Spaces:
Sleeping

Sleeping

Commit
·
be5548b
0
Parent(s):
Cleaned old git history
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .dockerignore +23 -0
- .gitignore +28 -0
- LICENSE.txt +8 -0
- README-rsrc/doorkey.png +0 -0
- README-rsrc/evaluate-terminal-logs.png +0 -0
- README-rsrc/model.png +0 -0
- README-rsrc/model.xml +1 -0
- README-rsrc/train-tensorboard.png +0 -0
- README-rsrc/train-terminal-logs.png +0 -0
- README.md +164 -0
- README_old.md +215 -0
- autocrop.sh +14 -0
- campain_continuer.py +282 -0
- campain_launcher.py +488 -0
- data_analysis.ipynb +0 -0
- data_analysis.py +1650 -0
- data_analysis_neurips.py +570 -0
- data_visualize.py +1436 -0
- display_LLM_evaluations.py +45 -0
- draw_tree.py +104 -0
- draw_trees.sh +19 -0
- dummy_run.sh +109 -0
- eval_LLMs.sh +42 -0
- gpuh.py +99 -0
- gym-minigrid/.gitignore +9 -0
- gym-minigrid/.travis.yml +10 -0
- gym-minigrid/LICENSE +201 -0
- gym-minigrid/README.md +511 -0
- gym-minigrid/benchmark.py +53 -0
- gym-minigrid/gym_minigrid/__init__.py +6 -0
- gym-minigrid/gym_minigrid/backup_envs/bobo.py +301 -0
- gym-minigrid/gym_minigrid/backup_envs/cointhief.py +431 -0
- gym-minigrid/gym_minigrid/backup_envs/dancewithonenpc.py +344 -0
- gym-minigrid/gym_minigrid/backup_envs/diverseexit.py +584 -0
- gym-minigrid/gym_minigrid/backup_envs/exiter.py +347 -0
- gym-minigrid/gym_minigrid/backup_envs/gotodoorpolite.py +292 -0
- gym-minigrid/gym_minigrid/backup_envs/gotodoorsesame.py +165 -0
- gym-minigrid/gym_minigrid/backup_envs/gotodoortalk.py +189 -0
- gym-minigrid/gym_minigrid/backup_envs/gotodoortalkhard.py +199 -0
- gym-minigrid/gym_minigrid/backup_envs/gotodoortalkhardnpc.py +283 -0
- gym-minigrid/gym_minigrid/backup_envs/gotodoortalkhardsesame.py +204 -0
- gym-minigrid/gym_minigrid/backup_envs/gotodoortalkhardsesamnpc.py +294 -0
- gym-minigrid/gym_minigrid/backup_envs/gotodoortalkhardsesamnpcguides.py +384 -0
- gym-minigrid/gym_minigrid/backup_envs/gotodoorwizard.py +209 -0
- gym-minigrid/gym_minigrid/backup_envs/guidethief.py +416 -0
- gym-minigrid/gym_minigrid/backup_envs/helper.py +295 -0
- gym-minigrid/gym_minigrid/backup_envs/showme.py +525 -0
- gym-minigrid/gym_minigrid/backup_envs/socialenv.py +194 -0
- gym-minigrid/gym_minigrid/backup_envs/spying.py +429 -0
- gym-minigrid/gym_minigrid/backup_envs/talkitout.py +385 -0
.dockerignore
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
storage/*
|
| 2 |
+
__pycache__/*
|
| 3 |
+
campain_logs/*
|
| 4 |
+
llm_log/*
|
| 5 |
+
*egg-info
|
| 6 |
+
.vscode
|
| 7 |
+
*.idea*
|
| 8 |
+
retrieve_plafrim_data.sh
|
| 9 |
+
sync_plafrim.sh
|
| 10 |
+
retrieve_remy.sh
|
| 11 |
+
sync_remy.sh
|
| 12 |
+
*.gif
|
| 13 |
+
viz/*
|
| 14 |
+
graphics/*
|
| 15 |
+
retrieve_graphics.sh
|
| 16 |
+
retrieve_grg.sh
|
| 17 |
+
run_seeds.sh
|
| 18 |
+
sync_grg.sh
|
| 19 |
+
get_node.sh
|
| 20 |
+
llm_log/
|
| 21 |
+
.git*
|
| 22 |
+
.cache*
|
| 23 |
+
storage_old_2021.tar.gz
|
.gitignore
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*__pycache__
|
| 2 |
+
storage/*
|
| 3 |
+
graphics/*
|
| 4 |
+
storage_old_2021.tar.gz
|
| 5 |
+
*egg-info
|
| 6 |
+
.vscode
|
| 7 |
+
*.idea*
|
| 8 |
+
retrieve_plafrim_data.sh
|
| 9 |
+
sync_plafrim.sh
|
| 10 |
+
retrieve_remy.sh
|
| 11 |
+
sync_remy.sh
|
| 12 |
+
*.gif
|
| 13 |
+
viz/*
|
| 14 |
+
retrieve_graphics.sh
|
| 15 |
+
retrieve_grg.sh
|
| 16 |
+
run_seeds.sh
|
| 17 |
+
sync_grg.sh
|
| 18 |
+
get_node.sh
|
| 19 |
+
llm_log/
|
| 20 |
+
.cache/
|
| 21 |
+
.ipynb_checkpoints/*
|
| 22 |
+
campain_logs
|
| 23 |
+
llm_data/backup
|
| 24 |
+
saved_logs_LLMs/*
|
| 25 |
+
plots/*
|
| 26 |
+
retrieve_viz_and_graphics.sh
|
| 27 |
+
retrieve_llm_log.sh
|
| 28 |
+
gym-minigrid/figures/*
|
LICENSE.txt
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
The MIT License (MIT)
|
| 2 |
+
Copyright © 2021 Flowers Team
|
| 3 |
+
|
| 4 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
|
| 5 |
+
|
| 6 |
+
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
|
| 7 |
+
|
| 8 |
+
THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
README-rsrc/doorkey.png
ADDED
|
README-rsrc/evaluate-terminal-logs.png
ADDED

|
README-rsrc/model.png
ADDED
|
README-rsrc/model.xml
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
<mxfile userAgent="Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/9.3.1 Chrome/66.0.3359.181 Electron/3.0.6 Safari/537.36" version="9.3.4" editor="www.draw.io" type="device"><diagram id="81a450cc-4610-c693-ab1c-18701f2b71dc" name="Page-1">7Vtbj5s4FP41SLsPW8UYSHhMssnsQytVnV3t9tEBh9ACjohz66+vCXYwNpkyEweS0Y40Gvv4fs53bsZjwWl6eMrRevWJhDix7EF4sOCflm0De2izPwXlWFJcb1ASojwOeaeK8Bz/wJwoum3jEG9qHSkhCY3XdWJAsgwHtEZDeU729W5LktRXXaOIrzioCM8BSrDW7d84pKuSOnKl3n/hOFqJlcGAtyxQ8D3KyTbj61k2XJ5+yuYUibl4/80KhWQvkeDMgtOcEFqW0sMUJwVvBdvKcfMLred95zijbQaIERt6FGfHIWMFr5KcrkhEMpTMKurkdD5czDBgtRVNE1YErIgPMf2vIH9wee0r78S2kx+lpqL6lY/6hik9cgygLSWMVK37kZA176efTWyebPOA754Dj6I8wmfplLTiYNI4zpAnTFLMdsM65DhBNN7VMYA4lKJzv4qdrMA5eoG75RQ7lGz5pFOS7RhF53qdp/tVTPHzGp1OtWc6VufzRU7scE7x4cVD8lZbIJZrKBSI3Fd4B4K2krAOB9fzxdH4oqMwC8eFIrNakKDNJg4UqL0AqIvskVFhtwSFxA+3gR2C1ho7fIXPJGabq8ThKeIYKWwuMc5HyQqtTjT8xUQlD7SJTiI7H7uVFF1NinFa2FXbSxhzJpvtghWjokgFjU0pkQV1kVcUBQYMzbQu+A3NyXc8JQnJGSUjWWGRlnGSKCSUxFFWoIeBADP6pNCNmJn4MW9I4zA8mbMmZaurowl9cxS5+Lq+OQ34sg2om/Cqj2DkZUky5xkiPFoGmthZy9ifOrNJW7fg6QbA78sreJrezNIFDsM4i65zCwZ51x7YfwAF2KClI3EMIHuom6CMnfYdmqAlyagkQW84nvhzMxKE/Vmm0W0DAYMKIVsO765CB9dQ5KA4KMe9WeDgdJ902PfmkHwdVmBo2iOdhjLtQUepw7qQ4KY1noA3eBE2aiKh9GeFcgNvBYuvmYinL/+8Az955nMXfrLJrt5rBNhKfUCDWQZtUzrjEZ3YjZ7o63zvO9E/J4idJPqPm3ksRwEOGq3CHPhT32+N1KYbKac3pF68koL3h9Qur6SAaxSpZzzKaCzB2RaPAu1AxvpphlshFXaB1OYoAqhRh+PXp7gQxb4hoBDHlFRg9ZqE8RHSw9nYm3ieGbX0FckMXU0rb5Ue2jdxH7pCtVXJb9t0LRaPTlJ4SdFvpaaOrqZ2R2oKlWtq4Cpqai5JhH7nocPw7mKHBlGbzxJbu0j9s83H578/XRc3GOTc2yMN0DYmtv3r2WhfD2zdDt1ZdjZsMFFtb82M4xZe70UekuFub4ZCv5ZnSUaAKM7Y73X2woD2A+UTKWibZxjRfj3P6gCMv7oo7/kytDHzgH3Bt+F5woUEYQL+TxIuBIYNWcL5kZTpNAFen7vfu4EXxlzWENjbfWfD04/5NkmOvZt29eOF16Flh977R2HDMwrY3+s6/SHFfaDQ7xGE+pcIazq3im/C3IGtUaY+fpA913RmTUashtKCL9lis5Y6Nr+dKKjSrL+x5T9YQ7bVAXnNvVox4BUXcb/fqZM1EaCq6anfoS+1NQDtOsTOjRHzII99THhCNSBrwBAwgyFWrR6slzd91X8FwNlP</diagram></mxfile>
|
README-rsrc/train-tensorboard.png
ADDED
|
README-rsrc/train-terminal-logs.png
ADDED

|
README.md
ADDED
|
@@ -0,0 +1,164 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: SocialAI School Demo
|
| 3 |
+
emoji: 🧙🏻♂️
|
| 4 |
+
colorFrom: gray
|
| 5 |
+
colorTo: indigo
|
| 6 |
+
sdk: docker
|
| 7 |
+
app_port: 7860
|
| 8 |
+
---
|
| 9 |
+
|
| 10 |
+
# SocialAI
|
| 11 |
+
|
| 12 |
+
[comment]: <> (This repository is the official implementation of [My Paper Title](https://arxiv.org/abs/2030.12345). )
|
| 13 |
+
|
| 14 |
+
[comment]: <> (TODO: add arxiv link later)
|
| 15 |
+
This repository is the official implementation of SocialAI: Benchmarking Socio-Cognitive Abilities inDeep Reinforcement Learning Agents.
|
| 16 |
+
|
| 17 |
+
The website of the project is [here](https://sites.google.com/view/socialai)
|
| 18 |
+
|
| 19 |
+
The code is based on:
|
| 20 |
+
[minigrid](https://github.com/maximecb/gym-minigrid)
|
| 21 |
+
|
| 22 |
+
Additional repositories used:
|
| 23 |
+
[BabyAI](https://github.com/mila-iqia/babyai)
|
| 24 |
+
[RIDE](https://github.com/facebookresearch/impact-driven-exploration)
|
| 25 |
+
[astar](https://github.com/jrialland/python-astar)
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
## Installation
|
| 29 |
+
|
| 30 |
+
[comment]: <> (Clone the repo)
|
| 31 |
+
|
| 32 |
+
[comment]: <> (```)
|
| 33 |
+
|
| 34 |
+
[comment]: <> (git clone https://gitlab.inria.fr/gkovac/act-and-speak.git)
|
| 35 |
+
|
| 36 |
+
[comment]: <> (```)
|
| 37 |
+
|
| 38 |
+
Create and activate your conda env
|
| 39 |
+
```
|
| 40 |
+
conda create --name social_ai python=3.7
|
| 41 |
+
conda activate social_ai
|
| 42 |
+
conda install -c anaconda graphviz
|
| 43 |
+
```
|
| 44 |
+
|
| 45 |
+
Install the required packages
|
| 46 |
+
```
|
| 47 |
+
pip install -r requirements.txt
|
| 48 |
+
pip install -e torch-ac
|
| 49 |
+
pip install -e gym-minigrid
|
| 50 |
+
conda install pytorch torchvision torchaudio pytorch-cuda=11.6 -c pytorch -c nvidia
|
| 51 |
+
```
|
| 52 |
+
|
| 53 |
+
## Interactive policy
|
| 54 |
+
|
| 55 |
+
To run an enviroment in the interactive mode run:
|
| 56 |
+
```
|
| 57 |
+
python -m scripts.manual_control.py
|
| 58 |
+
```
|
| 59 |
+
|
| 60 |
+
You can test different enviroments with the ```--env``` parameter.
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
# RL experiments
|
| 66 |
+
|
| 67 |
+
## Training
|
| 68 |
+
|
| 69 |
+
### Minimal example
|
| 70 |
+
|
| 71 |
+
To train a policy, run:
|
| 72 |
+
```train
|
| 73 |
+
python -m scripts.train --model test_model_name --seed 1 --compact-save --algo ppo --env SocialAI-AsocialBoxInformationSeekingParamEnv-v1 --dialogue --save-interval 1 --log-interval 1 --frames 5000000 --multi-modal-babyai11-agent --arch original_endpool_res --custom-ppo-2
|
| 74 |
+
`````
|
| 75 |
+
|
| 76 |
+
The policy should be above 0.95 success rate after the first 2M environment interactions.
|
| 77 |
+
|
| 78 |
+
### Recreating all the experiments
|
| 79 |
+
|
| 80 |
+
See ```run_SAI_final_case_studies.txt``` for the experiments in the paper.
|
| 81 |
+
|
| 82 |
+
#### Regular machine
|
| 83 |
+
|
| 84 |
+
To run the experiments on a regular machine `run_SAI_final_case_studies.txt` contains all the bash commands running the RL experiments.
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
#### Slurm based cluster (todo:)
|
| 89 |
+
|
| 90 |
+
To recreate all the experiments from the paper on a slurm based server configure the `campaign_launcher.py` script and run:
|
| 91 |
+
|
| 92 |
+
```
|
| 93 |
+
python campaign_launcher.py run_NeurIPS.txt
|
| 94 |
+
```
|
| 95 |
+
|
| 96 |
+
[//]: # (The list of all the experiments and their parameters can be seen in run_NeurIPS.txt)
|
| 97 |
+
|
| 98 |
+
[//]: # ()
|
| 99 |
+
[//]: # (For example the bash equivalent of the following configuration:)
|
| 100 |
+
|
| 101 |
+
[//]: # (```)
|
| 102 |
+
|
| 103 |
+
[//]: # (--slurm_conf jz_long_2gpus_32g --nb_seeds 16 --model NeurIPS_Help_NoSocial_NO_BONUS_ABL --compact-save --algo ppo --*env MiniGrid-AblationExiter-8x8-v0 --*env_args hidden_npc True --dialogue --save-interval 10 --frames 5000000 --*multi-modal-babyai11-agent --*arch original_endpool_res --*custom-ppo-2)
|
| 104 |
+
|
| 105 |
+
[//]: # (```)
|
| 106 |
+
|
| 107 |
+
[//]: # (is:)
|
| 108 |
+
|
| 109 |
+
[//]: # (```)
|
| 110 |
+
|
| 111 |
+
[//]: # (for SEED in {1..16})
|
| 112 |
+
|
| 113 |
+
[//]: # (do)
|
| 114 |
+
|
| 115 |
+
[//]: # ( python -m scripts.train --model NeurIPS_Help_NoSocial_NO_BONUS_ABL --compact-save --algo ppo --*env MiniGrid-AblationExiter-8x8-v0 --*env_args hidden_npc True --dialogue --save-interval 10 --frames 5000000 --*multi-modal-babyai11-agent --*arch original_endpool_res --*custom-ppo-2 --seed $SEED & )
|
| 116 |
+
|
| 117 |
+
[//]: # (done)
|
| 118 |
+
|
| 119 |
+
[//]: # (```)
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
## Evaluation
|
| 124 |
+
|
| 125 |
+
To evaluate a policy, run:
|
| 126 |
+
|
| 127 |
+
```eval
|
| 128 |
+
python -m scripts.evaluate_new --episodes 500 --test-set-seed 1 --model-label test_model --eval-env SocialAI-TestLanguageFeedbackSwitchesInformationSeekingParamEnv-v1 --model-to-evaluate storage/test/ --n-seeds 8
|
| 129 |
+
````
|
| 130 |
+
|
| 131 |
+
To visualize a policy, run:
|
| 132 |
+
```
|
| 133 |
+
python -m scripts.visualize --model storage/test_model_name/1/ --pause 0.1 --seed $RANDOM --episodes 20 --gif viz/test
|
| 134 |
+
```
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
# LLM experiments
|
| 138 |
+
|
| 139 |
+
For LLMs set your ```OPENAI_API_KEY``` (and ```HF_TOKEN```) variable in ```~/.bashrc``` or wherever you want.
|
| 140 |
+
|
| 141 |
+
### Creating in-context examples
|
| 142 |
+
To create in_context examples you can use the ```create_LLM_examples.py``` script.
|
| 143 |
+
|
| 144 |
+
This script will open an interactive window, where you can manually control the agent.
|
| 145 |
+
By default, nothing is saved.
|
| 146 |
+
The general procedure is to press 'enter' to skip over environments which you don't like.
|
| 147 |
+
When you see a wanted enviroment, move the agent in the wanted position and start recording (press 'r'). The current and the following steps in the episode will be recorded.
|
| 148 |
+
Then control the agent and finish the episode. The new episode will start and recording will be turned off again.
|
| 149 |
+
|
| 150 |
+
If you already like some of the previously collected examples and want to append to them you can use the ```--load``` argument.
|
| 151 |
+
|
| 152 |
+
### Evaluating LLM-based agents
|
| 153 |
+
|
| 154 |
+
The script ```eval_LLMs.sh``` contains the bash commands to run all the experiments in the paper.
|
| 155 |
+
|
| 156 |
+
Here is an example of running evaluation on the ```text-ada-001``` model on the AsocialBox environment:
|
| 157 |
+
```
|
| 158 |
+
python -m scripts.LLM_test --episodes 10 --max-steps 15 --model text-ada-001 --env-args size 7 --env-name SocialAI-AsocialBoxInformationSeekingParamEnv-v1 --in-context-path llm_data/in_context_examples/in_context_asocialbox_SocialAI-AsocialBoxInformationSeekingParamEnv-v1_2023_07_19_19_28_48/episodes.pkl
|
| 159 |
+
```
|
| 160 |
+
|
| 161 |
+
If you want to control the agent yourself you can set the model to ```interactive```.
|
| 162 |
+
```dummy``` agent just executes the move forward action, and ```random``` executes a random action. These agent are usefull for testing.
|
| 163 |
+
|
| 164 |
+
|
README_old.md
ADDED
|
@@ -0,0 +1,215 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Embodied acting and speaking
|
| 2 |
+
|
| 3 |
+
This code was based on these repositories:
|
| 4 |
+
|
| 5 |
+
[`gym-minigrid`](https://github.com/maximecb/gym-minigrid)
|
| 6 |
+
|
| 7 |
+
[`torch-ac`](https://github.com/lcswillems/torch-ac)
|
| 8 |
+
|
| 9 |
+
[`rl-starter-files`](add_url)
|
| 10 |
+
|
| 11 |
+
## Features
|
| 12 |
+
|
| 13 |
+
- **Script to train**, including:
|
| 14 |
+
- Log in txt, CSV and Tensorboard
|
| 15 |
+
- Save model
|
| 16 |
+
- Stop and restart training
|
| 17 |
+
- Use A2C or PPO algorithms
|
| 18 |
+
- **Script to visualize**, including:
|
| 19 |
+
- Act by sampling or argmax
|
| 20 |
+
- Save as Gif
|
| 21 |
+
- **Script to evaluate**, including:
|
| 22 |
+
- Act by sampling or argmax
|
| 23 |
+
- List the worst performed episodes
|
| 24 |
+
|
| 25 |
+
## Installation
|
| 26 |
+
|
| 27 |
+
### Option 1
|
| 28 |
+
|
| 29 |
+
[comment]: <> todo: add this part
|
| 30 |
+
[comment]: <> (Clone the repo)
|
| 31 |
+
|
| 32 |
+
[comment]: <> (```)
|
| 33 |
+
|
| 34 |
+
[comment]: <> (git clone https://gitlab.inria.fr/gkovac/act-and-speak.git)
|
| 35 |
+
|
| 36 |
+
[comment]: <> (```)
|
| 37 |
+
Create and activate your conda env
|
| 38 |
+
```
|
| 39 |
+
conda create --name act_and_speak python=3.6
|
| 40 |
+
conda activate act_and_speak
|
| 41 |
+
```
|
| 42 |
+
Install the required packages
|
| 43 |
+
```
|
| 44 |
+
pip install -r requirements.txt
|
| 45 |
+
pip install -e torch-ac
|
| 46 |
+
pip install -e gym-minigrid --use-feature=2020-resolver
|
| 47 |
+
```
|
| 48 |
+
|
| 49 |
+
### Option 2
|
| 50 |
+
Alternative use the conda yaml file:
|
| 51 |
+
```
|
| 52 |
+
TODO:
|
| 53 |
+
```
|
| 54 |
+
|
| 55 |
+
## Example of use
|
| 56 |
+
|
| 57 |
+
Train, visualize and evaluate an agent on the `MiniGrid-DoorKey-5x5-v0` environment:
|
| 58 |
+
|
| 59 |
+
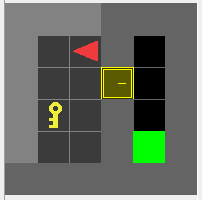
<p align="center"><img src="README-rsrc/doorkey.png"></p>
|
| 60 |
+
|
| 61 |
+
1. Train the agent on the `MiniGrid-DoorKey-5x5-v0` environment with PPO algorithm:
|
| 62 |
+
|
| 63 |
+
```
|
| 64 |
+
python3 -m scripts.train --algo ppo --env MiniGrid-DoorKey-5x5-v0 --model DoorKey --save-interval 10 --frames 80000
|
| 65 |
+
```
|
| 66 |
+
|
| 67 |
+
<p align="center"><img src="README-rsrc/train-terminal-logs.png"></p>
|
| 68 |
+
|
| 69 |
+
2. Visualize agent's behavior:
|
| 70 |
+
|
| 71 |
+
```
|
| 72 |
+
python3 -m scripts.visualize --env MiniGrid-DoorKey-5x5-v0 --model DoorKey
|
| 73 |
+
```
|
| 74 |
+
|
| 75 |
+
<p align="center"><img src="README-rsrc/visualize-doorkey.gif"></p>
|
| 76 |
+
|
| 77 |
+
3. Evaluate agent's performance:
|
| 78 |
+
|
| 79 |
+
```
|
| 80 |
+
python3 -m scripts.evaluate --env MiniGrid-DoorKey-5x5-v0 --model DoorKey
|
| 81 |
+
```
|
| 82 |
+
|
| 83 |
+
<p align="center"><img src="README-rsrc/evaluate-terminal-logs.png"></p>
|
| 84 |
+
|
| 85 |
+
**Note:** More details on the commands are given below.
|
| 86 |
+
|
| 87 |
+
## Other examples
|
| 88 |
+
|
| 89 |
+
### Handle textual instructions
|
| 90 |
+
|
| 91 |
+
In the `GoToDoor` environment, the agent receives an image along with a textual instruction. To handle the latter, add `--text` to the command:
|
| 92 |
+
|
| 93 |
+
```
|
| 94 |
+
python3 -m scripts.train --algo ppo --env MiniGrid-GoToDoor-5x5-v0 --model GoToDoor --text --save-interval 10 --frames 1000000
|
| 95 |
+
```
|
| 96 |
+
|
| 97 |
+
<p align="center"><img src="README-rsrc/visualize-gotodoor.gif"></p>
|
| 98 |
+
|
| 99 |
+
### Handle dialogue with multi a multi headed agent
|
| 100 |
+
|
| 101 |
+
In the `GoToDoorTalk` environment, the agent receives an image along with the dialogue. To handle the latter, add `--dialogue` and, to use the multi headed agent, add `--multi-headed-agent` to the command:
|
| 102 |
+
|
| 103 |
+
```
|
| 104 |
+
python3 -m scripts.train --algo ppo --env MiniGrid-GoToDoorTalk-5x5-v0 --model GoToDoorMultiHead --dialogue --multi-headed-agent --save-interval 10 --frames 1000000
|
| 105 |
+
```
|
| 106 |
+
|
| 107 |
+
### Add memory
|
| 108 |
+
|
| 109 |
+
In the `RedBlueDoors` environment, the agent has to open the red door then the blue one. To solve it efficiently, when it opens the red door, it has to remember it. To add memory to the agent, add `--recurrence X` to the command:
|
| 110 |
+
|
| 111 |
+
```
|
| 112 |
+
python3 -m scripts.train --algo ppo --env MiniGrid-RedBlueDoors-6x6-v0 --model RedBlueDoors --recurrence 4 --save-interval 10 --frames 1000000
|
| 113 |
+
```
|
| 114 |
+
|
| 115 |
+
<p align="center"><img src="README-rsrc/visualize-redbluedoors.gif"></p>
|
| 116 |
+
|
| 117 |
+
## Files
|
| 118 |
+
|
| 119 |
+
This package contains:
|
| 120 |
+
- scripts to:
|
| 121 |
+
- train an agent \
|
| 122 |
+
in `script/train.py` ([more details](#scripts-train))
|
| 123 |
+
- visualize agent's behavior \
|
| 124 |
+
in `script/visualize.py` ([more details](#scripts-visualize))
|
| 125 |
+
- evaluate agent's performances \
|
| 126 |
+
in `script/evaluate.py` ([more details](#scripts-evaluate))
|
| 127 |
+
- a default agent's model \
|
| 128 |
+
in `model.py` ([more details](#model))
|
| 129 |
+
- utilitarian classes and functions used by the scripts \
|
| 130 |
+
in `utils`
|
| 131 |
+
|
| 132 |
+
These files are suited for [`gym-minigrid`](https://github.com/maximecb/gym-minigrid) environments and [`torch-ac`](https://github.com/lcswillems/torch-ac) RL algorithms. They are easy to adapt to other environments and RL algorithms by modifying:
|
| 133 |
+
- `model.py`
|
| 134 |
+
- `utils/format.py`
|
| 135 |
+
|
| 136 |
+
<h2 id="scripts-train">scripts/train.py</h2>
|
| 137 |
+
|
| 138 |
+
An example of use:
|
| 139 |
+
|
| 140 |
+
```bash
|
| 141 |
+
python3 -m scripts.train --algo ppo --env MiniGrid-DoorKey-5x5-v0 --model DoorKey --save-interval 10 --frames 80000
|
| 142 |
+
```
|
| 143 |
+
|
| 144 |
+
The script loads the model in `storage/DoorKey` or creates it if it doesn't exist, then trains it with the PPO algorithm on the MiniGrid DoorKey environment, and saves it every 10 updates in `storage/DoorKey`. It stops after 80 000 frames.
|
| 145 |
+
|
| 146 |
+
**Note:** You can define a different storage location in the environment variable `PROJECT_STORAGE`.
|
| 147 |
+
|
| 148 |
+
More generally, the script has 2 required arguments:
|
| 149 |
+
- `--algo ALGO`: name of the RL algorithm used to train
|
| 150 |
+
- `--env ENV`: name of the environment to train on
|
| 151 |
+
|
| 152 |
+
and a bunch of optional arguments among which:
|
| 153 |
+
- `--recurrence N`: gradient will be backpropagated over N timesteps. By default, N = 1. If N > 1, a LSTM is added to the model to have memory.
|
| 154 |
+
- `--text`: a GRU is added to the model to handle text input.
|
| 155 |
+
- ... (see more using `--help`)
|
| 156 |
+
|
| 157 |
+
During training, logs are printed in your terminal (and saved in text and CSV format):
|
| 158 |
+
|
| 159 |
+
<p align="center"><img src="README-rsrc/train-terminal-logs.png"></p>
|
| 160 |
+
|
| 161 |
+
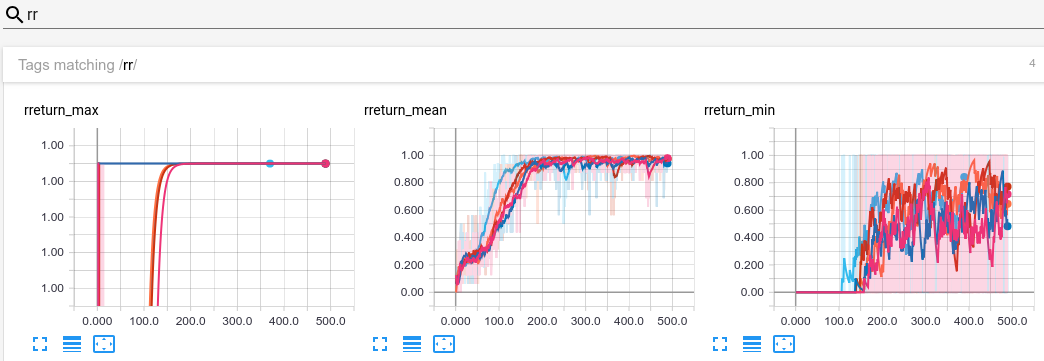
**Note:** `U` gives the update number, `F` the total number of frames, `FPS` the number of frames per second, `D` the total duration, `rR:μσmM` the mean, std, min and max reshaped return per episode, `F:μσmM` the mean, std, min and max number of frames per episode, `H` the entropy, `V` the value, `pL` the policy loss, `vL` the value loss and `∇` the gradient norm.
|
| 162 |
+
|
| 163 |
+
During training, logs are also plotted in Tensorboard:
|
| 164 |
+
|
| 165 |
+
<p><img src="README-rsrc/train-tensorboard.png"></p>
|
| 166 |
+
|
| 167 |
+
<h2 id="scripts-visualize">scripts/visualize.py</h2>
|
| 168 |
+
|
| 169 |
+
An example of use:
|
| 170 |
+
|
| 171 |
+
```
|
| 172 |
+
python3 -m scripts.visualize --env MiniGrid-DoorKey-5x5-v0 --model DoorKey
|
| 173 |
+
```
|
| 174 |
+
|
| 175 |
+
<p align="center"><img src="README-rsrc/visualize-doorkey.gif"></p>
|
| 176 |
+
|
| 177 |
+
In this use case, the script displays how the model in `storage/DoorKey` behaves on the MiniGrid DoorKey environment.
|
| 178 |
+
|
| 179 |
+
More generally, the script has 2 required arguments:
|
| 180 |
+
- `--env ENV`: name of the environment to act on.
|
| 181 |
+
- `--model MODEL`: name of the trained model.
|
| 182 |
+
|
| 183 |
+
and a bunch of optional arguments among which:
|
| 184 |
+
- `--argmax`: select the action with highest probability
|
| 185 |
+
- ... (see more using `--help`)
|
| 186 |
+
|
| 187 |
+
<h2 id="scripts-evaluate">scripts/evaluate.py</h2>
|
| 188 |
+
|
| 189 |
+
An example of use:
|
| 190 |
+
|
| 191 |
+
```
|
| 192 |
+
python3 -m scripts.evaluate --env MiniGrid-DoorKey-5x5-v0 --model DoorKey
|
| 193 |
+
```
|
| 194 |
+
|
| 195 |
+
<p align="center"><img src="README-rsrc/evaluate-terminal-logs.png"></p>
|
| 196 |
+
|
| 197 |
+
In this use case, the script prints in the terminal the performance among 100 episodes of the model in `storage/DoorKey`.
|
| 198 |
+
|
| 199 |
+
More generally, the script has 2 required arguments:
|
| 200 |
+
- `--env ENV`: name of the environment to act on.
|
| 201 |
+
- `--model MODEL`: name of the trained model.
|
| 202 |
+
|
| 203 |
+
and a bunch of optional arguments among which:
|
| 204 |
+
- `--episodes N`: number of episodes of evaluation. By default, N = 100.
|
| 205 |
+
- ... (see more using `--help`)
|
| 206 |
+
|
| 207 |
+
<h2 id="model">model.py</h2>
|
| 208 |
+
|
| 209 |
+
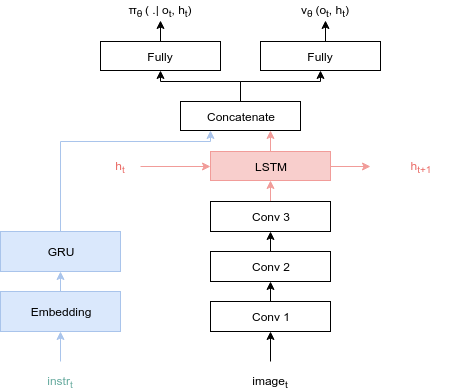
The default model is discribed by the following schema:
|
| 210 |
+
|
| 211 |
+
<p align="center"><img src="README-rsrc/model.png"></p>
|
| 212 |
+
|
| 213 |
+
By default, the memory part (in red) and the langage part (in blue) are disabled. They can be enabled by setting to `True` the `use_memory` and `use_text` parameters of the model constructor.
|
| 214 |
+
|
| 215 |
+
This model can be easily adapted to your needs.
|
autocrop.sh
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
|
| 3 |
+
|
| 4 |
+
# Loop through all files in the specified directory
|
| 5 |
+
for file in "$@"
|
| 6 |
+
do
|
| 7 |
+
# Check if the file is an image
|
| 8 |
+
if [[ $file == *.jpg || $file == *.png ]]
|
| 9 |
+
then
|
| 10 |
+
# Crop the image using the `convert` command from the ImageMagick suite
|
| 11 |
+
echo "Cropping $file"
|
| 12 |
+
convert $file -trim +repage $file
|
| 13 |
+
fi
|
| 14 |
+
done
|
campain_continuer.py
ADDED
|
@@ -0,0 +1,282 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
from datetime import date
|
| 4 |
+
import subprocess
|
| 5 |
+
import shutil
|
| 6 |
+
import os
|
| 7 |
+
import stat
|
| 8 |
+
import getpass
|
| 9 |
+
import re
|
| 10 |
+
import glob
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def process_arg_string(expe_args): # function to extract flagged (with a *) arguments as details for experience name
|
| 14 |
+
details_string = ''
|
| 15 |
+
processed_arg_string = expe_args.replace('*', '') # keep a version of args cleaned from exp name related flags
|
| 16 |
+
# args = [arg_chunk.split(' -') for arg_chunk in expe_args.split(' --')]
|
| 17 |
+
arg_chunks = [arg_chunk for arg_chunk in expe_args.split(' --')]
|
| 18 |
+
args_list = []
|
| 19 |
+
for arg in arg_chunks:
|
| 20 |
+
if ' -' in arg and arg.split(' -')[1].isalpha():
|
| 21 |
+
args_list.extend(arg.split(' -'))
|
| 22 |
+
else:
|
| 23 |
+
args_list.append(arg)
|
| 24 |
+
# args_list = [item for sublist in args for item in sublist] # flatten
|
| 25 |
+
for arg in args_list:
|
| 26 |
+
if arg == '':
|
| 27 |
+
continue
|
| 28 |
+
if arg[0] == '*':
|
| 29 |
+
if arg[-1] == ' ':
|
| 30 |
+
arg = arg[:-1]
|
| 31 |
+
details_string += '_' + arg[1:].replace(' ', '_').replace('/', '-')
|
| 32 |
+
return details_string, processed_arg_string
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
slurm_confs = {'curta_extra_long': "#SBATCH -p inria\n"
|
| 36 |
+
"#SBATCH -t 119:00:00\n",
|
| 37 |
+
'curta_long': "#SBATCH -p inria\n"
|
| 38 |
+
"#SBATCH -t 72:00:00\n",
|
| 39 |
+
'curta_medium': "#SBATCH -p inria\n"
|
| 40 |
+
"#SBATCH -t 48:00:00\n",
|
| 41 |
+
'curta_short': "#SBATCH -p inria\n"
|
| 42 |
+
"#SBATCH -t 24:00:00\n",
|
| 43 |
+
'jz_super_short_gpu':
|
| 44 |
+
'#SBATCH -A imi@v100\n'
|
| 45 |
+
'#SBATCH --gres=gpu:1\n'
|
| 46 |
+
"#SBATCH -t 9:59:00\n"
|
| 47 |
+
"#SBATCH --qos=qos_gpu-t3\n",
|
| 48 |
+
'jz_short_gpu': '#SBATCH -A imi@v100\n'
|
| 49 |
+
'#SBATCH --gres=gpu:1\n'
|
| 50 |
+
"#SBATCH -t 19:59:00\n"
|
| 51 |
+
"#SBATCH --qos=qos_gpu-t3\n",
|
| 52 |
+
'jz_short_gpu_chained': '#SBATCH -A imi@v100\n'
|
| 53 |
+
'#SBATCH --gres=gpu:1\n'
|
| 54 |
+
"#SBATCH -t 19:59:00\n"
|
| 55 |
+
"#SBATCH --qos=qos_gpu-t3\n",
|
| 56 |
+
'jz_short_2gpus_chained': '#SBATCH -A imi@v100\n'
|
| 57 |
+
'#SBATCH --gres=gpu:2\n'
|
| 58 |
+
"#SBATCH -t 19:59:00\n"
|
| 59 |
+
"#SBATCH --qos=qos_gpu-t3\n",
|
| 60 |
+
'jz_medium_gpu': '#SBATCH -A imi@v100\n'
|
| 61 |
+
'#SBATCH --gres=gpu:1\n'
|
| 62 |
+
"#SBATCH -t 48:00:00\n"
|
| 63 |
+
"#SBATCH --qos=qos_gpu-t4\n",
|
| 64 |
+
'jz_super_short_2gpus': '#SBATCH -A imi@v100\n'
|
| 65 |
+
'#SBATCH --gres=gpu:2\n'
|
| 66 |
+
"#SBATCH -t 14:59:00\n"
|
| 67 |
+
"#SBATCH --qos=qos_gpu-t3\n",
|
| 68 |
+
'jz_short_2gpus': '#SBATCH -A imi@v100\n'
|
| 69 |
+
'#SBATCH --gres=gpu:2\n'
|
| 70 |
+
"#SBATCH -t 19:59:00\n"
|
| 71 |
+
"#SBATCH --qos=qos_gpu-t3\n",
|
| 72 |
+
'jz_short_2gpus_32g': '#SBATCH -A imi@v100\n'
|
| 73 |
+
'#SBATCH -C v100-32g\n'
|
| 74 |
+
'#SBATCH --gres=gpu:2\n'
|
| 75 |
+
"#SBATCH -t 19:59:00\n"
|
| 76 |
+
"#SBATCH --qos=qos_gpu-t3\n",
|
| 77 |
+
'jz_medium_2gpus': '#SBATCH -A imi@v100\n'
|
| 78 |
+
'#SBATCH --gres=gpu:2\n'
|
| 79 |
+
"#SBATCH -t 48:00:00\n"
|
| 80 |
+
"#SBATCH --qos=qos_gpu-t4\n",
|
| 81 |
+
'jz_medium_2gpus_32g': '#SBATCH -A imi@v100\n'
|
| 82 |
+
'#SBATCH -C v100-32g\n'
|
| 83 |
+
'#SBATCH --gres=gpu:2\n'
|
| 84 |
+
"#SBATCH -t 48:00:00\n"
|
| 85 |
+
"#SBATCH --qos=qos_gpu-t4\n",
|
| 86 |
+
'jz_long_gpu': '#SBATCH -A imi@v100\n'
|
| 87 |
+
'#SBATCH --gres=gpu:1\n'
|
| 88 |
+
"#SBATCH -t 72:00:00\n"
|
| 89 |
+
"#SBATCH --qos=qos_gpu-t4\n",
|
| 90 |
+
'jz_long_2gpus': '#SBATCH -A imi@v100\n'
|
| 91 |
+
'#SBATCH --gres=gpu:2\n'
|
| 92 |
+
'#SBATCH -t 72:00:00\n'
|
| 93 |
+
'#SBATCH --qos=qos_gpu-t4\n',
|
| 94 |
+
'jz_long_2gpus_32g': '#SBATCH -A imi@v100\n'
|
| 95 |
+
'#SBATCH -C v100-32g\n'
|
| 96 |
+
'#SBATCH --gres=gpu:2\n'
|
| 97 |
+
"#SBATCH -t 72:00:00\n"
|
| 98 |
+
"#SBATCH --qos=qos_gpu-t4\n",
|
| 99 |
+
'jz_super_long_2gpus_32g': '#SBATCH -A imi@v100\n'
|
| 100 |
+
'#SBATCH -C v100-32g\n'
|
| 101 |
+
'#SBATCH --gres=gpu:2\n'
|
| 102 |
+
"#SBATCH -t 99:00:00\n"
|
| 103 |
+
"#SBATCH --qos=qos_gpu-t4\n",
|
| 104 |
+
'jz_short_cpu': '#SBATCH -A imi@cpu\n'
|
| 105 |
+
"#SBATCH -t 19:59:00\n"
|
| 106 |
+
"#SBATCH --qos=qos_cpu-t3\n",
|
| 107 |
+
'jz_medium_cpu': '#SBATCH -A imi@cpu\n'
|
| 108 |
+
"#SBATCH -t 48:00:00\n"
|
| 109 |
+
"#SBATCH --qos=qos_cpu-t4\n",
|
| 110 |
+
'jz_long_cpu': '#SBATCH -A imi@cpu\n'
|
| 111 |
+
"#SBATCH -t 72:00:00\n"
|
| 112 |
+
"#SBATCH --qos=qos_cpu-t4\n",
|
| 113 |
+
'plafrim_cpu_medium': "#SBATCH -t 48:00:00\n",
|
| 114 |
+
'plafrim_cpu_long': "#SBATCH -t 72:00:00\n",
|
| 115 |
+
'plafrim_gpu_medium': '#SBATCH -p long_sirocco\n'
|
| 116 |
+
"#SBATCH -t 48:00:00\n"
|
| 117 |
+
'#SBATCH --gres=gpu:1\n'
|
| 118 |
+
}
|
| 119 |
+
|
| 120 |
+
cur_path = str(Path.cwd())
|
| 121 |
+
date = date.today().strftime("%d-%m")
|
| 122 |
+
# create campain log dir if not already done
|
| 123 |
+
Path(cur_path + "/campain_logs/jobouts/").mkdir(parents=True, exist_ok=True)
|
| 124 |
+
Path(cur_path + "/campain_logs/scripts/").mkdir(parents=True, exist_ok=True)
|
| 125 |
+
# Load txt file containing experiments to run (give it as argument to this script)
|
| 126 |
+
filename = 'to_run.txt'
|
| 127 |
+
if len(sys.argv) >= 2:
|
| 128 |
+
filename = sys.argv[1]
|
| 129 |
+
launch = True
|
| 130 |
+
# Save a copy of txt file
|
| 131 |
+
shutil.copyfile(cur_path + "/" + filename, cur_path + '/campain_logs/scripts/' + date + '_' + filename)
|
| 132 |
+
|
| 133 |
+
# one_launch_per_n_seeds = 8
|
| 134 |
+
one_launch_per_n_seeds = 4
|
| 135 |
+
|
| 136 |
+
global_seed_offset = 0
|
| 137 |
+
incremental = False
|
| 138 |
+
if len(sys.argv) >= 3:
|
| 139 |
+
if sys.argv[2] == 'nolaunch':
|
| 140 |
+
launch = False
|
| 141 |
+
if sys.argv[2] == 'seed_offset':
|
| 142 |
+
global_seed_offset = int(sys.argv[3])
|
| 143 |
+
if sys.argv[2] == 'incremental_seed_offset':
|
| 144 |
+
global_seed_offset = int(sys.argv[3])
|
| 145 |
+
incremental = True
|
| 146 |
+
if launch:
|
| 147 |
+
print('Creating and Launching slurm scripts given arguments from {}'.format(filename))
|
| 148 |
+
# time.sleep(1.0)
|
| 149 |
+
expe_list = []
|
| 150 |
+
with open(filename, 'r') as f:
|
| 151 |
+
expe_list = [line.rstrip() for line in f]
|
| 152 |
+
|
| 153 |
+
exp_names = set()
|
| 154 |
+
for expe_args in expe_list:
|
| 155 |
+
seed_offset_to_use = global_seed_offset
|
| 156 |
+
|
| 157 |
+
if len(expe_args) == 0:
|
| 158 |
+
# empty line
|
| 159 |
+
continue
|
| 160 |
+
|
| 161 |
+
if expe_args[0] == '#':
|
| 162 |
+
# comment line
|
| 163 |
+
continue
|
| 164 |
+
|
| 165 |
+
exp_config = expe_args.split('--')[1:5]
|
| 166 |
+
|
| 167 |
+
if not [arg.split(' ')[0] for arg in exp_config] == ['slurm_conf', 'nb_seeds', 'frames', 'model']:
|
| 168 |
+
raise ValueError("Arguments must be in the following order {}".format(
|
| 169 |
+
['slurm_conf', 'nb_seeds', 'frames', 'model']))
|
| 170 |
+
|
| 171 |
+
slurm_conf_name, nb_seeds, frames, exp_name = [arg.split(' ')[1] for arg in exp_config]
|
| 172 |
+
|
| 173 |
+
user = getpass.getuser()
|
| 174 |
+
if 'curta' in slurm_conf_name:
|
| 175 |
+
gpu = ''
|
| 176 |
+
PYTHON_INTERP = "$HOME/anaconda3/envs/act_and_speak/bin/python"
|
| 177 |
+
n_cpus = 1
|
| 178 |
+
elif 'plafrim' in slurm_conf_name:
|
| 179 |
+
gpu = ''
|
| 180 |
+
PYTHON_INTERP = '/home/{}/USER/conda/envs/act_and_speak/bin/python'.format(user)
|
| 181 |
+
n_cpus = 1
|
| 182 |
+
elif 'jz' in slurm_conf_name:
|
| 183 |
+
|
| 184 |
+
if user == "utu57ed":
|
| 185 |
+
PYTHON_INTERP='/gpfsscratch/rech/imi/{}/miniconda3/envs/social_ai/bin/python'.format(user)
|
| 186 |
+
elif user == "uxo14qj":
|
| 187 |
+
PYTHON_INTERP='/gpfswork/rech/imi/{}/miniconda3/envs/act_and_speak/bin/python'.format(user)
|
| 188 |
+
else:
|
| 189 |
+
if user != "flowers":
|
| 190 |
+
raise ValueError("Who are you? User {} unknown.".format(user))
|
| 191 |
+
|
| 192 |
+
gpu = '' # '--gpu_id 0'
|
| 193 |
+
n_cpus = 2
|
| 194 |
+
|
| 195 |
+
n_cpus = 4
|
| 196 |
+
assert n_cpus*one_launch_per_n_seeds == 16 # cpus_per_task is 8 will result in 16 cpus
|
| 197 |
+
else:
|
| 198 |
+
raise Exception("Unrecognized conf name: {} ".format(slurm_conf_name))
|
| 199 |
+
|
| 200 |
+
# assert ((int(nb_seeds) % 8) == 0), 'number of seeds should be divisible by 8'
|
| 201 |
+
assert ((int(nb_seeds) % 4) == 0), 'number of seeds should be divisible by 8'
|
| 202 |
+
run_args = expe_args.split(exp_name, 1)[
|
| 203 |
+
1] # WARNING: assumes that exp_name comes after slurm_conf and nb_seeds and frames in txt
|
| 204 |
+
|
| 205 |
+
# prepare experiment name formatting (use --* or -* instead of -- or - to use argument in experiment name
|
| 206 |
+
# print(expe_args.split(exp_name))
|
| 207 |
+
exp_details, run_args = process_arg_string(run_args)
|
| 208 |
+
exp_name = date + '_' + exp_name + exp_details
|
| 209 |
+
|
| 210 |
+
# no two trains are to be put in the same dir
|
| 211 |
+
assert exp_names not in exp_names
|
| 212 |
+
exp_names.add(exp_name)
|
| 213 |
+
|
| 214 |
+
slurm_script_fullname = cur_path + "/campain_logs/scripts/{}".format(exp_name) + ".sh"
|
| 215 |
+
# create corresponding slurm script
|
| 216 |
+
|
| 217 |
+
# calculate how many chained jobs we need
|
| 218 |
+
chained_training = "chained" in slurm_conf_name
|
| 219 |
+
frames = int(frames)
|
| 220 |
+
|
| 221 |
+
if chained_training:
|
| 222 |
+
# assume 10M frames per 20h (fps 140 - very conservative)
|
| 223 |
+
timelimit = slurm_confs[slurm_conf_name].split("-t ")[-1].split("\n")[0]
|
| 224 |
+
assert timelimit == '19:59:00'
|
| 225 |
+
one_script_frames = 10000000
|
| 226 |
+
print(f"One script frames: {one_script_frames}")
|
| 227 |
+
|
| 228 |
+
num_chained_jobs = frames // one_script_frames + bool(frames % one_script_frames)
|
| 229 |
+
|
| 230 |
+
else:
|
| 231 |
+
one_script_frames = frames
|
| 232 |
+
num_chained_jobs = 1 # no chaining
|
| 233 |
+
|
| 234 |
+
assert "--frames " not in run_args
|
| 235 |
+
|
| 236 |
+
current_script_frames = min(one_script_frames, frames)
|
| 237 |
+
|
| 238 |
+
# launch scripts (1 launch per 4 seeds)
|
| 239 |
+
if launch:
|
| 240 |
+
for i in range(int(nb_seeds) // one_launch_per_n_seeds):
|
| 241 |
+
|
| 242 |
+
# continue jobs
|
| 243 |
+
cont_job_i = num_chained_jobs # last job
|
| 244 |
+
|
| 245 |
+
exp_name_no_date = exp_name[5:]
|
| 246 |
+
continue_slurm_script_fullname = cur_path + "/campain_logs/scripts/*{}_continue_{}".format(exp_name_no_date, "*")
|
| 247 |
+
matched_scripts = glob.glob(continue_slurm_script_fullname)
|
| 248 |
+
matched_scripts.sort(key=os.path.getctime)
|
| 249 |
+
|
| 250 |
+
for last_script in reversed(matched_scripts):
|
| 251 |
+
# start from the latest written script and start the first encountered that has a err file (that was ran)
|
| 252 |
+
|
| 253 |
+
p = re.compile("continue_(.*).sh")
|
| 254 |
+
last_job_id = int(p.search(last_script).group(1))
|
| 255 |
+
|
| 256 |
+
last_script_name = os.path.basename(last_script)[:-3].replace("_continue_", "_cont_")
|
| 257 |
+
if len(glob.glob(cur_path + "/campain_logs/jobouts/"+last_script_name+"*.sh.err")) == 1:
|
| 258 |
+
# error file found -> script was ran -> this is the script that crashed
|
| 259 |
+
break
|
| 260 |
+
|
| 261 |
+
print(f"Continuing job id: {last_job_id}")
|
| 262 |
+
# last_err_log = glob.glob(cur_path + "/campain_logs/jobouts/"+last_script_name+"*.sh.err")[0]
|
| 263 |
+
#
|
| 264 |
+
# print("Then ended with:\n")
|
| 265 |
+
# print('"""\n')
|
| 266 |
+
# for l in open(last_err_log).readlines():
|
| 267 |
+
# print("\t"+l, end='')
|
| 268 |
+
# print('"""\n')
|
| 269 |
+
|
| 270 |
+
# write continue script
|
| 271 |
+
cont_script_name = "{}_continue_{}.sh".format(exp_name, last_job_id)
|
| 272 |
+
continue_slurm_script_fullname = cur_path + "/campain_logs/scripts/"+cont_script_name
|
| 273 |
+
|
| 274 |
+
current_script_frames = min(one_script_frames*(2+cont_job_i), frames)
|
| 275 |
+
# run continue job
|
| 276 |
+
sbatch_pipe = subprocess.Popen(
|
| 277 |
+
['sbatch', 'campain_logs/scripts/{}'.format(os.path.basename(last_script)), str((i * one_launch_per_n_seeds) + seed_offset_to_use)], # 0 4 8 12
|
| 278 |
+
stdout=subprocess.PIPE
|
| 279 |
+
)
|
| 280 |
+
|
| 281 |
+
if incremental:
|
| 282 |
+
global_seed_offset += int(nb_seeds)
|
campain_launcher.py
ADDED
|
@@ -0,0 +1,488 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
import time
|
| 3 |
+
from pathlib import Path
|
| 4 |
+
from datetime import date
|
| 5 |
+
import subprocess
|
| 6 |
+
import shutil
|
| 7 |
+
import os
|
| 8 |
+
import stat
|
| 9 |
+
import getpass
|
| 10 |
+
|
| 11 |
+
def get_sec(time_str):
|
| 12 |
+
"""Get seconds from time."""
|
| 13 |
+
h, m, s = time_str.split(':')
|
| 14 |
+
return int(h) * 3600 + int(m) * 60 + int(s)
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def write_script(script_fullname, exp_name, PYTHON_INTERP, n_cpu_cores, slurm_conf_name, run_args, script_frames,
|
| 18 |
+
is_continue=False, dependecy_jobid=None):
|
| 19 |
+
|
| 20 |
+
print('creating slurm script with: --model {} {} --frames {} {}'.format(exp_name, run_args, script_frames, "--continue-train auto" if is_continue else ""))
|
| 21 |
+
logfile_name = "{}{}_jid_%A".format(exp_name, "_cont_"+dependecy_jobid if is_continue else "")
|
| 22 |
+
with open(script_fullname, 'w') as f:
|
| 23 |
+
f.write('#!/bin/sh\n')
|
| 24 |
+
|
| 25 |
+
if is_continue:
|
| 26 |
+
f.write('#SBATCH --dependency=afterok:{}\n'.format(dependecy_jobid))
|
| 27 |
+
f.write('#SBATCH --kill-on-invalid-dep=yes\n')
|
| 28 |
+
|
| 29 |
+
f.write('#SBATCH --ntasks=1\n')
|
| 30 |
+
f.write('#SBATCH --cpus-per-task={}\n'.format((n_cpu_cores * n_seeds_per_one_launch)//2)) # cpus asked = num_cores // 2
|
| 31 |
+
if "jz" in slurm_conf_name:
|
| 32 |
+
f.write('#SBATCH --hint=nomultithread\n')
|
| 33 |
+
f.write(slurm_confs[slurm_conf_name])
|
| 34 |
+
f.write('#SBATCH --open-mode=append\n') # append logs in logs files instead of truncating
|
| 35 |
+
f.write('#SBATCH -o campain_logs/jobouts/{}.sh.out\n'
|
| 36 |
+
'#SBATCH -e campain_logs/jobouts/{}.sh.err\n'.format(logfile_name, logfile_name))
|
| 37 |
+
f.write("export EXP_INTERP='{}' ;\n".format(PYTHON_INTERP))
|
| 38 |
+
f.write('# Launch !\n')
|
| 39 |
+
f.write(
|
| 40 |
+
'cpu_list=$(taskset -pc $$ | sed -E "s/(.*): (.*)/\\2/g" | tr "," "\\n" | sed -E "s/^[0-9]*$/&-&/g" | sed -E "s/-/ /g" | xargs -l seq | tr "\\n" " ")\n')
|
| 41 |
+
f.write('echo "cpu list: $cpu_list"\n')
|
| 42 |
+
f.write('COUNT=${1:-0}\n')
|
| 43 |
+
f.write('i=0\n')
|
| 44 |
+
f.write('cpus=""\n')
|
| 45 |
+
f.write('for cpu in $cpu_list; do\n')
|
| 46 |
+
f.write('cpus="$cpus$cpu"\n')
|
| 47 |
+
f.write('i=$(($i+1))\n')
|
| 48 |
+
f.write('if [ "$i" = "{}" ]; then\n'.format(n_cpu_cores))
|
| 49 |
+
|
| 50 |
+
if "2gpus" in slurm_conf_name:
|
| 51 |
+
f.write(
|
| 52 |
+
"{}".format('CUDA_VISIBLE_DEVICES=$(( $COUNT % 2 )); ') +
|
| 53 |
+
'taskset -c $cpus $EXP_INTERP -m scripts.train --model {}/$COUNT --seed $COUNT'.format(exp_name) +
|
| 54 |
+
run_args + " --frames {}".format(script_frames) + "{}".format(" --continue-train auto" if is_continue else "") + ' &\n')
|
| 55 |
+
|
| 56 |
+
elif "4gpus" in slurm_conf_name:
|
| 57 |
+
f.write(
|
| 58 |
+
"{}".format('CUDA_VISIBLE_DEVICES=$(( $COUNT % 4 )); ') +
|
| 59 |
+
'taskset -c $cpus $EXP_INTERP -m scripts.train --model {}/$COUNT --seed $COUNT'.format(exp_name) +
|
| 60 |
+
run_args + " --frames {}".format(script_frames) + "{}".format(" --continue-train auto" if is_continue else "") + ' &\n')
|
| 61 |
+
|
| 62 |
+
else:
|
| 63 |
+
f.write(
|
| 64 |
+
# "{}".format('CUDA_VISIBLE_DEVICES=$(( $COUNT % 2 )); ' if "2gpus" in slurm_conf_name else "") +
|
| 65 |
+
'taskset -c $cpus $EXP_INTERP -m scripts.train --model {}/$COUNT --seed $COUNT'.format(exp_name) +
|
| 66 |
+
run_args + " --frames {}".format(script_frames) + "{}".format(" --continue-train auto" if is_continue else "") + ' &\n')
|
| 67 |
+
|
| 68 |
+
f.write('echo "Using cpus $cpus for seed $COUNT"\n')
|
| 69 |
+
f.write('COUNT=$(( $COUNT + 1 ))\n')
|
| 70 |
+
f.write('cpus=""\n')
|
| 71 |
+
f.write('i=0\n')
|
| 72 |
+
f.write('else\n')
|
| 73 |
+
f.write('cpus="$cpus,"\n')
|
| 74 |
+
f.write('fi\n')
|
| 75 |
+
f.write('done\n')
|
| 76 |
+
f.write('wait\n')
|
| 77 |
+
f.close()
|
| 78 |
+
|
| 79 |
+
st = os.stat(script_fullname)
|
| 80 |
+
os.chmod(script_fullname, st.st_mode | stat.S_IEXEC)
|
| 81 |
+
|
| 82 |
+
def write_script_one_seed(script_fullname, exp_name, PYTHON_INTERP, n_cpu_cores, slurm_conf_name, run_args, script_frames,
|
| 83 |
+
is_continue=False, dependecy_jobid=None):
|
| 84 |
+
|
| 85 |
+
n_cpus = n_cpu_cores//2
|
| 86 |
+
|
| 87 |
+
assert n_seeds_per_one_launch == 1, "Use write_script_old"
|
| 88 |
+
print('creating slurm script with: --model {} {} --frames {} {}'.format(exp_name, run_args, script_frames, "--continue-train auto" if is_continue else ""))
|
| 89 |
+
logfile_name = "{}{}_jid_%A".format(exp_name, "_cont_"+dependecy_jobid if is_continue else "")
|
| 90 |
+
with open(script_fullname, 'w') as f:
|
| 91 |
+
f.write('#!/bin/sh\n')
|
| 92 |
+
|
| 93 |
+
if is_continue:
|
| 94 |
+
f.write('#SBATCH --dependency=afterok:{}\n'.format(dependecy_jobid))
|
| 95 |
+
f.write('#SBATCH --kill-on-invalid-dep=yes\n')
|
| 96 |
+
|
| 97 |
+
f.write('#SBATCH --ntasks=1\n')
|
| 98 |
+
f.write('#SBATCH --cpus-per-task={}\n'.format((n_cpus)))
|
| 99 |
+
if "jz" in slurm_conf_name:
|
| 100 |
+
f.write('#SBATCH --hint=nomultithread\n')
|
| 101 |
+
f.write(slurm_confs[slurm_conf_name])
|
| 102 |
+
f.write('#SBATCH --open-mode=append\n') # append logs in logs files instead of truncating
|
| 103 |
+
f.write('#SBATCH -o campain_logs/jobouts/{}.sh.out\n'
|
| 104 |
+
'#SBATCH -e campain_logs/jobouts/{}.sh.err\n'.format(logfile_name, logfile_name))
|
| 105 |
+
f.write("export EXP_INTERP='{}' ;\n".format(PYTHON_INTERP))
|
| 106 |
+
f.write('SEED=${1:-0}\n')
|
| 107 |
+
f.write('# Launch !\n')
|
| 108 |
+
f.write(
|
| 109 |
+
'$EXP_INTERP -m scripts.train --model {}/$SEED --seed $SEED'.format(exp_name) +
|
| 110 |
+
run_args + " --frames {}".format(script_frames) + "{}".format(" --continue-train auto" if is_continue else ""))
|
| 111 |
+
f.close()
|
| 112 |
+
|
| 113 |
+
st = os.stat(script_fullname)
|
| 114 |
+
os.chmod(script_fullname, st.st_mode | stat.S_IEXEC)
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
def process_arg_string(expe_args): # function to extract flagged (with a *) arguments as details for experience name
|
| 118 |
+
details_string = ''
|
| 119 |
+
processed_arg_string = expe_args.replace('*', '') # keep a version of args cleaned from exp name related flags
|
| 120 |
+
# args = [arg_chunk.split(' -') for arg_chunk in expe_args.split(' --')]
|
| 121 |
+
arg_chunks = [arg_chunk for arg_chunk in expe_args.split(' --')]
|
| 122 |
+
args_list = []
|
| 123 |
+
for arg in arg_chunks:
|
| 124 |
+
if ' -' in arg and arg.split(' -')[1].isalpha():
|
| 125 |
+
args_list.extend(arg.split(' -'))
|
| 126 |
+
else:
|
| 127 |
+
args_list.append(arg)
|
| 128 |
+
# args_list = [item for sublist in args for item in sublist] # flatten
|
| 129 |
+
for arg in args_list:
|
| 130 |
+
if arg == '':
|
| 131 |
+
continue
|
| 132 |
+
if arg[0] == '*':
|
| 133 |
+
if arg[-1] == ' ':
|
| 134 |
+
arg = arg[:-1]
|
| 135 |
+
details_string += '_' + arg[1:].replace(' ', '_').replace('/', '-')
|
| 136 |
+
return details_string, processed_arg_string
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
slurm_confs = {'curta_extra_long': "#SBATCH -p inria\n"
|
| 140 |
+
"#SBATCH -t 119:00:00\n",
|
| 141 |
+
'curta_long': "#SBATCH -p inria\n"
|
| 142 |
+
"#SBATCH -t 72:00:00\n",
|
| 143 |
+
'curta_medium': "#SBATCH -p inria\n"
|
| 144 |
+
"#SBATCH -t 48:00:00\n",
|
| 145 |
+
'curta_short': "#SBATCH -p inria\n"
|
| 146 |
+
"#SBATCH -t 24:00:00\n",
|
| 147 |
+
'jz_super_short_gpu':
|
| 148 |
+
'#SBATCH -A imi@v100\n'
|
| 149 |
+
'#SBATCH --gres=gpu:1\n'
|
| 150 |
+
"#SBATCH -t 3:59:00\n"
|
| 151 |
+
"#SBATCH --qos=qos_gpu-t3\n",
|
| 152 |
+
'jz_short_gpu': '#SBATCH -A imi@v100\n'
|
| 153 |
+
'#SBATCH --gres=gpu:1\n'
|
| 154 |
+
"#SBATCH -t 19:59:00\n"
|
| 155 |
+
"#SBATCH --qos=qos_gpu-t3\n",
|
| 156 |
+
'jz_super_short_gpu_chained':
|
| 157 |
+
'#SBATCH -A imi@v100\n'
|
| 158 |
+
'#SBATCH --gres=gpu:1\n'
|
| 159 |
+
"#SBATCH -t 3:59:00\n"
|
| 160 |
+
"#SBATCH -C v100\n"
|
| 161 |
+
"#SBATCH --qos=qos_gpu-t3\n",
|
| 162 |
+
'jz_short_gpu_chained': '#SBATCH -A imi@v100\n'
|
| 163 |
+
'#SBATCH --gres=gpu:1\n'
|
| 164 |
+
"#SBATCH -t 19:59:00\n"
|
| 165 |
+
"#SBATCH -C v100\n"
|
| 166 |
+
"#SBATCH --qos=qos_gpu-t3\n",
|
| 167 |
+
'jz_short_gpu_chained_a100_4h': '#SBATCH -A imi@a100\n'
|
| 168 |
+
'#SBATCH --gres=gpu:1\n'
|
| 169 |
+
"#SBATCH -t 3:59:00\n"
|
| 170 |
+
"#SBATCH -C a100\n"
|
| 171 |
+
"#SBATCH --qos=qos_gpu-t3\n",
|
| 172 |
+
'jz_short_gpu_chained_a100': '#SBATCH -A imi@a100\n'
|
| 173 |
+
'#SBATCH --gres=gpu:1\n'
|
| 174 |
+
"#SBATCH -t 19:59:00\n"
|
| 175 |
+
"#SBATCH -C a100\n"
|
| 176 |
+
"#SBATCH --qos=qos_gpu-t3\n",
|
| 177 |
+
'jz_short_2gpus_chained': '#SBATCH -A imi@v100\n'
|
| 178 |
+
'#SBATCH --gres=gpu:2\n'
|
| 179 |
+
"#SBATCH -t 19:59:00\n"
|
| 180 |
+
"#SBATCH -C v100\n"
|
| 181 |
+
"#SBATCH --qos=qos_gpu-t3\n",
|
| 182 |
+
'jz_short_4gpus_chained': '#SBATCH -A imi@v100\n'
|
| 183 |
+
'#SBATCH --gres=gpu:4\n'
|
| 184 |
+
"#SBATCH -t 19:59:00\n"
|
| 185 |
+
"#SBATCH -C v100\n"
|
| 186 |
+
"#SBATCH --qos=qos_gpu-t3\n",
|
| 187 |
+
'jz_medium_gpu': '#SBATCH -A imi@v100\n'
|
| 188 |
+
'#SBATCH --gres=gpu:1\n'
|
| 189 |
+
"#SBATCH -t 48:00:00\n"
|
| 190 |
+
"#SBATCH --qos=qos_gpu-t4\n",
|
| 191 |
+
'jz_super_short_2gpus': '#SBATCH -A imi@v100\n'
|
| 192 |
+
'#SBATCH --gres=gpu:2\n'
|
| 193 |
+
"#SBATCH -t 14:59:00\n"
|
| 194 |
+
"#SBATCH --qos=qos_gpu-t3\n",
|
| 195 |
+
'jz_short_2gpus': '#SBATCH -A imi@v100\n'
|
| 196 |
+
'#SBATCH --gres=gpu:2\n'
|
| 197 |
+
"#SBATCH -t 19:59:00\n"
|
| 198 |
+
"#SBATCH --qos=qos_gpu-t3\n",
|
| 199 |
+
'jz_short_2gpus_32g': '#SBATCH -A imi@v100\n'
|
| 200 |
+
'#SBATCH -C v100-32g\n'
|
| 201 |
+
'#SBATCH --gres=gpu:2\n'
|
| 202 |
+
"#SBATCH -t 19:59:00\n"
|
| 203 |
+
"#SBATCH --qos=qos_gpu-t3\n",
|
| 204 |
+
'jz_medium_2gpus': '#SBATCH -A imi@v100\n'
|
| 205 |
+
'#SBATCH --gres=gpu:2\n'
|
| 206 |
+
"#SBATCH -t 48:00:00\n"
|
| 207 |
+
"#SBATCH --qos=qos_gpu-t4\n",
|
| 208 |
+
'jz_medium_2gpus_32g': '#SBATCH -A imi@v100\n'
|
| 209 |
+
'#SBATCH -C v100-32g\n'
|
| 210 |
+
'#SBATCH --gres=gpu:2\n'
|
| 211 |
+
"#SBATCH -t 48:00:00\n"
|
| 212 |
+
"#SBATCH --qos=qos_gpu-t4\n",
|
| 213 |
+
'jz_long_gpu': '#SBATCH -A imi@v100\n'
|
| 214 |
+
'#SBATCH --gres=gpu:1\n'
|
| 215 |
+
"#SBATCH -t 72:00:00\n"
|
| 216 |
+
"#SBATCH --qos=qos_gpu-t4\n",
|
| 217 |
+
'jz_long_2gpus': '#SBATCH -A imi@v100\n'
|
| 218 |
+
'#SBATCH --gres=gpu:2\n'
|
| 219 |
+
'#SBATCH -t 72:00:00\n'
|
| 220 |
+
'#SBATCH --qos=qos_gpu-t4\n',
|
| 221 |
+
'jz_long_2gpus_32g': '#SBATCH -A imi@v100\n'
|
| 222 |
+
'#SBATCH -C v100-32g\n'
|
| 223 |
+
'#SBATCH --gres=gpu:2\n'
|
| 224 |
+
"#SBATCH -t 72:00:00\n"
|
| 225 |
+
"#SBATCH --qos=qos_gpu-t4\n",
|
| 226 |
+
'jz_super_long_2gpus_32g': '#SBATCH -A imi@v100\n'
|
| 227 |
+
'#SBATCH -C v100-32g\n'
|
| 228 |
+
'#SBATCH --gres=gpu:2\n'
|
| 229 |
+
"#SBATCH -t 99:00:00\n"
|
| 230 |
+
"#SBATCH --qos=qos_gpu-t4\n",
|
| 231 |
+
'jz_short_cpu_chained': '#SBATCH -A imi@cpu\n'
|
| 232 |
+
"#SBATCH -t 19:59:00\n"
|
| 233 |
+
"#SBATCH --qos=qos_cpu-t3\n",
|
| 234 |
+
'jz_short_cpu': '#SBATCH -A imi@cpu\n'
|
| 235 |
+
"#SBATCH -t 19:59:00\n"
|
| 236 |
+
"#SBATCH --qos=qos_cpu-t3\n",
|
| 237 |
+
'jz_medium_cpu': '#SBATCH -A imi@cpu\n'
|
| 238 |
+
"#SBATCH -t 48:00:00\n"
|
| 239 |
+
"#SBATCH --qos=qos_cpu-t4\n",
|
| 240 |
+
'jz_long_cpu': '#SBATCH -A imi@cpu\n'
|
| 241 |
+
"#SBATCH -t 72:00:00\n"
|
| 242 |
+
"#SBATCH --qos=qos_cpu-t4\n",
|
| 243 |
+
'plafrim_cpu_medium': "#SBATCH -t 48:00:00\n",
|
| 244 |
+
'plafrim_cpu_long': "#SBATCH -t 72:00:00\n",
|
| 245 |
+
'plafrim_gpu_medium': '#SBATCH -p long_sirocco\n'
|
| 246 |
+
"#SBATCH -t 48:00:00\n"
|
| 247 |
+
'#SBATCH --gres=gpu:1\n'
|
| 248 |
+
}
|
| 249 |
+
|
| 250 |
+
cur_path = str(Path.cwd())
|
| 251 |
+
date = date.today().strftime("%d-%m")
|
| 252 |
+
# create campain log dir if not already done
|
| 253 |
+
Path(cur_path + "/campain_logs/jobouts/").mkdir(parents=True, exist_ok=True)
|
| 254 |
+
Path(cur_path + "/campain_logs/scripts/").mkdir(parents=True, exist_ok=True)
|
| 255 |
+
# Load txt file containing experiments to run (give it as argument to this script)
|
| 256 |
+
filename = 'to_run.txt'
|
| 257 |
+
if len(sys.argv) >= 2:
|
| 258 |
+
filename = sys.argv[1]
|
| 259 |
+
launch = True
|
| 260 |
+
# Save a copy of txt file
|
| 261 |
+
shutil.copyfile(cur_path + "/" + filename, cur_path + '/campain_logs/scripts/' + date + '_' + filename)
|
| 262 |
+
|
| 263 |
+
# how many seeds does one launch launch
|
| 264 |
+
# one_launch_per_n_seeds = 8
|
| 265 |
+
|
| 266 |
+
global_seed_offset = 0
|
| 267 |
+
incremental = False
|
| 268 |
+
if len(sys.argv) >= 3:
|
| 269 |
+
if sys.argv[2] == 'nolaunch':
|
| 270 |
+
launch = False
|
| 271 |
+
if sys.argv[2] == 'seed_offset':
|
| 272 |
+
global_seed_offset = int(sys.argv[3])
|
| 273 |
+
if sys.argv[2] == 'incremental_seed_offset':
|
| 274 |
+
global_seed_offset = int(sys.argv[3])
|
| 275 |
+
incremental = True
|
| 276 |
+
if launch:
|
| 277 |
+
print('Creating and Launching slurm scripts given arguments from {}'.format(filename))
|
| 278 |
+
# time.sleep(1.0)
|
| 279 |
+
expe_list = []
|
| 280 |
+
with open(filename, 'r') as f:
|
| 281 |
+
expe_list = [line.rstrip() for line in f]
|
| 282 |
+
|
| 283 |
+
exp_names = set()
|
| 284 |
+
for expe_args in expe_list:
|
| 285 |
+
seed_offset_to_use = global_seed_offset
|
| 286 |
+
|
| 287 |
+
if len(expe_args) == 0:
|
| 288 |
+
# empty line
|
| 289 |
+
continue
|
| 290 |
+
|
| 291 |
+
if expe_args[0] == '#':
|
| 292 |
+
# comment line
|
| 293 |
+
continue
|
| 294 |
+
|
| 295 |
+
arguments = ['slurm_conf', 'nb_seeds', 'cpu_cores_per_seed', 'gpus_per_seed', 'seeds_per_launch', 'frames', 'model']
|
| 296 |
+
exp_config = expe_args.split('--')[1:len(arguments)+1]
|
| 297 |
+
given_args = [arg.split(' ')[0] for arg in exp_config]
|
| 298 |
+
|
| 299 |
+
if not given_args == arguments:
|
| 300 |
+
raise ValueError("Arguments must be in the following order {}, and are {}".format(arguments, given_args))
|
| 301 |
+
|
| 302 |
+
slurm_conf_name, nb_seeds, n_cpu_cores_per_seed, n_gpus_per_seed, n_seeds_per_one_launch, frames, exp_name = [arg.split(' ')[1] for arg in exp_config]
|
| 303 |
+
|
| 304 |
+
n_seeds_per_one_launch = int(n_seeds_per_one_launch)
|
| 305 |
+
n_cpu_cores_per_seed = int(n_cpu_cores_per_seed)
|
| 306 |
+
|
| 307 |
+
user = getpass.getuser()
|
| 308 |
+
if 'curta' in slurm_conf_name:
|
| 309 |
+
gpu = ''
|
| 310 |
+
PYTHON_INTERP = "$HOME/anaconda3/envs/act_and_speak/bin/python"
|
| 311 |
+
n_cpu_cores_per_seed = 1
|
| 312 |
+
|
| 313 |
+
elif 'plafrim' in slurm_conf_name:
|
| 314 |
+
gpu = ''
|
| 315 |
+
PYTHON_INTERP = '/home/{}/USER/conda/envs/act_and_speak/bin/python'.format(user)
|
| 316 |
+
n_cpu_cores_per_seed = 1
|
| 317 |
+
|
| 318 |
+
elif 'jz' in slurm_conf_name:
|
| 319 |
+
if user == "utu57ed" or user == 'flowers':
|
| 320 |
+
PYTHON_INTERP='/gpfsscratch/rech/imi/{}/miniconda3/envs/social_ai/bin/python'.format(user)
|
| 321 |
+
elif user == "uxo14qj":
|
| 322 |
+
PYTHON_INTERP='/gpfswork/rech/imi/{}/miniconda3/envs/act_and_speak/bin/python'.format(user)
|
| 323 |
+
else:
|
| 324 |
+
if user != "flowers":
|
| 325 |
+
raise ValueError("Who are you? User {} unknown.".format(user))
|
| 326 |
+
|
| 327 |
+
gpu = '' # '--gpu_id 0'
|
| 328 |
+
# n_cpus = 2
|
| 329 |
+
|
| 330 |
+
# n_seeds_per_one_launch = 4
|
| 331 |
+
# n_cpu_cores = 16 # n cpu cores for one seed
|
| 332 |
+
# assert n_cpu_cores * n_seeds_per_one_launch == 64
|
| 333 |
+
|
| 334 |
+
# n_seeds_per_one_launch = 2
|
| 335 |
+
# n_cpu_cores = 16 # n cpu cores for one seed
|
| 336 |
+
# assert n_cpu_cores * n_seeds_per_one_launch == 32
|
| 337 |
+
|
| 338 |
+
# n_seeds_per_one_launch = 2
|
| 339 |
+
# n_cpu_cores = 32 # n cpu cores for one seed
|
| 340 |
+
# assert n_cpu_cores * n_seeds_per_one_launch == 64
|
| 341 |
+
|
| 342 |
+
# n_seeds_per_one_launch = 1
|
| 343 |
+
# n_cpu_cores = 16 # n cpu cores for one seed
|
| 344 |
+
# assert n_cpu_cores * n_seeds_per_one_launch == 16
|
| 345 |
+
#
|
| 346 |
+
# n_seeds_per_one_launch = 1
|
| 347 |
+
# n_cpu_cores = 32 # n cpu cores for one seed
|
| 348 |
+
# assert n_cpu_cores * n_seeds_per_one_launch == 32
|
| 349 |
+
#
|
| 350 |
+
# assert n_seeds_per_one_launch == 1
|
| 351 |
+
# assert n_cpu_cores_per_seed == 64 # n cpu cores for one seed
|
| 352 |
+
# assert n_cpu_cores_per_seed * n_seeds_per_one_launch == 64
|
| 353 |
+
|
| 354 |
+
# n_cpus = 64 # n cpu cores for one seed
|
| 355 |
+
# assert n_cpus*one_launch_per_n_seeds == 256 # cpus_per_task is 8 will result in 16 cpu cores
|
| 356 |
+
|
| 357 |
+
if "2gpus" in slurm_conf_name:
|
| 358 |
+
job_gpus = 2
|
| 359 |
+
elif "4gpus" in slurm_conf_name:
|
| 360 |
+
job_gpus = 4
|
| 361 |
+
elif "gpu" in slurm_conf_name:
|
| 362 |
+
job_gpus = 1
|
| 363 |
+
else:
|
| 364 |
+
print("No gpus used")
|
| 365 |
+
job_gpus = 1
|
| 366 |
+
|
| 367 |
+
assert float(n_gpus_per_seed) == float(job_gpus / n_seeds_per_one_launch)
|
| 368 |
+
|
| 369 |
+
|
| 370 |
+
print(f"\nJob configuration (1 launch):")
|
| 371 |
+
print(f"\tSeeds: {n_seeds_per_one_launch}")
|
| 372 |
+
print(f"\tGPUs: {job_gpus}")
|
| 373 |
+
|
| 374 |
+
print(f"\n1 seed configuration:")
|
| 375 |
+
print(f"\tCPU cores {n_cpu_cores_per_seed}")
|
| 376 |
+
print(f"\tGPUs {job_gpus / n_seeds_per_one_launch}")
|
| 377 |
+
time.sleep(0.5)
|
| 378 |
+
|
| 379 |
+
else:
|
| 380 |
+
raise Exception("Unrecognized conf name: {} ".format(slurm_conf_name))
|
| 381 |
+
|
| 382 |
+
# assert ((int(nb_seeds) % 8) == 0), 'number of seeds should be divisible by 8'
|
| 383 |
+
assert ((int(nb_seeds) % 4) == 0) or (int(nb_seeds) == 1), f'number of seeds should be divisible by 4 or 1 and is {nb_seeds}'
|
| 384 |
+
run_args = expe_args.split(exp_name, 1)[
|
| 385 |
+
1] # WARNING: assumes that exp_name comes after slurm_conf and nb_seeds and frames in txt
|
| 386 |
+
|
| 387 |
+
# prepare experiment name formatting (use --* or -* instead of -- or - to use argument in experiment name
|
| 388 |
+
# print(expe_args.split(exp_name))
|
| 389 |
+
exp_details, run_args = process_arg_string(run_args)
|
| 390 |
+
exp_name = date + '_' + exp_name + exp_details
|
| 391 |
+
|
| 392 |
+
# no two trains are to be put in the same dir
|
| 393 |
+
assert exp_names not in exp_names
|
| 394 |
+
exp_names.add(exp_name)
|
| 395 |
+
|
| 396 |
+
slurm_script_fullname = cur_path + "/campain_logs/scripts/{}".format(exp_name) + ".sh"
|
| 397 |
+
# create corresponding slurm script
|
| 398 |
+
|
| 399 |
+
# calculate how many chained jobs we need
|
| 400 |
+
chained_training = "chained" in slurm_conf_name
|
| 401 |
+
frames = int(frames)
|
| 402 |
+
print(chained_training)
|
| 403 |
+
if chained_training:
|
| 404 |
+
# assume 10M frames per 20h (fps 140 - very conservative)
|
| 405 |
+
timelimit = slurm_confs[slurm_conf_name].split("-t ")[-1].split("\n")[0]
|
| 406 |
+
if timelimit == '19:59:00':
|
| 407 |
+
one_script_frames = 10000000
|
| 408 |
+
|
| 409 |
+
elif timelimit == "3:59:00":
|
| 410 |
+
one_script_frames = 2500000
|
| 411 |
+
else:
|
| 412 |
+
raise ValueError(f"Bad timelimit {timelimit}.")
|
| 413 |
+
|
| 414 |
+
print(f"One script frames: {one_script_frames}")
|
| 415 |
+
|
| 416 |
+
num_chained_jobs = frames // one_script_frames + bool(frames % one_script_frames)
|
| 417 |
+
|
| 418 |
+
# # assume conservative fps - 300 (for one seed per gpu)
|
| 419 |
+
# fps = 300
|
| 420 |
+
# timelimit = slurm_confs[slurm_conf_name].split("-t ")[-1].split("\n")[0]
|
| 421 |
+
# assert timelimit == '3:59:00'
|
| 422 |
+
# timelimit_secs = get_sec(timelimit)
|
| 423 |
+
#
|
| 424 |
+
# one_script_frames = fps*timelimit_secs
|
| 425 |
+
#
|
| 426 |
+
# num_chained_jobs = frames // one_script_frames + bool(frames % one_script_frames)
|
| 427 |
+
#
|
| 428 |
+
# print(f"One script frames: {one_script_frames} -> num chained jobs {num_chained_jobs}")
|
| 429 |
+
|
| 430 |
+
else:
|
| 431 |
+
one_script_frames = frames
|
| 432 |
+
num_chained_jobs = 1 # no chaining
|
| 433 |
+
|
| 434 |
+
assert "--frames " not in run_args
|
| 435 |
+
|
| 436 |
+
current_script_frames = min(one_script_frames, frames)
|
| 437 |
+
if n_seeds_per_one_launch == 1:
|
| 438 |
+
write_script_one_seed(slurm_script_fullname, exp_name, PYTHON_INTERP, n_cpu_cores_per_seed,
|
| 439 |
+
slurm_conf_name, run_args, current_script_frames, is_continue=False,
|
| 440 |
+
dependecy_jobid=None)
|
| 441 |
+
else:
|
| 442 |
+
write_script(slurm_script_fullname, exp_name, PYTHON_INTERP, n_cpu_cores_per_seed, slurm_conf_name,
|
| 443 |
+
run_args, current_script_frames, is_continue=False, dependecy_jobid=None)
|
| 444 |
+
|
| 445 |
+
# launch scripts
|
| 446 |
+
if launch:
|
| 447 |
+
for i in range(int(nb_seeds) // n_seeds_per_one_launch):
|
| 448 |
+
|
| 449 |
+
|
| 450 |
+
print('starting from seed {}'.format((i * n_seeds_per_one_launch) + global_seed_offset))
|
| 451 |
+
# run start job
|
| 452 |
+
sbatch_pipe = subprocess.Popen(
|
| 453 |
+
['sbatch', 'campain_logs/scripts/{}.sh'.format(exp_name), str((i * n_seeds_per_one_launch) + seed_offset_to_use)], # 0 4 8 12
|
| 454 |
+
stdout=subprocess.PIPE
|
| 455 |
+
)
|
| 456 |
+
job_id = subprocess.check_output(('cut', '-d', ' ', '-f', '4'), stdin=sbatch_pipe.stdout).decode("utf_8").rstrip()
|
| 457 |
+
sbatch_pipe.wait()
|
| 458 |
+
|
| 459 |
+
# out = subprocess.run(
|
| 460 |
+
# ['sbatch', 'campain_logs/scripts/{}.sh'.format(exp_name), str((i * one_launch_per_n_seeds) + seed_offset_to_use)], # 0 4 8 12
|
| 461 |
+
# capture_output=True
|
| 462 |
+
# ).stdout.decode("utf-8")
|
| 463 |
+
|
| 464 |
+
# continue jobs
|
| 465 |
+
for cont_job_i in range(num_chained_jobs-1):
|
| 466 |
+
# write continue script
|
| 467 |
+
cont_script_name = "{}_continue_{}.sh".format(exp_name, job_id)
|
| 468 |
+
continue_slurm_script_fullname = cur_path + "/campain_logs/scripts/"+cont_script_name
|
| 469 |
+
|
| 470 |
+
current_script_frames = min(one_script_frames*(2+cont_job_i), frames)
|
| 471 |
+
if n_seeds_per_one_launch == 1:
|
| 472 |
+
write_script_one_seed(continue_slurm_script_fullname, exp_name, PYTHON_INTERP, n_cpu_cores_per_seed,
|
| 473 |
+
slurm_conf_name, run_args, current_script_frames,
|
| 474 |
+
is_continue=True, dependecy_jobid=job_id)
|
| 475 |
+
else:
|
| 476 |
+
write_script(continue_slurm_script_fullname, exp_name, PYTHON_INTERP, n_cpu_cores_per_seed, slurm_conf_name, run_args, current_script_frames,
|
| 477 |
+
is_continue=True, dependecy_jobid=job_id)
|
| 478 |
+
|
| 479 |
+
# run continue job
|
| 480 |
+
sbatch_pipe = subprocess.Popen(
|
| 481 |
+
['sbatch', 'campain_logs/scripts/{}'.format(cont_script_name), str((i * n_seeds_per_one_launch) + seed_offset_to_use)], # 0 4 8 12
|
| 482 |
+
stdout=subprocess.PIPE
|
| 483 |
+
)
|
| 484 |
+
job_id = subprocess.check_output(('cut', '-d', ' ', '-f', '4'), stdin=sbatch_pipe.stdout).decode("utf_8").rstrip()
|
| 485 |
+
sbatch_pipe.wait()
|
| 486 |
+
|
| 487 |
+
if incremental:
|
| 488 |
+
global_seed_offset += int(nb_seeds)
|
data_analysis.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
data_analysis.py
ADDED
|
@@ -0,0 +1,1650 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
import re
|
| 3 |
+
import itertools
|
| 4 |
+
import math
|
| 5 |
+
from itertools import chain
|
| 6 |
+
import time
|
| 7 |
+
|
| 8 |
+
# import seaborn
|
| 9 |
+
import numpy as np
|
| 10 |
+
import os
|
| 11 |
+
from collections import OrderedDict, defaultdict
|
| 12 |
+
import pandas as pd
|
| 13 |
+
import matplotlib.pyplot as plt
|
| 14 |
+
import sys
|
| 15 |
+
from termcolor import cprint, colored
|
| 16 |
+
from pathlib import Path
|
| 17 |
+
import pickle
|
| 18 |
+
|
| 19 |
+
eval_metric = "test_success_rates"
|
| 20 |
+
# eval_metric = "exploration_bonus_mean"
|
| 21 |
+
|
| 22 |
+
super_title = ""
|
| 23 |
+
# super_title = "PPO - No exploration bonus"
|
| 24 |
+
# super_title = "Count Based exploration bonus (Grid Search)"
|
| 25 |
+
# super_title = "PPO + RND"
|
| 26 |
+
# super_title = "PPO + RIDE"
|
| 27 |
+
|
| 28 |
+
agg_title = ""
|
| 29 |
+
|
| 30 |
+
color_dict = None
|
| 31 |
+
eval_filename = None
|
| 32 |
+
|
| 33 |
+
max_frames = 20_000_000
|
| 34 |
+
|
| 35 |
+
draw_legend = True
|
| 36 |
+
per_seed = False
|
| 37 |
+
study_eval = True
|
| 38 |
+
|
| 39 |
+
plot_train = True
|
| 40 |
+
plot_test = True
|
| 41 |
+
|
| 42 |
+
plot_aggregated_test = False
|
| 43 |
+
plot_only_aggregated_test = False
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
train_inc_font = 3
|
| 47 |
+
|
| 48 |
+
xnbins = 4
|
| 49 |
+
ynbins = 3
|
| 50 |
+
|
| 51 |
+
steps_denom = 1e6
|
| 52 |
+
|
| 53 |
+
# Global vas for tracking and labeling data at load time.
|
| 54 |
+
exp_idx = 0
|
| 55 |
+
label_parser_dict = None
|
| 56 |
+
label_parser = lambda l, _, label_parser_dict: l
|
| 57 |
+
|
| 58 |
+
# smooth_factor = 100
|
| 59 |
+
smooth_factor = 10
|
| 60 |
+
smooth_factor = 0
|
| 61 |
+
print("smooth factor:", smooth_factor)
|
| 62 |
+
eval_smooth_factor = 1
|
| 63 |
+
leg_size = 30
|
| 64 |
+
|
| 65 |
+
def smooth(x_, n=50):
|
| 66 |
+
if type(x_) == list:
|
| 67 |
+
x_ = np.array(x_)
|
| 68 |
+
return np.array([x_[max(i - n, 0):i + 1].mean() for i in range(len(x_))])
|
| 69 |
+
|
| 70 |
+
sort_test = False
|
| 71 |
+
def sort_test_set(env_name):
|
| 72 |
+
helps = [
|
| 73 |
+
"LanguageFeedback",
|
| 74 |
+
"LanguageColor",
|
| 75 |
+
"Pointing",
|
| 76 |
+
"Emulation",
|
| 77 |
+
]
|
| 78 |
+
problems = [
|
| 79 |
+
"Boxes",
|
| 80 |
+
"Switches",
|
| 81 |
+
"Generators",
|
| 82 |
+
"Marble",
|
| 83 |
+
"Doors",
|
| 84 |
+
"Levers",
|
| 85 |
+
]
|
| 86 |
+
|
| 87 |
+
env_names = []
|
| 88 |
+
for p in problems:
|
| 89 |
+
for h in helps:
|
| 90 |
+
env_names.append(h+p)
|
| 91 |
+
|
| 92 |
+
env_names.extend([
|
| 93 |
+
"LeverDoorColl",
|
| 94 |
+
"MarblePushColl",
|
| 95 |
+
"MarblePassColl",
|
| 96 |
+
"AppleStealing"
|
| 97 |
+
])
|
| 98 |
+
|
| 99 |
+
for i, en in enumerate(env_names):
|
| 100 |
+
if en in env_name:
|
| 101 |
+
return i
|
| 102 |
+
|
| 103 |
+
raise ValueError(f"Test env {env_name} not known")
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
subsample_step = 1
|
| 108 |
+
load_subsample_step = 1
|
| 109 |
+
|
| 110 |
+
x_lim = 0
|
| 111 |
+
max_x_lim = 17
|
| 112 |
+
max_x_lim = np.inf
|
| 113 |
+
# x_lim = 100
|
| 114 |
+
|
| 115 |
+
summary_dict = {}
|
| 116 |
+
summary_dict_colors = {}
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
# default_colors = ["blue","orange","green","magenta", "brown", "red",'black',"grey",u'#ff7f0e',
|
| 120 |
+
# "cyan", "pink",'purple', u'#1f77b4',
|
| 121 |
+
# "darkorchid","sienna","lightpink", "indigo","mediumseagreen",'aqua',
|
| 122 |
+
# 'deeppink','silver','khaki','goldenrod','y','y','y','y','y','y','y','y','y','y','y','y' ] + ['y']*50
|
| 123 |
+
default_colors_ = ["blue","orange","green","magenta", "brown", "red",'black',"grey",u'#ff7f0e',
|
| 124 |
+
"cyan", "pink",'purple', u'#1f77b4',
|
| 125 |
+
"darkorchid","sienna","lightpink", "indigo","mediumseagreen",'aqua',
|
| 126 |
+
'deeppink','silver','khaki','goldenrod'] * 100
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
def get_eval_data(logdir, eval_metric):
|
| 130 |
+
eval_data = defaultdict(lambda :defaultdict(list))
|
| 131 |
+
|
| 132 |
+
for root, _, files in os.walk(logdir):
|
| 133 |
+
for file in files:
|
| 134 |
+
if 'testing_' in file:
|
| 135 |
+
assert ".pkl" in file
|
| 136 |
+
test_env_name = file.lstrip("testing_").rstrip(".pkl")
|
| 137 |
+
try:
|
| 138 |
+
with open(root+"/"+file, "rb") as f:
|
| 139 |
+
seed_eval_data = pickle.load(f)
|
| 140 |
+
except:
|
| 141 |
+
print("Pickle not loaded: ", root+"/"+file)
|
| 142 |
+
time.sleep(1)
|
| 143 |
+
continue
|
| 144 |
+
|
| 145 |
+
eval_data[test_env_name]["values"].append(seed_eval_data[eval_metric])
|
| 146 |
+
eval_data[test_env_name]["steps"].append(seed_eval_data["test_step_nb"])
|
| 147 |
+
|
| 148 |
+
# if 'log.csv' in files:
|
| 149 |
+
# run_name = root[8:]
|
| 150 |
+
# exp_name = None
|
| 151 |
+
#
|
| 152 |
+
# config = None
|
| 153 |
+
# exp_idx += 1
|
| 154 |
+
#
|
| 155 |
+
# # load progress data
|
| 156 |
+
# try:
|
| 157 |
+
# print(os.path.join(root, 'log.csv'))
|
| 158 |
+
# exp_data = pd.read_csv(os.path.join(root, 'log.csv'))
|
| 159 |
+
# except:
|
| 160 |
+
# size = (Path(root) / 'log.csv').stat().st_size
|
| 161 |
+
# if size == 0:
|
| 162 |
+
# raise ValueError("CSV {} empty".format(os.path.join(root, 'log.csv')))
|
| 163 |
+
# else:
|
| 164 |
+
# raise ValueError("CSV {} faulty".format(os.path.join(root, 'log.csv')))
|
| 165 |
+
#
|
| 166 |
+
# exp_data = exp_data[::load_subsample_step]
|
| 167 |
+
# data_dict = exp_data.to_dict("list")
|
| 168 |
+
#
|
| 169 |
+
# data_dict['config'] = config
|
| 170 |
+
# nb_epochs = len(data_dict['frames'])
|
| 171 |
+
# print('{} -> {}'.format(run_name, nb_epochs))
|
| 172 |
+
|
| 173 |
+
for test_env, seed_data in eval_data.items():
|
| 174 |
+
min_len_seed = min([len(s) for s in seed_data['steps']])
|
| 175 |
+
eval_data[test_env]["values"] = np.array([s[:min_len_seed] for s in eval_data[test_env]["values"]])
|
| 176 |
+
eval_data[test_env]["steps"] = np.array([s[:min_len_seed] for s in eval_data[test_env]["steps"]])
|
| 177 |
+
|
| 178 |
+
return eval_data
|
| 179 |
+
|
| 180 |
+
def get_all_runs(logdir, load_subsample_step=1):
|
| 181 |
+
"""
|
| 182 |
+
Recursively look through logdir for output files produced by
|
| 183 |
+
Assumes that any file "log.csv" is a valid hit.
