
rows += [[name + f':{idx}', '-', '-', output_shapes[idx], output_dtypes[idx]]]
|
| 236 |
+
param_total += param_size
|
| 237 |
+
buffer_total += buffer_size
|
| 238 |
+
rows += [['---'] * len(rows[0])]
|
| 239 |
+
rows += [['Total', str(param_total), str(buffer_total), '-', '-']]
|
| 240 |
+
|
| 241 |
+
# Print table.
|
| 242 |
+
widths = [max(len(cell) for cell in column) for column in zip(*rows)]
|
| 243 |
+
print()
|
| 244 |
+
for row in rows:
|
| 245 |
+
print(' '.join(cell + ' ' * (width - len(cell)) for cell, width in zip(row, widths)))
|
| 246 |
+
print()
|
| 247 |
+
return outputs
|
| 248 |
+
|
| 249 |
+
#----------------------------------------------------------------------------
|
torch_utils/ops/__init__.py
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
# empty
|
torch_utils/ops/bias_act.cpp
ADDED
|
@@ -0,0 +1,99 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
// Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
//
|
| 3 |
+
// NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
// and proprietary rights in and to this software, related documentation
|
| 5 |
+
// and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
// distribution of this software and related documentation without an express
|
| 7 |
+
// license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
#include <torch/extension.h>
|
| 10 |
+
#include <ATen/cuda/CUDAContext.h>
|
| 11 |
+
#include <c10/cuda/CUDAGuard.h>
|
| 12 |
+
#include "bias_act.h"
|
| 13 |
+
|
| 14 |
+
//------------------------------------------------------------------------
|
| 15 |
+
|
| 16 |
+
static bool has_same_layout(torch::Tensor x, torch::Tensor y)
|
| 17 |
+
{
|
| 18 |
+
if (x.dim() != y.dim())
|
| 19 |
+
return false;
|
| 20 |
+
for (int64_t i = 0; i < x.dim(); i++)
|
| 21 |
+
{
|
| 22 |
+
if (x.size(i) != y.size(i))
|
| 23 |
+
return false;
|
| 24 |
+
if (x.size(i) >= 2 && x.stride(i) != y.stride(i))
|
| 25 |
+
return false;
|
| 26 |
+
}
|
| 27 |
+
return true;
|
| 28 |
+
}
|
| 29 |
+
|
| 30 |
+
//------------------------------------------------------------------------
|
| 31 |
+
|
| 32 |
+
static torch::Tensor bias_act(torch::Tensor x, torch::Tensor b, torch::Tensor xref, torch::Tensor yref, torch::Tensor dy, int grad, int dim, int act, float alpha, float gain, float clamp)
|
| 33 |
+
{
|
| 34 |
+
// Validate arguments.
|
| 35 |
+
TORCH_CHECK(x.is_cuda(), "x must reside on CUDA device");
|
| 36 |
+
TORCH_CHECK(b.numel() == 0 || (b.dtype() == x.dtype() && b.device() == x.device()), "b must have the same dtype and device as x");
|
| 37 |
+
TORCH_CHECK(xref.numel() == 0 || (xref.sizes() == x.sizes() && xref.dtype() == x.dtype() && xref.device() == x.device()), "xref must have the same shape, dtype, and device as x");
|
| 38 |
+
TORCH_CHECK(yref.numel() == 0 || (yref.sizes() == x.sizes() && yref.dtype() == x.dtype() && yref.device() == x.device()), "yref must have the same shape, dtype, and device as x");
|
| 39 |
+
TORCH_CHECK(dy.numel() == 0 || (dy.sizes() == x.sizes() && dy.dtype() == x.dtype() && dy.device() == x.device()), "dy must have the same dtype and device as x");
|
| 40 |
+
TORCH_CHECK(x.numel() <= INT_MAX, "x is too large");
|
| 41 |
+
TORCH_CHECK(b.dim() == 1, "b must have rank 1");
|
| 42 |
+
TORCH_CHECK(b.numel() == 0 || (dim >= 0 && dim < x.dim()), "dim is out of bounds");
|
| 43 |
+
TORCH_CHECK(b.numel() == 0 || b.numel() == x.size(dim), "b has wrong number of elements");
|
| 44 |
+
TORCH_CHECK(grad >= 0, "grad must be non-negative");
|
| 45 |
+
|
| 46 |
+
// Validate layout.
|
| 47 |
+
TORCH_CHECK(x.is_non_overlapping_and_dense(), "x must be non-overlapping and dense");
|
| 48 |
+
TORCH_CHECK(b.is_contiguous(), "b must be contiguous");
|
| 49 |
+
TORCH_CHECK(xref.numel() == 0 || has_same_layout(xref, x), "xref must have the same layout as x");
|
| 50 |
+
TORCH_CHECK(yref.numel() == 0 || has_same_layout(yref, x), "yref must have the same layout as x");
|
| 51 |
+
TORCH_CHECK(dy.numel() == 0 || has_same_layout(dy, x), "dy must have the same layout as x");
|
| 52 |
+
|
| 53 |
+
// Create output tensor.
|
| 54 |
+
const at::cuda::OptionalCUDAGuard device_guard(device_of(x));
|
| 55 |
+
torch::Tensor y = torch::empty_like(x);
|
| 56 |
+
TORCH_CHECK(has_same_layout(y, x), "y must have the same layout as x");
|
| 57 |
+
|
| 58 |
+
// Initialize CUDA kernel parameters.
|
| 59 |
+
bias_act_kernel_params p;
|
| 60 |
+
p.x = x.data_ptr();
|
| 61 |
+
p.b = (b.numel()) ? b.data_ptr() : NULL;
|
| 62 |
+
p.xref = (xref.numel()) ? xref.data_ptr() : NULL;
|
| 63 |
+
p.yref = (yref.numel()) ? yref.data_ptr() : NULL;
|
| 64 |
+
p.dy = (dy.numel()) ? dy.data_ptr() : NULL;
|
| 65 |
+
p.y = y.data_ptr();
|
| 66 |
+
p.grad = grad;
|
| 67 |
+
p.act = act;
|
| 68 |
+
p.alpha = alpha;
|
| 69 |
+
p.gain = gain;
|
| 70 |
+
p.clamp = clamp;
|
| 71 |
+
p.sizeX = (int)x.numel();
|
| 72 |
+
p.sizeB = (int)b.numel();
|
| 73 |
+
p.stepB = (b.numel()) ? (int)x.stride(dim) : 1;
|
| 74 |
+
|
| 75 |
+
// Choose CUDA kernel.
|
| 76 |
+
void* kernel;
|
| 77 |
+
AT_DISPATCH_FLOATING_TYPES_AND2(at::ScalarType::Half, at::ScalarType::BFloat16, x.scalar_type(), "upfirdn2d_cuda", [&]
|
| 78 |
+
{
|
| 79 |
+
kernel = choose_bias_act_kernel<scalar_t>(p);
|
| 80 |
+
});
|
| 81 |
+
TORCH_CHECK(kernel, "no CUDA kernel found for the specified activation func");
|
| 82 |
+
|
| 83 |
+
// Launch CUDA kernel.
|
| 84 |
+
p.loopX = 4;
|
| 85 |
+
int blockSize = 4 * 32;
|
| 86 |
+
int gridSize = (p.sizeX - 1) / (p.loopX * blockSize) + 1;
|
| 87 |
+
void* args[] = {&p};
|
| 88 |
+
AT_CUDA_CHECK(cudaLaunchKernel(kernel, gridSize, blockSize, args, 0, at::cuda::getCurrentCUDAStream()));
|
| 89 |
+
return y;
|
| 90 |
+
}
|
| 91 |
+
|
| 92 |
+
//------------------------------------------------------------------------
|
| 93 |
+
|
| 94 |
+
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m)
|
| 95 |
+
{
|
| 96 |
+
m.def("bias_act", &bias_act);
|
| 97 |
+
}
|
| 98 |
+
|
| 99 |
+
//------------------------------------------------------------------------
|
torch_utils/ops/bias_act.cu
ADDED
|
@@ -0,0 +1,176 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
// Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
//
|
| 3 |
+
// NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
// and proprietary rights in and to this software, related documentation
|
| 5 |
+
// and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
// distribution of this software and related documentation without an express
|
| 7 |
+
// license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
#include <c10/util/Half.h>
|
| 10 |
+
#include <c10/util/BFloat16.h>
|
| 11 |
+
#include "bias_act.h"
|
| 12 |
+
|
| 13 |
+
//------------------------------------------------------------------------
|
| 14 |
+
// Helpers.
|
| 15 |
+
|
| 16 |
+
template <class T> struct InternalType;
|
| 17 |
+
template <> struct InternalType<double> { typedef double scalar_t; };
|
| 18 |
+
template <> struct InternalType<float> { typedef float scalar_t; };
|
| 19 |
+
template <> struct InternalType<c10::Half> { typedef float scalar_t; };
|
| 20 |
+
template <> struct InternalType<c10::BFloat16> { typedef float scalar_t; };
|
| 21 |
+
|
| 22 |
+
//------------------------------------------------------------------------
|
| 23 |
+
// CUDA kernel.
|
| 24 |
+
|
| 25 |
+
template <class T, int A>
|
| 26 |
+
__global__ void bias_act_kernel(bias_act_kernel_params p)
|
| 27 |
+
{
|
| 28 |
+
typedef typename InternalType<T>::scalar_t scalar_t;
|
| 29 |
+
int G = p.grad;
|
| 30 |
+
scalar_t alpha = (scalar_t)p.alpha;
|
| 31 |
+
scalar_t gain = (scalar_t)p.gain;
|
| 32 |
+
scalar_t clamp = (scalar_t)p.clamp;
|
| 33 |
+
scalar_t one = (scalar_t)1;
|
| 34 |
+
scalar_t two = (scalar_t)2;
|
| 35 |
+
scalar_t expRange = (scalar_t)80;
|
| 36 |
+
scalar_t halfExpRange = (scalar_t)40;
|
| 37 |
+
scalar_t seluScale = (scalar_t)1.0507009873554804934193349852946;
|
| 38 |
+
scalar_t seluAlpha = (scalar_t)1.6732632423543772848170429916717;
|
| 39 |
+
|
| 40 |
+
// Loop over elements.
|
| 41 |
+
int xi = blockIdx.x * p.loopX * blockDim.x + threadIdx.x;
|
| 42 |
+
for (int loopIdx = 0; loopIdx < p.loopX && xi < p.sizeX; loopIdx++, xi += blockDim.x)
|
| 43 |
+
{
|
| 44 |
+
// Load.
|
| 45 |
+
scalar_t x = (scalar_t)((const T*)p.x)[xi];
|
| 46 |
+
scalar_t b = (p.b) ? (scalar_t)((const T*)p.b)[(xi / p.stepB) % p.sizeB] : 0;
|
| 47 |
+
scalar_t xref = (p.xref) ? (scalar_t)((const T*)p.xref)[xi] : 0;
|
| 48 |
+
scalar_t yref = (p.yref) ? (scalar_t)((const T*)p.yref)[xi] : 0;
|
| 49 |
+
scalar_t dy = (p.dy) ? (scalar_t)((const T*)p.dy)[xi] : one;
|
| 50 |
+
scalar_t yy = (gain != 0) ? yref / gain : 0;
|
| 51 |
+
scalar_t y = 0;
|
| 52 |
+
|
| 53 |
+
// Apply bias.
|
| 54 |
+
((G == 0) ? x : xref) += b;
|
| 55 |
+
|
| 56 |
+
// linear
|
| 57 |
+
if (A == 1)
|
| 58 |
+
{
|
| 59 |
+
if (G == 0) y = x;
|
| 60 |
+
if (G == 1) y = x;
|
| 61 |
+
}
|
| 62 |
+
|
| 63 |
+
// relu
|
| 64 |
+
if (A == 2)
|
| 65 |
+
{
|
| 66 |
+
if (G == 0) y = (x > 0) ? x : 0;
|
| 67 |
+
if (G == 1) y = (yy > 0) ? x : 0;
|
| 68 |
+
}
|
| 69 |
+
|
| 70 |
+
// lrelu
|
| 71 |
+
if (A == 3)
|
| 72 |
+
{
|
| 73 |
+
if (G == 0) y = (x > 0) ? x : x * alpha;
|
| 74 |
+
if (G == 1) y = (yy > 0) ? x : x * alpha;
|
| 75 |
+
}
|
| 76 |
+
|
| 77 |
+
// tanh
|
| 78 |
+
if (A == 4)
|
| 79 |
+
{
|
| 80 |
+
if (G == 0) { scalar_t c = exp(x); scalar_t d = one / c; y = (x < -expRange) ? -one : (x > expRange) ? one : (c - d) / (c + d); }
|
| 81 |
+
if (G == 1) y = x * (one - yy * yy);
|
| 82 |
+
if (G == 2) y = x * (one - yy * yy) * (-two * yy);
|
| 83 |
+
}
|
| 84 |
+
|
| 85 |
+
// sigmoid
|
| 86 |
+
if (A == 5)
|
| 87 |
+
{
|
| 88 |
+
if (G == 0) y = (x < -expRange) ? 0 : one / (exp(-x) + one);
|
| 89 |
+
if (G == 1) y = x * yy * (one - yy);
|
| 90 |
+
if (G == 2) y = x * yy * (one - yy) * (one - two * yy);
|
| 91 |
+
}
|
| 92 |
+
|
| 93 |
+
// elu
|
| 94 |
+
if (A == 6)
|
| 95 |
+
{
|
| 96 |
+
if (G == 0) y = (x >= 0) ? x : exp(x) - one;
|
| 97 |
+
if (G == 1) y = (yy >= 0) ? x : x * (yy + one);
|
| 98 |
+
if (G == 2) y = (yy >= 0) ? 0 : x * (yy + one);
|
| 99 |
+
}
|
| 100 |
+
|
| 101 |
+
// selu
|
| 102 |
+
if (A == 7)
|
| 103 |
+
{
|
| 104 |
+
if (G == 0) y = (x >= 0) ? seluScale * x : (seluScale * seluAlpha) * (exp(x) - one);
|
| 105 |
+
if (G == 1) y = (yy >= 0) ? x * seluScale : x * (yy + seluScale * seluAlpha);
|
| 106 |
+
if (G == 2) y = (yy >= 0) ? 0 : x * (yy + seluScale * seluAlpha);
|
| 107 |
+
}
|
| 108 |
+
|
| 109 |
+
// softplus
|
| 110 |
+
if (A == 8)
|
| 111 |
+
{
|
| 112 |
+
if (G == 0) y = (x > expRange) ? x : log(exp(x) + one);
|
| 113 |
+
if (G == 1) y = x * (one - exp(-yy));
|
| 114 |
+
if (G == 2) { scalar_t c = exp(-yy); y = x * c * (one - c); }
|
| 115 |
+
}
|
| 116 |
+
|
| 117 |
+
// swish
|
| 118 |
+
if (A == 9)
|
| 119 |
+
{
|
| 120 |
+
if (G == 0)
|
| 121 |
+
y = (x < -expRange) ? 0 : x / (exp(-x) + one);
|
| 122 |
+
else
|
| 123 |
+
{
|
| 124 |
+
scalar_t c = exp(xref);
|
| 125 |
+
scalar_t d = c + one;
|
| 126 |
+
if (G == 1)
|
| 127 |
+
y = (xref > halfExpRange) ? x : x * c * (xref + d) / (d * d);
|
| 128 |
+
else
|
| 129 |
+
y = (xref > halfExpRange) ? 0 : x * c * (xref * (two - d) + two * d) / (d * d * d);
|
| 130 |
+
yref = (xref < -expRange) ? 0 : xref / (exp(-xref) + one) * gain;
|
| 131 |
+
}
|
| 132 |
+
}
|
| 133 |
+
|
| 134 |
+
// Apply gain.
|
| 135 |
+
y *= gain * dy;
|
| 136 |
+
|
| 137 |
+
// Clamp.
|
| 138 |
+
if (clamp >= 0)
|
| 139 |
+
{
|
| 140 |
+
if (G == 0)
|
| 141 |
+
y = (y > -clamp & y < clamp) ? y : (y >= 0) ? clamp : -clamp;
|
| 142 |
+
else
|
| 143 |
+
y = (yref > -clamp & yref < clamp) ? y : 0;
|
| 144 |
+
}
|
| 145 |
+
|
| 146 |
+
// Store.
|
| 147 |
+
((T*)p.y)[xi] = (T)y;
|
| 148 |
+
}
|
| 149 |
+
}
|
| 150 |
+
|
| 151 |
+
//------------------------------------------------------------------------
|
| 152 |
+
// CUDA kernel selection.
|
| 153 |
+
|
| 154 |
+
template <class T> void* choose_bias_act_kernel(const bias_act_kernel_params& p)
|
| 155 |
+
{
|
| 156 |
+
if (p.act == 1) return (void*)bias_act_kernel<T, 1>;
|
| 157 |
+
if (p.act == 2) return (void*)bias_act_kernel<T, 2>;
|
| 158 |
+
if (p.act == 3) return (void*)bias_act_kernel<T, 3>;
|
| 159 |
+
if (p.act == 4) return (void*)bias_act_kernel<T, 4>;
|
| 160 |
+
if (p.act == 5) return (void*)bias_act_kernel<T, 5>;
|
| 161 |
+
if (p.act == 6) return (void*)bias_act_kernel<T, 6>;
|
| 162 |
+
if (p.act == 7) return (void*)bias_act_kernel<T, 7>;
|
| 163 |
+
if (p.act == 8) return (void*)bias_act_kernel<T, 8>;
|
| 164 |
+
if (p.act == 9) return (void*)bias_act_kernel<T, 9>;
|
| 165 |
+
return NULL;
|
| 166 |
+
}
|
| 167 |
+
|
| 168 |
+
//------------------------------------------------------------------------
|
| 169 |
+
// Template specializations.
|
| 170 |
+
|
| 171 |
+
template void* choose_bias_act_kernel<double> (const bias_act_kernel_params& p);
|
| 172 |
+
template void* choose_bias_act_kernel<float> (const bias_act_kernel_params& p);
|
| 173 |
+
template void* choose_bias_act_kernel<c10::Half> (const bias_act_kernel_params& p);
|
| 174 |
+
template void* choose_bias_act_kernel<c10::BFloat16> (const bias_act_kernel_params& p);
|
| 175 |
+
|
| 176 |
+
//------------------------------------------------------------------------
|
torch_utils/ops/bias_act.h
ADDED
|
@@ -0,0 +1,38 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
// Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
//
|
| 3 |
+
// NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
// and proprietary rights in and to this software, related documentation
|
| 5 |
+
// and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
// distribution of this software and related documentation without an express
|
| 7 |
+
// license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
//------------------------------------------------------------------------
|
| 10 |
+
// CUDA kernel parameters.
|
| 11 |
+
|
| 12 |
+
struct bias_act_kernel_params
|
| 13 |
+
{
|
| 14 |
+
const void* x; // [sizeX]
|
| 15 |
+
const void* b; // [sizeB] or NULL
|
| 16 |
+
const void* xref; // [sizeX] or NULL
|
| 17 |
+
const void* yref; // [sizeX] or NULL
|
| 18 |
+
const void* dy; // [sizeX] or NULL
|
| 19 |
+
void* y; // [sizeX]
|
| 20 |
+
|
| 21 |
+
int grad;
|
| 22 |
+
int act;
|
| 23 |
+
float alpha;
|
| 24 |
+
float gain;
|
| 25 |
+
float clamp;
|
| 26 |
+
|
| 27 |
+
int sizeX;
|
| 28 |
+
int sizeB;
|
| 29 |
+
int stepB;
|
| 30 |
+
int loopX;
|
| 31 |
+
};
|
| 32 |
+
|
| 33 |
+
//------------------------------------------------------------------------
|
| 34 |
+
// CUDA kernel selection.
|
| 35 |
+
|
| 36 |
+
template <class T> void* choose_bias_act_kernel(const bias_act_kernel_params& p);
|
| 37 |
+
|
| 38 |
+
//------------------------------------------------------------------------
|
torch_utils/ops/bias_act.py
ADDED
|
@@ -0,0 +1,209 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
"""Custom PyTorch ops for efficient bias and activation."""
|
| 10 |
+
|
| 11 |
+
import os
|
| 12 |
+
import numpy as np
|
| 13 |
+
import torch
|
| 14 |
+
import dnnlib
|
| 15 |
+
|
| 16 |
+
from .. import custom_ops
|
| 17 |
+
from .. import misc
|
| 18 |
+
|
| 19 |
+
#----------------------------------------------------------------------------
|
| 20 |
+
|
| 21 |
+
activation_funcs = {
|
| 22 |
+
'linear': dnnlib.EasyDict(func=lambda x, **_: x, def_alpha=0, def_gain=1, cuda_idx=1, ref='', has_2nd_grad=False),
|
| 23 |
+
'relu': dnnlib.EasyDict(func=lambda x, **_: torch.nn.functional.relu(x), def_alpha=0, def_gain=np.sqrt(2), cuda_idx=2, ref='y', has_2nd_grad=False),
|
| 24 |
+
'lrelu': dnnlib.EasyDict(func=lambda x, alpha, **_: torch.nn.functional.leaky_relu(x, alpha), def_alpha=0.2, def_gain=np.sqrt(2), cuda_idx=3, ref='y', has_2nd_grad=False),
|
| 25 |
+
'tanh': dnnlib.EasyDict(func=lambda x, **_: torch.tanh(x), def_alpha=0, def_gain=1, cuda_idx=4, ref='y', has_2nd_grad=True),
|
| 26 |
+
'sigmoid': dnnlib.EasyDict(func=lambda x, **_: torch.sigmoid(x), def_alpha=0, def_gain=1, cuda_idx=5, ref='y', has_2nd_grad=True),
|
| 27 |
+
'elu': dnnlib.EasyDict(func=lambda x, **_: torch.nn.functional.elu(x), def_alpha=0, def_gain=1, cuda_idx=6, ref='y', has_2nd_grad=True),
|
| 28 |
+
'selu': dnnlib.EasyDict(func=lambda x, **_: torch.nn.functional.selu(x), def_alpha=0, def_gain=1, cuda_idx=7, ref='y', has_2nd_grad=True),
|
| 29 |
+
'softplus': dnnlib.EasyDict(func=lambda x, **_: torch.nn.functional.softplus(x), def_alpha=0, def_gain=1, cuda_idx=8, ref='y', has_2nd_grad=True),
|
| 30 |
+
'swish': dnnlib.EasyDict(func=lambda x, **_: torch.sigmoid(x) * x, def_alpha=0, def_gain=np.sqrt(2), cuda_idx=9, ref='x', has_2nd_grad=True),
|
| 31 |
+
}
|
| 32 |
+
|
| 33 |
+
#----------------------------------------------------------------------------
|
| 34 |
+
|
| 35 |
+
_plugin = None
|
| 36 |
+
_null_tensor = torch.empty([0])
|
| 37 |
+
|
| 38 |
+
def _init():
|
| 39 |
+
global _plugin
|
| 40 |
+
if _plugin is None:
|
| 41 |
+
_plugin = custom_ops.get_plugin(
|
| 42 |
+
module_name='bias_act_plugin',
|
| 43 |
+
sources=['bias_act.cpp', 'bias_act.cu'],
|
| 44 |
+
headers=['bias_act.h'],
|
| 45 |
+
source_dir=os.path.dirname(__file__),
|
| 46 |
+
extra_cuda_cflags=['--use_fast_math', '--allow-unsupported-compiler'],
|
| 47 |
+
)
|
| 48 |
+
return True
|
| 49 |
+
|
| 50 |
+
#----------------------------------------------------------------------------
|
| 51 |
+
|
| 52 |
+
def bias_act(x, b=None, dim=1, act='linear', alpha=None, gain=None, clamp=None, impl='cuda'):
|
| 53 |
+
r"""Fused bias and activation function.
|
| 54 |
+
|
| 55 |
+
Adds bias `b` to activation tensor `x`, evaluates activation function `act`,
|
| 56 |
+
and scales the result by `gain`. Each of the steps is optional. In most cases,
|
| 57 |
+
the fused op is considerably more efficient than performing the same calculation
|
| 58 |
+
using standard PyTorch ops. It supports first and second order gradients,
|
| 59 |
+
but not third order gradients.
|
| 60 |
+
|
| 61 |
+
Args:
|
| 62 |
+
x: Input activation tensor. Can be of any shape.
|
| 63 |
+
b: Bias vector, or `None` to disable. Must be a 1D tensor of the same type
|
| 64 |
+
as `x`. The shape must be known, and it must match the dimension of `x`
|
| 65 |
+
corresponding to `dim`.
|
| 66 |
+
dim: The dimension in `x` corresponding to the elements of `b`.
|
| 67 |
+
The value of `dim` is ignored if `b` is not specified.
|
| 68 |
+
act: Name of the activation function to evaluate, or `"linear"` to disable.
|
| 69 |
+
Can be e.g. `"relu"`, `"lrelu"`, `"tanh"`, `"sigmoid"`, `"swish"`, etc.
|
| 70 |
+
See `activation_funcs` for a full list. `None` is not allowed.
|
| 71 |
+
alpha: Shape parameter for the activation function, or `None` to use the default.
|
| 72 |
+
gain: Scaling factor for the output tensor, or `None` to use default.
|
| 73 |
+
See `activation_funcs` for the default scaling of each activation function.
|
| 74 |
+
If unsure, consider specifying 1.
|
| 75 |
+
clamp: Clamp the output values to `[-clamp, +clamp]`, or `None` to disable
|
| 76 |
+
the clamping (default).
|
| 77 |
+
impl: Name of the implementation to use. Can be `"ref"` or `"cuda"` (default).
|
| 78 |
+
|
| 79 |
+
Returns:
|
| 80 |
+
Tensor of the same shape and datatype as `x`.
|
| 81 |
+
"""
|
| 82 |
+
assert isinstance(x, torch.Tensor)
|
| 83 |
+
assert impl in ['ref', 'cuda']
|
| 84 |
+
if impl == 'cuda' and x.device.type == 'cuda' and _init():
|
| 85 |
+
return _bias_act_cuda(dim=dim, act=act, alpha=alpha, gain=gain, clamp=clamp).apply(x, b)
|
| 86 |
+
return _bias_act_ref(x=x, b=b, dim=dim, act=act, alpha=alpha, gain=gain, clamp=clamp)
|
| 87 |
+
|
| 88 |
+
#----------------------------------------------------------------------------
|
| 89 |
+
|
| 90 |
+
@misc.profiled_function
|
| 91 |
+
def _bias_act_ref(x, b=None, dim=1, act='linear', alpha=None, gain=None, clamp=None):
|
| 92 |
+
"""Slow reference implementation of `bias_act()` using standard TensorFlow ops.
|
| 93 |
+
"""
|
| 94 |
+
assert isinstance(x, torch.Tensor)
|
| 95 |
+
assert clamp is None or clamp >= 0
|
| 96 |
+
spec = activation_funcs[act]
|
| 97 |
+
alpha = float(alpha if alpha is not None else spec.def_alpha)
|
| 98 |
+
gain = float(gain if gain is not None else spec.def_gain)
|
| 99 |
+
clamp = float(clamp if clamp is not None else -1)
|
| 100 |
+
|
| 101 |
+
# Add bias.
|
| 102 |
+
if b is not None:
|
| 103 |
+
assert isinstance(b, torch.Tensor) and b.ndim == 1
|
| 104 |
+
assert 0 <= dim < x.ndim
|
| 105 |
+
assert b.shape[0] == x.shape[dim]
|
| 106 |
+
x = x + b.reshape([-1 if i == dim else 1 for i in range(x.ndim)])
|
| 107 |
+
|
| 108 |
+
# Evaluate activation function.
|
| 109 |
+
alpha = float(alpha)
|
| 110 |
+
x = spec.func(x, alpha=alpha)
|
| 111 |
+
|
| 112 |
+
# Scale by gain.
|
| 113 |
+
gain = float(gain)
|
| 114 |
+
if gain != 1:
|
| 115 |
+
x = x * gain
|
| 116 |
+
|
| 117 |
+
# Clamp.
|
| 118 |
+
if clamp >= 0:
|
| 119 |
+
x = x.clamp(-clamp, clamp) # pylint: disable=invalid-unary-operand-type
|
| 120 |
+
return x
|
| 121 |
+
|
| 122 |
+
#----------------------------------------------------------------------------
|
| 123 |
+
|
| 124 |
+
_bias_act_cuda_cache = dict()
|
| 125 |
+
|
| 126 |
+
def _bias_act_cuda(dim=1, act='linear', alpha=None, gain=None, clamp=None):
|
| 127 |
+
"""Fast CUDA implementation of `bias_act()` using custom ops.
|
| 128 |
+
"""
|
| 129 |
+
# Parse arguments.
|
| 130 |
+
assert clamp is None or clamp >= 0
|
| 131 |
+
spec = activation_funcs[act]
|
| 132 |
+
alpha = float(alpha if alpha is not None else spec.def_alpha)
|
| 133 |
+
gain = float(gain if gain is not None else spec.def_gain)
|
| 134 |
+
clamp = float(clamp if clamp is not None else -1)
|
| 135 |
+
|
| 136 |
+
# Lookup from cache.
|
| 137 |
+
key = (dim, act, alpha, gain, clamp)
|
| 138 |
+
if key in _bias_act_cuda_cache:
|
| 139 |
+
return _bias_act_cuda_cache[key]
|
| 140 |
+
|
| 141 |
+
# Forward op.
|
| 142 |
+
class BiasActCuda(torch.autograd.Function):
|
| 143 |
+
@staticmethod
|
| 144 |
+
def forward(ctx, x, b): # pylint: disable=arguments-differ
|
| 145 |
+
ctx.memory_format = torch.channels_last if x.ndim > 2 and x.stride(1) == 1 else torch.contiguous_format
|
| 146 |
+
x = x.contiguous(memory_format=ctx.memory_format)
|
| 147 |
+
b = b.contiguous() if b is not None else _null_tensor
|
| 148 |
+
y = x
|
| 149 |
+
if act != 'linear' or gain != 1 or clamp >= 0 or b is not _null_tensor:
|
| 150 |
+
y = _plugin.bias_act(x, b, _null_tensor, _null_tensor, _null_tensor, 0, dim, spec.cuda_idx, alpha, gain, clamp)
|
| 151 |
+
ctx.save_for_backward(
|
| 152 |
+
x if 'x' in spec.ref or spec.has_2nd_grad else _null_tensor,
|
| 153 |
+
b if 'x' in spec.ref or spec.has_2nd_grad else _null_tensor,
|
| 154 |
+
y if 'y' in spec.ref else _null_tensor)
|
| 155 |
+
return y
|
| 156 |
+
|
| 157 |
+
@staticmethod
|
| 158 |
+
def backward(ctx, dy): # pylint: disable=arguments-differ
|
| 159 |
+
dy = dy.contiguous(memory_format=ctx.memory_format)
|
| 160 |
+
x, b, y = ctx.saved_tensors
|
| 161 |
+
dx = None
|
| 162 |
+
db = None
|
| 163 |
+
|
| 164 |
+
if ctx.needs_input_grad[0] or ctx.needs_input_grad[1]:
|
| 165 |
+
dx = dy
|
| 166 |
+
if act != 'linear' or gain != 1 or clamp >= 0:
|
| 167 |
+
dx = BiasActCudaGrad.apply(dy, x, b, y)
|
| 168 |
+
|
| 169 |
+
if ctx.needs_input_grad[1]:
|
| 170 |
+
db = dx.sum([i for i in range(dx.ndim) if i != dim])
|
| 171 |
+
|
| 172 |
+
return dx, db
|
| 173 |
+
|
| 174 |
+
# Backward op.
|
| 175 |
+
class BiasActCudaGrad(torch.autograd.Function):
|
| 176 |
+
@staticmethod
|
| 177 |
+
def forward(ctx, dy, x, b, y): # pylint: disable=arguments-differ
|
| 178 |
+
ctx.memory_format = torch.channels_last if dy.ndim > 2 and dy.stride(1) == 1 else torch.contiguous_format
|
| 179 |
+
dx = _plugin.bias_act(dy, b, x, y, _null_tensor, 1, dim, spec.cuda_idx, alpha, gain, clamp)
|
| 180 |
+
ctx.save_for_backward(
|
| 181 |
+
dy if spec.has_2nd_grad else _null_tensor,
|
| 182 |
+
x, b, y)
|
| 183 |
+
return dx
|
| 184 |
+
|
| 185 |
+
@staticmethod
|
| 186 |
+
def backward(ctx, d_dx): # pylint: disable=arguments-differ
|
| 187 |
+
d_dx = d_dx.contiguous(memory_format=ctx.memory_format)
|
| 188 |
+
dy, x, b, y = ctx.saved_tensors
|
| 189 |
+
d_dy = None
|
| 190 |
+
d_x = None
|
| 191 |
+
d_b = None
|
| 192 |
+
d_y = None
|
| 193 |
+
|
| 194 |
+
if ctx.needs_input_grad[0]:
|
| 195 |
+
d_dy = BiasActCudaGrad.apply(d_dx, x, b, y)
|
| 196 |
+
|
| 197 |
+
if spec.has_2nd_grad and (ctx.needs_input_grad[1] or ctx.needs_input_grad[2]):
|
| 198 |
+
d_x = _plugin.bias_act(d_dx, b, x, y, dy, 2, dim, spec.cuda_idx, alpha, gain, clamp)
|
| 199 |
+
|
| 200 |
+
if spec.has_2nd_grad and ctx.needs_input_grad[2]:
|
| 201 |
+
d_b = d_x.sum([i for i in range(d_x.ndim) if i != dim])
|
| 202 |
+
|
| 203 |
+
return d_dy, d_x, d_b, d_y
|
| 204 |
+
|
| 205 |
+
# Add to cache.
|
| 206 |
+
_bias_act_cuda_cache[key] = BiasActCuda
|
| 207 |
+
return BiasActCuda
|
| 208 |
+
|
| 209 |
+
#----------------------------------------------------------------------------
|
torch_utils/ops/conv2d_gradfix.py
ADDED
|
@@ -0,0 +1,203 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
"""Custom replacement for `torch.nn.functional.conv2d` that supports
|
| 10 |
+
arbitrarily high order gradients with zero performance penalty."""