|
| 184 |
+
"""
|
| 185 |
+
global exp_idx
|
| 186 |
+
global units
|
| 187 |
+
datasets = []
|
| 188 |
+
for root, _, files in os.walk(logdir):
|
| 189 |
+
if 'log.csv' in files:
|
| 190 |
+
if (Path(root) / 'log.csv').stat().st_size == 0:
|
| 191 |
+
print("CSV {} empty".format(os.path.join(root, 'log.csv')))
|
| 192 |
+
continue
|
| 193 |
+
|
| 194 |
+
run_name = root[8:]
|
| 195 |
+
|
| 196 |
+
exp_name = None
|
| 197 |
+
|
| 198 |
+
config = None
|
| 199 |
+
exp_idx += 1
|
| 200 |
+
|
| 201 |
+
# load progress data
|
| 202 |
+
try:
|
| 203 |
+
exp_data = pd.read_csv(os.path.join(root, 'log.csv'))
|
| 204 |
+
print("Loaded:", os.path.join(root, 'log.csv'))
|
| 205 |
+
except:
|
| 206 |
+
raise ValueError("CSV {} faulty".format(os.path.join(root, 'log.csv')))
|
| 207 |
+
|
| 208 |
+
exp_data = exp_data[::load_subsample_step]
|
| 209 |
+
data_dict = exp_data.to_dict("list")
|
| 210 |
+
|
| 211 |
+
data_dict['config'] = config
|
| 212 |
+
nb_epochs = len(data_dict['frames'])
|
| 213 |
+
if nb_epochs == 1:
|
| 214 |
+
print(f'{run_name} -> {colored(f"nb_epochs {nb_epochs}", "red")}')
|
| 215 |
+
else:
|
| 216 |
+
print('{} -> nb_epochs {}'.format(run_name, nb_epochs))
|
| 217 |
+
|
| 218 |
+
datasets.append(data_dict)
|
| 219 |
+
|
| 220 |
+
return datasets
|
| 221 |
+
|
| 222 |
+
|
| 223 |
+
def get_datasets(rootdir, load_only="", load_subsample_step=1, ignore_patterns=("ignore"), require_patterns=()):
|
| 224 |
+
_, models_list, _ = next(os.walk(rootdir))
|
| 225 |
+
for dir_name in models_list.copy():
|
| 226 |
+
# add "ignore" in a directory name to avoid loading its content
|
| 227 |
+
for ignore_pattern in ignore_patterns:
|
| 228 |
+
if ignore_pattern in dir_name or load_only not in dir_name:
|
| 229 |
+
if dir_name in models_list:
|
| 230 |
+
models_list.remove(dir_name)
|
| 231 |
+
|
| 232 |
+
if len(require_patterns) > 0:
|
| 233 |
+
if not any([require_pattern in dir_name for require_pattern in require_patterns]):
|
| 234 |
+
if dir_name in models_list:
|
| 235 |
+
models_list.remove(dir_name)
|
| 236 |
+
|
| 237 |
+
for expe_name in list(labels.keys()):
|
| 238 |
+
if expe_name not in models_list:
|
| 239 |
+
del labels[expe_name]
|
| 240 |
+
|
| 241 |
+
|
| 242 |
+
# setting per-model type colors
|
| 243 |
+
for i, m_name in enumerate(models_list):
|
| 244 |
+
for m_type, m_color in per_model_colors.items():
|
| 245 |
+
if m_type in m_name:
|
| 246 |
+
colors[m_name] = m_color
|
| 247 |
+
print("extracting data for {}...".format(m_name))
|
| 248 |
+
m_id = m_name
|
| 249 |
+
models_saves[m_id] = OrderedDict()
|
| 250 |
+
models_saves[m_id]['data'] = get_all_runs(rootdir+m_name, load_subsample_step=load_subsample_step)
|
| 251 |
+
print("done")
|
| 252 |
+
|
| 253 |
+
if m_name not in labels:
|
| 254 |
+
labels[m_name] = m_name
|
| 255 |
+
|
| 256 |
+
model_eval_data[m_id] = get_eval_data(logdir=rootdir+m_name, eval_metric=eval_metric)
|
| 257 |
+
|
| 258 |
+
"""
|
| 259 |
+
retrieve all experiences located in "data to vizu" folder
|
| 260 |
+
"""
|
| 261 |
+
labels = OrderedDict()
|
| 262 |
+
per_model_colors = OrderedDict()
|
| 263 |
+
# per_model_colors = OrderedDict([('ALP-GMM',u'#1f77b4'),
|
| 264 |
+
# ('hmn','pink'),
|
| 265 |
+
# ('ADR','black')])
|
| 266 |
+
|
| 267 |
+
# LOAD DATA
|
| 268 |
+
models_saves = OrderedDict()
|
| 269 |
+
colors = OrderedDict()
|
| 270 |
+
model_eval_data = OrderedDict()
|
| 271 |
+
|
| 272 |
+
static_lines = {}
|
| 273 |
+
# get_datasets("storage/",load_only="RERUN_WizardGuide")
|
| 274 |
+
# get_datasets("storage/",load_only="RERUN_WizardTwoGuides")
|
| 275 |
+
try:
|
| 276 |
+
load_pattern = eval(sys.argv[1])
|
| 277 |
+
|
| 278 |
+
except:
|
| 279 |
+
load_pattern = sys.argv[1]
|
| 280 |
+
|
| 281 |
+
ignore_patterns = ["_ignore_"]
|
| 282 |
+
require_patterns = [
|
| 283 |
+
"_"
|
| 284 |
+
]
|
| 285 |
+
|
| 286 |
+
# require_patterns = [
|
| 287 |
+
# "dummy_cs_jz_scaf_A_E_N_A_E",
|
| 288 |
+
# "03-12_dummy_cs_jz_formats_AE",
|
| 289 |
+
# ]
|
| 290 |
+
#
|
| 291 |
+
# def label_parser(label, figure_id, label_parser_dict=None):
|
| 292 |
+
# if "single" in label:
|
| 293 |
+
# ty = "single"
|
| 294 |
+
# elif "group" in label:
|
| 295 |
+
# ty = "group"
|
| 296 |
+
#
|
| 297 |
+
# if "asoc" in label:
|
| 298 |
+
# return f"Asocial_pretrain({ty})"
|
| 299 |
+
#
|
| 300 |
+
# if "exp_soc" in label:
|
| 301 |
+
# return f"Role_B_pretrain({ty})"
|
| 302 |
+
#
|
| 303 |
+
# return label
|
| 304 |
+
|
| 305 |
+
|
| 306 |
+
#
|
| 307 |
+
# # DUMMY FORMATS
|
| 308 |
+
# require_patterns = [
|
| 309 |
+
# "03-12_dummy_cs_formats_CBL",
|
| 310 |
+
# "dummy_cs_formats_CBL_N_rec_5"
|
| 311 |
+
# "03-12_dummy_cs_jz_formats_",
|
| 312 |
+
# "dummy_cs_jz_formats_N_rec_5"
|
| 313 |
+
# ]
|
| 314 |
+
# def label_parser(label, figure_id, label_parser_dict=None):
|
| 315 |
+
# if "CBL" in label:
|
| 316 |
+
# eb = "CBL"
|
| 317 |
+
# else:
|
| 318 |
+
# eb = "no_bonus"
|
| 319 |
+
#
|
| 320 |
+
# if "AE" in label:
|
| 321 |
+
# label = f"AE_PPO_{eb}"
|
| 322 |
+
# elif "E" in label:
|
| 323 |
+
# label = f"E_PPO_{eb}"
|
| 324 |
+
# elif "A" in label:
|
| 325 |
+
# label = f"A_PPO_{eb}"
|
| 326 |
+
# elif "N" in label:
|
| 327 |
+
# label = f"N_PPO_{eb}"
|
| 328 |
+
#
|
| 329 |
+
# return label
|
| 330 |
+
#
|
| 331 |
+
|
| 332 |
+
# DUMMY CLASSIC
|
| 333 |
+
# require_patterns = [
|
| 334 |
+
# "07-12_dummy_cs_NEW2_Pointing_sm_CB_very_small",
|
| 335 |
+
# "dummy_cs_JA_Pointing_CB_sm",
|
| 336 |
+
|
| 337 |
+
# "06-12_dummy_cs_NEW_Color_CBL",
|
| 338 |
+
# "dummy_cs_JA_Color_CBL_new"
|
| 339 |
+
|
| 340 |
+
# "07-12_dummy_cs_NEW2_Feedback_CBL",
|
| 341 |
+
# "dummy_cs_JA_Feedback_CBL_new"
|
| 342 |
+
|
| 343 |
+
# "08-12_dummy_cs_emulation_no_distr_rec_5_CB_exploration-bonus-type_cell_exploration-bonus-params__1_50",
|
| 344 |
+
# "08-12_dummy_cs_emulation_no_distr_rec_5_CB",
|
| 345 |
+
|
| 346 |
+
# "dummy_cs_RR_ft_NEW_single_CB_marble_pass_B_exp_soc",
|
| 347 |
+
# "dummy_cs_RR_ft_NEW_single_CB_marble_pass_B_contr_asoc",
|
| 348 |
+
|
| 349 |
+
# "dummy_cs_RR_ft_NEW_group_CB_marble_pass_A_exp_soc",
|
| 350 |
+
# "dummy_cs_RR_ft_NEW_group_CB_marble_pass_A_contr_asoc"
|
| 351 |
+
|
| 352 |
+
# "03-12_dummy_cs_jz_formats_A",
|
| 353 |
+
# "03-12_dummy_cs_jz_formats_E",
|
| 354 |
+
# "03-12_dummy_cs_jz_formats_AE",
|
| 355 |
+
# "dummy_cs_jz_formats_N_rec_5"
|
| 356 |
+
|
| 357 |
+
# "03-12_dummy_cs_formats_CBL_A",
|
| 358 |
+
# "03-12_dummy_cs_formats_CBL_E",
|
| 359 |
+
# "03-12_dummy_cs_formats_CBL_AE",
|
| 360 |
+
# "dummy_cs_formats_CBL_N_rec_5"
|
| 361 |
+
|
| 362 |
+
# "03-12_dummy_cs_jz_formats_AE",
|
| 363 |
+
# "dummy_cs_jz_scaf_A_E_N_A_E_full-AEfull",
|
| 364 |
+
# "dummy_cs_jz_scaf_A_E_N_A_E_scaf_full-AEfull",
|
| 365 |
+
# ]
|
| 366 |
+
|
| 367 |
+
# def label_parser(label, figure_id, label_parser_dict=None):
|
| 368 |
+
# label = label.replace("07-12_dummy_cs_NEW2_Pointing_sm_CB_very_small", "PPO_CB")
|
| 369 |
+
# label = label.replace("dummy_cs_JA_Pointing_CB_sm", "JA_PPO_CB")
|
| 370 |
+
#
|
| 371 |
+
# label = label.replace("06-12_dummy_cs_NEW_Color_CBL", "PPO_CBL")
|
| 372 |
+
# label = label.replace("dummy_cs_JA_Color_CBL_new", "JA_PPO_CBL")
|
| 373 |
+
#
|
| 374 |
+
# label = label.replace("07-12_dummy_cs_NEW2_Feedback_CBL", "PPO_CBL")
|
| 375 |
+
# label = label.replace("dummy_cs_JA_Feedback_CBL_new", "JA_PPO_CBL")
|
| 376 |
+
#
|
| 377 |
+
# label = label.replace(
|
| 378 |
+
# "08-12_dummy_cs_emulation_no_distr_rec_5_CB_exploration-bonus-type_cell_exploration-bonus-params__1_50",
|
| 379 |
+
# "PPO_CB_1")
|
| 380 |
+
# label = label.replace(
|
| 381 |
+
# "08-12_dummy_cs_emulation_no_distr_rec_5_CB_exploration-bonus-type_cell_exploration-bonus-params__1_50",
|
| 382 |
+
# "PPO_CB_1")
|
| 383 |
+
#
|
| 384 |
+
# label = label.replace("dummy_cs_RR_ft_NEW_single_CB_marble_pass_B_exp_soc", "PPO_CB_role_B_single")
|
| 385 |
+
# label = label.replace("dummy_cs_RR_ft_NEW_single_CB_marble_pass_B_contr_asoc", "PPO_CB_asoc_single")
|
| 386 |
+
#
|
| 387 |
+
# label = label.replace("dummy_cs_RR_ft_NEW_group_CB_marble_pass_A_exp_soc", "PPO_CB_role_B_group")
|
| 388 |
+
# label = label.replace("dummy_cs_RR_ft_NEW_group_CB_marble_pass_A_contr_asoc", "PPO_CB_asoc_group")
|
| 389 |
+
#
|
| 390 |
+
# label = label.replace(
|
| 391 |
+
# "03-12_dummy_cs_formats_CBL_A_rec_5_env_SocialAI-ALangFeedbackTrainFormatsCSParamEnv-v1_recurrence_5_test-set-name_AFormatsTestSet_exploration-bonus-type_lang",
|
| 392 |
+
# "PPO_CBL_Ask")
|
| 393 |
+
# label = label.replace(
|
| 394 |
+
# "03-12_dummy_cs_formats_CBL_E_rec_5_env_SocialAI-ELangFeedbackTrainFormatsCSParamEnv-v1_recurrence_5_test-set-name_EFormatsTestSet_exploration-bonus-type_lang",
|
| 395 |
+
# "PPO_CBL_Eye_contact")
|
| 396 |
+
# label = label.replace(
|
| 397 |
+
# "03-12_dummy_cs_formats_CBL_AE_rec_5_env_SocialAI-AELangFeedbackTrainFormatsCSParamEnv-v1_recurrence_5_test-set-name_AEFormatsTestSet_exploration-bonus-type_lang",
|
| 398 |
+
# "PPO_CBL_Ask_Eye_contact")
|
| 399 |
+
# label = label.replace("dummy_cs_formats_CBL_N_rec_5", "PPO_CBL_No")
|
| 400 |
+
#
|
| 401 |
+
# label = label.replace(
|
| 402 |
+
# "03-12_dummy_cs_jz_formats_E_rec_5_env_SocialAI-ELangFeedbackTrainFormatsCSParamEnv-v1_recurrence_5_test-set-name_EFormatsTestSet",
|
| 403 |
+
# "PPO_no_bonus_Eye_contact")
|
| 404 |
+
# label = label.replace(
|
| 405 |
+
# "03-12_dummy_cs_jz_formats_A_rec_5_env_SocialAI-ALangFeedbackTrainFormatsCSParamEnv-v1_recurrence_5_test-set-name_AFormatsTestSet",
|
| 406 |
+
# "PPO_no_bonus_Ask")
|
| 407 |
+
# label = label.replace(
|
| 408 |
+
# "03-12_dummy_cs_jz_formats_AE_rec_5_env_SocialAI-AELangFeedbackTrainFormatsCSParamEnv-v1_recurrence_5_test-set-name_AEFormatsTestSet",
|
| 409 |
+
# "PPO_no_bonus_Ask_Eye_contact")
|
| 410 |
+
# label = label.replace("dummy_cs_jz_formats_N_rec_5", "PPO_no_bonus_No")
|
| 411 |
+
#
|
| 412 |
+
# label = label.replace("03-12_dummy_cs_jz_formats_AE", "PPO_no_bonus_no_scaf")
|
| 413 |
+
# label = label.replace("dummy_cs_jz_scaf_A_E_N_A_E_full-AEfull", "PPO_no_bonus_scaf_4")
|
| 414 |
+
# label = label.replace("dummy_cs_jz_scaf_A_E_N_A_E_scaf_full-AEfull", "PPO_no_bonus_scaf_8")
|
| 415 |
+
#
|
| 416 |
+
# return label
|
| 417 |
+
|
| 418 |
+
|
| 419 |
+
# Final case studies
|
| 420 |
+
require_patterns = [
|
| 421 |
+
"_",
|
| 422 |
+
# pointing
|
| 423 |
+
# "04-01_Pointing_CB_heldout_doors",
|
| 424 |
+
|
| 425 |
+
# # role reversal
|
| 426 |
+
# "03-01_RR_ft_single_CB_marble_pass_A_asoc_contr",
|
| 427 |
+
# "03-01_RR_ft_single_CB_marble_pass_A_soc_exp",
|
| 428 |
+
|
| 429 |
+
# "05-01_RR_ft_group_50M_CB_marble_pass_A_asoc_contr",
|
| 430 |
+
# "05-01_RR_ft_group_50M_CB_marble_pass_A_soc_exp",
|
| 431 |
+
|
| 432 |
+
# scaffolding
|
| 433 |
+
# "05-01_scaffolding_50M_no",
|
| 434 |
+
# "05-01_scaffolding_50M_acl_4_acl-type_intro_seq",
|
| 435 |
+
# "05-01_scaffolding_50M_acl_8_acl-type_intro_seq_scaf",
|
| 436 |
+
]
|
| 437 |
+
|
| 438 |
+
def label_parser(label, figure_id, label_parser_dict=None):
|
| 439 |
+
label = label.replace("04-01_Pointing_CB_heldout_doors", "PPO_CB")
|
| 440 |
+
|
| 441 |
+
label = label.replace("05-01_scaffolding_50M_no_acl", "PPO_no_scaf")
|
| 442 |
+
label = label.replace("05-01_scaffolding_50M_acl_4_acl-type_intro_seq", "PPO_scaf_4")
|
| 443 |
+
label = label.replace("05-01_scaffolding_50M_acl_8_acl-type_intro_seq_scaf", "PPO_scaf_8")
|
| 444 |
+
|
| 445 |
+
label = label.replace("03-01_RR_ft_single_CB_marble_pass_A_soc_exp", "PPO_CB_role_B")
|
| 446 |
+
label = label.replace("03-01_RR_ft_single_CB_marble_pass_A_asoc_contr", "PPO_CB_asocial")
|
| 447 |
+
|
| 448 |
+
label = label.replace("05-01_RR_ft_group_50M_CB_marble_pass_A_soc_exp", "PPO_CB_role_B")
|
| 449 |
+
label = label.replace("05-01_RR_ft_group_50M_CB_marble_pass_A_asoc_contr", "PPO_CB_asocial")
|
| 450 |
+
|
| 451 |
+
return label
|
| 452 |
+
|
| 453 |
+
|
| 454 |
+
color_dict = {
|
| 455 |
+
|
| 456 |
+
# JA
|
| 457 |
+
# "JA_PPO_CBL": "blue",
|
| 458 |
+
# "PPO_CBL": "orange",
|
| 459 |
+
|
| 460 |
+
# RR group
|
| 461 |
+
# "PPO_CB_role_B_group": "orange",
|
| 462 |
+
# "PPO_CB_asoc_group": "blue"
|
| 463 |
+
|
| 464 |
+
# formats No
|
| 465 |
+
# "PPO_no_bonus_No": "blue",
|
| 466 |
+
# "PPO_no_bonus_Eye_contact": "magenta",
|
| 467 |
+
# "PPO_no_bonus_Ask": "orange",
|
| 468 |
+
# "PPO_no_bonus_Ask_Eye_contact": "green"
|
| 469 |
+
|
| 470 |
+
# formats CBL
|
| 471 |
+
# "PPO_CBL_No": "blue",
|
| 472 |
+
# "PPO_CBL_Eye_contact": "magenta",
|
| 473 |
+
# "PPO_CBL_Ask": "orange",
|
| 474 |
+
# "PPO_CBL_Ask_Eye_contact": "green"
|
| 475 |
+
}
|
| 476 |
+
|
| 477 |
+
# # POINTING_GENERALIZATION (DUMMY)
|
| 478 |
+
# require_patterns = [
|
| 479 |
+
# "29-10_SAI_Pointing_CS_PPO_CB_",
|
| 480 |
+
# "29-10_SAI_LangColor_CS_PPO_CB_"
|
| 481 |
+
# ]
|
| 482 |
+
#
|
| 483 |
+
# color_dict = {
|
| 484 |
+
# "dummy_cs_JA_Feedback_CBL_new": "blue",
|
| 485 |
+
# "dummy_cs_Feedback_CBL": "orange",
|
| 486 |
+
# }
|
| 487 |
+
#
|
| 488 |
+
# def label_parser(label, figure_id, label_parser_dict=None):
|
| 489 |
+
# label = label.split("_env_")[0].split("SAI_")[1]
|
| 490 |
+
# label=label.replace("Pointing_CS_PPO_CB", "PPO_CB_train(DUMMY)")
|
| 491 |
+
# label=label.replace("LangColor_CS_PPO_CB", "PPO_CB_test(DUMMY)")
|
| 492 |
+
# return label
|
| 493 |
+
#
|
| 494 |
+
# eval_filename = f"/home/flowers/Documents/projects/embodied_acting_and_speaking/case_studies_figures/Pointing_gen_eval.png"
|
| 495 |
+
|
| 496 |
+
# # FEEDBACK GENERALIZATION (DUMMY)
|
| 497 |
+
# require_patterns = [
|
| 498 |
+
# "29-10_SAI_LangFeedback_CS_PPO_CBL_",
|
| 499 |
+
# "29-10_SAI_LangColor_CS_PPO_CB_"
|
| 500 |
+
# ]
|
| 501 |
+
#
|
| 502 |
+
# color_dict = {
|
| 503 |
+
# "PPO_CBL_train(DUMMY)": "blue",
|
| 504 |
+
# "PPO_CBL_test(DUMMY)": "maroon",
|
| 505 |
+
# }
|
| 506 |
+
#
|
| 507 |
+
# def label_parser(label, figure_id, label_parser_dict=None):
|
| 508 |
+
# label = label.split("_env_")[0].split("SAI_")[1]
|
| 509 |
+
# label=label.replace("LangFeedback_CS_PPO_CBL", "PPO_CBL_train(DUMMY)")
|
| 510 |
+
# label=label.replace("LangColor_CS_PPO_CB", "PPO_CBL_test(DUMMY)")
|
| 511 |
+
# return label
|
| 512 |
+
#
|
| 513 |
+
# eval_filename = f"/home/flowers/Documents/projects/embodied_acting_and_speaking/case_studies_figures/Feedback_gen_eval.png"
|
| 514 |
+
|
| 515 |
+
# # COLOR GENERALIZATION (DUMMY)
|
| 516 |
+
# require_patterns = [
|
| 517 |
+
# "29-10_SAI_LangColor_CS_PPO_CBL_",
|
| 518 |
+
# "29-10_SAI_LangColor_CS_PPO_CB_"
|
| 519 |
+
# ]
|
| 520 |
+
#
|
| 521 |
+
# color_dict = {
|
| 522 |
+
# "PPO_CBL_train(DUMMY)": "blue",
|
| 523 |
+
# "PPO_CBL_test(DUMMY)": "maroon",
|
| 524 |
+
# }
|
| 525 |
+
#
|
| 526 |
+
# def label_parser(label, figure_id, label_parser_dict=None):
|
| 527 |
+
# label = label.split("_env_")[0].split("SAI_")[1]
|
| 528 |
+
# label=label.replace("LangColor_CS_PPO_CBL", "PPO_CBL_train(DUMMY)")
|
| 529 |
+
# label=label.replace("LangColor_CS_PPO_CB", "PPO_CBL_test(DUMMY)")
|
| 530 |
+
# return label
|
| 531 |
+
#
|
| 532 |
+
# eval_filename = f"/home/flowers/Documents/projects/embodied_acting_and_speaking/case_studies_figures/Color_gen_eval.png"
|
| 533 |
+
|
| 534 |
+
# # POINTING - PILOT
|
| 535 |
+
# require_patterns = [
|
| 536 |
+
# "29-10_SAI_Pointing_CS_PPO_",
|
| 537 |
+
# ]
|
| 538 |
+
#
|
| 539 |
+
# color_dict = {
|
| 540 |
+
# "PPO_RIDE": "orange",
|
| 541 |
+
# "PPO_RND": "magenta",
|
| 542 |
+
# "PPO_no": "maroon",
|
| 543 |
+
# "PPO_CBL": "green",
|
| 544 |
+
# "PPO_CB": "blue",
|
| 545 |
+
# }
|
| 546 |
+
#
|
| 547 |
+
# def label_parser(label, figure_id, label_parser_dict=None):
|
| 548 |
+
# label = label.split("_env_")[0].split("SAI_")[1]
|
| 549 |
+
# label=label.replace("Pointing_CS_", "")
|
| 550 |
+
# return label
|
| 551 |
+
# #
|
| 552 |
+
# eval_filename = f"/home/flowers/Documents/projects/embodied_acting_and_speaking/case_studies_figures/Pointing_eval.png"
|
| 553 |
+
|
| 554 |
+
|
| 555 |
+
# LANGCOLOR - 7 Colors - PILOT
|
| 556 |
+
# require_patterns = [
|
| 557 |
+
# "29-10_SAI_LangColor_CS_PPO_",
|
| 558 |
+
# ]
|
| 559 |
+
#
|
| 560 |
+
# color_dict = {
|
| 561 |
+
# "PPO_RIDE": "orange",
|
| 562 |
+
# "PPO_RND": "magenta",
|
| 563 |
+
# "PPO_no": "maroon",
|
| 564 |
+
# "PPO_CBL": "green",
|
| 565 |
+
# "PPO_CB": "blue",
|
| 566 |
+
# }
|
| 567 |
+
#
|
| 568 |
+
# def label_parser(label, figure_id, label_parser_dict=None):
|
| 569 |
+
# label = label.split("_env_")[0].split("SAI_")[1]
|
| 570 |
+
# label=label.replace("LangColor_CS_", "")
|
| 571 |
+
# return label
|
| 572 |
+
#
|
| 573 |
+
# eval_filename = f"/home/flowers/Documents/projects/embodied_acting_and_speaking/case_studies_figures/Color_eval.png"
|
| 574 |
+
|
| 575 |
+
# # LangColor - CBL - 3 5 7
|
| 576 |
+
# require_patterns = [
|
| 577 |
+
# "02-11_SAI_LangColor_CS_5C_PPO_CBL",
|
| 578 |
+
# "02-11_SAI_LangColor_CS_3C_PPO_CBL",
|
| 579 |
+
# "29-10_SAI_LangColor_CS_PPO_CBL"
|
| 580 |
+
# ]
|
| 581 |
+
|
| 582 |
+
# RND RIDE reference : RIDE > RND > no
|
| 583 |
+
# require_patterns = [
|
| 584 |
+
# "24-08_new_ref",
|
| 585 |
+
# ]
|
| 586 |
+
|
| 587 |
+
|
| 588 |
+
# # # LANG FEEDBACK
|
| 589 |
+
# require_patterns = [
|
| 590 |
+
# "24-10_SAI_LangFeedback_CS_PPO_",
|
| 591 |
+
# "29-10_SAI_LangFeedback_CS_PPO_",
|
| 592 |
+
# ]
|
| 593 |
+
# color_dict = {
|
| 594 |
+
# "PPO_RIDE": "orange",
|
| 595 |
+
# "PPO_RND": "magenta",
|
| 596 |
+
# "PPO_no": "maroon",
|
| 597 |
+
# "PPO_CBL": "green",
|
| 598 |
+
# "PPO_CB": "blue",
|
| 599 |
+
# }
|
| 600 |
+
#
|
| 601 |
+
# def label_parser(label, figure_id, label_parser_dict=None):
|
| 602 |
+
# label = label.split("_env_")[0].split("SAI_")[1]
|
| 603 |
+
# label=label.replace("LangFeedback_CS_", "")
|
| 604 |
+
# return label
|
| 605 |
+
#
|
| 606 |
+
# # eval_filename = f"/home/flowers/Documents/projects/embodied_acting_and_speaking/case_studies_figures/Feedback_eval.png"
|
| 607 |
+
#
|
| 608 |
+
|
| 609 |
+
# # ROLE REVERSAL - group (DUMMY)
|
| 610 |
+
# require_patterns = [
|
| 611 |
+
# "24-10_SAI_LangFeedback_CS_PPO_CB_",
|
| 612 |
+
# "29-10_SAI_LangFeedback_CS_PPO_CBL_",
|
| 613 |
+
# ]
|
| 614 |
+
# color_dict = {
|
| 615 |
+
# "PPO_CB_experimental": "green",
|
| 616 |
+
# "PPO_CB_control": "blue",
|
| 617 |
+
# }
|
| 618 |
+
# color_dict=None
|
| 619 |
+
#
|
| 620 |
+
# def label_parser(label, figure_id, label_parser_dict=None):
|
| 621 |
+
# label = label.split("_env_")[0].split("SAI_")[1]
|
| 622 |
+
# label=label.replace("LangFeedback_CS_", "")
|
| 623 |
+
#
|
| 624 |
+
# label=label.replace("PPO_CB", "PPO_CB_control")
|
| 625 |
+
# label=label.replace("controlL", "experimental")
|
| 626 |
+
#
|
| 627 |
+
# return label
|
| 628 |
+
#
|
| 629 |
+
# eval_filename = f"/home/flowers/Documents/projects/embodied_acting_and_speaking/case_studies_figures/RR_dummy_group.png"
|
| 630 |
+
|
| 631 |
+
# # ROLE REVERSAL - single (DUMMY)
|
| 632 |
+
# require_patterns = [
|
| 633 |
+
# "24-10_SAI_LangFeedback_CS_PPO_CB_",
|
| 634 |
+
# "24-10_SAI_LangFeedback_CS_PPO_no_",
|
| 635 |
+
# ]
|
| 636 |
+
# color_dict = {
|
| 637 |
+
# "PPO_CB_experimental": "green",
|
| 638 |
+
# "PPO_CB_control": "blue",
|
| 639 |
+
# }
|
| 640 |
+
# color_dict=None
|
| 641 |
+
#
|
| 642 |
+
# def label_parser(label, figure_id, label_parser_dict=None):
|
| 643 |
+
# label = label.split("_env_")[0].split("SAI_")[1]
|
| 644 |
+
# label=label.replace("LangFeedback_CS_", "")
|
| 645 |
+
#
|
| 646 |
+
# label=label.replace("PPO_CB", "PPO_CB_control")
|
| 647 |
+
# label=label.replace("PPO_no", "PPO_CB_experimental")
|
| 648 |
+
#
|
| 649 |
+
# return label
|
| 650 |
+
#
|
| 651 |
+
# eval_filename = f"/home/flowers/Documents/projects/embodied_acting_and_speaking/case_studies_figures/RR_dummy_single.png"
|
| 652 |
+
|
| 653 |
+
# # IMITATION train (DUMMY)
|
| 654 |
+
# require_patterns = [
|
| 655 |
+
# "29-10_SAI_LangFeedback_CS_PPO_CBL_",
|
| 656 |
+
# "29-10_SAI_Pointing_CS_PPO_RIDE",
|
| 657 |
+
# ]
|
| 658 |
+
#
|
| 659 |
+
# color_dict = {
|
| 660 |
+
# "PPO_CB_no_distr(DUMMY)": "magenta",
|
| 661 |
+
# "PPO_CB_distr(DUMMY)": "orange",
|
| 662 |
+
# }
|
| 663 |
+
#
|
| 664 |
+
# def label_parser(label, figure_id, label_parser_dict=None):
|
| 665 |
+
# label = label.split("_env_")[0].split("SAI_")[1]
|
| 666 |
+
# label=label.replace("LangFeedback_CS_PPO_CBL", "PPO_CB_no_distr(DUMMY)")
|
| 667 |
+
# label=label.replace("Pointing_CS_PPO_RIDE", "PPO_CB_distr(DUMMY)")
|
| 668 |
+
# return label
|
| 669 |
+
#
|
| 670 |
+
# eval_filename = f"/home/flowers/Documents/projects/embodied_acting_and_speaking/case_studies_figures/Imitation_train.png"
|
| 671 |
+
|
| 672 |
+
# # IMITATION test (DUMMY)
|
| 673 |
+
# require_patterns = [
|
| 674 |
+
# "29-10_SAI_LangFeedback_CS_PPO_CBL_",
|
| 675 |
+
# "29-10_SAI_Pointing_CS_PPO_RIDE",
|
| 676 |
+
# ]
|
| 677 |
+
#
|
| 678 |
+
# color_dict = {
|
| 679 |
+
# "PPO_CB_no_distr(DUMMY)": "magenta",
|
| 680 |
+
# "PPO_CB_distr(DUMMY)": "orange",
|
| 681 |
+
# }
|
| 682 |
+
#
|
| 683 |
+
# def label_parser(label, figure_id, label_parser_dict=None):
|
| 684 |
+
# label = label.split("_env_")[0].split("SAI_")[1]
|
| 685 |
+
# label=label.replace("LangFeedback_CS_PPO_CBL", "PPO_CB_no_distr(DUMMY)")
|
| 686 |
+
# label=label.replace("Pointing_CS_PPO_RIDE", "PPO_CB_distr(DUMMY)")
|
| 687 |
+
# return label
|
| 688 |
+
#
|
| 689 |
+
# eval_filename = f"/home/flowers/Documents/projects/embodied_acting_and_speaking/case_studies_figures/Imitation_test.png"
|
| 690 |
+
|
| 691 |
+
|
| 692 |
+
# JA_POINTING
|
| 693 |
+
# require_patterns = [
|
| 694 |
+
# "29-10_SAI_Pointing_CS_PPO_CB_",
|
| 695 |
+
# "04-11_SAI_JA_Pointing_CS_PPO_CB_less", # less reward
|
| 696 |
+
# ]
|
| 697 |
+
# color_dict = {
|
| 698 |
+
# "JA_Pointing_PPO_CB": "orange",
|
| 699 |
+
# "Pointing_PPO_CB": "blue",
|
| 700 |
+
# }
|
| 701 |
+
#
|
| 702 |
+
# def label_parser(label, figure_id, label_parser_dict=None):
|
| 703 |
+
# label = label.split("_env_")[0].split("SAI_")[1]
|
| 704 |
+
# label=label.replace("_CS_", "_")
|
| 705 |
+
# label=label.replace("_less_", "")
|
| 706 |
+
# return label
|
| 707 |
+
#
|
| 708 |
+
# eval_filename = f"/home/flowers/Documents/projects/embodied_acting_and_speaking/case_studies_figures/JA_Pointing_eval.png"
|
| 709 |
+
|
| 710 |
+
|
| 711 |
+
# # JA_COLORS (JA, no) x (3,5,7)
|
| 712 |
+
# max_x_lim = 17
|
| 713 |
+
# require_patterns = [
|
| 714 |
+
# # "02-11_SAI_JA_LangColor", # max_x_lim = 17
|
| 715 |
+
# "02-11_SAI_JA_LangColor_CS_3C", # max_x_lim = 17
|
| 716 |
+
# # "02-11_SAI_LangColor_CS_5C_PPO_CBL", # max_x_lim = 17
|
| 717 |
+
# "02-11_SAI_LangColor_CS_3C_PPO_CBL",
|
| 718 |
+
# # "29-10_SAI_LangColor_CS_PPO_CBL"
|
| 719 |
+
# ]
|
| 720 |
+
# color_dict = {
|
| 721 |
+
# "JA_LangColor_PPO_CBL": "orange",
|
| 722 |
+
# "LangColor_PPO_CBL": "blue",
|
| 723 |
+
# }
|
| 724 |
+
|
| 725 |
+
# def label_parser(label, figure_id, label_parser_dict=None):
|
| 726 |
+
# label = label.split("_env_")[0].split("SAI_")[1]
|
| 727 |
+
# label=label.replace("_CS_", "_")
|
| 728 |
+
# label=label.replace("_3C_", "_")
|
| 729 |
+
# return label
|
| 730 |
+
|
| 731 |
+
# eval_filename = f"/home/flowers/Documents/projects/embodied_acting_and_speaking/case_studies_figures/JA_Color_eval.png"
|
| 732 |
+
|
| 733 |
+
|
| 734 |
+
# JA_FEEDBACK -> max_xlim=17
|
| 735 |
+
# max_x_lim = 17
|
| 736 |
+
# require_patterns = [
|
| 737 |
+
# "02-11_SAI_JA_LangFeedback_CS_PPO_CBL_",
|
| 738 |
+
# "29-10_SAI_LangFeedback_CS_PPO_CBL_",
|
| 739 |
+
# "dummy_cs_F",
|
| 740 |
+
# "dummy_cs_JA_F"
|
| 741 |
+
# ]
|
| 742 |
+
# color_dict = {
|
| 743 |
+
# "JA_LangFeedback_PPO_CBL": "orange",
|
| 744 |
+
# "LangFeedback_PPO_CBL": "blue",
|
| 745 |
+
# }
|
| 746 |
+
#
|
| 747 |
+
# def label_parser(label, figure_id, label_parser_dict=None):
|
| 748 |
+
# label = label.split("_env_")[0].split("SAI_")[1]
|
| 749 |
+
# label=label.replace("_CS_", "_")
|
| 750 |
+
# return label
|
| 751 |
+
#
|
| 752 |
+
# eval_filename = f"/home/flowers/Documents/projects/embodied_acting_and_speaking/case_studies_figures/JA_Feedback_eval.png"
|
| 753 |
+
|
| 754 |
+
# # Formats CBL
|
| 755 |
+
# require_patterns = [
|
| 756 |
+
# "03-11_SAI_LangFeedback_CS_F_NO_PPO_CBL_env_SocialAI",
|
| 757 |
+
# "29-10_SAI_LangFeedback_CS_PPO_CBL_env_SocialAI",
|
| 758 |
+
# "03-11_SAI_LangFeedback_CS_F_ASK_PPO_CBL_env_SocialAI",
|
| 759 |
+
# "03-11_SAI_LangFeedback_CS_F_ASK_EYE_PPO_CBL_env_SocialAI",
|
| 760 |
+
# ]
|
| 761 |
+
# color_dict = {
|
| 762 |
+
# "LangFeedback_Eye_PPO_CBL": "blue",
|
| 763 |
+
# "LangFeedback_Ask_PPO_CBL": "orange",
|
| 764 |
+
# "LangFeedback_NO_PPO_CBL": "green",
|
| 765 |
+
# "LangFeedback_AskEye_PPO_CBL": "magenta",
|
| 766 |
+
# }
|
| 767 |
+
#
|
| 768 |
+
# def label_parser(label, figure_id, label_parser_dict=None):
|
| 769 |
+
# label = label.split("_env_")[0].split("SAI_")[1]
|
| 770 |
+
# label=label.replace("_CS_", "_")
|
| 771 |
+
# label=label.replace("_F_", "_")
|
| 772 |
+
#
|
| 773 |
+
# label=label.replace("LangFeedback_PPO", "LangFeedback_EYE_PPO")
|
| 774 |
+
#
|
| 775 |
+
# label=label.replace("EYE", "Eye")
|
| 776 |
+
# label=label.replace("No", "No")
|
| 777 |
+
# label=label.replace("ASK", "Ask")
|
| 778 |
+
# label=label.replace("Ask_Eye", "AskEye")
|
| 779 |
+
# return label
|
| 780 |
+
#
|
| 781 |
+
# eval_filename = f"/home/flowers/Documents/projects/embodied_acting_and_speaking/case_studies_figures/Formats_CBL_eval.png"
|
| 782 |
+
|
| 783 |
+
# # Formats NO
|
| 784 |
+
# require_patterns = [
|
| 785 |
+
# "24-10_SAI_LangFeedback_CS_PPO_no", # EYE
|
| 786 |
+
# "04-11_SAI_LangFeedback_CS_F_NO_PPO_NO_env_SocialAI",
|
| 787 |
+
# "04-11_SAI_LangFeedback_CS_F_ASK_PPO_NO_env_SocialAI",
|
| 788 |
+
# "04-11_SAI_LangFeedback_CS_F_ASK_EYE_PPO_NO_env_SocialAI",
|
| 789 |
+
# ]
|
| 790 |
+
#
|
| 791 |
+
# color_dict = {
|
| 792 |
+
# "LangFeedback_Eye_PPO_no": "blue",
|
| 793 |
+
# "LangFeedback_Ask_PPO_no": "orange",
|
| 794 |
+
# "LangFeedback_NO_PPO_no": "green",
|
| 795 |
+
# "LangFeedback_AskEye_PPO_no": "magenta",
|
| 796 |
+
# }
|
| 797 |
+
#
|
| 798 |
+
# def label_parser(label, figure_id, label_parser_dict=None):
|
| 799 |
+
# label = label.split("_env_")[0].split("SAI_")[1]
|
| 800 |
+
# label=label.replace("_CS_", "_")
|
| 801 |
+
# label=label.replace("_F_", "_")
|
| 802 |
+
# #
|
| 803 |
+
# label=label.replace("LangFeedback_PPO", "LangFeedback_EYE_PPO")
|
| 804 |
+
# label=label.replace("PPO_NO", "PPO_no")
|
| 805 |
+
#
|
| 806 |
+
# label=label.replace("EYE", "Eye")
|
| 807 |
+
# label=label.replace("No", "No")
|
| 808 |
+
# label=label.replace("ASK", "Ask")
|
| 809 |
+
# label=label.replace("Ask_Eye", "AskEye")
|
| 810 |
+
# return label
|
| 811 |
+
#
|
| 812 |
+
# eval_filename = f"/home/flowers/Documents/projects/embodied_acting_and_speaking/case_studies_figures/Formats_no_eval.png"
|
| 813 |
+
|
| 814 |
+
|
| 815 |
+
#
|
| 816 |
+
# require_patterns = [
|
| 817 |
+
# "11-07_bAI_cb_GS_param_tanh_env_SocialAI-SocialAIParamEnv-v1_exploration-bonus-type_cell_exploration-bonus-params__2_50_exploration-bonus-tanh_0.6",
|
| 818 |
+
# # "04-11_SAI_ImitationDistr_CS_PPO_CB_small_env_SocialAI-EEmulationDistrInformationSeekingParamEnv-v1_recurrence_10",
|
| 819 |
+
# # "04-11_SAI_ImitationDistr_CS_PPO_CB_small_env_SocialAI-EEmulationDistrInformationSeekingParamEnv-v1_recurrence_10",
|
| 820 |
+
# "03-11_SAI_ImitationDistr_CS_PPO_CB_env_SocialAI-EEmulationDistrInformationSeekingParamEnv-v1_recurrence_10",
|
| 821 |
+
# # "04-11_SAI_ImitationNoDistr_CS_PPO_CB_small_env_SocialAI-EEmulationNoDistrInformationSeekingParamEnv-v1_recurrence_10",
|
| 822 |
+
# ]
|
| 823 |
+
|
| 824 |
+
# require_patterns = [
|
| 825 |
+
# "02-11_SAI_LangColor_CS_3C_PPO_CBL",
|
| 826 |
+
# "02-11_SAI_JA_LangColor_CS_3C_PPO_CBL",
|
| 827 |
+
# ] # at least one of those
|
| 828 |
+
|
| 829 |
+
|
| 830 |
+
# all of those
|
| 831 |
+
include_patterns = [
|
| 832 |
+
"_"
|
| 833 |
+
]
|
| 834 |
+
#include_patterns = ["rec_5"]
|
| 835 |
+
|
| 836 |
+
if eval_filename:
|
| 837 |
+
# saving
|
| 838 |
+
fontsize = 40
|
| 839 |
+
legend_fontsize = 30
|
| 840 |
+
linewidth = 10
|
| 841 |
+
else:
|
| 842 |
+
fontsize = 5
|
| 843 |
+
legend_fontsize = 5
|
| 844 |
+
linewidth = 1
|
| 845 |
+
|
| 846 |
+
fontsize = 5
|
| 847 |
+
legend_fontsize = 5
|
| 848 |
+
linewidth = 1
|
| 849 |
+
|
| 850 |
+
title_fontsize = int(fontsize*1.2)
|
| 851 |
+
|
| 852 |
+
|
| 853 |
+
storage_dir = "storage/"
|
| 854 |
+
if load_pattern.startswith(storage_dir):
|
| 855 |
+
load_pattern = load_pattern[len(storage_dir):]
|
| 856 |
+
|
| 857 |
+
if load_pattern.startswith("./storage/"):
|
| 858 |
+
load_pattern = load_pattern[len("./storage/"):]
|
| 859 |
+
|
| 860 |
+
get_datasets(storage_dir, str(load_pattern), load_subsample_step=load_subsample_step, ignore_patterns=ignore_patterns, require_patterns=require_patterns)
|
| 861 |
+
|
| 862 |
+
label_parser_dict = {
|
| 863 |
+
# "PPO_CB": "PPO_CB",
|
| 864 |
+
# "02-06_AppleStealing_experiments_cb_bonus_angle_occ_env_SocialAI-OthersPerceptionInferenceParamEnv-v1_exploration-bonus-type_cell": "NPC_visible",
|
| 865 |
+
}
|
| 866 |
+
|
| 867 |
+
env_type = str(load_pattern)
|
| 868 |
+
|
| 869 |
+
fig_type = "test"
|
| 870 |
+
try:
|
| 871 |
+
top_n = int(sys.argv[2])
|
| 872 |
+
except:
|
| 873 |
+
top_n = 8
|
| 874 |
+
|
| 875 |
+
to_remove = []
|
| 876 |
+
|
| 877 |
+
for tr_ in to_remove:
|
| 878 |
+
if tr_ in models_saves:
|
| 879 |
+
del models_saves[tr_]
|
| 880 |
+
|
| 881 |
+
print("Loaded:")
|
| 882 |
+
print("\n".join(list(models_saves.keys())))
|
| 883 |
+
|
| 884 |
+
#### get_datasets("storage/", "RERUN_WizardGuide_lang64_nameless")
|
| 885 |
+
#### get_datasets("storage/", "RERUN_WizardTwoGuides_lang64_nameless")
|
| 886 |
+
|
| 887 |
+
|
| 888 |
+
if per_model_colors: # order runs for legend order as in per_models_colors, with corresponding colors
|
| 889 |
+
ordered_labels = OrderedDict()
|
| 890 |
+
for teacher_type in per_model_colors.keys():
|
| 891 |
+
for k,v in labels.items():
|
| 892 |
+
if teacher_type in k:
|
| 893 |
+
ordered_labels[k] = v
|
| 894 |
+
labels = ordered_labels
|
| 895 |
+
else:
|
| 896 |
+
print('not using per_model_color')
|
| 897 |
+
for k in models_saves.keys():
|
| 898 |
+
labels[k] = k
|
| 899 |
+
|
| 900 |
+
def plot_with_shade_seed(subplot_nb, ax, x, y, err, color, shade_color, label,
|
| 901 |
+
y_min=None, y_max=None, legend=False, leg_size=30, leg_loc='best', title=None,
|
| 902 |
+
ylim=[0,100], xlim=[0,40], leg_args={}, leg_linewidth=13.0, linewidth=10.0, labelsize=20,
|
| 903 |
+
filename=None,
|
| 904 |
+
zorder=None, xlabel='perf', ylabel='Env steps'):
|
| 905 |
+
|
| 906 |
+
plt.rcParams.update({'font.size': 15})
|
| 907 |
+
|
| 908 |
+
plt.rcParams['axes.xmargin'] = 0
|
| 909 |
+
plt.rcParams['axes.ymargin'] = 0
|
| 910 |
+
|
| 911 |
+
ax.locator_params(axis='x', nbins=3)
|
| 912 |
+
ax.locator_params(axis='y', nbins=3)
|
| 913 |
+
ax.tick_params(axis='both', which='major', labelsize=labelsize)
|
| 914 |
+
|
| 915 |
+
x = x[:len(y)]
|
| 916 |
+
|
| 917 |
+
# ax.scatter(x, y, color=color, linewidth=linewidth, zorder=zorder)
|
| 918 |
+
ax.plot(x, y, color=color, label=label, linewidth=linewidth, zorder=zorder)
|
| 919 |
+
|
| 920 |
+
if err is not None:
|
| 921 |
+
ax.fill_between(x, y-err, y+err, color=shade_color, alpha=0.2)
|
| 922 |
+
|
| 923 |
+
if legend:
|
| 924 |
+
leg = ax.legend(loc=leg_loc, **leg_args) #34
|
| 925 |
+
for legobj in leg.legendHandles:
|
| 926 |
+
legobj.set_linewidth(leg_linewidth)
|
| 927 |
+
ax.set_xlabel(xlabel, fontsize=fontsize)
|
| 928 |
+
if subplot_nb == 0:
|
| 929 |
+
ax.set_ylabel(ylabel, fontsize=fontsize, labelpad=4)
|
| 930 |
+
|
| 931 |
+
ax.set_xlim(xmin=xlim[0],xmax=xlim[1])
|
| 932 |
+
ax.set_ylim(bottom=ylim[0],top=ylim[1])
|
| 933 |
+
if title:
|
| 934 |
+
ax.set_title(title, fontsize=fontsize)
|
| 935 |
+
|
| 936 |
+
# if filename is not None:
|
| 937 |
+
# f.savefig(filename)
|
| 938 |
+
|
| 939 |
+
|
| 940 |
+
# Plot utils
|
| 941 |
+
def plot_with_shade_grg(subplot_nb, ax, x, y, err, color, shade_color, label,
|
| 942 |
+
legend=False, leg_loc='best', title=None,
|
| 943 |
+
ylim=[0, 100], xlim=[0, 40], leg_args={}, leg_linewidth=13.0, linewidth=10.0, labelsize=20, fontsize=20, title_fontsize=30,
|
| 944 |
+
zorder=None, xlabel='Perf', ylabel='Env steps', linestyle="-", xnbins=3, ynbins=3, filename=None):
|
| 945 |
+
|
| 946 |
+
#plt.rcParams.update({'font.size': 15})
|
| 947 |
+
ax.locator_params(axis='x', nbins=xnbins)
|
| 948 |
+
ax.locator_params(axis='y', nbins=ynbins)
|
| 949 |
+
|
| 950 |
+
ax.tick_params(axis='y', which='both', labelsize=labelsize)
|
| 951 |
+
ax.tick_params(axis='x', which='both', labelsize=labelsize*0.8)
|
| 952 |
+
# ax.tick_params(axis='both', which='both', labelsize="small")
|
| 953 |
+
|
| 954 |
+
# ax.scatter(x, y, color=color,linewidth=linewidth,zorder=zorder, linestyle=linestyle)
|
| 955 |
+
ax.plot(x, y, color=color, label=label, linewidth=linewidth, zorder=zorder, linestyle=linestyle)
|
| 956 |
+
|
| 957 |
+
ax.fill_between(x, y-err, y+err, color=shade_color, alpha=0.2)
|
| 958 |
+
|
| 959 |
+
if legend:
|
| 960 |
+
leg = ax.legend(loc=leg_loc, **leg_args) # 34
|
| 961 |
+
for legobj in leg.legendHandles:
|
| 962 |
+
legobj.set_linewidth(leg_linewidth)
|
| 963 |
+
|
| 964 |
+
ax.set_xlabel(xlabel, fontsize=fontsize)
|
| 965 |
+
if subplot_nb == 0:
|
| 966 |
+
ax.set_ylabel(ylabel, fontsize=fontsize, labelpad=2)
|
| 967 |
+
|
| 968 |
+
ax.set_xlim(xmin=xlim[0], xmax=xlim[1])
|
| 969 |
+
ax.set_ylim(bottom=ylim[0], top=ylim[1])
|
| 970 |
+
if title:
|
| 971 |
+
ax.set_title(title, fontsize=title_fontsize)
|
| 972 |
+
|
| 973 |
+
# if filename is not None:
|
| 974 |
+
# f.savefig(filename)
|
| 975 |
+
|
| 976 |
+
|
| 977 |
+
# Metric plot
|
| 978 |
+
# metric = 'success_rate_mean'
|
| 979 |
+
# metric = 'mission_string_observed_mean'
|
| 980 |
+
# metric = 'extrinsic_return_mean'
|
| 981 |
+
# metric = 'extrinsic_return_max'
|
| 982 |
+
# metric = "rreturn_mean"
|
| 983 |
+
# metric = 'rreturn_max'
|
| 984 |
+
# metric = 'FPS'
|
| 985 |
+
# metric = 'duration'
|
| 986 |
+
# metric = 'intrinsic_reward_perf2_'
|
| 987 |
+
# metric = 'NPC_intro'
|
| 988 |
+
|
| 989 |
+
|
| 990 |
+
metrics = [
|
| 991 |
+
'success_rate_mean',
|
| 992 |
+
# 'FPS',
|
| 993 |
+
# 'extrinsic_return_mean',
|
| 994 |
+
# 'exploration_bonus_mean',
|
| 995 |
+
'NPC_intro',
|
| 996 |
+
# 'curriculum_param_mean',
|
| 997 |
+
# 'curriculum_max_success_rate_mean',
|
| 998 |
+
# 'rreturn_mean'
|
| 999 |
+
]
|
| 1000 |
+
|
| 1001 |
+
# f, ax = plt.subplots(1, len(metrics), figsize=(15.0, 9.0))
|
| 1002 |
+
f, ax = plt.subplots(1, len(metrics), figsize=(9.0, 9.0))
|
| 1003 |
+
# f, ax = plt.subplots(1, len(metrics), figsize=(20.0, 20.0))
|
| 1004 |
+
# f, ax = plt.subplots(1, 1, figsize=(5.0, 3.0))
|
| 1005 |
+
|
| 1006 |
+
if len(metrics) == 1:
|
| 1007 |
+
ax = [ax]
|
| 1008 |
+
|
| 1009 |
+
max_y = -np.inf
|
| 1010 |
+
min_y = np.inf
|
| 1011 |
+
# hardcoded
|
| 1012 |
+
min_y, max_y = 0.0, 1.0
|
| 1013 |
+
max_steps = 0
|
| 1014 |
+
exclude_patterns = []
|
| 1015 |
+
|
| 1016 |
+
|
| 1017 |
+
# def label_parser(label, figure_id, label_parser_dict=None):
|
| 1018 |
+
#
|
| 1019 |
+
# label = label.split("_env_")[0].split("SAI_")[1]
|
| 1020 |
+
#
|
| 1021 |
+
# # # Pointing
|
| 1022 |
+
# # label=label.replace("Pointing_CS_", "")
|
| 1023 |
+
#
|
| 1024 |
+
# # Feedback
|
| 1025 |
+
# label=label.replace("LangFeedback_CS_", "")
|
| 1026 |
+
#
|
| 1027 |
+
#
|
| 1028 |
+
# # label=label.replace("CS_PPO", "7COL_PPO")
|
| 1029 |
+
# # label=label.replace("CS_3C_PPO", "3COL_PPO")
|
| 1030 |
+
# # label=label.replace("CS_5C_PPO", "5COL_PPO")
|
| 1031 |
+
#
|
| 1032 |
+
# # label=label.replace("CS_PPO", "Eye_contact_PPO")
|
| 1033 |
+
# # label=label.replace("CS_F_ASK_PPO", "Ask_PPO")
|
| 1034 |
+
# # label=label.replace("CS_F_NO_PPO", "NO_PPO")
|
| 1035 |
+
# # label=label.replace("CS_F_ASK_EYE_PPO", "Ask_Eye_contact_PPO")
|
| 1036 |
+
# #
|
| 1037 |
+
# # label=label.replace("PPO_no", "PPO_no_bonus")
|
| 1038 |
+
# # label=label.replace("PPO_NO", "PPO_no_bonus")
|
| 1039 |
+
#
|
| 1040 |
+
# if label_parser_dict:
|
| 1041 |
+
# if sum([1 for k, v in label_parser_dict.items() if k in label]) != 1:
|
| 1042 |
+
# if label in label_parser_dict:
|
| 1043 |
+
# # see if there is an exact match
|
| 1044 |
+
# return label_parser_dict[label]
|
| 1045 |
+
# else:
|
| 1046 |
+
# print("ERROR multiple curves match a lable and there is no exact match for {}".format(label))
|
| 1047 |
+
# exit()
|
| 1048 |
+
#
|
| 1049 |
+
# for k, v in label_parser_dict.items():
|
| 1050 |
+
# if k in label: return v
|
| 1051 |
+
#
|
| 1052 |
+
# else:
|
| 1053 |
+
# # return label.split("_env_")[1]
|
| 1054 |
+
# if figure_id not in [1, 2, 3, 4]:
|
| 1055 |
+
# return label
|
| 1056 |
+
# else:
|
| 1057 |
+
# # default
|
| 1058 |
+
# pass
|
| 1059 |
+
#
|
| 1060 |
+
# return label
|
| 1061 |
+
|
| 1062 |
+
|
| 1063 |
+
for metric_i, metric in enumerate(metrics):
|
| 1064 |
+
min_y, max_y = 0.0, 1.0
|
| 1065 |
+
default_colors = default_colors_.copy()
|
| 1066 |
+
for model_i, m_id in enumerate(models_saves.keys()):
|
| 1067 |
+
|
| 1068 |
+
#excluding some experiments
|
| 1069 |
+
if any([ex_pat in m_id for ex_pat in exclude_patterns]):
|
| 1070 |
+
continue
|
| 1071 |
+
if len(include_patterns) > 0:
|
| 1072 |
+
if not any([in_pat in m_id for in_pat in include_patterns]):
|
| 1073 |
+
continue
|
| 1074 |
+
runs_data = models_saves[m_id]['data']
|
| 1075 |
+
ys = []
|
| 1076 |
+
|
| 1077 |
+
if runs_data[0]['frames'][1] == 'frames':
|
| 1078 |
+
runs_data[0]['frames'] = list(filter(('frames').__ne__, runs_data[0]['frames']))
|
| 1079 |
+
###########################################
|
| 1080 |
+
|
| 1081 |
+
if per_seed:
|
| 1082 |
+
min_len = None
|
| 1083 |
+
|
| 1084 |
+
else:
|
| 1085 |
+
# determine minimal run length across seeds
|
| 1086 |
+
lens = [len(run['frames']) for run in runs_data if len(run['frames'])]
|
| 1087 |
+
minimum = sorted(lens)[-min(top_n, len(lens))]
|
| 1088 |
+
min_len = np.min([len(run['frames']) for run in runs_data if len(run['frames']) >= minimum])
|
| 1089 |
+
|
| 1090 |
+
# keep only top k
|
| 1091 |
+
runs_data = [run for run in runs_data if len(run['frames']) >= minimum]
|
| 1092 |
+
|
| 1093 |
+
# min_len = np.min([len(run['frames']) for run in runs_data if len(run['frames']) > 10])
|
| 1094 |
+
|
| 1095 |
+
# compute env steps (x axis)
|
| 1096 |
+
longest_id = np.argmax([len(rd['frames']) for rd in runs_data])
|
| 1097 |
+
steps = np.array(runs_data[longest_id]['frames'], dtype=np.int) / steps_denom
|
| 1098 |
+
steps = steps[:min_len]
|
| 1099 |
+
|
| 1100 |
+
|
| 1101 |
+
for run in runs_data:
|
| 1102 |
+
if metric not in run:
|
| 1103 |
+
# succes_rate_mean <==> bin_extrinsic_return_mean
|
| 1104 |
+
if metric == 'success_rate_mean':
|
| 1105 |
+
metric_ = "bin_extrinsic_return_mean"
|
| 1106 |
+
if metric_ not in run:
|
| 1107 |
+
raise ValueError("Neither {} or {} is present: {} Possible metrics: {}. ".format(metric, metric_, list(run.keys())))
|
| 1108 |
+
|
| 1109 |
+
data = run[metric_]
|
| 1110 |
+
|
| 1111 |
+
else:
|
| 1112 |
+
raise ValueError("Unknown metric: {} Possible metrics: {}. ".format(metric, list(run.keys())))
|
| 1113 |
+
else:
|
| 1114 |
+
data = run[metric]
|
| 1115 |
+
|
| 1116 |
+
if data[1] == metric:
|
| 1117 |
+
data = np.array(list(filter((metric).__ne__, data)), dtype=np.float16)
|
| 1118 |
+
###########################################
|
| 1119 |
+
if per_seed:
|
| 1120 |
+
ys.append(data)
|
| 1121 |
+
else:
|
| 1122 |
+
if len(data) >= min_len:
|
| 1123 |
+
if len(data) > min_len:
|
| 1124 |
+
print("run has too many {} datapoints ({}). Discarding {}".format(m_id, len(data),
|
| 1125 |
+
len(data)-min_len))
|
| 1126 |
+
data = data[0:min_len]
|
| 1127 |
+
ys.append(data)
|
| 1128 |
+
else:
|
| 1129 |
+
raise ValueError("How can data be < min_len if it was capped above")
|
| 1130 |
+
|
| 1131 |
+
ys_same_len = ys
|
| 1132 |
+
|
| 1133 |
+
# computes stats
|
| 1134 |
+
n_seeds = len(ys_same_len)
|
| 1135 |
+
|
| 1136 |
+
if per_seed:
|
| 1137 |
+
sems = np.array(ys_same_len)
|
| 1138 |
+
stds = np.array(ys_same_len)
|
| 1139 |
+
means = np.array(ys_same_len)
|
| 1140 |
+
color = default_colors[model_i]
|
| 1141 |
+
|
| 1142 |
+
else:
|
| 1143 |
+
sems = np.std(ys_same_len, axis=0)/np.sqrt(len(ys_same_len)) # sem
|
| 1144 |
+
stds = np.std(ys_same_len, axis=0) # std
|
| 1145 |
+
means = np.mean(ys_same_len, axis=0)
|
| 1146 |
+
color = default_colors[model_i]
|
| 1147 |
+
|
| 1148 |
+
# per-metric adjustments
|
| 1149 |
+
ylabel = metric
|
| 1150 |
+
|
| 1151 |
+
ylabel = {
|
| 1152 |
+
"success_rate_mean" : "Success rate",
|
| 1153 |
+
"exploration_bonus_mean": "Exploration bonus",
|
| 1154 |
+
"NPC_intro": "Successful introduction (%)",
|
| 1155 |
+
}.get(ylabel, ylabel)
|
| 1156 |
+
|
| 1157 |
+
|
| 1158 |
+
if metric == 'duration':
|
| 1159 |
+
ylabel = "time (hours)"
|
| 1160 |
+
means = means / 3600
|
| 1161 |
+
sems = sems / 3600
|
| 1162 |
+
stds = stds / 3600
|
| 1163 |
+
|
| 1164 |
+
if per_seed:
|
| 1165 |
+
#plot x y bounds
|
| 1166 |
+
curr_max_y = np.max(np.max(means))
|
| 1167 |
+
curr_min_y = np.min(np.min(means))
|
| 1168 |
+
curr_max_steps = np.max(np.max(steps))
|
| 1169 |
+
|
| 1170 |
+
else:
|
| 1171 |
+
# plot x y bounds
|
| 1172 |
+
curr_max_y = np.max(means+stds)
|
| 1173 |
+
curr_min_y = np.min(means-stds)
|
| 1174 |
+
curr_max_steps = np.max(steps)
|
| 1175 |
+
|
| 1176 |
+
if curr_max_y > max_y:
|
| 1177 |
+
max_y = curr_max_y
|
| 1178 |
+
if curr_min_y < min_y:
|
| 1179 |
+
min_y = curr_min_y
|
| 1180 |
+
|
| 1181 |
+
if curr_max_steps > max_steps:
|
| 1182 |
+
max_steps = curr_max_steps
|
| 1183 |
+
|
| 1184 |
+
if subsample_step:
|
| 1185 |
+
steps = steps[0::subsample_step]
|
| 1186 |
+
means = means[0::subsample_step]
|
| 1187 |
+
stds = stds[0::subsample_step]
|
| 1188 |
+
sems = sems[0::subsample_step]
|
| 1189 |
+
ys_same_len = [y[0::subsample_step] for y in ys_same_len]
|
| 1190 |
+
|
| 1191 |
+
# display seeds separtely
|
| 1192 |
+
if per_seed:
|
| 1193 |
+
for s_i, seed_ys in enumerate(ys_same_len):
|
| 1194 |
+
seed_c = default_colors[model_i+s_i]
|
| 1195 |
+
# label = m_id#+"(s:{})".format(s_i)
|
| 1196 |
+
label = str(s_i)
|
| 1197 |
+
seed_ys = smooth(seed_ys, smooth_factor)
|
| 1198 |
+
plot_with_shade_seed(0, ax[metric_i], steps, seed_ys, None, seed_c, seed_c, label,
|
| 1199 |
+
legend=draw_legend, xlim=[0, max_steps], ylim=[min_y, max_y],
|
| 1200 |
+
leg_size=leg_size, xlabel=f"Env steps (1e6)", ylabel=ylabel, linewidth=linewidth,
|
| 1201 |
+
labelsize=fontsize,
|
| 1202 |
+
# fontsize=fontsize,
|
| 1203 |
+
)
|
| 1204 |
+
|
| 1205 |
+
summary_dict[s_i] = seed_ys[-1]
|
| 1206 |
+
summary_dict_colors[s_i] = seed_c
|
| 1207 |
+
else:
|
| 1208 |
+
label = label_parser(m_id, load_pattern, label_parser_dict=label_parser_dict)
|
| 1209 |
+
|
| 1210 |
+
if color_dict:
|
| 1211 |
+
color = color_dict[label]
|
| 1212 |
+
else:
|
| 1213 |
+
color = default_colors[model_i]
|
| 1214 |
+
|
| 1215 |
+
label = label+"({})".format(n_seeds)
|
| 1216 |
+
|
| 1217 |
+
|
| 1218 |
+
if smooth_factor:
|
| 1219 |
+
means = smooth(means, smooth_factor)
|
| 1220 |
+
stds = smooth(stds, smooth_factor)
|
| 1221 |
+
|
| 1222 |
+
x_lim = max(steps[-1], x_lim)
|
| 1223 |
+
x_lim = min(max_x_lim, x_lim)
|
| 1224 |
+
|
| 1225 |
+
leg_args = {
|
| 1226 |
+
'fontsize': legend_fontsize
|
| 1227 |
+
}
|
| 1228 |
+
|
| 1229 |
+
plot_with_shade_grg(
|
| 1230 |
+
0, ax[metric_i], steps, means, stds, color, color, label,
|
| 1231 |
+
legend=draw_legend and metric_i == 0,
|
| 1232 |
+
xlim=[0, x_lim],
|
| 1233 |
+
ylim=[0, max_y],
|
| 1234 |
+
xlabel=f"Env steps (1e6)",
|
| 1235 |
+
ylabel=ylabel,
|
| 1236 |
+
title=None,
|
| 1237 |
+
labelsize=fontsize*train_inc_font,
|
| 1238 |
+
fontsize=fontsize*train_inc_font,
|
| 1239 |
+
title_fontsize=title_fontsize,
|
| 1240 |
+
linewidth=linewidth,
|
| 1241 |
+
leg_linewidth=5,
|
| 1242 |
+
leg_args=leg_args,
|
| 1243 |
+
xnbins=xnbins,
|
| 1244 |
+
ynbins=ynbins,
|
| 1245 |
+
)
|
| 1246 |
+
summary_dict[label] = means[-1]
|
| 1247 |
+
summary_dict_colors[label] = color
|
| 1248 |
+
|
| 1249 |
+
if len(summary_dict) == 0:
|
| 1250 |
+
raise ValueError(f"No experiments found for {load_pattern}.")
|
| 1251 |
+
|
| 1252 |
+
# print summary
|
| 1253 |
+
best = max(summary_dict.values())
|
| 1254 |
+
|
| 1255 |
+
pc = 0.3
|
| 1256 |
+
n = int(len(summary_dict)*pc)
|
| 1257 |
+
print("top n: ", n)
|
| 1258 |
+
|
| 1259 |
+
top_pc = sorted(summary_dict.values())[-n:]
|
| 1260 |
+
bottom_pc = sorted(summary_dict.values())[:n]
|
| 1261 |
+
|
| 1262 |
+
print("legend:")
|
| 1263 |
+
cprint("\tbest", "green")
|
| 1264 |
+
cprint("\ttop {} %".format(pc), "blue")
|
| 1265 |
+
cprint("\tbottom {} %".format(pc), "red")
|
| 1266 |
+
print("\tothers")
|
| 1267 |
+
print()
|
| 1268 |
+
|
| 1269 |
+
|
| 1270 |
+
for l, p in sorted(summary_dict.items(), key=lambda kv: kv[1]):
|
| 1271 |
+
|
| 1272 |
+
c = summary_dict_colors[l]
|
| 1273 |
+
if p == best:
|
| 1274 |
+
cprint("label: {} ({})".format(l, c), "green")
|
| 1275 |
+
cprint("\t {}:{}".format(metric, p), "green")
|
| 1276 |
+
|
| 1277 |
+
elif p in top_pc:
|
| 1278 |
+
cprint("label: {} ({})".format(l, c), "blue")
|
| 1279 |
+
cprint("\t {}:{}".format(metric, p), "blue")
|
| 1280 |
+
|
| 1281 |
+
elif p in bottom_pc:
|
| 1282 |
+
cprint("label: {} ({})".format(l, c), "red")
|
| 1283 |
+
cprint("\t {}:{}".format(metric, p), "red")
|
| 1284 |
+
|
| 1285 |
+
else:
|
| 1286 |
+
print("label: {} ({})".format(l, c))
|
| 1287 |
+
print("\t {}:{}".format(metric, p))
|
| 1288 |
+
|
| 1289 |
+
for label, (mean, std, color) in static_lines.items():
|
| 1290 |
+
plot_with_shade_grg(
|
| 1291 |
+
0, ax[metric_i], steps, np.array([mean]*len(steps)), np.array([std]*len(steps)), color, color, label,
|
| 1292 |
+
legend=True,
|
| 1293 |
+
xlim=[0, x_lim],
|
| 1294 |
+
ylim=[0, 1.0],
|
| 1295 |
+
xlabel=f"Env steps (1e6)",
|
| 1296 |
+
ylabel=ylabel,
|
| 1297 |
+
linestyle=":",
|
| 1298 |
+
leg_args=leg_args,
|
| 1299 |
+
fontsize=fontsize,
|
| 1300 |
+
title_fontsize=title_fontsize,
|
| 1301 |
+
xnbins=xnbins,
|
| 1302 |
+
ynbins=ynbins,
|
| 1303 |
+
)
|
| 1304 |
+
|
| 1305 |
+
# plt.tight_layout()
|
| 1306 |
+
# f.savefig('graphics/{}_{}_results.svg'.format(str(figure_id, metric)))
|
| 1307 |
+
# f.savefig('graphics/{}_{}_results.png'.format(str(figure_id, metric)))
|
| 1308 |
+
cprint("Ignore pattern: {}".format(ignore_patterns), "blue")
|
| 1309 |
+
if plot_train:
|
| 1310 |
+
plt.tight_layout()
|
| 1311 |
+
# plt.subplots_adjust(hspace=1.5, wspace=0.5, left=0.1, right=0.9, bottom=0.1, top=0.85)
|
| 1312 |
+
plt.subplots_adjust(hspace=1.5, wspace=0.5, left=0.1, right=0.9, bottom=0.1, top=0.85)
|
| 1313 |
+
plt.suptitle(super_title)
|
| 1314 |
+
plt.show()
|
| 1315 |
+
plt.close()
|
| 1316 |
+
|
| 1317 |
+
curr_max_y = 0
|
| 1318 |
+
x_lim = 0
|
| 1319 |
+
|
| 1320 |
+
max_y = -np.inf
|
| 1321 |
+
min_y = np.inf
|
| 1322 |
+
# hardcoded
|
| 1323 |
+
min_y, max_y = 0.0, 1.0
|
| 1324 |
+
|
| 1325 |
+
grid = True
|
| 1326 |
+
draw_eval_legend = True
|
| 1327 |
+
|
| 1328 |
+
if study_eval:
|
| 1329 |
+
print("Evaluation")
|
| 1330 |
+
# evaluation sets
|
| 1331 |
+
number_of_eval_envs = max(list([len(v.keys()) for v in model_eval_data.values()]))
|
| 1332 |
+
|
| 1333 |
+
if plot_aggregated_test:
|
| 1334 |
+
number_of_eval_envs += 1
|
| 1335 |
+
|
| 1336 |
+
if number_of_eval_envs == 0:
|
| 1337 |
+
print("No eval envs")
|
| 1338 |
+
exit()
|
| 1339 |
+
|
| 1340 |
+
if plot_only_aggregated_test:
|
| 1341 |
+
f, ax = plt.subplots(1, 1, figsize=(9.0, 9.0))
|
| 1342 |
+
|
| 1343 |
+
else:
|
| 1344 |
+
if grid:
|
| 1345 |
+
# grid
|
| 1346 |
+
subplot_y = math.ceil(math.sqrt(number_of_eval_envs))
|
| 1347 |
+
subplot_x = math.ceil(number_of_eval_envs / subplot_y)
|
| 1348 |
+
# from IPython import embed; embed()
|
| 1349 |
+
|
| 1350 |
+
while subplot_x % 1 != 0:
|
| 1351 |
+
subplot_y -= 1
|
| 1352 |
+
subplot_x = number_of_eval_envs / subplot_y
|
| 1353 |
+
|
| 1354 |
+
if subplot_x == 1:
|
| 1355 |
+
subplot_y = math.ceil(math.sqrt(number_of_eval_envs))
|
| 1356 |
+
subplot_x = math.floor(math.sqrt(number_of_eval_envs))
|
| 1357 |
+
|
| 1358 |
+
subplot_y = int(subplot_y)
|
| 1359 |
+
subplot_x = int(subplot_x)
|
| 1360 |
+
|
| 1361 |
+
assert subplot_y * subplot_x >= number_of_eval_envs
|
| 1362 |
+
|
| 1363 |
+
f, ax_ = plt.subplots(subplot_y, subplot_x, figsize=(6.0, 6.0), sharey=False) #, sharex=True, sharey=True)
|
| 1364 |
+
|
| 1365 |
+
if subplot_y != 1:
|
| 1366 |
+
ax = list(chain.from_iterable(ax_))
|
| 1367 |
+
else:
|
| 1368 |
+
ax=ax_
|
| 1369 |
+
|
| 1370 |
+
else:
|
| 1371 |
+
# flat
|
| 1372 |
+
f, ax = plt.subplots(1, number_of_eval_envs, figsize=(15.0, 9.0)) #), sharey=True, sharex=True)
|
| 1373 |
+
|
| 1374 |
+
if number_of_eval_envs == 1:
|
| 1375 |
+
ax = [ax]
|
| 1376 |
+
|
| 1377 |
+
default_colors = default_colors_.copy()
|
| 1378 |
+
|
| 1379 |
+
test_summary_dict = defaultdict(dict)
|
| 1380 |
+
test_summary_dict_colors = defaultdict(dict)
|
| 1381 |
+
|
| 1382 |
+
for model_i, m_id in enumerate(model_eval_data.keys()):
|
| 1383 |
+
# excluding some experiments
|
| 1384 |
+
if any([ex_pat in m_id for ex_pat in exclude_patterns]):
|
| 1385 |
+
continue
|
| 1386 |
+
if len(include_patterns) > 0:
|
| 1387 |
+
if not any([in_pat in m_id for in_pat in include_patterns]):
|
| 1388 |
+
continue
|
| 1389 |
+
|
| 1390 |
+
# computes stats
|
| 1391 |
+
if sort_test:
|
| 1392 |
+
test_envs_sorted = enumerate(sorted(model_eval_data[m_id].items(), key=lambda kv: sort_test_set(kv[0])))
|
| 1393 |
+
else:
|
| 1394 |
+
test_envs_sorted = enumerate(model_eval_data[m_id].items())
|
| 1395 |
+
|
| 1396 |
+
if plot_aggregated_test:
|
| 1397 |
+
agg_means = []
|
| 1398 |
+
|
| 1399 |
+
for env_i, (test_env, env_data) in test_envs_sorted:
|
| 1400 |
+
ys_same_len = env_data["values"]
|
| 1401 |
+
steps = env_data["steps"].mean(0) / steps_denom
|
| 1402 |
+
n_seeds = len(ys_same_len)
|
| 1403 |
+
|
| 1404 |
+
if per_seed:
|
| 1405 |
+
sems = np.array(ys_same_len)
|
| 1406 |
+
stds = np.array(ys_same_len)
|
| 1407 |
+
means = np.array(ys_same_len)
|
| 1408 |
+
color = default_colors[model_i]
|
| 1409 |
+
|
| 1410 |
+
else:
|
| 1411 |
+
sems = np.std(ys_same_len, axis=0) / np.sqrt(len(ys_same_len)) # sem
|
| 1412 |
+
stds = np.std(ys_same_len, axis=0) # std
|
| 1413 |
+
means = np.mean(ys_same_len, axis=0)
|
| 1414 |
+
color = default_colors[model_i]
|
| 1415 |
+
|
| 1416 |
+
# per-metric adjusments
|
| 1417 |
+
|
| 1418 |
+
if per_seed:
|
| 1419 |
+
# plot x y bounds
|
| 1420 |
+
curr_max_y = np.max(np.max(means))
|
| 1421 |
+
curr_min_y = np.min(np.min(means))
|
| 1422 |
+
curr_max_steps = np.max(np.max(steps))
|
| 1423 |
+
|
| 1424 |
+
else:
|
| 1425 |
+
# plot x y bounds
|
| 1426 |
+
curr_max_y = np.max(means + stds)
|
| 1427 |
+
curr_min_y = np.min(means - stds)
|
| 1428 |
+
curr_max_steps = np.max(steps)
|
| 1429 |
+
|
| 1430 |
+
if plot_aggregated_test:
|
| 1431 |
+
agg_means.append(means)
|
| 1432 |
+
|
| 1433 |
+
if curr_max_y > max_y:
|
| 1434 |
+
max_y = curr_max_y
|
| 1435 |
+
if curr_min_y < min_y:
|
| 1436 |
+
min_y = curr_min_y
|
| 1437 |
+
|
| 1438 |
+
x_lim = max(steps[-1], x_lim)
|
| 1439 |
+
x_lim = min(max_x_lim, x_lim)
|
| 1440 |
+
|
| 1441 |
+
eval_metric_name = {
|
| 1442 |
+
"test_success_rates": "Success rate",
|
| 1443 |
+
'exploration_bonus_mean': "Exploration bonus",
|
| 1444 |
+
|
| 1445 |
+
}.get(eval_metric, eval_metric)
|
| 1446 |
+
|
| 1447 |
+
test_env_name = test_env.replace("Env", "").replace("Test", "")
|
| 1448 |
+
|
| 1449 |
+
env_types = ["InformationSeeking", "Collaboration", "PerspectiveTaking"]
|
| 1450 |
+
for env_type in env_types:
|
| 1451 |
+
if env_type in test_env_name:
|
| 1452 |
+
test_env_name = test_env_name.replace(env_type, "")
|
| 1453 |
+
test_env_name += f"\n({env_type})"
|
| 1454 |
+
|
| 1455 |
+
if grid:
|
| 1456 |
+
ylabel = eval_metric_name
|
| 1457 |
+
title = test_env_name
|
| 1458 |
+
|
| 1459 |
+
else:
|
| 1460 |
+
# flat
|
| 1461 |
+
ylabel = test_env_name
|
| 1462 |
+
title = eval_metric_name
|
| 1463 |
+
|
| 1464 |
+
leg_args = {
|
| 1465 |
+
'fontsize': legend_fontsize // 1
|
| 1466 |
+
}
|
| 1467 |
+
|
| 1468 |
+
if per_seed:
|
| 1469 |
+
for s_i, seed_ys in enumerate(ys_same_len):
|
| 1470 |
+
seed_c = default_colors[model_i + s_i]
|
| 1471 |
+
# label = m_id#+"(s:{})".format(s_i)
|
| 1472 |
+
label = str(s_i)
|
| 1473 |
+
|
| 1474 |
+
if not plot_only_aggregated_test:
|
| 1475 |
+
seed_ys = smooth(seed_ys, eval_smooth_factor)
|
| 1476 |
+
plot_with_shade_seed(0, ax[env_i], steps, seed_ys, None, seed_c, seed_c, label,
|
| 1477 |
+
legend=draw_eval_legend, xlim=[0, x_lim], ylim=[min_y, max_y],
|
| 1478 |
+
leg_size=leg_size, xlabel=f"Steps (1e6)", ylabel=ylabel, linewidth=linewidth, title=title)
|
| 1479 |
+
|
| 1480 |
+
test_summary_dict[s_i][test_env] = seed_ys[-1]
|
| 1481 |
+
test_summary_dict_colors[s_i] = seed_c
|
| 1482 |
+
else:
|
| 1483 |
+
label = label_parser(m_id, load_pattern, label_parser_dict=label_parser_dict)
|
| 1484 |
+
|
| 1485 |
+
if not plot_only_aggregated_test:
|
| 1486 |
+
|
| 1487 |
+
if color_dict:
|
| 1488 |
+
color = color_dict[label]
|
| 1489 |
+
else:
|
| 1490 |
+
color = default_colors[model_i]
|
| 1491 |
+
|
| 1492 |
+
label = label + "({})".format(n_seeds)
|
| 1493 |
+
|
| 1494 |
+
if smooth_factor:
|
| 1495 |
+
means = smooth(means, eval_smooth_factor)
|
| 1496 |
+
stds = smooth(stds, eval_smooth_factor)
|
| 1497 |
+
|
| 1498 |
+
plot_with_shade_grg(
|
| 1499 |
+
0, ax[env_i], steps, means, stds, color, color, label,
|
| 1500 |
+
legend=draw_eval_legend,
|
| 1501 |
+
xlim=[0, x_lim+1],
|
| 1502 |
+
ylim=[0, max_y],
|
| 1503 |
+
xlabel=f"Env steps (1e6)" if env_i // (subplot_x) == subplot_y -1 else None, # only last line
|
| 1504 |
+
ylabel=ylabel if env_i % subplot_x == 0 else None, # only first row
|
| 1505 |
+
title=title,
|
| 1506 |
+
title_fontsize=title_fontsize,
|
| 1507 |
+
labelsize=fontsize,
|
| 1508 |
+
fontsize=fontsize,
|
| 1509 |
+
linewidth=linewidth,
|
| 1510 |
+
leg_linewidth=5,
|
| 1511 |
+
leg_args=leg_args,
|
| 1512 |
+
xnbins=xnbins,
|
| 1513 |
+
ynbins=ynbins,
|
| 1514 |
+
)
|
| 1515 |
+
|
| 1516 |
+
test_summary_dict[label][test_env] = means[-1]
|
| 1517 |
+
test_summary_dict_colors[label] = color
|
| 1518 |
+
|
| 1519 |
+
if plot_aggregated_test:
|
| 1520 |
+
if plot_only_aggregated_test:
|
| 1521 |
+
agg_env_i = 0
|
| 1522 |
+
else:
|
| 1523 |
+
agg_env_i = number_of_eval_envs - 1 # last one
|
| 1524 |
+
|
| 1525 |
+
agg_means = np.array(agg_means)
|
| 1526 |
+
agg_mean = agg_means.mean(axis=0)
|
| 1527 |
+
agg_std = agg_means.std(axis=0) # std
|
| 1528 |
+
|
| 1529 |
+
if smooth_factor and not per_seed:
|
| 1530 |
+
agg_mean = smooth(agg_mean, eval_smooth_factor)
|
| 1531 |
+
agg_std = smooth(agg_std, eval_smooth_factor)
|
| 1532 |
+
|
| 1533 |
+
if color_dict:
|
| 1534 |
+
color = color_dict[re.sub("\([0-9]\)", '', label)]
|
| 1535 |
+
else:
|
| 1536 |
+
color = default_colors[model_i]
|
| 1537 |
+
|
| 1538 |
+
if per_seed:
|
| 1539 |
+
print("Not smooth aggregated because of per seed")
|
| 1540 |
+
for s_i, (seed_ys, seed_st) in enumerate(zip(agg_mean, agg_std)):
|
| 1541 |
+
seed_c = default_colors[model_i + s_i]
|
| 1542 |
+
# label = m_id#+"(s:{})".format(s_i)
|
| 1543 |
+
label = str(s_i)
|
| 1544 |
+
# seed_ys = smooth(seed_ys, eval_smooth_factor)
|
| 1545 |
+
plot_with_shade_seed(0,
|
| 1546 |
+
ax if plot_only_aggregated_test else ax[agg_env_i],
|
| 1547 |
+
steps, seed_ys, seed_st, seed_c, seed_c, label,
|
| 1548 |
+
legend=draw_eval_legend, xlim=[0, x_lim], ylim=[min_y, max_y],
|
| 1549 |
+
labelsize=fontsize,
|
| 1550 |
+
filename=eval_filename,
|
| 1551 |
+
leg_size=leg_size, xlabel=f"Steps (1e6)", ylabel=ylabel, linewidth=1, title=agg_title)
|
| 1552 |
+
else:
|
| 1553 |
+
|
| 1554 |
+
# just used for creating a dummy Imitation test figure -> delete
|
| 1555 |
+
# agg_mean = agg_mean * 0.1
|
| 1556 |
+
# agg_std = agg_std * 0.1
|
| 1557 |
+
# max_y = 1
|
| 1558 |
+
|
| 1559 |
+
plot_with_shade_grg(
|
| 1560 |
+
0,
|
| 1561 |
+
ax if plot_only_aggregated_test else ax[agg_env_i],
|
| 1562 |
+
steps, agg_mean, agg_std, color, color, label,
|
| 1563 |
+
legend=draw_eval_legend,
|
| 1564 |
+
xlim=[0, x_lim + 1],
|
| 1565 |
+
ylim=[0, max_y],
|
| 1566 |
+
xlabel=f"Steps (1e6)" if plot_only_aggregated_test or (agg_env_i // (subplot_x) == subplot_y - 1) else None, # only last line
|
| 1567 |
+
ylabel=ylabel if plot_only_aggregated_test or (agg_env_i % subplot_x == 0) else None, # only first row
|
| 1568 |
+
title_fontsize=title_fontsize,
|
| 1569 |
+
title=agg_title,
|
| 1570 |
+
labelsize=fontsize,
|
| 1571 |
+
fontsize=fontsize,
|
| 1572 |
+
linewidth=linewidth,
|
| 1573 |
+
leg_linewidth=5,
|
| 1574 |
+
leg_args=leg_args,
|
| 1575 |
+
xnbins=xnbins,
|
| 1576 |
+
ynbins=ynbins,
|
| 1577 |
+
filename=eval_filename,
|
| 1578 |
+
)
|
| 1579 |
+
|
| 1580 |
+
# print summary
|
| 1581 |
+
|
| 1582 |
+
means_dict = {
|
| 1583 |
+
lab: np.array(list(lab_sd.values())).mean() for lab, lab_sd in test_summary_dict.items()
|
| 1584 |
+
}
|
| 1585 |
+
best = max(means_dict.values())
|
| 1586 |
+
|
| 1587 |
+
pc = 0.3
|
| 1588 |
+
n = int(len(means_dict) * pc)
|
| 1589 |
+
print("top n: ", n)
|
| 1590 |
+
|
| 1591 |
+
top_pc = sorted(means_dict.values())[-n:]
|
| 1592 |
+
bottom_pc = sorted(means_dict.values())[:n]
|
| 1593 |
+
|
| 1594 |
+
print("Legend:")
|
| 1595 |
+
cprint("\tbest", "green")
|
| 1596 |
+
cprint("\ttop {} %".format(pc), "blue")
|
| 1597 |
+
cprint("\tbottom {} %".format(pc), "red")
|
| 1598 |
+
print("\tothers")
|
| 1599 |
+
print()
|
| 1600 |
+
|
| 1601 |
+
for l, l_mean in sorted(means_dict.items(), key=lambda kv: kv[1]):
|
| 1602 |
+
|
| 1603 |
+
l_summary_dict = test_summary_dict[l]
|
| 1604 |
+
|
| 1605 |
+
c = test_summary_dict_colors[l]
|
| 1606 |
+
print("label: {} ({})".format(l, c))
|
| 1607 |
+
|
| 1608 |
+
#print("\t{}({}) - Mean".format(l_mean, metric))
|
| 1609 |
+
|
| 1610 |
+
if l_mean == best:
|
| 1611 |
+
cprint("\t{}({}) - Mean".format(l_mean, eval_metric), "green")
|
| 1612 |
+
|
| 1613 |
+
elif l_mean in top_pc:
|
| 1614 |
+
cprint("\t{}({}) - Mean".format(l_mean, eval_metric), "blue")
|
| 1615 |
+
|
| 1616 |
+
elif l_mean in bottom_pc:
|
| 1617 |
+
cprint("\t{}({}) - Mean".format(l_mean, eval_metric), "red")
|
| 1618 |
+
|
| 1619 |
+
else:
|
| 1620 |
+
print("\t{}({})".format(l_mean, eval_metric))
|
| 1621 |
+
|
| 1622 |
+
n_over_50 = 0
|
| 1623 |
+
|
| 1624 |
+
if sort_test:
|
| 1625 |
+
sorted_envs = sorted(l_summary_dict.items(), key=lambda kv: sort_test_set(env_name=kv[0]))
|
| 1626 |
+
else:
|
| 1627 |
+
sorted_envs = l_summary_dict.items()
|
| 1628 |
+
|
| 1629 |
+
for tenv, p in sorted_envs:
|
| 1630 |
+
if p < 0.5:
|
| 1631 |
+
print("\t{:4f}({}) - \t{}".format(p, eval_metric, tenv))
|
| 1632 |
+
else:
|
| 1633 |
+
print("\t{:4f}({}) -*\t{}".format(p, eval_metric, tenv))
|
| 1634 |
+
n_over_50 += 1
|
| 1635 |
+
print("\tenv over 50 - {}/{}".format(n_over_50, len(l_summary_dict)))
|
| 1636 |
+
|
| 1637 |
+
if plot_test:
|
| 1638 |
+
plt.tight_layout()
|
| 1639 |
+
# plt.subplots_adjust(hspace=0.8, wspace=0.15, left=0.035, right=0.99, bottom=0.065, top=0.93)
|
| 1640 |
+
plt.show()
|
| 1641 |
+
|
| 1642 |
+
if eval_filename is not None:
|
| 1643 |
+
plt.subplots_adjust(hspace=0.8, wspace=0.15, left=0.15, right=0.99, bottom=0.15, top=0.93)
|
| 1644 |
+
|
| 1645 |
+
res= input(f"Save to {eval_filename} (y/n)?")
|
| 1646 |
+
if res == "y":
|
| 1647 |
+
f.savefig(eval_filename)
|
| 1648 |
+
print(f'saved to {eval_filename}')
|
| 1649 |
+
else:
|
| 1650 |
+
print('not saved')
|
data_analysis_neurips.py
ADDED
|
@@ -0,0 +1,570 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
import seaborn
|
| 3 |
+
import numpy as np
|
| 4 |
+
import os
|
| 5 |
+
from collections import OrderedDict
|
| 6 |
+
import pandas as pd
|
| 7 |
+
import matplotlib.pyplot as plt
|
| 8 |
+
import sys
|
| 9 |
+
from termcolor import cprint
|
| 10 |
+
|
| 11 |
+
# Load data
|
| 12 |
+
|
| 13 |
+
# Global vars for tracking and labeling data at load time.
|
| 14 |
+
exp_idx = 0
|
| 15 |
+
label_parser_dict = None
|
| 16 |
+
|
| 17 |
+
smooth_factor = 10
|
| 18 |
+
leg_size = 30
|
| 19 |
+
|
| 20 |
+
subsample_step = 1
|
| 21 |
+
load_subsample_step = 50
|
| 22 |
+
|
| 23 |
+
default_colors = ["blue","orange","green","magenta", "brown", "red",'black',"grey",u'#ff7f0e',
|
| 24 |
+
"cyan", "pink",'purple', u'#1f77b4',
|
| 25 |
+
"darkorchid","sienna","lightpink", "indigo","mediumseagreen",'aqua',
|
| 26 |
+
'deeppink','silver','khaki','goldenrod','y','y','y','y','y','y','y','y','y','y','y','y' ] + ['y']*50
|
| 27 |
+
|
| 28 |
+
def get_all_runs(logdir, load_subsample_step=1):
|
| 29 |
+
"""
|
| 30 |
+
Recursively look through logdir for output files produced by
|
| 31 |
+
Assumes that any file "progress.txt" is a valid hit.
|
| 32 |
+
"""
|
| 33 |
+
global exp_idx
|
| 34 |
+
global units
|
| 35 |
+
datasets = []
|
| 36 |
+
for root, _, files in os.walk(logdir):
|
| 37 |
+
if 'log.csv' in files:
|
| 38 |
+
run_name = root[8:]
|
| 39 |
+
exp_name = None
|
| 40 |
+
|
| 41 |
+
# try to load a config file containing hyperparameters
|
| 42 |
+
config = None
|
| 43 |
+
try:
|
| 44 |
+
config_path = open(os.path.join(root,'config.json'))
|
| 45 |
+
config = json.load(config_path)
|
| 46 |
+
if 'exp_name' in config:
|
| 47 |
+
exp_name = config['exp_name']
|
| 48 |
+
except:
|
| 49 |
+
print('No file named config.json')
|
| 50 |
+
|
| 51 |
+
exp_idx += 1
|
| 52 |
+
|
| 53 |
+
# load progress data
|
| 54 |
+
try:
|
| 55 |
+
print(os.path.join(root,'log.csv'))
|
| 56 |
+
exp_data = pd.read_csv(os.path.join(root,'log.csv'))
|
| 57 |
+
except:
|
| 58 |
+
raise ValueError("CSV {} faulty".format(os.path.join(root, 'log.csv')))
|
| 59 |
+
|
| 60 |
+
exp_data = exp_data[::load_subsample_step]
|
| 61 |
+
data_dict = exp_data.to_dict("list")
|
| 62 |
+
|
| 63 |
+
data_dict['config'] = config
|
| 64 |
+
nb_epochs = len(data_dict['frames'])
|
| 65 |
+
print('{} -> {}'.format(run_name, nb_epochs))
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
datasets.append(data_dict)
|
| 69 |
+
|
| 70 |
+
return datasets
|
| 71 |
+
|
| 72 |
+
def get_datasets(rootdir, load_only="", load_subsample_step=1, ignore_pattern="ignore"):
|
| 73 |
+
_, models_list, _ = next(os.walk(rootdir))
|
| 74 |
+
print(models_list)
|
| 75 |
+
for dir_name in models_list.copy():
|
| 76 |
+
# add "ignore" in a directory name to avoid loading its content
|
| 77 |
+
if ignore_pattern in dir_name or load_only not in dir_name:
|
| 78 |
+
models_list.remove(dir_name)
|
| 79 |
+
for expe_name in list(labels.keys()):
|
| 80 |
+
if expe_name not in models_list:
|
| 81 |
+
del labels[expe_name]
|
| 82 |
+
|
| 83 |
+
# setting per-model type colors
|
| 84 |
+
for i,m_name in enumerate(models_list):
|
| 85 |
+
for m_type, m_color in per_model_colors.items():
|
| 86 |
+
if m_type in m_name:
|
| 87 |
+
colors[m_name] = m_color
|
| 88 |
+
print("extracting data for {}...".format(m_name))
|
| 89 |
+
m_id = m_name
|
| 90 |
+
models_saves[m_id] = OrderedDict()
|
| 91 |
+
models_saves[m_id]['data'] = get_all_runs(rootdir+m_name, load_subsample_step=load_subsample_step)
|
| 92 |
+
print("done")
|
| 93 |
+
if m_name not in labels:
|
| 94 |
+
labels[m_name] = m_name
|
| 95 |
+
|
| 96 |
+
"""
|
| 97 |
+
retrieve all experiences located in "data to vizu" folder
|
| 98 |
+
"""
|
| 99 |
+
labels = OrderedDict()
|
| 100 |
+
per_model_colors = OrderedDict()
|
| 101 |
+
# per_model_colors = OrderedDict([('ALP-GMM',u'#1f77b4'),
|
| 102 |
+
# ('hmn','pink'),
|
| 103 |
+
# ('ADR','black')])
|
| 104 |
+
|
| 105 |
+
# LOAD DATA
|
| 106 |
+
models_saves = OrderedDict()
|
| 107 |
+
colors = OrderedDict()
|
| 108 |
+
|
| 109 |
+
static_lines = {}
|
| 110 |
+
# get_datasets("storage/",load_only="RERUN_WizardGuide")
|
| 111 |
+
# get_datasets("storage/",load_only="RERUN_WizardTwoGuides")
|
| 112 |
+
try:
|
| 113 |
+
figure_id = eval(sys.argv[1])
|
| 114 |
+
except:
|
| 115 |
+
figure_id = sys.argv[1]
|
| 116 |
+
|
| 117 |
+
print("fig:", figure_id)
|
| 118 |
+
if figure_id == 0:
|
| 119 |
+
# train change
|
| 120 |
+
env_type = "No_NPC_environment"
|
| 121 |
+
fig_type = "train"
|
| 122 |
+
|
| 123 |
+
get_datasets("storage/", "RERUN_WizardGuide_lang64_mm", load_subsample_step=load_subsample_step)
|
| 124 |
+
get_datasets("storage/", "RERUN_WizardGuide_lang64_deaf_no_explo", load_subsample_step=load_subsample_step)
|
| 125 |
+
get_datasets("storage/", "RERUN_WizardGuide_lang64_no_explo", load_subsample_step=load_subsample_step)
|
| 126 |
+
get_datasets("storage/", "RERUN_WizardGuide_lang64_curr_dial", load_subsample_step=load_subsample_step)
|
| 127 |
+
top_n = 16
|
| 128 |
+
elif figure_id == 1:
|
| 129 |
+
# arch change
|
| 130 |
+
env_type = "No_NPC_environment"
|
| 131 |
+
fig_type = "arch"
|
| 132 |
+
|
| 133 |
+
get_datasets("storage/", "RERUN_WizardGuide_lang64_mm", load_subsample_step=load_subsample_step)
|
| 134 |
+
get_datasets("storage/", "RERUN_WizardGuide_lang64_bow", load_subsample_step=load_subsample_step)
|
| 135 |
+
get_datasets("storage/", "RERUN_WizardGuide_lang64_no_mem", load_subsample_step=load_subsample_step)
|
| 136 |
+
get_datasets("storage/", "RERUN_WizardGuide_lang64_bigru", load_subsample_step=load_subsample_step)
|
| 137 |
+
get_datasets("storage/", "RERUN_WizardGuide_lang64_attgru", load_subsample_step=load_subsample_step)
|
| 138 |
+
top_n = 16
|
| 139 |
+
elif figure_id == 2:
|
| 140 |
+
# train change FULL
|
| 141 |
+
env_type = "FULL_environment"
|
| 142 |
+
fig_type = "train"
|
| 143 |
+
|
| 144 |
+
get_datasets("storage/", "RERUN_WizardTwoGuides_lang64_mm", load_subsample_step=load_subsample_step)
|
| 145 |
+
get_datasets("storage/", "RERUN_WizardTwoGuides_lang64_deaf_no_explo", load_subsample_step=load_subsample_step)
|
| 146 |
+
get_datasets("storage/", "RERUN_WizardTwoGuides_lang64_no_explo", load_subsample_step=load_subsample_step)
|
| 147 |
+
get_datasets("storage/", "RERUN_WizardTwoGuides_lang64_curr_dial", load_subsample_step=load_subsample_step)
|
| 148 |
+
top_n = 16
|
| 149 |
+
elif figure_id == 3:
|
| 150 |
+
# arch change FULL
|
| 151 |
+
env_type = "FULL_environment"
|
| 152 |
+
fig_type = "arch"
|
| 153 |
+
|
| 154 |
+
get_datasets("storage/", "RERUN_WizardTwoGuides_lang64_mm", load_subsample_step=load_subsample_step)
|
| 155 |
+
get_datasets("storage/", "RERUN_WizardTwoGuides_lang64_bow", load_subsample_step=load_subsample_step)
|
| 156 |
+
get_datasets("storage/", "RERUN_WizardTwoGuides_lang64_no_mem", load_subsample_step=load_subsample_step)
|
| 157 |
+
get_datasets("storage/", "RERUN_WizardTwoGuides_lang64_bigru", load_subsample_step=load_subsample_step)
|
| 158 |
+
get_datasets("storage/", "RERUN_WizardTwoGuides_lang64_attgru", load_subsample_step=load_subsample_step)
|
| 159 |
+
top_n = 16
|
| 160 |
+
elif str(figure_id) == "ShowMe":
|
| 161 |
+
|
| 162 |
+
get_datasets("storage/", "20-05_NeurIPS_ShowMe_ABL_CEB", load_subsample_step=load_subsample_step, ignore_pattern="tanh_0.3")
|
| 163 |
+
get_datasets("storage/", "20-05_NeurIPS_ShowMe_NO_BONUS_ABL", load_subsample_step=load_subsample_step)
|
| 164 |
+
get_datasets("storage/", "20-05_NeurIPS_ShowMe_CEB", load_subsample_step=load_subsample_step, ignore_pattern="tanh_0.3")
|
| 165 |
+
get_datasets("storage/", "20-05_NeurIPS_ShowMe_NO_BONUS_env", load_subsample_step=load_subsample_step)
|
| 166 |
+
|
| 167 |
+
label_parser_dict = {
|
| 168 |
+
"20-05_NeurIPS_ShowMe_ABL_CEB" : "ShowMe_exp_bonus_no_social_skills_required",
|
| 169 |
+
"20-05_NeurIPS_ShowMe_NO_BONUS_ABL" : "ShowMe_no_bonus_no_social_skills_required",
|
| 170 |
+
"20-05_NeurIPS_ShowMe_CEB" : "ShowMe_exp_bonus",
|
| 171 |
+
"20-05_NeurIPS_ShowMe_NO_BONUS_env" : "ShowMe_no_bonus",
|
| 172 |
+
}
|
| 173 |
+
|
| 174 |
+
env_type = str(figure_id)
|
| 175 |
+
|
| 176 |
+
fig_type = "test"
|
| 177 |
+
top_n = 16
|
| 178 |
+
|
| 179 |
+
elif str(figure_id) == "Help":
|
| 180 |
+
|
| 181 |
+
# env_type = "Bobo"
|
| 182 |
+
# get_datasets("storage/", "Bobo")
|
| 183 |
+
get_datasets("storage/", "24-05_NeurIPS_Help", load_subsample_step=load_subsample_step, ignore_pattern="ABL")
|
| 184 |
+
# get_datasets("storage/", "26-05_NeurIPS_gpu_Help_NoSocial_NO_BONUS_ABL", load_subsample_step=load_subsample_step)
|
| 185 |
+
get_datasets("storage/", "26-05_NeurIPS_gpu_Help_NoSocial_NO_BONUS_env", load_subsample_step=load_subsample_step)
|
| 186 |
+
|
| 187 |
+
label_parser_dict = {
|
| 188 |
+
"Help_NO_BONUS_env": "PPO",
|
| 189 |
+
"Help_BONUS_env": "PPO+Explo",
|
| 190 |
+
# "Help_NO_BONUS_ABL_env": "ExiterRole_no_bonus_no_NPC",
|
| 191 |
+
# "Help_BONUS_ABL_env": "ExiterRole_bonus_no_NPC",
|
| 192 |
+
"26-05_NeurIPS_gpu_Help_NoSocial_NO_BONUS_env": "Unsocial PPO",
|
| 193 |
+
# "26-05_NeurIPS_gpu_Help_NoSocial_NO_BONUS_ABL": "ExiterRole_Insocial_ABL"
|
| 194 |
+
}
|
| 195 |
+
|
| 196 |
+
static_lines = {
|
| 197 |
+
"PPO (helper)": (0.12, 0.05, "#1f77b4"),
|
| 198 |
+
"PPO+Explo (helper)": (0.11, 0.04, "indianred"),
|
| 199 |
+
# "Help_exp_bonus": (0.11525, 0.04916 , default_colors[2]),
|
| 200 |
+
# "HelperRole_ABL_no_exp_bonus": (0.022375, 0.01848, default_colors[3]),
|
| 201 |
+
"Unsocial PPO (helper)": (0.15, 0.06, "grey"),
|
| 202 |
+
# "HelperRole_ABL_Insocial": (0.01775, 0.010544, default_colors[4]),
|
| 203 |
+
}
|
| 204 |
+
|
| 205 |
+
env_type = str(figure_id)
|
| 206 |
+
|
| 207 |
+
fig_type = "test"
|
| 208 |
+
top_n = 16
|
| 209 |
+
|
| 210 |
+
elif str(figure_id) == "TalkItOut":
|
| 211 |
+
print("You mean Polite")
|
| 212 |
+
exit()
|
| 213 |
+
|
| 214 |
+
elif str(figure_id) == "TalkItOutPolite":
|
| 215 |
+
# env_type = "TalkItOut"
|
| 216 |
+
# get_datasets("storage/", "ORIENT_env_MiniGrid-TalkItOut")
|
| 217 |
+
|
| 218 |
+
# env_type = "GuideThief"
|
| 219 |
+
# get_datasets("storage/", "GuideThief")
|
| 220 |
+
|
| 221 |
+
# env_type = "Bobo"
|
| 222 |
+
# get_datasets("storage/", "Bobo")
|
| 223 |
+
get_datasets("storage/", "20-05_NeurIPS_TalkItOutPolite", load_subsample_step=load_subsample_step)
|
| 224 |
+
# get_datasets("storage/", "21-05_NeurIPS_small_bonus_TalkItOutPolite")
|
| 225 |
+
get_datasets("storage/", "26-05_NeurIPS_gpu_TalkItOutPolite_NoSocial_NO_BONUS_env", load_subsample_step=load_subsample_step)
|
| 226 |
+
get_datasets("storage/", "26-05_NeurIPS_gpu_TalkItOutPolite_NoSocial_NO_BONUS_NoLiar", load_subsample_step=load_subsample_step)
|
| 227 |
+
|
| 228 |
+
label_parser_dict = {
|
| 229 |
+
"TalkItOutPolite_NO_BONUS_env": "PPO",
|
| 230 |
+
"TalkItOutPolite_e": "PPO+Explo",
|
| 231 |
+
"TalkItOutPolite_NO_BONUS_NoLiar": "PPO (no liar)",
|
| 232 |
+
"TalkItOutPolite_NoLiar_e": "PPO+Explo (no liar)",
|
| 233 |
+
"26-05_NeurIPS_gpu_TalkItOutPolite_NoSocial_NO_BONUS_env": "Unsocial PPO",
|
| 234 |
+
"26-05_NeurIPS_gpu_TalkItOutPolite_NoSocial_NO_BONUS_NoLiar": "Unsocial PPO (no liar)",
|
| 235 |
+
}
|
| 236 |
+
|
| 237 |
+
|
| 238 |
+
env_type = str(figure_id)
|
| 239 |
+
|
| 240 |
+
fig_type = "test"
|
| 241 |
+
top_n = 16
|
| 242 |
+
|
| 243 |
+
elif str(figure_id) == "DiverseExit":
|
| 244 |
+
get_datasets("storage/", "24-05_NeurIPS_DiverseExit", load_subsample_step=load_subsample_step)
|
| 245 |
+
get_datasets("storage/", "26-05_NeurIPS_gpu_DiverseExit", load_subsample_step=load_subsample_step)
|
| 246 |
+
|
| 247 |
+
label_parser_dict = {
|
| 248 |
+
"DiverseExit_NO_BONUS": "No_bonus",
|
| 249 |
+
"DiverseExit_BONUS": "BOnus",
|
| 250 |
+
"gpu_DiverseExit_NoSocial": "No_social",
|
| 251 |
+
}
|
| 252 |
+
|
| 253 |
+
env_type = str(figure_id)
|
| 254 |
+
|
| 255 |
+
fig_type = "test"
|
| 256 |
+
top_n = 16
|
| 257 |
+
|
| 258 |
+
else:
|
| 259 |
+
get_datasets("storage/", str(figure_id), load_subsample_step=load_subsample_step)
|
| 260 |
+
|
| 261 |
+
env_type = str(figure_id)
|
| 262 |
+
|
| 263 |
+
fig_type = "test"
|
| 264 |
+
top_n = 8
|
| 265 |
+
|
| 266 |
+
#### get_datasets("storage/", "RERUN_WizardGuide_lang64_nameless")
|
| 267 |
+
#### get_datasets("storage/", "RERUN_WizardTwoGuides_lang64_nameless")
|
| 268 |
+
|
| 269 |
+
|
| 270 |
+
if per_model_colors: # order runs for legend order as in per_models_colors, with corresponding colors
|
| 271 |
+
ordered_labels = OrderedDict()
|
| 272 |
+
for teacher_type in per_model_colors.keys():
|
| 273 |
+
for k,v in labels.items():
|
| 274 |
+
if teacher_type in k:
|
| 275 |
+
ordered_labels[k] = v
|
| 276 |
+
labels = ordered_labels
|
| 277 |
+
else:
|
| 278 |
+
print('not using per_model_color')
|
| 279 |
+
for k in models_saves.keys():
|
| 280 |
+
labels[k] = k
|
| 281 |
+
|
| 282 |
+
def plot_with_shade(subplot_nb, ax,x,y,err,color,shade_color,label,
|
| 283 |
+
y_min=None,y_max=None, legend=False, leg_size=30, leg_loc='best', title=None,
|
| 284 |
+
ylim=[0,100], xlim=[0,40], leg_args={}, leg_linewidth=13.0, linewidth=10.0, ticksize=20,
|
| 285 |
+
zorder=None, xlabel='perf',ylabel='env steps'):
|
| 286 |
+
#plt.rcParams.update({'font.size': 15})
|
| 287 |
+
ax.locator_params(axis='x', nbins=4)
|
| 288 |
+
ax.locator_params(axis='y', nbins=3)
|
| 289 |
+
ax.tick_params(axis='both', which='major', labelsize=ticksize)
|
| 290 |
+
ax.plot(x,y, color=color, label=label,linewidth=linewidth,zorder=zorder)
|
| 291 |
+
ax.fill_between(x,y-err,y+err,color=shade_color,alpha=0.2)
|
| 292 |
+
if legend:
|
| 293 |
+
leg = ax.legend(loc=leg_loc, **leg_args) #34
|
| 294 |
+
for legobj in leg.legendHandles:
|
| 295 |
+
legobj.set_linewidth(leg_linewidth)
|
| 296 |
+
ax.set_xlabel(xlabel, fontsize=30)
|
| 297 |
+
if subplot_nb == 0:
|
| 298 |
+
ax.set_ylabel(ylabel, fontsize=30,labelpad=-4)
|
| 299 |
+
ax.set_xlim(xmin=xlim[0],xmax=xlim[1])
|
| 300 |
+
ax.set_ylim(bottom=ylim[0],top=ylim[1])
|
| 301 |
+
if title:
|
| 302 |
+
ax.set_title(title, fontsize=22)
|
| 303 |
+
# Plot utils
|
| 304 |
+
def plot_with_shade_grg(subplot_nb, ax,x,y,err,color,shade_color,label,
|
| 305 |
+
y_min=None,y_max=None, legend=False, leg_size=30, leg_loc='best', title=None,
|
| 306 |
+
ylim=[0,100], xlim=[0,40], leg_args={}, leg_linewidth=13.0, linewidth=10.0, ticksize=20,
|
| 307 |
+
zorder=None, xlabel='perf',ylabel='env steps', linestyle="-"):
|
| 308 |
+
#plt.rcParams.update({'font.size': 15})
|
| 309 |
+
ax.locator_params(axis='x', nbins=4)
|
| 310 |
+
ax.locator_params(axis='y', nbins=3)
|
| 311 |
+
ax.tick_params(axis='both', which='major', labelsize=ticksize)
|
| 312 |
+
|
| 313 |
+
|
| 314 |
+
ax.plot(x, y, color=color, label=label,linewidth=linewidth,zorder=zorder, linestyle=linestyle)
|
| 315 |
+
ax.fill_between(x, y-err, y+err,color=shade_color,alpha=0.2)
|
| 316 |
+
if legend:
|
| 317 |
+
leg = ax.legend(loc=leg_loc, **leg_args) #34
|
| 318 |
+
for legobj in leg.legendHandles:
|
| 319 |
+
legobj.set_linewidth(leg_linewidth)
|
| 320 |
+
ax.set_xlabel(xlabel, fontsize=30)
|
| 321 |
+
if subplot_nb == 0:
|
| 322 |
+
ax.set_ylabel(ylabel, fontsize=30, labelpad=-4)
|
| 323 |
+
ax.set_xlim(xmin=xlim[0],xmax=xlim[1])
|
| 324 |
+
ax.set_ylim(bottom=ylim[0],top=ylim[1])
|
| 325 |
+
if title:
|
| 326 |
+
ax.set_title(title, fontsize=22)
|
| 327 |
+
|
| 328 |
+
|
| 329 |
+
# Metric plot
|
| 330 |
+
metric = 'bin_extrinsic_return_mean'
|
| 331 |
+
# metric = 'mission_string_observed_mean'
|
| 332 |
+
# metric = 'extrinsic_return_mean'
|
| 333 |
+
# metric = 'extrinsic_return_max'
|
| 334 |
+
# metric = "rreturn_mean"
|
| 335 |
+
# metric = 'rreturn_max'
|
| 336 |
+
# metric = 'FPS'
|
| 337 |
+
|
| 338 |
+
f, ax = plt.subplots(1, 1, figsize=(10.0, 6.0))
|
| 339 |
+
ax = [ax]
|
| 340 |
+
max_y = -np.inf
|
| 341 |
+
min_y = np.inf
|
| 342 |
+
# hardcoded
|
| 343 |
+
min_y, max_y = 0.0, 1.0
|
| 344 |
+
max_steps = 0
|
| 345 |
+
exclude_patterns = []
|
| 346 |
+
include_patterns = []
|
| 347 |
+
|
| 348 |
+
|
| 349 |
+
def label_parser(label, figure_id, label_parser_dict=None):
|
| 350 |
+
if label_parser_dict:
|
| 351 |
+
if sum([1 for k, v in label_parser_dict.items() if k in label]) != 1:
|
| 352 |
+
if label in label_parser_dict:
|
| 353 |
+
# see if there is an exact match
|
| 354 |
+
return label_parser_dict[label]
|
| 355 |
+
else:
|
| 356 |
+
print("ERROR multiple curves match a lable and there is no exact match")
|
| 357 |
+
print(label)
|
| 358 |
+
exit()
|
| 359 |
+
|
| 360 |
+
for k, v in label_parser_dict.items():
|
| 361 |
+
if k in label: return v
|
| 362 |
+
|
| 363 |
+
else:
|
| 364 |
+
# return label.split("_env_")[1]
|
| 365 |
+
if figure_id not in [1,2,3,4]:
|
| 366 |
+
return label
|
| 367 |
+
else:
|
| 368 |
+
label_parser_dict = {
|
| 369 |
+
"RERUN_WizardGuide_lang64_no_explo": "MH-BabyAI",
|
| 370 |
+
"RERUN_WizardTwoGuides_lang64_no_explo": "MH-BabyAI",
|
| 371 |
+
|
| 372 |
+
"RERUN_WizardGuide_lang64_mm_baby_short_rec_env": "MH-BabyAI-ExpBonus",
|
| 373 |
+
"RERUN_WizardTwoGuides_lang64_mm_baby_short_rec_env": "MH-BabyAI-ExpBonus",
|
| 374 |
+
|
| 375 |
+
"RERUN_WizardGuide_lang64_deaf_no_explo": "Deaf-MH-BabyAI",
|
| 376 |
+
"RERUN_WizardTwoGuides_lang64_deaf_no_explo": "Deaf-MH-BabyAI",
|
| 377 |
+
|
| 378 |
+
"RERUN_WizardGuide_lang64_bow": "MH-BabyAI-ExpBonus-BOW",
|
| 379 |
+
"RERUN_WizardTwoGuides_lang64_bow": "MH-BabyAI-ExpBonus-BOW",
|
| 380 |
+
|
| 381 |
+
"RERUN_WizardGuide_lang64_no_mem": "MH-BabyAI-ExpBonus-no-mem",
|
| 382 |
+
"RERUN_WizardTwoGuides_lang64_no_mem": "MH-BabyAI-ExpBonus-no-mem",
|
| 383 |
+
|
| 384 |
+
"RERUN_WizardGuide_lang64_bigru": "MH-BabyAI-ExpBonus-bigru",
|
| 385 |
+
"RERUN_WizardTwoGuides_lang64_bigru": "MH-BabyAI-ExpBonus-bigru",
|
| 386 |
+
|
| 387 |
+
"RERUN_WizardGuide_lang64_attgru": "MH-BabyAI-ExpBonus-attgru",
|
| 388 |
+
"RERUN_WizardTwoGuides_lang64_attgru": "MH-BabyAI-ExpBonus-attgru",
|
| 389 |
+
|
| 390 |
+
"RERUN_WizardGuide_lang64_curr_dial": "MH-BabyAI-ExpBonus-current-dialogue",
|
| 391 |
+
"RERUN_WizardTwoGuides_lang64_curr_dial": "MH-BabyAI-ExpBonus-current-dialogue",
|
| 392 |
+
|
| 393 |
+
"RERUN_WizardTwoGuides_lang64_mm_baby_short_rec_100M": "MH-BabyAI-ExpBonus-100M"
|
| 394 |
+
}
|
| 395 |
+
if sum([1 for k, v in label_parser_dict.items() if k in label]) != 1:
|
| 396 |
+
print("ERROR multiple curves match a lable")
|
| 397 |
+
print(label)
|
| 398 |
+
exit()
|
| 399 |
+
|
| 400 |
+
for k, v in label_parser_dict.items():
|
| 401 |
+
if k in label: return v
|
| 402 |
+
|
| 403 |
+
return label
|
| 404 |
+
|
| 405 |
+
per_seed=False
|
| 406 |
+
|
| 407 |
+
for i, m_id in enumerate(models_saves.keys()):
|
| 408 |
+
#excluding some experiments
|
| 409 |
+
if any([ex_pat in m_id for ex_pat in exclude_patterns]):
|
| 410 |
+
continue
|
| 411 |
+
if len(include_patterns) > 0:
|
| 412 |
+
if not any([in_pat in m_id for in_pat in include_patterns]):
|
| 413 |
+
continue
|
| 414 |
+
runs_data = models_saves[m_id]['data']
|
| 415 |
+
ys = []
|
| 416 |
+
|
| 417 |
+
# DIRTY FIX FOR FAULTY LOGGING
|
| 418 |
+
print("m_id:", m_id)
|
| 419 |
+
if runs_data[0]['frames'][1] == 'frames':
|
| 420 |
+
runs_data[0]['frames'] = list(filter(('frames').__ne__, runs_data[0]['frames']))
|
| 421 |
+
###########################################
|
| 422 |
+
|
| 423 |
+
|
| 424 |
+
# determine minimal run length across seeds
|
| 425 |
+
minimum = sorted([len(run['frames']) for run in runs_data if len(run['frames'])])[-top_n]
|
| 426 |
+
min_len = np.min([len(run['frames']) for run in runs_data if len(run['frames']) >= minimum])
|
| 427 |
+
|
| 428 |
+
# min_len = np.min([len(run['frames']) for run in runs_data if len(run['frames']) > 10])
|
| 429 |
+
|
| 430 |
+
|
| 431 |
+
print("min_len:", min_len)
|
| 432 |
+
|
| 433 |
+
#compute env steps (x axis)
|
| 434 |
+
longest_id = np.argmax([len(rd['frames']) for rd in runs_data])
|
| 435 |
+
steps = np.array(runs_data[longest_id]['frames'], dtype=np.int) / 1000000
|
| 436 |
+
steps = steps[:min_len]
|
| 437 |
+
for run in runs_data:
|
| 438 |
+
data = run[metric]
|
| 439 |
+
# DIRTY FIX FOR FAULTY LOGGING (headers in data)
|
| 440 |
+
if data[1] == metric:
|
| 441 |
+
data = np.array(list(filter((metric).__ne__, data)), dtype=np.float16)
|
| 442 |
+
###########################################
|
| 443 |
+
if len(data) >= min_len:
|
| 444 |
+
if len(data) > min_len:
|
| 445 |
+
print("run has too many {} datapoints ({}). Discarding {}".format(m_id, len(data),
|
| 446 |
+
len(data)-min_len))
|
| 447 |
+
data = data[0:min_len]
|
| 448 |
+
ys.append(data)
|
| 449 |
+
ys_same_len = ys # RUNS MUST HAVE SAME LEN
|
| 450 |
+
|
| 451 |
+
# computes stats
|
| 452 |
+
n_seeds = len(ys_same_len)
|
| 453 |
+
sems = np.std(ys_same_len,axis=0)/np.sqrt(len(ys_same_len)) # sem
|
| 454 |
+
stds = np.std(ys_same_len,axis=0) # std
|
| 455 |
+
means = np.mean(ys_same_len,axis=0)
|
| 456 |
+
color = default_colors[i]
|
| 457 |
+
|
| 458 |
+
# per-metric adjusments
|
| 459 |
+
ylabel=metric
|
| 460 |
+
if metric == 'bin_extrinsic_return_mean':
|
| 461 |
+
ylabel = "success rate"
|
| 462 |
+
if metric == 'duration':
|
| 463 |
+
ylabel = "time (hours)"
|
| 464 |
+
means = means / 3600
|
| 465 |
+
sems = sems / 3600
|
| 466 |
+
stds = stds / 3600
|
| 467 |
+
|
| 468 |
+
#plot x y bounds
|
| 469 |
+
curr_max_y = np.max(means)
|
| 470 |
+
curr_min_y = np.min(means)
|
| 471 |
+
curr_max_steps = np.max(steps)
|
| 472 |
+
if curr_max_y > max_y:
|
| 473 |
+
max_y = curr_max_y
|
| 474 |
+
if curr_min_y < min_y:
|
| 475 |
+
min_y = curr_min_y
|
| 476 |
+
if curr_max_steps > max_steps:
|
| 477 |
+
max_steps = curr_max_steps
|
| 478 |
+
|
| 479 |
+
if subsample_step:
|
| 480 |
+
steps = steps[0::subsample_step]
|
| 481 |
+
means = means[0::subsample_step]
|
| 482 |
+
stds = stds[0::subsample_step]
|
| 483 |
+
sems = sems[0::subsample_step]
|
| 484 |
+
ys_same_len = [y[0::subsample_step] for y in ys_same_len]
|
| 485 |
+
|
| 486 |
+
# display seeds separtely
|
| 487 |
+
if per_seed:
|
| 488 |
+
for s_i, seed_ys in enumerate(ys_same_len):
|
| 489 |
+
seed_c = default_colors[i+s_i]
|
| 490 |
+
label = m_id#+"(s:{})".format(s_i)
|
| 491 |
+
plot_with_shade(0, ax[0], steps, seed_ys, stds*0, seed_c, seed_c, label,
|
| 492 |
+
legend=False, xlim=[0, max_steps], ylim=[min_y, max_y],
|
| 493 |
+
leg_size=leg_size, xlabel="env steps (millions)", ylabel=ylabel, smooth_factor=smooth_factor,
|
| 494 |
+
)
|
| 495 |
+
else:
|
| 496 |
+
label = label_parser(m_id, figure_id, label_parser_dict=label_parser_dict)
|
| 497 |
+
label = label #+"({})".format(n_seeds)
|
| 498 |
+
|
| 499 |
+
|
| 500 |
+
def smooth(x_, n=50):
|
| 501 |
+
if type(x_) == list:
|
| 502 |
+
x_ = np.array(x_)
|
| 503 |
+
return np.array([x_[max(i - n, 0):i + 1].mean() for i in range(len(x_))])
|
| 504 |
+
if smooth_factor:
|
| 505 |
+
means = smooth(means,smooth_factor)
|
| 506 |
+
stds = smooth(stds,smooth_factor)
|
| 507 |
+
x_lim = 30
|
| 508 |
+
if figure_id == "TalkItOutPolite":
|
| 509 |
+
leg_args = {
|
| 510 |
+
'ncol': 1,
|
| 511 |
+
'columnspacing': 1.0,
|
| 512 |
+
'handlelength': 1.0,
|
| 513 |
+
'frameon': False,
|
| 514 |
+
# 'bbox_to_anchor': (0.00, 0.23, 0.10, .102),
|
| 515 |
+
'bbox_to_anchor': (0.55, 0.35, 0.10, .102),
|
| 516 |
+
'labelspacing': 0.2,
|
| 517 |
+
'fontsize': 27
|
| 518 |
+
}
|
| 519 |
+
elif figure_id == "Help":
|
| 520 |
+
leg_args = {
|
| 521 |
+
'ncol': 1,
|
| 522 |
+
'columnspacing': 1.0,
|
| 523 |
+
'handlelength': 1.0,
|
| 524 |
+
'frameon': False,
|
| 525 |
+
# 'bbox_to_anchor': (0.00, 0.23, 0.10, .102),
|
| 526 |
+
'bbox_to_anchor': (0.39, 0.20, 0.10, .102),
|
| 527 |
+
'labelspacing': 0.2,
|
| 528 |
+
'fontsize': 27
|
| 529 |
+
}
|
| 530 |
+
else:
|
| 531 |
+
leg_args = {}
|
| 532 |
+
|
| 533 |
+
color_code = dict([
|
| 534 |
+
('PPO+Explo', 'indianred'),
|
| 535 |
+
('PPO', "#1f77b4"),
|
| 536 |
+
('Unsocial PPO', "grey"),
|
| 537 |
+
('PPO (no liar)', "#043252"),
|
| 538 |
+
('PPO+Explo (no liar)', "darkred"),
|
| 539 |
+
('Unsocial PPO (no liar)', "black"),
|
| 540 |
+
('PPO+Explo (helper)', 'indianred'),
|
| 541 |
+
('PPO (helper)', "#1f77b4"),
|
| 542 |
+
('Unsocial PPO (helper)', "grey")]
|
| 543 |
+
)
|
| 544 |
+
color = color_code.get(label, np.random.choice(default_colors))
|
| 545 |
+
print("C:",color)
|
| 546 |
+
plot_with_shade_grg(
|
| 547 |
+
0, ax[0], steps, means, stds, color, color, label,
|
| 548 |
+
legend=True,
|
| 549 |
+
xlim=[0, steps[-1] if not x_lim else x_lim],
|
| 550 |
+
ylim=[0, 1.0], xlabel="env steps (millions)", ylabel=ylabel, title=None,
|
| 551 |
+
leg_args =leg_args)
|
| 552 |
+
#
|
| 553 |
+
# plot_with_shade(0, ax[0], steps, means, stds, color, color,label,
|
| 554 |
+
# legend=True, xlim=[0, max_steps], ylim=[min_y, max_y],
|
| 555 |
+
# leg_size=leg_size, xlabel="Env steps (millions)", ylabel=ylabel, linewidth=5.0, smooth_factor=smooth_factor)
|
| 556 |
+
|
| 557 |
+
|
| 558 |
+
for label, (mean, std, color) in static_lines.items():
|
| 559 |
+
plot_with_shade_grg(
|
| 560 |
+
0, ax[0], steps, np.array([mean]*len(steps)), np.array([std]*len(steps)), color, color, label,
|
| 561 |
+
legend=True,
|
| 562 |
+
xlim=[0, max_steps],
|
| 563 |
+
ylim=[0, 1.0],
|
| 564 |
+
xlabel="env steps (millions)", ylabel=ylabel, linestyle=":",
|
| 565 |
+
leg_args=leg_args)
|
| 566 |
+
|
| 567 |
+
plt.tight_layout()
|
| 568 |
+
f.savefig('graphics/{}_results.svg'.format(str(figure_id)))
|
| 569 |
+
f.savefig('graphics/{}_results.png'.format(str(figure_id)))
|
| 570 |
+
plt.show()
|
data_visualize.py
ADDED
|
@@ -0,0 +1,1436 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
import re
|
| 3 |
+
import itertools
|
| 4 |
+
import math
|
| 5 |
+
from itertools import chain
|
| 6 |
+
import time
|
| 7 |
+
|
| 8 |
+
# import seaborn
|
| 9 |
+
import numpy as np
|
| 10 |
+
import os
|
| 11 |
+
from collections import OrderedDict, defaultdict
|
| 12 |
+
import pandas as pd
|
| 13 |
+
import matplotlib.pyplot as plt
|
| 14 |
+
import sys
|
| 15 |
+
from termcolor import cprint, colored
|
| 16 |
+
from pathlib import Path
|
| 17 |
+
import pickle
|
| 18 |
+
from scipy import stats
|
| 19 |
+
|
| 20 |
+
save = True
|
| 21 |
+
show_plot = False
|
| 22 |
+
|
| 23 |
+
metrics = [
|
| 24 |
+
'success_rate_mean',
|
| 25 |
+
# 'FPS',
|
| 26 |
+
# 'extrinsic_return_mean',
|
| 27 |
+
# 'exploration_bonus_mean',
|
| 28 |
+
# 'NPC_intro',
|
| 29 |
+
# 'curriculum_param_mean',
|
| 30 |
+
# 'curriculum_max_success_rate_mean',
|
| 31 |
+
# 'rreturn_mean'
|
| 32 |
+
]
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
eval_metric = "test_success_rates"
|
| 36 |
+
# eval_metric = "exploration_bonus_mean"
|
| 37 |
+
|
| 38 |
+
super_title = ""
|
| 39 |
+
# super_title = "PPO - No exploration bonus"
|
| 40 |
+
# super_title = "Count Based exploration bonus (Grid Search)"
|
| 41 |
+
# super_title = "PPO + RND"
|
| 42 |
+
# super_title = "PPO + RIDE"
|
| 43 |
+
|
| 44 |
+
# statistical evaluation p-value
|
| 45 |
+
test_p = 0.05
|
| 46 |
+
|
| 47 |
+
agg_title = ""
|
| 48 |
+
|
| 49 |
+
color_dict = None
|
| 50 |
+
eval_filename = None
|
| 51 |
+
|
| 52 |
+
max_frames = 20_000_000
|
| 53 |
+
|
| 54 |
+
legend_show_n_seeds = False
|
| 55 |
+
draw_legend = True
|
| 56 |
+
per_seed = False
|
| 57 |
+
|
| 58 |
+
study_train = False
|
| 59 |
+
study_eval = True
|
| 60 |
+
|
| 61 |
+
plot_test = True
|
| 62 |
+
|
| 63 |
+
plot_aggregated_test = True
|
| 64 |
+
plot_only_aggregated_test = True
|
| 65 |
+
|
| 66 |
+
|
| 67 |
+
xnbins = 4
|
| 68 |
+
ynbins = 3
|
| 69 |
+
|
| 70 |
+
steps_denom = 1e6
|
| 71 |
+
|
| 72 |
+
# Global vas for tracking and labeling data at load time.
|
| 73 |
+
exp_idx = 0
|
| 74 |
+
label_parser_dict = None
|
| 75 |
+
label_parser = lambda l, _, label_parser_dict: l
|
| 76 |
+
|
| 77 |
+
smooth_factor = 10 # used
|
| 78 |
+
# smooth_factor = 0
|
| 79 |
+
print("smooth factor:", smooth_factor)
|
| 80 |
+
eval_smooth_factor = None
|
| 81 |
+
leg_size = 30
|
| 82 |
+
|
| 83 |
+
def smooth(x_, n=50):
|
| 84 |
+
if n is None:
|
| 85 |
+
return x_
|
| 86 |
+
|
| 87 |
+
if type(x_) == list:
|
| 88 |
+
x_ = np.array(x_)
|
| 89 |
+
return np.array([x_[max(i - n, 0):i + 1].mean() for i in range(len(x_))])
|
| 90 |
+
|
| 91 |
+
sort_test = False
|
| 92 |
+
|
| 93 |
+
def sort_test_set(env_name):
|
| 94 |
+
helps = [
|
| 95 |
+
"LanguageFeedback",
|
| 96 |
+
"LanguageColor",
|
| 97 |
+
"Pointing",
|
| 98 |
+
"Emulation",
|
| 99 |
+
]
|
| 100 |
+
problems = [
|
| 101 |
+
"Boxes",
|
| 102 |
+
"Switches",
|
| 103 |
+
"Generators",
|
| 104 |
+
"Marble",
|
| 105 |
+
"Doors",
|
| 106 |
+
"Levers",
|
| 107 |
+
]
|
| 108 |
+
|
| 109 |
+
env_names = []
|
| 110 |
+
for p in problems:
|
| 111 |
+
for h in helps:
|
| 112 |
+
env_names.append(h+p)
|
| 113 |
+
|
| 114 |
+
env_names.extend([
|
| 115 |
+
"LeverDoorColl",
|
| 116 |
+
"MarblePushColl",
|
| 117 |
+
"MarblePassColl",
|
| 118 |
+
"AppleStealing"
|
| 119 |
+
])
|
| 120 |
+
|
| 121 |
+
for i, en in enumerate(env_names):
|
| 122 |
+
if en in env_name:
|
| 123 |
+
return i
|
| 124 |
+
|
| 125 |
+
raise ValueError(f"Test env {env_name} not known")
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
subsample_step = 1
|
| 130 |
+
load_subsample_step = 1
|
| 131 |
+
|
| 132 |
+
x_lim = 0
|
| 133 |
+
max_x_lim = np.inf
|
| 134 |
+
|
| 135 |
+
summary_dict = {}
|
| 136 |
+
summary_dict_colors = {}
|
| 137 |
+
to_plot_dict = {}
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
default_colors_ = ["blue","orange","green","magenta", "brown", "red",'black',"grey",u'#ff7f0e',
|
| 141 |
+
"cyan", "pink",'purple', u'#1f77b4',
|
| 142 |
+
"darkorchid","sienna","lightpink", "indigo","mediumseagreen",'aqua',
|
| 143 |
+
'deeppink','silver','khaki','goldenrod'] * 100
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
def get_eval_data(logdir, eval_metric):
|
| 147 |
+
eval_data = defaultdict(lambda :defaultdict(list))
|
| 148 |
+
|
| 149 |
+
for root, _, files in os.walk(logdir):
|
| 150 |
+
for file in files:
|
| 151 |
+
if 'testing_' in file:
|
| 152 |
+
assert ".pkl" in file
|
| 153 |
+
test_env_name = file.lstrip("testing_").rstrip(".pkl")
|
| 154 |
+
try:
|
| 155 |
+
with open(root+"/"+file, "rb") as f:
|
| 156 |
+
seed_eval_data = pickle.load(f)
|
| 157 |
+
except:
|
| 158 |
+
print("Pickle not loaded: ", root+"/"+file)
|
| 159 |
+
time.sleep(1)
|
| 160 |
+
continue
|
| 161 |
+
|
| 162 |
+
eval_data[test_env_name]["values"].append(seed_eval_data[eval_metric])
|
| 163 |
+
eval_data[test_env_name]["steps"].append(seed_eval_data["test_step_nb"])
|
| 164 |
+
|
| 165 |
+
for test_env, seed_data in eval_data.items():
|
| 166 |
+
min_len_seed = min([len(s) for s in seed_data['steps']])
|
| 167 |
+
eval_data[test_env]["values"] = np.array([s[:min_len_seed] for s in eval_data[test_env]["values"]])
|
| 168 |
+
eval_data[test_env]["steps"] = np.array([s[:min_len_seed] for s in eval_data[test_env]["steps"]])
|
| 169 |
+
|
| 170 |
+
return eval_data
|
| 171 |
+
|
| 172 |
+
def get_all_runs(logdir, load_subsample_step=1):
|
| 173 |
+
"""
|
| 174 |
+
Recursively look through logdir for output files produced by
|
| 175 |
+
Assumes that any file "log.csv" is a valid hit.
|
| 176 |
+
"""
|
| 177 |
+
global exp_idx
|
| 178 |
+
global units
|
| 179 |
+
datasets = []
|
| 180 |
+
for root, _, files in os.walk(logdir):
|
| 181 |
+
if 'log.csv' in files:
|
| 182 |
+
if (Path(root) / 'log.csv').stat().st_size == 0:
|
| 183 |
+
print("CSV {} empty".format(os.path.join(root, 'log.csv')))
|
| 184 |
+
continue
|
| 185 |
+
|
| 186 |
+
run_name = root[8:]
|
| 187 |
+
|
| 188 |
+
exp_name = None
|
| 189 |
+
|
| 190 |
+
config = None
|
| 191 |
+
exp_idx += 1
|
| 192 |
+
|
| 193 |
+
# load progress data
|
| 194 |
+
try:
|
| 195 |
+
exp_data = pd.read_csv(os.path.join(root, 'log.csv'))
|
| 196 |
+
print("Loaded:", os.path.join(root, 'log.csv'))
|
| 197 |
+
except:
|
| 198 |
+
raise ValueError("CSV {} faulty".format(os.path.join(root, 'log.csv')))
|
| 199 |
+
|
| 200 |
+
exp_data = exp_data[::load_subsample_step]
|
| 201 |
+
data_dict = exp_data.to_dict("list")
|
| 202 |
+
|
| 203 |
+
data_dict['config'] = config
|
| 204 |
+
nb_epochs = len(data_dict['frames'])
|
| 205 |
+
if nb_epochs == 1:
|
| 206 |
+
print(f'{run_name} -> {colored(f"nb_epochs {nb_epochs}", "red")}')
|
| 207 |
+
else:
|
| 208 |
+
print('{} -> nb_epochs {}'.format(run_name, nb_epochs))
|
| 209 |
+
|
| 210 |
+
datasets.append(data_dict)
|
| 211 |
+
|
| 212 |
+
return datasets
|
| 213 |
+
|
| 214 |
+
|
| 215 |
+
def get_datasets(rootdir, load_only="", load_subsample_step=1, ignore_patterns=("ignore"), require_patterns=()):
|
| 216 |
+
_, models_list, _ = next(os.walk(rootdir))
|
| 217 |
+
for dir_name in models_list.copy():
|
| 218 |
+
# add "ignore" in a directory name to avoid loading its content
|
| 219 |
+
for ignore_pattern in ignore_patterns:
|
| 220 |
+
if ignore_pattern in dir_name or load_only not in dir_name:
|
| 221 |
+
if dir_name in models_list:
|
| 222 |
+
models_list.remove(dir_name)
|
| 223 |
+
|
| 224 |
+
if len(require_patterns) > 0:
|
| 225 |
+
if not any([require_pattern in dir_name for require_pattern in require_patterns]):
|
| 226 |
+
if dir_name in models_list:
|
| 227 |
+
models_list.remove(dir_name)
|
| 228 |
+
|
| 229 |
+
for expe_name in list(labels.keys()):
|
| 230 |
+
if expe_name not in models_list:
|
| 231 |
+
del labels[expe_name]
|
| 232 |
+
|
| 233 |
+
# setting per-model type colors
|
| 234 |
+
for i, m_name in enumerate(models_list):
|
| 235 |
+
for m_type, m_color in per_model_colors.items():
|
| 236 |
+
if m_type in m_name:
|
| 237 |
+
colors[m_name] = m_color
|
| 238 |
+
print("extracting data for {}...".format(m_name))
|
| 239 |
+
m_id = m_name
|
| 240 |
+
models_saves[m_id] = OrderedDict()
|
| 241 |
+
models_saves[m_id]['data'] = get_all_runs(rootdir+m_name, load_subsample_step=load_subsample_step)
|
| 242 |
+
print("done")
|
| 243 |
+
|
| 244 |
+
if m_name not in labels:
|
| 245 |
+
labels[m_name] = m_name
|
| 246 |
+
|
| 247 |
+
model_eval_data[m_id] = get_eval_data(logdir=rootdir+m_name, eval_metric=eval_metric)
|
| 248 |
+
|
| 249 |
+
"""
|
| 250 |
+
retrieve all experiences located in "data to vizu" folder
|
| 251 |
+
"""
|
| 252 |
+
labels = OrderedDict()
|
| 253 |
+
per_model_colors = OrderedDict()
|
| 254 |
+
|
| 255 |
+
# LOAD DATA
|
| 256 |
+
models_saves = OrderedDict()
|
| 257 |
+
colors = OrderedDict()
|
| 258 |
+
model_eval_data = OrderedDict()
|
| 259 |
+
|
| 260 |
+
static_lines = {}
|
| 261 |
+
|
| 262 |
+
ignore_patterns = ["_ignore_"]
|
| 263 |
+
|
| 264 |
+
to_compare = None
|
| 265 |
+
load_pattern = sys.argv[1]
|
| 266 |
+
|
| 267 |
+
test_envs_to_plot = None # plot all
|
| 268 |
+
|
| 269 |
+
min_y, max_y = 0.0, 1.1
|
| 270 |
+
|
| 271 |
+
|
| 272 |
+
def label_parser(label):
|
| 273 |
+
label = label.replace("04-01_Pointing_CB_heldout_doors", "PPO_CB")
|
| 274 |
+
label = label.replace("19-01_Color_CB_heldout_doors", "PPO_CBL")
|
| 275 |
+
label = label.replace("19-01_Feedback_CB_heldout_doors_20M", "PPO_CBL")
|
| 276 |
+
|
| 277 |
+
label = label.replace("20-01_JA_Color_CB_heldout_doors", "JA_PPO_CBL")
|
| 278 |
+
|
| 279 |
+
label = label.replace("05-01_scaffolding_50M_no_acl", "PPO_no_scaf")
|
| 280 |
+
label = label.replace("05-01_scaffolding_50M_acl_4_acl-type_intro_seq", "PPO_scaf_4")
|
| 281 |
+
label = label.replace("05-01_scaffolding_50M_acl_8_acl-type_intro_seq_scaf", "PPO_scaf_8")
|
| 282 |
+
|
| 283 |
+
|
| 284 |
+
label = label.replace("03-01_RR_ft_single_CB_marble_pass_A_soc_exp", "PPO_CB_role_B")
|
| 285 |
+
label = label.replace("03-01_RR_ft_single_CB_marble_pass_A_asoc_contr", "PPO_CB_asocial")
|
| 286 |
+
|
| 287 |
+
label = label.replace("05-01_RR_ft_group_50M_CB_marble_pass_A_soc_exp", "PPO_CB_role_B")
|
| 288 |
+
label = label.replace("05-01_RR_ft_group_50M_CB_marble_pass_A_asoc_contr", "PPO_CB_asocial")
|
| 289 |
+
|
| 290 |
+
label = label.replace("20-01_Imitation_PPO_CB_exploration-bonus-type_cell_exploration-bonus-params__0.25_50",
|
| 291 |
+
"PPO_CB_0.25")
|
| 292 |
+
label = label.replace("20-01_Imitation_PPO_CB_exploration-bonus-type_cell_exploration-bonus-params__0.5_50",
|
| 293 |
+
"PPO_CB_0.5")
|
| 294 |
+
label = label.replace("20-01_Imitation_PPO_CB_exploration-bonus-type_cell_exploration-bonus-params__1_50",
|
| 295 |
+
"PPO_CB_1")
|
| 296 |
+
|
| 297 |
+
return label
|
| 298 |
+
|
| 299 |
+
color_dict = {
|
| 300 |
+
'PPO_CB': "blue",
|
| 301 |
+
'PPO_CB(train)': "blue",
|
| 302 |
+
"PPO_CB(test)": "orange",
|
| 303 |
+
|
| 304 |
+
'PPO_no_bonus': "orange",
|
| 305 |
+
|
| 306 |
+
'PPO_CBL': "blue",
|
| 307 |
+
'PPO_CBL(train)': "blue",
|
| 308 |
+
"PPO_CBL(test)": "orange",
|
| 309 |
+
'JA_PPO_CBL': "green",
|
| 310 |
+
|
| 311 |
+
"PPO_CB_role_B": "blue",
|
| 312 |
+
"PPO_CB_asocial": "orange",
|
| 313 |
+
|
| 314 |
+
'PPO_CB_0.25': "blue",
|
| 315 |
+
'PPO_CB_0.5': "green",
|
| 316 |
+
'PPO_CB_1': "orange",
|
| 317 |
+
|
| 318 |
+
}
|
| 319 |
+
|
| 320 |
+
if load_pattern == "RR_single":
|
| 321 |
+
save = False
|
| 322 |
+
show_plot = True
|
| 323 |
+
load_pattern = "_"
|
| 324 |
+
|
| 325 |
+
plot_path = "../case_studies_final_figures/RR_dummy_single"
|
| 326 |
+
|
| 327 |
+
require_patterns = [
|
| 328 |
+
"03-01_RR_ft_single_CB_marble_pass_A_asoc_contr",
|
| 329 |
+
"03-01_RR_ft_single_CB_marble_pass_A_soc_exp",
|
| 330 |
+
]
|
| 331 |
+
|
| 332 |
+
plot_aggregated_test = False
|
| 333 |
+
plot_only_aggregated_test = False
|
| 334 |
+
study_train = True
|
| 335 |
+
study_eval = False
|
| 336 |
+
|
| 337 |
+
elif load_pattern == "RR_group":
|
| 338 |
+
|
| 339 |
+
load_pattern = "_"
|
| 340 |
+
|
| 341 |
+
plot_path = "../case_studies_final_figures/RR_dummy_group"
|
| 342 |
+
|
| 343 |
+
require_patterns = [
|
| 344 |
+
"05-01_RR_ft_group_50M_CB_marble_pass_A_asoc_contr",
|
| 345 |
+
"05-01_RR_ft_group_50M_CB_marble_pass_A_soc_exp",
|
| 346 |
+
]
|
| 347 |
+
|
| 348 |
+
plot_aggregated_test = False
|
| 349 |
+
plot_only_aggregated_test = False
|
| 350 |
+
study_train = True
|
| 351 |
+
study_eval = False
|
| 352 |
+
|
| 353 |
+
|
| 354 |
+
elif load_pattern == "scaffolding":
|
| 355 |
+
load_pattern = "_"
|
| 356 |
+
|
| 357 |
+
plot_path = "../case_studies_final_figures/Scaffolding_test"
|
| 358 |
+
|
| 359 |
+
require_patterns = [
|
| 360 |
+
"05-01_scaffolding_50M_no_acl",
|
| 361 |
+
"05-01_scaffolding_50M_acl_4_acl-type_intro_seq",
|
| 362 |
+
"05-01_scaffolding_50M_acl_8_acl-type_intro_seq_scaf",
|
| 363 |
+
]
|
| 364 |
+
|
| 365 |
+
test_envs_to_plot = None # aggregate all of them
|
| 366 |
+
plot_aggregated_test = True
|
| 367 |
+
plot_only_aggregated_test = True
|
| 368 |
+
study_train = False
|
| 369 |
+
study_eval = True
|
| 370 |
+
|
| 371 |
+
to_compare = [
|
| 372 |
+
("05-01_scaffolding_50M_acl_4_acl-type_intro_seq_agg_test", "05-01_scaffolding_50M_no_acl_agg_test", "auto_color"),
|
| 373 |
+
("05-01_scaffolding_50M_acl_8_acl-type_intro_seq_scaf_agg_test", "05-01_scaffolding_50M_no_acl_agg_test", "auto_color"),
|
| 374 |
+
]
|
| 375 |
+
|
| 376 |
+
elif load_pattern == "pointing":
|
| 377 |
+
study_train = True
|
| 378 |
+
study_eval = True
|
| 379 |
+
|
| 380 |
+
plot_aggregated_test = False
|
| 381 |
+
plot_only_aggregated_test = False
|
| 382 |
+
|
| 383 |
+
load_pattern = "_"
|
| 384 |
+
|
| 385 |
+
test_envs_to_plot = [
|
| 386 |
+
"SocialAI-EPointingDoorsTestInformationSeekingParamEnv-v1",
|
| 387 |
+
]
|
| 388 |
+
|
| 389 |
+
plot_path = "../case_studies_final_figures/Pointing_train_test"
|
| 390 |
+
|
| 391 |
+
require_patterns = [
|
| 392 |
+
"04-01_Pointing_CB_heldout_doors",
|
| 393 |
+
]
|
| 394 |
+
|
| 395 |
+
to_compare = [
|
| 396 |
+
("04-01_Pointing_CB_heldout_doors", "04-01_Pointing_CB_heldout_doors_SocialAI-EPointingDoorsTestInformationSeekingParamEnv-v1", "black")
|
| 397 |
+
]
|
| 398 |
+
|
| 399 |
+
elif load_pattern == "color":
|
| 400 |
+
study_train = True
|
| 401 |
+
study_eval = True
|
| 402 |
+
|
| 403 |
+
plot_aggregated_test = False
|
| 404 |
+
plot_only_aggregated_test = False
|
| 405 |
+
|
| 406 |
+
max_x_lim = 18
|
| 407 |
+
|
| 408 |
+
load_pattern = "_"
|
| 409 |
+
|
| 410 |
+
test_envs_to_plot = [
|
| 411 |
+
"SocialAI-ELangColorDoorsTestInformationSeekingParamEnv-v1",
|
| 412 |
+
]
|
| 413 |
+
|
| 414 |
+
plot_path = "../case_studies_final_figures/Color_train_test"
|
| 415 |
+
|
| 416 |
+
require_patterns = [
|
| 417 |
+
"19-01_Color_CB_heldout_doors",
|
| 418 |
+
]
|
| 419 |
+
|
| 420 |
+
to_compare = [
|
| 421 |
+
("19-01_Color_CB_heldout_doors", "19-01_Color_CB_heldout_doors_SocialAI-ELangColorDoorsTestInformationSeekingParamEnv-v1", "black")
|
| 422 |
+
]
|
| 423 |
+
|
| 424 |
+
elif load_pattern == "ja_color":
|
| 425 |
+
|
| 426 |
+
study_train = True
|
| 427 |
+
study_eval = False
|
| 428 |
+
|
| 429 |
+
plot_aggregated_test = False
|
| 430 |
+
plot_only_aggregated_test = False
|
| 431 |
+
|
| 432 |
+
max_x_lim = 18
|
| 433 |
+
|
| 434 |
+
load_pattern = "_"
|
| 435 |
+
|
| 436 |
+
test_envs_to_plot = None
|
| 437 |
+
plot_path = "../case_studies_final_figures/JA_Color_train"
|
| 438 |
+
|
| 439 |
+
require_patterns = [
|
| 440 |
+
"19-01_Color_CB_heldout_doors",
|
| 441 |
+
"20-01_JA_Color_CB_heldout_doors",
|
| 442 |
+
]
|
| 443 |
+
|
| 444 |
+
to_compare = [
|
| 445 |
+
("19-01_Color_CB_heldout_doors", "20-01_JA_Color_CB_heldout_doors", "black")
|
| 446 |
+
]
|
| 447 |
+
|
| 448 |
+
elif load_pattern == "feedback_per_seed":
|
| 449 |
+
study_train = True
|
| 450 |
+
study_eval = False
|
| 451 |
+
per_seed = True
|
| 452 |
+
draw_legend = False
|
| 453 |
+
|
| 454 |
+
plot_aggregated_test = False
|
| 455 |
+
plot_only_aggregated_test = False
|
| 456 |
+
max_x_lim = 18
|
| 457 |
+
|
| 458 |
+
load_pattern = "_"
|
| 459 |
+
|
| 460 |
+
test_envs_to_plot = [
|
| 461 |
+
"SocialAI-ELangFeedbackDoorsTestInformationSeekingParamEnv-v1",
|
| 462 |
+
]
|
| 463 |
+
|
| 464 |
+
plot_path = "../case_studies_final_figures/Feedback_train_per_seed"
|
| 465 |
+
|
| 466 |
+
require_patterns = [
|
| 467 |
+
"19-01_Feedback_CB_heldout_doors",
|
| 468 |
+
]
|
| 469 |
+
|
| 470 |
+
to_compare = None
|
| 471 |
+
|
| 472 |
+
elif load_pattern == "feedback":
|
| 473 |
+
study_train = True
|
| 474 |
+
study_eval = True
|
| 475 |
+
|
| 476 |
+
plot_aggregated_test = False
|
| 477 |
+
plot_only_aggregated_test = False
|
| 478 |
+
max_x_lim = 18
|
| 479 |
+
|
| 480 |
+
load_pattern = "_"
|
| 481 |
+
|
| 482 |
+
test_envs_to_plot = [
|
| 483 |
+
"SocialAI-ELangFeedbackDoorsTestInformationSeekingParamEnv-v1",
|
| 484 |
+
]
|
| 485 |
+
|
| 486 |
+
plot_path = "../case_studies_final_figures/Feedback_train_test"
|
| 487 |
+
|
| 488 |
+
require_patterns = [
|
| 489 |
+
"19-01_Feedback_CB_heldout_doors",
|
| 490 |
+
]
|
| 491 |
+
|
| 492 |
+
to_compare = [
|
| 493 |
+
("19-01_Feedback_CB_heldout_doors_20M", "19-01_Feedback_CB_heldout_doors_20M_SocialAI-ELangFeedbackDoorsTestInformationSeekingParamEnv-v1", "black")
|
| 494 |
+
]
|
| 495 |
+
|
| 496 |
+
elif load_pattern == "imitation_train":
|
| 497 |
+
|
| 498 |
+
study_train = True
|
| 499 |
+
study_eval = False
|
| 500 |
+
|
| 501 |
+
plot_aggregated_test = False
|
| 502 |
+
plot_only_aggregated_test = False
|
| 503 |
+
|
| 504 |
+
max_x_lim = 18
|
| 505 |
+
|
| 506 |
+
load_pattern = "_"
|
| 507 |
+
|
| 508 |
+
test_envs_to_plot = None
|
| 509 |
+
plot_path = "../case_studies_final_figures/Imitation_train"
|
| 510 |
+
|
| 511 |
+
require_patterns = [
|
| 512 |
+
"20-01_Imitation_PPO_CB_exploration-bonus-type_cell_exploration-bonus-params__0.25_50",
|
| 513 |
+
"20-01_Imitation_PPO_CB_exploration-bonus-type_cell_exploration-bonus-params__0.5_50",
|
| 514 |
+
"20-01_Imitation_PPO_CB_exploration-bonus-type_cell_exploration-bonus-params__1_50",
|
| 515 |
+
]
|
| 516 |
+
|
| 517 |
+
# to_compare = [
|
| 518 |
+
# ("19-01_Color_CB_heldout_doors", "20-01_JA_Color_CB_heldout_doors", "black")
|
| 519 |
+
# ]
|
| 520 |
+
to_compare = None
|
| 521 |
+
|
| 522 |
+
elif load_pattern == "imitation_train_intro":
|
| 523 |
+
|
| 524 |
+
metrics = ["NPC_intro"]
|
| 525 |
+
|
| 526 |
+
show_plot = False
|
| 527 |
+
save = True
|
| 528 |
+
|
| 529 |
+
study_train = True
|
| 530 |
+
study_eval = False
|
| 531 |
+
|
| 532 |
+
plot_aggregated_test = False
|
| 533 |
+
plot_only_aggregated_test = False
|
| 534 |
+
|
| 535 |
+
max_x_lim = 18
|
| 536 |
+
|
| 537 |
+
load_pattern = "_"
|
| 538 |
+
|
| 539 |
+
test_envs_to_plot = None
|
| 540 |
+
plot_path = "../case_studies_final_figures/Imitation_train_intro"
|
| 541 |
+
|
| 542 |
+
require_patterns = [
|
| 543 |
+
"20-01_Imitation_PPO_CB_exploration-bonus-type_cell_exploration-bonus-params__0.25_50",
|
| 544 |
+
"20-01_Imitation_PPO_CB_exploration-bonus-type_cell_exploration-bonus-params__0.5_50",
|
| 545 |
+
"20-01_Imitation_PPO_CB_exploration-bonus-type_cell_exploration-bonus-params__1_50",
|
| 546 |
+
]
|
| 547 |
+
|
| 548 |
+
# to_compare = [
|
| 549 |
+
# ("19-01_Color_CB_heldout_doors", "20-01_JA_Color_CB_heldout_doors", "black")
|
| 550 |
+
# ]
|
| 551 |
+
to_compare = None
|
| 552 |
+
|
| 553 |
+
elif load_pattern == "imitation_test":
|
| 554 |
+
|
| 555 |
+
study_train = False
|
| 556 |
+
study_eval = True
|
| 557 |
+
|
| 558 |
+
plot_aggregated_test = False
|
| 559 |
+
plot_only_aggregated_test = False
|
| 560 |
+
|
| 561 |
+
max_x_lim = 18
|
| 562 |
+
|
| 563 |
+
load_pattern = "_"
|
| 564 |
+
|
| 565 |
+
test_envs_to_plot = None
|
| 566 |
+
plot_path = "../case_studies_final_figures/Imitation_test"
|
| 567 |
+
|
| 568 |
+
require_patterns = [
|
| 569 |
+
"20-01_Imitation_PPO_CB_exploration-bonus-type_cell_exploration-bonus-params__0.25_50",
|
| 570 |
+
"20-01_Imitation_PPO_CB_exploration-bonus-type_cell_exploration-bonus-params__0.5_50",
|
| 571 |
+
"20-01_Imitation_PPO_CB_exploration-bonus-type_cell_exploration-bonus-params__1_50",
|
| 572 |
+
]
|
| 573 |
+
|
| 574 |
+
# to_compare = [
|
| 575 |
+
# ("19-01_Color_CB_heldout_doors", "20-01_JA_Color_CB_heldout_doors", "black")
|
| 576 |
+
# ]
|
| 577 |
+
to_compare = None
|
| 578 |
+
|
| 579 |
+
elif load_pattern == "pilot_pointing":
|
| 580 |
+
|
| 581 |
+
study_train = True
|
| 582 |
+
study_eval = False
|
| 583 |
+
|
| 584 |
+
show_plot = False
|
| 585 |
+
save = True
|
| 586 |
+
plot_path = "../case_studies_final_figures/pilot_pointing"
|
| 587 |
+
|
| 588 |
+
load_pattern = "29-10_SAI_Pointing_CS_PPO_"
|
| 589 |
+
|
| 590 |
+
require_patterns = [
|
| 591 |
+
"29-10_SAI_Pointing_CS_PPO_CB_env_SocialAI-EPointingInformationSeekingParamEnv-v1_recurrence_5_lr_1e-4_exploration-bonus-type_cell_exploration-bonus-params__2_50_exploration-bonus-tanh_0.6",
|
| 592 |
+
"29-10_SAI_Pointing_CS_PPO_CBL_env_SocialAI-EPointingInformationSeekingParamEnv-v1_recurrence_5_lr_1e-4_exploration-bonus-type_lang_exploration-bonus-params__10_50_exploration-bonus-tanh_0.6",
|
| 593 |
+
"29-10_SAI_Pointing_CS_PPO_no_env_SocialAI-EPointingInformationSeekingParamEnv-v1_recurrence_5_lr_1e-4",
|
| 594 |
+
"29-10_SAI_Pointing_CS_PPO_RIDE_env_SocialAI-EPointingInformationSeekingParamEnv-v1_recurrence_5_lr_1e-4_exploration-bonus-type_ride_intrinsic-reward-coef_0.01",
|
| 595 |
+
"29-10_SAI_Pointing_CS_PPO_RND_env_SocialAI-EPointingInformationSeekingParamEnv-v1_recurrence_5_lr_1e-4_exploration-bonus-type_rnd_intrinsic-reward-coef_0.005",
|
| 596 |
+
]
|
| 597 |
+
|
| 598 |
+
color_dict = {
|
| 599 |
+
"PPO_RIDE": "orange",
|
| 600 |
+
"PPO_RND": "magenta",
|
| 601 |
+
"PPO_no": "maroon",
|
| 602 |
+
"PPO_CBL": "green",
|
| 603 |
+
"PPO_CB": "blue",
|
| 604 |
+
}
|
| 605 |
+
|
| 606 |
+
def label_parser(label):
|
| 607 |
+
label = label.split("_env_")[0].split("SAI_")[1]
|
| 608 |
+
label=label.replace("Pointing_CS_", "")
|
| 609 |
+
return label
|
| 610 |
+
|
| 611 |
+
to_compare = None
|
| 612 |
+
|
| 613 |
+
elif load_pattern == "pilot_color":
|
| 614 |
+
|
| 615 |
+
study_train = True
|
| 616 |
+
study_eval = False
|
| 617 |
+
|
| 618 |
+
show_plot = False
|
| 619 |
+
save = True
|
| 620 |
+
plot_path = "../case_studies_final_figures/pilot_color"
|
| 621 |
+
|
| 622 |
+
load_pattern = "29-10_SAI_LangColor_CS"
|
| 623 |
+
|
| 624 |
+
require_patterns = [
|
| 625 |
+
"29-10_SAI_LangColor_CS_PPO_CB_env_SocialAI-ELangColorInformationSeekingParamEnv-v1_recurrence_5_lr_1e-4_exploration-bonus-type_cell_exploration-bonus-params__2_50_exploration-bonus-tanh_0.6",
|
| 626 |
+
"29-10_SAI_LangColor_CS_PPO_CBL_env_SocialAI-ELangColorInformationSeekingParamEnv-v1_recurrence_5_lr_1e-4_exploration-bonus-type_lang_exploration-bonus-params__10_50_exploration-bonus-tanh_0.6",
|
| 627 |
+
"29-10_SAI_LangColor_CS_PPO_no_env_SocialAI-ELangColorInformationSeekingParamEnv-v1_recurrence_5_lr_1e-4",
|
| 628 |
+
"29-10_SAI_LangColor_CS_PPO_RIDE_env_SocialAI-ELangColorInformationSeekingParamEnv-v1_recurrence_5_lr_1e-4_exploration-bonus-type_ride_intrinsic-reward-coef_0.01",
|
| 629 |
+
"29-10_SAI_LangColor_CS_PPO_RND_env_SocialAI-ELangColorInformationSeekingParamEnv-v1_recurrence_5_lr_1e-4_exploration-bonus-type_rnd_intrinsic-reward-coef_0.005"
|
| 630 |
+
]
|
| 631 |
+
color_dict = {
|
| 632 |
+
"PPO_RIDE": "orange",
|
| 633 |
+
"PPO_RND": "magenta",
|
| 634 |
+
"PPO_no": "maroon",
|
| 635 |
+
"PPO_CBL": "green",
|
| 636 |
+
"PPO_CB": "blue",
|
| 637 |
+
}
|
| 638 |
+
|
| 639 |
+
def label_parser(label):
|
| 640 |
+
label = label.split("_env_")[0].split("SAI_")[1]
|
| 641 |
+
label=label.replace("LangColor_CS_", "")
|
| 642 |
+
return label
|
| 643 |
+
|
| 644 |
+
to_compare = None
|
| 645 |
+
|
| 646 |
+
elif load_pattern == "formats_train":
|
| 647 |
+
|
| 648 |
+
study_train = True
|
| 649 |
+
study_eval = False
|
| 650 |
+
|
| 651 |
+
plot_aggregated_test = False
|
| 652 |
+
plot_only_aggregated_test = False
|
| 653 |
+
|
| 654 |
+
max_x_lim = 45
|
| 655 |
+
|
| 656 |
+
load_pattern = "_"
|
| 657 |
+
|
| 658 |
+
test_envs_to_plot = None
|
| 659 |
+
plot_path = "../case_studies_final_figures/Formats_train"
|
| 660 |
+
|
| 661 |
+
require_patterns = [
|
| 662 |
+
"21-01_formats_50M_CBL",
|
| 663 |
+
"05-01_scaffolding_50M_no_acl",
|
| 664 |
+
]
|
| 665 |
+
|
| 666 |
+
to_compare = [
|
| 667 |
+
("21-01_formats_50M_CBL", "05-01_scaffolding_50M_no_acl", "black")
|
| 668 |
+
]
|
| 669 |
+
|
| 670 |
+
|
| 671 |
+
def label_parser(label):
|
| 672 |
+
label = label.replace("05-01_scaffolding_50M_no_acl", "PPO_no_bonus")
|
| 673 |
+
label = label.replace("21-01_formats_50M_CBL", "PPO_CBL")
|
| 674 |
+
return label
|
| 675 |
+
|
| 676 |
+
elif load_pattern == "adversarial":
|
| 677 |
+
|
| 678 |
+
show_plot = False
|
| 679 |
+
save = True
|
| 680 |
+
|
| 681 |
+
study_train = True
|
| 682 |
+
study_eval = False
|
| 683 |
+
|
| 684 |
+
plot_aggregated_test = False
|
| 685 |
+
plot_only_aggregated_test = False
|
| 686 |
+
|
| 687 |
+
# max_x_lim = 45
|
| 688 |
+
|
| 689 |
+
smooth_factor = 0
|
| 690 |
+
|
| 691 |
+
load_pattern = "_"
|
| 692 |
+
|
| 693 |
+
test_envs_to_plot = None
|
| 694 |
+
plot_path = "../case_studies_final_figures/adversarial"
|
| 695 |
+
|
| 696 |
+
require_patterns = [
|
| 697 |
+
"26-01_Adversarial_2M_PPO_CB_hidden_npc",
|
| 698 |
+
"26-01_Adversarial_2M_PPO_CB_asoc",
|
| 699 |
+
"26-01_Adversarial_2M_PPO_CB",
|
| 700 |
+
]
|
| 701 |
+
|
| 702 |
+
to_compare = [
|
| 703 |
+
("26-01_Adversarial_2M_PPO_CB", "26-01_Adversarial_2M_PPO_CB_hidden_npc", "orange"),
|
| 704 |
+
("26-01_Adversarial_2M_PPO_CB", "26-01_Adversarial_2M_PPO_CB_asoc", "green")
|
| 705 |
+
]
|
| 706 |
+
|
| 707 |
+
def label_parser(label):
|
| 708 |
+
label = label.replace("26-01_Adversarial_2M_PPO_CB_hidden_npc", "PPO_CB_invisible_peer")
|
| 709 |
+
label = label.replace("26-01_Adversarial_2M_PPO_CB_asoc", "PPO_CB_no_peer")
|
| 710 |
+
label = label.replace("26-01_Adversarial_2M_PPO_CB", "PPO_CB")
|
| 711 |
+
return label
|
| 712 |
+
|
| 713 |
+
color_dict = {
|
| 714 |
+
"PPO_CB": "blue",
|
| 715 |
+
"PPO_CB_invisible_peer": "orange",
|
| 716 |
+
"PPO_CB_no_peer": "green",
|
| 717 |
+
}
|
| 718 |
+
|
| 719 |
+
elif load_pattern == "adversarial_stumps":
|
| 720 |
+
|
| 721 |
+
|
| 722 |
+
study_train = True
|
| 723 |
+
study_eval = False
|
| 724 |
+
|
| 725 |
+
plot_aggregated_test = False
|
| 726 |
+
plot_only_aggregated_test = False
|
| 727 |
+
|
| 728 |
+
# max_x_lim = 45
|
| 729 |
+
|
| 730 |
+
smooth_factor = 0
|
| 731 |
+
|
| 732 |
+
load_pattern = "_"
|
| 733 |
+
|
| 734 |
+
test_envs_to_plot = None
|
| 735 |
+
plot_path = "../case_studies_final_figures/adversarial_stumps"
|
| 736 |
+
|
| 737 |
+
require_patterns = [
|
| 738 |
+
"26-01_Adversarial_5M_Stumps_PPO_CB_hidden_npc",
|
| 739 |
+
"26-01_Adversarial_5M_Stumps_PPO_CB_asoc",
|
| 740 |
+
"26-01_Adversarial_5M_Stumps_PPO_CB",
|
| 741 |
+
]
|
| 742 |
+
|
| 743 |
+
to_compare = [
|
| 744 |
+
("26-01_Adversarial_5M_Stumps_PPO_CB", "26-01_Adversarial_5M_Stumps_PPO_CB_hidden_npc", "orange"),
|
| 745 |
+
("26-01_Adversarial_5M_Stumps_PPO_CB", "26-01_Adversarial_5M_Stumps_PPO_CB_asoc", "green")
|
| 746 |
+
]
|
| 747 |
+
|
| 748 |
+
def label_parser(label):
|
| 749 |
+
label = label.replace("26-01_Adversarial_5M_Stumps_PPO_CB_hidden_npc", "PPO_CB_invisible_peer")
|
| 750 |
+
label = label.replace("26-01_Adversarial_5M_Stumps_PPO_CB_asoc", "PPO_CB_no_peer")
|
| 751 |
+
label = label.replace("26-01_Adversarial_5M_Stumps_PPO_CB", "PPO_CB")
|
| 752 |
+
return label
|
| 753 |
+
|
| 754 |
+
color_dict = {
|
| 755 |
+
"PPO_CB": "blue",
|
| 756 |
+
"PPO_CB_invisible_peer": "orange",
|
| 757 |
+
"PPO_CB_no_peer": "green",
|
| 758 |
+
}
|
| 759 |
+
|
| 760 |
+
else:
|
| 761 |
+
plot_path = "plots/testplot"
|
| 762 |
+
|
| 763 |
+
require_patterns = [
|
| 764 |
+
"_",
|
| 765 |
+
# pointing
|
| 766 |
+
# "04-01_Pointing_CB_heldout_doors",
|
| 767 |
+
]
|
| 768 |
+
|
| 769 |
+
if to_compare is None and len(require_patterns) == 2 and "_" not in require_patterns:
|
| 770 |
+
# if only two curves compare those two automatically
|
| 771 |
+
to_compare = [(require_patterns[0], require_patterns[1], "black")]
|
| 772 |
+
|
| 773 |
+
|
| 774 |
+
|
| 775 |
+
save=False
|
| 776 |
+
show_plot = True
|
| 777 |
+
|
| 778 |
+
|
| 779 |
+
# all of those
|
| 780 |
+
include_patterns = []
|
| 781 |
+
#include_patterns = ["rec_5"]
|
| 782 |
+
|
| 783 |
+
fontsize = 20
|
| 784 |
+
legend_fontsize = 20
|
| 785 |
+
linewidth = 5
|
| 786 |
+
# linewidth = 1
|
| 787 |
+
|
| 788 |
+
leg_args = {
|
| 789 |
+
'fontsize': legend_fontsize
|
| 790 |
+
}
|
| 791 |
+
|
| 792 |
+
title_fontsize = int(fontsize*1.2)
|
| 793 |
+
|
| 794 |
+
|
| 795 |
+
storage_dir = "storage/"
|
| 796 |
+
if load_pattern.startswith(storage_dir):
|
| 797 |
+
load_pattern = load_pattern[len(storage_dir):]
|
| 798 |
+
|
| 799 |
+
if load_pattern.startswith("./storage/"):
|
| 800 |
+
load_pattern = load_pattern[len("./storage/"):]
|
| 801 |
+
|
| 802 |
+
get_datasets(storage_dir, str(load_pattern), load_subsample_step=load_subsample_step, ignore_patterns=ignore_patterns, require_patterns=require_patterns)
|
| 803 |
+
|
| 804 |
+
label_parser_dict = {
|
| 805 |
+
# "PPO_CB": "PPO_CB",
|
| 806 |
+
# "02-06_AppleStealing_experiments_cb_bonus_angle_occ_env_SocialAI-OthersPerceptionInferenceParamEnv-v1_exploration-bonus-type_cell": "NPC_visible",
|
| 807 |
+
}
|
| 808 |
+
|
| 809 |
+
env_type = str(load_pattern)
|
| 810 |
+
|
| 811 |
+
fig_type = "test"
|
| 812 |
+
try:
|
| 813 |
+
top_n = int(sys.argv[2])
|
| 814 |
+
except:
|
| 815 |
+
top_n = 8
|
| 816 |
+
|
| 817 |
+
to_remove = []
|
| 818 |
+
|
| 819 |
+
for tr_ in to_remove:
|
| 820 |
+
if tr_ in models_saves:
|
| 821 |
+
del models_saves[tr_]
|
| 822 |
+
|
| 823 |
+
print("Loaded:")
|
| 824 |
+
print("\n".join(list(models_saves.keys())))
|
| 825 |
+
|
| 826 |
+
|
| 827 |
+
if per_model_colors: # order runs for legend order as in per_models_colors, with corresponding colors
|
| 828 |
+
ordered_labels = OrderedDict()
|
| 829 |
+
for teacher_type in per_model_colors.keys():
|
| 830 |
+
for k,v in labels.items():
|
| 831 |
+
if teacher_type in k:
|
| 832 |
+
ordered_labels[k] = v
|
| 833 |
+
labels = ordered_labels
|
| 834 |
+
else:
|
| 835 |
+
print('not using per_model_color')
|
| 836 |
+
for k in models_saves.keys():
|
| 837 |
+
labels[k] = k
|
| 838 |
+
|
| 839 |
+
# Plot utils
|
| 840 |
+
def plot_with_shade(subplot_nb, ax, x, y, err, color, shade_color, label,
|
| 841 |
+
legend=False, leg_loc='best', title=None,
|
| 842 |
+
ylim=[0, 100], xlim=[0, 40], leg_args={}, leg_linewidth=13.0, linewidth=10.0, labelsize=20, fontsize=20, title_fontsize=30,
|
| 843 |
+
zorder=None, xlabel='Perf', ylabel='Env steps', linestyle="-", xnbins=3, ynbins=3):
|
| 844 |
+
|
| 845 |
+
#plt.rcParams.update({'font.size': 15})
|
| 846 |
+
ax.locator_params(axis='x', nbins=xnbins)
|
| 847 |
+
ax.locator_params(axis='y', nbins=ynbins)
|
| 848 |
+
|
| 849 |
+
ax.tick_params(axis='y', which='both', labelsize=labelsize)
|
| 850 |
+
ax.tick_params(axis='x', which='both', labelsize=labelsize*0.8)
|
| 851 |
+
# ax.tick_params(axis='both', which='both', labelsize="small")
|
| 852 |
+
|
| 853 |
+
# ax.scatter(x, y, color=color,linewidth=linewidth,zorder=zorder, linestyle=linestyle)
|
| 854 |
+
ax.plot(x, y, color=color, label=label, linewidth=linewidth, zorder=zorder, linestyle=linestyle)
|
| 855 |
+
|
| 856 |
+
if not np.array_equal(err, np.zeros_like(err)):
|
| 857 |
+
ax.fill_between(x, y-err, y+err, color=shade_color, alpha=0.2)
|
| 858 |
+
|
| 859 |
+
if legend:
|
| 860 |
+
leg = ax.legend(loc=leg_loc, **leg_args) # 34
|
| 861 |
+
for legobj in leg.legendHandles:
|
| 862 |
+
legobj.set_linewidth(leg_linewidth)
|
| 863 |
+
|
| 864 |
+
ax.set_xlabel(xlabel, fontsize=fontsize)
|
| 865 |
+
if subplot_nb == 0:
|
| 866 |
+
ax.set_ylabel(ylabel, fontsize=fontsize, labelpad=2)
|
| 867 |
+
|
| 868 |
+
ax.set_xlim(xmin=xlim[0], xmax=xlim[1])
|
| 869 |
+
ax.set_ylim(bottom=ylim[0], top=ylim[1])
|
| 870 |
+
if title:
|
| 871 |
+
ax.set_title(title, fontsize=title_fontsize)
|
| 872 |
+
|
| 873 |
+
|
| 874 |
+
|
| 875 |
+
|
| 876 |
+
# only one figure is drawn -> maybe we can add loops later
|
| 877 |
+
assert len(metrics) == 1
|
| 878 |
+
|
| 879 |
+
f, ax = plt.subplots(1, 1, figsize=(9.0, 9.0))
|
| 880 |
+
|
| 881 |
+
if len(metrics) == 1:
|
| 882 |
+
ax = [ax]
|
| 883 |
+
|
| 884 |
+
# max_y = -np.inf
|
| 885 |
+
min_y = np.inf
|
| 886 |
+
|
| 887 |
+
max_steps = 0
|
| 888 |
+
exclude_patterns = []
|
| 889 |
+
|
| 890 |
+
metric = metrics[0]
|
| 891 |
+
|
| 892 |
+
ylabel = {
|
| 893 |
+
"success_rate_mean": "Success rate (%)",
|
| 894 |
+
"exploration_bonus_mean": "Exploration bonus",
|
| 895 |
+
"NPC_intro": "Successful introduction (%)",
|
| 896 |
+
}.get(metric, metric)
|
| 897 |
+
|
| 898 |
+
# for metric_i, metric in enumerate(metrics):
|
| 899 |
+
default_colors = default_colors_.copy()
|
| 900 |
+
|
| 901 |
+
if study_train:
|
| 902 |
+
for model_i, model_id in enumerate(models_saves.keys()):
|
| 903 |
+
|
| 904 |
+
#excluding some experiments
|
| 905 |
+
if any([ex_pat in model_id for ex_pat in exclude_patterns]):
|
| 906 |
+
continue
|
| 907 |
+
|
| 908 |
+
if len(include_patterns) > 0:
|
| 909 |
+
if not any([in_pat in model_id for in_pat in include_patterns]):
|
| 910 |
+
continue
|
| 911 |
+
|
| 912 |
+
runs_data = models_saves[model_id]['data']
|
| 913 |
+
ys = []
|
| 914 |
+
|
| 915 |
+
if runs_data[0]['frames'][1] == 'frames':
|
| 916 |
+
runs_data[0]['frames'] = list(filter(('frames').__ne__, runs_data[0]['frames']))
|
| 917 |
+
|
| 918 |
+
if per_seed:
|
| 919 |
+
min_len = None
|
| 920 |
+
|
| 921 |
+
else:
|
| 922 |
+
# determine minimal run length across seeds
|
| 923 |
+
lens = [len(run['frames']) for run in runs_data if len(run['frames'])]
|
| 924 |
+
minimum = sorted(lens)[-min(top_n, len(lens))]
|
| 925 |
+
min_len = np.min([len(run['frames']) for run in runs_data if len(run['frames']) >= minimum])
|
| 926 |
+
|
| 927 |
+
# keep only top k
|
| 928 |
+
runs_data = [run for run in runs_data if len(run['frames']) >= minimum]
|
| 929 |
+
|
| 930 |
+
# min_len = np.min([len(run['frames']) for run in runs_data if len(run['frames']) > 10])
|
| 931 |
+
|
| 932 |
+
# compute env steps (x axis)
|
| 933 |
+
longest_id = np.argmax([len(rd['frames']) for rd in runs_data])
|
| 934 |
+
steps = np.array(runs_data[longest_id]['frames'], dtype=np.int) / steps_denom
|
| 935 |
+
steps = steps[:min_len]
|
| 936 |
+
|
| 937 |
+
for run in runs_data:
|
| 938 |
+
if metric not in run:
|
| 939 |
+
raise ValueError(f"Metric {metric} not found. Possible metrics: {list(run.keys())}")
|
| 940 |
+
|
| 941 |
+
data = run[metric]
|
| 942 |
+
|
| 943 |
+
# checking for header
|
| 944 |
+
if data[1] == metric:
|
| 945 |
+
data = np.array(list(filter((metric).__ne__, data)), dtype=np.float16)
|
| 946 |
+
|
| 947 |
+
if per_seed:
|
| 948 |
+
ys.append(data)
|
| 949 |
+
|
| 950 |
+
else:
|
| 951 |
+
if len(data) >= min_len:
|
| 952 |
+
# discard extra
|
| 953 |
+
if len(data) > min_len:
|
| 954 |
+
print("run has too many {} datapoints ({}). Discarding {}".format(model_id, len(data),
|
| 955 |
+
len(data) - min_len))
|
| 956 |
+
data = data[0:min_len]
|
| 957 |
+
ys.append(data)
|
| 958 |
+
else:
|
| 959 |
+
raise ValueError("How can data be < min_len if it was capped above")
|
| 960 |
+
|
| 961 |
+
ys_same_len = ys
|
| 962 |
+
|
| 963 |
+
# computes stats
|
| 964 |
+
n_seeds = len(ys_same_len)
|
| 965 |
+
|
| 966 |
+
if per_seed:
|
| 967 |
+
sems = np.array(ys_same_len)
|
| 968 |
+
means = np.array(ys_same_len)
|
| 969 |
+
stds = np.zeros_like(means)
|
| 970 |
+
color = default_colors[model_i]
|
| 971 |
+
|
| 972 |
+
else:
|
| 973 |
+
sems = np.std(ys_same_len, axis=0)/np.sqrt(len(ys_same_len)) # sem
|
| 974 |
+
stds = np.std(ys_same_len, axis=0) # std
|
| 975 |
+
means = np.mean(ys_same_len, axis=0)
|
| 976 |
+
color = default_colors[model_i]
|
| 977 |
+
|
| 978 |
+
if metric == 'duration':
|
| 979 |
+
means = means / 3600
|
| 980 |
+
sems = sems / 3600
|
| 981 |
+
stds = stds / 3600
|
| 982 |
+
|
| 983 |
+
if per_seed:
|
| 984 |
+
# plot x y bounds
|
| 985 |
+
curr_max_steps = np.max(np.max(steps))
|
| 986 |
+
|
| 987 |
+
else:
|
| 988 |
+
# plot x y bounds
|
| 989 |
+
curr_max_steps = np.max(steps)
|
| 990 |
+
|
| 991 |
+
if curr_max_steps > max_steps:
|
| 992 |
+
max_steps = curr_max_steps
|
| 993 |
+
|
| 994 |
+
if subsample_step:
|
| 995 |
+
steps = steps[0::subsample_step]
|
| 996 |
+
means = means[0::subsample_step]
|
| 997 |
+
stds = stds[0::subsample_step]
|
| 998 |
+
sems = sems[0::subsample_step]
|
| 999 |
+
ys_same_len = [y[0::subsample_step] for y in ys_same_len]
|
| 1000 |
+
|
| 1001 |
+
# display seeds separately
|
| 1002 |
+
if per_seed:
|
| 1003 |
+
for s_i, seed_ys in enumerate(ys_same_len):
|
| 1004 |
+
|
| 1005 |
+
label = label_parser(model_id)
|
| 1006 |
+
|
| 1007 |
+
if study_eval:
|
| 1008 |
+
label = label + "_train_"
|
| 1009 |
+
|
| 1010 |
+
label = label + f"(s:{s_i})"
|
| 1011 |
+
|
| 1012 |
+
if label in color_dict:
|
| 1013 |
+
color = color_dict[label]
|
| 1014 |
+
else:
|
| 1015 |
+
color = default_colors[model_i*20+s_i]
|
| 1016 |
+
|
| 1017 |
+
curve_ID = f"{model_id}_{s_i}"
|
| 1018 |
+
assert np.array_equal(stds, np.zeros_like(stds))
|
| 1019 |
+
|
| 1020 |
+
if smooth_factor:
|
| 1021 |
+
means = smooth(means, smooth_factor)
|
| 1022 |
+
|
| 1023 |
+
to_plot_dict[curve_ID] = {
|
| 1024 |
+
"label": label,
|
| 1025 |
+
"steps": steps,
|
| 1026 |
+
"means": seed_ys,
|
| 1027 |
+
"stds": stds,
|
| 1028 |
+
"ys": ys_same_len,
|
| 1029 |
+
"color": color
|
| 1030 |
+
}
|
| 1031 |
+
|
| 1032 |
+
else:
|
| 1033 |
+
label = label_parser(model_id)
|
| 1034 |
+
|
| 1035 |
+
if study_eval:
|
| 1036 |
+
label = label+"(train)"
|
| 1037 |
+
|
| 1038 |
+
if color_dict:
|
| 1039 |
+
color = color_dict[label]
|
| 1040 |
+
else:
|
| 1041 |
+
color = default_colors[model_i]
|
| 1042 |
+
|
| 1043 |
+
if smooth_factor:
|
| 1044 |
+
means = smooth(means, smooth_factor)
|
| 1045 |
+
stds = smooth(stds, smooth_factor)
|
| 1046 |
+
|
| 1047 |
+
to_plot_dict[model_id] = {
|
| 1048 |
+
"label": label,
|
| 1049 |
+
"steps": steps,
|
| 1050 |
+
"means": means,
|
| 1051 |
+
"stds": stds,
|
| 1052 |
+
"sems": sems,
|
| 1053 |
+
"ys": ys_same_len,
|
| 1054 |
+
"color": color,
|
| 1055 |
+
}
|
| 1056 |
+
|
| 1057 |
+
|
| 1058 |
+
if study_eval:
|
| 1059 |
+
print("Evaluation")
|
| 1060 |
+
# evaluation sets
|
| 1061 |
+
number_of_eval_envs = max(list([len(v.keys()) for v in model_eval_data.values()]))
|
| 1062 |
+
|
| 1063 |
+
if plot_aggregated_test:
|
| 1064 |
+
number_of_eval_envs += 1
|
| 1065 |
+
|
| 1066 |
+
if number_of_eval_envs == 0:
|
| 1067 |
+
print("No eval envs")
|
| 1068 |
+
exit()
|
| 1069 |
+
|
| 1070 |
+
default_colors = default_colors_.copy()
|
| 1071 |
+
|
| 1072 |
+
test_summary_dict = defaultdict(dict)
|
| 1073 |
+
test_summary_dict_colors = defaultdict(dict)
|
| 1074 |
+
|
| 1075 |
+
for model_i, model_id in enumerate(model_eval_data.keys()):
|
| 1076 |
+
# excluding some experiments
|
| 1077 |
+
if any([ex_pat in model_id for ex_pat in exclude_patterns]):
|
| 1078 |
+
continue
|
| 1079 |
+
if len(include_patterns) > 0:
|
| 1080 |
+
if not any([in_pat in model_id for in_pat in include_patterns]):
|
| 1081 |
+
continue
|
| 1082 |
+
|
| 1083 |
+
# test envs
|
| 1084 |
+
test_envs = model_eval_data[model_id].items()
|
| 1085 |
+
|
| 1086 |
+
# filter unwanted eval envs
|
| 1087 |
+
if test_envs_to_plot is not None:
|
| 1088 |
+
test_envs = [(name, data) for name, data in test_envs if name in test_envs_to_plot]
|
| 1089 |
+
|
| 1090 |
+
# computes stats
|
| 1091 |
+
if sort_test:
|
| 1092 |
+
test_envs_sorted = list(sorted(test_envs, key=lambda kv: sort_test_set(kv[0])))
|
| 1093 |
+
else:
|
| 1094 |
+
test_envs_sorted = list(test_envs)
|
| 1095 |
+
|
| 1096 |
+
if plot_aggregated_test:
|
| 1097 |
+
agg_means = []
|
| 1098 |
+
|
| 1099 |
+
for env_i, (test_env, env_data) in enumerate(test_envs_sorted):
|
| 1100 |
+
ys_same_len = env_data["values"]
|
| 1101 |
+
steps = env_data["steps"].mean(0) / steps_denom
|
| 1102 |
+
n_seeds = len(ys_same_len)
|
| 1103 |
+
|
| 1104 |
+
if per_seed:
|
| 1105 |
+
sems = np.array(ys_same_len)
|
| 1106 |
+
stds = np.array(ys_same_len)
|
| 1107 |
+
means = np.array(ys_same_len)
|
| 1108 |
+
color = default_colors[model_i]
|
| 1109 |
+
|
| 1110 |
+
# plot x y bounds
|
| 1111 |
+
curr_max_steps = np.max(np.max(steps))
|
| 1112 |
+
|
| 1113 |
+
else:
|
| 1114 |
+
sems = np.std(ys_same_len, axis=0) / np.sqrt(len(ys_same_len)) # sem
|
| 1115 |
+
stds = np.std(ys_same_len, axis=0) # std
|
| 1116 |
+
means = np.mean(ys_same_len, axis=0)
|
| 1117 |
+
color = default_colors[model_i]
|
| 1118 |
+
|
| 1119 |
+
curr_max_steps = np.max(steps)
|
| 1120 |
+
|
| 1121 |
+
if plot_aggregated_test:
|
| 1122 |
+
agg_means.append(means)
|
| 1123 |
+
|
| 1124 |
+
|
| 1125 |
+
x_lim = max(steps[-1], x_lim)
|
| 1126 |
+
x_lim = min(max_x_lim, x_lim)
|
| 1127 |
+
|
| 1128 |
+
eval_metric_name = {
|
| 1129 |
+
"test_success_rates": "Success rate",
|
| 1130 |
+
'exploration_bonus_mean': "Exploration bonus",
|
| 1131 |
+
}.get(eval_metric, eval_metric)
|
| 1132 |
+
|
| 1133 |
+
test_env_name = test_env.replace("Env", "").replace("Test", "")
|
| 1134 |
+
|
| 1135 |
+
env_types = ["InformationSeeking", "Collaboration", "PerspectiveTaking"]
|
| 1136 |
+
for env_type in env_types:
|
| 1137 |
+
if env_type in test_env_name:
|
| 1138 |
+
test_env_name = test_env_name.replace(env_type, "")
|
| 1139 |
+
test_env_name += f"\n({env_type})"
|
| 1140 |
+
|
| 1141 |
+
if per_seed:
|
| 1142 |
+
for s_i, seed_ys in enumerate(ys_same_len):
|
| 1143 |
+
label = label_parser(model_id) + f"_{test_env}" + f"(s:{s_i})"
|
| 1144 |
+
|
| 1145 |
+
if eval_smooth_factor:
|
| 1146 |
+
seed_ys = smooth(seed_ys, eval_smooth_factor)
|
| 1147 |
+
|
| 1148 |
+
curve_ID = f"{model_id}_{test_env}_{s_i}"
|
| 1149 |
+
|
| 1150 |
+
to_plot_dict[curve_ID] = {
|
| 1151 |
+
"label": label,
|
| 1152 |
+
"steps": steps,
|
| 1153 |
+
"means": seed_ys,
|
| 1154 |
+
"stds": np.zeros_like(seed_ys),
|
| 1155 |
+
"ys": ys_same_len,
|
| 1156 |
+
"color": color
|
| 1157 |
+
}
|
| 1158 |
+
else:
|
| 1159 |
+
if len(test_envs_sorted) > 1:
|
| 1160 |
+
label = label_parser(model_id) + f"_{test_env}"
|
| 1161 |
+
else:
|
| 1162 |
+
label = label_parser(model_id)
|
| 1163 |
+
|
| 1164 |
+
if study_train:
|
| 1165 |
+
label=label+"(test)"
|
| 1166 |
+
|
| 1167 |
+
if not plot_only_aggregated_test:
|
| 1168 |
+
|
| 1169 |
+
if label in color_dict:
|
| 1170 |
+
color = color_dict[label]
|
| 1171 |
+
else:
|
| 1172 |
+
color = default_colors[model_i*len(test_envs_sorted)+env_i]
|
| 1173 |
+
|
| 1174 |
+
if legend_show_n_seeds:
|
| 1175 |
+
label = label + "({})".format(n_seeds)
|
| 1176 |
+
|
| 1177 |
+
if eval_smooth_factor:
|
| 1178 |
+
means = smooth(means, eval_smooth_factor)
|
| 1179 |
+
stds = smooth(stds, eval_smooth_factor)
|
| 1180 |
+
sems = smooth(sems, eval_smooth_factor)
|
| 1181 |
+
|
| 1182 |
+
to_plot_dict[model_id+f"_{test_env}"] = {
|
| 1183 |
+
"label": label,
|
| 1184 |
+
"steps": steps,
|
| 1185 |
+
"means": means,
|
| 1186 |
+
"stds": stds,
|
| 1187 |
+
"sems": sems,
|
| 1188 |
+
"ys": ys_same_len,
|
| 1189 |
+
"color": color,
|
| 1190 |
+
}
|
| 1191 |
+
|
| 1192 |
+
if plot_aggregated_test:
|
| 1193 |
+
|
| 1194 |
+
ys_same_len = agg_means
|
| 1195 |
+
agg_means = np.array(agg_means)
|
| 1196 |
+
agg_mean = agg_means.mean(axis=0)
|
| 1197 |
+
agg_std = agg_means.std(axis=0) # std
|
| 1198 |
+
agg_sems = ...