|
| 11 |
+
|
| 12 |
+
import contextlib
|
| 13 |
+
import torch
|
| 14 |
+
from pkg_resources import parse_version
|
| 15 |
+
|
| 16 |
+
# pylint: disable=redefined-builtin
|
| 17 |
+
# pylint: disable=arguments-differ
|
| 18 |
+
# pylint: disable=protected-access
|
| 19 |
+
|
| 20 |
+
#----------------------------------------------------------------------------
|
| 21 |
+
|
| 22 |
+
enabled = False # Enable the custom op by setting this to true.
|
| 23 |
+
weight_gradients_disabled = False # Forcefully disable computation of gradients with respect to the weights.
|
| 24 |
+
_use_pytorch_1_11_api = parse_version(torch.__version__) >= parse_version('1.11.0a') # Allow prerelease builds of 1.11
|
| 25 |
+
|
| 26 |
+
@contextlib.contextmanager
|
| 27 |
+
def no_weight_gradients(disable=True):
|
| 28 |
+
global weight_gradients_disabled
|
| 29 |
+
old = weight_gradients_disabled
|
| 30 |
+
if disable:
|
| 31 |
+
weight_gradients_disabled = True
|
| 32 |
+
yield
|
| 33 |
+
weight_gradients_disabled = old
|
| 34 |
+
|
| 35 |
+
#----------------------------------------------------------------------------
|
| 36 |
+
|
| 37 |
+
def conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1):
|
| 38 |
+
if _should_use_custom_op(input):
|
| 39 |
+
return _conv2d_gradfix(transpose=False, weight_shape=weight.shape, stride=stride, padding=padding, output_padding=0, dilation=dilation, groups=groups).apply(input, weight, bias)
|
| 40 |
+
return torch.nn.functional.conv2d(input=input, weight=weight, bias=bias, stride=stride, padding=padding, dilation=dilation, groups=groups)
|
| 41 |
+
|
| 42 |
+
def conv_transpose2d(input, weight, bias=None, stride=1, padding=0, output_padding=0, groups=1, dilation=1):
|
| 43 |
+
if _should_use_custom_op(input):
|
| 44 |
+
return _conv2d_gradfix(transpose=True, weight_shape=weight.shape, stride=stride, padding=padding, output_padding=output_padding, groups=groups, dilation=dilation).apply(input, weight, bias)
|
| 45 |
+
return torch.nn.functional.conv_transpose2d(input=input, weight=weight, bias=bias, stride=stride, padding=padding, output_padding=output_padding, groups=groups, dilation=dilation)
|
| 46 |
+
|
| 47 |
+
#----------------------------------------------------------------------------
|
| 48 |
+
|
| 49 |
+
def _should_use_custom_op(input):
|
| 50 |
+
assert isinstance(input, torch.Tensor)
|
| 51 |
+
if (not enabled) or (not torch.backends.cudnn.enabled):
|
| 52 |
+
return False
|
| 53 |
+
if _use_pytorch_1_11_api:
|
| 54 |
+
# The work-around code doesn't work on PyTorch 1.11.0 onwards
|
| 55 |
+
return False
|
| 56 |
+
if input.device.type != 'cuda':
|
| 57 |
+
return False
|
| 58 |
+
return True
|
| 59 |
+
|
| 60 |
+
def _tuple_of_ints(xs, ndim):
|
| 61 |
+
xs = tuple(xs) if isinstance(xs, (tuple, list)) else (xs,) * ndim
|
| 62 |
+
assert len(xs) == ndim
|
| 63 |
+
assert all(isinstance(x, int) for x in xs)
|
| 64 |
+
return xs
|
| 65 |
+
|
| 66 |
+
#----------------------------------------------------------------------------
|
| 67 |
+
|
| 68 |
+
_conv2d_gradfix_cache = dict()
|
| 69 |
+
_null_tensor = torch.empty([0])
|
| 70 |
+
|
| 71 |
+
def _conv2d_gradfix(transpose, weight_shape, stride, padding, output_padding, dilation, groups):
|
| 72 |
+
# Parse arguments.
|
| 73 |
+
ndim = 2
|
| 74 |
+
weight_shape = tuple(weight_shape)
|
| 75 |
+
stride = _tuple_of_ints(stride, ndim)
|
| 76 |
+
padding = _tuple_of_ints(padding, ndim)
|
| 77 |
+
output_padding = _tuple_of_ints(output_padding, ndim)
|
| 78 |
+
dilation = _tuple_of_ints(dilation, ndim)
|
| 79 |
+
|
| 80 |
+
# Lookup from cache.
|
| 81 |
+
key = (transpose, weight_shape, stride, padding, output_padding, dilation, groups)
|
| 82 |
+
if key in _conv2d_gradfix_cache:
|
| 83 |
+
return _conv2d_gradfix_cache[key]
|
| 84 |
+
|
| 85 |
+
# Validate arguments.
|
| 86 |
+
assert groups >= 1
|
| 87 |
+
assert len(weight_shape) == ndim + 2
|
| 88 |
+
assert all(stride[i] >= 1 for i in range(ndim))
|
| 89 |
+
assert all(padding[i] >= 0 for i in range(ndim))
|
| 90 |
+
assert all(dilation[i] >= 0 for i in range(ndim))
|
| 91 |
+
if not transpose:
|
| 92 |
+
assert all(output_padding[i] == 0 for i in range(ndim))
|
| 93 |
+
else: # transpose
|
| 94 |
+
assert all(0 <= output_padding[i] < max(stride[i], dilation[i]) for i in range(ndim))
|
| 95 |
+
|
| 96 |
+
# Helpers.
|
| 97 |
+
common_kwargs = dict(stride=stride, padding=padding, dilation=dilation, groups=groups)
|
| 98 |
+
def calc_output_padding(input_shape, output_shape):
|
| 99 |
+
if transpose:
|
| 100 |
+
return [0, 0]
|
| 101 |
+
return [
|
| 102 |
+
input_shape[i + 2]
|
| 103 |
+
- (output_shape[i + 2] - 1) * stride[i]
|
| 104 |
+
- (1 - 2 * padding[i])
|
| 105 |
+
- dilation[i] * (weight_shape[i + 2] - 1)
|
| 106 |
+
for i in range(ndim)
|
| 107 |
+
]
|
| 108 |
+
|
| 109 |
+
# Forward & backward.
|
| 110 |
+
class Conv2d(torch.autograd.Function):
|
| 111 |
+
@staticmethod
|
| 112 |
+
def forward(ctx, input, weight, bias):
|
| 113 |
+
assert weight.shape == weight_shape
|
| 114 |
+
ctx.save_for_backward(
|
| 115 |
+
input if weight.requires_grad else _null_tensor,
|
| 116 |
+
weight if input.requires_grad else _null_tensor,
|
| 117 |
+
)
|
| 118 |
+
ctx.input_shape = input.shape
|
| 119 |
+
|
| 120 |
+
# Simple 1x1 convolution => cuBLAS (only on Volta, not on Ampere).
|
| 121 |
+
if weight_shape[2:] == stride == dilation == (1, 1) and padding == (0, 0) and torch.cuda.get_device_capability(input.device) < (8, 0):
|
| 122 |
+
a = weight.reshape(groups, weight_shape[0] // groups, weight_shape[1])
|
| 123 |
+
b = input.reshape(input.shape[0], groups, input.shape[1] // groups, -1)
|
| 124 |
+
c = (a.transpose(1, 2) if transpose else a) @ b.permute(1, 2, 0, 3).flatten(2)
|
| 125 |
+
c = c.reshape(-1, input.shape[0], *input.shape[2:]).transpose(0, 1)
|
| 126 |
+
c = c if bias is None else c + bias.unsqueeze(0).unsqueeze(2).unsqueeze(3)
|
| 127 |
+
return c.contiguous(memory_format=(torch.channels_last if input.stride(1) == 1 else torch.contiguous_format))
|
| 128 |
+
|
| 129 |
+
# General case => cuDNN.
|
| 130 |
+
if transpose:
|
| 131 |
+
return torch.nn.functional.conv_transpose2d(input=input, weight=weight, bias=bias, output_padding=output_padding, **common_kwargs)
|
| 132 |
+
return torch.nn.functional.conv2d(input=input, weight=weight, bias=bias, **common_kwargs)
|
| 133 |
+
|
| 134 |
+
@staticmethod
|
| 135 |
+
def backward(ctx, grad_output):
|
| 136 |
+
input, weight = ctx.saved_tensors
|
| 137 |
+
input_shape = ctx.input_shape
|
| 138 |
+
grad_input = None
|
| 139 |
+
grad_weight = None
|
| 140 |
+
grad_bias = None
|
| 141 |
+
|
| 142 |
+
if ctx.needs_input_grad[0]:
|
| 143 |
+
p = calc_output_padding(input_shape=input_shape, output_shape=grad_output.shape)
|
| 144 |
+
op = _conv2d_gradfix(transpose=(not transpose), weight_shape=weight_shape, output_padding=p, **common_kwargs)
|
| 145 |
+
grad_input = op.apply(grad_output, weight, None)
|
| 146 |
+
assert grad_input.shape == input_shape
|
| 147 |
+
|
| 148 |
+
if ctx.needs_input_grad[1] and not weight_gradients_disabled:
|
| 149 |
+
grad_weight = Conv2dGradWeight.apply(grad_output, input)
|
| 150 |
+
assert grad_weight.shape == weight_shape
|
| 151 |
+
|
| 152 |
+
if ctx.needs_input_grad[2]:
|
| 153 |
+
grad_bias = grad_output.sum([0, 2, 3])
|
| 154 |
+
|
| 155 |
+
return grad_input, grad_weight, grad_bias
|
| 156 |
+
|
| 157 |
+
# Gradient with respect to the weights.
|
| 158 |
+
class Conv2dGradWeight(torch.autograd.Function):
|
| 159 |
+
@staticmethod
|
| 160 |
+
def forward(ctx, grad_output, input):
|
| 161 |
+
ctx.save_for_backward(
|
| 162 |
+
grad_output if input.requires_grad else _null_tensor,
|
| 163 |
+
input if grad_output.requires_grad else _null_tensor,
|
| 164 |
+
)
|
| 165 |
+
ctx.grad_output_shape = grad_output.shape
|
| 166 |
+
ctx.input_shape = input.shape
|
| 167 |
+
|
| 168 |
+
# Simple 1x1 convolution => cuBLAS (on both Volta and Ampere).
|
| 169 |
+
if weight_shape[2:] == stride == dilation == (1, 1) and padding == (0, 0):
|
| 170 |
+
a = grad_output.reshape(grad_output.shape[0], groups, grad_output.shape[1] // groups, -1).permute(1, 2, 0, 3).flatten(2)
|
| 171 |
+
b = input.reshape(input.shape[0], groups, input.shape[1] // groups, -1).permute(1, 2, 0, 3).flatten(2)
|
| 172 |
+
c = (b @ a.transpose(1, 2) if transpose else a @ b.transpose(1, 2)).reshape(weight_shape)
|
| 173 |
+
return c.contiguous(memory_format=(torch.channels_last if input.stride(1) == 1 else torch.contiguous_format))
|
| 174 |
+
|
| 175 |
+
# General case => cuDNN.
|
| 176 |
+
name = 'aten::cudnn_convolution_transpose_backward_weight' if transpose else 'aten::cudnn_convolution_backward_weight'
|
| 177 |
+
flags = [torch.backends.cudnn.benchmark, torch.backends.cudnn.deterministic, torch.backends.cudnn.allow_tf32]
|
| 178 |
+
return torch._C._jit_get_operation(name)(weight_shape, grad_output, input, padding, stride, dilation, groups, *flags)
|
| 179 |
+
|
| 180 |
+
@staticmethod
|
| 181 |
+
def backward(ctx, grad2_grad_weight):
|
| 182 |
+
grad_output, input = ctx.saved_tensors
|
| 183 |
+
grad_output_shape = ctx.grad_output_shape
|
| 184 |
+
input_shape = ctx.input_shape
|
| 185 |
+
grad2_grad_output = None
|
| 186 |
+
grad2_input = None
|
| 187 |
+
|
| 188 |
+
if ctx.needs_input_grad[0]:
|
| 189 |
+
grad2_grad_output = Conv2d.apply(input, grad2_grad_weight, None)
|
| 190 |
+
assert grad2_grad_output.shape == grad_output_shape
|
| 191 |
+
|
| 192 |
+
if ctx.needs_input_grad[1]:
|
| 193 |
+
p = calc_output_padding(input_shape=input_shape, output_shape=grad_output_shape)
|
| 194 |
+
op = _conv2d_gradfix(transpose=(not transpose), weight_shape=weight_shape, output_padding=p, **common_kwargs)
|
| 195 |
+
grad2_input = op.apply(grad_output, grad2_grad_weight, None)
|
| 196 |
+
assert grad2_input.shape == input_shape
|
| 197 |
+
|
| 198 |
+
return grad2_grad_output, grad2_input
|
| 199 |
+
|
| 200 |
+
_conv2d_gradfix_cache[key] = Conv2d
|
| 201 |
+
return Conv2d
|
| 202 |
+
|
| 203 |
+
#----------------------------------------------------------------------------
|
torch_utils/ops/conv2d_resample.py
ADDED
|
@@ -0,0 +1,143 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
"""2D convolution with optional up/downsampling."""
|
| 10 |
+
|
| 11 |
+
import torch
|
| 12 |
+
|
| 13 |
+
from .. import misc
|
| 14 |
+
from . import conv2d_gradfix
|
| 15 |
+
from . import upfirdn2d
|
| 16 |
+
from .upfirdn2d import _parse_padding
|
| 17 |
+
from .upfirdn2d import _get_filter_size
|
| 18 |
+
|
| 19 |
+
#----------------------------------------------------------------------------
|
| 20 |
+
|
| 21 |
+
def _get_weight_shape(w):
|
| 22 |
+
with misc.suppress_tracer_warnings(): # this value will be treated as a constant
|
| 23 |
+
shape = [int(sz) for sz in w.shape]
|
| 24 |
+
misc.assert_shape(w, shape)
|
| 25 |
+
return shape
|
| 26 |
+
|
| 27 |
+
#----------------------------------------------------------------------------
|
| 28 |
+
|
| 29 |
+
def _conv2d_wrapper(x, w, stride=1, padding=0, groups=1, transpose=False, flip_weight=True):
|
| 30 |
+
"""Wrapper for the underlying `conv2d()` and `conv_transpose2d()` implementations.
|
| 31 |
+
"""
|
| 32 |
+
_out_channels, _in_channels_per_group, kh, kw = _get_weight_shape(w)
|
| 33 |
+
|
| 34 |
+
# Flip weight if requested.
|
| 35 |
+
# Note: conv2d() actually performs correlation (flip_weight=True) not convolution (flip_weight=False).
|
| 36 |
+
if not flip_weight and (kw > 1 or kh > 1):
|
| 37 |
+
w = w.flip([2, 3])
|
| 38 |
+
|
| 39 |
+
# Execute using conv2d_gradfix.
|
| 40 |
+
op = conv2d_gradfix.conv_transpose2d if transpose else conv2d_gradfix.conv2d
|
| 41 |
+
return op(x, w, stride=stride, padding=padding, groups=groups)
|
| 42 |
+
|
| 43 |
+
#----------------------------------------------------------------------------
|
| 44 |
+
|
| 45 |
+
@misc.profiled_function
|
| 46 |
+
def conv2d_resample(x, w, f=None, up=1, down=1, padding=0, groups=1, flip_weight=True, flip_filter=False):
|
| 47 |
+
r"""2D convolution with optional up/downsampling.
|
| 48 |
+
|
| 49 |
+
Padding is performed only once at the beginning, not between the operations.
|
| 50 |
+
|
| 51 |
+
Args:
|
| 52 |
+
x: Input tensor of shape
|
| 53 |
+
`[batch_size, in_channels, in_height, in_width]`.
|
| 54 |
+
w: Weight tensor of shape
|
| 55 |
+
`[out_channels, in_channels//groups, kernel_height, kernel_width]`.
|
| 56 |
+
f: Low-pass filter for up/downsampling. Must be prepared beforehand by
|
| 57 |
+
calling upfirdn2d.setup_filter(). None = identity (default).
|
| 58 |
+
up: Integer upsampling factor (default: 1).
|
| 59 |
+
down: Integer downsampling factor (default: 1).
|
| 60 |
+
padding: Padding with respect to the upsampled image. Can be a single number
|
| 61 |
+
or a list/tuple `[x, y]` or `[x_before, x_after, y_before, y_after]`
|
| 62 |
+
(default: 0).
|
| 63 |
+
groups: Split input channels into N groups (default: 1).
|
| 64 |
+
flip_weight: False = convolution, True = correlation (default: True).
|
| 65 |
+
flip_filter: False = convolution, True = correlation (default: False).
|
| 66 |
+
|
| 67 |
+
Returns:
|
| 68 |
+
Tensor of the shape `[batch_size, num_channels, out_height, out_width]`.
|
| 69 |
+
"""
|
| 70 |
+
# Validate arguments.
|
| 71 |
+
assert isinstance(x, torch.Tensor) and (x.ndim == 4)
|
| 72 |
+
assert isinstance(w, torch.Tensor) and (w.ndim == 4) and (w.dtype == x.dtype)
|
| 73 |
+
assert f is None or (isinstance(f, torch.Tensor) and f.ndim in [1, 2] and f.dtype == torch.float32)
|
| 74 |
+
assert isinstance(up, int) and (up >= 1)
|
| 75 |
+
assert isinstance(down, int) and (down >= 1)
|
| 76 |
+
assert isinstance(groups, int) and (groups >= 1)
|
| 77 |
+
out_channels, in_channels_per_group, kh, kw = _get_weight_shape(w)
|
| 78 |
+
fw, fh = _get_filter_size(f)
|
| 79 |
+
px0, px1, py0, py1 = _parse_padding(padding)
|
| 80 |
+
|
| 81 |
+
# Adjust padding to account for up/downsampling.
|
| 82 |
+
if up > 1:
|
| 83 |
+
px0 += (fw + up - 1) // 2
|
| 84 |
+
px1 += (fw - up) // 2
|
| 85 |
+
py0 += (fh + up - 1) // 2
|
| 86 |
+
py1 += (fh - up) // 2
|
| 87 |
+
if down > 1:
|
| 88 |
+
px0 += (fw - down + 1) // 2
|
| 89 |
+
px1 += (fw - down) // 2
|
| 90 |
+
py0 += (fh - down + 1) // 2
|
| 91 |
+
py1 += (fh - down) // 2
|
| 92 |
+
|
| 93 |
+
# Fast path: 1x1 convolution with downsampling only => downsample first, then convolve.
|
| 94 |
+
if kw == 1 and kh == 1 and (down > 1 and up == 1):
|
| 95 |
+
x = upfirdn2d.upfirdn2d(x=x, f=f, down=down, padding=[px0,px1,py0,py1], flip_filter=flip_filter)
|
| 96 |
+
x = _conv2d_wrapper(x=x, w=w, groups=groups, flip_weight=flip_weight)
|
| 97 |
+
return x
|
| 98 |
+
|
| 99 |
+
# Fast path: 1x1 convolution with upsampling only => convolve first, then upsample.
|
| 100 |
+
if kw == 1 and kh == 1 and (up > 1 and down == 1):
|
| 101 |
+
x = _conv2d_wrapper(x=x, w=w, groups=groups, flip_weight=flip_weight)
|
| 102 |
+
x = upfirdn2d.upfirdn2d(x=x, f=f, up=up, padding=[px0,px1,py0,py1], gain=up**2, flip_filter=flip_filter)
|
| 103 |
+
return x
|
| 104 |
+
|
| 105 |
+
# Fast path: downsampling only => use strided convolution.
|
| 106 |
+
if down > 1 and up == 1:
|
| 107 |
+
x = upfirdn2d.upfirdn2d(x=x, f=f, padding=[px0,px1,py0,py1], flip_filter=flip_filter)
|
| 108 |
+
x = _conv2d_wrapper(x=x, w=w, stride=down, groups=groups, flip_weight=flip_weight)
|
| 109 |
+
return x
|
| 110 |
+
|
| 111 |
+
# Fast path: upsampling with optional downsampling => use transpose strided convolution.
|
| 112 |
+
if up > 1:
|
| 113 |
+
if groups == 1:
|
| 114 |
+
w = w.transpose(0, 1)
|
| 115 |
+
else:
|
| 116 |
+
w = w.reshape(groups, out_channels // groups, in_channels_per_group, kh, kw)
|
| 117 |
+
w = w.transpose(1, 2)
|
| 118 |
+
w = w.reshape(groups * in_channels_per_group, out_channels // groups, kh, kw)
|
| 119 |
+
px0 -= kw - 1
|
| 120 |
+
px1 -= kw - up
|
| 121 |
+
py0 -= kh - 1
|
| 122 |
+
py1 -= kh - up
|
| 123 |
+
pxt = max(min(-px0, -px1), 0)
|
| 124 |
+
pyt = max(min(-py0, -py1), 0)
|
| 125 |
+
x = _conv2d_wrapper(x=x, w=w, stride=up, padding=[pyt,pxt], groups=groups, transpose=True, flip_weight=(not flip_weight))
|
| 126 |
+
x = upfirdn2d.upfirdn2d(x=x, f=f, padding=[px0+pxt,px1+pxt,py0+pyt,py1+pyt], gain=up**2, flip_filter=flip_filter)
|
| 127 |
+
if down > 1:
|
| 128 |
+
x = upfirdn2d.upfirdn2d(x=x, f=f, down=down, flip_filter=flip_filter)
|
| 129 |
+
return x
|
| 130 |
+
|
| 131 |
+
# Fast path: no up/downsampling, padding supported by the underlying implementation => use plain conv2d.
|
| 132 |
+
if up == 1 and down == 1:
|
| 133 |
+
if px0 == px1 and py0 == py1 and px0 >= 0 and py0 >= 0:
|
| 134 |
+
return _conv2d_wrapper(x=x, w=w, padding=[py0,px0], groups=groups, flip_weight=flip_weight)
|
| 135 |
+
|
| 136 |
+
# Fallback: Generic reference implementation.
|
| 137 |
+
x = upfirdn2d.upfirdn2d(x=x, f=(f if up > 1 else None), up=up, padding=[px0,px1,py0,py1], gain=up**2, flip_filter=flip_filter)
|
| 138 |
+
x = _conv2d_wrapper(x=x, w=w, groups=groups, flip_weight=flip_weight)
|
| 139 |
+
if down > 1:
|
| 140 |
+
x = upfirdn2d.upfirdn2d(x=x, f=f, down=down, flip_filter=flip_filter)
|
| 141 |
+
return x
|
| 142 |
+
|
| 143 |
+
#----------------------------------------------------------------------------
|
torch_utils/ops/fma.py
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
"""Fused multiply-add, with slightly faster gradients than `torch.addcmul()`."""
|
| 10 |
+
|
| 11 |
+
import torch
|
| 12 |
+
|
| 13 |
+
#----------------------------------------------------------------------------
|
| 14 |
+
|
| 15 |
+
def fma(a, b, c): # => a * b + c
|
| 16 |
+
return _FusedMultiplyAdd.apply(a, b, c)
|
| 17 |
+
|
| 18 |
+
#----------------------------------------------------------------------------
|
| 19 |
+
|
| 20 |
+
class _FusedMultiplyAdd(torch.autograd.Function): # a * b + c
|
| 21 |
+
@staticmethod
|
| 22 |
+
def forward(ctx, a, b, c): # pylint: disable=arguments-differ
|
| 23 |
+
out = torch.addcmul(c, a, b)
|
| 24 |
+
ctx.save_for_backward(a, b)
|
| 25 |
+
ctx.c_shape = c.shape
|
| 26 |
+
return out
|
| 27 |
+
|
| 28 |
+
@staticmethod
|
| 29 |
+
def backward(ctx, dout): # pylint: disable=arguments-differ
|
| 30 |
+
a, b = ctx.saved_tensors
|
| 31 |
+
c_shape = ctx.c_shape
|
| 32 |
+
da = None
|
| 33 |
+
db = None
|
| 34 |
+
dc = None
|
| 35 |
+
|
| 36 |
+
if ctx.needs_input_grad[0]:
|
| 37 |
+
da = _unbroadcast(dout * b, a.shape)
|
| 38 |
+
|
| 39 |
+
if ctx.needs_input_grad[1]:
|
| 40 |
+
db = _unbroadcast(dout * a, b.shape)
|
| 41 |
+
|
| 42 |
+
if ctx.needs_input_grad[2]:
|
| 43 |
+
dc = _unbroadcast(dout, c_shape)
|
| 44 |
+
|
| 45 |
+
return da, db, dc
|
| 46 |
+
|
| 47 |
+
#----------------------------------------------------------------------------
|
| 48 |
+
|
| 49 |
+
def _unbroadcast(x, shape):
|
| 50 |
+
extra_dims = x.ndim - len(shape)
|
| 51 |
+
assert extra_dims >= 0
|
| 52 |
+
dim = [i for i in range(x.ndim) if x.shape[i] > 1 and (i < extra_dims or shape[i - extra_dims] == 1)]
|
| 53 |
+
if len(dim):
|
| 54 |
+
x = x.sum(dim=dim, keepdim=True)
|
| 55 |
+
if extra_dims:
|
| 56 |
+
x = x.reshape(-1, *x.shape[extra_dims+1:])
|
| 57 |
+
assert x.shape == shape
|
| 58 |
+
return x
|
| 59 |
+
|
| 60 |
+
#----------------------------------------------------------------------------
|
torch_utils/ops/grid_sample_gradfix.py
ADDED
|
@@ -0,0 +1,83 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
"""Custom replacement for `torch.nn.functional.grid_sample` that
|
| 10 |
+
supports arbitrarily high order gradients between the input and output.
|
| 11 |
+
Only works on 2D images and assumes
|
| 12 |
+
`mode='bilinear'`, `padding_mode='zeros'`, `align_corners=False`."""
|
| 13 |
+
|
| 14 |
+
import torch
|
| 15 |
+
from pkg_resources import parse_version
|
| 16 |
+
|
| 17 |
+
# pylint: disable=redefined-builtin
|
| 18 |
+
# pylint: disable=arguments-differ
|
| 19 |
+
# pylint: disable=protected-access
|
| 20 |
+
|
| 21 |
+
#----------------------------------------------------------------------------
|
| 22 |
+
|
| 23 |
+
enabled = False # Enable the custom op by setting this to true.
|
| 24 |
+
_use_pytorch_1_11_api = parse_version(torch.__version__) >= parse_version('1.11.0a') # Allow prerelease builds of 1.11
|
| 25 |
+
|
| 26 |
+
#----------------------------------------------------------------------------
|
| 27 |
+
|
| 28 |
+
def grid_sample(input, grid):
|
| 29 |
+
if _should_use_custom_op():
|
| 30 |
+
return _GridSample2dForward.apply(input, grid)
|
| 31 |
+
return torch.nn.functional.grid_sample(input=input, grid=grid, mode='bilinear', padding_mode='zeros', align_corners=False)
|
| 32 |
+
|
| 33 |
+
#----------------------------------------------------------------------------
|
| 34 |
+
|
| 35 |
+
def _should_use_custom_op():
|
| 36 |
+
return enabled
|
| 37 |
+
|
| 38 |
+
#----------------------------------------------------------------------------
|
| 39 |
+
|
| 40 |
+
class _GridSample2dForward(torch.autograd.Function):
|
| 41 |
+
@staticmethod
|
| 42 |
+
def forward(ctx, input, grid):
|
| 43 |
+
assert input.ndim == 4
|
| 44 |
+
assert grid.ndim == 4
|
| 45 |
+
output = torch.nn.functional.grid_sample(input=input, grid=grid, mode='bilinear', padding_mode='zeros', align_corners=False)
|
| 46 |
+
ctx.save_for_backward(input, grid)
|
| 47 |
+
return output
|
| 48 |
+
|
| 49 |
+
@staticmethod
|
| 50 |
+
def backward(ctx, grad_output):
|
| 51 |
+
input, grid = ctx.saved_tensors
|
| 52 |
+
grad_input, grad_grid = _GridSample2dBackward.apply(grad_output, input, grid)
|
| 53 |
+
return grad_input, grad_grid
|
| 54 |
+
|
| 55 |
+
#----------------------------------------------------------------------------
|
| 56 |
+
|
| 57 |
+
class _GridSample2dBackward(torch.autograd.Function):
|
| 58 |
+
@staticmethod
|
| 59 |
+
def forward(ctx, grad_output, input, grid):
|
| 60 |
+
op, _ = torch._C._jit_get_operation('aten::grid_sampler_2d_backward')
|
| 61 |
+
if _use_pytorch_1_11_api:
|
| 62 |
+
output_mask = (ctx.needs_input_grad[1], ctx.needs_input_grad[2])
|
| 63 |
+
grad_input, grad_grid = op(grad_output, input, grid, 0, 0, False, output_mask)
|
| 64 |
+
else:
|
| 65 |
+
grad_input, grad_grid = op(grad_output, input, grid, 0, 0, False)
|
| 66 |
+
ctx.save_for_backward(grid)
|
| 67 |
+
return grad_input, grad_grid
|
| 68 |
+
|
| 69 |
+
@staticmethod
|
| 70 |
+
def backward(ctx, grad2_grad_input, grad2_grad_grid):
|
| 71 |
+
_ = grad2_grad_grid # unused
|
| 72 |
+
grid, = ctx.saved_tensors
|
| 73 |
+
grad2_grad_output = None
|
| 74 |
+
grad2_input = None
|
| 75 |
+
grad2_grid = None
|
| 76 |
+
|
| 77 |
+
if ctx.needs_input_grad[0]:
|
| 78 |
+
grad2_grad_output = _GridSample2dForward.apply(grad2_grad_input, grid)
|
| 79 |
+
|
| 80 |
+
assert not ctx.needs_input_grad[2]
|
| 81 |
+
return grad2_grad_output, grad2_input, grad2_grid
|
| 82 |
+
|
| 83 |
+
#----------------------------------------------------------------------------
|
torch_utils/ops/upfirdn2d.cpp
ADDED
|
@@ -0,0 +1,107 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
// Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
//
|
| 3 |
+
// NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
// and proprietary rights in and to this software, related documentation
|
| 5 |
+
// and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
// distribution of this software and related documentation without an express
|
| 7 |
+
// license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
#include <torch/extension.h>
|
| 10 |
+
#include <ATen/cuda/CUDAContext.h>
|
| 11 |
+
#include <c10/cuda/CUDAGuard.h>
|
| 12 |
+
#include "upfirdn2d.h"
|
| 13 |
+
|
| 14 |
+
//------------------------------------------------------------------------
|
| 15 |
+
|
| 16 |
+
static torch::Tensor upfirdn2d(torch::Tensor x, torch::Tensor f, int upx, int upy, int downx, int downy, int padx0, int padx1, int pady0, int pady1, bool flip, float gain)
|
| 17 |
+
{
|
| 18 |
+
// Validate arguments.
|
| 19 |
+
TORCH_CHECK(x.is_cuda(), "x must reside on CUDA device");
|
| 20 |
+
TORCH_CHECK(f.device() == x.device(), "f must reside on the same device as x");
|
| 21 |
+
TORCH_CHECK(f.dtype() == torch::kFloat, "f must be float32");
|
| 22 |
+
TORCH_CHECK(x.numel() <= INT_MAX, "x is too large");
|
| 23 |
+
TORCH_CHECK(f.numel() <= INT_MAX, "f is too large");
|
| 24 |
+
TORCH_CHECK(x.numel() > 0, "x has zero size");
|
| 25 |
+
TORCH_CHECK(f.numel() > 0, "f has zero size");
|
| 26 |
+
TORCH_CHECK(x.dim() == 4, "x must be rank 4");
|
| 27 |
+
TORCH_CHECK(f.dim() == 2, "f must be rank 2");
|
| 28 |
+
TORCH_CHECK((x.size(0)-1)*x.stride(0) + (x.size(1)-1)*x.stride(1) + (x.size(2)-1)*x.stride(2) + (x.size(3)-1)*x.stride(3) <= INT_MAX, "x memory footprint is too large");
|
| 29 |
+
TORCH_CHECK(f.size(0) >= 1 && f.size(1) >= 1, "f must be at least 1x1");
|
| 30 |
+
TORCH_CHECK(upx >= 1 && upy >= 1, "upsampling factor must be at least 1");
|
| 31 |
+
TORCH_CHECK(downx >= 1 && downy >= 1, "downsampling factor must be at least 1");
|
| 32 |
+
|
| 33 |
+
// Create output tensor.
|
| 34 |
+
const at::cuda::OptionalCUDAGuard device_guard(device_of(x));
|
| 35 |
+
int outW = ((int)x.size(3) * upx + padx0 + padx1 - (int)f.size(1) + downx) / downx;
|
| 36 |
+
int outH = ((int)x.size(2) * upy + pady0 + pady1 - (int)f.size(0) + downy) / downy;
|
| 37 |
+
TORCH_CHECK(outW >= 1 && outH >= 1, "output must be at least 1x1");
|
| 38 |
+
torch::Tensor y = torch::empty({x.size(0), x.size(1), outH, outW}, x.options(), x.suggest_memory_format());
|
| 39 |
+
TORCH_CHECK(y.numel() <= INT_MAX, "output is too large");
|
| 40 |
+
TORCH_CHECK((y.size(0)-1)*y.stride(0) + (y.size(1)-1)*y.stride(1) + (y.size(2)-1)*y.stride(2) + (y.size(3)-1)*y.stride(3) <= INT_MAX, "output memory footprint is too large");
|
| 41 |
+
|
| 42 |
+
// Initialize CUDA kernel parameters.