|
| 1199 |
+
|
| 1200 |
+
label = label_parser(model_id)
|
| 1201 |
+
|
| 1202 |
+
if study_train:
|
| 1203 |
+
label = label + "(train)"
|
| 1204 |
+
|
| 1205 |
+
if eval_smooth_factor:
|
| 1206 |
+
agg_mean = smooth(agg_mean, eval_smooth_factor)
|
| 1207 |
+
agg_std = smooth(agg_std, eval_smooth_factor)
|
| 1208 |
+
agg_sems = smooth(agg_sems, eval_smooth_factor)
|
| 1209 |
+
|
| 1210 |
+
if per_seed:
|
| 1211 |
+
print("Not smooth aggregated because of per seed")
|
| 1212 |
+
for s_i, (seed_ys, seed_st) in enumerate(zip(agg_mean, agg_std)):
|
| 1213 |
+
seed_c = default_colors[model_i + s_i]
|
| 1214 |
+
label = str(s_i)
|
| 1215 |
+
|
| 1216 |
+
to_plot_dict[curve_ID] = {
|
| 1217 |
+
"label": label,
|
| 1218 |
+
"steps": steps,
|
| 1219 |
+
"means": seed_ys,
|
| 1220 |
+
"stds": seed_st,
|
| 1221 |
+
"ys": ys_same_len,
|
| 1222 |
+
"color": color
|
| 1223 |
+
}
|
| 1224 |
+
else:
|
| 1225 |
+
|
| 1226 |
+
if label in color_dict:
|
| 1227 |
+
color = color_dict[label]
|
| 1228 |
+
|
| 1229 |
+
else:
|
| 1230 |
+
color = default_colors[model_i]
|
| 1231 |
+
|
| 1232 |
+
to_plot_dict[model_id+"_agg_test"] = {
|
| 1233 |
+
"label": label,
|
| 1234 |
+
"steps": steps,
|
| 1235 |
+
"means": agg_mean,
|
| 1236 |
+
"stds": agg_std,
|
| 1237 |
+
"sems": agg_sems,
|
| 1238 |
+
"ys": ys_same_len,
|
| 1239 |
+
"color": color,
|
| 1240 |
+
}
|
| 1241 |
+
|
| 1242 |
+
|
| 1243 |
+
# should be labels
|
| 1244 |
+
to_scatter_dict = {}
|
| 1245 |
+
|
| 1246 |
+
if to_compare is not None:
|
| 1247 |
+
for comp_i, (a_model_id, b_model_id, color) in enumerate(to_compare):
|
| 1248 |
+
|
| 1249 |
+
a_data = to_plot_dict[a_model_id]["ys"]
|
| 1250 |
+
b_data = to_plot_dict[b_model_id]["ys"]
|
| 1251 |
+
|
| 1252 |
+
steps = to_plot_dict[a_model_id]["steps"]
|
| 1253 |
+
|
| 1254 |
+
if color == "auto_color":
|
| 1255 |
+
color = to_plot_dict[a_model_id]["color"]
|
| 1256 |
+
|
| 1257 |
+
if len(a_data[0]) != len(b_data[0]):
|
| 1258 |
+
# extract steps present in both
|
| 1259 |
+
a_steps = to_plot_dict[a_model_id]["steps"]
|
| 1260 |
+
b_steps = to_plot_dict[b_model_id]["steps"]
|
| 1261 |
+
|
| 1262 |
+
steps = list(set(a_steps) & set(b_steps))
|
| 1263 |
+
|
| 1264 |
+
# keep only the values for those steps
|
| 1265 |
+
mask_a = [(a_s in steps) for a_s in a_steps]
|
| 1266 |
+
a_data = np.array(a_data)[:, mask_a]
|
| 1267 |
+
|
| 1268 |
+
mask_b = [(b_s in steps) for b_s in b_steps]
|
| 1269 |
+
b_data = np.array(b_data)[:, mask_b]
|
| 1270 |
+
|
| 1271 |
+
p = stats.ttest_ind(
|
| 1272 |
+
a_data,
|
| 1273 |
+
b_data,
|
| 1274 |
+
equal_var=False
|
| 1275 |
+
).pvalue
|
| 1276 |
+
|
| 1277 |
+
steps = [s for s, p in zip(steps, p) if p < test_p]
|
| 1278 |
+
|
| 1279 |
+
ys = [1.02+0.02*comp_i]*len(steps)
|
| 1280 |
+
|
| 1281 |
+
to_scatter_dict[f"compare_{a_model_id}_{b_model_id}"] = {
|
| 1282 |
+
"label": "",
|
| 1283 |
+
"xs": steps,
|
| 1284 |
+
"ys": ys,
|
| 1285 |
+
"color": color,
|
| 1286 |
+
}
|
| 1287 |
+
|
| 1288 |
+
for scatter_i, (scatter_ID, scatter_id_data) in enumerate(to_scatter_dict.items()):
|
| 1289 |
+
|
| 1290 |
+
# unpack data
|
| 1291 |
+
label, xs, ys, color = (
|
| 1292 |
+
scatter_id_data["label"],
|
| 1293 |
+
scatter_id_data["xs"],
|
| 1294 |
+
scatter_id_data["ys"],
|
| 1295 |
+
scatter_id_data["color"],
|
| 1296 |
+
)
|
| 1297 |
+
|
| 1298 |
+
xlabel = f"Env steps (1e6)"
|
| 1299 |
+
|
| 1300 |
+
plt.scatter(
|
| 1301 |
+
xs,
|
| 1302 |
+
ys,
|
| 1303 |
+
color=color,
|
| 1304 |
+
marker="x"
|
| 1305 |
+
)
|
| 1306 |
+
|
| 1307 |
+
summary_dict[label] = xs[-1]
|
| 1308 |
+
summary_dict_colors[label] = color
|
| 1309 |
+
|
| 1310 |
+
for curve_i, (curve_ID, model_id_data) in enumerate(to_plot_dict.items()):
|
| 1311 |
+
|
| 1312 |
+
# unpack data
|
| 1313 |
+
label, steps, means, stds, sems, ys, color = (
|
| 1314 |
+
model_id_data["label"],
|
| 1315 |
+
model_id_data["steps"],
|
| 1316 |
+
model_id_data["means"],
|
| 1317 |
+
model_id_data["stds"],
|
| 1318 |
+
model_id_data["sems"],
|
| 1319 |
+
model_id_data["ys"],
|
| 1320 |
+
model_id_data["color"]
|
| 1321 |
+
)
|
| 1322 |
+
|
| 1323 |
+
# if smooth_factor:
|
| 1324 |
+
# means = smooth(means, smooth_factor)
|
| 1325 |
+
# stds = smooth(stds, smooth_factor)
|
| 1326 |
+
|
| 1327 |
+
if legend_show_n_seeds:
|
| 1328 |
+
n_seeds = len(ys)
|
| 1329 |
+
label = label+"({})".format(n_seeds)
|
| 1330 |
+
|
| 1331 |
+
|
| 1332 |
+
x_lim = max(steps[-1], x_lim)
|
| 1333 |
+
x_lim = min(max_x_lim, x_lim)
|
| 1334 |
+
|
| 1335 |
+
xlabel = f"Env steps (1e6)"
|
| 1336 |
+
|
| 1337 |
+
|
| 1338 |
+
plot_with_shade(
|
| 1339 |
+
0, ax[0], steps, means, stds, color, color, label,
|
| 1340 |
+
# 0, ax[0], steps, means, sems, color, color, label,
|
| 1341 |
+
legend=draw_legend,
|
| 1342 |
+
xlim=[0, x_lim],
|
| 1343 |
+
ylim=[0, max_y],
|
| 1344 |
+
xlabel=xlabel,
|
| 1345 |
+
ylabel=ylabel,
|
| 1346 |
+
title=None,
|
| 1347 |
+
labelsize=fontsize,
|
| 1348 |
+
fontsize=fontsize,
|
| 1349 |
+
title_fontsize=title_fontsize,
|
| 1350 |
+
linewidth=linewidth,
|
| 1351 |
+
leg_linewidth=5,
|
| 1352 |
+
leg_args=leg_args,
|
| 1353 |
+
xnbins=xnbins,
|
| 1354 |
+
ynbins=ynbins,
|
| 1355 |
+
)
|
| 1356 |
+
|
| 1357 |
+
summary_dict[label] = means[-1]
|
| 1358 |
+
summary_dict_colors[label] = color
|
| 1359 |
+
|
| 1360 |
+
# plot static lines
|
| 1361 |
+
if static_lines:
|
| 1362 |
+
for label, (mean, std, color) in static_lines.items():
|
| 1363 |
+
|
| 1364 |
+
if label == "":
|
| 1365 |
+
label = None
|
| 1366 |
+
|
| 1367 |
+
plot_with_shade(
|
| 1368 |
+
0, ax[0], steps, np.array([mean]*len(steps)), np.array([std]*len(steps)), color, color, label,
|
| 1369 |
+
legend=True,
|
| 1370 |
+
xlim=[0, x_lim],
|
| 1371 |
+
ylim=[0, 1.0],
|
| 1372 |
+
xlabel=f"Env steps (1e6)",
|
| 1373 |
+
ylabel=ylabel,
|
| 1374 |
+
linestyle=":",
|
| 1375 |
+
leg_args=leg_args,
|
| 1376 |
+
fontsize=fontsize,
|
| 1377 |
+
title_fontsize=title_fontsize,
|
| 1378 |
+
xnbins=xnbins,
|
| 1379 |
+
ynbins=ynbins,
|
| 1380 |
+
)
|
| 1381 |
+
|
| 1382 |
+
|
| 1383 |
+
if plot_path:
|
| 1384 |
+
f.savefig(plot_path+".png")
|
| 1385 |
+
f.savefig(plot_path+".svg")
|
| 1386 |
+
print(f"Plot saved to {plot_path}.[png/svg].")
|
| 1387 |
+
|
| 1388 |
+
|
| 1389 |
+
# Summary dict
|
| 1390 |
+
if len(summary_dict) == 0:
|
| 1391 |
+
raise ValueError(f"No experiments found for {load_pattern}.")
|
| 1392 |
+
else:
|
| 1393 |
+
# print summary
|
| 1394 |
+
best = max(summary_dict.values())
|
| 1395 |
+
|
| 1396 |
+
pc = 0.3
|
| 1397 |
+
n = int(len(summary_dict)*pc)
|
| 1398 |
+
print("top n: ", n)
|
| 1399 |
+
|
| 1400 |
+
top_pc = sorted(summary_dict.values())[-n:]
|
| 1401 |
+
bottom_pc = sorted(summary_dict.values())[:n]
|
| 1402 |
+
|
| 1403 |
+
print("legend:")
|
| 1404 |
+
cprint("\tbest", "green")
|
| 1405 |
+
cprint("\ttop {} %".format(pc), "blue")
|
| 1406 |
+
cprint("\tbottom {} %".format(pc), "red")
|
| 1407 |
+
print("\tothers")
|
| 1408 |
+
print()
|
| 1409 |
+
|
| 1410 |
+
for l, p in sorted(summary_dict.items(), key=lambda kv: kv[1]):
|
| 1411 |
+
|
| 1412 |
+
c = summary_dict_colors[l]
|
| 1413 |
+
if p == best:
|
| 1414 |
+
cprint("label: {} ({})".format(l, c), "green")
|
| 1415 |
+
cprint("\t {}:{}".format(metric, p), "green")
|
| 1416 |
+
|
| 1417 |
+
elif p in top_pc:
|
| 1418 |
+
cprint("label: {} ({})".format(l, c), "blue")
|
| 1419 |
+
cprint("\t {}:{}".format(metric, p), "blue")
|
| 1420 |
+
|
| 1421 |
+
elif p in bottom_pc:
|
| 1422 |
+
cprint("label: {} ({})".format(l, c), "red")
|
| 1423 |
+
cprint("\t {}:{}".format(metric, p), "red")
|
| 1424 |
+
|
| 1425 |
+
else:
|
| 1426 |
+
print("label: {} ({})".format(l, c))
|
| 1427 |
+
print("\t {}:{}".format(metric, p))
|
| 1428 |
+
|
| 1429 |
+
|
| 1430 |
+
if show_plot:
|
| 1431 |
+
plt.tight_layout()
|
| 1432 |
+
plt.subplots_adjust(hspace=1.5, wspace=0.5, left=0.1, right=0.9, bottom=0.1, top=0.85)
|
| 1433 |
+
plt.suptitle(super_title)
|
| 1434 |
+
plt.show()
|
| 1435 |
+
plt.close()
|
| 1436 |
+
|
display_LLM_evaluations.py
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
# Opening JSON file
|
| 4 |
+
def load_json(path):
|
| 5 |
+
with open(path) as f:
|
| 6 |
+
data = json.load(f)
|
| 7 |
+
return data
|
| 8 |
+
|
| 9 |
+
random_asocial = load_json(Path("llm_log/random_asocial_04_01_2023_14:28:53/evaluation_log.json"))
|
| 10 |
+
random_boxes = load_json(Path("llm_log/random_boxes_04_01_2023_14:32:17/evaluation_log.json"))
|
| 11 |
+
|
| 12 |
+
ada_asocial = load_json(Path("llm_log/ada_asocial_3_04_01_2023_14:53:16/evaluation_log.json"))
|
| 13 |
+
ada_boxes = load_json(Path("llm_log/ada_3st_boxes_04_01_2023_18:55:38/evaluation_log.json")) # no caretaker
|
| 14 |
+
ada_boxes_c = load_json(Path("llm_log/ada_3st_boxes_caretaker_04_01_2023_20:18:18/evaluation_log.json")) # caretaker
|
| 15 |
+
|
| 16 |
+
davinci_asocial = load_json(Path("llm_log/davinci_asocial_3st_04_01_2023_21:27:23/evaluation_log.json"))
|
| 17 |
+
davinci_boxes = load_json(Path("llm_log/davinci_3st_boxes_04_01_2023_20:37:28/evaluation_log.json"))
|
| 18 |
+
davinci_boxes_c = load_json(Path("llm_log/davinci_3st_boxes_caretaker_04_01_2023_21:17:44/evaluation_log.json"))
|
| 19 |
+
|
| 20 |
+
bloom_560_asocial = load_json(Path("llm_log/bloom_560m_asocial_3st_04_01_2023_14:59:44/evaluation_log.json"))
|
| 21 |
+
bloom_560_boxes = load_json(Path("llm_log/bloom_560_3st_boxes_04_01_2023_20:14:13/evaluation_log.json")) # no caretaker
|
| 22 |
+
bloom_560_boxes_c = load_json(Path("llm_log/bloom_560_3st_boxes_caretaker_04_01_2023_20:05:08/evaluation_log.json")) # caretaker
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
data = [
|
| 26 |
+
random_asocial,
|
| 27 |
+
random_boxes,
|
| 28 |
+
|
| 29 |
+
ada_asocial,
|
| 30 |
+
# ada_boxes,
|
| 31 |
+
ada_boxes_c,
|
| 32 |
+
|
| 33 |
+
davinci_asocial,
|
| 34 |
+
# davinci_boxes,
|
| 35 |
+
davinci_boxes_c,
|
| 36 |
+
|
| 37 |
+
bloom_560_asocial,
|
| 38 |
+
# bloom_560_boxes,
|
| 39 |
+
bloom_560_boxes_c,
|
| 40 |
+
|
| 41 |
+
]
|
| 42 |
+
|
| 43 |
+
for d in data:
|
| 44 |
+
print(f'Model: {d["model"]} Env: {d["env_name"]} {"hist" if d["feed_full_ep"] else ""} ---> {d["mean_success_rate"]} ({len(d["success_rates"])})')
|
| 45 |
+
|
draw_tree.py
ADDED
|
@@ -0,0 +1,104 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
import sys
|
| 3 |
+
|
| 4 |
+
from utils import *
|
| 5 |
+
from gym_minigrid.parametric_env import *
|
| 6 |
+
|
| 7 |
+
class DummyTreeParamEnv(gym.Env):
|
| 8 |
+
"""
|
| 9 |
+
Meta-Environment containing all other environment (multi-task learning)
|
| 10 |
+
"""
|
| 11 |
+
|
| 12 |
+
def __init__(
|
| 13 |
+
self,
|
| 14 |
+
):
|
| 15 |
+
|
| 16 |
+
# construct the tree
|
| 17 |
+
self.parameter_tree = self.construct_tree()
|
| 18 |
+
self.parameter_tree.print_tree()
|
| 19 |
+
|
| 20 |
+
def draw_tree(self, ignore_labels=[], folded_nodes=[]):
|
| 21 |
+
self.parameter_tree.draw_tree("viz/param_tree_{}".format(self.spec.id), ignore_labels=ignore_labels, folded_nodes=folded_nodes)
|
| 22 |
+
|
| 23 |
+
def print_tree(self):
|
| 24 |
+
self.parameter_tree.print_tree()
|
| 25 |
+
|
| 26 |
+
def construct_tree(self):
|
| 27 |
+
tree = ParameterTree()
|
| 28 |
+
|
| 29 |
+
env_type_nd = tree.add_node("Env_type", type="param")
|
| 30 |
+
|
| 31 |
+
# Information seeking
|
| 32 |
+
inf_seeking_nd = tree.add_node("Information_seeking", parent=env_type_nd, type="value")
|
| 33 |
+
|
| 34 |
+
prag_fr_compl_nd = tree.add_node("Introductory_sequence", parent=inf_seeking_nd, type="param")
|
| 35 |
+
tree.add_node("Eye_contact", parent=prag_fr_compl_nd, type="value")
|
| 36 |
+
|
| 37 |
+
# scaffolding
|
| 38 |
+
scaffolding_nd = tree.add_node("Scaffolding", parent=inf_seeking_nd, type="param")
|
| 39 |
+
scaffolding_N_nd = tree.add_node("N", parent=scaffolding_nd, type="value")
|
| 40 |
+
|
| 41 |
+
cue_type_nd = tree.add_node("Cue_type", parent=scaffolding_N_nd, type="param")
|
| 42 |
+
# tree.add_node("Language_Color", parent=cue_type_nd, type="value")
|
| 43 |
+
# tree.add_node("Language_Feedback", parent=cue_type_nd, type="value")
|
| 44 |
+
tree.add_node("Pointing", parent=cue_type_nd, type="value")
|
| 45 |
+
|
| 46 |
+
# N_bo_nd = tree.add_node("N", parent=inf_seeking_nd, type="param")
|
| 47 |
+
# tree.add_node("2", parent=N_bo_nd, type="value")
|
| 48 |
+
|
| 49 |
+
problem_nd = tree.add_node("Problem", parent=inf_seeking_nd, type="param")
|
| 50 |
+
tree.add_node("Boxes", parent=problem_nd, type="value")
|
| 51 |
+
tree.add_node("Switches", parent=problem_nd, type="value")
|
| 52 |
+
tree.add_node("Marbles", parent=problem_nd, type="value")
|
| 53 |
+
tree.add_node("Generators", parent=problem_nd, type="value")
|
| 54 |
+
tree.add_node("Doors", parent=problem_nd, type="value")
|
| 55 |
+
tree.add_node("Levers", parent=problem_nd, type="value")
|
| 56 |
+
|
| 57 |
+
return tree
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
filename = sys.argv[1]
|
| 62 |
+
|
| 63 |
+
if len(sys.argv) > 2:
|
| 64 |
+
env_name = sys.argv[2]
|
| 65 |
+
env = gym.make(env_name)
|
| 66 |
+
|
| 67 |
+
else:
|
| 68 |
+
env = DummyTreeParamEnv()
|
| 69 |
+
|
| 70 |
+
# draw tree
|
| 71 |
+
|
| 72 |
+
folded_nodes = [
|
| 73 |
+
# "Information_Seeking",
|
| 74 |
+
# "Perspective_Inference",
|
| 75 |
+
]
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
# selected_parameters_labels = {
|
| 79 |
+
# "Env_type": "Information_Seeking",
|
| 80 |
+
# "Distractor": "Yes",
|
| 81 |
+
# "Problem": "Boxes",
|
| 82 |
+
# }
|
| 83 |
+
|
| 84 |
+
env.parameter_tree.draw_tree(
|
| 85 |
+
filename=f"viz/{filename}",
|
| 86 |
+
ignore_labels=["Num_of_colors"],
|
| 87 |
+
# selected_parameters=selected_parameters_labels,
|
| 88 |
+
folded_nodes=folded_nodes,
|
| 89 |
+
label_parser={
|
| 90 |
+
"Scaffolding": "Help"
|
| 91 |
+
}
|
| 92 |
+
)
|
| 93 |
+
|
| 94 |
+
# for i in range(3):
|
| 95 |
+
# params = env.parameter_tree.sample_env_params()
|
| 96 |
+
# selected_parameters_labels = {k.label: v.label for k, v in params.items()}
|
| 97 |
+
#
|
| 98 |
+
# env.parameter_tree.draw_tree(
|
| 99 |
+
# filename=f"viz/{filename}_{i}",
|
| 100 |
+
# ignore_labels=["Num_of_colors"],
|
| 101 |
+
# selected_parameters=selected_parameters_labels,
|
| 102 |
+
# folded_nodes=folded_nodes,
|
| 103 |
+
# )
|
| 104 |
+
#
|
draw_trees.sh
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Pointing
|
| 2 |
+
#python draw_tree.py cs_trees/pointing_tree_train SocialAI-EPointingHeldoutDoorsTrainInformationSeekingParamEnv-v1
|
| 3 |
+
#python draw_tree.py cs_trees/pointing_tree_test SocialAI-EPointingDoorsTestInformationSeekingParamEnv-v1
|
| 4 |
+
#
|
| 5 |
+
## Role Reversal
|
| 6 |
+
#python draw_tree.py cs_trees/rr_tree_B_single SocialAI-MarblePassBCollaborationParamEnv-v1
|
| 7 |
+
#python draw_tree.py cs_trees/rr_tree_asoc_single SocialAI-AsocialMarbleCollaborationParamEnv-v1
|
| 8 |
+
#python draw_tree.py cs_trees/rr_tree_B_group SocialAI-RoleReversalGroupExperimentalCollaborationParamEnv-v1
|
| 9 |
+
#python draw_tree.py cs_trees/rr_tree_asoc_group SocialAI-RoleReversalGroupControlCollaborationParamEnv-v1
|
| 10 |
+
#python draw_tree.py cs_trees/rr_tree_A SocialAI-MarblePassACollaborationParamEnv-v1
|
| 11 |
+
#
|
| 12 |
+
## Scaffolding
|
| 13 |
+
#python draw_tree.py cs_trees/scaf_tree_test SocialAI-AELangFeedbackTrainFormatsCSParamEnv-v1
|
| 14 |
+
#python draw_tree.py cs_trees/scaf_tree_4 SocialAI-AELangFeedbackTrainScaffoldingCSParamEnv-v1 -acl-type intro_seq
|
| 15 |
+
#python draw_tree.py cs_trees/scaf_tree_8 SocialAI-AELangFeedbackTrainScaffoldingCSParamEnv-v1 --acl-type intro_seq_seq
|
| 16 |
+
|
| 17 |
+
# LLMs
|
| 18 |
+
#python draw_tree.py cs_trees/llms_tree_asoc_apple SocialAI-AsocialBoxInformationSeekingParamEnv-v1
|
| 19 |
+
#python draw_tree.py cs_trees/llms_tree_color_box SocialAI-ColorBoxesLLMCSParamEnv-v1
|
dummy_run.sh
ADDED
|
@@ -0,0 +1,109 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# test
|
| 2 |
+
#rm -rf storage/test && python -m scripts.train --frames 100000000 --model test --algo ppo --dialogue --save-interval 1 --log-interval 1 --test-interval 1 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-JAELangColorTrainInformationSeekingParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name JALangColorTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --exploration-bonus --episodic-exploration-bonus --exploration-bonus-type lang --exploration-bonus-params 10 50 --exploration-bonus-tanh 0.6 --test-seed 42 --seed 1234
|
| 3 |
+
|
| 4 |
+
# no test
|
| 5 |
+
#rm -rf storage/test && python -m scripts.train --frames 100000000 --model test --algo ppo --dialogue --save-interval 1 --log-interval 1 --test-interval 0 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-EPointingInformationSeekingParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name PointingTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --exploration-bonus --episodic-exploration-bonus --exploration-bonus-type cell --exploration-bonus-params 2 50 --exploration-bonus-tanh 0.6
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
# dummy case studies
|
| 9 |
+
#python -m scripts.train --frames 100000000 --model dummy_cs_Pointing_CB --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 100 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-EPointingTrainInformationSeekingParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name PointingTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --exploration-bonus --episodic-exploration-bonus --exploration-bonus-type cell --exploration-bonus-params 2 50 --exploration-bonus-tanh 0.6
|
| 10 |
+
#python -m scripts.train --frames 30000000 --model dummy_cs_NEW_Pointing_sm_CB --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 100 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-EPointingTrainInformationSeekingParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name PointingTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --exploration-bonus --episodic-exploration-bonus --exploration-bonus-type cell --exploration-bonus-params 1 50 --exploration-bonus-tanh 0.6
|
| 11 |
+
#python -m scripts.train --frames 15000000 --model dummy_cs_NEW_Color_CBL --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 100 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-ELangColorTrainInformationSeekingParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name LangColorTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --exploration-bonus --episodic-exploration-bonus --exploration-bonus-type lang --exploration-bonus-params 10 50 --exploration-bonus-tanh 0.6
|
| 12 |
+
#python -m scripts.train --frames 10000000 --model dummy_cs_NEW_Feedback_CBL --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 100 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-ELangFeedbackTrainInformationSeekingParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name LangFeedbackTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --exploration-bonus --episodic-exploration-bonus --exploration-bonus-type lang --exploration-bonus-params 10 50 --exploration-bonus-tanh 0.6
|
| 13 |
+
|
| 14 |
+
# dummy JA
|
| 15 |
+
#python -m scripts.train --frames 100000000 --model dummy_cs_JA_Pointing_CB --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 100 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-JAEPointingTrainInformationSeekingParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name JAPointingTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --exploration-bonus --episodic-exploration-bonus --exploration-bonus-type cell --exploration-bonus-params 2 50 --exploration-bonus-tanh 0.6
|
| 16 |
+
#python -m scripts.train --frames 100000000 --model dummy_cs_JA_Pointing_CB_sm --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 100 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-JAEPointingTrainInformationSeekingParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name JAPointingTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --exploration-bonus --episodic-exploration-bonus --exploration-bonus-type cell --exploration-bonus-params 1 50 --exploration-bonus-tanh 0.6
|
| 17 |
+
#python -m scripts.train --frames 100000000 --model dummy_cs_JA_Color_CBL_new --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 100 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-JAELangColorTrainInformationSeekingParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name JALangColorTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --exploration-bonus --episodic-exploration-bonus --exploration-bonus-type lang --exploration-bonus-params 10 50 --exploration-bonus-tanh 0.6
|
| 18 |
+
#python -m scripts.train --frames 100000000 --model dummy_cs_JA_Feedback_CBL_new --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 100 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-JAELangFeedbackTrainInformationSeekingParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name JALangFeedbackTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --exploration-bonus --episodic-exploration-bonus --exploration-bonus-type lang --exploration-bonus-params 10 50 --exploration-bonus-tanh 0.6
|
| 19 |
+
|
| 20 |
+
# Marble Feedback rec quick test
|
| 21 |
+
#python -m scripts.train --frames 30000000 --model dummy_marbl_rec_test_rec_5 --algo ppo --dialogue --save-interval 5 --log-interval 5 --test-interval 0 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-NLangFeedbackMarbleTestFormatsCSParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name NFormatsTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --continue storage/dummy_marbl_rec_test_rec_5
|
| 22 |
+
#python -m scripts.train --frames 30000000 --model dummy_marbl_rec_test_rec_10 --algo ppo --dialogue --save-interval 5 --log-interval 5 --test-interval 0 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-NLangFeedbackMarbleTestFormatsCSParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 10 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name NFormatsTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64
|
| 23 |
+
#python -m scripts.train --frames 30000000 --model dummy_marbl_rec_test_rec_20 --algo ppo --dialogue --save-interval 5 --log-interval 5 --test-interval 0 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-NLangFeedbackMarbleTestFormatsCSParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 20 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name NFormatsTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64
|
| 24 |
+
|
| 25 |
+
# dummy Formats
|
| 26 |
+
# CB
|
| 27 |
+
#python -m scripts.train --frames 30000000 --model dummy_cs_jz_formats_N_rec_5 --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 100 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-NLangFeedbackTrainFormatsCSParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name NFormatsTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64
|
| 28 |
+
#python -m scripts.train --frames 30000000 --model dummy_cs_jz_formats_N_rec_10 --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 100 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-NLangFeedbackTrainFormatsCSParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 10 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name NFormatsTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64
|
| 29 |
+
## CBL
|
| 30 |
+
#python -m scripts.train --frames 30000000 --model dummy_cs_formats_CBL_N_rec_5 --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 100 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-NLangFeedbackTrainFormatsCSParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name NFormatsTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --exploration-bonus --episodic-exploration-bonus --exploration-bonus-type lang --exploration-bonus-params 10 50 --exploration-bonus-tanh 0.6
|
| 31 |
+
#python -m scripts.train --frames 30000000 --model dummy_cs_formats_CBL_N_rec_10 --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 100 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-NLangFeedbackTrainFormatsCSParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 10 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name NFormatsTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --exploration-bonus --episodic-exploration-bonus --exploration-bonus-type lang --exploration-bonus-params 10 50 --exploration-bonus-tanh 0.6
|
| 32 |
+
|
| 33 |
+
# scaffolding
|
| 34 |
+
#python -m scripts.train --frames 30000000 --model dummy_cs_jz_scaf_AE --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 100 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-AELangFeedbackTrainScaffoldingCSParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name AEFormatsTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --acl --acl-thresholds 0.90 0.90 --acl-average-interval 500 --acl-minimum-episodes 1000
|
| 35 |
+
#python -m scripts.train --frames 30000000 --model dummy_cs_jz_scaf_E --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 100 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-ELangFeedbackTrainScaffoldingCSParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name EFormatsTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --acl --acl-thresholds 0.75 --acl-average-interval 500 --acl-minimum-episodes 1000
|
| 36 |
+
#python -m scripts.train --frames 30000000 --model dummy_cs_jz_scaf_A --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 100 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-ALangFeedbackTrainScaffoldingCSParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name AFormatsTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --acl --acl-thresholds 0.75 --acl-average-interval 500 --acl-minimum-episodes 1000
|
| 37 |
+
|
| 38 |
+
# test a100 vs v100
|
| 39 |
+
#python -m scripts.train --frames 100000 --model test_a100_rec_10 --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 0 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-NLangFeedbackTrainFormatsCSParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 10 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name NFormatsTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64
|
| 40 |
+
#python -m scripts.train --frames 100000 --model test_a100_rec_5 --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 0 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-NLangFeedbackTrainFormatsCSParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name NFormatsTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64
|
| 41 |
+
|
| 42 |
+
# case study - Generators heldoutgenerators
|
| 43 |
+
#python -m scripts.train --frames 30000000 --model dummy_cs_Feedback2_HGen_CBL --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 100 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-ELangFeedbackHeldoutGeneratorsTrainInformationSeekingParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name LangFeedbackHGenTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --exploration-bonus --episodic-exploration-bonus --exploration-bonus-type lang --exploration-bonus-params 10 50 --exploration-bonus-tanh 0.6
|
| 44 |
+
#python -m scripts.train --frames 30000000 --model dummy_cs_Feedback2_HMar_CBL --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 100 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-ELangFeedbackTrainInformationSeekingParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name LangFeedbackTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --exploration-bonus --episodic-exploration-bonus --exploration-bonus-type lang --exploration-bonus-params 10 50 --exploration-bonus-tanh 0.6
|
| 45 |
+
|
| 46 |
+
# old Emulation
|
| 47 |
+
#rm -rf storage/test_emulation_no_distr_cb && python -m scripts.train --frames 100000000 --model test_emulation_no_distr_cb --algo ppo --dialogue --save-interval 1 --log-interval 1 --test-interval 0 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-EEmulationNoDistrInformationSeekingParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 10 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --exploration-bonus --episodic-exploration-bonus --exploration-bonus-type cell --exploration-bonus-params 2 50 --exploration-bonus-tanh 0.6
|
| 48 |
+
#rm -rf storage/test && python -m scripts.train --frames 100000000 --model test --algo ppo --dialogue --save-interval 1 --log-interval 1 --test-interval 100 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-EPointingInformationSeekingParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name PointingTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --exploration-bonus --episodic-exploration-bonus --exploration-bonus-type cell --exploration-bonus-params 2 50 --exploration-bonus-tanh 0.6
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
# role reversal
|
| 52 |
+
#python -m scripts.train --frames 30000000 --model dummy_cs_RR_all_train --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 100 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-RoleReversalCollaborationParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name RoleReversalTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64
|
| 53 |
+
|
| 54 |
+
# single - experimental ( trained on marble pass B)
|
| 55 |
+
#python -m scripts.train --frames 10000000 --model dummy_cs_RR_single_marble_pass_B --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 0 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-MarblePassBCollaborationParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name RoleReversalTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64
|
| 56 |
+
# single - control ( trained on asocial marble)
|
| 57 |
+
#python -m scripts.train --frames 10000000 --model dummy_cs_RR_single_asoc_marble --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 0 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-AsocialMarbleInformationSeekingParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name RoleReversalTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64
|
| 58 |
+
|
| 59 |
+
# RR CB
|
| 60 |
+
|
| 61 |
+
# single
|
| 62 |
+
# experimental ( trained on marble pass B)
|
| 63 |
+
#python -m scripts.train --frames 5000000 --model dummy_cs_RR_single_CB_marble_pass_B --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 0 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-MarblePassBCollaborationParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name RoleReversalTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --exploration-bonus --episodic-exploration-bonus --exploration-bonus-type cell --exploration-bonus-params 2 50 --exploration-bonus-tanh 0.6
|
| 64 |
+
# control ( trained on asocial marble)
|
| 65 |
+
#python -m scripts.train --frames 5000000 --model dummy_cs_RR_single_CB_asoc_marble --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 0 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-AsocialMarbleInformationSeekingParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name RoleReversalTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --exploration-bonus --episodic-exploration-bonus --exploration-bonus-type cell --exploration-bonus-params 2 50 --exploration-bonus-tanh 0.6
|
| 66 |
+
# new env
|
| 67 |
+
#python -m scripts.train --frames 5000000 --model dummy_cs_RR_single_CB_asoc_marble_new --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 0 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-AsocialMarbleCollaborationParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name RoleReversalTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --exploration-bonus --episodic-exploration-bonus --exploration-bonus-type cell --exploration-bonus-params 2 50 --exploration-bonus-tanh 0.6
|
| 68 |
+
|
| 69 |
+
# RR evaluation training single
|
| 70 |
+
#python -m scripts.train --frames 1000000 --model dummy_cs_RR_ft_NEW_single_CB_marble_pass_B_exp_soc --algo ppo --dialogue --save-interval 1 --log-interval 1 --test-interval 0 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-MarblePassACollaborationParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name RoleReversalTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --exploration-bonus --episodic-exploration-bonus --exploration-bonus-type cell --exploration-bonus-params 2 50 --exploration-bonus-tanh 0.6 --finetune-train storage/dummy_cs_RR_single_CB_marble_pass_B
|
| 71 |
+
#python -m scripts.train --frames 1000000 --model dummy_cs_RR_ft_NEW_single_CB_marble_pass_B_contr_asoc --algo ppo --dialogue --save-interval 1 --log-interval 1 --test-interval 0 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-MarblePassACollaborationParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name RoleReversalTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --exploration-bonus --episodic-exploration-bonus --exploration-bonus-type cell --exploration-bonus-params 2 50 --exploration-bonus-tanh 0.6 --finetune-train storage/dummy_cs_RR_single_CB_asoc_marble_new
|
| 72 |
+
|
| 73 |
+
# group
|
| 74 |
+
# experimental ( trained on marble pass B)
|
| 75 |
+
#python -m scripts.train --frames 20000000 --model dummy_cs_RR_group_CB_marble_pass_B --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 100 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-RoleReversalGroupExperimentalCollaborationParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name RoleReversalTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --exploration-bonus --episodic-exploration-bonus --exploration-bonus-type cell --exploration-bonus-params 2 50 --exploration-bonus-tanh 0.6 --continue-train auto
|
| 76 |
+
# control ( trained on asocial marble)
|
| 77 |
+
#python -m scripts.train --frames 20000000 --model dummy_cs_RR_group_CB_asoc_marble --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 100 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-RoleReversalGroupControlCollaborationParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name RoleReversalTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --exploration-bonus --episodic-exploration-bonus --exploration-bonus-type cell --exploration-bonus-params 2 50 --exploration-bonus-tanh 0.6 --continue-train auto
|
| 78 |
+
|
| 79 |
+
# group-finetune
|
| 80 |
+
#python -m scripts.train --frames 500000 --model dummy_cs_RR_ft_NEW_group_CB_marble_pass_A_exp_soc --algo ppo --dialogue --save-interval 1 --log-interval 1 --test-interval 0 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-MarblePassACollaborationParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name RoleReversalTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --exploration-bonus --episodic-exploration-bonus --exploration-bonus-type cell --exploration-bonus-params 2 50 --exploration-bonus-tanh 0.6 --finetune-train storage/dummy_cs_RR_group_CB_marble_pass_B
|
| 81 |
+
#python -m scripts.train --frames 500000 --model dummy_cs_RR_ft_NEW_group_CB_marble_pass_A_contr_asoc --algo ppo --dialogue --save-interval 1 --log-interval 1 --test-interval 0 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-MarblePassACollaborationParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name RoleReversalTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --exploration-bonus --episodic-exploration-bonus --exploration-bonus-type cell --exploration-bonus-params 2 50 --exploration-bonus-tanh 0.6 --finetune-train storage/dummy_cs_RR_group_CB_asoc_marble
|
| 82 |
+
|
| 83 |
+
# 3 phase scaffolding
|
| 84 |
+
#python -m scripts.train --frames 30000000 --model dummy_cs_jz_scaf_Esc-AEsc-AEfull --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 100 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-AELangFeedbackTrainScaffoldingCSParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name AEFormatsTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --acl --acl-thresholds 0.90 0.90 --acl-average-interval 500 --acl-minimum-episodes 1000
|
| 85 |
+
#python -m scripts.train --frames 30000000 --model dummy_cs_jz_scaf_Esc-Efull-Acs_or_Efull-A_or_Efull-AEfull --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 100 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-AELangFeedbackTrainScaffoldingCSParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name AEFormatsTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --acl --acl-thresholds 0.90 0.90 --acl-average-interval 500 --acl-minimum-episodes 1000
|
| 86 |
+
#python -m scripts.train --frames 30000000 --model dummy_cs_jz_scaf_Esc-Efull-Acs_or_Efull-A_or_Efull-AEfull --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 100 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-AELangFeedbackTrainScaffoldingCSParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name AEFormatsTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --acl --acl-thresholds 0.90 0.90 --acl-average-interval 500 --acl-minimum-episodes 1000
|
| 87 |
+
# Ncs-Nfull-A_E_N_A_E_full-AEfull
|
| 88 |
+
#python -m scripts.train --frames 30000000 --model dummy_cs_jz_scaf_Ncs-Nfull-A_E_N_A_E_full-AEfull --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 100 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-AELangFeedbackTrainScaffoldingCSParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name AEFormatsTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --acl --acl-thresholds 0.90 0.90 0.90 0.90 --acl-average-interval 500 --acl-minimum-episodes 1000
|
| 89 |
+
#python -m scripts.train --frames 30000000 --model dummy_cs_jz_scaf_A_E_N_A_E_scaf_full-AEfull --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 100 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-AELangFeedbackTrainScaffoldingCSParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name AEFormatsTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --acl --acl-thresholds 0.90 0.90 0.90 0.90 --acl-average-interval 500 --acl-minimum-episodes 1000
|
| 90 |
+
#python -m scripts.train --frames 30000000 --model dummy_cs_jz_scaf_A_E_N_A_E_full-AEfull --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 100 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-AELangFeedbackTrainScaffoldingCSParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name AEFormatsTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --acl --acl-thresholds 0.90 0.90 0.90 0.90 --acl-average-interval 500 --acl-minimum-episodes 1000
|
| 91 |
+
#python -m scripts.train --frames 30000000 --model dummy_cs_jz_scaf_A_E_AE_scaf_full-AEfull --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 100 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-AELangFeedbackTrainScaffoldingCSParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name AEFormatsTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --acl --acl-thresholds 0.90 0.90 0.90 0.90 --acl-average-interval 500 --acl-minimum-episodes 1000
|
| 92 |
+
|
| 93 |
+
## Emulation
|
| 94 |
+
# dummy emulation rec 10
|
| 95 |
+
#python -m scripts.train --frames 20000000 --model dummy_cs_emulation_no_distr_rec_10 --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 100 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-EEmulationNoDistrInformationSeekingParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 10 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --test-set-name NoDistrEmulationTestSet
|
| 96 |
+
#python -m scripts.train --frames 20000000 --model dummy_cs_emulation_distr_rec_10 --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 100 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-EEmulationDistrInformationSeekingParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 10 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --test-set-name DistrEmulationTestSet
|
| 97 |
+
|
| 98 |
+
# rec 5
|
| 99 |
+
#python -m scripts.train --frames 20000000 --model dummy_cs_emulation_no_distr_rec_5 --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 100 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-EEmulationNoDistrInformationSeekingParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --test-set-name NoDistrEmulationTestSet
|
| 100 |
+
#python -m scripts.train --frames 20000000 --model dummy_cs_emulation_distr_rec_5 --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 100 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-EEmulationDistrInformationSeekingParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --test-set-name DistrEmulationTestSet
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
#python -m scripts.train --frames 40000000 --model 07-12_dummy_cs_emulation_distr_rec_10/0 --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 100 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-EEmulationDistrInformationSeekingParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 10 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --test-set-name DistrEmulationTestSet --continue-train auto
|
| 105 |
+
#python -m scripts.train --frames 40000000 --model 07-12_dummy_cs_emulation_distr_rec_5/0 --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 100 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-EEmulationDistrInformationSeekingParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --test-set-name DistrEmulationTestSet --continue-train auto
|
| 106 |
+
|
| 107 |
+
#python -m scripts.train --frames 40000000 --model test_a100 --algo ppo --dialogue --save-interval 10 --log-interval 10 --test-interval 100 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-EEmulationDistrInformationSeekingParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --test-set-name DistrEmulationTestSet
|
| 108 |
+
|
| 109 |
+
python -m scripts.train --frames 30000000 --model test_scaff --algo ppo --dialogue --save-interval 100 --log-interval 100 --test-interval 1000 --frames-per-proc 40 --multi-modal-babyai11-agent --env SocialAI-AELangFeedbackTrainScaffoldingCSParamEnv-v1 --clipped-rewards --batch-size 640 --clip-eps 0.2 --recurrence 5 --max-grad-norm 0.5 --epochs 4 --optim-eps 1e-05 --lr 1e-4 --entropy-coef 0.00001 --test-set-name AEFormatsTestSet --env-args see_through_walls False --arch bow_endpool_res --bAI-lang-model attgru --memory-dim 2048 --procs 64 --acl --acl-type intro_seq --acl-thresholds 0.90 0.90 0.90 0.90 --acl-average-interval 500 --acl-minimum-episodes 1000 --seed 1
|
eval_LLMs.sh
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# AsocialBox (6 in cont)
|
| 2 |
+
#python -m scripts.LLM_test --episodes 10 --max-steps 15 --model text-ada-001 --env-args size 7 --skip-check --env-name SocialAI-AsocialBoxInformationSeekingParamEnv-v1 --in-context-path llm_data/in_context_examples/in_context_asocialbox_SocialAI-AsocialBoxInformationSeekingParamEnv-v1_2023_07_19_19_28_48/episodes.pkl
|
| 3 |
+
#python -m scripts.LLM_test --episodes 10 --max-steps 15 --model gpt-3.5-turbo-0613 --env-args size 7 --skip-check --env-name SocialAI-AsocialBoxInformationSeekingParamEnv-v1 --in-context-path llm_data/in_context_examples/in_context_asocialbox_SocialAI-AsocialBoxInformationSeekingParamEnv-v1_2023_07_19_19_28_48/episodes.pkl
|
| 4 |
+
#python -m scripts.LLM_test --episodes 10 --max-steps 15 --model gpt-3.5-turbo-instruct-0914 --env-args size 7 --env-name SocialAI-AsocialBoxInformationSeekingParamEnv-v1 --in-context-path llm_data/in_context_examples/in_context_asocialbox_SocialAI-AsocialBoxInformationSeekingParamEnv-v1_2023_07_19_19_28_48/episodes.pkl
|
| 5 |
+
#python -m scripts.LLM_test --episodes 10 --max-steps 15 --model gpt-4-0613 --env-args size 7 --skip-check --env-name SocialAI-AsocialBoxInformationSeekingParamEnv-v1 --in-context-path llm_data/in_context_examples/in_context_asocialbox_SocialAI-AsocialBoxInformationSeekingParamEnv-v1_2023_07_19_19_28_48/episodes.pkl
|
| 6 |
+
#python -m scripts.LLM_test --episodes 10 --max-steps 15 --model text-davinci-003 --env-args size 7 --skip-check --env-name SocialAI-AsocialBoxInformationSeekingParamEnv-v1 --in-context-path llm_data/in_context_examples/in_context_asocialbox_SocialAI-AsocialBoxInformationSeekingParamEnv-v1_2023_07_19_19_28_48/episodes.pkl
|
| 7 |
+
#python -m scripts.LLM_test --episodes 10 --max-steps 15 --model bloom_560m --env-args size 7 --skip-check --env-name SocialAI-AsocialBoxInformationSeekingParamEnv-v1 --in-context-path llm_data/in_context_examples/in_context_asocialbox_SocialAI-AsocialBoxInformationSeekingParamEnv-v1_2023_07_19_19_28_48/episodes.pkl
|
| 8 |
+
#python -m scripts.LLM_test --episodes 10 --max-steps 15 --model random --env-args size 7 --skip-check --env-name SocialAI-AsocialBoxInformationSeekingParamEnv-v1 --in-context-path llm_data/in_context_examples/in_context_asocialbox_SocialAI-AsocialBoxInformationSeekingParamEnv-v1_2023_07_19_19_28_48/episodes.pkl
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
### ColorBoxes
|
| 12 |
+
|
| 13 |
+
# 10 episodes
|
| 14 |
+
#python -m scripts.LLM_test --episodes 10 --max-steps 15 --model text-ada-001 --env-args size 7 --skip-check --env-name SocialAI-ColorBoxesLLMCSParamEnv-v1 --in-context-path llm_data/in_context_examples/in_context_colorbox_SocialAI-ColorBoxesLLMCSParamEnv-v1_2023_07_20_13_11_54/episodes.pkl
|
| 15 |
+
#python -m scripts.LLM_test --episodes 10 --max-steps 15 --model gpt-3.5-turbo-0613 --env-args size 7 --skip-check --env-name SocialAI-ColorBoxesLLMCSParamEnv-v1 --in-context-path llm_data/in_context_examples/in_context_colorbox_SocialAI-ColorBoxesLLMCSParamEnv-v1_2023_07_20_13_11_54/episodes.pkl
|
| 16 |
+
#python -m scripts.LLM_test --episodes 10 --max-steps 15 --model gpt-4-0613 --env-args size 7 --skip-check --env-name SocialAI-ColorBoxesLLMCSParamEnv-v1 --in-context-path llm_data/in_context_examples/in_context_colorbox_SocialAI-ColorBoxesLLMCSParamEnv-v1_2023_07_20_13_11_54/episodes.pkl
|
| 17 |
+
#python -m scripts.LLM_test --episodes 10 --max-steps 15 --model text-davinci-003 --env-args size 7 --skip-check --env-name SocialAI-ColorBoxesLLMCSParamEnv-v1 --in-context-path llm_data/in_context_examples/in_context_colorbox_SocialAI-ColorBoxesLLMCSParamEnv-v1_2023_07_20_13_11_54/episodes.pkl
|
| 18 |
+
#python -m scripts.LLM_test --episodes 10 --max-steps 15 --model bloom_560m --env-args size 7 --skip-check --env-name SocialAI-ColorBoxesLLMCSParamEnv-v1 --in-context-path llm_data/in_context_examples/in_context_colorbox_SocialAI-ColorBoxesLLMCSParamEnv-v1_2023_07_20_13_11_54/episodes.pkl
|
| 19 |
+
#python -m scripts.LLM_test --episodes 10 --max-steps 15 --model random --env-args size 7 --skip-check --env-name SocialAI-ColorBoxesLLMCSParamEnv-v1 --in-context-path llm_data/in_context_examples/in_context_colorbox_SocialAI-ColorBoxesLLMCSParamEnv-v1_2023_07_20_13_11_54/episodes.pkl
|
| 20 |
+
|
| 21 |
+
# 20 episodes
|
| 22 |
+
#python -m scripts.LLM_test --episodes 20 --max-steps 15 --model gpt-4-0613 --env-args size 7 --env-name SocialAI-ColorBoxesLLMCSParamEnv-v1 --in-context-path llm_data/in_context_examples/in_context_colorbox_SocialAI-ColorBoxesLLMCSParamEnv-v1_2023_07_20_13_11_54/episodes.pkl
|
| 23 |
+
#python -m scripts.LLM_test --episodes 20 --max-steps 15 --model gpt-3.5-turbo-0613 --env-args size 7 --env-name SocialAI-ColorBoxesLLMCSParamEnv-v1 --in-context-path llm_data/in_context_examples/in_context_colorbox_SocialAI-ColorBoxesLLMCSParamEnv-v1_2023_07_20_13_11_54/episodes.pkl
|
| 24 |
+
#python -m scripts.LLM_test --episodes 20 --max-steps 15 --model gpt-3.5-turbo-instruct-0914 --env-args size 7 --env-name SocialAI-ColorBoxesLLMCSParamEnv-v1 --in-context-path llm_data/in_context_examples/in_context_colorbox_SocialAI-ColorBoxesLLMCSParamEnv-v1_2023_07_20_13_11_54/episodes.pkl
|
| 25 |
+
#python -m scripts.LLM_test --episodes 20 --max-steps 15 --model text-ada-001 --env-args size 7 --env-name SocialAI-ColorBoxesLLMCSParamEnv-v1 --in-context-path llm_data/in_context_examples/in_context_colorbox_SocialAI-ColorBoxesLLMCSParamEnv-v1_2023_07_20_13_11_54/episodes.pkl
|
| 26 |
+
#python -m scripts.LLM_test --episodes 20 --max-steps 15 --model text-davinci-003 --env-args size 7 --skip-check --env-name SocialAI-ColorBoxesLLMCSParamEnv-v1 --in-context-path llm_data/in_context_examples/in_context_colorbox_SocialAI-ColorBoxesLLMCSParamEnv-v1_2023_07_20_13_11_54/episodes.pkl
|
| 27 |
+
#python -m scripts.LLM_test --episodes 20 --max-steps 15 --model random --env-args size 7 --skip-check --env-name SocialAI-ColorBoxesLLMCSParamEnv-v1 --in-context-path llm_data/in_context_examples/in_context_colorbox_SocialAI-ColorBoxesLLMCSParamEnv-v1_2023_07_20_13_11_54/episodes.pkl
|
| 28 |
+
#python -m scripts.LLM_test --episodes 20 --max-steps 15 --model bloom_560m --env-args size 7 --skip-check --env-name SocialAI-ColorBoxesLLMCSParamEnv-v1 --in-context-path llm_data/in_context_examples/in_context_colorbox_SocialAI-ColorBoxesLLMCSParamEnv-v1_2023_07_20_13_11_54/episodes.pkl
|
| 29 |
+
|
| 30 |
+
### ColorBoxes generalization
|
| 31 |
+
# 10 episodes generalization
|
| 32 |
+
#python -m scripts.LLM_test --episodes 10 --max-steps 15 --model gpt-4-0613 --env-args size 7 --env-name SocialAI-ColorBoxesLLMCSParamEnv-v1 --in-context-path llm_data/in_context_examples/in_context_SocialAI-ColorLLMCSParamEnv-v1_2023_09_18_17_24_24/episodes.pkl
|
| 33 |
+
|
| 34 |
+
# 20 episodes generalization
|
| 35 |
+
#python -m scripts.LLM_test --episodes 20 --max-steps 15 --model gpt-4-0613 --env-args size 7 --env-name SocialAI-ColorBoxesLLMCSParamEnv-v1 --in-context-path llm_data/in_context_examples/in_context_SocialAI-ColorLLMCSParamEnv-v1_2023_09_18_17_24_24/episodes.pkl
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
python -m scripts.LLM_test --episodes 20 --max-steps 15 --model random --env-args size 7 --skip-check --env-name SocialAI-ColorBoxesLLMCSParamEnv-v1 --in-context-path llm_data/in_context_examples/in_context_SocialAI-ColorLLMCSParamEnv-v1_2023_09_18_17_24_24/episodes.pkl
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
|
gpuh.py
ADDED
|
@@ -0,0 +1,99 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
|
| 3 |
+
point_conf = 0.3
|
| 4 |
+
feedb_conf = 0.3
|
| 5 |
+
color_conf = 0.3
|
| 6 |
+
|
| 7 |
+
ja_point_conf = 0.3
|
| 8 |
+
ja_feedb_conf = 0.3
|
| 9 |
+
ja_color_conf = 0.3
|
| 10 |
+
|
| 11 |
+
emul_conf = 2
|
| 12 |
+
|
| 13 |
+
rri_conf = 0.2*4
|
| 14 |
+
|
| 15 |
+
op_conf = 0.5 * 3 # hidden, normal, expert
|
| 16 |
+
|
| 17 |
+
form_conf = 0.2*8
|
| 18 |
+
scaf_conf = 0.2*4
|
| 19 |
+
|
| 20 |
+
configurations = point_conf + feedb_conf + color_conf + ja_point_conf + ja_feedb_conf + ja_color_conf + emul_conf + rri_conf + op_conf + form_conf + scaf_conf
|
| 21 |
+
# configurations = 1
|
| 22 |
+
|
| 23 |
+
#
|
| 24 |
+
configurations = 0.3 + 0.3 + 0.3 + 8*0.3
|
| 25 |
+
|
| 26 |
+
# configurations = 3*0.2 + 0.5 + 0.04*2 + 0.5*2
|
| 27 |
+
|
| 28 |
+
# num_of_trains = 3 + 3 + 2 + 4 + 3 + 8 + 4
|
| 29 |
+
# print("num_of_trains:", num_of_trains)
|
| 30 |
+
|
| 31 |
+
configurations = 0.01 * 6
|
| 32 |
+
|
| 33 |
+
print(f"Number of trains: {configurations}")
|
| 34 |
+
|
| 35 |
+
frames = 100_000_000
|
| 36 |
+
# frames = 75_000_000
|
| 37 |
+
# frames = 50_000_000
|
| 38 |
+
|
| 39 |
+
seeds = 8
|
| 40 |
+
# seeds = 4
|
| 41 |
+
print(f"Number of seeds: {seeds}")
|
| 42 |
+
|
| 43 |
+
# ## one GPU
|
| 44 |
+
# fps = 300
|
| 45 |
+
fps = 580 # ssh jz
|
| 46 |
+
# fps = 500 # ssh pf
|
| 47 |
+
|
| 48 |
+
gpus_per_seed = 1
|
| 49 |
+
print(f"\n{gpus_per_seed} GPU")
|
| 50 |
+
|
| 51 |
+
seed_frames = frames
|
| 52 |
+
one_seed_time = 1_000_000 / (fps * 60 * 60)
|
| 53 |
+
print("train time (1M frames): {}h - {:d}d {:.0f}h".format(
|
| 54 |
+
one_seed_time,
|
| 55 |
+
int(one_seed_time // 24), one_seed_time % 24)
|
| 56 |
+
)
|
| 57 |
+
|
| 58 |
+
total_gpuh = configurations*seeds*gpus_per_seed*frames/(fps*60*60)
|
| 59 |
+
print("total gpu hours 1 gpups:", total_gpuh)
|
| 60 |
+
|
| 61 |
+
# ## half a GPU
|
| 62 |
+
#
|
| 63 |
+
# fps = 275
|
| 64 |
+
# fps = 370 # ssh jz
|
| 65 |
+
# # fps = 300 # ssh pf
|
| 66 |
+
# gpus_per_seed = 0.5
|
| 67 |
+
#
|
| 68 |
+
# print(f"\n{gpus_per_seed} GPU")
|
| 69 |
+
# one_seed = frames/(fps*60*60)
|
| 70 |
+
# print("train time: {}h - {:d}d {:.0f}h".format(one_seed, int(one_seed // 24), one_seed % 24))
|
| 71 |
+
#
|
| 72 |
+
# total_gpuh = configurations*seeds*gpus_per_seed*frames/(fps*60*60)
|
| 73 |
+
# print("total gpu hours 0.5 gpups:", total_gpuh)
|
| 74 |
+
#
|
| 75 |
+
# # ## 1/3 of a GPU
|
| 76 |
+
# fps = 250 # ssh jz 1/3
|
| 77 |
+
# # fps = 250 # ssh 1/3 pf
|
| 78 |
+
#
|
| 79 |
+
# gpus_per_seed = 0.33
|
| 80 |
+
# print(f"\n{gpus_per_seed} GPU")
|
| 81 |
+
#
|
| 82 |
+
# one_seed = frames/(fps*60*60)
|
| 83 |
+
# print("train time: {}h - {:d}d {:.0f}h".format(one_seed, int(one_seed // 24), one_seed % 24))
|
| 84 |
+
#
|
| 85 |
+
# total_gpuh = configurations*seeds*gpus_per_seed*frames/(fps*60*60)
|
| 86 |
+
# print("total gpu hours 0.33 gpups:", total_gpuh)
|
| 87 |
+
#
|
| 88 |
+
#
|
| 89 |
+
# # ## 1/4 of gpu
|
| 90 |
+
# # fps = 190 # ssh 1/4 pf
|
| 91 |
+
# #
|
| 92 |
+
# # gpus_per_seed = 0.25
|
| 93 |
+
# # print(f"\n{gpus_per_seed} GPU")
|
| 94 |
+
# #
|
| 95 |
+
# # one_seed = frames/(fps*60*60)
|
| 96 |
+
# # print("train time: {}h - {:d}d {:.0f}h".format(one_seed, int(one_seed // 24), one_seed % 24))
|
| 97 |
+
# #
|
| 98 |
+
# # total_gpuh = configurations*seeds*gpus_per_seed*frames/(fps*60*60)
|
| 99 |
+
# # print("total gpu hours 0.25 gpups:", total_gpuh)
|
gym-minigrid/.gitignore
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.pyc
|
| 2 |
+
*__pycache__
|
| 3 |
+
*egg-info
|
| 4 |
+
trained_models
|
| 5 |
+
|
| 6 |
+
# PyPI
|
| 7 |
+
build/*
|
| 8 |
+
dist/*
|
| 9 |
+
.idea/
|
gym-minigrid/.travis.yml
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
language: python
|
| 2 |
+
python:
|
| 3 |
+
- "3.5"
|
| 4 |
+
|
| 5 |
+
# command to install dependencies
|
| 6 |
+
install:
|
| 7 |
+
- pip3 install -e .
|
| 8 |
+
|
| 9 |
+
# command to run tests
|
| 10 |
+
script: ./run_tests.py
|
gym-minigrid/LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright 2019 Maxime Chevalier-Boisvert
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
gym-minigrid/README.md
ADDED
|
@@ -0,0 +1,511 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Minimalistic Gridworld Environment (MiniGrid)
|
| 2 |
+
|
| 3 |
+
[](https://travis-ci.org/maximecb/gym-minigrid)
|
| 4 |
+
|
| 5 |
+
There are other gridworld Gym environments out there, but this one is
|
| 6 |
+
designed to be particularly simple, lightweight and fast. The code has very few
|
| 7 |
+
dependencies, making it less likely to break or fail to install. It loads no
|
| 8 |
+
external sprites/textures, and it can run at up to 5000 FPS on a Core i7
|
| 9 |
+
laptop, which means you can run your experiments faster. A known-working RL
|
| 10 |
+
implementation can be found [in this repository](https://github.com/lcswillems/torch-rl).
|
| 11 |
+
|
| 12 |
+
Requirements:
|
| 13 |
+
- Python 3.5+
|
| 14 |
+
- OpenAI Gym
|
| 15 |
+
- NumPy
|
| 16 |
+
- Matplotlib (optional, only needed for display)
|
| 17 |
+
|
| 18 |
+
Please use this bibtex if you want to cite this repository in your publications:
|
| 19 |
+
|
| 20 |
+
```
|
| 21 |
+
@misc{gym_minigrid,
|
| 22 |
+
author = {Chevalier-Boisvert, Maxime and Willems, Lucas and Pal, Suman},
|
| 23 |
+
title = {Minimalistic Gridworld Environment for OpenAI Gym},
|
| 24 |
+
year = {2018},
|
| 25 |
+
publisher = {GitHub},
|
| 26 |
+
journal = {GitHub repository},
|
| 27 |
+
howpublished = {\url{https://github.com/maximecb/gym-minigrid}},
|
| 28 |
+
}
|
| 29 |
+
```
|
| 30 |
+
|
| 31 |
+
List of publications & submissions using MiniGrid or BabyAI (please open a pull request to add missing entries):
|
| 32 |
+
- [Prioritized Level Replay](https://arxiv.org/pdf/2010.03934.pdf) (FAIR, October 2020)
|
| 33 |
+
- [Learning with AMIGO: Adversarially Motivated Intrinsic Goals](https://arxiv.org/pdf/2006.12122.pdf) (MIT, FAIR, June 2020)
|
| 34 |
+
- [RIDE: Rewarding Impact-Driven Exploration for Procedurally-Generated Environments](https://openreview.net/forum?id=rkg-TJBFPB) (FAIR, ICLR 2020)
|
| 35 |
+
- [Learning to Request Guidance in Emergent Communication](https://arxiv.org/pdf/1912.05525.pdf) (University of Amsterdam, Dec 2019)
|
| 36 |
+
- [Working Memory Graphs](https://arxiv.org/abs/1911.07141) (MSR, Nov 2019)
|
| 37 |
+
- [Fast Task-Adaptation for Tasks Labeled Using
|
| 38 |
+
Natural Language in Reinforcement Learning](https://arxiv.org/pdf/1910.04040.pdf) (Oct 2019, University of Antwerp)
|
| 39 |
+
- [Generalization in Reinforcement Learning with Selective Noise Injection and Information Bottleneck
|
| 40 |
+
](https://arxiv.org/abs/1910.12911) (MSR, NeurIPS, Oct 2019)
|
| 41 |
+
- [Recurrent Independent Mechanisms](https://arxiv.org/pdf/1909.10893.pdf) (Mila, Sept 2019)
|
| 42 |
+
- [Learning Effective Subgoals with Multi-Task Hierarchical Reinforcement Learning](http://surl.tirl.info/proceedings/SURL-2019_paper_10.pdf) (Tsinghua University, August 2019)
|
| 43 |
+
- [Mastering emergent language: learning to guide in simulated navigation](https://arxiv.org/abs/1908.05135) (University of Amsterdam, Aug 2019)
|
| 44 |
+
- [Transfer Learning by Modeling a Distribution over Policies](https://arxiv.org/abs/1906.03574) (Mila, June 2019)
|
| 45 |
+
- [Reinforcement Learning with Competitive Ensembles
|
| 46 |
+
of Information-Constrained Primitives](https://arxiv.org/abs/1906.10667) (Mila, June 2019)
|
| 47 |
+
- [Learning distant cause and effect using only local and immediate credit assignment](https://arxiv.org/abs/1905.11589) (Incubator 491, May 2019)
|
| 48 |
+
- [Practical Open-Loop Optimistic Planning](https://arxiv.org/abs/1904.04700) (INRIA, April 2019)
|
| 49 |
+
- [Learning World Graphs to Accelerate Hierarchical Reinforcement Learning](https://arxiv.org/abs/1907.00664) (Salesforce Research, 2019)
|
| 50 |
+
- [Variational State Encoding as Intrinsic Motivation in Reinforcement Learning](https://mila.quebec/wp-content/uploads/2019/05/WebPage.pdf) (Mila, TARL 2019)
|
| 51 |
+
- [Unsupervised Discovery of Decision States Through Intrinsic Control](https://tarl2019.github.io/assets/papers/modhe2019unsupervised.pdf) (Georgia Tech, TARL 2019)
|
| 52 |
+
- [Modeling the Long Term Future in Model-Based Reinforcement Learning](https://openreview.net/forum?id=SkgQBn0cF7) (Mila, ICLR 2019)
|
| 53 |
+
- [Unifying Ensemble Methods for Q-learning via Social Choice Theory](https://arxiv.org/pdf/1902.10646.pdf) (Max Planck Institute, Feb 2019)
|
| 54 |
+
- [Planning Beyond The Sensing Horizon Using a Learned Context](https://personalrobotics.cs.washington.edu/workshops/mlmp2018/assets/docs/18_CameraReadySubmission.pdf) (MLMP@IROS, 2018)
|
| 55 |
+
- [Guiding Policies with Language via Meta-Learning](https://arxiv.org/abs/1811.07882) (UC Berkeley, Nov 2018)
|
| 56 |
+
- [On the Complexity of Exploration in Goal-Driven Navigation](https://arxiv.org/abs/1811.06889) (CMU, NeurIPS, Nov 2018)
|
| 57 |
+
- [Transfer and Exploration via the Information Bottleneck](https://openreview.net/forum?id=rJg8yhAqKm) (Mila, Nov 2018)
|
| 58 |
+
- [Creating safer reward functions for reinforcement learning agents in the gridworld](https://gupea.ub.gu.se/bitstream/2077/62445/1/gupea_2077_62445_1.pdf) (University of Gothenburg, 2018)
|
| 59 |
+
- [BabyAI: First Steps Towards Grounded Language Learning With a Human In the Loop](https://arxiv.org/abs/1810.08272) (Mila, ICLR, Oct 2018)
|
| 60 |
+
|
| 61 |
+
This environment has been built as part of work done at [Mila](https://mila.quebec). The Dynamic obstacles environment has been added as part of work done at [IAS in TU Darmstadt](https://www.ias.informatik.tu-darmstadt.de/) and the University of Genoa for mobile robot navigation with dynamic obstacles.
|
| 62 |
+
|
| 63 |
+
## Installation
|
| 64 |
+
|
| 65 |
+
There is now a [pip package](https://pypi.org/project/gym-minigrid/) available, which is updated periodically:
|
| 66 |
+
|
| 67 |
+
```
|
| 68 |
+
pip3 install gym-minigrid
|
| 69 |
+
```
|
| 70 |
+
|
| 71 |
+
Alternatively, to get the latest version of MiniGrid, you can clone this repository and install the dependencies with `pip3`:
|
| 72 |
+
|
| 73 |
+
```
|
| 74 |
+
git clone https://github.com/maximecb/gym-minigrid.git
|
| 75 |
+
cd gym-minigrid
|
| 76 |
+
pip3 install -e .
|
| 77 |
+
```
|
| 78 |
+
|
| 79 |
+
## Basic Usage
|
| 80 |
+
|
| 81 |
+
There is a UI application which allows you to manually control the agent with the arrow keys:
|
| 82 |
+
|
| 83 |
+
```
|
| 84 |
+
./manual_control.py
|
| 85 |
+
```
|
| 86 |
+
|
| 87 |
+
The environment being run can be selected with the `--env` option, eg:
|
| 88 |
+
|
| 89 |
+
```
|
| 90 |
+
./manual_control.py --env MiniGrid-Empty-8x8-v0
|
| 91 |
+
```
|
| 92 |
+
|
| 93 |
+
## Reinforcement Learning
|
| 94 |
+
|
| 95 |
+
If you want to train an agent with reinforcement learning, I recommend using the code found in the [torch-rl](https://github.com/lcswillems/torch-rl) repository. This code has been tested and is known to work with this environment. The default hyper-parameters are also known to converge.
|
| 96 |
+
|
| 97 |
+
A sample training command is:
|
| 98 |
+
|
| 99 |
+
```
|
| 100 |
+
cd torch-rl
|
| 101 |
+
python3 -m scripts.train --env MiniGrid-Empty-8x8-v0 --algo ppo
|
| 102 |
+
```
|
| 103 |
+
|
| 104 |
+
## Wrappers
|
| 105 |
+
|
| 106 |
+
MiniGrid is built to support tasks involving natural language and sparse rewards.
|
| 107 |
+
The observations are dictionaries, with an 'image' field, partially observable
|
| 108 |
+
view of the environment, a 'mission' field which is a textual string
|
| 109 |
+
describing the objective the agent should reach to get a reward, and a 'direction'
|
| 110 |
+
field which can be used as an optional compass. Using dictionaries makes it
|
| 111 |
+
easy for you to add additional information to observations
|
| 112 |
+
if you need to, without having to encode everything into a single tensor.
|
| 113 |
+
|
| 114 |
+
There are a variery of wrappers to change the observation format available in [gym_minigrid/wrappers.py](/gym_minigrid/wrappers.py). If your RL code expects one single tensor for observations, take a look at
|
| 115 |
+
`FlatObsWrapper`. There is also an `ImgObsWrapper` that gets rid of the 'mission' field in observations,
|
| 116 |
+
leaving only the image field tensor.
|
| 117 |
+
|
| 118 |
+
Please note that the default observation format is a partially observable view of the environment using a
|
| 119 |
+
compact and efficient encoding, with 3 input values per visible grid cell, 7x7x3 values total.
|
| 120 |
+
These values are **not pixels**. If you want to obtain an array of RGB pixels as observations instead,
|
| 121 |
+
use the `RGBImgPartialObsWrapper`. You can use it as follows:
|
| 122 |
+
|
| 123 |
+
```
|
| 124 |
+
from gym_minigrid.wrappers import *
|
| 125 |
+
env = gym.make('MiniGrid-Empty-8x8-v0')
|
| 126 |
+
env = RGBImgPartialObsWrapper(env) # Get pixel observations
|
| 127 |
+
env = ImgObsWrapper(env) # Get rid of the 'mission' field
|
| 128 |
+
obs = env.reset() # This now produces an RGB tensor only
|
| 129 |
+
```
|
| 130 |
+
|
| 131 |
+
## Design
|
| 132 |
+
|
| 133 |
+
Structure of the world:
|
| 134 |
+
- The world is an NxM grid of tiles
|
| 135 |
+
- Each tile in the grid world contains zero or one object
|
| 136 |
+
- Cells that do not contain an object have the value `None`
|
| 137 |
+
- Each object has an associated discrete color (string)
|
| 138 |
+
- Each object has an associated type (string)
|
| 139 |
+
- Provided object types are: wall, floor, lava, door, key, ball, box and goal
|
| 140 |
+
- The agent can pick up and carry exactly one object (eg: ball or key)
|
| 141 |
+
- To open a locked door, the agent has to be carrying a key matching the door's color
|
| 142 |
+
|
| 143 |
+
Actions in the basic environment:
|
| 144 |
+
- Turn left
|
| 145 |
+
- Turn right
|
| 146 |
+
- Move forward
|
| 147 |
+
- Pick up an object
|
| 148 |
+
- Drop the object being carried
|
| 149 |
+
- Toggle (open doors, interact with objects)
|
| 150 |
+
- Done (task completed, optional)
|
| 151 |
+
|
| 152 |
+
Default tile/observation encoding:
|
| 153 |
+
- Each tile is encoded as a 3 dimensional tuple: (OBJECT_IDX, COLOR_IDX, STATE)
|
| 154 |
+
- OBJECT_TO_IDX and COLOR_TO_IDX mapping can be found in [gym_minigrid/minigrid.py](gym_minigrid/minigrid.py)
|
| 155 |
+
- e.g. door STATE -> 0: open, 1: closed, 2: locked
|
| 156 |
+
|
| 157 |
+
By default, sparse rewards are given for reaching a green goal tile. A
|
| 158 |
+
reward of 1 is given for success, and zero for failure. There is also an
|
| 159 |
+
environment-specific time step limit for completing the task.
|
| 160 |
+
You can define your own reward function by creating a class derived
|
| 161 |
+
from `MiniGridEnv`. Extending the environment with new object types or new actions
|
| 162 |
+
should be very easy. If you wish to do this, you should take a look at the
|
| 163 |
+
[gym_minigrid/minigrid.py](gym_minigrid/minigrid.py) source file.
|
| 164 |
+
|
| 165 |
+
## Included Environments
|
| 166 |
+
|
| 167 |
+
The environments listed below are implemented in the [gym_minigrid/envs](/gym_minigrid/envs) directory.
|
| 168 |
+
Each environment provides one or more configurations registered with OpenAI gym. Each environment
|
| 169 |
+
is also programmatically tunable in terms of size/complexity, which is useful for curriculum learning
|
| 170 |
+
or to fine-tune difficulty.
|
| 171 |
+
|
| 172 |
+
### Empty environment
|
| 173 |
+
|
| 174 |
+
Registered configurations:
|
| 175 |
+
- `MiniGrid-Empty-5x5-v0`
|
| 176 |
+
- `MiniGrid-Empty-Random-5x5-v0`
|
| 177 |
+
- `MiniGrid-Empty-6x6-v0`
|
| 178 |
+
- `MiniGrid-Empty-Random-6x6-v0`
|
| 179 |
+
- `MiniGrid-Empty-8x8-v0`
|
| 180 |
+
- `MiniGrid-Empty-16x16-v0`
|
| 181 |
+
|
| 182 |
+
<p align="center">
|
| 183 |
+
<img src="/figures/empty-env.png" width=250>
|
| 184 |
+
</p>
|
| 185 |
+
|
| 186 |
+
This environment is an empty room, and the goal of the agent is to reach the
|
| 187 |
+
green goal square, which provides a sparse reward. A small penalty is
|
| 188 |
+
subtracted for the number of steps to reach the goal. This environment is
|
| 189 |
+
useful, with small rooms, to validate that your RL algorithm works correctly,
|
| 190 |
+
and with large rooms to experiment with sparse rewards and exploration.
|
| 191 |
+
The random variants of the environment have the agent starting at a random
|
| 192 |
+
position for each episode, while the regular variants have the agent always
|
| 193 |
+
starting in the corner opposite to the goal.
|
| 194 |
+
|
| 195 |
+
### Four rooms environment
|
| 196 |
+
|
| 197 |
+
Registered configurations:
|
| 198 |
+
- `MiniGrid-FourRooms-v0`
|
| 199 |
+
|
| 200 |
+
<p align="center">
|
| 201 |
+
<img src="/figures/four-rooms-env.png" width=380>
|
| 202 |
+
</p>
|
| 203 |
+
|
| 204 |
+
Classic four room reinforcement learning environment. The agent must navigate
|
| 205 |
+
in a maze composed of four rooms interconnected by 4 gaps in the walls. To
|
| 206 |
+
obtain a reward, the agent must reach the green goal square. Both the agent
|
| 207 |
+
and the goal square are randomly placed in any of the four rooms.
|
| 208 |
+
|
| 209 |
+
### Door & key environment
|
| 210 |
+
|
| 211 |
+
Registered configurations:
|
| 212 |
+
- `MiniGrid-DoorKey-5x5-v0`
|
| 213 |
+
- `MiniGrid-DoorKey-6x6-v0`
|
| 214 |
+
- `MiniGrid-DoorKey-8x8-v0`
|
| 215 |
+
- `MiniGrid-DoorKey-16x16-v0`
|
| 216 |
+
|
| 217 |
+
<p align="center">
|
| 218 |
+
<img src="/figures/door-key-env.png">
|
| 219 |
+
</p>
|
| 220 |
+
|
| 221 |
+
This environment has a key that the agent must pick up in order to unlock
|
| 222 |
+
a goal and then get to the green goal square. This environment is difficult,
|
| 223 |
+
because of the sparse reward, to solve using classical RL algorithms. It is
|
| 224 |
+
useful to experiment with curiosity or curriculum learning.
|
| 225 |
+
|
| 226 |
+
### Multi-room environment
|
| 227 |
+
|
| 228 |
+
Registered configurations:
|
| 229 |
+
- `MiniGrid-MultiRoom-N2-S4-v0` (two small rooms)
|
| 230 |
+
- `MiniGrid-MultiRoom-N4-S5-v0` (four rooms)
|
| 231 |
+
- `MiniGrid-MultiRoom-N6-v0` (six rooms)
|
| 232 |
+
|
| 233 |
+
<p align="center">
|
| 234 |
+
<img src="/figures/multi-room.gif" width=416 height=424>
|
| 235 |
+
</p>
|
| 236 |
+
|
| 237 |
+
This environment has a series of connected rooms with doors that must be
|
| 238 |
+
opened in order to get to the next room. The final room has the green goal
|
| 239 |
+
square the agent must get to. This environment is extremely difficult to
|
| 240 |
+
solve using RL alone. However, by gradually increasing the number of
|
| 241 |
+
rooms and building a curriculum, the environment can be solved.
|
| 242 |
+
|
| 243 |
+
### Fetch environment
|
| 244 |
+
|
| 245 |
+
Registered configurations:
|
| 246 |
+
- `MiniGrid-Fetch-5x5-N2-v0`
|
| 247 |
+
- `MiniGrid-Fetch-6x6-N2-v0`
|
| 248 |
+
- `MiniGrid-Fetch-8x8-N3-v0`
|
| 249 |
+
|
| 250 |
+
<p align="center">
|
| 251 |
+
<img src="/figures/fetch-env.png" width=450>
|
| 252 |
+
</p>
|
| 253 |
+
|
| 254 |
+
This environment has multiple objects of assorted types and colors. The
|
| 255 |
+
agent receives a textual string as part of its observation telling it
|
| 256 |
+
which object to pick up. Picking up the wrong object produces a negative
|
| 257 |
+
reward.
|
| 258 |
+
|
| 259 |
+
### Go-to-door environment
|
| 260 |
+
|
| 261 |
+
Registered configurations:
|
| 262 |
+
- `MiniGrid-GoToDoor-5x5-v0`
|
| 263 |
+
- `MiniGrid-GoToDoor-6x6-v0`
|
| 264 |
+
- `MiniGrid-GoToDoor-8x8-v0`
|
| 265 |
+
|
| 266 |
+
<p align="center">
|
| 267 |
+
<img src="/figures/gotodoor-6x6.png" width=400>
|
| 268 |
+
</p>
|
| 269 |
+
|
| 270 |
+
This environment is a room with four doors, one on each wall. The agent
|
| 271 |
+
receives a textual (mission) string as input, telling it which door to go to,
|
| 272 |
+
(eg: "go to the red door"). It receives a positive reward for performing the
|
| 273 |
+
`done` action next to the correct door, as indicated in the mission string.
|
| 274 |
+
|
| 275 |
+
### Put-near environment
|
| 276 |
+
|
| 277 |
+
Registered configurations:
|
| 278 |
+
- `MiniGrid-PutNear-6x6-N2-v0`
|
| 279 |
+
- `MiniGrid-PutNear-8x8-N3-v0`
|
| 280 |
+
|
| 281 |
+
The agent is instructed through a textual string to pick up an object and
|
| 282 |
+
place it next to another object. This environment is easy to solve with two
|
| 283 |
+
objects, but difficult to solve with more, as it involves both textual
|
| 284 |
+
understanding and spatial reasoning involving multiple objects.
|
| 285 |
+
|
| 286 |
+
### Red and blue doors environment
|
| 287 |
+
|
| 288 |
+
Registered configurations:
|
| 289 |
+
- `MiniGrid-RedBlueDoors-6x6-v0`
|
| 290 |
+
- `MiniGrid-RedBlueDoors-8x8-v0`
|
| 291 |
+
|
| 292 |
+
The purpose of this environment is to test memory.
|
| 293 |
+
The agent is randomly placed within a room with one red and one blue door
|
| 294 |
+
facing opposite directions. The agent has to open the red door and then open
|
| 295 |
+
the blue door, in that order. The agent, when facing one door, cannot see
|
| 296 |
+
the door behind him. Hence, the agent needs to remember whether or not he has
|
| 297 |
+
previously opened the other door in order to reliably succeed at completing
|
| 298 |
+
the task.
|
| 299 |
+
|
| 300 |
+
### Memory environment
|
| 301 |
+
|
| 302 |
+
Registered configurations:
|
| 303 |
+
- `MiniGrid-MemoryS17Random-v0`
|
| 304 |
+
- `MiniGrid-MemoryS13Random-v0`
|
| 305 |
+
- `MiniGrid-MemoryS13-v0`
|
| 306 |
+
- `MiniGrid-MemoryS11-v0`
|
| 307 |
+
- `MiniGrid-MemoryS9-v0`
|
| 308 |
+
- `MiniGrid-MemoryS7-v0`
|
| 309 |
+
|
| 310 |
+
This environment is a memory test. The agent starts in a small room
|
| 311 |
+
where it sees an object. It then has to go through a narrow hallway
|
| 312 |
+
which ends in a split. At each end of the split there is an object,
|
| 313 |
+
one of which is the same as the object in the starting room. The
|
| 314 |
+
agent has to remember the initial object, and go to the matching
|
| 315 |
+
object at split.
|
| 316 |
+
|
| 317 |
+
### Locked room environment
|
| 318 |
+
|
| 319 |
+
Registed configurations:
|
| 320 |
+
- `MiniGrid-LockedRoom-v0`
|
| 321 |
+
|
| 322 |
+
The environment has six rooms, one of which is locked. The agent receives
|
| 323 |
+
a textual mission string as input, telling it which room to go to in order
|
| 324 |
+
to get the key that opens the locked room. It then has to go into the locked
|
| 325 |
+
room in order to reach the final goal. This environment is extremely difficult
|
| 326 |
+
to solve with vanilla reinforcement learning alone.
|
| 327 |
+
|
| 328 |
+
### Key corridor environment
|
| 329 |
+
|
| 330 |
+
Registed configurations:
|
| 331 |
+
- `MiniGrid-KeyCorridorS3R1-v0`
|
| 332 |
+
- `MiniGrid-KeyCorridorS3R2-v0`
|
| 333 |
+
- `MiniGrid-KeyCorridorS3R3-v0`
|
| 334 |
+
- `MiniGrid-KeyCorridorS4R3-v0`
|
| 335 |
+
- `MiniGrid-KeyCorridorS5R3-v0`
|
| 336 |
+
- `MiniGrid-KeyCorridorS6R3-v0`
|
| 337 |
+
|
| 338 |
+
<p align="center">
|
| 339 |
+
<img src="figures/KeyCorridorS3R1.png" width="250">
|
| 340 |
+
<img src="figures/KeyCorridorS3R2.png" width="250">
|
| 341 |
+
<img src="figures/KeyCorridorS3R3.png" width="250">
|
| 342 |
+
<img src="figures/KeyCorridorS4R3.png" width="250">
|
| 343 |
+
<img src="figures/KeyCorridorS5R3.png" width="250">
|
| 344 |
+
<img src="figures/KeyCorridorS6R3.png" width="250">
|
| 345 |
+
</p>
|
| 346 |
+
|
| 347 |
+
This environment is similar to the locked room environment, but there are
|
| 348 |
+
multiple registered environment configurations of increasing size,
|
| 349 |
+
making it easier to use curriculum learning to train an agent to solve it.
|
| 350 |
+
The agent has to pick up an object which is behind a locked door. The key is
|
| 351 |
+
hidden in another room, and the agent has to explore the environment to find
|
| 352 |
+
it. The mission string does not give the agent any clues as to where the
|
| 353 |
+
key is placed. This environment can be solved without relying on language.
|
| 354 |
+
|
| 355 |
+
### Unlock environment
|
| 356 |
+
|
| 357 |
+
Registed configurations:
|
| 358 |
+
- `MiniGrid-Unlock-v0`
|
| 359 |
+
|
| 360 |
+
<p align="center">
|
| 361 |
+
<img src="figures/Unlock.png" width="200">
|
| 362 |
+
</p>
|
| 363 |
+
|
| 364 |
+
The agent has to open a locked door. This environment can be solved without
|
| 365 |
+
relying on language.
|
| 366 |
+
|
| 367 |
+
### Unlock pickup environment
|
| 368 |
+
|
| 369 |
+
Registed configurations:
|
| 370 |
+
- `MiniGrid-UnlockPickup-v0`
|
| 371 |
+
|
| 372 |
+
<p align="center">
|
| 373 |
+
<img src="figures/UnlockPickup.png" width="250">
|
| 374 |
+
</p>
|
| 375 |
+
|
| 376 |
+
The agent has to pick up a box which is placed in another room, behind a
|
| 377 |
+
locked door. This environment can be solved without relying on language.
|
| 378 |
+
|
| 379 |
+
### Blocked unlock pickup environment
|
| 380 |
+
|
| 381 |
+
Registed configurations:
|
| 382 |
+
- `MiniGrid-BlockedUnlockPickup-v0`
|
| 383 |
+
|
| 384 |
+
<p align="center">
|
| 385 |
+
<img src="figures/BlockedUnlockPickup.png" width="250">
|
| 386 |
+
</p>
|
| 387 |
+
|
| 388 |
+
The agent has to pick up a box which is placed in another room, behind a
|
| 389 |
+
locked door. The door is also blocked by a ball which the agent has to move
|
| 390 |
+
before it can unlock the door. Hence, the agent has to learn to move the ball,
|
| 391 |
+
pick up the key, open the door and pick up the object in the other room.
|
| 392 |
+
This environment can be solved without relying on language.
|
| 393 |
+
|
| 394 |
+
## Obstructed maze environment
|
| 395 |
+
|
| 396 |
+
Registered configurations:
|
| 397 |
+
- `MiniGrid-ObstructedMaze-1Dl-v0`
|
| 398 |
+
- `MiniGrid-ObstructedMaze-1Dlh-v0`
|
| 399 |
+
- `MiniGrid-ObstructedMaze-1Dlhb-v0`
|
| 400 |
+
- `MiniGrid-ObstructedMaze-2Dl-v0`
|
| 401 |
+
- `MiniGrid-ObstructedMaze-2Dlh-v0`
|
| 402 |
+
- `MiniGrid-ObstructedMaze-2Dlhb-v0`
|
| 403 |
+
- `MiniGrid-ObstructedMaze-1Q-v0`
|
| 404 |
+
- `MiniGrid-ObstructedMaze-2Q-v0`
|
| 405 |
+
- `MiniGrid-ObstructedMaze-Full-v0`
|
| 406 |
+
|
| 407 |
+
<p align="center">
|
| 408 |
+
<img src="figures/ObstructedMaze-1Dl.png" width="250">
|
| 409 |
+
<img src="figures/ObstructedMaze-1Dlh.png" width="250">
|
| 410 |
+
<img src="figures/ObstructedMaze-1Dlhb.png" width="250">
|
| 411 |
+
<img src="figures/ObstructedMaze-2Dl.png" width="100">
|
| 412 |
+
<img src="figures/ObstructedMaze-2Dlh.png" width="100">
|
| 413 |
+
<img src="figures/ObstructedMaze-2Dlhb.png" width="100">
|
| 414 |
+
<img src="figures/ObstructedMaze-1Q.png" width="250">
|
| 415 |
+
<img src="figures/ObstructedMaze-2Q.png" width="250">
|
| 416 |
+
<img src="figures/ObstructedMaze-4Q.png" width="250">
|
| 417 |
+
</p>
|
| 418 |
+
|
| 419 |
+
The agent has to pick up a box which is placed in a corner of a 3x3 maze.
|
| 420 |
+
The doors are locked, the keys are hidden in boxes and doors are obstructed
|
| 421 |
+
by balls. This environment can be solved without relying on language.
|
| 422 |
+
|
| 423 |
+
## Distributional shift environment
|
| 424 |
+
|
| 425 |
+
Registered configurations:
|
| 426 |
+
- `MiniGrid-DistShift1-v0`
|
| 427 |
+
- `MiniGrid-DistShift2-v0`
|
| 428 |
+
|
| 429 |
+
This environment is based on one of the DeepMind [AI safety gridworlds](https://github.com/deepmind/ai-safety-gridworlds).
|
| 430 |
+
The agent starts in the top-left corner and must reach the goal which is in the top-right corner, but has to avoid stepping
|
| 431 |
+
into lava on its way. The aim of this environment is to test an agent's ability to generalize. There are two slightly
|
| 432 |
+
different variants of the environment, so that the agent can be trained on one variant and tested on the other.
|
| 433 |
+
|
| 434 |
+
<p align="center">
|
| 435 |
+
<img src="figures/DistShift1.png" width="200">
|
| 436 |
+
<img src="figures/DistShift2.png" width="200">
|
| 437 |
+
</p>
|
| 438 |
+
|
| 439 |
+
## Lava gap environment
|
| 440 |
+
|
| 441 |
+
Registered configurations:
|
| 442 |
+
- `MiniGrid-LavaGapS5-v0`
|
| 443 |
+
- `MiniGrid-LavaGapS6-v0`
|
| 444 |
+
- `MiniGrid-LavaGapS7-v0`
|
| 445 |
+
|
| 446 |
+
<p align="center">
|
| 447 |
+
<img src="figures/LavaGapS6.png" width="200">
|
| 448 |
+
</p>
|
| 449 |
+
|
| 450 |
+
The agent has to reach the green goal square at the opposite corner of the room,
|
| 451 |
+
and must pass through a narrow gap in a vertical strip of deadly lava. Touching
|
| 452 |
+
the lava terminate the episode with a zero reward. This environment is useful
|
| 453 |
+
for studying safety and safe exploration.
|
| 454 |
+
|
| 455 |
+
## Lava crossing environment
|
| 456 |
+
|
| 457 |
+
Registered configurations:
|
| 458 |
+
- `MiniGrid-LavaCrossingS9N1-v0`
|
| 459 |
+
- `MiniGrid-LavaCrossingS9N2-v0`
|
| 460 |
+
- `MiniGrid-LavaCrossingS9N3-v0`
|
| 461 |
+
- `MiniGrid-LavaCrossingS11N5-v0`
|
| 462 |
+
|
| 463 |
+
<p align="center">
|
| 464 |
+
<img src="figures/LavaCrossingS9N1.png" width="200">
|
| 465 |
+
<img src="figures/LavaCrossingS9N2.png" width="200">
|
| 466 |
+
<img src="figures/LavaCrossingS9N3.png" width="200">
|
| 467 |
+
<img src="figures/LavaCrossingS11N5.png" width="250">
|
| 468 |
+
</p>
|
| 469 |
+
|
| 470 |
+
The agent has to reach the green goal square on the other corner of the room
|
| 471 |
+
while avoiding rivers of deadly lava which terminate the episode in failure.
|
| 472 |
+
Each lava stream runs across the room either horizontally or vertically, and
|
| 473 |
+
has a single crossing point which can be safely used; Luckily, a path to the
|
| 474 |
+
goal is guaranteed to exist. This environment is useful for studying safety and
|
| 475 |
+
safe exploration.
|
| 476 |
+
|
| 477 |
+
## Simple crossing environment
|
| 478 |
+
|
| 479 |
+
Registered configurations:
|
| 480 |
+
- `MiniGrid-SimpleCrossingS9N1-v0`
|
| 481 |
+
- `MiniGrid-SimpleCrossingS9N2-v0`
|
| 482 |
+
- `MiniGrid-SimpleCrossingS9N3-v0`
|
| 483 |
+
- `MiniGrid-SimpleCrossingS11N5-v0`
|
| 484 |
+
|
| 485 |
+
<p align="center">
|
| 486 |
+
<img src="figures/SimpleCrossingS9N1.png" width="200">
|
| 487 |
+
<img src="figures/SimpleCrossingS9N2.png" width="200">
|
| 488 |
+
<img src="figures/SimpleCrossingS9N3.png" width="200">
|
| 489 |
+
<img src="figures/SimpleCrossingS11N5.png" width="250">
|
| 490 |
+
</p>
|
| 491 |
+
|
| 492 |
+
Similar to the `LavaCrossing` environment, the agent has to reach the green
|
| 493 |
+
goal square on the other corner of the room, however lava is replaced by
|
| 494 |
+
walls. This MDP is therefore much easier and and maybe useful for quickly
|
| 495 |
+
testing your algorithms.
|
| 496 |
+
|
| 497 |
+
### Dynamic obstacles environment
|
| 498 |
+
|
| 499 |
+
Registered configurations:
|
| 500 |
+
- `MiniGrid-Dynamic-Obstacles-5x5-v0`
|
| 501 |
+
- `MiniGrid-Dynamic-Obstacles-Random-5x5-v0`
|
| 502 |
+
- `MiniGrid-Dynamic-Obstacles-6x6-v0`
|
| 503 |
+
- `MiniGrid-Dynamic-Obstacles-Random-6x6-v0`
|
| 504 |
+
- `MiniGrid-Dynamic-Obstacles-8x8-v0`
|
| 505 |
+
- `MiniGrid-Dynamic-Obstacles-16x16-v0`
|
| 506 |
+
|
| 507 |
+
<p align="center">
|
| 508 |
+
<img src="/figures/dynamic_obstacles.gif">
|
| 509 |
+
</p>
|
| 510 |
+
|
| 511 |
+
This environment is an empty room with moving obstacles. The goal of the agent is to reach the green goal square without colliding with any obstacle. A large penalty is subtracted if the agent collides with an obstacle and the episode finishes. This environment is useful to test Dynamic Obstacle Avoidance for mobile robots with Reinforcement Learning in Partial Observability.
|
gym-minigrid/benchmark.py
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python3
|
| 2 |
+
|
| 3 |
+
import time
|
| 4 |
+
import argparse
|
| 5 |
+
import gym_minigrid
|
| 6 |
+
import gym
|
| 7 |
+
from gym_minigrid.wrappers import *
|
| 8 |
+
|
| 9 |
+
parser = argparse.ArgumentParser()
|
| 10 |
+
parser.add_argument(
|
| 11 |
+
"--env-name",
|
| 12 |
+
dest="env_name",
|
| 13 |
+
help="gym environment to load",
|
| 14 |
+
default='MiniGrid-LavaGapS7-v0'
|
| 15 |
+
)
|
| 16 |
+
parser.add_argument("--num_resets", default=200)
|
| 17 |
+
parser.add_argument("--num_frames", default=5000)
|
| 18 |
+
args = parser.parse_args()
|
| 19 |
+
|
| 20 |
+
env = gym.make(args.env_name)
|
| 21 |
+
|
| 22 |
+
# Benchmark env.reset
|
| 23 |
+
t0 = time.time()
|
| 24 |
+
for i in range(args.num_resets):
|
| 25 |
+
env.reset()
|
| 26 |
+
t1 = time.time()
|
| 27 |
+
dt = t1 - t0
|
| 28 |
+
reset_time = (1000 * dt) / args.num_resets
|
| 29 |
+
|
| 30 |
+
# Benchmark rendering
|
| 31 |
+
t0 = time.time()
|
| 32 |
+
for i in range(args.num_frames):
|
| 33 |
+
env.render('rgb_array')
|
| 34 |
+
t1 = time.time()
|
| 35 |
+
dt = t1 - t0
|
| 36 |
+
frames_per_sec = args.num_frames / dt
|
| 37 |
+
|
| 38 |
+
# Create an environment with an RGB agent observation
|
| 39 |
+
env = gym.make(args.env_name)
|
| 40 |
+
env = RGBImgPartialObsWrapper(env)
|
| 41 |
+
env = ImgObsWrapper(env)
|
| 42 |
+
|
| 43 |
+
# Benchmark rendering
|
| 44 |
+
t0 = time.time()
|
| 45 |
+
for i in range(args.num_frames):
|
| 46 |
+
obs, reward, done, info = env.step(0)
|
| 47 |
+
t1 = time.time()
|
| 48 |
+
dt = t1 - t0
|
| 49 |
+
agent_view_fps = args.num_frames / dt
|
| 50 |
+
|
| 51 |
+
print('Env reset time: {:.1f} ms'.format(reset_time))
|
| 52 |
+
print('Rendering FPS : {:.0f}'.format(frames_per_sec))
|
| 53 |
+
print('Agent view FPS: {:.0f}'.format(agent_view_fps))
|
gym-minigrid/gym_minigrid/__init__.py
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Import the envs module so that envs register themselves
|
| 2 |
+
import gym_minigrid.envs
|
| 3 |
+
import gym_minigrid.social_ai_envs
|
| 4 |
+
|
| 5 |
+
# Import wrappers so it's accessible when installing with pip
|
| 6 |
+
import gym_minigrid.wrappers
|
gym-minigrid/gym_minigrid/backup_envs/bobo.py
ADDED
|
@@ -0,0 +1,301 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
|
| 3 |
+
from gym_minigrid.minigrid import *
|
| 4 |
+
from gym_minigrid.register import register
|
| 5 |
+
import time
|
| 6 |
+
from collections import deque
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class Peer(NPC):
|
| 10 |
+
"""
|
| 11 |
+
A dancing NPC that the agent has to copy
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
def __init__(self, color, name, env, knowledgeable=False):
|
| 15 |
+
super().__init__(color)
|
| 16 |
+
self.name = name
|
| 17 |
+
self.npc_dir = 1 # NPC initially looks downward
|
| 18 |
+
self.npc_type = 0
|
| 19 |
+
self.env = env
|
| 20 |
+
self.knowledgeable = knowledgeable
|
| 21 |
+
self.npc_actions = []
|
| 22 |
+
self.dancing_step_idx = 0
|
| 23 |
+
self.actions = MiniGridEnv.Actions
|
| 24 |
+
self.add_npc_direction = True
|
| 25 |
+
self.available_moves = [self.rotate_left, self.rotate_right, self.go_forward, self.toggle_action]
|
| 26 |
+
self.exited = False
|
| 27 |
+
|
| 28 |
+
def step(self):
|
| 29 |
+
if self.exited:
|
| 30 |
+
return
|
| 31 |
+
|
| 32 |
+
if all(np.array(self.cur_pos) == np.array(self.env.door_pos)):
|
| 33 |
+
# todo: disappear
|
| 34 |
+
# todo: close door
|
| 35 |
+
self.env.grid.set(*self.cur_pos, self.env.object)
|
| 36 |
+
self.cur_pos = np.array([np.nan, np.nan])
|
| 37 |
+
|
| 38 |
+
self.env.object.toggle(self.env, self.cur_pos)
|
| 39 |
+
|
| 40 |
+
self.exited = True
|
| 41 |
+
|
| 42 |
+
elif self.knowledgeable:
|
| 43 |
+
|
| 44 |
+
if all(self.front_pos == self.env.door_pos):
|
| 45 |
+
# in front of door
|
| 46 |
+
if self.env.object.is_open:
|
| 47 |
+
self.go_forward()
|
| 48 |
+
else:
|
| 49 |
+
self.toggle_action()
|
| 50 |
+
|
| 51 |
+
else:
|
| 52 |
+
if (self.cur_pos[0] == self.env.door_pos[0]) or (self.cur_pos[1] == self.env.door_pos[1]):
|
| 53 |
+
# is either in the correct row on in the correct column
|
| 54 |
+
next_wanted_position = self.env.door_pos
|
| 55 |
+
else:
|
| 56 |
+
# choose the midpoint
|
| 57 |
+
for cand_x, cand_y in [
|
| 58 |
+
(self.cur_pos[0], self.env.door_pos[1]),
|
| 59 |
+
(self.env.door_pos[0], self.cur_pos[1])
|
| 60 |
+
]:
|
| 61 |
+
if (
|
| 62 |
+
cand_x > 0 and cand_x < self.env.wall_x
|
| 63 |
+
) and (
|
| 64 |
+
cand_y > 0 and cand_y < self.env.wall_y
|
| 65 |
+
):
|
| 66 |
+
next_wanted_position = (cand_x, cand_y)
|
| 67 |
+
|
| 68 |
+
if self.cur_pos[1] == next_wanted_position[1]:
|
| 69 |
+
# same y
|
| 70 |
+
if self.cur_pos[0] < next_wanted_position[0]:
|
| 71 |
+
wanted_dir = 0
|
| 72 |
+
else:
|
| 73 |
+
wanted_dir = 2
|
| 74 |
+
if self.npc_dir == wanted_dir:
|
| 75 |
+
self.go_forward()
|
| 76 |
+
|
| 77 |
+
else:
|
| 78 |
+
self.rotate_left()
|
| 79 |
+
|
| 80 |
+
elif self.cur_pos[0] == next_wanted_position[0]:
|
| 81 |
+
# same x
|
| 82 |
+
if self.cur_pos[1] < next_wanted_position[1]:
|
| 83 |
+
wanted_dir = 1
|
| 84 |
+
else:
|
| 85 |
+
wanted_dir = 3
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
if self.npc_dir == wanted_dir:
|
| 89 |
+
self.go_forward()
|
| 90 |
+
|
| 91 |
+
else:
|
| 92 |
+
self.rotate_left()
|
| 93 |
+
else:
|
| 94 |
+
raise ValueError("Something is wrong.")
|
| 95 |
+
|
| 96 |
+
else:
|
| 97 |
+
self.env._rand_elem(self.available_moves)()
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
class BoboGrammar(object):
|
| 101 |
+
|
| 102 |
+
templates = ["Move your", "Shake your"]
|
| 103 |
+
things = ["body", "head"]
|
| 104 |
+
|
| 105 |
+
grammar_action_space = spaces.MultiDiscrete([len(templates), len(things)])
|
| 106 |
+
|
| 107 |
+
@classmethod
|
| 108 |
+
def construct_utterance(cls, action):
|
| 109 |
+
return cls.templates[int(action[0])] + " " + cls.things[int(action[1])] + " "
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
class BoboEnv(MultiModalMiniGridEnv):
|
| 113 |
+
"""
|
| 114 |
+
Environment in which the agent is instructed to go to a given object
|
| 115 |
+
named using an English text string
|
| 116 |
+
"""
|
| 117 |
+
|
| 118 |
+
def __init__(
|
| 119 |
+
self,
|
| 120 |
+
size=5,
|
| 121 |
+
diminished_reward=True,
|
| 122 |
+
step_penalty=False,
|
| 123 |
+
knowledgeable=False,
|
| 124 |
+
):
|
| 125 |
+
assert size >= 5
|
| 126 |
+
self.empty_symbol = "NA \n"
|
| 127 |
+
self.diminished_reward = diminished_reward
|
| 128 |
+
self.step_penalty = step_penalty
|
| 129 |
+
self.knowledgeable = knowledgeable
|
| 130 |
+
|
| 131 |
+
super().__init__(
|
| 132 |
+
grid_size=size,
|
| 133 |
+
max_steps=5*size**2,
|
| 134 |
+
# Set this to True for maximum speed
|
| 135 |
+
see_through_walls=True,
|
| 136 |
+
actions=MiniGridEnv.Actions,
|
| 137 |
+
action_space=spaces.MultiDiscrete([
|
| 138 |
+
len(MiniGridEnv.Actions),
|
| 139 |
+
*BoboGrammar.grammar_action_space.nvec
|
| 140 |
+
]),
|
| 141 |
+
add_npc_direction=True
|
| 142 |
+
)
|
| 143 |
+
|
| 144 |
+
print({
|
| 145 |
+
"size": size,
|
| 146 |
+
"diminished_reward": diminished_reward,
|
| 147 |
+
"step_penalty": step_penalty,
|
| 148 |
+
})
|
| 149 |
+
|
| 150 |
+
def _gen_grid(self, width, height):
|
| 151 |
+
# Create the grid
|
| 152 |
+
self.grid = Grid(width, height, nb_obj_dims=4)
|
| 153 |
+
|
| 154 |
+
# Randomly vary the room width and height
|
| 155 |
+
width = self._rand_int(5, width+1)
|
| 156 |
+
height = self._rand_int(5, height+1)
|
| 157 |
+
|
| 158 |
+
self.wall_x = width - 1
|
| 159 |
+
self.wall_y = height - 1
|
| 160 |
+
|
| 161 |
+
# Generate the surrounding walls
|
| 162 |
+
self.grid.wall_rect(0, 0, width, height)
|
| 163 |
+
|
| 164 |
+
door_color = self._rand_elem(COLOR_NAMES)
|
| 165 |
+
|
| 166 |
+
wall_for_door = self._rand_int(0, 4)
|
| 167 |
+
|
| 168 |
+
if wall_for_door < 2:
|
| 169 |
+
w = self._rand_int(1, width-1)
|
| 170 |
+
h = height-1 if wall_for_door == 0 else 0
|
| 171 |
+
else:
|
| 172 |
+
w = width-1 if wall_for_door == 3 else 0
|
| 173 |
+
h = self._rand_int(1, height-1)
|
| 174 |
+
|
| 175 |
+
self.door_pos = (w, h)
|
| 176 |
+
self.door = Door(door_color)
|
| 177 |
+
self.grid.set(*self.door_pos, self.door)
|
| 178 |
+
|
| 179 |
+
# Set a randomly coloured Dancer NPC
|
| 180 |
+
color = self._rand_elem(COLOR_NAMES)
|
| 181 |
+
self.peer = Peer(color, "Jim", self, knowledgeable=self.knowledgeable)
|
| 182 |
+
|
| 183 |
+
# Place it on the middle left side of the room
|
| 184 |
+
peer_pos = np.array((self._rand_int(1, width - 1), self._rand_int(1, height - 1)))
|
| 185 |
+
|
| 186 |
+
self.grid.set(*peer_pos, self.peer)
|
| 187 |
+
self.peer.init_pos = peer_pos
|
| 188 |
+
self.peer.cur_pos = peer_pos
|
| 189 |
+
|
| 190 |
+
# Randomize the agent's start position and orientation
|
| 191 |
+
self.place_agent(size=(width, height))
|
| 192 |
+
|
| 193 |
+
# Generate the mission string
|
| 194 |
+
self.mission = 'watch dancer and repeat his moves afterwards'
|
| 195 |
+
|
| 196 |
+
# Dummy beginning string
|
| 197 |
+
self.beginning_string = "This is what you hear. \n"
|
| 198 |
+
self.utterance = self.beginning_string
|
| 199 |
+
|
| 200 |
+
# utterance appended at the end of each step
|
| 201 |
+
self.utterance_history = ""
|
| 202 |
+
|
| 203 |
+
# used for rendering
|
| 204 |
+
self.conversation = self.utterance
|
| 205 |
+
|
| 206 |
+
def step(self, action):
|
| 207 |
+
p_action = action[0]
|
| 208 |
+
utterance_action = action[1:]
|
| 209 |
+
|
| 210 |
+
obs, reward, done, info = super().step(p_action)
|
| 211 |
+
|
| 212 |
+
if np.isnan(p_action):
|
| 213 |
+
pass
|
| 214 |
+
|
| 215 |
+
if p_action == self.actions.done:
|
| 216 |
+
done = True
|
| 217 |
+
|
| 218 |
+
self.peer.step()
|
| 219 |
+
|
| 220 |
+
if all(self.agent_pos == self.door_pos):
|
| 221 |
+
reward = self._reward()
|
| 222 |
+
done = True
|
| 223 |
+
|
| 224 |
+
# discount
|
| 225 |
+
if self.step_penalty:
|
| 226 |
+
reward = reward - 0.01
|
| 227 |
+
|
| 228 |
+
# fill observation with text
|
| 229 |
+
self.append_existing_utterance_to_history()
|
| 230 |
+
obs = self.add_utterance_to_observation(obs)
|
| 231 |
+
self.reset_utterance()
|
| 232 |
+
return obs, reward, done, info
|
| 233 |
+
|
| 234 |
+
def _reward(self):
|
| 235 |
+
if self.diminished_reward:
|
| 236 |
+
return super()._reward()
|
| 237 |
+
else:
|
| 238 |
+
return 1.0
|
| 239 |
+
|
| 240 |
+
def render(self, *args, **kwargs):
|
| 241 |
+
obs = super().render(*args, **kwargs)
|
| 242 |
+
print("conversation:\n", self.conversation)
|
| 243 |
+
print("utterance_history:\n", self.utterance_history)
|
| 244 |
+
self.window.set_caption(self.conversation, [self.peer.name])
|
| 245 |
+
return obs
|
| 246 |
+
|
| 247 |
+
|
| 248 |
+
class Bobo8x8Env(BoboEnv):
|
| 249 |
+
def __init__(self):
|
| 250 |
+
super().__init__(size=8)
|
| 251 |
+
|
| 252 |
+
|
| 253 |
+
class Bobo6x6Env(BoboEnv):
|
| 254 |
+
def __init__(self):
|
| 255 |
+
super().__init__(size=6)
|
| 256 |
+
|
| 257 |
+
|
| 258 |
+
# knowledgeable
|
| 259 |
+
class BoboKnowledgeableEnv(BoboEnv):
|
| 260 |
+
def __init__(self):
|
| 261 |
+
super().__init__(size=5, knowledgeable=True)
|
| 262 |
+
|
| 263 |
+
class BoboKnowledgeable6x6Env(BoboEnv):
|
| 264 |
+
def __init__(self):
|
| 265 |
+
super().__init__(size=6, knowledgeable=True)
|
| 266 |
+
|
| 267 |
+
class BoboKnowledgeable8x8Env(BoboEnv):
|
| 268 |
+
def __init__(self):
|
| 269 |
+
super().__init__(size=8, knowledgeable=True)
|
| 270 |
+
|
| 271 |
+
|
| 272 |
+
|
| 273 |
+
register(
|
| 274 |
+
id='MiniGrid-Bobo-5x5-v0',
|
| 275 |
+
entry_point='gym_minigrid.envs:BoboEnv'
|
| 276 |
+
)
|
| 277 |
+
|
| 278 |
+
register(
|
| 279 |
+
id='MiniGrid-Bobo-6x6-v0',
|
| 280 |
+
entry_point='gym_minigrid.envs:Bobo6x6Env'
|
| 281 |
+
)
|
| 282 |
+
|
| 283 |
+
register(
|
| 284 |
+
id='MiniGrid-Bobo-8x8-v0',
|
| 285 |
+
entry_point='gym_minigrid.envs:Bobo8x8Env'
|
| 286 |
+
)
|
| 287 |
+
|
| 288 |
+
register(
|
| 289 |
+
id='MiniGrid-BoboKnowledgeable-5x5-v0',
|
| 290 |
+
entry_point='gym_minigrid.envs:BoboKnowledgeableEnv'
|
| 291 |
+
)
|
| 292 |
+
|
| 293 |
+
register(
|
| 294 |
+
id='MiniGrid-BoboKnowledgeable-6x6-v0',
|
| 295 |
+
entry_point='gym_minigrid.envs:BoboKnowledgeable6x6Env'
|
| 296 |
+
)
|
| 297 |
+
|
| 298 |
+
register(
|
| 299 |
+
id='MiniGrid-BoboKnowledgeable-8x8-v0',
|
| 300 |
+
entry_point='gym_minigrid.envs:BoboKnowledgeable8x8Env'
|
| 301 |
+
)
|
gym-minigrid/gym_minigrid/backup_envs/cointhief.py
ADDED
|
@@ -0,0 +1,431 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from gym_minigrid.minigrid import *
|
| 2 |
+
from gym_minigrid.register import register
|
| 3 |
+
import time
|
| 4 |
+
from collections import deque
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class Thief(NPC):
|
| 8 |
+
"""
|
| 9 |
+
A dancing NPC that the agent has to copy
|
| 10 |
+
NPC executes a sequence of movement and utterances
|
| 11 |
+
"""
|
| 12 |
+
|
| 13 |
+
def __init__(self, color, name, env, thief_pos, hidden_npc=False, tag_visible_coins=False, view_size=5, look_around=True):
|
| 14 |
+
super().__init__(color)
|
| 15 |
+
self.name = name
|
| 16 |
+
self.npc_type = 0
|
| 17 |
+
self.env = env
|
| 18 |
+
self.cur_pos = thief_pos
|
| 19 |
+
self.init_pos = thief_pos
|
| 20 |
+
self.view_size = view_size
|
| 21 |
+
self.npc_dir = self._look_at_agent() # Thief stares at its victim
|
| 22 |
+
self.init_dir = self.npc_dir
|
| 23 |
+
self.actions = self.env.possible_actions
|
| 24 |
+
self.tag_visible_coins = tag_visible_coins
|
| 25 |
+
|
| 26 |
+
self.nb_given_coins = None
|
| 27 |
+
self.look_around = look_around
|
| 28 |
+
if self.look_around: # randomly select in which direction NPC is looking around
|
| 29 |
+
if np.random.random() > 0.5: # will look left
|
| 30 |
+
self.look = self.rotate_left
|
| 31 |
+
self.look_back = self.rotate_right
|
| 32 |
+
else: # will look right
|
| 33 |
+
self.look = self.rotate_right
|
| 34 |
+
self.look_back = self.rotate_left
|
| 35 |
+
|
| 36 |
+
self.nb_seen_coins = self._count_coins() # This is how much coins Thief wants, at least
|
| 37 |
+
self.add_npc_direction = True
|
| 38 |
+
self.nb_steps = 0
|
| 39 |
+
self.hidden_npc = hidden_npc
|
| 40 |
+
|
| 41 |
+
def step(self, agent_action, agent_utterance):
|
| 42 |
+
agent_disobeyed = False
|
| 43 |
+
agent_gave_coins = False
|
| 44 |
+
utterance = None
|
| 45 |
+
|
| 46 |
+
if self.nb_steps == 0:
|
| 47 |
+
utterance = "Freeze! Give me all the coins you have!"
|
| 48 |
+
|
| 49 |
+
if self.nb_steps >= 0 and self.look_around:
|
| 50 |
+
if self.npc_dir == self.init_dir: # start to look around
|
| 51 |
+
self.look()
|
| 52 |
+
else: # resume looking to agent
|
| 53 |
+
self.look_back()
|
| 54 |
+
|
| 55 |
+
if not(agent_utterance is None):
|
| 56 |
+
self.nb_given_coins = int(agent_utterance[-2])
|
| 57 |
+
|
| 58 |
+
if self.nb_given_coins >= self.nb_seen_coins:
|
| 59 |
+
agent_gave_coins = True
|
| 60 |
+
else: # agent gave not enough coins
|
| 61 |
+
agent_disobeyed = True
|
| 62 |
+
|
| 63 |
+
# The thief forbids the agent to move, apart from looking around (rotating)
|
| 64 |
+
if not (np.isnan(agent_action) or agent_action == self.actions.left or agent_action == self.actions.right):
|
| 65 |
+
agent_disobeyed = True
|
| 66 |
+
|
| 67 |
+
self.nb_steps += 1
|
| 68 |
+
return agent_disobeyed, agent_gave_coins, utterance
|
| 69 |
+
|
| 70 |
+
def get_status_str(self):
|
| 71 |
+
return "thief sees: {} \n agent gives: {}".format(self.nb_seen_coins, self.nb_given_coins)
|
| 72 |
+
|
| 73 |
+
def _count_coins(self):
|
| 74 |
+
# get seen coins
|
| 75 |
+
coins_pos = self.get_pos_visible_coins()
|
| 76 |
+
|
| 77 |
+
if self.look_around:
|
| 78 |
+
self.look()
|
| 79 |
+
# add coins visible from this new direction
|
| 80 |
+
coins_pos += self.get_pos_visible_coins()
|
| 81 |
+
# remove coins that we already saw
|
| 82 |
+
if len(coins_pos) > 0:
|
| 83 |
+
coins_pos = np.unique(coins_pos, axis=0).tolist()
|
| 84 |
+
self.look_back()
|
| 85 |
+
|
| 86 |
+
return len(coins_pos)
|
| 87 |
+
|
| 88 |
+
def _look_at_agent(self):
|
| 89 |
+
npc_dir = None
|
| 90 |
+
ax, ay = self.env.agent_pos
|
| 91 |
+
tx, ty = self.cur_pos
|
| 92 |
+
delta_x, delta_y = ax - tx, ay - ty
|
| 93 |
+
if delta_x == 1:
|
| 94 |
+
npc_dir = 0
|
| 95 |
+
elif delta_x == -1:
|
| 96 |
+
npc_dir = 2
|
| 97 |
+
elif delta_y == 1:
|
| 98 |
+
npc_dir = 1
|
| 99 |
+
elif delta_y == -1:
|
| 100 |
+
npc_dir = 3
|
| 101 |
+
else:
|
| 102 |
+
raise NotImplementedError
|
| 103 |
+
|
| 104 |
+
return npc_dir
|
| 105 |
+
|
| 106 |
+
def gen_npc_obs_grid(self):
|
| 107 |
+
"""
|
| 108 |
+
Generate the sub-grid observed by the npc.
|
| 109 |
+
This method also outputs a visibility mask telling us which grid
|
| 110 |
+
cells the npc can actually see.
|
| 111 |
+
"""
|
| 112 |
+
view_size = self.view_size
|
| 113 |
+
|
| 114 |
+
topX, topY, botX, botY = self.env.get_view_exts(dir=self.npc_dir, view_size=view_size, pos=self.cur_pos)
|
| 115 |
+
|
| 116 |
+
grid = self.env.grid.slice(topX, topY, view_size, view_size)
|
| 117 |
+
|
| 118 |
+
for i in range(self.npc_dir + 1):
|
| 119 |
+
grid = grid.rotate_left()
|
| 120 |
+
|
| 121 |
+
# Process occluders and visibility
|
| 122 |
+
# Note that this incurs some performance cost
|
| 123 |
+
if not self.env.see_through_walls:
|
| 124 |
+
vis_mask = grid.process_vis(agent_pos=(view_size // 2, view_size - 1))
|
| 125 |
+
else:
|
| 126 |
+
vis_mask = np.ones(shape=(grid.width, grid.height), dtype=np.bool)
|
| 127 |
+
|
| 128 |
+
# Make it so the agent sees what it's carrying
|
| 129 |
+
# We do this by placing the carried object at the agent's position
|
| 130 |
+
# in the agent's partially observable view
|
| 131 |
+
# agent_pos = grid.width // 2, grid.height - 1
|
| 132 |
+
# if self.carrying:
|
| 133 |
+
# grid.set(*agent_pos, self.carrying)
|
| 134 |
+
# else:
|
| 135 |
+
# grid.set(*agent_pos, None)
|
| 136 |
+
|
| 137 |
+
return grid, vis_mask
|
| 138 |
+
|
| 139 |
+
def get_pos_visible_coins(self):
|
| 140 |
+
"""
|
| 141 |
+
Generate the npc's view (partially observable, low-resolution encoding)
|
| 142 |
+
return the list of unique visible coins
|
| 143 |
+
"""
|
| 144 |
+
|
| 145 |
+
grid, vis_mask = self.gen_npc_obs_grid()
|
| 146 |
+
|
| 147 |
+
coins_pos = []
|
| 148 |
+
|
| 149 |
+
for obj in grid.grid:
|
| 150 |
+
if isinstance(obj, Ball):
|
| 151 |
+
coins_pos.append(obj.cur_pos)
|
| 152 |
+
if self.tag_visible_coins:
|
| 153 |
+
obj.tag()
|
| 154 |
+
|
| 155 |
+
return coins_pos
|
| 156 |
+
|
| 157 |
+
def can_overlap(self):
|
| 158 |
+
# If the NPC is hidden, agent can overlap on it
|
| 159 |
+
return self.hidden_npc
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
class CoinThiefGrammar(object):
|
| 163 |
+
|
| 164 |
+
templates = ["Here is"]
|
| 165 |
+
things = ["0","1","2","3","4","5","6"]
|
| 166 |
+
|
| 167 |
+
grammar_action_space = spaces.MultiDiscrete([len(templates), len(things)])
|
| 168 |
+
|
| 169 |
+
@classmethod
|
| 170 |
+
def construct_utterance(cls, action):
|
| 171 |
+
return cls.templates[int(action[0])] + " " + cls.things[int(action[1])] + " "
|
| 172 |
+
|
| 173 |
+
@classmethod
|
| 174 |
+
def random_utterance(cls):
|
| 175 |
+
return np.random.choice(cls.templates) + " " + np.random.choice(cls.things) + " "
|
| 176 |
+
|
| 177 |
+
|
| 178 |
+
class ThiefActions(IntEnum):
|
| 179 |
+
# Turn left, turn right, move forward
|
| 180 |
+
left = 0
|
| 181 |
+
right = 1
|
| 182 |
+
forward = 2
|
| 183 |
+
|
| 184 |
+
|
| 185 |
+
class CoinThiefEnv(MultiModalMiniGridEnv):
|
| 186 |
+
"""
|
| 187 |
+
Environment in which the agent is instructed to go to a given object
|
| 188 |
+
named using an English text string
|
| 189 |
+
"""
|
| 190 |
+
|
| 191 |
+
def __init__(
|
| 192 |
+
self,
|
| 193 |
+
size=5,
|
| 194 |
+
hear_yourself=False,
|
| 195 |
+
diminished_reward=True,
|
| 196 |
+
step_penalty=False,
|
| 197 |
+
hidden_npc=False,
|
| 198 |
+
max_steps=20,
|
| 199 |
+
full_obs=False,
|
| 200 |
+
few_actions=False,
|
| 201 |
+
tag_visible_coins=False,
|
| 202 |
+
nb_coins=6,
|
| 203 |
+
npc_view_size=5,
|
| 204 |
+
npc_look_around=True
|
| 205 |
+
|
| 206 |
+
):
|
| 207 |
+
assert size >= 5
|
| 208 |
+
self.empty_symbol = "NA \n"
|
| 209 |
+
self.hear_yourself = hear_yourself
|
| 210 |
+
self.diminished_reward = diminished_reward
|
| 211 |
+
self.step_penalty = step_penalty
|
| 212 |
+
self.hidden_npc = hidden_npc
|
| 213 |
+
self.few_actions = few_actions
|
| 214 |
+
self.possible_actions = ThiefActions if self.few_actions else MiniGridEnv.Actions
|
| 215 |
+
self.nb_coins = nb_coins
|
| 216 |
+
self.tag_visible_coins = tag_visible_coins
|
| 217 |
+
self.npc_view_size = npc_view_size
|
| 218 |
+
self.npc_look_around = npc_look_around
|
| 219 |
+
if max_steps is None:
|
| 220 |
+
max_steps = 5*size**2
|
| 221 |
+
|
| 222 |
+
super().__init__(
|
| 223 |
+
grid_size=size,
|
| 224 |
+
max_steps=max_steps,
|
| 225 |
+
# Set this to True for maximum speed
|
| 226 |
+
see_through_walls=True,
|
| 227 |
+
full_obs=full_obs,
|
| 228 |
+
actions=MiniGridEnv.Actions,
|
| 229 |
+
action_space=spaces.MultiDiscrete([
|
| 230 |
+
len(self.possible_actions),
|
| 231 |
+
*CoinThiefGrammar.grammar_action_space.nvec
|
| 232 |
+
]),
|
| 233 |
+
add_npc_direction=True
|
| 234 |
+
)
|
| 235 |
+
|
| 236 |
+
print({
|
| 237 |
+
"size": size,
|
| 238 |
+
"hear_yourself": hear_yourself,
|
| 239 |
+
"diminished_reward": diminished_reward,
|
| 240 |
+
"step_penalty": step_penalty,
|
| 241 |
+
})
|
| 242 |
+
|
| 243 |
+
def _gen_grid(self, width, height):
|
| 244 |
+
# Create the grid
|
| 245 |
+
self.grid = Grid(width, height, nb_obj_dims=4)
|
| 246 |
+
|
| 247 |
+
# Randomly vary the room width and height
|
| 248 |
+
# width = self._rand_int(5, width+1)
|
| 249 |
+
# height = self._rand_int(5, height+1)
|
| 250 |
+
|
| 251 |
+
# Generate the surrounding walls
|
| 252 |
+
self.grid.wall_rect(0, 0, width, height)
|
| 253 |
+
|
| 254 |
+
# Generate the surrounding walls
|
| 255 |
+
self.grid.wall_rect(0, 0, width, height)
|
| 256 |
+
|
| 257 |
+
# Randomize the agent's start position and orientation
|
| 258 |
+
self.place_agent(size=(width, height))
|
| 259 |
+
|
| 260 |
+
# Get possible near-agent positions, and place thief in one of them
|
| 261 |
+
ax, ay = self.agent_pos
|
| 262 |
+
near_agent_pos = [[ax, ay + 1], [ax, ay - 1], [ax - 1, ay], [ax + 1, ay]]
|
| 263 |
+
# get empty cells positions
|
| 264 |
+
available_pos = []
|
| 265 |
+
for p in near_agent_pos:
|
| 266 |
+
if self.grid.get(*p) is None:
|
| 267 |
+
available_pos.append(p)
|
| 268 |
+
thief_pos = self._rand_elem(available_pos)
|
| 269 |
+
|
| 270 |
+
# Add randomly placed coins
|
| 271 |
+
# Types and colors of objects we can generate
|
| 272 |
+
types = ['ball']
|
| 273 |
+
objs = []
|
| 274 |
+
objPos = []
|
| 275 |
+
|
| 276 |
+
# Until we have generated all the objects
|
| 277 |
+
while len(objs) < self.nb_coins:
|
| 278 |
+
objType = self._rand_elem(types)
|
| 279 |
+
objColor = 'yellow'
|
| 280 |
+
|
| 281 |
+
if objType == 'ball':
|
| 282 |
+
obj = Ball(objColor)
|
| 283 |
+
else:
|
| 284 |
+
raise NotImplementedError
|
| 285 |
+
|
| 286 |
+
pos = self.place_obj(obj, reject_fn=lambda env,pos: pos.tolist() == thief_pos)
|
| 287 |
+
objs.append((objType, objColor))
|
| 288 |
+
objPos.append(pos)
|
| 289 |
+
|
| 290 |
+
# Set a randomly coloured Thief NPC next to the agent
|
| 291 |
+
color = self._rand_elem(COLOR_NAMES)
|
| 292 |
+
|
| 293 |
+
self.thief = Thief(color, "Eve", self, thief_pos,
|
| 294 |
+
hidden_npc=self.hidden_npc,
|
| 295 |
+
tag_visible_coins=self.tag_visible_coins,
|
| 296 |
+
view_size=self.npc_view_size,
|
| 297 |
+
look_around=self.npc_look_around)
|
| 298 |
+
|
| 299 |
+
self.grid.set(*thief_pos, self.thief)
|
| 300 |
+
|
| 301 |
+
# Generate the mission string
|
| 302 |
+
self.mission = 'save as much coins as possible'
|
| 303 |
+
|
| 304 |
+
# Dummy beginning string
|
| 305 |
+
self.beginning_string = "This is what you hear. \n"
|
| 306 |
+
self.utterance = self.beginning_string
|
| 307 |
+
|
| 308 |
+
# utterance appended at the end of each step
|
| 309 |
+
self.utterance_history = ""
|
| 310 |
+
|
| 311 |
+
# used for rendering
|
| 312 |
+
self.conversation = self.utterance
|
| 313 |
+
self.outcome_info = None
|
| 314 |
+
|
| 315 |
+
def step(self, action):
|
| 316 |
+
p_action = action[0] if np.isnan(action[0]) else int(action[0])
|
| 317 |
+
if len(action) == 1: # agent cannot speak
|
| 318 |
+
utterance_action = [np.nan, np.nan]
|
| 319 |
+
else:
|
| 320 |
+
utterance_action = action[1:]
|
| 321 |
+
|
| 322 |
+
obs, reward, done, info = super().step(p_action)
|
| 323 |
+
|
| 324 |
+
# assert all nan or neither nan
|
| 325 |
+
assert len(set(np.isnan(utterance_action))) == 1
|
| 326 |
+
speak_flag = not all(np.isnan(utterance_action))
|
| 327 |
+
|
| 328 |
+
if speak_flag:
|
| 329 |
+
utterance = CoinThiefGrammar.construct_utterance(utterance_action)
|
| 330 |
+
self.conversation += "{}: {} \n".format("Agent", utterance)
|
| 331 |
+
|
| 332 |
+
# Don't let the agent open any doors
|
| 333 |
+
if not self.few_actions and p_action == self.actions.toggle:
|
| 334 |
+
done = True
|
| 335 |
+
|
| 336 |
+
if not self.few_actions and p_action == self.actions.done:
|
| 337 |
+
done = True
|
| 338 |
+
|
| 339 |
+
# npc's turn
|
| 340 |
+
agent_disobeyed, agent_gave_coins, npc_utterance = self.thief.step(p_action, utterance if speak_flag else None)
|
| 341 |
+
|
| 342 |
+
if self.hidden_npc:
|
| 343 |
+
npc_utterance = None
|
| 344 |
+
|
| 345 |
+
if npc_utterance:
|
| 346 |
+
self.utterance += "{} \n".format(npc_utterance)
|
| 347 |
+
self.conversation += "{}: {} \n".format(self.thief.name, npc_utterance)
|
| 348 |
+
|
| 349 |
+
if agent_disobeyed:
|
| 350 |
+
done = True
|
| 351 |
+
|
| 352 |
+
if agent_gave_coins:
|
| 353 |
+
done = True
|
| 354 |
+
if self.thief.nb_seen_coins == self.thief.nb_given_coins:
|
| 355 |
+
reward = self._reward()
|
| 356 |
+
self.outcome_info = "SUCCESS: agent got {} reward \n".format(np.round(reward,1))
|
| 357 |
+
|
| 358 |
+
if done and reward == 0:
|
| 359 |
+
self.outcome_info = "FAILURE: agent got {} reward \n".format(reward)
|
| 360 |
+
|
| 361 |
+
# discount
|
| 362 |
+
if self.step_penalty:
|
| 363 |
+
reward = reward - 0.01
|
| 364 |
+
|
| 365 |
+
if self.hidden_npc:
|
| 366 |
+
# remove npc from agent view
|
| 367 |
+
npc_obs_idx = np.argwhere(obs['image'] == 11)
|
| 368 |
+
if npc_obs_idx.size != 0: # agent sees npc
|
| 369 |
+
obs['image'][npc_obs_idx[0][0], npc_obs_idx[0][1], :] = [1, 0, 0, 0]
|
| 370 |
+
|
| 371 |
+
# fill observation with text
|
| 372 |
+
self.append_existing_utterance_to_history()
|
| 373 |
+
obs = self.add_utterance_to_observation(obs)
|
| 374 |
+
self.reset_utterance()
|
| 375 |
+
|
| 376 |
+
return obs, reward, done, info
|
| 377 |
+
|
| 378 |
+
def _reward(self):
|
| 379 |
+
if self.diminished_reward:
|
| 380 |
+
return super()._reward()
|
| 381 |
+
else:
|
| 382 |
+
return 1.0
|
| 383 |
+
|
| 384 |
+
def render(self, *args, **kwargs):
|
| 385 |
+
obs = super().render(*args, **kwargs)
|
| 386 |
+
|
| 387 |
+
print("conversation:\n", self.conversation)
|
| 388 |
+
print("utterance_history:\n", self.utterance_history)
|
| 389 |
+
|
| 390 |
+
self.window.clear_text() # erase previous text
|
| 391 |
+
|
| 392 |
+
self.window.set_caption(self.conversation) # overwrites super class caption
|
| 393 |
+
self.window.ax.set_title(self.thief.get_status_str(), loc="left")
|
| 394 |
+
if self.outcome_info:
|
| 395 |
+
color = None
|
| 396 |
+
if "SUCCESS" in self.outcome_info:
|
| 397 |
+
color = "lime"
|
| 398 |
+
elif "FAILURE" in self.outcome_info:
|
| 399 |
+
color = "red"
|
| 400 |
+
self.window.add_text(*(0.01, 0.85, self.outcome_info),
|
| 401 |
+
**{'fontsize':15, 'color':color, 'weight':"bold"})
|
| 402 |
+
|
| 403 |
+
self.window.show_img(obs) # re-draw image to add changes to window
|
| 404 |
+
|
| 405 |
+
return obs
|
| 406 |
+
|
| 407 |
+
|
| 408 |
+
class CoinThief8x8Env(CoinThiefEnv):
|
| 409 |
+
def __init__(self, **kwargs):
|
| 410 |
+
super().__init__(size=8, **kwargs)
|
| 411 |
+
|
| 412 |
+
|
| 413 |
+
class CoinThief6x6Env(CoinThiefEnv):
|
| 414 |
+
def __init__(self, **kwargs):
|
| 415 |
+
super().__init__(size=6, **kwargs)
|
| 416 |
+
|
| 417 |
+
|
| 418 |
+
register(
|
| 419 |
+
id='MiniGrid-CoinThief-5x5-v0',
|
| 420 |
+
entry_point='gym_minigrid.envs:CoinThiefEnv'
|
| 421 |
+
)
|
| 422 |
+
|
| 423 |
+
register(
|
| 424 |
+
id='MiniGrid-CoinThief-6x6-v0',
|
| 425 |
+
entry_point='gym_minigrid.envs:CoinThief6x6Env'
|
| 426 |
+
)
|
| 427 |
+
|
| 428 |
+
register(
|
| 429 |
+
id='MiniGrid-CoinThief-8x8-v0',
|
| 430 |
+
entry_point='gym_minigrid.envs:CoinThief8x8Env'
|
| 431 |
+
)
|
gym-minigrid/gym_minigrid/backup_envs/dancewithonenpc.py
ADDED
|
@@ -0,0 +1,344 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from gym_minigrid.minigrid import *
|
| 2 |
+
from gym_minigrid.register import register
|
| 3 |
+
|
| 4 |
+
import time
|
| 5 |
+
from collections import deque
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class Dancer(NPC):
|
| 9 |
+
"""
|
| 10 |
+
A dancing NPC that the agent has to copy
|
| 11 |
+
NPC executes a sequence of movement and utterances
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
def __init__(self, color, name, env, dancing_pattern=None,
|
| 15 |
+
dance_len=3, p_sing=.5, hidden_npc=False, sing_only=False):
|
| 16 |
+
super().__init__(color)
|
| 17 |
+
self.name = name
|
| 18 |
+
self.npc_dir = 1 # NPC initially looks downward
|
| 19 |
+
self.npc_type = 0
|
| 20 |
+
self.env = env
|
| 21 |
+
self.actions = self.env.possible_actions
|
| 22 |
+
self.p_sing = p_sing
|
| 23 |
+
self.sing_only = sing_only
|
| 24 |
+
if self.sing_only:
|
| 25 |
+
p_sing = 1
|
| 26 |
+
self.dancing_pattern = dancing_pattern if dancing_pattern else self._gen_dancing_pattern(dance_len, p_sing)
|
| 27 |
+
self.agent_actions = deque(maxlen=len(self.dancing_pattern))
|
| 28 |
+
self.movement_id_to_fun = {self.actions.left: self.rotate_left,
|
| 29 |
+
self.actions.right: self.rotate_right,
|
| 30 |
+
self.actions.forward: self.go_forward}
|
| 31 |
+
# for vizualisation only
|
| 32 |
+
self.movement_id_to_str = {self.actions.left: "left",
|
| 33 |
+
self.actions.right: "right",
|
| 34 |
+
self.actions.forward: "forward",
|
| 35 |
+
self.actions.pickup: "pickup",
|
| 36 |
+
self.actions.drop: "drop",
|
| 37 |
+
self.actions.toggle: "toggle",
|
| 38 |
+
self.actions.done: "done",
|
| 39 |
+
None: "None"}
|
| 40 |
+
self.dancing_step_idx = 0
|
| 41 |
+
self.done_dancing = False
|
| 42 |
+
self.add_npc_direction = True
|
| 43 |
+
self.nb_steps = 0
|
| 44 |
+
self.hidden_npc = hidden_npc
|
| 45 |
+
|
| 46 |
+
def step(self, agent_action, agent_utterance):
|
| 47 |
+
agent_matched_moves = False
|
| 48 |
+
utterance = None
|
| 49 |
+
|
| 50 |
+
if self.nb_steps == 0:
|
| 51 |
+
utterance = "Look at me!"
|
| 52 |
+
if self.nb_steps >= 2: # Wait a couple steps before dancing
|
| 53 |
+
if not self.done_dancing:
|
| 54 |
+
if self.dancing_step_idx == len(self.dancing_pattern):
|
| 55 |
+
self.done_dancing = True
|
| 56 |
+
utterance = "Now repeat my moves!"
|
| 57 |
+
else:
|
| 58 |
+
# NPC moves and speaks according to dance step
|
| 59 |
+
move_id, utterance = self.dancing_pattern[self.dancing_step_idx]
|
| 60 |
+
self.movement_id_to_fun[move_id]()
|
| 61 |
+
|
| 62 |
+
self.dancing_step_idx += 1
|
| 63 |
+
else: # record agent dancing pattern
|
| 64 |
+
self.agent_actions.append((agent_action, agent_utterance))
|
| 65 |
+
|
| 66 |
+
if not self.sing_only and list(self.agent_actions) == list(self.dancing_pattern):
|
| 67 |
+
agent_matched_moves = True
|
| 68 |
+
if self.sing_only: # only compare utterances
|
| 69 |
+
if [x[1] for x in self.agent_actions] == [x[1] for x in self.dancing_pattern]:
|
| 70 |
+
agent_matched_moves = True
|
| 71 |
+
|
| 72 |
+
self.nb_steps += 1
|
| 73 |
+
return agent_matched_moves, utterance
|
| 74 |
+
|
| 75 |
+
def get_status_str(self):
|
| 76 |
+
readable_dancing_pattern = [(self.movement_id_to_str[dp[0]], dp[1]) for dp in self.dancing_pattern]
|
| 77 |
+
readable_agent_actions = [(self.movement_id_to_str[aa[0]], aa[1]) for aa in self.agent_actions]
|
| 78 |
+
return "dance: {} \n agent: {}".format(readable_dancing_pattern, readable_agent_actions)
|
| 79 |
+
|
| 80 |
+
def _gen_dancing_pattern(self, dance_len, p_sing):
|
| 81 |
+
available_moves = [self.actions.left, self.actions.right, self.actions.forward]
|
| 82 |
+
dance_pattern = []
|
| 83 |
+
for _ in range(dance_len):
|
| 84 |
+
move = self.env._rand_elem(available_moves)
|
| 85 |
+
sing = None
|
| 86 |
+
if np.random.random() < p_sing:
|
| 87 |
+
sing = DanceWithOneNPCGrammar.random_utterance()
|
| 88 |
+
dance_pattern.append((move, sing))
|
| 89 |
+
return dance_pattern
|
| 90 |
+
|
| 91 |
+
def can_overlap(self):
|
| 92 |
+
# If the NPC is hidden, agent can overlap on it
|
| 93 |
+
return self.hidden_npc
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
class DanceWithOneNPCGrammar(object):
|
| 98 |
+
|
| 99 |
+
templates = ["Move your", "Shake your"]
|
| 100 |
+
things = ["body", "head"]
|
| 101 |
+
|
| 102 |
+
grammar_action_space = spaces.MultiDiscrete([len(templates), len(things)])
|
| 103 |
+
|
| 104 |
+
@classmethod
|
| 105 |
+
def construct_utterance(cls, action):
|
| 106 |
+
return cls.templates[int(action[0])] + " " + cls.things[int(action[1])] + " "
|
| 107 |
+
|
| 108 |
+
@classmethod
|
| 109 |
+
def random_utterance(cls):
|
| 110 |
+
return np.random.choice(cls.templates) + " " + np.random.choice(cls.things) + " "
|
| 111 |
+
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
class DanceActions(IntEnum):
|
| 115 |
+
# Turn left, turn right, move forward
|
| 116 |
+
left = 0
|
| 117 |
+
right = 1
|
| 118 |
+
forward = 2
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
class DanceWithOneNPCEnv(MultiModalMiniGridEnv):
|
| 122 |
+
"""
|
| 123 |
+
Environment in which the agent is instructed to go to a given object
|
| 124 |
+
named using an English text string
|
| 125 |
+
"""
|
| 126 |
+
|
| 127 |
+
def __init__(
|
| 128 |
+
self,
|
| 129 |
+
size=5,
|
| 130 |
+
hear_yourself=False,
|
| 131 |
+
diminished_reward=True,
|
| 132 |
+
step_penalty=False,
|
| 133 |
+
dance_len=3,
|
| 134 |
+
hidden_npc=False,
|
| 135 |
+
p_sing=.5,
|
| 136 |
+
max_steps=20,
|
| 137 |
+
full_obs=False,
|
| 138 |
+
few_actions=False,
|
| 139 |
+
sing_only=False
|
| 140 |
+
|
| 141 |
+
):
|
| 142 |
+
assert size >= 5
|
| 143 |
+
self.empty_symbol = "NA \n"
|
| 144 |
+
self.hear_yourself = hear_yourself
|
| 145 |
+
self.diminished_reward = diminished_reward
|
| 146 |
+
self.step_penalty = step_penalty
|
| 147 |
+
self.dance_len = dance_len
|
| 148 |
+
self.hidden_npc = hidden_npc
|
| 149 |
+
self.p_sing = p_sing
|
| 150 |
+
self.few_actions = few_actions
|
| 151 |
+
self.possible_actions = DanceActions if self.few_actions else MiniGridEnv.Actions
|
| 152 |
+
self.sing_only = sing_only
|
| 153 |
+
if max_steps is None:
|
| 154 |
+
max_steps = 5*size**2
|
| 155 |
+
|
| 156 |
+
super().__init__(
|
| 157 |
+
grid_size=size,
|
| 158 |
+
max_steps=max_steps,
|
| 159 |
+
# Set this to True for maximum speed
|
| 160 |
+
see_through_walls=True,
|
| 161 |
+
full_obs=full_obs,
|
| 162 |
+
actions=MiniGridEnv.Actions,
|
| 163 |
+
action_space=spaces.MultiDiscrete([
|
| 164 |
+
len(self.possible_actions),
|
| 165 |
+
*DanceWithOneNPCGrammar.grammar_action_space.nvec
|
| 166 |
+
]),
|
| 167 |
+
add_npc_direction=True
|
| 168 |
+
)
|
| 169 |
+
|
| 170 |
+
print({
|
| 171 |
+
"size": size,
|
| 172 |
+
"hear_yourself": hear_yourself,
|
| 173 |
+
"diminished_reward": diminished_reward,
|
| 174 |
+
"step_penalty": step_penalty,
|
| 175 |
+
})
|
| 176 |
+
|
| 177 |
+
def _gen_grid(self, width, height):
|
| 178 |
+
# Create the grid
|
| 179 |
+
self.grid = Grid(width, height, nb_obj_dims=4)
|
| 180 |
+
|
| 181 |
+
# Randomly vary the room width and height
|
| 182 |
+
width = self._rand_int(5, width+1)
|
| 183 |
+
height = self._rand_int(5, height+1)
|
| 184 |
+
|
| 185 |
+
# Generate the surrounding walls
|
| 186 |
+
self.grid.wall_rect(0, 0, width, height)
|
| 187 |
+
|
| 188 |
+
# Generate the surrounding walls
|
| 189 |
+
self.grid.wall_rect(0, 0, width, height)
|
| 190 |
+
|
| 191 |
+
|
| 192 |
+
# Set a randomly coloured Dancer NPC
|
| 193 |
+
color = self._rand_elem(COLOR_NAMES)
|
| 194 |
+
self.dancer = Dancer(color, "Ren", self, dance_len=self.dance_len,
|
| 195 |
+
p_sing=self.p_sing, hidden_npc=self.hidden_npc, sing_only=self.sing_only)
|
| 196 |
+
|
| 197 |
+
# Place it on the middle left side of the room
|
| 198 |
+
left_pos = (int((width / 2) - 1), int(height / 2))
|
| 199 |
+
#right_pos = [(width / 2) + 1, height / 2]
|
| 200 |
+
|
| 201 |
+
self.grid.set(*left_pos, self.dancer)
|
| 202 |
+
self.dancer.init_pos = left_pos
|
| 203 |
+
self.dancer.cur_pos = left_pos
|
| 204 |
+
|
| 205 |
+
# Place it randomly left or right
|
| 206 |
+
#self.place_obj(self.dancer,
|
| 207 |
+
# size=(width, height))
|
| 208 |
+
|
| 209 |
+
# Randomize the agent's start position and orientation
|
| 210 |
+
self.place_agent(size=(width, height))
|
| 211 |
+
|
| 212 |
+
# Generate the mission string
|
| 213 |
+
self.mission = 'watch dancer and repeat his moves afterwards'
|
| 214 |
+
|
| 215 |
+
# Dummy beginning string
|
| 216 |
+
self.beginning_string = "This is what you hear. \n"
|
| 217 |
+
self.utterance = self.beginning_string
|
| 218 |
+
|
| 219 |
+
# utterance appended at the end of each step
|
| 220 |
+
self.utterance_history = ""
|
| 221 |
+
|
| 222 |
+
# used for rendering
|
| 223 |
+
self.conversation = self.utterance
|
| 224 |
+
self.outcome_info = None
|
| 225 |
+
|
| 226 |
+
def step(self, action):
|
| 227 |
+
p_action = action[0] if np.isnan(action[0]) else int(action[0])
|
| 228 |
+
if len(action) == 1: # agent cannot speak
|
| 229 |
+
assert self.p_sing == 0, "Non speaking agent used in a dance env requiring to speak"
|
| 230 |
+
utterance_action = [np.nan, np.nan]
|
| 231 |
+
else:
|
| 232 |
+
utterance_action = action[1:]
|
| 233 |
+
|
| 234 |
+
obs, reward, done, info = super().step(p_action)
|
| 235 |
+
|
| 236 |
+
if np.isnan(p_action):
|
| 237 |
+
pass
|
| 238 |
+
|
| 239 |
+
|
| 240 |
+
# assert all nan or neither nan
|
| 241 |
+
assert len(set(np.isnan(utterance_action))) == 1
|
| 242 |
+
speak_flag = not all(np.isnan(utterance_action))
|
| 243 |
+
|
| 244 |
+
if speak_flag:
|
| 245 |
+
utterance = DanceWithOneNPCGrammar.construct_utterance(utterance_action)
|
| 246 |
+
self.conversation += "{}: {} \n".format("Agent", utterance)
|
| 247 |
+
|
| 248 |
+
# Don't let the agent open any of the doors
|
| 249 |
+
if not self.few_actions and p_action == self.actions.toggle:
|
| 250 |
+
done = True
|
| 251 |
+
|
| 252 |
+
if not self.few_actions and p_action == self.actions.done:
|
| 253 |
+
done = True
|
| 254 |
+
|
| 255 |
+
# npc's turn
|
| 256 |
+
agent_matched_moves, npc_utterance = self.dancer.step(p_action if not np.isnan(p_action) else None,
|
| 257 |
+
utterance if speak_flag else None)
|
| 258 |
+
if self.hidden_npc:
|
| 259 |
+
npc_utterance = None
|
| 260 |
+
if npc_utterance:
|
| 261 |
+
self.utterance += "{} \n".format(npc_utterance)
|
| 262 |
+
self.conversation += "{}: {} \n".format(self.dancer.name, npc_utterance)
|
| 263 |
+
if agent_matched_moves:
|
| 264 |
+
reward = self._reward()
|
| 265 |
+
self.outcome_info = "SUCCESS: agent got {} reward \n".format(np.round(reward, 1))
|
| 266 |
+
done = True
|
| 267 |
+
|
| 268 |
+
# discount
|
| 269 |
+
if self.step_penalty:
|
| 270 |
+
reward = reward - 0.01
|
| 271 |
+
|
| 272 |
+
if self.hidden_npc:
|
| 273 |
+
# remove npc from agent view
|
| 274 |
+
npc_obs_idx = np.argwhere(obs['image'] == 11)
|
| 275 |
+
if npc_obs_idx.size != 0: # agent sees npc
|
| 276 |
+
obs['image'][npc_obs_idx[0][0], npc_obs_idx[0][1], :] = [1, 0, 0, 0]
|
| 277 |
+
|
| 278 |
+
if done and reward == 0:
|
| 279 |
+
self.outcome_info = "FAILURE: agent got {} reward \n".format(reward)
|
| 280 |
+
|
| 281 |
+
# fill observation with text
|
| 282 |
+
self.append_existing_utterance_to_history()
|
| 283 |
+
obs = self.add_utterance_to_observation(obs)
|
| 284 |
+
self.reset_utterance()
|
| 285 |
+
|
| 286 |
+
return obs, reward, done, info
|
| 287 |
+
|
| 288 |
+
|
| 289 |
+
def _reward(self):
|
| 290 |
+
if self.diminished_reward:
|
| 291 |
+
return super()._reward()
|
| 292 |
+
else:
|
| 293 |
+
return 1.0
|
| 294 |
+
|
| 295 |
+
def render(self, *args, **kwargs):
|
| 296 |
+
obs = super().render(*args, **kwargs)
|
| 297 |
+
|
| 298 |
+
print("conversation:\n", self.conversation)
|
| 299 |
+
print("utterance_history:\n", self.utterance_history)
|
| 300 |
+
|
| 301 |
+
self.window.clear_text() # erase previous text
|
| 302 |
+
|
| 303 |
+
self.window.set_caption(self.conversation) # overwrites super class caption
|
| 304 |
+
self.window.ax.set_title(self.dancer.get_status_str(), loc="left", fontsize=10)
|
| 305 |
+
if self.outcome_info:
|
| 306 |
+
color = None
|
| 307 |
+
if "SUCCESS" in self.outcome_info:
|
| 308 |
+
color = "lime"
|
| 309 |
+
elif "FAILURE" in self.outcome_info:
|
| 310 |
+
color = "red"
|
| 311 |
+
self.window.add_text(*(0.01, 0.85, self.outcome_info),
|
| 312 |
+
**{'fontsize':15, 'color':color, 'weight':"bold"})
|
| 313 |
+
|
| 314 |
+
self.window.show_img(obs) # re-draw image to add changes to window
|
| 315 |
+
|
| 316 |
+
return obs
|
| 317 |
+
|
| 318 |
+
|
| 319 |
+
|
| 320 |
+
|
| 321 |
+
class DanceWithOneNPC8x8Env(DanceWithOneNPCEnv):
|
| 322 |
+
def __init__(self, **kwargs):
|
| 323 |
+
super().__init__(size=8, **kwargs)
|
| 324 |
+
|
| 325 |
+
class DanceWithOneNPC6x6Env(DanceWithOneNPCEnv):
|
| 326 |
+
def __init__(self, **kwargs):
|
| 327 |
+
super().__init__(size=6, **kwargs)
|
| 328 |
+
|
| 329 |
+
|
| 330 |
+
|
| 331 |
+
register(
|
| 332 |
+
id='MiniGrid-DanceWithOneNPC-5x5-v0',
|
| 333 |
+
entry_point='gym_minigrid.envs:DanceWithOneNPCEnv'
|
| 334 |
+
)
|
| 335 |
+
|
| 336 |
+
register(
|
| 337 |
+
id='MiniGrid-DanceWithOneNPC-6x6-v0',
|
| 338 |
+
entry_point='gym_minigrid.envs:DanceWithOneNPC6x6Env'
|
| 339 |
+
)
|
| 340 |
+
|
| 341 |
+
register(
|
| 342 |
+
id='MiniGrid-DanceWithOneNPC-8x8-v0',
|
| 343 |
+
entry_point='gym_minigrid.envs:DanceWithOneNPC8x8Env'
|
| 344 |
+
)
|
gym-minigrid/gym_minigrid/backup_envs/diverseexit.py
ADDED
|
@@ -0,0 +1,584 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
|
| 3 |
+
from gym_minigrid.minigrid import *
|
| 4 |
+
from gym_minigrid.register import register
|
| 5 |
+
|
| 6 |
+
import time
|
| 7 |
+
from collections import deque
|
| 8 |
+
|
| 9 |
+
class TeacherPeer(NPC):
|
| 10 |
+
"""
|
| 11 |
+
A dancing NPC that the agent has to copy
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
def __init__(self, color, name, env, npc_type=0, knowledgeable=False, easier=False, idl=False):
|
| 15 |
+
super().__init__(color)
|
| 16 |
+
self.name = name
|
| 17 |
+
self.npc_dir = 1 # NPC initially looks downward
|
| 18 |
+
self.npc_type = npc_type
|
| 19 |
+
self.env = env
|
| 20 |
+
self.knowledgeable = knowledgeable
|
| 21 |
+
self.npc_actions = []
|
| 22 |
+
self.dancing_step_idx = 0
|
| 23 |
+
self.actions = MiniGridEnv.Actions
|
| 24 |
+
self.add_npc_direction = True
|
| 25 |
+
self.available_moves = [self.rotate_left, self.rotate_right, self.go_forward, self.toggle_action]
|
| 26 |
+
self.was_introduced_to = False
|
| 27 |
+
self.easier = easier
|
| 28 |
+
assert not self.easier
|
| 29 |
+
self.idl = idl
|
| 30 |
+
|
| 31 |
+
self.must_eye_contact = True if (self.npc_type // 3) % 2 == 0 else False
|
| 32 |
+
self.wanted_intro_utterances = [
|
| 33 |
+
EasyTeachingGamesGrammar.construct_utterance([2, 2]),
|
| 34 |
+
EasyTeachingGamesGrammar.construct_utterance([0, 1])
|
| 35 |
+
]
|
| 36 |
+
self.wanted_intro_utterance = self.wanted_intro_utterances[0] if (self.npc_type // 3) // 2 == 0 else self.wanted_intro_utterances[1]
|
| 37 |
+
if self.npc_type % 3 == 0:
|
| 38 |
+
# must be far, must not poke
|
| 39 |
+
self.must_be_poked = False
|
| 40 |
+
self.must_be_close = False
|
| 41 |
+
|
| 42 |
+
elif self.npc_type % 3 == 1:
|
| 43 |
+
# must be close, must not poke
|
| 44 |
+
self.must_be_poked = False
|
| 45 |
+
self.must_be_close = True
|
| 46 |
+
|
| 47 |
+
elif self.npc_type % 3 == 2:
|
| 48 |
+
# must be close, must poke
|
| 49 |
+
self.must_be_poked = True
|
| 50 |
+
self.must_be_close = True
|
| 51 |
+
|
| 52 |
+
else:
|
| 53 |
+
raise ValueError("npc tyep {} unknown". format(self.npc_type))
|
| 54 |
+
|
| 55 |
+
# print("Peer type: ", self.npc_type)
|
| 56 |
+
# print("Peer conf: ", self.wanted_intro_utterance, self.must_eye_contact, self.must_be_close, self.must_be_poked)
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
if self.must_be_poked and not self.must_be_close:
|
| 60 |
+
raise ValueError("Must be poked means it must be close also.")