|
| 43 |
+
upfirdn2d_kernel_params p;
|
| 44 |
+
p.x = x.data_ptr();
|
| 45 |
+
p.f = f.data_ptr<float>();
|
| 46 |
+
p.y = y.data_ptr();
|
| 47 |
+
p.up = make_int2(upx, upy);
|
| 48 |
+
p.down = make_int2(downx, downy);
|
| 49 |
+
p.pad0 = make_int2(padx0, pady0);
|
| 50 |
+
p.flip = (flip) ? 1 : 0;
|
| 51 |
+
p.gain = gain;
|
| 52 |
+
p.inSize = make_int4((int)x.size(3), (int)x.size(2), (int)x.size(1), (int)x.size(0));
|
| 53 |
+
p.inStride = make_int4((int)x.stride(3), (int)x.stride(2), (int)x.stride(1), (int)x.stride(0));
|
| 54 |
+
p.filterSize = make_int2((int)f.size(1), (int)f.size(0));
|
| 55 |
+
p.filterStride = make_int2((int)f.stride(1), (int)f.stride(0));
|
| 56 |
+
p.outSize = make_int4((int)y.size(3), (int)y.size(2), (int)y.size(1), (int)y.size(0));
|
| 57 |
+
p.outStride = make_int4((int)y.stride(3), (int)y.stride(2), (int)y.stride(1), (int)y.stride(0));
|
| 58 |
+
p.sizeMajor = (p.inStride.z == 1) ? p.inSize.w : p.inSize.w * p.inSize.z;
|
| 59 |
+
p.sizeMinor = (p.inStride.z == 1) ? p.inSize.z : 1;
|
| 60 |
+
|
| 61 |
+
// Choose CUDA kernel.
|
| 62 |
+
upfirdn2d_kernel_spec spec;
|
| 63 |
+
AT_DISPATCH_FLOATING_TYPES_AND2(at::ScalarType::Half, at::ScalarType::BFloat16, x.scalar_type(), "upfirdn2d_cuda", [&]
|
| 64 |
+
{
|
| 65 |
+
spec = choose_upfirdn2d_kernel<scalar_t>(p);
|
| 66 |
+
});
|
| 67 |
+
|
| 68 |
+
// Set looping options.
|
| 69 |
+
p.loopMajor = (p.sizeMajor - 1) / 16384 + 1;
|
| 70 |
+
p.loopMinor = spec.loopMinor;
|
| 71 |
+
p.loopX = spec.loopX;
|
| 72 |
+
p.launchMinor = (p.sizeMinor - 1) / p.loopMinor + 1;
|
| 73 |
+
p.launchMajor = (p.sizeMajor - 1) / p.loopMajor + 1;
|
| 74 |
+
|
| 75 |
+
// Compute grid size.
|
| 76 |
+
dim3 blockSize, gridSize;
|
| 77 |
+
if (spec.tileOutW < 0) // large
|
| 78 |
+
{
|
| 79 |
+
blockSize = dim3(4, 32, 1);
|
| 80 |
+
gridSize = dim3(
|
| 81 |
+
((p.outSize.y - 1) / blockSize.x + 1) * p.launchMinor,
|
| 82 |
+
(p.outSize.x - 1) / (blockSize.y * p.loopX) + 1,
|
| 83 |
+
p.launchMajor);
|
| 84 |
+
}
|
| 85 |
+
else // small
|
| 86 |
+
{
|
| 87 |
+
blockSize = dim3(256, 1, 1);
|
| 88 |
+
gridSize = dim3(
|
| 89 |
+
((p.outSize.y - 1) / spec.tileOutH + 1) * p.launchMinor,
|
| 90 |
+
(p.outSize.x - 1) / (spec.tileOutW * p.loopX) + 1,
|
| 91 |
+
p.launchMajor);
|
| 92 |
+
}
|
| 93 |
+
|
| 94 |
+
// Launch CUDA kernel.
|
| 95 |
+
void* args[] = {&p};
|
| 96 |
+
AT_CUDA_CHECK(cudaLaunchKernel(spec.kernel, gridSize, blockSize, args, 0, at::cuda::getCurrentCUDAStream()));
|
| 97 |
+
return y;
|
| 98 |
+
}
|
| 99 |
+
|
| 100 |
+
//------------------------------------------------------------------------
|
| 101 |
+
|
| 102 |
+
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m)
|
| 103 |
+
{
|
| 104 |
+
m.def("upfirdn2d", &upfirdn2d);
|
| 105 |
+
}
|
| 106 |
+
|
| 107 |
+
//------------------------------------------------------------------------
|
torch_utils/ops/upfirdn2d.cu
ADDED
|
@@ -0,0 +1,387 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
// Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
//
|
| 3 |
+
// NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
// and proprietary rights in and to this software, related documentation
|
| 5 |
+
// and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
// distribution of this software and related documentation without an express
|
| 7 |
+
// license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
#include <c10/util/Half.h>
|
| 10 |
+
#include <c10/util/BFloat16.h>
|
| 11 |
+
#include "upfirdn2d.h"
|
| 12 |
+
|
| 13 |
+
//------------------------------------------------------------------------
|
| 14 |
+
// Helpers.
|
| 15 |
+
|
| 16 |
+
template <class T> struct InternalType;
|
| 17 |
+
template <> struct InternalType<double> { typedef double scalar_t; };
|
| 18 |
+
template <> struct InternalType<float> { typedef float scalar_t; };
|
| 19 |
+
template <> struct InternalType<c10::Half> { typedef float scalar_t; };
|
| 20 |
+
template <> struct InternalType<c10::BFloat16> { typedef float scalar_t; };
|
| 21 |
+
|
| 22 |
+
static __device__ __forceinline__ int floor_div(int a, int b)
|
| 23 |
+
{
|
| 24 |
+
int t = 1 - a / b;
|
| 25 |
+
return (a + t * b) / b - t;
|
| 26 |
+
}
|
| 27 |
+
|
| 28 |
+
//------------------------------------------------------------------------
|
| 29 |
+
// Generic CUDA implementation for large filters.
|
| 30 |
+
|
| 31 |
+
template <class T> static __global__ void upfirdn2d_kernel_large(upfirdn2d_kernel_params p)
|
| 32 |
+
{
|
| 33 |
+
typedef typename InternalType<T>::scalar_t scalar_t;
|
| 34 |
+
|
| 35 |
+
// Calculate thread index.
|
| 36 |
+
int minorBase = blockIdx.x * blockDim.x + threadIdx.x;
|
| 37 |
+
int outY = minorBase / p.launchMinor;
|
| 38 |
+
minorBase -= outY * p.launchMinor;
|
| 39 |
+
int outXBase = blockIdx.y * p.loopX * blockDim.y + threadIdx.y;
|
| 40 |
+
int majorBase = blockIdx.z * p.loopMajor;
|
| 41 |
+
if (outXBase >= p.outSize.x | outY >= p.outSize.y | majorBase >= p.sizeMajor)
|
| 42 |
+
return;
|
| 43 |
+
|
| 44 |
+
// Setup Y receptive field.
|
| 45 |
+
int midY = outY * p.down.y + p.up.y - 1 - p.pad0.y;
|
| 46 |
+
int inY = min(max(floor_div(midY, p.up.y), 0), p.inSize.y);
|
| 47 |
+
int h = min(max(floor_div(midY + p.filterSize.y, p.up.y), 0), p.inSize.y) - inY;
|
| 48 |
+
int filterY = midY + p.filterSize.y - (inY + 1) * p.up.y;
|
| 49 |
+
if (p.flip)
|
| 50 |
+
filterY = p.filterSize.y - 1 - filterY;
|
| 51 |
+
|
| 52 |
+
// Loop over major, minor, and X.
|
| 53 |
+
for (int majorIdx = 0, major = majorBase; majorIdx < p.loopMajor & major < p.sizeMajor; majorIdx++, major++)
|
| 54 |
+
for (int minorIdx = 0, minor = minorBase; minorIdx < p.loopMinor & minor < p.sizeMinor; minorIdx++, minor += p.launchMinor)
|
| 55 |
+
{
|
| 56 |
+
int nc = major * p.sizeMinor + minor;
|
| 57 |
+
int n = nc / p.inSize.z;
|
| 58 |
+
int c = nc - n * p.inSize.z;
|
| 59 |
+
for (int loopX = 0, outX = outXBase; loopX < p.loopX & outX < p.outSize.x; loopX++, outX += blockDim.y)
|
| 60 |
+
{
|
| 61 |
+
// Setup X receptive field.
|
| 62 |
+
int midX = outX * p.down.x + p.up.x - 1 - p.pad0.x;
|
| 63 |
+
int inX = min(max(floor_div(midX, p.up.x), 0), p.inSize.x);
|
| 64 |
+
int w = min(max(floor_div(midX + p.filterSize.x, p.up.x), 0), p.inSize.x) - inX;
|
| 65 |
+
int filterX = midX + p.filterSize.x - (inX + 1) * p.up.x;
|
| 66 |
+
if (p.flip)
|
| 67 |
+
filterX = p.filterSize.x - 1 - filterX;
|
| 68 |
+
|
| 69 |
+
// Initialize pointers.
|
| 70 |
+
const T* xp = &((const T*)p.x)[inX * p.inStride.x + inY * p.inStride.y + c * p.inStride.z + n * p.inStride.w];
|
| 71 |
+
const float* fp = &p.f[filterX * p.filterStride.x + filterY * p.filterStride.y];
|
| 72 |
+
int filterStepX = ((p.flip) ? p.up.x : -p.up.x) * p.filterStride.x;
|
| 73 |
+
int filterStepY = ((p.flip) ? p.up.y : -p.up.y) * p.filterStride.y;
|
| 74 |
+
|
| 75 |
+
// Inner loop.
|
| 76 |
+
scalar_t v = 0;
|
| 77 |
+
for (int y = 0; y < h; y++)
|
| 78 |
+
{
|
| 79 |
+
for (int x = 0; x < w; x++)
|
| 80 |
+
{
|
| 81 |
+
v += (scalar_t)(*xp) * (scalar_t)(*fp);
|
| 82 |
+
xp += p.inStride.x;
|
| 83 |
+
fp += filterStepX;
|
| 84 |
+
}
|
| 85 |
+
xp += p.inStride.y - w * p.inStride.x;
|
| 86 |
+
fp += filterStepY - w * filterStepX;
|
| 87 |
+
}
|
| 88 |
+
|
| 89 |
+
// Store result.
|
| 90 |
+
v *= p.gain;
|
| 91 |
+
((T*)p.y)[outX * p.outStride.x + outY * p.outStride.y + c * p.outStride.z + n * p.outStride.w] = (T)v;
|
| 92 |
+
}
|
| 93 |
+
}
|
| 94 |
+
}
|
| 95 |
+
|
| 96 |
+
//------------------------------------------------------------------------
|
| 97 |
+
// Specialized CUDA implementation for small filters.
|
| 98 |
+
|
| 99 |
+
template <class T, int upx, int upy, int downx, int downy, int filterW, int filterH, int tileOutW, int tileOutH, int loopMinor>
|
| 100 |
+
static __global__ void upfirdn2d_kernel_small(upfirdn2d_kernel_params p)
|
| 101 |
+
{
|
| 102 |
+
typedef typename InternalType<T>::scalar_t scalar_t;
|
| 103 |
+
const int tileInW = ((tileOutW - 1) * downx + filterW - 1) / upx + 1;
|
| 104 |
+
const int tileInH = ((tileOutH - 1) * downy + filterH - 1) / upy + 1;
|
| 105 |
+
__shared__ volatile scalar_t sf[filterH][filterW];
|
| 106 |
+
__shared__ volatile scalar_t sx[tileInH][tileInW][loopMinor];
|
| 107 |
+
|
| 108 |
+
// Calculate tile index.
|
| 109 |
+
int minorBase = blockIdx.x;
|
| 110 |
+
int tileOutY = minorBase / p.launchMinor;
|
| 111 |
+
minorBase -= tileOutY * p.launchMinor;
|
| 112 |
+
minorBase *= loopMinor;
|
| 113 |
+
tileOutY *= tileOutH;
|
| 114 |
+
int tileOutXBase = blockIdx.y * p.loopX * tileOutW;
|
| 115 |
+
int majorBase = blockIdx.z * p.loopMajor;
|
| 116 |
+
if (tileOutXBase >= p.outSize.x | tileOutY >= p.outSize.y | majorBase >= p.sizeMajor)
|
| 117 |
+
return;
|
| 118 |
+
|
| 119 |
+
// Load filter (flipped).
|
| 120 |
+
for (int tapIdx = threadIdx.x; tapIdx < filterH * filterW; tapIdx += blockDim.x)
|
| 121 |
+
{
|
| 122 |
+
int fy = tapIdx / filterW;
|
| 123 |
+
int fx = tapIdx - fy * filterW;
|
| 124 |
+
scalar_t v = 0;
|
| 125 |
+
if (fx < p.filterSize.x & fy < p.filterSize.y)
|
| 126 |
+
{
|
| 127 |
+
int ffx = (p.flip) ? fx : p.filterSize.x - 1 - fx;
|
| 128 |
+
int ffy = (p.flip) ? fy : p.filterSize.y - 1 - fy;
|
| 129 |
+
v = (scalar_t)p.f[ffx * p.filterStride.x + ffy * p.filterStride.y];
|
| 130 |
+
}
|
| 131 |
+
sf[fy][fx] = v;
|
| 132 |
+
}
|
| 133 |
+
|
| 134 |
+
// Loop over major and X.
|
| 135 |
+
for (int majorIdx = 0, major = majorBase; majorIdx < p.loopMajor & major < p.sizeMajor; majorIdx++, major++)
|
| 136 |
+
{
|
| 137 |
+
int baseNC = major * p.sizeMinor + minorBase;
|
| 138 |
+
int n = baseNC / p.inSize.z;
|
| 139 |
+
int baseC = baseNC - n * p.inSize.z;
|
| 140 |
+
for (int loopX = 0, tileOutX = tileOutXBase; loopX < p.loopX & tileOutX < p.outSize.x; loopX++, tileOutX += tileOutW)
|
| 141 |
+
{
|
| 142 |
+
// Load input pixels.
|
| 143 |
+
int tileMidX = tileOutX * downx + upx - 1 - p.pad0.x;
|
| 144 |
+
int tileMidY = tileOutY * downy + upy - 1 - p.pad0.y;
|
| 145 |
+
int tileInX = floor_div(tileMidX, upx);
|
| 146 |
+
int tileInY = floor_div(tileMidY, upy);
|
| 147 |
+
__syncthreads();
|
| 148 |
+
for (int inIdx = threadIdx.x; inIdx < tileInH * tileInW * loopMinor; inIdx += blockDim.x)
|
| 149 |
+
{
|
| 150 |
+
int relC = inIdx;
|
| 151 |
+
int relInX = relC / loopMinor;
|
| 152 |
+
int relInY = relInX / tileInW;
|
| 153 |
+
relC -= relInX * loopMinor;
|
| 154 |
+
relInX -= relInY * tileInW;
|
| 155 |
+
int c = baseC + relC;
|
| 156 |
+
int inX = tileInX + relInX;
|
| 157 |
+
int inY = tileInY + relInY;
|
| 158 |
+
scalar_t v = 0;
|
| 159 |
+
if (inX >= 0 & inY >= 0 & inX < p.inSize.x & inY < p.inSize.y & c < p.inSize.z)
|
| 160 |
+
v = (scalar_t)((const T*)p.x)[inX * p.inStride.x + inY * p.inStride.y + c * p.inStride.z + n * p.inStride.w];
|
| 161 |
+
sx[relInY][relInX][relC] = v;
|
| 162 |
+
}
|
| 163 |
+
|
| 164 |
+
// Loop over output pixels.
|
| 165 |
+
__syncthreads();
|
| 166 |
+
for (int outIdx = threadIdx.x; outIdx < tileOutH * tileOutW * loopMinor; outIdx += blockDim.x)
|
| 167 |
+
{
|
| 168 |
+
int relC = outIdx;
|
| 169 |
+
int relOutX = relC / loopMinor;
|
| 170 |
+
int relOutY = relOutX / tileOutW;
|
| 171 |
+
relC -= relOutX * loopMinor;
|
| 172 |
+
relOutX -= relOutY * tileOutW;
|
| 173 |
+
int c = baseC + relC;
|
| 174 |
+
int outX = tileOutX + relOutX;
|
| 175 |
+
int outY = tileOutY + relOutY;
|
| 176 |
+
|
| 177 |
+
// Setup receptive field.
|
| 178 |
+
int midX = tileMidX + relOutX * downx;
|
| 179 |
+
int midY = tileMidY + relOutY * downy;
|
| 180 |
+
int inX = floor_div(midX, upx);
|
| 181 |
+
int inY = floor_div(midY, upy);
|
| 182 |
+
int relInX = inX - tileInX;
|
| 183 |
+
int relInY = inY - tileInY;
|
| 184 |
+
int filterX = (inX + 1) * upx - midX - 1; // flipped
|
| 185 |
+
int filterY = (inY + 1) * upy - midY - 1; // flipped
|
| 186 |
+
|
| 187 |
+
// Inner loop.
|
| 188 |
+
if (outX < p.outSize.x & outY < p.outSize.y & c < p.outSize.z)
|
| 189 |
+
{
|
| 190 |
+
scalar_t v = 0;
|
| 191 |
+
#pragma unroll
|
| 192 |
+
for (int y = 0; y < filterH / upy; y++)
|
| 193 |
+
#pragma unroll
|
| 194 |
+
for (int x = 0; x < filterW / upx; x++)
|
| 195 |
+
v += sx[relInY + y][relInX + x][relC] * sf[filterY + y * upy][filterX + x * upx];
|
| 196 |
+
v *= p.gain;
|
| 197 |
+
((T*)p.y)[outX * p.outStride.x + outY * p.outStride.y + c * p.outStride.z + n * p.outStride.w] = (T)v;
|
| 198 |
+
}
|
| 199 |
+
}
|
| 200 |
+
}
|
| 201 |
+
}
|
| 202 |
+
}
|
| 203 |
+
|
| 204 |
+
//------------------------------------------------------------------------
|
| 205 |
+
// CUDA kernel selection.
|
| 206 |
+
|
| 207 |
+
template <class T> upfirdn2d_kernel_spec choose_upfirdn2d_kernel(const upfirdn2d_kernel_params& p)
|
| 208 |
+
{
|
| 209 |
+
int s = p.inStride.z, fx = p.filterSize.x, fy = p.filterSize.y;
|
| 210 |
+
upfirdn2d_kernel_spec spec = {(void*)upfirdn2d_kernel_large<T>, -1,-1,1, 4}; // contiguous
|
| 211 |
+
if (s == 1) spec = {(void*)upfirdn2d_kernel_large<T>, -1,-1,4, 1}; // channels_last
|
| 212 |
+
|
| 213 |
+
// No up/downsampling.
|
| 214 |
+
if (p.up.x == 1 && p.up.y == 1 && p.down.x == 1 && p.down.y == 1)
|
| 215 |
+
{
|
| 216 |
+
// contiguous
|
| 217 |
+
if (s != 1 && fx <= 24 && fy <= 24) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 1,1, 24,24, 64,32,1>, 64,32,1, 1};
|
| 218 |
+
if (s != 1 && fx <= 16 && fy <= 16) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 1,1, 16,16, 64,32,1>, 64,32,1, 1};
|
| 219 |
+
if (s != 1 && fx <= 7 && fy <= 7 ) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 1,1, 7,7, 64,16,1>, 64,16,1, 1};
|
| 220 |
+
if (s != 1 && fx <= 6 && fy <= 6 ) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 1,1, 6,6, 64,16,1>, 64,16,1, 1};
|
| 221 |
+
if (s != 1 && fx <= 5 && fy <= 5 ) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 1,1, 5,5, 64,16,1>, 64,16,1, 1};
|
| 222 |
+
if (s != 1 && fx <= 4 && fy <= 4 ) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 1,1, 4,4, 64,16,1>, 64,16,1, 1};
|
| 223 |
+
if (s != 1 && fx <= 3 && fy <= 3 ) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 1,1, 3,3, 64,16,1>, 64,16,1, 1};
|
| 224 |
+
if (s != 1 && fx <= 24 && fy <= 1 ) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 1,1, 24,1, 128,8,1>, 128,8,1, 1};
|
| 225 |
+
if (s != 1 && fx <= 16 && fy <= 1 ) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 1,1, 16,1, 128,8,1>, 128,8,1, 1};
|
| 226 |
+
if (s != 1 && fx <= 8 && fy <= 1 ) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 1,1, 8,1, 128,8,1>, 128,8,1, 1};
|
| 227 |
+
if (s != 1 && fx <= 1 && fy <= 24) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 1,1, 1,24, 32,32,1>, 32,32,1, 1};
|
| 228 |
+
if (s != 1 && fx <= 1 && fy <= 16) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 1,1, 1,16, 32,32,1>, 32,32,1, 1};
|
| 229 |
+
if (s != 1 && fx <= 1 && fy <= 8 ) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 1,1, 1,8, 32,32,1>, 32,32,1, 1};
|
| 230 |
+
// channels_last
|
| 231 |
+
if (s == 1 && fx <= 24 && fy <= 24) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 1,1, 24,24, 32,32,1>, 32,32,1, 1};
|
| 232 |
+
if (s == 1 && fx <= 16 && fy <= 16) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 1,1, 16,16, 32,32,1>, 32,32,1, 1};
|
| 233 |
+
if (s == 1 && fx <= 7 && fy <= 7 ) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 1,1, 7,7, 16,16,8>, 16,16,8, 1};
|
| 234 |
+
if (s == 1 && fx <= 6 && fy <= 6 ) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 1,1, 6,6, 16,16,8>, 16,16,8, 1};
|
| 235 |
+
if (s == 1 && fx <= 5 && fy <= 5 ) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 1,1, 5,5, 16,16,8>, 16,16,8, 1};
|
| 236 |
+
if (s == 1 && fx <= 4 && fy <= 4 ) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 1,1, 4,4, 16,16,8>, 16,16,8, 1};
|
| 237 |
+
if (s == 1 && fx <= 3 && fy <= 3 ) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 1,1, 3,3, 16,16,8>, 16,16,8, 1};
|
| 238 |
+
if (s == 1 && fx <= 24 && fy <= 1 ) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 1,1, 24,1, 128,1,16>, 128,1,16, 1};
|
| 239 |
+
if (s == 1 && fx <= 16 && fy <= 1 ) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 1,1, 16,1, 128,1,16>, 128,1,16, 1};
|
| 240 |
+
if (s == 1 && fx <= 8 && fy <= 1 ) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 1,1, 8,1, 128,1,16>, 128,1,16, 1};
|
| 241 |
+
if (s == 1 && fx <= 1 && fy <= 24) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 1,1, 1,24, 1,128,16>, 1,128,16, 1};
|
| 242 |
+
if (s == 1 && fx <= 1 && fy <= 16) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 1,1, 1,16, 1,128,16>, 1,128,16, 1};
|
| 243 |
+
if (s == 1 && fx <= 1 && fy <= 8 ) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 1,1, 1,8, 1,128,16>, 1,128,16, 1};
|
| 244 |
+
}
|
| 245 |
+
|
| 246 |
+
// 2x upsampling.
|
| 247 |
+
if (p.up.x == 2 && p.up.y == 2 && p.down.x == 1 && p.down.y == 1)
|
| 248 |
+
{
|
| 249 |
+
// contiguous
|
| 250 |
+
if (s != 1 && fx <= 24 && fy <= 24) spec = {(void*)upfirdn2d_kernel_small<T, 2,2, 1,1, 24,24, 64,32,1>, 64,32,1, 1};
|
| 251 |
+
if (s != 1 && fx <= 16 && fy <= 16) spec = {(void*)upfirdn2d_kernel_small<T, 2,2, 1,1, 16,16, 64,32,1>, 64,32,1, 1};
|
| 252 |
+
if (s != 1 && fx <= 8 && fy <= 8 ) spec = {(void*)upfirdn2d_kernel_small<T, 2,2, 1,1, 8,8, 64,16,1>, 64,16,1, 1};
|
| 253 |
+
if (s != 1 && fx <= 6 && fy <= 6 ) spec = {(void*)upfirdn2d_kernel_small<T, 2,2, 1,1, 6,6, 64,16,1>, 64,16,1, 1};
|
| 254 |
+
if (s != 1 && fx <= 4 && fy <= 4 ) spec = {(void*)upfirdn2d_kernel_small<T, 2,2, 1,1, 4,4, 64,16,1>, 64,16,1, 1};
|
| 255 |
+
if (s != 1 && fx <= 2 && fy <= 2 ) spec = {(void*)upfirdn2d_kernel_small<T, 2,2, 1,1, 2,2, 64,16,1>, 64,16,1, 1};
|
| 256 |
+
// channels_last
|
| 257 |
+
if (s == 1 && fx <= 24 && fy <= 24) spec = {(void*)upfirdn2d_kernel_small<T, 2,2, 1,1, 24,24, 32,32,1>, 32,32,1, 1};
|
| 258 |
+
if (s == 1 && fx <= 16 && fy <= 16) spec = {(void*)upfirdn2d_kernel_small<T, 2,2, 1,1, 16,16, 32,32,1>, 32,32,1, 1};
|
| 259 |
+
if (s == 1 && fx <= 8 && fy <= 8 ) spec = {(void*)upfirdn2d_kernel_small<T, 2,2, 1,1, 8,8, 16,16,8>, 16,16,8, 1};
|
| 260 |
+
if (s == 1 && fx <= 6 && fy <= 6 ) spec = {(void*)upfirdn2d_kernel_small<T, 2,2, 1,1, 6,6, 16,16,8>, 16,16,8, 1};
|
| 261 |
+
if (s == 1 && fx <= 4 && fy <= 4 ) spec = {(void*)upfirdn2d_kernel_small<T, 2,2, 1,1, 4,4, 16,16,8>, 16,16,8, 1};
|
| 262 |
+
if (s == 1 && fx <= 2 && fy <= 2 ) spec = {(void*)upfirdn2d_kernel_small<T, 2,2, 1,1, 2,2, 16,16,8>, 16,16,8, 1};
|
| 263 |
+
}
|
| 264 |
+
if (p.up.x == 2 && p.up.y == 1 && p.down.x == 1 && p.down.y == 1)
|
| 265 |
+
{
|
| 266 |
+
// contiguous
|
| 267 |
+
if (s != 1 && fx <= 24 && fy <= 1) spec = {(void*)upfirdn2d_kernel_small<T, 2,1, 1,1, 24,1, 128,8,1>, 128,8,1, 1};
|
| 268 |
+
if (s != 1 && fx <= 16 && fy <= 1) spec = {(void*)upfirdn2d_kernel_small<T, 2,1, 1,1, 16,1, 128,8,1>, 128,8,1, 1};
|
| 269 |
+
if (s != 1 && fx <= 8 && fy <= 1) spec = {(void*)upfirdn2d_kernel_small<T, 2,1, 1,1, 8,1, 128,8,1>, 128,8,1, 1};
|
| 270 |
+
// channels_last
|
| 271 |
+
if (s == 1 && fx <= 24 && fy <= 1) spec = {(void*)upfirdn2d_kernel_small<T, 2,1, 1,1, 24,1, 128,1,16>, 128,1,16, 1};
|
| 272 |
+
if (s == 1 && fx <= 16 && fy <= 1) spec = {(void*)upfirdn2d_kernel_small<T, 2,1, 1,1, 16,1, 128,1,16>, 128,1,16, 1};
|
| 273 |
+
if (s == 1 && fx <= 8 && fy <= 1) spec = {(void*)upfirdn2d_kernel_small<T, 2,1, 1,1, 8,1, 128,1,16>, 128,1,16, 1};
|
| 274 |
+
}
|
| 275 |
+
if (p.up.x == 1 && p.up.y == 2 && p.down.x == 1 && p.down.y == 1)
|
| 276 |
+
{
|
| 277 |
+
// contiguous
|
| 278 |
+
if (s != 1 && fx <= 1 && fy <= 24) spec = {(void*)upfirdn2d_kernel_small<T, 1,2, 1,1, 1,24, 32,32,1>, 32,32,1, 1};
|
| 279 |
+
if (s != 1 && fx <= 1 && fy <= 16) spec = {(void*)upfirdn2d_kernel_small<T, 1,2, 1,1, 1,16, 32,32,1>, 32,32,1, 1};
|
| 280 |
+
if (s != 1 && fx <= 1 && fy <= 8 ) spec = {(void*)upfirdn2d_kernel_small<T, 1,2, 1,1, 1,8, 32,32,1>, 32,32,1, 1};
|
| 281 |
+
// channels_last
|
| 282 |
+
if (s == 1 && fx <= 1 && fy <= 24) spec = {(void*)upfirdn2d_kernel_small<T, 1,2, 1,1, 1,24, 1,128,16>, 1,128,16, 1};
|
| 283 |
+
if (s == 1 && fx <= 1 && fy <= 16) spec = {(void*)upfirdn2d_kernel_small<T, 1,2, 1,1, 1,16, 1,128,16>, 1,128,16, 1};
|
| 284 |
+
if (s == 1 && fx <= 1 && fy <= 8 ) spec = {(void*)upfirdn2d_kernel_small<T, 1,2, 1,1, 1,8, 1,128,16>, 1,128,16, 1};
|
| 285 |
+
}
|
| 286 |
+
|
| 287 |
+
// 2x downsampling.
|
| 288 |
+
if (p.up.x == 1 && p.up.y == 1 && p.down.x == 2 && p.down.y == 2)
|
| 289 |
+
{
|
| 290 |
+
// contiguous
|
| 291 |
+
if (s != 1 && fx <= 24 && fy <= 24) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 2,2, 24,24, 32,16,1>, 32,16,1, 1};
|
| 292 |
+
if (s != 1 && fx <= 16 && fy <= 16) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 2,2, 16,16, 32,16,1>, 32,16,1, 1};
|
| 293 |
+
if (s != 1 && fx <= 8 && fy <= 8 ) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 2,2, 8,8, 32,8,1>, 32,8,1, 1};
|
| 294 |
+
if (s != 1 && fx <= 6 && fy <= 6 ) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 2,2, 6,6, 32,8,1>, 32,8,1, 1};
|
| 295 |
+
if (s != 1 && fx <= 4 && fy <= 4 ) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 2,2, 4,4, 32,8,1>, 32,8,1, 1};
|
| 296 |
+
if (s != 1 && fx <= 2 && fy <= 2 ) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 2,2, 2,2, 32,8,1>, 32,8,1, 1};
|
| 297 |
+
// channels_last
|
| 298 |
+
if (s == 1 && fx <= 24 && fy <= 24) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 2,2, 24,24, 16,16,1>, 16,16,1, 1};
|
| 299 |
+
if (s == 1 && fx <= 16 && fy <= 16) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 2,2, 16,16, 16,16,1>, 16,16,1, 1};
|
| 300 |
+
if (s == 1 && fx <= 8 && fy <= 8 ) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 2,2, 8,8, 8,8,8>, 8,8,8, 1};
|
| 301 |
+
if (s == 1 && fx <= 6 && fy <= 6 ) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 2,2, 6,6, 8,8,8>, 8,8,8, 1};
|
| 302 |
+
if (s == 1 && fx <= 4 && fy <= 4 ) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 2,2, 4,4, 8,8,8>, 8,8,8, 1};
|
| 303 |
+
if (s == 1 && fx <= 2 && fy <= 2 ) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 2,2, 2,2, 8,8,8>, 8,8,8, 1};
|
| 304 |
+
}
|
| 305 |
+
if (p.up.x == 1 && p.up.y == 1 && p.down.x == 2 && p.down.y == 1)
|
| 306 |
+
{
|
| 307 |
+
// contiguous
|
| 308 |
+
if (s != 1 && fx <= 24 && fy <= 1) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 2,1, 24,1, 64,8,1>, 64,8,1, 1};
|
| 309 |
+
if (s != 1 && fx <= 16 && fy <= 1) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 2,1, 16,1, 64,8,1>, 64,8,1, 1};
|
| 310 |
+
if (s != 1 && fx <= 8 && fy <= 1) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 2,1, 8,1, 64,8,1>, 64,8,1, 1};
|
| 311 |
+
// channels_last
|
| 312 |
+
if (s == 1 && fx <= 24 && fy <= 1) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 2,1, 24,1, 64,1,8>, 64,1,8, 1};
|
| 313 |
+
if (s == 1 && fx <= 16 && fy <= 1) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 2,1, 16,1, 64,1,8>, 64,1,8, 1};
|
| 314 |
+
if (s == 1 && fx <= 8 && fy <= 1) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 2,1, 8,1, 64,1,8>, 64,1,8, 1};
|
| 315 |
+
}
|
| 316 |
+
if (p.up.x == 1 && p.up.y == 1 && p.down.x == 1 && p.down.y == 2)
|
| 317 |
+
{
|
| 318 |
+
// contiguous
|
| 319 |
+
if (s != 1 && fx <= 1 && fy <= 24) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 1,2, 1,24, 32,16,1>, 32,16,1, 1};
|
| 320 |
+
if (s != 1 && fx <= 1 && fy <= 16) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 1,2, 1,16, 32,16,1>, 32,16,1, 1};
|
| 321 |
+
if (s != 1 && fx <= 1 && fy <= 8 ) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 1,2, 1,8, 32,16,1>, 32,16,1, 1};
|
| 322 |
+
// channels_last
|
| 323 |
+
if (s == 1 && fx <= 1 && fy <= 24) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 1,2, 1,24, 1,64,8>, 1,64,8, 1};
|
| 324 |
+
if (s == 1 && fx <= 1 && fy <= 16) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 1,2, 1,16, 1,64,8>, 1,64,8, 1};
|
| 325 |
+
if (s == 1 && fx <= 1 && fy <= 8 ) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 1,2, 1,8, 1,64,8>, 1,64,8, 1};
|
| 326 |
+
}
|
| 327 |
+
|
| 328 |
+
// 4x upsampling.
|
| 329 |
+
if (p.up.x == 4 && p.up.y == 4 && p.down.x == 1 && p.down.y == 1)
|
| 330 |
+
{
|
| 331 |
+
// contiguous
|
| 332 |
+
if (s != 1 && fx <= 48 && fy <= 48) spec = {(void*)upfirdn2d_kernel_small<T, 4,4, 1,1, 48,48, 64,32,1>, 64,32,1, 1};
|
| 333 |
+
if (s != 1 && fx <= 32 && fy <= 32) spec = {(void*)upfirdn2d_kernel_small<T, 4,4, 1,1, 32,32, 64,32,1>, 64,32,1, 1};
|
| 334 |
+
// channels_last
|
| 335 |
+
if (s == 1 && fx <= 48 && fy <= 48) spec = {(void*)upfirdn2d_kernel_small<T, 4,4, 1,1, 48,48, 32,32,1>, 32,32,1, 1};
|
| 336 |
+
if (s == 1 && fx <= 32 && fy <= 32) spec = {(void*)upfirdn2d_kernel_small<T, 4,4, 1,1, 32,32, 32,32,1>, 32,32,1, 1};
|
| 337 |
+
}
|
| 338 |
+
if (p.up.x == 4 && p.up.y == 1 && p.down.x == 1 && p.down.y == 1)
|
| 339 |
+
{
|
| 340 |
+
// contiguous
|
| 341 |
+
if (s != 1 && fx <= 48 && fy <= 1) spec = {(void*)upfirdn2d_kernel_small<T, 4,1, 1,1, 48,1, 128,8,1>, 128,8,1, 1};
|
| 342 |
+
if (s != 1 && fx <= 32 && fy <= 1) spec = {(void*)upfirdn2d_kernel_small<T, 4,1, 1,1, 32,1, 128,8,1>, 128,8,1, 1};
|
| 343 |
+
// channels_last
|
| 344 |
+
if (s == 1 && fx <= 48 && fy <= 1) spec = {(void*)upfirdn2d_kernel_small<T, 4,1, 1,1, 48,1, 128,1,16>, 128,1,16, 1};
|
| 345 |
+
if (s == 1 && fx <= 32 && fy <= 1) spec = {(void*)upfirdn2d_kernel_small<T, 4,1, 1,1, 32,1, 128,1,16>, 128,1,16, 1};
|
| 346 |
+
}
|
| 347 |
+
if (p.up.x == 1 && p.up.y == 4 && p.down.x == 1 && p.down.y == 1)
|
| 348 |
+
{
|
| 349 |
+
// contiguous
|
| 350 |
+
if (s != 1 && fx <= 1 && fy <= 48) spec = {(void*)upfirdn2d_kernel_small<T, 1,4, 1,1, 1,48, 32,32,1>, 32,32,1, 1};
|
| 351 |
+
if (s != 1 && fx <= 1 && fy <= 32) spec = {(void*)upfirdn2d_kernel_small<T, 1,4, 1,1, 1,32, 32,32,1>, 32,32,1, 1};
|
| 352 |
+
// channels_last
|
| 353 |
+
if (s == 1 && fx <= 1 && fy <= 48) spec = {(void*)upfirdn2d_kernel_small<T, 1,4, 1,1, 1,48, 1,128,16>, 1,128,16, 1};
|
| 354 |
+
if (s == 1 && fx <= 1 && fy <= 32) spec = {(void*)upfirdn2d_kernel_small<T, 1,4, 1,1, 1,32, 1,128,16>, 1,128,16, 1};
|
| 355 |
+
}
|
| 356 |
+
|
| 357 |
+
// 4x downsampling (inefficient).
|
| 358 |
+
if (p.up.x == 1 && p.up.y == 1 && p.down.x == 4 && p.down.y == 1)
|
| 359 |
+
{
|
| 360 |
+
// contiguous
|
| 361 |
+
if (s != 1 && fx <= 48 && fy <= 1) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 4,1, 48,1, 32,8,1>, 32,8,1, 1};
|
| 362 |
+
if (s != 1 && fx <= 32 && fy <= 1) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 4,1, 32,1, 32,8,1>, 32,8,1, 1};
|
| 363 |
+
// channels_last
|
| 364 |
+
if (s == 1 && fx <= 48 && fy <= 1) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 4,1, 48,1, 32,1,8>, 32,1,8, 1};
|
| 365 |
+
if (s == 1 && fx <= 32 && fy <= 1) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 4,1, 32,1, 32,1,8>, 32,1,8, 1};
|
| 366 |
+
}
|
| 367 |
+
if (p.up.x == 1 && p.up.y == 1 && p.down.x == 1 && p.down.y == 4)
|
| 368 |
+
{
|
| 369 |
+
// contiguous
|
| 370 |
+
if (s != 1 && fx <= 1 && fy <= 48) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 1,4, 1,48, 32,8,1>, 32,8,1, 1};
|
| 371 |
+
if (s != 1 && fx <= 1 && fy <= 32) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 1,4, 1,32, 32,8,1>, 32,8,1, 1};
|
| 372 |
+
// channels_last
|
| 373 |
+
if (s == 1 && fx <= 1 && fy <= 48) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 1,4, 1,48, 1,32,8>, 1,32,8, 1};
|
| 374 |
+
if (s == 1 && fx <= 1 && fy <= 32) spec = {(void*)upfirdn2d_kernel_small<T, 1,1, 1,4, 1,32, 1,32,8>, 1,32,8, 1};
|
| 375 |
+
}
|
| 376 |
+
return spec;
|
| 377 |
+
}
|
| 378 |
+
|
| 379 |
+
//------------------------------------------------------------------------
|
| 380 |
+
// Template specializations.
|
| 381 |
+
|
| 382 |
+
template upfirdn2d_kernel_spec choose_upfirdn2d_kernel<double> (const upfirdn2d_kernel_params& p);
|
| 383 |
+
template upfirdn2d_kernel_spec choose_upfirdn2d_kernel<float> (const upfirdn2d_kernel_params& p);
|
| 384 |
+
template upfirdn2d_kernel_spec choose_upfirdn2d_kernel<c10::Half>(const upfirdn2d_kernel_params& p);
|
| 385 |
+
template upfirdn2d_kernel_spec choose_upfirdn2d_kernel<c10::BFloat16>(const upfirdn2d_kernel_params& p);
|
| 386 |
+
|
| 387 |
+
//------------------------------------------------------------------------
|
torch_utils/ops/upfirdn2d.h
ADDED
|
@@ -0,0 +1,59 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
// Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
//
|
| 3 |
+
// NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
// and proprietary rights in and to this software, related documentation
|
| 5 |
+
// and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
// distribution of this software and related documentation without an express
|
| 7 |
+
// license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
#include <cuda_runtime.h>
|
| 10 |
+
|
| 11 |
+
//------------------------------------------------------------------------
|
| 12 |
+
// CUDA kernel parameters.
|
| 13 |
+
|
| 14 |
+
struct upfirdn2d_kernel_params
|
| 15 |
+
{
|
| 16 |
+
const void* x;
|
| 17 |
+
const float* f;
|
| 18 |
+
void* y;
|
| 19 |
+
|
| 20 |
+
int2 up;
|
| 21 |
+
int2 down;
|
| 22 |
+
int2 pad0;
|
| 23 |
+
int flip;
|
| 24 |
+
float gain;
|
| 25 |
+
|
| 26 |
+
int4 inSize; // [width, height, channel, batch]
|
| 27 |
+
int4 inStride;
|
| 28 |
+
int2 filterSize; // [width, height]
|
| 29 |
+
int2 filterStride;
|
| 30 |
+
int4 outSize; // [width, height, channel, batch]
|
| 31 |
+
int4 outStride;
|
| 32 |
+
int sizeMinor;
|
| 33 |
+
int sizeMajor;
|
| 34 |
+
|
| 35 |
+
int loopMinor;
|
| 36 |
+
int loopMajor;
|
| 37 |
+
int loopX;
|
| 38 |
+
int launchMinor;
|
| 39 |
+
int launchMajor;
|
| 40 |
+
};
|
| 41 |
+
|
| 42 |
+
//------------------------------------------------------------------------
|
| 43 |
+
// CUDA kernel specialization.
|
| 44 |
+
|
| 45 |
+
struct upfirdn2d_kernel_spec
|
| 46 |
+
{
|
| 47 |
+
void* kernel;
|
| 48 |
+
int tileOutW;
|
| 49 |
+
int tileOutH;
|
| 50 |
+
int loopMinor;
|
| 51 |
+
int loopX;
|
| 52 |
+
};
|
| 53 |
+
|
| 54 |
+
//------------------------------------------------------------------------
|
| 55 |
+
// CUDA kernel selection.
|
| 56 |
+
|
| 57 |
+
template <class T> upfirdn2d_kernel_spec choose_upfirdn2d_kernel(const upfirdn2d_kernel_params& p);
|
| 58 |
+
|
| 59 |
+
//------------------------------------------------------------------------
|
torch_utils/ops/upfirdn2d.py
ADDED
|
@@ -0,0 +1,389 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
"""Custom PyTorch ops for efficient resampling of 2D images."""
|
| 10 |
+
|
| 11 |
+
import os
|
| 12 |
+
import numpy as np
|
| 13 |
+
import torch
|
| 14 |
+
|
| 15 |
+
from .. import custom_ops
|
| 16 |
+
from .. import misc
|
| 17 |
+
from . import conv2d_gradfix
|
| 18 |
+
|
| 19 |
+
#----------------------------------------------------------------------------
|
| 20 |
+
|
| 21 |
+
_plugin = None
|
| 22 |
+
|
| 23 |
+
def _init():
|
| 24 |
+
global _plugin
|
| 25 |
+
if _plugin is None:
|
| 26 |
+
_plugin = custom_ops.get_plugin(
|
| 27 |
+
module_name='upfirdn2d_plugin',
|
| 28 |
+
sources=['upfirdn2d.cpp', 'upfirdn2d.cu'],
|
| 29 |
+
headers=['upfirdn2d.h'],
|
| 30 |
+
source_dir=os.path.dirname(__file__),
|
| 31 |
+
extra_cuda_cflags=['--use_fast_math', '--allow-unsupported-compiler'],
|
| 32 |
+
)
|
| 33 |
+
return True
|
| 34 |
+
|
| 35 |
+
def _parse_scaling(scaling):
|
| 36 |
+
if isinstance(scaling, int):
|
| 37 |
+
scaling = [scaling, scaling]
|
| 38 |
+
assert isinstance(scaling, (list, tuple))
|
| 39 |
+
assert all(isinstance(x, int) for x in scaling)
|
| 40 |
+
sx, sy = scaling
|
| 41 |
+
assert sx >= 1 and sy >= 1
|
| 42 |
+
return sx, sy
|
| 43 |
+
|
| 44 |
+
def _parse_padding(padding):
|
| 45 |
+
if isinstance(padding, int):
|
| 46 |
+
padding = [padding, padding]
|
| 47 |
+
assert isinstance(padding, (list, tuple))
|
| 48 |
+
assert all(isinstance(x, int) for x in padding)
|
| 49 |
+
if len(padding) == 2:
|
| 50 |
+
padx, pady = padding
|
| 51 |
+
padding = [padx, padx, pady, pady]
|
| 52 |
+
padx0, padx1, pady0, pady1 = padding
|
| 53 |
+
return padx0, padx1, pady0, pady1
|
| 54 |
+
|
| 55 |
+
def _get_filter_size(f):
|
| 56 |
+
if f is None:
|
| 57 |
+
return 1, 1
|
| 58 |
+
assert isinstance(f, torch.Tensor) and f.ndim in [1, 2]
|
| 59 |
+
fw = f.shape[-1]
|
| 60 |
+
fh = f.shape[0]
|
| 61 |
+
with misc.suppress_tracer_warnings():
|
| 62 |
+
fw = int(fw)
|
| 63 |
+
fh = int(fh)
|
| 64 |
+
misc.assert_shape(f, [fh, fw][:f.ndim])
|
| 65 |
+
assert fw >= 1 and fh >= 1
|
| 66 |
+
return fw, fh
|
| 67 |
+
|
| 68 |
+
#----------------------------------------------------------------------------
|
| 69 |
+
|
| 70 |
+
def setup_filter(f, device=torch.device('cpu'), normalize=True, flip_filter=False, gain=1, separable=None):
|
| 71 |
+
r"""Convenience function to setup 2D FIR filter for `upfirdn2d()`.
|
| 72 |
+
|
| 73 |
+
Args:
|
| 74 |
+
f: Torch tensor, numpy array, or python list of the shape
|
| 75 |
+
`[filter_height, filter_width]` (non-separable),
|
| 76 |
+
`[filter_taps]` (separable),
|
| 77 |
+
`[]` (impulse), or
|
| 78 |
+
`None` (identity).
|
| 79 |
+
device: Result device (default: cpu).
|
| 80 |
+
normalize: Normalize the filter so that it retains the magnitude
|
| 81 |
+
for constant input signal (DC)? (default: True).
|
| 82 |
+
flip_filter: Flip the filter? (default: False).
|
| 83 |
+
gain: Overall scaling factor for signal magnitude (default: 1).
|
| 84 |
+
separable: Return a separable filter? (default: select automatically).
|
| 85 |
+
|
| 86 |
+
Returns:
|
| 87 |
+
Float32 tensor of the shape
|
| 88 |
+
`[filter_height, filter_width]` (non-separable) or
|
| 89 |
+
`[filter_taps]` (separable).
|
| 90 |
+
"""
|
| 91 |
+
# Validate.
|
| 92 |
+
if f is None:
|
| 93 |
+
f = 1
|
| 94 |
+
f = torch.as_tensor(f, dtype=torch.float32)
|
| 95 |
+
assert f.ndim in [0, 1, 2]
|
| 96 |
+
assert f.numel() > 0
|
| 97 |
+
if f.ndim == 0:
|
| 98 |
+
f = f[np.newaxis]
|
| 99 |
+
|
| 100 |
+
# Separable?
|
| 101 |
+
if separable is None:
|
| 102 |
+
separable = (f.ndim == 1 and f.numel() >= 8)
|
| 103 |
+
if f.ndim == 1 and not separable:
|
| 104 |
+
f = f.ger(f)
|
| 105 |
+
assert f.ndim == (1 if separable else 2)
|
| 106 |
+
|
| 107 |
+
# Apply normalize, flip, gain, and device.
|
| 108 |
+
if normalize:
|
| 109 |
+
f /= f.sum()
|
| 110 |
+
if flip_filter:
|
| 111 |
+
f = f.flip(list(range(f.ndim)))
|
| 112 |
+
f = f * (gain ** (f.ndim / 2))
|
| 113 |
+
f = f.to(device=device)
|
| 114 |
+
return f
|
| 115 |
+
|
| 116 |
+
#----------------------------------------------------------------------------
|
| 117 |
+
|
| 118 |
+
def upfirdn2d(x, f, up=1, down=1, padding=0, flip_filter=False, gain=1, impl='cuda'):
|
| 119 |
+
r"""Pad, upsample, filter, and downsample a batch of 2D images.
|
| 120 |
+
|
| 121 |
+
Performs the following sequence of operations for each channel:
|
| 122 |
+
|
| 123 |
+
1. Upsample the image by inserting N-1 zeros after each pixel (`up`).
|
| 124 |
+
|
| 125 |
+
2. Pad the image with the specified number of zeros on each side (`padding`).
|
| 126 |
+
Negative padding corresponds to cropping the image.
|
| 127 |
+
|
| 128 |
+
3. Convolve the image with the specified 2D FIR filter (`f`), shrinking it
|
| 129 |
+
so that the footprint of all output pixels lies within the input image.
|
| 130 |
+
|
| 131 |
+
4. Downsample the image by keeping every Nth pixel (`down`).
|
| 132 |
+
|
| 133 |
+
This sequence of operations bears close resemblance to scipy.signal.upfirdn().
|
| 134 |
+
The fused op is considerably more efficient than performing the same calculation
|
| 135 |
+
using standard PyTorch ops. It supports gradients of arbitrary order.
|
| 136 |
+
|
| 137 |
+
Args:
|
| 138 |
+
x: Float32/float64/float16 input tensor of the shape
|
| 139 |
+
`[batch_size, num_channels, in_height, in_width]`.
|
| 140 |
+
f: Float32 FIR filter of the shape
|
| 141 |
+
`[filter_height, filter_width]` (non-separable),
|
| 142 |
+
`[filter_taps]` (separable), or
|
| 143 |
+
`None` (identity).
|
| 144 |
+
up: Integer upsampling factor. Can be a single int or a list/tuple
|
| 145 |
+
`[x, y]` (default: 1).
|
| 146 |
+
down: Integer downsampling factor. Can be a single int or a list/tuple
|
| 147 |
+
`[x, y]` (default: 1).
|
| 148 |
+
padding: Padding with respect to the upsampled image. Can be a single number
|
| 149 |
+
or a list/tuple `[x, y]` or `[x_before, x_after, y_before, y_after]`
|
| 150 |
+
(default: 0).
|
| 151 |
+
flip_filter: False = convolution, True = correlation (default: False).
|
| 152 |
+
gain: Overall scaling factor for signal magnitude (default: 1).
|
| 153 |
+
impl: Implementation to use. Can be `'ref'` or `'cuda'` (default: `'cuda'`).
|
| 154 |
+
|
| 155 |
+
Returns:
|
| 156 |
+
Tensor of the shape `[batch_size, num_channels, out_height, out_width]`.
|
| 157 |
+
"""
|
| 158 |
+
assert isinstance(x, torch.Tensor)
|
| 159 |
+
assert impl in ['ref', 'cuda']
|
| 160 |
+
if impl == 'cuda' and x.device.type == 'cuda' and _init():
|
| 161 |
+
return _upfirdn2d_cuda(up=up, down=down, padding=padding, flip_filter=flip_filter, gain=gain).apply(x, f)
|
| 162 |
+
return _upfirdn2d_ref(x, f, up=up, down=down, padding=padding, flip_filter=flip_filter, gain=gain)
|
| 163 |
+
|
| 164 |
+
#----------------------------------------------------------------------------
|
| 165 |
+
|
| 166 |
+
@misc.profiled_function
|
| 167 |
+
def _upfirdn2d_ref(x, f, up=1, down=1, padding=0, flip_filter=False, gain=1):
|
| 168 |
+
"""Slow reference implementation of `upfirdn2d()` using standard PyTorch ops.
|
| 169 |
+
"""
|
| 170 |
+
# Validate arguments.
|
| 171 |
+
assert isinstance(x, torch.Tensor) and x.ndim == 4
|
| 172 |
+
if f is None:
|
| 173 |
+
f = torch.ones([1, 1], dtype=torch.float32, device=x.device)
|
| 174 |
+
assert isinstance(f, torch.Tensor) and f.ndim in [1, 2]
|
| 175 |
+
assert f.dtype == torch.float32 and not f.requires_grad
|
| 176 |
+
batch_size, num_channels, in_height, in_width = x.shape
|
| 177 |
+
upx, upy = _parse_scaling(up)
|
| 178 |
+
downx, downy = _parse_scaling(down)
|
| 179 |
+
padx0, padx1, pady0, pady1 = _parse_padding(padding)
|
| 180 |
+
|
| 181 |
+
# Check that upsampled buffer is not smaller than the filter.
|
| 182 |
+
upW = in_width * upx + padx0 + padx1
|
| 183 |
+
upH = in_height * upy + pady0 + pady1
|
| 184 |
+
assert upW >= f.shape[-1] and upH >= f.shape[0]
|
| 185 |
+
|
| 186 |
+
# Upsample by inserting zeros.
|
| 187 |
+
x = x.reshape([batch_size, num_channels, in_height, 1, in_width, 1])
|
| 188 |
+
x = torch.nn.functional.pad(x, [0, upx - 1, 0, 0, 0, upy - 1])
|
| 189 |
+
x = x.reshape([batch_size, num_channels, in_height * upy, in_width * upx])
|
| 190 |
+
|
| 191 |
+
# Pad or crop.
|
| 192 |
+
x = torch.nn.functional.pad(x, [max(padx0, 0), max(padx1, 0), max(pady0, 0), max(pady1, 0)])
|
| 193 |
+
x = x[:, :, max(-pady0, 0) : x.shape[2] - max(-pady1, 0), max(-padx0, 0) : x.shape[3] - max(-padx1, 0)]
|
| 194 |
+
|
| 195 |
+
# Setup filter.
|
| 196 |
+
f = f * (gain ** (f.ndim / 2))
|
| 197 |
+
f = f.to(x.dtype)
|
| 198 |
+
if not flip_filter:
|
| 199 |
+
f = f.flip(list(range(f.ndim)))
|
| 200 |
+
|
| 201 |
+
# Convolve with the filter.
|
| 202 |
+
f = f[np.newaxis, np.newaxis].repeat([num_channels, 1] + [1] * f.ndim)
|
| 203 |
+
if f.ndim == 4:
|
| 204 |
+
x = conv2d_gradfix.conv2d(input=x, weight=f, groups=num_channels)
|
| 205 |
+
else:
|
| 206 |
+
x = conv2d_gradfix.conv2d(input=x, weight=f.unsqueeze(2), groups=num_channels)
|
| 207 |
+
x = conv2d_gradfix.conv2d(input=x, weight=f.unsqueeze(3), groups=num_channels)
|
| 208 |
+
|
| 209 |
+
# Downsample by throwing away pixels.
|
| 210 |
+
x = x[:, :, ::downy, ::downx]
|
| 211 |
+
return x
|
| 212 |
+
|
| 213 |
+
#----------------------------------------------------------------------------
|
| 214 |
+
|
| 215 |
+
_upfirdn2d_cuda_cache = dict()
|
| 216 |
+
|
| 217 |
+
def _upfirdn2d_cuda(up=1, down=1, padding=0, flip_filter=False, gain=1):
|
| 218 |
+
"""Fast CUDA implementation of `upfirdn2d()` using custom ops.
|
| 219 |
+
"""
|
| 220 |
+
# Parse arguments.
|
| 221 |
+
upx, upy = _parse_scaling(up)
|
| 222 |
+
downx, downy = _parse_scaling(down)
|
| 223 |
+
padx0, padx1, pady0, pady1 = _parse_padding(padding)
|
| 224 |
+
|
| 225 |
+
# Lookup from cache.
|
| 226 |
+
key = (upx, upy, downx, downy, padx0, padx1, pady0, pady1, flip_filter, gain)
|
| 227 |
+
if key in _upfirdn2d_cuda_cache:
|
| 228 |
+
return _upfirdn2d_cuda_cache[key]
|
| 229 |
+
|
| 230 |
+
# Forward op.
|
| 231 |
+
class Upfirdn2dCuda(torch.autograd.Function):
|
| 232 |
+
@staticmethod
|
| 233 |
+
def forward(ctx, x, f): # pylint: disable=arguments-differ
|
| 234 |
+
assert isinstance(x, torch.Tensor) and x.ndim == 4
|
| 235 |
+
if f is None:
|
| 236 |
+
f = torch.ones([1, 1], dtype=torch.float32, device=x.device)
|
| 237 |
+
if f.ndim == 1 and f.shape[0] == 1:
|
| 238 |
+
f = f.square().unsqueeze(0) # Convert separable-1 into full-1x1.
|
| 239 |
+
assert isinstance(f, torch.Tensor) and f.ndim in [1, 2]
|
| 240 |
+
y = x
|
| 241 |
+
if f.ndim == 2:
|
| 242 |
+
y = _plugin.upfirdn2d(y, f, upx, upy, downx, downy, padx0, padx1, pady0, pady1, flip_filter, gain)
|
| 243 |
+
else:
|
| 244 |
+
y = _plugin.upfirdn2d(y, f.unsqueeze(0), upx, 1, downx, 1, padx0, padx1, 0, 0, flip_filter, 1.0)
|
| 245 |
+
y = _plugin.upfirdn2d(y, f.unsqueeze(1), 1, upy, 1, downy, 0, 0, pady0, pady1, flip_filter, gain)
|
| 246 |
+
ctx.save_for_backward(f)
|
| 247 |
+
ctx.x_shape = x.shape
|
| 248 |
+
return y
|
| 249 |
+
|
| 250 |
+
@staticmethod
|
| 251 |
+
def backward(ctx, dy): # pylint: disable=arguments-differ
|
| 252 |
+
f, = ctx.saved_tensors
|
| 253 |
+
_, _, ih, iw = ctx.x_shape
|
| 254 |
+
_, _, oh, ow = dy.shape
|
| 255 |
+
fw, fh = _get_filter_size(f)
|
| 256 |
+
p = [
|
| 257 |
+
fw - padx0 - 1,
|
| 258 |
+
iw * upx - ow * downx + padx0 - upx + 1,
|
| 259 |
+
fh - pady0 - 1,
|
| 260 |
+
ih * upy - oh * downy + pady0 - upy + 1,
|
| 261 |
+
]
|
| 262 |
+
dx = None
|
| 263 |
+
df = None
|
| 264 |
+
|
| 265 |
+
if ctx.needs_input_grad[0]:
|
| 266 |
+
dx = _upfirdn2d_cuda(up=down, down=up, padding=p, flip_filter=(not flip_filter), gain=gain).apply(dy, f)
|
| 267 |
+
|
| 268 |
+
assert not ctx.needs_input_grad[1]
|
| 269 |
+
return dx, df
|
| 270 |
+
|
| 271 |
+
# Add to cache.
|
| 272 |
+
_upfirdn2d_cuda_cache[key] = Upfirdn2dCuda
|
| 273 |
+
return Upfirdn2dCuda
|
| 274 |
+
|
| 275 |
+
#----------------------------------------------------------------------------
|
| 276 |
+
|
| 277 |
+
def filter2d(x, f, padding=0, flip_filter=False, gain=1, impl='cuda'):
|
| 278 |
+
r"""Filter a batch of 2D images using the given 2D FIR filter.
|
| 279 |
+
|
| 280 |
+
By default, the result is padded so that its shape matches the input.
|
| 281 |
+
User-specified padding is applied on top of that, with negative values
|
| 282 |
+
indicating cropping. Pixels outside the image are assumed to be zero.
|
| 283 |
+
|
| 284 |
+
Args:
|
| 285 |
+
x: Float32/float64/float16 input tensor of the shape
|
| 286 |
+
`[batch_size, num_channels, in_height, in_width]`.
|
| 287 |
+
f: Float32 FIR filter of the shape
|
| 288 |
+
`[filter_height, filter_width]` (non-separable),
|
| 289 |
+
`[filter_taps]` (separable), or
|
| 290 |
+
`None` (identity).
|
| 291 |
+
padding: Padding with respect to the output. Can be a single number or a
|
| 292 |
+
list/tuple `[x, y]` or `[x_before, x_after, y_before, y_after]`
|
| 293 |
+
(default: 0).
|
| 294 |
+
flip_filter: False = convolution, True = correlation (default: False).
|
| 295 |
+
gain: Overall scaling factor for signal magnitude (default: 1).
|
| 296 |
+
impl: Implementation to use. Can be `'ref'` or `'cuda'` (default: `'cuda'`).
|
| 297 |
+
|
| 298 |
+
Returns:
|
| 299 |
+
Tensor of the shape `[batch_size, num_channels, out_height, out_width]`.
|
| 300 |
+
"""
|
| 301 |
+
padx0, padx1, pady0, pady1 = _parse_padding(padding)
|
| 302 |
+
fw, fh = _get_filter_size(f)
|
| 303 |
+
p = [
|
| 304 |
+
padx0 + fw // 2,
|
| 305 |
+
padx1 + (fw - 1) // 2,
|
| 306 |
+
pady0 + fh // 2,
|
| 307 |
+
pady1 + (fh - 1) // 2,
|
| 308 |
+
]
|
| 309 |
+
return upfirdn2d(x, f, padding=p, flip_filter=flip_filter, gain=gain, impl=impl)
|
| 310 |
+
|
| 311 |
+
#----------------------------------------------------------------------------
|
| 312 |
+
|
| 313 |
+
def upsample2d(x, f, up=2, padding=0, flip_filter=False, gain=1, impl='cuda'):
|
| 314 |
+
r"""Upsample a batch of 2D images using the given 2D FIR filter.
|
| 315 |
+
|
| 316 |
+
By default, the result is padded so that its shape is a multiple of the input.
|
| 317 |
+
User-specified padding is applied on top of that, with negative values
|
| 318 |
+
indicating cropping. Pixels outside the image are assumed to be zero.
|
| 319 |
+
|
| 320 |
+
Args:
|
| 321 |
+
x: Float32/float64/float16 input tensor of the shape
|
| 322 |
+
`[batch_size, num_channels, in_height, in_width]`.
|
| 323 |
+
f: Float32 FIR filter of the shape
|
| 324 |
+
`[filter_height, filter_width]` (non-separable),
|
| 325 |
+
`[filter_taps]` (separable), or
|
| 326 |
+
`None` (identity).
|
| 327 |
+
up: Integer upsampling factor. Can be a single int or a list/tuple
|
| 328 |
+
`[x, y]` (default: 1).
|
| 329 |
+
padding: Padding with respect to the output. Can be a single number or a
|
| 330 |
+
list/tuple `[x, y]` or `[x_before, x_after, y_before, y_after]`
|
| 331 |
+
(default: 0).
|
| 332 |
+
flip_filter: False = convolution, True = correlation (default: False).
|
| 333 |
+
gain: Overall scaling factor for signal magnitude (default: 1).
|
| 334 |
+
impl: Implementation to use. Can be `'ref'` or `'cuda'` (default: `'cuda'`).
|
| 335 |
+
|
| 336 |
+
Returns:
|
| 337 |
+
Tensor of the shape `[batch_size, num_channels, out_height, out_width]`.
|
| 338 |
+
"""
|
| 339 |
+
upx, upy = _parse_scaling(up)
|
| 340 |
+
padx0, padx1, pady0, pady1 = _parse_padding(padding)
|
| 341 |
+
fw, fh = _get_filter_size(f)
|
| 342 |
+
p = [
|
| 343 |
+
padx0 + (fw + upx - 1) // 2,
|
| 344 |
+
padx1 + (fw - upx) // 2,
|
| 345 |
+
pady0 + (fh + upy - 1) // 2,
|
| 346 |
+
pady1 + (fh - upy) // 2,
|
| 347 |
+
]
|
| 348 |
+
return upfirdn2d(x, f, up=up, padding=p, flip_filter=flip_filter, gain=gain*upx*upy, impl=impl)
|
| 349 |
+
|
| 350 |
+
#----------------------------------------------------------------------------
|
| 351 |
+
|
| 352 |
+
def downsample2d(x, f, down=2, padding=0, flip_filter=False, gain=1, impl='cuda'):
|
| 353 |
+
r"""Downsample a batch of 2D images using the given 2D FIR filter.
|
| 354 |
+
|
| 355 |
+
By default, the result is padded so that its shape is a fraction of the input.
|
| 356 |
+
User-specified padding is applied on top of that, with negative values
|
| 357 |
+
indicating cropping. Pixels outside the image are assumed to be zero.
|
| 358 |
+
|
| 359 |
+
Args:
|
| 360 |
+
x: Float32/float64/float16 input tensor of the shape
|
| 361 |
+
`[batch_size, num_channels, in_height, in_width]`.
|
| 362 |
+
f: Float32 FIR filter of the shape
|
| 363 |
+
`[filter_height, filter_width]` (non-separable),
|
| 364 |
+
`[filter_taps]` (separable), or
|
| 365 |
+
`None` (identity).
|
| 366 |
+
down: Integer downsampling factor. Can be a single int or a list/tuple
|
| 367 |
+
`[x, y]` (default: 1).
|
| 368 |
+
padding: Padding with respect to the input. Can be a single number or a
|
| 369 |
+
list/tuple `[x, y]` or `[x_before, x_after, y_before, y_after]`
|
| 370 |
+
(default: 0).
|
| 371 |
+
flip_filter: False = convolution, True = correlation (default: False).
|
| 372 |
+
gain: Overall scaling factor for signal magnitude (default: 1).
|
| 373 |
+
impl: Implementation to use. Can be `'ref'` or `'cuda'` (default: `'cuda'`).
|
| 374 |
+
|
| 375 |
+
Returns:
|
| 376 |
+
Tensor of the shape `[batch_size, num_channels, out_height, out_width]`.
|
| 377 |
+
"""
|
| 378 |
+
downx, downy = _parse_scaling(down)
|
| 379 |
+
padx0, padx1, pady0, pady1 = _parse_padding(padding)
|
| 380 |
+
fw, fh = _get_filter_size(f)
|
| 381 |
+
p = [
|
| 382 |
+
padx0 + (fw - downx + 1) // 2,
|
| 383 |
+
padx1 + (fw - downx) // 2,
|
| 384 |
+
pady0 + (fh - downy + 1) // 2,
|
| 385 |
+
pady1 + (fh - downy) // 2,
|
| 386 |
+
]
|
| 387 |
+
return upfirdn2d(x, f, down=down, padding=p, flip_filter=flip_filter, gain=gain, impl=impl)
|
| 388 |
+
|
| 389 |
+
#----------------------------------------------------------------------------
|
torch_utils/persistence.py
ADDED
|
@@ -0,0 +1,251 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
"""Facilities for pickling Python code alongside other data.
|
| 10 |
+
|
| 11 |
+
The pickled code is automatically imported into a separate Python module
|
| 12 |
+
during unpickling. This way, any previously exported pickles will remain
|
| 13 |
+
usable even if the original code is no longer available, or if the current
|
| 14 |
+
version of the code is not consistent with what was originally pickled."""
|
| 15 |
+
|
| 16 |
+
import sys
|
| 17 |
+
import pickle
|
| 18 |
+
import io
|
| 19 |
+
import inspect
|
| 20 |
+
import copy
|
| 21 |
+
import uuid
|
| 22 |
+
import types
|
| 23 |
+
import dnnlib
|
| 24 |
+
|
| 25 |
+
#----------------------------------------------------------------------------
|
| 26 |
+
|
| 27 |
+
_version = 6 # internal version number
|
| 28 |
+
_decorators = set() # {decorator_class, ...}
|
| 29 |
+
_import_hooks = [] # [hook_function, ...]