|
| 61 |
+
|
| 62 |
+
self.poked = False
|
| 63 |
+
|
| 64 |
+
self.exited = False
|
| 65 |
+
self.joint_attention_achieved = False
|
| 66 |
+
|
| 67 |
+
def toggle(self, env, pos):
|
| 68 |
+
"""Method to trigger/toggle an action this object performs"""
|
| 69 |
+
self.poked = True
|
| 70 |
+
return True
|
| 71 |
+
|
| 72 |
+
def is_introduction_state_ok(self):
|
| 73 |
+
if (self.must_be_poked and self.introduction_state["poked"]) or (
|
| 74 |
+
not self.must_be_poked and not self.introduction_state["poked"]):
|
| 75 |
+
if (self.must_be_close and self.introduction_state["close"]) or (
|
| 76 |
+
not self.must_be_close and not self.introduction_state["close"]):
|
| 77 |
+
if (self.must_eye_contact and self.introduction_state["eye_contact"]) or (
|
| 78 |
+
not self.must_eye_contact and not self.introduction_state["eye_contact"]
|
| 79 |
+
):
|
| 80 |
+
if self.introduction_state["intro_utterance"] == self.wanted_intro_utterance:
|
| 81 |
+
return True
|
| 82 |
+
|
| 83 |
+
return False
|
| 84 |
+
|
| 85 |
+
def can_overlap(self):
|
| 86 |
+
# If the NPC is hidden, agent can overlap on it
|
| 87 |
+
return self.env.hidden_npc
|
| 88 |
+
|
| 89 |
+
def encode(self, nb_dims=3):
|
| 90 |
+
if self.env.hidden_npc:
|
| 91 |
+
if nb_dims == 3:
|
| 92 |
+
return (1, 0, 0)
|
| 93 |
+
elif nb_dims == 4:
|
| 94 |
+
return (1, 0, 0, 0)
|
| 95 |
+
else:
|
| 96 |
+
return super().encode(nb_dims=nb_dims)
|
| 97 |
+
|
| 98 |
+
def step(self, agent_utterance):
|
| 99 |
+
super().step()
|
| 100 |
+
|
| 101 |
+
if self.knowledgeable:
|
| 102 |
+
if self.easier:
|
| 103 |
+
raise DeprecationWarning()
|
| 104 |
+
# wanted_dir = self.compute_wanted_dir(self.env.agent_pos)
|
| 105 |
+
# action = self.compute_turn_action(wanted_dir)
|
| 106 |
+
# action()
|
| 107 |
+
# if not self.was_introduced_to and (agent_utterance in self.wanted_intro_utterances):
|
| 108 |
+
# self.was_introduced_to = True
|
| 109 |
+
# self.introduction_state = {
|
| 110 |
+
# "poked": self.poked,
|
| 111 |
+
# "close": self.is_near_agent(),
|
| 112 |
+
# "eye_contact": self.is_eye_contact(),
|
| 113 |
+
# "correct_intro_utterance": agent_utterance == self.wanted_intro_utterance
|
| 114 |
+
# }
|
| 115 |
+
# if self.is_introduction_state_ok():
|
| 116 |
+
# utterance = "Go to the {} door \n".format(self.env.target_color)
|
| 117 |
+
# return utterance
|
| 118 |
+
|
| 119 |
+
else:
|
| 120 |
+
wanted_dir = self.compute_wanted_dir(self.env.agent_pos)
|
| 121 |
+
action = self.compute_turn_action(wanted_dir)
|
| 122 |
+
action()
|
| 123 |
+
if not self.was_introduced_to and (agent_utterance in self.wanted_intro_utterances):
|
| 124 |
+
self.was_introduced_to = True
|
| 125 |
+
self.introduction_state = {
|
| 126 |
+
"poked": self.poked,
|
| 127 |
+
"close": self.is_near_agent(),
|
| 128 |
+
"eye_contact": self.is_eye_contact(),
|
| 129 |
+
"intro_utterance": agent_utterance,
|
| 130 |
+
}
|
| 131 |
+
if not self.is_introduction_state_ok():
|
| 132 |
+
if self.idl:
|
| 133 |
+
if self.env.hidden_npc:
|
| 134 |
+
return None
|
| 135 |
+
else:
|
| 136 |
+
return "I don't like that \n"
|
| 137 |
+
else:
|
| 138 |
+
return None
|
| 139 |
+
|
| 140 |
+
if self.is_eye_contact() and self.was_introduced_to:
|
| 141 |
+
|
| 142 |
+
if self.is_introduction_state_ok():
|
| 143 |
+
utterance = "Go to the {} door \n".format(self.env.target_color)
|
| 144 |
+
if self.env.hidden_npc:
|
| 145 |
+
return None
|
| 146 |
+
else:
|
| 147 |
+
return utterance
|
| 148 |
+
else:
|
| 149 |
+
# no utterance
|
| 150 |
+
return None
|
| 151 |
+
|
| 152 |
+
else:
|
| 153 |
+
self.env._rand_elem(self.available_moves)()
|
| 154 |
+
return None
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
def render(self, img):
|
| 158 |
+
c = COLORS[self.color]
|
| 159 |
+
|
| 160 |
+
npc_shapes = []
|
| 161 |
+
# Draw eyes
|
| 162 |
+
|
| 163 |
+
if self.npc_type % 3 == 0:
|
| 164 |
+
npc_shapes.append(point_in_circle(cx=0.70, cy=0.50, r=0.10))
|
| 165 |
+
npc_shapes.append(point_in_circle(cx=0.30, cy=0.50, r=0.10))
|
| 166 |
+
# Draw mouth
|
| 167 |
+
npc_shapes.append(point_in_rect(0.20, 0.80, 0.72, 0.81))
|
| 168 |
+
# Draw top hat
|
| 169 |
+
npc_shapes.append(point_in_rect(0.30, 0.70, 0.05, 0.28))
|
| 170 |
+
|
| 171 |
+
elif self.npc_type % 3 == 1:
|
| 172 |
+
npc_shapes.append(point_in_circle(cx=0.70, cy=0.50, r=0.10))
|
| 173 |
+
npc_shapes.append(point_in_circle(cx=0.30, cy=0.50, r=0.10))
|
| 174 |
+
# Draw mouth
|
| 175 |
+
npc_shapes.append(point_in_rect(0.20, 0.80, 0.72, 0.81))
|
| 176 |
+
# Draw bottom hat
|
| 177 |
+
npc_shapes.append(point_in_triangle((0.15, 0.28),
|
| 178 |
+
(0.85, 0.28),
|
| 179 |
+
(0.50, 0.05)))
|
| 180 |
+
elif self.npc_type % 3 == 2:
|
| 181 |
+
npc_shapes.append(point_in_circle(cx=0.70, cy=0.50, r=0.10))
|
| 182 |
+
npc_shapes.append(point_in_circle(cx=0.30, cy=0.50, r=0.10))
|
| 183 |
+
# Draw mouth
|
| 184 |
+
npc_shapes.append(point_in_rect(0.20, 0.80, 0.72, 0.81))
|
| 185 |
+
# Draw bottom hat
|
| 186 |
+
npc_shapes.append(point_in_triangle((0.15, 0.28),
|
| 187 |
+
(0.85, 0.28),
|
| 188 |
+
(0.50, 0.05)))
|
| 189 |
+
# Draw top hat
|
| 190 |
+
npc_shapes.append(point_in_rect(0.30, 0.70, 0.05, 0.28))
|
| 191 |
+
|
| 192 |
+
|
| 193 |
+
# todo: move this to super function
|
| 194 |
+
# todo: super.render should be able to take the npc_shapes and then rotate them
|
| 195 |
+
|
| 196 |
+
if hasattr(self, "npc_dir"):
|
| 197 |
+
# Pre-rotation to ensure npc_dir = 1 means NPC looks downwards
|
| 198 |
+
npc_shapes = [rotate_fn(v, cx=0.5, cy=0.5, theta=-1 * (math.pi / 2)) for v in npc_shapes]
|
| 199 |
+
# Rotate npc based on its direction
|
| 200 |
+
npc_shapes = [rotate_fn(v, cx=0.5, cy=0.5, theta=(math.pi / 2) * self.npc_dir) for v in npc_shapes]
|
| 201 |
+
|
| 202 |
+
# Draw shapes
|
| 203 |
+
for v in npc_shapes:
|
| 204 |
+
fill_coords(img, v, c)
|
| 205 |
+
|
| 206 |
+
# class EasyTeachingGamesSmallGrammar(object):
|
| 207 |
+
#
|
| 208 |
+
# templates = ["Where is", "Open", "What is"]
|
| 209 |
+
# things = ["sesame", "the exit", "the password"]
|
| 210 |
+
#
|
| 211 |
+
# grammar_action_space = spaces.MultiDiscrete([len(templates), len(things)])
|
| 212 |
+
#
|
| 213 |
+
# @classmethod
|
| 214 |
+
# def construct_utterance(cls, action):
|
| 215 |
+
# if all(np.isnan(action)):
|
| 216 |
+
# return ""
|
| 217 |
+
# return cls.templates[int(action[0])] + " " + cls.things[int(action[1])] + " "
|
| 218 |
+
|
| 219 |
+
|
| 220 |
+
class EasyTeachingGamesGrammar(object):
|
| 221 |
+
|
| 222 |
+
templates = ["Where is", "Open", "Which is", "How are"]
|
| 223 |
+
things = [
|
| 224 |
+
"sesame", "the exit", "the correct door", "you", "the ceiling", "the window", "the entrance", "the closet",
|
| 225 |
+
"the drawer", "the fridge", "the floor", "the lamp", "the trash can", "the chair", "the bed", "the sofa"
|
| 226 |
+
]
|
| 227 |
+
|
| 228 |
+
grammar_action_space = spaces.MultiDiscrete([len(templates), len(things)])
|
| 229 |
+
|
| 230 |
+
@classmethod
|
| 231 |
+
def construct_utterance(cls, action):
|
| 232 |
+
if all(np.isnan(action)):
|
| 233 |
+
return ""
|
| 234 |
+
return cls.templates[int(action[0])] + " " + cls.things[int(action[1])] + " "
|
| 235 |
+
|
| 236 |
+
|
| 237 |
+
class EasyTeachingGamesEnv(MultiModalMiniGridEnv):
|
| 238 |
+
"""
|
| 239 |
+
Environment in which the agent is instructed to go to a given object
|
| 240 |
+
named using an English text string
|
| 241 |
+
"""
|
| 242 |
+
|
| 243 |
+
def __init__(
|
| 244 |
+
self,
|
| 245 |
+
size=5,
|
| 246 |
+
diminished_reward=True,
|
| 247 |
+
step_penalty=False,
|
| 248 |
+
knowledgeable=False,
|
| 249 |
+
hard_password=False,
|
| 250 |
+
max_steps=50,
|
| 251 |
+
n_switches=3,
|
| 252 |
+
peer_type=None,
|
| 253 |
+
no_turn_off=False,
|
| 254 |
+
easier=False,
|
| 255 |
+
idl=False,
|
| 256 |
+
hidden_npc = False,
|
| 257 |
+
):
|
| 258 |
+
assert size >= 5
|
| 259 |
+
self.empty_symbol = "NA \n"
|
| 260 |
+
self.diminished_reward = diminished_reward
|
| 261 |
+
self.step_penalty = step_penalty
|
| 262 |
+
self.knowledgeable = knowledgeable
|
| 263 |
+
self.hard_password = hard_password
|
| 264 |
+
self.n_switches = n_switches
|
| 265 |
+
self.peer_type = peer_type
|
| 266 |
+
self.no_turn_off = no_turn_off
|
| 267 |
+
self.easier = easier
|
| 268 |
+
self.idl = idl
|
| 269 |
+
self.hidden_npc = hidden_npc
|
| 270 |
+
|
| 271 |
+
super().__init__(
|
| 272 |
+
grid_size=size,
|
| 273 |
+
max_steps=max_steps,
|
| 274 |
+
# Set this to True for maximum speed
|
| 275 |
+
see_through_walls=True,
|
| 276 |
+
actions=MiniGridEnv.Actions,
|
| 277 |
+
action_space=spaces.MultiDiscrete([
|
| 278 |
+
len(MiniGridEnv.Actions),
|
| 279 |
+
*EasyTeachingGamesGrammar.grammar_action_space.nvec
|
| 280 |
+
]),
|
| 281 |
+
add_npc_direction=True
|
| 282 |
+
)
|
| 283 |
+
|
| 284 |
+
print({
|
| 285 |
+
"size": size,
|
| 286 |
+
"diminished_reward": diminished_reward,
|
| 287 |
+
"step_penalty": step_penalty,
|
| 288 |
+
})
|
| 289 |
+
|
| 290 |
+
|
| 291 |
+
def _gen_grid(self, width, height):
|
| 292 |
+
# Create the grid
|
| 293 |
+
self.grid = Grid(width, height, nb_obj_dims=4)
|
| 294 |
+
|
| 295 |
+
# Randomly vary the room width and height
|
| 296 |
+
width = self._rand_int(5, width+1)
|
| 297 |
+
height = self._rand_int(5, height+1)
|
| 298 |
+
|
| 299 |
+
self.wall_x = width - 1
|
| 300 |
+
self.wall_y = height - 1
|
| 301 |
+
|
| 302 |
+
# Generate the surrounding walls
|
| 303 |
+
self.grid.wall_rect(0, 0, width, height)
|
| 304 |
+
|
| 305 |
+
self.door_pos = []
|
| 306 |
+
self.door_front_pos = [] # Remembers positions in front of door to avoid setting wizard here
|
| 307 |
+
|
| 308 |
+
self.door_pos.append((self._rand_int(2, width-2), 0))
|
| 309 |
+
self.door_front_pos.append((self.door_pos[-1][0], self.door_pos[-1][1]+1))
|
| 310 |
+
|
| 311 |
+
self.door_pos.append((self._rand_int(2, width-2), height-1))
|
| 312 |
+
self.door_front_pos.append((self.door_pos[-1][0], self.door_pos[-1][1] - 1))
|
| 313 |
+
|
| 314 |
+
self.door_pos.append((0, self._rand_int(2, height-2)))
|
| 315 |
+
self.door_front_pos.append((self.door_pos[-1][0] + 1, self.door_pos[-1][1]))
|
| 316 |
+
|
| 317 |
+
self.door_pos.append((width-1, self._rand_int(2, height-2)))
|
| 318 |
+
self.door_front_pos.append((self.door_pos[-1][0] - 1, self.door_pos[-1][1]))
|
| 319 |
+
|
| 320 |
+
# Generate the door colors
|
| 321 |
+
self.door_colors = []
|
| 322 |
+
while len(self.door_colors) < len(self.door_pos):
|
| 323 |
+
color = self._rand_elem(COLOR_NAMES)
|
| 324 |
+
if color in self.door_colors:
|
| 325 |
+
continue
|
| 326 |
+
self.door_colors.append(color)
|
| 327 |
+
|
| 328 |
+
# Place the doors in the grid
|
| 329 |
+
for idx, pos in enumerate(self.door_pos):
|
| 330 |
+
color = self.door_colors[idx]
|
| 331 |
+
self.grid.set(*pos, Door(color))
|
| 332 |
+
|
| 333 |
+
# Select a random target door
|
| 334 |
+
self.doorIdx = self._rand_int(0, len(self.door_pos))
|
| 335 |
+
self.target_pos = self.door_pos[self.doorIdx]
|
| 336 |
+
self.target_color = self.door_colors[self.doorIdx]
|
| 337 |
+
|
| 338 |
+
# Set a randomly coloured Dancer NPC
|
| 339 |
+
color = self._rand_elem(COLOR_NAMES)
|
| 340 |
+
|
| 341 |
+
if self.peer_type is None:
|
| 342 |
+
self.current_peer_type = self._rand_int(0, 12)
|
| 343 |
+
else:
|
| 344 |
+
self.current_peer_type = self.peer_type
|
| 345 |
+
|
| 346 |
+
self.peer = TeacherPeer(
|
| 347 |
+
color,
|
| 348 |
+
["Bobby", "Robby", "Toby"][self.current_peer_type % 3],
|
| 349 |
+
self,
|
| 350 |
+
knowledgeable=self.knowledgeable,
|
| 351 |
+
npc_type=self.current_peer_type,
|
| 352 |
+
easier=self.easier,
|
| 353 |
+
idl=self.idl
|
| 354 |
+
)
|
| 355 |
+
|
| 356 |
+
# height -2 so its not in front of the buttons in the way
|
| 357 |
+
while True:
|
| 358 |
+
peer_pos = np.array((self._rand_int(1, width - 1), self._rand_int(1, height - 2)))
|
| 359 |
+
|
| 360 |
+
if (
|
| 361 |
+
# not in front of any door
|
| 362 |
+
not tuple(peer_pos) in self.door_front_pos
|
| 363 |
+
) and (
|
| 364 |
+
# no_close npc is not in the middle of the 5x5 env
|
| 365 |
+
not (not self.peer.must_be_close and (width == 5 and height == 5) and all(peer_pos == (2, 2)))
|
| 366 |
+
):
|
| 367 |
+
break
|
| 368 |
+
|
| 369 |
+
self.grid.set(*peer_pos, self.peer)
|
| 370 |
+
self.peer.init_pos = peer_pos
|
| 371 |
+
self.peer.cur_pos = peer_pos
|
| 372 |
+
|
| 373 |
+
# Randomize the agent's start position and orientation
|
| 374 |
+
self.place_agent(size=(width, height))
|
| 375 |
+
|
| 376 |
+
# Generate the mission string
|
| 377 |
+
self.mission = 'exit the room'
|
| 378 |
+
|
| 379 |
+
# Dummy beginning string
|
| 380 |
+
self.beginning_string = "This is what you hear. \n"
|
| 381 |
+
self.utterance = self.beginning_string
|
| 382 |
+
|
| 383 |
+
# utterance appended at the end of each step
|
| 384 |
+
self.utterance_history = ""
|
| 385 |
+
|
| 386 |
+
# used for rendering
|
| 387 |
+
self.conversation = self.utterance
|
| 388 |
+
self.outcome_info = None
|
| 389 |
+
|
| 390 |
+
|
| 391 |
+
def step(self, action):
|
| 392 |
+
p_action = action[0]
|
| 393 |
+
utterance_action = action[1:]
|
| 394 |
+
|
| 395 |
+
obs, reward, done, info = super().step(p_action)
|
| 396 |
+
|
| 397 |
+
if p_action == self.actions.done:
|
| 398 |
+
done = True
|
| 399 |
+
|
| 400 |
+
peer_utterance = EasyTeachingGamesGrammar.construct_utterance(utterance_action)
|
| 401 |
+
peer_reply = self.peer.step(peer_utterance)
|
| 402 |
+
|
| 403 |
+
if peer_reply is not None:
|
| 404 |
+
self.utterance += "{}: {} \n".format(self.peer.name, peer_reply)
|
| 405 |
+
self.conversation += "{}: {} \n".format(self.peer.name, peer_reply)
|
| 406 |
+
|
| 407 |
+
if all(self.agent_pos == self.target_pos):
|
| 408 |
+
done = True
|
| 409 |
+
reward = self._reward()
|
| 410 |
+
|
| 411 |
+
elif tuple(self.agent_pos) in self.door_pos:
|
| 412 |
+
done = True
|
| 413 |
+
|
| 414 |
+
# discount
|
| 415 |
+
if self.step_penalty:
|
| 416 |
+
reward = reward - 0.01
|
| 417 |
+
|
| 418 |
+
if self.hidden_npc:
|
| 419 |
+
# all npc are hidden
|
| 420 |
+
assert np.argwhere(obs['image'][:,:,0] == OBJECT_TO_IDX['npc']).size == 0
|
| 421 |
+
assert "{}:".format(self.peer.name) not in self.utterance
|
| 422 |
+
|
| 423 |
+
# fill observation with text
|
| 424 |
+
self.append_existing_utterance_to_history()
|
| 425 |
+
obs = self.add_utterance_to_observation(obs)
|
| 426 |
+
self.reset_utterance()
|
| 427 |
+
|
| 428 |
+
if done:
|
| 429 |
+
if reward > 0:
|
| 430 |
+
self.outcome_info = "SUCCESS: agent got {} reward \n".format(np.round(reward, 1))
|
| 431 |
+
else:
|
| 432 |
+
self.outcome_info = "FAILURE: agent got {} reward \n".format(reward)
|
| 433 |
+
|
| 434 |
+
return obs, reward, done, info
|
| 435 |
+
|
| 436 |
+
def _reward(self):
|
| 437 |
+
if self.diminished_reward:
|
| 438 |
+
return super()._reward()
|
| 439 |
+
else:
|
| 440 |
+
return 1.0
|
| 441 |
+
|
| 442 |
+
def render(self, *args, **kwargs):
|
| 443 |
+
obs = super().render(*args, **kwargs)
|
| 444 |
+
self.window.clear_text() # erase previous text
|
| 445 |
+
|
| 446 |
+
self.window.set_caption(self.conversation, self.peer.name)
|
| 447 |
+
|
| 448 |
+
self.window.ax.set_title("correct door: {}".format(self.target_color), loc="left", fontsize=10)
|
| 449 |
+
if self.outcome_info:
|
| 450 |
+
color = None
|
| 451 |
+
if "SUCCESS" in self.outcome_info:
|
| 452 |
+
color = "lime"
|
| 453 |
+
elif "FAILURE" in self.outcome_info:
|
| 454 |
+
color = "red"
|
| 455 |
+
self.window.add_text(*(0.01, 0.85, self.outcome_info),
|
| 456 |
+
**{'fontsize':15, 'color':color, 'weight':"bold"})
|
| 457 |
+
|
| 458 |
+
self.window.show_img(obs) # re-draw image to add changes to window
|
| 459 |
+
return obs
|
| 460 |
+
|
| 461 |
+
|
| 462 |
+
# # must be far, must not poke
|
| 463 |
+
# class EasyTeachingGames8x8Env(EasyTeachingGamesEnv):
|
| 464 |
+
# def __init__(self):
|
| 465 |
+
# super().__init__(size=8, knowledgeable=True, max_steps=50, peer_type=0)
|
| 466 |
+
#
|
| 467 |
+
# # must be close, must not poke
|
| 468 |
+
# class EasyTeachingGamesClose8x8Env(EasyTeachingGamesEnv):
|
| 469 |
+
# def __init__(self):
|
| 470 |
+
# super().__init__(size=8, knowledgeable=True, max_steps=50, peer_type=1)
|
| 471 |
+
#
|
| 472 |
+
# # must be close, must poke
|
| 473 |
+
# class EasyTeachingGamesPoke8x8Env(EasyTeachingGamesEnv):
|
| 474 |
+
# def __init__(self):
|
| 475 |
+
# super().__init__(size=8, knowledgeable=True, max_steps=50, peer_type=2)
|
| 476 |
+
#
|
| 477 |
+
# # 100 multi
|
| 478 |
+
# class EasyTeachingGamesMulti8x8Env(EasyTeachingGamesEnv):
|
| 479 |
+
# def __init__(self):
|
| 480 |
+
# super().__init__(size=8, knowledgeable=True, max_steps=50, peer_type=None)
|
| 481 |
+
#
|
| 482 |
+
#
|
| 483 |
+
#
|
| 484 |
+
# # speaking 50 steps
|
| 485 |
+
# register(
|
| 486 |
+
# id='MiniGrid-EasyTeachingGames-8x8-v0',
|
| 487 |
+
# entry_point='gym_minigrid.envs:EasyTeachingGames8x8Env'
|
| 488 |
+
# )
|
| 489 |
+
#
|
| 490 |
+
# # demonstrating 50 steps
|
| 491 |
+
# register(
|
| 492 |
+
# id='MiniGrid-EasyTeachingGamesPoke-8x8-v0',
|
| 493 |
+
# entry_point='gym_minigrid.envs:EasyTeachingGamesPoke8x8Env'
|
| 494 |
+
# )
|
| 495 |
+
#
|
| 496 |
+
# # demonstrating 50 steps
|
| 497 |
+
# register(
|
| 498 |
+
# id='MiniGrid-EasyTeachingGamesClose-8x8-v0',
|
| 499 |
+
# entry_point='gym_minigrid.envs:EasyTeachingGamesClose8x8Env'
|
| 500 |
+
# )
|
| 501 |
+
#
|
| 502 |
+
# # speaking 50 steps
|
| 503 |
+
# register(
|
| 504 |
+
# id='MiniGrid-EasyTeachingGamesMulti-8x8-v0',
|
| 505 |
+
# entry_point='gym_minigrid.envs:EasyTeachingGamesMulti8x8Env'
|
| 506 |
+
# )
|
| 507 |
+
|
| 508 |
+
# # must be far, must not poke
|
| 509 |
+
# class EasierTeachingGames8x8Env(EasyTeachingGamesEnv):
|
| 510 |
+
# def __init__(self):
|
| 511 |
+
# super().__init__(size=8, knowledgeable=True, max_steps=50, peer_type=0, easier=True)
|
| 512 |
+
#
|
| 513 |
+
# # must be close, must not poke
|
| 514 |
+
# class EasierTeachingGamesClose8x8Env(EasyTeachingGamesEnv):
|
| 515 |
+
# def __init__(self):
|
| 516 |
+
# super().__init__(size=8, knowledgeable=True, max_steps=50, peer_type=1, easier=True)
|
| 517 |
+
#
|
| 518 |
+
# # must be close, must poke
|
| 519 |
+
# class EasierTeachingGamesPoke8x8Env(EasyTeachingGamesEnv):
|
| 520 |
+
# def __init__(self):
|
| 521 |
+
# super().__init__(size=8, knowledgeable=True, max_steps=50, peer_type=2, easier=True)
|
| 522 |
+
#
|
| 523 |
+
# # 100 multi
|
| 524 |
+
# class EasierTeachingGamesMulti8x8Env(EasyTeachingGamesEnv):
|
| 525 |
+
# def __init__(self):
|
| 526 |
+
# super().__init__(size=8, knowledgeable=True, max_steps=50, peer_type=None, easier=True)
|
| 527 |
+
#
|
| 528 |
+
# # Multi Many
|
| 529 |
+
# class ManyTeachingGamesMulti8x8Env(EasyTeachingGamesEnv):
|
| 530 |
+
# def __init__(self):
|
| 531 |
+
# super().__init__(size=8, knowledgeable=True, max_steps=50, peer_type=None, easier=False, many=True)
|
| 532 |
+
#
|
| 533 |
+
# class ManyTeachingGamesMultiIDL8x8Env(EasyTeachingGamesEnv):
|
| 534 |
+
# def __init__(self):
|
| 535 |
+
# super().__init__(size=8, knowledgeable=True, max_steps=50, peer_type=None, easier=False, many=True, idl=True)
|
| 536 |
+
|
| 537 |
+
|
| 538 |
+
# # speaking 50 steps
|
| 539 |
+
# register(
|
| 540 |
+
# id='MiniGrid-EasierTeachingGames-8x8-v0',
|
| 541 |
+
# entry_point='gym_minigrid.envs:EasierTeachingGames8x8Env'
|
| 542 |
+
# )
|
| 543 |
+
#
|
| 544 |
+
# # demonstrating 50 steps
|
| 545 |
+
# register(
|
| 546 |
+
# id='MiniGrid-EasierTeachingGamesPoke-8x8-v0',
|
| 547 |
+
# entry_point='gym_minigrid.envs:EasierTeachingGamesPoke8x8Env'
|
| 548 |
+
# )
|
| 549 |
+
#
|
| 550 |
+
# # demonstrating 50 steps
|
| 551 |
+
# register(
|
| 552 |
+
# id='MiniGrid-EasierTeachingGamesClose-8x8-v0',
|
| 553 |
+
# entry_point='gym_minigrid.envs:EasierTeachingGamesClose8x8Env'
|
| 554 |
+
# )
|
| 555 |
+
#
|
| 556 |
+
# # speaking 50 steps
|
| 557 |
+
# register(
|
| 558 |
+
# id='MiniGrid-EasierTeachingGamesMulti-8x8-v0',
|
| 559 |
+
# entry_point='gym_minigrid.envs:EasierTeachingGamesMulti8x8Env'
|
| 560 |
+
# )
|
| 561 |
+
#
|
| 562 |
+
# # speaking 50 steps
|
| 563 |
+
# register(
|
| 564 |
+
# id='MiniGrid-ManyTeachingGamesMulti-8x8-v0',
|
| 565 |
+
# entry_point='gym_minigrid.envs:ManyTeachingGamesMulti8x8Env'
|
| 566 |
+
# )
|
| 567 |
+
#
|
| 568 |
+
# # speaking 50 steps
|
| 569 |
+
# register(
|
| 570 |
+
# id='MiniGrid-ManyTeachingGamesMultiIDL-8x8-v0',
|
| 571 |
+
# entry_point='gym_minigrid.envs:ManyTeachingGamesMultiIDL8x8Env'
|
| 572 |
+
# )
|
| 573 |
+
|
| 574 |
+
# Multi Many
|
| 575 |
+
class DiverseExit8x8Env(EasyTeachingGamesEnv):
|
| 576 |
+
def __init__(self, **kwargs):
|
| 577 |
+
super().__init__(size=8, knowledgeable=True, max_steps=50, peer_type=None, easier=False, **kwargs)
|
| 578 |
+
|
| 579 |
+
# speaking 50 steps
|
| 580 |
+
register(
|
| 581 |
+
id='MiniGrid-DiverseExit-8x8-v0',
|
| 582 |
+
entry_point='gym_minigrid.envs:DiverseExit8x8Env'
|
| 583 |
+
)
|
| 584 |
+
|
gym-minigrid/gym_minigrid/backup_envs/exiter.py
ADDED
|
@@ -0,0 +1,347 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
|
| 3 |
+
from gym_minigrid.minigrid import *
|
| 4 |
+
from gym_minigrid.register import register
|
| 5 |
+
|
| 6 |
+
import time
|
| 7 |
+
from collections import deque
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
class Peer(NPC):
|
| 11 |
+
"""
|
| 12 |
+
A dancing NPC that the agent has to copy
|
| 13 |
+
"""
|
| 14 |
+
|
| 15 |
+
def __init__(self, color, name, env, random_actions=False):
|
| 16 |
+
super().__init__(color)
|
| 17 |
+
self.name = name
|
| 18 |
+
self.npc_dir = 1 # NPC initially looks downward
|
| 19 |
+
self.npc_type = 0
|
| 20 |
+
self.env = env
|
| 21 |
+
self.npc_actions = []
|
| 22 |
+
self.dancing_step_idx = 0
|
| 23 |
+
self.actions = MiniGridEnv.Actions
|
| 24 |
+
self.add_npc_direction = True
|
| 25 |
+
self.available_moves = [self.rotate_left, self.rotate_right, self.go_forward, self.toggle_action]
|
| 26 |
+
self.random_actions = random_actions
|
| 27 |
+
self.joint_attention_achieved = False
|
| 28 |
+
|
| 29 |
+
def can_overlap(self):
|
| 30 |
+
# If the NPC is hidden, agent can overlap on it
|
| 31 |
+
return self.env.hidden_npc
|
| 32 |
+
|
| 33 |
+
def encode(self, nb_dims=3):
|
| 34 |
+
if self.env.hidden_npc:
|
| 35 |
+
if nb_dims == 3:
|
| 36 |
+
return (1, 0, 0)
|
| 37 |
+
elif nb_dims == 4:
|
| 38 |
+
return (1, 0, 0, 0)
|
| 39 |
+
else:
|
| 40 |
+
return super().encode(nb_dims=nb_dims)
|
| 41 |
+
|
| 42 |
+
def step(self):
|
| 43 |
+
super().step()
|
| 44 |
+
if self.random_actions:
|
| 45 |
+
if type(self.env.grid.get(*self.front_pos)) == Lava:
|
| 46 |
+
# can't walk into lava
|
| 47 |
+
act = self.env._rand_elem([
|
| 48 |
+
m for m in self.available_moves if m != self.go_forward
|
| 49 |
+
])
|
| 50 |
+
elif type(self.env.grid.get(*self.front_pos)) == Switch:
|
| 51 |
+
# can't toggle switches
|
| 52 |
+
act = self.env._rand_elem([
|
| 53 |
+
m for m in self.available_moves if m != self.toggle_action
|
| 54 |
+
])
|
| 55 |
+
else:
|
| 56 |
+
act = self.env._rand_elem(self.available_moves)
|
| 57 |
+
|
| 58 |
+
act()
|
| 59 |
+
|
| 60 |
+
else:
|
| 61 |
+
distances = np.abs(self.env.agent_pos - self.env.door_pos).sum(-1)
|
| 62 |
+
|
| 63 |
+
door_id = np.argmin(distances)
|
| 64 |
+
wanted_switch_pos = self.env.switches_pos[door_id]
|
| 65 |
+
sw = self.env.switches[door_id]
|
| 66 |
+
|
| 67 |
+
distance_to_switch = np.abs(wanted_switch_pos - self.cur_pos ).sum(-1)
|
| 68 |
+
|
| 69 |
+
# corresponding switch
|
| 70 |
+
if all(self.front_pos == wanted_switch_pos) and self.joint_attention_achieved:
|
| 71 |
+
# in agent front of door, looking at the door
|
| 72 |
+
if tuple(self.env.front_pos) == tuple(self.env.door_pos[door_id]):
|
| 73 |
+
if not sw.is_on:
|
| 74 |
+
self.toggle_action()
|
| 75 |
+
|
| 76 |
+
elif distance_to_switch == 1:
|
| 77 |
+
if not self.joint_attention_achieved:
|
| 78 |
+
# looks at he agent
|
| 79 |
+
wanted_dir = self.compute_wanted_dir(self.env.agent_pos)
|
| 80 |
+
else:
|
| 81 |
+
# turns to the switch
|
| 82 |
+
wanted_dir = self.compute_wanted_dir(wanted_switch_pos)
|
| 83 |
+
|
| 84 |
+
action = self.compute_turn_action(wanted_dir)
|
| 85 |
+
action()
|
| 86 |
+
if self.is_eye_contact():
|
| 87 |
+
self.joint_attention_achieved = True
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
else:
|
| 91 |
+
act = self.path_to_pos(wanted_switch_pos)
|
| 92 |
+
act()
|
| 93 |
+
|
| 94 |
+
# not really important as the NPC doesn't speak
|
| 95 |
+
if self.env.hidden_npc:
|
| 96 |
+
return None
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
class ExiterGrammar(object):
|
| 101 |
+
|
| 102 |
+
templates = ["Move your", "Shake your"]
|
| 103 |
+
things = ["body", "head"]
|
| 104 |
+
|
| 105 |
+
grammar_action_space = spaces.MultiDiscrete([len(templates), len(things)])
|
| 106 |
+
|
| 107 |
+
@classmethod
|
| 108 |
+
def construct_utterance(cls, action):
|
| 109 |
+
return cls.templates[int(action[0])] + " " + cls.things[int(action[1])] + " "
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
class ExiterEnv(MultiModalMiniGridEnv):
|
| 113 |
+
"""
|
| 114 |
+
Environment in which the agent is instructed to go to a given object
|
| 115 |
+
named using an English text string
|
| 116 |
+
"""
|
| 117 |
+
|
| 118 |
+
def __init__(
|
| 119 |
+
self,
|
| 120 |
+
size=5,
|
| 121 |
+
diminished_reward=True,
|
| 122 |
+
step_penalty=False,
|
| 123 |
+
knowledgeable=False,
|
| 124 |
+
ablation=False,
|
| 125 |
+
max_steps=20,
|
| 126 |
+
hidden_npc=False,
|
| 127 |
+
):
|
| 128 |
+
assert size >= 5
|
| 129 |
+
self.empty_symbol = "NA \n"
|
| 130 |
+
self.diminished_reward = diminished_reward
|
| 131 |
+
self.step_penalty = step_penalty
|
| 132 |
+
self.knowledgeable = knowledgeable
|
| 133 |
+
self.ablation = ablation
|
| 134 |
+
self.hidden_npc = hidden_npc
|
| 135 |
+
|
| 136 |
+
super().__init__(
|
| 137 |
+
grid_size=size,
|
| 138 |
+
max_steps=max_steps,
|
| 139 |
+
# Set this to True for maximum speed
|
| 140 |
+
see_through_walls=True,
|
| 141 |
+
actions=MiniGridEnv.Actions,
|
| 142 |
+
action_space=spaces.MultiDiscrete([
|
| 143 |
+
len(MiniGridEnv.Actions),
|
| 144 |
+
*ExiterGrammar.grammar_action_space.nvec
|
| 145 |
+
]),
|
| 146 |
+
add_npc_direction=True
|
| 147 |
+
)
|
| 148 |
+
|
| 149 |
+
print({
|
| 150 |
+
"size": size,
|
| 151 |
+
"diminished_reward": diminished_reward,
|
| 152 |
+
"step_penalty": step_penalty,
|
| 153 |
+
})
|
| 154 |
+
|
| 155 |
+
def _gen_grid(self, width, height):
|
| 156 |
+
# Create the grid
|
| 157 |
+
self.grid = Grid(width, height, nb_obj_dims=4)
|
| 158 |
+
|
| 159 |
+
# Randomly vary the room width and height
|
| 160 |
+
width = self._rand_int(5, width+1)
|
| 161 |
+
height = self._rand_int(5, height+1)
|
| 162 |
+
|
| 163 |
+
self.wall_x = width-1
|
| 164 |
+
self.wall_y = height-1
|
| 165 |
+
|
| 166 |
+
# Generate the surrounding walls
|
| 167 |
+
self.grid.wall_rect(0, 0, width, height)
|
| 168 |
+
|
| 169 |
+
# add lava
|
| 170 |
+
self.grid.vert_wall(width//2, 1, height - 2, Lava)
|
| 171 |
+
|
| 172 |
+
# door top
|
| 173 |
+
door_color_top = self._rand_elem(COLOR_NAMES)
|
| 174 |
+
self.door_pos_top = (width-1, 1)
|
| 175 |
+
self.door_top = Door(door_color_top, is_locked=False if self.ablation else True)
|
| 176 |
+
self.grid.set(*self.door_pos_top, self.door_top)
|
| 177 |
+
|
| 178 |
+
# switch top
|
| 179 |
+
self.switch_pos_top = (0, 1)
|
| 180 |
+
self.switch_top = Switch(door_color_top, lockable_object=self.door_top, locker_switch=True)
|
| 181 |
+
self.grid.set(*self.switch_pos_top, self.switch_top)
|
| 182 |
+
|
| 183 |
+
# door bottom
|
| 184 |
+
door_color_bottom = self._rand_elem(COLOR_NAMES)
|
| 185 |
+
self.door_pos_bottom = (width-1, height-2)
|
| 186 |
+
self.door_bottom = Door(door_color_bottom, is_locked=False if self.ablation else True)
|
| 187 |
+
self.grid.set(*self.door_pos_bottom, self.door_bottom)
|
| 188 |
+
|
| 189 |
+
# switch bottom
|
| 190 |
+
self.switch_pos_bottom = (0, height-2)
|
| 191 |
+
self.switch_bottom = Switch(door_color_bottom, lockable_object=self.door_bottom, locker_switch=True)
|
| 192 |
+
self.grid.set(*self.switch_pos_bottom, self.switch_bottom)
|
| 193 |
+
|
| 194 |
+
self.switches = [self.switch_top, self.switch_bottom]
|
| 195 |
+
self.switches_pos = [self.switch_pos_top, self.switch_pos_bottom]
|
| 196 |
+
self.door = [self.door_top, self.door_bottom]
|
| 197 |
+
self.door_pos = [self.door_pos_top, self.door_pos_bottom]
|
| 198 |
+
|
| 199 |
+
# Set a randomly coloured Dancer NPC
|
| 200 |
+
color = self._rand_elem(COLOR_NAMES)
|
| 201 |
+
self.peer = Peer(color, "Jill", self, random_actions=self.ablation)
|
| 202 |
+
|
| 203 |
+
# Place it on the middle right side of the room
|
| 204 |
+
peer_pos = np.array((self._rand_int(1, width//2), self._rand_int(1, height - 1)))
|
| 205 |
+
|
| 206 |
+
self.grid.set(*peer_pos, self.peer)
|
| 207 |
+
self.peer.init_pos = peer_pos
|
| 208 |
+
self.peer.cur_pos = peer_pos
|
| 209 |
+
|
| 210 |
+
# Randomize the agent's start position and orientation
|
| 211 |
+
agent = self.place_agent(top=(width // 2, 0), size=(width // 2, height))
|
| 212 |
+
|
| 213 |
+
# Generate the mission string
|
| 214 |
+
self.mission = 'watch dancer and repeat his moves afterwards'
|
| 215 |
+
|
| 216 |
+
# Dummy beginning string
|
| 217 |
+
self.beginning_string = "This is what you hear. \n"
|
| 218 |
+
self.utterance = self.beginning_string
|
| 219 |
+
|
| 220 |
+
# utterance appended at the end of each step
|
| 221 |
+
self.utterance_history = ""
|
| 222 |
+
|
| 223 |
+
# used for rendering
|
| 224 |
+
self.conversation = self.utterance
|
| 225 |
+
self.outcome_info = None
|
| 226 |
+
|
| 227 |
+
def step(self, action):
|
| 228 |
+
p_action = action[0]
|
| 229 |
+
utterance_action = action[1:]
|
| 230 |
+
|
| 231 |
+
obs, reward, done, info = super().step(p_action)
|
| 232 |
+
self.peer.step()
|
| 233 |
+
|
| 234 |
+
if np.isnan(p_action):
|
| 235 |
+
pass
|
| 236 |
+
|
| 237 |
+
if p_action == self.actions.done:
|
| 238 |
+
done = True
|
| 239 |
+
|
| 240 |
+
elif all([self.switch_top.is_on, self.switch_bottom.is_on]):
|
| 241 |
+
# if both witches are on: no reward is given and the episode ends
|
| 242 |
+
done = True
|
| 243 |
+
|
| 244 |
+
elif tuple(self.agent_pos) in [self.door_pos_top, self.door_pos_bottom]:
|
| 245 |
+
# agent has exited
|
| 246 |
+
reward = self._reward()
|
| 247 |
+
done = True
|
| 248 |
+
|
| 249 |
+
# discount
|
| 250 |
+
if self.step_penalty:
|
| 251 |
+
reward = reward - 0.01
|
| 252 |
+
|
| 253 |
+
if self.hidden_npc:
|
| 254 |
+
# all npc are hidden
|
| 255 |
+
assert np.argwhere(obs['image'][:,:,0] == OBJECT_TO_IDX['npc']).size == 0
|
| 256 |
+
assert "{}:".format(self.peer.name) not in self.utterance
|
| 257 |
+
|
| 258 |
+
# fill observation with text
|
| 259 |
+
self.append_existing_utterance_to_history()
|
| 260 |
+
obs = self.add_utterance_to_observation(obs)
|
| 261 |
+
self.reset_utterance()
|
| 262 |
+
|
| 263 |
+
if done:
|
| 264 |
+
if reward > 0:
|
| 265 |
+
self.outcome_info = "SUCCESS: agent got {} reward \n".format(np.round(reward, 1))
|
| 266 |
+
else:
|
| 267 |
+
self.outcome_info = "FAILURE: agent got {} reward \n".format(reward)
|
| 268 |
+
|
| 269 |
+
return obs, reward, done, info
|
| 270 |
+
|
| 271 |
+
def _reward(self):
|
| 272 |
+
if self.diminished_reward:
|
| 273 |
+
return super()._reward()
|
| 274 |
+
else:
|
| 275 |
+
return 1.0
|
| 276 |
+
|
| 277 |
+
def render(self, *args, **kwargs):
|
| 278 |
+
obs = super().render(*args, **kwargs)
|
| 279 |
+
self.window.clear_text() # erase previous text
|
| 280 |
+
|
| 281 |
+
# self.window.set_caption(self.conversation, [self.peer.name])
|
| 282 |
+
# self.window.ax.set_title("correct door: {}".format(self.true_guide.target_color), loc="left", fontsize=10)
|
| 283 |
+
if self.outcome_info:
|
| 284 |
+
color = None
|
| 285 |
+
if "SUCCESS" in self.outcome_info:
|
| 286 |
+
color = "lime"
|
| 287 |
+
elif "FAILURE" in self.outcome_info:
|
| 288 |
+
color = "red"
|
| 289 |
+
self.window.add_text(*(0.01, 0.85, self.outcome_info),
|
| 290 |
+
**{'fontsize':15, 'color':color, 'weight':"bold"})
|
| 291 |
+
|
| 292 |
+
self.window.show_img(obs) # re-draw image to add changes to window
|
| 293 |
+
return obs
|
| 294 |
+
|
| 295 |
+
|
| 296 |
+
class Exiter8x8Env(ExiterEnv):
|
| 297 |
+
def __init__(self, **kwargs):
|
| 298 |
+
super().__init__(size=8, max_steps=20, **kwargs)
|
| 299 |
+
|
| 300 |
+
|
| 301 |
+
class Exiter6x6Env(ExiterEnv):
|
| 302 |
+
def __init__(self):
|
| 303 |
+
super().__init__(size=6, max_steps=20)
|
| 304 |
+
|
| 305 |
+
class AblationExiterEnv(ExiterEnv):
|
| 306 |
+
def __init__(self):
|
| 307 |
+
super().__init__(size=5, ablation=True, max_steps=20)
|
| 308 |
+
|
| 309 |
+
class AblationExiter8x8Env(ExiterEnv):
|
| 310 |
+
def __init__(self, **kwargs):
|
| 311 |
+
super().__init__(size=8, ablation=True, max_steps=20, **kwargs)
|
| 312 |
+
|
| 313 |
+
|
| 314 |
+
class AblationExiter6x6Env(ExiterEnv):
|
| 315 |
+
def __init__(self):
|
| 316 |
+
super().__init__(size=6, ablation=True, max_steps=20)
|
| 317 |
+
|
| 318 |
+
|
| 319 |
+
|
| 320 |
+
register(
|
| 321 |
+
id='MiniGrid-Exiter-5x5-v0',
|
| 322 |
+
entry_point='gym_minigrid.envs:ExiterEnv'
|
| 323 |
+
)
|
| 324 |
+
|
| 325 |
+
register(
|
| 326 |
+
id='MiniGrid-Exiter-6x6-v0',
|
| 327 |
+
entry_point='gym_minigrid.envs:Exiter6x6Env'
|
| 328 |
+
)
|
| 329 |
+
|
| 330 |
+
register(
|
| 331 |
+
id='MiniGrid-Exiter-8x8-v0',
|
| 332 |
+
entry_point='gym_minigrid.envs:Exiter8x8Env'
|
| 333 |
+
)
|
| 334 |
+
register(
|
| 335 |
+
id='MiniGrid-AblationExiter-5x5-v0',
|
| 336 |
+
entry_point='gym_minigrid.envs:AblationExiterEnv'
|
| 337 |
+
)
|
| 338 |
+
|
| 339 |
+
register(
|
| 340 |
+
id='MiniGrid-AblationExiter-6x6-v0',
|
| 341 |
+
entry_point='gym_minigrid.envs:AblationExiter6x6Env'
|
| 342 |
+
)
|
| 343 |
+
|
| 344 |
+
register(
|
| 345 |
+
id='MiniGrid-AblationExiter-8x8-v0',
|
| 346 |
+
entry_point='gym_minigrid.envs:AblationExiter8x8Env'
|
| 347 |
+
)
|
gym-minigrid/gym_minigrid/backup_envs/gotodoorpolite.py
ADDED
|
@@ -0,0 +1,292 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from gym_minigrid.minigrid import *
|
| 2 |
+
from gym_minigrid.register import register
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
class Guide(NPC):
|
| 6 |
+
"""
|
| 7 |
+
A simple NPC that wants an agent to go to an object (randomly chosen among object_pos list)
|
| 8 |
+
"""
|
| 9 |
+
|
| 10 |
+
def __init__(self, color, name, env):
|
| 11 |
+
super().__init__(color)
|
| 12 |
+
self.name = name
|
| 13 |
+
self.env = env
|
| 14 |
+
self.introduced = False
|
| 15 |
+
|
| 16 |
+
# Select a random target object as mission
|
| 17 |
+
obj_idx = self.env._rand_int(0, len(self.env.door_pos))
|
| 18 |
+
self.target_pos = self.env.door_pos[obj_idx]
|
| 19 |
+
self.target_color = self.env.door_colors[obj_idx]
|
| 20 |
+
|
| 21 |
+
def listen(self, utterance):
|
| 22 |
+
if utterance == PoliteGrammar.construct_utterance([0, 2]):
|
| 23 |
+
self.introduced = True
|
| 24 |
+
return "I am good. Thank you."
|
| 25 |
+
elif utterance == PoliteGrammar.construct_utterance([1, 1]):
|
| 26 |
+
if self.introduced:
|
| 27 |
+
return self.env.mission
|
| 28 |
+
|
| 29 |
+
return None
|
| 30 |
+
|
| 31 |
+
# def is_near_agent(self):
|
| 32 |
+
# ax, ay = self.env.agent_pos
|
| 33 |
+
# wx, wy = self.cur_pos
|
| 34 |
+
# if (ax == wx and abs(ay - wy) == 1) or (ay == wy and abs(ax - wx) == 1):
|
| 35 |
+
# return True
|
| 36 |
+
# return False
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
class PoliteGrammar(object):
|
| 40 |
+
|
| 41 |
+
templates = ["How are", "Where is", "Open"]
|
| 42 |
+
things = ["sesame", "the exit", 'you']
|
| 43 |
+
|
| 44 |
+
grammar_action_space = spaces.MultiDiscrete([len(templates), len(things)])
|
| 45 |
+
|
| 46 |
+
@classmethod
|
| 47 |
+
def construct_utterance(cls, action):
|
| 48 |
+
return cls.templates[int(action[0])] + " " + cls.things[int(action[1])] + " "
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
class GoToDoorPoliteEnv(MultiModalMiniGridEnv):
|
| 52 |
+
"""
|
| 53 |
+
Environment in which the agent is instructed to go to a given object
|
| 54 |
+
named using an English text string
|
| 55 |
+
"""
|
| 56 |
+
|
| 57 |
+
def __init__(
|
| 58 |
+
self,
|
| 59 |
+
size=5,
|
| 60 |
+
hear_yourself=False,
|
| 61 |
+
diminished_reward=True,
|
| 62 |
+
step_penalty=False,
|
| 63 |
+
max_steps=100,
|
| 64 |
+
):
|
| 65 |
+
assert size >= 5
|
| 66 |
+
|
| 67 |
+
super().__init__(
|
| 68 |
+
grid_size=size,
|
| 69 |
+
max_steps=max_steps,
|
| 70 |
+
# Set this to True for maximum speed
|
| 71 |
+
see_through_walls=True,
|
| 72 |
+
actions=MiniGridEnv.Actions,
|
| 73 |
+
action_space=spaces.MultiDiscrete([
|
| 74 |
+
len(MiniGridEnv.Actions),
|
| 75 |
+
*PoliteGrammar.grammar_action_space.nvec
|
| 76 |
+
])
|
| 77 |
+
)
|
| 78 |
+
self.hear_yourself = hear_yourself
|
| 79 |
+
self.diminished_reward = diminished_reward
|
| 80 |
+
self.step_penalty = step_penalty
|
| 81 |
+
|
| 82 |
+
self.empty_symbol = "NA \n"
|
| 83 |
+
|
| 84 |
+
print({
|
| 85 |
+
"size": size,
|
| 86 |
+
"hear_yourself": hear_yourself,
|
| 87 |
+
"diminished_reward": diminished_reward,
|
| 88 |
+
"step_penalty": step_penalty,
|
| 89 |
+
})
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
def _gen_grid(self, width, height):
|
| 93 |
+
# Create the grid
|
| 94 |
+
self.grid = Grid(width, height)
|
| 95 |
+
|
| 96 |
+
# Randomly vary the room width and height
|
| 97 |
+
width = self._rand_int(5, width+1)
|
| 98 |
+
height = self._rand_int(5, height+1)
|
| 99 |
+
|
| 100 |
+
# Generate the surrounding walls
|
| 101 |
+
self.grid.wall_rect(0, 0, width, height)
|
| 102 |
+
|
| 103 |
+
# Generate the surrounding walls
|
| 104 |
+
self.grid.wall_rect(0, 0, width, height)
|
| 105 |
+
|
| 106 |
+
# Generate the 4 doors at random positions
|
| 107 |
+
self.door_pos = []
|
| 108 |
+
self.door_front_pos = [] # Remembers positions in front of door to avoid setting wizard here
|
| 109 |
+
|
| 110 |
+
self.door_pos.append((self._rand_int(2, width-2), 0))
|
| 111 |
+
self.door_front_pos.append((self.door_pos[-1][0], self.door_pos[-1][1]+1))
|
| 112 |
+
|
| 113 |
+
self.door_pos.append((self._rand_int(2, width-2), height-1))
|
| 114 |
+
self.door_front_pos.append((self.door_pos[-1][0], self.door_pos[-1][1] - 1))
|
| 115 |
+
|
| 116 |
+
self.door_pos.append((0, self._rand_int(2, height-2)))
|
| 117 |
+
self.door_front_pos.append((self.door_pos[-1][0] + 1, self.door_pos[-1][1]))
|
| 118 |
+
|
| 119 |
+
self.door_pos.append((width-1, self._rand_int(2, height-2)))
|
| 120 |
+
self.door_front_pos.append((self.door_pos[-1][0] - 1, self.door_pos[-1][1]))
|
| 121 |
+
|
| 122 |
+
# Generate the door colors
|
| 123 |
+
self.door_colors = []
|
| 124 |
+
while len(self.door_colors) < len(self.door_pos):
|
| 125 |
+
color = self._rand_elem(COLOR_NAMES)
|
| 126 |
+
if color in self.door_colors:
|
| 127 |
+
continue
|
| 128 |
+
self.door_colors.append(color)
|
| 129 |
+
|
| 130 |
+
# Place the doors in the grid
|
| 131 |
+
for idx, pos in enumerate(self.door_pos):
|
| 132 |
+
color = self.door_colors[idx]
|
| 133 |
+
self.grid.set(*pos, Door(color))
|
| 134 |
+
|
| 135 |
+
# Set a randomly coloured NPC at a random position
|
| 136 |
+
color = self._rand_elem(COLOR_NAMES)
|
| 137 |
+
self.wizard = Guide(color, "Gandalf", self)
|
| 138 |
+
|
| 139 |
+
# Place it randomly, omitting front of door positions
|
| 140 |
+
self.place_obj(self.wizard,
|
| 141 |
+
size=(width, height),
|
| 142 |
+
reject_fn=lambda _, p: tuple(p) in self.door_front_pos)
|
| 143 |
+
|
| 144 |
+
# Randomize the agent start position and orientation
|
| 145 |
+
self.place_agent(size=(width, height))
|
| 146 |
+
|
| 147 |
+
# Select a random target door
|
| 148 |
+
self.doorIdx = self._rand_int(0, len(self.door_pos))
|
| 149 |
+
self.target_pos = self.door_pos[self.doorIdx]
|
| 150 |
+
self.target_color = self.door_colors[self.doorIdx]
|
| 151 |
+
|
| 152 |
+
# Generate the mission string
|
| 153 |
+
self.mission = 'go to the %s door' % self.target_color
|
| 154 |
+
|
| 155 |
+
# Dummy beginning string
|
| 156 |
+
self.beginning_string = "This is what you hear. \n"
|
| 157 |
+
self.utterance = self.beginning_string
|
| 158 |
+
|
| 159 |
+
# utterance appended at the end of each step
|
| 160 |
+
self.utterance_history = ""
|
| 161 |
+
|
| 162 |
+
def step(self, action):
|
| 163 |
+
p_action = action[0]
|
| 164 |
+
utterance_action = action[1:]
|
| 165 |
+
|
| 166 |
+
assert len(set(np.isnan(utterance_action))) == 1
|
| 167 |
+
|
| 168 |
+
speak_flag = not all(np.isnan(utterance_action))
|
| 169 |
+
|
| 170 |
+
obs, reward, done, info = super().step(p_action)
|
| 171 |
+
|
| 172 |
+
if speak_flag:
|
| 173 |
+
agent_utterance = PoliteGrammar.construct_utterance(utterance_action)
|
| 174 |
+
if self.hear_yourself:
|
| 175 |
+
self.utterance += "YOU: {} \n".format(agent_utterance)
|
| 176 |
+
|
| 177 |
+
# check if near wizard
|
| 178 |
+
if self.wizard.is_near_agent():
|
| 179 |
+
reply = self.wizard.listen(agent_utterance)
|
| 180 |
+
|
| 181 |
+
if reply:
|
| 182 |
+
self.utterance += "{}: {} \n".format(self.wizard.name, reply)
|
| 183 |
+
|
| 184 |
+
# Don't let the agent open any of the doors
|
| 185 |
+
if p_action == self.actions.toggle:
|
| 186 |
+
done = True
|
| 187 |
+
|
| 188 |
+
if p_action == self.actions.done:
|
| 189 |
+
ax, ay = self.agent_pos
|
| 190 |
+
tx, ty = self.target_pos
|
| 191 |
+
|
| 192 |
+
if (ax == tx and abs(ay - ty) == 1) or (ay == ty and abs(ax - tx) == 1):
|
| 193 |
+
reward = self._reward()
|
| 194 |
+
done = True
|
| 195 |
+
|
| 196 |
+
# discount
|
| 197 |
+
if self.step_penalty:
|
| 198 |
+
reward = reward - 0.01
|
| 199 |
+
|
| 200 |
+
# fill observation with text
|
| 201 |
+
self.append_existing_utterance_to_history()
|
| 202 |
+
obs = self.add_utterance_to_observation(obs)
|
| 203 |
+
self.reset_utterance()
|
| 204 |
+
|
| 205 |
+
return obs, reward, done, info
|
| 206 |
+
|
| 207 |
+
def _reward(self):
|
| 208 |
+
if self.diminished_reward:
|
| 209 |
+
return super()._reward()
|
| 210 |
+
else:
|
| 211 |
+
return 1.0
|
| 212 |
+
|
| 213 |
+
def render(self, *args, **kwargs):
|
| 214 |
+
obs = super().render(*args, **kwargs)
|
| 215 |
+
self.window.set_caption(self.utterance_history, [
|
| 216 |
+
"Gandalf:",
|
| 217 |
+
"Jack:",
|
| 218 |
+
"John:",
|
| 219 |
+
"Where is the exit",
|
| 220 |
+
"Open sesame",
|
| 221 |
+
])
|
| 222 |
+
return obs
|
| 223 |
+
|
| 224 |
+
|
| 225 |
+
class GoToDoorPoliteTesting(GoToDoorPoliteEnv):
|
| 226 |
+
def __init__(self):
|
| 227 |
+
super().__init__(
|
| 228 |
+
size=5,
|
| 229 |
+
hear_yourself=False,
|
| 230 |
+
diminished_reward=False,
|
| 231 |
+
step_penalty=True,
|
| 232 |
+
max_steps=100
|
| 233 |
+
)
|
| 234 |
+
|
| 235 |
+
class GoToDoorPolite8x8Env(GoToDoorPoliteEnv):
|
| 236 |
+
def __init__(self):
|
| 237 |
+
super().__init__(size=8, max_steps=100)
|
| 238 |
+
|
| 239 |
+
|
| 240 |
+
class GoToDoorPolite6x6Env(GoToDoorPoliteEnv):
|
| 241 |
+
def __init__(self):
|
| 242 |
+
super().__init__(size=6, max_steps=100)
|
| 243 |
+
|
| 244 |
+
|
| 245 |
+
# hear yourself
|
| 246 |
+
class GoToDoorPoliteHY8x8Env(GoToDoorPoliteEnv):
|
| 247 |
+
def __init__(self):
|
| 248 |
+
super().__init__(size=8, hear_yourself=True, max_steps=100)
|
| 249 |
+
|
| 250 |
+
|
| 251 |
+
class GoToDoorPoliteHY6x6Env(GoToDoorPoliteEnv):
|
| 252 |
+
def __init__(self):
|
| 253 |
+
super().__init__(size=6, hear_yourself=True, max_steps=100)
|
| 254 |
+
|
| 255 |
+
|
| 256 |
+
class GoToDoorPoliteHY5x5Env(GoToDoorPoliteEnv):
|
| 257 |
+
def __init__(self):
|
| 258 |
+
super().__init__(size=5, hear_yourself=True, max_steps=100)
|
| 259 |
+
|
| 260 |
+
register(
|
| 261 |
+
id='MiniGrid-GoToDoorPolite-Testing-v0',
|
| 262 |
+
entry_point='gym_minigrid.envs:GoToDoorPoliteTesting'
|
| 263 |
+
)
|
| 264 |
+
|
| 265 |
+
register(
|
| 266 |
+
id='MiniGrid-GoToDoorPolite-5x5-v0',
|
| 267 |
+
entry_point='gym_minigrid.envs:GoToDoorPoliteEnv'
|
| 268 |
+
)
|
| 269 |
+
|
| 270 |
+
register(
|
| 271 |
+
id='MiniGrid-GoToDoorPolite-6x6-v0',
|
| 272 |
+
entry_point='gym_minigrid.envs:GoToDoorPolite6x6Env'
|
| 273 |
+
)
|
| 274 |
+
|
| 275 |
+
register(
|
| 276 |
+
id='MiniGrid-GoToDoorPolite-8x8-v0',
|
| 277 |
+
entry_point='gym_minigrid.envs:GoToDoorPolite8x8Env'
|
| 278 |
+
)
|
| 279 |
+
register(
|
| 280 |
+
id='MiniGrid-GoToDoorPoliteHY-5x5-v0',
|
| 281 |
+
entry_point='gym_minigrid.envs:GoToDoorPoliteHY5x5Env'
|
| 282 |
+
)
|
| 283 |
+
|
| 284 |
+
register(
|
| 285 |
+
id='MiniGrid-GoToDoorPoliteHY-6x6-v0',
|
| 286 |
+
entry_point='gym_minigrid.envs:GoToDoorPoliteHY6x6Env'
|
| 287 |
+
)
|
| 288 |
+
|
| 289 |
+
register(
|
| 290 |
+
id='MiniGrid-GoToDoorPoliteHY-8x8-v0',
|
| 291 |
+
entry_point='gym_minigrid.envs:GoToDoorPoliteHY8x8Env'
|
| 292 |
+
)
|
gym-minigrid/gym_minigrid/backup_envs/gotodoorsesame.py
ADDED
|
@@ -0,0 +1,165 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from gym_minigrid.minigrid import *
|
| 2 |
+
from gym_minigrid.register import register
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
class SesameGrammar(object):
|
| 6 |
+
|
| 7 |
+
templates = ["Open", "Who is", "Where is"]
|
| 8 |
+
things = ["the exit", "sesame", "the chest", "him", "that"]
|
| 9 |
+
|
| 10 |
+
grammar_action_space = spaces.MultiDiscrete([len(templates), len(things)])
|
| 11 |
+
|
| 12 |
+
@classmethod
|
| 13 |
+
def construct_utterance(cls, action):
|
| 14 |
+
return cls.templates[int(action[0])] + " " + cls.things[int(action[1])] + "."
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class GoToDoorSesameEnv(MultiModalMiniGridEnv):
|
| 18 |
+
"""
|
| 19 |
+
Environment in which the agent is instructed to go to a given object
|
| 20 |
+
named using an English text string
|
| 21 |
+
"""
|
| 22 |
+
|
| 23 |
+
def __init__(
|
| 24 |
+
self,
|
| 25 |
+
size=5
|
| 26 |
+
):
|
| 27 |
+
assert size >= 5
|
| 28 |
+
|
| 29 |
+
super().__init__(
|
| 30 |
+
grid_size=size,
|
| 31 |
+
max_steps=5*size**2,
|
| 32 |
+
# Set this to True for maximum speed
|
| 33 |
+
see_through_walls=True,
|
| 34 |
+
actions=MiniGridEnv.Actions,
|
| 35 |
+
action_space=spaces.MultiDiscrete([
|
| 36 |
+
len(MiniGridEnv.Actions),
|
| 37 |
+
*SesameGrammar.grammar_action_space.nvec
|
| 38 |
+
])
|
| 39 |
+
)
|
| 40 |
+
|
| 41 |
+
def _gen_grid(self, width, height):
|
| 42 |
+
# Create the grid
|
| 43 |
+
self.grid = Grid(width, height)
|
| 44 |
+
|
| 45 |
+
# Randomly vary the room width and height
|
| 46 |
+
width = self._rand_int(5, width+1)
|
| 47 |
+
height = self._rand_int(5, height+1)
|
| 48 |
+
|
| 49 |
+
# Generate the surrounding walls
|
| 50 |
+
self.grid.wall_rect(0, 0, width, height)
|
| 51 |
+
|
| 52 |
+
# Generate the 4 doors at random positions
|
| 53 |
+
doorPos = (self._rand_int(2, width-2), 0)
|
| 54 |
+
doorColors = self._rand_elem(COLOR_NAMES)
|
| 55 |
+
self.grid.set(*doorPos, Door(doorColors))
|
| 56 |
+
|
| 57 |
+
# doorPos = []
|
| 58 |
+
# doorPos.append((self._rand_int(2, width-2), 0))
|
| 59 |
+
#
|
| 60 |
+
# # Generate the door colors
|
| 61 |
+
# doorColors = []
|
| 62 |
+
# while len(doorColors) < len(doorPos):
|
| 63 |
+
# color = self._rand_elem(COLOR_NAMES)
|
| 64 |
+
# if color in doorColors:
|
| 65 |
+
# continue
|
| 66 |
+
# doorColors.append(color)
|
| 67 |
+
#
|
| 68 |
+
# # Place the doors in the grid
|
| 69 |
+
# for idx, pos in enumerate(doorPos):
|
| 70 |
+
# color = doorColors[idx]
|
| 71 |
+
# self.grid.set(*pos, Door(color))
|
| 72 |
+
|
| 73 |
+
# Randomize the agent start position and orientation
|
| 74 |
+
self.place_agent(size=(width, height))
|
| 75 |
+
|
| 76 |
+
# Select a random target door
|
| 77 |
+
# doorIdx = self._rand_int(0, len(doorPos))
|
| 78 |
+
# self.target_pos = doorPos[doorIdx]
|
| 79 |
+
# self.target_color = doorColors[doorIdx]
|
| 80 |
+
self.target_pos = doorPos
|
| 81 |
+
self.target_color = doorColors
|
| 82 |
+
|
| 83 |
+
# Generate the mission string
|
| 84 |
+
self.mission = 'go to the %s door' % self.target_color
|
| 85 |
+
|
| 86 |
+
# Initialize the dialogue string
|
| 87 |
+
self.dialogue = "This is what you hear. \n"
|
| 88 |
+
|
| 89 |
+
def gen_obs(self):
|
| 90 |
+
obs = super().gen_obs()
|
| 91 |
+
|
| 92 |
+
# add dialogue to obs
|
| 93 |
+
obs["dialogue"] = self.dialogue
|
| 94 |
+
|
| 95 |
+
return obs
|
| 96 |
+
|
| 97 |
+
def step(self, action):
|
| 98 |
+
p_action = action[0]
|
| 99 |
+
utterance_action = action[1:]
|
| 100 |
+
|
| 101 |
+
assert len(set(np.isnan(utterance_action))) == 1
|
| 102 |
+
|
| 103 |
+
speak_flag = not all(np.isnan(utterance_action))
|
| 104 |
+
|
| 105 |
+
obs, reward, done, info = super().step(p_action)
|
| 106 |
+
|
| 107 |
+
ax, ay = self.agent_pos
|
| 108 |
+
tx, ty = self.target_pos
|
| 109 |
+
|
| 110 |
+
# Don't let the agent open any of the doors
|
| 111 |
+
if p_action == self.actions.toggle:
|
| 112 |
+
done = True
|
| 113 |
+
|
| 114 |
+
# magic words if front of the door
|
| 115 |
+
if speak_flag:
|
| 116 |
+
utterance = SesameGrammar.construct_utterance(utterance_action)
|
| 117 |
+
self.dialogue += "YOU: " + utterance + "\n"
|
| 118 |
+
|
| 119 |
+
if utterance == SesameGrammar.construct_utterance([0, 1]):
|
| 120 |
+
if (ax == tx and abs(ay - ty) == 1) or (ay == ty and abs(ax - tx) == 1):
|
| 121 |
+
reward = self._reward()
|
| 122 |
+
done = True
|
| 123 |
+
|
| 124 |
+
# Reward performing done action in front of the target door
|
| 125 |
+
# if p_action == self.actions.done:
|
| 126 |
+
# if (ax == tx and abs(ay - ty) == 1) or (ay == ty and abs(ax - tx) == 1):
|
| 127 |
+
# reward = self._reward()
|
| 128 |
+
# done = True
|
| 129 |
+
|
| 130 |
+
return obs, reward, done, info
|
| 131 |
+
|
| 132 |
+
def render(self, *args, **kwargs):
|
| 133 |
+
obs = super().render(*args, **kwargs)
|
| 134 |
+
self.window.set_caption(self.dialogue, [
|
| 135 |
+
"Gandalf:",
|
| 136 |
+
"Jack:",
|
| 137 |
+
"John:",
|
| 138 |
+
"Where is the exit",
|
| 139 |
+
"Open sesame",
|
| 140 |
+
])
|
| 141 |
+
return obs
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
class GoToDoorSesame8x8Env(GoToDoorSesameEnv):
|
| 145 |
+
def __init__(self):
|
| 146 |
+
super().__init__(size=8)
|
| 147 |
+
|
| 148 |
+
class GoToDoorSesame6x6Env(GoToDoorSesameEnv):
|
| 149 |
+
def __init__(self):
|
| 150 |
+
super().__init__(size=6)
|
| 151 |
+
|
| 152 |
+
register(
|
| 153 |
+
id='MiniGrid-GoToDoorSesame-5x5-v0',
|
| 154 |
+
entry_point='gym_minigrid.envs:GoToDoorSesameEnv'
|
| 155 |
+
)
|
| 156 |
+
|
| 157 |
+
register(
|
| 158 |
+
id='MiniGrid-GoToDoorSesame-6x6-v0',
|
| 159 |
+
entry_point='gym_minigrid.envs:GoToDoorSesame6x6Env'
|
| 160 |
+
)
|
| 161 |
+
|
| 162 |
+
register(
|
| 163 |
+
id='MiniGrid-GoToDoorSesame-8x8-v0',
|
| 164 |
+
entry_point='gym_minigrid.envs:GoToDoorSesame8x8Env'
|
| 165 |
+
)
|
gym-minigrid/gym_minigrid/backup_envs/gotodoortalk.py
ADDED
|
@@ -0,0 +1,189 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from gym_minigrid.minigrid import *
|
| 2 |
+
from gym_minigrid.register import register
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
# these two classes should maybe be extracted to a utils file so they can be used all over our envs
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class GoToDoorTalkEnv(MultiModalMiniGridEnv):
|
| 9 |
+
"""
|
| 10 |
+
Environment in which the agent is instructed to go to a given object
|
| 11 |
+
named using an English text string
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
def __init__(
|
| 15 |
+
self,
|
| 16 |
+
size=5,
|
| 17 |
+
hear_yourself=False,
|
| 18 |
+
):
|
| 19 |
+
assert size >= 5
|
| 20 |
+
|
| 21 |
+
super().__init__(
|
| 22 |
+
grid_size=size,
|
| 23 |
+
max_steps=5*size**2,
|
| 24 |
+
# Set this to True for maximum speed
|
| 25 |
+
see_through_walls=True,
|
| 26 |
+
actions=MiniGridEnv.Actions,
|
| 27 |
+
action_space=spaces.MultiDiscrete([
|
| 28 |
+
len(MiniGridEnv.Actions),
|
| 29 |
+
*Grammar.grammar_action_space.nvec
|
| 30 |
+
])
|
| 31 |
+
)
|
| 32 |
+
self.hear_yourself = hear_yourself
|
| 33 |
+
|
| 34 |
+
self.empty_symbol = "NA \n"
|
| 35 |
+
|
| 36 |
+
def _gen_grid(self, width, height):
|
| 37 |
+
# Create the grid
|
| 38 |
+
self.grid = Grid(width, height)
|
| 39 |
+
|
| 40 |
+
# Randomly vary the room width and height
|
| 41 |
+
width = self._rand_int(5, width+1)
|
| 42 |
+
height = self._rand_int(5, height+1)
|
| 43 |
+
|
| 44 |
+
# Generate the surrounding walls
|
| 45 |
+
self.grid.wall_rect(0, 0, width, height)
|
| 46 |
+
|
| 47 |
+
# Generate the 4 doors at random positions
|
| 48 |
+
doorPos = []
|
| 49 |
+
doorPos.append((self._rand_int(2, width-2), 0))
|
| 50 |
+
doorPos.append((self._rand_int(2, width-2), height-1))
|
| 51 |
+
doorPos.append((0, self._rand_int(2, height-2)))
|
| 52 |
+
doorPos.append((width-1, self._rand_int(2, height-2)))
|
| 53 |
+
|
| 54 |
+
# Generate the door colors
|
| 55 |
+
doorColors = []
|
| 56 |
+
while len(doorColors) < len(doorPos):
|
| 57 |
+
color = self._rand_elem(COLOR_NAMES)
|
| 58 |
+
if color in doorColors:
|
| 59 |
+
continue
|
| 60 |
+
doorColors.append(color)
|
| 61 |
+
|
| 62 |
+
# Place the doors in the grid
|
| 63 |
+
for idx, pos in enumerate(doorPos):
|
| 64 |
+
color = doorColors[idx]
|
| 65 |
+
self.grid.set(*pos, Door(color))
|
| 66 |
+
|
| 67 |
+
# Randomize the agent start position and orientation
|
| 68 |
+
self.place_agent(size=(width, height))
|
| 69 |
+
|
| 70 |
+
# Select a random target door
|
| 71 |
+
doorIdx = self._rand_int(0, len(doorPos))
|
| 72 |
+
self.target_pos = doorPos[doorIdx]
|
| 73 |
+
self.target_color = doorColors[doorIdx]
|
| 74 |
+
|
| 75 |
+
# Generate the mission string
|
| 76 |
+
self.mission = 'go to the %s door' % self.target_color
|
| 77 |
+
|
| 78 |
+
# Dummy beginning string
|
| 79 |
+
self.beginning_string = "This is what you hear. \n"
|
| 80 |
+
self.utterance = self.beginning_string
|
| 81 |
+
|
| 82 |
+
# utterance appended at the end of each step
|
| 83 |
+
self.utterance_history = ""
|
| 84 |
+
|
| 85 |
+
def step(self, action):
|
| 86 |
+
p_action = action[0]
|
| 87 |
+
utterance_action = action[1:]
|
| 88 |
+
|
| 89 |
+
assert len(set(np.isnan(utterance_action))) == 1
|
| 90 |
+
|
| 91 |
+
speak_flag = not all(np.isnan(utterance_action))
|
| 92 |
+
|
| 93 |
+
if speak_flag:
|
| 94 |
+
agent_utterance = Grammar.construct_utterance(utterance_action)
|
| 95 |
+
|
| 96 |
+
reply = self.mission
|
| 97 |
+
NPC_name = "Wizard"
|
| 98 |
+
|
| 99 |
+
if self.hear_yourself:
|
| 100 |
+
self.utterance += "YOU: {} \n".format(agent_utterance)
|
| 101 |
+
|
| 102 |
+
self.utterance += "{}: {} \n".format(NPC_name, reply)
|
| 103 |
+
|
| 104 |
+
obs, reward, done, info = super().step(p_action)
|
| 105 |
+
|
| 106 |
+
# Don't let the agent open any of the doors
|
| 107 |
+
if p_action == self.actions.toggle:
|
| 108 |
+
done = True
|
| 109 |
+
|
| 110 |
+
# Reward performing done action in front of the target door
|
| 111 |
+
if p_action == self.actions.done:
|
| 112 |
+
ax, ay = self.agent_pos
|
| 113 |
+
tx, ty = self.target_pos
|
| 114 |
+
|
| 115 |
+
if (ax == tx and abs(ay - ty) == 1) or (ay == ty and abs(ax - tx) == 1):
|
| 116 |
+
reward = self._reward()
|
| 117 |
+
done = True
|
| 118 |
+
|
| 119 |
+
# fill observation with text
|
| 120 |
+
self.append_existing_utterance_to_history()
|
| 121 |
+
obs = self.add_utterance_to_observation(obs)
|
| 122 |
+
self.reset_utterance()
|
| 123 |
+
|
| 124 |
+
return obs, reward, done, info
|
| 125 |
+
|
| 126 |
+
def render(self, *args, **kwargs):
|
| 127 |
+
obs = super().render(*args, **kwargs)
|
| 128 |
+
self.window.set_caption(self.utterance_history, [
|
| 129 |
+
"Gandalf:",
|
| 130 |
+
"Jack:",
|
| 131 |
+
"John:",
|
| 132 |
+
"Where is the exit",
|
| 133 |
+
"Open sesame",
|
| 134 |
+
])
|
| 135 |
+
return obs
|
| 136 |
+
|
| 137 |
+
|
| 138 |
+
class GoToDoorTalk8x8Env(GoToDoorTalkEnv):
|
| 139 |
+
def __init__(self):
|
| 140 |
+
super().__init__(size=8)
|
| 141 |
+
|
| 142 |
+
class GoToDoorTalk6x6Env(GoToDoorTalkEnv):
|
| 143 |
+
def __init__(self):
|
| 144 |
+
super().__init__(size=6)
|
| 145 |
+
|
| 146 |
+
# hear yourself
|
| 147 |
+
class GoToDoorTalkHY8x8Env(GoToDoorTalkEnv):
|
| 148 |
+
def __init__(self):
|
| 149 |
+
super().__init__(size=8, hear_yourself=True)
|
| 150 |
+
|
| 151 |
+
class GoToDoorTalkHY6x6Env(GoToDoorTalkEnv):
|
| 152 |
+
def __init__(self):
|
| 153 |
+
super().__init__(size=6, hear_yourself=True)
|
| 154 |
+
|
| 155 |
+
class GoToDoorTalkHYEnv(GoToDoorTalkEnv):
|
| 156 |
+
def __init__(self):
|
| 157 |
+
super().__init__(size=5, hear_yourself=True)
|
| 158 |
+
|
| 159 |
+
|
| 160 |
+
register(
|
| 161 |
+
id='MiniGrid-GoToDoorTalk-5x5-v0',
|
| 162 |
+
entry_point='gym_minigrid.envs:GoToDoorTalkEnv'
|
| 163 |
+
)
|
| 164 |
+
|
| 165 |
+
register(
|
| 166 |
+
id='MiniGrid-GoToDoorTalk-6x6-v0',
|
| 167 |
+
entry_point='gym_minigrid.envs:GoToDoorTalk6x6Env'
|
| 168 |
+
)
|
| 169 |
+
|
| 170 |
+
register(
|
| 171 |
+
id='MiniGrid-GoToDoorTalk-8x8-v0',
|
| 172 |
+
entry_point='gym_minigrid.envs:GoToDoorTalk8x8Env'
|
| 173 |
+
)
|
| 174 |
+
|
| 175 |
+
# hear yourself
|
| 176 |
+
register(
|
| 177 |
+
id='MiniGrid-GoToDoorTalkHY-5x5-v0',
|
| 178 |
+
entry_point='gym_minigrid.envs:GoToDoorTalkHYEnv'
|
| 179 |
+
)
|
| 180 |
+
|
| 181 |
+
register(
|
| 182 |
+
id='MiniGrid-GoToDoorTalkHY-6x6-v0',
|
| 183 |
+
entry_point='gym_minigrid.envs:GoToDoorTalkHY6x6Env'
|
| 184 |
+
)
|
| 185 |
+
|
| 186 |
+
register(
|
| 187 |
+
id='MiniGrid-GoToDoorTalkHY-8x8-v0',
|
| 188 |
+
entry_point='gym_minigrid.envs:GoToDoorTalkHY8x8Env'
|
| 189 |
+
)
|
gym-minigrid/gym_minigrid/backup_envs/gotodoortalkhard.py
ADDED
|
@@ -0,0 +1,199 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from gym_minigrid.minigrid import *
|
| 2 |
+
from gym_minigrid.register import register
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class TalkHardGrammar(object):
|
| 7 |
+
|
| 8 |
+
templates = ["Where is", "What is"]
|
| 9 |
+
things = ["the exit", "the chair"]
|
| 10 |
+
|
| 11 |
+
grammar_action_space = spaces.MultiDiscrete([len(templates), len(things)])
|
| 12 |
+
|
| 13 |
+
@classmethod
|
| 14 |
+
def construct_utterance(cls, action):
|
| 15 |
+
return cls.templates[int(action[0])] + " " + cls.things[int(action[1])] + "."