|
| 30 |
+
_module_to_src_dict = dict() # {module: src, ...}
|
| 31 |
+
_src_to_module_dict = dict() # {src: module, ...}
|
| 32 |
+
|
| 33 |
+
#----------------------------------------------------------------------------
|
| 34 |
+
|
| 35 |
+
def persistent_class(orig_class):
|
| 36 |
+
r"""Class decorator that extends a given class to save its source code
|
| 37 |
+
when pickled.
|
| 38 |
+
|
| 39 |
+
Example:
|
| 40 |
+
|
| 41 |
+
from torch_utils import persistence
|
| 42 |
+
|
| 43 |
+
@persistence.persistent_class
|
| 44 |
+
class MyNetwork(torch.nn.Module):
|
| 45 |
+
def __init__(self, num_inputs, num_outputs):
|
| 46 |
+
super().__init__()
|
| 47 |
+
self.fc = MyLayer(num_inputs, num_outputs)
|
| 48 |
+
...
|
| 49 |
+
|
| 50 |
+
@persistence.persistent_class
|
| 51 |
+
class MyLayer(torch.nn.Module):
|
| 52 |
+
...
|
| 53 |
+
|
| 54 |
+
When pickled, any instance of `MyNetwork` and `MyLayer` will save its
|
| 55 |
+
source code alongside other internal state (e.g., parameters, buffers,
|
| 56 |
+
and submodules). This way, any previously exported pickle will remain
|
| 57 |
+
usable even if the class definitions have been modified or are no
|
| 58 |
+
longer available.
|
| 59 |
+
|
| 60 |
+
The decorator saves the source code of the entire Python module
|
| 61 |
+
containing the decorated class. It does *not* save the source code of
|
| 62 |
+
any imported modules. Thus, the imported modules must be available
|
| 63 |
+
during unpickling, also including `torch_utils.persistence` itself.
|
| 64 |
+
|
| 65 |
+
It is ok to call functions defined in the same module from the
|
| 66 |
+
decorated class. However, if the decorated class depends on other
|
| 67 |
+
classes defined in the same module, they must be decorated as well.
|
| 68 |
+
This is illustrated in the above example in the case of `MyLayer`.
|
| 69 |
+
|
| 70 |
+
It is also possible to employ the decorator just-in-time before
|
| 71 |
+
calling the constructor. For example:
|
| 72 |
+
|
| 73 |
+
cls = MyLayer
|
| 74 |
+
if want_to_make_it_persistent:
|
| 75 |
+
cls = persistence.persistent_class(cls)
|
| 76 |
+
layer = cls(num_inputs, num_outputs)
|
| 77 |
+
|
| 78 |
+
As an additional feature, the decorator also keeps track of the
|
| 79 |
+
arguments that were used to construct each instance of the decorated
|
| 80 |
+
class. The arguments can be queried via `obj.init_args` and
|
| 81 |
+
`obj.init_kwargs`, and they are automatically pickled alongside other
|
| 82 |
+
object state. A typical use case is to first unpickle a previous
|
| 83 |
+
instance of a persistent class, and then upgrade it to use the latest
|
| 84 |
+
version of the source code:
|
| 85 |
+
|
| 86 |
+
with open('old_pickle.pkl', 'rb') as f:
|
| 87 |
+
old_net = pickle.load(f)
|
| 88 |
+
new_net = MyNetwork(*old_obj.init_args, **old_obj.init_kwargs)
|
| 89 |
+
misc.copy_params_and_buffers(old_net, new_net, require_all=True)
|
| 90 |
+
"""
|
| 91 |
+
assert isinstance(orig_class, type)
|
| 92 |
+
if is_persistent(orig_class):
|
| 93 |
+
return orig_class
|
| 94 |
+
|
| 95 |
+
assert orig_class.__module__ in sys.modules
|
| 96 |
+
orig_module = sys.modules[orig_class.__module__]
|
| 97 |
+
orig_module_src = _module_to_src(orig_module)
|
| 98 |
+
|
| 99 |
+
class Decorator(orig_class):
|
| 100 |
+
_orig_module_src = orig_module_src
|
| 101 |
+
_orig_class_name = orig_class.__name__
|
| 102 |
+
|
| 103 |
+
def __init__(self, *args, **kwargs):
|
| 104 |
+
super().__init__(*args, **kwargs)
|
| 105 |
+
self._init_args = copy.deepcopy(args)
|
| 106 |
+
self._init_kwargs = copy.deepcopy(kwargs)
|
| 107 |
+
assert orig_class.__name__ in orig_module.__dict__
|
| 108 |
+
_check_pickleable(self.__reduce__())
|
| 109 |
+
|
| 110 |
+
@property
|
| 111 |
+
def init_args(self):
|
| 112 |
+
return copy.deepcopy(self._init_args)
|
| 113 |
+
|
| 114 |
+
@property
|
| 115 |
+
def init_kwargs(self):
|
| 116 |
+
return dnnlib.EasyDict(copy.deepcopy(self._init_kwargs))
|
| 117 |
+
|
| 118 |
+
def __reduce__(self):
|
| 119 |
+
fields = list(super().__reduce__())
|
| 120 |
+
fields += [None] * max(3 - len(fields), 0)
|
| 121 |
+
if fields[0] is not _reconstruct_persistent_obj:
|
| 122 |
+
meta = dict(type='class', version=_version, module_src=self._orig_module_src, class_name=self._orig_class_name, state=fields[2])
|
| 123 |
+
fields[0] = _reconstruct_persistent_obj # reconstruct func
|
| 124 |
+
fields[1] = (meta,) # reconstruct args
|
| 125 |
+
fields[2] = None # state dict
|
| 126 |
+
return tuple(fields)
|
| 127 |
+
|
| 128 |
+
Decorator.__name__ = orig_class.__name__
|
| 129 |
+
_decorators.add(Decorator)
|
| 130 |
+
return Decorator
|
| 131 |
+
|
| 132 |
+
#----------------------------------------------------------------------------
|
| 133 |
+
|
| 134 |
+
def is_persistent(obj):
|
| 135 |
+
r"""Test whether the given object or class is persistent, i.e.,
|
| 136 |
+
whether it will save its source code when pickled.
|
| 137 |
+
"""
|
| 138 |
+
try:
|
| 139 |
+
if obj in _decorators:
|
| 140 |
+
return True
|
| 141 |
+
except TypeError:
|
| 142 |
+
pass
|
| 143 |
+
return type(obj) in _decorators # pylint: disable=unidiomatic-typecheck
|
| 144 |
+
|
| 145 |
+
#----------------------------------------------------------------------------
|
| 146 |
+
|
| 147 |
+
def import_hook(hook):
|
| 148 |
+
r"""Register an import hook that is called whenever a persistent object
|
| 149 |
+
is being unpickled. A typical use case is to patch the pickled source
|
| 150 |
+
code to avoid errors and inconsistencies when the API of some imported
|
| 151 |
+
module has changed.
|
| 152 |
+
|
| 153 |
+
The hook should have the following signature:
|
| 154 |
+
|
| 155 |
+
hook(meta) -> modified meta
|
| 156 |
+
|
| 157 |
+
`meta` is an instance of `dnnlib.EasyDict` with the following fields:
|
| 158 |
+
|
| 159 |
+
type: Type of the persistent object, e.g. `'class'`.
|
| 160 |
+
version: Internal version number of `torch_utils.persistence`.
|
| 161 |
+
module_src Original source code of the Python module.
|
| 162 |
+
class_name: Class name in the original Python module.
|
| 163 |
+
state: Internal state of the object.
|
| 164 |
+
|
| 165 |
+
Example:
|
| 166 |
+
|
| 167 |
+
@persistence.import_hook
|
| 168 |
+
def wreck_my_network(meta):
|
| 169 |
+
if meta.class_name == 'MyNetwork':
|
| 170 |
+
print('MyNetwork is being imported. I will wreck it!')
|
| 171 |
+
meta.module_src = meta.module_src.replace("True", "False")
|
| 172 |
+
return meta
|
| 173 |
+
"""
|
| 174 |
+
assert callable(hook)
|
| 175 |
+
_import_hooks.append(hook)
|
| 176 |
+
|
| 177 |
+
#----------------------------------------------------------------------------
|
| 178 |
+
|
| 179 |
+
def _reconstruct_persistent_obj(meta):
|
| 180 |
+
r"""Hook that is called internally by the `pickle` module to unpickle
|
| 181 |
+
a persistent object.
|
| 182 |
+
"""
|
| 183 |
+
meta = dnnlib.EasyDict(meta)
|
| 184 |
+
meta.state = dnnlib.EasyDict(meta.state)
|
| 185 |
+
for hook in _import_hooks:
|
| 186 |
+
meta = hook(meta)
|
| 187 |
+
assert meta is not None
|
| 188 |
+
|
| 189 |
+
assert meta.version == _version
|
| 190 |
+
module = _src_to_module(meta.module_src)
|
| 191 |
+
|
| 192 |
+
assert meta.type == 'class'
|
| 193 |
+
orig_class = module.__dict__[meta.class_name]
|
| 194 |
+
decorator_class = persistent_class(orig_class)
|
| 195 |
+
obj = decorator_class.__new__(decorator_class)
|
| 196 |
+
|
| 197 |
+
setstate = getattr(obj, '__setstate__', None)
|
| 198 |
+
if callable(setstate):
|
| 199 |
+
setstate(meta.state) # pylint: disable=not-callable
|
| 200 |
+
else:
|
| 201 |
+
obj.__dict__.update(meta.state)
|
| 202 |
+
return obj
|
| 203 |
+
|
| 204 |
+
#----------------------------------------------------------------------------
|
| 205 |
+
|
| 206 |
+
def _module_to_src(module):
|
| 207 |
+
r"""Query the source code of a given Python module.
|
| 208 |
+
"""
|
| 209 |
+
src = _module_to_src_dict.get(module, None)
|
| 210 |
+
if src is None:
|
| 211 |
+
src = inspect.getsource(module)
|
| 212 |
+
_module_to_src_dict[module] = src
|
| 213 |
+
_src_to_module_dict[src] = module
|
| 214 |
+
return src
|
| 215 |
+
|
| 216 |
+
def _src_to_module(src):
|
| 217 |
+
r"""Get or create a Python module for the given source code.
|
| 218 |
+
"""
|
| 219 |
+
module = _src_to_module_dict.get(src, None)
|
| 220 |
+
if module is None:
|
| 221 |
+
module_name = "_imported_module_" + uuid.uuid4().hex
|
| 222 |
+
module = types.ModuleType(module_name)
|
| 223 |
+
sys.modules[module_name] = module
|
| 224 |
+
_module_to_src_dict[module] = src
|
| 225 |
+
_src_to_module_dict[src] = module
|
| 226 |
+
exec(src, module.__dict__) # pylint: disable=exec-used
|
| 227 |
+
return module
|
| 228 |
+
|
| 229 |
+
#----------------------------------------------------------------------------
|
| 230 |
+
|
| 231 |
+
def _check_pickleable(obj):
|
| 232 |
+
r"""Check that the given object is pickleable, raising an exception if
|
| 233 |
+
it is not. This function is expected to be considerably more efficient
|
| 234 |
+
than actually pickling the object.
|
| 235 |
+
"""
|
| 236 |
+
def recurse(obj):
|
| 237 |
+
if isinstance(obj, (list, tuple, set)):
|
| 238 |
+
return [recurse(x) for x in obj]
|
| 239 |
+
if isinstance(obj, dict):
|
| 240 |
+
return [[recurse(x), recurse(y)] for x, y in obj.items()]
|
| 241 |
+
if isinstance(obj, (str, int, float, bool, bytes, bytearray)):
|
| 242 |
+
return None # Python primitive types are pickleable.
|
| 243 |
+
if f'{type(obj).__module__}.{type(obj).__name__}' in ['numpy.ndarray', 'torch.Tensor', 'torch.nn.parameter.Parameter']:
|
| 244 |
+
return None # NumPy arrays and PyTorch tensors are pickleable.
|
| 245 |
+
if is_persistent(obj):
|
| 246 |
+
return None # Persistent objects are pickleable, by virtue of the constructor check.
|
| 247 |
+
return obj
|
| 248 |
+
with io.BytesIO() as f:
|
| 249 |
+
pickle.dump(recurse(obj), f)
|
| 250 |
+
|
| 251 |
+
#----------------------------------------------------------------------------
|
torch_utils/training_stats.py
ADDED
|
@@ -0,0 +1,268 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
"""Facilities for reporting and collecting training statistics across
|
| 10 |
+
multiple processes and devices. The interface is designed to minimize
|
| 11 |
+
synchronization overhead as well as the amount of boilerplate in user
|
| 12 |
+
code."""
|
| 13 |
+
|
| 14 |
+
import re
|
| 15 |
+
import numpy as np
|
| 16 |
+
import torch
|
| 17 |
+
import dnnlib
|
| 18 |
+
|
| 19 |
+
from . import misc
|
| 20 |
+
|
| 21 |
+
#----------------------------------------------------------------------------
|
| 22 |
+
|
| 23 |
+
_num_moments = 3 # [num_scalars, sum_of_scalars, sum_of_squares]
|
| 24 |
+
_reduce_dtype = torch.float32 # Data type to use for initial per-tensor reduction.
|
| 25 |
+
_counter_dtype = torch.float64 # Data type to use for the internal counters.
|
| 26 |
+
_rank = 0 # Rank of the current process.
|
| 27 |
+
_sync_device = None # Device to use for multiprocess communication. None = single-process.
|
| 28 |
+
_sync_called = False # Has _sync() been called yet?
|
| 29 |
+
_counters = dict() # Running counters on each device, updated by report(): name => device => torch.Tensor
|
| 30 |
+
_cumulative = dict() # Cumulative counters on the CPU, updated by _sync(): name => torch.Tensor
|
| 31 |
+
|
| 32 |
+
#----------------------------------------------------------------------------
|
| 33 |
+
|
| 34 |
+
def init_multiprocessing(rank, sync_device):
|
| 35 |
+
r"""Initializes `torch_utils.training_stats` for collecting statistics
|
| 36 |
+
across multiple processes.
|
| 37 |
+
|
| 38 |
+
This function must be called after
|
| 39 |
+
`torch.distributed.init_process_group()` and before `Collector.update()`.
|
| 40 |
+
The call is not necessary if multi-process collection is not needed.
|
| 41 |
+
|
| 42 |
+
Args:
|
| 43 |
+
rank: Rank of the current process.
|
| 44 |
+
sync_device: PyTorch device to use for inter-process
|
| 45 |
+
communication, or None to disable multi-process
|
| 46 |
+
collection. Typically `torch.device('cuda', rank)`.
|
| 47 |
+
"""
|
| 48 |
+
global _rank, _sync_device
|
| 49 |
+
assert not _sync_called
|
| 50 |
+
_rank = rank
|
| 51 |
+
_sync_device = sync_device
|
| 52 |
+
|
| 53 |
+
#----------------------------------------------------------------------------
|
| 54 |
+
|
| 55 |
+
@misc.profiled_function
|
| 56 |
+
def report(name, value):
|
| 57 |
+
r"""Broadcasts the given set of scalars to all interested instances of
|
| 58 |
+
`Collector`, across device and process boundaries.
|
| 59 |
+
|
| 60 |
+
This function is expected to be extremely cheap and can be safely
|
| 61 |
+
called from anywhere in the training loop, loss function, or inside a
|
| 62 |
+
`torch.nn.Module`.
|
| 63 |
+
|
| 64 |
+
Warning: The current implementation expects the set of unique names to
|
| 65 |
+
be consistent across processes. Please make sure that `report()` is
|
| 66 |
+
called at least once for each unique name by each process, and in the
|
| 67 |
+
same order. If a given process has no scalars to broadcast, it can do
|
| 68 |
+
`report(name, [])` (empty list).
|
| 69 |
+
|
| 70 |
+
Args:
|
| 71 |
+
name: Arbitrary string specifying the name of the statistic.
|
| 72 |
+
Averages are accumulated separately for each unique name.
|
| 73 |
+
value: Arbitrary set of scalars. Can be a list, tuple,
|
| 74 |
+
NumPy array, PyTorch tensor, or Python scalar.
|
| 75 |
+
|
| 76 |
+
Returns:
|
| 77 |
+
The same `value` that was passed in.
|
| 78 |
+
"""
|
| 79 |
+
if name not in _counters:
|
| 80 |
+
_counters[name] = dict()
|
| 81 |
+
|
| 82 |
+
elems = torch.as_tensor(value)
|
| 83 |
+
if elems.numel() == 0:
|
| 84 |
+
return value
|
| 85 |
+
|
| 86 |
+
elems = elems.detach().flatten().to(_reduce_dtype)
|
| 87 |
+
moments = torch.stack([
|
| 88 |
+
torch.ones_like(elems).sum(),
|
| 89 |
+
elems.sum(),
|
| 90 |
+
elems.square().sum(),
|
| 91 |
+
])
|
| 92 |
+
assert moments.ndim == 1 and moments.shape[0] == _num_moments
|
| 93 |
+
moments = moments.to(_counter_dtype)
|
| 94 |
+
|
| 95 |
+
device = moments.device
|
| 96 |
+
if device not in _counters[name]:
|
| 97 |
+
_counters[name][device] = torch.zeros_like(moments)
|
| 98 |
+
_counters[name][device].add_(moments)
|
| 99 |
+
return value
|
| 100 |
+
|
| 101 |
+
#----------------------------------------------------------------------------
|
| 102 |
+
|
| 103 |
+
def report0(name, value):
|
| 104 |
+
r"""Broadcasts the given set of scalars by the first process (`rank = 0`),
|
| 105 |
+
but ignores any scalars provided by the other processes.
|
| 106 |
+
See `report()` for further details.
|
| 107 |
+
"""
|
| 108 |
+
report(name, value if _rank == 0 else [])
|
| 109 |
+
return value
|
| 110 |
+
|
| 111 |
+
#----------------------------------------------------------------------------
|
| 112 |
+
|
| 113 |
+
class Collector:
|
| 114 |
+
r"""Collects the scalars broadcasted by `report()` and `report0()` and
|
| 115 |
+
computes their long-term averages (mean and standard deviation) over
|
| 116 |
+
user-defined periods of time.
|
| 117 |
+
|
| 118 |
+
The averages are first collected into internal counters that are not
|
| 119 |
+
directly visible to the user. They are then copied to the user-visible
|
| 120 |
+
state as a result of calling `update()` and can then be queried using
|
| 121 |
+
`mean()`, `std()`, `as_dict()`, etc. Calling `update()` also resets the
|
| 122 |
+
internal counters for the next round, so that the user-visible state
|
| 123 |
+
effectively reflects averages collected between the last two calls to
|
| 124 |
+
`update()`.
|
| 125 |
+
|
| 126 |
+
Args:
|
| 127 |
+
regex: Regular expression defining which statistics to
|
| 128 |
+
collect. The default is to collect everything.
|
| 129 |
+
keep_previous: Whether to retain the previous averages if no
|
| 130 |
+
scalars were collected on a given round
|
| 131 |
+
(default: True).
|
| 132 |
+
"""
|
| 133 |
+
def __init__(self, regex='.*', keep_previous=True):
|
| 134 |
+
self._regex = re.compile(regex)
|
| 135 |
+
self._keep_previous = keep_previous
|
| 136 |
+
self._cumulative = dict()
|
| 137 |
+
self._moments = dict()
|
| 138 |
+
self.update()
|
| 139 |
+
self._moments.clear()
|
| 140 |
+
|
| 141 |
+
def names(self):
|
| 142 |
+
r"""Returns the names of all statistics broadcasted so far that
|
| 143 |
+
match the regular expression specified at construction time.
|
| 144 |
+
"""
|
| 145 |
+
return [name for name in _counters if self._regex.fullmatch(name)]
|
| 146 |
+
|
| 147 |
+
def update(self):
|
| 148 |
+
r"""Copies current values of the internal counters to the
|
| 149 |
+
user-visible state and resets them for the next round.
|
| 150 |
+
|
| 151 |
+
If `keep_previous=True` was specified at construction time, the
|
| 152 |
+
operation is skipped for statistics that have received no scalars
|
| 153 |
+
since the last update, retaining their previous averages.
|
| 154 |
+
|
| 155 |
+
This method performs a number of GPU-to-CPU transfers and one
|
| 156 |
+
`torch.distributed.all_reduce()`. It is intended to be called
|
| 157 |
+
periodically in the main training loop, typically once every
|
| 158 |
+
N training steps.
|
| 159 |
+
"""
|
| 160 |
+
if not self._keep_previous:
|
| 161 |
+
self._moments.clear()
|
| 162 |
+
for name, cumulative in _sync(self.names()):
|
| 163 |
+
if name not in self._cumulative:
|
| 164 |
+
self._cumulative[name] = torch.zeros([_num_moments], dtype=_counter_dtype)
|
| 165 |
+
delta = cumulative - self._cumulative[name]
|
| 166 |
+
self._cumulative[name].copy_(cumulative)
|
| 167 |
+
if float(delta[0]) != 0:
|
| 168 |
+
self._moments[name] = delta
|
| 169 |
+
|
| 170 |
+
def _get_delta(self, name):
|
| 171 |
+
r"""Returns the raw moments that were accumulated for the given
|
| 172 |
+
statistic between the last two calls to `update()`, or zero if
|
| 173 |
+
no scalars were collected.
|
| 174 |
+
"""
|
| 175 |
+
assert self._regex.fullmatch(name)
|
| 176 |
+
if name not in self._moments:
|
| 177 |
+
self._moments[name] = torch.zeros([_num_moments], dtype=_counter_dtype)
|
| 178 |
+
return self._moments[name]
|
| 179 |
+
|
| 180 |
+
def num(self, name):
|
| 181 |
+
r"""Returns the number of scalars that were accumulated for the given
|
| 182 |
+
statistic between the last two calls to `update()`, or zero if
|
| 183 |
+
no scalars were collected.
|
| 184 |
+
"""
|
| 185 |
+
delta = self._get_delta(name)
|
| 186 |
+
return int(delta[0])
|
| 187 |
+
|
| 188 |
+
def mean(self, name):
|
| 189 |
+
r"""Returns the mean of the scalars that were accumulated for the
|
| 190 |
+
given statistic between the last two calls to `update()`, or NaN if
|
| 191 |
+
no scalars were collected.
|
| 192 |
+
"""
|
| 193 |
+
delta = self._get_delta(name)
|
| 194 |
+
if int(delta[0]) == 0:
|
| 195 |
+
return float('nan')
|
| 196 |
+
return float(delta[1] / delta[0])
|
| 197 |
+
|
| 198 |
+
def std(self, name):
|
| 199 |
+
r"""Returns the standard deviation of the scalars that were
|
| 200 |
+
accumulated for the given statistic between the last two calls to
|
| 201 |
+
`update()`, or NaN if no scalars were collected.
|
| 202 |
+
"""
|
| 203 |
+
delta = self._get_delta(name)
|
| 204 |
+
if int(delta[0]) == 0 or not np.isfinite(float(delta[1])):
|
| 205 |
+
return float('nan')
|
| 206 |
+
if int(delta[0]) == 1:
|
| 207 |
+
return float(0)
|
| 208 |
+
mean = float(delta[1] / delta[0])
|
| 209 |
+
raw_var = float(delta[2] / delta[0])
|
| 210 |
+
return np.sqrt(max(raw_var - np.square(mean), 0))
|
| 211 |
+
|
| 212 |
+
def as_dict(self):
|
| 213 |
+
r"""Returns the averages accumulated between the last two calls to
|
| 214 |
+
`update()` as an `dnnlib.EasyDict`. The contents are as follows:
|
| 215 |
+
|
| 216 |
+
dnnlib.EasyDict(
|
| 217 |
+
NAME = dnnlib.EasyDict(num=FLOAT, mean=FLOAT, std=FLOAT),
|
| 218 |
+
...
|
| 219 |
+
)
|
| 220 |
+
"""
|
| 221 |
+
stats = dnnlib.EasyDict()
|
| 222 |
+
for name in self.names():
|
| 223 |
+
stats[name] = dnnlib.EasyDict(num=self.num(name), mean=self.mean(name), std=self.std(name))
|
| 224 |
+
return stats
|
| 225 |
+
|
| 226 |
+
def __getitem__(self, name):
|
| 227 |
+
r"""Convenience getter.
|
| 228 |
+
`collector[name]` is a synonym for `collector.mean(name)`.
|
| 229 |
+
"""
|
| 230 |
+
return self.mean(name)
|
| 231 |
+
|
| 232 |
+
#----------------------------------------------------------------------------
|
| 233 |
+
|
| 234 |
+
def _sync(names):
|
| 235 |
+
r"""Synchronize the global cumulative counters across devices and
|
| 236 |
+
processes. Called internally by `Collector.update()`.
|
| 237 |
+
"""
|
| 238 |
+
if len(names) == 0:
|
| 239 |
+
return []
|
| 240 |
+
global _sync_called
|
| 241 |
+
_sync_called = True
|
| 242 |
+
|
| 243 |
+
# Collect deltas within current rank.
|
| 244 |
+
deltas = []
|
| 245 |
+
device = _sync_device if _sync_device is not None else torch.device('cpu')
|
| 246 |
+
for name in names:
|
| 247 |
+
delta = torch.zeros([_num_moments], dtype=_counter_dtype, device=device)
|
| 248 |
+
for counter in _counters[name].values():
|
| 249 |
+
delta.add_(counter.to(device))
|
| 250 |
+
counter.copy_(torch.zeros_like(counter))
|
| 251 |
+
deltas.append(delta)
|
| 252 |
+
deltas = torch.stack(deltas)
|
| 253 |
+
|
| 254 |
+
# Sum deltas across ranks.
|
| 255 |
+
if _sync_device is not None:
|
| 256 |
+
torch.distributed.all_reduce(deltas)
|
| 257 |
+
|
| 258 |
+
# Update cumulative values.
|
| 259 |
+
deltas = deltas.cpu()
|
| 260 |
+
for idx, name in enumerate(names):
|
| 261 |
+
if name not in _cumulative:
|
| 262 |
+
_cumulative[name] = torch.zeros([_num_moments], dtype=_counter_dtype)
|
| 263 |
+
_cumulative[name].add_(deltas[idx])
|
| 264 |
+
|
| 265 |
+
# Return name-value pairs.
|
| 266 |
+
return [(name, _cumulative[name]) for name in names]
|
| 267 |
+
|
| 268 |
+
#----------------------------------------------------------------------------
|
train.py
ADDED
|
@@ -0,0 +1,322 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
import os
|
| 10 |
+
import click
|
| 11 |
+
import re
|
| 12 |
+
import json
|
| 13 |
+
import tempfile
|
| 14 |
+
import torch
|
| 15 |
+
|
| 16 |
+
import dnnlib
|
| 17 |
+
from training import training_loop
|
| 18 |
+
from metrics import metric_main
|
| 19 |
+
from torch_utils import training_stats
|
| 20 |
+
from torch_utils import custom_ops
|
| 21 |
+
|
| 22 |
+
#----------------------------------------------------------------------------
|
| 23 |
+
|
| 24 |
+
def subprocess_fn(rank, c, temp_dir):
|
| 25 |
+
dnnlib.util.Logger(file_name=os.path.join(c.run_dir, 'log.txt'), file_mode='a', should_flush=True)
|
| 26 |
+
|
| 27 |
+
# Init torch.distributed.
|
| 28 |
+
if c.num_gpus > 1:
|
| 29 |
+
init_file = os.path.abspath(os.path.join(temp_dir, '.torch_distributed_init'))
|
| 30 |
+
if os.name == 'nt':
|
| 31 |
+
init_method = 'file:///' + init_file.replace('\\', '/')
|
| 32 |
+
torch.distributed.init_process_group(backend='gloo', init_method=init_method, rank=rank, world_size=c.num_gpus)
|
| 33 |
+
else:
|
| 34 |
+
init_method = f'file://{init_file}'
|
| 35 |
+
torch.distributed.init_process_group(backend='nccl', init_method=init_method, rank=rank, world_size=c.num_gpus)
|
| 36 |
+
|
| 37 |
+
# Init torch_utils.
|
| 38 |
+
sync_device = torch.device('cuda', rank) if c.num_gpus > 1 else None
|
| 39 |
+
training_stats.init_multiprocessing(rank=rank, sync_device=sync_device)
|
| 40 |
+
if rank != 0:
|
| 41 |
+
custom_ops.verbosity = 'none'
|
| 42 |
+
|
| 43 |
+
# Execute training loop.
|
| 44 |
+
training_loop.training_loop(rank=rank, **c)
|
| 45 |
+
|
| 46 |
+
#----------------------------------------------------------------------------
|
| 47 |
+
|
| 48 |
+
def launch_training(c, desc, outdir, dry_run):
|
| 49 |
+
dnnlib.util.Logger(should_flush=True)
|
| 50 |
+
|
| 51 |
+
# Pick output directory.
|
| 52 |
+
prev_run_dirs = []
|
| 53 |
+
if os.path.isdir(outdir):
|
| 54 |
+
prev_run_dirs = [x for x in os.listdir(outdir) if os.path.isdir(os.path.join(outdir, x))]
|
| 55 |
+
prev_run_ids = [re.match(r'^\d+', x) for x in prev_run_dirs]
|
| 56 |
+
prev_run_ids = [int(x.group()) for x in prev_run_ids if x is not None]
|
| 57 |
+
cur_run_id = max(prev_run_ids, default=-1) + 1
|
| 58 |
+
c.run_dir = os.path.join(outdir, f'{cur_run_id:05d}-{desc}')
|
| 59 |
+
assert not os.path.exists(c.run_dir)
|
| 60 |
+
|
| 61 |
+
# Print options.
|
| 62 |
+
print()
|
| 63 |
+
print('Training options:')
|
| 64 |
+
print(json.dumps(c, indent=2))
|
| 65 |
+
print()
|
| 66 |
+
print(f'Output directory: {c.run_dir}')
|
| 67 |
+
print(f'Number of GPUs: {c.num_gpus}')
|
| 68 |
+
print(f'Batch size: {c.batch_size} images')
|
| 69 |
+
print(f'Training duration: {c.total_kimg} kimg')
|
| 70 |
+
print(f'Dataset path: {c.training_set_kwargs.path}')
|
| 71 |
+
print(f'Dataset size: {c.training_set_kwargs.max_size} images')
|
| 72 |
+
print(f'Dataset resolution: {c.training_set_kwargs.resolution}')
|
| 73 |
+
print(f'Dataset labels: {c.training_set_kwargs.use_labels}')
|
| 74 |
+
print(f'Dataset x-flips: {c.training_set_kwargs.xflip}')
|
| 75 |
+
print()
|
| 76 |
+
|
| 77 |
+
# Dry run?
|
| 78 |
+
if dry_run:
|
| 79 |
+
print('Dry run; exiting.')
|
| 80 |
+
return
|
| 81 |
+
|
| 82 |
+
# Create output directory.
|
| 83 |
+
print('Creating output directory...')
|
| 84 |
+
os.makedirs(c.run_dir)
|
| 85 |
+
with open(os.path.join(c.run_dir, 'training_options.json'), 'wt') as f:
|
| 86 |
+
json.dump(c, f, indent=2)
|
| 87 |
+
|
| 88 |
+
# Launch processes.
|
| 89 |
+
print('Launching processes...')
|
| 90 |
+
torch.multiprocessing.set_start_method('spawn')
|
| 91 |
+
with tempfile.TemporaryDirectory() as temp_dir:
|
| 92 |
+
if c.num_gpus == 1:
|
| 93 |
+
subprocess_fn(rank=0, c=c, temp_dir=temp_dir)
|
| 94 |
+
else:
|
| 95 |
+
torch.multiprocessing.spawn(fn=subprocess_fn, args=(c, temp_dir), nprocs=c.num_gpus)
|
| 96 |
+
|
| 97 |
+
#----------------------------------------------------------------------------
|
| 98 |
+
|
| 99 |
+
def init_dataset_kwargs(data):
|
| 100 |
+
try:
|
| 101 |
+
dataset_kwargs = dnnlib.EasyDict(class_name='training.dataset.ImageFolderDataset', path=data, use_labels=True, max_size=None, xflip=False)
|
| 102 |
+
dataset_obj = dnnlib.util.construct_class_by_name(**dataset_kwargs) # Subclass of training.dataset.Dataset.
|
| 103 |
+
dataset_kwargs.resolution = dataset_obj.resolution # Be explicit about resolution.
|
| 104 |
+
dataset_kwargs.use_labels = dataset_obj.has_labels # Be explicit about labels.
|
| 105 |
+
dataset_kwargs.max_size = len(dataset_obj) # Be explicit about dataset size.
|
| 106 |
+
return dataset_kwargs, dataset_obj.name
|
| 107 |
+
except IOError as err:
|
| 108 |
+
raise click.ClickException(f'--data: {err}')
|
| 109 |
+
|
| 110 |
+
#----------------------------------------------------------------------------
|
| 111 |
+
|
| 112 |
+
def parse_comma_separated_list(s):
|
| 113 |
+
if isinstance(s, list):
|
| 114 |
+
return s
|
| 115 |
+
if s is None or s.lower() == 'none' or s == '':
|
| 116 |
+
return []
|
| 117 |
+
return s.split(',')
|
| 118 |
+
|
| 119 |
+
#----------------------------------------------------------------------------
|
| 120 |
+
|
| 121 |
+
@click.command()
|
| 122 |
+
|
| 123 |
+
# Required.
|
| 124 |
+
@click.option('--outdir', help='Where to save the results', metavar='DIR', required=True)
|
| 125 |
+
@click.option('--data', help='Training data', metavar='[ZIP|DIR]', type=str, required=True)
|
| 126 |
+
@click.option('--gpus', help='Number of GPUs to use', metavar='INT', type=click.IntRange(min=1), required=True)
|
| 127 |
+
@click.option('--batch', help='Total batch size', metavar='INT', type=click.IntRange(min=1), required=True)
|
| 128 |
+
@click.option('--preset', help='Preset configs', metavar='STR', type=str, required=True)
|
| 129 |
+
|
| 130 |
+
# Optional features.
|
| 131 |
+
@click.option('--cond', help='Train conditional model', metavar='BOOL', type=bool, default=False, show_default=True)
|
| 132 |
+
@click.option('--mirror', help='Enable dataset x-flips', metavar='BOOL', type=bool, default=False, show_default=True)
|
| 133 |
+
@click.option('--aug', help='Enable Augmentation', metavar='BOOL', type=bool, default=True, show_default=True)
|
| 134 |
+
@click.option('--resume', help='Resume from given network pickle', metavar='[PATH|URL]', type=str)
|
| 135 |
+
|
| 136 |
+
# Misc hyperparameters.
|
| 137 |
+
@click.option('--g-batch-gpu', help='Limit batch size per GPU for G', metavar='INT', type=click.IntRange(min=1))
|
| 138 |
+
@click.option('--d-batch-gpu', help='Limit batch size per GPU for D', metavar='INT', type=click.IntRange(min=1))
|
| 139 |
+
|
| 140 |
+
# Misc settings.
|
| 141 |
+
@click.option('--desc', help='String to include in result dir name', metavar='STR', type=str)
|
| 142 |
+
@click.option('--metrics', help='Quality metrics', metavar='[NAME|A,B,C|none]', type=parse_comma_separated_list, default='fid50k_full', show_default=True)
|
| 143 |
+
@click.option('--kimg', help='Total training duration', metavar='KIMG', type=click.IntRange(min=1), default=10000000, show_default=True)
|
| 144 |
+
@click.option('--tick', help='How often to print progress', metavar='KIMG', type=click.IntRange(min=1), default=4, show_default=True)
|
| 145 |
+
@click.option('--snap', help='How often to save snapshots', metavar='TICKS', type=click.IntRange(min=1), default=50, show_default=True)
|
| 146 |
+
@click.option('--seed', help='Random seed', metavar='INT', type=click.IntRange(min=0), default=0, show_default=True)
|
| 147 |
+
@click.option('--nobench', help='Disable cuDNN benchmarking', metavar='BOOL', type=bool, default=False, show_default=True)
|
| 148 |
+
@click.option('--workers', help='DataLoader worker processes', metavar='INT', type=click.IntRange(min=1), default=3, show_default=True)
|
| 149 |
+
@click.option('-n','--dry-run', help='Print training options and exit', is_flag=True)
|
| 150 |
+
|
| 151 |
+
def main(**kwargs):
|
| 152 |
+
# Initialize config.
|
| 153 |
+
opts = dnnlib.EasyDict(kwargs) # Command line arguments.
|
| 154 |
+
c = dnnlib.EasyDict() # Main config dict.
|
| 155 |
+
|
| 156 |
+
c.G_kwargs = dnnlib.EasyDict(class_name='training.networks.Generator')
|
| 157 |
+
c.D_kwargs = dnnlib.EasyDict(class_name='training.networks.Discriminator')
|
| 158 |
+
|
| 159 |
+
c.G_opt_kwargs = dnnlib.EasyDict(class_name='torch.optim.Adam', betas=[0,0], eps=1e-8)
|
| 160 |
+
c.D_opt_kwargs = dnnlib.EasyDict(class_name='torch.optim.Adam', betas=[0,0], eps=1e-8)
|
| 161 |
+
|
| 162 |
+
c.loss_kwargs = dnnlib.EasyDict(class_name='training.loss.R3GANLoss')
|
| 163 |
+
c.data_loader_kwargs = dnnlib.EasyDict(pin_memory=True, prefetch_factor=2)
|
| 164 |
+
|
| 165 |
+
# Training set.
|
| 166 |
+
c.training_set_kwargs, dataset_name = init_dataset_kwargs(data=opts.data)
|
| 167 |
+
if opts.cond and not c.training_set_kwargs.use_labels:
|
| 168 |
+
raise click.ClickException('--cond=True requires labels specified in dataset.json')
|
| 169 |
+
c.training_set_kwargs.use_labels = opts.cond
|
| 170 |
+
c.training_set_kwargs.xflip = opts.mirror
|
| 171 |
+
|
| 172 |
+
# Hyperparameters & settings.
|
| 173 |
+
c.num_gpus = opts.gpus
|
| 174 |
+
c.batch_size = opts.batch
|
| 175 |
+
c.g_batch_gpu = opts.g_batch_gpu or opts.batch // opts.gpus
|
| 176 |
+
c.d_batch_gpu = opts.d_batch_gpu or opts.batch // opts.gpus
|
| 177 |
+
|
| 178 |
+
if opts.preset == 'CIFAR10':
|
| 179 |
+
WidthPerStage = [3 * x // 4 for x in [1024, 1024, 1024, 1024]]
|
| 180 |
+
BlocksPerStage = [2 * x for x in [1, 1, 1, 1]]
|
| 181 |
+
CardinalityPerStage = [3 * x for x in [32, 32, 32, 32]]
|
| 182 |
+
FP16Stages = [-1, -2, -3]
|
| 183 |
+
NoiseDimension = 64
|
| 184 |
+
|
| 185 |
+
c.G_kwargs.ConditionEmbeddingDimension = NoiseDimension
|
| 186 |
+
c.D_kwargs.ConditionEmbeddingDimension = WidthPerStage[0]
|
| 187 |
+
|
| 188 |
+
ema_nimg = 5000 * 1000
|
| 189 |
+
decay_nimg = 2e7
|
| 190 |
+
|
| 191 |
+
c.ema_scheduler = { 'base_value': 0, 'final_value': ema_nimg, 'total_nimg': decay_nimg }
|
| 192 |
+
c.aug_scheduler = { 'base_value': 0, 'final_value': 0.55, 'total_nimg': decay_nimg }
|
| 193 |
+
c.lr_scheduler = { 'base_value': 2e-4, 'final_value': 5e-5, 'total_nimg': decay_nimg }
|
| 194 |
+
c.gamma_scheduler = { 'base_value': 0.05, 'final_value': 0.005, 'total_nimg': decay_nimg }
|
| 195 |
+
c.beta2_scheduler = { 'base_value': 0.9, 'final_value': 0.99, 'total_nimg': decay_nimg }
|
| 196 |
+
|
| 197 |
+
if opts.preset == 'FFHQ-64':
|
| 198 |
+
WidthPerStage = [3 * x // 4 for x in [1024, 1024, 1024, 1024, 512]]
|
| 199 |
+
BlocksPerStage = [2 * x for x in [1, 1, 1, 1, 1]]
|
| 200 |
+
CardinalityPerStage = [3 * x for x in [32, 32, 32, 32, 16]]
|
| 201 |
+
FP16Stages = [-1, -2, -3, -4]
|
| 202 |
+
NoiseDimension = 64
|
| 203 |
+
|
| 204 |
+
ema_nimg = 500 * 1000
|
| 205 |
+
decay_nimg = 2e7
|
| 206 |
+
|
| 207 |
+
c.ema_scheduler = { 'base_value': 0, 'final_value': ema_nimg, 'total_nimg': decay_nimg }
|
| 208 |
+
c.aug_scheduler = { 'base_value': 0, 'final_value': 0.3, 'total_nimg': decay_nimg }
|
| 209 |
+
c.lr_scheduler = { 'base_value': 2e-4, 'final_value': 5e-5, 'total_nimg': decay_nimg }
|
| 210 |
+
c.gamma_scheduler = { 'base_value': 2, 'final_value': 0.2, 'total_nimg': decay_nimg }
|
| 211 |
+
c.beta2_scheduler = { 'base_value': 0.9, 'final_value': 0.99, 'total_nimg': decay_nimg }
|
| 212 |
+
|
| 213 |
+
if opts.preset == 'FFHQ-256':
|
| 214 |
+
WidthPerStage = [3 * x // 4 for x in [1024, 1024, 1024, 1024, 512, 256, 128]]
|
| 215 |
+
BlocksPerStage = [2 * x for x in [1, 1, 1, 1, 1, 1, 1]]
|
| 216 |
+
CardinalityPerStage = [3 * x for x in [32, 32, 32, 32, 16, 8, 4]]
|
| 217 |
+
FP16Stages = [-1, -2, -3, -4]
|
| 218 |
+
NoiseDimension = 64
|
| 219 |
+
|
| 220 |
+
ema_nimg = 500 * 1000
|
| 221 |
+
decay_nimg = 2e7
|
| 222 |
+
|
| 223 |
+
c.ema_scheduler = { 'base_value': 0, 'final_value': ema_nimg, 'total_nimg': decay_nimg }
|
| 224 |
+
c.aug_scheduler = { 'base_value': 0, 'final_value': 0.3, 'total_nimg': decay_nimg }
|
| 225 |
+
c.lr_scheduler = { 'base_value': 2e-4, 'final_value': 5e-5, 'total_nimg': decay_nimg }
|
| 226 |
+
c.gamma_scheduler = { 'base_value': 150, 'final_value': 15, 'total_nimg': decay_nimg }
|
| 227 |
+
c.beta2_scheduler = { 'base_value': 0.9, 'final_value': 0.99, 'total_nimg': decay_nimg }
|
| 228 |
+
|
| 229 |
+
if opts.preset == 'ImageNet-32':
|
| 230 |
+
WidthPerStage = [6 * x // 4 for x in [1024, 1024, 1024, 1024]]
|
| 231 |
+
BlocksPerStage = [2 * x for x in [1, 1, 1, 1]]
|
| 232 |
+
CardinalityPerStage = [3 * x for x in [32, 32, 32, 32]]
|
| 233 |
+
FP16Stages = [-1, -2, -3]
|
| 234 |
+
NoiseDimension = 64
|
| 235 |
+
|
| 236 |
+
c.G_kwargs.ConditionEmbeddingDimension = NoiseDimension
|
| 237 |
+
c.D_kwargs.ConditionEmbeddingDimension = WidthPerStage[0]
|
| 238 |
+
|
| 239 |
+
ema_nimg = 50000 * 1000
|
| 240 |
+
decay_nimg = 2e8
|
| 241 |
+
|
| 242 |
+
c.ema_scheduler = { 'base_value': 0, 'final_value': ema_nimg, 'total_nimg': decay_nimg }
|
| 243 |
+
c.aug_scheduler = { 'base_value': 0, 'final_value': 0.5, 'total_nimg': decay_nimg }
|
| 244 |
+
c.lr_scheduler = { 'base_value': 2e-4, 'final_value': 5e-5, 'total_nimg': decay_nimg }
|
| 245 |
+
c.gamma_scheduler = { 'base_value': 0.5, 'final_value': 0.05, 'total_nimg': decay_nimg }
|
| 246 |
+
c.beta2_scheduler = { 'base_value': 0.9, 'final_value': 0.99, 'total_nimg': decay_nimg }
|
| 247 |
+
|
| 248 |
+
if opts.preset == 'ImageNet-64':
|
| 249 |
+
WidthPerStage = [6 * x // 4 for x in [1024, 1024, 1024, 1024, 1024]]
|
| 250 |
+
BlocksPerStage = [2 * x for x in [1, 1, 1, 1, 1]]
|
| 251 |
+
CardinalityPerStage = [3 * x for x in [32, 32, 32, 32, 32]]
|
| 252 |
+
FP16Stages = [-1, -2, -3, -4]
|
| 253 |
+
NoiseDimension = 64
|
| 254 |
+
|
| 255 |
+
c.G_kwargs.ConditionEmbeddingDimension = NoiseDimension
|
| 256 |
+
c.D_kwargs.ConditionEmbeddingDimension = WidthPerStage[0]
|
| 257 |
+
|
| 258 |
+
ema_nimg = 50000 * 1000
|
| 259 |
+
decay_nimg = 2e8
|
| 260 |
+
|
| 261 |
+
c.ema_scheduler = { 'base_value': 0, 'final_value': ema_nimg, 'total_nimg': decay_nimg }
|
| 262 |
+
c.aug_scheduler = { 'base_value': 0, 'final_value': 0.4, 'total_nimg': decay_nimg }
|
| 263 |
+
c.lr_scheduler = { 'base_value': 2e-4, 'final_value': 5e-5, 'total_nimg': decay_nimg }
|
| 264 |
+
c.gamma_scheduler = { 'base_value': 1, 'final_value': 0.1, 'total_nimg': decay_nimg }
|
| 265 |
+
c.beta2_scheduler = { 'base_value': 0.9, 'final_value': 0.99, 'total_nimg': decay_nimg }
|
| 266 |
+
|
| 267 |
+
c.G_kwargs.NoiseDimension = NoiseDimension
|
| 268 |
+
c.G_kwargs.WidthPerStage = WidthPerStage
|
| 269 |
+
c.G_kwargs.CardinalityPerStage = CardinalityPerStage
|
| 270 |
+
c.G_kwargs.BlocksPerStage = BlocksPerStage
|
| 271 |
+
c.G_kwargs.ExpansionFactor = 2
|
| 272 |
+
c.G_kwargs.FP16Stages = FP16Stages
|
| 273 |
+
|
| 274 |
+
c.D_kwargs.WidthPerStage = [*reversed(WidthPerStage)]
|
| 275 |
+
c.D_kwargs.CardinalityPerStage = [*reversed(CardinalityPerStage)]
|
| 276 |
+
c.D_kwargs.BlocksPerStage = [*reversed(BlocksPerStage)]
|
| 277 |
+
c.D_kwargs.ExpansionFactor = 2
|
| 278 |
+
c.D_kwargs.FP16Stages = [x + len(FP16Stages) for x in FP16Stages]
|
| 279 |
+
|
| 280 |
+
|
| 281 |
+
c.metrics = opts.metrics
|
| 282 |
+
c.total_kimg = opts.kimg
|
| 283 |
+
c.kimg_per_tick = opts.tick
|
| 284 |
+
c.image_snapshot_ticks = c.network_snapshot_ticks = opts.snap
|
| 285 |
+
c.random_seed = c.training_set_kwargs.random_seed = opts.seed
|
| 286 |
+
c.data_loader_kwargs.num_workers = opts.workers
|
| 287 |
+
|
| 288 |
+
# Sanity checks.
|
| 289 |
+
if c.batch_size % c.num_gpus != 0:
|
| 290 |
+
raise click.ClickException('--batch must be a multiple of --gpus')
|
| 291 |
+
if c.batch_size % (c.num_gpus * c.g_batch_gpu) != 0 or c.batch_size % (c.num_gpus * c.d_batch_gpu) != 0:
|
| 292 |
+
raise click.ClickException('--batch must be a multiple of --gpus times --batch-gpu')
|
| 293 |
+
if any(not metric_main.is_valid_metric(metric) for metric in c.metrics):
|
| 294 |
+
raise click.ClickException('\n'.join(['--metrics can only contain the following values:'] + metric_main.list_valid_metrics()))
|
| 295 |
+
|
| 296 |
+
|
| 297 |
+
# Augmentation.
|
| 298 |
+
if opts.aug:
|
| 299 |
+
c.augment_kwargs = dnnlib.EasyDict(class_name='training.augment.AugmentPipe', xflip=1, rotate90=1, xint=1, scale=1, rotate=1, aniso=1, xfrac=1, brightness=0.5, contrast=0.5, lumaflip=0.5, hue=0.5, saturation=0.5, cutout=1)
|
| 300 |
+
|
| 301 |
+
# Resume.
|
| 302 |
+
if opts.resume is not None:
|
| 303 |
+
c.resume_pkl = opts.resume
|
| 304 |
+
|
| 305 |
+
# Performance-related toggles.
|
| 306 |
+
if opts.nobench:
|
| 307 |
+
c.cudnn_benchmark = False
|
| 308 |
+
|
| 309 |
+
# Description string.
|
| 310 |
+
desc = f'{dataset_name:s}-gpus{c.num_gpus:d}-batch{c.batch_size:d}'
|
| 311 |
+
if opts.desc is not None:
|
| 312 |
+
desc += f'-{opts.desc}'
|
| 313 |
+
|
| 314 |
+
# Launch.
|
| 315 |
+
launch_training(c=c, desc=desc, outdir=opts.outdir, dry_run=opts.dry_run)
|
| 316 |
+
|
| 317 |
+
#----------------------------------------------------------------------------
|
| 318 |
+
|
| 319 |
+
if __name__ == "__main__":
|
| 320 |
+
main() # pylint: disable=no-value-for-parameter
|
| 321 |
+
|
| 322 |
+
#----------------------------------------------------------------------------
|
training/__init__.py
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
# empty
|
training/augment.py
ADDED
|
@@ -0,0 +1,437 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
"""Augmentation pipeline from the paper
|
| 10 |
+
"Training Generative Adversarial Networks with Limited Data".
|
| 11 |
+
Matches the original implementation by Karras et al. at
|
| 12 |
+
https://github.com/NVlabs/stylegan2-ada/blob/main/training/augment.py"""
|
| 13 |
+
|
| 14 |
+
import numpy as np
|
| 15 |
+
import scipy.signal
|
| 16 |
+
import torch
|
| 17 |
+
from torch_utils import persistence
|
| 18 |
+
from torch_utils import misc
|
| 19 |
+
from torch_utils.ops import upfirdn2d
|
| 20 |
+
from torch_utils.ops import grid_sample_gradfix
|
| 21 |
+
from torch_utils.ops import conv2d_gradfix
|
| 22 |
+
|
| 23 |
+
#----------------------------------------------------------------------------
|
| 24 |
+
# Coefficients of various wavelet decomposition low-pass filters.
|
| 25 |
+
|
| 26 |
+
wavelets = {
|
| 27 |
+
'haar': [0.7071067811865476, 0.7071067811865476],
|
| 28 |
+
'db1': [0.7071067811865476, 0.7071067811865476],
|
| 29 |
+
'db2': [-0.12940952255092145, 0.22414386804185735, 0.836516303737469, 0.48296291314469025],
|
| 30 |
+
'db3': [0.035226291882100656, -0.08544127388224149, -0.13501102001039084, 0.4598775021193313, 0.8068915093133388, 0.3326705529509569],
|
| 31 |
+
'db4': [-0.010597401784997278, 0.032883011666982945, 0.030841381835986965, -0.18703481171888114, -0.02798376941698385, 0.6308807679295904, 0.7148465705525415, 0.23037781330885523],
|
| 32 |
+
'db5': [0.003335725285001549, -0.012580751999015526, -0.006241490213011705, 0.07757149384006515, -0.03224486958502952, -0.24229488706619015, 0.13842814590110342, 0.7243085284385744, 0.6038292697974729, 0.160102397974125],
|
| 33 |
+
'db6': [-0.00107730108499558, 0.004777257511010651, 0.0005538422009938016, -0.031582039318031156, 0.02752286553001629, 0.09750160558707936, -0.12976686756709563, -0.22626469396516913, 0.3152503517092432, 0.7511339080215775, 0.4946238903983854, 0.11154074335008017],
|
| 34 |
+
'db7': [0.0003537138000010399, -0.0018016407039998328, 0.00042957797300470274, 0.012550998556013784, -0.01657454163101562, -0.03802993693503463, 0.0806126091510659, 0.07130921926705004, -0.22403618499416572, -0.14390600392910627, 0.4697822874053586, 0.7291320908465551, 0.39653931948230575, 0.07785205408506236],
|
| 35 |
+
'db8': [-0.00011747678400228192, 0.0006754494059985568, -0.0003917403729959771, -0.00487035299301066, 0.008746094047015655, 0.013981027917015516, -0.04408825393106472, -0.01736930100202211, 0.128747426620186, 0.00047248457399797254, -0.2840155429624281, -0.015829105256023893, 0.5853546836548691, 0.6756307362980128, 0.3128715909144659, 0.05441584224308161],
|
| 36 |
+
'sym2': [-0.12940952255092145, 0.22414386804185735, 0.836516303737469, 0.48296291314469025],
|
| 37 |
+
'sym3': [0.035226291882100656, -0.08544127388224149, -0.13501102001039084, 0.4598775021193313, 0.8068915093133388, 0.3326705529509569],
|
| 38 |
+
'sym4': [-0.07576571478927333, -0.02963552764599851, 0.49761866763201545, 0.8037387518059161, 0.29785779560527736, -0.09921954357684722, -0.012603967262037833, 0.0322231006040427],
|
| 39 |
+
'sym5': [0.027333068345077982, 0.029519490925774643, -0.039134249302383094, 0.1993975339773936, 0.7234076904024206, 0.6339789634582119, 0.01660210576452232, -0.17532808990845047, -0.021101834024758855, 0.019538882735286728],
|
| 40 |
+
'sym6': [0.015404109327027373, 0.0034907120842174702, -0.11799011114819057, -0.048311742585633, 0.4910559419267466, 0.787641141030194, 0.3379294217276218, -0.07263752278646252, -0.021060292512300564, 0.04472490177066578, 0.0017677118642428036, -0.007800708325034148],
|
| 41 |
+
'sym7': [0.002681814568257878, -0.0010473848886829163, -0.01263630340325193, 0.03051551316596357, 0.0678926935013727, -0.049552834937127255, 0.017441255086855827, 0.5361019170917628, 0.767764317003164, 0.2886296317515146, -0.14004724044296152, -0.10780823770381774, 0.004010244871533663, 0.010268176708511255],
|
| 42 |
+
'sym8': [-0.0033824159510061256, -0.0005421323317911481, 0.03169508781149298, 0.007607487324917605, -0.1432942383508097, -0.061273359067658524, 0.4813596512583722, 0.7771857517005235, 0.3644418948353314, -0.05194583810770904, -0.027219029917056003, 0.049137179673607506, 0.003808752013890615, -0.01495225833704823, -0.0003029205147213668, 0.0018899503327594609],
|
| 43 |
+
}
|
| 44 |
+
|
| 45 |
+
#----------------------------------------------------------------------------
|
| 46 |
+
# Helpers for constructing transformation matrices.
|
| 47 |
+
|
| 48 |
+
def matrix(*rows, device=None):
|
| 49 |
+
assert all(len(row) == len(rows[0]) for row in rows)
|
| 50 |
+
elems = [x for row in rows for x in row]
|
| 51 |
+
ref = [x for x in elems if isinstance(x, torch.Tensor)]
|
| 52 |
+
if len(ref) == 0:
|
| 53 |
+
return misc.constant(np.asarray(rows), device=device)
|
| 54 |
+
assert device is None or device == ref[0].device
|
| 55 |
+
elems = [x if isinstance(x, torch.Tensor) else misc.constant(x, shape=ref[0].shape, device=ref[0].device) for x in elems]
|
| 56 |
+
return torch.stack(elems, dim=-1).reshape(ref[0].shape + (len(rows), -1))
|
| 57 |
+
|
| 58 |
+
def translate2d(tx, ty, **kwargs):
|
| 59 |
+
return matrix(
|
| 60 |
+
[1, 0, tx],
|
| 61 |
+
[0, 1, ty],
|
| 62 |
+
[0, 0, 1],
|
| 63 |
+
**kwargs)
|
| 64 |
+
|
| 65 |
+
def translate3d(tx, ty, tz, **kwargs):
|
| 66 |
+
return matrix(
|
| 67 |
+
[1, 0, 0, tx],
|
| 68 |
+
[0, 1, 0, ty],
|
| 69 |
+
[0, 0, 1, tz],
|
| 70 |
+
[0, 0, 0, 1],
|
| 71 |
+
**kwargs)
|
| 72 |
+
|
| 73 |
+
def scale2d(sx, sy, **kwargs):
|
| 74 |
+
return matrix(
|
| 75 |
+
[sx, 0, 0],
|
| 76 |
+
[0, sy, 0],
|
| 77 |
+
[0, 0, 1],
|
| 78 |
+
**kwargs)
|
| 79 |
+
|
| 80 |
+
def scale3d(sx, sy, sz, **kwargs):
|
| 81 |
+
return matrix(
|
| 82 |
+
[sx, 0, 0, 0],
|
| 83 |
+
[0, sy, 0, 0],
|
| 84 |
+
[0, 0, sz, 0],
|
| 85 |
+
[0, 0, 0, 1],
|
| 86 |
+
**kwargs)
|
| 87 |
+
|
| 88 |
+
def rotate2d(theta, **kwargs):
|
| 89 |
+
return matrix(
|
| 90 |
+
[torch.cos(theta), torch.sin(-theta), 0],
|
| 91 |
+
[torch.sin(theta), torch.cos(theta), 0],
|
| 92 |
+
[0, 0, 1],
|
| 93 |
+
**kwargs)
|
| 94 |
+
|
| 95 |
+
def rotate3d(v, theta, **kwargs):
|
| 96 |
+
vx = v[..., 0]; vy = v[..., 1]; vz = v[..., 2]
|
| 97 |
+
s = torch.sin(theta); c = torch.cos(theta); cc = 1 - c
|
| 98 |
+
return matrix(
|
| 99 |
+
[vx*vx*cc+c, vx*vy*cc-vz*s, vx*vz*cc+vy*s, 0],
|
| 100 |
+
[vy*vx*cc+vz*s, vy*vy*cc+c, vy*vz*cc-vx*s, 0],
|
| 101 |
+
[vz*vx*cc-vy*s, vz*vy*cc+vx*s, vz*vz*cc+c, 0],
|
| 102 |
+
[0, 0, 0, 1],
|
| 103 |
+
**kwargs)
|
| 104 |
+
|
| 105 |
+
def translate2d_inv(tx, ty, **kwargs):
|
| 106 |
+
return translate2d(-tx, -ty, **kwargs)
|
| 107 |
+
|
| 108 |
+
def scale2d_inv(sx, sy, **kwargs):
|
| 109 |
+
return scale2d(1 / sx, 1 / sy, **kwargs)
|
| 110 |
+
|
| 111 |
+
def rotate2d_inv(theta, **kwargs):
|
| 112 |
+
return rotate2d(-theta, **kwargs)
|
| 113 |
+
|
| 114 |
+
#----------------------------------------------------------------------------
|
| 115 |
+
# Versatile image augmentation pipeline from the paper
|
| 116 |
+
# "Training Generative Adversarial Networks with Limited Data".
|
| 117 |
+
#
|
| 118 |
+
# All augmentations are disabled by default; individual augmentations can
|
| 119 |
+
# be enabled by setting their probability multipliers to 1.
|
| 120 |
+
|
| 121 |
+
@persistence.persistent_class
|
| 122 |
+
class AugmentPipe(torch.nn.Module):
|
| 123 |
+
def __init__(self,
|
| 124 |
+
xflip=0, rotate90=0, xint=0, xint_max=0.125,
|
| 125 |
+
scale=0, rotate=0, aniso=0, xfrac=0, scale_std=0.2, rotate_max=1, aniso_std=0.2, xfrac_std=0.125,
|
| 126 |
+
brightness=0, contrast=0, lumaflip=0, hue=0, saturation=0, brightness_std=0.2, contrast_std=0.5, hue_max=1, saturation_std=1,
|
| 127 |
+
imgfilter=0, imgfilter_bands=[1,1,1,1], imgfilter_std=1,
|
| 128 |
+
noise=0, cutout=0, noise_std=0.1, cutout_size=0.5,
|
| 129 |
+
):
|
| 130 |
+
super().__init__()
|
| 131 |
+
self.register_buffer('p', torch.ones([])) # Overall multiplier for augmentation probability.
|
| 132 |
+
|
| 133 |
+
# Pixel blitting.
|
| 134 |
+
self.xflip = float(xflip) # Probability multiplier for x-flip.
|
| 135 |
+
self.rotate90 = float(rotate90) # Probability multiplier for 90 degree rotations.
|
| 136 |
+
self.xint = float(xint) # Probability multiplier for integer translation.
|
| 137 |
+
self.xint_max = float(xint_max) # Range of integer translation, relative to image dimensions.
|
| 138 |
+
|
| 139 |
+
# General geometric transformations.
|
| 140 |
+
self.scale = float(scale) # Probability multiplier for isotropic scaling.
|
| 141 |
+
self.rotate = float(rotate) # Probability multiplier for arbitrary rotation.
|
| 142 |
+
self.aniso = float(aniso) # Probability multiplier for anisotropic scaling.
|
| 143 |
+
self.xfrac = float(xfrac) # Probability multiplier for fractional translation.
|
| 144 |
+
self.scale_std = float(scale_std) # Log2 standard deviation of isotropic scaling.
|
| 145 |
+
self.rotate_max = float(rotate_max) # Range of arbitrary rotation, 1 = full circle.
|
| 146 |
+
self.aniso_std = float(aniso_std) # Log2 standard deviation of anisotropic scaling.
|
| 147 |
+
self.xfrac_std = float(xfrac_std) # Standard deviation of frational translation, relative to image dimensions.
|
| 148 |
+
|
| 149 |
+
# Color transformations.
|
| 150 |
+
self.brightness = float(brightness) # Probability multiplier for brightness.
|
| 151 |
+
self.contrast = float(contrast) # Probability multiplier for contrast.
|
| 152 |
+
self.lumaflip = float(lumaflip) # Probability multiplier for luma flip.
|
| 153 |
+
self.hue = float(hue) # Probability multiplier for hue rotation.
|
| 154 |
+
self.saturation = float(saturation) # Probability multiplier for saturation.
|
| 155 |
+
self.brightness_std = float(brightness_std) # Standard deviation of brightness.
|
| 156 |
+
self.contrast_std = float(contrast_std) # Log2 standard deviation of contrast.
|
| 157 |
+
self.hue_max = float(hue_max) # Range of hue rotation, 1 = full circle.
|
| 158 |
+
self.saturation_std = float(saturation_std) # Log2 standard deviation of saturation.
|
| 159 |
+
|
| 160 |
+
# Image-space filtering.
|
| 161 |
+
self.imgfilter = float(imgfilter) # Probability multiplier for image-space filtering.
|
| 162 |
+
self.imgfilter_bands = list(imgfilter_bands) # Probability multipliers for individual frequency bands.
|
| 163 |
+
self.imgfilter_std = float(imgfilter_std) # Log2 standard deviation of image-space filter amplification.
|
| 164 |
+
|
| 165 |
+
# Image-space corruptions.
|
| 166 |
+
self.noise = float(noise) # Probability multiplier for additive RGB noise.
|
| 167 |
+
self.cutout = float(cutout) # Probability multiplier for cutout.
|
| 168 |
+
self.noise_std = float(noise_std) # Standard deviation of additive RGB noise.
|
| 169 |
+
self.cutout_size = float(cutout_size) # Size of the cutout rectangle, relative to image dimensions.
|
| 170 |
+
|
| 171 |
+
# Setup orthogonal lowpass filter for geometric augmentations.
|
| 172 |
+
self.register_buffer('Hz_geom', upfirdn2d.setup_filter(wavelets['sym6']))
|
| 173 |
+
|
| 174 |
+
# Construct filter bank for image-space filtering.
|
| 175 |
+
Hz_lo = np.asarray(wavelets['sym2']) # H(z)
|
| 176 |
+
Hz_hi = Hz_lo * ((-1) ** np.arange(Hz_lo.size)) # H(-z)
|
| 177 |
+
Hz_lo2 = np.convolve(Hz_lo, Hz_lo[::-1]) / 2 # H(z) * H(z^-1) / 2
|
| 178 |
+
Hz_hi2 = np.convolve(Hz_hi, Hz_hi[::-1]) / 2 # H(-z) * H(-z^-1) / 2
|
| 179 |
+
Hz_fbank = np.eye(4, 1) # Bandpass(H(z), b_i)
|
| 180 |
+
for i in range(1, Hz_fbank.shape[0]):
|
| 181 |
+
Hz_fbank = np.dstack([Hz_fbank, np.zeros_like(Hz_fbank)]).reshape(Hz_fbank.shape[0], -1)[:, :-1]
|
| 182 |
+
Hz_fbank = scipy.signal.convolve(Hz_fbank, [Hz_lo2])
|
| 183 |
+
Hz_fbank[i, (Hz_fbank.shape[1] - Hz_hi2.size) // 2 : (Hz_fbank.shape[1] + Hz_hi2.size) // 2] += Hz_hi2
|
| 184 |
+
self.register_buffer('Hz_fbank', torch.as_tensor(Hz_fbank, dtype=torch.float32))
|
| 185 |
+
|
| 186 |
+
def forward(self, images, debug_percentile=None):
|
| 187 |
+
assert isinstance(images, torch.Tensor) and images.ndim == 4
|
| 188 |
+
batch_size, num_channels, height, width = images.shape
|
| 189 |
+
device = images.device
|
| 190 |
+
if debug_percentile is not None:
|
| 191 |
+
debug_percentile = torch.as_tensor(debug_percentile, dtype=torch.float32, device=device)
|
| 192 |
+
|
| 193 |
+
# -------------------------------------
|
| 194 |
+
# Select parameters for pixel blitting.
|
| 195 |
+
# -------------------------------------
|
| 196 |
+
|
| 197 |
+
# Initialize inverse homogeneous 2D transform: G_inv @ pixel_out ==> pixel_in
|
| 198 |
+
I_3 = torch.eye(3, device=device)
|
| 199 |
+
G_inv = I_3
|
| 200 |
+
|
| 201 |
+
# Apply x-flip with probability (xflip * strength).
|
| 202 |
+
if self.xflip > 0:
|
| 203 |
+
i = torch.floor(torch.rand([batch_size], device=device) * 2)
|
| 204 |
+
i = torch.where(torch.rand([batch_size], device=device) < self.xflip * self.p, i, torch.zeros_like(i))
|
| 205 |
+
if debug_percentile is not None:
|
| 206 |
+
i = torch.full_like(i, torch.floor(debug_percentile * 2))
|
| 207 |
+
G_inv = G_inv @ scale2d_inv(1 - 2 * i, 1)
|
| 208 |
+
|
| 209 |
+
# Apply 90 degree rotations with probability (rotate90 * strength).
|
| 210 |
+
if self.rotate90 > 0:
|
| 211 |
+
i = torch.floor(torch.rand([batch_size], device=device) * 4)
|
| 212 |
+
i = torch.where(torch.rand([batch_size], device=device) < self.rotate90 * self.p, i, torch.zeros_like(i))
|
| 213 |
+
if debug_percentile is not None:
|
| 214 |
+
i = torch.full_like(i, torch.floor(debug_percentile * 4))
|
| 215 |
+
G_inv = G_inv @ rotate2d_inv(-np.pi / 2 * i)
|
| 216 |
+
|
| 217 |
+
# Apply integer translation with probability (xint * strength).
|
| 218 |
+
if self.xint > 0:
|
| 219 |
+
t = (torch.rand([batch_size, 2], device=device) * 2 - 1) * self.xint_max
|
| 220 |
+
t = torch.where(torch.rand([batch_size, 1], device=device) < self.xint * self.p, t, torch.zeros_like(t))
|
| 221 |
+
if debug_percentile is not None:
|
| 222 |
+
t = torch.full_like(t, (debug_percentile * 2 - 1) * self.xint_max)
|
| 223 |
+
G_inv = G_inv @ translate2d_inv(torch.round(t[:,0] * width), torch.round(t[:,1] * height))
|
| 224 |
+
|
| 225 |
+
# --------------------------------------------------------
|
| 226 |
+
# Select parameters for general geometric transformations.
|
| 227 |
+
# --------------------------------------------------------
|
| 228 |
+
|
| 229 |
+
# Apply isotropic scaling with probability (scale * strength).
|
| 230 |
+
if self.scale > 0:
|
| 231 |
+
s = torch.exp2(torch.randn([batch_size], device=device) * self.scale_std)
|
| 232 |
+
s = torch.where(torch.rand([batch_size], device=device) < self.scale * self.p, s, torch.ones_like(s))
|
| 233 |
+
if debug_percentile is not None:
|
| 234 |
+
s = torch.full_like(s, torch.exp2(torch.erfinv(debug_percentile * 2 - 1) * self.scale_std))
|
| 235 |
+
G_inv = G_inv @ scale2d_inv(s, s)
|
| 236 |
+
|
| 237 |
+
# Apply pre-rotation with probability p_rot.
|
| 238 |
+
p_rot = 1 - torch.sqrt((1 - self.rotate * self.p).clamp(0, 1)) # P(pre OR post) = p
|
| 239 |
+
if self.rotate > 0:
|
| 240 |
+
theta = (torch.rand([batch_size], device=device) * 2 - 1) * np.pi * self.rotate_max
|
| 241 |
+
theta = torch.where(torch.rand([batch_size], device=device) < p_rot, theta, torch.zeros_like(theta))
|
| 242 |
+
if debug_percentile is not None:
|
| 243 |
+
theta = torch.full_like(theta, (debug_percentile * 2 - 1) * np.pi * self.rotate_max)
|
| 244 |
+
G_inv = G_inv @ rotate2d_inv(-theta) # Before anisotropic scaling.