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class GoToDoorTalkHardEnv(MultiModalMiniGridEnv):
|
| 19 |
+
"""
|
| 20 |
+
Environment in which the agent is instructed to go to a given object
|
| 21 |
+
named using an English text string
|
| 22 |
+
"""
|
| 23 |
+
|
| 24 |
+
def __init__(
|
| 25 |
+
self,
|
| 26 |
+
size=5,
|
| 27 |
+
hear_yourself=False,
|
| 28 |
+
):
|
| 29 |
+
assert size >= 5
|
| 30 |
+
|
| 31 |
+
super().__init__(
|
| 32 |
+
grid_size=size,
|
| 33 |
+
max_steps=5*size**2,
|
| 34 |
+
# Set this to True for maximum speed
|
| 35 |
+
see_through_walls=True,
|
| 36 |
+
actions=MiniGridEnv.Actions,
|
| 37 |
+
action_space=spaces.MultiDiscrete([
|
| 38 |
+
len(MiniGridEnv.Actions),
|
| 39 |
+
*TalkHardGrammar.grammar_action_space.nvec
|
| 40 |
+
])
|
| 41 |
+
)
|
| 42 |
+
self.hear_yourself = hear_yourself
|
| 43 |
+
|
| 44 |
+
def _gen_grid(self, width, height):
|
| 45 |
+
# Create the grid
|
| 46 |
+
self.grid = Grid(width, height)
|
| 47 |
+
|
| 48 |
+
# Randomly vary the room width and height
|
| 49 |
+
width = self._rand_int(5, width+1)
|
| 50 |
+
height = self._rand_int(5, height+1)
|
| 51 |
+
|
| 52 |
+
# Generate the surrounding walls
|
| 53 |
+
self.grid.wall_rect(0, 0, width, height)
|
| 54 |
+
|
| 55 |
+
# Generate the 4 doors at random positions
|
| 56 |
+
doorPos = []
|
| 57 |
+
doorPos.append((self._rand_int(2, width-2), 0))
|
| 58 |
+
doorPos.append((self._rand_int(2, width-2), height-1))
|
| 59 |
+
doorPos.append((0, self._rand_int(2, height-2)))
|
| 60 |
+
doorPos.append((width-1, self._rand_int(2, height-2)))
|
| 61 |
+
|
| 62 |
+
# Generate the door colors
|
| 63 |
+
doorColors = []
|
| 64 |
+
while len(doorColors) < len(doorPos):
|
| 65 |
+
color = self._rand_elem(COLOR_NAMES)
|
| 66 |
+
if color in doorColors:
|
| 67 |
+
continue
|
| 68 |
+
doorColors.append(color)
|
| 69 |
+
|
| 70 |
+
# Place the doors in the grid
|
| 71 |
+
for idx, pos in enumerate(doorPos):
|
| 72 |
+
color = doorColors[idx]
|
| 73 |
+
self.grid.set(*pos, Door(color))
|
| 74 |
+
|
| 75 |
+
# Randomize the agent start position and orientation
|
| 76 |
+
self.place_agent(size=(width, height))
|
| 77 |
+
|
| 78 |
+
# Select a random target door
|
| 79 |
+
doorIdx = self._rand_int(0, len(doorPos))
|
| 80 |
+
self.target_pos = doorPos[doorIdx]
|
| 81 |
+
self.target_color = doorColors[doorIdx]
|
| 82 |
+
|
| 83 |
+
# Generate the mission string
|
| 84 |
+
self.mission = 'go to the %s door' % self.target_color
|
| 85 |
+
|
| 86 |
+
# Initialize the dialogue string
|
| 87 |
+
self.dialogue = "This is what you hear. "
|
| 88 |
+
|
| 89 |
+
def gen_obs(self):
|
| 90 |
+
obs = super().gen_obs()
|
| 91 |
+
|
| 92 |
+
# add dialogue to obs
|
| 93 |
+
obs["dialogue"] = self.dialogue
|
| 94 |
+
|
| 95 |
+
return obs
|
| 96 |
+
|
| 97 |
+
def step(self, action):
|
| 98 |
+
p_action = action[0]
|
| 99 |
+
utterance_action = action[1:]
|
| 100 |
+
|
| 101 |
+
# assert all nan or neither nan
|
| 102 |
+
assert len(set(np.isnan(utterance_action))) == 1
|
| 103 |
+
|
| 104 |
+
speak_flag = not all(np.isnan(utterance_action))
|
| 105 |
+
|
| 106 |
+
if speak_flag:
|
| 107 |
+
utterance = TalkHardGrammar.construct_utterance(utterance_action)
|
| 108 |
+
|
| 109 |
+
reply = self.mission
|
| 110 |
+
NPC_name = "Wizard"
|
| 111 |
+
|
| 112 |
+
if self.hear_yourself:
|
| 113 |
+
self.dialogue += "YOU: {} \n".format(utterance)
|
| 114 |
+
|
| 115 |
+
if utterance == TalkHardGrammar.construct_utterance([0, 0]):
|
| 116 |
+
self.dialogue += "{}: {} \n".format(NPC_name, reply) # dummy reply gives mission
|
| 117 |
+
|
| 118 |
+
obs, reward, done, info = super().step(p_action)
|
| 119 |
+
|
| 120 |
+
ax, ay = self.agent_pos
|
| 121 |
+
tx, ty = self.target_pos
|
| 122 |
+
|
| 123 |
+
# Don't let the agent open any of the doors
|
| 124 |
+
if p_action == self.actions.toggle:
|
| 125 |
+
done = True
|
| 126 |
+
|
| 127 |
+
# Reward performing done action in front of the target door
|
| 128 |
+
if p_action == self.actions.done:
|
| 129 |
+
if (ax == tx and abs(ay - ty) == 1) or (ay == ty and abs(ax - tx) == 1):
|
| 130 |
+
reward = self._reward()
|
| 131 |
+
done = True
|
| 132 |
+
|
| 133 |
+
return obs, reward, done, info
|
| 134 |
+
|
| 135 |
+
def render(self, *args, **kwargs):
|
| 136 |
+
obs = super().render(*args, **kwargs)
|
| 137 |
+
self.window.set_caption(self.dialogue, [
|
| 138 |
+
"Gandalf:",
|
| 139 |
+
"Jack:",
|
| 140 |
+
"John:",
|
| 141 |
+
"Where is the exit",
|
| 142 |
+
"Open sesame",
|
| 143 |
+
])
|
| 144 |
+
return obs
|
| 145 |
+
|
| 146 |
+
|
| 147 |
+
class GoToDoorTalkHard8x8Env(GoToDoorTalkHardEnv):
|
| 148 |
+
def __init__(self):
|
| 149 |
+
super().__init__(size=8)
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
class GoToDoorTalkHard6x6Env(GoToDoorTalkHardEnv):
|
| 153 |
+
def __init__(self):
|
| 154 |
+
super().__init__(size=6)
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
# hear yourself
|
| 158 |
+
class GoToDoorTalkHardHY8x8Env(GoToDoorTalkHardEnv):
|
| 159 |
+
def __init__(self):
|
| 160 |
+
super().__init__(size=8, hear_yourself=True)
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
class GoToDoorTalkHardHY6x6Env(GoToDoorTalkHardEnv):
|
| 164 |
+
def __init__(self):
|
| 165 |
+
super().__init__(size=6, hear_yourself=True)
|
| 166 |
+
|
| 167 |
+
|
| 168 |
+
class GoToDoorTalkHardHY5x5Env(GoToDoorTalkHardEnv):
|
| 169 |
+
def __init__(self):
|
| 170 |
+
super().__init__(size=5, hear_yourself=True)
|
| 171 |
+
|
| 172 |
+
register(
|
| 173 |
+
id='MiniGrid-GoToDoorTalkHard-5x5-v0',
|
| 174 |
+
entry_point='gym_minigrid.envs:GoToDoorTalkHardEnv'
|
| 175 |
+
)
|
| 176 |
+
|
| 177 |
+
register(
|
| 178 |
+
id='MiniGrid-GoToDoorTalkHard-6x6-v0',
|
| 179 |
+
entry_point='gym_minigrid.envs:GoToDoorTalkHard6x6Env'
|
| 180 |
+
)
|
| 181 |
+
|
| 182 |
+
register(
|
| 183 |
+
id='MiniGrid-GoToDoorTalkHard-8x8-v0',
|
| 184 |
+
entry_point='gym_minigrid.envs:GoToDoorTalkHard8x8Env'
|
| 185 |
+
)
|
| 186 |
+
register(
|
| 187 |
+
id='MiniGrid-GoToDoorTalkHardHY-5x5-v0',
|
| 188 |
+
entry_point='gym_minigrid.envs:GoToDoorTalkHardHY5x5Env'
|
| 189 |
+
)
|
| 190 |
+
|
| 191 |
+
register(
|
| 192 |
+
id='MiniGrid-GoToDoorTalkHardHY-6x6-v0',
|
| 193 |
+
entry_point='gym_minigrid.envs:GoToDoorTalkHardHY6x6Env'
|
| 194 |
+
)
|
| 195 |
+
|
| 196 |
+
register(
|
| 197 |
+
id='MiniGrid-GoToDoorTalkHardHY-8x8-v0',
|
| 198 |
+
entry_point='gym_minigrid.envs:GoToDoorTalkHardHY8x8Env'
|
| 199 |
+
)
|
gym-minigrid/gym_minigrid/backup_envs/gotodoortalkhardnpc.py
ADDED
|
@@ -0,0 +1,283 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from gym_minigrid.minigrid import *
|
| 2 |
+
from gym_minigrid.register import register
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
class Guide(NPC):
|
| 6 |
+
"""
|
| 7 |
+
A simple NPC that wants an agent to go to an object (randomly chosen among object_pos list)
|
| 8 |
+
"""
|
| 9 |
+
|
| 10 |
+
def __init__(self, color, name, env):
|
| 11 |
+
super().__init__(color)
|
| 12 |
+
self.name = name
|
| 13 |
+
self.env = env
|
| 14 |
+
self.has_spoken = False # wizards only speak once
|
| 15 |
+
self.npc_type = 0
|
| 16 |
+
|
| 17 |
+
def listen(self, utterance):
|
| 18 |
+
if utterance == TalkHardSesameGrammar.construct_utterance([0, 1]):
|
| 19 |
+
return self.env.mission
|
| 20 |
+
|
| 21 |
+
return None
|
| 22 |
+
|
| 23 |
+
# def is_near_agent(self):
|
| 24 |
+
# ax, ay = self.env.agent_pos
|
| 25 |
+
# wx, wy = self.cur_pos
|
| 26 |
+
# if (ax == wx and abs(ay - wy) == 1) or (ay == wy and abs(ax - wx) == 1):
|
| 27 |
+
# return True
|
| 28 |
+
# return False
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
class TalkHardSesameGrammar(object):
|
| 32 |
+
|
| 33 |
+
templates = ["Where is", "Open"]
|
| 34 |
+
things = ["sesame", "the exit"]
|
| 35 |
+
|
| 36 |
+
grammar_action_space = spaces.MultiDiscrete([len(templates), len(things)])
|
| 37 |
+
|
| 38 |
+
@classmethod
|
| 39 |
+
def construct_utterance(cls, action):
|
| 40 |
+
return cls.templates[int(action[0])] + " " + cls.things[int(action[1])] + " "
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
class GoToDoorTalkHardNPCEnv(MultiModalMiniGridEnv):
|
| 44 |
+
"""
|
| 45 |
+
Environment in which the agent is instructed to go to a given object
|
| 46 |
+
named using an English text string
|
| 47 |
+
"""
|
| 48 |
+
|
| 49 |
+
def __init__(
|
| 50 |
+
self,
|
| 51 |
+
size=5,
|
| 52 |
+
hear_yourself=False,
|
| 53 |
+
diminished_reward=True,
|
| 54 |
+
step_penalty=False
|
| 55 |
+
):
|
| 56 |
+
assert size >= 5
|
| 57 |
+
|
| 58 |
+
super().__init__(
|
| 59 |
+
grid_size=size,
|
| 60 |
+
max_steps=5*size**2,
|
| 61 |
+
# Set this to True for maximum speed
|
| 62 |
+
see_through_walls=True,
|
| 63 |
+
actions=MiniGridEnv.Actions,
|
| 64 |
+
action_space=spaces.MultiDiscrete([
|
| 65 |
+
len(MiniGridEnv.Actions),
|
| 66 |
+
*TalkHardSesameGrammar.grammar_action_space.nvec
|
| 67 |
+
])
|
| 68 |
+
)
|
| 69 |
+
self.hear_yourself = hear_yourself
|
| 70 |
+
self.diminished_reward = diminished_reward
|
| 71 |
+
self.step_penalty = step_penalty
|
| 72 |
+
|
| 73 |
+
self.empty_symbol = "NA \n"
|
| 74 |
+
|
| 75 |
+
print({
|
| 76 |
+
"size": size,
|
| 77 |
+
"hear_yourself": hear_yourself,
|
| 78 |
+
"diminished_reward": diminished_reward,
|
| 79 |
+
"step_penalty": step_penalty,
|
| 80 |
+
})
|
| 81 |
+
|
| 82 |
+
def _gen_grid(self, width, height):
|
| 83 |
+
# Create the grid
|
| 84 |
+
self.grid = Grid(width, height)
|
| 85 |
+
|
| 86 |
+
# Randomly vary the room width and height
|
| 87 |
+
width = self._rand_int(5, width+1)
|
| 88 |
+
height = self._rand_int(5, height+1)
|
| 89 |
+
|
| 90 |
+
# Generate the surrounding walls
|
| 91 |
+
self.grid.wall_rect(0, 0, width, height)
|
| 92 |
+
|
| 93 |
+
# Generate the surrounding walls
|
| 94 |
+
self.grid.wall_rect(0, 0, width, height)
|
| 95 |
+
|
| 96 |
+
# Generate the 4 doors at random positions
|
| 97 |
+
self.door_pos = []
|
| 98 |
+
self.door_front_pos = [] # Remembers positions in front of door to avoid setting wizard here
|
| 99 |
+
|
| 100 |
+
self.door_pos.append((self._rand_int(2, width-2), 0))
|
| 101 |
+
self.door_front_pos.append((self.door_pos[-1][0], self.door_pos[-1][1]+1))
|
| 102 |
+
|
| 103 |
+
self.door_pos.append((self._rand_int(2, width-2), height-1))
|
| 104 |
+
self.door_front_pos.append((self.door_pos[-1][0], self.door_pos[-1][1] - 1))
|
| 105 |
+
|
| 106 |
+
self.door_pos.append((0, self._rand_int(2, height-2)))
|
| 107 |
+
self.door_front_pos.append((self.door_pos[-1][0] + 1, self.door_pos[-1][1]))
|
| 108 |
+
|
| 109 |
+
self.door_pos.append((width-1, self._rand_int(2, height-2)))
|
| 110 |
+
self.door_front_pos.append((self.door_pos[-1][0] - 1, self.door_pos[-1][1]))
|
| 111 |
+
|
| 112 |
+
# Generate the door colors
|
| 113 |
+
self.door_colors = []
|
| 114 |
+
while len(self.door_colors) < len(self.door_pos):
|
| 115 |
+
color = self._rand_elem(COLOR_NAMES)
|
| 116 |
+
if color in self.door_colors:
|
| 117 |
+
continue
|
| 118 |
+
self.door_colors.append(color)
|
| 119 |
+
|
| 120 |
+
# Place the doors in the grid
|
| 121 |
+
for idx, pos in enumerate(self.door_pos):
|
| 122 |
+
color = self.door_colors[idx]
|
| 123 |
+
self.grid.set(*pos, Door(color))
|
| 124 |
+
|
| 125 |
+
# Set a randomly coloured NPC at a random position
|
| 126 |
+
color = self._rand_elem(COLOR_NAMES)
|
| 127 |
+
self.wizard = Guide(color, "Gandalf", self)
|
| 128 |
+
|
| 129 |
+
# Place it randomly, omitting front of door positions
|
| 130 |
+
self.place_obj(self.wizard,
|
| 131 |
+
size=(width, height),
|
| 132 |
+
reject_fn=lambda _, p: tuple(p) in self.door_front_pos)
|
| 133 |
+
|
| 134 |
+
# Randomize the agent start position and orientation
|
| 135 |
+
self.place_agent(size=(width, height))
|
| 136 |
+
|
| 137 |
+
# Select a random target door
|
| 138 |
+
self.doorIdx = self._rand_int(0, len(self.door_pos))
|
| 139 |
+
self.target_pos = self.door_pos[self.doorIdx]
|
| 140 |
+
self.target_color = self.door_colors[self.doorIdx]
|
| 141 |
+
|
| 142 |
+
# Generate the mission string
|
| 143 |
+
self.mission = 'go to the %s door' % self.target_color
|
| 144 |
+
|
| 145 |
+
# Dummy beginning string
|
| 146 |
+
self.beginning_string = "This is what you hear. \n"
|
| 147 |
+
self.utterance = self.beginning_string
|
| 148 |
+
|
| 149 |
+
# utterance appended at the end of each step
|
| 150 |
+
self.utterance_history = ""
|
| 151 |
+
|
| 152 |
+
def step(self, action):
|
| 153 |
+
p_action = action[0]
|
| 154 |
+
utterance_action = action[1:]
|
| 155 |
+
|
| 156 |
+
# assert all nan or neither nan
|
| 157 |
+
assert len(set(np.isnan(utterance_action))) == 1
|
| 158 |
+
|
| 159 |
+
speak_flag = not all(np.isnan(utterance_action))
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
obs, reward, done, info = super().step(p_action)
|
| 163 |
+
|
| 164 |
+
if speak_flag:
|
| 165 |
+
agent_utterance = TalkHardSesameGrammar.construct_utterance(utterance_action)
|
| 166 |
+
if self.hear_yourself:
|
| 167 |
+
self.utterance += "YOU: {} \n".format(agent_utterance)
|
| 168 |
+
|
| 169 |
+
# check if near wizard
|
| 170 |
+
if self.wizard.is_near_agent():
|
| 171 |
+
reply = self.wizard.listen(agent_utterance)
|
| 172 |
+
|
| 173 |
+
if reply:
|
| 174 |
+
self.utterance += "{}: {} \n".format(self.wizard.name, reply)
|
| 175 |
+
|
| 176 |
+
# Don't let the agent open any of the doors
|
| 177 |
+
if p_action == self.actions.toggle:
|
| 178 |
+
done = True
|
| 179 |
+
|
| 180 |
+
if p_action == self.actions.done:
|
| 181 |
+
ax, ay = self.agent_pos
|
| 182 |
+
tx, ty = self.target_pos
|
| 183 |
+
|
| 184 |
+
if (ax == tx and abs(ay - ty) == 1) or (ay == ty and abs(ax - tx) == 1):
|
| 185 |
+
reward = self._reward()
|
| 186 |
+
done = True
|
| 187 |
+
|
| 188 |
+
# discount
|
| 189 |
+
if self.step_penalty:
|
| 190 |
+
reward = reward - 0.01
|
| 191 |
+
|
| 192 |
+
# fill observation with text
|
| 193 |
+
self.append_existing_utterance_to_history()
|
| 194 |
+
obs = self.add_utterance_to_observation(obs)
|
| 195 |
+
self.reset_utterance()
|
| 196 |
+
|
| 197 |
+
return obs, reward, done, info
|
| 198 |
+
|
| 199 |
+
def _reward(self):
|
| 200 |
+
if self.diminished_reward:
|
| 201 |
+
return super()._reward()
|
| 202 |
+
else:
|
| 203 |
+
return 1.0
|
| 204 |
+
|
| 205 |
+
def render(self, *args, **kwargs):
|
| 206 |
+
obs = super().render(*args, **kwargs)
|
| 207 |
+
self.window.set_caption(self.utterance_history, [
|
| 208 |
+
"Gandalf:",
|
| 209 |
+
"Jack:",
|
| 210 |
+
"John:",
|
| 211 |
+
"Where is the exit",
|
| 212 |
+
"Open sesame",
|
| 213 |
+
])
|
| 214 |
+
return obs
|
| 215 |
+
|
| 216 |
+
|
| 217 |
+
class GoToDoorTalkHardNPCTesting(GoToDoorTalkHardNPCEnv):
|
| 218 |
+
def __init__(self):
|
| 219 |
+
super().__init__(
|
| 220 |
+
size=5,
|
| 221 |
+
hear_yourself=False,
|
| 222 |
+
diminished_reward=False,
|
| 223 |
+
step_penalty=True
|
| 224 |
+
)
|
| 225 |
+
|
| 226 |
+
class GoToDoorTalkHardNPC8x8Env(GoToDoorTalkHardNPCEnv):
|
| 227 |
+
def __init__(self):
|
| 228 |
+
super().__init__(size=8)
|
| 229 |
+
|
| 230 |
+
|
| 231 |
+
class GoToDoorTalkHardNPC6x6Env(GoToDoorTalkHardNPCEnv):
|
| 232 |
+
def __init__(self):
|
| 233 |
+
super().__init__(size=6)
|
| 234 |
+
|
| 235 |
+
|
| 236 |
+
# hear yourself
|
| 237 |
+
class GoToDoorTalkHardNPCHY8x8Env(GoToDoorTalkHardNPCEnv):
|
| 238 |
+
def __init__(self):
|
| 239 |
+
super().__init__(size=8, hear_yourself=True)
|
| 240 |
+
|
| 241 |
+
|
| 242 |
+
class GoToDoorTalkHardNPCHY6x6Env(GoToDoorTalkHardNPCEnv):
|
| 243 |
+
def __init__(self):
|
| 244 |
+
super().__init__(size=6, hear_yourself=True)
|
| 245 |
+
|
| 246 |
+
|
| 247 |
+
class GoToDoorTalkHardNPCHY5x5Env(GoToDoorTalkHardNPCEnv):
|
| 248 |
+
def __init__(self):
|
| 249 |
+
super().__init__(size=5, hear_yourself=True)
|
| 250 |
+
|
| 251 |
+
register(
|
| 252 |
+
id='MiniGrid-GoToDoorTalkHardNPC-Testing-v0',
|
| 253 |
+
entry_point='gym_minigrid.envs:GoToDoorTalkHardNPCTesting'
|
| 254 |
+
)
|
| 255 |
+
|
| 256 |
+
register(
|
| 257 |
+
id='MiniGrid-GoToDoorTalkHardNPC-5x5-v0',
|
| 258 |
+
entry_point='gym_minigrid.envs:GoToDoorTalkHardNPCEnv'
|
| 259 |
+
)
|
| 260 |
+
|
| 261 |
+
register(
|
| 262 |
+
id='MiniGrid-GoToDoorTalkHardNPC-6x6-v0',
|
| 263 |
+
entry_point='gym_minigrid.envs:GoToDoorTalkHardNPC6x6Env'
|
| 264 |
+
)
|
| 265 |
+
|
| 266 |
+
register(
|
| 267 |
+
id='MiniGrid-GoToDoorTalkHardNPC-8x8-v0',
|
| 268 |
+
entry_point='gym_minigrid.envs:GoToDoorTalkHardNPC8x8Env'
|
| 269 |
+
)
|
| 270 |
+
register(
|
| 271 |
+
id='MiniGrid-GoToDoorTalkHardNPCHY-5x5-v0',
|
| 272 |
+
entry_point='gym_minigrid.envs:GoToDoorTalkHardNPCHY5x5Env'
|
| 273 |
+
)
|
| 274 |
+
|
| 275 |
+
register(
|
| 276 |
+
id='MiniGrid-GoToDoorTalkHardNPCHY-6x6-v0',
|
| 277 |
+
entry_point='gym_minigrid.envs:GoToDoorTalkHardNPCHY6x6Env'
|
| 278 |
+
)
|
| 279 |
+
|
| 280 |
+
register(
|
| 281 |
+
id='MiniGrid-GoToDoorTalkHardNPCHY-8x8-v0',
|
| 282 |
+
entry_point='gym_minigrid.envs:GoToDoorTalkHardNPCHY8x8Env'
|
| 283 |
+
)
|
gym-minigrid/gym_minigrid/backup_envs/gotodoortalkhardsesame.py
ADDED
|
@@ -0,0 +1,204 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from gym_minigrid.minigrid import *
|
| 2 |
+
from gym_minigrid.register import register
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class TalkHardSesameGrammar(object):
|
| 7 |
+
|
| 8 |
+
templates = ["Where is", "Open"]
|
| 9 |
+
things = ["sesame", "the exit"]
|
| 10 |
+
|
| 11 |
+
grammar_action_space = spaces.MultiDiscrete([len(templates), len(things)])
|
| 12 |
+
|
| 13 |
+
@classmethod
|
| 14 |
+
def construct_utterance(cls, action):
|
| 15 |
+
return cls.templates[int(action[0])] + " " + cls.things[int(action[1])] + " "
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class GoToDoorTalkHardSesameEnv(MultiModalMiniGridEnv):
|
| 19 |
+
"""
|
| 20 |
+
Environment in which the agent is instructed to go to a given object
|
| 21 |
+
named using an English text string
|
| 22 |
+
"""
|
| 23 |
+
|
| 24 |
+
def __init__(
|
| 25 |
+
self,
|
| 26 |
+
size=5,
|
| 27 |
+
hear_yourself=False,
|
| 28 |
+
):
|
| 29 |
+
assert size >= 5
|
| 30 |
+
|
| 31 |
+
super().__init__(
|
| 32 |
+
grid_size=size,
|
| 33 |
+
max_steps=5*size**2,
|
| 34 |
+
# Set this to True for maximum speed
|
| 35 |
+
see_through_walls=True,
|
| 36 |
+
actions=MiniGridEnv.Actions,
|
| 37 |
+
action_space=spaces.MultiDiscrete([
|
| 38 |
+
len(MiniGridEnv.Actions),
|
| 39 |
+
*TalkHardSesameGrammar.grammar_action_space.nvec
|
| 40 |
+
])
|
| 41 |
+
)
|
| 42 |
+
self.hear_yourself = hear_yourself
|
| 43 |
+
|
| 44 |
+
self.empty_symbol = "NA \n"
|
| 45 |
+
|
| 46 |
+
def _gen_grid(self, width, height):
|
| 47 |
+
# Create the grid
|
| 48 |
+
self.grid = Grid(width, height)
|
| 49 |
+
|
| 50 |
+
# Randomly vary the room width and height
|
| 51 |
+
width = self._rand_int(5, width+1)
|
| 52 |
+
height = self._rand_int(5, height+1)
|
| 53 |
+
|
| 54 |
+
# Generate the surrounding walls
|
| 55 |
+
self.grid.wall_rect(0, 0, width, height)
|
| 56 |
+
|
| 57 |
+
# Generate the 4 doors at random positions
|
| 58 |
+
self.doorPos = []
|
| 59 |
+
self.doorPos.append((self._rand_int(2, width-2), 0))
|
| 60 |
+
self.doorPos.append((self._rand_int(2, width-2), height-1))
|
| 61 |
+
self.doorPos.append((0, self._rand_int(2, height-2)))
|
| 62 |
+
self.doorPos.append((width-1, self._rand_int(2, height-2)))
|
| 63 |
+
|
| 64 |
+
# Generate the door colors
|
| 65 |
+
doorColors = []
|
| 66 |
+
while len(doorColors) < len(self.doorPos):
|
| 67 |
+
color = self._rand_elem(COLOR_NAMES)
|
| 68 |
+
if color in doorColors:
|
| 69 |
+
continue
|
| 70 |
+
doorColors.append(color)
|
| 71 |
+
|
| 72 |
+
# Place the doors in the grid
|
| 73 |
+
for idx, pos in enumerate(self.doorPos):
|
| 74 |
+
color = doorColors[idx]
|
| 75 |
+
self.grid.set(*pos, Door(color))
|
| 76 |
+
|
| 77 |
+
# Randomize the agent start position and orientation
|
| 78 |
+
self.place_agent(size=(width, height))
|
| 79 |
+
|
| 80 |
+
# Select a random target door
|
| 81 |
+
doorIdx = self._rand_int(0, len(self.doorPos))
|
| 82 |
+
self.target_pos = self.doorPos[doorIdx]
|
| 83 |
+
self.target_color = doorColors[doorIdx]
|
| 84 |
+
|
| 85 |
+
# Generate the mission string
|
| 86 |
+
self.mission = 'go to the %s door' % self.target_color
|
| 87 |
+
|
| 88 |
+
# Dummy beginning string
|
| 89 |
+
self.beginning_string = "This is what you hear. \n"
|
| 90 |
+
self.utterance = self.beginning_string
|
| 91 |
+
|
| 92 |
+
# utterance appended at the end of each step
|
| 93 |
+
self.utterance_history = ""
|
| 94 |
+
|
| 95 |
+
def step(self, action):
|
| 96 |
+
p_action = action[0]
|
| 97 |
+
utterance_action = action[1:]
|
| 98 |
+
|
| 99 |
+
# assert all nan or neither nan
|
| 100 |
+
assert len(set(np.isnan(utterance_action))) == 1
|
| 101 |
+
|
| 102 |
+
speak_flag = not all(np.isnan(utterance_action))
|
| 103 |
+
|
| 104 |
+
obs, reward, done, info = super().step(p_action)
|
| 105 |
+
|
| 106 |
+
if speak_flag:
|
| 107 |
+
utterance = TalkHardSesameGrammar.construct_utterance(utterance_action)
|
| 108 |
+
|
| 109 |
+
if self.hear_yourself:
|
| 110 |
+
self.utterance += "YOU: {} \n".format(utterance)
|
| 111 |
+
|
| 112 |
+
if utterance == TalkHardSesameGrammar.construct_utterance([0, 1]):
|
| 113 |
+
reply = self.mission
|
| 114 |
+
NPC_name = "Wizard"
|
| 115 |
+
self.utterance += "{}: {} \n".format(NPC_name, reply) # dummy reply gives mission
|
| 116 |
+
|
| 117 |
+
elif utterance == TalkHardSesameGrammar.construct_utterance([1, 0]):
|
| 118 |
+
ax, ay = self.agent_pos
|
| 119 |
+
tx, ty = self.target_pos
|
| 120 |
+
|
| 121 |
+
if (ax == tx and abs(ay - ty) == 1) or (ay == ty and abs(ax - tx) == 1):
|
| 122 |
+
reward = self._reward()
|
| 123 |
+
|
| 124 |
+
for dx, dy in self.doorPos:
|
| 125 |
+
if (ax == dx and abs(ay - dy) == 1) or (ay == dy and abs(ax - dx) == 1):
|
| 126 |
+
# agent has chosen some door episode, regardless of if the door is correct the episode is over
|
| 127 |
+
done = True
|
| 128 |
+
|
| 129 |
+
# Don't let the agent open any of the doors
|
| 130 |
+
if p_action == self.actions.toggle:
|
| 131 |
+
done = True
|
| 132 |
+
|
| 133 |
+
# fill observation with text
|
| 134 |
+
self.append_existing_utterance_to_history()
|
| 135 |
+
obs = self.add_utterance_to_observation(obs)
|
| 136 |
+
self.reset_utterance()
|
| 137 |
+
|
| 138 |
+
return obs, reward, done, info
|
| 139 |
+
|
| 140 |
+
def render(self, *args, **kwargs):
|
| 141 |
+
obs = super().render(*args, **kwargs)
|
| 142 |
+
self.window.set_caption(self.dialogue, [
|
| 143 |
+
"Gandalf:",
|
| 144 |
+
"Jack:",
|
| 145 |
+
"John:",
|
| 146 |
+
"Where is the exit",
|
| 147 |
+
"Open sesame",
|
| 148 |
+
])
|
| 149 |
+
return obs
|
| 150 |
+
|
| 151 |
+
|
| 152 |
+
class GoToDoorTalkHardSesame8x8Env(GoToDoorTalkHardSesameEnv):
|
| 153 |
+
def __init__(self):
|
| 154 |
+
super().__init__(size=8)
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
class GoToDoorTalkHardSesame6x6Env(GoToDoorTalkHardSesameEnv):
|
| 158 |
+
def __init__(self):
|
| 159 |
+
super().__init__(size=6)
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
# hear yourself
|
| 163 |
+
class GoToDoorTalkHardSesameHY8x8Env(GoToDoorTalkHardSesameEnv):
|
| 164 |
+
def __init__(self):
|
| 165 |
+
super().__init__(size=8, hear_yourself=True)
|
| 166 |
+
|
| 167 |
+
|
| 168 |
+
class GoToDoorTalkHardSesameHY6x6Env(GoToDoorTalkHardSesameEnv):
|
| 169 |
+
def __init__(self):
|
| 170 |
+
super().__init__(size=6, hear_yourself=True)
|
| 171 |
+
|
| 172 |
+
|
| 173 |
+
class GoToDoorTalkHardSesameHY5x5Env(GoToDoorTalkHardSesameEnv):
|
| 174 |
+
def __init__(self):
|
| 175 |
+
super().__init__(size=5, hear_yourself=True)
|
| 176 |
+
|
| 177 |
+
register(
|
| 178 |
+
id='MiniGrid-GoToDoorTalkHardSesame-5x5-v0',
|
| 179 |
+
entry_point='gym_minigrid.envs:GoToDoorTalkHardSesameEnv'
|
| 180 |
+
)
|
| 181 |
+
|
| 182 |
+
register(
|
| 183 |
+
id='MiniGrid-GoToDoorTalkHardSesame-6x6-v0',
|
| 184 |
+
entry_point='gym_minigrid.envs:GoToDoorTalkHardSesame6x6Env'
|
| 185 |
+
)
|
| 186 |
+
|
| 187 |
+
register(
|
| 188 |
+
id='MiniGrid-GoToDoorTalkHardSesame-8x8-v0',
|
| 189 |
+
entry_point='gym_minigrid.envs:GoToDoorTalkHardSesame8x8Env'
|
| 190 |
+
)
|
| 191 |
+
register(
|
| 192 |
+
id='MiniGrid-GoToDoorTalkHardSesameHY-5x5-v0',
|
| 193 |
+
entry_point='gym_minigrid.envs:GoToDoorTalkHardSesameHY5x5Env'
|
| 194 |
+
)
|
| 195 |
+
|
| 196 |
+
register(
|
| 197 |
+
id='MiniGrid-GoToDoorTalkHardSesameHY-6x6-v0',
|
| 198 |
+
entry_point='gym_minigrid.envs:GoToDoorTalkHardSesameHY6x6Env'
|
| 199 |
+
)
|
| 200 |
+
|
| 201 |
+
register(
|
| 202 |
+
id='MiniGrid-GoToDoorTalkHardSesameHY-8x8-v0',
|
| 203 |
+
entry_point='gym_minigrid.envs:GoToDoorTalkHardSesameHY8x8Env'
|
| 204 |
+
)
|
gym-minigrid/gym_minigrid/backup_envs/gotodoortalkhardsesamnpc.py
ADDED
|
@@ -0,0 +1,294 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from gym_minigrid.minigrid import *
|
| 2 |
+
from gym_minigrid.register import register
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
class Guide(NPC):
|
| 6 |
+
"""
|
| 7 |
+
A simple NPC that wants an agent to go to an object (randomly chosen among object_pos list)
|
| 8 |
+
"""
|
| 9 |
+
|
| 10 |
+
def __init__(self, color, name, env):
|
| 11 |
+
super().__init__(color)
|
| 12 |
+
self.name = name
|
| 13 |
+
self.env = env
|
| 14 |
+
self.npc_type = 0
|
| 15 |
+
|
| 16 |
+
def listen(self, utterance):
|
| 17 |
+
if utterance == TalkHardSesameGrammar.construct_utterance([0, 1]):
|
| 18 |
+
return self.env.mission
|
| 19 |
+
|
| 20 |
+
return None
|
| 21 |
+
|
| 22 |
+
def is_near_agent(self):
|
| 23 |
+
ax, ay = self.env.agent_pos
|
| 24 |
+
wx, wy = self.cur_pos
|
| 25 |
+
if (ax == wx and abs(ay - wy) == 1) or (ay == wy and abs(ax - wx) == 1):
|
| 26 |
+
return True
|
| 27 |
+
return False
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
class TalkHardSesameGrammar(object):
|
| 31 |
+
|
| 32 |
+
templates = ["Where is", "Open"]
|
| 33 |
+
things = ["sesame", "the exit"]
|
| 34 |
+
|
| 35 |
+
grammar_action_space = spaces.MultiDiscrete([len(templates), len(things)])
|
| 36 |
+
|
| 37 |
+
@classmethod
|
| 38 |
+
def construct_utterance(cls, action):
|
| 39 |
+
return cls.templates[int(action[0])] + " " + cls.things[int(action[1])] + " "
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
class GoToDoorTalkHardSesameNPCEnv(MultiModalMiniGridEnv):
|
| 43 |
+
"""
|
| 44 |
+
Environment in which the agent is instructed to go to a given object
|
| 45 |
+
named using an English text string
|
| 46 |
+
"""
|
| 47 |
+
|
| 48 |
+
def __init__(
|
| 49 |
+
self,
|
| 50 |
+
size=5,
|
| 51 |
+
hear_yourself=False,
|
| 52 |
+
diminished_reward=True,
|
| 53 |
+
step_penalty=False
|
| 54 |
+
):
|
| 55 |
+
assert size >= 5
|
| 56 |
+
|
| 57 |
+
super().__init__(
|
| 58 |
+
grid_size=size,
|
| 59 |
+
max_steps=5*size**2,
|
| 60 |
+
# Set this to True for maximum speed
|
| 61 |
+
see_through_walls=True,
|
| 62 |
+
actions=MiniGridEnv.Actions,
|
| 63 |
+
action_space=spaces.MultiDiscrete([
|
| 64 |
+
len(MiniGridEnv.Actions),
|
| 65 |
+
*TalkHardSesameGrammar.grammar_action_space.nvec
|
| 66 |
+
])
|
| 67 |
+
)
|
| 68 |
+
self.hear_yourself = hear_yourself
|
| 69 |
+
self.diminished_reward = diminished_reward
|
| 70 |
+
self.step_penalty = step_penalty
|
| 71 |
+
|
| 72 |
+
self.empty_symbol = "NA \n"
|
| 73 |
+
|
| 74 |
+
print({
|
| 75 |
+
"size": size,
|
| 76 |
+
"hear_yourself": hear_yourself,
|
| 77 |
+
"diminished_reward": diminished_reward,
|
| 78 |
+
"step_penalty": step_penalty,
|
| 79 |
+
})
|
| 80 |
+
|
| 81 |
+
def _gen_grid(self, width, height):
|
| 82 |
+
# Create the grid
|
| 83 |
+
self.grid = Grid(width, height)
|
| 84 |
+
|
| 85 |
+
# Randomly vary the room width and height
|
| 86 |
+
width = self._rand_int(5, width+1)
|
| 87 |
+
height = self._rand_int(5, height+1)
|
| 88 |
+
|
| 89 |
+
# Generate the surrounding walls
|
| 90 |
+
self.grid.wall_rect(0, 0, width, height)
|
| 91 |
+
|
| 92 |
+
# Generate the surrounding walls
|
| 93 |
+
self.grid.wall_rect(0, 0, width, height)
|
| 94 |
+
|
| 95 |
+
# Generate the 4 doors at random positions
|
| 96 |
+
self.door_pos = []
|
| 97 |
+
self.door_front_pos = [] # Remembers positions in front of door to avoid setting wizard here
|
| 98 |
+
|
| 99 |
+
self.door_pos.append((self._rand_int(2, width-2), 0))
|
| 100 |
+
self.door_front_pos.append((self.door_pos[-1][0], self.door_pos[-1][1]+1))
|
| 101 |
+
|
| 102 |
+
self.door_pos.append((self._rand_int(2, width-2), height-1))
|
| 103 |
+
self.door_front_pos.append((self.door_pos[-1][0], self.door_pos[-1][1] - 1))
|
| 104 |
+
|
| 105 |
+
self.door_pos.append((0, self._rand_int(2, height-2)))
|
| 106 |
+
self.door_front_pos.append((self.door_pos[-1][0] + 1, self.door_pos[-1][1]))
|
| 107 |
+
|
| 108 |
+
self.door_pos.append((width-1, self._rand_int(2, height-2)))
|
| 109 |
+
self.door_front_pos.append((self.door_pos[-1][0] - 1, self.door_pos[-1][1]))
|
| 110 |
+
|
| 111 |
+
# Generate the door colors
|
| 112 |
+
self.door_colors = []
|
| 113 |
+
while len(self.door_colors) < len(self.door_pos):
|
| 114 |
+
color = self._rand_elem(COLOR_NAMES)
|
| 115 |
+
if color in self.door_colors:
|
| 116 |
+
continue
|
| 117 |
+
self.door_colors.append(color)
|
| 118 |
+
|
| 119 |
+
# Place the doors in the grid
|
| 120 |
+
for idx, pos in enumerate(self.door_pos):
|
| 121 |
+
color = self.door_colors[idx]
|
| 122 |
+
self.grid.set(*pos, Door(color))
|
| 123 |
+
|
| 124 |
+
# Set a randomly coloured NPC at a random position
|
| 125 |
+
color = self._rand_elem(COLOR_NAMES)
|
| 126 |
+
self.wizard = Guide(color, "Gandalf", self)
|
| 127 |
+
|
| 128 |
+
# Place it randomly, omitting front of door positions
|
| 129 |
+
self.place_obj(self.wizard,
|
| 130 |
+
size=(width, height),
|
| 131 |
+
reject_fn=lambda _, p: tuple(p) in self.door_front_pos)
|
| 132 |
+
|
| 133 |
+
# Randomize the agent start position and orientation
|
| 134 |
+
self.place_agent(size=(width, height))
|
| 135 |
+
|
| 136 |
+
# Select a random target door
|
| 137 |
+
self.doorIdx = self._rand_int(0, len(self.door_pos))
|
| 138 |
+
self.target_pos = self.door_pos[self.doorIdx]
|
| 139 |
+
self.target_color = self.door_colors[self.doorIdx]
|
| 140 |
+
|
| 141 |
+
# Generate the mission string
|
| 142 |
+
self.mission = 'go to the %s door' % self.target_color
|
| 143 |
+
|
| 144 |
+
# Dummy beginning string
|
| 145 |
+
self.beginning_string = "This is what you hear. \n"
|
| 146 |
+
self.utterance = self.beginning_string
|
| 147 |
+
|
| 148 |
+
# utterance appended at the end of each step
|
| 149 |
+
self.utterance_history = ""
|
| 150 |
+
|
| 151 |
+
self.conversation = self.utterance
|
| 152 |
+
|
| 153 |
+
def step(self, action):
|
| 154 |
+
p_action = action[0]
|
| 155 |
+
utterance_action = action[1:]
|
| 156 |
+
|
| 157 |
+
# assert all nan or neither nan
|
| 158 |
+
assert len(set(np.isnan(utterance_action))) == 1
|
| 159 |
+
|
| 160 |
+
speak_flag = not all(np.isnan(utterance_action))
|
| 161 |
+
|
| 162 |
+
obs, reward, done, info = super().step(p_action)
|
| 163 |
+
|
| 164 |
+
if speak_flag:
|
| 165 |
+
utterance = TalkHardSesameGrammar.construct_utterance(utterance_action)
|
| 166 |
+
if self.hear_yourself:
|
| 167 |
+
self.utterance += "YOU: {} \n".format(utterance)
|
| 168 |
+
|
| 169 |
+
self.conversation += "YOU: {} \n".format(utterance)
|
| 170 |
+
|
| 171 |
+
# check if near wizard
|
| 172 |
+
if self.wizard.is_near_agent():
|
| 173 |
+
reply = self.wizard.listen(utterance)
|
| 174 |
+
|
| 175 |
+
if reply:
|
| 176 |
+
self.utterance += "{}: {} \n".format(self.wizard.name, reply)
|
| 177 |
+
self.conversation += "{}: {} \n".format(self.wizard.name, reply)
|
| 178 |
+
|
| 179 |
+
if utterance == TalkHardSesameGrammar.construct_utterance([1, 0]):
|
| 180 |
+
ax, ay = self.agent_pos
|
| 181 |
+
tx, ty = self.target_pos
|
| 182 |
+
|
| 183 |
+
if (ax == tx and abs(ay - ty) == 1) or (ay == ty and abs(ax - tx) == 1):
|
| 184 |
+
reward = self._reward()
|
| 185 |
+
|
| 186 |
+
for dx, dy in self.door_pos:
|
| 187 |
+
if (ax == dx and abs(ay - dy) == 1) or (ay == dy and abs(ax - dx) == 1):
|
| 188 |
+
# agent has chosen some door episode, regardless of if the door is correct the episode is over
|
| 189 |
+
done = True
|
| 190 |
+
|
| 191 |
+
# Don't let the agent open any of the doors
|
| 192 |
+
if p_action == self.actions.toggle:
|
| 193 |
+
done = True
|
| 194 |
+
|
| 195 |
+
if p_action == self.actions.done:
|
| 196 |
+
done = True
|
| 197 |
+
|
| 198 |
+
# discount
|
| 199 |
+
if self.step_penalty:
|
| 200 |
+
reward = reward - 0.01
|
| 201 |
+
|
| 202 |
+
# fill observation with text
|
| 203 |
+
# fill observation with text
|
| 204 |
+
self.append_existing_utterance_to_history()
|
| 205 |
+
obs = self.add_utterance_to_observation(obs)
|
| 206 |
+
self.reset_utterance()
|
| 207 |
+
|
| 208 |
+
return obs, reward, done, info
|
| 209 |
+
|
| 210 |
+
def _reward(self):
|
| 211 |
+
if self.diminished_reward:
|
| 212 |
+
return super()._reward()
|
| 213 |
+
else:
|
| 214 |
+
return 1.0
|
| 215 |
+
|
| 216 |
+
def render(self, *args, **kwargs):
|
| 217 |
+
obs = super().render(*args, **kwargs)
|
| 218 |
+
self.window.set_caption(self.conversation, [
|
| 219 |
+
"Gandalf:",
|
| 220 |
+
"Jack:",
|
| 221 |
+
"John:",
|
| 222 |
+
"Where is the exit",
|
| 223 |
+
"Open sesame",
|
| 224 |
+
])
|
| 225 |
+
return obs
|
| 226 |
+
|
| 227 |
+
|
| 228 |
+
class GoToDoorTalkHardSesameNPCTesting(GoToDoorTalkHardSesameNPCEnv):
|
| 229 |
+
def __init__(self):
|
| 230 |
+
super().__init__(
|
| 231 |
+
size=5,
|
| 232 |
+
hear_yourself=False,
|
| 233 |
+
diminished_reward=False,
|
| 234 |
+
step_penalty=True
|
| 235 |
+
)
|
| 236 |
+
|
| 237 |
+
class GoToDoorTalkHardSesameNPC8x8Env(GoToDoorTalkHardSesameNPCEnv):
|
| 238 |
+
def __init__(self):
|
| 239 |
+
super().__init__(size=8)
|
| 240 |
+
|
| 241 |
+
|
| 242 |
+
class GoToDoorTalkHardSesameNPC6x6Env(GoToDoorTalkHardSesameNPCEnv):
|
| 243 |
+
def __init__(self):
|
| 244 |
+
super().__init__(size=6)
|
| 245 |
+
|
| 246 |
+
|
| 247 |
+
# hear yourself
|
| 248 |
+
class GoToDoorTalkHardSesameNPCHY8x8Env(GoToDoorTalkHardSesameNPCEnv):
|
| 249 |
+
def __init__(self):
|
| 250 |
+
super().__init__(size=8, hear_yourself=True)
|
| 251 |
+
|
| 252 |
+
|
| 253 |
+
class GoToDoorTalkHardSesameNPCHY6x6Env(GoToDoorTalkHardSesameNPCEnv):
|
| 254 |
+
def __init__(self):
|
| 255 |
+
super().__init__(size=6, hear_yourself=True)
|
| 256 |
+
|
| 257 |
+
|
| 258 |
+
class GoToDoorTalkHardSesameNPCHY5x5Env(GoToDoorTalkHardSesameNPCEnv):
|
| 259 |
+
def __init__(self):
|
| 260 |
+
super().__init__(size=5, hear_yourself=True)
|
| 261 |
+
|
| 262 |
+
register(
|
| 263 |
+
id='MiniGrid-GoToDoorTalkHardSesameNPC-Testing-v0',
|
| 264 |
+
entry_point='gym_minigrid.envs:GoToDoorTalkHardSesameNPCTesting'
|
| 265 |
+
)
|
| 266 |
+
|
| 267 |
+
register(
|
| 268 |
+
id='MiniGrid-GoToDoorTalkHardSesameNPC-5x5-v0',
|
| 269 |
+
entry_point='gym_minigrid.envs:GoToDoorTalkHardSesameNPCEnv'
|
| 270 |
+
)
|
| 271 |
+
|
| 272 |
+
register(
|
| 273 |
+
id='MiniGrid-GoToDoorTalkHardSesameNPC-6x6-v0',
|
| 274 |
+
entry_point='gym_minigrid.envs:GoToDoorTalkHardSesameNPC6x6Env'
|
| 275 |
+
)
|
| 276 |
+
|
| 277 |
+
register(
|
| 278 |
+
id='MiniGrid-GoToDoorTalkHardSesameNPC-8x8-v0',
|
| 279 |
+
entry_point='gym_minigrid.envs:GoToDoorTalkHardSesameNPC8x8Env'
|
| 280 |
+
)
|
| 281 |
+
register(
|
| 282 |
+
id='MiniGrid-GoToDoorTalkHardSesameNPCHY-5x5-v0',
|
| 283 |
+
entry_point='gym_minigrid.envs:GoToDoorTalkHardSesameNPCHY5x5Env'
|
| 284 |
+
)
|
| 285 |
+
|
| 286 |
+
register(
|
| 287 |
+
id='MiniGrid-GoToDoorTalkHardSesameNPCHY-6x6-v0',
|
| 288 |
+
entry_point='gym_minigrid.envs:GoToDoorTalkHardSesameNPCHY6x6Env'
|
| 289 |
+
)
|
| 290 |
+
|
| 291 |
+
register(
|
| 292 |
+
id='MiniGrid-GoToDoorTalkHardSesameNPCHY-8x8-v0',
|
| 293 |
+
entry_point='gym_minigrid.envs:GoToDoorTalkHardSesameNPCHY8x8Env'
|
| 294 |
+
)
|
gym-minigrid/gym_minigrid/backup_envs/gotodoortalkhardsesamnpcguides.py
ADDED
|
@@ -0,0 +1,384 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from gym_minigrid.minigrid import *
|
| 2 |
+
from gym_minigrid.register import register
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
class Wizard(NPC):
|
| 6 |
+
"""
|
| 7 |
+
A simple NPC that knows who is telling the truth
|
| 8 |
+
"""
|
| 9 |
+
|
| 10 |
+
def __init__(self, color, name, env):
|
| 11 |
+
super().__init__(color)
|
| 12 |
+
self.name = name
|
| 13 |
+
self.env = env
|
| 14 |
+
self.npc_type = 0 # this will be put into the encoding
|
| 15 |
+
|
| 16 |
+
def listen(self, utterance):
|
| 17 |
+
if utterance == TalkHardSesameNPCGuidesGrammar.construct_utterance([0, 1]):
|
| 18 |
+
return "Ask {}.".format(self.env.true_guide.name)
|
| 19 |
+
|
| 20 |
+
return None
|
| 21 |
+
|
| 22 |
+
def is_near_agent(self):
|
| 23 |
+
ax, ay = self.env.agent_pos
|
| 24 |
+
wx, wy = self.cur_pos
|
| 25 |
+
if (ax == wx and abs(ay - wy) == 1) or (ay == wy and abs(ax - wx) == 1):
|
| 26 |
+
return True
|
| 27 |
+
return False
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
class Guide(NPC):
|
| 31 |
+
"""
|
| 32 |
+
A simple NPC that knows the correct door.
|
| 33 |
+
"""
|
| 34 |
+
|
| 35 |
+
def __init__(self, color, name, env, liar=False):
|
| 36 |
+
super().__init__(color)
|
| 37 |
+
self.name = name
|
| 38 |
+
self.env = env
|
| 39 |
+
self.liar = liar
|
| 40 |
+
self.npc_type = 1 # this will be put into the encoding
|
| 41 |
+
|
| 42 |
+
# Select a random target object as mission
|
| 43 |
+
obj_idx = self.env._rand_int(0, len(self.env.door_pos))
|
| 44 |
+
self.target_pos = self.env.door_pos[obj_idx]
|
| 45 |
+
self.target_color = self.env.door_colors[obj_idx]
|
| 46 |
+
|
| 47 |
+
def listen(self, utterance):
|
| 48 |
+
if utterance == TalkHardSesameNPCGuidesGrammar.construct_utterance([0, 1]):
|
| 49 |
+
if self.liar:
|
| 50 |
+
fake_colors = [c for c in self.env.door_colors if c != self.env.target_color]
|
| 51 |
+
fake_color = self.env._rand_elem(fake_colors)
|
| 52 |
+
|
| 53 |
+
# Generate the mission string
|
| 54 |
+
assert fake_color != self.env.target_color
|
| 55 |
+
return 'go to the %s door' % fake_color
|
| 56 |
+
|
| 57 |
+
else:
|
| 58 |
+
return self.env.mission
|
| 59 |
+
|
| 60 |
+
return None
|
| 61 |
+
|
| 62 |
+
def render(self, img):
|
| 63 |
+
c = COLORS[self.color]
|
| 64 |
+
|
| 65 |
+
# Draw eyes
|
| 66 |
+
fill_coords(img, point_in_circle(cx=0.70, cy=0.50, r=0.10), c)
|
| 67 |
+
fill_coords(img, point_in_circle(cx=0.30, cy=0.50, r=0.10), c)
|
| 68 |
+
|
| 69 |
+
# Draw mouth
|
| 70 |
+
fill_coords(img, point_in_rect(0.20, 0.80, 0.72, 0.81), c)
|
| 71 |
+
|
| 72 |
+
# #Draw hat
|
| 73 |
+
# tri_fn = point_in_triangle(
|
| 74 |
+
# (0.15, 0.25),
|
| 75 |
+
# (0.85, 0.25),
|
| 76 |
+
# (0.50, 0.05),
|
| 77 |
+
# )
|
| 78 |
+
# fill_coords(img, tri_fn, c)
|
| 79 |
+
|
| 80 |
+
def is_near_agent(self):
|
| 81 |
+
ax, ay = self.env.agent_pos
|
| 82 |
+
wx, wy = self.cur_pos
|
| 83 |
+
if (ax == wx and abs(ay - wy) == 1) or (ay == wy and abs(ax - wx) == 1):
|
| 84 |
+
return True
|
| 85 |
+
return False
|
| 86 |
+
|
| 87 |
+
|
| 88 |
+
class TalkHardSesameNPCGuidesGrammar(object):
|
| 89 |
+
|
| 90 |
+
templates = ["Where is", "Open"]
|
| 91 |
+
things = ["sesame", "the exit"]
|
| 92 |
+
|
| 93 |
+
grammar_action_space = spaces.MultiDiscrete([len(templates), len(things)])
|
| 94 |
+
|
| 95 |
+
@classmethod
|
| 96 |
+
def construct_utterance(cls, action):
|
| 97 |
+
return cls.templates[int(action[0])] + " " + cls.things[int(action[1])] + " "
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
class GoToDoorTalkHardSesameNPCGuidesEnv(MultiModalMiniGridEnv):
|
| 101 |
+
"""
|
| 102 |
+
Environment in which the agent is instructed to go to a given object
|
| 103 |
+
named using an English text string
|
| 104 |
+
"""
|
| 105 |
+
|
| 106 |
+
def __init__(
|
| 107 |
+
self,
|
| 108 |
+
size=5,
|
| 109 |
+
hear_yourself=False,
|
| 110 |
+
diminished_reward=True,
|
| 111 |
+
step_penalty=False
|
| 112 |
+
):
|
| 113 |
+
assert size >= 5
|
| 114 |
+
|
| 115 |
+
super().__init__(
|
| 116 |
+
grid_size=size,
|
| 117 |
+
max_steps=5*size**2,
|
| 118 |
+
# Set this to True for maximum speed
|
| 119 |
+
see_through_walls=True,
|
| 120 |
+
actions=MiniGridEnv.Actions,
|
| 121 |
+
action_space=spaces.MultiDiscrete([
|
| 122 |
+
len(MiniGridEnv.Actions),
|
| 123 |
+
*TalkHardSesameNPCGuidesGrammar.grammar_action_space.nvec
|
| 124 |
+
])
|
| 125 |
+
)
|
| 126 |
+
self.hear_yourself = hear_yourself
|
| 127 |
+
self.diminished_reward = diminished_reward
|
| 128 |
+
self.step_penalty = step_penalty
|
| 129 |
+
|
| 130 |
+
self.empty_symbol = "NA \n"
|
| 131 |
+
|
| 132 |
+
print({
|
| 133 |
+
"size": size,
|
| 134 |
+
"hear_yourself": hear_yourself,
|
| 135 |
+
"diminished_reward": diminished_reward,
|
| 136 |
+
"step_penalty": step_penalty,
|
| 137 |
+
})
|
| 138 |
+
|
| 139 |
+
def _gen_grid(self, width, height):
|
| 140 |
+
# Create the grid
|
| 141 |
+
self.grid = Grid(width, height)
|
| 142 |
+
|
| 143 |
+
# Randomly vary the room width and height
|
| 144 |
+
width = self._rand_int(5, width+1)
|
| 145 |
+
height = self._rand_int(5, height+1)
|
| 146 |
+
|
| 147 |
+
# Generate the surrounding walls
|
| 148 |
+
self.grid.wall_rect(0, 0, width, height)
|
| 149 |
+
|
| 150 |
+
# Generate the surrounding walls
|
| 151 |
+
self.grid.wall_rect(0, 0, width, height)
|
| 152 |
+
|
| 153 |
+
# Generate the 4 doors at random positions
|
| 154 |
+
self.door_pos = []
|
| 155 |
+
self.door_front_pos = [] # Remembers positions in front of door to avoid setting wizard here
|
| 156 |
+
|
| 157 |
+
self.door_pos.append((self._rand_int(2, width-2), 0))
|
| 158 |
+
self.door_front_pos.append((self.door_pos[-1][0], self.door_pos[-1][1]+1))
|
| 159 |
+
|
| 160 |
+
self.door_pos.append((self._rand_int(2, width-2), height-1))
|
| 161 |
+
self.door_front_pos.append((self.door_pos[-1][0], self.door_pos[-1][1] - 1))
|
| 162 |
+
|
| 163 |
+
self.door_pos.append((0, self._rand_int(2, height-2)))
|
| 164 |
+
self.door_front_pos.append((self.door_pos[-1][0] + 1, self.door_pos[-1][1]))
|
| 165 |
+
|
| 166 |
+
self.door_pos.append((width-1, self._rand_int(2, height-2)))
|
| 167 |
+
self.door_front_pos.append((self.door_pos[-1][0] - 1, self.door_pos[-1][1]))
|
| 168 |
+
|
| 169 |
+
# Generate the door colors
|
| 170 |
+
self.door_colors = []
|
| 171 |
+
while len(self.door_colors) < len(self.door_pos):
|
| 172 |
+
color = self._rand_elem(COLOR_NAMES)
|
| 173 |
+
if color in self.door_colors:
|
| 174 |
+
continue
|
| 175 |
+
self.door_colors.append(color)
|
| 176 |
+
|
| 177 |
+
# Place the doors in the grid
|
| 178 |
+
for idx, pos in enumerate(self.door_pos):
|
| 179 |
+
color = self.door_colors[idx]
|
| 180 |
+
self.grid.set(*pos, Door(color))
|
| 181 |
+
|
| 182 |
+
|
| 183 |
+
# Set a randomly coloured WIZARD at a random position
|
| 184 |
+
color = self._rand_elem(COLOR_NAMES)
|
| 185 |
+
self.wizard = Wizard(color, "Gandalf", self)
|
| 186 |
+
|
| 187 |
+
# Place it randomly, omitting front of door positions
|
| 188 |
+
self.place_obj(self.wizard,
|
| 189 |
+
size=(width, height),
|
| 190 |
+
reject_fn=lambda _, p: tuple(p) in self.door_front_pos)
|
| 191 |
+
|
| 192 |
+
|
| 193 |
+
# add guides
|
| 194 |
+
GUIDE_NAMES = ["John", "Jack"]
|
| 195 |
+
|
| 196 |
+
# Set a randomly coloured TRUE GUIDE at a random position
|
| 197 |
+
name = self._rand_elem(GUIDE_NAMES)
|
| 198 |
+
color = self._rand_elem(COLOR_NAMES)
|
| 199 |
+
self.true_guide = Guide(color, name, self, liar=False)
|
| 200 |
+
|
| 201 |
+
# Place it randomly, omitting invalid positions
|
| 202 |
+
self.place_obj(self.true_guide,
|
| 203 |
+
size=(width, height),
|
| 204 |
+
# reject_fn=lambda _, p: tuple(p) in self.door_front_pos)
|
| 205 |
+
reject_fn=lambda _, p: tuple(p) in [*self.door_front_pos, tuple(self.wizard.cur_pos)])
|
| 206 |
+
|
| 207 |
+
# Set a randomly coloured FALSE GUIDE at a random position
|
| 208 |
+
name = self._rand_elem([n for n in GUIDE_NAMES if n != self.true_guide.name])
|
| 209 |
+
color = self._rand_elem(COLOR_NAMES)
|
| 210 |
+
self.false_guide = Guide(color, name, self, liar=True)
|
| 211 |
+
|
| 212 |
+
# Place it randomly, omitting invalid positions
|
| 213 |
+
self.place_obj(self.false_guide,
|
| 214 |
+
size=(width, height),
|
| 215 |
+
reject_fn=lambda _, p: tuple(p) in [
|
| 216 |
+
*self.door_front_pos, tuple(self.wizard.cur_pos), tuple(self.true_guide.cur_pos)])
|
| 217 |
+
assert self.true_guide.name != self.false_guide.name
|
| 218 |
+
|
| 219 |
+
# Randomize the agent's start position and orientation
|
| 220 |
+
self.place_agent(size=(width, height))
|
| 221 |
+
|
| 222 |
+
# Select a random target door
|
| 223 |
+
self.doorIdx = self._rand_int(0, len(self.door_pos))
|
| 224 |
+
self.target_pos = self.door_pos[self.doorIdx]
|
| 225 |
+
self.target_color = self.door_colors[self.doorIdx]
|
| 226 |
+
|
| 227 |
+
# Generate the mission string
|
| 228 |
+
self.mission = 'go to the %s door' % self.target_color
|
| 229 |
+
|
| 230 |
+
# Dummy beginning string
|
| 231 |
+
self.beginning_string = "This is what you hear. \n"
|
| 232 |
+
self.utterance = self.beginning_string
|
| 233 |
+
|
| 234 |
+
# utterance appended at the end of each step
|
| 235 |
+
self.utterance_history = ""
|
| 236 |
+
|
| 237 |
+
self.conversation = self.utterance
|
| 238 |
+
|
| 239 |
+
def step(self, action):
|
| 240 |
+
p_action = action[0]
|
| 241 |
+
utterance_action = action[1:]
|
| 242 |
+
|
| 243 |
+
# assert all nan or neither nan
|
| 244 |
+
assert len(set(np.isnan(utterance_action))) == 1
|
| 245 |
+
|
| 246 |
+
speak_flag = not all(np.isnan(utterance_action))
|
| 247 |
+
|
| 248 |
+
obs, reward, done, info = super().step(p_action)
|
| 249 |
+
|
| 250 |
+
if speak_flag:
|
| 251 |
+
utterance = TalkHardSesameNPCGuidesGrammar.construct_utterance(utterance_action)
|
| 252 |
+
if self.hear_yourself:
|
| 253 |
+
self.utterance += "YOU: {} \n".format(utterance)
|
| 254 |
+
|
| 255 |
+
self.conversation += "YOU: {} \n".format(utterance)
|
| 256 |
+
|
| 257 |
+
# check if near wizard
|
| 258 |
+
if hasattr(self, "wizard"):
|
| 259 |
+
if self.wizard.is_near_agent():
|
| 260 |
+
reply = self.wizard.listen(utterance)
|
| 261 |
+
|
| 262 |
+
if reply:
|
| 263 |
+
self.utterance += "{}: {} \n".format(self.wizard.name, reply)
|
| 264 |
+
self.conversation += "{}: {} \n".format(self.wizard.name, reply)
|
| 265 |
+
|
| 266 |
+
if self.true_guide.is_near_agent():
|
| 267 |
+
reply = self.true_guide.listen(utterance)
|
| 268 |
+
|
| 269 |
+
if reply:
|
| 270 |
+
self.utterance += "{}: {} \n".format(self.true_guide.name, reply)
|
| 271 |
+
self.conversation += "{}: {} \n".format(self.true_guide.name, reply)
|
| 272 |
+
|
| 273 |
+
if hasattr(self, "false_guide"):
|
| 274 |
+
if self.false_guide.is_near_agent():
|
| 275 |
+
reply = self.false_guide.listen(utterance)
|
| 276 |
+
|
| 277 |
+
if reply:
|
| 278 |
+
self.utterance += "{}: {} \n".format(self.false_guide.name, reply)
|
| 279 |
+
self.conversation += "{}: {} \n".format(self.false_guide.name, reply)
|
| 280 |
+
|
| 281 |
+
if utterance == TalkHardSesameNPCGuidesGrammar.construct_utterance([1, 0]):
|
| 282 |
+
ax, ay = self.agent_pos
|
| 283 |
+
tx, ty = self.target_pos
|
| 284 |
+
|
| 285 |
+
if (ax == tx and abs(ay - ty) == 1) or (ay == ty and abs(ax - tx) == 1):
|
| 286 |
+
reward = self._reward()
|
| 287 |
+
|
| 288 |
+
for dx, dy in self.door_pos:
|
| 289 |
+
if (ax == dx and abs(ay - dy) == 1) or (ay == dy and abs(ax - dx) == 1):
|
| 290 |
+
# agent has chosen some door episode, regardless of if the door is correct the episode is over
|
| 291 |
+
done = True
|
| 292 |
+
|
| 293 |
+
# Don't let the agent open any of the doors
|
| 294 |
+
if p_action == self.actions.toggle:
|
| 295 |
+
done = True
|
| 296 |
+
|
| 297 |
+
if p_action == self.actions.done:
|
| 298 |
+
done = True
|
| 299 |
+
|
| 300 |
+
# discount
|
| 301 |
+
if self.step_penalty:
|
| 302 |
+
reward = reward - 0.01
|
| 303 |
+
|
| 304 |
+
# fill observation with text
|
| 305 |
+
# fill observation with text
|
| 306 |
+
self.append_existing_utterance_to_history()
|
| 307 |
+
obs = self.add_utterance_to_observation(obs)
|
| 308 |
+
self.reset_utterance()
|
| 309 |
+
|
| 310 |
+
return obs, reward, done, info
|
| 311 |
+
|
| 312 |
+
def _reward(self):
|
| 313 |
+
if self.diminished_reward:
|
| 314 |
+
return super()._reward()
|
| 315 |
+
else:
|
| 316 |
+
return 1.0
|
| 317 |
+
|
| 318 |
+
def render(self, *args, **kwargs):
|
| 319 |
+
obs = super().render(*args, **kwargs)
|
| 320 |
+
print(self.conversation)
|
| 321 |
+
self.window.set_caption(self.conversation, [
|
| 322 |
+
"Gandalf:",
|
| 323 |
+
"Jack:",
|
| 324 |
+
"John:",
|
| 325 |
+
"Where is the exit",
|
| 326 |
+
"Open sesame",
|
| 327 |
+
])
|
| 328 |
+
return obs
|
| 329 |
+
|
| 330 |
+
|
| 331 |
+
|
| 332 |
+
class GoToDoorTalkHardSesameNPCGuides8x8Env(GoToDoorTalkHardSesameNPCGuidesEnv):
|
| 333 |
+
def __init__(self):
|
| 334 |
+
super().__init__(size=8)
|
| 335 |
+
|
| 336 |
+
|
| 337 |
+
class GoToDoorTalkHardSesameNPCGuides6x6Env(GoToDoorTalkHardSesameNPCGuidesEnv):
|
| 338 |
+
def __init__(self):
|
| 339 |
+
super().__init__(size=6)
|
| 340 |
+
|
| 341 |
+
|
| 342 |
+
# hear yourself
|
| 343 |
+
class GoToDoorTalkHardSesameNPCGuidesHY8x8Env(GoToDoorTalkHardSesameNPCGuidesEnv):
|
| 344 |
+
def __init__(self):
|
| 345 |
+
super().__init__(size=8, hear_yourself=True)
|
| 346 |
+
|
| 347 |
+
|
| 348 |
+
class GoToDoorTalkHardSesameNPCGuidesHY6x6Env(GoToDoorTalkHardSesameNPCGuidesEnv):
|
| 349 |
+
def __init__(self):
|
| 350 |
+
super().__init__(size=6, hear_yourself=True)
|
| 351 |
+
|
| 352 |
+
|
| 353 |
+
class GoToDoorTalkHardSesameNPCGuidesHY5x5Env(GoToDoorTalkHardSesameNPCGuidesEnv):
|
| 354 |
+
def __init__(self):
|
| 355 |
+
super().__init__(size=5, hear_yourself=True)
|
| 356 |
+
|
| 357 |
+
register(
|
| 358 |
+
id='MiniGrid-GoToDoorTalkHardSesameNPCGuides-5x5-v0',
|
| 359 |
+
entry_point='gym_minigrid.envs:GoToDoorTalkHardSesameNPCGuidesEnv'
|
| 360 |
+
)
|
| 361 |
+
|
| 362 |
+
register(
|
| 363 |
+
id='MiniGrid-GoToDoorTalkHardSesameNPCGuides-6x6-v0',
|
| 364 |
+
entry_point='gym_minigrid.envs:GoToDoorTalkHardSesameNPCGuides6x6Env'
|
| 365 |
+
)
|
| 366 |
+
|
| 367 |
+
register(
|
| 368 |
+
id='MiniGrid-GoToDoorTalkHardSesameNPCGuides-8x8-v0',
|
| 369 |
+
entry_point='gym_minigrid.envs:GoToDoorTalkHardSesameNPCGuides8x8Env'
|
| 370 |
+
)
|
| 371 |
+
register(
|
| 372 |
+
id='MiniGrid-GoToDoorTalkHardSesameNPCGuidesHY-5x5-v0',
|
| 373 |
+
entry_point='gym_minigrid.envs:GoToDoorTalkHardSesameNPCGuidesHY5x5Env'
|
| 374 |
+
)
|
| 375 |
+
|
| 376 |
+
register(
|
| 377 |
+
id='MiniGrid-GoToDoorTalkHardSesameNPCGuidesHY-6x6-v0',
|
| 378 |
+
entry_point='gym_minigrid.envs:GoToDoorTalkHardSesameNPGuidesCHY6x6Env'
|
| 379 |
+
)
|
| 380 |
+
|
| 381 |
+
register(
|
| 382 |
+
id='MiniGrid-GoToDoorTalkHardSesameNPCGuidesHY-8x8-v0',
|
| 383 |
+
entry_point='gym_minigrid.envs:GoToDoorTalkHardSesameNPCGuidesHY8x8Env'
|
| 384 |
+
)
|
gym-minigrid/gym_minigrid/backup_envs/gotodoorwizard.py
ADDED
|
@@ -0,0 +1,209 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from gym_minigrid.minigrid import *
|
| 2 |
+
from gym_minigrid.register import register
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class simpleWizard(NPC):
|
| 7 |
+
"""
|
| 8 |
+
A simple NPC that wants an agent to go to an object (randomly chosen among object_pos list)
|
| 9 |
+
"""
|
| 10 |
+
def __init__(self, color, name, env):
|
| 11 |
+
super().__init__(color)
|
| 12 |
+
self.name = name
|
| 13 |
+
self.env = env
|
| 14 |
+
self.has_spoken = False # wizards only speak once
|
| 15 |
+
|
| 16 |
+
# Select a random target object as mission
|
| 17 |
+
obj_idx = self.env._rand_int(0, len(self.env.door_pos))
|
| 18 |
+
self.target_pos = self.env.door_pos[obj_idx]
|
| 19 |
+
self.target_color = self.env.door_colors[obj_idx]
|
| 20 |
+
|
| 21 |
+
# Generate the mission string
|
| 22 |
+
self.wizard_mission = 'go to the %s door' % self.target_color
|
| 23 |
+
|
| 24 |
+
def listen(self, utterance):
|
| 25 |
+
if not self.has_spoken:
|
| 26 |
+
self.has_spoken = True
|
| 27 |
+
return self.wizard_mission
|
| 28 |
+
return None
|
| 29 |
+
|
| 30 |
+
def is_satisfied(self):
|
| 31 |
+
ax, ay = self.env.agent_pos
|
| 32 |
+
tx, ty = self.target_pos
|
| 33 |
+
if (ax == tx and abs(ay - ty) == 1) or (ay == ty and abs(ax - tx) == 1):
|
| 34 |
+
return True
|
| 35 |
+
return False
|
| 36 |
+
|
| 37 |
+
def is_near_agent(self):
|
| 38 |
+
ax, ay = self.env.agent_pos
|
| 39 |
+
wx, wy = self.cur_pos
|
| 40 |
+
if (ax == wx and abs(ay - wy) == 1) or (ay == wy and abs(ax - wx) == 1):
|
| 41 |
+
return True
|
| 42 |
+
return False
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
class GoToDoorWizard(MiniGridEnv):
|
| 46 |
+
"""
|
| 47 |
+
Environment in which the agent is instructed to "please the wizard",
|
| 48 |
+
i.e. to go ask him for a quest (which is goto door)
|
| 49 |
+
"""
|
| 50 |
+
|
| 51 |
+
def __init__(
|
| 52 |
+
self,
|
| 53 |
+
size=5,
|
| 54 |
+
hear_yourself=False,
|
| 55 |
+
):
|
| 56 |
+
assert size >= 5
|
| 57 |
+
|
| 58 |
+
super().__init__(
|
| 59 |
+
grid_size=size,
|
| 60 |
+
max_steps=5*size**2,
|
| 61 |
+
# Set this to True for maximum speed
|
| 62 |
+
see_through_walls=True,
|
| 63 |
+
actions=MiniGridEnv.Actions,
|
| 64 |
+
action_space=spaces.MultiDiscrete([
|
| 65 |
+
len(MiniGridEnv.Actions),
|
| 66 |
+
*Grammar.grammar_action_space.nvec
|
| 67 |
+
])
|
| 68 |
+
)
|
| 69 |
+
self.hear_yourself = hear_yourself
|
| 70 |
+
|
| 71 |
+
def _gen_grid(self, width, height):
|
| 72 |
+
# Create the grid
|
| 73 |
+
self.grid = Grid(width, height)
|
| 74 |
+
|
| 75 |
+
# Randomly vary the room width and height
|
| 76 |
+
width = self._rand_int(5, width+1)
|
| 77 |
+
height = self._rand_int(5, height+1)
|
| 78 |
+
|
| 79 |
+
# Generate the surrounding walls
|
| 80 |
+
self.grid.wall_rect(0, 0, width, height)
|
| 81 |
+
|
| 82 |
+
# Generate the 4 doors at random positions
|
| 83 |
+
self.door_pos = []
|
| 84 |
+
self.door_front_pos = [] # Remembers positions in front of door to avoid setting wizard here
|
| 85 |
+
|
| 86 |
+
self.door_pos.append((self._rand_int(2, width-2), 0))
|
| 87 |
+
self.door_front_pos.append((self.door_pos[-1][0], self.door_pos[-1][1]+1))
|
| 88 |
+
|
| 89 |
+
self.door_pos.append((self._rand_int(2, width-2), height-1))
|
| 90 |
+
self.door_front_pos.append((self.door_pos[-1][0], self.door_pos[-1][1] - 1))
|
| 91 |
+
|
| 92 |
+
self.door_pos.append((0, self._rand_int(2, height-2)))
|
| 93 |
+
self.door_front_pos.append((self.door_pos[-1][0] + 1, self.door_pos[-1][1]))
|
| 94 |
+
|
| 95 |
+
self.door_pos.append((width-1, self._rand_int(2, height-2)))
|
| 96 |
+
self.door_front_pos.append((self.door_pos[-1][0] - 1, self.door_pos[-1][1]))
|
| 97 |
+
|
| 98 |
+
# Generate the door colors
|
| 99 |
+
self.door_colors = []
|
| 100 |
+
while len(self.door_colors) < len(self.door_pos):
|
| 101 |
+
color = self._rand_elem(COLOR_NAMES)
|
| 102 |
+
if color in self.door_colors:
|
| 103 |
+
continue
|
| 104 |
+
self.door_colors.append(color)
|
| 105 |
+
|
| 106 |
+
# Place the doors in the grid
|
| 107 |
+
for idx, pos in enumerate(self.door_pos):
|
| 108 |
+
color = self.door_colors[idx]
|
| 109 |
+
self.grid.set(*pos, Door(color))
|
| 110 |
+
|
| 111 |
+
# Set a randomly coloured NPC at a random position
|
| 112 |
+
color = self._rand_elem(COLOR_NAMES)
|
| 113 |
+
self.wizard = simpleWizard(color, "Gandalf", self)
|
| 114 |
+
|
| 115 |
+
# Place it randomly, omitting front of door positions
|
| 116 |
+
self.place_obj(self.wizard,
|
| 117 |
+
size=(width, height),
|
| 118 |
+
reject_fn=lambda _, p: tuple(p) in self.door_front_pos)
|
| 119 |
+
|
| 120 |
+
# Randomize the agent start position and orientation
|
| 121 |
+
self.place_agent(size=(width, height))
|
| 122 |
+
|
| 123 |
+
# Generate the mission string
|
| 124 |
+
self.mission = 'please the wizard'
|
| 125 |
+
|
| 126 |
+
# Initialize the dialogue string
|
| 127 |
+
self.dialogue = "This is what you hear. "
|
| 128 |
+
|
| 129 |
+
def gen_obs(self):
|
| 130 |
+
obs = super().gen_obs()
|
| 131 |
+
|
| 132 |
+
# add dialogue to obs
|
| 133 |
+
obs["dialogue"] = self.dialogue
|
| 134 |
+
|
| 135 |
+
return obs
|
| 136 |
+
|
| 137 |
+
def step(self, action):
|
| 138 |
+
|
| 139 |
+
# dirty handle of action provided by manual_control todo improve
|
| 140 |
+
if type(action) == MiniGridEnv.Actions:
|
| 141 |
+
action = [action, None]
|
| 142 |
+
|
| 143 |
+
p_action = action[0]
|
| 144 |
+
utterance_action = action[1:]
|
| 145 |
+
|
| 146 |
+
obs, reward, done, info = super().step(p_action)
|
| 147 |
+
|
| 148 |
+
# check if near wizard
|
| 149 |
+
if self.wizard.is_near_agent():#p_action == self.actions.talk and self.near_wizard:
|
| 150 |
+
#utterance = Grammar.construct_utterance(utterance_action)
|
| 151 |
+
reply = self.wizard.listen("")
|
| 152 |
+
# if self.hear_yourself:
|
| 153 |
+
# self.dialogue += "YOU: " + utterance
|
| 154 |
+
if reply:
|
| 155 |
+
self.dialogue += "{}: {}".format(self.wizard.name, reply)
|
| 156 |
+
|
| 157 |
+
# Don't let the agent open any of the doors
|
| 158 |
+
if p_action == self.actions.toggle:
|
| 159 |
+
done = True
|
| 160 |
+
|
| 161 |
+
# Reward performing done action if pleasing the wizard
|
| 162 |
+
if p_action == self.actions.done:
|
| 163 |
+
if self.wizard.is_satisfied():
|
| 164 |
+
reward = self._reward()
|
| 165 |
+
done = True
|
| 166 |
+
return obs, reward, done, info
|
| 167 |
+
|
| 168 |
+
def render(self, *args, **kwargs):
|
| 169 |
+
obs = super().render(*args, **kwargs)
|
| 170 |
+
self.window.set_caption(self.dialogue, [
|
| 171 |
+
"Gandalf:",
|
| 172 |
+
"Jack:",
|
| 173 |
+
"John:",
|
| 174 |
+
"Where is the exit",
|
| 175 |
+
"Open sesame",
|
| 176 |
+
])
|
| 177 |
+
self.window.fig.gca().set_title("goal: "+self.mission)
|
| 178 |
+
return obs
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
class GoToDoorWizard5x5Env(GoToDoorWizard):
|
| 182 |
+
def __init__(self):
|
| 183 |
+
super().__init__(size=5)
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
class GoToDoorWizard7x7Env(GoToDoorWizard):
|
| 187 |
+
def __init__(self):
|
| 188 |
+
super().__init__(size=7)
|
| 189 |
+
|
| 190 |
+
class GoToDoorWizard8x8Env(GoToDoorWizard):
|
| 191 |
+
def __init__(self):
|
| 192 |
+
super().__init__(size=8)
|
| 193 |
+
|
| 194 |
+
|
| 195 |
+
|
| 196 |
+
register(
|
| 197 |
+
id='MiniGrid-GoToDoorWizard-5x5-v0',
|
| 198 |
+
entry_point='gym_minigrid.envs:GoToDoorWizard5x5Env'
|
| 199 |
+
)
|
| 200 |
+
|
| 201 |
+
register(
|
| 202 |
+
id='MiniGrid-GoToDoorWizard-7x7-v0',
|
| 203 |
+
entry_point='gym_minigrid.envs:GoToDoorWizard7x7Env'
|
| 204 |
+
)
|
| 205 |
+
|
| 206 |
+
register(
|
| 207 |
+
id='MiniGrid-GoToDoorWizard-8x8-v0',
|
| 208 |
+
entry_point='gym_minigrid.envs:GoToDoorWizard8x8Env'
|
| 209 |
+
)
|
gym-minigrid/gym_minigrid/backup_envs/guidethief.py
ADDED
|
@@ -0,0 +1,416 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from gym_minigrid.minigrid import *
|
| 2 |
+
from gym_minigrid.register import register
|
| 3 |
+
|
| 4 |
+
class Guide(NPC):
|
| 5 |
+
"""
|
| 6 |
+
A simple NPC that knows the correct door.
|
| 7 |
+
"""
|
| 8 |
+
|
| 9 |
+
def __init__(self, color, name, id, env, liar=False):
|
| 10 |
+
super().__init__(color)
|
| 11 |
+
self.name = name
|
| 12 |
+
self.env = env
|
| 13 |
+
self.liar = liar
|
| 14 |
+
self.npc_dir = 1 # NPC initially looks downward
|
| 15 |
+
self.npc_type = id # this will be put into the encoding
|
| 16 |
+
|
| 17 |
+
# Select a random target object as mission
|
| 18 |
+
obj_idx = self.env._rand_int(0, len(self.env.door_pos))
|
| 19 |
+
self.target_pos = self.env.door_pos[obj_idx]
|
| 20 |
+
self.target_color = self.env.door_colors[obj_idx]
|
| 21 |
+
|
| 22 |
+
def listen(self, utterance):
|
| 23 |
+
if utterance == GuideThiefGrammar.construct_utterance([0, 1]):
|
| 24 |
+
if self.liar:
|
| 25 |
+
fake_colors = [c for c in self.env.door_colors if c != self.env.target_color]
|
| 26 |
+
fake_color = self.env._rand_elem(fake_colors)
|
| 27 |
+
|
| 28 |
+
# Generate the mission string
|
| 29 |
+
assert fake_color != self.env.target_color
|
| 30 |
+
if self.env.one_word:
|
| 31 |
+
return '%s' % fake_color
|
| 32 |
+
elif self.env.very_diff:
|
| 33 |
+
return 'you want the %s door' % fake_color
|
| 34 |
+
else:
|
| 35 |
+
return 'go to the %s door' % fake_color
|
| 36 |
+
|
| 37 |
+
else:
|
| 38 |
+
return self.env.mission
|
| 39 |
+
|
| 40 |
+
return None
|
| 41 |
+
|
| 42 |
+
def render(self, img):
|
| 43 |
+
c = COLORS[self.color]
|
| 44 |
+
|
| 45 |
+
npc_shapes = []
|
| 46 |
+
# Draw eyes
|
| 47 |
+
npc_shapes.append(point_in_circle(cx=0.70, cy=0.50, r=0.10))
|
| 48 |
+
npc_shapes.append(point_in_circle(cx=0.30, cy=0.50, r=0.10))
|
| 49 |
+
|
| 50 |
+
# Draw mouth
|
| 51 |
+
npc_shapes.append(point_in_rect(0.20, 0.80, 0.72, 0.81))
|
| 52 |
+
|
| 53 |
+
# todo: move this to super function
|
| 54 |
+
# todo: super.render should be able to take the npc_shapes and then rotate them
|
| 55 |
+
|
| 56 |
+
if hasattr(self, "npc_dir"):
|
| 57 |
+
# Pre-rotation to ensure npc_dir = 1 means NPC looks downwards
|
| 58 |
+
npc_shapes = [rotate_fn(v, cx=0.5, cy=0.5, theta=-1*(math.pi / 2)) for v in npc_shapes]
|
| 59 |
+
# Rotate npc based on its direction
|
| 60 |
+
npc_shapes = [rotate_fn(v, cx=0.5, cy=0.5, theta=(math.pi/2) * self.npc_dir) for v in npc_shapes]
|
| 61 |
+
|
| 62 |
+
# Draw shapes
|
| 63 |
+
for v in npc_shapes:
|
| 64 |
+
fill_coords(img, v, c)
|
| 65 |
+
|
| 66 |
+
def is_near_agent(self):
|
| 67 |
+
ax, ay = self.env.agent_pos
|
| 68 |
+
wx, wy = self.cur_pos
|
| 69 |
+
if (ax == wx and abs(ay - wy) == 1) or (ay == wy and abs(ax - wx) == 1):
|
| 70 |
+
return True
|
| 71 |
+
return False
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
class GuideThiefGrammar(object):
|
| 75 |
+
|
| 76 |
+
templates = ["Where is", "Open", "Close", "What is"]
|
| 77 |
+
things = [
|
| 78 |
+
"sesame", "the exit", "the wall", "the floor", "the ceiling", "the window", "the entrance", "the closet",
|
| 79 |
+
"the drawer", "the fridge", "oven", "the lamp", "the trash can", "the chair", "the bed", "the sofa"
|
| 80 |
+
]
|
| 81 |
+
|
| 82 |
+
grammar_action_space = spaces.MultiDiscrete([len(templates), len(things)])
|
| 83 |
+
|
| 84 |
+
@classmethod
|
| 85 |
+
def construct_utterance(cls, action):
|
| 86 |
+
return cls.templates[int(action[0])] + " " + cls.things[int(action[1])] + " "
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
class GuideThiefEnv(MultiModalMiniGridEnv):
|
| 90 |
+
"""
|
| 91 |
+
Environment in which the agent is instructed to go to a given object
|
| 92 |
+
named using an English text string
|
| 93 |
+
"""
|
| 94 |
+
|
| 95 |
+
def __init__(
|
| 96 |
+
self,
|
| 97 |
+
size=5,
|
| 98 |
+
hear_yourself=False,
|
| 99 |
+
diminished_reward=True,
|
| 100 |
+
step_penalty=False,
|
| 101 |
+
nameless=False,
|
| 102 |
+
max_steps=None,
|
| 103 |
+
very_diff=False,
|
| 104 |
+
one_word=False,
|
| 105 |
+
):
|
| 106 |
+
assert size >= 5
|
| 107 |
+
self.empty_symbol = "NA \n"
|
| 108 |
+
self.hear_yourself = hear_yourself
|
| 109 |
+
self.diminished_reward = diminished_reward
|
| 110 |
+
self.step_penalty = step_penalty
|
| 111 |
+
self.nameless = nameless
|
| 112 |
+
self.very_diff = very_diff
|
| 113 |
+
self.one_word = one_word
|
| 114 |
+
|
| 115 |
+
super().__init__(
|
| 116 |
+
grid_size=size,
|
| 117 |
+
max_steps=max_steps or 5*size**2,
|
| 118 |
+
# Set this to True for maximum speed
|
| 119 |
+
see_through_walls=True,
|
| 120 |
+
actions=MiniGridEnv.Actions,
|
| 121 |
+
action_space=spaces.MultiDiscrete([
|
| 122 |
+
len(MiniGridEnv.Actions),
|
| 123 |
+
*GuideThiefGrammar.grammar_action_space.nvec
|
| 124 |
+
]),
|
| 125 |
+
add_npc_direction=True
|
| 126 |
+
)
|
| 127 |
+
|
| 128 |
+
print({
|
| 129 |
+
"size": size,
|
| 130 |
+
"hear_yourself": hear_yourself,
|
| 131 |
+
"diminished_reward": diminished_reward,
|
| 132 |
+
"step_penalty": step_penalty,
|
| 133 |
+
})
|
| 134 |
+
|
| 135 |
+
def _gen_grid(self, width, height):
|
| 136 |
+
# Create the grid
|
| 137 |
+
self.grid = Grid(width, height, nb_obj_dims=4)
|
| 138 |
+
|
| 139 |
+
# Randomly vary the room width and height
|
| 140 |
+
width = self._rand_int(5, width+1)
|
| 141 |
+
height = self._rand_int(5, height+1)
|
| 142 |
+
|
| 143 |
+
# Generate the surrounding walls
|
| 144 |
+
self.grid.wall_rect(0, 0, width, height)
|
| 145 |
+
|
| 146 |
+
# Generate the surrounding walls
|
| 147 |
+
self.grid.wall_rect(0, 0, width, height)
|
| 148 |
+
|
| 149 |
+
# Generate the 4 doors at random positions
|
| 150 |
+
self.door_pos = []
|
| 151 |
+
self.door_front_pos = []
|
| 152 |
+
|
| 153 |
+
self.door_pos.append((self._rand_int(2, width-2), 0))
|
| 154 |
+
self.door_front_pos.append((self.door_pos[-1][0], self.door_pos[-1][1]+1))
|
| 155 |
+
|
| 156 |
+
self.door_pos.append((self._rand_int(2, width-2), height-1))
|
| 157 |
+
self.door_front_pos.append((self.door_pos[-1][0], self.door_pos[-1][1] - 1))
|
| 158 |
+
|
| 159 |
+
self.door_pos.append((0, self._rand_int(2, height-2)))
|
| 160 |
+
self.door_front_pos.append((self.door_pos[-1][0] + 1, self.door_pos[-1][1]))
|
| 161 |
+
|
| 162 |
+
self.door_pos.append((width-1, self._rand_int(2, height-2)))
|
| 163 |
+
self.door_front_pos.append((self.door_pos[-1][0] - 1, self.door_pos[-1][1]))
|
| 164 |
+
|
| 165 |
+
# Generate the door colors
|
| 166 |
+
self.door_colors = []
|
| 167 |
+
while len(self.door_colors) < len(self.door_pos):
|
| 168 |
+
color = self._rand_elem(COLOR_NAMES)
|
| 169 |
+
if color in self.door_colors:
|
| 170 |
+
continue
|
| 171 |
+
self.door_colors.append(color)
|
| 172 |
+
|
| 173 |
+
# Place the doors in the grid
|
| 174 |
+
for idx, pos in enumerate(self.door_pos):
|
| 175 |
+
color = self.door_colors[idx]
|
| 176 |
+
self.grid.set(*pos, Door(color))
|
| 177 |
+
|
| 178 |
+
|
| 179 |
+
# Set a randomly coloured WIZARD at a random position
|
| 180 |
+
color = self._rand_elem(COLOR_NAMES)
|
| 181 |
+
|
| 182 |
+
# Place it randomly, omitting front of door positions
|
| 183 |
+
|
| 184 |
+
# add guides
|
| 185 |
+
GUIDE_NAMES = ["John", "Jack"]
|
| 186 |
+
name_2_id = {name: id for id, name in enumerate(GUIDE_NAMES)}
|
| 187 |
+
|
| 188 |
+
# Set a randomly coloured TRUE GUIDE at a random position
|
| 189 |
+
|
| 190 |
+
true_guide_name = GUIDE_NAMES[0]
|
| 191 |
+
color = self._rand_elem(COLOR_NAMES)
|
| 192 |
+
self.true_guide = Guide(
|
| 193 |
+
color=color,
|
| 194 |
+
name=true_guide_name,
|
| 195 |
+
id=name_2_id[true_guide_name],
|
| 196 |
+
env=self,
|
| 197 |
+
liar=False
|
| 198 |
+
)
|
| 199 |
+
|
| 200 |
+
# Place it randomly, omitting invalid positions
|
| 201 |
+
self.place_obj(self.true_guide,
|
| 202 |
+
size=(width, height),
|
| 203 |
+
# reject_fn=lambda _, p: tuple(p) in self.door_front_pos)
|
| 204 |
+
reject_fn=lambda _, p: tuple(p) in self.door_front_pos)
|
| 205 |
+
|
| 206 |
+
# Set a randomly coloured FALSE GUIDE at a random position
|
| 207 |
+
false_guide_name = GUIDE_NAMES[1]
|
| 208 |
+
if self.nameless:
|
| 209 |
+
color = self._rand_elem([c for c in COLOR_NAMES if c != self.true_guide.color])
|
| 210 |
+
else:
|
| 211 |
+
color = self._rand_elem(COLOR_NAMES)
|
| 212 |
+
|
| 213 |
+
self.false_guide = Guide(
|
| 214 |
+
color=color,
|
| 215 |
+
name=false_guide_name,
|
| 216 |
+
id=name_2_id[false_guide_name],
|
| 217 |
+
env=self,
|
| 218 |
+
liar=True
|
| 219 |
+
)
|
| 220 |
+
|
| 221 |
+
# Place it randomly, omitting invalid positions
|
| 222 |
+
self.place_obj(self.false_guide,
|
| 223 |
+
size=(width, height),
|
| 224 |
+
reject_fn=lambda _, p: tuple(p) in [
|
| 225 |
+
*self.door_front_pos, tuple(self.true_guide.cur_pos)])
|
| 226 |
+
assert self.true_guide.name != self.false_guide.name
|
| 227 |
+
|
| 228 |
+
# Randomize the agent's start position and orientation
|
| 229 |
+
self.place_agent(size=(width, height))
|
| 230 |
+
|
| 231 |
+
# Select a random target door
|
| 232 |
+
self.doorIdx = self._rand_int(0, len(self.door_pos))
|
| 233 |
+
self.target_pos = self.door_pos[self.doorIdx]
|
| 234 |
+
self.target_color = self.door_colors[self.doorIdx]
|
| 235 |
+
|
| 236 |
+
# Generate the mission string
|
| 237 |
+
self.mission = 'go to the %s door' % self.target_color
|
| 238 |
+
|
| 239 |
+
# Dummy beginning string
|
| 240 |
+
self.beginning_string = "This is what you hear. \n"
|
| 241 |
+
self.utterance = self.beginning_string
|
| 242 |
+
|
| 243 |
+
# utterance appended at the end of each step
|
| 244 |
+
self.utterance_history = ""
|
| 245 |
+
|
| 246 |
+
# used for rendering
|
| 247 |
+
self.conversation = self.utterance
|
| 248 |
+
|
| 249 |
+
def step(self, action):
|
| 250 |
+
p_action = action[0]
|
| 251 |
+
utterance_action = action[1:]
|
| 252 |
+
|
| 253 |
+
# assert all nan or neither nan
|
| 254 |
+
assert len(set(np.isnan(utterance_action))) == 1
|
| 255 |
+
|
| 256 |
+
speak_flag = not all(np.isnan(utterance_action))
|
| 257 |
+
|
| 258 |
+
obs, reward, done, info = super().step(p_action)
|
| 259 |
+
|
| 260 |
+
if speak_flag:
|
| 261 |
+
utterance = GuideThiefGrammar.construct_utterance(utterance_action)
|
| 262 |
+
if self.hear_yourself:
|
| 263 |
+
if self.nameless:
|
| 264 |
+
self.utterance += "{} \n".format(utterance)
|
| 265 |
+
else:
|
| 266 |
+
self.utterance += "YOU: {} \n".format(utterance)
|
| 267 |
+
|
| 268 |
+
self.conversation += "YOU: {} \n".format(utterance)
|
| 269 |
+
|
| 270 |
+
if self.true_guide.is_near_agent():
|
| 271 |
+
reply = self.true_guide.listen(utterance)
|
| 272 |
+
|
| 273 |
+
if reply:
|
| 274 |
+
if self.nameless:
|
| 275 |
+
self.utterance += "{} \n".format(reply)
|
| 276 |
+
else:
|
| 277 |
+
self.utterance += "{}: {} \n".format(self.true_guide.name, reply)
|
| 278 |
+
|
| 279 |
+
self.conversation += "{}: {} \n".format(self.true_guide.name, reply)
|
| 280 |
+
|
| 281 |
+
if self.false_guide.is_near_agent():
|
| 282 |
+
reply = self.false_guide.listen(utterance)
|
| 283 |
+
|
| 284 |
+
if reply:
|
| 285 |
+
if self.nameless:
|
| 286 |
+
self.utterance += "{} \n".format(reply)
|
| 287 |
+
else:
|
| 288 |
+
self.utterance += "{}: {} \n".format(self.false_guide.name, reply)
|
| 289 |
+
|
| 290 |
+
self.conversation += "{}: {} \n".format(self.false_guide.name, reply)
|
| 291 |
+
|
| 292 |
+
if utterance == GuideThiefGrammar.construct_utterance([1, 0]):
|
| 293 |
+
ax, ay = self.agent_pos
|
| 294 |
+
tx, ty = self.target_pos
|
| 295 |
+
|
| 296 |
+
if (ax == tx and abs(ay - ty) == 1) or (ay == ty and abs(ax - tx) == 1):
|
| 297 |
+
reward = self._reward()
|
| 298 |
+
|
| 299 |
+
for dx, dy in self.door_pos:
|
| 300 |
+
if (ax == dx and abs(ay - dy) == 1) or (ay == dy and abs(ax - dx) == 1):
|
| 301 |
+
# agent has chosen some door episode, regardless of if the door is correct the episode is over
|
| 302 |
+
done = True
|
| 303 |
+
|
| 304 |
+
# Don't let the agent open any of the doors
|
| 305 |
+
if p_action == self.actions.toggle:
|
| 306 |
+
done = True
|
| 307 |
+
|
| 308 |
+
if p_action == self.actions.done:
|
| 309 |
+
done = True
|
| 310 |
+
|
| 311 |
+
# discount
|
| 312 |
+
if self.step_penalty:
|
| 313 |
+
reward = reward - 0.01
|
| 314 |
+
|
| 315 |
+
# fill observation with text
|
| 316 |
+
self.append_existing_utterance_to_history()
|
| 317 |
+
obs = self.add_utterance_to_observation(obs)
|
| 318 |
+
self.reset_utterance()
|
| 319 |
+
|
| 320 |
+
return obs, reward, done, info
|
| 321 |
+
|
| 322 |
+
def _reward(self):
|
| 323 |
+
if self.diminished_reward:
|
| 324 |
+
return super()._reward()
|
| 325 |
+
else:
|
| 326 |
+
return 1.0
|
| 327 |
+
|
| 328 |
+
def render(self, *args, **kwargs):
|
| 329 |
+
obs = super().render(*args, **kwargs)
|
| 330 |
+
print("conversation:\n", self.conversation)
|
| 331 |
+
print("utterance_history:\n", self.utterance_history)
|
| 332 |
+
self.window.set_caption(self.conversation, [
|
| 333 |
+
"Gandalf:",
|
| 334 |
+
"Jack:",
|
| 335 |
+
"John:",
|
| 336 |
+
"Where is the exit",
|
| 337 |
+
"Open sesame",
|
| 338 |
+
])
|
| 339 |
+
return obs
|
| 340 |
+
|
| 341 |
+
|
| 342 |
+
class GuideThief8x8Env(GuideThiefEnv):
|
| 343 |
+
def __init__(self):
|
| 344 |
+
super().__init__(size=8)
|
| 345 |
+
|
| 346 |
+
|
| 347 |
+
class GuideThief6x6Env(GuideThiefEnv):
|
| 348 |
+
def __init__(self):
|
| 349 |
+
super().__init__(size=6)
|
| 350 |
+
|
| 351 |
+
|
| 352 |
+
class GuideThiefNameless8x8Env(GuideThiefEnv):
|
| 353 |
+
def __init__(self):
|
| 354 |
+
super().__init__(size=8, nameless=True)
|
| 355 |