|
| 245 |
+
|
| 246 |
+
# Apply anisotropic scaling with probability (aniso * strength).
|
| 247 |
+
if self.aniso > 0:
|
| 248 |
+
s = torch.exp2(torch.randn([batch_size], device=device) * self.aniso_std)
|
| 249 |
+
s = torch.where(torch.rand([batch_size], device=device) < self.aniso * self.p, s, torch.ones_like(s))
|
| 250 |
+
if debug_percentile is not None:
|
| 251 |
+
s = torch.full_like(s, torch.exp2(torch.erfinv(debug_percentile * 2 - 1) * self.aniso_std))
|
| 252 |
+
G_inv = G_inv @ scale2d_inv(s, 1 / s)
|
| 253 |
+
|
| 254 |
+
# Apply post-rotation with probability p_rot.
|
| 255 |
+
if self.rotate > 0:
|
| 256 |
+
theta = (torch.rand([batch_size], device=device) * 2 - 1) * np.pi * self.rotate_max
|
| 257 |
+
theta = torch.where(torch.rand([batch_size], device=device) < p_rot, theta, torch.zeros_like(theta))
|
| 258 |
+
if debug_percentile is not None:
|
| 259 |
+
theta = torch.zeros_like(theta)
|
| 260 |
+
G_inv = G_inv @ rotate2d_inv(-theta) # After anisotropic scaling.
|
| 261 |
+
|
| 262 |
+
# Apply fractional translation with probability (xfrac * strength).
|
| 263 |
+
if self.xfrac > 0:
|
| 264 |
+
t = torch.randn([batch_size, 2], device=device) * self.xfrac_std
|
| 265 |
+
t = torch.where(torch.rand([batch_size, 1], device=device) < self.xfrac * self.p, t, torch.zeros_like(t))
|
| 266 |
+
if debug_percentile is not None:
|
| 267 |
+
t = torch.full_like(t, torch.erfinv(debug_percentile * 2 - 1) * self.xfrac_std)
|
| 268 |
+
G_inv = G_inv @ translate2d_inv(t[:,0] * width, t[:,1] * height)
|
| 269 |
+
|
| 270 |
+
# ----------------------------------
|
| 271 |
+
# Execute geometric transformations.
|
| 272 |
+
# ----------------------------------
|
| 273 |
+
|
| 274 |
+
# Execute if the transform is not identity.
|
| 275 |
+
if G_inv is not I_3:
|
| 276 |
+
|
| 277 |
+
# Calculate padding.
|
| 278 |
+
cx = (width - 1) / 2
|
| 279 |
+
cy = (height - 1) / 2
|
| 280 |
+
cp = matrix([-cx, -cy, 1], [cx, -cy, 1], [cx, cy, 1], [-cx, cy, 1], device=device) # [idx, xyz]
|
| 281 |
+
cp = G_inv @ cp.t() # [batch, xyz, idx]
|
| 282 |
+
Hz_pad = self.Hz_geom.shape[0] // 4
|
| 283 |
+
margin = cp[:, :2, :].permute(1, 0, 2).flatten(1) # [xy, batch * idx]
|
| 284 |
+
margin = torch.cat([-margin, margin]).max(dim=1).values # [x0, y0, x1, y1]
|
| 285 |
+
margin = margin + misc.constant([Hz_pad * 2 - cx, Hz_pad * 2 - cy] * 2, device=device)
|
| 286 |
+
margin = margin.max(misc.constant([0, 0] * 2, device=device))
|
| 287 |
+
margin = margin.min(misc.constant([width-1, height-1] * 2, device=device))
|
| 288 |
+
mx0, my0, mx1, my1 = margin.ceil().to(torch.int32)
|
| 289 |
+
|
| 290 |
+
# Pad image and adjust origin.
|
| 291 |
+
images = torch.nn.functional.pad(input=images, pad=[mx0,mx1,my0,my1], mode='reflect')
|
| 292 |
+
G_inv = translate2d((mx0 - mx1) / 2, (my0 - my1) / 2) @ G_inv
|
| 293 |
+
|
| 294 |
+
# Upsample.
|
| 295 |
+
images = upfirdn2d.upsample2d(x=images, f=self.Hz_geom, up=2)
|
| 296 |
+
G_inv = scale2d(2, 2, device=device) @ G_inv @ scale2d_inv(2, 2, device=device)
|
| 297 |
+
G_inv = translate2d(-0.5, -0.5, device=device) @ G_inv @ translate2d_inv(-0.5, -0.5, device=device)
|
| 298 |
+
|
| 299 |
+
# Execute transformation.
|
| 300 |
+
shape = [batch_size, num_channels, (height + Hz_pad * 2) * 2, (width + Hz_pad * 2) * 2]
|
| 301 |
+
G_inv = scale2d(2 / images.shape[3], 2 / images.shape[2], device=device) @ G_inv @ scale2d_inv(2 / shape[3], 2 / shape[2], device=device)
|
| 302 |
+
grid = torch.nn.functional.affine_grid(theta=G_inv[:,:2,:], size=shape, align_corners=False)
|
| 303 |
+
images = grid_sample_gradfix.grid_sample(images, grid)
|
| 304 |
+
|
| 305 |
+
# Downsample and crop.
|
| 306 |
+
images = upfirdn2d.downsample2d(x=images, f=self.Hz_geom, down=2, padding=-Hz_pad*2, flip_filter=True)
|
| 307 |
+
|
| 308 |
+
# --------------------------------------------
|
| 309 |
+
# Select parameters for color transformations.
|
| 310 |
+
# --------------------------------------------
|
| 311 |
+
|
| 312 |
+
# Initialize homogeneous 3D transformation matrix: C @ color_in ==> color_out
|
| 313 |
+
I_4 = torch.eye(4, device=device)
|
| 314 |
+
C = I_4
|
| 315 |
+
|
| 316 |
+
# Apply brightness with probability (brightness * strength).
|
| 317 |
+
if self.brightness > 0:
|
| 318 |
+
b = torch.randn([batch_size], device=device) * self.brightness_std
|
| 319 |
+
b = torch.where(torch.rand([batch_size], device=device) < self.brightness * self.p, b, torch.zeros_like(b))
|
| 320 |
+
if debug_percentile is not None:
|
| 321 |
+
b = torch.full_like(b, torch.erfinv(debug_percentile * 2 - 1) * self.brightness_std)
|
| 322 |
+
C = translate3d(b, b, b) @ C
|
| 323 |
+
|
| 324 |
+
# Apply contrast with probability (contrast * strength).
|
| 325 |
+
if self.contrast > 0:
|
| 326 |
+
c = torch.exp2(torch.randn([batch_size], device=device) * self.contrast_std)
|
| 327 |
+
c = torch.where(torch.rand([batch_size], device=device) < self.contrast * self.p, c, torch.ones_like(c))
|
| 328 |
+
if debug_percentile is not None:
|
| 329 |
+
c = torch.full_like(c, torch.exp2(torch.erfinv(debug_percentile * 2 - 1) * self.contrast_std))
|
| 330 |
+
C = scale3d(c, c, c) @ C
|
| 331 |
+
|
| 332 |
+
# Apply luma flip with probability (lumaflip * strength).
|
| 333 |
+
v = misc.constant(np.asarray([1, 1, 1, 0]) / np.sqrt(3), device=device) # Luma axis.
|
| 334 |
+
if self.lumaflip > 0:
|
| 335 |
+
i = torch.floor(torch.rand([batch_size, 1, 1], device=device) * 2)
|
| 336 |
+
i = torch.where(torch.rand([batch_size, 1, 1], device=device) < self.lumaflip * self.p, i, torch.zeros_like(i))
|
| 337 |
+
if debug_percentile is not None:
|
| 338 |
+
i = torch.full_like(i, torch.floor(debug_percentile * 2))
|
| 339 |
+
C = (I_4 - 2 * v.ger(v) * i) @ C # Householder reflection.
|
| 340 |
+
|
| 341 |
+
# Apply hue rotation with probability (hue * strength).
|
| 342 |
+
if self.hue > 0 and num_channels > 1:
|
| 343 |
+
theta = (torch.rand([batch_size], device=device) * 2 - 1) * np.pi * self.hue_max
|
| 344 |
+
theta = torch.where(torch.rand([batch_size], device=device) < self.hue * self.p, theta, torch.zeros_like(theta))
|
| 345 |
+
if debug_percentile is not None:
|
| 346 |
+
theta = torch.full_like(theta, (debug_percentile * 2 - 1) * np.pi * self.hue_max)
|
| 347 |
+
C = rotate3d(v, theta) @ C # Rotate around v.
|
| 348 |
+
|
| 349 |
+
# Apply saturation with probability (saturation * strength).
|
| 350 |
+
if self.saturation > 0 and num_channels > 1:
|
| 351 |
+
s = torch.exp2(torch.randn([batch_size, 1, 1], device=device) * self.saturation_std)
|
| 352 |
+
s = torch.where(torch.rand([batch_size, 1, 1], device=device) < self.saturation * self.p, s, torch.ones_like(s))
|
| 353 |
+
if debug_percentile is not None:
|
| 354 |
+
s = torch.full_like(s, torch.exp2(torch.erfinv(debug_percentile * 2 - 1) * self.saturation_std))
|
| 355 |
+
C = (v.ger(v) + (I_4 - v.ger(v)) * s) @ C
|
| 356 |
+
|
| 357 |
+
# ------------------------------
|
| 358 |
+
# Execute color transformations.
|
| 359 |
+
# ------------------------------
|
| 360 |
+
|
| 361 |
+
# Execute if the transform is not identity.
|
| 362 |
+
if C is not I_4:
|
| 363 |
+
images = images.reshape([batch_size, num_channels, height * width])
|
| 364 |
+
if num_channels == 3:
|
| 365 |
+
images = C[:, :3, :3] @ images + C[:, :3, 3:]
|
| 366 |
+
elif num_channels == 1:
|
| 367 |
+
C = C[:, :3, :].mean(dim=1, keepdims=True)
|
| 368 |
+
images = images * C[:, :, :3].sum(dim=2, keepdims=True) + C[:, :, 3:]
|
| 369 |
+
else:
|
| 370 |
+
raise ValueError('Image must be RGB (3 channels) or L (1 channel)')
|
| 371 |
+
images = images.reshape([batch_size, num_channels, height, width])
|
| 372 |
+
|
| 373 |
+
# ----------------------
|
| 374 |
+
# Image-space filtering.
|
| 375 |
+
# ----------------------
|
| 376 |
+
|
| 377 |
+
if self.imgfilter > 0:
|
| 378 |
+
num_bands = self.Hz_fbank.shape[0]
|
| 379 |
+
assert len(self.imgfilter_bands) == num_bands
|
| 380 |
+
expected_power = misc.constant(np.array([10, 1, 1, 1]) / 13, device=device) # Expected power spectrum (1/f).
|
| 381 |
+
|
| 382 |
+
# Apply amplification for each band with probability (imgfilter * strength * band_strength).
|
| 383 |
+
g = torch.ones([batch_size, num_bands], device=device) # Global gain vector (identity).
|
| 384 |
+
for i, band_strength in enumerate(self.imgfilter_bands):
|
| 385 |
+
t_i = torch.exp2(torch.randn([batch_size], device=device) * self.imgfilter_std)
|
| 386 |
+
t_i = torch.where(torch.rand([batch_size], device=device) < self.imgfilter * self.p * band_strength, t_i, torch.ones_like(t_i))
|
| 387 |
+
if debug_percentile is not None:
|
| 388 |
+
t_i = torch.full_like(t_i, torch.exp2(torch.erfinv(debug_percentile * 2 - 1) * self.imgfilter_std)) if band_strength > 0 else torch.ones_like(t_i)
|
| 389 |
+
t = torch.ones([batch_size, num_bands], device=device) # Temporary gain vector.
|
| 390 |
+
t[:, i] = t_i # Replace i'th element.
|
| 391 |
+
t = t / (expected_power * t.square()).sum(dim=-1, keepdims=True).sqrt() # Normalize power.
|
| 392 |
+
g = g * t # Accumulate into global gain.
|
| 393 |
+
|
| 394 |
+
# Construct combined amplification filter.
|
| 395 |
+
Hz_prime = g @ self.Hz_fbank # [batch, tap]
|
| 396 |
+
Hz_prime = Hz_prime.unsqueeze(1).repeat([1, num_channels, 1]) # [batch, channels, tap]
|
| 397 |
+
Hz_prime = Hz_prime.reshape([batch_size * num_channels, 1, -1]) # [batch * channels, 1, tap]
|
| 398 |
+
|
| 399 |
+
# Apply filter.
|
| 400 |
+
p = self.Hz_fbank.shape[1] // 2
|
| 401 |
+
images = images.reshape([1, batch_size * num_channels, height, width])
|
| 402 |
+
images = torch.nn.functional.pad(input=images, pad=[p,p,p,p], mode='reflect')
|
| 403 |
+
images = conv2d_gradfix.conv2d(input=images, weight=Hz_prime.unsqueeze(2), groups=batch_size*num_channels)
|
| 404 |
+
images = conv2d_gradfix.conv2d(input=images, weight=Hz_prime.unsqueeze(3), groups=batch_size*num_channels)
|
| 405 |
+
images = images.reshape([batch_size, num_channels, height, width])
|
| 406 |
+
|
| 407 |
+
# ------------------------
|
| 408 |
+
# Image-space corruptions.
|
| 409 |
+
# ------------------------
|
| 410 |
+
|
| 411 |
+
# Apply additive RGB noise with probability (noise * strength).
|
| 412 |
+
if self.noise > 0:
|
| 413 |
+
sigma = torch.randn([batch_size, 1, 1, 1], device=device).abs() * self.noise_std
|
| 414 |
+
sigma = torch.where(torch.rand([batch_size, 1, 1, 1], device=device) < self.noise * self.p, sigma, torch.zeros_like(sigma))
|
| 415 |
+
if debug_percentile is not None:
|
| 416 |
+
sigma = torch.full_like(sigma, torch.erfinv(debug_percentile) * self.noise_std)
|
| 417 |
+
images = images + torch.randn([batch_size, num_channels, height, width], device=device) * sigma
|
| 418 |
+
|
| 419 |
+
# Apply cutout with probability (cutout * strength).
|
| 420 |
+
if self.cutout > 0:
|
| 421 |
+
size = torch.full([batch_size, 2, 1, 1, 1], self.cutout_size, device=device)
|
| 422 |
+
size = torch.where(torch.rand([batch_size, 1, 1, 1, 1], device=device) < self.cutout * self.p, size, torch.zeros_like(size))
|
| 423 |
+
center = torch.rand([batch_size, 2, 1, 1, 1], device=device)
|
| 424 |
+
if debug_percentile is not None:
|
| 425 |
+
size = torch.full_like(size, self.cutout_size)
|
| 426 |
+
center = torch.full_like(center, debug_percentile)
|
| 427 |
+
coord_x = torch.arange(width, device=device).reshape([1, 1, 1, -1])
|
| 428 |
+
coord_y = torch.arange(height, device=device).reshape([1, 1, -1, 1])
|
| 429 |
+
mask_x = (((coord_x + 0.5) / width - center[:, 0]).abs() >= size[:, 0] / 2)
|
| 430 |
+
mask_y = (((coord_y + 0.5) / height - center[:, 1]).abs() >= size[:, 1] / 2)
|
| 431 |
+
mask_x, mask_y = torch.broadcast_tensors(mask_x, mask_y)
|
| 432 |
+
mask = torch.logical_or(mask_x, mask_y).to(torch.float32)
|
| 433 |
+
images = images * mask
|
| 434 |
+
|
| 435 |
+
return images
|
| 436 |
+
|
| 437 |
+
#----------------------------------------------------------------------------
|
training/dataset.py
ADDED
|
@@ -0,0 +1,238 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
"""Streaming images and labels from datasets created with dataset_tool.py."""
|
| 10 |
+
|
| 11 |
+
import os
|
| 12 |
+
import numpy as np
|
| 13 |
+
import zipfile
|
| 14 |
+
import PIL.Image
|
| 15 |
+
import json
|
| 16 |
+
import torch
|
| 17 |
+
import dnnlib
|
| 18 |
+
|
| 19 |
+
try:
|
| 20 |
+
import pyspng
|
| 21 |
+
except ImportError:
|
| 22 |
+
pyspng = None
|
| 23 |
+
|
| 24 |
+
#----------------------------------------------------------------------------
|
| 25 |
+
|
| 26 |
+
class Dataset(torch.utils.data.Dataset):
|
| 27 |
+
def __init__(self,
|
| 28 |
+
name, # Name of the dataset.
|
| 29 |
+
raw_shape, # Shape of the raw image data (NCHW).
|
| 30 |
+
max_size = None, # Artificially limit the size of the dataset. None = no limit. Applied before xflip.
|
| 31 |
+
use_labels = False, # Enable conditioning labels? False = label dimension is zero.
|
| 32 |
+
xflip = False, # Artificially double the size of the dataset via x-flips. Applied after max_size.
|
| 33 |
+
random_seed = 0, # Random seed to use when applying max_size.
|
| 34 |
+
):
|
| 35 |
+
self._name = name
|
| 36 |
+
self._raw_shape = list(raw_shape)
|
| 37 |
+
self._use_labels = use_labels
|
| 38 |
+
self._raw_labels = None
|
| 39 |
+
self._label_shape = None
|
| 40 |
+
|
| 41 |
+
# Apply max_size.
|
| 42 |
+
self._raw_idx = np.arange(self._raw_shape[0], dtype=np.int64)
|
| 43 |
+
if (max_size is not None) and (self._raw_idx.size > max_size):
|
| 44 |
+
np.random.RandomState(random_seed).shuffle(self._raw_idx)
|
| 45 |
+
self._raw_idx = np.sort(self._raw_idx[:max_size])
|
| 46 |
+
|
| 47 |
+
# Apply xflip.
|
| 48 |
+
self._xflip = np.zeros(self._raw_idx.size, dtype=np.uint8)
|
| 49 |
+
if xflip:
|
| 50 |
+
self._raw_idx = np.tile(self._raw_idx, 2)
|
| 51 |
+
self._xflip = np.concatenate([self._xflip, np.ones_like(self._xflip)])
|
| 52 |
+
|
| 53 |
+
def _get_raw_labels(self):
|
| 54 |
+
if self._raw_labels is None:
|
| 55 |
+
self._raw_labels = self._load_raw_labels() if self._use_labels else None
|
| 56 |
+
if self._raw_labels is None:
|
| 57 |
+
self._raw_labels = np.zeros([self._raw_shape[0], 0], dtype=np.float32)
|
| 58 |
+
assert isinstance(self._raw_labels, np.ndarray)
|
| 59 |
+
assert self._raw_labels.shape[0] == self._raw_shape[0]
|
| 60 |
+
assert self._raw_labels.dtype in [np.float32, np.int64]
|
| 61 |
+
if self._raw_labels.dtype == np.int64:
|
| 62 |
+
assert self._raw_labels.ndim == 1
|
| 63 |
+
assert np.all(self._raw_labels >= 0)
|
| 64 |
+
return self._raw_labels
|
| 65 |
+
|
| 66 |
+
def close(self): # to be overridden by subclass
|
| 67 |
+
pass
|
| 68 |
+
|
| 69 |
+
def _load_raw_image(self, raw_idx): # to be overridden by subclass
|
| 70 |
+
raise NotImplementedError
|
| 71 |
+
|
| 72 |
+
def _load_raw_labels(self): # to be overridden by subclass
|
| 73 |
+
raise NotImplementedError
|
| 74 |
+
|
| 75 |
+
def __getstate__(self):
|
| 76 |
+
return dict(self.__dict__, _raw_labels=None)
|
| 77 |
+
|
| 78 |
+
def __del__(self):
|
| 79 |
+
try:
|
| 80 |
+
self.close()
|
| 81 |
+
except:
|
| 82 |
+
pass
|
| 83 |
+
|
| 84 |
+
def __len__(self):
|
| 85 |
+
return self._raw_idx.size
|
| 86 |
+
|
| 87 |
+
def __getitem__(self, idx):
|
| 88 |
+
image = self._load_raw_image(self._raw_idx[idx])
|
| 89 |
+
assert isinstance(image, np.ndarray)
|
| 90 |
+
assert list(image.shape) == self.image_shape
|
| 91 |
+
assert image.dtype == np.uint8
|
| 92 |
+
if self._xflip[idx]:
|
| 93 |
+
assert image.ndim == 3 # CHW
|
| 94 |
+
image = image[:, :, ::-1]
|
| 95 |
+
return image.copy(), self.get_label(idx)
|
| 96 |
+
|
| 97 |
+
def get_label(self, idx):
|
| 98 |
+
label = self._get_raw_labels()[self._raw_idx[idx]]
|
| 99 |
+
if label.dtype == np.int64:
|
| 100 |
+
onehot = np.zeros(self.label_shape, dtype=np.float32)
|
| 101 |
+
onehot[label] = 1
|
| 102 |
+
label = onehot
|
| 103 |
+
return label.copy()
|
| 104 |
+
|
| 105 |
+
def get_details(self, idx):
|
| 106 |
+
d = dnnlib.EasyDict()
|
| 107 |
+
d.raw_idx = int(self._raw_idx[idx])
|
| 108 |
+
d.xflip = (int(self._xflip[idx]) != 0)
|
| 109 |
+
d.raw_label = self._get_raw_labels()[d.raw_idx].copy()
|
| 110 |
+
return d
|
| 111 |
+
|
| 112 |
+
@property
|
| 113 |
+
def name(self):
|
| 114 |
+
return self._name
|
| 115 |
+
|
| 116 |
+
@property
|
| 117 |
+
def image_shape(self):
|
| 118 |
+
return list(self._raw_shape[1:])
|
| 119 |
+
|
| 120 |
+
@property
|
| 121 |
+
def num_channels(self):
|
| 122 |
+
assert len(self.image_shape) == 3 # CHW
|
| 123 |
+
return self.image_shape[0]
|
| 124 |
+
|
| 125 |
+
@property
|
| 126 |
+
def resolution(self):
|
| 127 |
+
assert len(self.image_shape) == 3 # CHW
|
| 128 |
+
assert self.image_shape[1] == self.image_shape[2]
|
| 129 |
+
return self.image_shape[1]
|
| 130 |
+
|
| 131 |
+
@property
|
| 132 |
+
def label_shape(self):
|
| 133 |
+
if self._label_shape is None:
|
| 134 |
+
raw_labels = self._get_raw_labels()
|
| 135 |
+
if raw_labels.dtype == np.int64:
|
| 136 |
+
self._label_shape = [int(np.max(raw_labels)) + 1]
|
| 137 |
+
else:
|
| 138 |
+
self._label_shape = raw_labels.shape[1:]
|
| 139 |
+
return list(self._label_shape)
|
| 140 |
+
|
| 141 |
+
@property
|
| 142 |
+
def label_dim(self):
|
| 143 |
+
assert len(self.label_shape) == 1
|
| 144 |
+
return self.label_shape[0]
|
| 145 |
+
|
| 146 |
+
@property
|
| 147 |
+
def has_labels(self):
|
| 148 |
+
return any(x != 0 for x in self.label_shape)
|
| 149 |
+
|
| 150 |
+
@property
|
| 151 |
+
def has_onehot_labels(self):
|
| 152 |
+
return self._get_raw_labels().dtype == np.int64
|
| 153 |
+
|
| 154 |
+
#----------------------------------------------------------------------------
|
| 155 |
+
|
| 156 |
+
class ImageFolderDataset(Dataset):
|
| 157 |
+
def __init__(self,
|
| 158 |
+
path, # Path to directory or zip.
|
| 159 |
+
resolution = None, # Ensure specific resolution, None = highest available.
|
| 160 |
+
**super_kwargs, # Additional arguments for the Dataset base class.
|
| 161 |
+
):
|
| 162 |
+
self._path = path
|
| 163 |
+
self._zipfile = None
|
| 164 |
+
|
| 165 |
+
if os.path.isdir(self._path):
|
| 166 |
+
self._type = 'dir'
|
| 167 |
+
self._all_fnames = {os.path.relpath(os.path.join(root, fname), start=self._path) for root, _dirs, files in os.walk(self._path) for fname in files}
|
| 168 |
+
elif self._file_ext(self._path) == '.zip':
|
| 169 |
+
self._type = 'zip'
|
| 170 |
+
self._all_fnames = set(self._get_zipfile().namelist())
|
| 171 |
+
else:
|
| 172 |
+
raise IOError('Path must point to a directory or zip')
|
| 173 |
+
|
| 174 |
+
PIL.Image.init()
|
| 175 |
+
self._image_fnames = sorted(fname for fname in self._all_fnames if self._file_ext(fname) in PIL.Image.EXTENSION)
|
| 176 |
+
if len(self._image_fnames) == 0:
|
| 177 |
+
raise IOError('No image files found in the specified path')
|
| 178 |
+
|
| 179 |
+
name = os.path.splitext(os.path.basename(self._path))[0]
|
| 180 |
+
raw_shape = [len(self._image_fnames)] + list(self._load_raw_image(0).shape)
|
| 181 |
+
if resolution is not None and (raw_shape[2] != resolution or raw_shape[3] != resolution):
|
| 182 |
+
raise IOError('Image files do not match the specified resolution')
|
| 183 |
+
super().__init__(name=name, raw_shape=raw_shape, **super_kwargs)
|
| 184 |
+
|
| 185 |
+
@staticmethod
|
| 186 |
+
def _file_ext(fname):
|
| 187 |
+
return os.path.splitext(fname)[1].lower()
|
| 188 |
+
|
| 189 |
+
def _get_zipfile(self):
|
| 190 |
+
assert self._type == 'zip'
|
| 191 |
+
if self._zipfile is None:
|
| 192 |
+
self._zipfile = zipfile.ZipFile(self._path)
|
| 193 |
+
return self._zipfile
|
| 194 |
+
|
| 195 |
+
def _open_file(self, fname):
|
| 196 |
+
if self._type == 'dir':
|
| 197 |
+
return open(os.path.join(self._path, fname), 'rb')
|
| 198 |
+
if self._type == 'zip':
|
| 199 |
+
return self._get_zipfile().open(fname, 'r')
|
| 200 |
+
return None
|
| 201 |
+
|
| 202 |
+
def close(self):
|
| 203 |
+
try:
|
| 204 |
+
if self._zipfile is not None:
|
| 205 |
+
self._zipfile.close()
|
| 206 |
+
finally:
|
| 207 |
+
self._zipfile = None
|
| 208 |
+
|
| 209 |
+
def __getstate__(self):
|
| 210 |
+
return dict(super().__getstate__(), _zipfile=None)
|
| 211 |
+
|
| 212 |
+
def _load_raw_image(self, raw_idx):
|
| 213 |
+
fname = self._image_fnames[raw_idx]
|
| 214 |
+
with self._open_file(fname) as f:
|
| 215 |
+
if pyspng is not None and self._file_ext(fname) == '.png':
|
| 216 |
+
image = pyspng.load(f.read())
|
| 217 |
+
else:
|
| 218 |
+
image = np.array(PIL.Image.open(f))
|
| 219 |
+
if image.ndim == 2:
|
| 220 |
+
image = image[:, :, np.newaxis] # HW => HWC
|
| 221 |
+
image = image.transpose(2, 0, 1) # HWC => CHW
|
| 222 |
+
return image
|
| 223 |
+
|
| 224 |
+
def _load_raw_labels(self):
|
| 225 |
+
fname = 'dataset.json'
|
| 226 |
+
if fname not in self._all_fnames:
|
| 227 |
+
return None
|
| 228 |
+
with self._open_file(fname) as f:
|
| 229 |
+
labels = json.load(f)['labels']
|
| 230 |
+
if labels is None:
|
| 231 |
+
return None
|
| 232 |
+
labels = dict(labels)
|
| 233 |
+
labels = [labels[fname.replace('\\', '/')] for fname in self._image_fnames]
|
| 234 |
+
labels = np.array(labels)
|
| 235 |
+
labels = labels.astype({1: np.int64, 2: np.float32}[labels.ndim])
|
| 236 |
+
return labels
|
| 237 |
+
|
| 238 |
+
#----------------------------------------------------------------------------
|
training/loss.py
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
"""Loss functions."""
|
| 10 |
+
|
| 11 |
+
from torch_utils import training_stats
|
| 12 |
+
from R3GAN.Trainer import AdversarialTraining
|
| 13 |
+
import torch
|
| 14 |
+
|
| 15 |
+
#----------------------------------------------------------------------------
|
| 16 |
+
|
| 17 |
+
class R3GANLoss:
|
| 18 |
+
def __init__(self, G, D, augment_pipe=None):
|
| 19 |
+
self.trainer = AdversarialTraining(G, D)
|
| 20 |
+
if augment_pipe is not None:
|
| 21 |
+
self.preprocessor = lambda x: augment_pipe(x.to(torch.float32)).to(x.dtype)
|
| 22 |
+
else:
|
| 23 |
+
self.preprocessor = lambda x: x
|
| 24 |
+
|
| 25 |
+
def accumulate_gradients(self, phase, real_img, real_c, gen_z, gamma, gain):
|
| 26 |
+
# G
|
| 27 |
+
if phase == 'G':
|
| 28 |
+
AdversarialLoss, RelativisticLogits = self.trainer.AccumulateGeneratorGradients(gen_z, real_img, real_c, gain, self.preprocessor)
|
| 29 |
+
|
| 30 |
+
training_stats.report('Loss/scores/fake', RelativisticLogits)
|
| 31 |
+
training_stats.report('Loss/signs/fake', RelativisticLogits.sign())
|
| 32 |
+
training_stats.report('Loss/G/loss', AdversarialLoss)
|
| 33 |
+
|
| 34 |
+
# D
|
| 35 |
+
if phase == 'D':
|
| 36 |
+
AdversarialLoss, RelativisticLogits, R1Penalty, R2Penalty = self.trainer.AccumulateDiscriminatorGradients(gen_z, real_img, real_c, gamma, gain, self.preprocessor)
|
| 37 |
+
|
| 38 |
+
training_stats.report('Loss/scores/real', RelativisticLogits)
|
| 39 |
+
training_stats.report('Loss/signs/real', RelativisticLogits.sign())
|
| 40 |
+
training_stats.report('Loss/D/loss', AdversarialLoss)
|
| 41 |
+
training_stats.report('Loss/r1_penalty', R1Penalty)
|
| 42 |
+
training_stats.report('Loss/r2_penalty', R2Penalty)
|
| 43 |
+
#----------------------------------------------------------------------------
|
training/networks.py
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import copy
|
| 4 |
+
import R3GAN.Networks
|
| 5 |
+
|
| 6 |
+
class Generator(nn.Module):
|
| 7 |
+
def __init__(self, *args, **kw):
|
| 8 |
+
super(Generator, self).__init__()
|
| 9 |
+
|
| 10 |
+
config = copy.deepcopy(kw)
|
| 11 |
+
del config['FP16Stages']
|
| 12 |
+
del config['c_dim']
|
| 13 |
+
del config['img_resolution']
|
| 14 |
+
|
| 15 |
+
if kw['c_dim'] != 0:
|
| 16 |
+
config['ConditionDimension'] = kw['c_dim']
|
| 17 |
+
|
| 18 |
+
self.Model = R3GAN.Networks.Generator(*args, **config)
|
| 19 |
+
self.z_dim = kw['NoiseDimension']
|
| 20 |
+
self.c_dim = kw['c_dim']
|
| 21 |
+
self.img_resolution = kw['img_resolution']
|
| 22 |
+
|
| 23 |
+
for x in kw['FP16Stages']:
|
| 24 |
+
self.Model.MainLayers[x].DataType = torch.bfloat16
|
| 25 |
+
|
| 26 |
+
def forward(self, x, c):
|
| 27 |
+
return self.Model(x, c)
|
| 28 |
+
|
| 29 |
+
class Discriminator(nn.Module):
|
| 30 |
+
def __init__(self, *args, **kw):
|
| 31 |
+
super(Discriminator, self).__init__()
|
| 32 |
+
|
| 33 |
+
config = copy.deepcopy(kw)
|
| 34 |
+
del config['FP16Stages']
|
| 35 |
+
del config['c_dim']
|
| 36 |
+
del config['img_resolution']
|
| 37 |
+
|
| 38 |
+
if kw['c_dim'] != 0:
|
| 39 |
+
config['ConditionDimension'] = kw['c_dim']
|
| 40 |
+
|
| 41 |
+
self.Model = R3GAN.Networks.Discriminator(*args, **config)
|
| 42 |
+
|
| 43 |
+
for x in kw['FP16Stages']:
|
| 44 |
+
self.Model.MainLayers[x].DataType = torch.bfloat16
|
| 45 |
+
|
| 46 |
+
def forward(self, x, c):
|
| 47 |
+
return self.Model(x, c)
|
training/training_loop.py
ADDED
|
@@ -0,0 +1,474 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) 2021, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
|
| 2 |
+
#
|
| 3 |
+
# NVIDIA CORPORATION and its licensors retain all intellectual property
|
| 4 |
+
# and proprietary rights in and to this software, related documentation
|
| 5 |
+
# and any modifications thereto. Any use, reproduction, disclosure or
|
| 6 |
+
# distribution of this software and related documentation without an express
|
| 7 |
+
# license agreement from NVIDIA CORPORATION is strictly prohibited.
|
| 8 |
+
|
| 9 |
+
"""Main training loop."""