+
|
| 356 |
+
|
| 357 |
+
class GuideThiefTestEnv(GuideThiefEnv):
|
| 358 |
+
def __init__(self):
|
| 359 |
+
super().__init__(
|
| 360 |
+
size=5,
|
| 361 |
+
nameless=False,
|
| 362 |
+
max_steps=20,
|
| 363 |
+
)
|
| 364 |
+
|
| 365 |
+
class GuideThiefVeryDiff(GuideThiefEnv):
|
| 366 |
+
def __init__(self):
|
| 367 |
+
super().__init__(
|
| 368 |
+
size=5,
|
| 369 |
+
nameless=False,
|
| 370 |
+
max_steps=20,
|
| 371 |
+
very_diff=True,
|
| 372 |
+
)
|
| 373 |
+
|
| 374 |
+
class GuideThiefOneWord(GuideThiefEnv):
|
| 375 |
+
def __init__(self):
|
| 376 |
+
super().__init__(
|
| 377 |
+
size=5,
|
| 378 |
+
nameless=False,
|
| 379 |
+
max_steps=20,
|
| 380 |
+
very_diff=False,
|
| 381 |
+
one_word=True
|
| 382 |
+
)
|
| 383 |
+
|
| 384 |
+
register(
|
| 385 |
+
id='MiniGrid-GuideThief-5x5-v0',
|
| 386 |
+
entry_point='gym_minigrid.envs:GuideThiefEnv'
|
| 387 |
+
)
|
| 388 |
+
|
| 389 |
+
register(
|
| 390 |
+
id='MiniGrid-GuideThief-6x6-v0',
|
| 391 |
+
entry_point='gym_minigrid.envs:GuideThief6x6Env'
|
| 392 |
+
)
|
| 393 |
+
|
| 394 |
+
register(
|
| 395 |
+
id='MiniGrid-GuideThief-8x8-v0',
|
| 396 |
+
entry_point='gym_minigrid.envs:GuideThief8x8Env'
|
| 397 |
+
)
|
| 398 |
+
|
| 399 |
+
register(
|
| 400 |
+
id='MiniGrid-GuideThiefNameless-8x8-v0',
|
| 401 |
+
entry_point='gym_minigrid.envs:GuideThiefNameless8x8Env'
|
| 402 |
+
)
|
| 403 |
+
|
| 404 |
+
register(
|
| 405 |
+
id='MiniGrid-GuideThiefTest-v0',
|
| 406 |
+
entry_point='gym_minigrid.envs:GuideThiefTestEnv'
|
| 407 |
+
)
|
| 408 |
+
|
| 409 |
+
register(
|
| 410 |
+
id='MiniGrid-GuideThiefVeryDiff-v0',
|
| 411 |
+
entry_point='gym_minigrid.envs:GuideThiefVeryDiff'
|
| 412 |
+
)
|
| 413 |
+
register(
|
| 414 |
+
id='MiniGrid-GuideThiefOneWord-v0',
|
| 415 |
+
entry_point='gym_minigrid.envs:GuideThiefOneWord'
|
| 416 |
+
)
|
gym-minigrid/gym_minigrid/backup_envs/helper.py
ADDED
|
@@ -0,0 +1,295 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
|
| 3 |
+
from gym_minigrid.minigrid import *
|
| 4 |
+
from gym_minigrid.register import register
|
| 5 |
+
|
| 6 |
+
import time
|
| 7 |
+
from collections import deque
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
class Peer(NPC):
|
| 11 |
+
"""
|
| 12 |
+
A dancing NPC that the agent has to copy
|
| 13 |
+
"""
|
| 14 |
+
|
| 15 |
+
def __init__(self, color, name, env):
|
| 16 |
+
super().__init__(color)
|
| 17 |
+
self.name = name
|
| 18 |
+
self.npc_dir = 1 # NPC initially looks downward
|
| 19 |
+
self.npc_type = 0
|
| 20 |
+
self.env = env
|
| 21 |
+
self.npc_actions = []
|
| 22 |
+
self.dancing_step_idx = 0
|
| 23 |
+
self.actions = MiniGridEnv.Actions
|
| 24 |
+
self.add_npc_direction = True
|
| 25 |
+
self.available_moves = [self.rotate_left, self.rotate_right, self.go_forward, self.toggle_action]
|
| 26 |
+
|
| 27 |
+
selected_door_id = self.env._rand_elem([0, 1])
|
| 28 |
+
self.selected_door_pos = [self.env.door_pos_top, self.env.door_pos_bottom][selected_door_id]
|
| 29 |
+
self.selected_door = [self.env.door_top, self.env.door_bottom][selected_door_id]
|
| 30 |
+
self.joint_attention_achieved = False
|
| 31 |
+
|
| 32 |
+
def can_overlap(self):
|
| 33 |
+
# If the NPC is hidden, agent can overlap on it
|
| 34 |
+
return self.env.hidden_npc
|
| 35 |
+
|
| 36 |
+
def encode(self, nb_dims=3):
|
| 37 |
+
if self.env.hidden_npc:
|
| 38 |
+
if nb_dims == 3:
|
| 39 |
+
return (1, 0, 0)
|
| 40 |
+
elif nb_dims == 4:
|
| 41 |
+
return (1, 0, 0, 0)
|
| 42 |
+
else:
|
| 43 |
+
return super().encode(nb_dims=nb_dims)
|
| 44 |
+
|
| 45 |
+
def step(self):
|
| 46 |
+
|
| 47 |
+
distance_to_door = np.abs(self.selected_door_pos - self.cur_pos).sum(-1)
|
| 48 |
+
|
| 49 |
+
if all(self.front_pos == self.selected_door_pos) and self.selected_door.is_open:
|
| 50 |
+
# in front of door
|
| 51 |
+
self.go_forward()
|
| 52 |
+
|
| 53 |
+
elif distance_to_door == 1 and not self.joint_attention_achieved:
|
| 54 |
+
# before turning to the door look at the agent
|
| 55 |
+
wanted_dir = self.compute_wanted_dir(self.env.agent_pos)
|
| 56 |
+
act = self.compute_turn_action(wanted_dir)
|
| 57 |
+
act()
|
| 58 |
+
if self.is_eye_contact():
|
| 59 |
+
self.joint_attention_achieved = True
|
| 60 |
+
|
| 61 |
+
else:
|
| 62 |
+
act = self.path_to_toggle_pos(self.selected_door_pos)
|
| 63 |
+
act()
|
| 64 |
+
|
| 65 |
+
# not really important as the NPC doesn't speak
|
| 66 |
+
if self.env.hidden_npc:
|
| 67 |
+
return None
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
class HelperGrammar(object):
|
| 72 |
+
|
| 73 |
+
templates = ["Move your", "Shake your"]
|
| 74 |
+
things = ["body", "head"]
|
| 75 |
+
|
| 76 |
+
grammar_action_space = spaces.MultiDiscrete([len(templates), len(things)])
|
| 77 |
+
|
| 78 |
+
@classmethod
|
| 79 |
+
def construct_utterance(cls, action):
|
| 80 |
+
return cls.templates[int(action[0])] + " " + cls.things[int(action[1])] + " "
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
class HelperEnv(MultiModalMiniGridEnv):
|
| 84 |
+
"""
|
| 85 |
+
Environment in which the agent is instructed to go to a given object
|
| 86 |
+
named using an English text string
|
| 87 |
+
"""
|
| 88 |
+
|
| 89 |
+
def __init__(
|
| 90 |
+
self,
|
| 91 |
+
size=5,
|
| 92 |
+
diminished_reward=True,
|
| 93 |
+
step_penalty=False,
|
| 94 |
+
knowledgeable=False,
|
| 95 |
+
max_steps=20,
|
| 96 |
+
hidden_npc=False,
|
| 97 |
+
):
|
| 98 |
+
assert size >= 5
|
| 99 |
+
self.empty_symbol = "NA \n"
|
| 100 |
+
self.diminished_reward = diminished_reward
|
| 101 |
+
self.step_penalty = step_penalty
|
| 102 |
+
self.knowledgeable = knowledgeable
|
| 103 |
+
self.hidden_npc = hidden_npc
|
| 104 |
+
|
| 105 |
+
super().__init__(
|
| 106 |
+
grid_size=size,
|
| 107 |
+
max_steps=max_steps,
|
| 108 |
+
# Set this to True for maximum speed
|
| 109 |
+
see_through_walls=True,
|
| 110 |
+
actions=MiniGridEnv.Actions,
|
| 111 |
+
action_space=spaces.MultiDiscrete([
|
| 112 |
+
len(MiniGridEnv.Actions),
|
| 113 |
+
*HelperGrammar.grammar_action_space.nvec
|
| 114 |
+
]),
|
| 115 |
+
add_npc_direction=True
|
| 116 |
+
)
|
| 117 |
+
|
| 118 |
+
print({
|
| 119 |
+
"size": size,
|
| 120 |
+
"diminished_reward": diminished_reward,
|
| 121 |
+
"step_penalty": step_penalty,
|
| 122 |
+
})
|
| 123 |
+
|
| 124 |
+
def _gen_grid(self, width, height):
|
| 125 |
+
# Create the grid
|
| 126 |
+
self.grid = Grid(width, height, nb_obj_dims=4)
|
| 127 |
+
|
| 128 |
+
# Randomly vary the room width and height
|
| 129 |
+
width = self._rand_int(5, width+1)
|
| 130 |
+
height = self._rand_int(5, height+1)
|
| 131 |
+
|
| 132 |
+
self.wall_x = width-1
|
| 133 |
+
self.wall_y = height-1
|
| 134 |
+
|
| 135 |
+
# Generate the surrounding walls
|
| 136 |
+
self.grid.wall_rect(0, 0, width, height)
|
| 137 |
+
|
| 138 |
+
# add lava
|
| 139 |
+
self.grid.vert_wall(width//2, 1, height - 2, Lava)
|
| 140 |
+
|
| 141 |
+
# door top
|
| 142 |
+
door_color_top = self._rand_elem(COLOR_NAMES)
|
| 143 |
+
self.door_pos_top = (width-1, 1)
|
| 144 |
+
self.door_top = Door(door_color_top, is_locked=True)
|
| 145 |
+
self.grid.set(*self.door_pos_top, self.door_top)
|
| 146 |
+
|
| 147 |
+
# switch top
|
| 148 |
+
self.switch_pos_top = (0, 1)
|
| 149 |
+
self.switch_top = Switch(door_color_top, lockable_object=self.door_top, locker_switch=True)
|
| 150 |
+
self.grid.set(*self.switch_pos_top, self.switch_top)
|
| 151 |
+
|
| 152 |
+
# door bottom
|
| 153 |
+
door_color_bottom = self._rand_elem(COLOR_NAMES)
|
| 154 |
+
self.door_pos_bottom = (width-1, height-2)
|
| 155 |
+
self.door_bottom = Door(door_color_bottom, is_locked=True)
|
| 156 |
+
self.grid.set(*self.door_pos_bottom, self.door_bottom)
|
| 157 |
+
|
| 158 |
+
# switch bottom
|
| 159 |
+
self.switch_pos_bottom = (0, height-2)
|
| 160 |
+
self.switch_bottom = Switch(door_color_bottom, lockable_object=self.door_bottom, locker_switch=True)
|
| 161 |
+
self.grid.set(*self.switch_pos_bottom, self.switch_bottom)
|
| 162 |
+
|
| 163 |
+
# save to variables
|
| 164 |
+
self.switches = [self.switch_top, self.switch_bottom]
|
| 165 |
+
self.switches_pos = [self.switch_pos_top, self.switch_pos_bottom]
|
| 166 |
+
self.door = [self.door_top, self.door_bottom]
|
| 167 |
+
self.door_pos = [self.door_pos_top, self.door_pos_bottom]
|
| 168 |
+
|
| 169 |
+
# Set a randomly coloured Dancer NPC
|
| 170 |
+
color = self._rand_elem(COLOR_NAMES)
|
| 171 |
+
self.peer = Peer(color, "Jill", self)
|
| 172 |
+
|
| 173 |
+
# Place it on the middle right side of the room
|
| 174 |
+
peer_pos = np.array((self._rand_int(width//2+1, width - 1), self._rand_int(1, height - 1)))
|
| 175 |
+
|
| 176 |
+
self.grid.set(*peer_pos, self.peer)
|
| 177 |
+
self.peer.init_pos = peer_pos
|
| 178 |
+
self.peer.cur_pos = peer_pos
|
| 179 |
+
|
| 180 |
+
# Randomize the agent's start position and orientation
|
| 181 |
+
self.place_agent(size=(width//2, height))
|
| 182 |
+
|
| 183 |
+
# Generate the mission string
|
| 184 |
+
self.mission = 'watch dancer and repeat his moves afterwards'
|
| 185 |
+
|
| 186 |
+
# Dummy beginning string
|
| 187 |
+
self.beginning_string = "This is what you hear. \n"
|
| 188 |
+
self.utterance = self.beginning_string
|
| 189 |
+
|
| 190 |
+
# utterance appended at the end of each step
|
| 191 |
+
self.utterance_history = ""
|
| 192 |
+
|
| 193 |
+
# used for rendering
|
| 194 |
+
self.conversation = self.utterance
|
| 195 |
+
self.outcome_info = None
|
| 196 |
+
|
| 197 |
+
def step(self, action):
|
| 198 |
+
p_action = action[0]
|
| 199 |
+
utterance_action = action[1:]
|
| 200 |
+
|
| 201 |
+
obs, reward, done, info = super().step(p_action)
|
| 202 |
+
self.peer.step()
|
| 203 |
+
|
| 204 |
+
if np.isnan(p_action):
|
| 205 |
+
pass
|
| 206 |
+
|
| 207 |
+
if p_action == self.actions.done:
|
| 208 |
+
done = True
|
| 209 |
+
|
| 210 |
+
elif all(self.agent_pos == self.door_pos_top):
|
| 211 |
+
done = True
|
| 212 |
+
|
| 213 |
+
elif all(self.agent_pos == self.door_pos_bottom):
|
| 214 |
+
done = True
|
| 215 |
+
|
| 216 |
+
elif all([self.switch_top.is_on, self.switch_bottom.is_on]):
|
| 217 |
+
# if both switches are on no reward is given and episode ends
|
| 218 |
+
done = True
|
| 219 |
+
|
| 220 |
+
elif all(self.peer.cur_pos == self.peer.selected_door_pos):
|
| 221 |
+
reward = self._reward()
|
| 222 |
+
done = True
|
| 223 |
+
|
| 224 |
+
# discount
|
| 225 |
+
if self.step_penalty:
|
| 226 |
+
reward = reward - 0.01
|
| 227 |
+
|
| 228 |
+
if self.hidden_npc:
|
| 229 |
+
# all npc are hidden
|
| 230 |
+
assert np.argwhere(obs['image'][:,:,0] == OBJECT_TO_IDX['npc']).size == 0
|
| 231 |
+
assert "{}:".format(self.peer.name) not in self.utterance
|
| 232 |
+
|
| 233 |
+
# fill observation with text
|
| 234 |
+
self.append_existing_utterance_to_history()
|
| 235 |
+
obs = self.add_utterance_to_observation(obs)
|
| 236 |
+
self.reset_utterance()
|
| 237 |
+
|
| 238 |
+
if done:
|
| 239 |
+
if reward > 0:
|
| 240 |
+
self.outcome_info = "SUCCESS: agent got {} reward \n".format(np.round(reward, 1))
|
| 241 |
+
else:
|
| 242 |
+
self.outcome_info = "FAILURE: agent got {} reward \n".format(reward)
|
| 243 |
+
|
| 244 |
+
return obs, reward, done, info
|
| 245 |
+
|
| 246 |
+
def _reward(self):
|
| 247 |
+
if self.diminished_reward:
|
| 248 |
+
return super()._reward()
|
| 249 |
+
else:
|
| 250 |
+
return 1.0
|
| 251 |
+
|
| 252 |
+
def render(self, *args, **kwargs):
|
| 253 |
+
obs = super().render(*args, **kwargs)
|
| 254 |
+
self.window.clear_text() # erase previous text
|
| 255 |
+
|
| 256 |
+
# self.window.set_caption(self.conversation, [self.peer.name])
|
| 257 |
+
# self.window.ax.set_title("correct door: {}".format(self.true_guide.target_color), loc="left", fontsize=10)
|
| 258 |
+
if self.outcome_info:
|
| 259 |
+
color = None
|
| 260 |
+
if "SUCCESS" in self.outcome_info:
|
| 261 |
+
color = "lime"
|
| 262 |
+
elif "FAILURE" in self.outcome_info:
|
| 263 |
+
color = "red"
|
| 264 |
+
self.window.add_text(*(0.01, 0.85, self.outcome_info),
|
| 265 |
+
**{'fontsize':15, 'color':color, 'weight':"bold"})
|
| 266 |
+
|
| 267 |
+
self.window.show_img(obs) # re-draw image to add changes to window
|
| 268 |
+
return obs
|
| 269 |
+
|
| 270 |
+
|
| 271 |
+
class Helper8x8Env(HelperEnv):
|
| 272 |
+
def __init__(self, **kwargs):
|
| 273 |
+
super().__init__(size=8, max_steps=20, **kwargs)
|
| 274 |
+
|
| 275 |
+
|
| 276 |
+
class Helper6x6Env(HelperEnv):
|
| 277 |
+
def __init__(self):
|
| 278 |
+
super().__init__(size=6, max_steps=20)
|
| 279 |
+
|
| 280 |
+
|
| 281 |
+
|
| 282 |
+
register(
|
| 283 |
+
id='MiniGrid-Helper-5x5-v0',
|
| 284 |
+
entry_point='gym_minigrid.envs:HelperEnv'
|
| 285 |
+
)
|
| 286 |
+
|
| 287 |
+
register(
|
| 288 |
+
id='MiniGrid-Helper-6x6-v0',
|
| 289 |
+
entry_point='gym_minigrid.envs:Helper6x6Env'
|
| 290 |
+
)
|
| 291 |
+
|
| 292 |
+
register(
|
| 293 |
+
id='MiniGrid-Helper-8x8-v0',
|
| 294 |
+
entry_point='gym_minigrid.envs:Helper8x8Env'
|
| 295 |
+
)
|
gym-minigrid/gym_minigrid/backup_envs/showme.py
ADDED
|
@@ -0,0 +1,525 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
|
| 3 |
+
from gym_minigrid.minigrid import *
|
| 4 |
+
from gym_minigrid.register import register
|
| 5 |
+
|
| 6 |
+
import time
|
| 7 |
+
from collections import deque
|
| 8 |
+
|
| 9 |
+
class DemonstratingPeer(NPC):
|
| 10 |
+
"""
|
| 11 |
+
A dancing NPC that the agent has to copy
|
| 12 |
+
"""
|
| 13 |
+
def __init__(self, color, name, env, knowledgeable=False):
|
| 14 |
+
super().__init__(color)
|
| 15 |
+
self.name = name
|
| 16 |
+
self.npc_dir = 1 # NPC initially looks downward
|
| 17 |
+
self.npc_type = 0
|
| 18 |
+
self.env = env
|
| 19 |
+
self.knowledgeable = knowledgeable
|
| 20 |
+
self.npc_actions = []
|
| 21 |
+
self.dancing_step_idx = 0
|
| 22 |
+
self.actions = MiniGridEnv.Actions
|
| 23 |
+
self.add_npc_direction = True
|
| 24 |
+
self.available_moves = [self.rotate_left, self.rotate_right, self.go_forward, self.toggle_action]
|
| 25 |
+
self.exited = False
|
| 26 |
+
self.joint_attention_achieved = False
|
| 27 |
+
|
| 28 |
+
def can_overlap(self):
|
| 29 |
+
# If the NPC is hidden, agent can overlap on it
|
| 30 |
+
return self.env.hidden_npc
|
| 31 |
+
|
| 32 |
+
def encode(self, nb_dims=3):
|
| 33 |
+
if self.env.hidden_npc:
|
| 34 |
+
if nb_dims == 3:
|
| 35 |
+
return (1, 0, 0)
|
| 36 |
+
elif nb_dims == 4:
|
| 37 |
+
return (1, 0, 0, 0)
|
| 38 |
+
else:
|
| 39 |
+
return super().encode(nb_dims=nb_dims)
|
| 40 |
+
|
| 41 |
+
def step(self):
|
| 42 |
+
super().step()
|
| 43 |
+
reply = None
|
| 44 |
+
if self.exited:
|
| 45 |
+
return
|
| 46 |
+
|
| 47 |
+
if all(np.array(self.cur_pos) == np.array(self.env.door_pos)):
|
| 48 |
+
# disappear
|
| 49 |
+
self.env.grid.set(*self.cur_pos, self.env.object)
|
| 50 |
+
self.cur_pos = np.array([np.nan, np.nan])
|
| 51 |
+
|
| 52 |
+
# close door
|
| 53 |
+
self.env.object.toggle(self.env, self.cur_pos)
|
| 54 |
+
|
| 55 |
+
# reset switches door
|
| 56 |
+
for s in self.env.switches:
|
| 57 |
+
s.is_on = False
|
| 58 |
+
|
| 59 |
+
# update door
|
| 60 |
+
self.env.update_door_lock()
|
| 61 |
+
|
| 62 |
+
self.exited = True
|
| 63 |
+
|
| 64 |
+
elif self.knowledgeable:
|
| 65 |
+
|
| 66 |
+
if self.joint_attention_achieved:
|
| 67 |
+
if self.env.object.is_locked:
|
| 68 |
+
first_wrong_id = np.where(self.env.get_selected_password() != self.env.password)[0][0]
|
| 69 |
+
goal_pos = self.env.switches_pos[first_wrong_id]
|
| 70 |
+
act = self.path_to_toggle_pos(goal_pos)
|
| 71 |
+
act()
|
| 72 |
+
|
| 73 |
+
else:
|
| 74 |
+
if all(self.front_pos == self.env.door_pos) and self.env.object.is_open:
|
| 75 |
+
self.go_forward()
|
| 76 |
+
|
| 77 |
+
else:
|
| 78 |
+
act = self.path_to_toggle_pos(self.env.door_pos)
|
| 79 |
+
act()
|
| 80 |
+
else:
|
| 81 |
+
wanted_dir = self.compute_wanted_dir(self.env.agent_pos)
|
| 82 |
+
action = self.compute_turn_action(wanted_dir)
|
| 83 |
+
action()
|
| 84 |
+
|
| 85 |
+
if self.is_eye_contact():
|
| 86 |
+
self.joint_attention_achieved = True
|
| 87 |
+
reply = "Look at me"
|
| 88 |
+
|
| 89 |
+
else:
|
| 90 |
+
self.env._rand_elem(self.available_moves)()
|
| 91 |
+
|
| 92 |
+
self.env.update_door_lock()
|
| 93 |
+
|
| 94 |
+
if self.env.hidden_npc:
|
| 95 |
+
reply = None
|
| 96 |
+
|
| 97 |
+
return reply
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
class DemonstrationGrammar(object):
|
| 101 |
+
|
| 102 |
+
templates = ["Move your", "Shake your"]
|
| 103 |
+
things = ["body", "head"]
|
| 104 |
+
|
| 105 |
+
grammar_action_space = spaces.MultiDiscrete([len(templates), len(things)])
|
| 106 |
+
|
| 107 |
+
@classmethod
|
| 108 |
+
def construct_utterance(cls, action):
|
| 109 |
+
return cls.templates[int(action[0])] + " " + cls.things[int(action[1])] + " "
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
class DemonstrationEnv(MultiModalMiniGridEnv):
|
| 113 |
+
"""
|
| 114 |
+
Environment in which the agent is instructed to go to a given object
|
| 115 |
+
named using an English text string
|
| 116 |
+
"""
|
| 117 |
+
|
| 118 |
+
def __init__(
|
| 119 |
+
self,
|
| 120 |
+
size=5,
|
| 121 |
+
diminished_reward=True,
|
| 122 |
+
step_penalty=False,
|
| 123 |
+
knowledgeable=False,
|
| 124 |
+
hard_password=False,
|
| 125 |
+
max_steps=100,
|
| 126 |
+
n_switches=3,
|
| 127 |
+
augmentation=False,
|
| 128 |
+
stump=False,
|
| 129 |
+
no_turn_off=False,
|
| 130 |
+
no_light=False,
|
| 131 |
+
hidden_npc=False
|
| 132 |
+
):
|
| 133 |
+
assert size >= 5
|
| 134 |
+
self.empty_symbol = "NA \n"
|
| 135 |
+
self.diminished_reward = diminished_reward
|
| 136 |
+
self.step_penalty = step_penalty
|
| 137 |
+
self.knowledgeable = knowledgeable
|
| 138 |
+
self.hard_password = hard_password
|
| 139 |
+
self.n_switches = n_switches
|
| 140 |
+
self.augmentation = augmentation
|
| 141 |
+
self.stump = stump
|
| 142 |
+
self.no_turn_off=no_turn_off
|
| 143 |
+
self.hidden_npc = hidden_npc
|
| 144 |
+
|
| 145 |
+
if self.augmentation:
|
| 146 |
+
assert not no_light
|
| 147 |
+
|
| 148 |
+
self.no_light = no_light
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
super().__init__(
|
| 152 |
+
grid_size=size,
|
| 153 |
+
max_steps=max_steps,
|
| 154 |
+
# Set this to True for maximum speed
|
| 155 |
+
see_through_walls=False if self.stump else True,
|
| 156 |
+
actions=MiniGridEnv.Actions,
|
| 157 |
+
action_space=spaces.MultiDiscrete([
|
| 158 |
+
len(MiniGridEnv.Actions),
|
| 159 |
+
*DemonstrationGrammar.grammar_action_space.nvec
|
| 160 |
+
]),
|
| 161 |
+
add_npc_direction=True
|
| 162 |
+
)
|
| 163 |
+
|
| 164 |
+
print({
|
| 165 |
+
"size": size,
|
| 166 |
+
"diminished_reward": diminished_reward,
|
| 167 |
+
"step_penalty": step_penalty,
|
| 168 |
+
})
|
| 169 |
+
|
| 170 |
+
def get_selected_password(self):
|
| 171 |
+
return np.array([int(s.is_on) for s in self.switches])
|
| 172 |
+
|
| 173 |
+
def _gen_grid(self, width, height):
|
| 174 |
+
# Create the grid
|
| 175 |
+
self.grid = Grid(width, height, nb_obj_dims=4)
|
| 176 |
+
|
| 177 |
+
# Randomly vary the room width and height
|
| 178 |
+
width = self._rand_int(5, width+1)
|
| 179 |
+
height = self._rand_int(5, height+1)
|
| 180 |
+
|
| 181 |
+
self.wall_x = width - 1
|
| 182 |
+
self.wall_y = height - 1
|
| 183 |
+
|
| 184 |
+
# Generate the surrounding walls
|
| 185 |
+
self.grid.wall_rect(0, 0, width, height)
|
| 186 |
+
|
| 187 |
+
door_color = self._rand_elem(COLOR_NAMES)
|
| 188 |
+
|
| 189 |
+
if self.stump:
|
| 190 |
+
wall_for_door = 1
|
| 191 |
+
else:
|
| 192 |
+
wall_for_door = self._rand_int(1, 4)
|
| 193 |
+
|
| 194 |
+
if wall_for_door < 2:
|
| 195 |
+
w = self._rand_int(1, width-1)
|
| 196 |
+
h = height-1 if wall_for_door == 0 else 0
|
| 197 |
+
else:
|
| 198 |
+
w = width-1 if wall_for_door == 3 else 0
|
| 199 |
+
h = self._rand_int(1, height-1)
|
| 200 |
+
|
| 201 |
+
assert h != height-1 # door mustn't be on the bottom wall
|
| 202 |
+
|
| 203 |
+
self.door_pos = (w, h)
|
| 204 |
+
self.door = Door(door_color, is_locked=True)
|
| 205 |
+
self.grid.set(*self.door_pos, self.door)
|
| 206 |
+
|
| 207 |
+
if self.stump:
|
| 208 |
+
self.stump_pos = (w, h+2)
|
| 209 |
+
self.stump_obj = Wall()
|
| 210 |
+
self.grid.set(*self.stump_pos, self.stump_obj)
|
| 211 |
+
|
| 212 |
+
# sample password
|
| 213 |
+
if self.hard_password:
|
| 214 |
+
self.password = np.array([self._rand_int(0, 2) for _ in range(self.n_switches)])
|
| 215 |
+
|
| 216 |
+
else:
|
| 217 |
+
idx = self._rand_int(0, self.n_switches)
|
| 218 |
+
self.password = np.zeros(self.n_switches)
|
| 219 |
+
self.password[idx] = 1.0
|
| 220 |
+
|
| 221 |
+
# add the switches
|
| 222 |
+
self.switches = []
|
| 223 |
+
self.switches_pos = []
|
| 224 |
+
for i in range(self.n_switches):
|
| 225 |
+
c = COLOR_NAMES[i]
|
| 226 |
+
pos = np.array([i+1, height-1])
|
| 227 |
+
sw = Switch(c, is_on=bool(self.password[i]) if self.augmentation else False, no_light=self.no_light)
|
| 228 |
+
self.grid.set(*pos, sw)
|
| 229 |
+
self.switches.append(sw)
|
| 230 |
+
self.switches_pos.append(pos)
|
| 231 |
+
|
| 232 |
+
# Set a randomly coloured Dancer NPC
|
| 233 |
+
color = self._rand_elem(COLOR_NAMES)
|
| 234 |
+
|
| 235 |
+
if not self.augmentation:
|
| 236 |
+
self.peer = DemonstratingPeer(color, "Jim", self, knowledgeable=self.knowledgeable)
|
| 237 |
+
|
| 238 |
+
# height -2 so its not in front of the buttons in the way
|
| 239 |
+
peer_pos = np.array((self._rand_int(1, width - 1), self._rand_int(1, height - 2)))
|
| 240 |
+
|
| 241 |
+
self.grid.set(*peer_pos, self.peer)
|
| 242 |
+
self.peer.init_pos = peer_pos
|
| 243 |
+
self.peer.cur_pos = peer_pos
|
| 244 |
+
|
| 245 |
+
# Randomize the agent's start position and orientation
|
| 246 |
+
self.place_agent(size=(width, height))
|
| 247 |
+
|
| 248 |
+
# Generate the mission string
|
| 249 |
+
self.mission = 'exit the room'
|
| 250 |
+
|
| 251 |
+
# Dummy beginning string
|
| 252 |
+
self.beginning_string = "This is what you hear. \n"
|
| 253 |
+
self.utterance = self.beginning_string
|
| 254 |
+
|
| 255 |
+
# utterance appended at the end of each step
|
| 256 |
+
self.utterance_history = ""
|
| 257 |
+
|
| 258 |
+
# used for rendering
|
| 259 |
+
self.conversation = self.utterance
|
| 260 |
+
self.outcome_info = None
|
| 261 |
+
|
| 262 |
+
def update_door_lock(self):
|
| 263 |
+
if self.augmentation and self.step_count <= 10:
|
| 264 |
+
self.door.is_locked = True
|
| 265 |
+
self.door.is_open = False
|
| 266 |
+
else:
|
| 267 |
+
if np.array_equal(self.get_selected_password(), self.password):
|
| 268 |
+
self.door.is_locked = False
|
| 269 |
+
else:
|
| 270 |
+
self.door.is_locked = True
|
| 271 |
+
self.door.is_open = False
|
| 272 |
+
|
| 273 |
+
def step(self, action):
|
| 274 |
+
p_action = action[0]
|
| 275 |
+
utterance_action = action[1:]
|
| 276 |
+
|
| 277 |
+
obs, reward, done, info = super().step(p_action)
|
| 278 |
+
self.update_door_lock()
|
| 279 |
+
# print("pass:", self.password)
|
| 280 |
+
# print("selected pass:", self.get_selected_password())
|
| 281 |
+
|
| 282 |
+
if self.augmentation and self.step_count == 10:
|
| 283 |
+
# reset switches door
|
| 284 |
+
for s in self.switches:
|
| 285 |
+
s.is_on = False
|
| 286 |
+
|
| 287 |
+
# update door
|
| 288 |
+
self.update_door_lock()
|
| 289 |
+
|
| 290 |
+
if p_action == self.actions.done:
|
| 291 |
+
done = True
|
| 292 |
+
|
| 293 |
+
if not self.augmentation:
|
| 294 |
+
peer_reply = self.peer.step()
|
| 295 |
+
|
| 296 |
+
if peer_reply is not None:
|
| 297 |
+
self.utterance += "{}: {} \n".format(self.peer.name, peer_reply)
|
| 298 |
+
self.conversation += "{}: {} \n".format(self.peer.name, peer_reply)
|
| 299 |
+
|
| 300 |
+
if all(self.agent_pos == self.door_pos):
|
| 301 |
+
done = True
|
| 302 |
+
if not self.augmentation:
|
| 303 |
+
if self.peer.exited:
|
| 304 |
+
# only give reward if both exited
|
| 305 |
+
reward = self._reward()
|
| 306 |
+
else:
|
| 307 |
+
reward = self._reward()
|
| 308 |
+
|
| 309 |
+
# discount
|
| 310 |
+
if self.step_penalty:
|
| 311 |
+
reward = reward - 0.01
|
| 312 |
+
|
| 313 |
+
if self.hidden_npc:
|
| 314 |
+
# all npc are hidden
|
| 315 |
+
assert np.argwhere(obs['image'][:,:,0] == OBJECT_TO_IDX['npc']).size == 0
|
| 316 |
+
if not self.augmentation:
|
| 317 |
+
assert "{}:".format(self.peer.name) not in self.utterance
|
| 318 |
+
|
| 319 |
+
# fill observation with text
|
| 320 |
+
self.append_existing_utterance_to_history()
|
| 321 |
+
obs = self.add_utterance_to_observation(obs)
|
| 322 |
+
self.reset_utterance()
|
| 323 |
+
|
| 324 |
+
if done:
|
| 325 |
+
if reward > 0:
|
| 326 |
+
self.outcome_info = "SUCCESS: agent got {} reward \n".format(np.round(reward, 1))
|
| 327 |
+
else:
|
| 328 |
+
self.outcome_info = "FAILURE: agent got {} reward \n".format(reward)
|
| 329 |
+
|
| 330 |
+
return obs, reward, done, info
|
| 331 |
+
|
| 332 |
+
def _reward(self):
|
| 333 |
+
if self.diminished_reward:
|
| 334 |
+
return super()._reward()
|
| 335 |
+
else:
|
| 336 |
+
return 1.0
|
| 337 |
+
|
| 338 |
+
def render(self, *args, **kwargs):
|
| 339 |
+
obs = super().render(*args, **kwargs)
|
| 340 |
+
self.window.clear_text() # erase previous text
|
| 341 |
+
self.window.set_caption(self.conversation)
|
| 342 |
+
sw_color = self.switches[np.argmax(self.password)].color
|
| 343 |
+
self.window.ax.set_title("correct switch: {}".format(sw_color), loc="left", fontsize=10)
|
| 344 |
+
if self.outcome_info:
|
| 345 |
+
color = None
|
| 346 |
+
if "SUCCESS" in self.outcome_info:
|
| 347 |
+
color = "lime"
|
| 348 |
+
elif "FAILURE" in self.outcome_info:
|
| 349 |
+
color = "red"
|
| 350 |
+
self.window.add_text(*(0.01, 0.85, self.outcome_info),
|
| 351 |
+
**{'fontsize':15, 'color':color, 'weight':"bold"})
|
| 352 |
+
|
| 353 |
+
self.window.show_img(obs) # re-draw image to add changes to window
|
| 354 |
+
return obs
|
| 355 |
+
|
| 356 |
+
|
| 357 |
+
## 100 Demonstrating
|
| 358 |
+
# register(
|
| 359 |
+
# id='MiniGrid-DemonstrationNoLightNoTurnOff100-8x8-v0',
|
| 360 |
+
# entry_point='gym_minigrid.envs:DemonstrationNoLightNoTurnOff1008x8Env'
|
| 361 |
+
# )
|
| 362 |
+
#class Demonstration100TwoSwitches8x8Env(DemonstrationEnv):
|
| 363 |
+
# def __init__(self):
|
| 364 |
+
# super().__init__(size=8, knowledgeable=True, max_steps=100, n_switches=2)
|
| 365 |
+
#
|
| 366 |
+
#class Demonstration100TwoSwitchesHard8x8Env(DemonstrationEnv):
|
| 367 |
+
# def __init__(self):
|
| 368 |
+
# super().__init__(size=8, knowledgeable=True, max_steps=100, n_switches=2, hard_password=True)
|
| 369 |
+
#
|
| 370 |
+
## 100 AUG Demonstrating
|
| 371 |
+
#class AugmentationDemonstration100TwoSwitches8x8Env(DemonstrationEnv):
|
| 372 |
+
# def __init__(self):
|
| 373 |
+
# super().__init__(size=8, knowledgeable=True, max_steps=100, n_switches=2, augmentation=True)
|
| 374 |
+
#
|
| 375 |
+
#class AugmentationDemonstration100TwoSwitchesHard8x8Env(DemonstrationEnv):
|
| 376 |
+
# def __init__(self):
|
| 377 |
+
# super().__init__(size=8, knowledgeable=True, max_steps=100, n_switches=2, hard_password=True, augmentation=True)
|
| 378 |
+
#
|
| 379 |
+
#
|
| 380 |
+
## Three switches
|
| 381 |
+
## 100 Demonstrating
|
| 382 |
+
#class Demonstration1008x8Env(DemonstrationEnv):
|
| 383 |
+
# def __init__(self):
|
| 384 |
+
# super().__init__(size=8, knowledgeable=True, max_steps=100)
|
| 385 |
+
#
|
| 386 |
+
#class Demonstration100Hard8x8Env(DemonstrationEnv):
|
| 387 |
+
# def __init__(self):
|
| 388 |
+
# super().__init__(size=8, knowledgeable=True, max_steps=100, hard_password=True)
|
| 389 |
+
#
|
| 390 |
+
## 100 AUG Demonstrating
|
| 391 |
+
#class AugmentationDemonstration1008x8Env(DemonstrationEnv):
|
| 392 |
+
# def __init__(self):
|
| 393 |
+
# super().__init__(size=8, knowledgeable=True, max_steps=100, augmentation=True)
|
| 394 |
+
#
|
| 395 |
+
#class AugmentationDemonstration100Hard8x8Env(DemonstrationEnv):
|
| 396 |
+
# def __init__(self):
|
| 397 |
+
# super().__init__(size=8, knowledgeable=True, max_steps=100, hard_password=True, augmentation=True)
|
| 398 |
+
#
|
| 399 |
+
## No turn off
|
| 400 |
+
## 100 Demonstrating: No light, no turn off
|
| 401 |
+
#
|
| 402 |
+
#class DemonstrationNoLightNoTurnOff100Hard8x8Env(DemonstrationEnv):
|
| 403 |
+
# def __init__(self):
|
| 404 |
+
# super().__init__(size=8, knowledgeable=True, max_steps=100, no_turn_off=True, hard_password=True, no_light=True)
|
| 405 |
+
#
|
| 406 |
+
## 100 no turn off
|
| 407 |
+
#class DemonstrationNoTurnOff1008x8Env(DemonstrationEnv):
|
| 408 |
+
# def __init__(self):
|
| 409 |
+
# super().__init__(size=8, knowledgeable=True, max_steps=100, no_turn_off=True)
|
| 410 |
+
#
|
| 411 |
+
#class DemonstrationNoTurnOff100Hard8x8Env(DemonstrationEnv):
|
| 412 |
+
# def __init__(self):
|
| 413 |
+
# super().__init__(size=8, knowledgeable=True, max_steps=100, no_turn_off=True, hard_password=True)
|
| 414 |
+
#
|
| 415 |
+
## 100 AUG Demonstrating
|
| 416 |
+
#
|
| 417 |
+
#class AugmentationDemonstrationNoTurnOff100Hard8x8Env(DemonstrationEnv):
|
| 418 |
+
# def __init__(self):
|
| 419 |
+
# super().__init__(size=8, knowledgeable=True, max_steps=100, no_turn_off=True, hard_password=True, augmentation=True)
|
| 420 |
+
|
| 421 |
+
|
| 422 |
+
## demonstrating 100 steps
|
| 423 |
+
#register(
|
| 424 |
+
# id='MiniGrid-Demonstration100TwoSwitches-8x8-v0',
|
| 425 |
+
# entry_point='gym_minigrid.envs:Demonstration100TwoSwitches8x8Env'
|
| 426 |
+
#)
|
| 427 |
+
#register(
|
| 428 |
+
# id='MiniGrid-Demonstration100TwoSwitchesHard-8x8-v0',
|
| 429 |
+
# entry_point='gym_minigrid.envs:Demonstration100TwoSwitchesHard8x8Env'
|
| 430 |
+
#)
|
| 431 |
+
#
|
| 432 |
+
## AUG demonstrating 100 steps
|
| 433 |
+
#register(
|
| 434 |
+
# id='MiniGrid-AugmentationDemonstration100TwoSwitches-8x8-v0',
|
| 435 |
+
# entry_point='gym_minigrid.envs:AugmentationDemonstration100TwoSwitches8x8Env'
|
| 436 |
+
#)
|
| 437 |
+
#register(
|
| 438 |
+
# id='MiniGrid-AugmentationDemonstration100TwoSwitchesHard-8x8-v0',
|
| 439 |
+
# entry_point='gym_minigrid.envs:AugmentationDemonstration100TwoSwitchesHard8x8Env'
|
| 440 |
+
#)
|
| 441 |
+
#
|
| 442 |
+
## three switches
|
| 443 |
+
#
|
| 444 |
+
## demonstrating 100 steps
|
| 445 |
+
#register(
|
| 446 |
+
# id='MiniGrid-Demonstration100-8x8-v0',
|
| 447 |
+
# entry_point='gym_minigrid.envs:Demonstration1008x8Env'
|
| 448 |
+
#)
|
| 449 |
+
#register(
|
| 450 |
+
# id='MiniGrid-Demonstration100Hard-8x8-v0',
|
| 451 |
+
# entry_point='gym_minigrid.envs:Demonstration100Hard8x8Env'
|
| 452 |
+
#)
|
| 453 |
+
#
|
| 454 |
+
## AUG demonstrating 100 steps
|
| 455 |
+
#register(
|
| 456 |
+
# id='MiniGrid-AugmentationDemonstration100-8x8-v0',
|
| 457 |
+
# entry_point='gym_minigrid.envs:AugmentationDemonstration1008x8Env'
|
| 458 |
+
#)
|
| 459 |
+
#register(
|
| 460 |
+
# id='MiniGrid-AugmentationDemonstration100Hard-8x8-v0',
|
| 461 |
+
# entry_point='gym_minigrid.envs:AugmentationDemonstration100Hard8x8Env'
|
| 462 |
+
#)
|
| 463 |
+
#
|
| 464 |
+
## no turn off three switches
|
| 465 |
+
#
|
| 466 |
+
## demonstrating 100 steps
|
| 467 |
+
#register(
|
| 468 |
+
# id='MiniGrid-DemonstrationNoTurnOff100-8x8-v0',
|
| 469 |
+
# entry_point='gym_minigrid.envs:DemonstrationNoTurnOff1008x8Env'
|
| 470 |
+
#)
|
| 471 |
+
#register(
|
| 472 |
+
# id='MiniGrid-DemonstrationNoTurnOff100Hard-8x8-v0',
|
| 473 |
+
# entry_point='gym_minigrid.envs:DemonstrationNoTurnOff100Hard8x8Env'
|
| 474 |
+
#)
|
| 475 |
+
#
|
| 476 |
+
## demonstrating 100 steps no light
|
| 477 |
+
#register(
|
| 478 |
+
# id='MiniGrid-DemonstrationNoLightNoTurnOff100-8x8-v0',
|
| 479 |
+
# entry_point='gym_minigrid.envs:DemonstrationNoLightNoTurnOff1008x8Env'
|
| 480 |
+
#)
|
| 481 |
+
#register(
|
| 482 |
+
# id='MiniGrid-DemonstrationNoLightNoTurnOff100Hard-8x8-v0',
|
| 483 |
+
# entry_point='gym_minigrid.envs:DemonstrationNoLightNoTurnOff100Hard8x8Env'
|
| 484 |
+
#)
|
| 485 |
+
#
|
| 486 |
+
## AUG demonstrating 100 steps
|
| 487 |
+
#register(
|
| 488 |
+
# id='MiniGrid-AugmentationDemonstrationNoTurnOff100-8x8-v0',
|
| 489 |
+
# entry_point='gym_minigrid.envs:AugmentationDemonstrationNoTurnOff1008x8Env'
|
| 490 |
+
#)
|
| 491 |
+
#register(
|
| 492 |
+
# id='MiniGrid-AugmentationDemonstrationNoTurnOff100Hard-8x8-v0',
|
| 493 |
+
# entry_point='gym_minigrid.envs:AugmentationDemonstrationNoTurnOff100Hard8x8Env'
|
| 494 |
+
#)
|
| 495 |
+
# register(
|
| 496 |
+
# id='MiniGrid-AugmentationDemonstrationNoTurnOff100-8x8-v0',
|
| 497 |
+
# entry_point='gym_minigrid.envs:AugmentationDemonstrationNoTurnOff1008x8Env'
|
| 498 |
+
# )
|
| 499 |
+
#
|
| 500 |
+
# class DemonstrationNoLightNoTurnOff1008x8Env(DemonstrationEnv):
|
| 501 |
+
# def __init__(self):
|
| 502 |
+
# super().__init__(size=8, knowledgeable=True, max_steps=100, no_turn_off=True, no_light=True)
|
| 503 |
+
#
|
| 504 |
+
# class AugmentationDemonstrationNoTurnOff1008x8Env(DemonstrationEnv):
|
| 505 |
+
# def __init__(self):
|
| 506 |
+
# super().__init__(size=8, knowledgeable=True, max_steps=100, no_turn_off=True, augmentation=True)
|
| 507 |
+
|
| 508 |
+
class ShowMe8x8Env(DemonstrationEnv):
|
| 509 |
+
def __init__(self, **kwargs):
|
| 510 |
+
super().__init__(size=8, knowledgeable=True, max_steps=100, no_turn_off=True, no_light=True, **kwargs)
|
| 511 |
+
|
| 512 |
+
class ShowMeNoSocial8x8Env(DemonstrationEnv):
|
| 513 |
+
def __init__(self, **kwargs):
|
| 514 |
+
super().__init__(size=8, knowledgeable=True, max_steps=100, no_turn_off=True, augmentation=True, **kwargs)
|
| 515 |
+
|
| 516 |
+
|
| 517 |
+
# AUG demonstrating 100 steps
|
| 518 |
+
register(
|
| 519 |
+
id='MiniGrid-ShowMeNoSocial-8x8-v0',
|
| 520 |
+
entry_point='gym_minigrid.envs:ShowMeNoSocial8x8Env'
|
| 521 |
+
)
|
| 522 |
+
register(
|
| 523 |
+
id='MiniGrid-ShowMe-8x8-v0',
|
| 524 |
+
entry_point='gym_minigrid.envs:ShowMe8x8Env'
|
| 525 |
+
)
|
gym-minigrid/gym_minigrid/backup_envs/socialenv.py
ADDED
|
@@ -0,0 +1,194 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from itertools import chain
|
| 2 |
+
from gym_minigrid.minigrid import *
|
| 3 |
+
from gym_minigrid.register import register
|
| 4 |
+
|
| 5 |
+
from gym_minigrid.envs import DanceWithOneNPC8x8Env, CoinThief8x8Env, TalkItOutPolite8x8Env, ShowMe8x8Env, \
|
| 6 |
+
DiverseExit8x8Env, Exiter8x8Env, Helper8x8Env
|
| 7 |
+
from gym_minigrid.envs import DanceWithOneNPCGrammar, CoinThiefGrammar, TalkItOutPoliteGrammar, DemonstrationGrammar, \
|
| 8 |
+
EasyTeachingGamesGrammar, ExiterGrammar
|
| 9 |
+
import time
|
| 10 |
+
from collections import deque
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class SocialEnvMetaGrammar(object):
|
| 14 |
+
|
| 15 |
+
def __init__(self, grammar_list, env_list):
|
| 16 |
+
self.templates = []
|
| 17 |
+
self.things = []
|
| 18 |
+
self.original_template_idx = []
|
| 19 |
+
self.original_thing_idx = []
|
| 20 |
+
|
| 21 |
+
self.meta_template_idx_to_env_name = {}
|
| 22 |
+
self.meta_thing_idx_to_env_name = {}
|
| 23 |
+
self.template_idx, self.thing_idx = 0, 0
|
| 24 |
+
env_names = [e.__class__.__name__ for e in env_list]
|
| 25 |
+
|
| 26 |
+
for g, env_name in zip(grammar_list, env_names):
|
| 27 |
+
# add templates
|
| 28 |
+
self.templates += g.templates
|
| 29 |
+
# add things
|
| 30 |
+
self.things += g.things
|
| 31 |
+
|
| 32 |
+
# save original idx for both
|
| 33 |
+
self.original_template_idx += list(range(0, len(g.templates)))
|
| 34 |
+
self.original_thing_idx += list(range(0, len(g.things)))
|
| 35 |
+
|
| 36 |
+
# update meta_idx to env_names dictionaries
|
| 37 |
+
self.meta_template_idx_to_env_name.update(dict.fromkeys(list(range(self.template_idx,
|
| 38 |
+
self.template_idx + len(g.templates))),
|
| 39 |
+
env_name))
|
| 40 |
+
self.template_idx += len(g.templates)
|
| 41 |
+
|
| 42 |
+
self.meta_thing_idx_to_env_name.update(dict.fromkeys(list(range(self.thing_idx,
|
| 43 |
+
self.thing_idx + len(g.things))),
|
| 44 |
+
env_name))
|
| 45 |
+
self.thing_idx += len(g.things)
|
| 46 |
+
|
| 47 |
+
self.grammar_action_space = spaces.MultiDiscrete([len(self.templates), len(self.things)])
|
| 48 |
+
|
| 49 |
+
@classmethod
|
| 50 |
+
def construct_utterance(self, action):
|
| 51 |
+
return self.templates[int(action[0])] + " " + self.things[int(action[1])] + " "
|
| 52 |
+
|
| 53 |
+
@classmethod
|
| 54 |
+
def random_utterance(self):
|
| 55 |
+
return np.random.choice(self.templates) + " " + np.random.choice(self.things) + " "
|
| 56 |
+
|
| 57 |
+
def construct_original_action(self, action, current_env_name):
|
| 58 |
+
template_env_name = self.meta_template_idx_to_env_name[int(action[0])]
|
| 59 |
+
thing_env_name = self.meta_thing_idx_to_env_name[int(action[1])]
|
| 60 |
+
|
| 61 |
+
if template_env_name == current_env_name and thing_env_name == current_env_name:
|
| 62 |
+
original_action = [self.original_template_idx[int(action[0])], self.original_thing_idx[int(action[1])]]
|
| 63 |
+
else:
|
| 64 |
+
original_action = [np.nan, np.nan]
|
| 65 |
+
return original_action
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
class SocialEnv(gym.Env):
|
| 69 |
+
"""
|
| 70 |
+
Meta-Environment containing all other environment (multi-task learning)
|
| 71 |
+
"""
|
| 72 |
+
|
| 73 |
+
def __init__(
|
| 74 |
+
self,
|
| 75 |
+
size=8,
|
| 76 |
+
hidden_npc=False,
|
| 77 |
+
is_test_env=False
|
| 78 |
+
|
| 79 |
+
):
|
| 80 |
+
|
| 81 |
+
# Number of cells (width and height) in the agent view
|
| 82 |
+
self.agent_view_size = 7
|
| 83 |
+
|
| 84 |
+
# Number of object dimensions (i.e. number of channels in symbolic image)
|
| 85 |
+
self.nb_obj_dims = 4
|
| 86 |
+
|
| 87 |
+
# Observations are dictionaries containing an
|
| 88 |
+
# encoding of the grid and a textual 'mission' string
|
| 89 |
+
self.observation_space = spaces.Box(
|
| 90 |
+
low=0,
|
| 91 |
+
high=255,
|
| 92 |
+
shape=(self.agent_view_size, self.agent_view_size, self.nb_obj_dims),
|
| 93 |
+
dtype='uint8'
|
| 94 |
+
)
|
| 95 |
+
self.observation_space = spaces.Dict({
|
| 96 |
+
'image': self.observation_space
|
| 97 |
+
})
|
| 98 |
+
|
| 99 |
+
self.hidden_npc = hidden_npc # TODO: implement hidden npc
|
| 100 |
+
|
| 101 |
+
# TODO get max step from env list
|
| 102 |
+
|
| 103 |
+
self.env_list = [DanceWithOneNPC8x8Env, CoinThief8x8Env, TalkItOutPolite8x8Env, ShowMe8x8Env, DiverseExit8x8Env,
|
| 104 |
+
Exiter8x8Env]
|
| 105 |
+
self.all_npc_utterance_actions = sorted(list(set(chain(*[e.all_npc_utterance_actions for e in self.env_list]))))
|
| 106 |
+
self.grammar_list = [DanceWithOneNPCGrammar, CoinThiefGrammar, TalkItOutPoliteGrammar, DemonstrationGrammar,
|
| 107 |
+
EasyTeachingGamesGrammar, ExiterGrammar]
|
| 108 |
+
|
| 109 |
+
if is_test_env:
|
| 110 |
+
self.env_list[-1] = Helper8x8Env
|
| 111 |
+
|
| 112 |
+
# instanciate all envs
|
| 113 |
+
self.env_list = [env() for env in self.env_list]
|
| 114 |
+
|
| 115 |
+
self.current_env = None
|
| 116 |
+
|
| 117 |
+
self.metaGrammar = SocialEnvMetaGrammar(self.grammar_list, self.env_list)
|
| 118 |
+
|
| 119 |
+
# Actions are discrete integer values
|
| 120 |
+
self.action_space = spaces.MultiDiscrete([len(MiniGridEnv.Actions),
|
| 121 |
+
*self.metaGrammar.grammar_action_space.nvec])
|
| 122 |
+
self.actions = MiniGridEnv.Actions
|
| 123 |
+
|
| 124 |
+
self._window = None
|
| 125 |
+
|
| 126 |
+
def reset(self):
|
| 127 |
+
# select a new social environment at random, for each new episode
|
| 128 |
+
|
| 129 |
+
old_window = None
|
| 130 |
+
if self.current_env: # a previous env exists, save old window
|
| 131 |
+
old_window = self.current_env.window
|
| 132 |
+
|
| 133 |
+
# sample new environment
|
| 134 |
+
self.current_env = np.random.choice(self.env_list)
|
| 135 |
+
obs = self.current_env.reset()
|
| 136 |
+
|
| 137 |
+
# carry on window if this env is not the first
|
| 138 |
+
if old_window:
|
| 139 |
+
self.current_env.window = old_window
|
| 140 |
+
return obs
|
| 141 |
+
|
| 142 |
+
def seed(self, seed=1337):
|
| 143 |
+
# Seed the random number generator
|
| 144 |
+
for env in self.env_list:
|
| 145 |
+
env.seed(seed)
|
| 146 |
+
np.random.seed(seed)
|
| 147 |
+
return [seed]
|
| 148 |
+
|
| 149 |
+
def step(self, action):
|
| 150 |
+
assert (self.current_env)
|
| 151 |
+
if len(action) == 1: # agent cannot speak
|
| 152 |
+
utterance_action = [np.nan, np.nan]
|
| 153 |
+
else:
|
| 154 |
+
utterance_action = action[1:]
|
| 155 |
+
|
| 156 |
+
if len(action) >= 1 and not all(np.isnan(utterance_action)): # if agent speaks, contruct env-specific action
|
| 157 |
+
action[1:] = self.metaGrammar.construct_original_action(action[1:], self.current_env.__class__.__name__)
|
| 158 |
+
|
| 159 |
+
return self.current_env.step(action)
|
| 160 |
+
|
| 161 |
+
@property
|
| 162 |
+
def window(self):
|
| 163 |
+
return self.current_env.window
|
| 164 |
+
|
| 165 |
+
@window.setter
|
| 166 |
+
def window(self, value):
|
| 167 |
+
self.current_env.window = value
|
| 168 |
+
|
| 169 |
+
def render(self, *args, **kwargs):
|
| 170 |
+
assert self.current_env
|
| 171 |
+
return self.current_env.render(*args, **kwargs)
|
| 172 |
+
|
| 173 |
+
@property
|
| 174 |
+
def step_count(self):
|
| 175 |
+
return self.current_env.step_count
|
| 176 |
+
|
| 177 |
+
def get_mission(self):
|
| 178 |
+
return self.current_env.get_mission()
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
class SocialEnv8x8Env(SocialEnv):
|
| 182 |
+
def __init__(self, **kwargs):
|
| 183 |
+
super().__init__(size=8, **kwargs)
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
register(
|
| 187 |
+
id='MiniGrid-SocialEnv-5x5-v0',
|
| 188 |
+
entry_point='gym_minigrid.envs:SocialEnvEnv'
|
| 189 |
+
)
|
| 190 |
+
|
| 191 |
+
register(
|
| 192 |
+
id='MiniGrid-SocialEnv-8x8-v0',
|
| 193 |
+
entry_point='gym_minigrid.envs:SocialEnv8x8Env'
|
| 194 |
+
)
|
gym-minigrid/gym_minigrid/backup_envs/spying.py
ADDED
|
@@ -0,0 +1,429 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
|
| 3 |
+
from gym_minigrid.minigrid import *
|
| 4 |
+
from gym_minigrid.register import register
|
| 5 |
+
|
| 6 |
+
import time
|
| 7 |
+
from collections import deque
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
class Peer(NPC):
|
| 11 |
+
"""
|
| 12 |
+
A dancing NPC that the agent has to copy
|
| 13 |
+
"""
|
| 14 |
+
|
| 15 |
+
def __init__(self, color, name, env, knowledgeable=False):
|
| 16 |
+
super().__init__(color)
|
| 17 |
+
self.name = name
|
| 18 |
+
self.npc_dir = 1 # NPC initially looks downward
|
| 19 |
+
self.npc_type = 0
|
| 20 |
+
self.env = env
|
| 21 |
+
self.knowledgeable = knowledgeable
|
| 22 |
+
self.npc_actions = []
|
| 23 |
+
self.dancing_step_idx = 0
|
| 24 |
+
self.actions = MiniGridEnv.Actions
|
| 25 |
+
self.add_npc_direction = True
|
| 26 |
+
self.available_moves = [self.rotate_left, self.rotate_right, self.go_forward, self.toggle_action]
|
| 27 |
+
self.exited = False
|
| 28 |
+
|
| 29 |
+
def step(self):
|
| 30 |
+
if self.exited:
|
| 31 |
+
return
|
| 32 |
+
|
| 33 |
+
if all(np.array(self.cur_pos) == np.array(self.env.door_pos)):
|
| 34 |
+
# disappear
|
| 35 |
+
self.env.grid.set(*self.cur_pos, self.env.object)
|
| 36 |
+
self.cur_pos = np.array([np.nan, np.nan])
|
| 37 |
+
|
| 38 |
+
# close door
|
| 39 |
+
self.env.object.toggle(self.env, self.cur_pos)
|
| 40 |
+
|
| 41 |
+
# reset switches door
|
| 42 |
+
for s in self.env.switches:
|
| 43 |
+
s.is_on = False
|
| 44 |
+
|
| 45 |
+
# update door
|
| 46 |
+
self.env.update_door_lock()
|
| 47 |
+
|
| 48 |
+
self.exited = True
|
| 49 |
+
|
| 50 |
+
elif self.knowledgeable:
|
| 51 |
+
|
| 52 |
+
if self.env.object.is_locked:
|
| 53 |
+
first_wrong_id = np.where(self.env.get_selected_password() != self.env.password)[0][0]
|
| 54 |
+
print("first_wrong_id:", first_wrong_id)
|
| 55 |
+
goal_pos = self.env.switches_pos[first_wrong_id]
|
| 56 |
+
act = self.path_to_toggle_pos(goal_pos)
|
| 57 |
+
act()
|
| 58 |
+
|
| 59 |
+
else:
|
| 60 |
+
if all(self.front_pos == self.env.door_pos) and self.env.object.is_open:
|
| 61 |
+
self.go_forward()
|
| 62 |
+
|
| 63 |
+
else:
|
| 64 |
+
act = self.path_to_toggle_pos(self.env.door_pos)
|
| 65 |
+
act()
|
| 66 |
+
|
| 67 |
+
else:
|
| 68 |
+
self.env._rand_elem(self.available_moves)()
|
| 69 |
+
|
| 70 |
+
self.env.update_door_lock()
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
class SpyingGrammar(object):
|
| 74 |
+
|
| 75 |
+
templates = ["Move your", "Shake your"]
|
| 76 |
+
things = ["body", "head"]
|
| 77 |
+
|
| 78 |
+
grammar_action_space = spaces.MultiDiscrete([len(templates), len(things)])
|
| 79 |
+
|
| 80 |
+
@classmethod
|
| 81 |
+
def construct_utterance(cls, action):
|
| 82 |
+
return cls.templates[int(action[0])] + " " + cls.things[int(action[1])] + " "
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
class SpyingEnv(MultiModalMiniGridEnv):
|
| 86 |
+
"""
|
| 87 |
+
Environment in which the agent is instructed to go to a given object
|
| 88 |
+
named using an English text string
|
| 89 |
+
"""
|
| 90 |
+
|
| 91 |
+
def __init__(
|
| 92 |
+
self,
|
| 93 |
+
size=5,
|
| 94 |
+
diminished_reward=True,
|
| 95 |
+
step_penalty=False,
|
| 96 |
+
knowledgeable=False,
|
| 97 |
+
hard_password=False,
|
| 98 |
+
max_steps=None,
|
| 99 |
+
n_switches=3
|
| 100 |
+
):
|
| 101 |
+
assert size >= 5
|
| 102 |
+
self.empty_symbol = "NA \n"
|
| 103 |
+
self.diminished_reward = diminished_reward
|
| 104 |
+
self.step_penalty = step_penalty
|
| 105 |
+
self.knowledgeable = knowledgeable
|
| 106 |
+
self.hard_password = hard_password
|
| 107 |
+
self.n_switches = n_switches
|
| 108 |
+
|
| 109 |
+
super().__init__(
|
| 110 |
+
grid_size=size,
|
| 111 |
+
max_steps=max_steps or 5*size**2,
|
| 112 |
+
# Set this to True for maximum speed
|
| 113 |
+
see_through_walls=True,
|
| 114 |
+
actions=MiniGridEnv.Actions,
|
| 115 |
+
action_space=spaces.MultiDiscrete([
|
| 116 |
+
len(MiniGridEnv.Actions),
|
| 117 |
+
*SpyingGrammar.grammar_action_space.nvec
|
| 118 |
+
]),
|
| 119 |
+
add_npc_direction=True
|
| 120 |
+
)
|
| 121 |
+
|
| 122 |
+
print({
|
| 123 |
+
"size": size,
|
| 124 |
+
"diminished_reward": diminished_reward,
|
| 125 |
+
"step_penalty": step_penalty,
|
| 126 |
+
})
|
| 127 |
+
|
| 128 |
+
def get_selected_password(self):
|
| 129 |
+
return np.array([int(s.is_on) for s in self.switches])
|
| 130 |
+
|
| 131 |
+
def _gen_grid(self, width, height):
|
| 132 |
+
# Create the grid
|
| 133 |
+
self.grid = Grid(width, height, nb_obj_dims=4)
|
| 134 |
+
|
| 135 |
+
# Randomly vary the room width and height
|
| 136 |
+
width = self._rand_int(5, width+1)
|
| 137 |
+
height = self._rand_int(5, height+1)
|
| 138 |
+
|
| 139 |
+
self.wall_x = width - 1
|
| 140 |
+
self.wall_y = height - 1
|
| 141 |
+
|
| 142 |
+
# Generate the surrounding walls
|
| 143 |
+
self.grid.wall_rect(0, 0, width, height)
|
| 144 |
+
|
| 145 |
+
door_color = self._rand_elem(COLOR_NAMES)
|
| 146 |
+
|
| 147 |
+
wall_for_door = self._rand_int(1, 4)
|
| 148 |
+
|
| 149 |
+
if wall_for_door < 2:
|
| 150 |
+
w = self._rand_int(1, width-1)
|
| 151 |
+
h = height-1 if wall_for_door == 0 else 0
|
| 152 |
+
else:
|
| 153 |
+
w = width-1 if wall_for_door == 3 else 0
|
| 154 |
+
h = self._rand_int(1, height-1)
|
| 155 |
+
|
| 156 |
+
assert h != height-1 # door mustn't be on the bottom wall
|
| 157 |
+
|
| 158 |
+
self.door_pos = (w, h)
|
| 159 |
+
self.door = Door(door_color, is_locked=True)
|
| 160 |
+
self.grid.set(*self.door_pos, self.door)
|
| 161 |
+
|
| 162 |
+
# add the switches
|
| 163 |
+
self.switches = []
|
| 164 |
+
self.switches_pos = []
|
| 165 |
+
for i in range(self.n_switches):
|
| 166 |
+
c = COLOR_NAMES[i]
|
| 167 |
+
pos = np.array([i+1, height-1])
|
| 168 |
+
sw = Switch(c)
|
| 169 |
+
self.grid.set(*pos, sw)
|
| 170 |
+
self.switches.append(sw)
|
| 171 |
+
self.switches_pos.append(pos)
|
| 172 |
+
|
| 173 |
+
# sample password
|
| 174 |
+
if self.hard_password:
|
| 175 |
+
self.password = np.array([self._rand_int(0, 2) for _ in range(self.n_switches)])
|
| 176 |
+
|
| 177 |
+
else:
|
| 178 |
+
idx = self._rand_int(0, self.n_switches)
|
| 179 |
+
self.password = np.zeros(self.n_switches)
|
| 180 |
+
self.password[idx] = 1.0
|
| 181 |
+
|
| 182 |
+
# Set a randomly coloured Dancer NPC
|
| 183 |
+
color = self._rand_elem(COLOR_NAMES)
|
| 184 |
+
self.peer = Peer(color, "Jim", self, knowledgeable=self.knowledgeable)
|
| 185 |
+
|
| 186 |
+
# Place it on the middle left side of the room
|
| 187 |
+
peer_pos = np.array((self._rand_int(1, width - 1), self._rand_int(1, height - 1)))
|
| 188 |
+
|
| 189 |
+
self.grid.set(*peer_pos, self.peer)
|
| 190 |
+
self.peer.init_pos = peer_pos
|
| 191 |
+
self.peer.cur_pos = peer_pos
|
| 192 |
+
|
| 193 |
+
# Randomize the agent's start position and orientation
|
| 194 |
+
self.place_agent(size=(width, height))
|
| 195 |
+
|
| 196 |
+
# Generate the mission string
|
| 197 |
+
self.mission = 'exit the room'
|
| 198 |
+
|
| 199 |
+
# Dummy beginning string
|
| 200 |
+
self.beginning_string = "This is what you hear. \n"
|
| 201 |
+
self.utterance = self.beginning_string
|
| 202 |
+
|
| 203 |
+
# utterance appended at the end of each step
|
| 204 |
+
self.utterance_history = ""
|
| 205 |
+
|
| 206 |
+
# used for rendering
|
| 207 |
+
self.conversation = self.utterance
|
| 208 |
+
|
| 209 |
+
def update_door_lock(self):
|
| 210 |
+
if np.array_equal(self.get_selected_password(), self.password):
|
| 211 |
+
self.door.is_locked = False
|
| 212 |
+
else:
|
| 213 |
+
self.door.is_locked = True
|
| 214 |
+
self.door.is_open = False
|
| 215 |
+
|
| 216 |
+
def step(self, action):
|
| 217 |
+
p_action = action[0]
|
| 218 |
+
utterance_action = action[1:]
|
| 219 |
+
|
| 220 |
+
obs, reward, done, info = super().step(p_action)
|
| 221 |
+
self.update_door_lock()
|
| 222 |
+
|
| 223 |
+
print("pass:", self.password)
|
| 224 |
+
|
| 225 |
+
if p_action == self.actions.done:
|
| 226 |
+
done = True
|
| 227 |
+
|
| 228 |
+
self.peer.step()
|
| 229 |
+
|
| 230 |
+
if all(self.agent_pos == self.door_pos):
|
| 231 |
+
done = True
|
| 232 |
+
if self.peer.exited:
|
| 233 |
+
# only give reward of both exited
|
| 234 |
+
reward = self._reward()
|
| 235 |
+
|
| 236 |
+
# discount
|
| 237 |
+
if self.step_penalty:
|
| 238 |
+
reward = reward - 0.01
|
| 239 |
+
|
| 240 |
+
# fill observation with text
|
| 241 |
+
self.append_existing_utterance_to_history()
|
| 242 |
+
obs = self.add_utterance_to_observation(obs)
|
| 243 |
+
self.reset_utterance()
|
| 244 |
+
return obs, reward, done, info
|
| 245 |
+
|
| 246 |
+
def _reward(self):
|
| 247 |
+
if self.diminished_reward:
|
| 248 |
+
return super()._reward()
|
| 249 |
+
else:
|
| 250 |
+
return 1.0
|
| 251 |
+
|
| 252 |
+
def render(self, *args, **kwargs):
|
| 253 |
+
obs = super().render(*args, **kwargs)
|
| 254 |
+
print("conversation:\n", self.conversation)
|
| 255 |
+
print("utterance_history:\n", self.utterance_history)
|
| 256 |
+
self.window.set_caption(self.conversation, [self.peer.name])
|
| 257 |
+
return obs
|
| 258 |
+
|
| 259 |
+
|
| 260 |
+
class Spying8x8Env(SpyingEnv):
|
| 261 |
+
def __init__(self):
|
| 262 |
+
super().__init__(size=8)
|
| 263 |
+
|
| 264 |
+
|
| 265 |
+
class Spying6x6Env(SpyingEnv):
|
| 266 |
+
def __init__(self):
|
| 267 |
+
super().__init__(size=6)
|
| 268 |
+
|
| 269 |
+
|
| 270 |
+
# knowledgeable
|
| 271 |
+
class SpyingKnowledgeableEnv(SpyingEnv):
|
| 272 |
+
def __init__(self):
|
| 273 |
+
super().__init__(size=5, knowledgeable=True)
|
| 274 |
+
|
| 275 |
+
class SpyingKnowledgeable6x6Env(SpyingEnv):
|
| 276 |
+
def __init__(self):
|
| 277 |
+
super().__init__(size=6, knowledgeable=True)
|
| 278 |
+
|
| 279 |
+
class SpyingKnowledgeable8x8Env(SpyingEnv):
|
| 280 |
+
def __init__(self):
|
| 281 |
+
super().__init__(size=8, knowledgeable=True)
|
| 282 |
+
|
| 283 |
+
class SpyingKnowledgeableHardPassword8x8Env(SpyingEnv):
|
| 284 |
+
def __init__(self):
|
| 285 |
+
super().__init__(size=8, knowledgeable=True, hard_password=True)
|
| 286 |
+
|
| 287 |
+
class Spying508x8Env(SpyingEnv):
|
| 288 |
+
def __init__(self):
|
| 289 |
+
super().__init__(size=8, max_steps=50)
|
| 290 |
+
|
| 291 |
+
class SpyingKnowledgeable508x8Env(SpyingEnv):
|
| 292 |
+
def __init__(self):
|
| 293 |
+
super().__init__(size=8, knowledgeable=True, max_steps=50)
|
| 294 |
+
|
| 295 |
+
class SpyingKnowledgeableHardPassword508x8Env(SpyingEnv):
|
| 296 |
+
def __init__(self):
|
| 297 |
+
super().__init__(size=8, knowledgeable=True, hard_password=True, max_steps=50)
|
| 298 |
+
|
| 299 |
+
class SpyingKnowledgeable1008x8Env(SpyingEnv):
|
| 300 |
+
def __init__(self):
|
| 301 |
+
super().__init__(size=8, knowledgeable=True, max_steps=100)
|
| 302 |
+
|
| 303 |
+
class SpyingKnowledgeable100OneSwitch8x8Env(SpyingEnv):
|
| 304 |
+
def __init__(self):
|
| 305 |
+
super().__init__(size=8, knowledgeable=True, max_steps=100, n_switches=1)
|
| 306 |
+
|
| 307 |
+
class SpyingKnowledgeable50OneSwitch5x5Env(SpyingEnv):
|
| 308 |
+
def __init__(self):
|
| 309 |
+
super().__init__(size=5, knowledgeable=True, max_steps=50, n_switches=1)
|
| 310 |
+
|
| 311 |
+
|
| 312 |
+
class SpyingKnowledgeable505x5Env(SpyingEnv):
|
| 313 |
+
def __init__(self):
|
| 314 |
+
super().__init__(size=5, knowledgeable=True, max_steps=50, n_switches=3)
|
| 315 |
+
|
| 316 |
+
class SpyingKnowledgeable50TwoSwitches8x8Env(SpyingEnv):
|
| 317 |
+
def __init__(self):
|
| 318 |
+
super().__init__(size=8, knowledgeable=True, max_steps=50, n_switches=2)
|
| 319 |
+
|
| 320 |
+
class SpyingKnowledgeable50TwoSwitchesHard8x8Env(SpyingEnv):
|
| 321 |
+
def __init__(self):
|
| 322 |
+
super().__init__(size=8, knowledgeable=True, max_steps=50, n_switches=2, hard_password=True)
|
| 323 |
+
|
| 324 |
+
|
| 325 |
+
class SpyingKnowledgeable100TwoSwitches8x8Env(SpyingEnv):
|
| 326 |
+
def __init__(self):
|
| 327 |
+
super().__init__(size=8, knowledgeable=True, max_steps=100, n_switches=2)
|
| 328 |
+
|
| 329 |
+
class SpyingKnowledgeable100TwoSwitchesHard8x8Env(SpyingEnv):
|
| 330 |
+
def __init__(self):
|
| 331 |
+
super().__init__(size=8, knowledgeable=True, max_steps=100, n_switches=2, hard_password=True)
|
| 332 |
+
|
| 333 |
+
|
| 334 |
+
|
| 335 |
+
|
| 336 |
+
register(
|
| 337 |
+
id='MiniGrid-Spying-5x5-v0',
|
| 338 |
+
entry_point='gym_minigrid.envs:SpyingEnv'
|
| 339 |
+
)
|
| 340 |
+
|
| 341 |
+
register(
|
| 342 |
+
id='MiniGrid-Spying-6x6-v0',
|
| 343 |
+
entry_point='gym_minigrid.envs:Spying6x6Env'
|
| 344 |
+
)
|
| 345 |
+
|
| 346 |
+
register(
|
| 347 |
+
id='MiniGrid-Spying-8x8-v0',
|
| 348 |
+
entry_point='gym_minigrid.envs:Spying8x8Env'
|
| 349 |
+
)
|
| 350 |
+
|
| 351 |
+
register(
|
| 352 |
+
id='MiniGrid-SpyingKnowledgeable-5x5-v0',
|
| 353 |
+
entry_point='gym_minigrid.envs:SpyingKnowledgeableEnv'
|
| 354 |
+
)
|
| 355 |
+
|
| 356 |
+
register(
|
| 357 |
+
id='MiniGrid-SpyingKnowledgeable-6x6-v0',
|
| 358 |
+
entry_point='gym_minigrid.envs:SpyingKnowledgeable6x6Env'
|
| 359 |
+
)
|
| 360 |
+
|
| 361 |
+
register(
|
| 362 |
+
id='MiniGrid-SpyingKnowledgeable-8x8-v0',
|
| 363 |
+
entry_point='gym_minigrid.envs:SpyingKnowledgeable8x8Env'
|
| 364 |
+
)
|
| 365 |
+
|
| 366 |
+
register(
|
| 367 |
+
id='MiniGrid-SpyingKnowledgeableHardPassword-8x8-v0',
|
| 368 |
+
entry_point='gym_minigrid.envs:SpyingKnowledgeableHardPassword8x8Env'
|
| 369 |
+
)
|
| 370 |
+
|
| 371 |
+
# max len 50
|
| 372 |
+
register(
|
| 373 |
+
id='MiniGrid-Spying50-8x8-v0',
|
| 374 |
+
entry_point='gym_minigrid.envs:Spying508x8Env'
|
| 375 |
+
)
|
| 376 |
+
|
| 377 |
+
register(
|
| 378 |
+
id='MiniGrid-SpyingKnowledgeable50-8x8-v0',
|
| 379 |
+
entry_point='gym_minigrid.envs:SpyingKnowledgeable508x8Env'
|
| 380 |
+
)
|
| 381 |
+
|
| 382 |
+
register(
|
| 383 |
+
id='MiniGrid-SpyingKnowledgeableHardPassword50-8x8-v0',
|
| 384 |
+
entry_point='gym_minigrid.envs:SpyingKnowledgeableHardPassword508x8Env'
|
| 385 |
+
)
|
| 386 |
+
|
| 387 |
+
# max len 100
|
| 388 |
+
register(
|
| 389 |
+
id='MiniGrid-SpyingKnowledgeable100-8x8-v0',
|
| 390 |
+
entry_point='gym_minigrid.envs:SpyingKnowledgeable1008x8Env'
|
| 391 |
+
)
|
| 392 |
+
|
| 393 |
+
# max len OneSwitch
|
| 394 |
+
register(
|
| 395 |
+
id='MiniGrid-SpyingKnowledgeable100OneSwitch-8x8-v0',
|
| 396 |
+
entry_point='gym_minigrid.envs:SpyingKnowledgeable100OneSwitch8x8Env'
|
| 397 |
+
)
|
| 398 |
+
|
| 399 |
+
register(
|
| 400 |
+
id='MiniGrid-SpyingKnowledgeable50OneSwitch-5x5-v0',
|
| 401 |
+
entry_point='gym_minigrid.envs:SpyingKnowledgeable50OneSwitch5x5Env'
|
| 402 |
+
)
|
| 403 |
+
|
| 404 |
+
register(
|
| 405 |
+
id='MiniGrid-SpyingUnknowledgeable50OneSwitch-5x5-v0',
|
| 406 |
+
entry_point='gym_minigrid.envs:SpyingUnknowledgeable50OneSwitch5x5Env'
|
| 407 |
+
)
|
| 408 |
+
|
| 409 |
+
register(
|
| 410 |
+
id='MiniGrid-SpyingKnowledgeable50-5x5-v0',
|
| 411 |
+
entry_point='gym_minigrid.envs:SpyingKnowledgeable505x5Env'
|
| 412 |
+
)
|
| 413 |
+
|
| 414 |
+
register(
|
| 415 |
+
id='MiniGrid-SpyingKnowledgeable50TwoSwitches-8x8-v0',
|
| 416 |
+
entry_point='gym_minigrid.envs:SpyingKnowledgeable50TwoSwitches8x8Env'
|
| 417 |
+
)
|
| 418 |
+
register(
|
| 419 |
+
id='MiniGrid-SpyingKnowledgeable50TwoSwitchesHard-8x8-v0',
|
| 420 |
+
entry_point='gym_minigrid.envs:SpyingKnowledgeable50TwoSwitchesHard8x8Env'
|
| 421 |
+
)
|
| 422 |
+
register(
|
| 423 |
+
id='MiniGrid-SpyingKnowledgeable100TwoSwitches-8x8-v0',
|
| 424 |
+
entry_point='gym_minigrid.envs:SpyingKnowledgeable100TwoSwitches8x8Env'
|
| 425 |
+
)
|
| 426 |
+
register(
|
| 427 |
+
id='MiniGrid-SpyingKnowledgeable100TwoSwitchesHard-8x8-v0',
|
| 428 |
+
entry_point='gym_minigrid.envs:SpyingKnowledgeable100TwoSwitchesHard8x8Env'
|
| 429 |
+
)
|
gym-minigrid/gym_minigrid/backup_envs/talkitout.py
ADDED
|
@@ -0,0 +1,385 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from gym_minigrid.minigrid import *
|
| 2 |
+
from gym_minigrid.register import register
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
class Wizard(NPC):
|
| 6 |
+
"""
|
| 7 |
+
A simple NPC that knows who is telling the truth
|
| 8 |
+
"""
|
| 9 |
+
|
| 10 |
+
def __init__(self, color, name, env):
|
| 11 |
+
super().__init__(color)
|
| 12 |
+
self.name = name
|
| 13 |
+
self.env = env
|
| 14 |
+
self.npc_dir = 1 # NPC initially looks downward
|
| 15 |
+
# todo: this should be id == name
|
| 16 |
+
self.npc_type = 0 # this will be put into the encoding
|
| 17 |
+
|
| 18 |
+
def listen(self, utterance):
|
| 19 |
+
if utterance == TalkItOutGrammar.construct_utterance([0, 1]):
|
| 20 |
+
if self.env.nameless:
|
| 21 |
+
return "Ask the {} guide.".format(self.env.true_guide.color)
|
| 22 |
+
else:
|
| 23 |
+
return "Ask {}.".format(self.env.true_guide.name)
|
| 24 |
+
|
| 25 |
+
return None
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
class Guide(NPC):
|
| 29 |
+
"""
|
| 30 |
+
A simple NPC that knows the correct door.
|
| 31 |
+
"""
|
| 32 |
+
|
| 33 |
+
def __init__(self, color, name, env, liar=False):
|
| 34 |
+
super().__init__(color)
|
| 35 |
+
self.name = name
|
| 36 |
+
self.env = env
|
| 37 |
+
self.liar = liar
|
| 38 |
+
self.npc_dir = 1 # NPC initially looks downward
|
| 39 |
+
# todo: this should be id == name
|
| 40 |
+
self.npc_type = 1 # this will be put into the encoding
|
| 41 |
+
|
| 42 |
+
# Select a random target object as mission
|
| 43 |
+
obj_idx = self.env._rand_int(0, len(self.env.door_pos))
|
| 44 |
+
self.target_pos = self.env.door_pos[obj_idx]
|
| 45 |
+
self.target_color = self.env.door_colors[obj_idx]
|
| 46 |
+
|
| 47 |
+
def listen(self, utterance):
|
| 48 |
+
if utterance == TalkItOutGrammar.construct_utterance([0, 1]):
|
| 49 |
+
if self.liar:
|
| 50 |
+
fake_colors = [c for c in self.env.door_colors if c != self.env.target_color]
|
| 51 |
+
fake_color = self.env._rand_elem(fake_colors)
|
| 52 |
+
|
| 53 |
+
# Generate the mission string
|
| 54 |
+
assert fake_color != self.env.target_color
|
| 55 |
+
return 'go to the %s door' % fake_color
|
| 56 |
+
|
| 57 |
+
else:
|
| 58 |
+
return self.env.mission
|
| 59 |
+
|
| 60 |
+
return None
|
| 61 |
+
|
| 62 |
+
def render(self, img):
|
| 63 |
+
c = COLORS[self.color]
|
| 64 |
+
|
| 65 |
+
npc_shapes = []
|
| 66 |
+
# Draw eyes
|
| 67 |
+
npc_shapes.append(point_in_circle(cx=0.70, cy=0.50, r=0.10))
|
| 68 |
+
npc_shapes.append(point_in_circle(cx=0.30, cy=0.50, r=0.10))
|
| 69 |
+
|
| 70 |
+
# Draw mouth
|
| 71 |
+
npc_shapes.append(point_in_rect(0.20, 0.80, 0.72, 0.81))
|
| 72 |
+
|
| 73 |
+
# todo: move this to super function
|
| 74 |
+
# todo: super.render should be able to take the npc_shapes and then rotate them
|
| 75 |
+
|
| 76 |
+
if hasattr(self, "npc_dir"):
|
| 77 |
+
# Pre-rotation to ensure npc_dir = 1 means NPC looks downwards
|
| 78 |
+
npc_shapes = [rotate_fn(v, cx=0.5, cy=0.5, theta=-1*(math.pi / 2)) for v in npc_shapes]
|
| 79 |
+
# Rotate npc based on its direction
|
| 80 |
+
npc_shapes = [rotate_fn(v, cx=0.5, cy=0.5, theta=(math.pi/2) * self.npc_dir) for v in npc_shapes]
|
| 81 |
+
|
| 82 |
+
# Draw shapes
|
| 83 |
+
for v in npc_shapes:
|
| 84 |
+
fill_coords(img, v, c)
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
class TalkItOutGrammar(object):
|
| 88 |
+
|
| 89 |
+
templates = ["Where is", "Open", "Close", "What is"]
|
| 90 |
+
things = [
|
| 91 |
+
"sesame", "the exit", "the wall", "the floor", "the ceiling", "the window", "the entrance", "the closet",
|
| 92 |
+
"the drawer", "the fridge", "oven", "the lamp", "the trash can", "the chair", "the bed", "the sofa"
|
| 93 |
+
]
|
| 94 |
+
|
| 95 |
+
grammar_action_space = spaces.MultiDiscrete([len(templates), len(things)])
|
| 96 |
+
|
| 97 |
+
@classmethod
|
| 98 |
+
def construct_utterance(cls, action):
|
| 99 |
+
return cls.templates[int(action[0])] + " " + cls.things[int(action[1])] + " "
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
class TalkItOutEnv(MultiModalMiniGridEnv):
|
| 103 |
+
"""
|
| 104 |
+
Environment in which the agent is instructed to go to a given object
|
| 105 |
+
named using an English text string
|
| 106 |
+
"""
|
| 107 |
+
|
| 108 |
+
def __init__(
|
| 109 |
+
self,
|
| 110 |
+
size=5,
|
| 111 |
+
hear_yourself=False,
|
| 112 |
+
diminished_reward=True,
|
| 113 |
+
step_penalty=False,
|
| 114 |
+
nameless=False,
|
| 115 |
+
):
|
| 116 |
+
assert size >= 5
|
| 117 |
+
self.empty_symbol = "NA \n"
|
| 118 |
+
self.hear_yourself = hear_yourself
|
| 119 |
+
self.diminished_reward = diminished_reward
|
| 120 |
+
self.step_penalty = step_penalty
|
| 121 |
+
self.nameless = nameless
|
| 122 |
+
|
| 123 |
+
super().__init__(
|
| 124 |
+
grid_size=size,
|
| 125 |
+
max_steps=5*size**2,
|
| 126 |
+
# Set this to True for maximum speed
|
| 127 |
+
see_through_walls=True,
|
| 128 |
+
actions=MiniGridEnv.Actions,
|
| 129 |
+
action_space=spaces.MultiDiscrete([
|
| 130 |
+
len(MiniGridEnv.Actions),
|
| 131 |
+
*TalkItOutGrammar.grammar_action_space.nvec
|
| 132 |
+
]),
|
| 133 |
+
add_npc_direction=True
|
| 134 |
+
)
|
| 135 |
+
|
| 136 |
+
print({
|
| 137 |
+
"size": size,
|
| 138 |
+
"hear_yourself": hear_yourself,
|
| 139 |
+
"diminished_reward": diminished_reward,
|
| 140 |
+
"step_penalty": step_penalty,
|
| 141 |
+
})
|
| 142 |
+
|
| 143 |
+
def _gen_grid(self, width, height):
|
| 144 |
+
# Create the grid
|
| 145 |
+
self.grid = Grid(width, height, nb_obj_dims=4)
|
| 146 |
+
|
| 147 |
+
# Randomly vary the room width and height
|
| 148 |
+
width = self._rand_int(5, width+1)
|
| 149 |
+
height = self._rand_int(5, height+1)
|
| 150 |
+
|
| 151 |
+
# Generate the surrounding walls
|
| 152 |
+
self.grid.wall_rect(0, 0, width, height)
|
| 153 |
+
|
| 154 |
+
# Generate the surrounding walls
|
| 155 |
+
self.grid.wall_rect(0, 0, width, height)
|
| 156 |
+
|
| 157 |
+
# Generate the 4 doors at random positions
|
| 158 |
+
self.door_pos = []
|
| 159 |
+
self.door_front_pos = [] # Remembers positions in front of door to avoid setting wizard here
|
| 160 |
+
|
| 161 |
+
self.door_pos.append((self._rand_int(2, width-2), 0))
|
| 162 |
+
self.door_front_pos.append((self.door_pos[-1][0], self.door_pos[-1][1]+1))
|
| 163 |
+
|
| 164 |
+
self.door_pos.append((self._rand_int(2, width-2), height-1))
|
| 165 |
+
self.door_front_pos.append((self.door_pos[-1][0], self.door_pos[-1][1] - 1))
|
| 166 |
+
|
| 167 |
+
self.door_pos.append((0, self._rand_int(2, height-2)))
|
| 168 |
+
self.door_front_pos.append((self.door_pos[-1][0] + 1, self.door_pos[-1][1]))
|
| 169 |
+
|
| 170 |
+
self.door_pos.append((width-1, self._rand_int(2, height-2)))
|
| 171 |
+
self.door_front_pos.append((self.door_pos[-1][0] - 1, self.door_pos[-1][1]))
|
| 172 |
+
|
| 173 |
+
# Generate the door colors
|
| 174 |
+
self.door_colors = []
|
| 175 |
+
while len(self.door_colors) < len(self.door_pos):
|
| 176 |
+
color = self._rand_elem(COLOR_NAMES)
|
| 177 |
+
if color in self.door_colors:
|
| 178 |
+
continue
|
| 179 |
+
self.door_colors.append(color)
|
| 180 |
+
|
| 181 |
+
# Place the doors in the grid
|
| 182 |
+
for idx, pos in enumerate(self.door_pos):
|
| 183 |
+
color = self.door_colors[idx]
|
| 184 |
+
self.grid.set(*pos, Door(color))
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
# Set a randomly coloured WIZARD at a random position
|
| 188 |
+
color = self._rand_elem(COLOR_NAMES)
|
| 189 |
+
self.wizard = Wizard(color, "Gandalf", self)
|
| 190 |
+
|
| 191 |
+
# Place it randomly, omitting front of door positions
|
| 192 |
+
self.place_obj(self.wizard,
|
| 193 |
+
size=(width, height),
|
| 194 |
+
reject_fn=lambda _, p: tuple(p) in self.door_front_pos)
|
| 195 |
+
|
| 196 |
+
# add guides
|
| 197 |
+
GUIDE_NAMES = ["John", "Jack"]
|
| 198 |
+
|
| 199 |
+
# Set a randomly coloured TRUE GUIDE at a random position
|
| 200 |
+
name = self._rand_elem(GUIDE_NAMES)
|
| 201 |
+
color = self._rand_elem(COLOR_NAMES)
|
| 202 |
+
self.true_guide = Guide(color, name, self, liar=False)
|
| 203 |
+
|
| 204 |
+
# Place it randomly, omitting invalid positions
|
| 205 |
+
self.place_obj(self.true_guide,
|
| 206 |
+
size=(width, height),
|
| 207 |
+
# reject_fn=lambda _, p: tuple(p) in self.door_front_pos)
|
| 208 |
+
reject_fn=lambda _, p: tuple(p) in [*self.door_front_pos, tuple(self.wizard.cur_pos)])
|
| 209 |
+
|
| 210 |
+
# Set a randomly coloured FALSE GUIDE at a random position
|
| 211 |
+
name = self._rand_elem([n for n in GUIDE_NAMES if n != self.true_guide.name])
|
| 212 |
+
|
| 213 |
+
if self.nameless:
|
| 214 |
+
color = self._rand_elem([c for c in COLOR_NAMES if c != self.true_guide.color])
|
| 215 |
+
else:
|
| 216 |
+
color = self._rand_elem(COLOR_NAMES)
|
| 217 |
+
|
| 218 |
+
self.false_guide = Guide(color, name, self, liar=True)
|
| 219 |
+
|
| 220 |
+
# Place it randomly, omitting invalid positions
|
| 221 |
+
self.place_obj(self.false_guide,
|
| 222 |
+
size=(width, height),
|
| 223 |
+
reject_fn=lambda _, p: tuple(p) in [
|
| 224 |
+
*self.door_front_pos, tuple(self.wizard.cur_pos), tuple(self.true_guide.cur_pos)])
|
| 225 |
+
assert self.true_guide.name != self.false_guide.name
|
| 226 |
+
|
| 227 |
+
# Randomize the agent's start position and orientation
|
| 228 |
+
self.place_agent(size=(width, height))
|
| 229 |
+
|
| 230 |
+
# Select a random target door
|
| 231 |
+
self.doorIdx = self._rand_int(0, len(self.door_pos))
|
| 232 |
+
self.target_pos = self.door_pos[self.doorIdx]
|
| 233 |
+
self.target_color = self.door_colors[self.doorIdx]
|
| 234 |
+
|
| 235 |
+
# Generate the mission string
|
| 236 |
+
self.mission = 'go to the %s door' % self.target_color
|
| 237 |
+
|
| 238 |
+
# Dummy beginning string
|
| 239 |
+
self.beginning_string = "This is what you hear. \n"
|
| 240 |
+
self.utterance = self.beginning_string
|
| 241 |
+
|
| 242 |
+
# utterance appended at the end of each step
|
| 243 |
+
self.utterance_history = ""
|
| 244 |
+
|
| 245 |
+
# used for rendering
|
| 246 |
+
self.conversation = self.utterance
|
| 247 |
+
|
| 248 |
+
def step(self, action):
|
| 249 |
+
p_action = action[0]
|
| 250 |
+
utterance_action = action[1:]
|
| 251 |
+
|
| 252 |
+
# assert all nan or neither nan
|
| 253 |
+
assert len(set(np.isnan(utterance_action))) == 1
|
| 254 |
+
|
| 255 |
+
speak_flag = not all(np.isnan(utterance_action))
|
| 256 |
+
|
| 257 |
+
obs, reward, done, info = super().step(p_action)
|
| 258 |
+
|
| 259 |
+
if speak_flag:
|
| 260 |
+
utterance = TalkItOutGrammar.construct_utterance(utterance_action)
|
| 261 |
+
if self.hear_yourself:
|
| 262 |
+
if self.nameless:
|
| 263 |
+
self.utterance += "{} \n".format(utterance)
|
| 264 |
+
else:
|
| 265 |
+
self.utterance += "YOU: {} \n".format(utterance)
|
| 266 |
+
|
| 267 |
+
self.conversation += "YOU: {} \n".format(utterance)
|
| 268 |
+
|
| 269 |
+
# check if near wizard
|
| 270 |
+
if self.wizard.is_near_agent():
|
| 271 |
+
reply = self.wizard.listen(utterance)
|
| 272 |
+
|
| 273 |
+
if reply:
|
| 274 |
+
if self.nameless:
|
| 275 |
+
self.utterance += "{} \n".format(reply)
|
| 276 |
+
else:
|
| 277 |
+
self.utterance += "{}: {} \n".format(self.wizard.name, reply)
|
| 278 |
+
|
| 279 |
+
self.conversation += "{}: {} \n".format(self.wizard.name, reply)
|
| 280 |
+
|
| 281 |
+
if self.true_guide.is_near_agent():
|
| 282 |
+
reply = self.true_guide.listen(utterance)
|
| 283 |
+
|
| 284 |
+
if reply:
|
| 285 |
+
if self.nameless:
|
| 286 |
+
self.utterance += "{} \n".format(reply)
|
| 287 |
+
else:
|
| 288 |
+
self.utterance += "{}: {} \n".format(self.true_guide.name, reply)
|
| 289 |
+
|
| 290 |
+
self.conversation += "{}: {} \n".format(self.true_guide.name, reply)
|
| 291 |
+
|
| 292 |
+
if self.false_guide.is_near_agent():
|
| 293 |
+
reply = self.false_guide.listen(utterance)
|
| 294 |
+
|
| 295 |
+
if reply:
|
| 296 |
+
if self.nameless:
|
| 297 |
+
self.utterance += "{} \n".format(reply)
|
| 298 |
+
else:
|
| 299 |
+
self.utterance += "{}: {} \n".format(self.false_guide.name, reply)
|
| 300 |
+
|
| 301 |
+
self.conversation += "{}: {} \n".format(self.false_guide.name, reply)
|
| 302 |
+
|
| 303 |
+
if utterance == TalkItOutGrammar.construct_utterance([1, 0]):
|
| 304 |
+
ax, ay = self.agent_pos
|
| 305 |
+
tx, ty = self.target_pos
|
| 306 |
+
|
| 307 |
+
if (ax == tx and abs(ay - ty) == 1) or (ay == ty and abs(ax - tx) == 1):
|
| 308 |
+
reward = self._reward()
|
| 309 |
+
|
| 310 |
+
for dx, dy in self.door_pos:
|
| 311 |
+
if (ax == dx and abs(ay - dy) == 1) or (ay == dy and abs(ax - dx) == 1):
|
| 312 |
+
# agent has chosen some door episode, regardless of if the door is correct the episode is over
|
| 313 |
+
done = True
|
| 314 |
+
|
| 315 |
+
# Don't let the agent open any of the doors
|
| 316 |
+
if p_action == self.actions.toggle:
|
| 317 |
+
done = True
|
| 318 |
+
|
| 319 |
+
if p_action == self.actions.done:
|
| 320 |
+
done = True
|
| 321 |
+
|
| 322 |
+
# discount
|
| 323 |
+
if self.step_penalty:
|
| 324 |
+
reward = reward - 0.01
|
| 325 |
+
|
| 326 |
+
# fill observation with text
|
| 327 |
+
self.append_existing_utterance_to_history()
|
| 328 |
+
obs = self.add_utterance_to_observation(obs)
|
| 329 |
+
self.reset_utterance()
|
| 330 |
+
|
| 331 |
+
return obs, reward, done, info
|
| 332 |
+
|
| 333 |
+
def _reward(self):
|
| 334 |
+
if self.diminished_reward:
|
| 335 |
+
return super()._reward()
|
| 336 |
+
else:
|
| 337 |
+
return 1.0
|
| 338 |
+
|
| 339 |
+
def render(self, *args, **kwargs):
|
| 340 |
+
obs = super().render(*args, **kwargs)
|
| 341 |
+
print("conversation:\n", self.conversation)
|
| 342 |
+
print("utterance_history:\n", self.utterance_history)
|
| 343 |
+
self.window.set_caption(self.conversation, [
|
| 344 |
+
"Gandalf:",
|
| 345 |
+
"Jack:",
|
| 346 |
+
"John:",
|
| 347 |
+
"Where is the exit",
|
| 348 |
+
"Open sesame",
|
| 349 |
+
])
|
| 350 |
+
return obs
|
| 351 |
+
|
| 352 |
+
|
| 353 |
+
class TalkItOut8x8Env(TalkItOutEnv):
|
| 354 |
+
def __init__(self):
|
| 355 |
+
super().__init__(size=8)
|
| 356 |
+
|
| 357 |
+
|
| 358 |
+
class TalkItOut6x6Env(TalkItOutEnv):
|
| 359 |
+
def __init__(self):
|
| 360 |
+
super().__init__(size=6)
|
| 361 |
+
|
| 362 |
+
|
| 363 |
+
class TalkItOutNameless8x8Env(TalkItOutEnv):
|
| 364 |
+
def __init__(self):
|
| 365 |
+
super().__init__(size=8, nameless=True)
|
| 366 |
+
|
| 367 |
+
register(
|
| 368 |
+
id='MiniGrid-TalkItOut-5x5-v0',
|
| 369 |
+
entry_point='gym_minigrid.envs:TalkItOutEnv'
|
| 370 |
+
)
|
| 371 |
+
|
| 372 |
+
register(
|
| 373 |
+
id='MiniGrid-TalkItOut-6x6-v0',
|
| 374 |
+
entry_point='gym_minigrid.envs:TalkItOut6x6Env'
|
| 375 |
+
)
|
| 376 |
+
|
| 377 |
+
register(
|
| 378 |
+
id='MiniGrid-TalkItOut-8x8-v0',
|
| 379 |
+
entry_point='gym_minigrid.envs:TalkItOut8x8Env'
|
| 380 |
+
)
|
| 381 |
+
|
| 382 |
+
register(
|
| 383 |
+
id='MiniGrid-TalkItOutNameless-8x8-v0',
|
| 384 |
+
entry_point='gym_minigrid.envs:TalkItOutNameless8x8Env'
|
| 385 |
+
)
|