|
| 10 |
+
|
| 11 |
+
import os
|
| 12 |
+
import time
|
| 13 |
+
import copy
|
| 14 |
+
import json
|
| 15 |
+
import pickle
|
| 16 |
+
import psutil
|
| 17 |
+
import PIL.Image
|
| 18 |
+
import numpy as np
|
| 19 |
+
import torch
|
| 20 |
+
import dnnlib
|
| 21 |
+
from torch_utils import misc
|
| 22 |
+
from torch_utils import training_stats
|
| 23 |
+
from torch_utils.ops import conv2d_gradfix
|
| 24 |
+
from torch_utils.ops import grid_sample_gradfix
|
| 25 |
+
|
| 26 |
+
import legacy
|
| 27 |
+
from metrics import metric_main
|
| 28 |
+
|
| 29 |
+
def cosine_decay_with_warmup(cur_nimg, base_value, total_nimg, final_value=0.0, warmup_value=0.0, warmup_nimg=0, hold_base_value_nimg=0):
|
| 30 |
+
decay = 0.5 * (1 + np.cos(np.pi * (cur_nimg - warmup_nimg - hold_base_value_nimg) / float(total_nimg - warmup_nimg - hold_base_value_nimg)))
|
| 31 |
+
cur_value = base_value + (1 - decay) * (final_value - base_value)
|
| 32 |
+
if hold_base_value_nimg > 0:
|
| 33 |
+
cur_value = np.where(cur_nimg > warmup_nimg + hold_base_value_nimg, cur_value, base_value)
|
| 34 |
+
if warmup_nimg > 0:
|
| 35 |
+
slope = (base_value - warmup_value) / warmup_nimg
|
| 36 |
+
warmup_v = slope * cur_nimg + warmup_value
|
| 37 |
+
cur_value = np.where(cur_nimg < warmup_nimg, warmup_v, cur_value)
|
| 38 |
+
return float(np.where(cur_nimg > total_nimg, final_value, cur_value))
|
| 39 |
+
|
| 40 |
+
#----------------------------------------------------------------------------
|
| 41 |
+
|
| 42 |
+
def setup_snapshot_image_grid(training_set, random_seed=0):
|
| 43 |
+
rnd = np.random.RandomState(random_seed)
|
| 44 |
+
gw = np.clip(7680 // training_set.image_shape[2], 7, 32)
|
| 45 |
+
gh = np.clip(4320 // training_set.image_shape[1], 4, 32)
|
| 46 |
+
|
| 47 |
+
# No labels => show random subset of training samples.
|
| 48 |
+
if not training_set.has_labels:
|
| 49 |
+
all_indices = list(range(len(training_set)))
|
| 50 |
+
rnd.shuffle(all_indices)
|
| 51 |
+
grid_indices = [all_indices[i % len(all_indices)] for i in range(gw * gh)]
|
| 52 |
+
|
| 53 |
+
else:
|
| 54 |
+
# Group training samples by label.
|
| 55 |
+
label_groups = dict() # label => [idx, ...]
|
| 56 |
+
for idx in range(len(training_set)):
|
| 57 |
+
label = tuple(training_set.get_details(idx).raw_label.flat[::-1])
|
| 58 |
+
if label not in label_groups:
|
| 59 |
+
label_groups[label] = []
|
| 60 |
+
label_groups[label].append(idx)
|
| 61 |
+
|
| 62 |
+
# Reorder.
|
| 63 |
+
label_order = sorted(label_groups.keys())
|
| 64 |
+
for label in label_order:
|
| 65 |
+
rnd.shuffle(label_groups[label])
|
| 66 |
+
|
| 67 |
+
# Organize into grid.
|
| 68 |
+
grid_indices = []
|
| 69 |
+
for y in range(gh):
|
| 70 |
+
label = label_order[y % len(label_order)]
|
| 71 |
+
indices = label_groups[label]
|
| 72 |
+
grid_indices += [indices[x % len(indices)] for x in range(gw)]
|
| 73 |
+
label_groups[label] = [indices[(i + gw) % len(indices)] for i in range(len(indices))]
|
| 74 |
+
|
| 75 |
+
# Load data.
|
| 76 |
+
images, labels = zip(*[training_set[i] for i in grid_indices])
|
| 77 |
+
return (gw, gh), np.stack(images), np.stack(labels)
|
| 78 |
+
|
| 79 |
+
#----------------------------------------------------------------------------
|
| 80 |
+
|
| 81 |
+
def save_image_grid(img, fname, drange, grid_size):
|
| 82 |
+
lo, hi = drange
|
| 83 |
+
img = np.asarray(img, dtype=np.float32)
|
| 84 |
+
img = (img - lo) * (255 / (hi - lo))
|
| 85 |
+
img = np.rint(img).clip(0, 255).astype(np.uint8)
|
| 86 |
+
|
| 87 |
+
gw, gh = grid_size
|
| 88 |
+
_N, C, H, W = img.shape
|
| 89 |
+
img = img.reshape([gh, gw, C, H, W])
|
| 90 |
+
img = img.transpose(0, 3, 1, 4, 2)
|
| 91 |
+
img = img.reshape([gh * H, gw * W, C])
|
| 92 |
+
|
| 93 |
+
assert C in [1, 3]
|
| 94 |
+
if C == 1:
|
| 95 |
+
PIL.Image.fromarray(img[:, :, 0], 'L').save(fname)
|
| 96 |
+
if C == 3:
|
| 97 |
+
PIL.Image.fromarray(img, 'RGB').save(fname)
|
| 98 |
+
|
| 99 |
+
#----------------------------------------------------------------------------
|
| 100 |
+
|
| 101 |
+
def remap_optimizer_state_dict(state_dict, device):
|
| 102 |
+
state_dict = copy.deepcopy(state_dict)
|
| 103 |
+
for param in state_dict['state'].values():
|
| 104 |
+
if isinstance(param, torch.Tensor):
|
| 105 |
+
param.data = param.data.to(device)
|
| 106 |
+
if param._grad is not None:
|
| 107 |
+
param._grad.data = param._grad.data.to(device)
|
| 108 |
+
elif isinstance(param, dict):
|
| 109 |
+
for subparam in param.values():
|
| 110 |
+
if isinstance(subparam, torch.Tensor):
|
| 111 |
+
subparam.data = subparam.data.to(device)
|
| 112 |
+
if subparam._grad is not None:
|
| 113 |
+
subparam._grad.data = subparam._grad.data.to(device)
|
| 114 |
+
return state_dict
|
| 115 |
+
|
| 116 |
+
#----------------------------------------------------------------------------
|
| 117 |
+
|
| 118 |
+
def training_loop(
|
| 119 |
+
run_dir = '.', # Output directory.
|
| 120 |
+
training_set_kwargs = {}, # Options for training set.
|
| 121 |
+
data_loader_kwargs = {}, # Options for torch.utils.data.DataLoader.
|
| 122 |
+
G_kwargs = {}, # Options for generator network.
|
| 123 |
+
D_kwargs = {}, # Options for discriminator network.
|
| 124 |
+
G_opt_kwargs = {}, # Options for generator optimizer.
|
| 125 |
+
D_opt_kwargs = {}, # Options for discriminator optimizer.
|
| 126 |
+
lr_scheduler = None,
|
| 127 |
+
beta2_scheduler = None,
|
| 128 |
+
augment_kwargs = None, # Options for augmentation pipeline. None = disable.
|
| 129 |
+
loss_kwargs = {}, # Options for loss function.
|
| 130 |
+
gamma_scheduler = None,
|
| 131 |
+
metrics = [], # Metrics to evaluate during training.
|
| 132 |
+
random_seed = 0, # Global random seed.
|
| 133 |
+
num_gpus = 1, # Number of GPUs participating in the training.
|
| 134 |
+
rank = 0, # Rank of the current process in [0, num_gpus[.
|
| 135 |
+
batch_size = 4, # Total batch size for one training iteration. Can be larger than batch_gpu * num_gpus.
|
| 136 |
+
g_batch_gpu = 4, # Number of samples processed at a time by one GPU.
|
| 137 |
+
d_batch_gpu = 4, # Number of samples processed at a time by one GPU.
|
| 138 |
+
ema_scheduler = None,
|
| 139 |
+
aug_scheduler = None,
|
| 140 |
+
total_kimg = 25000, # Total length of the training, measured in thousands of real images.
|
| 141 |
+
kimg_per_tick = 4, # Progress snapshot interval.
|
| 142 |
+
image_snapshot_ticks = 50, # How often to save image snapshots? None = disable.
|
| 143 |
+
network_snapshot_ticks = 50, # How often to save network snapshots? None = disable.
|
| 144 |
+
resume_pkl = None, # Network pickle to resume training from.
|
| 145 |
+
cudnn_benchmark = True, # Enable torch.backends.cudnn.benchmark?
|
| 146 |
+
abort_fn = None, # Callback function for determining whether to abort training. Must return consistent results across ranks.
|
| 147 |
+
progress_fn = None, # Callback function for updating training progress. Called for all ranks.
|
| 148 |
+
):
|
| 149 |
+
# Initialize.
|
| 150 |
+
start_time = time.time()
|
| 151 |
+
device = torch.device('cuda', rank)
|
| 152 |
+
np.random.seed(random_seed * num_gpus + rank)
|
| 153 |
+
torch.manual_seed(random_seed * num_gpus + rank)
|
| 154 |
+
torch.backends.cudnn.benchmark = cudnn_benchmark # Improves training speed.
|
| 155 |
+
torch.backends.cuda.matmul.allow_tf32 = False # Improves numerical accuracy.
|
| 156 |
+
torch.backends.cudnn.allow_tf32 = False # Improves numerical accuracy.
|
| 157 |
+
conv2d_gradfix.enabled = True # Improves training speed.
|
| 158 |
+
grid_sample_gradfix.enabled = True # Avoids errors with the augmentation pipe.
|
| 159 |
+
|
| 160 |
+
# Load training set.
|
| 161 |
+
if rank == 0:
|
| 162 |
+
print('Loading training set...')
|
| 163 |
+
training_set = dnnlib.util.construct_class_by_name(**training_set_kwargs) # subclass of training.dataset.Dataset
|
| 164 |
+
training_set_sampler = misc.InfiniteSampler(dataset=training_set, rank=rank, num_replicas=num_gpus, seed=random_seed)
|
| 165 |
+
training_set_iterator = iter(torch.utils.data.DataLoader(dataset=training_set, sampler=training_set_sampler, batch_size=batch_size//num_gpus, **data_loader_kwargs))
|
| 166 |
+
if rank == 0:
|
| 167 |
+
print()
|
| 168 |
+
print('Num images: ', len(training_set))
|
| 169 |
+
print('Image shape:', training_set.image_shape)
|
| 170 |
+
print('Label shape:', training_set.label_shape)
|
| 171 |
+
print()
|
| 172 |
+
|
| 173 |
+
# Construct networks.
|
| 174 |
+
if rank == 0:
|
| 175 |
+
print('Constructing networks...')
|
| 176 |
+
common_kwargs = dict(c_dim=training_set.label_dim, img_resolution=training_set.resolution)
|
| 177 |
+
G = dnnlib.util.construct_class_by_name(**G_kwargs, **common_kwargs).train().requires_grad_(False).to(device) # subclass of torch.nn.Module
|
| 178 |
+
D = dnnlib.util.construct_class_by_name(**D_kwargs, **common_kwargs).train().requires_grad_(False).to(device) # subclass of torch.nn.Module
|
| 179 |
+
G_ema = copy.deepcopy(G).eval()
|
| 180 |
+
|
| 181 |
+
# Resume from existing pickle.
|
| 182 |
+
if resume_pkl is not None:
|
| 183 |
+
with dnnlib.util.open_url(resume_pkl) as f:
|
| 184 |
+
resume_data = legacy.load_network_pkl(f)
|
| 185 |
+
if rank == 0:
|
| 186 |
+
print(f'Resuming from "{resume_pkl}"')
|
| 187 |
+
for name, module in [('G', G), ('D', D), ('G_ema', G_ema)]:
|
| 188 |
+
misc.copy_params_and_buffers(resume_data[name], module, require_all=False)
|
| 189 |
+
|
| 190 |
+
# Print network summary tables.
|
| 191 |
+
if rank == 0:
|
| 192 |
+
z = torch.empty([min(g_batch_gpu, d_batch_gpu), G.z_dim], device=device)
|
| 193 |
+
c = torch.empty([min(g_batch_gpu, d_batch_gpu), G.c_dim], device=device)
|
| 194 |
+
img = misc.print_module_summary(G, [z, c])
|
| 195 |
+
misc.print_module_summary(D, [img, c])
|
| 196 |
+
|
| 197 |
+
# Setup augmentation.
|
| 198 |
+
if rank == 0:
|
| 199 |
+
print('Setting up augmentation...')
|
| 200 |
+
augment_pipe = None
|
| 201 |
+
|
| 202 |
+
if (augment_kwargs is not None) and (aug_scheduler is not None):
|
| 203 |
+
augment_pipe = dnnlib.util.construct_class_by_name(**augment_kwargs).train().requires_grad_(False).to(device) # subclass of torch.nn.Module
|
| 204 |
+
|
| 205 |
+
# Distribute across GPUs.
|
| 206 |
+
if rank == 0:
|
| 207 |
+
print(f'Distributing across {num_gpus} GPUs...')
|
| 208 |
+
for module in [G, D, G_ema]:
|
| 209 |
+
if module is not None and num_gpus > 1:
|
| 210 |
+
for param in misc.params_and_buffers(module):
|
| 211 |
+
torch.distributed.broadcast(param, src=0)
|
| 212 |
+
|
| 213 |
+
# Setup training phases.
|
| 214 |
+
if rank == 0:
|
| 215 |
+
print('Setting up training phases...')
|
| 216 |
+
loss = dnnlib.util.construct_class_by_name(G=G, D=D, augment_pipe=augment_pipe, **loss_kwargs) # subclass of training.loss.Loss
|
| 217 |
+
phases = []
|
| 218 |
+
|
| 219 |
+
opt = dnnlib.util.construct_class_by_name(params=D.parameters(), **D_opt_kwargs)
|
| 220 |
+
if resume_pkl is not None:
|
| 221 |
+
opt.load_state_dict(remap_optimizer_state_dict(resume_data['D_opt_state'], device))
|
| 222 |
+
phases += [dnnlib.EasyDict(name='D', module=D, opt=opt, batch_gpu=d_batch_gpu)]
|
| 223 |
+
|
| 224 |
+
opt = dnnlib.util.construct_class_by_name(params=G.parameters(), **G_opt_kwargs)
|
| 225 |
+
if resume_pkl is not None:
|
| 226 |
+
opt.load_state_dict(remap_optimizer_state_dict(resume_data['G_opt_state'], device))
|
| 227 |
+
phases += [dnnlib.EasyDict(name='G', module=G, opt=opt, batch_gpu=g_batch_gpu)]
|
| 228 |
+
|
| 229 |
+
for phase in phases:
|
| 230 |
+
phase.start_event = None
|
| 231 |
+
phase.end_event = None
|
| 232 |
+
if rank == 0:
|
| 233 |
+
phase.start_event = torch.cuda.Event(enable_timing=True)
|
| 234 |
+
phase.end_event = torch.cuda.Event(enable_timing=True)
|
| 235 |
+
|
| 236 |
+
# Export sample images.
|
| 237 |
+
grid_size = None
|
| 238 |
+
grid_z = None
|
| 239 |
+
grid_c = None
|
| 240 |
+
if rank == 0:
|
| 241 |
+
print('Exporting sample images...')
|
| 242 |
+
grid_size, images, labels = setup_snapshot_image_grid(training_set=training_set)
|
| 243 |
+
save_image_grid(images, os.path.join(run_dir, 'reals.png'), drange=[0,255], grid_size=grid_size)
|
| 244 |
+
grid_z = torch.randn([labels.shape[0], G.z_dim], device=device).split(g_batch_gpu)
|
| 245 |
+
grid_c = torch.from_numpy(labels).to(device).split(g_batch_gpu)
|
| 246 |
+
images = torch.cat([G_ema(z, c).cpu() for z, c in zip(grid_z, grid_c)]).to(torch.float).numpy()
|
| 247 |
+
save_image_grid(images, os.path.join(run_dir, 'fakes_init.png'), drange=[-1,1], grid_size=grid_size)
|
| 248 |
+
|
| 249 |
+
# Initialize logs.
|
| 250 |
+
if rank == 0:
|
| 251 |
+
print('Initializing logs...')
|
| 252 |
+
stats_collector = training_stats.Collector(regex='.*')
|
| 253 |
+
stats_metrics = dict()
|
| 254 |
+
stats_jsonl = None
|
| 255 |
+
stats_tfevents = None
|
| 256 |
+
if rank == 0:
|
| 257 |
+
stats_jsonl = open(os.path.join(run_dir, 'stats.jsonl'), 'wt')
|
| 258 |
+
try:
|
| 259 |
+
import torch.utils.tensorboard as tensorboard
|
| 260 |
+
stats_tfevents = tensorboard.SummaryWriter(run_dir)
|
| 261 |
+
except ImportError as err:
|
| 262 |
+
print('Skipping tfevents export:', err)
|
| 263 |
+
|
| 264 |
+
# Train.
|
| 265 |
+
if rank == 0:
|
| 266 |
+
print(f'Training for {total_kimg} kimg...')
|
| 267 |
+
print()
|
| 268 |
+
cur_nimg = resume_data['cur_nimg'] if resume_pkl is not None else 0
|
| 269 |
+
cur_tick = 0
|
| 270 |
+
tick_start_nimg = cur_nimg
|
| 271 |
+
tick_start_time = time.time()
|
| 272 |
+
maintenance_time = tick_start_time - start_time
|
| 273 |
+
batch_idx = 0
|
| 274 |
+
if progress_fn is not None:
|
| 275 |
+
progress_fn(0, total_kimg)
|
| 276 |
+
|
| 277 |
+
# Dummy Timing, required to fix phase shift
|
| 278 |
+
for phase in phases:
|
| 279 |
+
if phase.start_event is not None:
|
| 280 |
+
phase.start_event.record(torch.cuda.current_stream(device))
|
| 281 |
+
if phase.end_event is not None:
|
| 282 |
+
phase.end_event.record(torch.cuda.current_stream(device))
|
| 283 |
+
|
| 284 |
+
while True:
|
| 285 |
+
# Fetch training data.
|
| 286 |
+
with torch.autograd.profiler.record_function('data_fetch'):
|
| 287 |
+
D_img, D_img_c = next(training_set_iterator)
|
| 288 |
+
D_z = torch.randn([batch_size, G.z_dim], device=device)
|
| 289 |
+
|
| 290 |
+
G_img, G_img_c = next(training_set_iterator)
|
| 291 |
+
G_z = torch.randn([batch_size, G.z_dim], device=device)
|
| 292 |
+
|
| 293 |
+
all_real_img = []
|
| 294 |
+
all_real_c = []
|
| 295 |
+
all_gen_z = []
|
| 296 |
+
|
| 297 |
+
# D
|
| 298 |
+
all_real_img += [(D_img.detach().clone().to(device).to(torch.float32) / 127.5 - 1).split(d_batch_gpu)]
|
| 299 |
+
all_real_c += [D_img_c.detach().clone().to(device).split(d_batch_gpu)]
|
| 300 |
+
all_gen_z += [D_z.detach().clone().split(d_batch_gpu)]
|
| 301 |
+
|
| 302 |
+
# G
|
| 303 |
+
all_real_img += [(G_img.detach().clone().to(device).to(torch.float32) / 127.5 - 1).split(g_batch_gpu)]
|
| 304 |
+
all_real_c += [G_img_c.detach().clone().to(device).split(g_batch_gpu)]
|
| 305 |
+
all_gen_z += [G_z.detach().clone().split(g_batch_gpu)]
|
| 306 |
+
|
| 307 |
+
cur_lr = cosine_decay_with_warmup(cur_nimg, **lr_scheduler)
|
| 308 |
+
cur_beta2 = cosine_decay_with_warmup(cur_nimg, **beta2_scheduler)
|
| 309 |
+
cur_gamma = cosine_decay_with_warmup(cur_nimg, **gamma_scheduler)
|
| 310 |
+
cur_ema_nimg = cosine_decay_with_warmup(cur_nimg, **ema_scheduler)
|
| 311 |
+
cur_aug_p = cosine_decay_with_warmup(cur_nimg, **aug_scheduler)
|
| 312 |
+
|
| 313 |
+
if augment_pipe is not None:
|
| 314 |
+
augment_pipe.p.copy_(misc.constant(cur_aug_p, device=device))
|
| 315 |
+
|
| 316 |
+
# Execute training phases.
|
| 317 |
+
for phase, phase_gen_z, phase_real_img, phase_real_c in zip(phases, all_gen_z, all_real_img, all_real_c):
|
| 318 |
+
if phase.start_event is not None:
|
| 319 |
+
phase.start_event.record(torch.cuda.current_stream(device))
|
| 320 |
+
|
| 321 |
+
# Accumulate gradients.
|
| 322 |
+
phase.opt.zero_grad(set_to_none=True)
|
| 323 |
+
phase.module.requires_grad_(True)
|
| 324 |
+
for real_img, real_c, gen_z in zip(phase_real_img, phase_real_c, phase_gen_z):
|
| 325 |
+
loss.accumulate_gradients(phase=phase.name, real_img=real_img, real_c=real_c, gen_z=gen_z, gamma=cur_gamma, gain=num_gpus * phase.batch_gpu / batch_size)
|
| 326 |
+
phase.module.requires_grad_(False)
|
| 327 |
+
|
| 328 |
+
# Update weights.
|
| 329 |
+
for g in phase.opt.param_groups:
|
| 330 |
+
g['lr'] = cur_lr
|
| 331 |
+
g['betas'] = (0, cur_beta2)
|
| 332 |
+
|
| 333 |
+
with torch.autograd.profiler.record_function(phase.name + '_opt'):
|
| 334 |
+
params = [param for param in phase.module.parameters() if param.grad is not None]
|
| 335 |
+
if len(params) > 0:
|
| 336 |
+
flat = torch.cat([param.grad.flatten() for param in params])
|
| 337 |
+
if num_gpus > 1:
|
| 338 |
+
torch.distributed.all_reduce(flat)
|
| 339 |
+
flat /= num_gpus
|
| 340 |
+
grads = flat.split([param.numel() for param in params])
|
| 341 |
+
for param, grad in zip(params, grads):
|
| 342 |
+
param.grad = grad.reshape(param.shape)
|
| 343 |
+
phase.opt.step()
|
| 344 |
+
|
| 345 |
+
# Phase done.
|
| 346 |
+
if phase.end_event is not None:
|
| 347 |
+
phase.end_event.record(torch.cuda.current_stream(device))
|
| 348 |
+
|
| 349 |
+
# Update G_ema.
|
| 350 |
+
with torch.autograd.profiler.record_function('Gema'):
|
| 351 |
+
ema_beta = 0.5 ** (batch_size / max(cur_ema_nimg, 1e-8))
|
| 352 |
+
for p_ema, p in zip(G_ema.parameters(), G.parameters()):
|
| 353 |
+
p_ema.copy_(p.lerp(p_ema, ema_beta))
|
| 354 |
+
for b_ema, b in zip(G_ema.buffers(), G.buffers()):
|
| 355 |
+
b_ema.copy_(b)
|
| 356 |
+
|
| 357 |
+
# Update state.
|
| 358 |
+
cur_nimg += batch_size
|
| 359 |
+
batch_idx += 1
|
| 360 |
+
|
| 361 |
+
# Perform maintenance tasks once per tick.
|
| 362 |
+
done = (cur_nimg >= total_kimg * 1000)
|
| 363 |
+
if (not done) and (cur_tick != 0) and (cur_nimg < tick_start_nimg + kimg_per_tick * 1000):
|
| 364 |
+
continue
|
| 365 |
+
|
| 366 |
+
# Print status line, accumulating the same information in training_stats.
|
| 367 |
+
tick_end_time = time.time()
|
| 368 |
+
fields = []
|
| 369 |
+
fields += [f"tick {training_stats.report0('Progress/tick', cur_tick):<5d}"]
|
| 370 |
+
fields += [f"kimg {training_stats.report0('Progress/kimg', cur_nimg / 1e3):<8.1f}"]
|
| 371 |
+
fields += [f"time {dnnlib.util.format_time(training_stats.report0('Timing/total_sec', tick_end_time - start_time)):<12s}"]
|
| 372 |
+
fields += [f"sec/tick {training_stats.report0('Timing/sec_per_tick', tick_end_time - tick_start_time):<7.1f}"]
|
| 373 |
+
fields += [f"sec/kimg {training_stats.report0('Timing/sec_per_kimg', (tick_end_time - tick_start_time) / (cur_nimg - tick_start_nimg) * 1e3):<7.2f}"]
|
| 374 |
+
fields += [f"maintenance {training_stats.report0('Timing/maintenance_sec', maintenance_time):<6.1f}"]
|
| 375 |
+
fields += [f"cpumem {training_stats.report0('Resources/cpu_mem_gb', psutil.Process(os.getpid()).memory_info().rss / 2**30):<6.2f}"]
|
| 376 |
+
fields += [f"gpumem {training_stats.report0('Resources/peak_gpu_mem_gb', torch.cuda.max_memory_allocated(device) / 2**30):<6.2f}"]
|
| 377 |
+
fields += [f"reserved {training_stats.report0('Resources/peak_gpu_mem_reserved_gb', torch.cuda.max_memory_reserved(device) / 2**30):<6.2f}"]
|
| 378 |
+
torch.cuda.reset_peak_memory_stats()
|
| 379 |
+
fields += [f"augment {training_stats.report0('Progress/augment', float(augment_pipe.p.cpu()) if augment_pipe is not None else 0):.3f}"]
|
| 380 |
+
training_stats.report0('Progress/lr', cur_lr)
|
| 381 |
+
training_stats.report0('Progress/ema_mimg', cur_ema_nimg / 1e6)
|
| 382 |
+
training_stats.report0('Progress/beta2', cur_beta2)
|
| 383 |
+
training_stats.report0('Progress/gamma', cur_gamma)
|
| 384 |
+
training_stats.report0('Timing/total_hours', (tick_end_time - start_time) / (60 * 60))
|
| 385 |
+
training_stats.report0('Timing/total_days', (tick_end_time - start_time) / (24 * 60 * 60))
|
| 386 |
+
if rank == 0:
|
| 387 |
+
print(' '.join(fields))
|
| 388 |
+
|
| 389 |
+
# Check for abort.
|
| 390 |
+
if (not done) and (abort_fn is not None) and abort_fn():
|
| 391 |
+
done = True
|
| 392 |
+
if rank == 0:
|
| 393 |
+
print()
|
| 394 |
+
print('Aborting...')
|
| 395 |
+
|
| 396 |
+
# Save image snapshot.
|
| 397 |
+
if (rank == 0) and (image_snapshot_ticks is not None) and (done or cur_tick % image_snapshot_ticks == 0):
|
| 398 |
+
images = torch.cat([G_ema(z, c).cpu() for z, c in zip(grid_z, grid_c)]).to(torch.float).numpy()
|
| 399 |
+
save_image_grid(images, os.path.join(run_dir, f'fakes{cur_nimg//1000:09d}.png'), drange=[-1,1], grid_size=grid_size)
|
| 400 |
+
|
| 401 |
+
# Save network snapshot.
|
| 402 |
+
snapshot_pkl = None
|
| 403 |
+
snapshot_data = None
|
| 404 |
+
if (network_snapshot_ticks is not None) and (done or cur_tick % network_snapshot_ticks == 0):
|
| 405 |
+
snapshot_data = dict(G=G, D=D, G_ema=G_ema, training_set_kwargs=dict(training_set_kwargs), cur_nimg=cur_nimg)
|
| 406 |
+
for phase in phases:
|
| 407 |
+
snapshot_data[phase.name + '_opt_state'] = remap_optimizer_state_dict(phase.opt.state_dict(), 'cpu')
|
| 408 |
+
for key, value in snapshot_data.items():
|
| 409 |
+
if isinstance(value, torch.nn.Module):
|
| 410 |
+
value = copy.deepcopy(value).eval().requires_grad_(False)
|
| 411 |
+
if num_gpus > 1:
|
| 412 |
+
misc.check_ddp_consistency(value, ignore_regex=r'.*\.[^.]+_(avg|ema)')
|
| 413 |
+
for param in misc.params_and_buffers(value):
|
| 414 |
+
torch.distributed.broadcast(param, src=0)
|
| 415 |
+
snapshot_data[key] = value.cpu()
|
| 416 |
+
del value # conserve memory
|
| 417 |
+
snapshot_pkl = os.path.join(run_dir, f'network-snapshot-{cur_nimg//1000:09d}.pkl')
|
| 418 |
+
if rank == 0:
|
| 419 |
+
with open(snapshot_pkl, 'wb') as f:
|
| 420 |
+
pickle.dump(snapshot_data, f)
|
| 421 |
+
|
| 422 |
+
# Evaluate metrics.
|
| 423 |
+
if (snapshot_data is not None) and (len(metrics) > 0):
|
| 424 |
+
if rank == 0:
|
| 425 |
+
print('Evaluating metrics...')
|
| 426 |
+
for metric in metrics:
|
| 427 |
+
result_dict = metric_main.calc_metric(metric=metric, G=snapshot_data['G_ema'],
|
| 428 |
+
dataset_kwargs=training_set_kwargs, num_gpus=num_gpus, rank=rank, device=device)
|
| 429 |
+
if rank == 0:
|
| 430 |
+
metric_main.report_metric(result_dict, run_dir=run_dir, snapshot_pkl=snapshot_pkl)
|
| 431 |
+
stats_metrics.update(result_dict.results)
|
| 432 |
+
del snapshot_data # conserve memory
|
| 433 |
+
|
| 434 |
+
# Collect statistics.
|
| 435 |
+
for phase in phases:
|
| 436 |
+
value = []
|
| 437 |
+
if (phase.start_event is not None) and (phase.end_event is not None):
|
| 438 |
+
phase.end_event.synchronize()
|
| 439 |
+
value = phase.start_event.elapsed_time(phase.end_event)
|
| 440 |
+
training_stats.report0('Timing/' + phase.name, value)
|
| 441 |
+
stats_collector.update()
|
| 442 |
+
stats_dict = stats_collector.as_dict()
|
| 443 |
+
|
| 444 |
+
# Update logs.
|
| 445 |
+
timestamp = time.time()
|
| 446 |
+
if stats_jsonl is not None:
|
| 447 |
+
fields = dict(stats_dict, timestamp=timestamp)
|
| 448 |
+
stats_jsonl.write(json.dumps(fields) + '\n')
|
| 449 |
+
stats_jsonl.flush()
|
| 450 |
+
if stats_tfevents is not None:
|
| 451 |
+
global_step = int(cur_nimg / 1e3)
|
| 452 |
+
walltime = timestamp - start_time
|
| 453 |
+
for name, value in stats_dict.items():
|
| 454 |
+
stats_tfevents.add_scalar(name, value.mean, global_step=global_step, walltime=walltime)
|
| 455 |
+
for name, value in stats_metrics.items():
|
| 456 |
+
stats_tfevents.add_scalar(f'Metrics/{name}', value, global_step=global_step, walltime=walltime)
|
| 457 |
+
stats_tfevents.flush()
|
| 458 |
+
if progress_fn is not None:
|
| 459 |
+
progress_fn(cur_nimg // 1000, total_kimg)
|
| 460 |
+
|
| 461 |
+
# Update state.
|
| 462 |
+
cur_tick += 1
|
| 463 |
+
tick_start_nimg = cur_nimg
|
| 464 |
+
tick_start_time = time.time()
|
| 465 |
+
maintenance_time = tick_start_time - tick_end_time
|
| 466 |
+
if done:
|
| 467 |
+
break
|
| 468 |
+
|
| 469 |
+
# Done.
|
| 470 |
+
if rank == 0:
|
| 471 |
+
print()
|
| 472 |
+
print('Exiting...')
|
| 473 |
+
|
| 474 |
+
#----------------------------------------------------------------------------
|